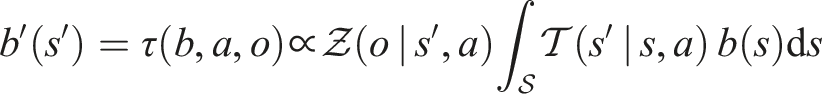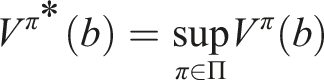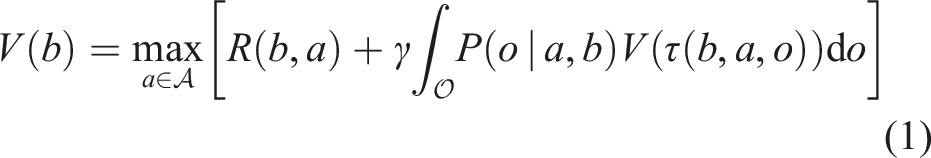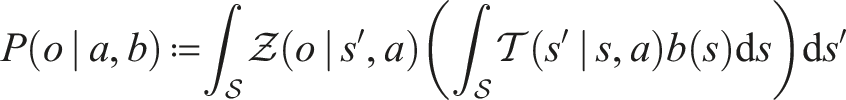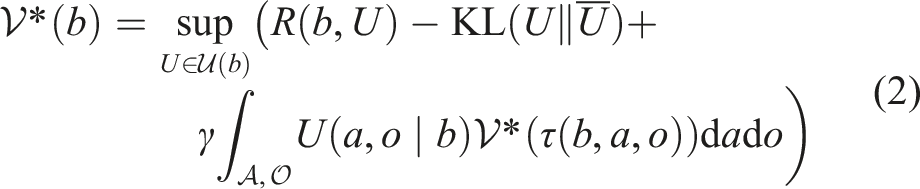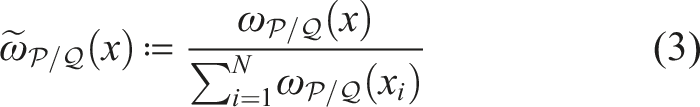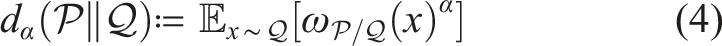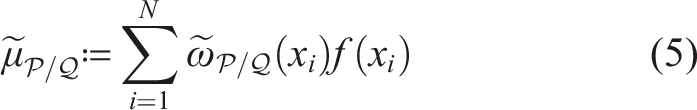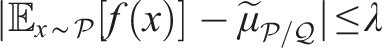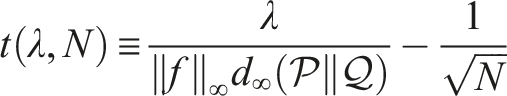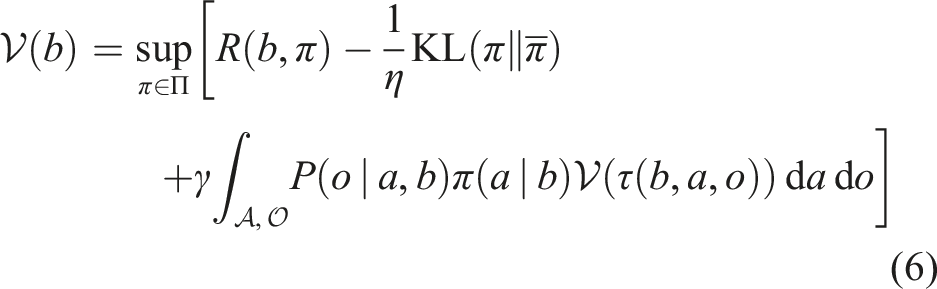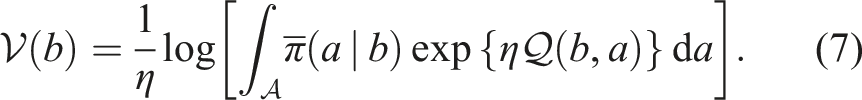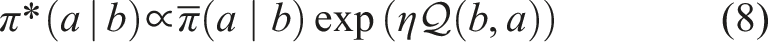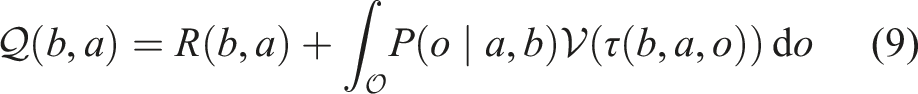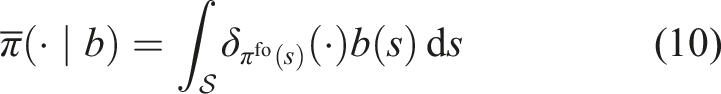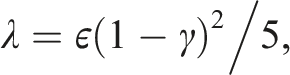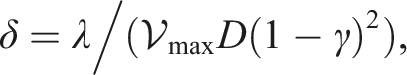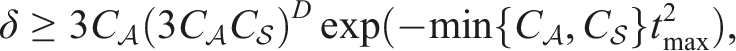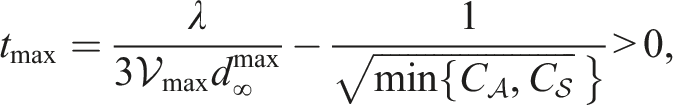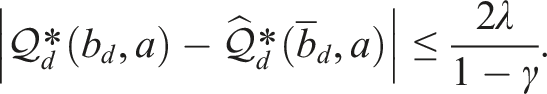Partially observable Markov decision processes (pomdps) are a general and principled framework for motion planning under uncertainty. Despite tremendous improvement in the scalability of pomdp solvers, long-horizon pomdps remain difficult to solve. To alleviate the difficulty, this paper proposes a new approximate online pomdp solver, called reference-based online pomdp planning via rapid state space sampling (rop-ras3). rop-ras3 uses novel extremely fast sampling-based motion planning techniques to sample the state space and generate a diverse set of macro-actions online, which are then used to bias belief-space sampling and infer high-quality policies without requiring exhaustive enumeration of the action space—a fundamental constraint for modern online pomdp solvers. rop-ras3 converges to a near-optimal reference-based solution at a rate that depends on the number of sampled actions, rather than the size of the action space. rop-ras3 is evaluated on various long-horizon pomdps with up to 3000 lookahead steps and 35-dimensional state spaces, where the state, action and observation spaces can be continuous, discrete, or a hybrid of discrete and continuous. Although the reference-based optimal solution may not be the same as the optimal pomdp solution, empirical results indicate that in all of these problems, in terms of success rate, rop-ras3outperforms other state-of-the-art methods by up to multiple folds. We also demonstrate the capability of our approach on a physical robot demonstration. This work extends the theory and empirical results of our ISRR24 paper. Code can be found at https://github.com/RDLLab/ROPRAS3.
Motion planning in partially observed and non-deterministic environments is a critical component of reliable and robust robot operation. Partially observable Markov decision processes (pomdps) (Kaebling et al., 1998; Smallwood and Sondik, 1973) are a natural way to formulate such problems. The key insight of the pomdp framework is to represent uncertainty on the effects of actions, perceptions and initial states as probability distributions, and then reason about the best strategy to perform with respect to distributions over the problem’s state space, called beliefs, rather than the state space itself.
Although pomdps’ methodical reasoning about uncertainty comes at the cost of high computational complexity (Papadimitriou and Tsitsiklis, 1987), the pomdp framework is practical for many robotics problems, thanks in large part to sampling-based approaches. These approaches relax the problem of finding an optimal solution to an approximate one by sampling states from the belief space and computing the best action from only the samples. Scalable anytime methods under this approach (surveyed by Kurniawati (2022)) have been proposed for solving large pomdp problems. However, computing good solutions to long-horizon (e.g., lookahead steps) pomdps remains difficult. Here, lookahead steps refer to the minimum number of actions needed for the agent to identify which action is most beneficial to reach the goal under the partially observable characteristics of the problem.
Early results from the literature (Kurniawati et al., 2011) indicate that sampling-based motion planning (sbmp)—sampling-based approaches designed for deterministic motion planning—can be used to tackle the challenges of long-horizon problems in offline pomdp planning. Specifically, sbmps can be used to generate suitable macro-actions (i.e., sequences of actions) to reduce the effective planning horizon for a pomdp solver. Macro-actions generated via sbmp automatically adapt to geometric features of the valid region and tend to cover diverse paths in the state space.
Although this approach performs well for offline pomdp planning, it is often impractical for online planning for two reasons. First is the speed of sbmps, which historically required hundreds of milliseconds to tens of seconds to find a single motion plan. Second, most online pomdp planners (Kurniawati and Yadav, 2013; Silver and Veness, 2010; Ye et al., 2017) exhaustively enumerate each action at each sampled belief in computing the best action to perform. Such enumerations limit the number of actions sampled at run time, hence restricting online planners to quickly cover a good reachable belief space, from which the optimal solution can be computed efficiently (Lee et al., 2007). However, the recently proposed vector-accelerated motion planning (vamp) framework (Thomason et al., 2024) enables sbmps to find solutions on microsecond timescales, multiple orders of magnitude faster than prior approaches. Concurrently, recently proposed reference-basedpomdpplanners (Kim et al., 2023) remove the requirement for exhaustive enumeration of the entire action space to compute approximately optimal POMDP solutions.
Leveraging the above two advances, we propose an online pomdp solver, called reference-based online pomdp planning via rapid state space sampling (rop-ras3), which is a reference-based pomdp planner that employs a vamp-enhanced macro-action sampler as its underlying reference policy. We modify the formulation from Kim et al. (2023) so that the reference is defined as a policy instead of a belief-to-belief transition, which makes it easier to generate suitable macro-actions and apply them to the reference-based pomdp solving approach. We show that the modified reference-based Bellman backup naturally allows processing continuous action spaces by replacing the optimization procedures in the pomdp Bellman backup with expectations. By adopting the analysis strategy used in Lim et al. (2020, 2023), we show a convergence rate that depends on , the number of actions a planner samples at each belief node instead of , the size of the action space reported in Lim et al. (2020, 2023). Although an optimal solution of a reference-based pomdp can be different from the original pomdp, the empirical section of our work demonstrates how this formulation enables us to solve challenging robotics tasks. We evaluate rop-ras3 on multiple long-horizon pomdps, including four navigation tasks and three manipulation tasks, which require planning horizons of hundreds to thousands of steps. Comparisons with state-of-the-art online pomdp planners—including pomcp (Silver and Veness, 2010), a pomcp modification that uses vamp to generate macro-actions, and despot (Ye et al., 2017) with learned macro-actions (Lee et al., 2021; Liang and Kurniawati, 2023)—indicate that rop-ras3 substantially outperforms state-of-the-art methods in all evaluation scenarios. Learning-based methods like magic (Lee et al., 2021) do not naturally extend to high-dimensional motion planning domains, but rop-ras3 is able to solve problems with dimensionality up to 35. rop-ras3 is also deployed to a Hello-Robot Stretch 3 mobile base manipulator. In our pedestrian crossing scenario, rop-ras3 is the only method that demonstrates smart maneuvers to dodge a moving pedestrian and navigate to the goal. Our code will be released after publication.
