
Abstract
Background
Breast cancer diagnoses are limited in low- and middle-income settings due to lack of medical resources. In these settings, point-of-care ultrasound (POCUS) combined with artificial intelligence (AI)-based interpretation could be a suitable approach.
Purpose
To compare the performance of an AI-based breast cancer classification algorithm with radiologists and assess whether POCUS performs comparably to standard breast ultrasound (BUS) as a stand-alone imaging technique.
Material and Methods
A total of 70 POCUS and 70 case-matched BUS images (11 malignant, 21 benign, 38 normal) from 40 women (mean age=50.3 ± 16.65) were interpreted by four breast radiologists in a multi-reader, multi-case setup. Readers rated risk of malignancy on single images on a 5-point scale similar to BI-RADS (≥3 considered positive, i.e. malignant). An in-house–developed AI-based algorithm also analyzed the images. The breast cancer detection performance for all modalities was assessed using area under the receiver operating characteristic curve (AUC), sensitivity, and specificity.
Results
On BUS, AI and radiologists performed comparably (AUC=0.98 [95% confidence interval (CI)=0.93–1.00] vs. 0.97 [95% CI=0.93–1.00]; sensitivity 1.00 vs. 1.00; specificity 0.75 vs. 0.78). The performance was similar on POCUS, for both AI and radiologists (AUC 0.99 [95% CI=0.98–1.00] vs. 0.99 [95% CI=0.96–1.00]; sensitivity 1.00 vs. 1.00; specificity 0.92 vs. 0.77). No statistically significant differences were observed between BUS and POCUS or radiologists and AI.
Conclusion
This study demonstrates the potential of reliable AI-based breast cancer detection, both in standard ultrasound imaging and in POCUS imaging.
Introduction
Low- and middle-income countries (LMICs) have higher mortality in breast cancer compared to high-income countries (HICs), with sub-Saharan African countries having some of the highest mortality rates in the world ((1–3)). The poor survival rates in many low-income countries (LICs) are linked to healthcare infrastructure and services ((4,5)), and late-stage presentation ((6)). A recent study estimated that at least one-third of breast cancer deaths in sub-Saharan countries could be prevented through earlier diagnosis of symptomatic disease together with improvements in treatment ((7)). The World Health Organization (WHO) has addressed the global health inequity in breast cancer care and emphasizes the need for methods to enable a timely diagnosis for downstaging ((3,4)). Mammography screening is not feasible in many limited-resource settings due to the cost, a lack of needed infrastructure and trained personnel, together with the problematic effect of overdiagnosis in limited-resource settings ((8–10)). Thus, rather than large-scale screenings, alternative cost-effective approaches to enable a timely diagnosis of symptomatic breast cancer in limited-resource settings are needed ((11)).
Point-of-care ultrasound (POCUS) is a low-cost, portable ultrasound approach that consists of a stand-alone ultrasound probe where the images are read on a smartphone or tablet. POCUS has been used for a broad range of medical applications, especially in emergency and critical care ((12,13)), and could potentially also be used in the assessment of breast symptoms ((12)). POCUS as a cost-effective and accessible imaging method in limited-resource settings has lately attracted increasing attention ((14,15)). To face the pronounced lack of radiologists in many LMICs ((16)), artificial intelligence (AI) has been suggested to be used to automatically analyze POCUS images ((17,18)).
Several studies have shown good performance of deep learning (DL)-based AI on the classification of breast ultrasound images ((18–21)). We are developing an AI tool to analyze POCUS breast images with recent tests showing high accuracy (area under the receiver operating characteristic [ROC] curve [AUC] = 91.2%) using a simple convolutional neural network ((22)) and AUC of 95.6% using a neural network ensemble ((23)). Using POCUS combined with AI could potentially be a valuable method to enable a timely diagnosis of breast cancer in limited-resource breast cancer care.
The aim of the present study was to assess the feasibility of POCUS as opposed to standard BUS, as well as the performance of AI on POCUS and standard BUS compared to breast radiologists. An overview of the study is shown in Fig. 1.
