
Abstract
Allocation of informative regions in images depends on a visual task. We propose two criteria for allocation of informative regions in images considering visual recognition of objects in images using a space-variant foveal filter. The first criterion relates to descriptor completeness. This criterion is formalized as a measure of similarity of an original image to an image reconstructed from foveal filter responses. The second criterion relates to descriptor distinctiveness. This criterion relates to the problem of retrieving discriminative and repeatable features in images of objects. It is formalized as a variation of descriptor elements of different objects within the same class. We reveal that regions of interest produced by these criteria are distributed in the areas of high variety of brightness gradients orientations.
Introduction
The problem of localization of the most informative regions in images is common in biological and computer vision studies. In biological vision research, it is associated with the temporal and spatial dynamics of visual attention that affects the characteristics of eye movements and the distribution of fixation points. In model-based studies, the most informative regions relate to visual saliency maps. Finally, in computer vision, informative regions are formalized in the form of keypoints for object detection and recognition. Localization of the most informative regions depends on the visual task. Considering computer vision methods for recognition of objects in images, such localization depends on a particular object descriptor. Various image descriptors are used for computer vision purposes, such as the Histogram of Oriented Gradients (Dalal & Triggs, 2005), the SIFT descriptor (Lowe, 1999), and the Shape Context (Belongie, Malik, & Puzicha, 2002). The foveal filter (or space-variant filter) is one such effective descriptor extractor (Alahi, Ortiz, & Vandergheynst, 2012; Rybak, Gusakova, Golovan, Podladchikova, & Shevtsova, 1998) that simulates the heterogeneity of the spatial resolution of a retina. It utilizes information about the distribution of elementary features (like color, intensity gradients, etc.) over image regions. The size of these regions grows from the center to the periphery of a filter input window. The foveal filter was shown to be robust enough for applied usage: For instance, it was successfully used for face recognition (Petrushan & Samarin, 2012).
We consider the problem of localization of the most informative regions in images that are optimal for the positioning of an input window of a foveal descriptor extractor. Areas of input window positioning are called fixation points by analogy with natural vision. Two criteria of optimality are proposed herein.
The first criterion relates to descriptor completeness. The ratio of information extracted from an image during viewing to the total information contained in an image depends on the coordinates of the fixation points. The criterion of descriptor completeness is linked to the problem of optimal viewing in terms of maximization of information extraction with simultaneous minimization of the number of fixation points. This criterion formalizes the measure of similarity between an original image and the image reconstructed from descriptors. Maximal similarity is considered to correspond to the optimal distribution of fixation points.
The second criterion relates to descriptor distinctiveness. This criterion is linked to the problem of retrieving discriminative and repeatable features of objects. The distinctiveness criterion is formalized as a cumulative variation of descriptor elements of different objects within the same class.
Analogies of completeness and distinctiveness criteria may be found in natural vision; for instance, they may be associated with top-down determinants of gaze behavior. Eye movement characteristics, such as saccade, convergence, and fixation attributes, depend on the dynamics of spatial- and object-based attention (Unema, Pannasch, Joos, & Velichkovsky, 2005) and are modulated by the current task and the observer’s emotional and functional state (Carniglia, Caputi, Manfredi, Zambarbieri, & Pessa, 2012). The relations between these characteristics and the processes of perception, cognition, and recognition are ambiguous. For example, gaze trajectory depends on image-domain features and on current cognitive processes, that is, it is simultaneously driven by bottom-up and top-down control (Theeuwes, 2010). Different approaches to model gaze trajectories and simulate visual saliency were proposed and discovered (Kienzle, Wichmann, Schölkopf, & Franz, 2007; Yanga, Tang, Fang, Shang, & Lin, 2013). A few generalized approaches are based on the Behavioral Model of Vision (Rybak et al., 1998). In particular, based on this behavioral model, four different determinants of gaze trajectory were proposed (Osinov & Shaposhnikov, 2012). According to the model, eye movements are conditioned by local image-domain features, such as gradient and color (Itti & Koch, 2000), the spatial structure of the visual sensor, and top-down components, such as inhibition of return (Lupianez, Klein, & Bartolomeo, 2006). Although the model predicts general types of gaze trajectories (Podladchikova, Shaposhnikov, Koltunova, Dyachenko, & Gusakova, 2009), it does not take task-specific determinants into account.