Remark. This work extends our ISRR24 paper (Liang et al., 2024). We modified the original algorithm to deal with continuous action and observation spaces and provided a neater way to do backups in the belief tree. The convergence analysis of rop-ras3 is added together with three new manipulation simulations and one physical robot demonstrations.
2. Background and related work
2.1. Sampling-based motion planners
Sampling-based motion planning (sbmp) is a common, effective family of algorithms (e.g., Kavraki et al. (1996); Kuffner and LaValle (2000)) for solving deterministic motion planning problems (LaValle, 2006). They are able to find collision-free motions for high degree-of-freedom (dof) robots in environments containing many obstacles by drawing samples from a robot’s configuration space, the set of all possible robot configurations, q ∈ Q. Collisions between the robot and the environment or with itself partition the configuration space into valid (Qfree) and invalid (Q\ Qfree) configurations. A deterministic motion planning problem is then a tuple (Qfree, qI, QG) representing the task of finding a continuous path, p: [0, 1] → Qfree, from an initial configuration, qI, to a goal region, QG ⊆ Qfree (i.e., p (0) = qI and p (1) ∈ QG). sbmps solve such problems by building a discrete approximation of Qfree as a graph or tree connecting sampled configurations in Qfree by short, local motions. Once both qI and QG are connected by this structure, a valid robot motion plan can be found with graph search methods. The solutions are deterministic, open-loop plans, and may not be robust against uncertainties or changes in configuration spaces.
2.2. POMDP background
An infinite-horizon pomdp is defined as the tuple where denotes the set of all possible states of the system being considered, denotes the set of all possible actions, and denotes the set of all possible observations. We assume measures are properly defined for these spaces. In our context, the state space encompasses the robot’s configuration space . The transition function is the conditional probability that the robot will be in state after performing action from state . The observation function is the conditional probability that the agent perceives when it is in state after performing action . The reward is a bounded real-valued function . The parameter γ ∈ (0, 1) is the discount factor which ensures the objective function is well-defined.
In general, the robot does not know the true state. At each time-step, the robot maintains a belief about its state, which is a probability distribution over the state space. The space of all possible beliefs is denoted by . The agent starts from a given initial belief, denoted as b0.
If b′ denotes the agent’s next belief after taking an action and receiving the corresponding observation , then the updated belief is given by
For any given belief b and action a, the expected reward is given by . A (stochastic) policy is a mapping . We denote its distribution for any given input by π(⋅ | b). A policy is deterministic if it only has support at a single point . Let Π be the class of all policies.
Given a policy π ∈ Π, we define the value function to be the expected total discounted reward, , where the expectation is taken with respect to the policy and the transition probability.
In this paper, a solution to the pomdp is a deterministic policy π∗ ∈ Π satisfying
on . The Bellman equation
is satisfied by the optimal value function . The intrinsic conditional probability
is the probability that the agent perceives o, having performed the action a, under the belief b.
2.3. Long-horizon POMDPs
Solving long-horizon pomdps is a significant challenge: the branching factor as a result of actions and observation grows exponentially with respect to the planning horizon. Planning over macro-actions (i.e., a set of action sequences) is a common approach to deal with long-horizon pomdps (Flaspohler et al., 2020; He et al., 2010; Kurniawati et al., 2011; Lee et al., 2021; Liang and Kurniawati, 2023; Theocharous and Kaelbling, 2003). Although this reduces the effective planning horizon, choosing a set of good macro-actions for planning is critical and automatic construction of macro-actions can require significant effort; for example, the learning time for magic (Lee et al., 2021) can be on the order of hours.
Irrespective of macro-action use, most online pomdp planners (Kurniawati and Yadav, 2013; Silver and Veness, 2010; Ye et al., 2017) exhaustively enumerate all actions from each sampled belief in order to estimate the optimal action. Many efficient optimization methods, which are generally based on gradient ascent, cannot be used effectively because computing the gradient of the pomdp value function is very expensive. Therefore, existing planners seldom explore long-term information and tend to perform poorly for horizons greater than 15 steps.
Recently, Kim et al. (2023) have mitigated this limitation by solving a reference-basedpomdp: a reformulated pomdp whose reward objective incurs a kl-penalty for deviating too far from a given stochastic reference belief-to-belief transition: where is a given stochastic reference policy. The reward with respect to U is defined as . The value of a belief is given by
where is the set of admissible transitions at belief b. The rhs can be optimized analytically, effectively removing the need for enumerative optimization in online pomdp solving and thereby reducing the branching factor of the belief tree. Preliminary results from Kim et al. (2023) indicate that policies generated by this procedure can outperform state-of-the-art pomdp benchmarks on long-horizon pomdps. However, the assumption of having access to a belief-to-belief transition is very strong and cumbersome to work with in practice. Kim et al. (2023) also employ relatively crude reference policies and does not incorporate macro-actions into planning.
2.4. Convergence of online sampling-based POMDP planners
Despite many empirical advances for online pomdp planning, little theoretical justification for the convergence rates of these planners has been provided. Recently, Lim et al. (2020, 2023) formally showed that a planner that uses observation likelihood weightings (a technique adopted by many online pomdp planners) can estimate Q-values accurately with a convergence rate , where is the size of the action space, is the number of state samples in a belief node, D is the depth of the belief tree, and tmax is a problem-specific bounding constant. The key of their analysis is to treat observation likelihood weighting as a self-normalized (SN) importance sampling process (Shachter and Peot, 1990). The latter aims to estimate the expectation of an arbitrary function f(x) where x is drawn from distribution , while the estimator only has access to another distribution along with the importance weights . The following three quantities related to importance sampling are frequently used,
Here, (3) is the SN importance weight, (4) is the Rényi divergence, and (5) is the SN estimator. Central to their analysis is the following self-normalized d∞-concentration bound, where d∞ is the infinite Rényi divergence.
Theorem 1. [SN d∞-Concentration Bound (Lim et al., 2020)]. Let and be two probability measures on the measurable space with and . Let x1, …, xN be i.i.d. random variables sampled from and be a bounded Borel function (‖f‖∞ < + ∞). Then for any λ > 0 and N large enough such that , the following bound holds with probability at least 1 − 3 exp (−N ⋅ t2 (λ, N)):
wheret (λ, N) is defined as,
However, their analysis does not cover the case of continuous action spaces as exhaustively enumerating all actions for maximization is impossible. A subsequent work (Lim et al., 2021) proposed a Voronoi progressive widening technique to extend the convergence analysis to continuous action spaces. Instead of relying on Voronoi optimistic optimization and its convergence, we show that the reference policy acts as a natural action sampler that removes the need of online Q-value optimization, hence replacing the in the convergence rate with , the number of actions we sample.
3. Continuous reference-based POMDPs over stochastic actions
The concept of a reference-based pomdp was introduced in Kim et al. (2023) as a generalization to pomdps of the mdp formulations using kl-penalization in Azar et al. (2012) and Todorov (2006). One limitation is that the formulation given by (2) is somewhat artificial in that reference policies are stated with respect to belief-to-belief transitions (see discussion in §8 of Kim et al. (2023)). In this paper, we will use a more natural formulation of a reference-based pomdp over stochastic policies rather than belief-to-belief transitions as in Kim et al. (2023). This allows us to directly work with reference policies which are easy to define and handcraft compared to belief-to-belief transitions. Further, the latter is less realistic as one does not have the choice of picking specific observations that resulted in the desired transitions, but is allowed to choose heuristic reference policies. Note that in doing so, all the benefits of the formulation in Kim et al. (2023) are still preserved.
Specifically, a reference-based pomdp over stochastic actions is specified by the tuple . The presentation here treats the state, action, and observation spaces as continuous spaces and assumes that the associated Borel σ-algebra exists and probability measures are properly defined with respect to the underlying σ-algebra. In addition to the standard parameters, we have a temperature parameter η > 0 and a given (stochastic) reference policy. We assume that . The value (distinguished from the pomdpV-value) of a reference-based pomdp for a given satisfies the reference-based Bellman equation,
where is the reward estimate. A solution is a stochastic policy π ∈ Π that maximizes . The problem can therefore be viewed as a kl-penalized pomdp whose objective is modified to trade-off two (potentially competing) objectives: (1) abide by the reference policy, and (2) maximize reward. The trade-off is balanced by η and the quality of the reference policy—higher-quality reference policies are those that reduce the kl-divergence between the solution of the unpenalized pomdp (1) and the reference policy. The kl-penalty implies that for any . When the optimal policy is used as the reference policy, we trivially obtain the optimal policy as the solution, since the optimal policy is deterministic and the only solution that maximizes rewards and minimizes KL-divergence is itself.
For an arbitrary , the supremum in (6) can be attained analytically by extending an argument of Azar et al. (2011, 2012) to pomdps,
Theorem 2. [Analytical Solution of Reference-basedPOMDP]. The exact solution of (6) is given by,
Moreover, the exact solution of the Reference-basedPOMDPis given by,
In above theorem, we have defined the reference-based Q-value,
Derivation details can be found in Appendix A.1.1. The iterative backup procedure is guaranteed to converge to a unique solution from which the policy can be read off using (8) (Kim et al., 2023). The main point is that enumerative maximization in (1) is replaced with expectation.
This new backup brings multiple advantages. First, gradients of the Bellman equation in pomdps are generally hard to compute because it requires an estimate of the expected total future reward. This difficulty in computing gradients makes numerical optimization in pomdp solving to generally be very computationally expensive. Our method removes this barrier and opens new ways to solve pomdps. Specifically, it partially solves the optimization analytically, leaving numerical computation to only estimation of expectation, which can often be computed quickly via the Monte Carlo approach. Of course, if the probability distribution function is one that the Monte Carlo approach struggles with, such as those with rapidly oscillating functions or has very high variance, for instance, rop-ras3 requires much more careful consideration in its action selection (i.e., sampling strategy and selection of the reference policy). Second, the effective action space is reduced to the support of the reference policy, which can be much smaller than the entire action space, making rop-ras3 scalable to high-dimensional continuous action space.
These ideas are elaborated upon in the later sections, where we show that replacing exhaustive enumeration with Monte Carlo estimation provides a convergence rate that depends on , the number of actions sampled, rather than |A|, the size of the action space. Meanwhile, our algorithm rop-ras3, using the new backup, outperforms many baselines across diverse long-horizon tasks.
Remark. The optimal solution of a reference-based pomdp considered here is not the same as the optimal solution to the standard pomdp, as the objective functions considered are different. It is natural to ask whether it is possible to improve the reference policy over time by treating the newly obtained solution as the next-step reference policy, leading to convergence to the optimal solution of the standard POMDP. The answer is positive, as presented in Kim and Kurniawati (2025). However, such a convergence requires higher computational resources and is beyond the scope of this paper. In this work, we demonstrate how reference policies constructed based on fast motion plans in the state space can lead to scalable robust solutions for robots operating in a non-deterministic and partially observable world.
