
Abstract
Whereas reproducibility of studies is a prerequisite for trustworthy deep learning (DL) in veterinary histopathology and microscopy, the actual degree of methodological transparency that exists in the literature remains uncertain. We performed a Preferred Reporting Items for Systematic Reviews and Meta-Analyses-guided systematic review to quantify the degree to which supervised DL and supervised machine learning studies report reproducibility-critical details. Using a veterinary-journal-restricted Boolean search executed in PubMed and Scopus, we screened 180 unique records and included 50 primary research articles for full-text analysis. Based on a recently published guideline for the development of DL models in veterinary pathology, we extracted information for each study across 5 dimensions: (1) study and task characterization, (2) data transparency, (3) experimental design and data-leakage control, (4) model and training details, and (5) performance evaluation and reporting. Among the included studies, private data sets predominated, with 90% of studies relying on private data. Sharing of code was uncommon (3%). Key training details such as augmentation and hyperparameters were often incompletely reported; augmentation was not reported in 56% of studies, and key hyperparameters were absent in 40% of studies. It was often not clear whether patient-level stratification (necessary to avoid data leakage) was performed. In summary, these results highlight major deficits in the reporting of details and experimental design necessary for reproducing DL results in veterinary histopathology. This review provides a practical baseline and reporting roadmap to support more transparent and reproducible research in veterinary computational pathology.
Keywords
Techniques based on deep learning (DL) and machine learning (ML) have become a major trend in veterinary pathology over the past years, with use cases varying from mitotic figure detection 2 and tumor grading 58 to lesion segmentation. 53 The increasing adoption of these methods is driven by the time-consuming and tedious nature of many routine histologic tasks and interobserver variability,5,72,75 for which algorithmic approaches are expected to help standardize diagnostic assessments. 7 At the same time, the artificial intelligence (AI) ecosystem has also undergone a significant transformation with more accessible software frameworks, low-code interfaces, and a broad range of online tutorials now allows researchers without any formal ML training to develop or modify DL pipelines for their tasks.31,65 Consequently, DL has become an attractive approach for many practitioners and researchers in veterinary pathology.
Crucially, the widespread use and low barrier to entry of these techniques demands particular attention. Due to their expressiveness, DL models will almost invariably yield some result, even if the data are not suitable, the task is not well defined, or the training is incorrect. This can lead to situations where the seemingly impressive performance conceals severe methodological problems. Moreover, model behavior depends not only on the data set and model architecture, but also on the exact details of the training, such as which data were used for training and testing, augmentation, loss functions, optimization strategy, learning rate schedules, and other hyperparameters. Without knowledge of these crucial elements of the experimental setup, reproducing reported results can become tedious to impossible. This has contributed to the well-known reproducibility crisis in the broader ML community, 32 and in particular in the medical imaging community, 61 whereby the outcomes of studies cannot be consistently reproduced by others. These pitfalls may affect scientists without sufficient training in ML and without knowledge about DL best practices even more strongly.
The field of pathology is no exception to this: Training in ML techniques is not part of the regular curriculum in either human or veterinary pathology. Yet, the application of ML and DL methods is attractive to researchers with this background that have only recently started to utilize them and have not received any in-depth training. This gives rise to the potential for methodological mistakes that stem from insufficient knowledge about the details of the methods, their limitations, and boundary conditions. In particular, as not every part of a data pipeline is necessarily understood in its full detail, we hypothesize that authors from these fields are more prone to not reporting all relevant parameters of the experimental setup, which would significantly impact reproducibility of their approach.
The existing review literature about AI in veterinary diagnostics has mainly focused on identifying application areas and summarizing the usage of DL rather than systematically quantifying whether studies are reported in such a way that would enable them to be reliably reproduced. Broad overviews of veterinary DL applications further reveal that practical translation is commonly constrained due to small data sets, heterogeneity, and continuing needs for stronger standardization and validation practices. 74 A complementary synthesis of real-world adoption barriers highlights how issues related to access to limited data, poorly described methods, and scarce independent external testing can directly undermine confidence and reproducibility. 16
Survey-based evidence, coming from professional communities, further strengthens these concerns and points out that readiness depends on more than benchmark performance. The reported barriers include annotation burden, skill gaps, uncertainty about validation requirements, and trust in model outputs, collectively shaping whether AI tools can be integrated into routine practice. 49
Reproducibility has also become a central theme in computational pathology and, more broadly, digital pathology. Analyses centered on reproduction show that the whole-slide image pipelines published cannot be reproduced, or it is very hard to do so, when crucial implementation details are not available, which motivates the checklist-style reporting of data handling, preprocessing, training, and evaluation. 17 Related work on reproducibility and reusability in computational pathology further argues that verification and downstream reuse are hindered when artifacts are not shared and methodological reporting is incomplete. 69
Apart from academic publishing, there is a growing interest in the transparency of the publicly available evidence base for pathology AI systems put into clinical use. Analyses of AI products in digital pathology reveal that there is considerable variation in public evidence and make a case for more standardized and comparable documentation to allow independent scrutiny. 39 Guidance on how to interpret ML studies in clinical contexts highlights the importance of careful appraisals of validation strategy, bias, overfitting, and generalizability, further underlining that trustworthy claims must explicitly report study design and evaluation. 37 Cumulatively, these analyses make the case for transparency at the levels of data, annotations, training procedures, and evaluation. Besides, they indicate that reproducibility and the documentation of evidence are active concerns in pathology AI. Yet, to date, there is no systematic analysis in the field of veterinary pathology that investigates the availability of methodological details required for the reproducibility of results when ML and, in particular, DL models are involved. This review addresses this gap by quantifying reporting practices in veterinary articles that evaluated DL for analysis of microscopic images and identifies recurring omissions that impede reproducibility and thereby limit robust assessment of the results reported. We performed a systematic, PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses)-guided approach to cover the field of veterinary pathology. The overarching aim was to characterize the extent to which published articles provide sufficient detail on data, code availability, model development, and model evaluation to enable rigorous assessment and reproducibility.
