
Abstract
The goal of this article is to enable robots to perform robust task execution following human instructions in partially observable environments. A robot’s ability to interpret and execute commands is fundamentally tied to its semantic world knowledge. Commonly, robots use exteroceptive sensors, such as cameras or LiDAR, to detect entities in the workspace and infer their visual properties and spatial relationships. However, semantic world properties are often visually imperceptible. We posit the use of non-exteroceptive modalities including physical proprioception, factual descriptions, and domain knowledge as mechanisms for inferring semantic properties of objects. We introduce a probabilistic model that fuses linguistic knowledge with visual and haptic observations into a cumulative belief over latent world attributes to infer the meaning of instructions and execute the instructed tasks in a manner robust to erroneous, noisy, or contradictory evidence. In addition, we provide a method that allows the robot to communicate knowledge dissonance back to the human as a means of correcting errors in the operator’s world model. Finally, we propose an efficient framework that anticipates possible linguistic interactions and infers the associated groundings for the current world state, thereby bootstrapping both language understanding and generation. We present experiments on manipulators for tasks that require inference over partially observed semantic properties, and evaluate our framework’s ability to exploit expressed information and knowledge bases to facilitate convergence, and generate statements to correct declared facts that were observed to be inconsistent with the robot’s estimate of object properties.
Keywords
1. Introduction
Our goal is to enable a robot to understand and robustly execute high-level commands from a human in partially known workspaces. Communication is integral to effective coordination and collaboration among human–robot teams. In human teams, perceptual and auditory descriptions are often used to understand the environment and communicate intent about the task and/or environment that may not otherwise be directly observable. Similarly, robots that primarily rely on visual sensors cannot directly observe all attributes of objects in which some attributes may be necessary for reference resolution or task execution. For example, as shown in Figure 1, the knowledge of whether an object can be pushed or moved by a robot manipulator, or whether it is heavier in comparison with another object, may be relevant for manipulation tasks but difficult to estimate from vision alone. The lack of knowledge of non-visual properties may make it impossible to synthesize plans or lead to unanticipated failures during plan execution.

Bi-directional communication for human–robot teams: (a) a Husky with a UR5 arm, understanding language utterances in a partially known environment; (b) multimodal semantic knowledge estimation followed by linguistic feedback generation to the human operator. A human operator can share his mental model of an object with a robot by stating declaratively that “the barrel on the right is full.” However, the shared world knowledge can be inaccurate in partially observable environments. Upon updating the world knowledge state via physical estimation, the robot reports back a declarative statement in order to correct the operator’s mental model.
In this work, we address the problem of inferring semantic properties of the world that may not be observable from exteroceptive modalities such as visual or LiDAR sensors. We incorporate three information sources for estimating the latent world properties. First, we use factual, task-relevant knowledge that is implicit or explicit in the natural language communication between the robot and its human partner. For example, the utterance “the nearest barrel is empty” provides factual knowledge about a property of the indicated object. Second, we leverage the robot’s ability to directly interact with the world to inform its belief over the latent attributes of the environment. Force and torque observations and other end-effector measurements provide cues about physical properties of an object, such as whether it can be pushed or lifted, or whether it is pliable. Third, we utilize commonsense knowledge about particular object types (e.g., that plastic containers are typically lighter and less rigid than their metal counterparts) present in crowdsourced corpora, such as the VerbPhysics dataset (Forbes and Choi, 2017), derived from human judgement annotations.
We present a probabilistic model and inference algorithm that estimate semantic knowledge about the workspace through natural language communication, physical interaction measurements, and background knowledge sources. This is a challenging estimation problem as it involves distilling high-level semantic knowledge from low-level measurements arising from physical interactions or highly complex and varied sources such as human language utterances and relational data stores. We present a probabilistic model that fuses measurements from multiple modalities into a probabilistic belief over the latent semantic knowledge about world entities. We factor the inference task into one of estimating the presence of semantic properties from each modality and of temporally fusing the semantic observations into a probabilistic belief that is robust to erroneous or contradictory evidence. We show how the robot can use this model to plan exploratory actions to improve its belief over latent semantic properties of its world model. The ability to infer missing semantic aspects of the world allows robots to follow instructions while remaining resilient to incomplete or inaccurate workspace knowledge.
Further, we observe that effective human–robot teaming requires seamless communication as well as transparent ways to provide feedback in case of observed discrepancies between the mental model of the human and that of the robot. We describe how a robot can learn to synthesize linguistic feedback to the human operator when the robot’s direct observations differ from the inferred model of the human. Finally, we address the problem of reducing latency in instruction interpretation and feedback generation that arises while evaluating possible associations between language utterances and semantic entities in the world, particularly in large environments. We propose an approach that anticipates future language interactions based on changes in the environmental context and the robot’s environmental knowledge. This allows the robot to pre-compute associations, thereby reducing the latency of future command interpretation and language generation tasks.
We demonstrate the model’s effectiveness in real-world scenarios in which fixed or mobile manipulation platforms follow natural language instructions in environments that are only partially known. By fusing declarative knowledge provided by natural language with observations made during physical interactions, our method successfully infers the latent object attributes necessary for task execution. We show that the proactive approach to language understanding and feedback generation improves the runtime performance. The proposed model builds on the following lines of work: (i) efficient language grounding in large semantic spaces (Paul et al., 2018), where the approximation of the complete model is fundamental to efficient inference; (ii) acquiring factual knowledge (Paul et al., 2017) over a temporally extended visual and linguistic interaction; (iii) learning an informed belief from background knowledge corpora; and (iv) improved efficient communication by proactively searching for and inferring the meaning of likely phrases given the interaction history and current state of the world (Arkin and Howard, 2018).
Contemporary approaches that incorporate declarative knowledge (Kollar et al., 2013b; Matuszek et al., 2012a; Paul et al., 2017) assume that such information is correct and sufficient for task execution and, thus, are not robust to situations in which the declared knowledge is incorrectly understood by the robot or factually inaccurate. Approaches such as those of Walter et al. (2013), Walter et al. (2014b), Hemachandra et al. (2015), and Duvallet et al. (2014) incorporate language in semantic mapping in partially known environments in order to simultaneously infer a metric map and semantic labels for regions from visual or range-based observations. Similarly, Daniele et al. (2017a) used language to learn kinematic models of articulated objects. Our work expands the scope of semantic properties from region types alone to fine-grained physical and abstract properties of objects and further incorporates active interaction and high-level commonsense knowledge for making predictions.
This article expands significantly on an earlier conference paper describing this framework (Arkin et al., 2018). We present a thorough exposition of the proposed model with additional technical details, an expanded background and problem formulation, and a more thorough description of related work. We extend the core technical contributions in the following ways. First, we incorporate a data-driven model to estimate an informed prior over object attributes derived from background commonsense knowledge corpora. Second, we extend the model to provide linguistic feedback to the human in the event that there is disagreement between the human’s inferred model of the environment and the robot’s internal estimate derived from physical interaction. Third, we include new experimental results and additional field demonstrations.
This article is organized as follows. We present the background material and problem formulation in Section 2. Section 3 presents the model for representing semantic knowledge and details the process of fusing multiple modalities into a probabilistic belief over the correctness of semantic aspects of the world model. Section 4 approaches the problem of command following in a manner that takes into account uncertainty in the acquired knowledge of entities in the scene. In Section 5, we present an approach for providing feedback to the human operator when discrepancies are detected between the human’s inferred model of the environment and that of the robot. Section 6 tackles the crucial issue of reducing latency in command understanding as well as linguistic feedback generation. The experimental evaluation and results are described in detail in Section 7. Section 8 is devoted to reviewing related efforts. Finally, Section 9 concludes the article and lays out avenues for future research.
2. Problem formulation
2.1. Robot and workspace model
We consider a robot manipulator operating in a workspace populated with a set of rigid bodies
The robot’s goal is to derive a plan that affects the world state in order to satisfy the human’s command. We model the plan
The robot’s decision-making and planning requires semantic knowledge about the world. We present a representation and a framework for estimating semantic aspects of the world in the next section.
2.2. Semantic attributes and knowledge
Let

A class of grounding symbols models Boolean object categories such as
A robot’s ability to follow commands is fundamentally tied to its knowledge about the world. The robot’s semantic knowledge about the world is typically informed via sensors that are noisy and error-prone. Hence, we introduce a representation to model the robot’s belief over semantic knowledge of the world. Let

Here, we assume that the distributions over each semantic property are independent. For example, if the workspace contains a “cup” and a “box,” the knowledge state
2.3. Following instructions under semantic knowledge uncertainty
The robot’s goal is to interpret and act according to the human’s instruction in the context of its current knowledge about the world. A planning model that reasons over which actions are applicable requires some knowledge about the objects the robot can potentially interact with. Note that we consider planning domains that may only be partially known. In particular, the robot may lack relevant semantic knowledge that is required for planning manipulation interactions. For example, manipulation tasks may require knowledge of the intrinsic object attributes that cannot be determined from visual observations alone. Consider executing the instruction “clear away the cups on the table,” in which empty cups should go in the trash and full cups should be put aside. This task requires knowledge of the internal states of the cups (full or empty) to decide how each cup should be treated. We consider three sources of non-exteroceptive knowledge for “filling in” knowledge about latent aspects of the world model: linguistic communication from the human, direct physical interaction by the robot, and commonsense knowledge corpora.
Formally, the robot is assumed to be primed with a background knowledge corpus
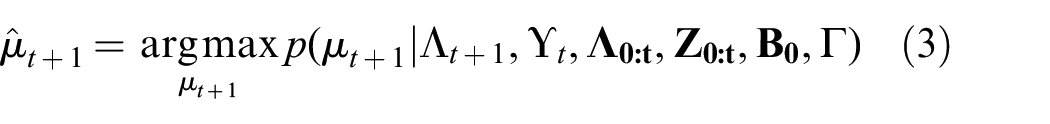
Equation (3) involves deriving actions from past linguistic and physical interaction measurements. This inference problem is intractable due to the large space of language and intrinsic force measurements. We introduce the explicit representation of semantic world knowledge
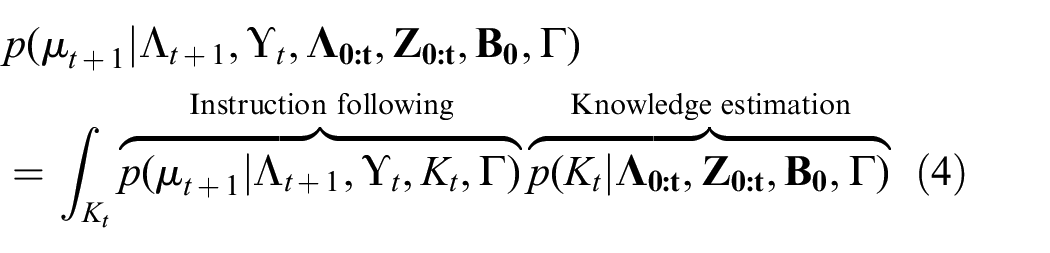
Here, learning the factor
Section 3 presents a probabilistic model of the belief over latent semantic properties informed by observations and prior knowledge. The factor
3. Bayesian multimodal semantic knowledge estimation
This section addresses the problem of estimating latent semantic attributes associated with objects in the world model from multimodal observations and background knowledge corpora. We first introduce a probabilistic representation of semantic knowledge and then present a Bayesian formulation for incremental online estimation using past language descriptions, direct physical interaction, and background knowledge corpora.