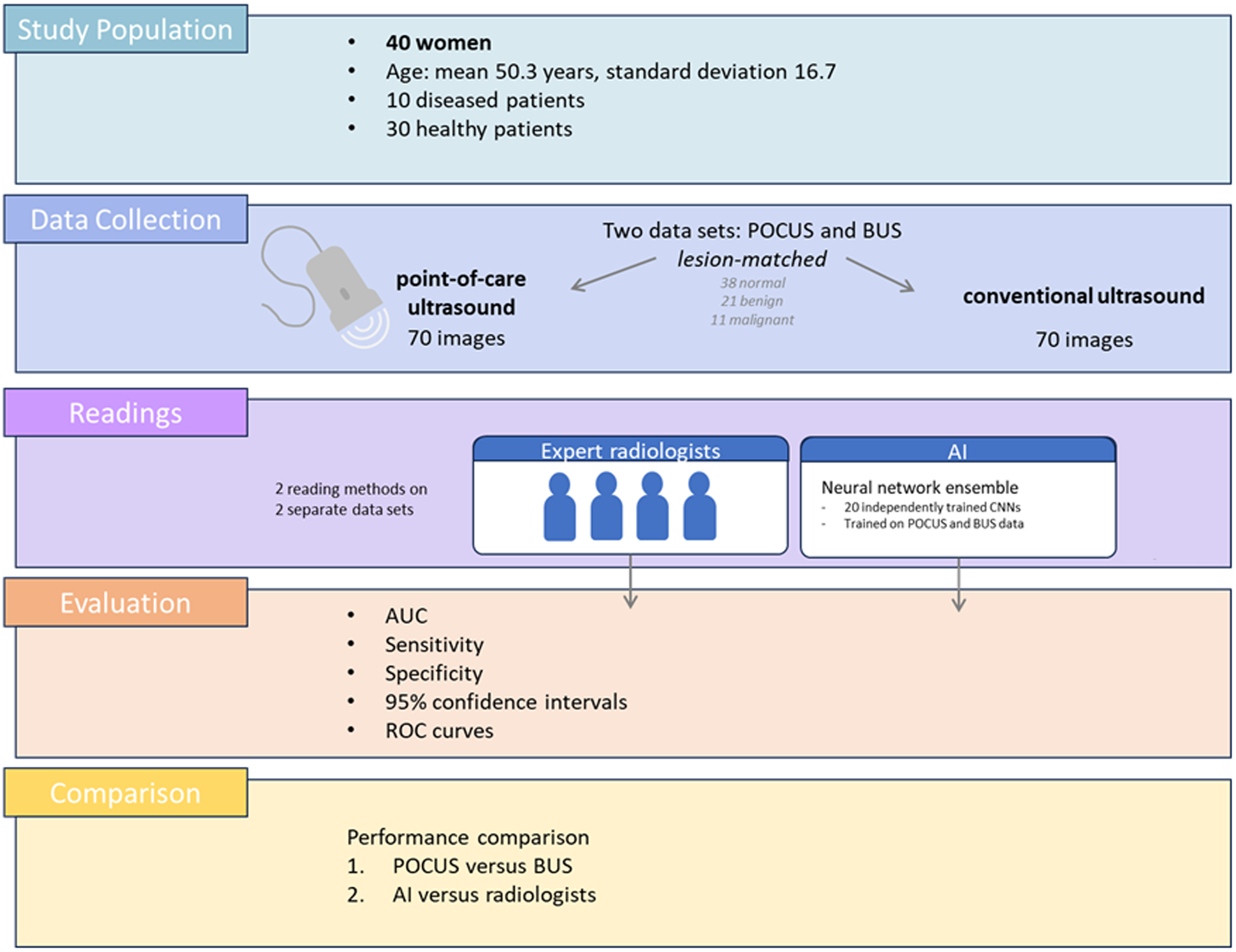
Workflow of the present study. Diseased/healthy refers to patients with/without malignant findings.
Material and Methods
The study was approved by the Swedish Ethical Review Authority (reference no. 2019-04607).
It includes 40 randomly selected patients undergoing diagnostic imaging between January 2022 and November 2022 at the Mammography Unit in Skåne University Hospital, Malmö, Sweden. After written and oral informed consent, the patients were examined with POCUS (GE Vscan air CL probe) and standard BUS (GE Logiq E9 and Logiq E10) to collect a series of POCUS images with lesion-corresponding standard BUS images. The images were retrospectively read by four breast radiologists and were also analyzed by an AI classification algorithm.
The ground truth was determined by a standard assessment consisting of a mammography and ultrasound exam by a breast radiologist (KL), followed by a biopsy for findings classified as 3 (equivalent to Breast Imaging-Reporting and Data System [BI-RADS] 3).
Acquired images were used to create two datasets with 70 case-matched lesions (38 normal, 21 benign, 11 malignant): one POCUS dataset and one matching BUS dataset (Fig. 2). The case-matching was performed by an experienced breast radiologist (KL) with all imaging and pathology data available for correlation. The images were preprocessed before further evaluation, which involved cropping to exclude patient- and case-level information and resizing to 318×318 pixels.
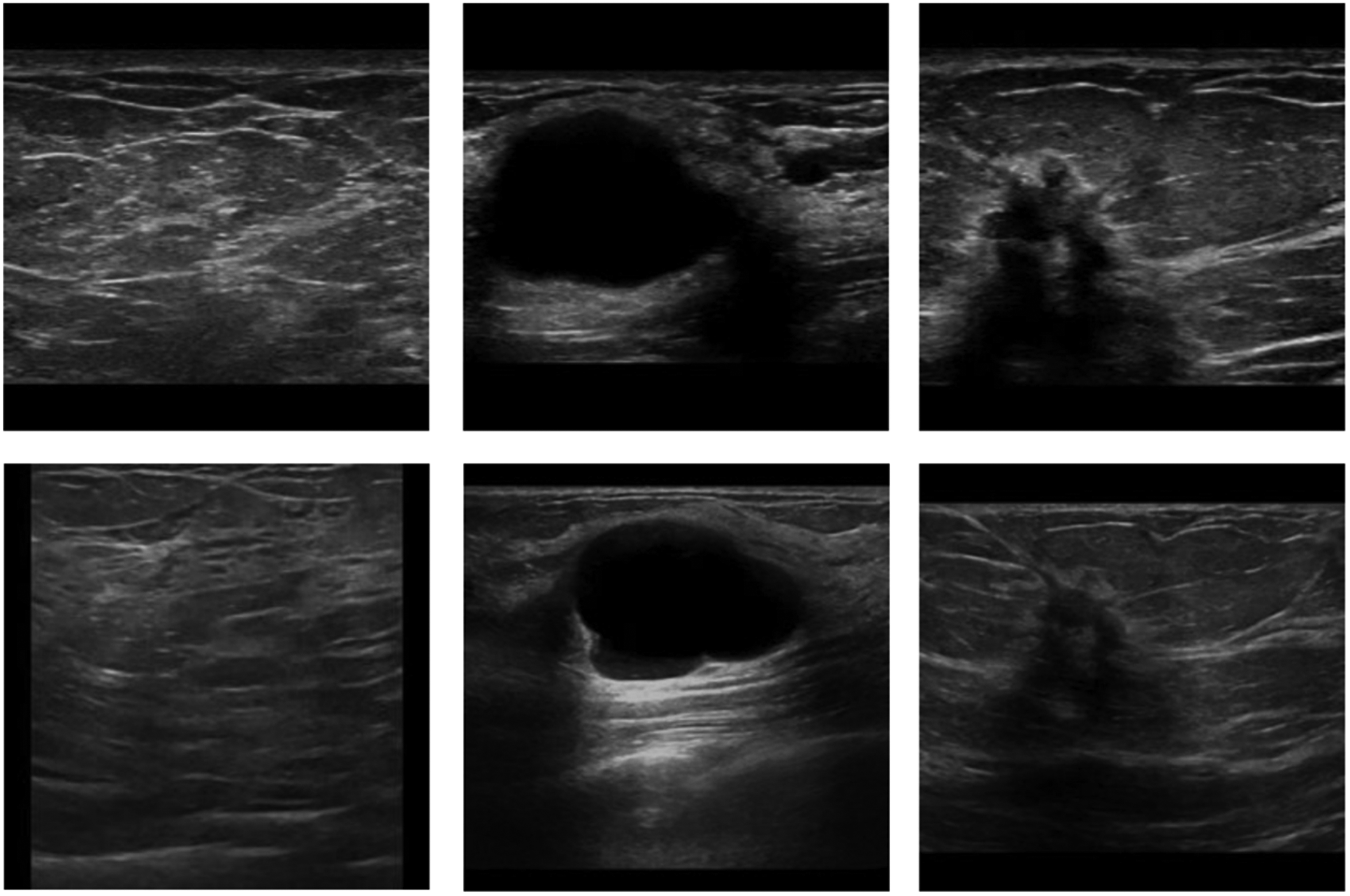
Example of point-of-care ultrasound (top) and standard breast ultrasound (bottom) images labeled as normal, benign, and malignant (left to right).
Reader study
Four breast radiologists (with 6 months, 1 year, 2 years, and 15 years of experience) participated in the reader study. The reader task was to classify each case on a 5-level scale, similar to BI-RADS (1 = normal, 2 = benign, 3 = probably benign, 4 = suspicious of malignancy, and 5 = highly suspicious of malignancy). A score of 3 or higher was considered positive. The POCUS and BUS datasets were read independently, with at least a 4-week washout period between readings. The ViewDex user interface was used for case reading and scoring ((24)).
AI algorithm
A DL-based AI (for access to the code, model and data, please reach out to the authors) was trained for the task of automatically classifying POCUS and BUS images as normal, benign or malignant. The AI model was implemented as a neural network ensemble ((25)) consisting of 20 independently trained models. Each model's architecture was a convolutional neural network with six layers of convolution and max-pooling and a multi-layer perceptron with two layers, inspired by Karlsson et al. ((22)). The AI was tested on the same POCUS and BUS datasets as in the reader study.