4. Algorithm
We introduce reference-based online pomdp planning via rapid state space sampling (rop-ras3), our online anytime planner that uses sampling techniques to rapidly estimate -Values and -Values for inferring good actions to execute. We motivate its design by briefly outlining vamp’s capability to induce high-quality reference policies. A general algorithm is proposed to utilize vamp to infer actions for online pomdp planning. Then we elaborate rop-ras3 and analyze its online convergence rate.
4.1. Vector-accelerated motion planning (VAMP)
Toward fast deterministic motion planning, recent works have introduced new perspectives on hardware-accelerated sampling-based motion planning (sbmps), using either cpu single-instruction, multiple-data (simd) (Thomason et al., 2024) or gpu single-instruction, multiple-thread (simt) (Sundaralingam et al., 2023) parallelism to find complete motion plans in tens of microseconds to tens of milliseconds. In particular, the authors of vamp (Thomason et al., 2024) proposed a simd-vectorized approach to computing sbmp primitives (i.e., local motion validation) that applies to all sbmps thus, it is now possible to generate probabilistically-complete, global, collision-free trajectories for high-dof systems at kilohertz rates—on the scale of tens of thousands of plans per second. The key insight of this work is to lift the “primitive” operations of the sbmp (e.g., forward kinematics and collision checking) to operate over vectors of configurations in parallel. Robot-specific code that uses these vector primitives is generated from a URDF using a tracing compiler—this pre-processing step is general to any robot. Functionally, this enables checking validity of a spatially distributed set of configurations over a candidate motion in parallel for the cost of a single collision check, massively lowering the expected time it takes to find colliding configurations along said motion. This development has called into question previously held perceptions that sbmps are relatively time-expensive subroutines and—in the context of planning under uncertainty—opens the door to using sbmps to guide pomdp planning on the fly.
4.2. POMDP planning with SBMP-generated trajectories
A stochastic reference policy can be constructed from a deterministic policy. In robotics, such a representation can be naturally obtained by integrating deterministic motion plans with belief-space sampling. We begin by presenting a general tree node expansion mechanism in Algorithm 1 to integrate belief-space sampling of a canonical online pomdp planner with state space sampling to generate macro-actions using sbmp. Since an expansion mechanism to get new actions for a new belief node is universal in online pomdp planning, Algorithm 1 can use any sbmp planner and can generalize to most existing online particle-based pomdp planners, such as pomcp (Silver and Veness, 2010), despot (Ye et al., 2017), and their derivatives (Cai et al., 2021; Kurniawati and Yadav, 2013; Lee et al., 2021; Liang and Kurniawati, 2023).
At a newly encountered belief node , SBMPExpand in Algorithm 1 aims to expand of actions by first sampling a source state from the belief particles. In line 4, a target state is drawn from a distribution , a distribution over the state space conditioned on the current belief particles. In robotics, target states can be states that reveal a certain amount of information to the robot, including states with high reward or penalty and states with observations. A deterministic motion plan is then constructed using any existing sbmp in line 6. The path is converted to a macro-action via PathToMacroAction and added to the return list.
The choice of sbmp is an essential component for achieving high-quality policies online. vamp enables rapid generation of collision-free state space paths to goals or to highly informative states, which in turn can be used as macro-actions for the pomdp planner. Thus, promising macro-actions can be dynamically created as a subroutine (line 5 in SBMPExpandTree) within a pomdp planner itself in fractions of a second. In contrast, the state-of-the-art planner magic (Lee et al., 2021) takes on the order of hours to learn macro-actions.
However, fast macro-action sampling alone is not sufficient, as current online pomdp planners perform numerical optimization via enumeration of all (macro) actions at each sampled belief, which results in a time and space complexity of , where denotes the space of the macro-actions, h is the planning horizon. This complexity significantly limits the number of macro-actions and the depth of the tree it can construct, thereby significantly limiting the benefit of sbmp for pomdp solving. To tackle this problem, we propose rop-ras3 next that draws on insights from Section 4 while, in tandem, exploiting the speed of vamp (Thomason et al., 2024)—an implementation of simd-vectorized sbmp—to create a rich set of diverse macro-actions, which the planner uses to efficiently explore relevant parts of the belief space.
4.3. ROP-RAS3
We propose rop-ras3 (Algorithm 2), a practical and scalable reference-based pomdp online planner for motion planning under uncertainty. We use arrows on top of letters to indicate macro elements associated to that letter (e.g., is a macro-action). With a slight abuse of notation, denotes the belief node in a tree, denotes the action node associated with and is the next belief node given and . The curly indicates the children of a belief node (e.g., returns all actions associated with ). And N (⋅) denotes the visitation count of a node. Values are initialized to zero by default.
4.3.1. Numerical backup
Recall from Theorem 2, the reference-based Bellman backup can be broken down into two parts, the -value defined in (9) and the -value defined in (7). The -value can be viewed as an expected total future reward, , where Ri is the reward return from the i-th simulation at the node . From (7), by realizing that , we can then estimate this term with . The iterative versions of both estimators are given in lines 4 and 5 of the Backup function in Algorithm 2. Further details and convergence rates of such nested Monte Carlo Estimators can be found in Rainforth et al. (2018).
Due to the closed-form solution found in Theorem 2, we do not need to solve the bandit problem, which is typical of many online pomdp planners, dropping the need for UCB-like techniques. Second, without the need to expand all actions encountered at a given new node and restarting search from the root node, we can search deeper earlier by continuing to simulate from the newly sampled action, prioritizing long-horizon search commonly found in many robotics problems. Such tree search strategy is tightly linked to the backup equation (7).
4.3.2. Planning tree construction
rop-ras3 uses unweighted belief particles. This has the speed advantage of only retaining particles that have been sampled and obtained from the generative model during simulations. In simulation, rop-ras3 aims to get an action and query the generative model to simulate for the next state, rewards and observations. Since both the action space and the observation space can be continuous, we apply the double progressive widening technique (Sunberg and Kochenderfer, 2018) to ensure sampled elements can be revisited again in a new simulation. Our progressive widening technique is different to the standard implementation in the sense that we only need to uniformly sample from the existing actions and observations if the widening condition is not met, thanks to Monte Carlo estimations in our backup procedures. If the condition of expanding a new action is met, then rop-ras3 proceeds to query a macro-action from a reference policy induced from a sbmp (see SampleMacroActionSBMP), instead of uniformly sampling from the free action space as done in Sunberg and Kochenderfer (2018). The generative model is used to simulate for the next state, reward, and observations. The macro-action, observation, and the next state are added to the tree if they are not created yet. This repeats up to a predefined depth D. When the required depth is reached, rop-ras3 obtains an estimate of the node’s value by rollouts, a standard operation used by other online planners. The planner then approximates the exact backup (Backup) by carefully maintaining an empirical expectation, repeating backups on the simulated belief-tree path up to the root node. The above procedure is repeated until exhausting a computation budget (e.g., time), at which point the estimate of the optimal policy is read off from the tree’s root node via (8).
4.3.3. Reference policy
The simplicity offered by the formulation comes at a cost: if the optimal policy of the pomdp with an unmodified objective is too far from the reference policy (in the sense of the kl-divergence), pure reward maximization can be compromised. Of course, the optimal policy and hence this divergence are not known a priori. Instead rop-ras3 assumes that reference policies generated by accelerated sbmps (vamp) provide a reasonable starting point, leveraging them to rapidly sample high-quality deterministic policies to induce a reasonable partially observed reference policy which it deforms online. The subroutine SampleMacroActionSBMP acts as the foundation for our reference policies. It lifts vamp to belief space by sampling a state from the input belief particles, pick a target state with information (observation or reward) and query vamp to build a deterministic motion plan connecting the two states. This motion plan is then converted to macro-actions for rop-ras3. The target states can be either uniformly drawn from the free space or dynamically sampled based on the belief of the agent. Sampling these informative states ensure our planning tree only cover a compact reachable belief space, retaining optimal solution while reducing the search complexity as uninformative path occurs less frequently.
We emphasize that this modification is not negligible. Indeed, our results show that the performance deteriorates with problem complexity if the agent only executes the sbmp reference policy as an open-controller without planning for uncertainty. More implementation details are discussed in Section 5 and our code website.
4.4. Convergence analysis
With the maximization steps in pomdp planning being replaced by an expectation estimation, rop-ras3’s convergence can be analyzed by bounding -value estimations and -value estimations at all nodes of the tree. To make analysis tractable, we simplify rop-ras3 and distill its core computations into a theoretical algorithm, Reference-based Sparse Sampling (Algorithm 3). At the core of RBSS is a recursive self-normalized importance sampling process to estimate the beliefs based on the observation weightings. At a belief node, RBSS expands all sampled actions and observations to obtain a full belief particle set in the next step. This does not have the same computational advantage of only updating those particles that are sampled for the next step simulation as done in rop-ras3, but allows us to leverage Theorem 1 to provide anytime estimation error bounds at all nodes. Further, by noticing that the reference policy in rop-ras3 is created from deterministic motion plans by sampling the source state from the belief and the target state from a heuristic, we assume that the reference policy used in RBSS is also created from an underlying fully observable policy as a pushforward measure of b(s),
where δ denotes the Dirac measure. Such representation allows us to compute the weights of an action based on the particle representation of the belief. More details about RBSS are discussed in Appendix A.1.2. Theorem 3 shows RBSS has a convergence rate of .
Theorem 3. [Accuracy of RBSS-value Estimate]. For any ϵ > 0, choose constants , , λ, δ that satisfy,
Then, the-values estimates obtained for all depth D and sampled actionsaare near-optimal with probability at least 1 − δ,
The proof is adapted from Lim et al. (2020) and is detailed in Appendix A.1.2. The key contribution in our proof is to view the Estimate- as another SN importance sampling estimator. For this estimator to be properly defined, we need to rely on the representation of reference policy defined in (10). Since (10) is a pushforward measure of b(s) and b(s) is estimated via observation weightings (see Estimate-), the importance weightings of are simply the observation weightings reweighted by the support of πfo. Then, we can apply the SN concentration bound from Theorem 1 to bound the estimation errors incurred in the Estimate- step. Further, the estimation errors from Estimate- can be calculated following the same steps as the presentation of Lim et al. (2020). Hence, the final result is a worst-case union bound that combines all estimation errors from all depths of the tree. Since our Estimate- procedure does not exhaustively enumerate through the action space, we can directly work with continuous action spaces where the number of actions we sample is a key parameter that controls the convergence rate.
5. Experiments
We evaluated rop-ras3 on seven different long-horizon simulated pomdp problems, systematically analyzing the effects of its respective components on its performance. The simulated testing scenarios include 2D navigation, 3D navigation, multi-robot tag, and manipulation problems. We also demonstrate rop-ras3’s practicality by deploying it to a Hello-Robot Stretch 3 mobile manipulator. Finally, an ablation study is carried out to understand rop-ras3’s performance as the reference policy gradually deteriorates to a purely uniform policy. Empirically, we show that the success of rop-ras3 is a combination of the new tree search method and reference policies induced from vamp.
