
Abstract
The non-linear influence of hot metal composition and scrap ratio on flux addition requires accurate predictive models to optimise charging operations. A random forest (RF) model was developed using multi-heat industrial data to predict lime and light-burned dolomite additions. The model effectively captured non-linear interactions between key process variables and flux inputs but showed slight systematic deviations under fluctuating operating conditions. To improve prediction accuracy and physical consistency, metallurgical mechanisms were embedded into the data-driven framework. Empirical features for light-burned dolomite were obtained by polynomial fitting, while theoretical lime additions were derived from quaternary basicity theory and used as mechanistic constraints. This hybrid model retained the non-linear learning capability of RF while enhancing interpretability and robustness. After feature enhancement, all performance indicators improved markedly: for dolomite, the coefficient of determination (R2) increased from 0.4801 to 0.5675, the mean absolute error (MAE) decreased from 123.17 kg to 116.52 kg and the root mean square error (RMSE) from 152.90 kg to 139.46 kg; for lime, R2 rose from 0.5843 to 0.7553 and MAE and RMSE dropped by 24.1% and 23.3%, respectively. The proportion of samples within ±5% error increased significantly, confirming improved reliability for basic oxygen furnace (BOF) charge prediction and physically consistent steelmaking control.
Keywords
Introduction
In the integrated steelmaking route, the basic oxygen furnace (BOF) serves as the pivotal link between ironmaking and secondary refining, where its operational control directly governs molten steel quality, energy efficiency and overall process economy.1–3 The rational addition of fluxes is fundamental to BOF operations.4,5 Fluxes maintain slag basicity, facilitate dephosphorisation and desulphurisation, and play key roles in slag-metal separation, refractory protection, temperature regulation and inclusion removal. 6 Insufficient flux leads to inadequate slag basicity and poor dephosphorisation, whereas excessive flux increases slag volume, heat loss and production cost. 7 Therefore, precise prediction of lime and lightly burned dolomite additions is essential for achieving intelligent control and low-carbon operation in modern BOF steelmaking. 8 Flux addition is governed by complex and highly non-linear interactions among multiple process variables, including hot metal composition, scrap ratio and blowing conditions. 9 Traditional empirical or rule-based methods fail to capture such non-linear dependencies, relying heavily on operator experience and lacking adaptability across varying process conditions. 10 With the growing variability of raw materials and increasing scrap utilisation, the uncertainty in flux consumption behaviour has intensified, further challenging conventional control strategies. Consequently, high-precision prediction of flux additions has become a key prerequisite for intelligent BOF charge control.
The advent of big data and intelligent manufacturing has facilitated the rapid adoption of data-driven approaches in metallurgy. Machine learning (ML) models, such as support vector machines (SVM), random forests (RF), extreme learning machines (ELMs) and deep neural networks (DNN), have demonstrated strong capabilities in capturing complex non-linear relationships, showing excellent performance in endpoint temperature and composition prediction.11–14 Moreover, hybrid models integrating optimisation algorithms – such as particle swarm optimisation (PSO), genetic algorithms (GA), firefly algorithms and grey wolf optimisation (GWO) – have further enhanced model adaptability and predictive precision.15–19 For instance, Guo et al. 20 developed a Kernel Feature Analysis-Grey Wolf Optimiser-Gradient Boosting Decision Tree (KFA-GWO-GBDT) model that significantly improved both accuracy and generalization in BOF endpoint temperature prediction. Qiu et al. 21 optimised BP neural networks using a chaos-enhanced sparrow search algorithm (CSSA-BP), reducing prediction errors of endpoint carbon and temperature by approximately 30% and improving model interpretability through SHapley Additive exPlanations (SHAP) analysis. Similarly, Xin et al. 22 applied a PSO-optimised BP model, enhancing the ±10 °C, ±15 °C and ±20 °C prediction accuracies from 63.64%, 79.22% and 87.45% to 68.40%, 84.85% and 94.81%, respectively.
Despite these advances, most existing studies emphasise algorithmic design and parameter tuning while neglecting the integration of metallurgical domain knowledge. 23 Purely data-driven models, while capable of strong fitting, often violate physical constraints – such as material balance and thermodynamic consistency – when pre- and post-processing are neglected, leading to unreliable predictions under abnormal or extreme conditions. Moreover, industrial data are frequently affected by noise, outliers and non-uniform feature distributions, which, without appropriate preprocessing, can undermine model stability and generalisation. 24 Hence, a unified framework that couples metallurgical mechanism constraints with data-driven modelling is urgently needed to ensure both physical consistency and predictive robustness. 25
In recent years, physics-informed neural networks (PINNs) have emerged as a promising framework that integrates physical constraints into neural network training, embedding governing equations – such as mass, momentum and energy conservation – directly into the loss function. This approach effectively bridges the gap between purely data-driven and mechanistic models, allowing the network to satisfy both empirical observations and physical laws. In metallurgical applications, PINNs have been successfully applied to process parameter prediction, thermodynamic property estimation and microstructure evolution modelling, demonstrating excellent potential for extending physics-guided learning to complex steelmaking systems.26–28
However, in complex BOF steelmaking systems, the practical application of PINNs remains limited by factors such as data resolution, variable coupling and the difficulty of explicitly formulating governing equations. Inspired by the same principle of integrating domain knowledge to enhance model reliability, this study proposes a domain-feature-enhanced random forest (RF) model as a more data-efficient and physically interpretable alternative for industrial applications. By embedding metallurgical knowledge – such as theoretical lime demand and fitted dolomite addition – into the model input, the proposed method explicitly incorporates material balance and slag basicity control relationships, thereby strengthening the coupling representation among key process variables. Using multi-heat industrial datasets, separate prediction models for lime and dolomite were constructed and evaluated through determination coefficient (R2), mean absolute error (MAE), root mean square error (RMSE) and mean bias error (MBE). This approach maintains modelling flexibility while ensuring physical interpretability, offering a scalable pathway for intelligent flux optimisation, heat balance regulation and carbon footprint assessment in BOF steelmaking.
