
Abstract
In everyday life people use music to adjust their levels of arousal, to regulate their mood and emotions, and to cope with previous experiences, indicating that music plays an important role for everyday wellbeing. While the relationship between music and emotions has received considerable interest in past decades, little is known about the self-esteem boosting function of empowering music. In the present study, we investigated the relationship of music listening and self-esteem, by examining how momentary explicit and implicit self-esteem are (a) influenced by the expressive properties of music and (b) predicted by individual differences in responses to music. Results indicate that both explicit and implicit self-esteem are affected by music listening but in different ways. While momentary explicit self-esteem changed as a function of the expressive properties of the music and was positively predicted by liking, implicit self-esteem was positively predicted by empathy and negatively predicted by nostalgia. In contrast to changes in self-esteem, no changes in mood were observed. We anticipate our findings to be a starting point for further investigations of the cognitive and affective processes involved when listening to empowering music.
In this article, we contribute to the notion of music as a “technology of the self” (DeNora, 1999), by conceptualizing music listening as self-enhancement, a self-evaluation motive that operates to make people feel good about themselves and helps in maintaining self-esteem (Sedikides & Gregg, 2008). We introduce the concept of empowering music, discuss the theoretical relation between music listening and self-esteem, and present empirical findings on how music listening evokes changes in self-esteem.
Empowering music
Anecdotal evidence suggests that there is a wide range of ways in which people engage with empowering music today. One particularly apparent way is its use by athletes. Laukka and Quick (2011) inquired after the uses of music among Swedish elite athletes and found that the three most frequently mentioned functions were (1) “to increase pre-event activation/to pump up”, (2) “to increase positive affect”, and (3) “to get help with my motivation”. Other themes were “performance enhancement”, as well as enhancement of “self-efficacy and self-confidence” (p. 204). Another study established a link between powerful music and the feeling of power: Hsu, Huang, Nordgren, Rucker, and Galinsky (2014) showed that music perceived as powerful makes people feel more powerful, activates the concept of power implicitly, and influences power-related behavior and cognition.
Although the empirical examination of music’s empowering potential has begun only recently, the notion that music is related to empowerment is very old. In Plato’s Republic we find one of the first descriptions of music’s powerful functions reaching into dimensions of agency and the self by equipping men’s characters with attitudes of strength and braveness and preparing them to deal with challenging consequences of everyday life (Woerther, 2008). Functions of music listening can be found in many different cultures and societies, which ethnomusicologists have documented in the past (Dissanayake, 2006). In ritual ceremonies music and dance often function as displays of prestige, strength, and power. For example, New Zealand sport teams are still regularly performing the Haka (World Rugby, 2015), a traditional Maori battle cry, prior to competitions. Today, the link between music and empowerment becomes particularly apparent in the realm of hip hop culture. Rap music has been associated with the ability to voice reality and formulate a meaningful social and personal identity (Krims, 2000), which in turn bolsters esteem, resilience, growth, community, and change (Travis, 2012; Travis & Bowman, 2012). The topic of empowerment migrated into various musical styles and is a vital part of today’s popular music. In a recent online article, Romano (2013) identified a trend that he calls “Selfie Pop”, which refers to artists like Katy Perry, Ke$ha, Pink, and the Black Eyed Peas who present themselves as strong, powerful, confident, and beautiful persons in a way that makes it almost irresistible to not engage and empathize with them.
Music and self-esteem
One of the central constructs related to empowerment is self-esteem. Self-esteem broadly describes the evaluative component of the self-system, while its exact meaning varies. It can be understood as a global judgment of self-worth (Rosenberg, 1965), as domain-specific judgments such as appearance or athletics, or it may be understood as an indicator of self-competence (James, 1890/1983). In this article, we refer to self-esteem as global judgments of self-worth. Self-esteem can be considered as a trait, which is more or less stable over time, or as a state, which is fluctuating and moment-specific (Heatherton & Polivy, 1991). Crocker and Wolfe (2001) proposed a framework which assumes that every person has an individual average trait level of self-esteem, where different state levels fluctuate around this baseline in response to external circumstances and events. Typically, self-esteem is believed to be obtained by positive social feedback and individual achievements (Leary, 2005), or by performing culturally meaningful actions (Pyszczynski, Greenberg, Solomon, Arndt, & Schimel, 2004).
The concept can be further divided into explicit and implicit self-esteem, where the former refers to either trait or state self-esteem, while the latter is thought of as implicit evaluative attitude towards the self (Farnham, Greenwald, & Banaji, 1999). Implicit attitudes are assumed to operate automatically and unconsciously, but may have important consequences on judgments and behavior (Greenwald & Banaji, 1995). While self-report questionnaires are usually administered for the assessment of explicit self-esteem, implicit self-esteem is measured indirectly by using procedures such as the Implicit Association Test (IAT; Greenwald, McGhee, & Schwartz, 1998) or the Name Letter Task (NLT; Kitayama & Karasawa, 1997; Nuttin, 1987).
Music and “musicking” in their broadest sense may serve as important resources for the achievement of self-esteem in everyday life, however, empirical evidence corroborating this assumption is limited. Longitudinal studies show that instrumental music lessons (Costa-Giomi, 2004) as well as special music therapeutic interventions (Choi, Lee, & Lee, 2010) enhanced self-esteem. However, other music therapeutic interventions failed to improve self-esteem in participants (Haines, 1989; Henderson, 1983). Additionally, music listening has been linked to various functions related to self-esteem such as self-confirmation and self-actualization (Gabrielsson, 2011), affect regulation (Brown & Mankowski, 1993; Saarikallio, 2010; Saarikallio, Nieminen, & Brattico, 2012), and coping (Miranda & Claes, 2009; Skanland, 2011).
Mechanisms of musical self-enhancement 1
An intuitive way to think of how empowering music might enhance self-esteem is the following: when we listen to an empowering song in which the singer expresses a positive self-view, we empathize and identify with the singer. Through this process we adopt and project the expressed self-view onto ourselves, at least to a certain extent. In this account the self-enhancing effect comes into play via some form of empathy. With regard to music, empathy has been discussed as an important mechanism for explaining emotional reactions (Clarke, 2014; Koelsch, 2013; Scherer & Zentner, 2001; Zentner, Grandjean, & Scherer, 2008). Self-enhancement through music may thus rely on an empathic reaction with a real or imagined state of the musician or the musical persona (Cone, 1974; Levinson, 2006; Robinson, 2005, Wald-Fuhrmann, 2013), which expresses a high sense of self-esteem and self-confidence.