5.1. Simulation scenarios and benchmark methods
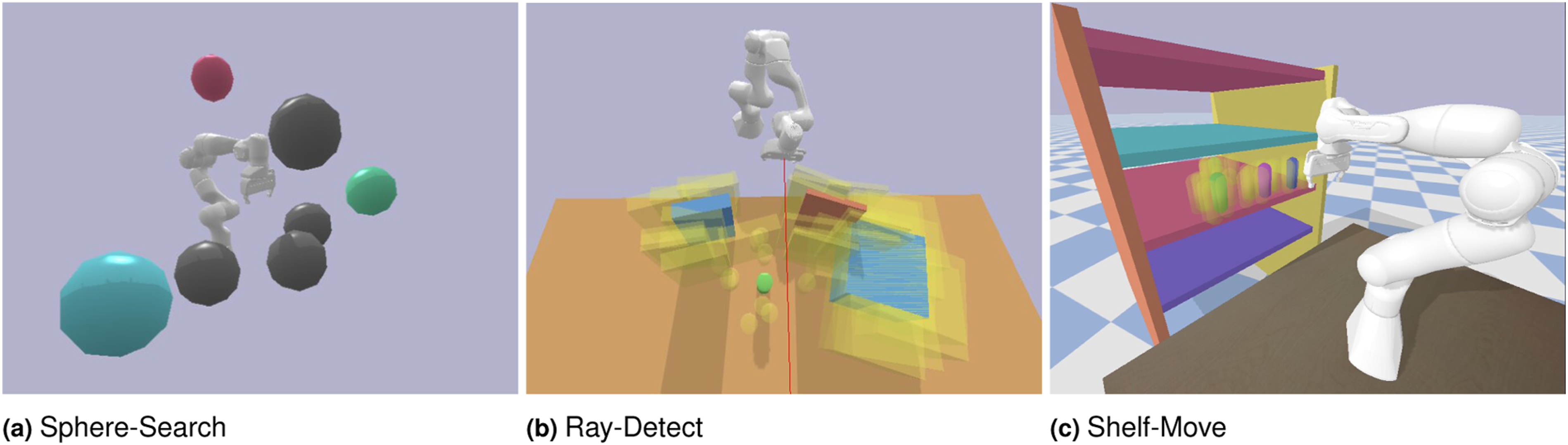
The scenarios are described next, while a summary of the corresponding pomdp models is provided in Table 1. More detailed pomdp definitions of each scenario are described in Appendix A.2.1 and Tables 6 and 7.
POMDP summary of simulation scenarios. Hmin denotes the minimum number of steps needed to complete the goal without any uncertainty. Since these scenarios are goal-reaching problems, the minimum planning horizon of the pomdp problem must be higher than the respective Hmin. Discrete(x) indicates the action space consists of x discrete actions. None corresponds to no observation due to partial observability. Discretized motion path refers to snapping primitive actions to a motion path.
Hmin
Uncertainties
PathToMacroActions
Light Dark
Discrete (4)
8
Initial position
Discretized motion path up to a predefined length
Maze2D
Discrete (4)
100
Initial position, drone transitions odometry
Discretized motion path up to a predefined length
Random3D
Discrete (6)
40
Initial position
Discretized motion path up to a predefined length
Drone transitions
Odometry
Multi-Drone
Discrete (24)
20
Target locations
Discretized motion path up to a predefined length
Sphere-Search
50
Target locations
Motion path up to a predefined length
Arm transitions
Ray-Detect
80
Obstacle poses
Motion path up to a predefined length
Arm transitions
Shelf-Move
300
Obstacle poses
Entire motion path
Arm transitions
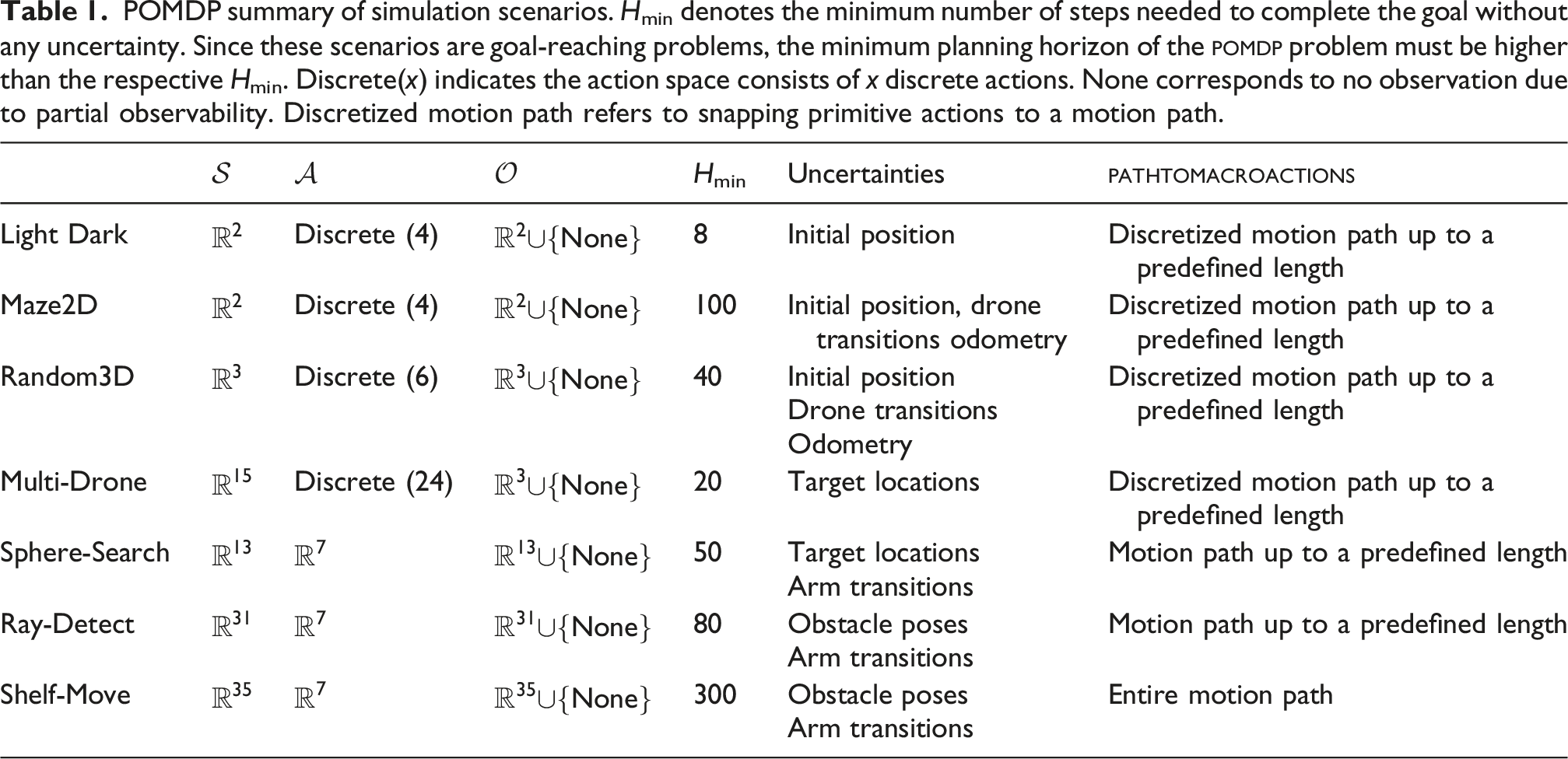
Light Dark (Figure 1(a)). A variation of the classical Light Dark problem. The agent needs to navigate to a goal region with an initially unknown location. It can only localize in the light stripe.
Navigation benchmark environments. All modes of starting locations, if any, are marked in orange. Goals are marked in green. Purple boxes, if any, indicate observation zones. Sampled belief particles are displayed in Yellow and the opacity denotes the weight of the particle. Red boxes are danger zones. Fixed walls are marked in gray and randomly sampled obstacles are marked in cyan.
Maze2D (Figure 1(b)). This is a long-horizon problem, modified from the discrete 2D Navigation scenario in Kurniawati et al. (2011). A 2-dof mobile robot must navigate from one of the two potential initial positions to a goal region without entering a danger zone and dodge obstacles. The robot receives position readings with small Gaussian noise inside the landmarks and no observations otherwise. This limited localization capability results in a minimum of 100 primitive actions to reach the goal, as the robot must take detours to localize and avoid danger zones.
Random3D (Figure 1(c)). A 3D navigation problem with randomly placed obstacles, landmarks, danger zones, and goals. The goals are initialized to be far away from the initial position of the drone. We systematically evaluate rop-ras3 on environments with progressively increasing obstacle density. The chance that the sbmp fails to find a path due to narrow passages within a given time limit increases with the obstacle density and a pomdp planner needs to consider more diverse macro-actions to find a good motion strategy.
Multi-Drone with A Teleporting Target (Figure 1(d)). In a 3D open area, four drones need to work together to capture a moving target (in green) whose initial position is not known to the drones. Moreover, the target can teleport to the opposite side of the map once it collides with the map boundaries but drones cannot. The target is equipped with the strategy of moving away from the closest drone. This strategy is known to the drones. The drone can only detect the target if they are within a small detection range. And the target is captured as long as one drone is within the capture radius (smaller than detection range).
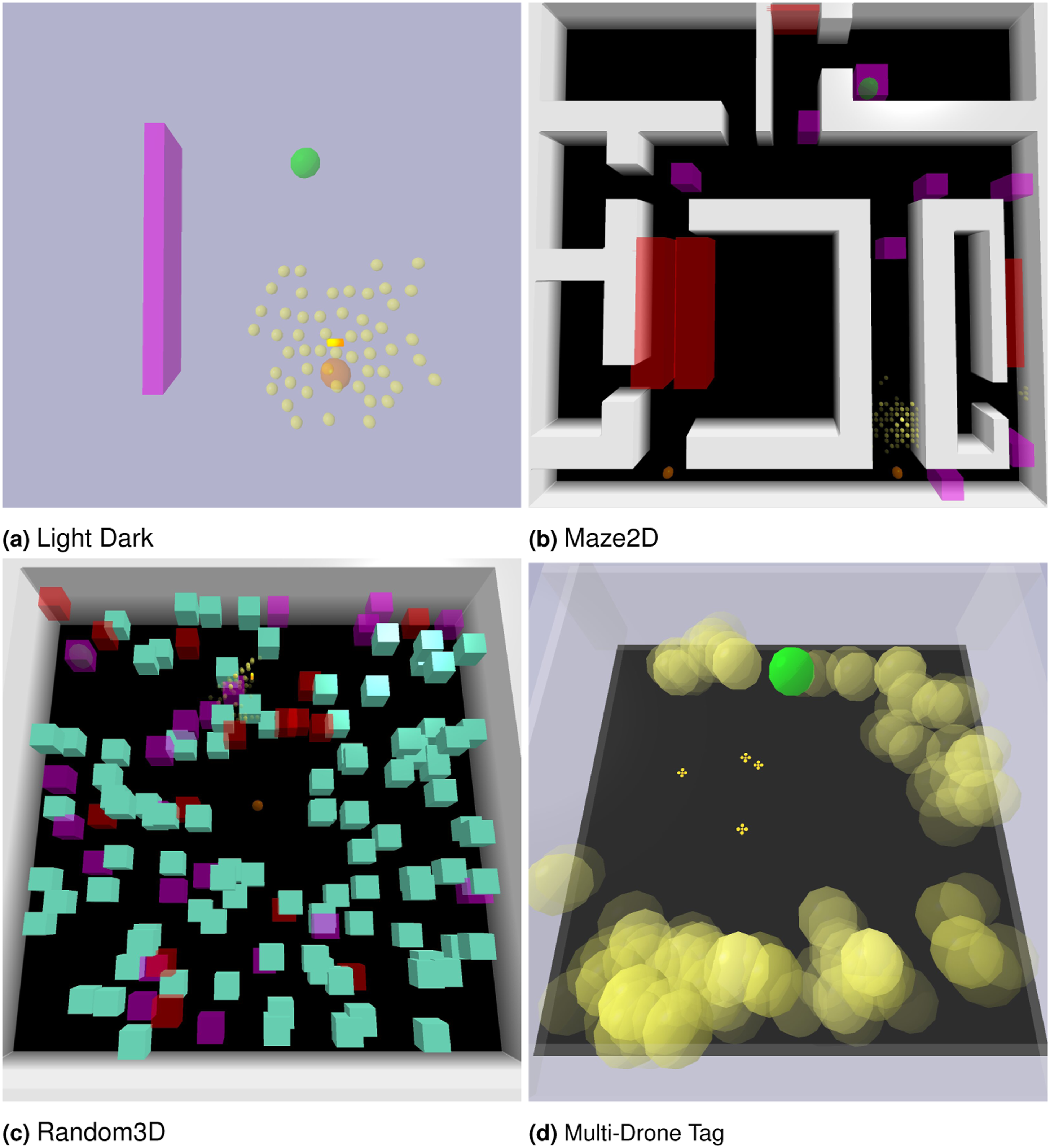
Sphere-Search (Figure 2(a)). A 7-DOF manipulator needs to move from its initial configuration to an initially unknown goal location. The robot needs to take a detour to reach a light using its end effector and observe the exact goal location.