The remainder of this paper is organised as follows: section ‘Methodology and model development’ introduces the research methodology and model development; section ‘Domain feature construction’ presents the domain-feature construction approach based on metallurgical knowledge; section ‘Domain feature enhancement effect evaluation’ evaluates the effect of domain-feature enhancement on model performance; and finally, section ‘Conclusions’ concludes the study.
Methodology and model development
Data preprocessing and feature selection
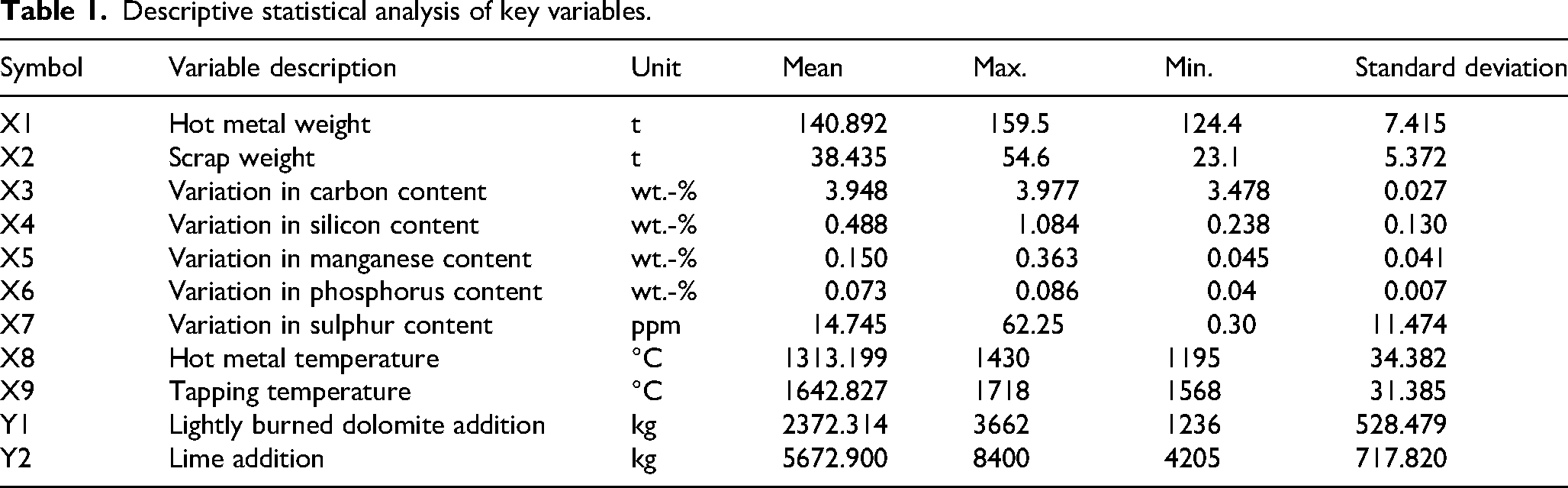
This study utilises industrial-scale production data from BOF steelmaking process of an industrial steel plant. Considering the presence of missing and anomalous records in the raw dataset, a systematic data-cleaning and preprocessing procedure was applied to ensure model reliability and generalisation. Samples containing incomplete entries or unreasonable outliers were removed to eliminate potential bias in model training. Outlier identification was based on domain expertise and empirical inspection, including the removal of records with missing values, zero additions, or extreme quantities far beyond the normal operational range. A total of 900 valid heat samples were finally retained. Among them, 820 heats were randomly selected for model training and 80 heats were reserved as the test set. The input features consisted of nine process variables, including the hot metal weight, scrap weight, variations in carbon, silicon, manganese, phosphorus and sulphur contents, hot metal temperature and tapping temperature. The output variables were the addition amounts of lightly burned dolomite and lime. The statistical characteristics of all variables – including their mean, maximum, minimum and standard deviation – are summarised in Table 1.
Descriptive statistical analysis of key variables.
To eliminate the influence of differing magnitudes and physical dimensions among variables, all input features were normalised prior to model training. Owing to variations in unit definitions and numerical scales, the raw process variables exhibited significant disparities in magnitude, which could otherwise bias the learning process. Therefore, a linear min-max normalisation was applied to each input feature, scaling all variables into the range of [0,1].
The normalisation procedure was implemented using the mapminmax function in MATLAB, as defined by the following expression:
Correlation analysis and evaluation metrics
To quantitatively assess the relationships between input and target variables, Pearson correlation analysis was employed to evaluate the strength and direction of linear associations among features. The Pearson correlation coefficient ranges from −1 to 1, where positive and negative values indicate positive and negative correlations, respectively, and an absolute value closer to 1 represents a stronger linear relationship. The correlation matrix is illustrated in Figure 1, where the colour intensity reflects the absolute magnitude of the correlation coefficients: red denotes positive correlations, blue indicates negative correlations and deeper shades correspond to stronger relationships.