Also, specific emotional reactions to music may help explain its self-enhancing function. Nostalgia – being one of the most frequently evoked emotions by music (Juslin, Liljestrom, Vastfjall, Barradas, & Silva, 2008) – has been shown to contribute to social connectedness, self-esteem, and optimism (Cheung et al., 2013). Self-enhancing functions of music listening may also relate to its social dimension. Shared musical preferences have been shown to facilitate social bonding (Boer et al., 2011) and to provide social identity. Furthermore, it has been shown that joint music making promotes social cohesion (Kirschner & Tomasello, 2009; Tarr, Launay, & Dunbar, 2014). That self-esteem is highly sensitive to relational value has been most prominently proposed in Sociometer Theory (ST; Leary, 2005; Leary & Downs, 1995). In ST, self-esteem is considered a part of a psychological system that indicates one’s social acceptance and relational value. An increase in social cohesion or social acceptance elicited by the music could thus directly feed into the “sociometer”. Since it has been shown that positive affect is positively related to self-esteem (Pelham & Swann, 1989), music’s strong potential to evoke pleasure can be regarded as yet another potential contributor to its self-enhancing capacity. A globular framework was outlined with the intention to illustrate the potential network of processes and elements in musical self-enhancement (see Figure 1).
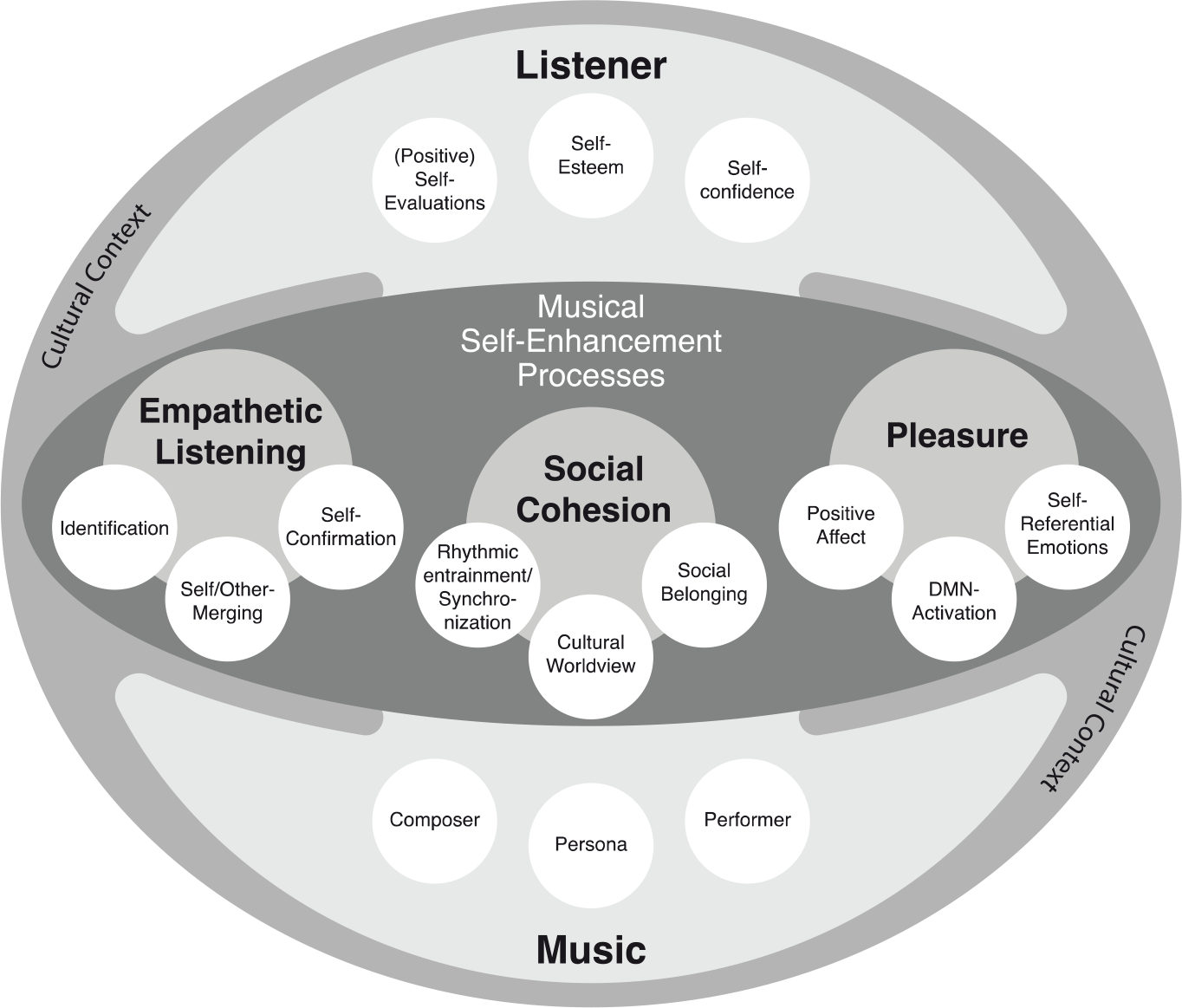
The relationship between the music and the listener is placed within a cultural context, which implies that musical self-enhancement is considered to be a culturally established phenomenon. The process of musical self-enhancement is realized in terms of three main mechanisms: empathy, social cohesion, and pleasure, each encompassing a range of sub-processes, which may operate individually or together at the same time. In sum, the process of self-enhancement through music may be regarded as the result of an interplay of the external properties of the aesthetic object, as well as specific subjective features such as dispositional empathy, or a particular preference for the music that is listened to in order to self-enhance. Source: reproduced with permission from Frontiers in Psychology, Elvers (2016).
Aims of the study
Testing the multitude of relations of the theoretical model outlined above is beyond the scope of one experimental study. Thus, only a limited set of hypotheses derived from the framework were tested here. First and foremost, it was the aim to test whether listening to music would affect momentary explicit and implicit self-esteem and if so, in what way. Since, to the researchers’ knowledge, no previous attempts have been made in this direction, testing the effects of music listening on both aspects of self-esteem would give valuable insights for future research. Second, our aim was to test the effectiveness of different types of music on self-esteem. This aspect was primarily related to the empathy route of the outlined model, since it was argued that the musically expressed self-view plays a crucial part in how self-esteem is influenced by listening to music. It was therefore hypothesized that (1) music expressing a positive self-view and being perceived as motivating enhances self-esteem, while music that expresses a negative self-view and being perceived as demotivating reduces self-esteem. Further, it was intended to test two different types of empowering music. One type is characterized by an extremely positive self-view, while the other one describes a shift from a negative towards a positive self-view. Both types were conceptually linked to the empathy route and were assumed to enhance listener’s self-esteem. The types are explained in more detail below. Another hypothesis relating to this aspect of the framework was that (2) explicit empathy (assessed by self-report) predicts a gain in momentary self-esteem. To test whether pleasure or positive appraisal of the music contributes to self-esteem enhancement, a further hypothesis tested (3) whether liking of the music positively predicts self-esteem enhancement. Finally, it was also hypothesized that (4) nostalgia predicts positive changes in self-esteem. It was assumed that these hypotheses apply to both changes in explicit and implicit self-esteem.
