
Abstract
Predicting the quality indicators of the sintering process is a core component in the intelligent regulation of the steel industry, directly impacting production efficiency and product quality. However, existing research faces two key issues: first, traditional single-task models struggle to leverage the correlations between indicators to improve prediction accuracy, and are prone to performance degradation due to conflicts in feature sharing. Second, noise and outliers in industrial data interfere with model training, reducing prediction robustness. To address these issues, this paper proposes a multi-gate expert mixture model that integrates an attention mechanism and dynamic loss weighting. The model achieves collaborative optimization through a three-layer innovative architecture. First, it uses a multi-expert network and task gating mechanism to dynamically balance feature sharing and specificity between indicators, and integrates a task attention layer to enhance the key features of each indicator, improving the model's adaptability to task differences. It also uses a dynamic loss weighting strategy combining L1 loss and Smooth L1 loss to adaptively suppress outlier interference. Experimental results show that the prediction performance on the sintering industrial dataset significantly outperforms traditional models, with R2 values of 0.967, 0.982, and 0.986 for product yield, drum index, and RDI+3.15, respectively. This model provides an efficient solution for the multi-quality indicator collaborative prediction of complex industrial processes, with strong engineering application value.
Keywords
Introduction
In modern industrial production, the sintering process plays a crucial role in iron and steel as well as in chemical and other heavy industries, such as powder metallurgy and advanced ceramics, directly influencing production efficiency, energy consumption, and final product quality. 1 With the continuous development of industrial automation and data-driven approaches, optimizing the sintering process through data-driven methods has become an urgent issue to address. Accurate sintering quality prediction can not only effectively improve production efficiency and reduce waste rates but also significantly save energy and reduce environmental pollution. 2
In recent years, sintering quality prediction has garnered widespread attention as a key component in the intelligent development of the steel industry. Li et al. 3 addressed the dynamic characteristics and time-delay issues of the sintering process by proposing dynamic time feature extraction and state-space reconstruction methods. Jiang et al. 4 employed infrared thermography and image processing techniques to develop an FeO content prediction model based on image features, achieving non-contact, high-precision online predictions. Additionally, Shao et al. 5 utilized artificial neural networks and convolutional neural networks, combined with process mechanisms, to enhance the prediction performance of key quality indicators such as drum index. In terms of tree models and ensemble learning, Jiang et al. 6 addressed the issue of unstable predictions for RDI and RI by combining CatBoost and XGBoost with the SHAP method, leveraging the nonlinear fitting capabilities of tree models and the feature contribution analysis mechanism. Xia et al. 7 addressed the uncertainty in drum index prediction by using LightGBM combined with kernel density estimation to construct an interval prediction model. Li et al. 8 proposed a prediction system combining Granger causality selection and Stacking ensemble learning to address the challenge of multi-quality indicator linked predictions. In the field of sequential deep learning, Li et al. 9 addressed the issues of difficulty in parameter tuning, insufficient self-learning ability, and poor generalization in traditional methods with multiple parameter inputs by employing the optimized Optuna-DFNN. Chen et al. 10 developed a spatiotemporal feature extraction model driven by dynamic working condition recognition to address the impact of working condition switching on drum strength. Yang et al. 11 addressed the cross-domain generalization issue for sintering composite quality indicators by employing latent space transfer and domain adaptation methods. In the field of visual soft sensing, Zhang et al. 12 addressed the difficulty of online FeO measurement and experimental delay by using infrared machine vision combined with CNN models. Tang et al. 13 addressed the need for mixed material particle recognition and batching evaluation by using micro-CT 3D reconstruction combined with machine learning to construct a particle-level multi-label classification model. In the single-objective optimization of emissions and process condition predictions, Li et al. 14 developed an emission prediction model using a PSO-BP neural network to achieve prior control of sintering flue gas SO2 and NOX. Wang et al. 15 addressed the issue of joint prediction of SO2, NOX, and PM by using a deep ensemble model combining GBDT, RNN, and GRU. Wang et al. 16 addressed the issues of sintering negative pressure and flue gas pressure fluctuations in the main sintering exhaust pipe by using a CNN-GRU prediction model combined with a single-objective optimization approach, they achieved overshoot suppression of negative pressure and energy consumption improvement. In the field of data-driven modeling for core KPIs such as strength, yield, and output, Gao et al. 17 developed a PCA combined with GA-optimized ANN model for drum strength prediction. Mallick et al. 18 compared linear regression and ANN models for sintering machine productivity prediction and confirmed that ANN performs better in nonlinear scenarios. Fan et al. 19 employed ICEEMDAN combined with CNN-BiLSTM-Attention models to predict the time series of FeO composition under complex disturbances. Zhou et al. 20 addressed the cross-source fusion issue of FeO soft measurement by using a heterogeneous data-driven fusion method combined with tensor decomposition. Li et al. 21 developed a system that combines a big data platform with an integrated deep model cascade to meet the needs of full-process cascade prediction.
With the deepening of research, multi-source data fusion and multi-task modeling have gradually become important directions for sintering quality prediction. Table 1 summarizes key studies on multi-source data fusion, multi-task modeling, and system optimization for sintering quality prediction.
Comparison of methods in sintering quality prediction.

Through the above research, it has been found that despite extensive studies on the sintering process using machine learning in recent years, most existing models still face challenges when dealing with the multi-task and multi-indicator issues in the sintering process. Existing methods often overlook the interrelationships between different tasks, resulting in suboptimal model performance during multi-task collaborative prediction. Furthermore, traditional single-task learning methods are limited in their predictive generalization ability because they fail to fully consider the shared features between tasks. The specific issues are reflected in the following: first, multiple quality indicators in the sintering process are highly correlated, but existing models fail to effectively utilize this relationship. Second, when handling multiple objectives, balancing the prediction accuracy of each task and reducing interference between tasks remains an urgent issue to address.
To address these issues, this paper proposes a novel multi-task learning model: Attention-MMoE-DLW (Attention Multi-gate Mixture-of-Experts with Dynamic Loss Weighting), which aims to optimize the prediction of multiple quality indicators in the sintering process through multi-task collaborative learning. Specifically, this study proposes solutions in the following areas: first, the MMoE algorithm is used to achieve feature sharing between tasks, dynamically allocating expert weights through multiple expert networks and task-specific gating mechanisms. Second, a task attention mechanism is incorporated to adaptively enhance task-specific information. Finally, a dynamic weighting strategy based on L1 loss and Smooth L1 loss is designed to further improve the model's robustness and prediction accuracy. Additionally, Optuna is used for hyperparameter optimization, automatically adjusting the model's hyperparameters to further enhance its performance and adaptability. Through these designs, the Attention-MMoE-DLW model effectively addresses the limitations of traditional methods in handling multi-task and multi-indicator problems, providing an effective solution for precise control of the sintering process and multi-objective optimization in industrial processes.
Data processing
Data description
The dataset used in this study consists of operational plant data collected during controlled production trials on an industrial sintering strand, with each sample corresponding to one complete sintering cycle. It includes input features such as raw material particle size, moisture content, thermal parameters, sintering layer thickness, and chemical composition, as well as the corresponding product quality indicators. Each sample contains 17 input variables and 3 output indicators. Table 2 lists all the dimensions of the data used in this study, with the first 17 being input parameters and the 18th to 20th being the output results.
Data description.

Data cleaning
To identify potential outliers in multi-dimensional feature combinations, this study employs the Isolation Forest algorithm for unsupervised anomaly detection. This method constructs multiple randomly partitioned tree models to measure how easily each sample can be “isolated” and calculates its anomaly score. The lower the anomaly score, the more easily the sample can be isolated, indicating a higher likelihood of being an outlier. Figure 1 shows the distribution of anomaly scores for all samples. It can be observed that most of the samples have scores concentrated between 0.05 and 0.12, while samples with scores less than 0 exhibit a distinctly left-skewed distribution, with fewer samples but greater deviations.