3.1. Probabilistic knowledge
The knowledge state

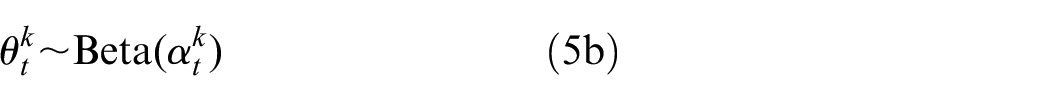
The distribution over
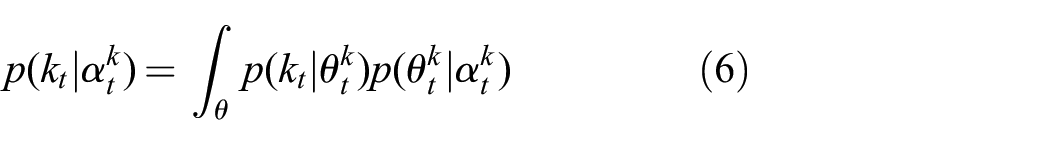
where the beta -distributed random variable
Our goal is to infer the knowledge state given past observations that arise from language and physical interaction
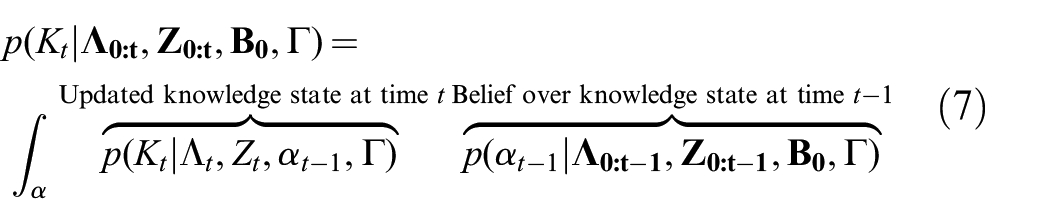
Here, the beta distribution parameter
Note that the factorization in Equation (7) assumes that, given the prior and current observation, the knowledge state is independent of the previous observations and background knowledge. Formally, the belief over the knowledge state
Now, we turn our attention to initializing the dynamic Bayesian network at time
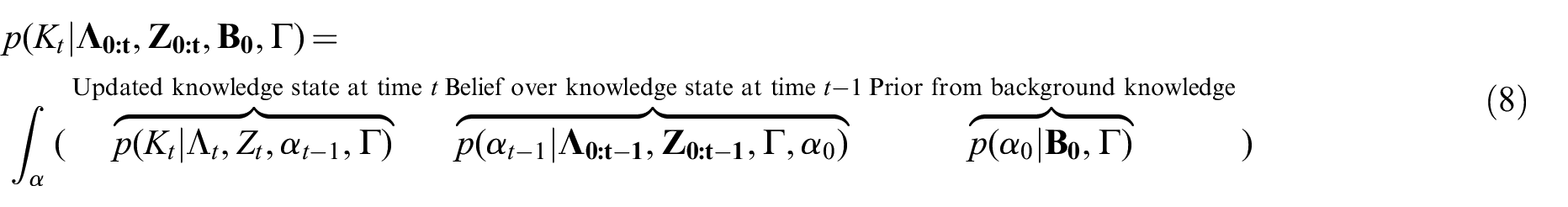
where the parameters
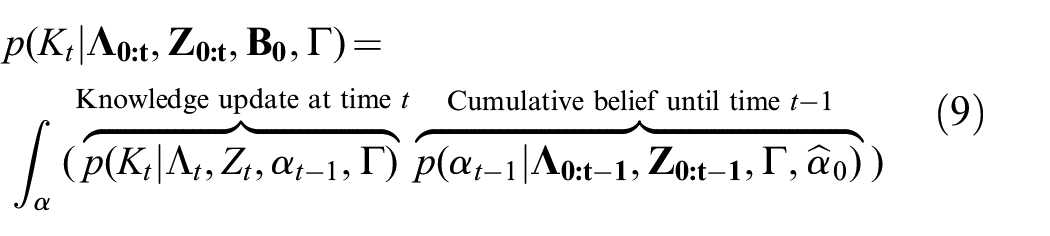
Figure 2 illustrates the overall probabilistic model. The remainder of this section is organized as follows. Section 3.2 describes the inference procedure at each step in the temporal model, specifically the updates to the distribution to account for language utterances and direct physical interaction. Section 3.3 addresses the problem of learning an informed prior over semantic knowledge from background commonsense corpora. Finally, Section 3.4 shows how semantic observations from multiple modalities can be fused into a probabilistic belief over world knowledge.
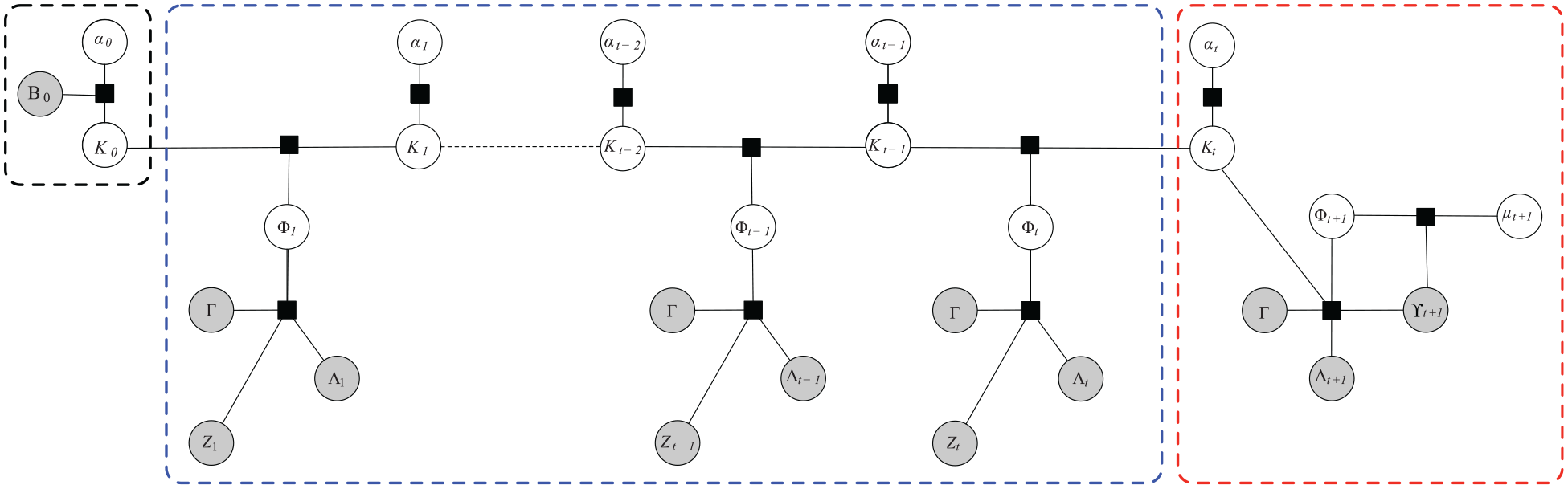
A probabilistic model for robot command following with learned semantic knowledge about world model entities. The model estimates a belief over the knowledge state
3.2. Estimating semantic observations from multimodal percepts
This section details the estimation of the knowledge state
Following earlier work on probabilistic language grounding (Howard et al., 2014a,b; Liang et al., 2013; Paul et al., 2018, 2017; Tellex et al., 2011b), we employ a binary correspondence variable
We extend the use of correspondence variables to associate physical interaction-based observations with the latent semantic object attributes. For example, a slowly increasing force profile while poking a barrel object is indicative of the object being pushable. Alternatively, if the force profile saturates rapidly, the robot can infer that the object is likely to be less pliable during manipulation.
The introduction of the correspondence variable allows us to factorize the distribution over the knowledge state as

Here, the factor
Note that Equation (10) involves directly fusing observations derived from multiple modalities into a belief over semantic attributes. Learning in the joint space of multiple modalities is likely to be tractable with a small number of modes. Further, we observe that language descriptions and force interactions arise from independent sources and may arrive at different instances in time. Language descriptions arrive opportunistically from the human, while force interactions are likely to arise from planned and controlled interactions by the robot. Hence, we assume conditional independence between observations arising from different modalities, which enables Equation (10) to be expressed as
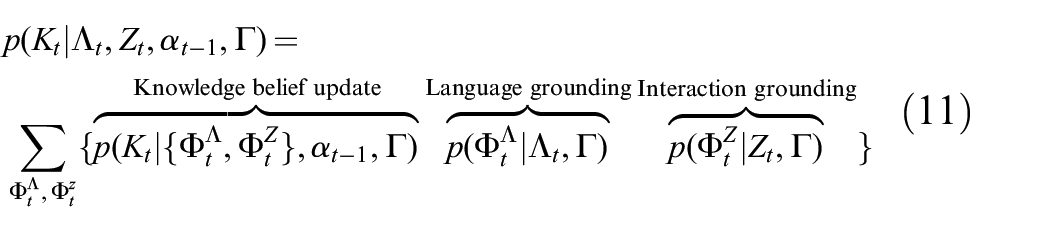
where
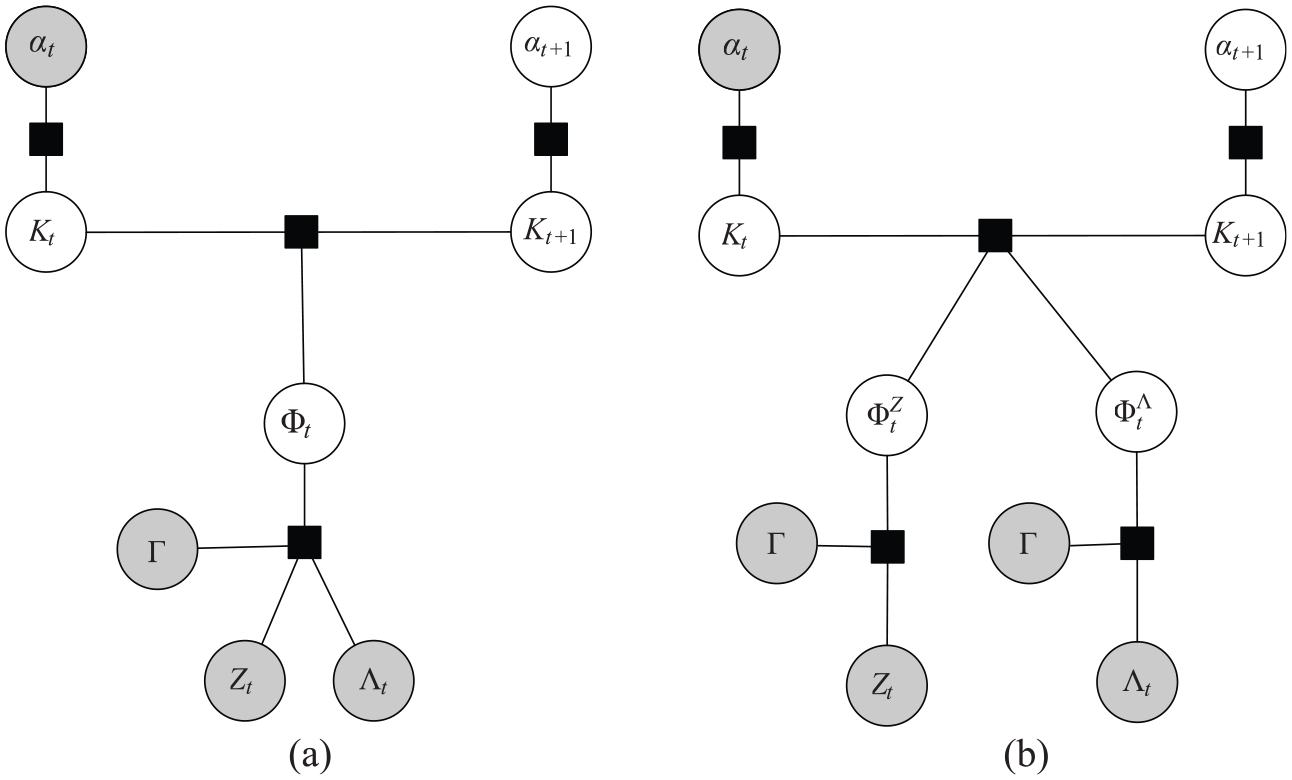
Probabilistic model for knowledge acquisition over latent object attributes from descriptive language utterances and physical interaction measurements instantiated at each time step t in the dynamic Bayesian network. (a) Joint model. Semantic observations are derived jointly from physical interaction measurement
Next, we discuss methods for deriving semantic observations from language and physical interactions. We then detail the belief update over the latent object attribute given the inferred semantic observations from each modality.
3.2.1. Estimating groundings from declarative language
We now consider the problem of interpreting factual knowledge about the world present in natural language utterances from the human. As an example, we aim to ground the declarative language utterance “the cup on the table is empty” to the predicate
The factor
We incorporate a contemporary approach to grounding factual knowledge from natural language utterances (Howard et al., 2014b; Paul et al., 2017). The approach exploits the linguistic parse structure of the utterance to factor the grounding problem into separate terms for each constituent phrase. This factorization permits inference over individual phrases rather than joint inference over the entire utterance, improving scalability. For example, the model learns a grounding for the utterance “the nearest cup” as the “cup”-type object nearest to the speaker. We represent the association between individual linguistic elements and semantic concepts using a log-linear model that expresses the likelihood of the linguistic features in each parsed constituent phrase and the corresponding “grounded” attributes of the world model. We train the model using an aligned corpus of utterances and known groundings in the context of a physical world model. The model leverages the inherent compositional structure in language and learns to assign meaning to simpler constituent phrases and structure them together to infer the meaning of an instruction received at runtime (Howard et al., 2014b).