Method
Ethics statement
All experimental procedures were ethically approved by the Ethics Council of the Max Planck Society, and were undertaken with written informed consent of each participant.
Experiment design
To test the effectiveness of different types of music, we defined three experimental conditions that were expected to manipulate self-esteem in different ways. The first condition – labeled as “confident music” – was comprised of empowering musical pieces that were expected to enhance self-esteem. These pieces typically entail expressive qualities that are associated with a positive and confident self-view. The second condition – labeled as “depressing music” – was comprised of musical pieces entailing opposing qualities that were expected to lower self-esteem. The third condition – labeled as “uplifting music” – consisted of musical pieces that were also expected to enhance self-esteem, but the pieces were different from those of the first condition with regard to their structure. While pieces in the first condition expressed a consistent positive self-view, the pieces in the third condition shifted from a negative to a positive self-view. They usually employed a second person perspective addressing the listener directly, while pieces in the first condition usually employed a first-person perspective.
We chose a pretest-posttest design to compare groups and changes in self-esteem that result from the experimental treatments. Self-esteem baseline scores may vary between participants and thus only comparing posttest scores might be potentially biased due to different levels of trait self-esteem. The inclusion of pretest scores allows for a reduction of error variance and provides a more powerful test than simple posttest group designs (Dimitrov & Rumrill, 2003). In addition to the between-groups conditions, we obtained ratings for different aspects of a participant’s responses. Since the degree of liking and familiarity of the music are likely to influence the effect of the music on self-esteem, they were obtained and controlled for in subsequent between-groups analyses. Additionally, ratings for explicit empathy (i.e., the degree to which participants identified themselves with the singer) and feelings of nostalgia were obtained. These music ratings served as independent variables for the second part of the analysis, where we tested their predictive power with regard to changes of self-esteem that occurred during music listening.
Stimulus material and evaluation
Because most musical pieces that are associated with empowerment are songs, it was decided to select songs as musical stimuli. And because the experiment was conducted in Germany, it was decided to only include songs that contain German lyrics. For each condition the experimenters selected five musical pieces. To ensure that the musical pieces met the intended criteria, each piece was subsequently evaluated by 26 German participants (58% female; mean age = 33 years, Mdn = 29) on two scales with bipolar adjectives. One of them measured the expressive quality of the musical pieces with regard to a positive or negative self-view. It was comprised of adjective pairs such as “strong – weak”, “powerful – powerless”, and “successful – unsuccessful”. 2 The bipolar adjectives were associated with differences in self-esteem. Since all stimuli contained lyrics, their expressiveness was expected to mainly rely on the singer or the persona of that song. It therefore seemed viable to evaluate the expressiveness of the songs with concepts generally used to evaluate psychological states of persons. A similar approach to musical meaning based on bipolar adjectives associated with human agency can be found in Watt and Ash (1998). The other scale measured how motivating the musical piece was perceived. It comprised bipolar adjectives such as “motivating – demotivating”, “strengthening – weakening”, and “uplifting – depressing”. 3
As a result, three out of the five musical pieces that were evaluated as being most appropriate for each condition were implemented in the experimental setup resulting in a total of nine musical pieces (see Figure 2). Pieces in the first condition scored highest on both scales, meaning that they were perceived as both motivating and expressing a positive self-view. Pieces in the third condition were perceived as equally motivating while the expressed self-view is more ambiguous, resulting from the shift from a negative to a positive self-view in the song. Pieces in the second condition were perceived as demotivating and expressing a negative self-view. A list of all musical pieces including descriptive statistics is in the Appendix.
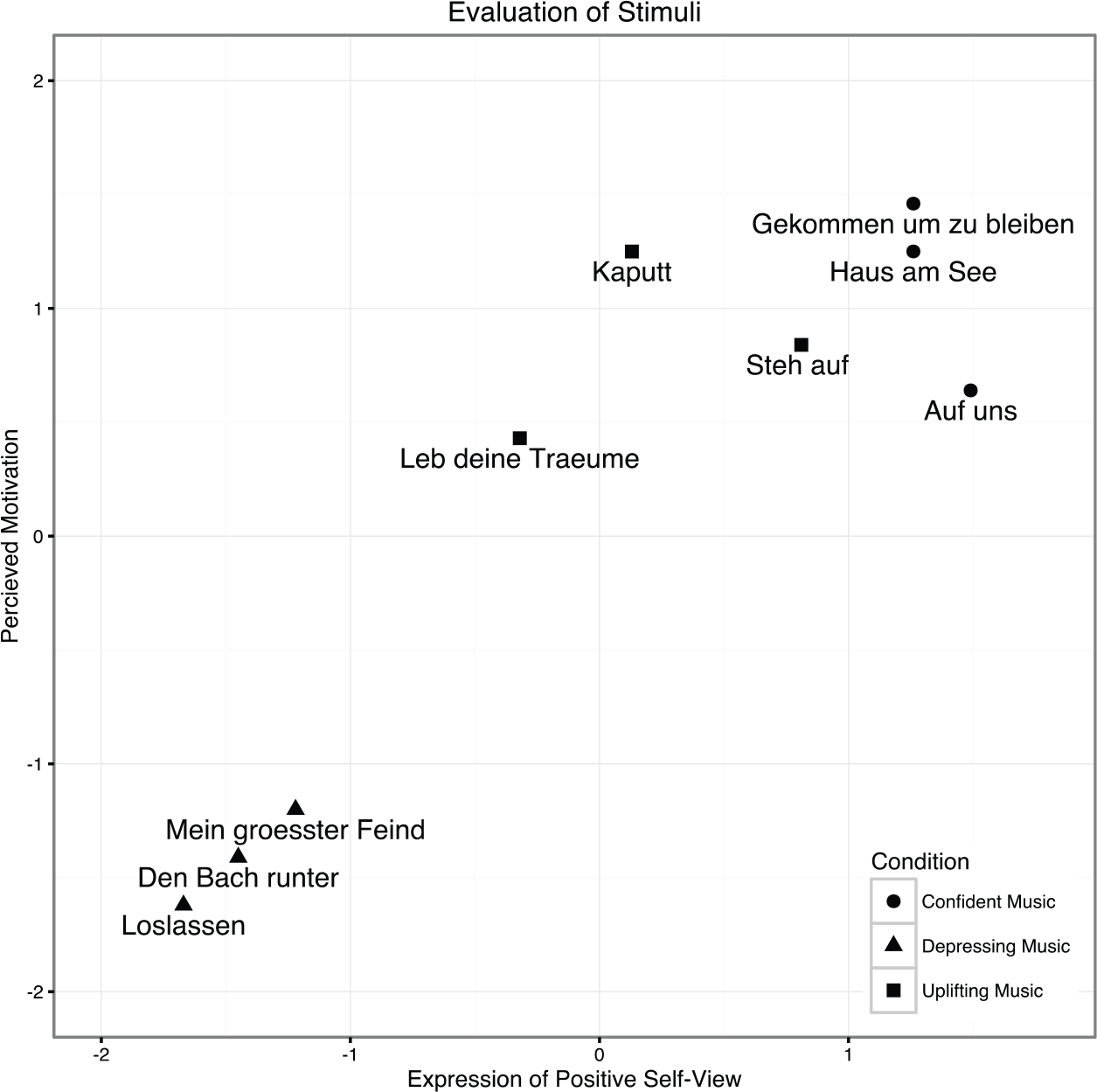
Musical stimuli (short song titles) used in the experiment presented in a two-dimensional space. The y-axis displays the scale measuring the degree of motivation, the x-axis displays the self-view that was expressed through the music. All information on the musical stimuli can be found in the Appendix.