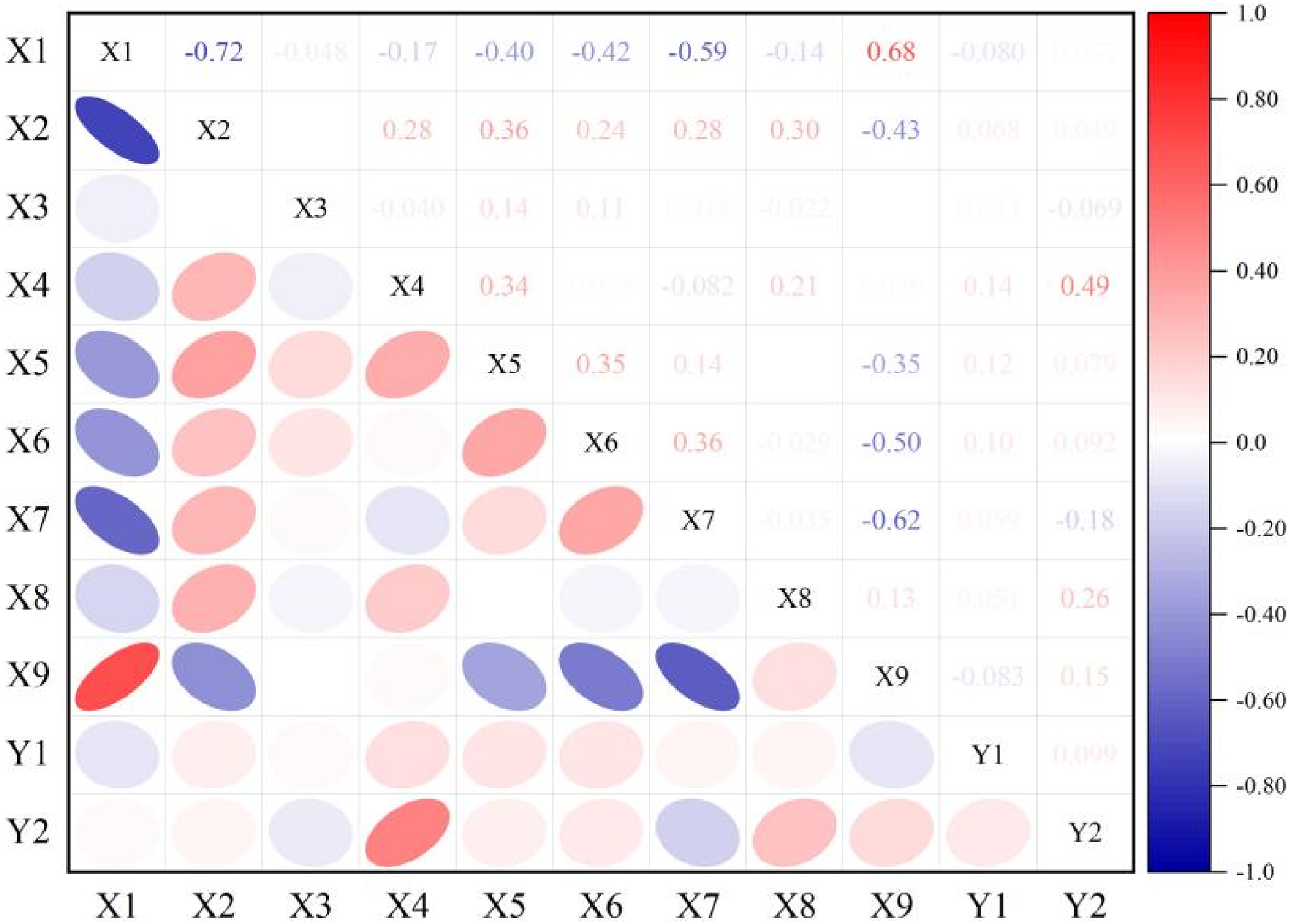
Pearson correlation coefficient matrix of input and output variables.
Overall, the input variables exhibited relatively weak intercorrelations, and no significant multicollinearity was detected, confirming their suitability as inputs for RF model. Moreover, several feature pairs demonstrated weak but physically meaningful correlations consistent with metallurgical principles – for instance, the correspondence between variations in hot metal composition and the addition of fluxes – further validating the rationality of feature selection. In summary, the Pearson correlation analysis confirmed that the selected features maintain both statistical independence and physical consistency, thereby providing a robust data foundation for subsequent RF model development.
To evaluate the predictive performance of the model for BOF material additions, four widely used regression metrics were adopted:
Mean Absolute Error (MAE): Mean Bias Error (MBE): MBE quantifies the systematic bias of the predictions, indicating whether the model tends to overestimate or underestimate the target variable. An MBE close to zero implies negligible bias; positive and negative values correspond to overall underestimation and overestimation, respectively. Root Mean Square Error (RMSE): RMSE is more sensitive to large deviations than MAE, capturing the variability of prediction errors. Compared to MAE, RMSE emphasises extreme errors, and lower values indicate better performance in controlling large deviations. Coefficient of determination (R2):
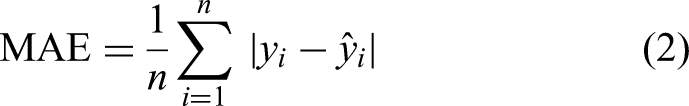
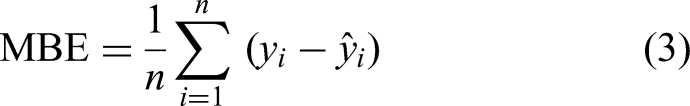
Baseline model training and result analysis
To achieve accurate predictions of BOF material additions, a RF algorithm was employed to construct the baseline model. RF is a classical ensemble learning technique that aggregates the outputs of multiple decision trees to reduce variance and enhance generalisation. Its core principle involves generating multiple training subsets via bootstrap sampling and randomly selecting candidate features at each split to grow a set of independent decision trees. The final prediction is obtained by averaging the outputs of all trees, which effectively mitigates overfitting and improves model stability. The RF algorithm was adopted in this study because it demonstrated superior robustness and predictive accuracy in previous comparative research, 15 where its performance in predicting lime and light-burned dolomite additions consistently surpassed that of BP, RBF and SVM models. In this study, the model was configured with 1000 trees and a minimum of 2 samples per leaf node, and out-of-bag (OOB) error was used to evaluate generalisation performance. To further verify the rationality of feature selection, the feature importance values calculated by the RF model were analysed for both light-burned dolomite and lime additions, as shown in Figure 2. The feature importance indicates that the selected features contribute substantially to the model output, confirming their metallurgical relevance.
Feature importance based on the random forest model.
The predicted addition amounts of lightly burned dolomite and lime are presented in Figure 3, demonstrating the model's capability to capture the underlying relationships between process variables and material additions.
Prediction results on test set: (a) light-burned dolomite; (b) lime.
As shown in Figure 3, the predicted values closely match the observed data across the entire distribution, effectively capturing the non-linear mapping between input features and target variables. For lightly burned dolomite addition (Y1), the test set performance was: R2 = 0.4801, MAE = 123.17 kg, MBE = −30.35 kg and RMSE = 152.90 kg. The model maintained relatively low errors for most samples, with an MAE of approximately 123 kg, reflecting satisfactory local prediction accuracy. For lime addition (Y2), the prediction performance was higher, with R2 = 0.5843, MAE = 277.51 kg, MBE = −45.76 kg and RMSE = 325.34 kg. Compared to the dolomite model, the lime model exhibited better goodness-of-fit, confirming the effectiveness of the selected input feature set and the data preprocessing strategy. These baseline results provide a solid reference for the subsequent enhancement of the model via domain-specific feature integration.