In this study, we associate proposed completeness and distinctiveness criteria with two tasks: image memorization, where an image of an object is to be observed in an optimal way for memorization; and image differentiation, where an image of an object is to be observed in an optimal way for the distinction of the image of the current object from images of other objects within the same class (e.g., differentiation of facial images). Corresponding tasks from computer vision research can be formulated as follows: complete image describing, where the description of an object image must be complete enough for image reconstruction (from descriptors); and specific image describing, where the description of an object image must be distinctive from descriptions of other objects within the same class. The considered tasks determine the optimal viewing strategies, and thereby the optimal distributions of fixation points, that are simulated by the proposed model according to the completeness and distinctiveness criteria.
In contrast to the various methods of visual saliency simulation (Kienzle et al., 2007; Li & Ngan, 2011; Marat et al., 2009; Yanga et al., 2013) that utilize image-domain features and the distribution of spatial and temporal (for video) features to calculate saliency, we propose new components that can affect saliency distribution: descriptor completeness and distinctiveness principles. According to these principles, image regions that are more optimal for image reconstruction (from descriptors derived from foveal filters responses in these regions) and for image differentiation are to be more salient.
In the Methods section, we describe the model of foveal filter and the structure of its input window. Completeness and distinctiveness criteria are formulated to choose optimal allocation of the foveal filter input window. In the Results section, we compare three types of distribution of the fixation points for the foveal filter over facial images (uniform, random, and gradient-based) to find out which of the considered distributions fits more to descriptor completeness criterion. Generalized portrait and intraclass variation maps were generated from the sequence of facial images to identify distinctive regions in facial images that fit to descriptor distinctiveness criterion. In the Discussion section, the relations of task-specific completeness and distinctiveness criteria with image-domain rules for fixation points allocation are considered.
Methods
Criteria of descriptor completeness and distinctiveness
We consider a set of foveal filter responses in certain fixation points as an image descriptor. Thus, the efficiency of the fixation points distribution as a means of maximizing descriptor completeness or distinctiveness can be estimated. Descriptor completeness is evaluated as a measure of similarity between an initial image and an image reconstructed from the descriptor. Descriptor distinctiveness is evaluated as a cumulative intraclass variation of descriptor components.
The criterion of descriptor completeness relates to the optimal positioning of an input window of a simple foveal filter, with increasing averaging field size from the center to the periphery (Figure 1). We consider the task of finding an optimal viewing strategy for the maximization of the image descriptor completeness (in terms of the measure of similarity of the image restored from descriptors, and the original one) with a minimal number of fixation points in the image. A response of foveal filter was considered as a descriptor. The spatial distribution of averaging fields and their sizes are shown in Figure 1.