Further, the model uses linguistic structure and part-of-speech information to partition the sentence (Paul et al., 2017) into (i) phrases that can be associated with physical aspects of the world (e.g., detected objects and spatial relations) and (ii) phrases that convey facts about the world (e.g., knowledge about the latent state of objects). The inferred factual knowledge conveyed in language provides positive or negative evidence for the underlying knowledge state of the entities described in the utterance. The ability to infer factual knowledge derived from language descriptions is particularly useful if the expressed facts relate to unobserved aspects of the world state. For example, the phrase, “the nearest cup is empty,” conveys information that is otherwise unobservable unless the robot interacts with the cup, i.e.,
We assume that the user’s utterances convey factual knowledge that they believe to be true according to their internal model of the world. In practice, we store each correspondence
The estimation of semantic attributes from the human’s utterance can be viewed as a declarative top-down inference over semantic world knowledge. Next, we address the problem of deriving semantic observations from proprioceptive measurements that arise as the robot physically interacts with the world.
3.2.2. Estimating semantic properties from physical interaction
The estimation of object attributes from physical interaction is an extensively explored area (Bhattacharjee et al., 2013; Chitta et al., 2011; Chu et al., 2015). The ability to infer certain sementic properties of objects from physical interaction helps to determine an appropriate plan in visually unobservable environment. In this work, we perform offline classification of object attributes (e.g.,
The factor
We use HMMs to define an object attribute estimator
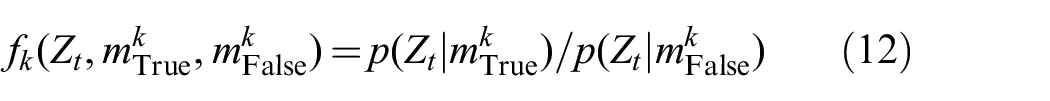
We threshold the above likelihood ratio to arrive at a binary classification, and thus
The HMM model m consists of state transition probability, emission probability, and initial state distribution: us from
3.3. Learning informed priors over semantic knowledge from commonsense corpora
In this section, we focus on the problem of inferring an informed prior over world knowledge derived from a noisy commonsense corpus. In the absence of any background domain knowledge, the initial prior of the model introduced in Section 3.1 can be left uninformed and as more observations and interactions are received, the model gradually converges to the true object attributes. However, estimating the latent object attributes can be hastened if we have an informed prior that is guided by experience. A source of experience can be found in commonsense corpora derived from human judgement tasks (Forbes and Choi, 2017; Rashkin et al., 2018; Vedantam et al., 2015; Yatskar et al., 2016). Such corpora contain crowdsourced human annotations indicating whether an attribute or a relationship is true for certain object types. For example, human judgements about the relative rigidness of plastic and metal containers would result in relational facts indicating that containers made of plastic are less rigid compared with metal containers.
Learning an informed prior over semantic knowledge

The factor
Learning the factor
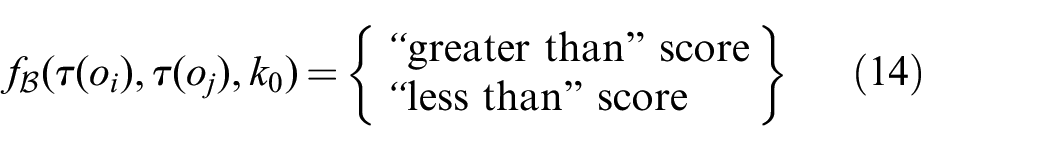
where
The aforementioned function
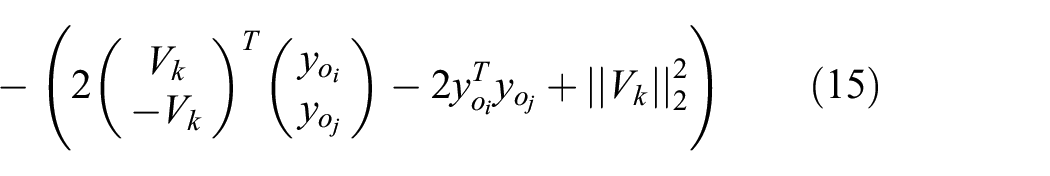
Bilinear
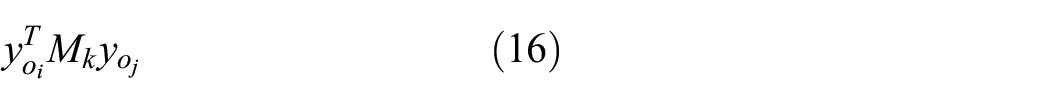
In the above definitions,
The learned function provides the prior distribution over knowledge state incorporated in Equation (8). Note that the learned relational model predicts the presence of relative physical properties from abstract object-type data before fusing observations. Online, the model is conditioned on the world model to obtain a distribution over semantic attributes that are relevant for the world model. Next, we turn our attention to the problem of fusing semantic observations derived from multiple modalities into a cumulative belief over latent semantic knowledge.
3.4. Estimating belief over knowledge from multimodal semantic observations
The set of semantic observations of the world state derived from language and physical interaction must be fused into the robot’s belief over semantic knowledge. The current observation
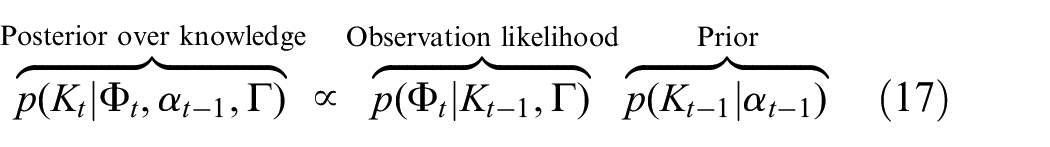
As the beta distribution serves as a conjugate prior for the
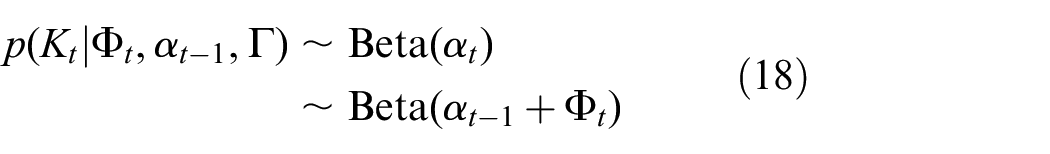
Here, the notation
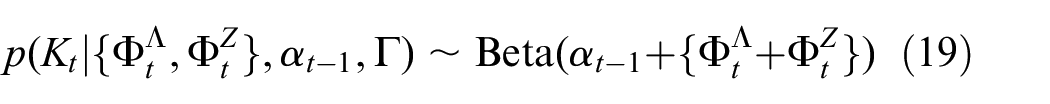
The posterior distribution over the latent knowledge variable evolves incrementally with each observation. The current beta distribution parameters after fusing current observation
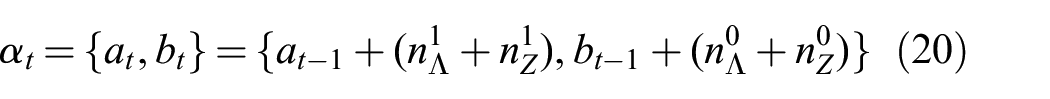
Here,
Finally, we turn our attention to representing the informed prior belief over
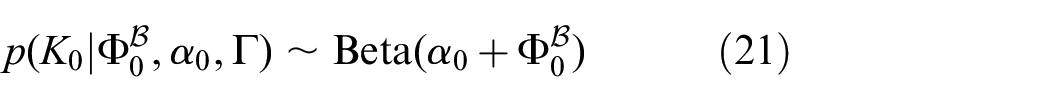
Recall, that prior knowledge derived from commonsense corpora serve as noisy observations of the latent semantic knowledge. As indicated in Equation (21), possibly noisy semantic assertions from background knowledge serve as pseudo-measurements and bias the beta distribution parameters before incorporating physical measurements.
Finally, we make a few remarks on the modeling choices in our probabilistic model. The model presented in this section allows the estimation and propagation of the belief over knowledge states derived from multiple and diverse sources. The ability to model uncertainty over latent state and to efficiently fuse multiple modalities provides robustness to noisy and possibly contradictory measurements. Our approach leverages conjugate priors over the likelihood over the correctness of semantic properties in the world model, enabling tractable and efficient posterior updates using observations collected online. The probabilistic formulation can be viewed as a form of semantic state estimation. Note that we perform inference over a restricted set of symbolic aspects of the world model. This approach can be considered a special case of more general models that represent beliefs over more complex logical rules (Zettlemoyer et al., 2008). The approach presented is also closely related to histogram filtering, which has been employed effectively for robot mapping and tracking applications (Thrun et al., 2005). The measurement updates in a histogram filter require empirically estimating sensor-specific detector rates. On the other hand, the Bayesian approach uses less-prescriptive uninformed priors that are updated with new evidence and is expected to be more robust to noise and erroneous measurements.
4. Instruction-following by introspecting knowledge uncertainty
Recall that our goal is to enable a robot to follow instructions in partially known domains where some object attributes necessary for synthesizing a plan are unobserved. For example, following the instruction “clear the cups on the table’ requires knowledge of the internal states of the cups to decide their appropriate destinations in the clearing task (i.e., empty cups should go in the trash and full cups should be put aside). Given the probabilistic model laid out in the previous section, the robot can form a belief over the unobserved semantic properties of the world model by integrating past observations and any available prior domain knowledge. We now consider the task of synthesizing a plan as per the human’s command in the context of the acquired knowledge about the world.
Formally, the robot determines a plan
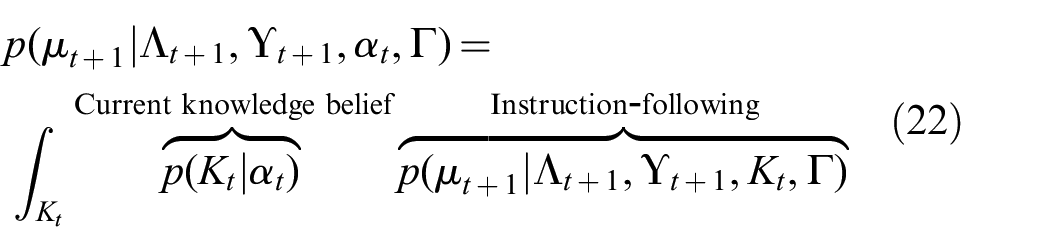
The instruction-following task, represented as
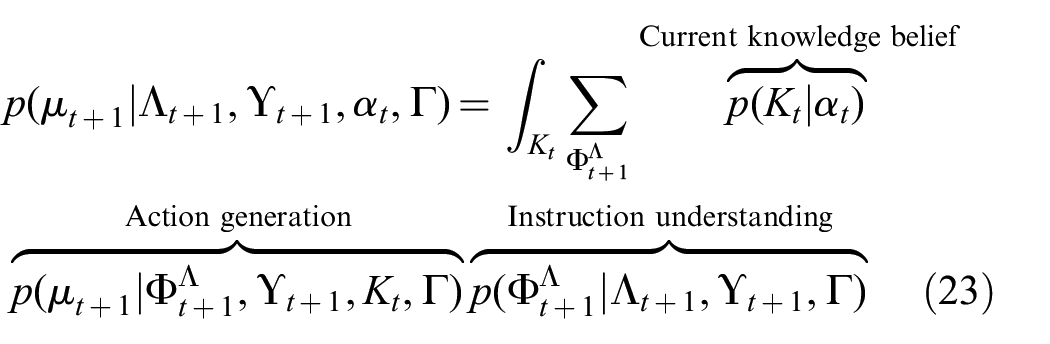
Using the maximum likelihood estimates for the knowledge state
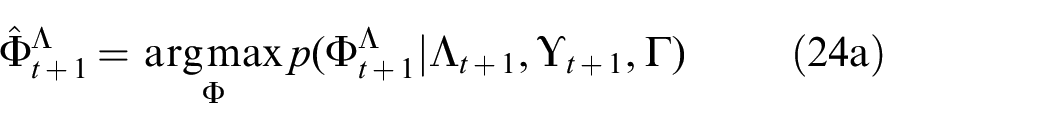

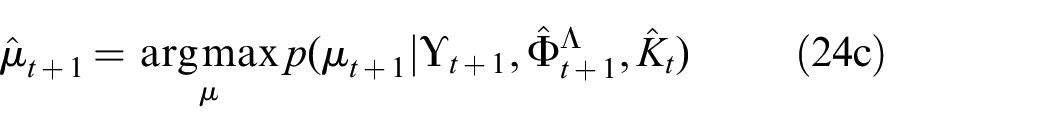
Here, the maximum likelihood estimate indicating the presence of a semantic property
The robot’s action generation takes into account the degree of uncertainty in the robot’s knowledge about the semantic properties of objects relevant to the input instruction. We compute the normalized entropy of the latent belief over semantic properties as a confidence measure for quantifying the robot’s uncertainty over semantic aspects of the world (Grimmett et al., 2016; Paul et al., 2013; Triebel et al., 2016). The presence of significant uncertainty in the robot’s knowledge belief (as indicated by high entropy of the belief distribution) allows the robot to take information gathering actions such as lifting, pushing, poking, or sliding. The new set of observations are used to update the robot’s belief over the latent object states. The robot continues to interact until the latent belief is sufficiently likely that the robot can execute the final action to complete a task described in the language instruction
5. Knowledge-state feedback to the human
Humans working in teams often share world knowledge to help accomplish tasks, such as letting a teammate know that a box is exceptionally heavy. When a teammate observes that the shared knowledge is not true, it is useful to share the corrected information, improving the entire team’s world model. One limitation of the system presented in Arkin et al. (2018) is the lack of a mechanism to provide direct feedback to the human teammate. Providing robots with the capacity to generate linguistic feedback is of particular use for cases in which the robot makes proprioceptive observations during object interaction that contradict world knowledge provided by the human. If we assume that the human teammate only shares world knowledge that they believe is true, then the robot has an opportunity to provide corrective feedback regarding the contradictory observations that should be useful for the human. Such feedback can help the human make better decisions in the future and can help prevent miscommunications owing to incompatible world models.