Manipulation benchmark environments. Belief particles of observed obstacles are displayed in yellow. In Sphere-Search, light is denoted as a purple sphere. Goals are marked in green. Obstacles are marked in gray. In Ray-Detect, obstacles are placed on a table. Rays from the arm is displayed as a red straight line. In shelf-move, movable obstacles are the cylinders inside the shelf.
Ray-Detect (Figure 2(b)). A 7-DOF manipulator is tasked to use a fixed line of sight detector mounted at its end effector to scan environments, receives noisy readings of the obstacle positions and find a robust way to reach the target cylinder at the center of the table.
Shelf-Move (Figure 2(c)). This is the hardest problem that incorporates the difficulties of the other scenarios. A 7-DOF manipulator can move its end effector close to obstacles to sense their positions. It is tasked to retrieve a target can, placed at the back of the shelf where the front is packed with obstacles, and put the target can at the intended location on the top shelf. The robot can remove the blocking obstacles, but needs to be careful not to place the obstacles at the location reserved for the target.
The following baselines are used for comparisons, Belief-VAMP (B-VAMP). The planner maintains the belief of the current state of the agent, but only takes actions returned by vamp’s macro-action sampler withoutpomdp planning. It resembles the reference policy used by rop-ras3.
Ref-Basic (Kim et al., 2023). A reference-based pomdp planner with a uniform sampling reference policy but no vamp.
R-POMCP. An instantiation of Algorithm 1 using pomcp with macro-actions generated by the same reference policy as rop-ras3, but a finite set of macro-actions is sampled for each belief node over which pomcp optimizes. The sample size at each node is set to be roughly equal to that of rop-ras3 after progressive widening for fair comparisons.
MAGIC (Lee et al., 2021). A variation of despot (Ye et al., 2017) that uses learnable macro-actions generated via an actor-critic approach.
RMAG (Liang and Kurniawati, 2023). despot with macro-action learning boosted by recurrent neural networks.
5.2. Sampling heuristics
We detail the sampling heuristics (see SampleMacroActionSBMP in Algorithm 2) used to create the reference policies for each problem. Biased sampling of informative states is not in itself a new idea, for example, Kurniawati et al. (2011) and Flaspohler et al. (2020); however, using such an idea to construct reference policies is fundamental to the success of rop-ras3. Although it is generally impossible to encode (near) optimal solutions as the reference policy, it is much easier to create a reference policy that has compact support over actions that cover the optimal reachable belief space, which in turn makes pomdps efficient to solve (Lee et al., 2007). In our case, such a policy can be obtained by constructing deterministic motion plans to informative states in the world. Informative states refer to states with observations (e.g., landmarks) and rewards (e.g., goals). When these states are not known exactly by the agent, they are modeled as part of the state variable so we can sample these states from the belief particles.
We create two types of sampling heuristics for ablation purposes to understand the importance of the level of information revealed to the agent. The Uniform heuristic samples informative states in a uniform manner. It samples the goal state with probability 0.5 and samples the rest of informative states uniformly. The Dynamic heuristic varies its sampling strategy according to the belief such that when it is well informed, it is steered toward reaching the goal and when it is less informed, it inclines to gather information. Specifically, it samples the goal with probability , where is the normalized entropy of the current belief bt. With probability , it samples the rest of the informative states with probability inversely proportional to the distance of the agent to those states.
An exception is the Multi-Drone problem due to its multi-agent and limited information nature. Since information is only revealed when the drones detect the target, previous heuristics would not be enough to cover the optimal solution as the target can teleport elsewhere but drones cannot. Instead, we create a sampling heuristic that commands the nearest drone to move toward a possible target location sampled from the belief and the rest of the drones spread out uniformly. To further understand how well our method performs, we also conduct ablation studies that gradually remove the information carried by the sampling heuristics in Section 5.6.
5.3. Experimental setup
For evaluation, all variants of rop-ras3 are implemented in Python following Zheng and Tellex (2020). vamp is implemented in C++ and is used via a Python api. We avoid implementing benchmark methods from scratch for a fairer comparison; the pomcp implementation is from Zheng and Tellex (2020) and the implementations of pomcp, magic, rmag and Ref-Basic all use the code implemented by their respective authors (Lee et al., 2021; Liang and Kurniawati, 2023). PyBullet (Coumans and Bai, 2016–2021) is used as a visualizer only. For the first four navigation problems, all methods are provided with the same planning time of 1 s in all scenarios with the exception of Light Dark where the planning time is 0.1 s. For manipulation problems, we fix the number of simulations per planning iteration and report the average planning time, as these problems have more computational overhead compared to navigation problems. The temperature parameter η for rop-ras3 and Ref-Basic is η = 0.2. The action progressive widening parameter is set to βa = 6 and αa = 0.05. magic and rmag are trained on a 4070 GPU with data collected in 500,000 runs ( ∼3 h of training). The parameters have been tuned to optimize performance for each problem. Other implementation details can be found in Appendix A.2.2.
5.4. Results and discussions
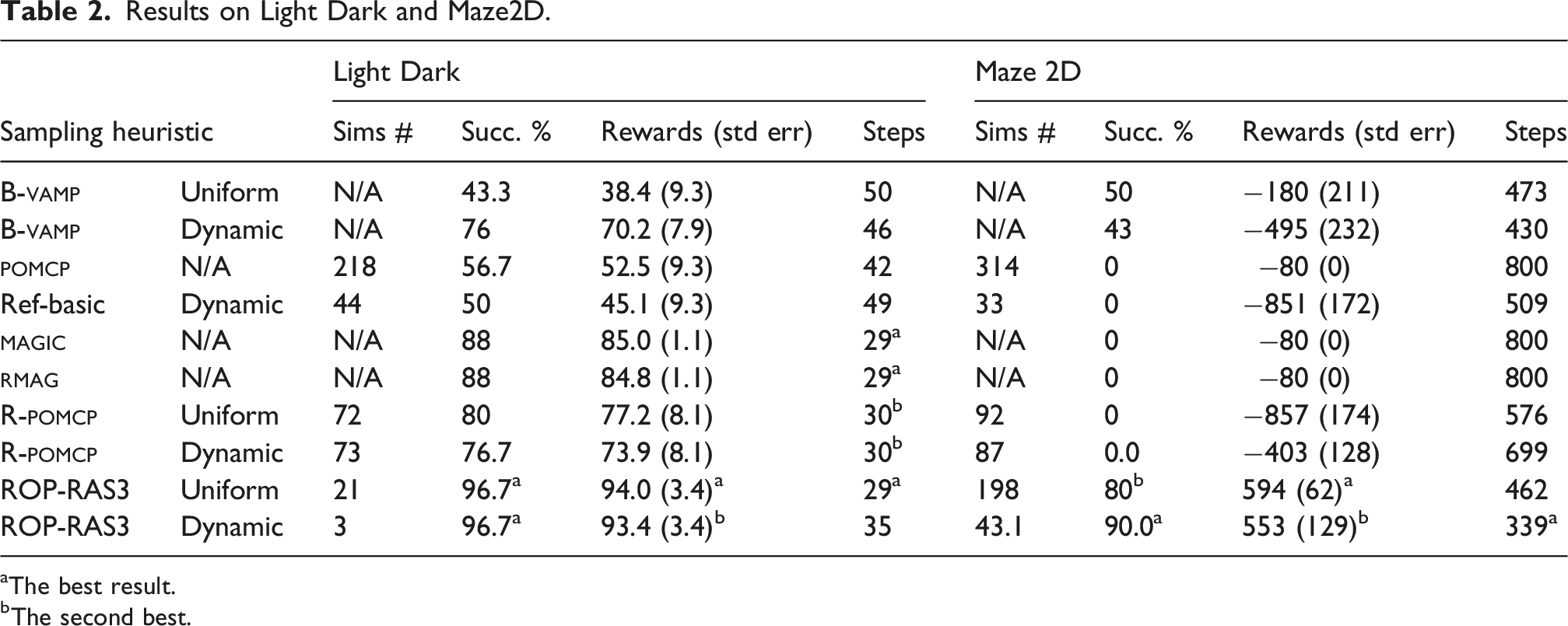
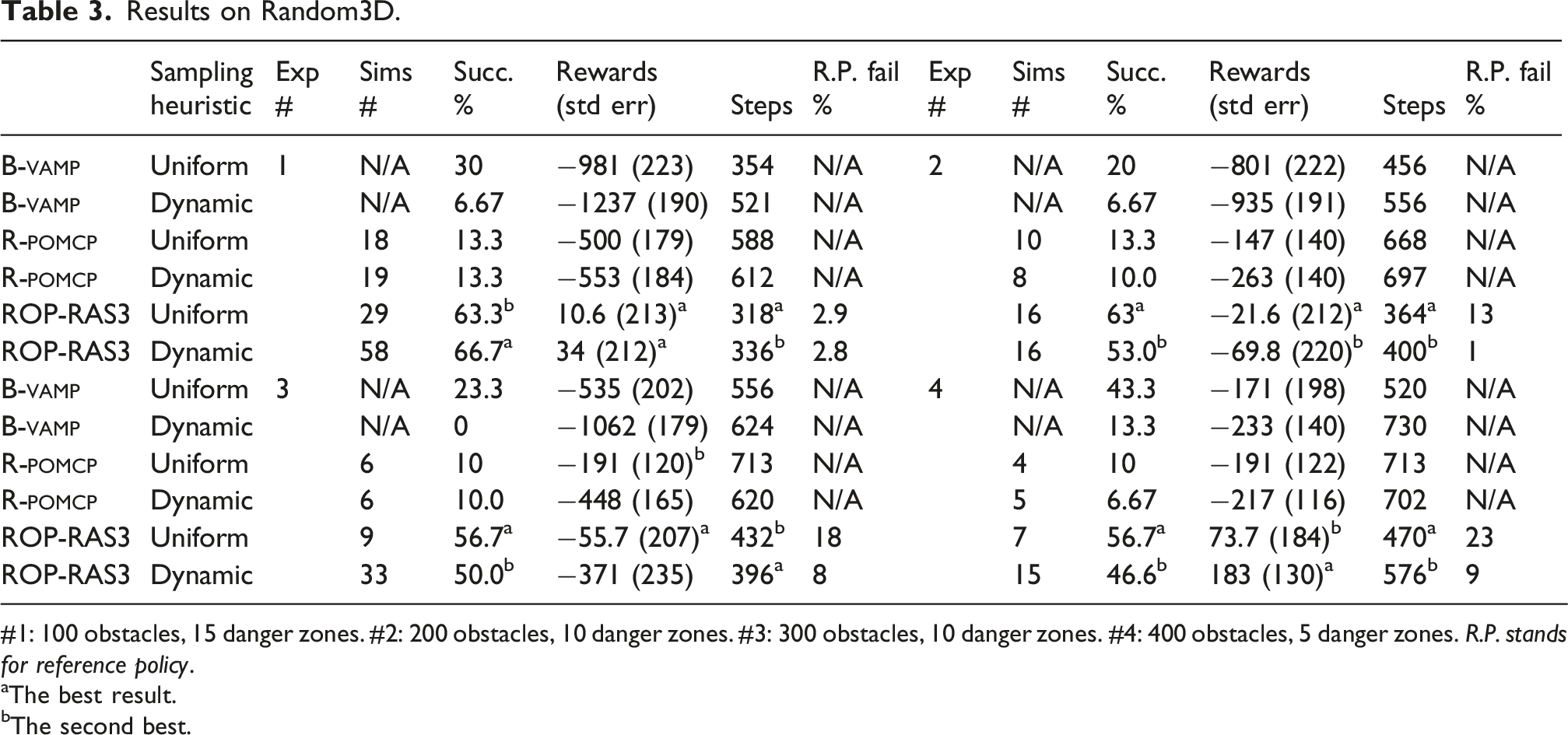
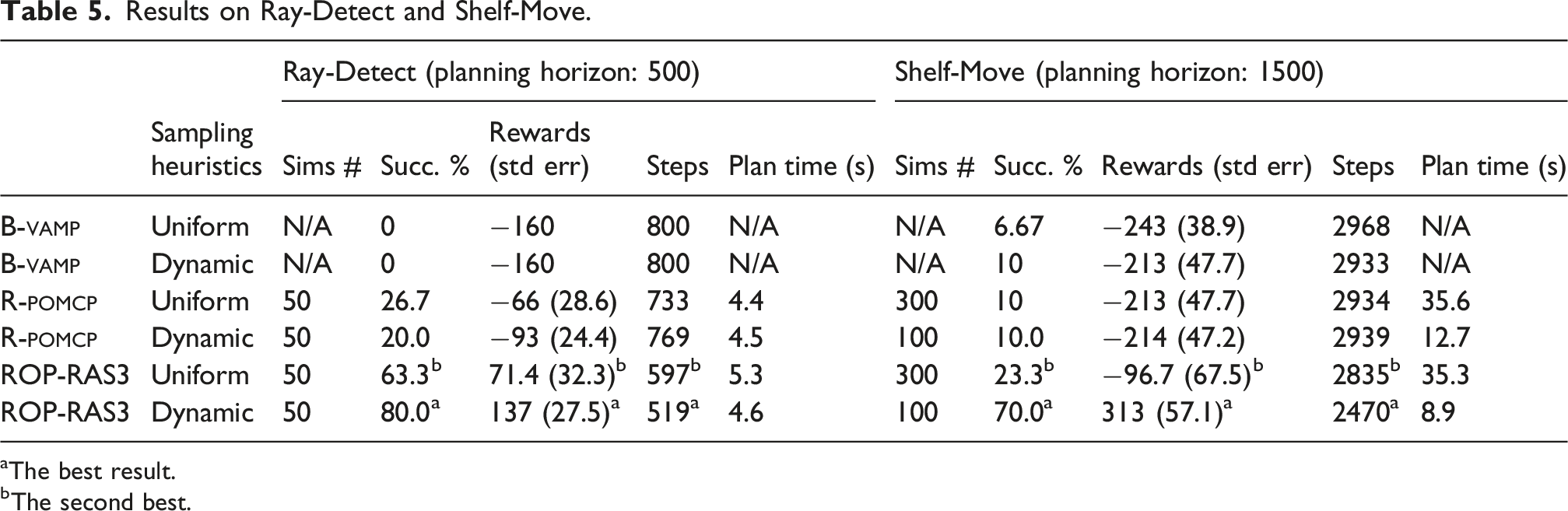