Spatial structure of the input window of a foveal filter. Each square represents an averaging field.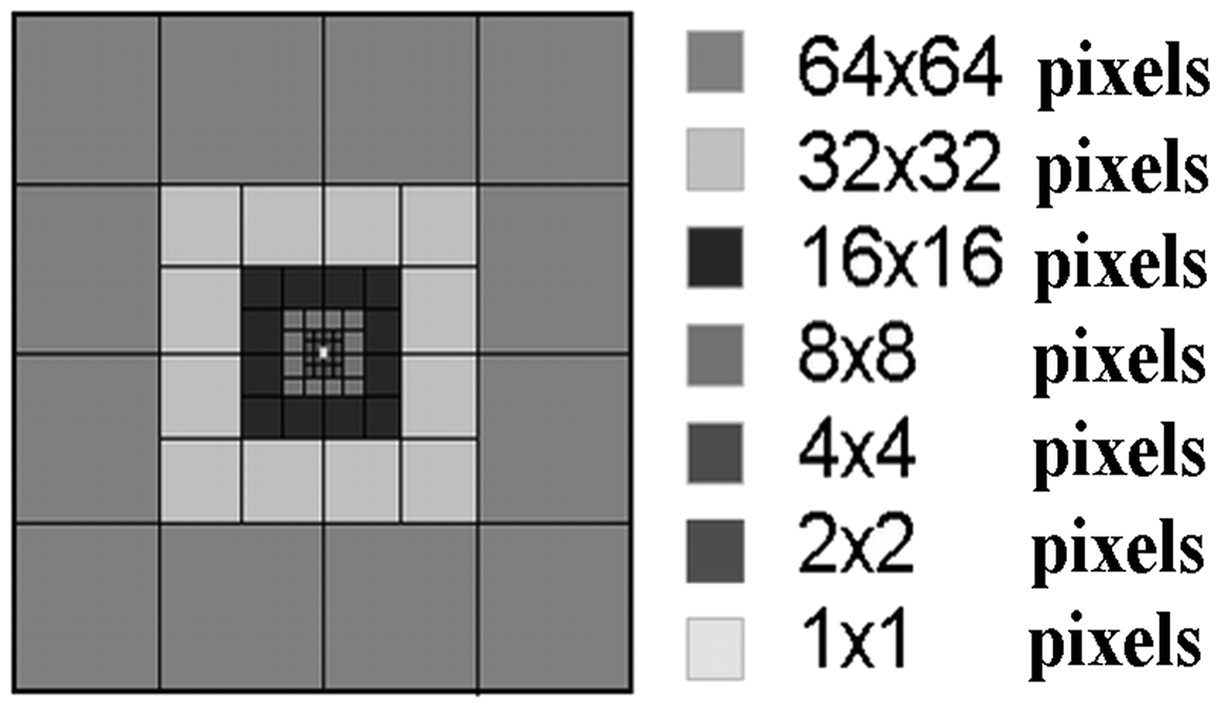
In each field (except for the central part of the input window), the average brightness is calculated. The central part of the window contains 4 × 4 averaging fields (each of 1 × 1 pixel size). Each noncentral peripheral field covers a region averaging 2
n
× 2
n
pixels, where n = 1–6. Twelve outer peripheral fields cover a region averaging 64 × 64 pixels each. The total number of the averaging regions in such a space-variant filter is 88; they cover 256 × 256 pixels in the image at each fixation (the points of the foveal filter center positioning). Figure 2 shows the response of the foveal filter at a single fixation point within the right eye in the facial image.
The response (b) of the foveal filter at a single fixation point, marked by the white spot in (a).
The visual image can be reconstructed from a set of the foveal filter responses using different numbers of fixation points within different strategies for viewing. The reconstruction algorithm is based on finding the nearest fixation point for each pixel in a restoring image and assigning the brightness value of this pixel to the value of brightness in the correspondent averaging field (in which this pixel is located) of the foveal filter, positioned in the nearest fixation point. Examples of reconstructed images for different number of fixation points are shown in Figure 3.
Reconstructed images for different number of fixation points: (a) 3 fixation points; (b) 12 fixation points; (c) 30 fixation points.
Dissimilarity between the original and restored images is measured by the first-order Minkowski distance
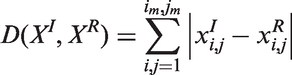
Three types of distribution of the fixation points for the foveal filter were compared on the set of 10 facial images in the framework of the problem of descriptor completeness: uniform (Figure 4(a)), random (Figure 4(b)), and gradient-based (Figure 4(c)). The gradient-based distribution of the fixation points is determined by two rules: A fixation point should be located in the area with a high variety of orientations of local brightness gradients, and the distance between any two fixation points has to be larger than a distance threshold, to prevent the grouping of fixation points within one region of high variety of gradient orientations. Brightness gradients were calculated using a discrete differentiation operator (Sobel). The number of fixation points was varied from 25 to 49.