For training the network, a dataset with both POCUS and standard BUS images was used. This dataset consisted of 6153 images, of which 983 were POCUS (532 normal, 218 benign, 233 malignant) and 5170 were standard BUS (803 normal, 1391 benign, 2976 malignant). An additional dataset with 531 POCUS images (284 normal, 131 benign, 116 malignant) was used to pick the classification threshold based on Youden's J statistic. The classification threshold was used to binarize the networks output before computing sensitivity and specificity. The POCUS images were acquired examining patients undergoing diagnostic imaging at the Mammography Unit in Skåne University Hospital, Malmö, Sweden between 2021 and 2024, selected sporadically based on the availability of the examiner (KL) and sufficient time in the clinical schedule. BUS images were retrospectively collected between 2019 and 2025. The patients included in the development datasets were not included in the evaluation. The images were classified as normal, benign, or malignant by an experienced breast radiologist (KL) with all imaging and pathology data available.
The 20 ensemble members were trained individually. To ensure diversification, the training hyperparameters were chosen randomly for each model from a list of suitable values, inspired by Wodrich et al. ((23)).
The same model was used for both the BUS and the POCUS datasets. During inference, one image is presented to the ensemble network at a time. Each ensemble member makes a prediction with a probability value for each of the three classes. Average ensembling is used to create the final prediction. To be comparable to the radiologists’ classification of either malignant or non-suspicious, the classes normal and benign were grouped together as non-malignant, as opposed to the malignant class.
Performance evaluation and comparison
The performance of the average radiologist was compared to the performance of AI for the two datasets separately. The average radiologist's performance was calculated based on individual performance evaluations for each radiologist. Classification performance was measured using the ROC curve and the area under the ROC curve (AUC), using the 5-level scale for the radiologists and the predicted probability for the AI algorithm. Furthermore, sensitivity and specificity were measured, considering a score ≥3 as positive for radiologists and using the predefined classification threshold for the AI algorithm (see “AI algorithm” section).
Statistical significance between two AUCs was measured by estimating the confidence interval over the difference in the metric. This was done by performing bootstrap on the test set, i.e. resample the test set with replacement 1000 times. The significance level was picked at P <0.05 and Bonferroni correction was used to compensate for multiple comparisons. The performance on POCUS compared to BUS was analyzed within the radiologists, as well as within the AI-based method.
Results
The mean age of the cohort was 50.3 ± 16.7 years (range = 26–82 years). Cancer characteristics are presented in Table 1; distribution of types of benign lesions are shown in Table 2.