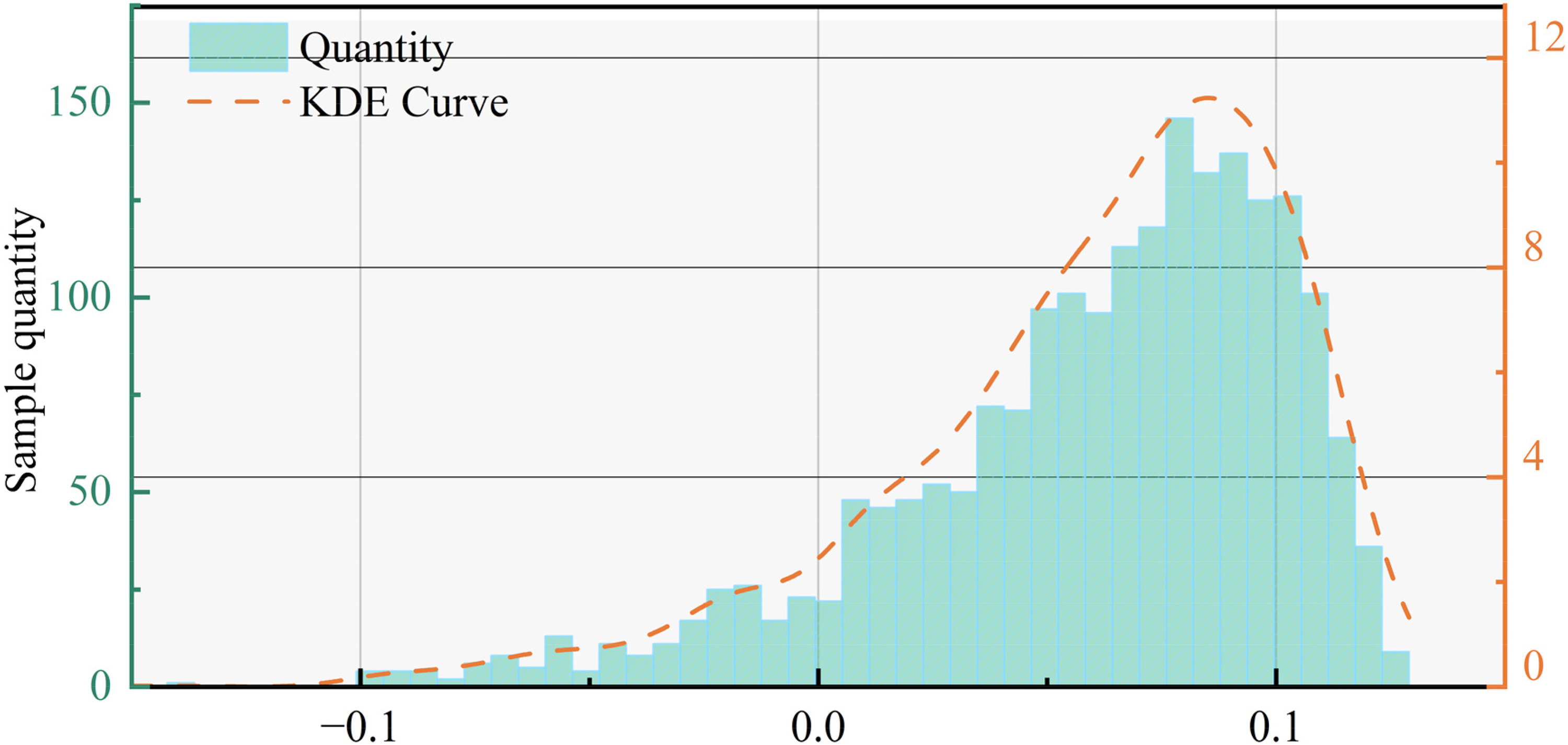
Distribution of anomaly scores
The dataset used in this study consists of operational data collected from the same batch of material over a consistent time interval. After preprocessing, 95% of the original samples were retained following the removal of anomalies. Anomalies were identified using a 5% threshold for anomaly detection, which is consistent with the 95% control limit commonly used in statistical process control. This threshold was set to ensure that the probability of a false negative remains below 5%. The threshold value is indirectly determined by a pollution factor, which controls the expected proportion of anomalies in the dataset. Unless otherwise specified, the pollution factor is set to 5%, ensuring a balance between effective outlier removal and maintaining a sufficient number of valid samples for analysis.
35
After removing the outliers, all input variables were standardized using the Z-score method. The formula is as follows:
Where x represents the original feature value,
Model construction
To address the complexity of multi-quality indicator collaborative prediction in the sintering process, a novel multi-task learning model called Attention-MMoE-DLW is proposed. This model combines the multi-gate expert mixture mechanism with a task attention module, using a “shared-private feature” learning framework to effectively capture the coupling relationships between multiple indicators and task specificity. The execution process of the entire model is shown in Figure 2.
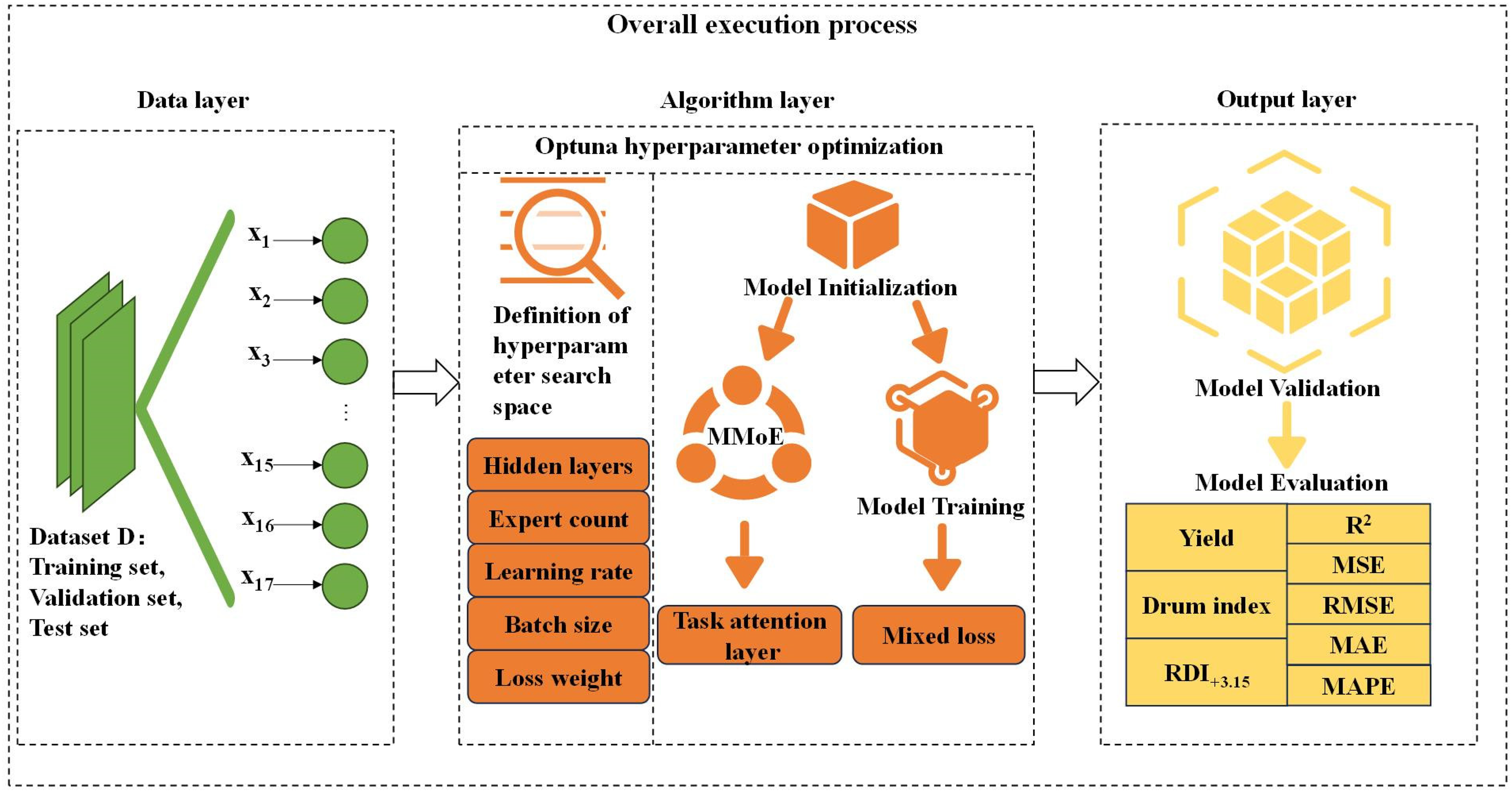
Overall execution flow of the model
Below is an introduction to the various model modules and the model construction process.