Domain feature construction
Empirical feature construction for lightly burned dolomite
In the BOF steelmaking process, the addition of lightly burned dolomite significantly influences slag basicity, MgO content and refractory wear rates. Therefore, accurate prediction of its addition is critical for optimising charge composition and stabilising melt quality. Although the baseline RF model already demonstrated satisfactory predictive performance, there remains room for further error reduction. Traditional model optimisation strategies typically focus on algorithm-level improvements, such as hyperparameter tuning or ensemble structure refinement, with limited incorporation of domain knowledge into feature representation. In industrial practice, operators often rely on experience or proportional rules to estimate additions; for instance, the typical dolomite addition is approximately 20 to 40 kg per ton of hot metal based on historical production experience.
To integrate such empirical knowledge into model training, a domain-informed feature enhancement approach was proposed, in which ‘empirical features’ are derived from historical data and incorporated as input variables to strengthen the model's representation of process patterns. Specifically, the relationship between hot metal weight (X) and dolomite addition (Y) was analysed using historical heats. Locally weighted scatterplot smoothing (LOESS), a non-parametric regression method, was applied to fit the data. LOESS performs weighted least squares regression within a local neighbourhood for each sampling point, assigning higher weights to nearby observations to capture non-linear trends while smoothing out noise. This yields a fitted curve that closely follows actual operational practices. A smoothing parameter of span = 0.4 was selected to balance curve smoothness and detail preservation. As illustrated in Figure 4, the LOESS-fitted trend captures the overall distribution of dolomite addition with respect to variations in hot metal weight. The standard deviation of the residuals was further calculated to construct upper and lower bounds, defining an empirical feature interval that reflects practical operational practices.
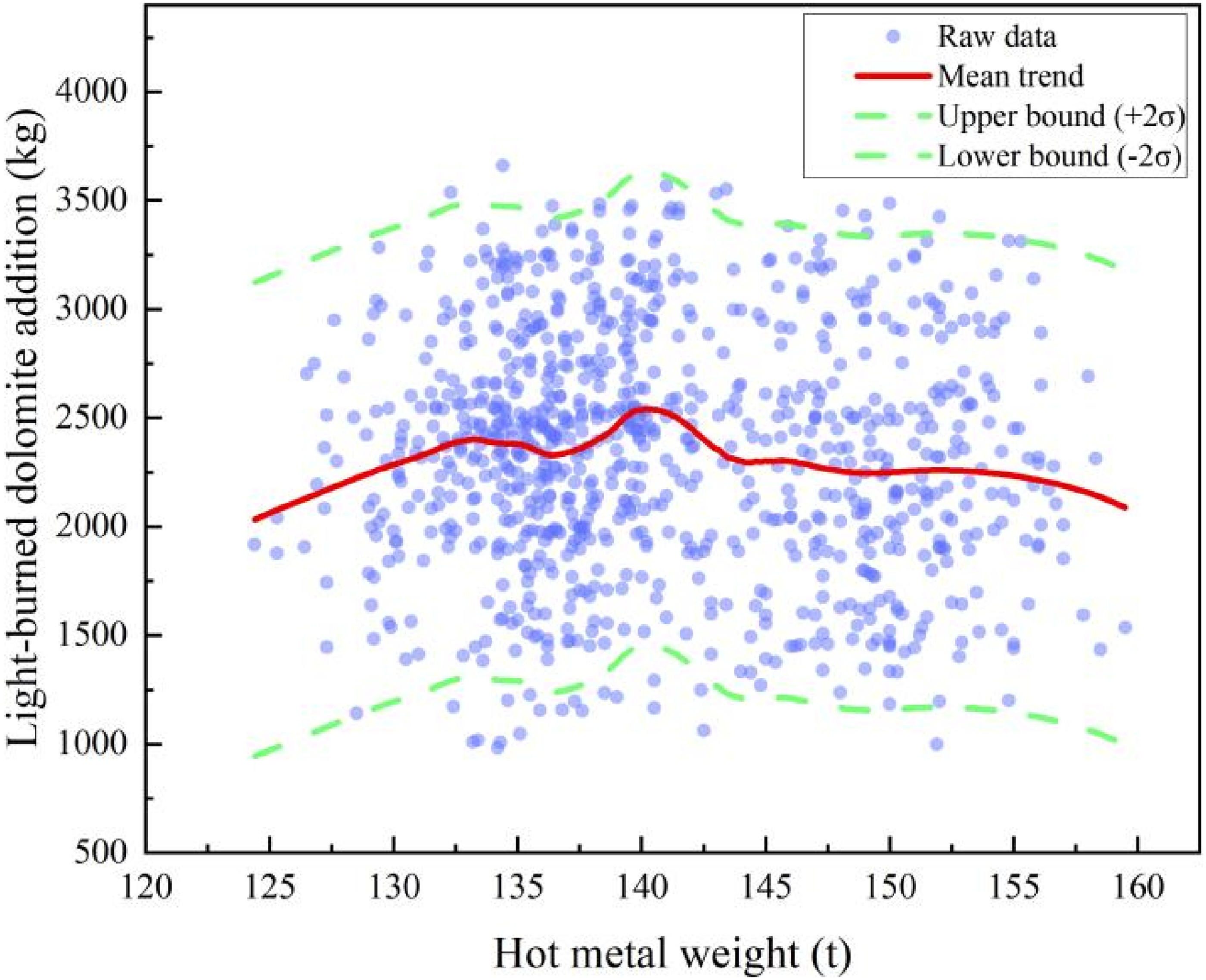
LOESS smoothing fitting results: relationship between hot metal weight and light-burned dolomite addition.
However, the LOESS method has inherent limitations: its predictions are confined to the range of observed data, and extrapolation beyond the sampled hot metal weights is unreliable. This poses challenges for processing heats with input values outside the original data range. To address this issue, a third-order polynomial regression was employed to model the functional relationship between hot metal weight and dolomite addition. Experimental results indicate that the cubic polynomial not only captures the overall trend effectively but also better represents local variations, aligning well with the non-linear process characteristics of dolomite addition relative to hot metal weight.