Histological types, sizes, and molecular subtypes of the malignant cases.
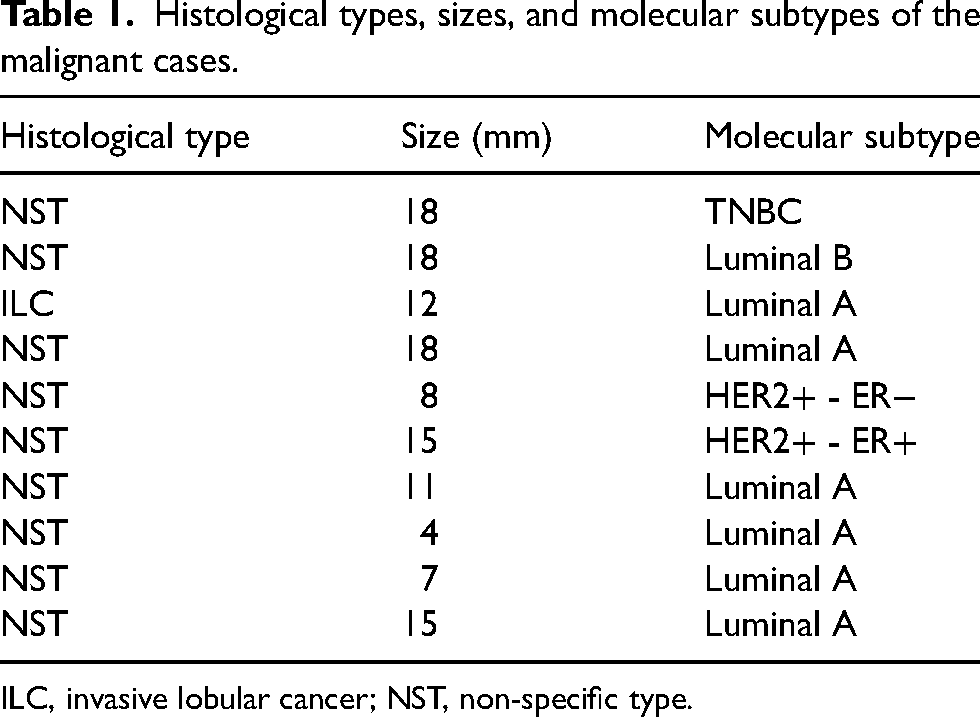
ILC, invasive lobular cancer; NST, non-specific type.
Distribution of subtypes (n = number of occurrences) of benign lesions.

Types were identified via biopsy, unless clearly deemed benign by the radiologist in which case no biopsy was taken, as according to the Swedish healthcare standard.
The AUC, sensitivity, and specificity with corresponding 95% CIs for the POCUS and BUS, evaluated by the radiologists and the AI-based algorithm, are shown in Table 3. Corresponding ROC curves are shown in Fig. 3. Scores from the AI and the four radiologists for all misclassified cases are shown in Table 4. Scores for all malignant cases are shown in Table 5. Examples of images included in Tables 4 and 5 are shown in Fig. 4.
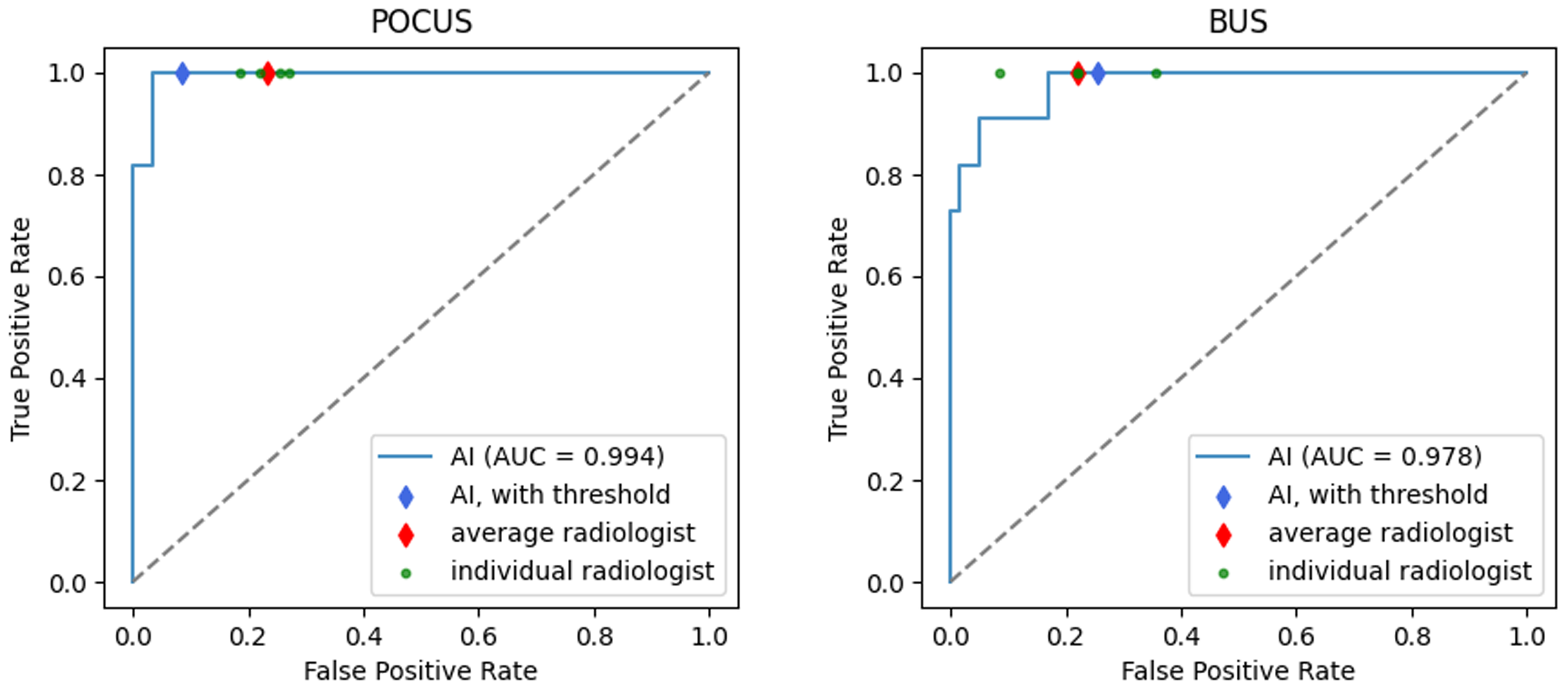
ROC curves for breast cancer detection using the AI-based algorithm (blue) for the POCUS and BUS test datasets. The blue points mark the performance using the predefined classification threshold. The green points mark the achieved performances of the radiologists, the red points mark the average radiologist. AI, artificial intelligence; BUS, breast ultrasound; POCUS, point-of-care ultrasound; ROC, receiver operating characteristic.