Methods
Search Strategy and Study Selection
To evaluate the degree of reproducibility in reported DL methods for microscopic image analysis within veterinary medicine, a PRISMA 2020-style systematic review 48 was conducted on 4 November 2025, covering publications from 1 January 2010 to the search date. This lower bound was chosen because the widespread adoption of DL methods in image analysis began in the early 2010s, making earlier literature unlikely to contain relevant supervised DL studies. After several rounds of refinement, a Boolean search query was developed and is provided in full in the Supplemental Materials due to its length. In brief, the query consisted of 4 major OR-blocks combined with AND, capturing (1) AI-related terms, (2) pathology-related terms, (3) imaging-related terms, and (4) journals (Fig. 1). The search was limited to veterinary science journals, according to the categorization in the Clarivate database in an effort to meaningfully restrict the search scope to veterinary medicine and exclude studies from human medicine that would use animal models and otherwise show up in large quantities in our search results. Our search was intentionally restricted to veterinary journals, as our goal was to characterize the transparency standards of research conducted within and for the veterinary community, regardless of the disciplinary background of contributing authors. The identical search was executed in both PubMed and Scopus. Google Sheets was used to store and manage the extracted study characteristics, which was then exported as a comma separated value (csv) file, and Python programming language was used to process the csv and derive aggregated results. The first author (SB) reviewed all papers in detail for eligibility according to the inclusion and exclusion criteria (Table 1) and then, for the included papers, extracted all information according to defined reproducibility criteria. To ensure extraction quality, all 50 included papers were first annotated by the first author (SB). The 50 papers were then divided into 3 subsets (17, 17, and 16 papers), each independently re-reviewed by 1 additional co-author (CAB, MA, and JA, respectively), such that each paper was reviewed by exactly 2 annotators. Disagreements between the first author and the respective coreviewer were resolved by structured discussion until consensus was reached. The assessment items used for full-text extraction were aligned with recent minimum reporting guidelines for automated image analysis in veterinary pathology. 9

Illustration of the final search string used in the systematic review.
Eligibility criteria used for study screening.
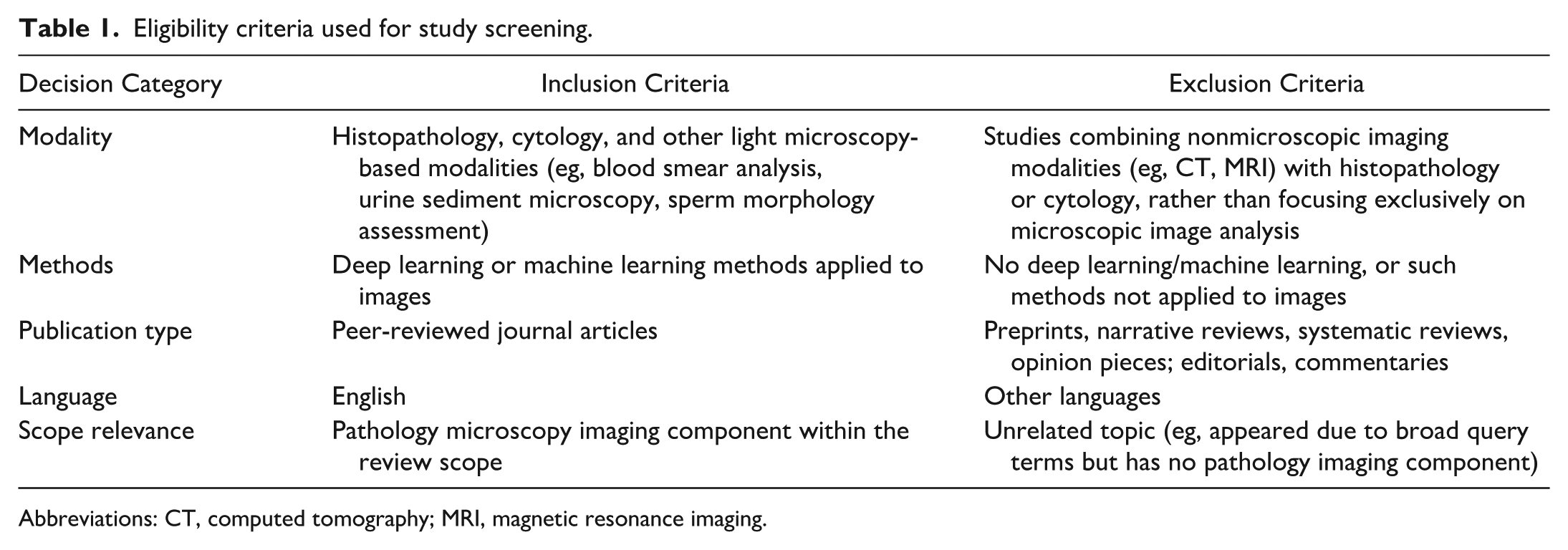
Abbreviations: CT, computed tomography; MRI, magnetic resonance imaging.
Data Extraction and Reproducibility Framework
For each of the included studies, information was extracted along 5 major dimensions according to a recent minimum reporting guidelines for automated image analysis in veterinary pathology, 9 which together formed the reproducibility framework. Extraction decisions were independently verified by coreviewer assessment across all 50 studies.