Reconstructed images (d–f) from the set of the responses of the foveal filter at different distribution of fixation points: (a) uniform, (b) random, and (c) gradient-based. The number of fixation points is equal (n = 36) within each distribution.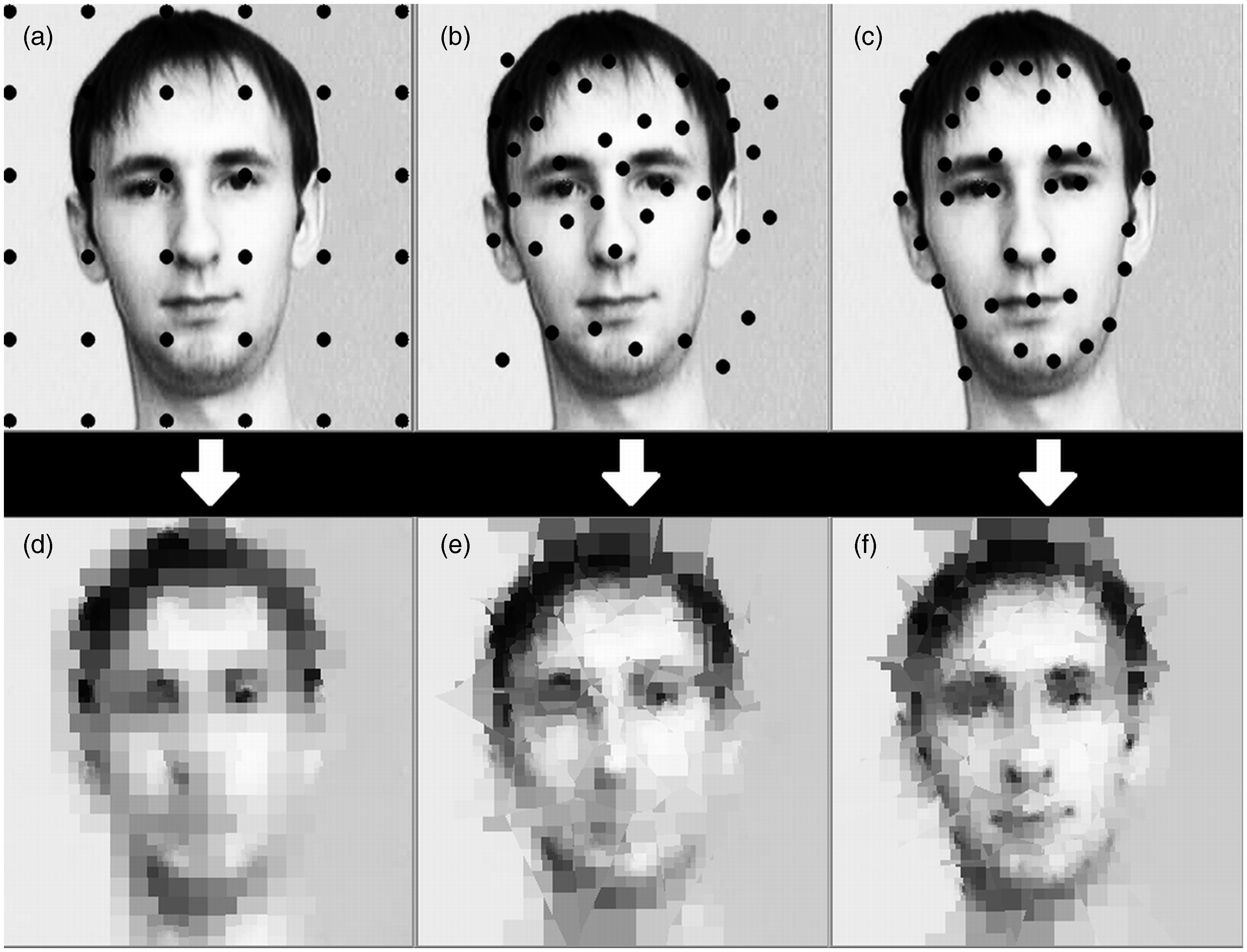
The criterion of descriptor completeness is formalized as the distance D and should be minimized within a set of possible distributions of fixation points (with a constant number of points). This criterion raises a question: What is an optimal distribution of fixation points over the image for the most effective restoration in terms of minimization of the distance D?