Participants
One hundred and eighteen people participated in the experiment (mean age = 25.05 years, SD = 4.45, min = 19, max = 54 years; 58% female). Most participants were students from the Goethe-University in Frankfurt/Main. All participants were remunerated for their participation. No significant differences were found with regard to gender: χ2(2, N = 118) = 2.88, p = .57, Cramer’s V = .11, or age: F(2, 38) = .094, p = .91, ηp2 = .002, as a function of condition, Confident music: Mage = 25.18, SD age = 5.69, 61% percent female; Depressing music: M age = 24.8, SD age = 3.2, 60% percent female; Uplifting music: M age = 25.17, SD age = 4.25, 52% percent female.
Materials
Rosenberg self-esteem scale
For the assessment of explicit state self-esteem, a short version of the 10-item Rosenberg Self-Esteem Scale (RSES; Rosenberg, 1965) was administered. The scale asked participants to evaluate a list of statements as to how much they apply to them on a 7-point scale with endpoints at very much and not at all. It comprised of four items that have been modified to capture momentary self-evaluations by adding phrases such as “Right now I feel like…”, or “In this moment…”. The scale was previously used in ambulatory assessment studies and proved to be a reliable measure (Nezlek & Kuppens, 2008; Zeiger-Hill & Abraham, 2006). The internal consistency of the measure in the present study (averaged across measurement before and after stimulus presentation) was α = .88.
Implicit association test
The Implicit Association Test (IAT; Greenwald et al., 1998) was used to measure implicit self-esteem as described by Greenwald and Farnham (2000). The self-esteem IAT measures a person’s implicit self-evaluation. The IAT is a widely-used measure in social psychology research applied to examine various implicit attitudes (Greenwald, Poehlman, Uhlmann, & Banaji, 2009). The IAT basically works as follows: in the top left-hand and top right-hand corners of a computer screen target concepts are displayed. Words appear in the middle of the screen, which belong to either one of the concepts. The participant’s task is to sort the stimuli as quickly as possible to the correct target concept. The target concepts again consist of two different classes: two target concepts have either positive or negative valence (i.e., “good” and “bad”), the other two represent the objects towards which the implicit attitudes are supposed to be measured (in case of implicit self-esteem this is “self” and “other”). The IAT consists of seven blocks. During some blocks, only one of the two classes is displayed as target concept. During the critical blocks, however, the two classes are displayed simultaneously (e.g., “me” and “good” in one corner, “other” and “bad” in the other) and the stimuli in the middle of the screen belong to one of the four concepts. The IAT effect (i.e., the strength of the implicit attitude) is based on the difference in mean response time when the attitude object (“me”) is displayed together with a positive target concept (“good”) in one corner, as compared to when it is displayed with a negative word. The concepts we used here were taken from a German version of the self-esteem IAT (Buhlmann, Teachman, Naumann, Fehlinger, & Rief, 2009). The procedure followed the same instructions as documented in Buhlmann et al. (2009). The order of congruent and incongruent tasks was counterbalanced as recommended by Schnabel, Asendorpf, and Greenwald (2007).
Mood questionnaire
To control for a possible mood induction, we administered a six-item scale as reported by Schoebi and Wilhelm (2007), which assessed mood on three dimensions: valence (v), energetic arousal (e), and calmness (c). The measurement is a shortened version of the German Multidimensional Mood Questionnaire (MDMQ) that employs four items on each dimension, and has proven to be a reliable measure (Steyer, Schwenkmezger, Notz, & Eid, 1997). Participants responded to the statement “At this moment I feel:” by indicating their current mood on the following 7-point bipolar scales: “tired – awake” (e), “content – discontent” (v), “agitated – calm” (c), “full of energy – without energy” (e), “unwell – well” (v), and “relaxed – tense” (c). The internal consistency of the measure in the present study (averaged across measurement before and after stimulus presentation) was α = .73 for each of the three dimensions.
Music ratings
In each experimental condition three musical pieces were presented. After the presentation of each musical piece, participants were asked to indicate their liking, their empathetic reaction, the familiarity of the piece, and the degree to which the piece elicited nostalgia on a 7-point scale with endpoints at “very much” and “not at all”. Empathy ratings were assessed by asking how much the participant identified with the singer. For the nostalgia ratings participants indicated how much the music made them think of the past. Each variable was assessed with a single item in order to keep time demands as short as possible. In a similar methodological context, the use of one-item music ratings has proven to be a reliable method assessing liking, familiarity, and empathy (see Egermann & McAdams, 2013).
Procedure
After participants gave informed consent to partake in the study, they were randomly assigned to one of the three experimental conditions and brought into the group laboratory of the Max Planck Institute for Empirical Aesthetics. They were then seated in front of a personal computer on which the study was presented. The experiment was performed using Presentation software.
