
Abstract
Here we present an investigation into whether vocal timbre impacts on emotional perception of sung words, and whether this effect is intersubjective. That is, does vocal timbre influence the processing of emotion in words, and does it do so in a similar way across listeners? If so, this could help overcome the lack of appropriate analytical techniques for vocal timbre analysis in popular music by approaching such analysis from the perspective of vocal timbres emotive content and how this emotive content impacts emotional perception of sung words (lyrics), specifically in popular, lyric-based, vocal songs. The results of a reception test on emotional word perception according to timbre valence show that participants are significantly less accurate in identifying the emotional valence of words when they are sung with a vocal timbre that has an incongruent emotional valence and, for sad words, they are also slower in arriving at a correct identification of the word’s emotional valence when sung with an emotionally incongruent timbre. This supports the hypothesis that timbre conveys emotional meaning and that the experience of vocal timbre may be intersubjective.
We can find out a lot about a thing by the way it sounds. Is that a car or a bus? A child’s laugh or an adult’s? A scream of joy or a cry for help? A happy song or a sad song? In music, sounds are used and manipulated in the composition of everything from popular songs, to classical concertos, to Chinese operas. But how these sounds are used in the creation of music, and how they are manipulated, is constantly evolving. It follows, then, that in order to continually engage in meaningful musicological discussions, we must have a set of techniques that are appropriate for the analysis of a variety of musical features in a variety of contexts. However, this is not always the case, particularly in the instance of popular music. There are many reasons why analysis techniques have not always kept pace with the changes in popular music – historical lag, prescriptive vs. descriptive writing, and issues of notation are just a few of the most obvious and early issues facing popular music analysis (Seeger, 1977). However, one central reason is that popular music aesthetics differ substantially from those reflected in traditional musical analysis techniques. Furthermore, it is also not uncommon for aesthetics to vary quite substantially between different genres of popular music, making it difficult to develop a definitive set of tools for popular music analysis. 1
One of the most difficult to analyse, yet essential, aspects of the popular music aesthetic is vocal timbre. For the purposes of this article, the following preliminary definition of vocal timbre has been synthesised (primarily from definitions given by Houtsma, 1997, p. 105; Bregman 1990, p. 92; and Hajda, Kendall, Carterette, & Harshberger, 2004, p. 282): Vocal timbre (1) is the characteristic sound of a singer’s voice that differentiates it from other sound sources (and indeed from other singers), even when they share the same volume (dynamic), frequency (pitch), and time (duration); and (2) may include the way a singer is able to use their voice to evoke an emotional response through both pitched and unpitched sounds (breathiness, stylised screams/cries, throaty sounds, etc.)
Vocal timbre is often central to our understanding of popular, lyric-based, vocal song genres (henceforth referred to as popular vocal songs), contributing to the unique aural experience of an individual song. One way in which this is best illustrated is in song covers (i.e., when an artist makes their own version of someone else’s song). Consider, for example, Marilyn Manson’s cover of Gloria Jones’s Tainted Love. Although all the basic structural elements remain the same (harmony, rhythm structures, pitch), it is easy to tell the difference between Manson’s cover and Jones’s original. That is to say, the song no longer sounds the same, despite being structurally quite similar. One reason for this is that the vocal timbres in the songs are very different (think about the sound of Manson’s singing voice compared to Jones’s). Vocal timbre is, in this way, both most immediately apparent to the listener and most notoriously difficult to encapsulate in musical analysis.
It is our belief that one way to approach the analysis of vocal timbre of popular vocal songs is by considering how the emotive content of vocal timbre impacts emotional perception of sung words (i.e., lyrics). For an analytical technique 2 based on such a hypothesis to be considered robust (i.e., intersubjective, applicable beyond the idiosyncratic experience of the listener) it is important to first put this hypothesis to the test. This paper presents a reception test developed to examine how a word is emotionally classified depending on whether the timbral emotion with which it is sung is congruent or incongruent with the word’s emotional meaning.
Why should timbre impact the emotional charge of lyrics?
Studies into emotional tone of voice have revealed that the way something is said is just as important as what is being said. In such experiments, the participant is first presented with an emotional tone of voice (i.e., a “prime” that is meant to bias the participant), then presented with a congruent or incongruent emotional word to which they must respond. In a 2002 study by Nygaard and Lundersl, it was found that “emotional tone of voice affects the processing of lexically ambiguous words by biasing the selection of word meaning” (Nygaard & Lundersl, 2002, p. 583). That is, when the meaning of a word is not immediately clear, the speakers’ emotional tone of voice appears to influence how listeners perceive its meaning.
Similar results have been found with words that are not lexically ambiguous. A 2008 study by Nygaard and Quees found that faster processing of spoken words was facilitated when emotional tone of voice was concurrent with the intrinsic emotional connotation of the word (e.g., happy word spoken in a happy tone of voice; Nygaard & Quees, 2008). It was also found that the integration of paralinguistic (e.g., tone of voice) and linguistic elements of speech occurred relatively early in the perception process, suggesting that the perception of spoken words is not independent of perception of emotional prosody (Nygaard & Quees, 2008). This research suggests that emotional tone of voice does have the potential to impact perception of emotion and meaning and, by extension, so could other paralinguistic features such as vocal timbre.