The polynomial fitting procedure can be summarised as follows:
Import historical production data and extract hot metal weight x and dolomite addition y. Sort the samples according to x to ensure an ordered dataset. Specify the polynomial degree n and compute coefficients Calculate fitted values Compute the standard deviation of residuals Output the fitted curve along with the confidence interval.
The resulting third-order polynomial fit is shown in Figure 5. The curve accurately reflects the non-linear influence of hot metal weight on dolomite addition, providing a solid basis for constructing empirical features to be integrated into the RF model. This feature not only captures the empirical relationship between dolomite addition and hot metal weight but also enhances the model's representation of process constraints, effectively combining data-driven learning with domain knowledge. Consequently, it contributes to higher predictive accuracy and stability, forming a reliable foundation for subsequent feature optimisation and model enhancement.
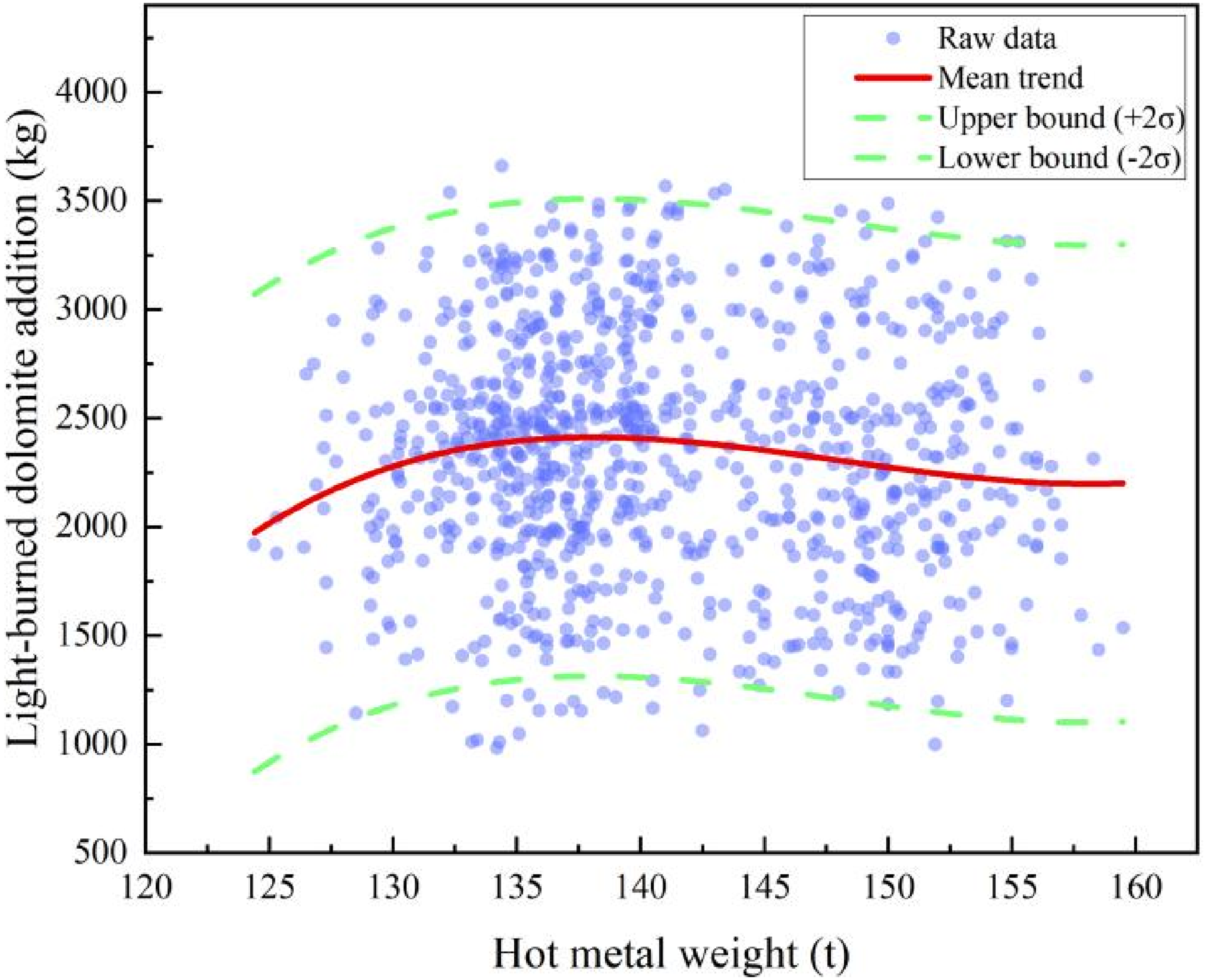
Third-order polynomial fitting results for light-burned dolomite addition versus hot metal weight.
Mechanism-constrained feature embedding for lime addition
In BOF steelmaking, lime addition plays a critical role in regulating slag basicity and stabilising the final steel composition. Conventional machine learning models typically rely solely on statistical features, without fully incorporating metallurgical process knowledge, which can result in biased predictions or limited generalisation under specific operating conditions. To address this limitation, this study computes the theoretical lime addition based on BOF metallurgical principles and integrates it as a mechanistic feature into the model, thereby enhancing the physical consistency and interpretability of predictions.
In industrial practice, lime addition primarily depends on the target slag basicity and the composition of hot metal. Slag basicity is defined as the ratio of basic oxides to acidic oxides. Once the target basicity is set, the required lime quantity can be derived from slag composition balance. Accordingly, this study calculates the content of key slag components (CaO, SiO2, MgO, Al2O3) through material balance, and establishes a quantitative relationship between lime addition and slag chemistry using empirical basicity formulas. The resulting mechanistic feature can be directly incorporated into the predictive model as an input variable.
To illustrate the calculation, a representative heat was selected: hot metal weight of 138.5 t, scrap addition of 38.3 t and lightly burned dolomite addition of 2910 kg. Based on the observed chemical composition changes, the primary oxidation reactions of hot metal and scrap during the blowing process are summarised in Table 2.
Comparison of elemental oxidation amounts between hot metal and scrap.