To keep potential demand characteristics as low as possible, participants were told that they were partaking in a study on how they experience music. To further rule out any demand characteristics, a short version of the German Big Five Inventory (BFI-K; Rammstedt & John, 2005) and a questionnaire on musical taste were administered as filler questionnaires. After the RSES, IAT, and Mood questionnaire were administered, participants listened to three musical pieces and gave music ratings for each piece. The duration of the music listening phase was 12 minutes on average. The order of the pieces was counterbalanced. After listening, the RSES, IAT, and Mood questionnaire were administered again in the same order. The duration of the whole experimental procedure was on average 45 minutes.
Results
Our analytic strategy was twofold. First, we analyzed the main effect of the experimental manipulation on self-esteem by comparing how a participant’s self-esteem changed after listening to either “confident”, “uplifting”, or “depressing” musical pieces. Here, we decided to analyze the effect of the experimental manipulation, controlling for familiarity and liking. Second, we analyzed whether individual differences in a listener’s response to music predicted changes in self-esteem. To this end, we tested the predictive power of the music ratings (liking, familiarity, explicit empathy, and nostalgia) on changes in both explicit and implicit self-esteem.
Effects of experimental manipulation on self-esteem and mood
Explicit self-esteem
Mean score for pretest self-esteem was 22.07 (SD = 5.25, min = 6, max = 28) and for posttest self-esteem, 22.86 (SD = 4.54, min = 6, max = 28). Distribution of pretest and posttest self-esteem was negatively skewed suggesting that the administered four-item scale was subject to a ceiling effect, meaning that potential variance above the scale maximum – i.e., higher levels of self-esteem – may not have been accounted for. In order to account for individual differences in baseline self-esteem, we calculated gain scores for each participant by subtracting pretest self-esteem scores from posttest self-esteem scores, resulting in a new variable indicating music-induced manipulations of explicit state self-esteem. The resulting gain scores were normally distributed.
We performed a one-way ANCOVA to determine differences in explicit self-esteem as a function of the experimental condition (“confident music”, “depressing music”, and “uplifting music”) controlling for familiarity and liking. The results show that there is a significant effect of the type of music (i.e. “confident music”, “depressing music”, or “uplifting music”) on explicit momentary self-esteem, F(2, 113) = 4.67, p = .01, ηp2 = .08. Using Fisher’s least significant difference method, post-hoc comparisons of the estimated marginal means were made. The results indicated that the mean score for the “confident music” condition (M = 2.09, SE = 0.46) was significantly higher than the “depressing music” condition (M = −0.03, SE = 0.42) and the “uplifting music” condition (M = 0.47, SE = 0.36). However, the mean score for the “uplifting music” condition was not significantly different from the “depressing music” condition (Figure 3).
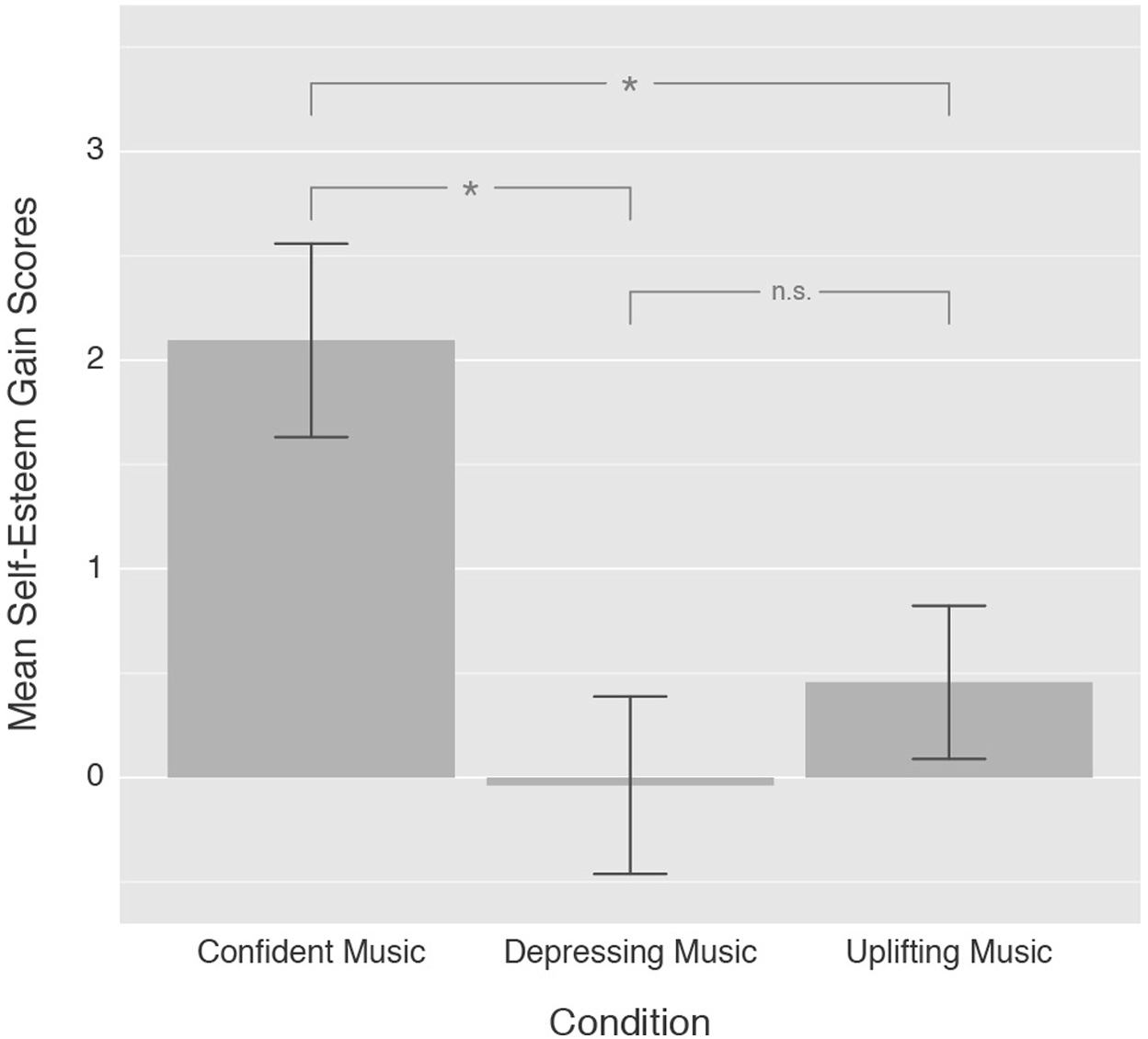
N = 118. The figure displays estimated marginal means of explicit self-esteem gain scores controlling for familiarity and liking in each of the three conditions: “confident music”, “depressing music”, and “uplifting music”. Error bars show one standard error around the mean. Significant differences between means are displayed using Fisher’s least significant difference (LSD) method. * = Difference is significant at the p < .01 level, n.s. = Difference is not significant.