The experimental approach used in this article is similar to that of the abovementioned studies. In the current study, the participant is presented (i.e. primed) with the phrase “the word I will now sing is [Target Word]”. Sung with an emotional vocal timbre then presented with a congruent or incongruent emotional target word.
Another paradigm that has been used to investigate the same effect is the emotional Stroop task. The Stroop effect was most famously documented in J. Ridley Stroop’s 1935 article “Studies of interference in serial verbal reactions”. In his article, Stroop observed that participants were slower at naming colours when they were presented with an incongruent colour word (e.g., when the word “blue” was written in red ink, participants were slower to say “red”). This is due to semantic interference: the automatic processing of the written colour word interferes with the production of the word that describes the ink colour because both belong to the same semantic field but are incompatible. This task, now called the Stroop task, has been used many times and with many variations (MacLeod, 1991). One variation is the emotional Stroop task. Particularly of interest to this study are emotional Stroop tasks that involve emotional prosody–emotional word interference. The underlying assumption in such tasks is that, if prosody is processed in terms of emotional valence, interference between this valence and that of an emotional word should arise when they are incompatible.
Studies employing the emotional Stroop task have produced mixed results. Studies have found differing patterns of interference between emotional prosody and emotional words (Grimshaw, 1998; Schirmer & Kotz, 2003). Others have found this effect to be modulated by factors such as age (Wurm, Labouvie-Vief, Aycock, Rebucal, & Koch, 2004, p. 523), and context (i.e., in languages where contextual and non-verbal cues play a greater role than purely linguistic cues in conveying information, interference between emotional prosody and emotional words is stronger; Kitayama & Ishii, 2002).
These conflicting results raise questions about the reliability of the findings, making it difficult to determine conclusively whether paralinguistic emotional valence such as that ascribed to prosody can truly and consistently affect lexical processing. If the effect of prosody is so unreliable, will any potential effect of timbre on sung words be any more trustworthy?
There are two reasons to believe it will. First, the problem of the conflicting results for emotional Stroop tasks is likely to lie in the task itself and its suitability for investigating the effect of emotional prosody on lexical processing. In particular, differences in results may be due to the relative speed of processing of the emotional valence of prosody in relation to that of lexical access. If lexical access is generally faster than prosody processing, the latter would not usually be able to interfere with the former. However, an effect would be expected if the task is inverted – that is, when participants respond to the valence of the prosody while having to ignore the valence of the spoken words, as Grimshaw (1998) found. Also, any manipulation that either speeds prosody processing or delays lexical processing should have a greater chance of delivering an effect. This could explain the age effect found by Wurm et al. (2004) since lexical access slows down with age (Lima, Hale, & Myerson, 1991). More generally, it could explain why the effect is more likely to surface when the task is made more difficult in general (Schirmer & Kotz, 2003, p. 1146). This interpretation is compatible with the work of Krestar and McLennan (2013). They found that, when the time-course of spoken word recognition and processing is relatively fast, word processing was affected less by variation in emotional tone of voice. When word recognition and processing was slow, word processing was affected more by variations in emotional tone of voice, possibly because the listener is then relying on a representation based on previous encounters with this word in real life.
The problems just identified, however, are not likely to affect the current study because the task here is a priming one where the equivalent to the emotional valence of prosody (i.e., the emotional valence of vocal timbre) is presented ahead of the word to be assessed, so there should be enough time for it to have been processed by the time the stimulus word is presented. Furthermore, the slow tempo in which words are sung in this study should maximise the chances of an effect of paralinguistic emotional valence on lexical processing.
A second reason why the reception tests presented in this paper should be more reliable is that singing may exaggerate the emotive qualities of speech, making emotional vocal timbres more likely to impact emotional perception of sung words. In fact, exaggerated prosody in speech appears to result in a greater impact of prosody on word processing (Kitayama & Ishii, 2002), and it is possible that the variable results of the emotional Stroop task are also in part due to variability in the “salience of the vocally expressed emotion” (Schirmer & Kotz, 2003, p. 1145).
It has been argued that music could draw on emotive speech qualities in the expression of emotion in performance: “That many features of expression in performance are similar to vocal expression of emotion … suggests that we get aroused by ‘voice-like’ features in music performance” (Juslin & Timmers, 2011, p. 477). And listeners may also mimic these emotions within themselves (Juslin & Laukka, 2004). In this way, music seems to heighten the focus on emotive voice-like qualities, making it a highly evocative emotional stimulus. Therefore, the emotive non-linguistic content in the form of vocal timbre in the current study may be a heightened, stylised form of emotional prosody, thus making it more likely to impact perception of sung words than has been found for prosody in spoken language.