Input layer
The input to the Attention-MMoE-DLW model consists of 17-dimensional process parameters from the sintering process. These parameters are derived from the preprocessed dataset and form the input feature vector,
Multi-experts and gating mechanism
MMoE is the core algorithm in the Attention-MMoE-DLW model for implementing multi-task feature selective sharing. It consists of the expert network and task gating network. The expert network extracts features from different perspectives, while the task gating mechanism dynamically allocates expert weights based on the prediction target. The calculation formula is given by:
Where E is the number of experts,
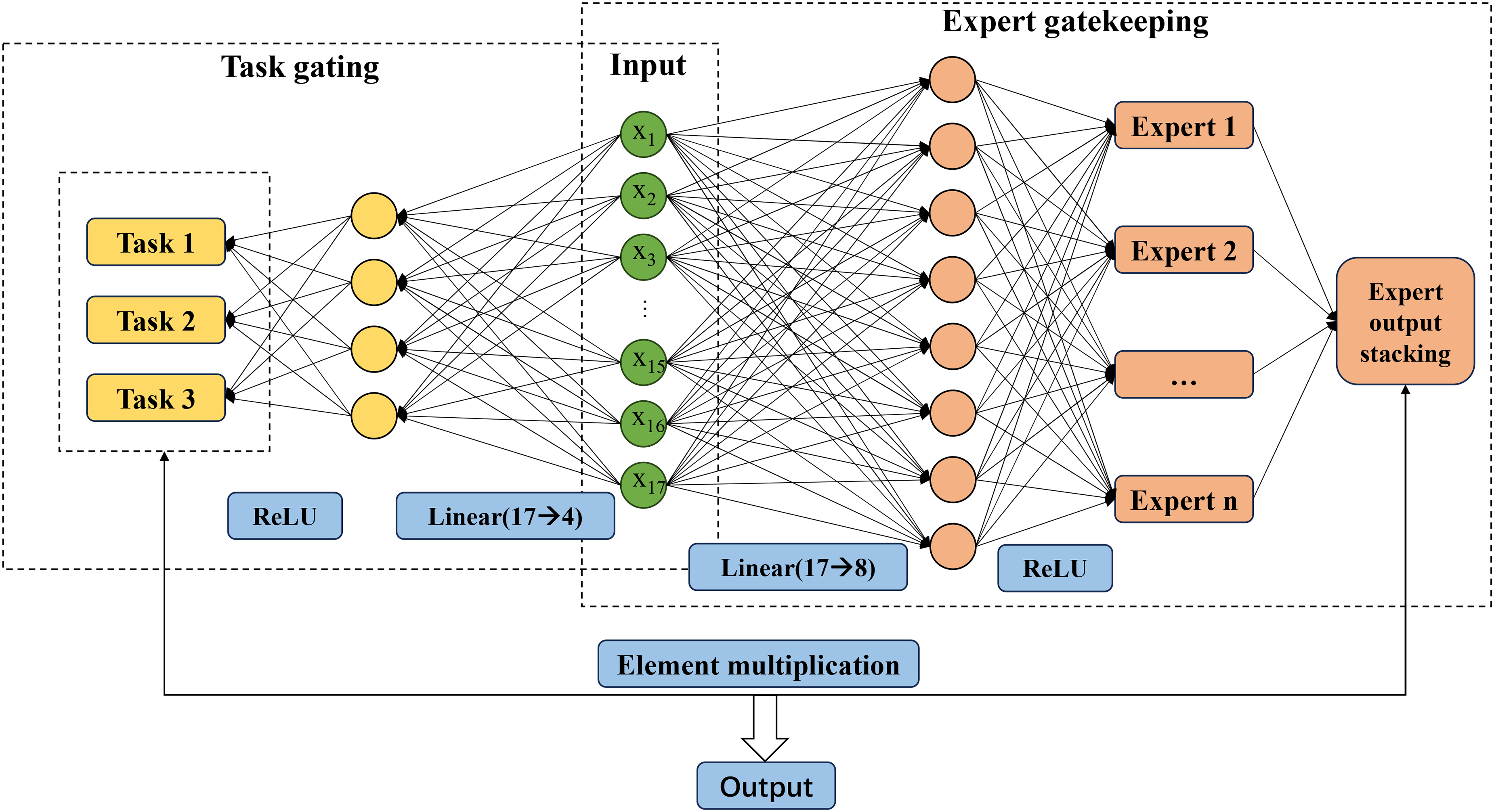
MMoE model structure
Task attention layer
The task attention layer is a key module in the Attention-MMoE-DLW model for strengthening task-specific features, i.e., a feature-weighted attention mechanism. Through the “feature-weighted enhancement” mechanism, the module further amplifies the task-relevant information in the MMoE output features while suppressing noise interference. This layer corresponds to the number of tasks, with each task equipped with an independent attention generation network. The input consists of the 8-dimensional task features output by MMoE, and the output is the enhanced feature vector. The model structure of this layer is shown in Figure 4.
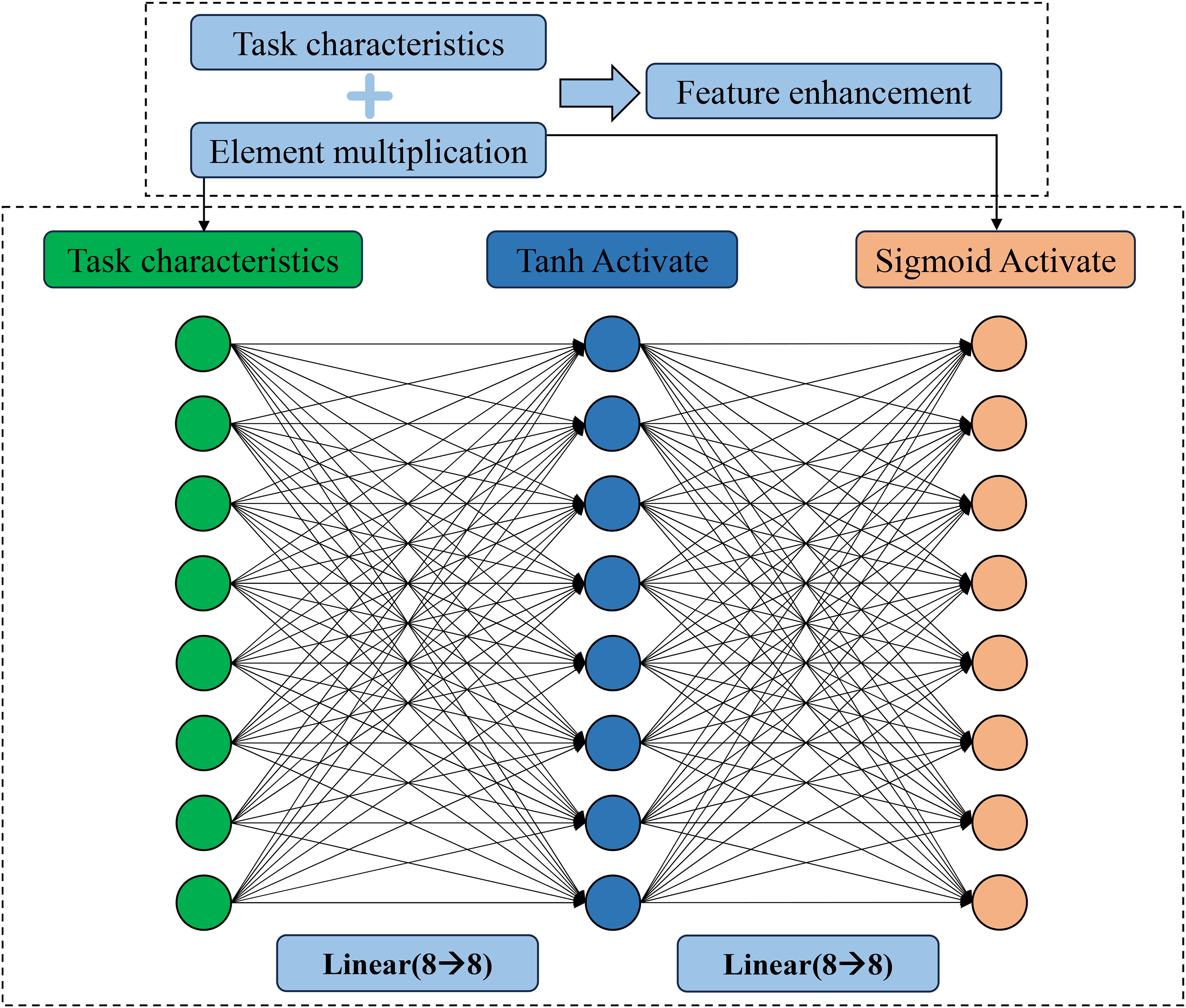
Attention layer structure
In the attention-weight generation mechanism, each task's attention network adopts a serial architecture of “two fully connected layers plus a nonlinear activation.” The first fully connected layer applies a linear transformation to the 8-dimensional input features, introduces nonlinearity via the Tanh activation function, and yields intermediate features; the computation is given by: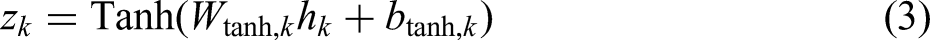
Here, 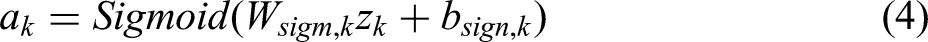
In Eq.(4),
Under the feature-enhancement mechanism, the task feature is produced by “original feature + self-gated enhancement,” as formulated in Eq. (5):
Here,
Dynamic loss weighting and optimization strategy
Dynamic loss weighting (DLW) is the core mechanism in the Attention-MMoE-DLW model for enhancing prediction robustness. It adaptively balances the contributions of L1 loss and Smooth L1 loss, suppressing outlier interference while ensuring gradient stability, thereby ensuring efficient model training.
For sintering quality indicator prediction tasks, the model uses “weighted combined loss” as the optimization objective, defined as the linear weighted sum of L1 loss and Smooth L1 loss. For the k-th task, its loss component is: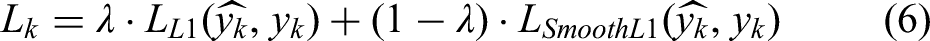
Where: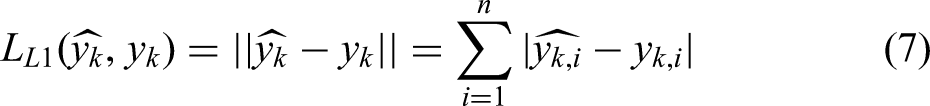
This is the L1 loss, which is naturally robust to outliers but has a discontinuous gradient at zero.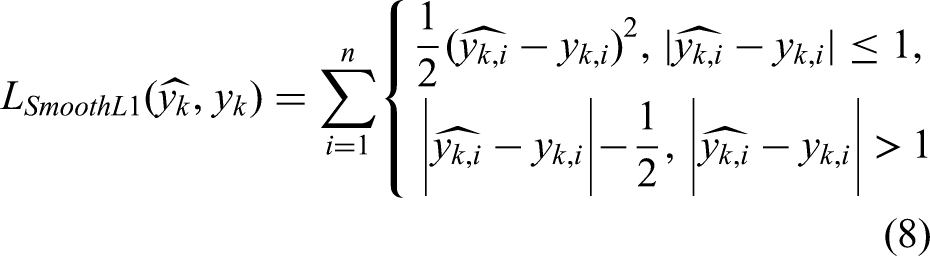
This is the Smooth L1 loss, which resolves the gradient discontinuity problem of L1 loss while retaining sensitivity to large errors.
