
Abstract
Continual locomotion learning faces four challenges: incomprehensibility, sample inefficiency, lack of knowledge exploitation, and catastrophic forgetting. Thus, this work introduces growable online locomotion learning under multicondition (GOLLUM), which exploits the interpretability feature to address the aforementioned challenges. GOLLUM has two dimensions of interpretability: layer-wise interpretability for neural control function encoding and column-wise interpretability for robot skill encoding. With this interpretable control structure, GOLLUM utilizes neurogenesis to unsupervisely increment columns (ring-like networks); each column is trained separately to encode and maintain a specific primary robot skill. GOLLUM also transfers the parameters to new skills and supplements the learned combination of acquired skills through another neural mapping layer added (layer-wise) with online supplementary learning. On a physical hexapod robot, GOLLUM successfully acquired multiple locomotion skills (e.g., walking, slope climbing, and bouncing) autonomously and continuously within an hour using a simple reward function. Furthermore, it demonstrated the capability of combining previous learned skills to facilitate the learning process of new skills while preventing catastrophic forgetting. Compared to state-of-the-art locomotion learning approaches, GOLLUM is the only approach that addresses the four challenges above mentioned without human intervention. It also emphasizes the potential exploitation of interpretability to achieve autonomous lifelong learning machines.
Keywords
1. Introduction
While animals can improve their locomotion skills throughout their lifetime (Kudithipudi et al., 2022), robots are currently designed for certain predefined environment conditions and requires human involvement for pretraining in simulation (Bellegarda and Ijspeert, 2022; Choi et al., 2023; Deshpande et al., 2023; Ding and Zhu, 2022; Gai et al., 2024; Hiraoka et al., 2021; Lee et al., 2020; Li et al., 2024; Margolis et al., 2022; Nahrendra et al., 2023; Rudin et al., 2022; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Shafiee et al., 2024; Smith et al., 2022a; Thor et al., 2020; Xie et al., 2020; Yang et al., 2020; Yu et al., 2023; Zhang et al., 2023), providing task context (Ding and Zhu, 2022; Smith et al., 2022a), designing leg encoding rules (Thor et al., 2020; Thor and Manoonpong, 2022), and/or collecting sufficient fundamental skills/options (Cully et al., 2015; Ding and Zhu, 2022; Zhang et al., 2023). This is owing to four key challenges (Glanois et al., 2021; Kudithipudi et al., 2022; Parisi et al., 2019): sample inefficiency, lack of knowledge exploitation, catastrophic forgetting, and incomprehensibility.
The first challenge exists even when robots experience a static environment. Given that most robots learn by trail-and-error using reinforcement learning (Sutton and Barto, 2018) to maximize the reward feedback received from the interaction with the environment, learning requires a massive amount of training samples to estimate the reward gradient for stable policy update. This results in extensive training time, which ranges from 1 h to 22 days (Bellegarda and Ijspeert, 2022; Choi et al., 2023; Deshpande et al., 2023; Ding and Zhu, 2022; Gai et al., 2024; Hiraoka et al., 2021; Lee et al., 2020; Li et al., 2024; Margolis et al., 2022; Nahrendra et al., 2023; Rudin et al., 2022; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Shafiee et al., 2024; Smith et al., 2022a; Thor et al., 2020; Xie et al., 2020; Yang et al., 2020; Yu et al., 2023; Zhang et al., 2023). For this reason, the majority of robot training occurs in accelerated simulations, which could later suffer from the reality gap due to simulation inaccuracy. This reality gap is a major problem that could affect robustness and performance (Margolis et al., 2022; Rudin et al., 2022). Several methods, such as online system identification (Lee et al., 2020; Margolis et al., 2022), have been proposed to mitigate the impact on performance; however, some performance gap still remains. An effective solution to achieve higher performance seems to be real-world fine tuning, which could add two extra hours (Smith et al., 2022a).
The second challenge emerges as soon as the second environment condition is introduced. To learn locomotion on different environment conditions, one approach is training different skills simultaneously (Rudin et al., 2022). However, this takes a significant amount of time and yields lower performance (Ribeiro et al., 2019; Rossi and Eiben, 2014). Therefore, incremental training has been suggested as a more viable option (Ding and Zhu, 2022; Ribeiro et al., 2019; Rossi and Eiben, 2014). Nevertheless, the worst-case scenario of training time when implementing incremental training is expected to grow proportionally to the number of conditions. Therefore, it is necessary to leverage the knowledge from one condition and efficiently apply it on the subsequent ones. One potential solution is to share the same parts of the network between different behaviors or skills (Thor and Manoonpong, 2022; Yang et al., 2020); however, a straightforward implementation could lead to the third challenge: catastrophic forgetting.
In the third challenge, catastrophic forgetting means that previous knowledge encoded in learned parameters (learned weights) of a neural control network may be replaced by the new knowledge (new weights) (Ding and Zhu, 2022; Khetarpal et al., 2022; Kudithipudi et al., 2022; Parisi et al., 2019; Ribeiro et al., 2019) when experiencing new conditions. This can cause 5–70% reduction in performance (Ding and Zhu, 2022; Ribeiro et al., 2019) causing what has been learned to be forgotten. To tackle this problem, researchers have explored regularization-based techniques (Ribeiro et al., 2019; Schwarz et al., 2018; Wang et al., 2024) and rehearsal-based techniques with experience replay (Hafez et al., 2023; Isele and Cosgun, 2018; Kalashnikov et al., 2021; Li et al., 2021; Wang et al., 2024). While the former techniques can be effective, they may still suffer from performance degradation due to improper regularization scaling. For example, Ribeiro et al. (2019) reported a 20% decrease in performance using elastic weight consolidation. The latter techniques, on the other hand, can be computationally expensive. For example, the technique required 800k episodes of data when implemented straightforwardly (Kalashnikov et al., 2021). Additionally, this technique could suffer from performance degradation when the selected data (Hafez et al., 2023; Isele and Cosgun, 2018) is insufficient or the generated data (Li et al., 2021) is inaccurate. Li et al. (2021) reported 50% performance degradation in such cases. Therefore, the most efficient solution might be to completely separate different domains of knowledge from each other (Ding and Zhu, 2022; Smith et al., 2022a; Wang et al., 2021); yet, this approach brings us back to the second challenge of neglecting the exploitation of similarity. As a consequence, some roboticists tend to define a fixed working domain and then freeze the network after extensive training (Rudin et al., 2022; Thor and Manoonpong, 2022; Wang et al., 2021; Yang et al., 2020).
While the first three challenges remain unresolved, a fourth challenge emerges with the use of black-box models, such as large or deep neural networks. These models, along with their learning outcomes, are difficult to comprehend (Arrieta et al., 2020; DW, 2019; Glanois et al., 2021; Lipton, 2018; Rudin, 2019). As a result, decomposing such a large black-box network into submodules or subnetworks for local functional analysis (decomposability), understanding its underlying learning process (transparency), simulating its working process (simulatability), verifying its results, and even making effective modifications all become highly challenging. Consequently, current legged robots are not only limited to a specific set of behaviors/environments defined at the design time but also lack the trustworthiness after extensive training.
Previous studies tried to address all these challenges using progressively complex techniques. These include (i) architecture-based approaches that utilize complex rules to dynamically change the network structure and/or combine multiple trained networks (Gai et al., 2024; Hafez and Wermter, 2023; Schwarz et al., 2018; Wang et al., 2024; Yang et al., 2020; Zhang et al., 2023) and (ii) representation-based approaches that employ complex processes to extract and maintain proper shared representations (Ding and Zhu, 2022; Lee et al., 2020; Wang et al., 2024; Xie et al., 2020). In contrast, we propose here a less complex architecture-based approach designed based on interpretability. In particular, this study hypothesizes that the interpretability introduced by two dimensions neural control and a dual layer learning mechanism could not only provide understanding of the control system but also address other challenges, achieving lifelong learning locomotion intelligence through simpler mechanisms. Following this concept, we developed growable online locomotion learning under multicondition (GOLLUM, Figure 1), which is a locomotion control and learning framework consisting of three key components: (1) an interpretable neural control network for motor command generation, observation prediction, and value prediction; (2) neurogenesis for incorporating new skills throughout operational lifetime; and (3) a dual layer learning mechanism for fast and efficient learning without catastrophic forgetting, as summarized in Figure 1. (a) Growable online locomotion learning under multicondition (GOLLUM) consists of an interpretable neural control for motor command generation, a dual learning mechanism (primary learning for efficient locomotion learning and supplementary learning for exploiting shared skills), and a neurogenesis for implementing new skills. The interpretable neural control has two interpretation dimensions (column-wise and layer-wise). (b) In the horizontal/column-wise interpretation, neural columns are created by neurogenesis based on observation and value prediction mismatches. Each encodes a specific behavior/skill, which further includes multiple actions/target configurations. (c) In the vertical/layer-wise interpretation, four neural modules (sensory preprocessing, internal state, premotor/pattern, and motor/output modules) are stacked to fulfill network functionalities. The sensory preprocessing module is trained supervisedly on observation templates/predictions. The internal state module is precomputed and then fixed during the training. The premotor/pattern module is trained with the supplementary learning to exploit other learned behaviors/skills. The motor/output module is trained with the primary learning to refine/learn behaviors/skills. Combining horizontal and vertical interpretations, each interpretation coordinate thus represents a specific functionality at a specific action of a specific skill. For example, the neuron C9 encodes the discrete internal state of the first action of the third skill. The neuron PM10 encodes the pattern of the second action of the third skill, and the connection between PM10 and an output encodes the output motor command (motor angle) for the second action in the third skill. A video with the neural visualization (Srisuchinnawong et al., 2021a) is available at https://youtu.be/PxAl___xCT8.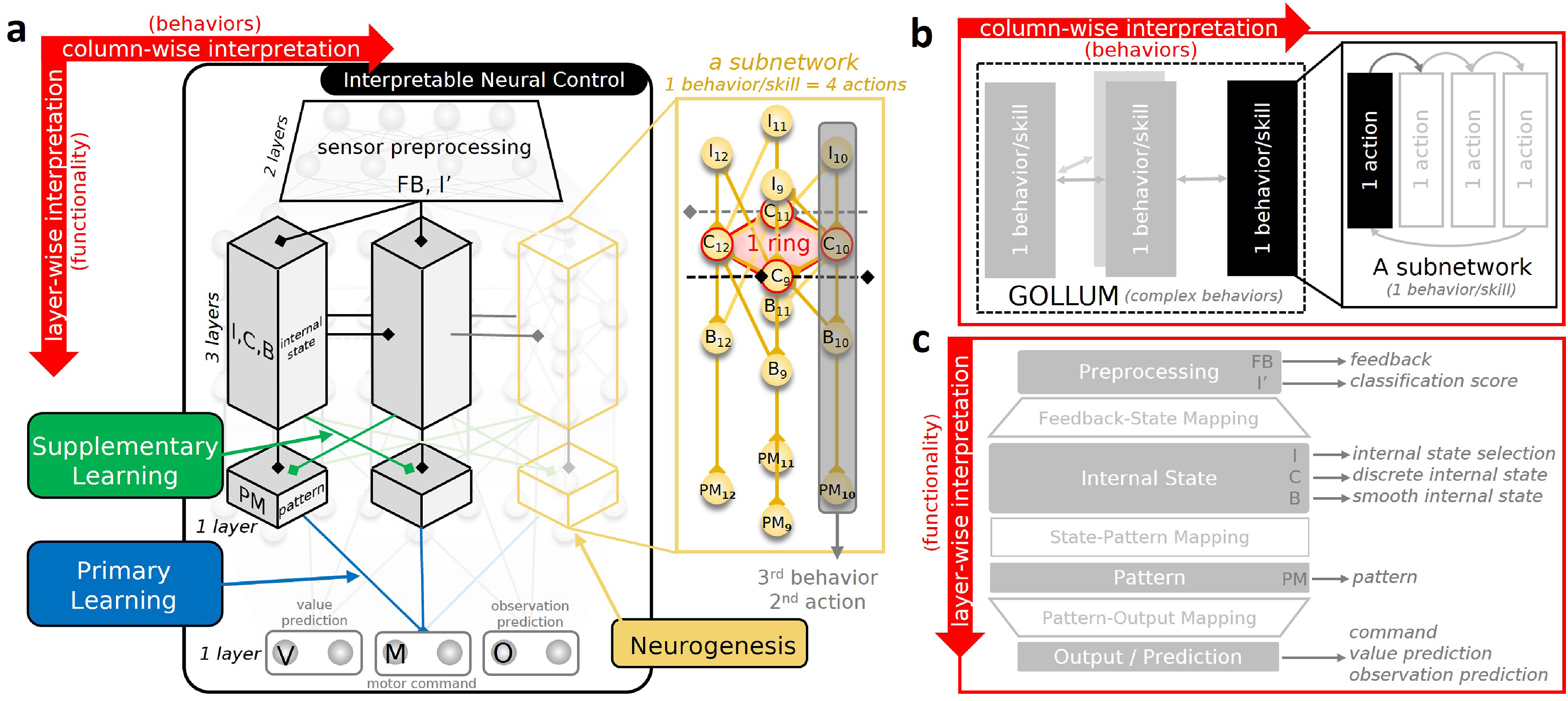
2. Methods
GOLLUM consists of three key components (Figure 1). 1. An interpretable neural control is a neural network that maps sensory feedback/observation to motor commands and observation/value predictions. The motor commands are then used as the target positional trajectories for the robot, while the observation/value predictions are used during learning. 2. A dual layer learning mechanism is a learning mechanism that employs primary learning of motor command mapping connections to update the primary skills and employs the supplementary learning of inter-subnetwork connections to access other skills previously learned. 3. A subnetwork neurogenesis is a mechanism that gradually creates new subnetworks when new conditions are detected through the deviation of the value and observation from predictions, providing new subnetworks/experts for encoding new skills.
2.1. Interpretable neural control
The neural control is an interpretable neural network that maps sensory feedback/observation to motor command outputs: a vector of N a independent action values, each of which is within the joint limits. N a is the number of motors (N a = 18 for hexapod robot). The network is divided horizontally and vertically into different layers/subnetworks (Glanois et al., 2021; Rudin, 2019), as shown in Figure 1. This results in two interpretation dimensions: column-wise interpretation (Figure 1(b)) and layer-wise interpretation (Figure 1(c)).
In the column-wise interpretation (top view, Figure 1(a) and (b)), the neural control consists of multiple columns/subnetworks, with ring neural networks (i.e., groups of CPGs (Bellegarda and Ijspeert, 2022; Li et al., 2024; Pasemann et al., 2003; Thor et al., 2020) that generate periodic outputs even in the absence of input signals), as highlighted in red in Figure 1(a). Each column/subnetwork encodes a specific behavior/skill, constructed from multiple neural structures connected in a loop, representing various corresponding actions highlighted by the dark transparent box. In this work, four actions per subnetwork are used: two for the swing phase and two for the stance phase. The columns/subnetworks, connected via inter-subnetwork connections, allow transitions from one behavior/skill to another. Therefore, a neural activation within a subnetwork can be interpreted as the current condition/behavior and the corresponding actions (see https://youtu.be/PxAl___xCT8). The inter-subnetwork connections reflect the self-organized structure of complex behaviors (i.e., behavior model (Jaeger, 1995; Mansard et al., 2005)), as shown in https://youtu.be/EGElrNx_kCE.