Study and task characterization
This dimension captured the pattern recognition task addressed by the model itself (eg, classification, object detection, semantic segmentation, or instance segmentation), not any downstream postprocessing steps, as well as whether the ML/DL models were trained as part of the reported work or used off-the-shelf without modification.
Data transparency
Data-related reporting was assessed in terms of transparency, completeness, and potential for reuse. We recorded whether the data set used for model development and evaluation was public, private, or mixed. A data set was considered public if both the images and their corresponding annotations were openly accessible without restriction. Studies that used images from a publicly available resource but did not release their annotations were treated as private, since reproducibility requires access to both. Data sets were coded as mixed if a portion of the images and their corresponding annotations were publicly accessible, but not the complete data set. Statements such as “available upon request” were treated as private, as conditional access does not guarantee reproducibility. We also recorded additional characteristics of the data. These included species, whether histochemical staining or immunochemical labeling was reported, and whether the digitization device was reported. We further extracted information on data set scale and structure, recording whether the number of whole-slide images or image patches was reported, and whether the image or patch size was reported when larger images were systematically tiled into smaller patches for model input. We also evaluated the description of the annotation process. Studies were categorized according to whether annotations were:
Manual. Labels or region annotations were created directly by one or more experts using dedicated software tools.
Automatic. Labels were derived by an existing algorithm (eg, a pretrained DL model) without direct per-instance human verification/correction.
Semi-automatic. Annotations were produced through a combination of algorithmic preannotation and subsequent review, correction, or refinement by pathologists.
Molecular/PCR. Labels were derived from molecular or polymerase chain reaction (PCR)-based assays rather than direct image annotation.
Experimental design and data leakage
This dimension focused on how rigorously the experimental setup was planned and described, with particular attention to prevention of data leakage and overfitting. We recorded whether the data set was explicitly partitioned into distinct training, validation, and test sets. We further recorded whether data augmentation (eg, geometric transformations, color jittering, and stain normalization) was reported. To evaluate safeguards against data leakage, we examined how studies handled multiple samples from the same individual. In settings where more than 1 image, slide, or tile per patient was available, we recorded whether patient-level stratification was explicitly enforced, such that all data from a given individual were restricted to a single partition (training, validation, or test).
Model and training details