Experiment
Model evaluation metrics
The model performance evaluation metrics selected include the coefficient of determination (R2), mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE). The calculation formulas are as follows: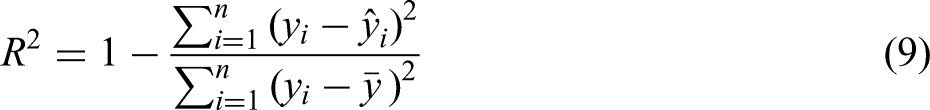

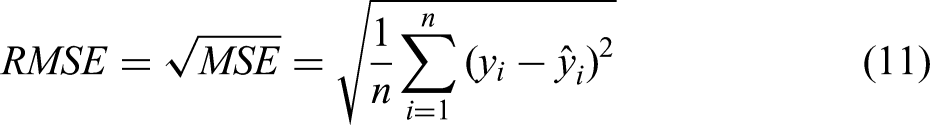

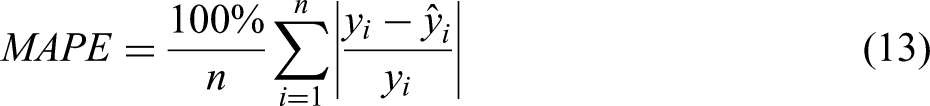
Where n is the number of samples,
Model comparison
To verify the performance advantage of the proposed Attention-MMoE-DLW model in multi-indicator prediction tasks for sintering quality, five representative architectures were selected for comparison experiments. These include the single-task learning model EMD-ISBM-FNN, 36 the shared bottom-layer feature network model SSA-MLP-BPNN, 37 the multi-gate expert model Mamba-MoE, 38 the progressive feature extraction model HBPLE 39 and the improved structure proposed in this paper, Attention-MMoE-DLW. The above models were compared under the same dataset, training iterations, and parameter settings, predicting the three key quality indicators: product yield (%), drum index (%), and RDI+3.15. The results are shown in Table 3.
Comparison of experimental results.
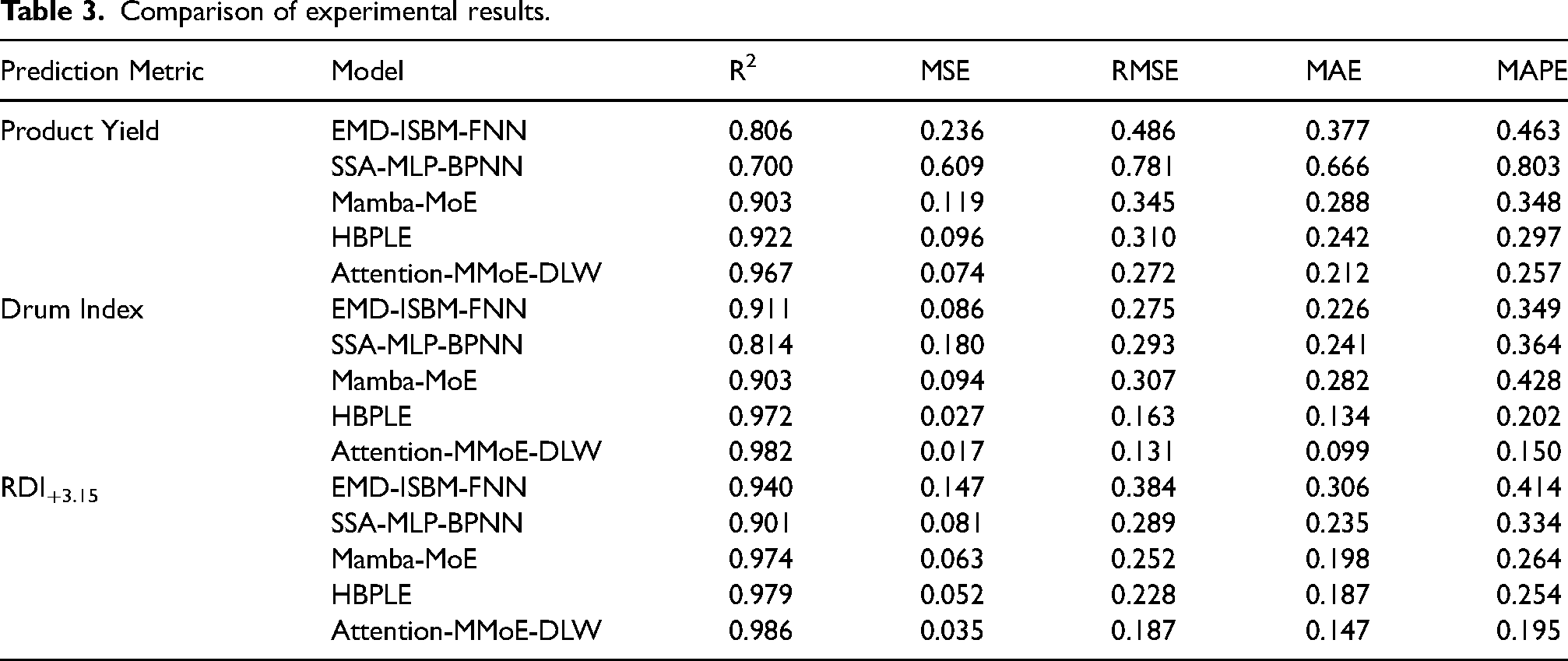
As shown in Table 3 and Figure 5, in the product yield prediction task, the Attention-MMoE-DLW model achieves a coefficient of determination (R2) of 0.967, higher than the other four models. It also demonstrates optimal performance in error metrics such as MSE, MAE, and MAPE, with values of 0.074, 0.212, and 0.257, respectively. This reflects its strong capability in handling nonlinear coupled features and imbalanced tasks. In the drum index prediction task, Attention-MMoE-DLW also shows significant improvement, with an R2 of 0.982. The root mean square error is only 0.131, and MAE and MAPE decrease to 0.099 and 0.150, respectively, further validating the advantage of the task attention mechanism in fine-grained feature extraction. In the RDI+3.15 task, Attention-MMoE-DLW also performs best, with an R2 of 0.986 and prediction error metrics that outperform all other comparison methods. The reasons for the poor performance of the four comparison models are as follows: Operating point changes produce distinct input and output regimes; single expert or fixed capacity models struggle to represent these piecewise behaviors, leading to unstable errors across regimes. In addition, there is strong coupling among process variables, including basicity with iron content, ignition temperature with pressure, and moisture with particle size. Conventional multilayer perceptron and backpropagation baseline methods tend to overfit these correlations and fail to generalize beyond them.
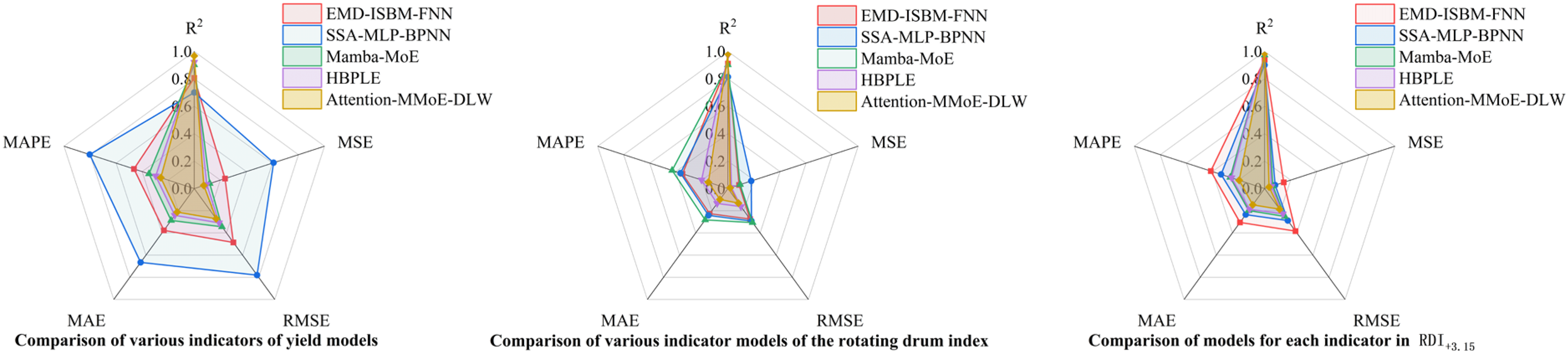
Comparison of model performance
To compare the performance of different models in product yield prediction, the prediction errors of each model on the same test set were analyzed, and the results are shown in Figure 6. The Attention-MMoE-DLW model has a maximum absolute error of 0.8257 and a minimum absolute error of 0.0005 in product yield prediction, with the overall error controlled within 1.48%. The error distribution is uniform with no noticeable bias, indicating that the model maintains high accuracy and stability in the product yield prediction task.