One approach to providing such feedback via a language interface is to store both the imperative phrase used by the human to reference the object of interest and the declarative phrase used to convey the specific world knowledge. By keeping track of knowledge that was provided by the human (as opposed to other sources of knowledge, e.g., from a commonsense database), the robot can trigger a feedback response upon making a contradictory observation. The linguistic feedback can be composed of the stored imperative and declarative phrases to indicate which object and associated semantic property were different than expected. This approach has the advantage of being computationally inexpensive in that the feedback can be generated by executing a simple lookup for the phrases stored previously. However, this mechanism is brittle to changes in the world that invalidate the stored reference phrase. For example, if the robot has moved close to an object in order to interact with it, what once may have best been described as “the barrel on the left” may now better be referred to as “the barrel directly in front” or “the nearest barrel.” As such, a declarative phrase such as “the barrel on the left is heavy” might best be corrected with linguistic feedback such as “the barrel nearest to me was not heavy.”
In order to address this brittleness, we pursue an alternative approach by inverting the learned language understanding model to generate phrases associated with the symbolic representation for both the object and hidden semantic state of interest as conditioned on the current spatial configuration of objects in the world. While this does make the feedback robust to changes in the world, it trades off the relatively low computational cost of looking up stored phrases for a significantly higher computational burden of searching over language phrases for one that sufficiently expresses the meaning intended by the symbolic representation. This section details the process for generating linguistic feedback via inverting a language understanding model.
5.1. Communicating knowledge-dissonance to the human
Consider a scenario in which a human teammate says, “the cup on the table is empty.” The robot will ground this declared knowledge and update its belief over the hidden state of the cup’s fullness. Unless the human is intentionally giving false information, the robot can also note that the human’s model of the world includes the confident belief that the cup on the table is empty. Suppose the robot then interacts with the cup and makes an observation indicating that the cup is actually full. In this case, it would be useful for the robot to be able to express this disagreement back to the human, thereby providing a correction to the human’s world model and allowing them to make more informed decisions in the future.
We are interested in a mechanism that facilitates providing this kind of feedback via a natural language interface, namely generating sentences to convey observations that contradict human-provided knowledge. By inverting the learned language understanding model used to ground declarative knowledge, the robot can effectively search for the most likely phrases that map to the set of groundings representing the object of interest and its semantic state. In related work (Tellex et al., 2014), this problem has been referred to as inverse semantics. Here, forward semantics refers to the process of taking language and finding associated entities or concepts in the physical world, and while inverse semantics refers to the process of takings aspects of the world and finding language to describe them. The problem formulation and subsequent factorization is inspired by Tellex et al. (2014). The main difference between their approach and what is being done in this work lies in the language understanding model. Tellex et al. (2014) used generalized grounding graphs (Tellex et al., 2011a) as the underlying language understanding model, whereas the work presented here uses distributed correspondence graphs (Howard et al., 2014b). Using a different underlying language understanding model has important implications for the subsequent model formulation and factorization. The main advantage in this case is the improved runtime performance, the results of which are presented in Howard et al. (2014b).
The problem of inverse semantics for generating feedback can be formulated as search for the most likely sentence corresponding to the intended meaning in the context of the robot’s knowledge about its world. Formally, we estimate a feedback language utterance
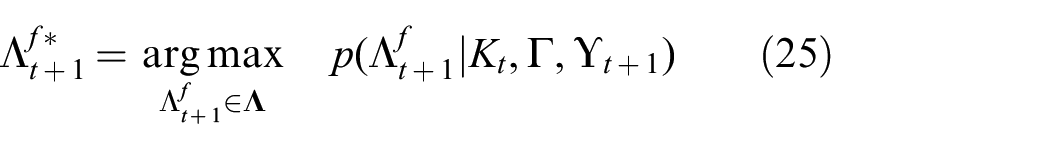
The space of possible sentences
As we have done for language understanding, we can model this inference process as a correspondence problem wherein the value of a correspondence variable
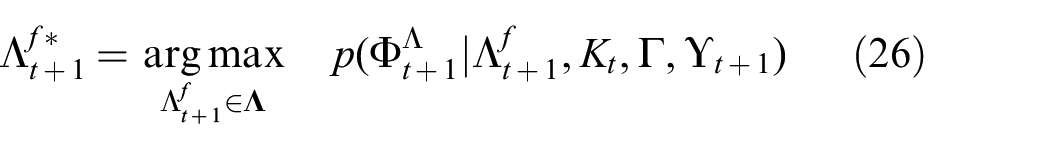
In practice, the inverse semantics process is a series of forward semantics evaluations in which the choice of language is an element from
6. Improving runtime performance of language understanding and generation
When designing language interfaces, it is important to consider how long the system takes to react or take an action after receiving an utterance from the human. In the proposed system, the runtime performance of the inference process is the main computational bottleneck that contributes to this latency. Interfaces to robotic systems should aim to achieve real-time responsiveness in order to maintain their effectiveness, as motivated in Section 1 with respect to mission tempo. While the work presented thus far leverages prior research on model approximations for fast inference, language grounding is treated as a reactive process. We propose further addressing this latency problem by precomputing language and grounding solutions for a given environmental context, a process we refer to as proactive symbol grounding. By instead proactively inferring the meaning of utterances a human teammate might say (in the context of the current state of the environment), the system has the possibility of receiving a new utterance with the solution already in-hand.
6.1. Proactive symbol grounding for language understanding
In our model, the language grounding factor acts as a computational bottleneck as it involves a search over a large space of interpretations for an input instruction. Rather than reactively interpreting a full instruction, which introduces an interaction latency as previously described, we instead proactively compute groundings for phrases that are likely to be relevant for future instructions. This improves the inference runtime by boot-strapping a novel utterance with estimated groundings (true correspondences) from the set of proactively grounded phrases possessing a similar parse structure. For example, consider the novel instruction “put the empty cup in the trash can.” If the robot has already proactively grounded the constituent phrase “the trash can” for the current state of the world, then the reactive inference process can simply insert the solution for “the trash can” and move on to other phrases in the parse tree.
Formally, the set of proactive correspondences
Recall that the command-following task can be formulated as Equation (23) defined in Section 4. Interpreting the instruction requires computing the groundings for the full instruction, i.e., for each phrase in the parse tree. A proactive approach precomputes a set of candidate correspondences for likely phrases as denoted as
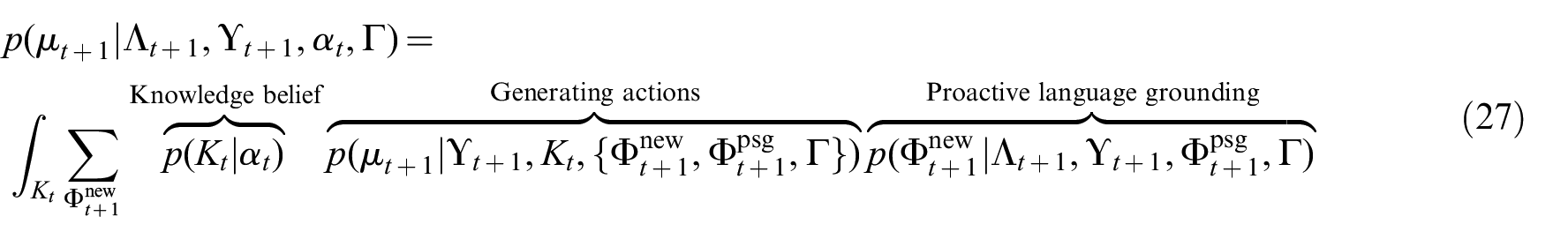
Note that the factor

Experiment evaluating knowledge acquisition over latent object attributes from declarative knowledge and physical interaction. The Baxter robot was instructed to “clear away the cups on the table.” Top: The robot attempts to pick up each cup in turn and infers the latent attribute of the cups from the time series of interactions. Once the belief is sufficiently confident, the robot discards the empty cup in the trash bin and puts the filled cup on the tray. Bottom: The human informs the robot that “the cups on the table are empty” a fact that is true only for only one of the cups. The robot’s physical interaction results in a posterior belief correcting the prior that resulted from the incorrectly stated fact. The posterior allows the robot to correctly accomplish the task of clearing in correct locations.
6.2. Proactive symbol grounding for feedback generation
One of the main limitations of the approach introduced in Section 5 is the runtime performance. Finding the sentence that maximizes the probability of the known set of groundings can be thought of as a series of forward passes through the learned language understanding model. As a result, the time it takes to finish the search process depends on the runtime of each forward pass. Depending on the size of the search space, this can be prohibitively long. Fortunately, the set of proactively grounded phrases
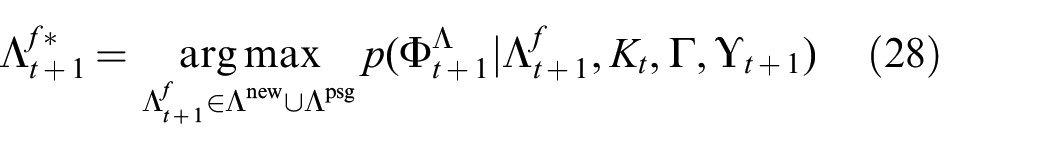
By effectively bootstrapping the search over language with a subset of already-grounded sentences, the reactive language generation process has fewer computations. In the best case, the proactive language grounding process will have already exhausted
7. Experiments and results
In order to validate the performance of the proposed system and its components, we designed independent qualitative and quantitative experiments.
7.1. Qualitative evaluation
The first experiment aims to show knowledge acquisition over latent object attributes from declarative knowledge and physical interaction. We used a Baxter Research Robot in a tabletop setup populated with household objects as shown in Figure 4. In the first scenario, the robot’s workspace contained two coffee cups (with closed lids), a tray and a trash can; the internal state of the cups was hidden with one cup being empty and the other full. We assume that the robot possesses learned background knowledge that empty cups are to be discarded in the trash and full cups are to be placed on the tray. As discussed in Section 3.2, the robot also possesses trained HMMs for classifying signatures from physical interaction with the cups. A plot of the different z-axis force measurements for a full and an empty cup can be seen in Figure 5(a). The robot did not have access to the internal state of the cups. The robot was instructed to “clear away the cups on the table” resulting in a grounded solution referencing the two coffee cups. The grounding model estimated the probable grounding of the sentence as the two cups on the table. The robot picked up each, updating the belief over the latent attributes according to force/torque sensing. This knowledge allowed the robot to estimate the correct location to discard the empty cups in the trash and place the filled cups on the tray.