The chemical compositions of the fluxes (lime and lightly burned dolomite) and refractory materials were quantified on a mass fraction basis, and refractory wear was estimated as 0.30% of the hot metal weight. Table 3 summarises the typical chemical compositions of these materials (mass fraction, %).
Main chemical compositions of lime, light-burned dolomite and refractory (mass fraction, %).

Based on these compositions, the contributions of each source to the major slag oxides (CaO, SiO2, MgO, Al2O3) were calculated, as summarised in Table 4.
Contributions of different sources to major oxides and totals (kg).
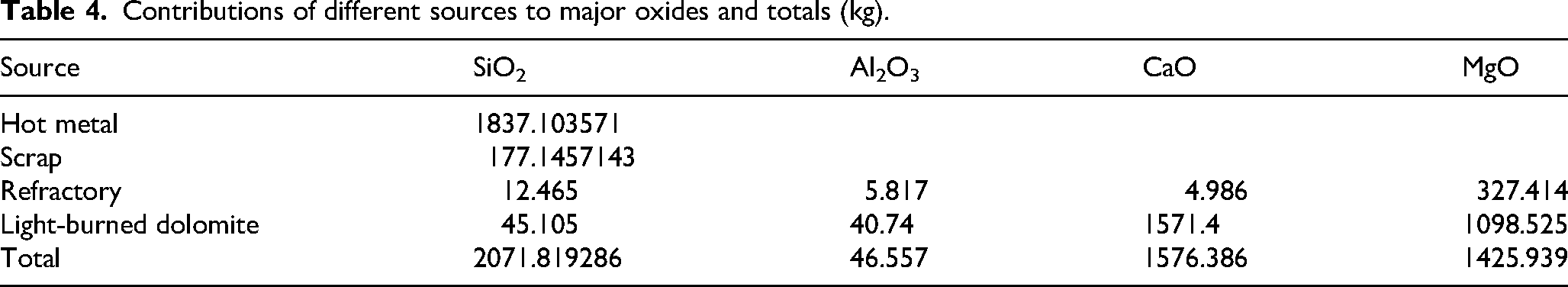
Based on these contributions, the total masses of the major oxides from hot metal, scrap, refractory and dolomite were summed. The required lime mass was then calculated using the quaternary basicity relation
29
: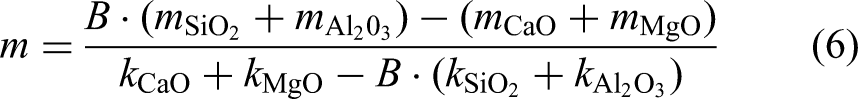
Domain feature enhancement effect evaluation
Comparative analysis of model performance
To evaluate the impact of mechanism-constrained features on predictive performance, the optimised feature vectors were retrained and tested for both light-burned dolomite and lime addition models. The enhanced feature set incorporated metallurgical mechanism descriptors on top of the original process parameters, explicitly embedding the physical constraints of the BOF operation into the model. Model performance was systematically assessed using the selected evaluation metrics.
For light-burned dolomite prediction, the baseline model achieved an R2 of 0.4801, MAE of 123.17 kg, MBE of −30.35 kg and RMSE of 152.90 kg on the test set. After introducing mechanism-based features, performance improved substantially: R2 increased to 0.5675, while MAE and RMSE decreased to 116.52 kg and 139.46 kg, respectively, and MBE was reduced to −20.56 kg. The 18.2% rise in R2 demonstrates a stronger model-data correspondence; the concurrent decreases in MAE and RMSE indicate tighter error dispersion and improved predictive stability; and the diminished negative MBE suggests correction of underestimation bias. However, the R2 value remains moderate mainly due to measurement uncertainty inherent in industrial field sampling, which introduces random noise and limits the attainable prediction accuracy. Collectively, the enhanced model exhibits greater accuracy and robustness in capturing the non-linear variation of dolomite addition (Figure 6(a)).
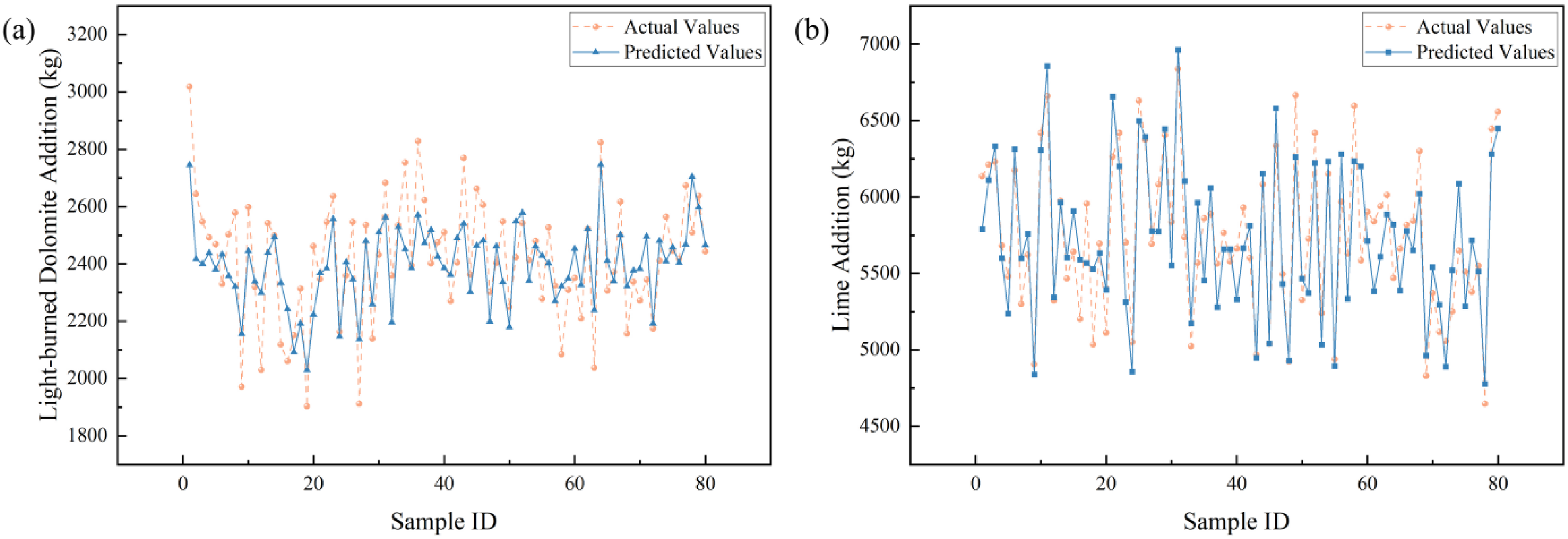
Prediction results on the test set after optimisation: (a) light-burned dolomite; (b) lime.