This dimension evaluated the transparency of model specification and training procedures. We first recorded whether the ML/DL models were trained as part of the reported work or used off-the-shelf without modification, the latter including commercial or proprietary tools. For studies that trained models, we assessed the reporting of key training hyperparameters, specifically the learning rate, loss function, number of epochs, and optimization algorithm. Studies were classified as having all hyperparameters mentioned, partially mentioned, or none mentioned. For studies relying on commercial or proprietary tools where training was not performed as part of the work, hyperparameter reporting was recorded as not applicable where no training details could be expected or assessed against the above criteria where the tool provided partial transparency about its underlying methodology.
Evaluation and reporting of performance
The final dimension addressed how model performance was evaluated and reported. We recorded whether quantitative performance metrics were reported, specifically metrics evaluating the DL model itself, regardless of their appropriateness for the task at hand.
Results
Our search query resulted in 180 papers from the PubMed database. On the Scopus database, our query resulted in 63 papers, of which all but 1 were already found by the query on PubMed, resulting in a total of 181 papers to be screened after removal of duplicates. Following our inclusion/exclusion criteria, 98 papers were excluded as they were of unrelated topics (eg, studies not involving pathology images despite matching the search terms) or combined microscopic imaging with radiology-based experiments, and 33 as review or opinion articles. This left 50 primary research articles1,3,4,6–8,10,12–15,18–21,23–30,33–36,40–45,47,50–52,54–57,59,60,62–64,66–68,73 that applied ML or DL to veterinary medicine tasks as the final corpus for the systematic analysis. A PRISMA 2020 flow diagram summarizing the screening process is presented in Fig. 2. The assessment items were aligned with recent minimum reporting guidelines for automated image analysis in veterinary pathology. 9
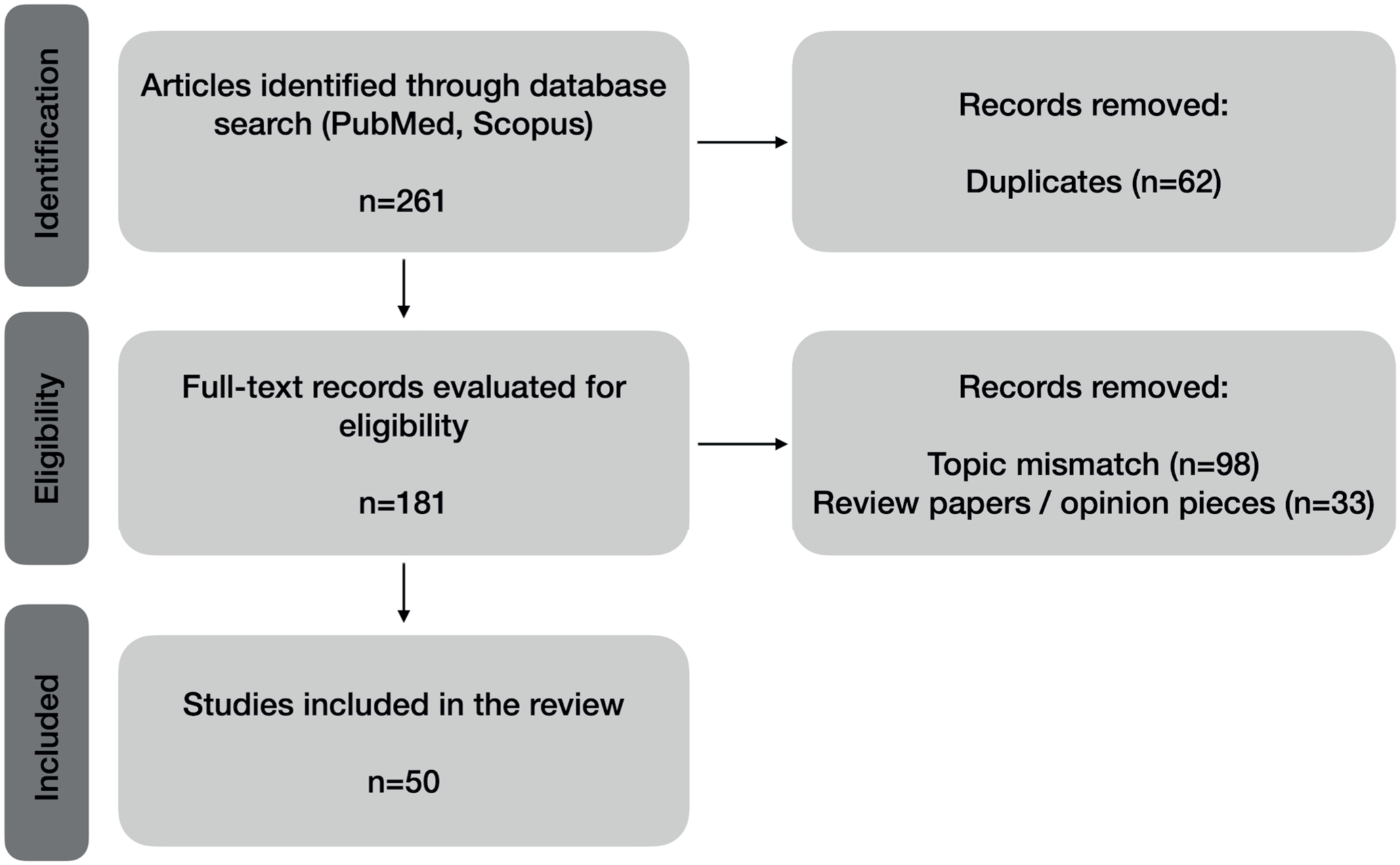
PRISMA flow diagram, visualizing the final corpus (N = 50).
Study and Task Characterization
Out of the 50 evaluated studies, the majority of papers (n = 44) involved the training of some kind of DL/ML model, whereas in 6 papers, either no model was trained or a previously published model was used (Fig. 4a and Supplemental Table S1—Review and Analysis). Across the included studies, semantic segmentation was the most frequently applied pattern recognition task (n = 29), followed by classification (n = 19), object detection (n = 7), and instance segmentation (n = 5). We note that some papers developed multiple DL/ML models addressing different pattern recognition tasks, often to reflect a sequential processing pipeline in which, for example, 1 model first localizes or segments a region of interest and a subsequent model classifies it, as seen in spermatogenic staging combining semantic segmentation with classification 14 and the automated diagnosis of canine skin tumors combining semantic segmentation with classification. 18 This explains why the total count of tasks to exceeded 50.
Data Transparency