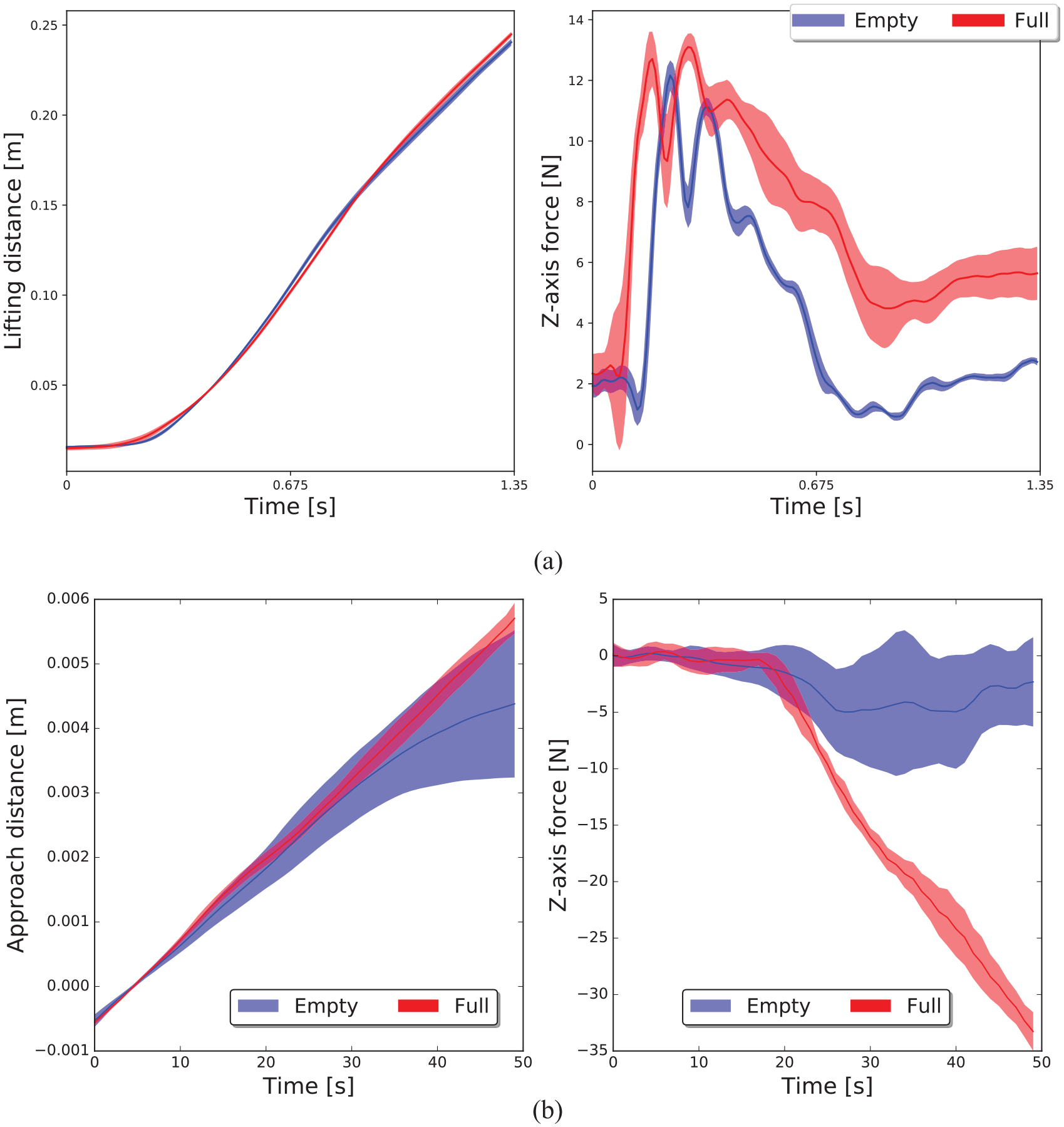
Distribution of physical interaction time-series measurement during manipulation. (a) Lifting distance and z-axis force measurements over time for both full (red) and empty (blue) cups in Figure 4. (b) Approaching distance and z-axis force measurements over time for both full (red) and empty (blue) barrels in Figure 8. The time-series force measurements for the “full” and “empty” object states. The patterns of force measurements over distances are modeled by two HMMs that are then leveraged during log-likelihood-based binary classification to infer an object’s attribute.
In a subsequent scenario, the human declared “the cups on the table are empty” before instructing the robot to “clear away the cups.” Contradictory to the initial statement, the actual state of one of the cups is filled and should not be discarded. The robot determined the true state of the cups during interaction, correctly updating its prior belief from force/torque sensing and choosing the correct actions.
Figure 6 shows the resulting changes to both the beta distribution and the expected likelihood of the expressed fact as the robot interacts with one of the cups in the first scenario. The robot first receives a declarative fact from language expressed as “the cups on the table are empty,” leading to a posterior update to the Beta hyper-prior for the likelihood using the estimated grounding
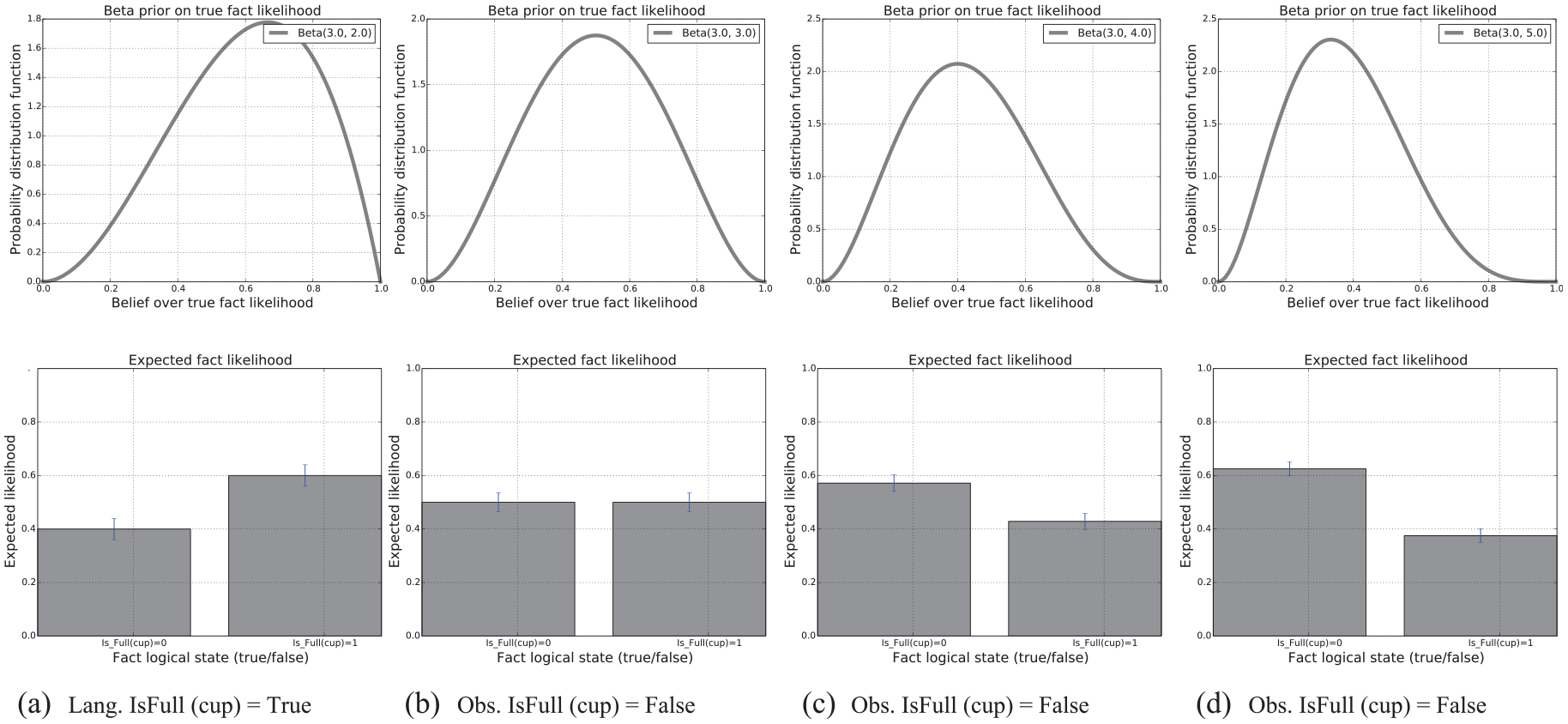
The temporal evolution of belief over factual knowledge informed by language and interaction. The beta distribution at time t for the Bernoulli likelihood over factual groundings is plotted in the top row. The maximum likelihood for a predicate state appears below. Temporal evaluation from left to right. The initials “Lang.” and “Obs.” denote estimated groundings obtained from language and time-series interaction data, respectively. The estimation of the correct belief allows the robot to correctly follow the instruction of clearing the empty cups to the trash and placing the fill cup on the tray.
In the second experimental evaluation, we tested an integrated system that incorporates both the proactive symbol grounding process for fast inference and the joint use of declarative knowledge and force sensing for updating beliefs about objects’ attributes. The goal of this qualitative experiment was twofold: (1) to demonstrate a scenario in which faster task completion can be achieved by incorporating human-declared knowledge about the world as compared with relying on physical interaction observations alone, and (2) to demonstrate robust task execution when provided incorrect world knowledge by a human. For this second experiment, we used a Clearpath Husky A200 mounted with a Universal Robots UR5 manipulator in a mobile manipulation setting composed of two Pelican cases, as shown in Figure 7; the internal state of the Pelican cases was hidden. The Pelican case on the robot’s left was full and heavy, and the Pelican case on the right was empty and light. We executed three different types of scenarios in this experiment: (i) no declarative knowledge, (ii) accurate declarative knowledge describing the state of the two Pelican cases, and (iii) inaccurate declarative knowledge. In one case of (i), the Husky was instructed to “pick up the heavy case,” resulting in an ambiguous grounded reference solution. The robot picked up the left case, updating the belief that it was heavy; a second interaction made the robot confident enough to complete the action. In one case of (ii), the human accurately declared “the case on the left is heavy,” followed by “pick up the heavy case.” The robot picked up the left case, updating its belief, which reinforced the human’s provided fact. A single force/torque interaction and the accurate declared fact made the robot sufficiently confident to complete the action; the fact reduced the number of required interactions. In one case of (iii), the human declared “the case on the right is heavy,” followed by “pick up the heavy case.” The robot picked up the case on the right, updating its belief in contradiction to the human’s provided fact. The robot then lifted the left case twice to be sufficiently confident and complete the action.

An experiment incorporating both proactive symbol grounding and updates to beliefs about objects’ attributes via declarative knowledge and force/torque sensing. (a) Initial state of the right case is heavy. (b) Updated belief is uncertain about heavy case. (c) Interaction with the other case. (d) Updated belief that the left case is heavy. The Husky robot with a mounted robot arm was inaccurately told “the case on the right is heavy” before receiving the instruction “pick up the heavy case.”
The third experiment, illustrated in Figure 8, was a part of a field test held in a mock village marketplace at an undisclosed testing facility. Deployed on a separate Husky with a UR5 manipulator, we demonstrated an integrated system that incorporated both previously evaluated components and declarative knowledge feedback. Similar to previous experiments, we trained an

Experiment demonstrating the declarative knowledge feedback and latent attribute update by declarative language utterance and physical interaction. The Husky robot with a UR5 arm is placed in a outdoor test site filled with doors, windows, barrels, bicycles, among other objects. A user verbally provided wrong and right declarative knowledge for empty and full barrels, respectively. The robot then estimates and reports the latent attribute to the user by pushing each.
Videos for all qualitative evaluations are submitted as a multimedia Extensions 1–3.