Examples of pairs with case matched images from point-of-care ultrasound (left) and standard breast ultrasound (right). The case numbers refer to the case numbers in Tables 4 and 5, where corresponding breast cancer classification scores from the AI and the radiologists can be found. Ground truth by case numbers: normal (case 3), benign (cases 13, 15, 16, 20), malignant (cases 22, 26, 27, 28, 31). Colored dots stand for misclassification by AI (orange) and radiologists (blue).
Breast cancer classification performance on both test datasets (POCUS and BUS) for individual radiologists (radiologists A–D), average radiologist (radiologists), and the AI-based algorithm.
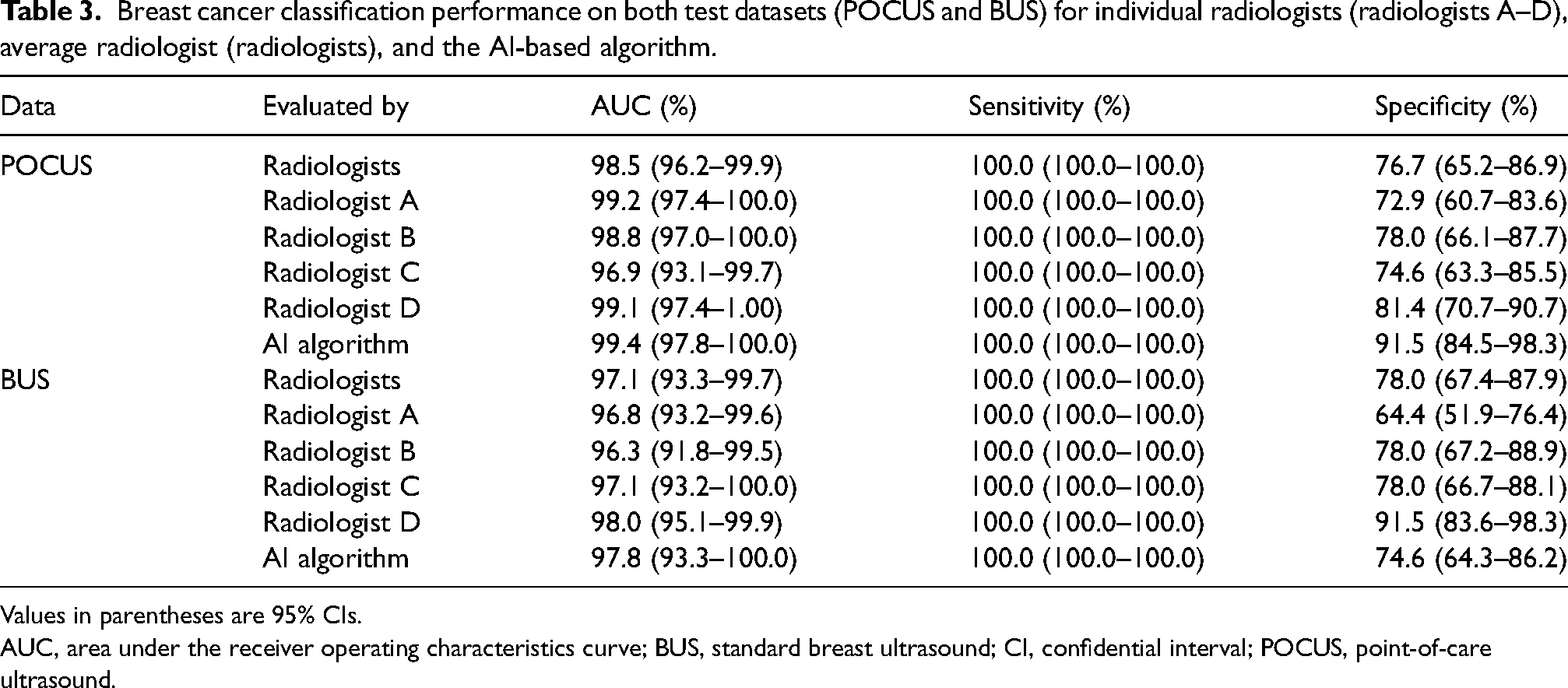
Values in parentheses are 95% CIs.