In the layer-wise interpretation (side view, Figure 1(a) and (c)), the neural control comprises seven layers of interpretable neural regressions (Arrieta et al., 2020; Glanois et al., 2021; Rudin, 2019). The layers are divided into four modules; each serves as a specific function as shown in Figure 1(c), providing interpretation transparency (Glanois et al., 2021; Rudin, 2019). In this work, each layer is modeled as a discrete-time non-spiking interpretable single neural regression layer (Arrieta et al., 2020; Glanois et al., 2021), the activity of which is governed by
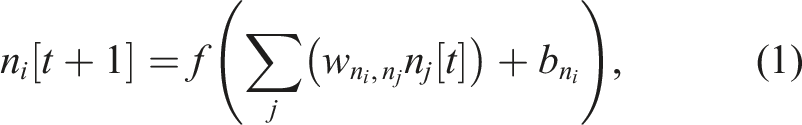
In the first module (Figure 1), the observations/sensory feedback signals are fed to sensory feedback neurons in the sensory feedback layer (FB). The first input preprocessing layer (I′) maps the sensory feedback to intermediate preprocessed inputs, acting as the subnetwork/skill classification scores. These classification scores are then used by the column structures/subnetworks distributed in the horizontal plane as the selection signals, choosing between those locomotion skills/behaviors. In the second module (Figure 1), the second input preprocessing layer (I) inhibits the classification signals that correspond to the inactive internal states, represented by the activities of the sequential central pattern generator layer (C). Thus, only the classification signals that correspond to the active behaviors/active states activate, resulting in one hidden state and one action/configuration used at a time. In this layer, there are two types of C neurons: feedback-independent and feedback-dependent neurons. The former connects in loops forming multiple ring structures (a ring structure is highlighted in red in Figure 1(a)), where the activation of one neuron always propagates to another, while the latter is employed for transition, where the activation in one ring structure transitions to the next when its input is presented (this is indicated by the neuron with inter-subnetwork connections in Figure 1(a)). Thus, the connectivity in the layer determines the transition sequence/activation order of both the C neurons themselves and the ones in other layers. Subsequently, the basis layer (B) maps them to the corresponding sparse triangular shape bases, which are later used to create the outputs. The sparse bases are employed to ease learning with less correlated bases. In the third module (Figure 1), the premotor layer (PM) serves as a layer of neurons encoding action patterns (i.e., sets of target joint configurations represented by the corresponding output mapping weights). This allows for the sharing of learned pattern/output mapping between different skills/subnetworks. Finally, in the last module (Figure 1), the output layer (M, V, and O) maps the action patterns and bases to motor positional commands (M) for controlling the robot, value predictions (V) for the dual layer learning and new context identification by the neurogenesis, and observation predictions (O) serving as the observation template for learning the preprocessing module and context identification by neurogenesis. The details are depicted in Figure 2 as well as discussed layer by layer below. GOLLUM framework, presented along with the corresponding neural activity signals: feedback (FB [t], where θ denotes the robot pitch angle), first sensory preprocessing (I′[t], classification score), second sensory preprocessing (I [t], internal state selection), sequential central pattern (C [t], discrete internal state), basis (B, smooth internal state), premotor (PM [t], pattern), and output (M [t], motor command). The parameters of the network are summarized in Tables S1 and S2 in the supplementary document. The signals from the first subnetwork are presented in gray scale, while those from the second subnetworks are in color. Receiving multiple feedback signals at the feedback layer (FB), the first sensory preprocessing layer (I′) produces classification signals, which are later selected at the second sensory preprocessing layer (I) based on the activation of the sequential central pattern layer (C). The C layer produces two different sets of discrete internal states: the first group, in gray scale, activates at the start and after the selection signal I1 [t]; the second group, in yellowish, activates after the selection signal I4 [t]. The basis layer (B) then converts these discrete internal states to smooth internal states, forming the bases for shared action patterns at the premotor layer (PM). The action patterns are then projected to the outputs at the output layer (M, V, and O). The mapping from B to PM is trained by the supplementary learning to activate the proper patterns, while that from PM to M is trained by the primary learning to learn the proper action patterns. Upon encountering new conditions, indicated by a mismatch in value and observation predictions (V and O), the neurogenesis creates new subnetworks for learning new skills. Finally, due to the sparse neuron activation signals, the user/developer can gain insight into the network’s processes and learned skills for further modify the results. A video demonstrating the mechanisms of GOLLUM along with the neural visualization (Srisuchinnawong et al., 2021a) is available at https://youtu.be/PxAl___xCT8.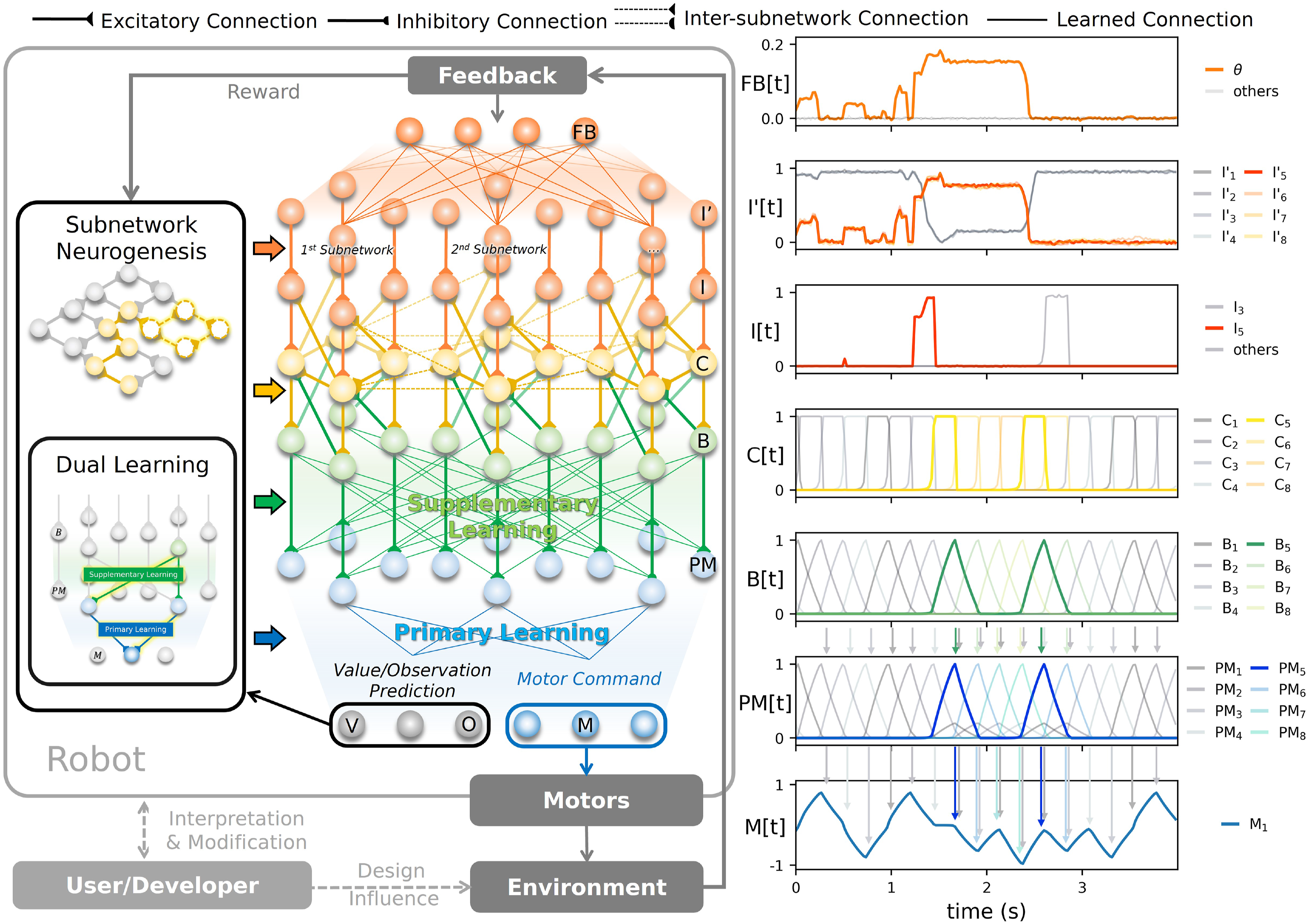
Given that the connectivity within the C layers determines the network structure, a connection matrix κ is used to parameterize the network. The element at row r, column c (κ rc ) is a binary value representing the existence of the connection (i.e., transition) from neuron C r to C c , which also determines the structure of other neurons as described in the following paragraphs. For each neuron C c , decision making/path selection is not needed providing that it always activates after certain neurons (∑ r κ rc = 1). Thus, C c is a feedback-independent neuron, connecting in a loop within each ring-like structure/subnetwork. On the other hand, C c requires decision making/path selection if it activates after two or more. Thus, C k is a feedback-dependent neuron, linking ring-like structures/subnetworks.
2.1.1. Sensory feedback (FB)
Four types of sensory feedback are provided to the robot as observations, namely, a body pitch feedback estimated from the tracking camera (Realsense T265) for slope detection, 18 signals of motor state feedback for motor dysfunction detection, the hue mean computed from the average hue pixels of images from the robot’s COG for terrain color feature, and the hue standard deviation computed also from the standard deviation of hue pixels for terrain color range feature, as shown in Figure 3. In total, the robot receives 21 dimensions of observation that are passed to 21 sensory feedback neurons in the first layer. Note that other types of sensory feedback could be employed. MORF hexapod robot employed in this work presented long with its sensors, GOLLUM, the robot interface, and the training process.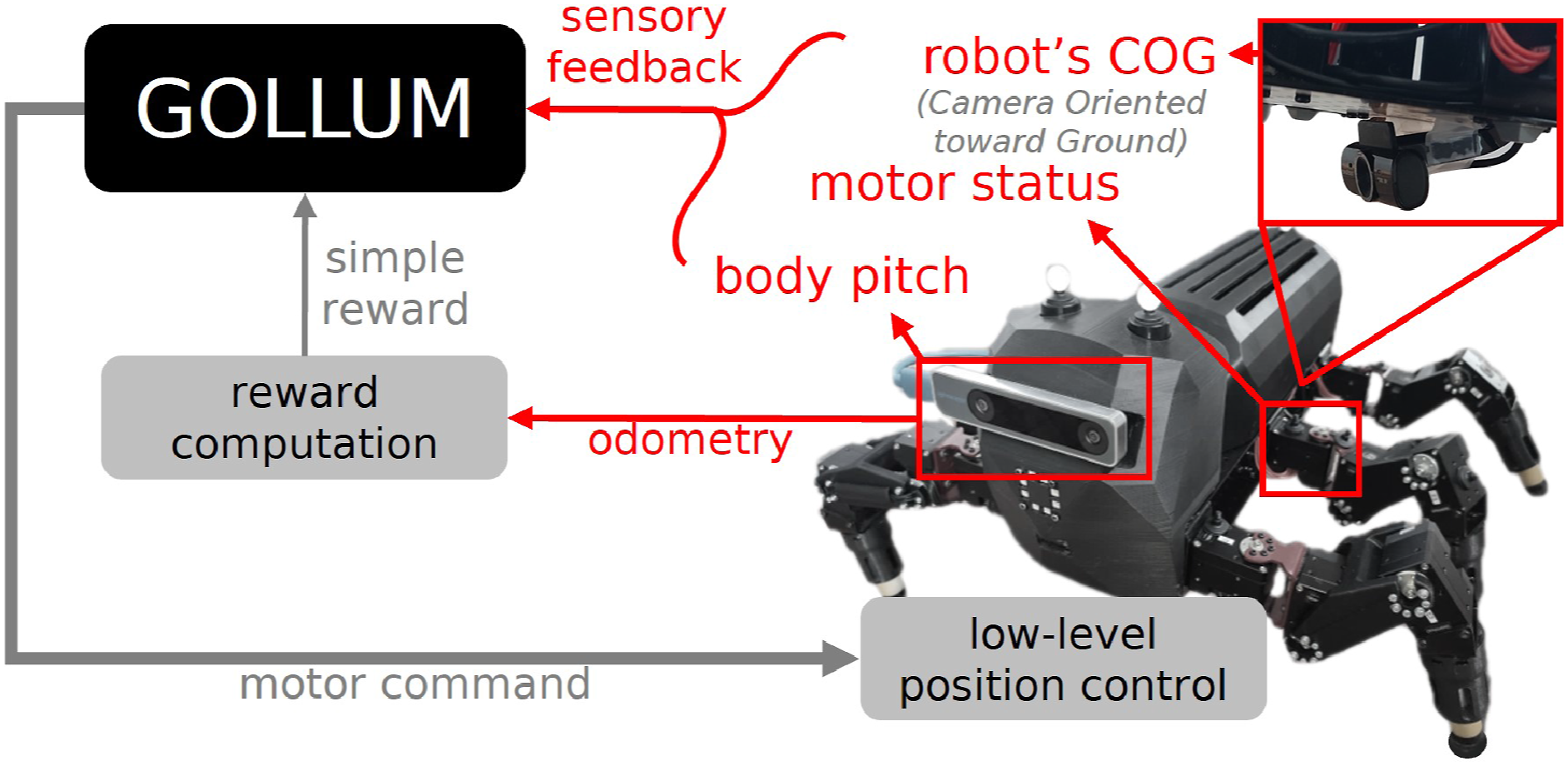
2.1.2. First input preprocessing (I′)
The first input preprocessing layer (I′) maps the sensory feedback/observation (FB
k
[t]) to the intermediate preprocessed input
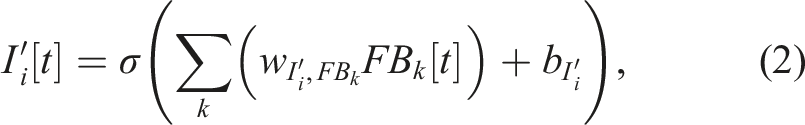
Examples of the classification signals
2.1.3. Second input preprocessing (I)
Receiving the classification signals, the second input preprocessing layer (I) blocks those that do not correspond to the current internal states and forwards the others to the next layer as the selection signals (I
i
[t]). The layer is modeled as an interpretable neural rule-based regression layer (Arrieta et al., 2020; Glanois et al., 2021):
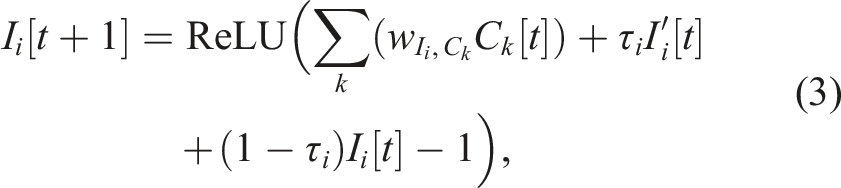
Examples of the selection signals (I
i
[t]) are depicted in Figure 2, where merely two selection signals (I3 [t] and I5 [t]) can be observed while the other classification signals observed in I′ [t] are blocked. The first signal
2.1.4. Sequential central pattern generator (C)
In this layer, series of two neurons with forward excitation and backward inhibition connections are connected in loops, forming ring structures. This structure is based on central pattern generator (CPG) in animal locomotion (Deshpande et al., 2023; Shafiee et al., 2024), neural locomotion circuit of Caenorhabditis elegans (Lechner et al., 2019; Yan et al., 2017), and mushroom body of Drosophila melanogaster (Turner-Evans et al., 2020; Wolff et al., 2015). The ring-like network structure serves as the main components for generating rhythmic patterns, which are then used as the internal states for forming repeated sequential actions, that is, different locomotion patterns. Given the demonstrated rhythmic patterns in robot locomotion from previous studies (Bellegarda and Ijspeert, 2022; Choi et al., 2023; Deshpande et al., 2023; Ding and Zhu, 2022; Gai et al., 2024; Hiraoka et al., 2021; Lee et al., 2020; Li et al., 2024; Margolis et al., 2022; Nahrendra et al., 2023; Rudin et al., 2022; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Shafiee et al., 2024; Smith et al., 2022a; Thor et al., 2020; Xie et al., 2020; Yang et al., 2020; Yu et al., 2023; Zhang et al., 2023), GOLLUM incorporates the rhythmic prior into its network structure, while maintaining a full action space. This enables the robot to learn diverse inter- and intra-leg coordination patterns.