In terms of data transparency (Fig. 3), data accessibility was limited. Of 50 papers, 45 used in-house private data sets, only 2 used fully public data sets, and 3 used a mix of public and private data (Fig. 3a). Similarly, the reporting of model code or implementation details was also limited. Of the 50 papers, 19 used commercial software, for which code sharing is inherently not applicable; of the remaining 31 studies that developed custom pipelines, 29 reported no code repository and only 1 provided a link to an online code repository. For the remaining 1 paper, the code requirements were not applicable as they were using a model from a previous publication. This makes almost all evaluated pipelines difficult to reproduce independently.
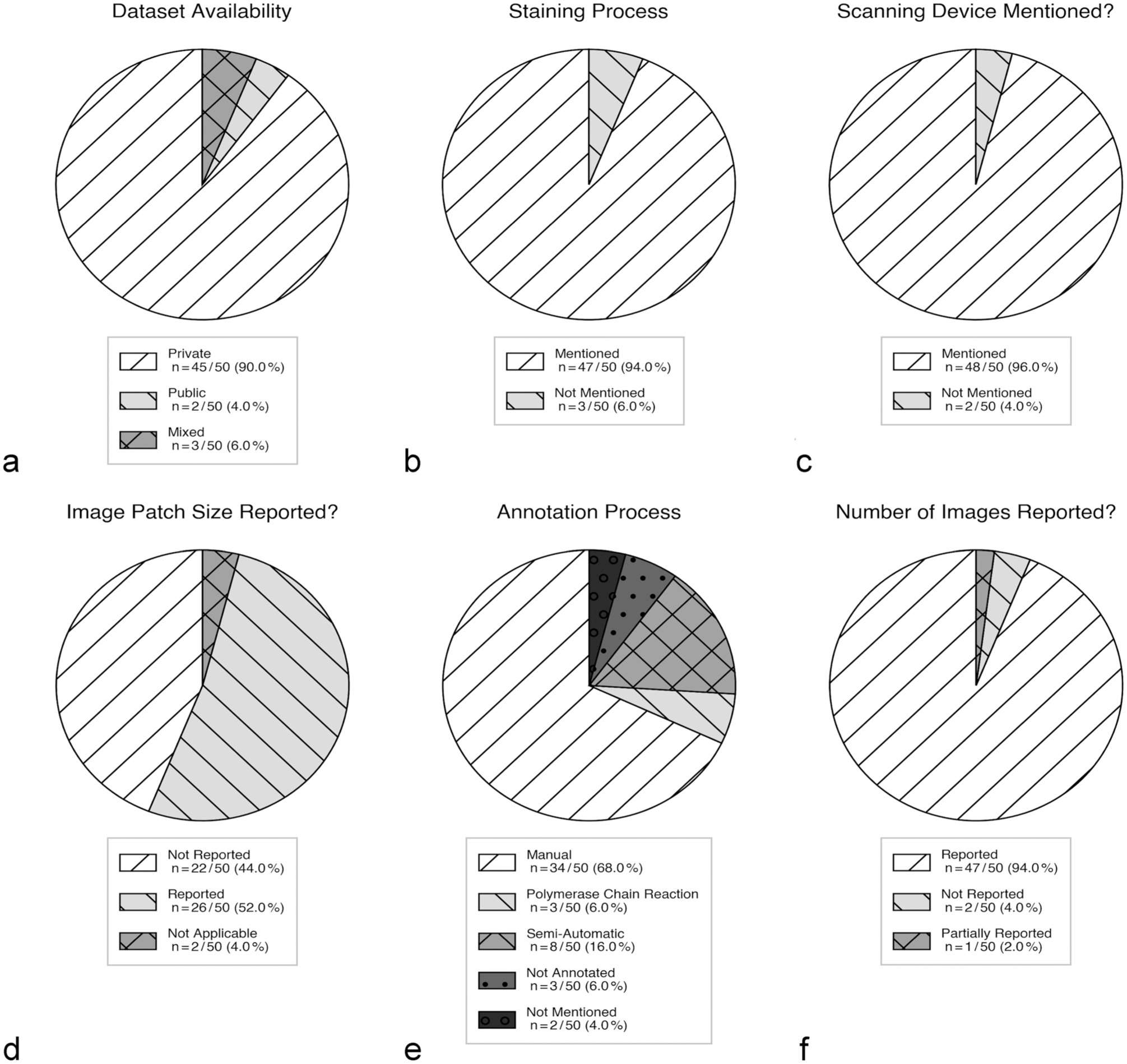
Results of our analysis in the “data transparency” category, reporting about which data details were reported in the analyzed manuscripts, including data set availability (a), staining process (b), scanning device (c), image patch size (d), annotation process (e), and the number of images (f).
Of 50 studies, almost half used murine specimen (n = 24), followed by studies on canine specimen (n = 12). Research based on feline (n = 3), avian (n = 3), porcine (n = 4), simian (n = 2), and equine (n = 2) tissues contributed to a smaller number of publications. One study each used bovine, ovine, and equine, and a combination of canine and feline tissues. In 1 study, blood parasites from unknown host animals were analyzed. A large number of application studies concentrated on the quantification of certain histologic features (eg, mitoses, necrosis, fibrosis, and inflammatory infiltrates) or on the derivation of prognostically relevant indices, whereas lesion detection, grading, or cellular subtyping in immunohistochemically labeled or histochemically stained slides were some of the topics in the remaining studies. Almost all papers mentioned the staining process (n = 47), with 2 papers reporting no staining and 1 using unstained specimens (Fig. 3b). Most papers also referred to the digitization device used for obtaining images (n = 48, Fig. 3c). The number of images/data set size was mostly provided (n = 47, Fig. 3f); however, a few papers failed to report this information (n = 2) or reported it partially (n = 1). On the contrary, the patch size used as the model input was reported in approximately half of papers (n = 26, Fig. 3d). Finally, most of the studies had their annotation done manually (n = 34), and some were annotated semi-automatically (n = 8, Fig. 3e). For 2 papers, we were not able to determine the method of annotation, while in 3 papers, the images were not annotated. In 3 papers, labels were generated with the help of PCR.
Experimental Design and Data Leakage
With regards to reporting of data splitting, just over half of studies used an explicit train/validation/test split (n = 26), while 7 used only a train/test split and 5 used only a train/validation split (Fig. 4b). A substantial portion did not mention any split strategy (n = 10), and for 2 studies, data splitting was not applicable as they applied a model from a previous publication. Potential data leakage control via patient-level stratification was also rare—only 13 studies explicitly or implicitly indicated patient-level stratification, while most reported no stratification or did not mention it (n = 29). In 5 studies, this criterion was not applicable, and only 2 explicitly reported that no patient-level stratification was performed (Fig. 4c).