The criterion of descriptor distinctiveness is formalized as a cumulative variation (within a series of images of some object) of brightness in a set of fixation points {P}
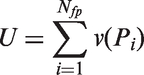
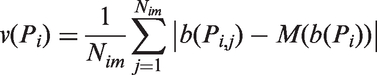
The effectiveness of the certain distribution of fixation points in a sense of maximizing descriptor distinctiveness can be estimated by using this criterion. Only sparse distributions of fixation points are considered (to prevent grouping of fixation points within one region of high variation) such that the distance between each pair of points (Pi, Pj) is larger than some threshold distance k
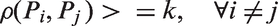
The criterion of descriptor distinctiveness raises a question: Which fixation points in an image of an object cover common features of objects of a class, and which points cover individual characteristics? This problem was studied for facial images using anthropological techniques for generalized portrait constructing (Hrisanova & Perevozchikov, 2005), which is based on the averaging of brightness in the same locations in the eye coordinate system within a large series of facial images. Before averaging, each image is centered and morphed so that the eyes centers in each image are positioned in the same pixel coordinates. Brightness variation (equation (3)) was calculated at each point of the generalized portrait in order to identify common and individual areas within the facial image. Generalized portraits and intraclass variation maps were calculated from the set of facial images (n = 30) of different persons (males and females) aged from 18 to 25 years. It was assumed that a small variation corresponds to the general facial features, while areas with a large variation values correspond to the individual facial features. Thus, due to the criterion of descriptor distinctiveness, fixation points are proposed to be positioned in the regions with low intraclass variation (minimizing criterion U) when the task is to verify object class and should lie in the regions with high intraclass variation (maximizing the criterion U) when the task is to perform fine-grained recognition within the known class.
Results
We have considered three types of distribution of the fixation points for the foveal filter positioning, to find out which one fits more to the descriptor completeness criterion, and then compare the optimal distribution with the variation map generated according to the distinctiveness criterion. Examples of images of two different scales reconstructed from the foveal filter responses for different distributions of fixation points are shown in Figures 4 and 5.
Fixation points distributions (a–b) that are the same as in Figure 4 and reconstructed images (d–f). The number of fixation points is equal (n = 36) within each distribution.
We have revealed that the gradient-based distribution of foveal filter positioning mostly leads to more effective image description in a sense of minimization of the distance D (equation (1)) between original and restored images (within the set of 10 testing images) than uniform or random allocations. In particular, for examples shown in Figure 4, the values of the distance D (divided by total number of pixels in image) were equal to 16.92, 16.53, and 14.96 for uniform, random, and gradient-based distributions, respectively. The values of the distance D (divided by total number of pixels in image) calculated for examples shown in Figure 5 were equal to 15.02, 17.55, and 13.37 for uniform, random, and gradient-based distributions, respectively. Thus, the criterion of descriptor completeness leads to such movements of the foveal filter input window that pass over the scattered regions with a high variety of orientations of local brightness gradients. The gradient-based distribution, motivated by the descriptor completeness criterion, describes the general properties of the distribution of fixation points over facial images, registered in humans in Yarbus’ experiments (Yarbus, 1967). In particular, such distribution of fixation points produces a high density of fixation points within such facial areas as the eyes, nose, and lips, similar to psychophysics data.