Additionally, in this work, inter-connections between different rings are added, as shown in Figure 2. This allows activity patterns to propagate between columns/subnetworks, resulting in behavior transitions. To achieve such complex central pattern signals, two types of C neurons are designed: feedback-independent neurons (Figure 4(a)), which always allow activity propagation to the next neuron and generate rhythmic patterns, and feedback-dependent neurons (Figure 4(b)), which allow activity propagation only when the corresponding selection signal from the second preprocessing layer (I) is provided, enabling behavior transitions. (a) Feedback independent and (b) feedback dependent sequential central pattern generator neurons (C
i
). The former always propagates the activity of the former neuron (Ci−1) forward to the next (Ci+1) due to the excitatory connections from C
i
to Ci+1, C
i
to B
i
, and from B
i
to Ci+1. The latter allows the propagation only when the selection input (Ii+1) is provided due to the excitatory connections from C
i
to Ci+1, from C
i
to Ii+1, and from Ii+1 to Ci+1.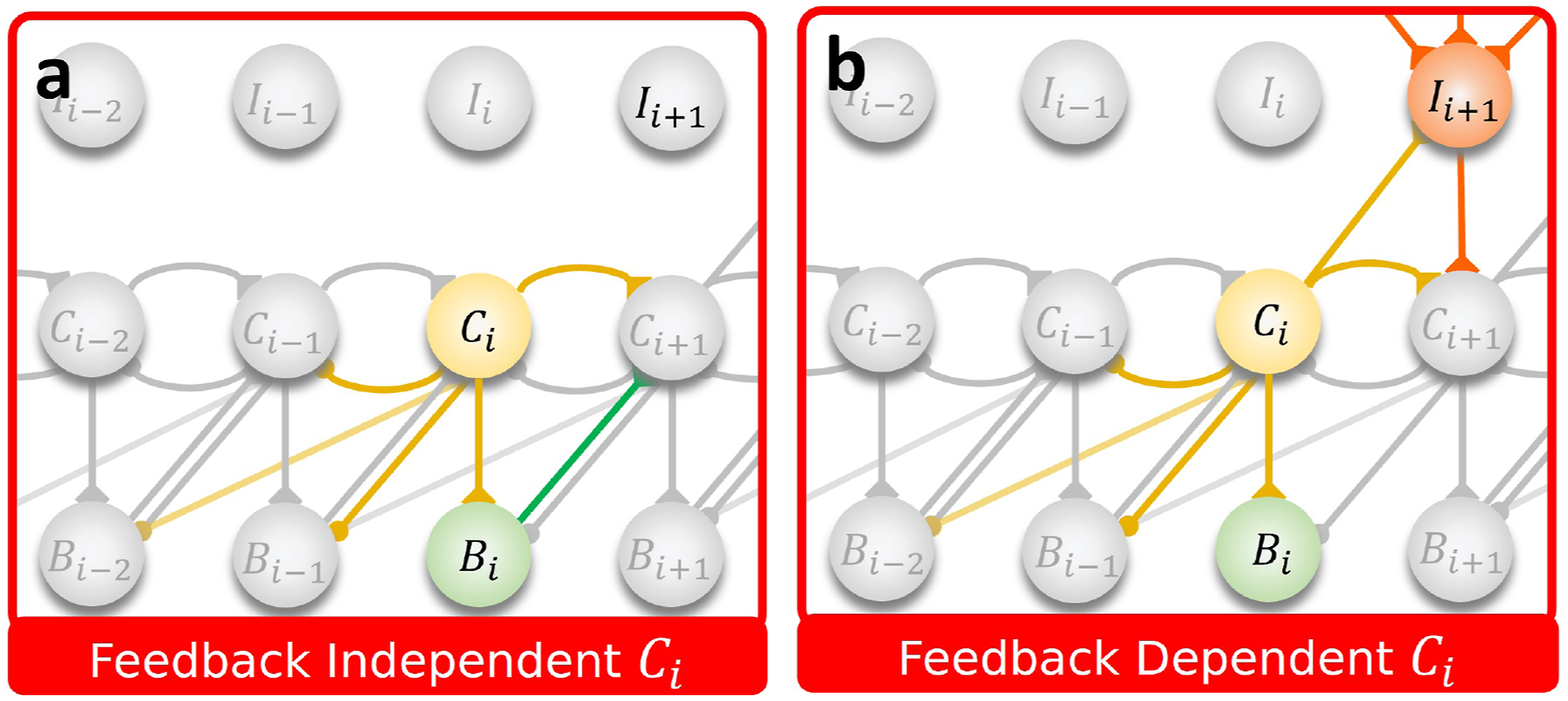
Despite having different functions, these two types are modeled as an interpretable neural rule-based regression layer (Arrieta et al., 2020; Glanois et al., 2021) according to:
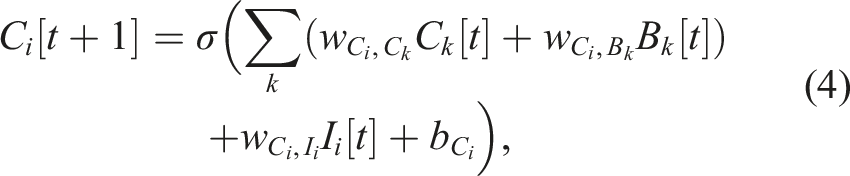
Example of the central pattern signals (C i [t]) is depicted in Figure 2, where the activity of the feedback-dependent state C5 [t] is triggered by the selection signal of the second behavior/skill (I5 [t]). After C5 [t] is active, it triggers others feedback-independent states (C5[t]–C8[t]) until the selection signal of the first behavior/skill (I3 [t]) becomes active. Similarly, after C3[t] is active, it triggers other feedback-independent states in the first subnetworks (C1[t]–C4 [t]). These discrete internal states are then smoothed to create the bases, which are later weight summed as the outputs.
2.1.5. Basis (B)
Taken the C activities as inputs, the discrete internal states are smoothed and converted to triangular basis signals depicted in Figure 2. These triangular basis signals (B
i
[t]) are passed through the premotor layer (PM) and finally linearly combined to produce the outputs. To produce triangular basis signals, this layer is modeled as an interpretable neural rule-based regression layer, according to:
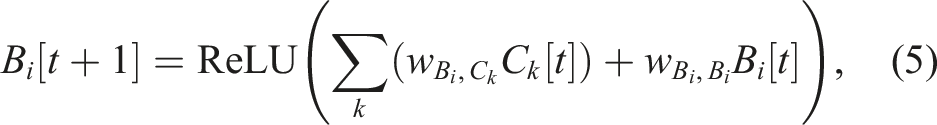
Examples of the basis signals (B i [t]) are depicted in Figure 2, where the activities of sequential central pattern signals/discrete internal states (C i [t]) are smoothed. This results in triangular signals, where each only intersects with its neighbor basis signals. For example, the basis B5 [t] only activates when B4 [t], B6 [t], and B8 [t] are non-zero. These triangular bases are used as the foundation, where their outputs are fed to the premotor layer (PM) to activate the corresponding action patterns and allow for the sharing of action patterns between different subnetworks (i.e., through different sets of bases). Subsequently, the signals are linearly combined to produce outputs.
2.1.6. Premotor layer (PM)
To allow the sharing of the action patterns between different behaviors/skills, the premotor layer (PM) is added as an intermediate layer between the basis layer (B) and the output layer (M, V, and O). The activities of these neurons represent shared action patterns (i.e., sets of target joint configurations). They can be accessed by other behaviors/skills by simply activating the corresponding PM neurons at different desired levels for exploitation of similarity between the learned behaviors/skills. This layer is modeled as an interpretable linear regression (Arrieta et al., 2020; Glanois et al., 2021), according to:
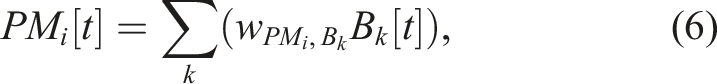
Examples of the premotor signals (PM i [t]) are depicted in Figure 2, where the bases (B i [t]) activate the action patterns with the same index (PM i [t]), for example, B5 [t] activates PM5 [t]. Additionally, the second subnetwork is trained with the supplementary learning to exploit the action patterns from the first, resulting in the small supplementary action patterns of the first set (PM1 [t]–PM4 [t], grayscale) being activated along with the action patterns of the second set (PM5 [t]–PM8 [t], blues). These action patterns are then mapped to the outputs through the mapping connection weights trained by the primary learning.
2.1.7. Output layer (M, V, and O)
To produce the outputs of the network, the output layer (M, V, and O) directly multiplies the activities of action patterns (PM
k
[t]) or those of the bases (B
k
[t]) before combining them. Given the sparse nature of the action patterns and bases, the mapping connection weights thus determine the corresponding output values. The connection weights
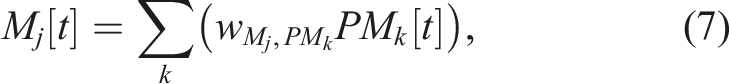
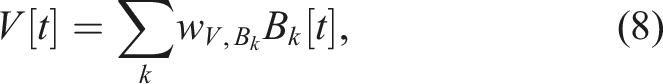
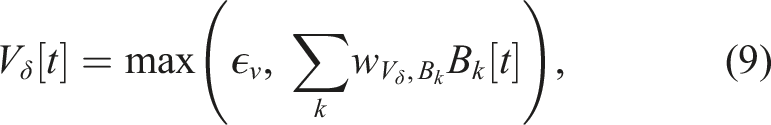
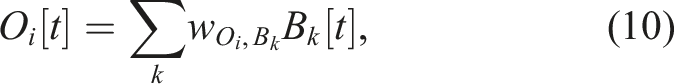
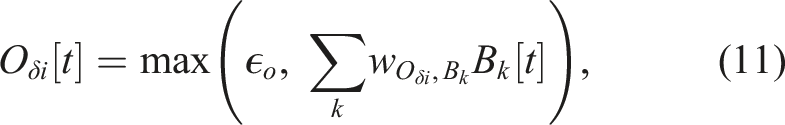
An example output signal (M1 [t]) is depicted in Figure 2, where each action pattern (PM i [t]) is mapped to the corresponding action, that is, each key point of M1 [t]. For example, PM4 [t] (the primary action pattern) produces the lower peak of around −0.8 at 1 s and 3 s. An output command value of −0.8 is determined by the mapping connection weight from PM4 to M1. Similarly, PM5 [t] (the primary action pattern) is scaled by the mapping weight and is combined with that from PM1[t] (the supplementary action pattern) to produce the output value of around 0.0 at 2.0 s and 2.5 s. As a result of having two sets of internal states (C1 [t]–C4 [t] and C4 [t]–C8 [t]), the robot uses the first locomotion pattern in the period between 0.0 s and 1.5 s before switching to the second in the period between 1.5 s and 3.0 s and returning to the first after 3.0 s.
2.2. Dual layer learning mechanism
The dual layer learning mechanism is a reward-based reinforcement learning algorithm that includes two learning types to exploit similarity and overcome catastrophic forgetting. First, the primary learning updates the motor command mapping connections (i.e., primary connections, from the action patterns (PM, blue, Figure 1) to the motor command (M, gray neurons, Figure 1)) to learn the primary skills (action patterns encoded in PM) corresponding to the active behavior while overcoming catastrophic forgetting. Second, the supplementary learning updates the connections between subnetworks (i.e., supplementary connections, from the basis (B, green) to the action patterns (PM, blue)) to supplement the active primary skill with the exploitation of action patterns of other inactive behaviors without changing the primary connections.
Both of the primary and supplementary connections are updated using the gradient-weighted policy gradient with consistent parameter-based exploration, modified from that reported in Sehnke et al. (2010) and Stulp and Sigaud (2012), as described in equations (12) and (13). The modified learning rule exploits the sparse basis signals by added weighting gain computed from the absolute of backpropagated gradient Visualization of the learning rule (equation (12)) applied to the connection weights between two premotor neurons (PM1 and PM2) and a motor output (M1), where the star denotes the coordinate of the current parameter values, blue dots denote the coordinates of the explored parameters with above-average returns (positive advantages), red dots denote the coordinates of the explored parameters with below-average returns (negative advantages), small gray arrows denote per-sample update gradients, and black arrow denotes the combined parameter update gradient applied to the connection weights. Note that, the size of the dots is proportional to the magnitude of the difference from the average, that is, the advantages. Therefore, this visualization presents the working process of the learning rule that the update gradient is applied to move the parameters away from the bad explorations with fewer returns and toward the good explorations with higher returns.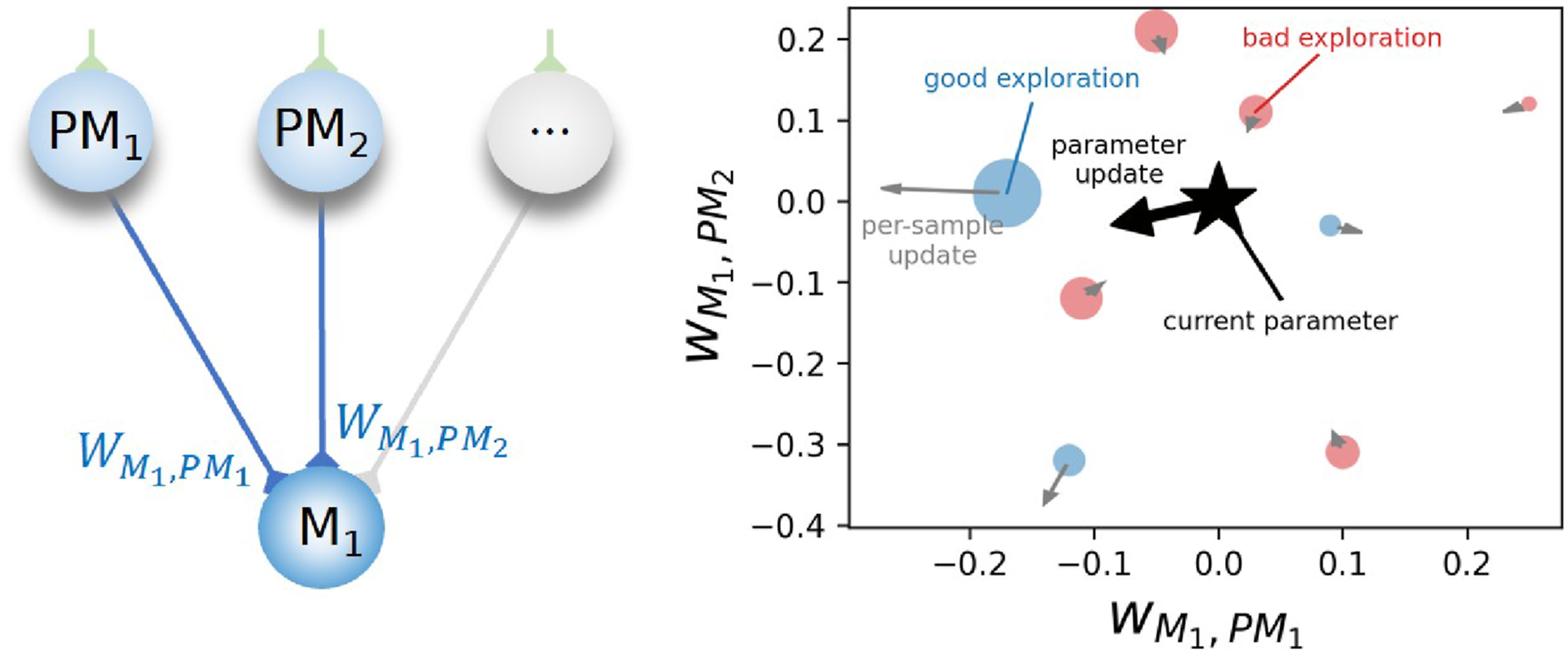
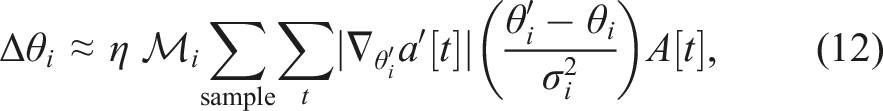
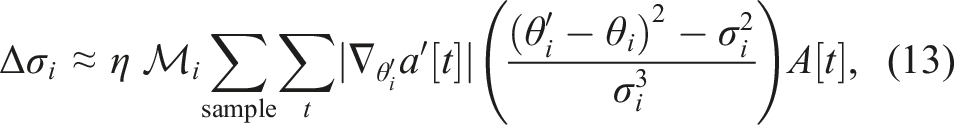
2.2.1. Primary skill contribution
Given that GOLLUM uses one primary skill at a time for overcoming catastrophic forgetting, the primary skill contribution is always (1, or 100%) and can be represented by the subnetwork activities. The primary skill contribution or the activity of the subnetwork sub
j
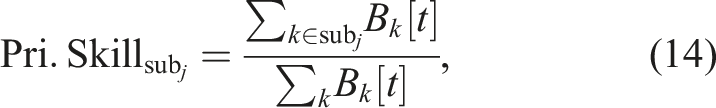
2.2.1. Supplementary skill contribution
Given that the supplementary learning learns the combination ratio between the skills/action patterns from all subnetworks, the supplementary skill contribution of subnetwork sub
j
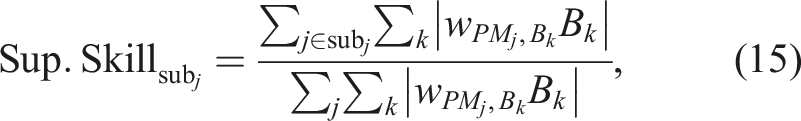
Figure 6 presents an example of online continual locomotion learning on different terrains, where the robot uses incremented primary skills (equation (14)), presented by the activation of b, while exploiting the evolving ratio of supplementary skills (equation (15)), presented by the evolution of the magnitude of the weights between the B and PM. (a) Graphical illustration of locomotion learning on different terrains: (I) flat rigid floor, (II) thin mat (soft/deformable terrain), (III) thick sponge (highly soft/highly deformable terrain), (IV) rough paver, (V) inclined paver, and (VI) gravel field. (b) Corresponding primary skill contribution (i.e., the activation of the subnetworks/bases (B)) and supplementary skill contribution (i.e., the magnitude ratio of the inter-subnetwork connection from the active hidden states/bases (B) to the action patterns encoded in premotor neurons of other inactive subnetworks (PM)).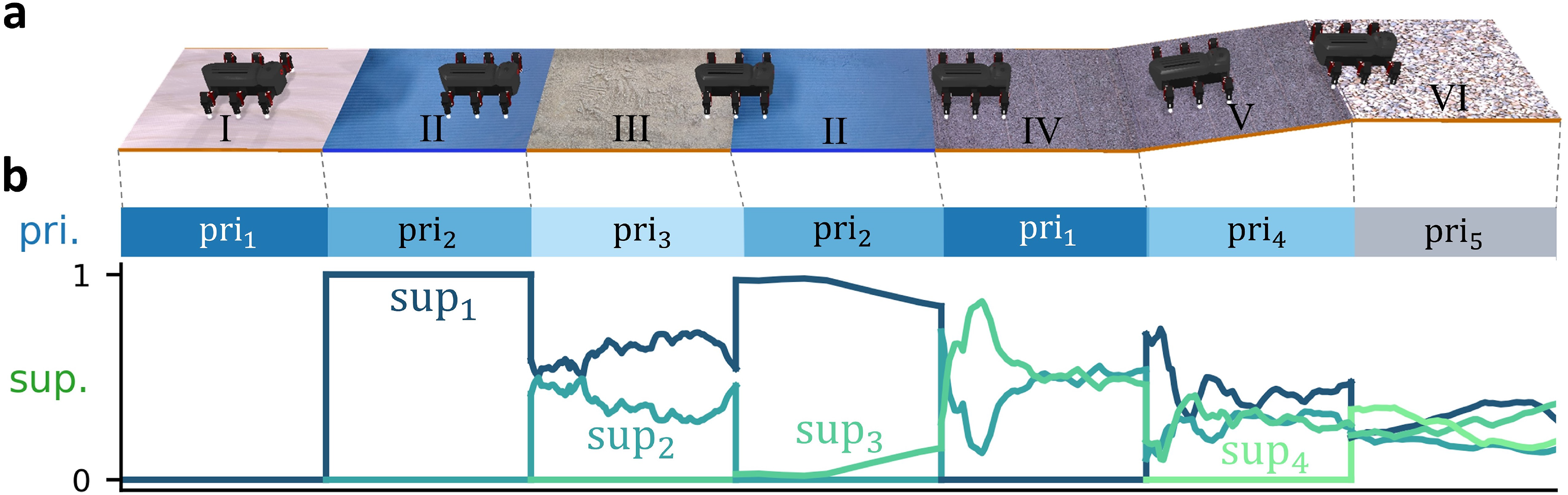