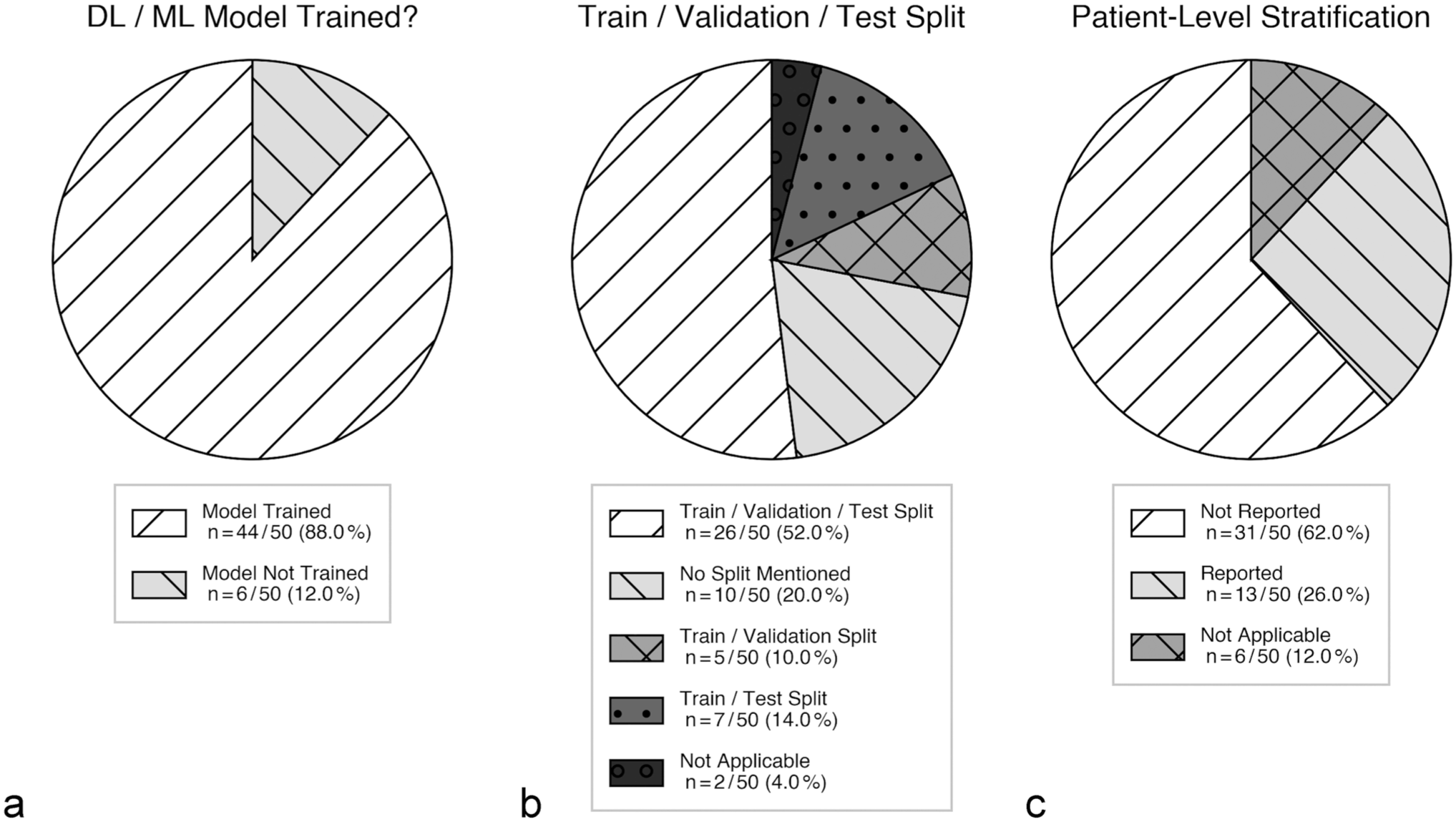
Results of our analysis in the “experimental design” category, including whether a deep learning (DL) or machine learning (ML) model was trained (a), the train/validation/test split strategy used (b), and patient-level stratification (c).
Model and Training Details
When it comes to the training of the DL models, the description of the architectures varied from very brief, high-level mentions of a specific backbone by name (eg, U-Net, ResNet, Mask R-CNN, and MIL frameworks) to more detailed descriptions of the individual layers, but this information was not consistent across the papers. Information on hyperparameters was similarly variable (Fig. 5). In terms of learning rate, loss function, number of epochs, and optimizer, only 9 papers provided details of all the essential hyperparameters, 19 papers provided only a partial list, 20 papers did not report any hyperparameters, and for 2 papers it was not applicable (Fig. 5b). Information on data augmentation was likewise insufficient, with only 18 papers reporting augmentation for all models, 1 paper reporting it partially, and 28 papers not mentioning augmentation. For 3 papers, augmentation was not applicable as no model was trained (Fig. 5a).
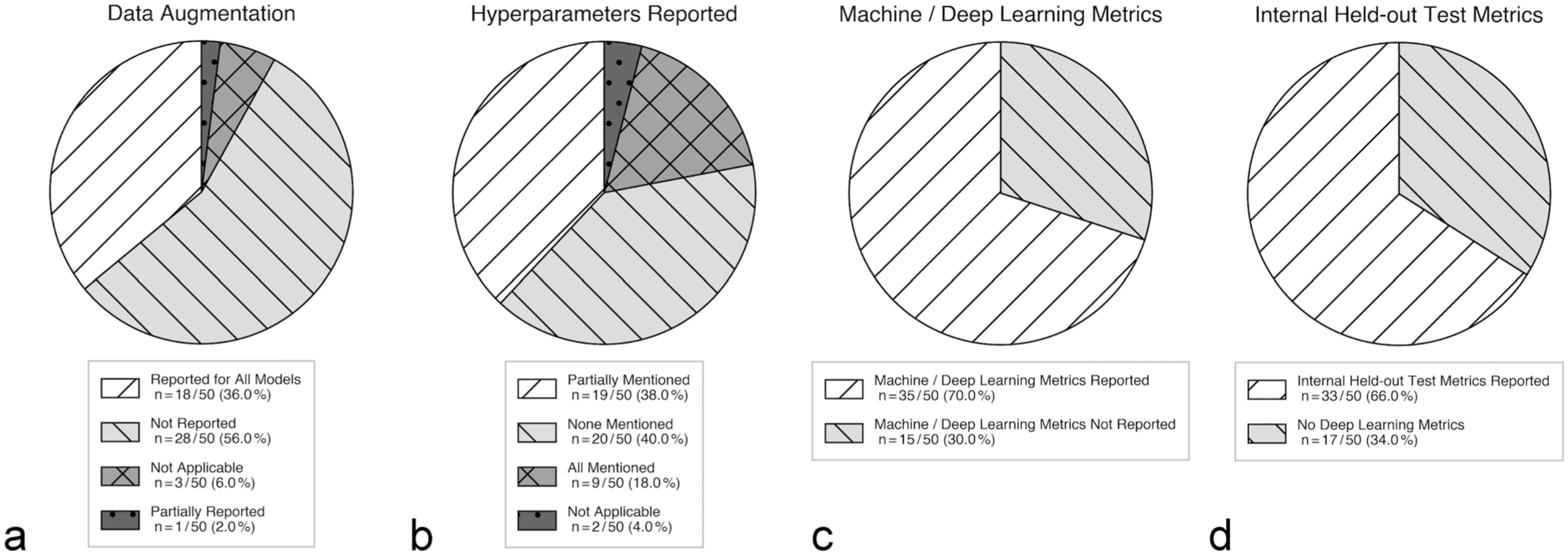
Results of our analysis in the “training details” and “evaluation and reporting of performance” category, including data augmentation (a), hyperparameter reporting (b), machine/deep learning metrics (c), and internal held-out test metrics (d).