Implicit self-esteem
For the analysis of implicit self-esteem IAT scores were aggregated as recommended by Greenwald, Nosek, and Banaji (2003). Data aggregation was performed in R (R-Core-Team, 2015) by using the function “cleanIAT()” from the package “IAT” (Martin, 2016) specifying means for entire latencies, no extreme value treatment, and block SD including error trials. This algorithm includes data from the practice trials (Block 3 and 6) and is calibrated by each participant’s latency variability. It also includes a penalty scoring for errors. The resulting D1 effect indicates the strength of a participant’s implicit self-esteem in the way that higher scores indicate higher self-esteem. Mean score for pretest implicit self-esteem was 0.59 (SD = 0.33) and for posttest implicit self-esteem 0.53 (SD = 0.4). Mean values correspond to average implicit self-esteem values as documented in other studies (Grumm, Nestler, & Collani, 2009). Implicit and explicit self-esteem were not significantly correlated on both pretest (r = .052, p = .58) and posttest (r = .105, p = .26) scores, which suggests that the measures are not capturing the same construct.
Similar to the analysis of explicit self-esteem, we calculated gain scores for each participant by subtracting pretest scores from posttest scores. The resulting variable indicated the change in implicit self-esteem induced by the experimental treatment. Against what was expected, mean gain scores in all three conditions were close to zero: mean gain score for the first condition was −0.10 (SD = 0.30), for the second −0.09 (SD = 0.31), and for the third −0.02 (SD = 0.37). A one-way ANCOVA of the implicit self-esteem gain scores as a function of treatment condition controlling for familiarity and liking indicated no significant difference between the conditions: F(2, 114) = .61, p = .55, ηp2 =.01.
Mood ratings
To test whether experimental treatment had an effect on mood, we also calculated gain scores for mood ratings by subtracting pretest from posttest scores on each of the three mood dimensions, resulting in three new variables that indicate the change in mood on valence, energetic arousal, and calmness dimensions. One-way ANCOVAs for each mood dimension as a function of the experimental condition, controlling for familiarity and liking indicated no significant differences: valence: F(2, 113) = 1.91, p = .15, ηp2 = .03; calmness: F(2, 113) = .67,p = .51, ηp2 = .01; energetic arousal: F(2, 113) = 2.37,p = .10, ηp2 = .04. The treatment had no significant effect on mood.
The effect of music ratings on self-esteem changes
With this second step of the analysis, we investigated whether the music-related variables predicted changes in self-esteem. Means and standard deviations across the three musical pieces of the ratings were the following: Mliking = 13.42, SDliking = 3.93, Mempathy = 13.39, SDempathy = 3.96, Mfamiliarity = 8.62, SDfamiliarity = 5.88, Mnostalgia = 9.81, SDnostalgia = 3.93. To test whether the music ratings predicted changes in self-esteem, multiple linear regressions were performed, predicting changes in either explicit or implicit self-esteem. Stepwise multiple regression revealed that only liking significantly predicted changes in explicit state self-esteem. Thus, a simple linear regression with liking as predictor provided the best model fit; R2 = .07, F(1, 116) = 8.34, p = .005. For implicit self-esteem, empathy and nostalgia were found as significant predictors. A multiple linear regression predicting changes in implicit self-esteem by empathy and nostalgia had the following model statistics: R2 = .10, F(2, 116) = 6.18, p = .003. While empathy positively predicted changes in implicit self-esteem (b = .03, t = 3.11, p = .002), it was negatively predicted by nostalgia (b = –.03, t = −3.08, p = .003).
Discussion
Overall, our results show a multifaceted picture of the relationship of music listening and momentary self-esteem. While we found that explicit momentary self-esteem changed significantly as a function of condition, implicit self-esteem did not. Furthermore, changes of implicit self-esteem were positively predicted by empathy and negatively predicted by nostalgia; however, none of these variables predicted changes in explicit self-esteem. In turn, changes in explicit self-esteem were predicted by the degree of liking of the music. In addition to the finding that explicit and implicit self-esteem scores were not correlated, the results should be interpreted as relating to two different constructs. Therefore, in what follows the results for explicit and implicit self-esteem will be discussed separately.
Explicit momentary self-esteem
Regarding our first hypothesis, we found that “confident music” but not “uplifting music” enhanced explicit momentary self-esteem. Thus, songs where the singer is expressing an extremely positive self-view from a first-person perspective, communicating strength and self-confidence, were most effective in enhancing momentary explicit self-esteem. It is likely that this effect occurs via some form of empathy, where the listener “puts herself in the shoes of the singer” and adopts the expressed self-view to a certain extent onto herself. However, it was also found that the degree of liking of the music positively predicted changes in explicit momentary self-esteem, suggesting that positive appraisal and pleasure may also play a role in self-enhancement processes.
The findings regarding the effect of music listening on explicit momentary self-esteem may be further interpreted in the following way: when the music is positively appraised, listening to it is enjoyed and it instills positive feelings and evokes pleasure. This in turn may either directly result in enhanced explicit momentary self-esteem or – when listening to empowering music (i.e., “confident music” condition) – become even more amplified. However, even when controlling for liking, listening to “confident music” enhanced explicit momentary self-esteem. This suggests that both internal cognitive processes (e.g., positively appraising the music) as well as processing the expressive properties of the music contribute to an enhancement effect of music listening on explicit momentary self-esteem. Both aspects may work independently but are likely to exert a greater influence when working together.
Implicit momentary self-esteem
Accounts of musical affectivity often emphasize that music has an important effect on automatic processes (e.g., Clarke, 2014; Overy & Molnar-Szakacs, 2009). However, the impact of music on implicit attitudes has rarely been investigated (for exceptions, see Clarke, DeNora, & Vuoskoski, 2015; Rodriguez-Bailon, Ruiz, & Moya, 2009; Rudman & Lee, 2002). Although it was assumed that music listening would affect both explicit and implicit self-esteem, with regard to the scarce research on implicit attitudes, the hypotheses were weaker concerning the latter. Current literature assumes that the relationship between implicit and explicit attitudes is complicated and findings concerning them are oftentimes incongruent (cf., Gawronski & Bodenhausen, 2006). With regard to implicit self-esteem, a suggestion has been made to consider it as a construct that is related to explicit self-esteem, but targets yet another facet of self-evaluation that may be more appropriately described as implicit affect (Buhrmester, Blanton, & Swann, 2011). Against this background, it appears plausible why different effects for explicit and implicit self-esteem were found: implicit self-esteem did not change as a function of the experimental condition, as did explicit self-esteem.