2.3. Subnetwork neurogenesis
To deal with newly introduce conditions, the neurogenesis is activated to create new subnetworks/behaviors by modifying the Boolean connection matrix κ that parameterizes the structure of the network. Taken the advantage of highly structure nature of the interpretable neural control, new columns/subnetworks, each of which has only few parameters (≈ 200 sparse parameters that can be further compressed (Lee et al., 2018; Zhao et al., 2024)), can be created and added while slightly increasing memory and computational resources, as presented and discussed in Figures S17 and S18 in the supplementary document. Inspired by the biological neuromodulators that are released as a result of uncertainty and surprise (Angela and Dayan, 2005), new conditions are detected by the deviation in both the value (if
After the detection and creation of the new subnetworks, they are employed for learning the new primary skills. Given that the robot autonomously switches to other behaviors featuring the most similar observation for realization of behavior transition, the weights from the previously active subnetwork are copied to the new subnetworks, thereby implementing the replication of the one with most similar feedback. This mechanism contributes to the exploitation of similarity during direct knowledge transfer.
2.4. Experimental robotics platform
In this work, a hexapod robot (Modular Robot Framework (MORF); Thor et al., 2018), shown in Figure 3, is employed as the experimental platform. The robot has six legs, denoted as LF (left front leg), LM (left middle leg), LH (left hind leg), RF (right front leg), RM (right middle leg), and RH (right hind leg). Each leg consists of three joints, denoted as number 1 (first joint, body-coxa joint), 2 (second joint, coxa-femur joint), and 3 (third joint, femur-tibia joint). There is a total of 18 active revolute joints, controlled by 18 XM430-W350-R Dynamixel motors with embedded positional sensors for low-level position control, torque sensors for reward calculation, and operating state feedback for broken motor/joint detection. The robot also includes an Intel RealSense tracking camera (T265) for odometry estimation, and a COG for obtaining terrain color features (Gonzalez, 2009). For simplicity, this work employs hue channel mean and standard deviation as inspired by HSI color space in image processing (Gonzalez, 2009) and variational autoencoder (Hu and O’Connor, 2018). Due to similar concept, other types of pre-trained latent variables could also be used, for example, the latent space from pre-trained autoencoder (Hu and O’Connor, 2018). In total, the robot weights approximately 4.7 kg.
To control the robot, motor target position commands are generated from a neural controller implemented on an external computer. In this experimental setup, the computer was an Intel Core i7 8750H CPU and Nvidia GeForce GTX 1050, and the motor position commands were generated at 20 Hz. The generated commands were sent via ROS wifi network to an onboard Intel NUC board (NUC717DNBE), serving as an onboard controller passing the target position commands to a standard low-level controller embedded in each motor via a U2D2 motor interface. Upon receiving the target positions, the Dynamixel low-level controller computes the velocity profiles with a maximum speed of 23 rad/s and follows the profile with the default P-controller and K p = 800 Dynamixel unit.
3. Experiments and results
To evaluate the performance of GOLLUM, four locomotion learning experiments were performed on MORF robot (Thor et al., 2018). The first experiment investigated primitive locomotion learning in terms of sample efficiency on a regular flat terrain, while the next three experiments shifted the focus toward continual energy-efficient locomotion learning in on different slopes, on different slopes with potential motor dysfunction, and on different terrains.
In each experiment, the network was updated every single episode, using the trajectory from a short episodic experience replay of N previous episodes (N = 8, as in Thor et al. (2020) and Thor and Manoonpong (2022)). Each episode took 30 timesteps, being equivalent to approximately 1 gait cycle or 5 s. The hyperparameters of the training are summarized in Table S2 in the supplementary document. Owing to the limitation of the testing area, in all the experiments, the robot was halted when the end of the testing area was reached and kept returning to the starting point until stable locomotion was obtained, that is, until no further improvement was observed. The return R[t] is computed from two types of single-term simple reward functions (r [t]) to demonstrate the locomotion learning with GOLLUM under simple reward functions and remove the process of tuning multiple gains (Choi et al., 2023; Margolis et al., 2022; Thor et al., 2020).
In the first experiment on primitive locomotion learning on regular terrain, the objective is to compare the learning efficiency and performance against the previous works in terms of speed-based reward function on regular flat terrain (Bellegarda and Ijspeert, 2022; Choi et al., 2023; Deshpande et al., 2023; Ding and Zhu, 2022; Gai et al., 2024; Hiraoka et al., 2021; Lee et al., 2020; Li et al., 2024; Margolis et al., 2022; Nahrendra et al., 2023; Rudin et al., 2022; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Shafiee et al., 2024; Smith et al., 2022a; Thor et al., 2020; Xie et al., 2020; Yang et al., 2020; Yu et al., 2023; Zhang et al., 2023). Therefore, the reward function r [τ] is defined as the forward speed v [τ] estimated from the robot odometry, as shown in equation (16). After that, the return R [t] is computed from the summation of the future reward over the horizon H, which is set as twice each basis activation time (14 timesteps) given that each basis signal overlaps (i.e., has influences) over its neighbors, as shown in equation (17).


In the following experiments on continual locomotion learning, the objective is to study GOLLUM under different environment conditions. The experiments began under a variation of one environmental feature (i.e., different slopes) to investigate the robot’s ability to overcome catastrophic forgetting when encountering slopes beyond its hardware limit. This was then extended to two environmental features (i.e., slopes and potential motor dysfunction) and their combination, exploring how the robot could exploit similarity between conditions (i.e., combining locomotion skills for a slope and motor dysfunction to tackle motor dysfunction on a slope). Finally, a more abstract and realistic example was demonstrated using real terrains. Given that the hexapod robot can achieve similar walking speed when traversing different terrain conditions (Homchanthanakul et al., 2019; Homchanthanakul and Manoonpong, 2021; Luneckas et al., 2019), using the speed reward in equation (16) can produce similar values across various terrain conditions. Thus, in the second, third, and fourth experiments (i.e., continual learning under multiple conditions), the reward function was changed to the inverse cost of transport (COT [τ]), depending on both the speed and energy consumption, as shown in equation (18). This energy-related evaluation function has been shown to vary across multiple terrain conditions (Homchanthanakul et al., 2019; Homchanthanakul and Manoonpong, 2021; Luneckas et al., 2019), thus ensuring different optimal behaviors under different conditions and increasing the complexity of locomotion learning. The return is then computed from the summation of reward over the same horizon (H = 14) to emphasize optimizing the minimum performance, as shown in equation (19).
Overview of the ablation study, where three main key components of GOLLUM: the neural control, neurogenesis, and dual learning, are studied.
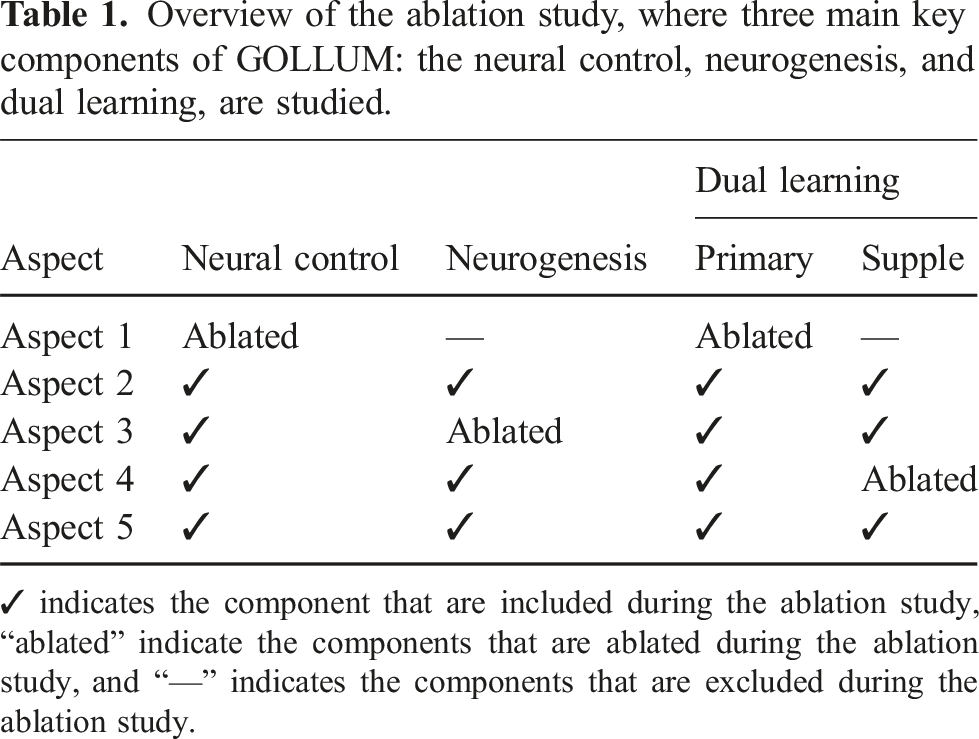
✓ indicates the component that are included during the ablation study, “ablated” indicate the components that are ablated during the ablation study, and “—” indicates the components that are excluded during the ablation study.
3.1. Primitive locomotion learning
Figure 7 and a video at https://youtu.be/MWWjpvYuwh0 reveal that the primitive locomotion learning on a regular flat terrain was achieved from scratch within the first 200 episodes (≈ 10 mins) with final average walking speed of almost 10 cm/s after 10 repetitions. (a) Average episodic speed reward the physical robot locomotion learning on the flat rigid floor (I) and (b) corresponding snapshots. The video is available at https://youtu.be/MWWjpvYuwh0.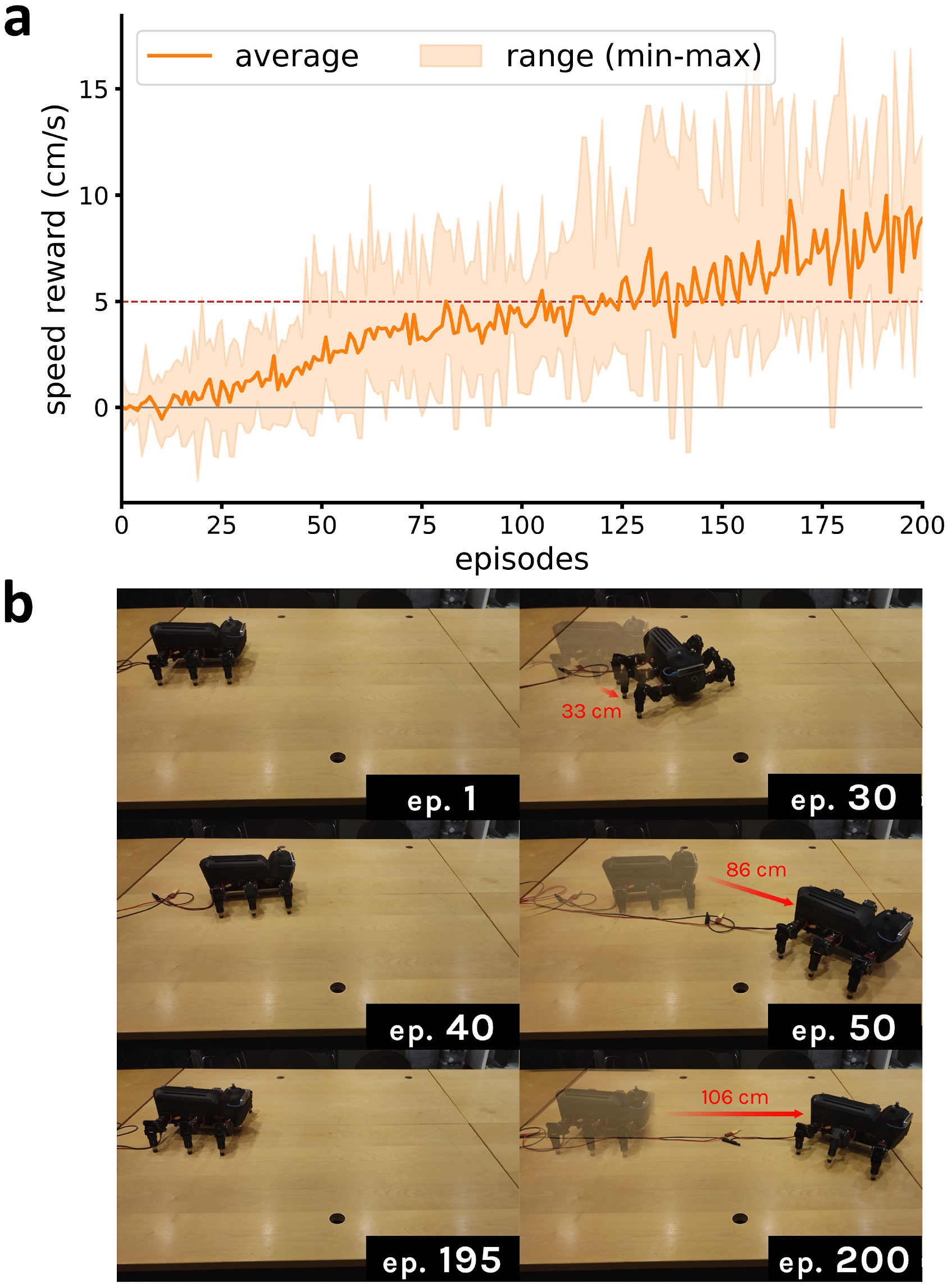
At approximately 30 episodes, the robot started moving forward, as shown in the first row of Figure 7(b). The robot began turning because it found that this could be a probabilistically simple strategy for receiving positive rewards. Merely 20 episodes after that, it demonstrated the capability of correcting its locomotion path and obtaining a faster forward speed, as shown in the second row of Figure 7(b). By the 100th episode, the robot had developed a gait with a forward speed of approximately 5 cm/s on average, which is equivalent to the result obtained from a manually designed controller (Homchanthanakul and Manoonpong, 2021), validated on the same robot. Finally, by the 200th episode, the average walking speed had reached almost 10 cm/s.