Generalized portrait and intraclass variation map of facial images were created in order to determine generalizing and individualizing facial features. An example of such a generalized portrait is shown in Figure 6(a). Figure 6(b) shows the intraclass variation map for the generalized face.
Generalized portrait (a) and intraclass variation map (b) made from the series of the 30 facial images, high values of brightness in the variance map correspond to the high values of intraclass variances.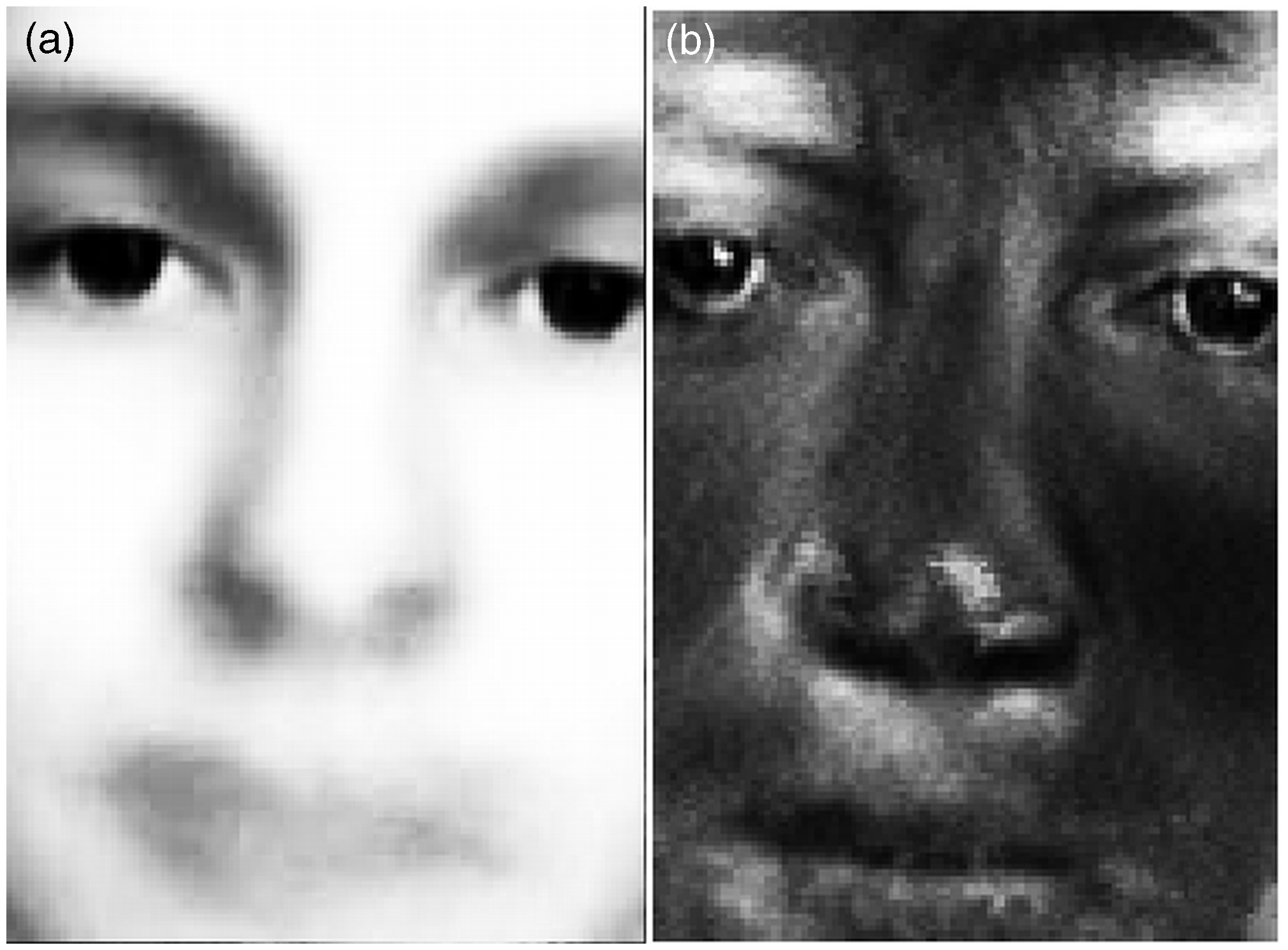
Areas with high values of intraclass brightness variation lay around the eyes, eyebrows, nose, and lips. The distribution of these areas, generated according to the maximization of criterion of descriptor distinctiveness U is similar to the gradient-based distribution of the fixation points correspondent to the minimization of criterion of descriptor completeness D. As this result is common both in psychophysics and computer vision, we treat it mostly as a validation of the method for allocation of informative regions, rather than new data on informative facial features.