However, implicit self-esteem did respond to measures of how the music was experienced: it was found that empathy positively predicted changes in implicit self-esteem, which confirmed the second hypothesis with regard to this construct. Higher degrees of identification with the singer of a song predicted higher gains in implicit self-esteem. One interpretation of these findings may be that higher feelings of empathy with the singer resulted in a stronger affective response, which is more likely to affect the implicit but not the explicit dimension of self-esteem. This converges with other work that found empathy ratings as a significant moderator for music-induced emotions (Egermann & McAdams, 2013; Vuoskoski & Eerola, 2012). Furthermore, it aligns with previous studies investigating the effect of music listening on implicit attitudes: Clarke et al. (2015) found that listening to music from a foreign culture decreased implicit racial prejudice in participants with high dispositional empathy. This suggests that empathic reactions occurring during music listening may serve as an indicator of changes of implicit attitudes.
It has been reported in previous literature (Cheung et al., 2013) that feelings of nostalgia in response to music promote (explicit) self-esteem. Here, it was also found that nostalgia negatively predicted changes in implicit momentary self-esteem but not in explicit self-esteem. The finding is congruent with the claim that implicit self-esteem is more likely to be affected by affective processes as compared to explicit self-esteem, since nostalgia is an affective process (Barrett et al., 2010). Nostalgia has been characterized as a complex emotion that may comprise positive and/or negative affective components (Barrett et al., 2010). It therefore appears difficult to predict the directionality of the elicited reaction, which may explain why a negative effect of nostalgia was found. Since research on the relationship of emotional responses to music and implicit self-esteem is scarce, further studies are needed in order to understand how nostalgia influences musical self-enhancement processes.
Implications for musical self-enhancement model
The different responses found for explicit and implicit self-esteem suggest that the model of musical self-enhancement should incorporate separate routes for explicit and implicit self-esteem changes. However, it is likely that both routes operate via some form of empathy. It has been emphasized that empathy, being a multidimensional construct, encompasses both an affective and a cognitive dimension (Davis, 1980; Goldman, 2011). Affective empathy occurs via automatic and unconscious processes (e.g., mimicry or imitation) and has been characterized as sharing the feeling of another person (de Vignemont & Singer, 2006; Singer et al., 2004), while cognitive empathy involves perspective-taking that occurs via some form of theory of mind (Davis, 1980). Therefore, implicit self-esteem presumably is more closely related to the affective and automatic aspect of empathy, while explicit self-esteem is more responsive to processes relating to cognitive empathy.
This assumption is supported by our finding that explicit self-esteem was positively influenced by the expressive properties of the music, while implicit self-esteem was predicted by the internal response of experiencing empathy with the singer. Therefore, there may be two different, yet, related routes of empathy: being immersed in the music and experiencing the music as “merging with oneself” presumably operates automatically and mostly on an unconscious level, which is more likely to affect implicit self-esteem. Cognitively taking the stance of the singer involves adopting the positive self-evaluative attitudes expressed through the music for oneself and presumably affects explicit but not implicit self-esteem. For the latter, it is assumed that the propositional content of the lyrics plays a more dominant role. This makes the process comparable to those outlined in the general learning model (Greitemeyer, 2011a), which has been applied to explain how songs and other media types influence subsequent behavior and cognition (Greitemeyer, 2009, 2011b).
Taken together, the process of identification that positively predicted changes in implicit self-esteem may be characterized as an intense form of empathy (Cohen, 2001) and merged subjectivity (Clarke et al., 2015), which arises through an immediate and automatic empathic response to the music, comparable to other types of affective empathy (e.g., empathy for pain; Singer et al., 2004). On the contrary, the positive effect of the “confident music” condition on explicit self-esteem presumably stems from the cognitive processing of the music, involving perspective-taking and adopting self-evaluative attitudes for oneself. This interpretation does also align with dual-process models of implicit and explicit attitudes that assume the former to be linked to associative and the latter to propositional processes (Gawronski & Bodenhausen, 2006). It further converges with the assumption that implicit and explicit self-esteem represent two distinct, yet, interrelated constructs, where explicit self-esteem is characterized by a cognitive evaluation of self-worth (Rosenberg, Schooler, Schoenbach, & Rosenberg, 1995) and implicit self-esteem, as assed by the IAT, represents generalized implicit affect (Buhrmester et al., 2011).
With regard to the pleasure route, no changes in mood were observed as a function of the experimental condition. That changes in self-esteem occurred independently of mood changes suggests musical self-enhancement and mood regulation with music (Saarikallio, 2010; Saarikallio & Erkkilä, 2007) may be considered as two distinct processes. Although mood regulation and self-enhancement have common functionalities and resources (Sedikides & Gregg, 2008), listening to empowering music may specifically pertain to self-enhancement needs, whereas for mood regulatory purposes, other types of music may be more suitable (Västfjäll, 2002).
However, the finding that liking positively predicted changes in explicit momentary self-esteem suggests that positive appraisal and/or pleasure may indeed exert a positive effect on self-esteem, which suggests that there may be an alternative route to empathy. Appraisal processes (Scherer, 2001) in particular may play a more important role in musical self-enhancement than it has previously been assumed. The cognitive appraisal of music may indeed be an important and early reaction to music that influences subsequent affective processes (Juslin & Vastfjall, 2008; Scherer & Zentner, 2001). Appraisal therefore presumably also plays a role in musical self-enhancement. However, it is considered as one potential mechanism that is complemented by others as outlined in the model. Since the third aspect of social cohesion was not addressed in this study, no conclusions can be drawn.
Limitations and future directions
Our study is limited in the sense that a ceiling effect of the explicit self-esteem measure was identified, which is likely to be responsible for the high amount of zero gain scores (37%) in the sample. People may have been willing to report an increase in self-esteem, but weren’t able to do so because of the limitation of the scale. A similar limitation applies to the employed mood scale (MDBF; Schoebi & Wilhelm, 2007), which only comprised of two items for each mood dimension.