To compare with the state-of-the-art methods, we conducted an extensive experiment. The locomotion learning of the simulated hexapod robot was evaluated on regular flat terrain using four different techniques, including GOLLUM, a CPG-based technique (CPGRBF + PIBB) (Thor et al., 2020; Thor and Manoonpong, 2022), an off-policy deep reinforcement learning technique (DNN + DroQ) (Hiraoka et al., 2021; Smith et al., 2022b), and an on-policy deep reinforcement learning technique (DNN + PPO) (Schulman et al., 2017). The results, presented in Figure 8, demonstrate GOLLUM’s advantage in learning speed. The robot using GOLLUM achieved a speed of 5 cm/s after just 100 episodes, and nearly 10 cm/s by episode 200 (similar to Figure 7). In contrast, CPGRBF + PIBB (Thor et al., 2020, 2021) reached a final speed of only 5 cm/s, which is 50% lower than GOLLUM (p-value Average speed reward per gait cycle and its range (min–max), obtained from the simulated hexapod robot trained with different methods (GOLLUM, CPGRBF + PIBB, DNN + DroQ, and DNN + PPO, see text for details). Note that the hyper-parameters of the methods (see Tables S2–S5 in the supplementary document) were obtained from grid search, performed around the values reported in their original works.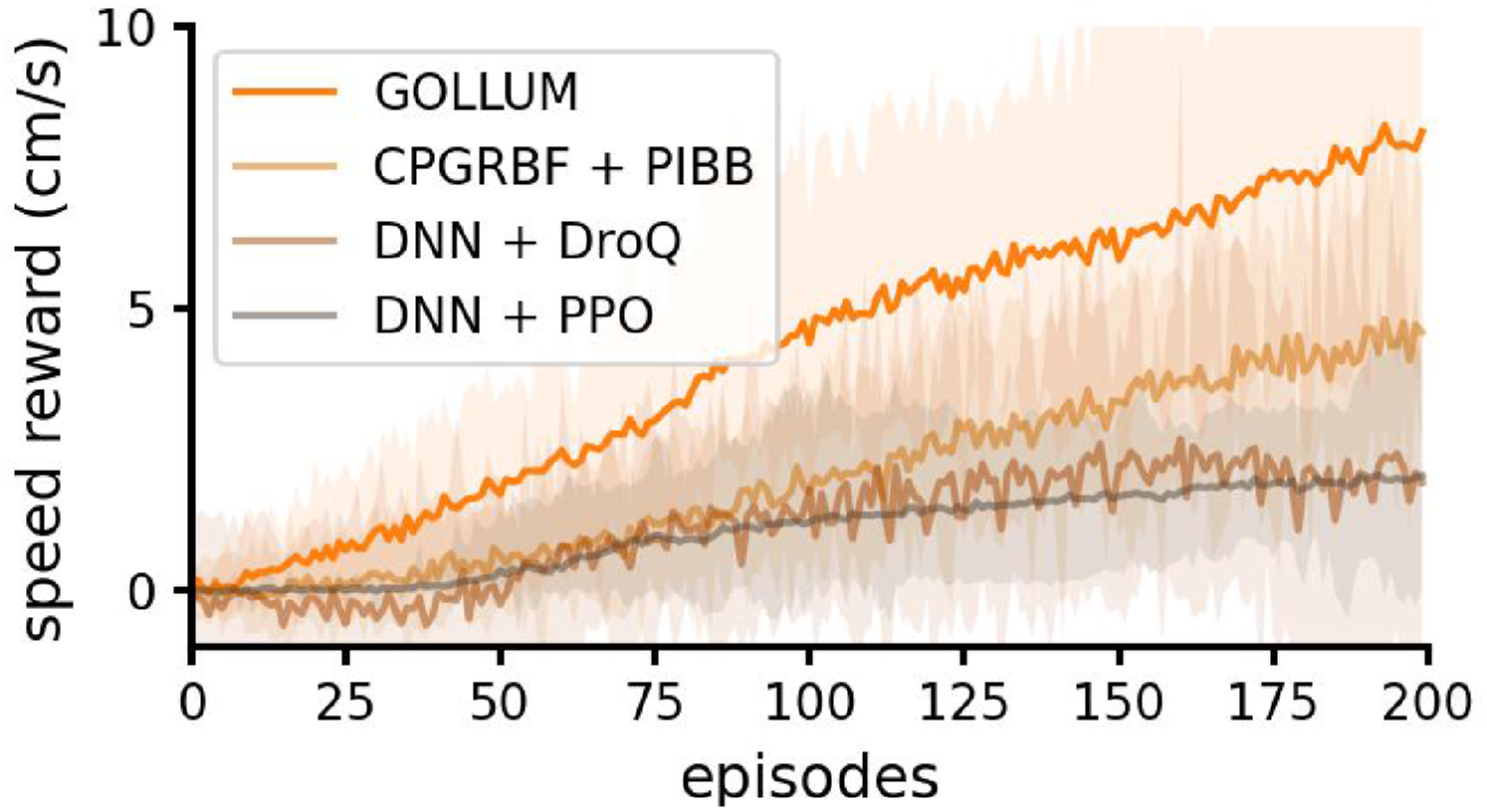
Taken together, these results highlight GOLLUM’s sample efficiency. It achieves higher rewards and performance within the same number of learning episodes (or uses less learning time to reach equivalent reward levels) compared to the state-of-the-art methods, including CPG-based (Thor et al., 2020; Thor and Manoonpong, 2022) and deep reinforcement learning techniques (Hiraoka et al., 2021; Rudin et al., 2022; Schulman et al., 2017; Smith et al., 2022b), in the context of locomotion learning. This efficiency advantage makes GOLLUM more practical for real world applications, as it requires significantly less learning time (on the order of minutes) to achieve comparable performance compared to previous methods, which typically require from hours to days in simulation (Bellegarda and Ijspeert, 2022; Choi et al., 2023; Deshpande et al., 2023; Ding and Zhu, 2022; Gai et al., 2024; Hiraoka et al., 2021; Lee et al., 2020; Li et al., 2024; Margolis et al., 2022; Nahrendra et al., 2023; Rudin et al., 2022; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Shafiee et al., 2024; Smith et al., 2022a; Thor et al., 2020; Xie et al., 2020; Yang et al., 2020; Yu et al., 2023; Zhang et al., 2023).
3.2. General continual locomotion learning
Extending from one environmental condition to multiple conditions, the robot demonstrated online continual locomotion learning on 4–6 new skills within an hour; each behavior/skill was learned under a similar timescale (≈ 100–200 episodes or 10–20 mins). The new skills enabled the robot to walk on a deformable terrain (Choi et al., 2023), different slopes (Srisuchinnawong et al., 2019), and a slope with motor dysfunction (Feber et al., 2022).
During the locomotion learning on different slopes, shown in Figure 9(a), the robot started on a confined level floor with no previously learned knowledge (all output mapping weights are zero). It took merely 70 episodes to develop a proper locomotion pattern, receiving a reward of 0.5 (COT ≈ 190) and reaching the end of the platform, and it took 150 episodes to triple the reward up to 1.8 (COT ≈ 50). At approximately 160 and 230 episodes, the platform was inclined to 10° and 15°, respectively. This involved a difficulty in climbing up the slope at different angles; thus, the reward decreased to almost 1.0 (COT ≈ 90). To deal with these changes, the robot exploited previous knowledge to autonomously and continuously learn to find new locomotion skills. Based on this learning mechanism, it took merely 20 additional learning episodes (≈ 2 mins) approximately to increase the reward to 1.2 (COT ≈ 80). After that, at approximately 300 episodes, the slope was further increased to 25°, which was beyond the robot capability. Interestingly, although the reward remained around 0.0, indicating that the robot did not move forward climbing, it learned to reduce the degree in sliding backward, as illustrated by the increase in the minimum reward and highlighted by the red arrow (Figure 9(a)). Finally, at approximately 500 episodes, the platform was returned to 0°. The robot could quickly recovered its locomotion to a regular gait for walking on the level floor. It later improved the locomotion and increased the reward from 1.8 (COT ≈ 50) to approximately 2.6 (COT ≈ 40) at 150 episodes. Snapshots and inverse cost of transport (COT)-based rewards (equation (19)) obtained from a physical hexapod robot under online continual locomotion learning (a) on different slopes (0°, 10°, 15°, and 25°), (b) on different slopes with potential motor dysfunction (0°, 10°, 0° with RF2 dysfunction, and 10° with RF2 dysfunction), and (c) on different terrains (flat rigid floor, thin mat, thick sponge, rough paver, inclined paver, and gravel field). Details plots of the signals along with the learned foot trajectories are provided in Figures S4–S6 in the supplementary document, while the videos of the experiments are available at https://youtu.be/znNi1mlLjEQ, https://youtu.be/HugIBO6cnNo, and https://youtu.be/fGCy8CXPuO0.
During the locomotion learning on different slopes with potential motor dysfunction, shown in Figure 9(b), the robot also started on a confined level floor with no previously learned knowledge (all output mapping weights are zero), before experiencing a 10° slope at approximately 160–230 episodes and returning to the level floor at approximately 230–260 episodes. However, after 260 episodes, the second motor of the right front leg (RF2, see Figure 1) was frozen (kept fixed), simulating the Dynamixel motor over-torque protection mechanism, where the RF leg obstructed the movement instead of contributing the locomotion, resulting in the drop of the reward from 1.8 (COT ≈ 50) to 0.8 (COT ≈ 130). Nevertheless, the robot could quickly deal with this incident and adapted its motion to increase the reward from 0.8 (COT ≈ 130) to 1.0 (COT ≈ 100) by the 350th episode (using ≈ 2 mins). At approximately 360 episodes, the platform was inclined again to 10°, simultaneously introducing two difficulties (i.e., slope and motor dysfunction) for learning, causing a reward reduction to 0.00. Interestingly, having learned the locomotion on slope and that with motor dysfunction, the robot took merely required 30 additional episodes to discover a proper locomotion pattern with a reward of 0.4 (COT ≈ 230) and slowly climbed up the slope. Finally, when the platform was returned to 0° at approximately 480 episodes and the RF2 motor was kept fixed at approximately 500 episodes, the robot achieved the same reward as that at approximately 360 episodes and 260 episodes, respectively.
During the locomotion learning on different terrains shown in Figure 9(c), the robot started on a flat rigid floor with no previously learned knowledge (all output mapping weights are zero), where it began moving forward with a reward of 0.8 after 30 learning episodes (≈ 3 mins) and achieved a reward of 2.0 (COT ≈ 49) after 150 episodes (≈ 15 mins). After that, the robot was transferred to a soft thin mat, where the reward dropped significantly to nearly 0.00 and then improved to 1.0 (COT ≈ 90) after 50 additional episodes (≈ 6 mins). After 220 episodes, the robot was transferred to a thick sponge terrain, where the robot’s feet got stuck owing to the deformation of the terrain. However, it required approximately 100 episodes of learning to start developing a bouncing gait, bouncing on the thick sponge to avoid getting stuck and receiving a reward of 0.6 (COT ≈ 170). After 360 episodes, the robot was transferred back to the thin mat to demonstrate recalling a previously learned skill, and after 370 episodes, it was transferred to a rough paver to learn a new skill. Interestingly, on the rough paver, the robot found that the locomotion pattern for a flat rigid floor could be used here given that it yielded a similar reward of approximately 2.0, which was then slightly increased to 2.5 (COT ≈ 40) in the following 80 episodes (≈ 8 mins). After 450 episodes, the robot reached an inclined paver, where the reward dropped to 0.6 (COT ≈ 160), but it later increased to 0.8 (COT ≈ 120) after 60 episodes (≈ 6 mins). Finally, the robot was transferred to a gravel field, where reward dropped to nearly 0.00; however, it was able to find a new gait for which the reward was increased to 1.2 (COT ≈ 80) after 50 episodes (≈ 6 mins).
All these results demonstrate that, unlike several previous works (Azayev and Zimmerman, 2020; Deshpande et al., 2023; Ruppert and Badri-Spröwitz, 2022; Schilling et al., 2020; Thor et al., 2020; Thor and Manoonpong, 2022; Xie et al., 2020; Yang et al., 2020), which often employ fixed networks after training, GOLLUM can enable the robot to continuously and autonomously improve its locomotion to handle multiple (unseen) conditions less than 10 min per condition, even without prior simulation-based pretraining. The robot successfully adapted its locomotion patterns to walk up slopes near its hardware limits and cope with motor dysfunction within a confined testing platform. Moreover, the robot could also learn to handle real-world terrains, including highly deformable ones, such as thick sponges and gravel fields, which are difficult to accurately model. The results presented in the following sections aim to verify that GOLLUM can also maintain previously learned locomotion patterns (i.e., overcoming catastrophic forgetting) and efficiently utilize learned locomotion patterns to quickly find new patterns for new conditions (i.e., leveraging knowledge exploitation).