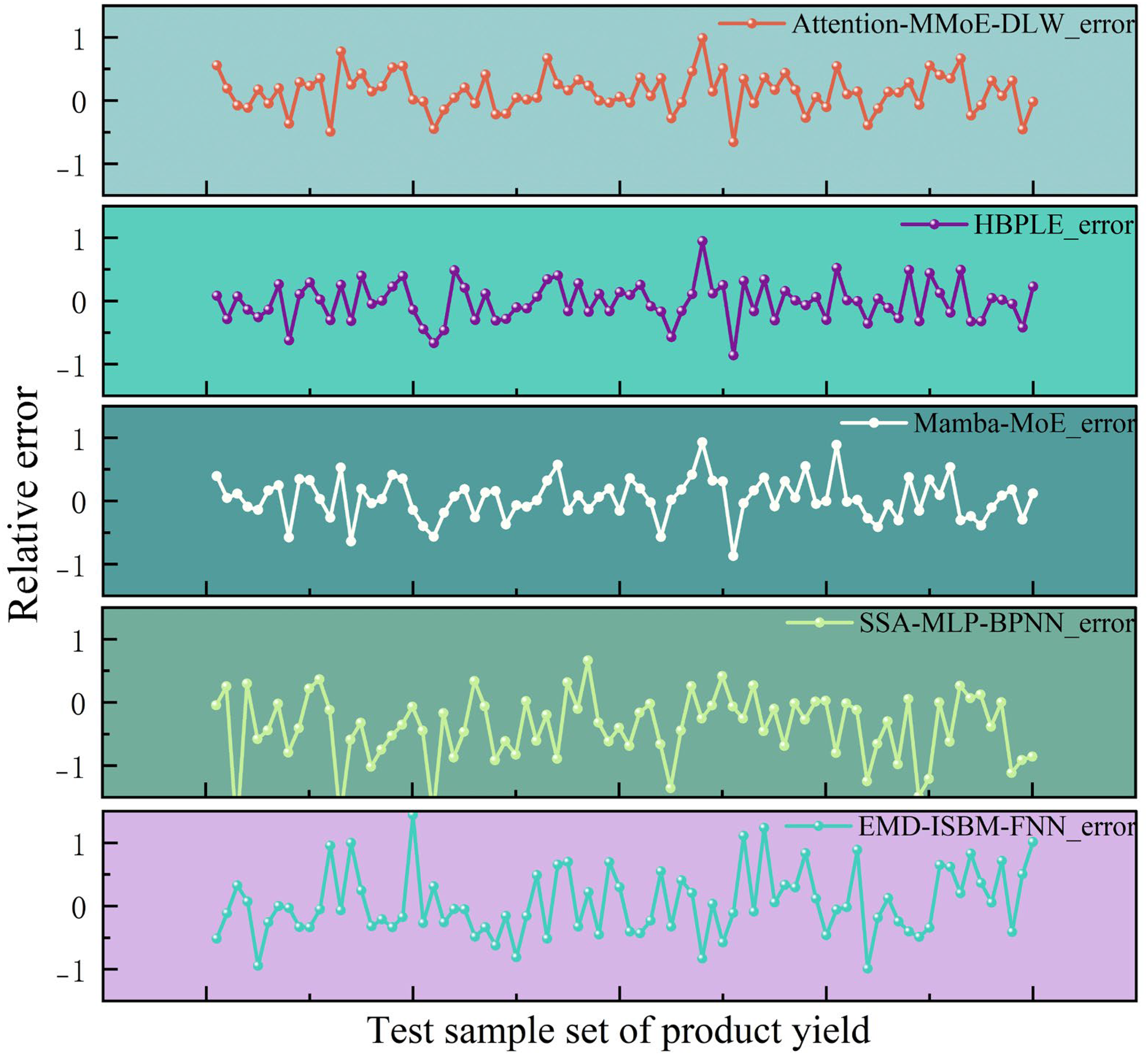
Comparison of true and predicted values for product yield
In the drum index prediction task, the error comparison of each model is shown in Figure 7. The Attention-MMoE-DLW model has a minimum absolute error of 0.0003 and a maximum absolute error of 0.3638, with the error values consistently distributed around zero, showing a small fluctuation range. This indicates that the model has better robustness and accuracy in predicting the drum index, effectively avoiding large deviations. Compared to traditional single-task models, this model not only ensures the convergence of overall errors but also provides a closer approximation to the real production patterns in its detailed performance.
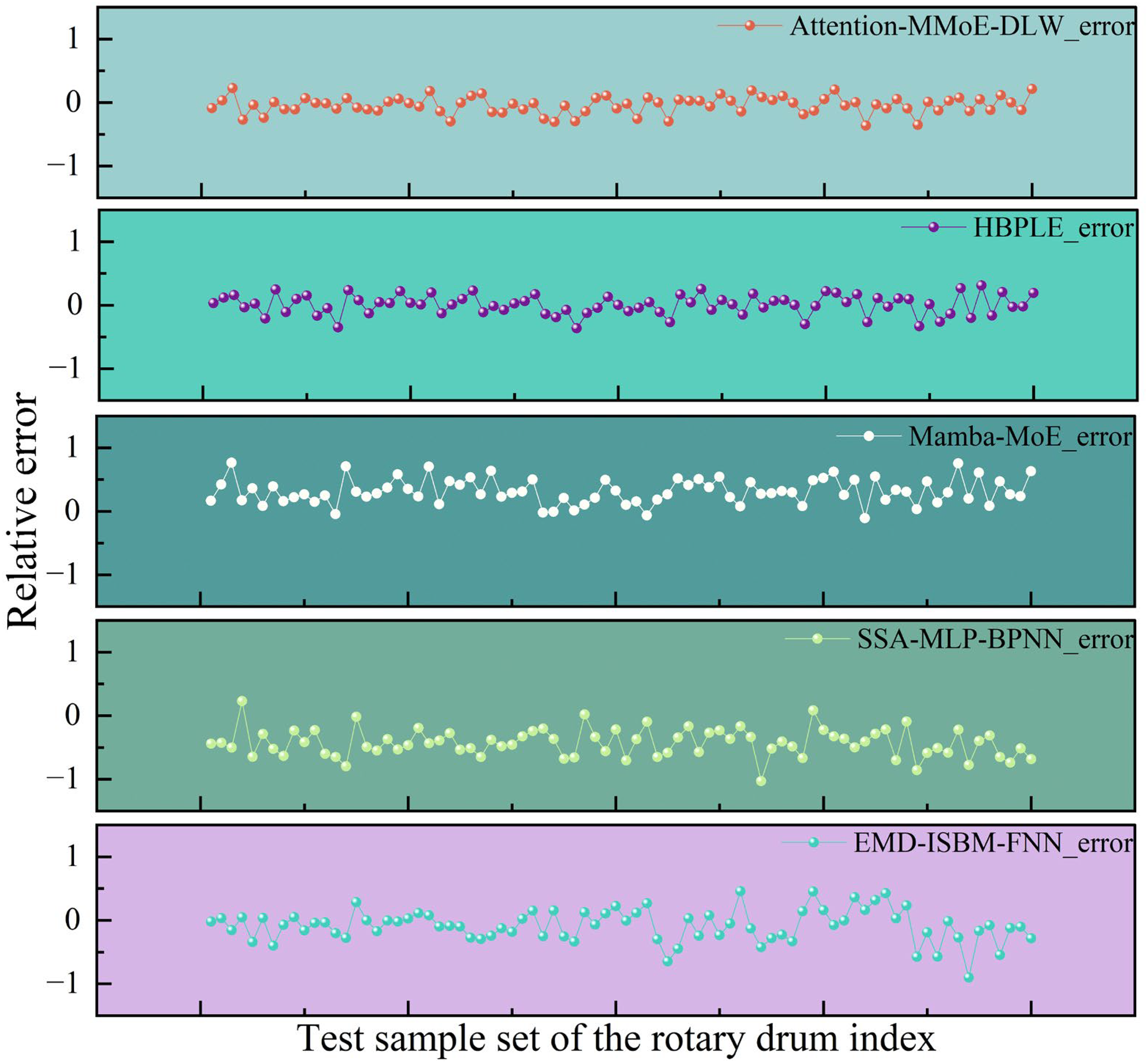
Comparison of drum Index errors for different models
For the RDI+3.15 prediction results, Figure 8 shows the error comparison among different models. The Attention-MMoE-DLW model has a minimum absolute error of 0.0034 and a maximum absolute error of 0.5414, with the error controlled within a reasonable range. This further validates the model's feasibility in predicting complex quality indicators. Overall, the model demonstrates significant advantages in key indicators such as product yield, drum index, and RDI+3.15. It not only improves prediction accuracy but also shows a strong ability to capture the coupled relationships among multiple indicators.