Evaluation and Reporting of Performance
Among all the papers, 35 papers used ML/DL-related metrics, and 15 papers did not report any ML/DL metrics (only statistical metrics, Fig. 5c). Finally, in 33 of the papers, hold-out test metrics were reported (such as accuracy, F1-score, area under the curve, and Dice), whereas in 17 papers, no DL-based test metrics were reported (Fig. 5d).
Temporal Trends in Reporting Practices
A year-stratified analysis comparing earlier (2010–2021, n = 16) and more recent (2022–2025, n = 34) studies revealed only modest improvement in reporting practices over time. The proportion of studies reporting a full train/validation/test split increased from 50% to 56%, and patient-level stratification from 25% to 27%. Hyperparameter reporting remained unchanged at approximately 19% in both periods. The proportion of studies using private data sets decreased slightly from 100% to 85% in more recent work, suggesting a gradual but limited trend toward greater data accessibility.
Discussion
This systematic review gives a quantitative overview of how reproducible DL and ML studies in veterinary pathology and microscopy are currently reported in 5 aspects: task characterization, data transparency, experimental design and data leakage, model and training details, and evaluation. A consistent pattern emerged across 50 primary studies that, although many papers describe parts of the laboratory context reasonably well, key elements necessary to independently reproduce the work and to rigorously judge their validity are frequently missing or only partially reported.
A positive finding is that reporting of factors related to image acquisition was comparatively strong. The large majority of studies stated both the staining process and the scanning device, and a majority also reported either the data set size or number of images. These items help readers understand the data generation pipeline. However, reproducibility is fundamentally hindered by limited accessibility of data and code; there is a prevalence of private in-house data sets, which prevents independent verification and benchmarking. Similarly, a general lack of public code repositories restricts reproducibility of training and evaluation procedures. Notably, when commercial software is used, code sharing is inherently not possible; however, this places greater responsibility on authors to report all software versions, parameter settings, and configurations in full, which was not consistently observed in the commercial software studies in our corpus. While data sharing by private diagnostic companies and toxicologic laboratories might be restricted due to legal and data privacy constraints as well as to proprietary considerations, we want to emphasize the value of open data beyond transparency and reproducibility, which includes acceleration of methodological innovations by other research groups, broadening the availability of training data with real-world variability, and reduction of redundant efforts. 70 In cases where sharing of data sets or code is not feasible due to proprietary or legal constraints, the minimum reporting checklist can still be partially satisfied by sharing model weights, inference scripts, and fully specified configuration files. Specific recommendations for veterinary pathology, considering the individual disciplines’ restrictions, are not available yet. However, there are ongoing initiatives for large data repositories, such as BigPicture, that will be extremely valuable in overcoming the legal and proprietary restrictions. 46 The FAIR (findability, accessibility, interoperability, and reusability) principle should serve as a guideline to make future initiatives of open data most meaningful in advancing AI. 71
The most worrying issues concern experimental design and data leakage. Explicit reporting of a train/validation/test split was only performed by half of the studies, while many omitted split information altogether. In our corpus, very few studies performed explicit patient/subject-level stratification, and almost none described any efforts taken to prevent leakage. Similarly to our findings, a survey of toxicologic pathologists revealed that almost a quarter of participants were not following a 3-fold split. 49 This has particular implications for veterinary pathology pipelines that typically output multiple images or tiles per animal; if samples coming from the same animal appear in both training and test sets, it can result in misguiding results due to data bleeding. Because many veterinary data sets are small and includes data from the same institution and similar preparation protocols, transparent reporting of splits and data leakage should be treated as important requirements to ensure that overoptimistic performance evaluation is avoided. Splitting data at the wrong level can considerably bias performance metrics. In digital pathology, an image-wise split that lets images from the same subject appear in both training and validation can inflate predictive scores by up to 41%. 11 Studies that verify subject separation show much lower accuracy compared to those likely to have data leaks. One study even showed a 28-percentage point drop (from 94 to 66%) after introducing a proper data split. 76 We therefore suggest that studies involving veterinary pathology and microscopy adopt established reporting guidelines 9 that provide structured recommendations for documenting data partitioning strategies, cross-validation procedures, and measures taken to prevent data leakage.
Model and training descriptions were also often insufficient for replication. Although most studies trained a model, the reporting of model development details varied widely. In many cases, architectures were referenced only at a high level—naming U-Net, ResNet, Mask R-CNN, or MIL—without sufficient specification to reconstruct the pipeline. 49 Crucial information including model configuration, input tile size, magnification or resolution, normalization or stain processing, sampling strategy for class imbalance, loss configuration, optimizers, and training schedules was often absent. Reporting of hyperparameters and data augmentation was particularly scarce. All of these criteria are known to impact results and are commonly optimized in the development process; hence, the nonreporting of those significantly impacts reproducibility of results. To address this, studies should adopt a minimum checklist of reporting for model development and training that allows for the full pipeline to be reproduced. 9 First, an explicit description of architecture and configuration should be provided, for example, backbone variant, depth/width, heads, and pretrained weights. In case a commercial software is used, the version and all the settings and hyperparameters should be reported. Second, the formation of inputs, such as digitization device, magnification/resolution, image size, and staining process should be reported. Third, training details should be reported with enough details to reproduce them, including loss functions and class-imbalance handling, optimizer and learning-rate schedule, batch size, epochs, regularization, augmentation with parameter ranges, early stopping/model selection, and random seeds. Where possible, these items should be complemented by sharing code, or at least a runnable configuration file, and releasing trained weights and inference scripts.