3.3. Separation and incrementation of knowledge/skills
Figure 10 plots the return, observation, network structure, and subnetwork activities, recorded from continual locomotion learning on different terrains, to further demonstrates the separation of knowledge/skills and the incrementation process. Overall, as highlighted in red, the neurogenesis was triggered when the return dropped below the lower value prediction boundary, as shown in Figure 10(a), and the observation exceeded the previous observation prediction boundary, as shown in Figure 10(b). This created new subnetworks/neurons, as illustrated in Figure 10(c), and activated the learning of the corresponding subnetworks/skills, as illustrated in Figure 10(d). (a) Returns and lower prediction boundary obtained from locomotion learning on different terrains. (b) Trajectory of the sensory feedback in the observation space (hue mean 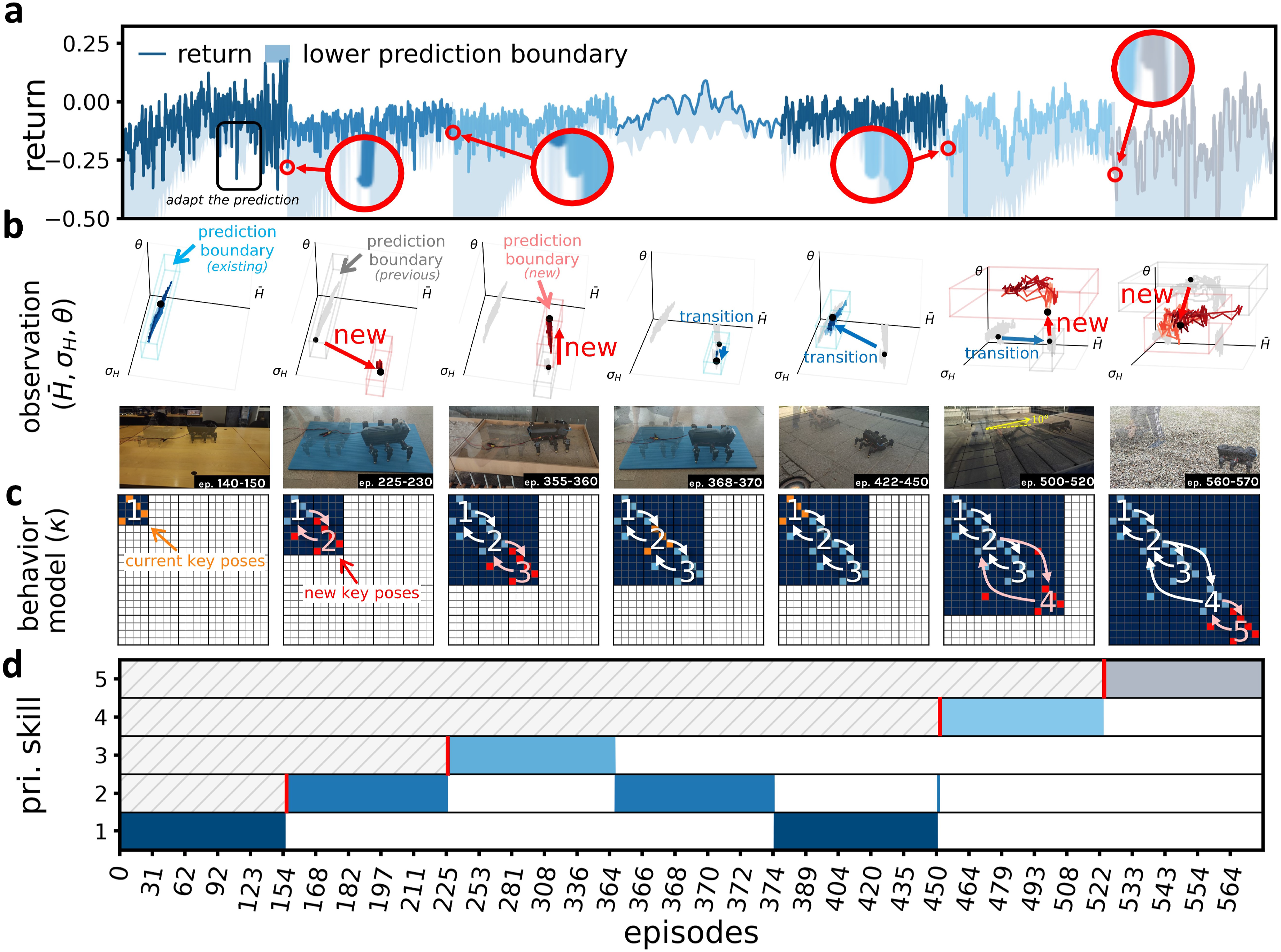
Between 1 and 150 episodes, the robot had only one untrained subnetwork, that is, the set of four neurons indicated in orange in Figure 10(c), which was used and trained, as shown in Figure 10(d). During this period, the robot also learned to predict the return and observation, and adapt their prediction boundaries (i.e., uncertainty) to cover all the data points, as shown in Figure 10(a) and (b). However, when the robot was transferred to the thin mat at approximately 150 episodes, the first locomotion pattern/skill could no longer produce high return, causing the return falling below the lower value prediction boundary (i.e., shaded region in Figure 10(a)), and the observation went over the previous observation prediction boundary (i.e., gray box in Figure 10(b)). These two events together triggered the neurogenesis, which created the second set of neurons/subnetworks, as illustrated in red in Figure 10(c); moreover, their connection weights were also initialized with those of the previous set (refer to as direct knowledge transfer mechanism) to facilitate the learning. Following that, the robot used and trained the second subnetwork/primary skill, as shown in Figure 10(d). This process repeated when the robot was transferred to the thick sponge terrain at approximately 220 episodes, creating the third subnetwork/primary skill. Note that, a significant reduction solely in the return did not trigger the neurogenesis; nevertheless, it expanded the value prediction boundary and prepared the robot for a sudden change in reward/return, as can be observed at approximately 100 episodes.
When the robot was re-transferred to the thin mat at approximately 360 episodes, it successfully recalled the second subnetwork learned previously using observation, as shown in Figure 10(b). Interestingly, when being transferred to the rough paver, there was no significant change in both return and observation, as shown in Figure 10(a) and (b); as a result, the robot autonomously switched to the first primary skill (locomotion on flat rigid floor), which exhibited the most similar observation patterns without creating any new subnetwork. This could also be considered a strategy for exploitation of similarity.
When the robot was on the inclined paver at approximately 450 episodes, the robot immediately switched from the first behavior/primary skill to the second one, given that the observation pattern received was more similar to the second condition (thin mat) than the other. However, after trying the second primary skill, it found that the return was still below the low prediction boundary while the observation also exceeded the previous observation previous prediction boundary (i.e., gray box in Figure 10(b)). As a result, the fourth subnetwork was created and connected to the previously active one (i.e., the second subnetwork, locomotion learning on thin mat), as illustrated in Figure 10(c). Interestingly, leveraging the direct knowledge transfer mechanism, the new subnetwork was not trained entirely from scratch; it was initialized with the connection weights of the previously active skill (i.e., locomotion on the thin mat), which was the most similar ones in the observation space, and underwent almost instantaneously transition based on the activity of the neurons, as demonstrated in Figure 10(d). Starting from such activity, the robot kept using and refining the fourth primary skill until it encountered the gravel field, where the fifth subnetwork was autonomously created following a similar processes. Note that, this behavior model, that is, the organization of behaviors (refereed to behavior model), can be observed from the connection matrix (i.e., κ, which represents also the connections between C neurons), as illustrated in Figure 10(c). The visualizations of locomotion learning on different slopes and on different slopes with potential motor dysfunction are available in Figures S7–S8 of the supplementary document.
Figure 11 shows that the robot suffers from catastrophic forgetting if it performs locomotion learning on different slopes without any knowledge separation mechanism. With the proposed neurogenesis (blue line), the locomotion skill on 0° learned previously was successfully recalled, and the robot received a reward of approximately 1.8, which was later increased to approximately 2.6 as a result of continual learning. Figure 12 further reveals that, when using neurogenesis, GOLLUM did not update the connection weights of inactive subnetworks. As a result, those inactive behaviors/skills remained unchanged; thereby preventing catastrophic forgetting. By contrast, without the neurogenesis (gray line), the locomotion on 0° learned previously was interfered by the locomotion on 25°, which focused on reducing sliding backward instead of moving forward. This is because all the connection weights changed throughout the training sequence when only one subnetwork was used. Thus, the reward remained at approximately 0.4 throughout the training, or rather merely 20% of the previous value (p-value Comparison of the rewards from locomotion learning on different slopes (blue line) with and (gray line) without neurogenesis. The normalized magnitude of the weight updates (|∇w|) computed from the learning rule during the learning, presented alongside the activation of four subnetworks (i.e., the activation/usage of the primary skills) and the training sequence. Given that the connection weights encode the knowledge of the behaviors/skills, non-zero weight updates indicate changes in the corresponding behavior/skill, while zero weight updates indicate no change. In this example, MORF walked from a level floor up a slope with varying angles and then returned to the level floor. Note that the blue color with different shades represents the activation of different primary skills and the corresponding weight updates, while the gray diagonal line pattern indicates that the primary skills have not yet been learned.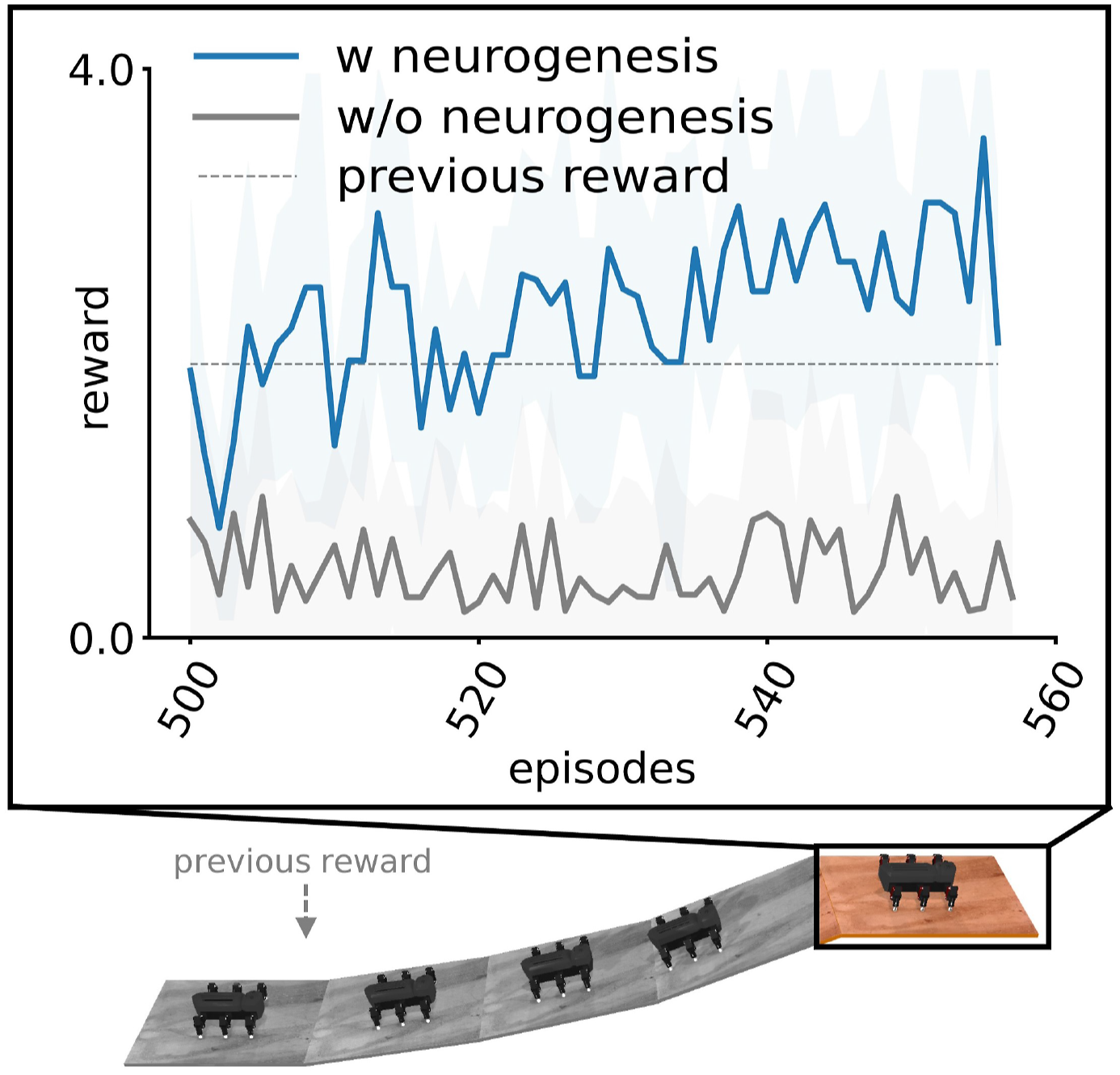
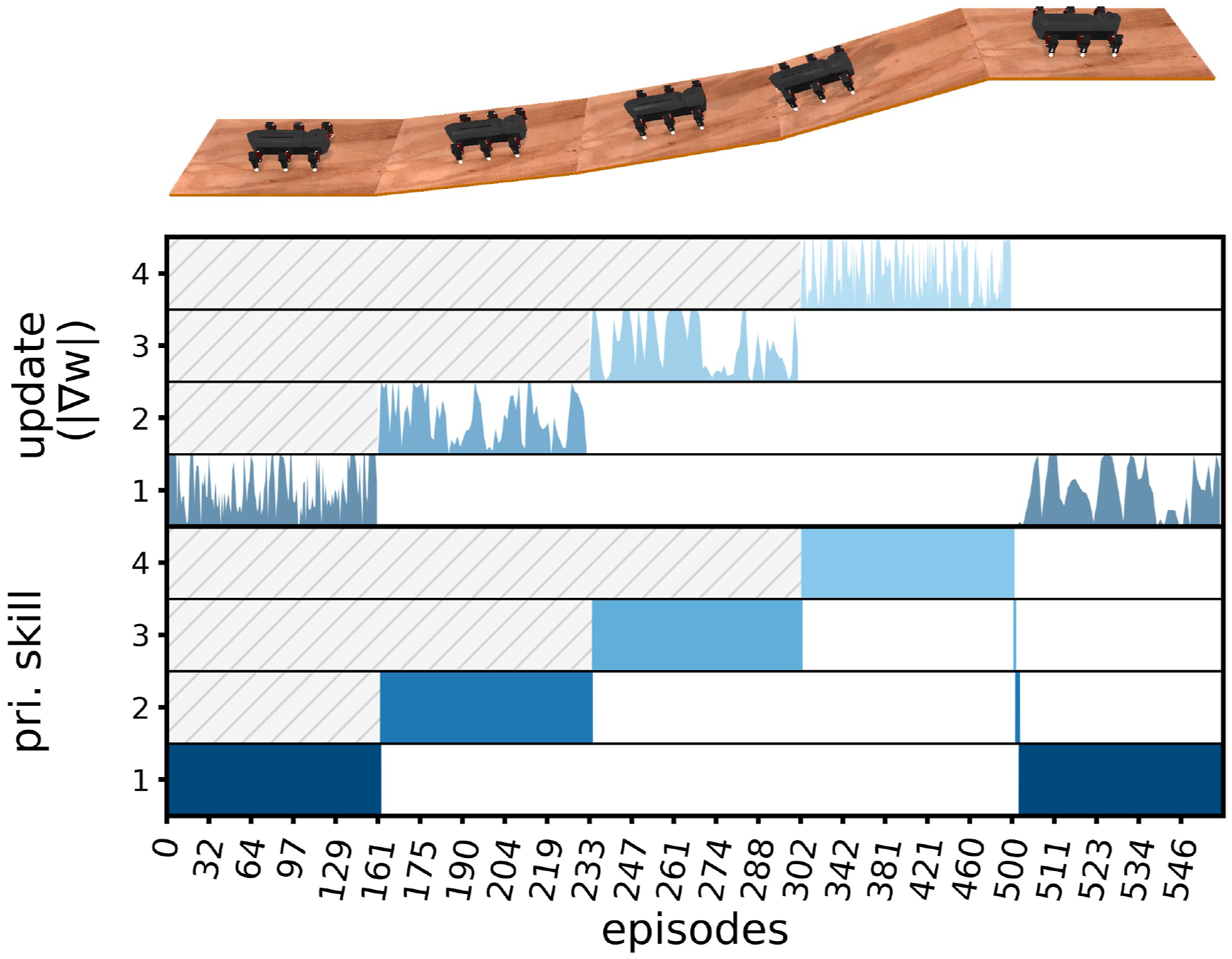
Figure 13 also shows that, after adding a new subnetwork, the skill initialization could affect performance at the very first few episodes. Using GOLLUM with the direct knowledge transfer mechanism (blue line) automatically selected the previously learned knowledge according to the most similar skill on observation-based behavior transition. In this case, the robot chose the locomotion pattern on 0° floor with frozen RF2 as the initialization of the fourth behavior/skill. As a result, the reward started at 0.36 around 360 episodes before increasing to around 0.60 after 460 episodes. However, when simply using the regular locomotion pattern (gray line), the locomotion on 0° floor was used as the initialization (referred to as the naive approach); as a result, the reward started around 0.0, which was significantly lower than that with the direct knowledge transfer (p-value Comparison of the rewards from locomotion learning on different slopes with potential motor dysfunction when the fourth subnetwork/skill was initialized (blue line) with the locomotion on 0° slope with frozen RF2 (direct knowledge transfer) and (gray line) with regular locomotion on 0° (naive approach).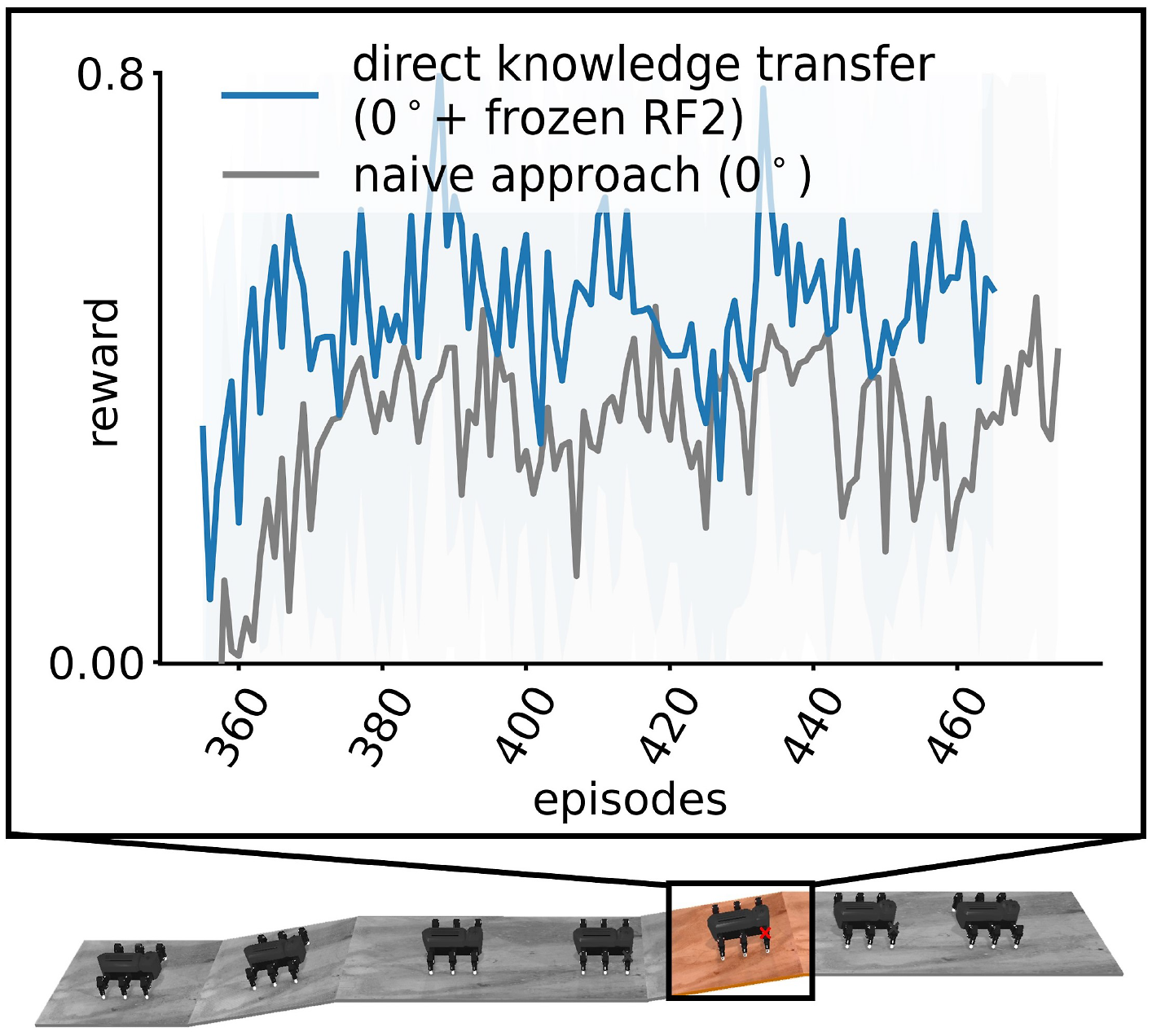
3.4. Exploitation of similarity
While the robot primarily uses and learns intra-subnetwork connections from high-level patterns (PM) to motor commands (M), it also learns the supporting inter-subnetwork connections from internal states/bases (B) to action patterns encoded in the premotor neurons (PM), as depicted in Figure 1, to supplement the combination of all acquired skills under adaptive combination percentages. Accordingly, the contribution percentages can be obtained by visualizing such connection weights, as shown in Figure 14(a)–(c), where the weight matrix represents the magnitude of each supplementary skill (i.e., each column) according to each internal state (i.e., each row). In general, the robot learned and adapted the supplementary contributions that corresponded to the active bases, as highlighted in green, while maintaining those contributions that corresponded to inactive bases to prevent forgetting as depicted in gray. Snapshots and connection weight matrices for exploiting task similarity obtained from the locomotion learning (a) on different slopes, (b) on different slopes with potential motor dysfunction, and (c) on different terrains. The rows highlighted in green indicate the supplementary skill contribution percentages (i.e., the current exploitation ratio of all skills) under different environments. (d, e) Comparison of the rewards and supplementary skill contribution percentages obtained from the locomotion learning on different slopes and on different slopes with potential motor dysfunction (green line) with and (gray line) without supplementary learning.