We ran all methods 30× for each scenario and method, and the results are summarized in Tables 2–5. Regardless of success or failure, the “Sims. #” and “Planning Times” columns present the average number of episodes simulated or the time spent in seconds in one planning call, whereas the steps column records the average execution steps for each run. Reward columns indicate the average total reward, and the standard errors are put in brackets. In Table 3, “R.P. Fail %” column indicates the percentage of reference policy failures across 30 runs. Variants of magic and rmag were run only on Light Dark and Maze2D because they do not naturally extend to high-dimensional motion planning problems (e.g., manipulation and multi-agent tasks). pomcp and Ref-Basic failed on all runs of Random3D and Multi-Drones Tag and are therefore excluded from the corresponding tables. Subsequently, we do not expect that these two methods will perform well on manipulation tasks with even longer horizons and higher state dimensions, and hence they are excluded from those experiments. Refer to Figures 6–10 in the Appendix for examples of critical time stamps of rop-ras3 in performing each tasks.
The results indicate that all variants of rop-ras3 substantially outperform all baseline methods in all evaluation scenarios. The improvement provided by rop-ras3 is the smallest for Light Dark and Sphere-Search (the simplest evaluation scenarios for navigation and manipulations, respectively) where all variants of rop-ras3 achieved a success rate of up to 28% higher than R-pomcp, magic, and rmag. The reason is that both of these scenarios require a much lower planning horizon and have less uncertainties compared to other scenarios. In Light Dark, this simplicity is indicated by the good performance of methods that do not use macro-actions, such as pomcp and Ref-Basic, and by the good performance of B-vamp, which reasons with respect to only a sampled state of the belief. In Sphere-Search, the bimodal uncertainties associated with the goal cause troubles to B-vamp, however, since the partial observability is fully resolved by reaching the light once and the light is not placed too far away from the manipulator, this problem has a relatively short effective horizon compared to other problems and therefore both R-pomcp and rop-ras3 perform well with rop-ras3 outperforming R-pomcp by 30%.
In the other scenarios, all variants of rop-ras3 improved the success rate of the benchmark methods by many folds. When the scenario requires a much longer planning horizon (e.g., Maze2D, Shelf-Move) or has higher uncertainty and more complex geometric structures (e.g., Ray-Detect and Shelf-Move), the benefit of rop-ras3 increases. By using vamp, rop-ras3 can quickly generate much more diverse macro-actions that capture the geometric features of the problem well. Simultaneously, the reference-based pomdp objective (6) enables rop-ras3 to utilize the sampled macro-actions more efficiently than other benchmark methods. The result is that rop-ras3 can consistently find the most robust motion path (often requiring longer horizons but has overall greater accumulated rewards) to interact with the environment and reach the goal. Unlike rop-ras3, R-pomcp expands all reference policy actions at once when encountering a new belief node in the tree, which means the actions being expanded cannot be adaptive as new belief particles were introduced to the node during planning. By growing the tree in a depth-first-search manner, rop-ras3 expands a new action edge at a belief node every time a new particle is added; this way, it benefits the most from the underlying reference policy. As theoretically shown, rop-ras3 removes the cumbersome optimization procedures in traditional methods with Monte Carlo estimations, significantly reducing the number of samples of simulations required to achieve a high success rate in all benchmarks. For the most sophisticated benchmark—Shelf-Move, rop-ras3 only requires 100 simulations with under 10 s planning time to achieve high success rate (see Table 5). Learning-based methods perform poorly in Maze2D due to the difficulty in learning suitable macro-actions with fixed length. In contrast, by using sbmp, rop-ras3 is able to better capture the fine motions the robot needs to navigate the geometric features of the environment.
rop-ras3 is also robust to performance degradation from the underlying reference policies. We ran four variants of Random3D with an increasing number of obstacles. The results in Table 3 indicate that rop-ras3’s performance (especially with uniform random sampling heuristics) does not degrade much even when the reference policy’s (i.e., rrt-Connect) failure percentage increases due to increasingly narrower passages in the maze. This is because rop-ras3 uses the results of rrt-Connect only to provide a set of alternative sequences of actions to perform. As long as there is sufficient diversity of macro-actions (i.e., sufficient support of the reference policy), the reference-based pomdp planner can converge to a reasonable policy of the pomdp problem fast. This is especially true for the uniform sampling heuristic, as it can provide better diversity which results in more collision-free path than dynamic heuristic does and leads to better performances in very cluttered environments.
For the high-dimensional navigation planning problem—Multi-Drones Tag, rop-ras3 performs at least four times better than the rest of the methods as it is the only method that exhibits strategies where drones actively discover and spread out to surround the tag. Both B-vamp and pomcp cannot easily adapt to the uncertainties from deterministic planning. B-vamp does not incorporate any uncertainty in the effects of actions and pomcp fixes a set of macro-actions from the reference policy for each belief node based only on a single sampled particle. Hence, the expanded set could be insufficient to fully represent the support of the belief, which is a problem that can be further compounded if the reference policy keeps failing.
In Ray-Detect (Table 5), rop-ras3 is the only method that consistently realizes that the most robust way to reach the cylinder is to use the ray to observe obstacles on the path and swing around the obstacles to avoid getting trapped by cluttered obstacles. Although the belief tree from R-pomcp can reach the same depth as rop-ras3, the UCB action selection strategy used by R-pomcp ignores the benefits brought by the sampling heuristics and converges more slowly to find the optimal action. Interestingly, we found out that R-pomcp benefits more from a uniform sampling strategy than a more complex dynamic sampling strategy, as expanding all actions at once requires the underlying sampling strategy to have built-in action diversity, whereas rop-ras3 expands action as new particles are introduced to a node, tremendously benefiting from the dynamic sampling strategy.