Reporting of evaluation methods was inconsistent. Not all studies reported standard ML/DL performance metrics and instead, relied on statistical summaries or visual examination without clear reporting of model-centric metrics such as the area under the receiver operating characteristic curve, F1-score, or Dice coefficient. Better separation between model-performance evaluation and downstream statistical or biological interpretation would be advantageous for transparency and comparability across studies. In veterinary pathology, there are currently no clear recommendations to which extent the performance of DL models need to be evaluated before they can be used in research, toxicologic studies, or diagnostic settings. An existing white paper for human diagnostics on patient samples can be used as an orientation for veterinary use cases. 22 Furthermore, the metrics reloaded initiatives provides a step-by-step decision workflow how the most suitable performance metrics can be selected for performance evaluation. 38 These authors suggest that for many use cases, a combination of different performance metrics is necessary to account for the statistical limitations that an individual metrics might have.
Considering these findings, we recommend that future veterinary pathology ML/DL studies standardize reporting based on a minimum set of items critical for reproducibility. At a minimum, studies should transparently mention the split strategy (including whether splitting was performed at the animal/patient level), describe how data leakage was prevented, and provide full training configuration reports (loss function, optimizer, learning rate and schedule, batch size, epochs, augmentation, and model selection criteria). The preprocessing and tiling decisions should be documented, including tile size, magnification, tissue filtering, and stain normalization, if used. Finally, authors are encouraged to share data, code, and weights whenever possible. Reporting guidelines, for example, the one developed for the journal Veterinary Pathology, may support authors in including all relevant information in manuscripts. 9
This review has some limitations. To begin with, interdisciplinary work published in computer vision or biomedical imaging venues was out of scope by design and therefore not all studies from the veterinary community had been included in this review. However, our search was intentionally restricted to peer-reviewed articles indexed in veterinary-scoped journals, as our aim was to characterize reporting practices within the veterinary research community rather than the broader computational pathology field. However, depending on the journal (eg, medical journals vs computer science journals), a variable level of computer science expertise may have been included in manuscript preparation (authors) and review (editors and reviewers), which are likely to affect the completeness of reporting. To support veterinary researchers and reviewers in ensuring complete and transparent reporting, the journal Veterinary Pathology has established a reporting checklist for studies that use DL-based image analysis. 9 Second, because we relied on what authors explicitly reported, our extraction likely underestimates the presence of good practices that were performed but not documented; we could not independently verify, for example, the correctness of reported practices (eg, whether patient-level splitting was truly enforced). Finally, even though more people are using ML and DL in veterinary histopathology, the way they report their methods is not consistent. Too often, studies skip important details about how they set up their experiments, control for data leakage, or train their models. Most do not share their code. These practices limit reproducibility or the ability to compare one study to another. Closing these gaps would make studies more reliable, facilitate meaningful cross-study comparisons, and accelerate their safe translational potential into veterinary research and practice.
Supplemental Material
sj-xlsx-1-vet-10.1177_03009858261459452 – Supplemental material for Reporting transparency in veterinary pathology deep learning: A systematic review of reproducibility-critical details
Supplemental material, sj-xlsx-1-vet-10.1177_03009858261459452 for Reporting transparency in veterinary pathology deep learning: A systematic review of reproducibility-critical details by Sweta Banerjee, Christof A. Bertram, Viktoria Weiss, Jonas Ammeling, Thomas Conrad, Nils Porsche, Robert Klopfleisch, Christoph Stroblberger, Christopher Kaltenecker, Katharina Breininger and Marc Aubreville in Veterinary Pathology
Supplemental Material
sj-pdf-1-vet-10.1177_03009858261459452 – Supplemental material for Reporting transparency in veterinary pathology deep learning: A systematic review of reproducibility-critical details
Supplemental material, sj-pdf-1-vet-10.1177_03009858261459452 for Reporting transparency in veterinary pathology deep learning: A systematic review of reproducibility-critical details by Sweta Banerjee, Christof A. Bertram, Viktoria Weiss, Jonas Ammeling, Thomas Conrad, Nils Porsche, Robert Klopfleisch, Christoph Stroblberger, Christopher Kaltenecker, Katharina Breininger and Marc Aubreville in Veterinary Pathology
Footnotes
Supplemental material for this article is available online.
Author Contributions
SB assessed all manuscripts, performed analysis, and wrote the main manuscript. MA, CAB, and JA were involved in coreviewing subsets of the corpus as second reviewers. MA and CAB were involved in reviewing manuscripts where the decision was doubtful. CAB, KB, MA, and SB designed the inclusion and exclusion criteria and search terms and edited the manuscript. MA contributed one of the figures. All authors discussed the scope of the review and reviewed and contributed to the final manuscript.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Authors Marc Aubreville and Christof Bertram are members of the Editorial Board of Veterinary Pathology but were not involved with handling the manuscript and have no further conflicts to declare. The remaining authors declare no conflicts of interest.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: CAB, VW, CS, and CK acknowledge the support from the Austrian Research Fund (FWF, project number: I 6555). SB, TC, RK, and MA acknowledge support by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation, project number: 520330054). KB acknowledges support by the DFG (project numbers: 405969122, 505539112, and 460333672 CRC1540 EBM).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.