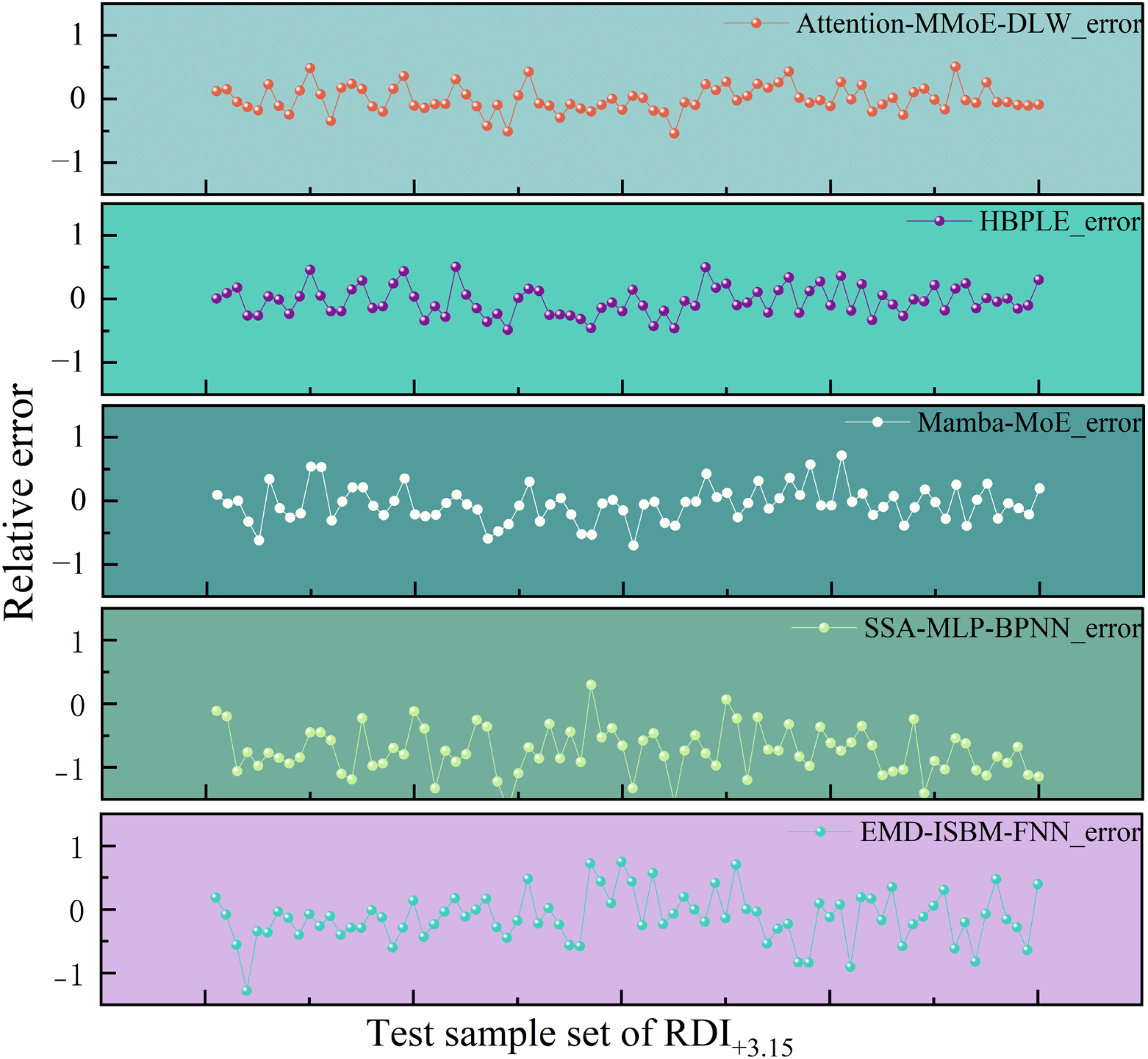
Comparison of RDI+3.15 errors for different models
The results indicate that the Attention-MMoE-DLW model has significant advantages in multi-indicator prediction tasks. It can provide effective support for quality assessment and operational state prediction in the sintering process, thereby improving the predictability and stability of the production process.
Ablation study
To further validate the contribution of key components in the model to overall performance, an ablation study was conducted, removing the task attention mechanism and dynamic loss weighting strategy to create two ablation models for comparative analysis. First, to test the effectiveness of the task attention mechanism, the Task Attention layer was removed from the original model, retaining only the multi-gate expert structure and loss weighting strategy to form the no-attention version of the model (No-Attention). Secondly, to evaluate the role of GradNorm, the loss function was adjusted to an equally weighted sum, keeping the MMoE and Task Attention structures unchanged, forming the no-dynamic-weighting version of the model (No-DLW). Under the same training and testing conditions, the performance metrics of the three models on product yield (%), drum index (%), and RDI+3.15 prediction tasks are shown in Table 4.
Ablation study results.
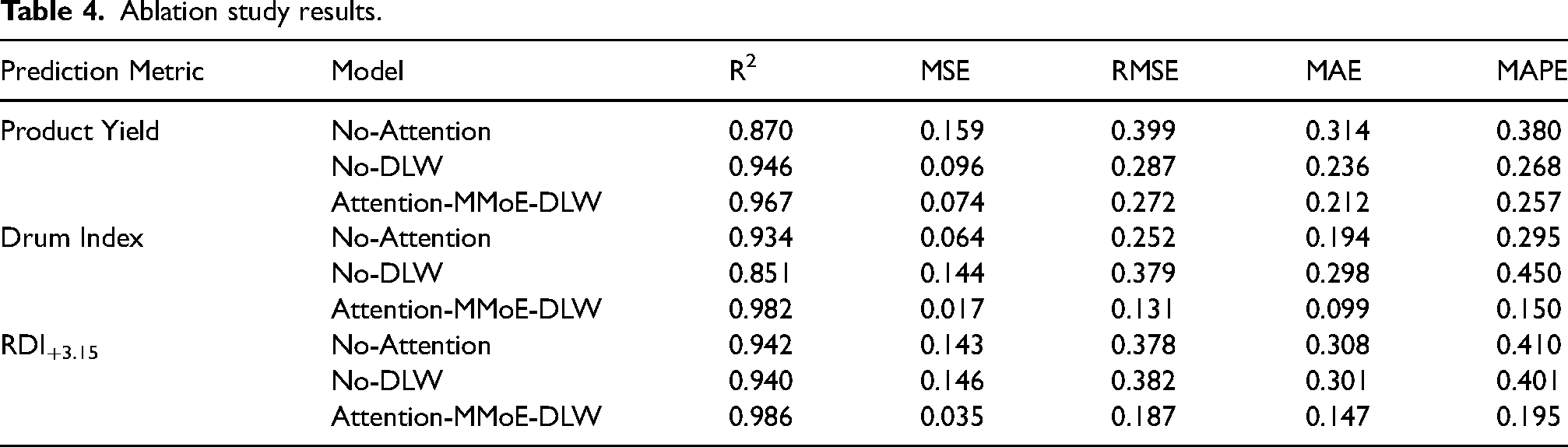
To conduct a detailed comparative analysis of the model performance, Figure 9 shows the performance comparison of the three models across different metrics. As shown in Figure 9, Attention-MMoE-DLW demonstrates a clear advantage in all evaluation metrics, particularly in R2 and MAE. Specifically, Attention-MMoE-DLW achieves an R2 of 0.967 for product yield, significantly outperforming No-Attention (0.870) and No-DLW (0.946). At the same time, Attention-MMoE-DLW's MSE, RMSE, MAE, and MAPE are also significantly lower than the other two models, demonstrating its higher prediction accuracy and stability. In predicting the drum index and RDI+3.15, Attention-MMoE-DLW also exhibits strong advantages, especially with an R2 of 0.982 for the drum index and 0.986 for RDI+3.15, clearly outperforming No-Attention and No-DLW. These results indicate that the complete model, which combines the task attention mechanism and dynamic loss weighting strategy, can significantly improve the model's accuracy and prediction performance in the complex multi-task learning scenario.