Shelf-Move is the most sophisticated problem that combines the difficulties of previous problems. Besides requiring very long horizon (H = 3000) to deliberately put obstacle cylinders away at carefully planned locations so that the target cylinder can be retrieved and placed at the target location, the scenario itself consists of a non-trivial amount of uncertainties and the clutter of the environment implies occasional failures of finding a deterministic path. Unlike previous problems with a single winning strategy, this problem has many different choices for grasping and placing the cylinders. rop-ras3 equipped with the dynamic sampling heuristic is the only one that demonstrates smart grasping and placing of these objects (see the 3rd row of Figure 10). It often identifies that removing two obstacles away at non-target locations will clear a sufficiently large path to retrieve the target cylinder at the back, and place it at the intended location. In case of mistakenly placing an obstacle at the target location, rop-ras3 can often find a way to arrange the obstacles correctly for the placement of the target cylinder. Other methods do not exhibit this kind of long-horizon thinking and their successful runs were often lucky runs.
5.5. Physical robot demonstrations
We deploy rop-ras3 on a Hello-Robot Stretch 3 in an uncertain and dynamic environment. In a lab environment, a pedestrian whose position is not exactly known to Stretch moves across the lab with a roughly constant speed. Stretch is tasked to navigate to a goal placed on the other side of the pedestrian. The pedestrian’s speed is set such that if going straight, Stretch would most likely run into the pedestrian. The state space has 16 dimensions, of which 13 comes from Stretch, and the remaining 3 are the pedestrian’s location as we model the pedestrian as a sphere. We discretize the action space into 45 primitive open-loop twist controls that correspond to straight line and curved motions of the mobile base. The mobile base of Stretch is controlled by twist controllers. We use a simple Euler integrator as the transition function and add noises to it to compensate for the errors between the realized Stretch motion and integrated solution. Stretch can query its IMU sensors to provide actual observations for belief updates. Such an update serves as a filtering step to better localize Stretch and reduce odometry uncertainties. The problem horizon is set to 75, with the planning horizon set to 25. A reward of 800 is provided to the agent for reaching the goal. A −800 penalty is provided for colliding with the pedestrian. A −20 penalty is given for being too close (within 0.3 m) to the pedestrian. Otherwise, a −1 penalty is given for each primitive step taken. We compare rop-ras3 with B-vamp and R-pomcp in a few trials. As shown in Figures 3 and 11, rop-ras3 is the only method that demonstrates a consistent smart and robust strategy of taking an efficient detour to go behind the moving pedestrian without colliding with other parts of the environment. B-vamp in Figure 11 steers straight and bumps the pedestrian as it does not incorporate pomdp planning, whereas R-pomcp took a long detour and ran into the tables. See Appendix A.2.3 for more details on the Stretch implementations.
Stretch demonstrations using rop-ras3. It smartly navigates around the moving pedestrian and quickly reaches the goal without waiting for the pedestrian or colliding with the environment.
5.6. Ablation study
5.6.1. Explorative reference policy
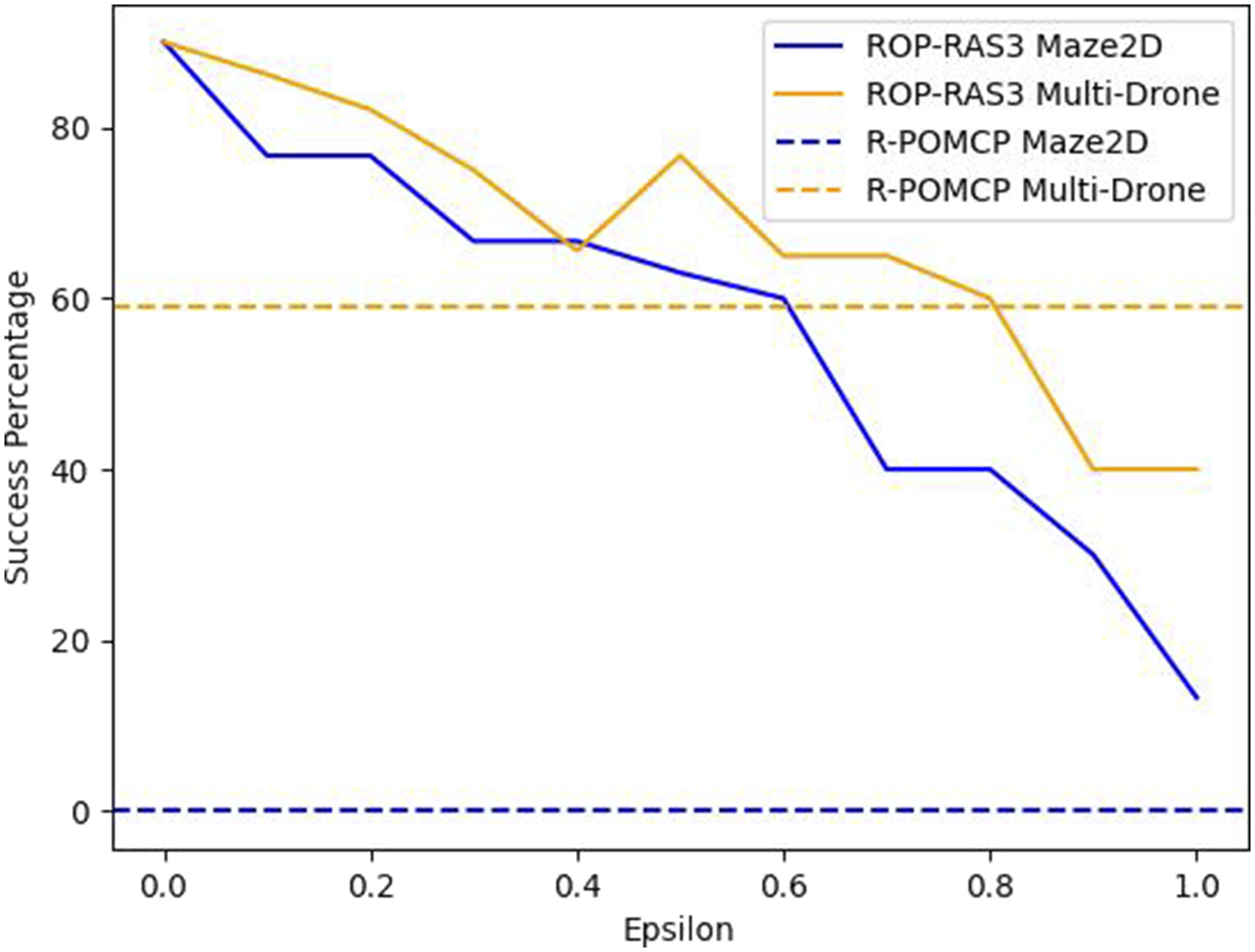
One might be concerned that limiting state sampling to only hand-picked information states in the reference policy (see Section 5.2) is too restrictive. Therefore, we also evaluate rop-ras3 when these states are sampled in an ϵ-greedy fashion, where with probability ϵ, the sampling heuristic samples from the entire state space, and it samples those information states with (1 − ϵ) probability. When ϵ is 0, it corresponds to the unmodified sampling strategy, and when ϵ is 1, the hand-crafted sampling strategy is purely replaced with uniform random sampling of the state space.
For this ablation study, we test the above sampling strategy on the Maze2D and Multi-Drone Tag scenarios. We also increase the planning time per step from 1 s to 3 s to allow proper belief space coverage due to the increase of sampling possibilities. For a fair comparison, we also ran the strong baseline, R-pomcp, on the two scenarios for 3 s planning time per step.
The results are displayed in Figure 4. As expected, when the reference policy gradually approaches uniform, rop-ras3’s performance decreases. The reference policy becomes farther away from the deterministic optimal policy with respect to the KL-divergence, as a result the found policy can only perturb the reference policy so much to collect more rewards. However, the performance drop is not linear with respect to ϵ. For instance, in Maze2D, significant amount of drop is seen when ϵ is increased from 0.6 to 1.
Ablation study of rop-ras3’s performances with ϵ-exploration in Maze2D and Multi-Drone.
Despite the decreasing performance of rop-ras3, it generally still performs better than the strong baseline R-pomcp (without any ϵ − explorations when sampling actions). In Maze2D, rop-ras3 with pure explorative reference policy (i.e., ϵ = 1) still outperforms R-pomcp, with 13% success rate when the policy is generated using rop-ras3 and 0% success rate when using R-pomcp. In Multi-Drone scenario, with ϵ < = 0.8, rop-ras3 outperforms R-pomcp scenario, indicating the importance of our novel tree search and backup steps.
Finally, this ablation study indicates rop-ras3 is less sensitive to the sampling heuristics in Multi-Drone Tag, as its worst success rate is retained at 40%. This is due to the fact that Maze2D is more geometrically complex than Multi-Drone Tag, that is, the chance of sampling the right states to form a robust path is much less in Maze2D than that in Multi-Drone Tag (there are many different ways to surround and capture the target).
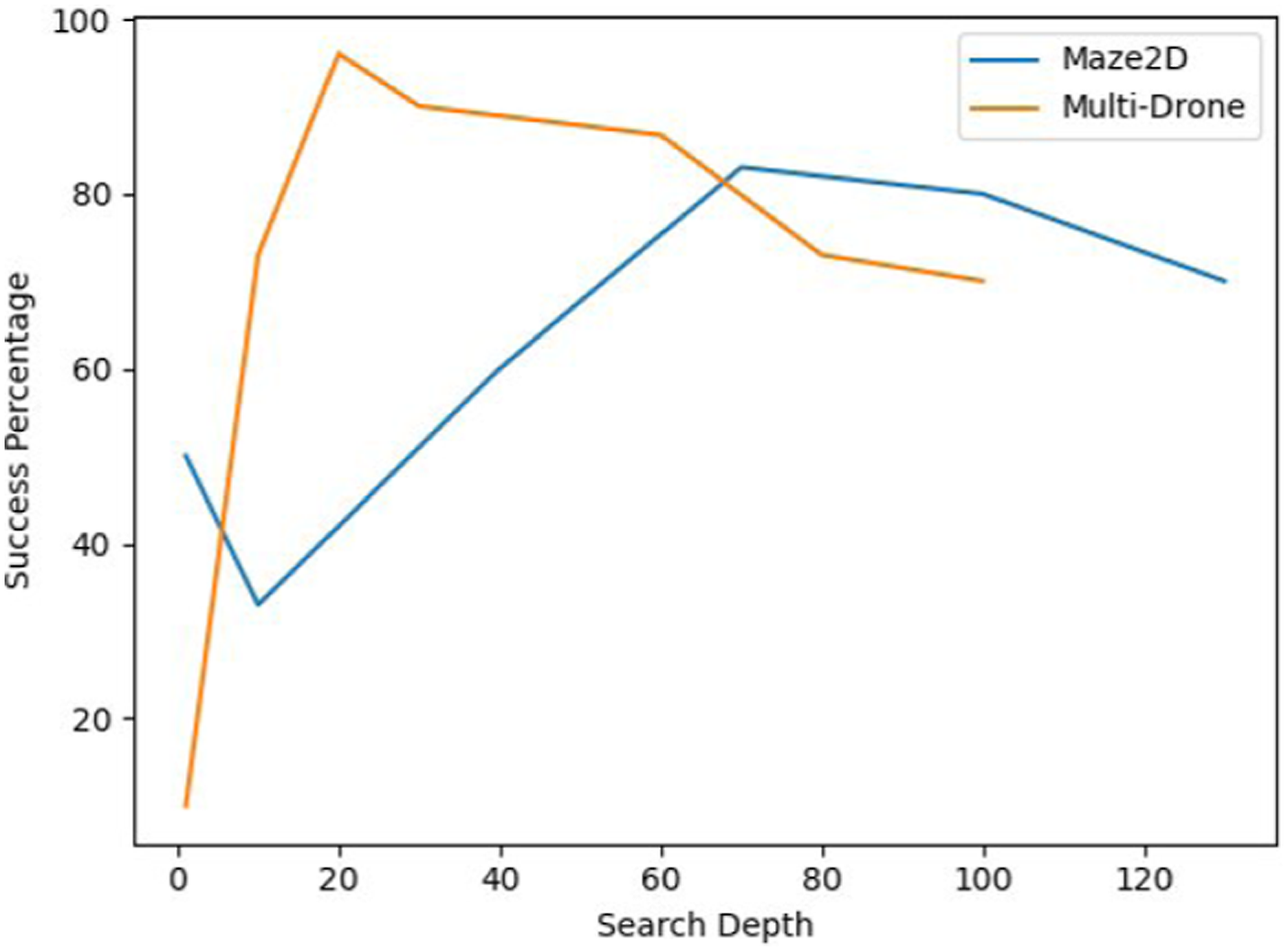
5.6.2. Effects of tree search depths
Hyperparameters such as the tree search depth are important to the performance of rop-ras3. Under tight computational budgets (e.g., one second of planning), the right tree search depth needs to balance collecting long-horizon information and Monte Carlo estimation accuracies. This ablation study perturbs the tree search depth across two experiments for rop-ras3 with the Uniform sampling heuristic. Results are shown in Figure 5. We see that performance drops as the tree depth increases or decreases; a good rule-of-thumb we found is to set the tree depth to be roughly the number of steps needed to solve the problem under deterministic settings.