7.2. Quantitative evaluation
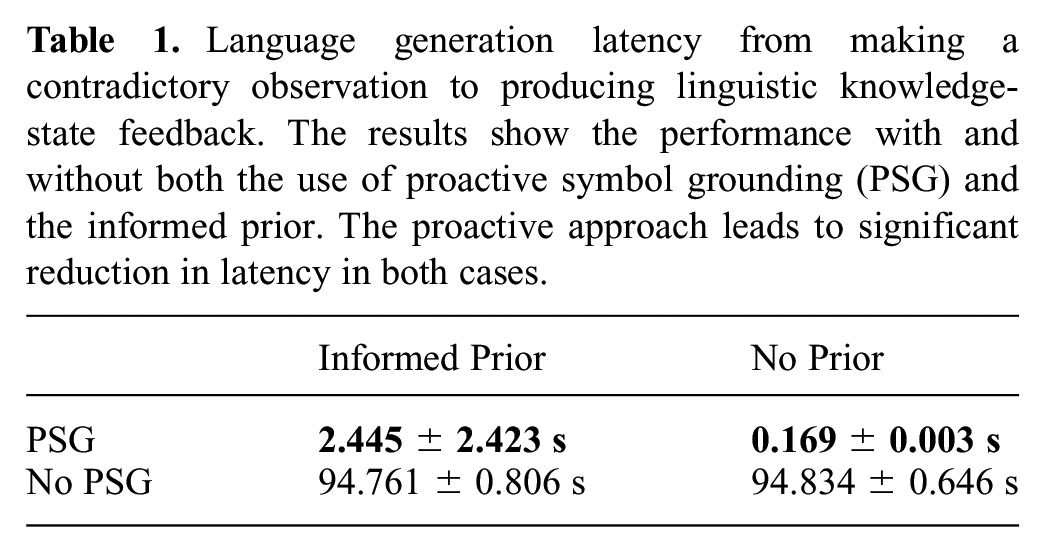
The first statistical evaluation targets the impact of both the PSG component and use of the commonsense knowledge base informed priors on the latency of generating linguistic knowledge-state feedback. In particular, this evaluation seeks to quantify the change in feedback generation time (i.e., from the time the utterance is received to the time a response is generated) as a result of including one or both of these system components. The forward semantics model was trained on a corpus of 807 annotated examples composed of a variety of symbolic concepts including objects in the world, object categories, physical object properties, spatial relationships, regions, and symbolic actions (see Section 2). By leveraging idle system time while the robot physically interacted with an object, the PSG process was able to precompute the solutions for a subset of 550 different language phrases that could describe the object. When the robot identifies an incorrect fact, it searches over six possible fact templates that are populated using the most likely phrase describing the object of interest, where this phrase is found via the inverse semantics process described in Section 5. The baseline case allowed no time for PSG to run, instead requiring the process to trigger reactively. In the best case, it was able to exhaust the full set of language phrases and provide fast feedback. As can be seen in Table 1, proactive symbol grounding contributed a significant reduction in the latency of feedback generation. Because the use of an informed prior can reduce the number of physical interactions necessary for the robot to become sufficiently confident about a contradictory observation, it consequently limits the idle system time that can be used for PSG.
Language generation latency from making a contradictory observation to producing linguistic knowledge-state feedback. The results show the performance with and without both the use of proactive symbol grounding (PSG) and the informed prior. The proactive approach leads to significant reduction in latency in both cases.
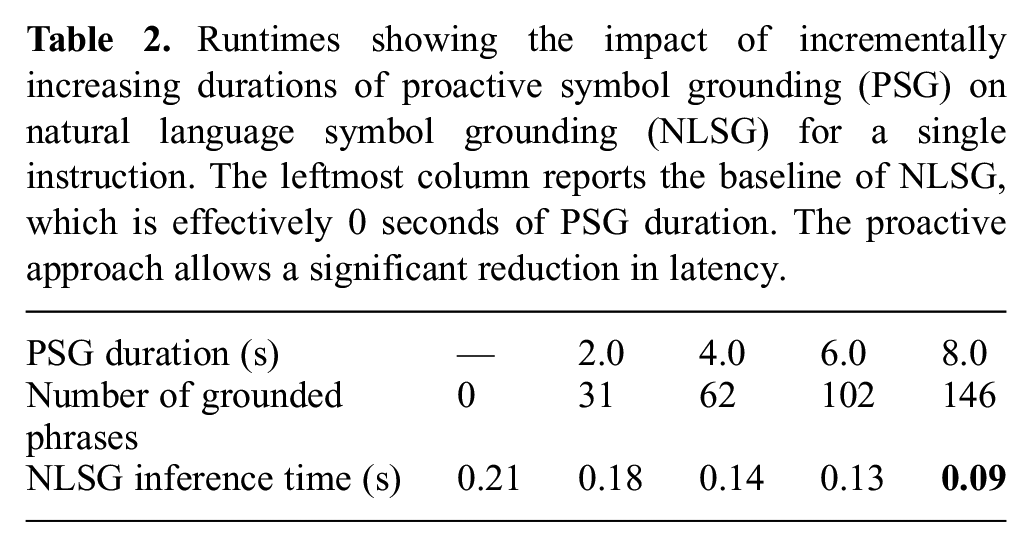
A second statistical evaluation targets the proactive symbol grounding component for natural language symbol grounding in simulation and quantitatively compares the inference runtime to a reactive baseline. This experiment is designed to address the question of how the amount of idle system time impacts the contribution of PSG on improved runtime performance of the inference process. For this experiment, we assumed a sufficiently expressive symbolic representation (Paul et al., 2018), a grammar, and a corpus of annotated examples used for training. To quantify performance, we trialed different durations of proactive grounding time, increasing from 0 seconds to 8 seconds in 2 second intervals, during which the process grounded candidate phases, illustrated in Table 2 as “PSG duration” (proactive symbol grounding duration) and “Number of grounded phrases,” respectively. The row “NLSG inference time” (natural language symbol grounding time) reports the runtime for a novel utterance; as expected, the runtime decreases as a function of the PSG duration owing to the process generating more matches to phrases in the novel utterance’s parse tree and, thus, reducing the number of phrases to be computed at inference time. We include a trial with 0 seconds of proactive grounding time to establish a baseline of performance for the natural language symbol grounding process without any bootstrapping by the proactive grounding module.
Runtimes showing the impact of incrementally increasing durations of proactive symbol grounding (PSG) on natural language symbol grounding (NLSG) for a single instruction. The leftmost column reports the baseline of NLSG, which is effectively 0 seconds of PSG duration. The proactive approach allows a significant reduction in latency.
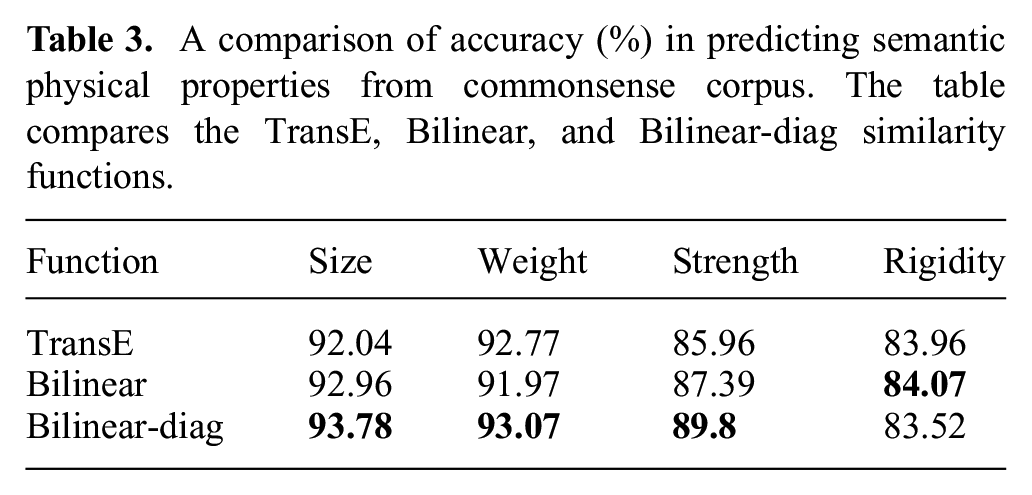
Next, we evaluated the accuracy of predicting semantic properties using the model trained from commonsense corpora. We evaluated the performance of three scoring functions that were introduced in Section 3.3. We trained the model using the aforementioned scoring functions with the VerbPhysics dataset containing 2,500 object pairs annotated with relative physical properties. The goal of the classifiers is to predict one of the four classes (greater, less, equal, or unknown) given an object pair and a physical property as input. The corpus was split into training, development and test set in the ratio
A comparison of accuracy (%) in predicting semantic physical properties from commonsense corpus. The table compares the TransE, Bilinear, and Bilinear-diag similarity functions.
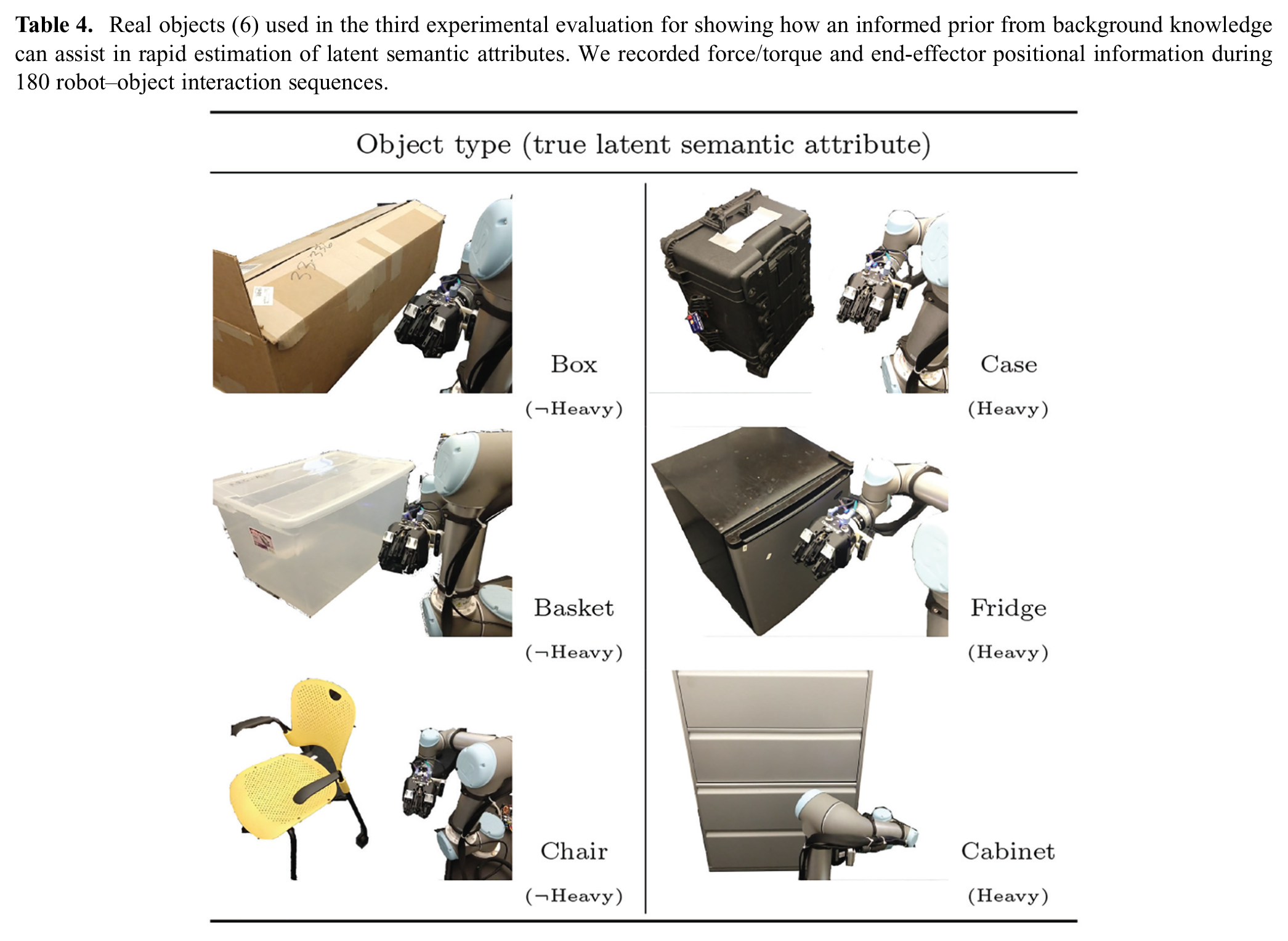
We also quantitatively evaluated the impact of using an informed prior on the accuracy and rate of convergence of the belief to the correct estimate of a semantic property as the robot interacts with an object. We selected six objects for our environment: a box, a basket, a chair, a case, a fridge and a cabinet (see the images in Table 4). For each object, we focus on estimating whether each of the objects is heavy or light for the purposes of manipulation using a UR5 manipulator. The robot interacted with each object
Real objects (6) used in the third experimental evaluation for showing how an informed prior from background knowledge can assist in rapid estimation of latent semantic attributes. We recorded force/torque and end-effector positional information during 180 robot–object interaction sequences.