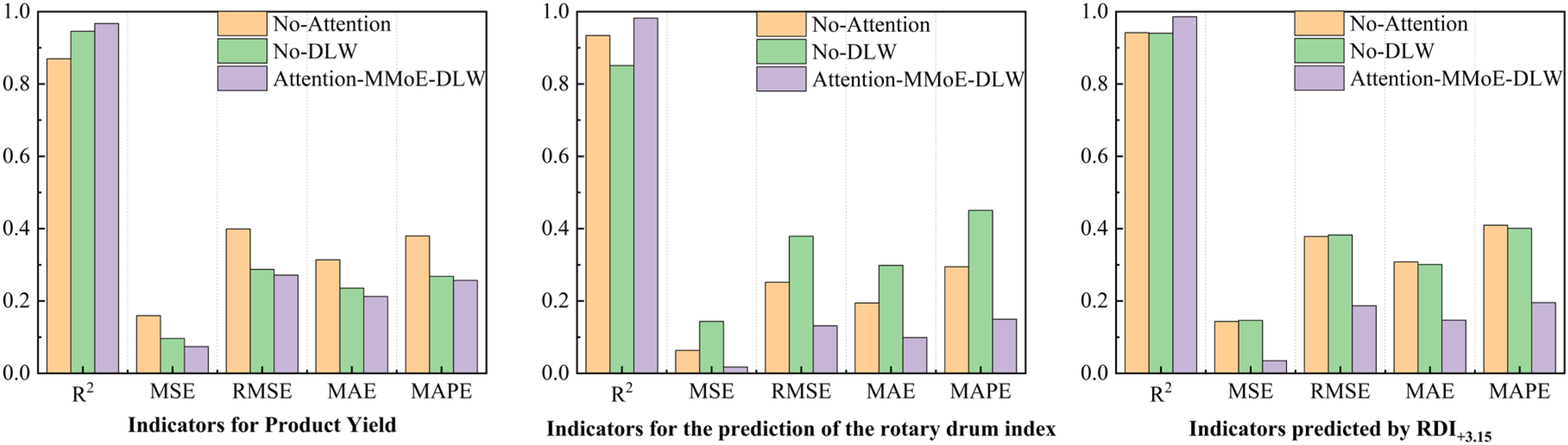
Comparison of ablation study results
Model prediction results analysis
To ensure reproducibility, the software stack used in this study is reported as follows: Optuna [4.4.0]; Python [3.11]; PyTorch [2.5.1]; NumPy [1.26.4]; pandas [2.2.3]; scikit-learn [1.6.1]. Optuna was used for hyperparameter optimization, and the optimization results are shown in Table 5. The optimization ranges for the parameters num_experts, hidden_dim, learning_rate, batch_size, and weight_l1 were set as follows: [2,8], [64,256], [1e-4,1e-2], [32,128], and [0.4,0.9], respectively. Training was run for up to 100 epochs with early stopping, using the validation mean
Hyperparameter optimization results for attention-MMoE-DLW.

The parameter hidden_dim represents the dimension of the network's hidden layers, determining the model's ability to extract and transform features, which directly impacts its ability to capture complex patterns. num_experts is the number of expert networks in the MMoE structure, which affects the model's ability to specialize in learning features for different tasks. Too few experts may result in insufficient task feature learning, while too many can increase model complexity. Learning_rate determines the update step size of the optimizer in each iteration, which is a key factor in the model's convergence speed and final performance. A step size that is too large may cause oscillation and prevent convergence, while one that is too small can result in low training efficiency. Batch_size refers to the number of samples used for each parameter update, affecting the stability and efficiency of training, and also indirectly influencing the model's generalization ability. Weight_l1 is the weight of the L1 loss in the total loss, which balances the focus of the model's learning by adjusting the proportion of different loss functions. Patience is the patience value in the early stopping strategy, controlling the stopping point when the model's performance on the validation set no longer improves. It is used to prevent overfitting and enhance training efficiency.
To better validate the model's superiority, the following are the simulation results of the Attention-MMoE-DLW model for predicting three indicators.
For product yield, Figure 10 shows the comparison between the true and predicted values. It can be seen that the model's predictions closely match the trend of the true values, with both showing a good fit in overall fluctuation trends.
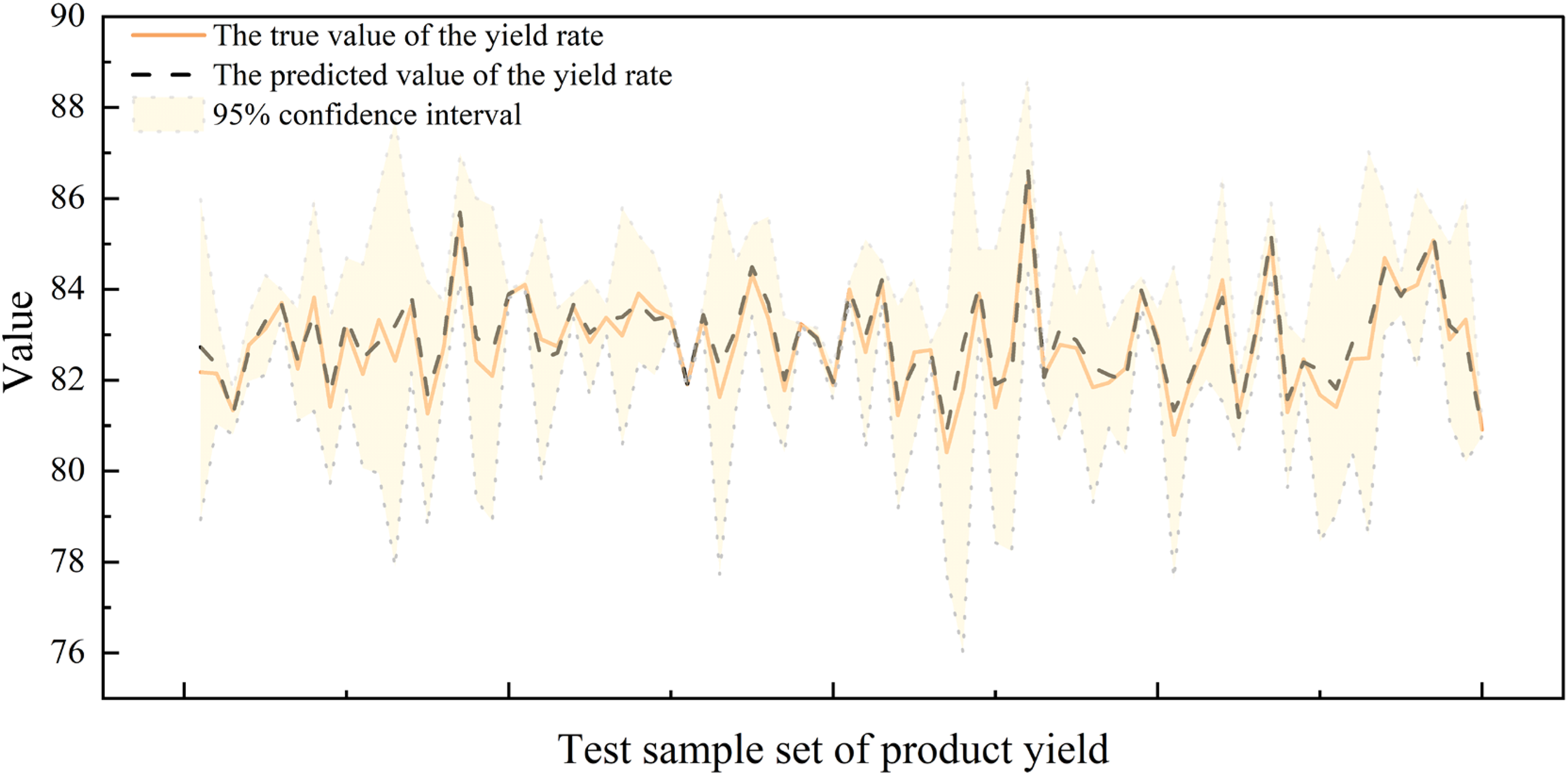
Comparison of true and predicted values for product yield
For the drum index, Figure 11 shows the comparison between the true and predicted values. The Attention-MMoE-DLW model has a minimum absolute error of 0.0003 and a maximum absolute error of 0.3638, with error values remaining close to zero, indicating that the model experiences very little fluctuation in error when predicting the drum index. This shows excellent stability and accuracy.