AUC, area under the receiver operating characteristics curve; BUS, standard breast ultrasound; CI, confidential interval; POCUS, point-of-care ultrasound.
Scores from the AI and the four individual radiologists for all misclassified cases.
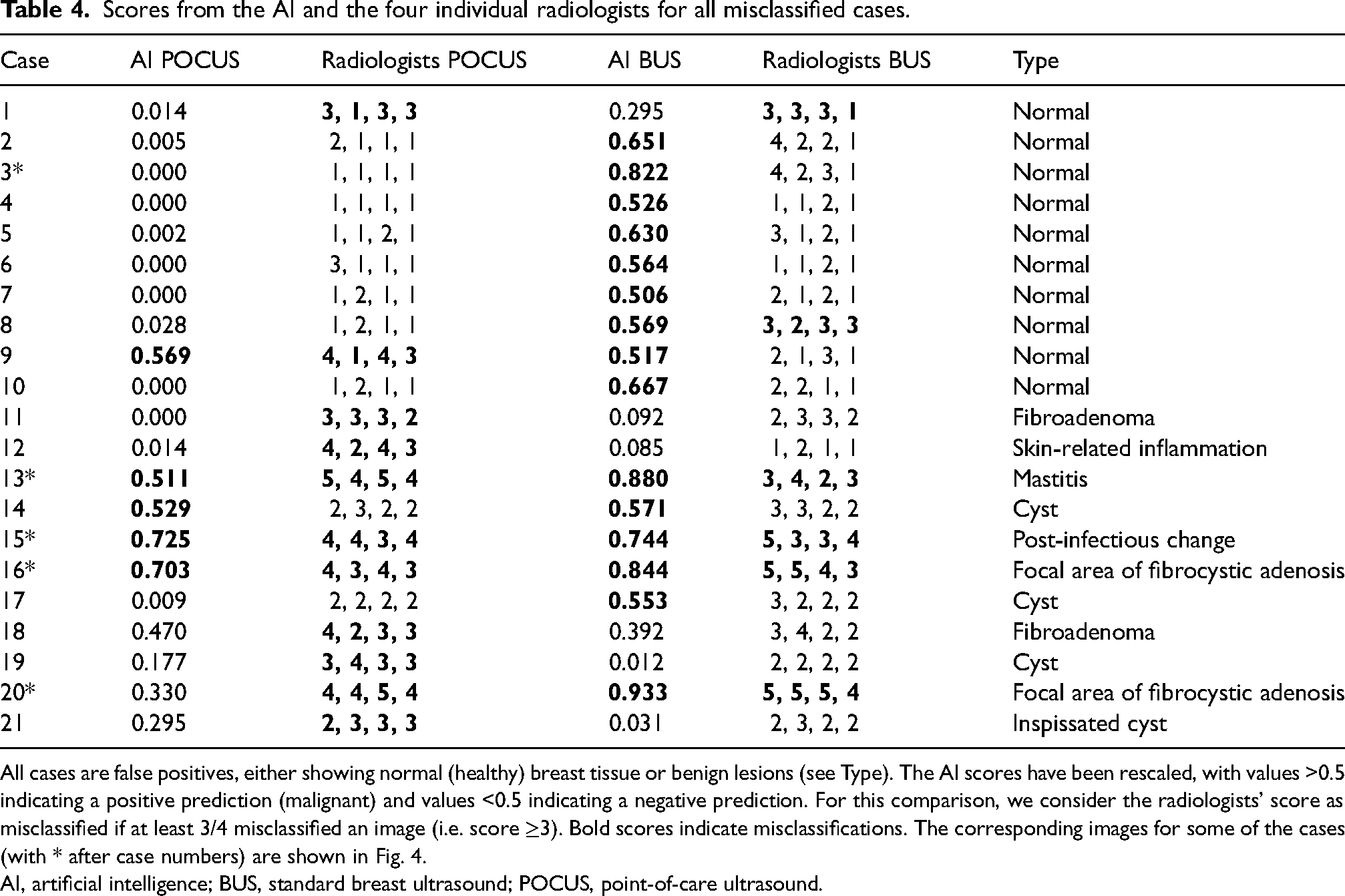
All cases are false positives, either showing normal (healthy) breast tissue or benign lesions (see Type). The AI scores have been rescaled, with values >0.5 indicating a positive prediction (malignant) and values <0.5 indicating a negative prediction. For this comparison, we consider the radiologists’ score as misclassified if at least 3/4 misclassified an image (i.e. score ≥3). Bold scores indicate misclassifications. The corresponding images for some of the cases (with * after case numbers) are shown in Fig. 4.
AI, artificial intelligence; BUS, standard breast ultrasound; POCUS, point-of-care ultrasound.
Scores from the AI and the four individual radiologists for all malignant cases.