Although using songs in our experiment was considered as the most ecologically valid stimulus selection, it bears the limitation that music and propositional content were confounded and no assertions can be made as to whether the effect relies on both or either one of them. Since a great body of research has documented that music is frequently used in ways that closely relate to self-enhancement and there is no such activity documented with regard to literary reading activities, it is assumed that music is driving the effect. However, this question should be addressed in subsequent studies. Finally, although a balanced selection of music stimuli between conditions was intended (e.g., by matching artists), there were differences with regard to the popularity, release date, and musical style.
Conclusion
Our study offers a novel perspective on the functions of music listening in everyday life by linking music listening to changes in self-esteem. By showing that listening to empowering music affects self-esteem, it provides initial empirical evidence that music provides a resource for self-enhancement. As an aesthetic surrogate of social interaction that is needed to maintain high self-esteem (Pyszczynski et al., 2004), music may be particularly suitable for providing social images and subjectivities that people identify and empathically engage with in order to satisfy self-enhancement needs.
Footnotes
Appendix
List of musical stimuli used in the experiment.
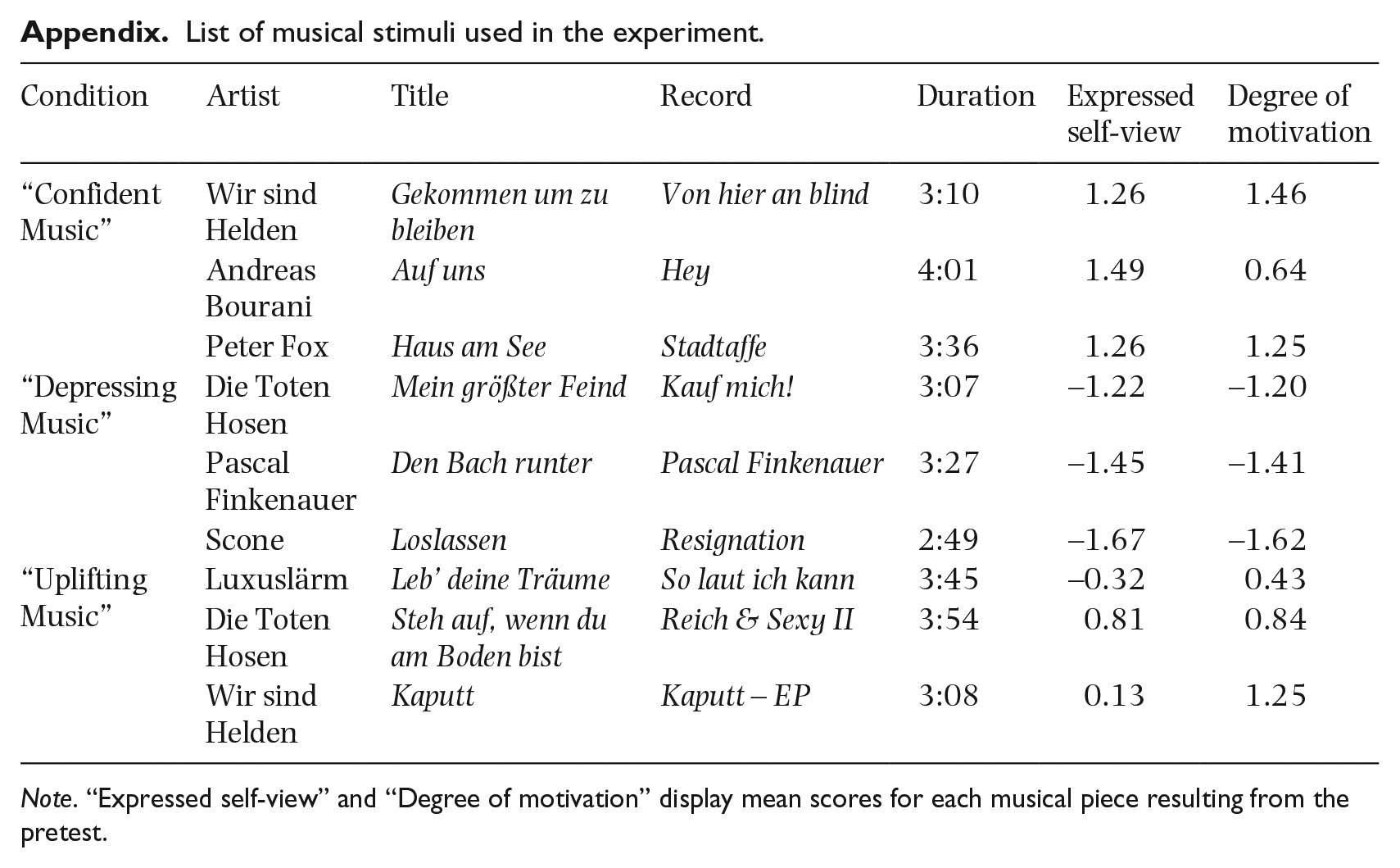
| Condition | Artist | Title | Record | Duration | Expressed self-view | Degree of motivation |
|---|---|---|---|---|---|---|
| “Confident Music” | Wir sind Helden | Gekommen um zu bleiben | Von hier an blind | 3:10 | 1.26 | 1.46 |
| Andreas Bourani | Auf uns | Hey | 4:01 | 1.49 | 0.64 | |
| Peter Fox | Haus am See | Stadtaffe | 3:36 | 1.26 | 1.25 | |
| “Depressing Music” | Die Toten Hosen | Mein größter Feind | Kauf mich! | 3:07 | −1.22 | −1.20 |
| Pascal Finkenauer | Den Bach runter | Pascal Finkenauer | 3:27 | −1.45 | −1.41 | |
| Scone | Loslassen | Resignation | 2:49 | −1.67 | −1.62 | |
| “Uplifting Music” | Luxuslärm | Leb’ deine Träume | So laut ich kann | 3:45 | −0.32 | 0.43 |
| Die Toten Hosen | Steh auf, wenn du am Boden bist | Reich & Sexy II | 3:54 | 0.81 | 0.84 | |
| Wir sind Helden | Kaputt | Kaputt – EP | 3:08 | 0.13 | 1.25 |
Note. “Expressed self-view” and “Degree of motivation” display mean scores for each musical piece resulting from the pretest.
Acknowledgements
The authors are thankful to the reviewers for their insightful comments and to Melanie Wald-Fuhrmann for her critical reading of earlier versions of the manuscript. The authors would also like to thank Muralikrishnan, Claudia Lehr, Elena Felker, Myra Huymayer, and Felix Bernoully whose support has been of value for the realization of the study.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.