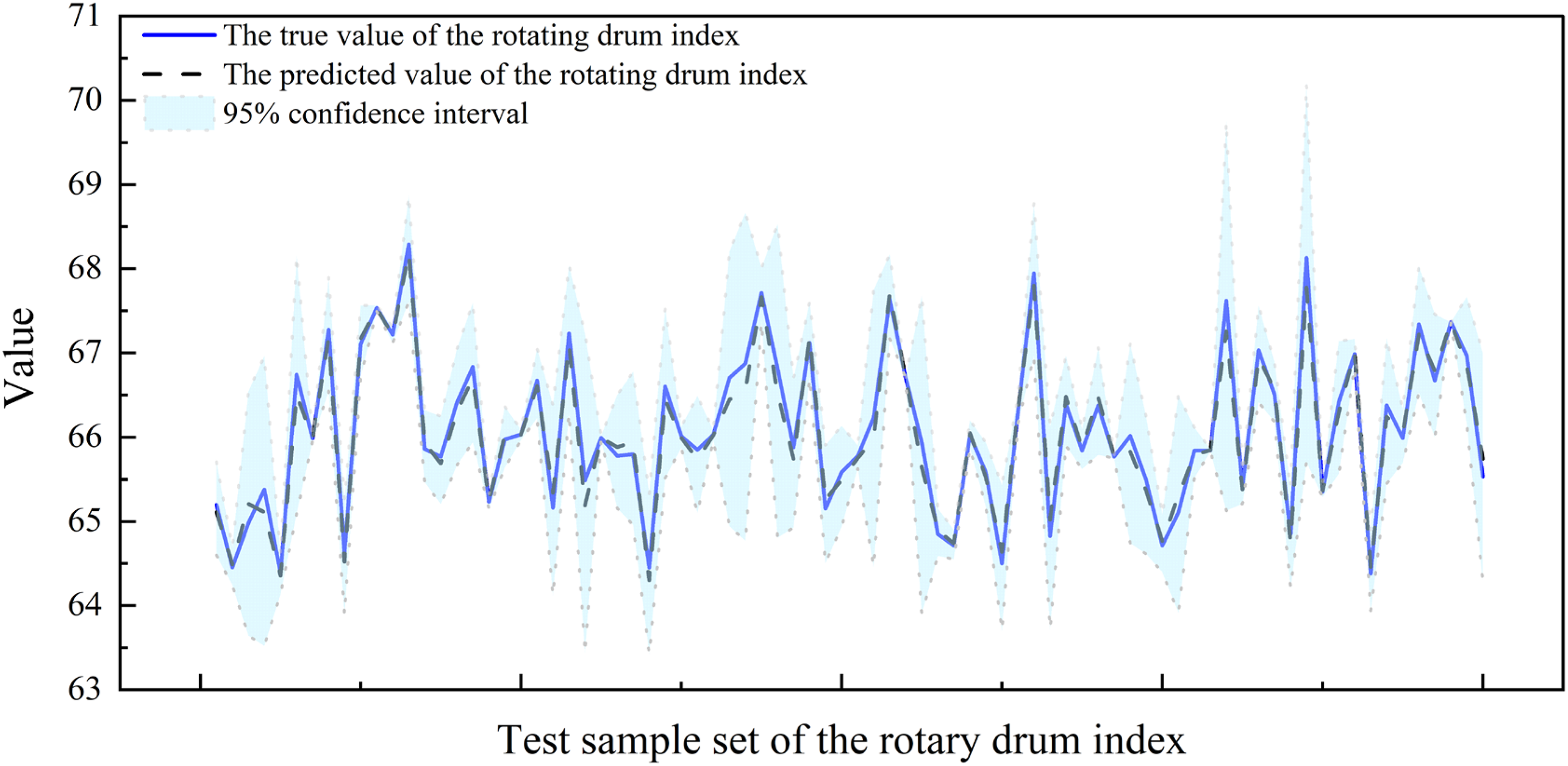
Comparison of true and predicted values for drum Index
Figure 12 shows the comparison between the true and predicted values for RDI+3.15. As seen in the figure, the model's predictions closely follow the overall trend of the true values. Despite some fluctuations, the general trend remains consistent, indicating that the model has a good fit.
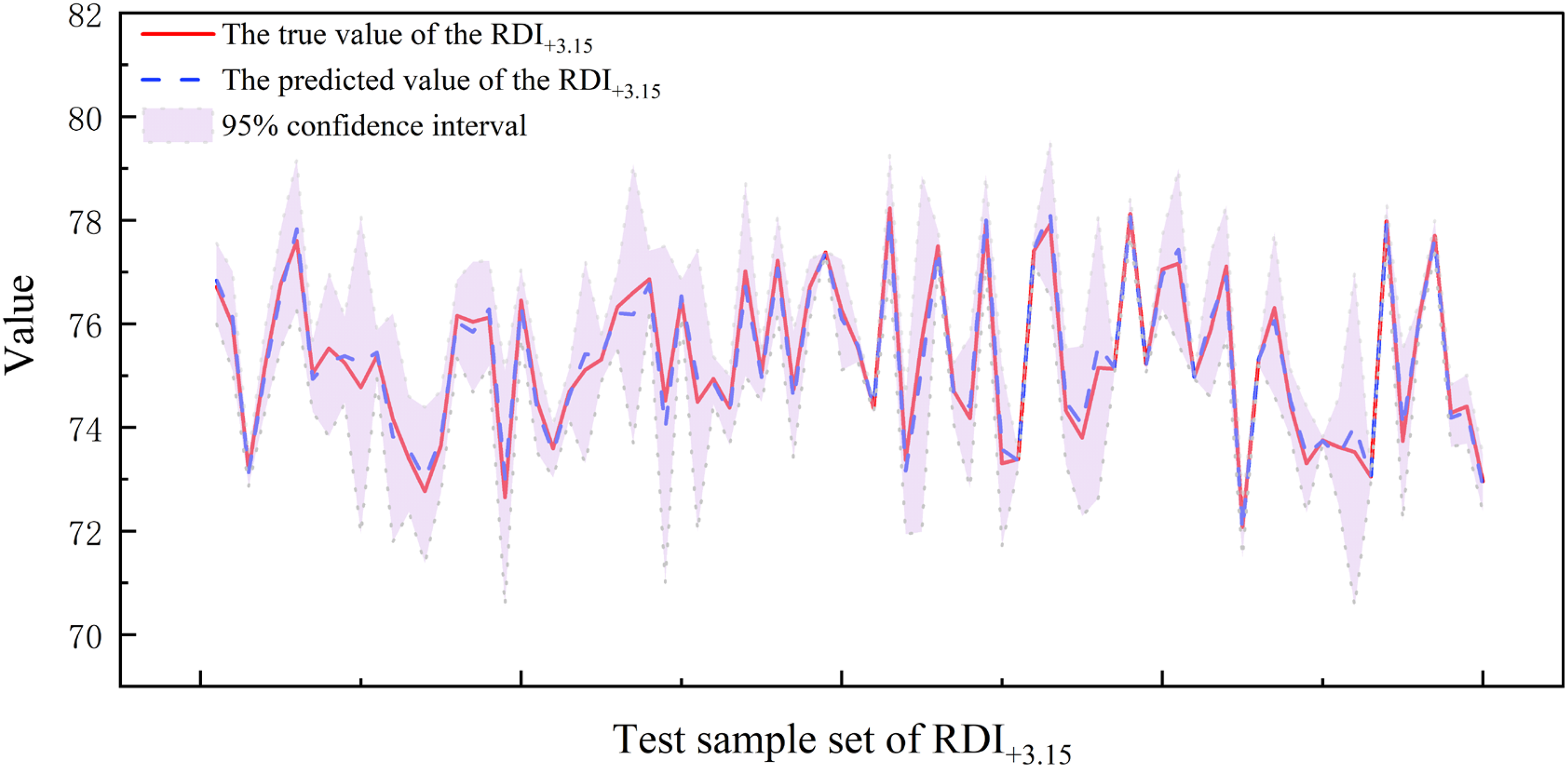
Comparison of true and predicted values for RDI+3.15
To better understand the factors affecting product yield, index, and RDI+3.15 predictions, we performed feature importance analysis using SHAP values. This analysis helps identify which parameters have the most significant impact on the model's predictions for each target. These parameters were selected based on their higher mean absolute SHAP values, indicating that they exert the greatest influence on the model's predictions. Table 6 summarizes the top three key parameters affecting the three metrics.
Top parameters influencing product yield, drum Index, and RDI+3.15 predictions.

This improves the interpretability of the model by clearly identifying the key features driving predictions for each target.
Conclusion
Existing models often overlook the relationships between different tasks when handling multi-task and multi-indicator problems in the sintering process, resulting in suboptimal model performance during multi-task collaborative prediction. This paper constructs a multi-objective quality prediction model for sintered ore based on operational plant data from industrial production trials, combining sintering production theory, artificial intelligence, and machine learning algorithms. It effectively addresses the shortcomings of traditional methods in handling multi-task and multi-indicator problems, providing an effective solution for precise control of the sintering process and multi-objective optimization of industrial processes.
The specific conclusions of the study are as follows:
A multi-task prediction model is constructed using MMoE, with the introduction of expert networks and a task attention mechanism to simultaneously predict multiple target parameters. The model structure includes the MMoE layer for feature specialization learning, and the Task Attention layer enhances task feature interaction, validating the effectiveness of the multi-task learning framework in predicting related indicators. The MMoE model is optimized using the Optuna framework, with key parameters such as hidden_dim, num_experts, learning rate, and batch_size being tuned. R2, MSE, RMSE, MAE, and MAPE are used as evaluation metrics. The results show that the Attention-MMoE-DLW model outperforms the other four advanced models across all prediction metrics, with R2 exceeding 96%, proving the algorithm's outstanding performance and good generalization ability in multi-objective quality prediction. The optimized MMoE multi-task model was tested and evaluated, with the results showing that the model performs well in predicting all three target parameters. All metrics reached their optimal levels, fully validating the model's accuracy and reliability in multi-objective collaborative prediction tasks.
While the proposed Attention MMoE DLW model demonstrates strong performance on operational plant data, several limitations remain for practical deployment. Performance may degrade under extreme distribution shifts, for example substantial changes in feed composition, ambient conditions, or control policies that fall outside the training regime. Adaptability to new tasks and new target indicators may require additional data, retraining, and careful mitigation of negative transfer. The computational cost of multi expert architectures and hyperparameter optimization can affect training efficiency and online latency in resource constrained environments. These issues motivate future work on drift detection and periodic recalibration, parameter efficient task expansion, and model compression and distillation to better meet plant level requirements. Future research can further expand the application of the MMoE multi-task model in multi-objective prediction scenarios, such as incorporating more industrial production data related to product yield, drum index, and RDI+3.15. It could also explore the impact mechanisms of dynamic interactions between production parameters on target indicators, further enhancing the model's adaptability to complex industrial environments.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Supported by the Graduate Student Innovation Fund of North China University of Science and Technology (No. 2026S27).