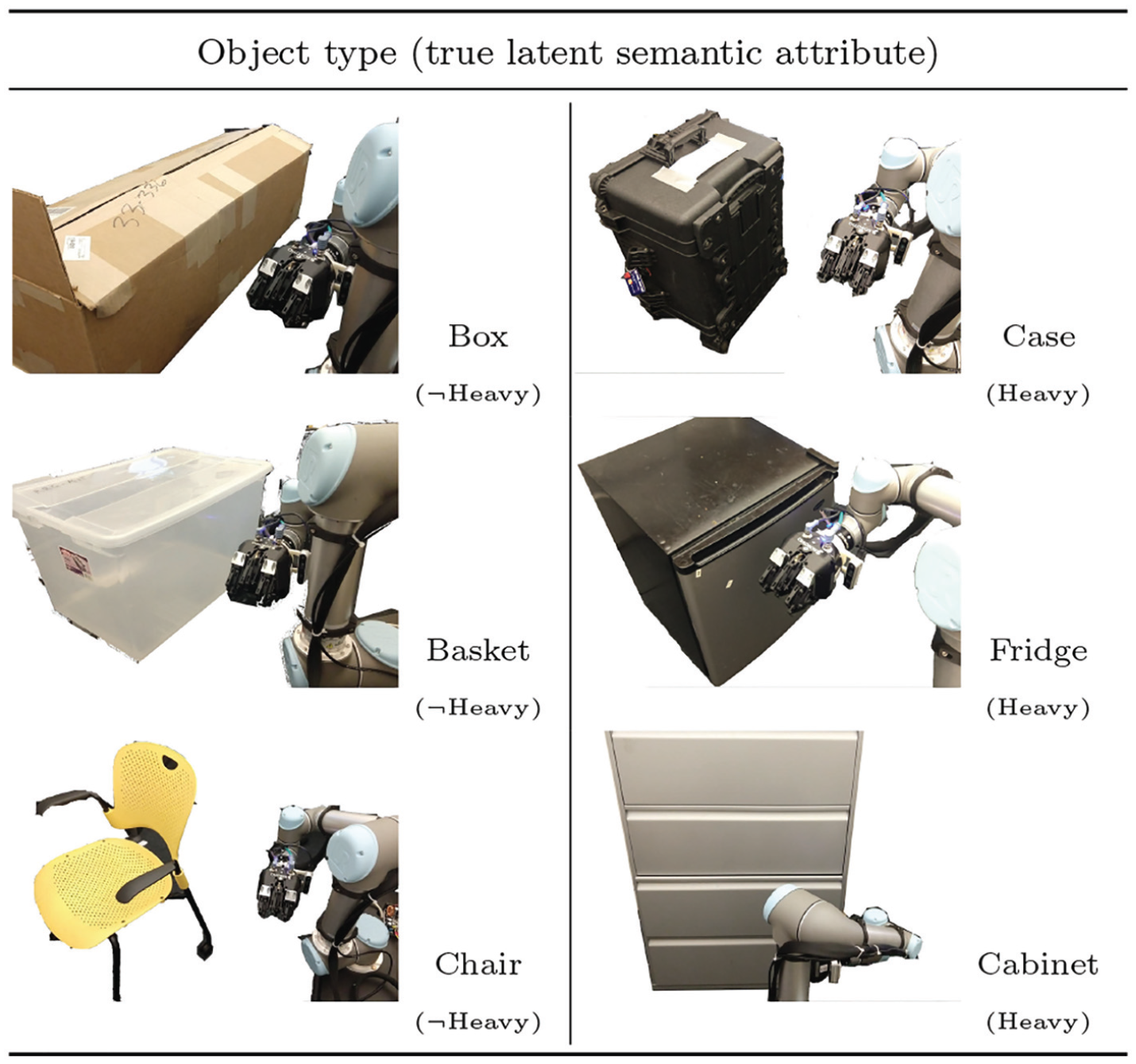
Next, we estimated the heavy/light semantic property using the physical interactions alone and subsequently incorporated the informed priors along with the physical interactions. In each trial, we recorded the number of interaction attempts necessary to infer the property of the object. If we inferred the wrong attribute or we were not able to infer the correct property even after incorporating the entire sequence, the number of attempts was set to
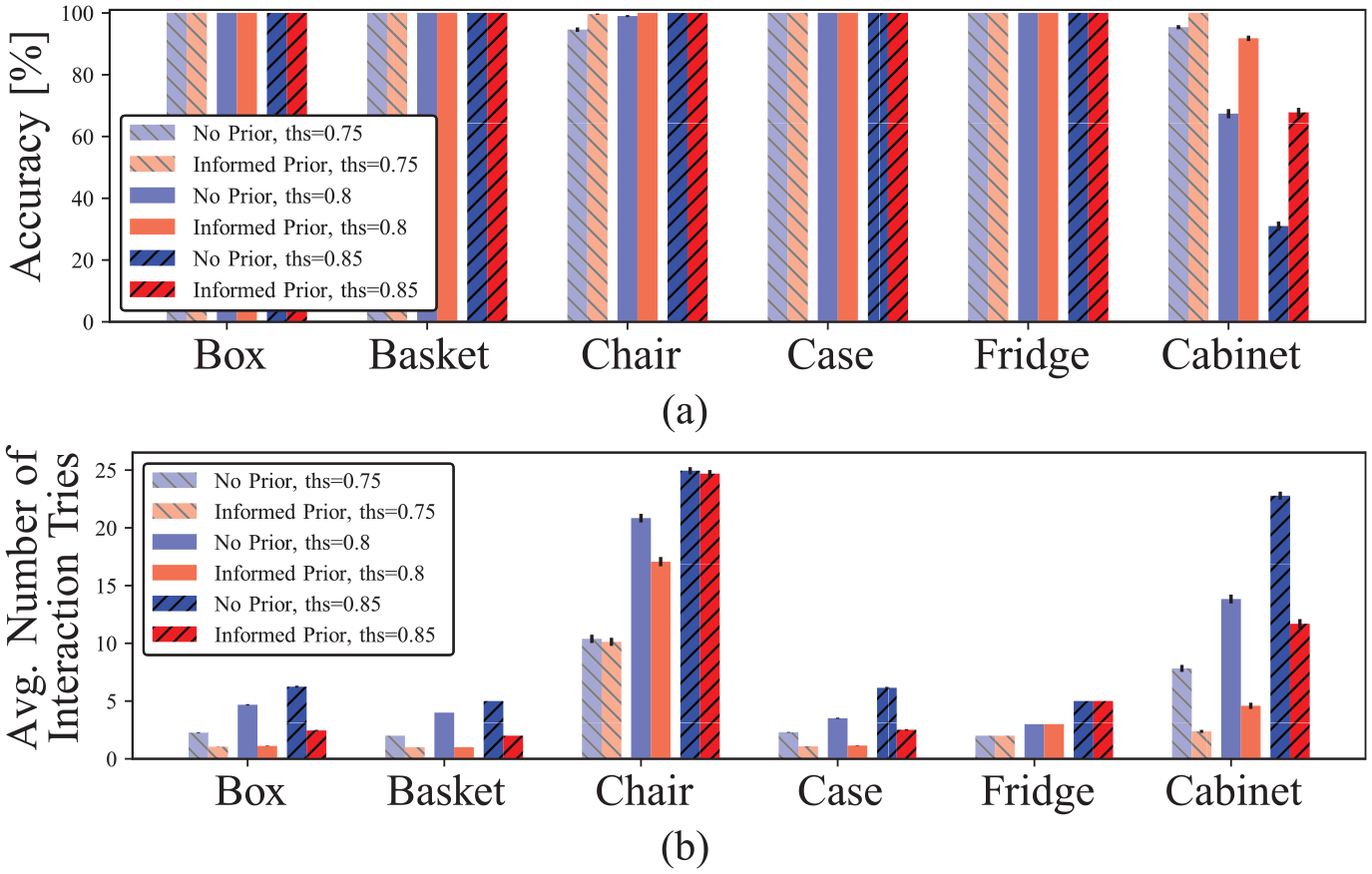
Comparison of latent-attribute estimation results with or without informed prior over three likelihood thresholds,
Finally, we evaluated a fully integrated system that incorporated previously evaluated components, PSG, and linguistic feedback generation. As shown in Figure 10, we placed a Husky with a UR5 manipulator in a partially observable environment with a “full” semantic attribute of a Pelican case. In the scenario, the robot first recognized the Pelican case by using a RealSense camera mounted on the rear sensor arch. A human operator then provided a declarative fact, “the case is full” or “the case is empty.” Otherwise, the operator did not provide any fact. The robot was then commanded to infer the Pelican case’s latent attribute through physical interactions with or without informed prior. Once the belief over any latent attribute is higher than a threshold (i.e., 0.9) via Bayesian update, the robot reported the inference result. The robot performed five experiments per each scenario (total six scenarios), correctly estimated the true attribute (i.e., “full”), and recorded the number of required physical interactions with belief changes per each. Figure 11 shows both informed prior and correct factual knowledge are helpful to minimize the number of required physical interactions. It shows the Bayesian semantic knowledge estimator successfully propagated the belief over semantic world properties from multiple and diverse sources, and also presents the probabilistic model corrected inaccurate knowledge, “empty” or no prior, online.

Semantic latent-attribute estimation experiment. The Husky robot with a UR5 manipulator detects a Pelican case using a RealSense camera and attempts to touch it to infer a latent attribute that is not visually observable.
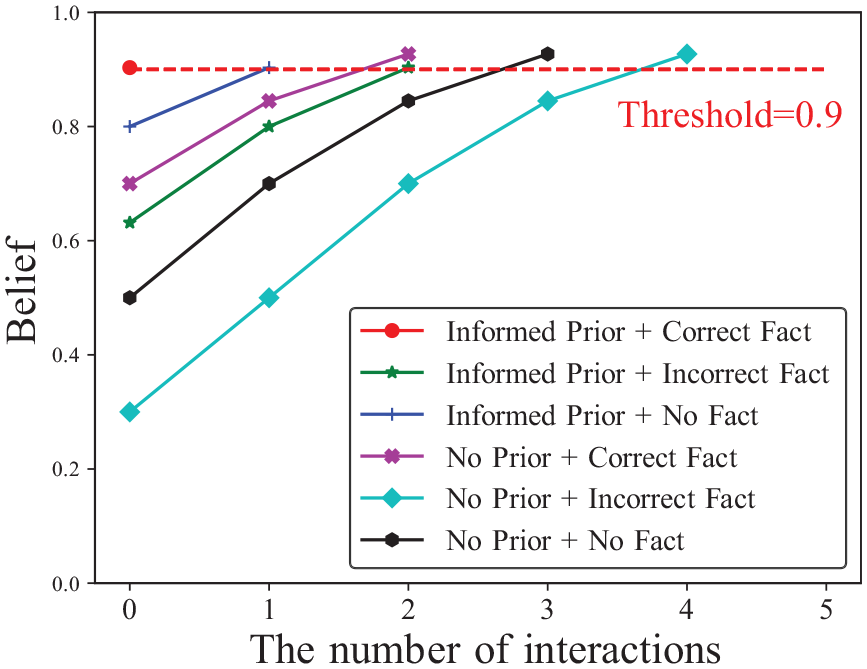
Comparison of semantic latent-attribute estimation with or without informed prior over declarative knowledge. The Husky robot with a UR5 manipulator attempted to touch a Pelican case (see Figure 10) and infers its latent attribute (i.e., full). Once the belief over any attribute is higher than the 0.9 threshold via Bayesian update, the manipulator finishes the estimation.
Note that the commonsense corpora derived from human annotations might contain erroneous facts resulting in incorrectly informed priors. Either incorrect utterance or incorrectly informed priors may lead to incorrect linguistic feedback, which is not observed in our experiments.
8. Related work
Significant attention has been paid to the problem of endowing robots to interpret natural language instructions. Contemporary statistical approaches to language understanding been developed that enable robots to follow complex free-form instructions that involving object manipulation (Misra et al., 2016; Paul et al., 2018; Shridhar and Hsu, 2018; Thomason et al., 2016), navigation (Howard et al., 2014b; Kollar et al., 2010; Matuszek et al., 2010, 2012b; Thomason et al., 2015), and mobile manipulation (Tellex et al., 2011b; Walter et al., 2014a). Such approaches commonly formulate language understanding as a problem of learning a model that associates (i.e., “grounds”) each word in a free-form utterance to its corresponding referent in the robot’s model of its state and action space (Harnad, 1990; Howard et al., 2014a,b; Tellex et al., 2011b). Most existing methods assume that the robot’s model of the environment (the “world model”) is known a priori, typically in the form of a map that expresses the semantic and metric properties of objects and locations necessary to interpret the command.