Ablation study of rop-ras3’s performances with different tree search depths in Maze2D and Multi-Drone.
6. Summary
This paper presents a continuous reference-based pomdp framework to handle large scale robotic problems. The objective of the reference-based pomdp can be partially solved analytically, resulting in a backup equation that can be estimated with sampling without online numerical optimizations. We then present a new online approximate reference-based pomdp solver, reference-based online pomdp planning via rapid state space sampling (rop-ras3), which uses vamp to sample the state space and rapidly generate a large number of macro-actions online. These macro-actions reduce the effective planning horizon required and are adaptive to geometric features of the robot’s free space. Since reference-based pomdp planners use macro-actions only to bias belief-space sampling and do not require exhaustive enumeration of macro-actions, rop-ras3 can efficiently exploit many diverse macro-actions to compute good pomdp policies fast. It is shown that the number of belief particles and actions sampled controls the convergence of rop-ras3 s online planning. Evaluations on various long-horizon pomdps indicate that rop-ras3 outperforms state-of-the-art methods by multiple factors. Avenues of future works abounds. Hinted in the ablation study, a poorly selected reference policy could lead to inferior performance, and one may ask what are the characteristics of a reference policy that can guarantee a certain level of performance. Overall, the substantial increase in the capability of online approximate pomdp solvers in long-horizon problems brought by rop-ras3 enables improved robustness in wide ranges of robotics applications.
Footnotes
ORCID iDs
Yuanchu Liang
Wil Thomason
Zachary Kingston
Lydia E. Kavraki
Hanna Kurniawati
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: YL, EK, and HK have been partially supported by the ANU Futures Scheme. YL has been partially supported by Australia RTP scholarship. EK has been partially supported by ARC LP200301612. HK has been partially supported by the SmartSat CRC and ARC IH210100030. JAK, ZK, and LEK have been supported in part by NSF 2008720, 2336612, and Rice University Funds. WT has been supported by NSF ITR 2127309—CRA CIFellows Project.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix
References
1.
AzarMGGómezVKappenH (2011) Dynamic policy programming with function approximation. International Conference on Artificial Intelligence and Statistics15: 119–127.
CaiPLuoYHsuD, et al. (2021) HyP-DESPOT: a hybrid parallel algorithm for online planning under uncertainty. International Journal of Robotics Research40(2–3): 558–573. https://doi.org/10.1177/0278364920937074
4.
CoumansEBaiY (2016) 2021 Pybullet, a python module for physics simulation for games. Robotics and Machine Learning. https://pybullet.org/
5.
DuSKakadeSLeeJ, et al. (2021) Bilinear classes: a structural framework for provable generalization in RL. In: International conference on machine learning, virtual, 18–24 July 2021. PMLR, pp. 2826–2836.
6.
FlaspohlerGRoyNAFisherIIIJW (2020) Belief-dependent macro-action discovery in POMDPs using the value of information. In: LarochelleHRanzatoMHadsellR, et al. (eds) Advances in Neural Information Processing Systems. Curran Associates, Inc, Vol. 33, pp. 11108–11118.
7.
HeRBrunskillERoyN (2010) PUMA: planning under uncertainty with macro-actions. In: FoxMPooleD (eds). AAAI Conference on Artificial Intelligence. AAAI Press, 1024–1029.
8.
JinCYangZWangZ, et al. (2020) Provably efficient reinforcement learning with linear function approximation. In: Conference on Learning Theory. PMLR, pp. 2137–2143.
9.
KaeblingLLittmanMCassandraA (1998) Planning and acting in partially observable stochastic domains. Artificial Intelligence101(1–2): 99–134.
10.
KavrakiLESvestkaPLatombeJC, et al. (1996) Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Transactions on Robotics and Automation12(4): 566–580. https://doi.org/10.1109/70.508439
11.
KimEKurniawatiH (2025) Partially observable reference policy programming. In: KwokJ (ed) International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, pp. 8536–8543. https://doi.org/10.24963/ijcai.2025/949
12.
KimEKarunanayakeYKurniawatiH (2023) Reference-based POMDPs. In: Advances in neural information processing systems, Louisiana, USA, 10–16 December 2023.
13.
KuffnerJJLaValleSM (2000) RRT-connect: an efficient approach to single-query path planning. IEEE International Conference on Robotics and Automation2: 995–1001.
14.
KurniawatiH (2022) Partially observed Markov decision processes and robotics. Annual Review of Control, Robotics, and Autonomous Systems5: 254–277.
15.
KurniawatiHYadavV (2013) An online POMDP solver for uncertainty planning in dynamic environment. International Symposium on Robotics Research. Springer, 611–629.
16.
KurniawatiHDuYHsuD, et al. (2011) Motion planning under uncertainty for robotic tasks with long time horizons. International Journal of Robotics Research30(3): 308–323.
17.
LaValleSM (2006) Planning Algorithms. Cambridge University Press.
18.
LeeWRongNHsuD (2007) What makes some POMDP problems easy to approximate? In: PlattJKollerDSingerY, et al. (eds) Advances in Neural Information Processing Systems. Curran Associates, Inc, Vol. 20.
19.
LeeYCaiPHsuD (2021) MAGIC: learning macro-actions for online POMDP planning. Robotics: Science and Systems. Virtual, 041. Available at: https://doi.org/10.15607/RSS.2021.XVII.041
20.
LiangYKurniawatiH (2023) Recurrent Macro Actions Generator for POMDP Planning. IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 2026–2033. https://doi.org/10.1109/IROS55552.2023.10341759
21.
LiangYKimEThomasonW, et al. (2024) Scaling long-horizon online POMDP planning via rapid state space sampling.International Symposium on Robotics Research.
22.
LimMHTomlinCSunbergZN (2020) Sparse tree search optimality guarantees in POMDPs with continuous observation spaces. In: BessiereC (ed) International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, pp. 4135–4142. https://doi.org/10.24963/ijcai.2020/572
23.
LimMHTomlinCJSunbergZN (2021) Voronoi progressive widening: efficient online solvers for continuous state, action, and observation POMDPs. In: IEEE Conference on Decision and Control (CDC). IEEE, pp. 4493–4500.
24.
LimMHBeckerTJKochenderferMJ, et al. (2023) Optimality guarantees for particle belief approximation of POMDPs. Journal of Artificial Intelligence Research77: 1591–1636. https://doi.org/10.1613/jair.1.14525
25.
PapadimitriouCHTsitsiklisJN (1987) The complexity of Markov decision processes. Mathematics of Operations Research12(3): 441–450. https://doi.org/10.1287/moor.12.3.441
26.
RainforthTCornishRYangH, et al. (2018) On nesting monte carlo estimators. In: International Conference on Machine Learning. PMLR, pp. 4267–4276.
27.
ShachterRDPeotMA (1990) Simulation approaches to general probabilistic inference on belief networks. Machine Intelligence and Pattern Recognition10: 221–231. Elsevier.
28.
SilverDVenessJ (2010) Monte-carlo planning in large POMDPs. In: LaffertyJWilliamsCShawe-TaylorJ, et al. (eds) Advances in Neural Information Processing Systems. Curran Associates, Inc, p. 23.
29.
SmallwoodRDSondikEJ (1973) The optimal control of partially observable Markov processes over a finite horizon. Operations Research21(5): 1071–1088. https://doi.org/10.1287/opre.21.5.1071
30.
SunbergZKochenderferM (2018) Online algorithms for POMDPs with continuous state, action, and observation spaces. International Conference on Automated Planning and Scheduling28: 259–263. https://doi.org/10.1609/icaps.v28i1.13882
31.
SundaralingamBHariSKSFishmanA, et al. (2023) CuRobo: parallelized collision-free robot motion generation. In: IEEE International Conference on Robotics and Automation, pp. 8112–8119. https://doi.org/10.1109/ICRA48891.2023.10160765
32.
TheocharousGKaelblingL (2003) Approximate planning in POMDPs with macro-actions. In: ThrunSSaulLSchölkopfB (eds). Advances in Neural Information Processing Systems. The MIT Press, 1425–1432.
33.
ThomasonWKingstonZKavrakiLE (2024) Motions in microseconds via vectorized sampling-based planning. In: IEEE international conference on robotics and automation, Yokohama, Japan, 13–17 May 2024.
34.
TodorovE (2006) Linearly-solvable Markov decision problems. In: SchölkopfBPlattJHoffmanT (eds) Advances in Neural Information Processing Systems. MIT Press, p. 19.
35.
UeharaMZhangXSunW (2022) Representation Learning for online and offline RL in low-rank MDPs. International Conference on Learning Representations. Available at: https://openreview.net/forum?id=J4iSIR9fhY0.
36.
YeNSomaniAHsuD, et al. (2017) DESPOT: online POMDP planning with regularization. Journal of Artificial Intelligence Research58: 231–266. https://doi.org/10.1613/jair.5328
37.
ZhengKTellexS (2020) pomdp_py: a framework to build and solve POMDP problems. In: ICAPS workshop on planning and robotics (Planrob), France, 19–30 October 2020.