As a first example, Figure 14(a) presents the supplementary contribution learned during locomotion learning on different slopes, where the robot exploited the locomotion skills learned on lower slopes for supporting the learning on steeper slopes, and vice versa. Initially, the robot had acquired only the first skill from the confined level platform; thus, there was no exploitation of similarity in this stage. Later, when the robot was on a 10° slope, GOLLUM automatically created and trained the second skills and supplemented the first skill (i.e., locomotion on 0°) to ease the learning. Similarly, on 15° and 25° slopes, GOLLUM created and trained the third and fourth skills, respectively, and supplemented other locomotion skills with a slightly greater contribution offered from the locomotion skill on higher slopes. Interestingly, the supplementary learning proved crucial when the robot returned to the level platform after experiencing a 25° slope, which was beyond the robot capability (see Figure 14(d)). Without the supplementary learning, the robot autonomously switched to the first locomotion skill (0°) and was unable to access other skills, resulting in a consistent reward of approximately 1.8 (p-value
As a second example, Figure 14(b) presents the supplementary contribution learned during locomotion learning on different slopes with potential motor dysfunction, where the robot learned to exploit the locomotion skill trained on slope and that trained with motor dysfunction to ease the locomotion learning both on slope and with the motor dysfunction. Unlike the previous example, after the robot was transferred from the slope back to the level platform, it autonomously recalled the locomotion skill for the level platform while supplementing the locomotion skill for slope to facilitate the learning. Subsequently, after the RF2 motor was frozen, the robot autonomously learned to exploit the locomotion skill for the level platform at 72% contribution given that it was on 0° slope, and supplemented the locomotion skill on slope at 26% contribution. Interestingly, later on, when the RF2 motor was frozen on the slope, the robot used 39% of the supplementary skill contribution from the locomotion skill on slope to deal with the inclined platform and 36% of that contribution with the frozen RF2 motor to deal with the motor dysfunction. This resulted in an increase of the reward from nearly 0.0 to approximately 0.5 in merely 20 episodes, as shown by the green line in Figure 14(e). However, when the supplementary learning was disabled during this stage, the robot could neither access nor utilize the locomotion skills on slope and with frozen RF2 motor, causing a the reward to increase to 0.2 under a similar learning time, or rather 60% less (p-value
As a third example, Figure 14(c) presents the supplementary contribution learned during the locomotion learning on different terrains, where the robot exploited and combined the locomotion skills learned under different terrains. Initially, the robot acquired the first and second locomotion skills for the flat rigid floor and thin mat. On the thick sponge, the robot learned to utilize 56% of the supplementary contribution from the locomotion on the flat rigid floor plus 44% from that on the thin mat to prevent its legs getting stuck in the thick deformable (soft) terrain. Next, after returning to the thin mat, the robot learned to incorporate the newly acquired skill as the contribution rose from 0% to 15%. After that, on the rough paver, it found that the locomotion on the flat rigid floor could be reused; additionally, it supplemented the locomotion skills on the thin mat and thick sponge to ease the learning, contributing to a slight increase of the reward, as shown in Figure 9(c). Interestingly, on the inclined paver, the robot autonomously learned to supplement a majority of 47% from the locomotion on the flat rigid floor/rough paver given that the inclined paver was similar to the rough paver, differing only in the inclination. Finally, on the gravel field, it used 37% of the contribution from the locomotion on the thick sponge to deal with the deformable nature of the gravel field, combined with 29% of the contribution from the locomotion on the flat rigid floor/rough paver to deal with this rough terrain.
3.5. Interpretation and modification
To present and validate the interpretability of GOLLUM, this study employs both empirical demonstrations and quantitative comparison.
To empirically demonstrate the interpretability and its benefits, three characteristics of GOLLUM: decomposability, transparency, and simulability (Arrieta et al., 2020; Glanois et al., 2021; Lipton, 2018), are presented. First, decomposability is achieved as GOLLUM is built from different interpretable modular layers combined with column-wise subnetworks, making it a white-box model. As shown in Figure 1 and https://youtu.be/PxAl___xCT8, each component in an “interpretation coordinate” serves a specific function for a certain action, with each network parameter having a distinct function as summarized in Table S1 in the supplementary document. Second, transparency is reflected in how learning resembles training multiple stacked linear regressions with sparse inputs, as illustrated in Figure 15(a) and (b). The weights for behavior classification directly reflect the contributions of sensory feedback signals for behavior transitions (Figure 15(c)). Additionally, the learned weights for output and pattern mapping are adjusted toward previously tried leg configurations/actions and previously accessed patterns/skills with high rewards (Figure 5 and eq. (12)). Lastly, simulability is demonstrated by the ability to convert a trained neural control network into a behavior model (Figure 15(c) and https://youtu.be/EGElrNx_kCE), revealing the organization of complex behaviors and their transitions. By possessing these three key interpretation characteristics, GOLLUM allows for understanding of how the robot adapts to different conditions. It achieves this by combining neural control networks trained under various conditions (Figure 15(c) and https://youtu.be/EGElrNx_kCE) and adjusting network parameters, for example, increasing the locomotion frequency parameter (increasing τ
i
, https://youtu.be/MWWjpvYuwh0 after 0:50 mins), to achieve desired behaviors without the need for additional training. (a) Trade-off between interpretability and performance in various machine learning methods (DW, 2019), including GOLLUM, which has a higher interpretability and performance (see Figure 8). This figure is a conceptual representation that broadly illustrates the overall trend rather than precise, scale-accurate measurements of interpretability and performance. (b) GOLLUM represented as the combination of multiple interpretable models: a linear regression for sensory preprocessing, a decision tree for internal state generation, a sparse linear regression for sharing different action patterns trained with supplementary learning, and another sparse linear regression for output mapping trained with primary learning. (c) Behavior model extracted from an interpretable neural control, specifically the structure of the sequential central pattern generator layer. The interpretable neural control is trained on a level floor and 10° slope with possible motor dysfunction before adding a portion of another interpretable neural control trained on multiple slopes, demonstrating modifiability. The extracted behavior model also includes feedback contributions for two behavior transitions (i.e., from the locomotion on level floor to the locomotion on a 10° slope and the locomotion with motor dysfunction), which are visualized directly from the weight values in the first sensory preprocessing layer. (d–g) Quantitative interpretation evaluation metrics, including compactness (the sparsity of the neural networks and the depth and the number of nodes of the post-hoc decision tree-based explanations) and completeness (the fidelity of the post-hoc decision tree-based explanations), presented along with the range (min–max). These metrics are compared across GOLLUM, CPGRBF trained with PIBB (Thor et al., 2020), DNN trained with DroQ (Hiraoka et al., 2021; Smith et al., 2022b), and DNN trained with PPO (Rudin et al., 2022; Schulman et al., 2017).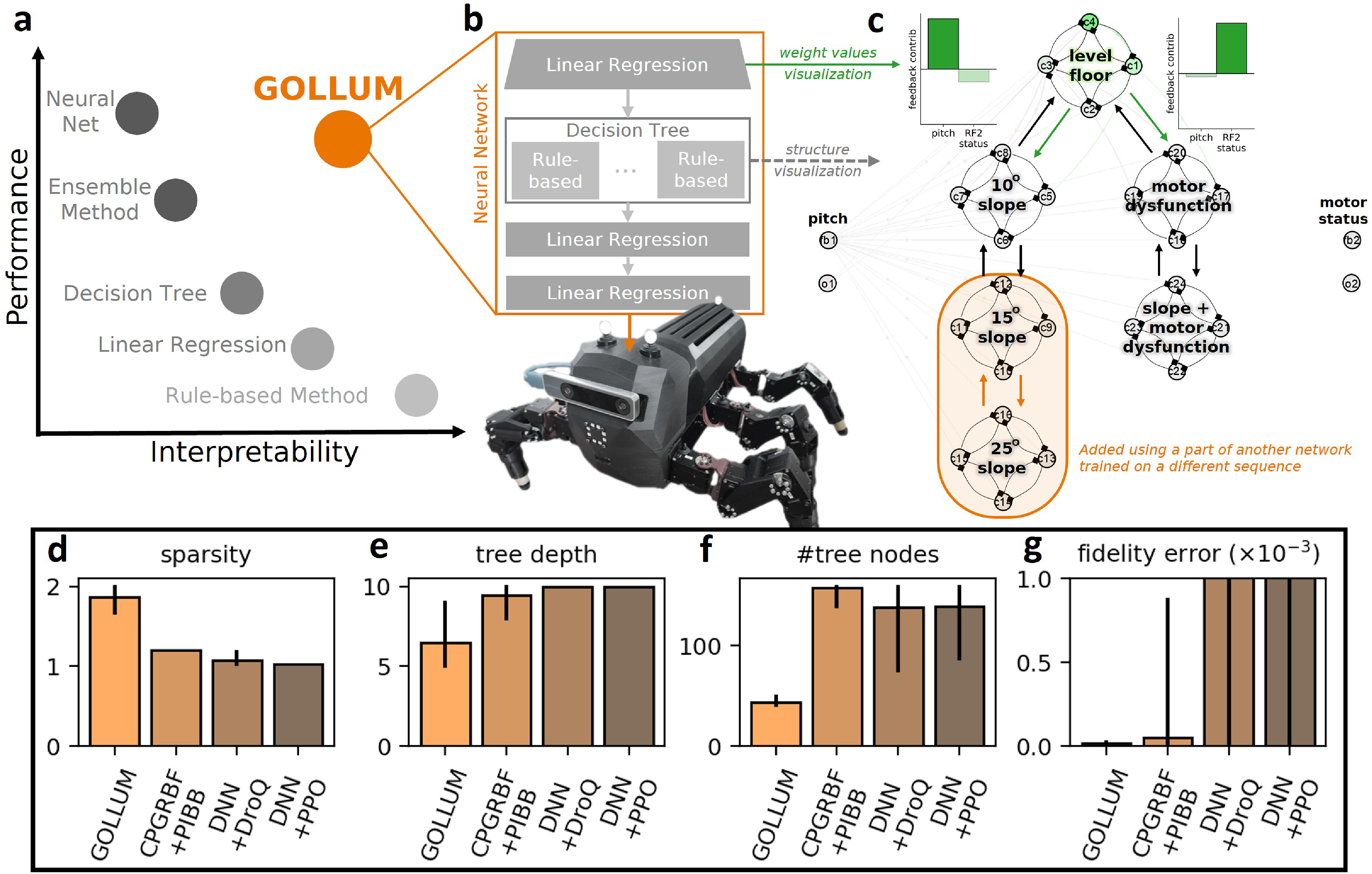
To quantitatively assess interpretability, four XAI evaluation metrics were used, following Nauta et al. (2023): sparsity (i.e., the inverse of the active neuron ratio (activation
In addition to this, Figure 15(e) and (f) reveal that the depth and the number of nodes of the decision tree-based explanation obtained from GOLLUM are receptively 30% and 70% less than those from the others (p-value
4. Discussion
4.1. Life-long locomotion learning research aspect
This study proposes a life-long locomotion learning framework, called GOLLUM, for robot locomotion intelligence. It also demonstrates that interpretability (white-box machine learning) could be utilized to deal with four key challenges of locomotion learning.