Instead, we have proposed and evaluated a probabilistic framework that enables robots to exploit multimodal observations, including linguistic, visual, and haptic measurements, to infer latent properties of its environment necessary for human–robot collaboration in partially observed settings. Earlier work in this area includes that of Duvallet et al. (2013), which learns to follow navigational instructions in unknown environments based upon human demonstrations, as well as recent work on language-based visual navigation in novel environments (Anderson et al., 2018; Mei et al., 2016a). More closely related to our framework are methods that leverage metric and semantic information implicit or explicit in the command to learn a distribution over world models that facilitates natural language understanding in a priori unknown environments (Duvallet et al., 2014; Hemachandra et al., 2015; Oh et al., 2016; Walter et al., 2014b). We address a different element of “partial observability” by inferring the state of object attributes as opposed to hypothesized locations of objects or landmarks that exist beyond the robot’s field of view or its internal map of the explored world. We also incorporate a novel knowledge state variable in our graphical model and incrementally update a distribution over that knowledge state rather than reason over a distribution of maps.
Meanwhile, recent methods similarly exploit multimodal observations to learn object attributes. Of this body of work, some approaches incorporate human gestures as an input modality to learn object and relation classifiers, as well as attributes such as color (Kollar et al., 2013a; Matuszek et al., 2014; Whitney et al., 2016). Others incorporate audio and haptic measurements as sensing modalities to learn attributes that are not visually observable (Chu et al., 2015), such as whether a container is full or not based on the sounds produced while picking up and shaking (Sinapov and Stoytchev, 2009). Related, some methods directly learn behavior- or sensorimotor-grounded classifications (Hogman et al., 2013), such as the work of Sinapov et al. (2014) that uses vision, proprioception, and audio to learn semantic labels for objects while the robot interactions with them.
Relevant to the goals of this work are methods that consider the problem of understanding instructions that are ambiguous in the context of the robot’s model of its state and action space. Among these methods are those that employ inverse groundings (Gong and Zhang, 2018; Tellex et al., 2014) as a means of asking targeted questions that are believed to be most informative in an estimation-theoretic sense (Tellex et al., 2012). Related, a number of techniques have been proposed to learn a priori unknown grounding models by exploring models that relate novel linguistic predicates to the robot’s world model or directly to its percepts (She and Chai, 2017; Thomason et al., 2018, 2016; Tucker et al., 2017). Our work differs in that we assume that the concepts are known, but that the instantiation of these concepts in the robot’s environment are unknown.
Our contribution leverages language as a source of information about latent object states by grounding declarative statements from user utterances. Other natural language symbol grounding approaches that incorporate declarative knowledge (Kollar et al., 2013b; Matuszek et al., 2012a; Paul et al., 2017; Perera and Allen, 2013; Thomason et al., 2016) assume that such information is correct and sufficient for task execution. In contrast, our model incrementally fuses information from language and force/torque interactions, making task execution more robust to inaccurate or incorrectly understood declarations.
In the event that the robot identifies discrepancies between the declared knowledge and its observation of the environment, our framework conveys this disagreement to the user via generated language. Our approach is related to recent work on inverse symbol grounding (Tellex et al., 2014), which is typically considered in the context of engaging the user in dialog to resolve ambiguities in the task (Deits et al., 2013; Hemachandra and Walter, 2015; Raman et al., 2013; Tellex et al., 2012). With this approach, we invert our learned language understanding model to identify the set of phrases that are most likely to correspond to the particular properties of the environment of interest. Unlike Tellex et al. (2014), who used generalized grounding graphs (Tellex et al., 2011b), we use the distributed correspondence graph language model (Howard et al., 2014a), which affords more efficient inference. We also identify phrases by explicitly optimizing over their likelihood rather than maximizing over a scoring function.
Highly relevant is work on referring expression generation, which is concerned with producing a textual description that allows a human to correctly identify a target object or other entity that is known only to the generator. In the computer vision and natural language processing communities, the task typically involves conveying information about objects or locations within an image (Kazemzadeh et al., 2014; Luo and Shakhnarovich, 2017; Mao et al., 2016; Yu et al., 2016). Contemporary approaches to this problem employ neural network architectures for language generation, and thus require access to large datasets for training, which are typically not available for robotics or other embodied domains. In robotic applications, referring expression problems often involve reasoning over spatially extended 3D environments (e.g., at the room, floor, or building level). Consequently, generation algorithms (Fang et al., 2015; Kelleher and Kruijff, 2006; Zender et al., 2009) must provide enough information for the listener, whose context will often be limited.
Related, other researchers have endowed robots with language generation capabilities as a means of conveying task information to their human partners (Andrist et al., 2013; Dzindolet et al., 2003; Wang et al., 2016). Among these are methods that consider the problem of producing free-form instructions that allow humans to perform a task, such as navigation (Curry et al., 2015; Goeddel and Olson, 2012; Oswald et al., 2014). Traditionally, solutions to this problem have relied upon hand-crafted rules that are designed to mimic the way in which humans generate instructions (e.g., via a set of composition rules and language templates). Much like language understanding, recent work employs statistical and learned models (Cuayáhuitl et al., 2010; Daniele et al., 2017b; Oswald et al., 2014) that can be trained from natural language corpora, and are thus able to produce utterances that are easier for people to follow.
Significant effort in the natural language processing community has focused on the problem of generation. This includes work on selective generation, which considers the problem of producing a natural language utterance that effectively expresses the content of a rich database. Selective generation has traditionally been formulated as two separate problems: content selection (Barzilay and Lapata, 2005; Barzilay and Lee, 2004), which reasons over what to talk about, and surface realization (Liang et al., 2009; Walker et al., 2001), which decides how to convey the selected content via natural language. Relevant to our inverse semantics approach, Wong and Mooney (2007) effectively inverted a semantic parser to generate natural language text from formal meaning representations using synchronous context-free grammars.
Recent work performs selective generation via a single framework (Angeli et al., 2010; Chen and Mooney, 2008; Kim and Mooney, 2010; Konstas and Lapata, 2012; Mei et al., 2016b), rather than treating it as two separate sub-problems. Angeli et al. (2010) formulate content selection and surface realization as local decision problems via log-linear models, and employ templates for generation. Mei et al. (2016b) proposed a recurrent neural network encoder–aligner–decoder model that jointly learns to perform content selection and surface realization from database–text pairs, thereby treating the selective generation as an end-to-end learning problem.
9. Discussion and conclusion
We have introduced a probabilistic model for inferring the latent semantic properties of the world to correctly follow high-level human instructions in partially observable environments. We have demonstrated how both linguistic descriptions from a human and signatures derived from the robot’s physical interaction can be used to infer the latent semantic properties of the environment required for task execution. Further, we have leveraged background commonsense knowledge corpora to learn an informed prior when initializing the model for efficient subsequent inference.
We have also presented an approach for generating linguistic feedback to the human in the case where discrepancies are observed between the robot’s and the human’s semantic knowledge about the world. Finally, we have addressed the issue of reducing latency in both instruction interpretation and feedback generation that stems from the computation complexity of associating language with semantic entities in the world. We have introduced a proactive grounding approach that predicts future utterances and selectively computes candidate interpretations from incremental observations of the world. We have demonstrated the approach on fixed and mobile manipulators executing high-level tasks by “filling in” semantic knowledge about world entities from both declarative knowledge sources as well as physical interactions.
The experiments in this work contribute towards bridging the gap between higher-order inputs such as language from the human and low-level representation such as interaction forces for the robot via grounded learning of semantic concepts by fusing acquired semantic knowledge. The experimental evaluations on multiple platforms and the field deployment test contribute toward validating the reproducibility and robustness in the presence of uncertain environment conditions. Further, the ability to provide online linguistic feedback for resolving differences in the robot’s and the human’s mental models contributes to addressing the transparency and op-tempo communication requirements of real-world human–robot teaming scenarios.
There are several avenues for future work that emerge from the current investigation. Our current approach for deciding and taking information gathering actions is myopic because we only utilize a one-step look ahead. The decision is also based on the entropy of the underlying distribution but does not explicitly compute the information gain associated with actions. There is scope to integrate multistep planning to gain information about uncertain semantic properties. Further, we considered semantic attributes associated with an object to be independent while fusing knowledge from multiple sources. Often, physical properties are correlated. For example, heavy objects are often difficult to slide. Hence, future work will explore Bayesian priors that preserve correlations. There is scope to leveraging similar work in correlated topics modeling (Blei and Lafferty, 2006). 7 Similarly, there is scope to use a correlated measurement model that accounts for correlated observations. For example, observing items such as cups and tables are highly predictive of the presence of humans in a building.
The current model assumes that the space of semantic concepts is fixed a priori, thereby making the overall system less robust for situations in which the plan execution requires knowledge of a novel semantic property that was not seen during training. This limitation can be addressed in two ways. First, we can incorporate non-parametric Bayesian models that expand with data complexity (Blei and Jordan, 2006). Second, we may explore ways to detect the presence of a new concept and acquire new recognition models online with limited interaction (Tucker et al., 2017), thereby allowing our model to grow its space of semantic concepts in an online fashion. Our experiments so far have focused on the robot interacting with the world to improve its understanding. There is further scope to acquire semantic knowledge by observing the behavior of other agents, either during an intentional demonstration or via happenstance while executing a collaborative task. As an example, if the robot observes a person struggle to lift a box, it can incorporate that observation as evidence about the box’s heaviness.
The present formulation incorporated binary predicate symbols to represent symbolic states. The model can be extended in case of ternary or multi-ary properties as well by incorporating a multi-dimensional conjugate distribution. For example, we can extend the Beta-Bernoulli prior to a Dirichlet-multinomial prior to incorporate multi-ary properties.
This work has explored the use of natural language to inform the latent properties of objects in the robot’s world model that were corroborated or corrected by the haptic modality. However, unlike touch, language utterances are often ambiguous and may only implicitly communicate information. For example, the a language instruction may be ambiguous in terms of which objects are referenced. Consider the utterance, “the barrel on the left is empty” when there are two barrels on the left side of the robot. Such ambiguity can be addressed by engaging in dialog with the operator. The natural language generation system presented in this work can be extended and used to generate disambiguation queries to resolve the ambiguity. Now, we turn our attention to the problem of implicit knowledge that we did not consider in this work. Consider the scenario where the operator informs the robot that “all the oil in the barrel was removed today.” Common sense reasoning informs us that the barrel is now empty. However, the presented system would not use such knowledge as it cannot reason about implicit knowledge. The problem can be addressed by incorporating (learning) common sense knowledge and performing a form of logical inference or logical state estimation to determine the implicit states from the explicitly stated knowledge. Exploration in this direction remains part of future extensions.
Further, the current model assumes that the linguistic, haptic, and knowledge-based priors are equally weighted. In practical contexts, one modality may be more informative than others. Learning per-modality sensor models and context-specific weightings remains part of future work.
Finally, we seek to expand the scope of language feedback to also include explanations (Parkash and Parikh, 2012; Selvaraju et al., 2017). We envision that the robot should be able to communicate not only that a piece of factual knowledge is incorrect, but describe how it arrived at such a conclusion, for example, by interacting with it. We intend to explore richer multimodal communication as part of future research.
Footnotes
Appendix. Index to multimedia extensions
Archives of IJRR multimedia extensions published prior to 2014 can be found at http://www.ijrr.org, after 2014 all videos are available on the IJRR YouTube channel at http://www.youtube.com/user/ijrrmultimedia
Demonstration of physical interaction with closed cases for inferring hidden states via a Clearpath Husky A200 with a Universal Robotics UR5 manipulator.
Demonstration of physical interaction with barrels to estimate their pliability/pushability via a Husky with a UR5 manipulator.
Demonstration of physical interaction with cups in a tabletop domain to estimate their internal state as empty or full on a Rethink Robotics Baxter Research Platform. The determination of latent states allows completion of a tabletop clearing task.
Acknowledgements
We thank Michael Noseworthy for valuable feedback on this manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Robotics Consortium of the US Army Research Laboratory under the Collaborative Technology Alliance Program (RCTA; ARO grant W911NF-15-1-0402), the Toyota Research Institute (TRI; award number LP-C000765-SR), and Lockheed Martin Co.
Supplemental material
Supplemental material for this article is available online.