Performance gains were even more pronounced in the lime addition prediction. The baseline model yielded R2 = 0.5843, MAE = 277.51 kg, MBE = −45.76 kg and RMSE = 325.34 kg. Incorporation of mechanism-constrained features elevated R2 to 0.7553, while MAE and RMSE dropped to 210.51 kg and 249.64 kg, respectively, and MBE decreased markedly to −11.74 kg. Compared with the baseline, R2 increased by 29.3%, MAE and RMSE decreased by 24.14% and 23.27%, and the systematic bias magnitude was reduced by ∼74%. These results indicate that the optimised model responds more precisely to the actual lime addition pattern (Figure 6(b)).
Overall, the incorporation of mechanism-constrained features significantly enhanced the model's physical consistency, aligning the predictions more closely with metallurgical behaviour observed in practice. Particularly in lime prediction, the model exhibited improved generalisation and numerical stability, confirming the feasibility and necessity of integrating metallurgical principles into data-driven frameworks. This approach provides a methodological foundation for extending data-mechanism fusion toward multi-stage material prediction and holistic process optimisation in steelmaking.
Analysis of prediction error distribution and model stability
To further evaluate the stability and error distribution of the model predictions, we compared the distributions of prediction deviations and the proportions of absolute errors on the test set before and after optimisation. Figures 7 and 8 illustrate the error distribution characteristics for lightly burned dolomite and lime additions, respectively, as well as the changes in sample proportions across different absolute error intervals.
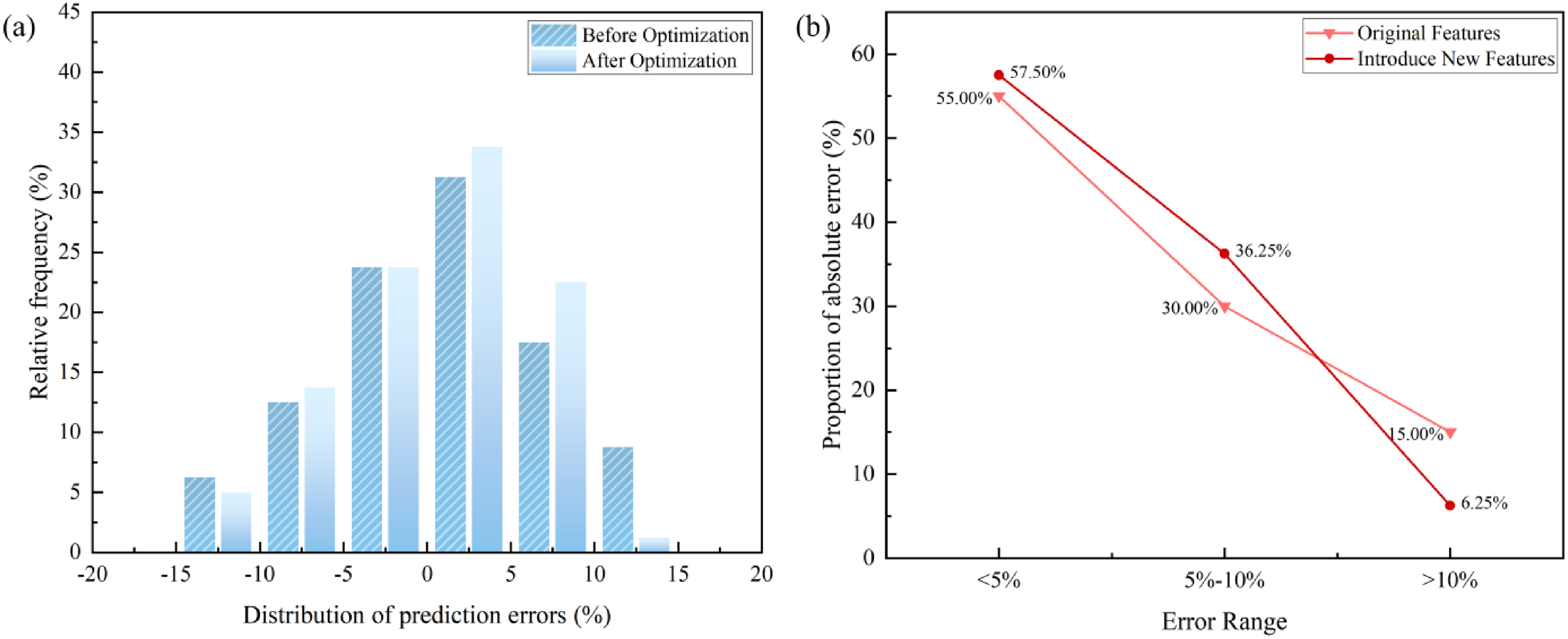
Distribution of prediction errors (a) and variation of absolute error proportions (b) before and after optimisation for lightly burned dolomite addition.