4.1.1. Sample efficiency challenge
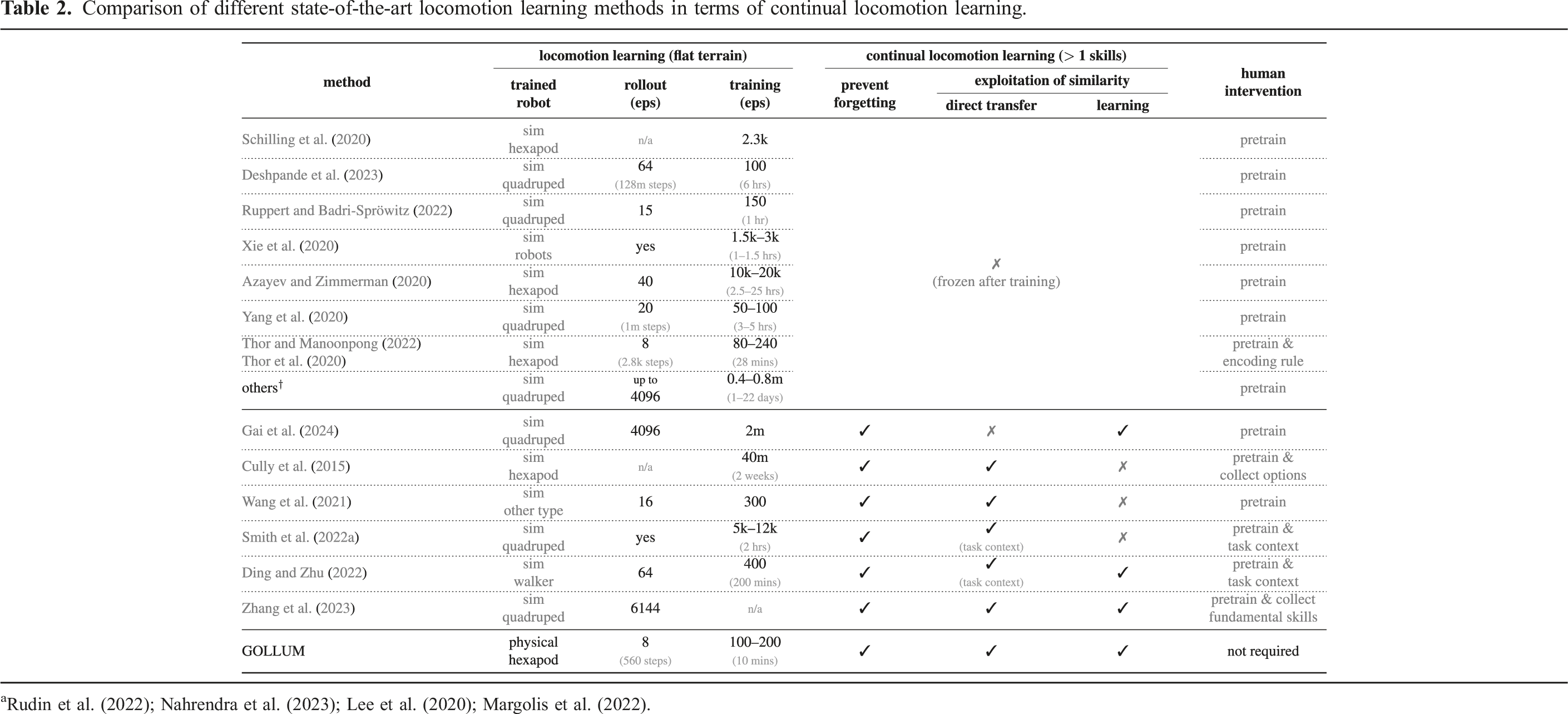
Comparison of different state-of-the-art locomotion learning methods in terms of continual locomotion learning.
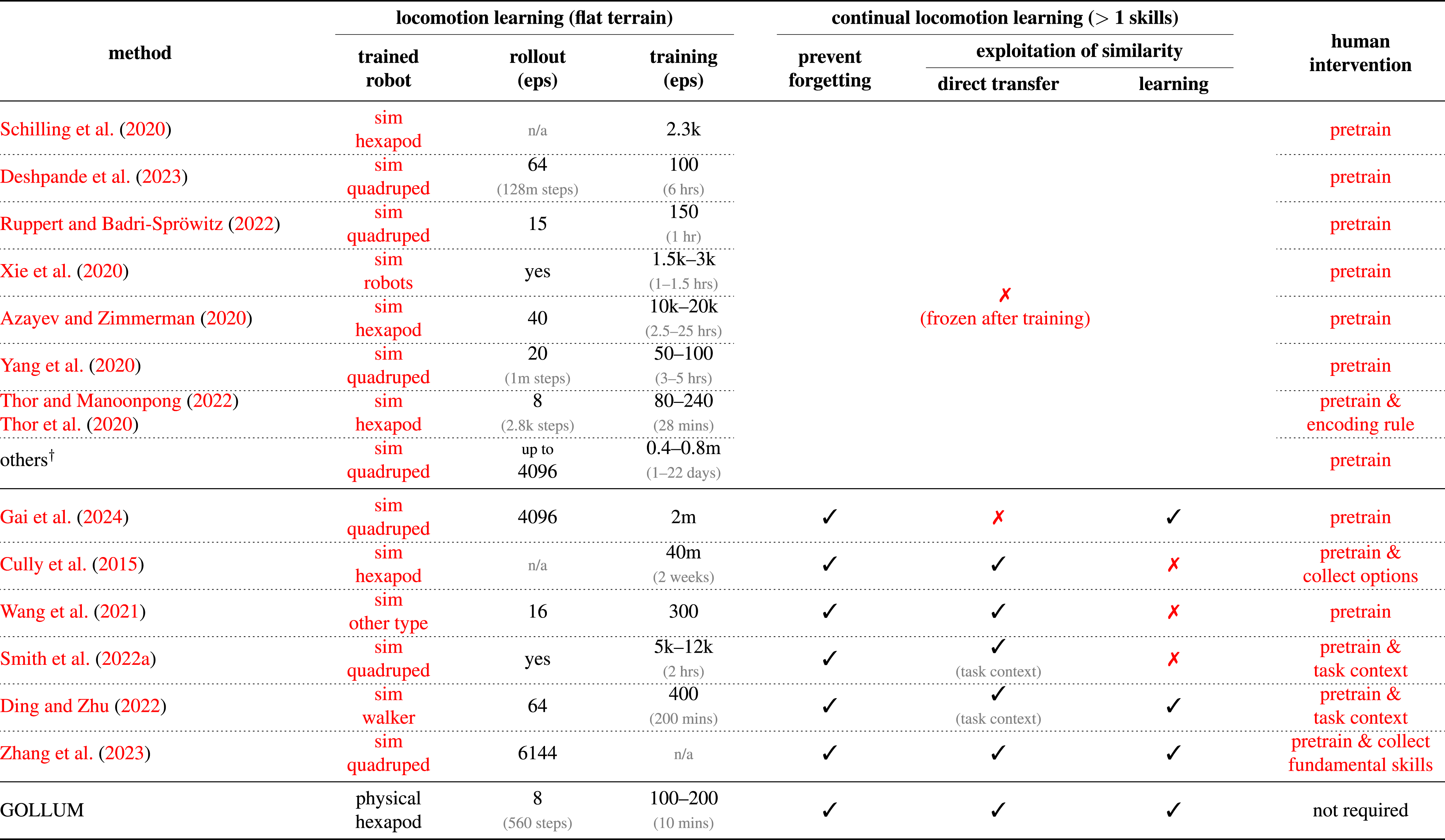
4.1.2. Overcoming catastrophic forgetting and exploitation of task similarity challenges
The second and third challenges are jointly known as the dilemma of “overcoming catastrophic forgetting-exploitation of similarity” (Kudithipudi et al., 2022; Parisi et al., 2019), which prevents robots from efficient learning and maintaining of multiple behaviors/skills throughout their life time. To deal with this, GOLLUM employs a dual layer learning mechanism. The first learning layer is called primary learning. It separately updates each primary skill encoded within each column/ring subnetwork to maintain the condition-specific skill. To exploit the other learned skills and facilitate learning, the second learning layer, called supplementary learning, updates the contribution shared between different skills/subnetworks. With this dual layer learning mechanism, GOLLUM successfully demonstrates the ability to maintain existing skills for overcoming catastrophic forgetting and the ability to accelerate/improve the performance through the exploitation of similarity with other skills.
As summarized in the last three columns of Table 2, 12 out of the 18 presented locomotion learning methods (70%) cannot perform continual learning given that the controller remains frozen to prevent catastrophic forgetting (Azayev and Zimmerman, 2020; Lee et al., 2020; Thor and Manoonpong, 2022; Yang et al., 2020). For examples, two-level policy (Azayev and Zimmerman, 2020), MELA (Yang et al., 2020), and VMNC (Thor and Manoonpong, 2022), which adopt a straightforward mixture of experts, do not update the controller after training on a predefined set of environments. From 12 methods, six methods are capable of continual locomotion learning without forgetting. One of those, Piggyback (Gai et al., 2024), requires some training before the skills encoded in share parameters are exploited because of the non-interpretable parameter structure of deep fully connected neural networks. Other five methods initialize new skills with the learned skills that have highest observation similarity (Wang et al., 2021; Zhang et al., 2023), have high value/reward after trial-and-error (Cully et al., 2015), have been predefined by a given task-context (Ding and Zhu, 2022; Smith et al., 2022a), or have been identified autonomously using observation and value/reward predictions (GOLLUM). From those six methods, only three of them (HlifeRL (Ding and Zhu, 2022), RSG (Zhang et al., 2023), and GOLLUM) manage to incorporate exploitation of similarity also during the learning (i.e., lifelong learning of exploitation of similarity). HlifeRL (Ding and Zhu, 2022) learns to combine different skill options using simulation and task context provided; consequently, it cannot operate autonomously without human intervention. Similarly, RSG (Zhang et al., 2023) constructs an initial skill graph using large and diverse fundamental skills of up to 320 skills, which are pretrained in simulation.
In contrast to those previous works, GOLLUM demonstrates the utilization of interpretable neural control structure in distributing the functions to different components, enabling the sharing of learned skills during both direct knowledge transfer and learning while preventing the robot-skill encoding parameters from catastrophic forgetting under autonomous lifelong learning directly in the real world. Therefore, to the best of our knowledge, GOLLUM is the only locomotion learning framework that realizes online continual locomotion learning in the real world without catastrophic forgetting while exploiting task similarity during both the direct knowledge transfer and learning phases without task context or human intervention (under unlimited space).
4.1.3. Interpretability challenge
The last challenge is the inability to understand and verify the neural controllers owing to their black-box nature. To deal with this, GOLLUM is designed to include three characteristics: decomposability, transparency, and simulability (Arrieta et al., 2020; Glanois et al., 2021; Lipton, 2018). GOLLUM uses interpretable modular layers and column-wise subnetworks to enhance its decomposability, assign distinct functions to individual parameters, provide a transparent learning process, and enable simulability by allowing the conversion between neural control networks and behavior models, which present complex behavior organization and transitions. These characteristics are supported by quantitative assessments using compactness and completeness (Nauta et al., 2023), which reveal that GOLLUM is simpler to interpret (due to its compactness) without significantly compromising fidelity (due to its completeness).
4.2. Engineering aspect
Concerning the engineering aspect, GOLLUM can be applied for developing robot locomotion in different unseen condition, including energy efficient gaits on different terrains (Luneckas et al., 2019), changing slope (Srisuchinnawong et al., 2021b), and abnormal conditions (Feber et al., 2022) or be employed for developing simple unsupervised decision making, for example, to classify terrains (Azayev and Zimmerman, 2020; Zenker et al., 2013) unsupervisedly without true targets. Additionally, GOLLUM provide an option for developing various behaviors which are self-organized in an interpretable hierarchical structure, resembling a state machine, a behavior tree, or a motion primitive graph (Ghzouli et al., 2023; Kulić et al., 2012), which human can understand and modify. This developed behavior hierarchy can also be interpreted as a map, inferring the robot path and the structure of the learning environment. Lastly, all these are not limited to solely to hexapod robot locomotion as it can be applied to other types of robot, for example, a hexapod robot with amputated middle legs (Figure S9 in the supplementary document and https://youtu.be/cmjijGxLLvA) and a quadruped robot (Figure S10 in the supplementary document and https://youtu.be/qEqFoGwawpo) by only changing the output dimension from 18 joints to 12 joints. Moreover, GOLLUM can be extended to other domains, such as, programming by demonstration. This can be achieved by only replacing the locomotion reward (locomotion pattern mapping) and value prediction (neurogenesis) with a fitting error function (supervised learning, see Algorithm 1 in the supplementary document). The core neural control structure (Figure 2), however, remains unchanged. This GOLLUM-based programming-by-demonstration method has been applied to robot arm manipulation involving action sequences (see https://youtu.be/mgONmN1hBwo&t=34). Additionally, it can be also used to program hexapod leg motion through kinesthetic demonstration (see https://youtu.be/fnWl33OQpak).
4.3. Bio-inspired robotics and robotics-inspired biology aspects
Regarding the bio-inspired robotics and robotics-inspired biology aspects, GOLLUM exhibits several bio-inspired lifelong learning features (Kudithipudi et al., 2022), as summarized in Figure S11 in the supplementary document. In addition, GOLLUM constitutes another possible supporting model/hypothesis for future biology research and robotics-inspired biology (Gravish and Lauder, 2018). Apart from providing a supporting mechanism for lifelong learning (Kudithipudi et al., 2022; Parisi et al., 2019), neural control exhibits the combination of feedback independent activity propagation for rhythmic generation, such as central pattern generators (Steuer and Guertin, 2019), and feedback dependent activity propagation for conditional process, such as decision making in humans (Christopoulos and Schrater, 2015; Cisek, 2006) and animals (Yan et al., 2017) as well as perception-like orientation estimation in Drosophila melanogaster (Turner-Evans et al., 2020). Additionally, the adaptation of the exploration rate based on reward/penalty as well as learning prediction uncertainty boundaries with a slow learning rate in GOLLUM could be analogies and possible mathematical models for studying biological adaptation signals, such as neuromodulation (Angela and Dayan, 2005; Van Damme et al., 2021).
Ultimately, GOLLUM could pave the way for fully autonomous lifelong learning machines with motion intelligence that can adapt and learn in diverse conditions without human intervention. This could introduce a new form of collaboration between humans and robots where individuals can actively cooperate with these lifelong learning machines by interpreting their learning results and introducing them to new environments for further learning. Moreover, it could redefine our role, shifting from extensive robot programming to active robot supervision, empowering individuals to train and engage with their own robots regardless of their robotics knowledge and further contributing to the rapid development of robotics technologies.
Supplemental Material
Supplemental Material - Growable and interpretable neural control with online continual learning for autonomous lifelong locomotion learning machines
Supplemental Material for Growable and interpretable neural control with online continual learning for autonomous lifelong locomotion learning machines by Arthicha Srisuchinnawong and Poramate Manoonpong in the International Journal of Robotics Research.
Supplemental Material
Supplemental Material - Growable and interpretable neural control with online continual learning for autonomous lifelong locomotion learning machines
Supplemental Material for Growable and interpretable neural control with online continual learning for autonomous lifelong locomotion learning machines by Arthicha Srisuchinnawong and Poramate Manoonpong in the International Journal of Robotics Research.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Acknowledgments
In addition, we thank Kasper Støy and Chaicharn Akkawutvanich for discussions and suggestions, Cao Dah Do and Atthanat Harnkhamen for the hardware and experimental support, and Senior Editor Prof. Huaping Liu and Associate Editor Dr. Danfei Xu for their supervision of the review process.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the fellowship from Vidyasirimedhi Institute of Science and Technology and by the Marie Skłodowska-Curie Actions-Doctoral Networks grant agreement No 101119614 (MAESTRI) (PM, WP6-PI).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.