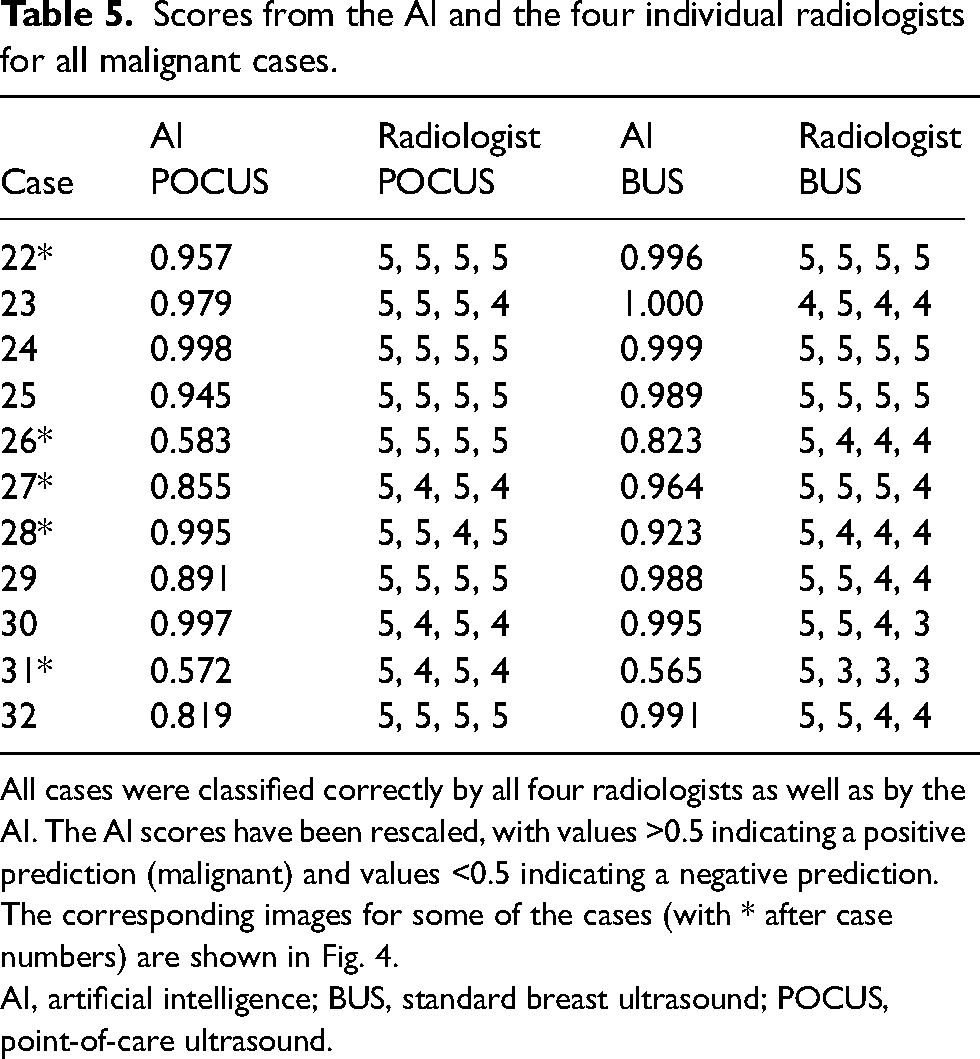
All cases were classified correctly by all four radiologists as well as by the AI. The AI scores have been rescaled, with values >0.5 indicating a positive prediction (malignant) and values <0.5 indicating a negative prediction. The corresponding images for some of the cases (with * after case numbers) are shown in Fig. 4.
AI, artificial intelligence; BUS, standard breast ultrasound; POCUS, point-of-care ultrasound.
Comparison of expert radiologists and AI model
The average radiologist achieves an AUC of 98.5% on the POCUS data and 97.1% on the BUS data. The AI model achieved an AUC of 99.4% on POCUS images and 97.8% on BUS images. Detailed results for each dataset are described in the sections below.
POCUS dataset
There was no significant difference when comparing the AUCs for AI and radiologists in the POCUS dataset. Both radiologists and the AI algorithm had a sensitivity of 100.0%, while the specificity was higher for the AI algorithm (91.5% as opposed to 76.7% for the average radiologist). On the ROC curve, all the radiologists are outperformed by the AI algorithm (Fig. 3).
BUS dataset
There was no significant difference when comparing the AUCs for AI and radiologists on BUS. Both radiologists and AI had a sensitivity of 100.0%. The specificity was slightly lower for AI (74.6% compared to 78.0% for the average radiologist). Three radiologists have a higher specificity than the AI (Fig. 3).
Misclassified cases
There was some overlap of images that the radiologists misclassified with cases that were difficult for the AI algorithm (Table 4). For POCUS, 11 images were misclassified by at least 3/4 radiologists; of those, the AI misclassified 4 (36%) images. In total, the AI misclassified five of the POCUS images. For BUS, six images were misclassified by at least 3/4 radiologists, whereof the AI misclassified 5 (83%) images. In total, the AI misclassified 15 of the BUS images.
Comparison of POCUS and standard ultrasound
There was no significant difference found for the AUCs of either the average radiologist or the AI between the BUS data and the POCUS data.
Discussion
This paired reader study evaluated the stand-alone performance of breast radiologists and AI on POCUS and BUS. Overall, the AI's performance on POCUS and BUS was comparable and had no significant difference to that of radiologists. No significant difference in AUCs was observed between POCUS and BUS for either the radiologists or the AI. These findings highlight the potential of combining POCUS and AI as a stand-alone method for assessing women with focal breast complaints, particularly in limited-resource settings.
Earlier studies have shown that DL could be used to reliably classify BUS ((26)), as well as POCUS images ((18,22,27)). Our results support that hypothesis, as the AI-based algorithm performed at similar level as the average radiologist on both the BUS and the POCUS dataset. This suggests that the algorithm could serve not only as a supportive tool for radiologists but also as a stand-alone diagnostic solution in areas with limited available radiologists.