Discussion
Localization of the most informative regions in images depends on the visual task. We have considered two visual tasks in computer vision: complete image describing and distinctive image describing, and associated tasks in natural vision: image memorization and image differentiation. Considering these tasks, gradient-based distribution of such regions was shown to be more optimal than random or uniform allocation in a sense that it better fits the criteria of completeness D (equation (1)) and distinctiveness U (equation (2)).
А distribution of fixation points over facial images (near the lips, nose, and eyes) generated in accordance with considered criteria is similar to those generated within different frameworks and by different models of human vision. For example, Itti and Koch (2000) calculated visual saliency (represented by a fixation density map) as the weighted sum of image-domain low-level features, while Judd, Ehinger, Durand, and Torralba (2009) used a combination of high-, intermediate-, and low-level features. High-level SIFT features were evaluated for saliency calculation, and the similarity between model-based and real saliency maps was demonstrated (Hamdi, 2014). To improve the similarity between real and model-based saliency maps, learning algorithms were used to adjust the weights of different-level image-domain features (Hamdi, 2014; Judd et al., 2009; Kienzle et al., 2007). A face detector in combination with the detection and evaluation of low-level features was used for the same objective by Cert, Harel, Einhauser, and Koch (2007). The similarity of the saliency distribution, generated in accordance with different image-domain method and with the top-down (completeness and distinctiveness) criteria described herein, may be explained by the optimality of gradient-based fixation points distribution, that is, it is possible to suggest that gradient-based distribution is an optimal viewing strategy for various visual tasks.
The criterion of descriptor distinctiveness was successfully used for applied purposes; in particular, it was applied to determine optimal points for foveal filter positioning within the development of the biometric system for face recognition (Petrushan & Samarin, 2012). The minimum of false reject rate (FRR) = 0.06 with fixed false accept rate (FAR) = 10−4 was achieved on the facial images test base (n = 120; described in Petrushan & Samarin, 2012), along with a distribution of foveal filter positioning points that corresponded to the areas with high values of intraclass variation of some features. In a simple case, pixel brightness can be used as such a feature, as it is demonstrated in Figure 6(b); in the other cases, features can be more complex, like foveal filter responses. In particular, centers of facial areas with high values of variance in foveal filter responses were used as keypoints for descriptor extractor in the biometric system.
In this study, we generalize the method of allocation of informative image regions by combining two task-specific determinants. This method can be applied to determine the optimal positioning of fixation points in images of different objects (not only facial images) and using different descriptors (not only foveal). The general allocation rule claims that fixation points should be positioned in regions such that it leads to a maximization of similarity between restored and original images, and a maximization of distinctiveness from images of objects of the same class. In the particular case of facial images described by foveal filters, gradient-based distribution fits the proposed rule.
Conclusions
Using the completeness and distinctiveness criteria considered here allows identification of informative regions in images. The use of these determinants produces similar gradient-based distributions of fixation points. This similarity may be explained by the optimality of gradient-based distribution in different visual tasks. The gradient-based allocation of input windows of foveal filters was also shown to be appropriate for the face recognition task.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by SFedU Project No. 213.01-2014/001.