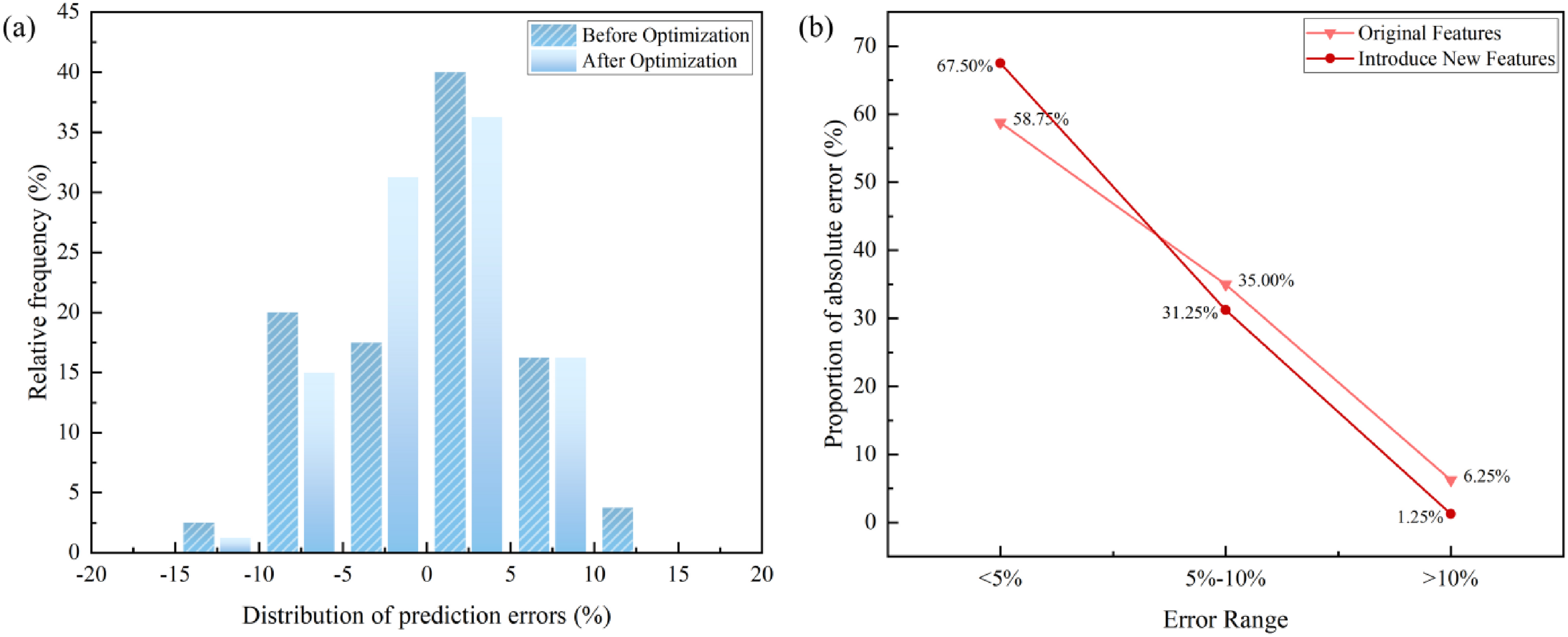
Distribution of prediction errors (a) and variation of absolute error proportions (b) before and after optimisation for lime addition.
For lightly burned dolomite prediction (Figure 7), the pre-optimisation model exhibited a relatively dispersed error distribution: 55.0% of predictions fell within ±5%, 30.0% within 5% to 10% and 15.0% exceeded 10% absolute error. After optimisation, the proportion of samples within ±5% increased to 57.5%, 5% to 10% rose to 36.25% and large errors (>10%) declined sharply to 6.25%. The post-optimisation error distribution shows that predictions are more concentrated in the low-error range, extreme deviations are markedly reduced and overall variability is decreased, demonstrating the effectiveness of the optimisation strategy in enhancing prediction stability and reducing large errors.
For lime addition prediction (Figure 8), improvements are even more pronounced. Before optimisation, 58.75% of predictions exhibited absolute errors below 5%, while 6.25% exceeded 10%. Following optimisation, small-error predictions (<5%) increased to 67.50%, and large-error predictions (>10%) dropped to 1.25%. Errors are now predominantly concentrated within ±5%, accounting for over two-thirds of the samples, and systematic bias is effectively eliminated. This indicates that incorporating mechanism-informed features enables the model to more accurately capture the non-linear response of lime addition, enhancing both robustness and generalisation.
Conclusions
In this study, a RF based prediction model was developed to accurately estimate the addition amounts of lightly burned dolomite and lime in BOF steelmaking process. Building upon this framework, domain feature information derived from metallurgical mechanisms was incorporated to achieve physics-informed model integration, thereby improving both the accuracy and robustness of additive prediction. The main conclusions are summarised as follows:
A RF model was first established to enable high-precision prediction of lightly burned dolomite and lime additions. Training and validation using multi-heat industrial data demonstrated strong predictive performance for both materials. For lightly burned dolomite, the test-set R2 reached 0.4801, with a MAE of 123.17 kg and a RMSE of 152.90 kg. For lime, R2 was 0.5843, MAE was 277.51 kg, and RMSE was 325.34 kg. The model can effectively capture the complex non-linear relationships between process parameters and additive quantities, providing a reliable foundation for subsequent domain feature enhancement. Based on the baseline model, a domain feature-enhanced RF method was proposed and validated. This method explicitly embedded metallurgical mechanism information – such as material balance constraints and slag basicity control – into the model inputs by introducing empirical features for lightly burned dolomite and theoretically derived lime addition features. The integration of these mechanism-informed variables enhanced the model's physical consistency and interpretability, achieving a deep coupling between data-driven learning and metallurgical process knowledge. As a result, the improved model exhibited greater robustness and generalisation capability under complex operating conditions. The domain feature-enhanced model outperformed the baseline model across all evaluation metrics, showing significant improvements in prediction accuracy and stability. In the test set, the R2 for lightly burned dolomite increased from 0.4801 to 0.5675, with MAE decreased from 123.17 kg to 116.52 kg, and RMSE decreased from 152.90 kg to 139.46 kg, respectively. For lime, the R2 improved from 0.5843 to 0.755, and MAE and RMSE decreased by 24.14% and 23.27%, respectively. Error distribution analysis further revealed a substantial increase in the proportion of samples within the ±5% error range, indicating more concentrated prediction results and reduced systematic bias. Overall, the proposed approach achieved high prediction accuracy and robustness while maintaining physical rationality and mechanistic consistency. This work provides a generalisable framework for intelligent modelling of complex metallurgical processes and establishes a theoretical foundation for automatic control and process optimisation in BOF steelmaking.
Footnotes
Acknowledgements
Besides, the numerical calculation is supported by High-Performance Computing Center of Wuhan University of Science and Technology.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the National Natural Science Foundation of China and Central Leading Local Science and Technology Development Fund Project of Guangxi Province (grant numbers 52004191 and GuiKeZY23055009).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.