A deeper analysis of misclassified cases revealed that the AI and radiologists tended to make different errors (Table 4), with the AI performing better on the POCUS data and radiologist better on BUS data. When the average radiologist failed on the POCUS cases, the AI correctly classified seven out of the 11 cases, whereas when the AI failed on the BUS cases, the average radiologist correctly classified 10 of the 15 cases. Thus, there was a largely non-overlapping error pattern. Noticeably, the AI tends to on average give higher malignancy scores to BUS data compared to POCUS data, which could be due to different class imbalances in the BUS and POCUS training dataset. Many cases where AI and radiologists disagree are benign cases, most of which are cysts or fibroadenomas. Although the AI and the radiologists misclassify different cysts, the AI tends to perform better than the radiologists on the fibroadenomas. Consequently, radiologists using our algorithm as a supportive diagnostic tool could potentially increase their performance and it could help in cases that are difficult to interpret. Further research is needed to investigate this potential.
Several recent studies have highlighted the potential of POCUS and AI in breast imaging. Prior work by Acuña et al. ((28)) demonstrated the clinical utility of POCUS for the evaluation of a range of different breast complaints in the emergency department (ED), although with generalizability limitations due to a small sample size and the physicians being highly trained in using POCUS compared to other EDs. More recently, Plöger et al. ((29)) found that POCUS is a reliable alternative to BUS, matching it closely in terms of morphological descriptors and BI-RADS categories, histological results, agreement rate and Cohen's kappa, supporting POCUS as a breast imaging diagnostic standard in EDs, as well as in rural outreach programs. Malherbe et al. ((30)) showed that AI integration in POCUS provides clinically meaningful support in breast lesion identification, particularly supporting its usage as an adjunctive triage modality in settings with limited resources or high-volume clinical environments. Their work proposes a three-tier risk stratification model as opposed to our AI model, which provides direct classification into normal, benign, and malignant findings. Using an optimal threshold for identifying malignant cases, their model achieves a sensitivity of 67.2% and a specificity of 79.4%, which is lower than ours. Ochoa et al. ((31)) proposed a fully automated system based on standardized breast volume sweep imaging using BUS, with an AI that selects frames from the videos and classifies them, achieving an AUC of 91.0% for breast cancer detection, lower than our model's AUC on both POCUS and BUS. In a recent study about AI-based breast cancer classification in POCUS, Karlsson et al. ((32)) show that AI model performance is highly dependent on the size, diversity, and quality of the training data. They find that data augmentation as well as adding BUS images to the training data can significantly improve classification results on POCUS, as opposed to training a network solely on POCUS images.
In contrast to prior works, the present study shows that AI-based breast cancer classification can achieve high performance comparable to expert breast radiologists in both POCUS and BUS. Most notably, no significant differences were found between POCUS and BUS in a case-matched setting. These findings extend prior work by showing that a high diagnostic performance is not limited to BUS but may also be achieved in more flexible scenarios using POCUS, and these images can be reliably classified by AI with performance comparable to expert breast radiologists.
The present study has some limitations. Most notably, the sample size was small, consisting of only 70 POCUS and 70 case-matched BUS images, whereof only 11 cases were malignant. Furthermore, the POCUS as well as the BUS datasets were collected by ultrasound machines from only one vendor. Although the findings offer a valuable proof of concept, demonstrating the strong potential of POCUS for breast imaging and of AI for breast cancer classification, a larger dataset is necessary to confirm and generalize these results. Another limitation is that the labels for the POCUS training and validation data are based on a single experienced radiologist, rather than multiple readers. Although unclear cases were always verified via biopsy, the impact of individual subjectivity is a limitation. A potential selection bias is also introduced by choosing patients for the AI training and validation data based on the examiner's availability and time schedule, rather than consecutive sampling. Furthermore, although the risk of shortcut learning ((33)) is reduced by having a small model and regularization techniques like dropout, the training data has class imbalance with the BUS training set having a higher ratio of malignant cases than the POCUS training set (57.6% vs. 23.7%), which could result in risk of shortcut learning bias. Potentially this could explain why we get a higher specificity in POCUS compared to BUS (91.5% vs. 74.6%). Future studies should aim to address these limitations by incorporating more diverse and extensive datasets. Regarding model design, although large networks are often preferred due to their improved ability to capture complex concepts, this study presents an ensemble of smaller AI models with just six layers. For the intended application in low-resource settings, it is crucial that the model is able to run in real time on small devices making smaller models preferable. Together with the limited training data, a small model was preferred over a larger one.
In conclusion, this study demonstrates that an AI-based breast cancer classification approach could perform similar to radiologists on both POCUS and BUS. Given its high performance comparable to radiologists, the AI model holds the potential to diagnose women with focal breast complaints in a cost- and time-effective manner by non-experts. The findings also support the feasibility of using POCUS as a stand-alone imaging modality in low-resource settings, offering diagnostic performance similar to that of standard BUS. Integrating AI into clinical workflows could be a valuable step toward accessible and reliable breast cancer assessment worldwide.
Footnotes
Acknowledgements
We would like to acknowledge the radiologists (David Schmidt, Catharina Behmer, Lisa Ander Olsson, Hanna Sartor) involved in the reader study and Oskar Hagberg for statistical support.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: JK, IA, KL are stockholders of N23 Health AB, a company focusing on AI supported ultrasound analysis for early detection of breast cancer in low-resource settings. N23 Health AB was founded after this study was conducted. IA is stockholder of Eigenvision AB, a company specializing in research and development in automated image analysis, computer vision, and machine learning. The other authors declare that they have no conflicts of interest.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was funded by governmental funding for clinical research (ALF), strategic research area eSSENCE, and Analytic Imaging Diagnostics Arena (AIDA), Vinnova (grant no. 2021-01420).