The current study
The purpose of the reception test presented here is to investigate whether the emotional valence expressed by a vocal timbre impacts on emotional perception of sung words. To this end, participants were asked to judge the emotional meaning of words in the presence of different emotionally charged vocal timbres. The emotional valences of the timbres either coincided or conflicted with those of the words. It was reasoned that, if the emotional charge of vocal timbre has the capacity to affect how sung words are perceived, we should see participants identifying the emotional valence of words faster and more accurately when they are sung in an emotionally matched vocal timbre than when they are sung in an emotionally mismatched vocal timbre.
Method
Participants
Twenty participants (40% male; 70% aged 18–30, 20% aged 31–40, 10% aged 41–50) from the general population (i.e., who were not required to be musically trained or have any specialised musical knowledge) were recruited from the University of New England and surrounding community. Participants who had a hearing impairment, who were not native speakers of English, and who had not spent most of their lives in Australia were excluded from the study. Participation was voluntary. Participants were paid AU$15.
Procedures and materials
The study was conducted as a priming task in which the reaction times and response accuracy to different target words in different conditions was measured. Participants were required to listen to a musical phrase sung with timbres of different emotional valences and containing an emotional (either happy or sad) word (see Appendix).
The valence of the vocal timbres to be used was determined in a pre-test. In this pre-test, 119 participants from the general population (i.e., not required to be musically trained or have any specialised musical knowledge) were required to judge the emotional valence of 324 musical items on a Likert scale of 1 to 5, with 1 being very sad and 5 being very happy. The musical items consisted of one of three melodic contours sung imitating the vocal timbre of one of six happy, six neutral, and six sad vocal timbre tokens. The vocal timbre tokens were those from songs in musicals (e.g., “I’ll cover you” from Rent, “Windy City” from Calamity Jane, and “Somewhere” from West Side Story) in which the vocal timbre of the singer was considered happy, neutral, or sad by virtue of its association with scenes whose role within the story was happy, neutral, or sad (e.g., a song in a mourning scene would be considered to have a sad timbre). Their purpose was to provide the singers with something to imitate. Singers sang each musical item on the syllable “la”. Each musical item was recorded by three male and three female singers. Items were counterbalanced across six lists so that each participant only heard each item once, while being exposed to all the different timbres, melodic contours, and singers an equal number of times. The presentation was individually randomised. From this total sample of 324 items, a total of three vocal timbres were selected for the final reception test: the one most typically rated happy (mean rating of 2.60 out of 5), the one most typically rated sad (mean rating of 3.67 out of 5), and the one most typically rated neutral (mean rating of 3.07 out of 5).
The chosen vocal timbres (happy and sad) were given to the male singer associated with the clearest timbral differences (mean happy score = 2.55, mean sad score = 3.83) to replicate while singing a musical phrase with the sentence “The word I will now sing is ____” plus one of the words. The pitches which the singer sang for all recordings can be seen in Figure 1. The emotional target words were recorded twice: once with a sad timbre and once with a happy timbre. For the target words, the emotional valence of the vocal timbre were thus either congruent or incongruent with the emotional valence of the word. The neutral words were only recorded with the neutral vocal timbre and used as fillers. In all cases, participants were asked to decide as quickly as possible whether each of the words was happy or sad.

The musical phrase used in the reception test, sung with the words “The word I will now sing is …”.
The stimuli so created were later tested against the example stimuli from the pre-test to check whether the timbres were the same as those they were supposed to replicate. Eight experienced musicians were asked to rate how similar the happy and sad vocal timbres in the final reception test (i.e., the timbres used for the experimental stimuli) were to the happy, neutral, and sad examples from the pre-test. This comparison test showed that the sad vocal timbres were perceived as being most similar to the sad example (74%), but the happy vocal timbres were less clearly identified with the happy example (31%), being often assimilated to the neutral one (53%). This shows an asymmetry in timbral emotional valence that may be inbuilt rather than an artefact of the way the materials were prepared: for listeners, sadness seems to be more salient than happiness (Rozin & Royzman, 2001). This asymmetry will be discussed later in more detail. Given the nature of the task (i.e., choosing between “happy” and “sad” only, with no possibility of choosing “neutral”), the fact that the happy vocal timbres were unlikely to be assimilated to the sad example (18% of the time), and that sad vocal timbres were unlikely to be assimilated to the happy example (4% of the time), was thought to be sufficient to test the differential effect of the timbre’s emotion. However, the difference between the “happiness” of the happy timbre and the “sadness” of the sad timbre will be taken into account when interpreting the results.
The words used in the final reception test, 56 in total, were selected from the Affective Norms for English Words (Bradley & Lang, 1999; see Appendix). Eighteen words with a happy valence and 18 words with a sad valence were selected as experimental items. Since all the contrasts were within-item (i.e., reaction times and accuracy rates for happy word 1 sung with a happy vocal timbre was tested against happy word 1 sung in sad vocal timbre, and so on for all the target words), there was no need to match the words on lexical parameters known to affect lexical retrieval. Additionally, 20 words with a neutral valence were used as fillers. As described above, every word with a happy and sad valence was recorded, together with the rest of the phrase “The word I will now sing is ___”, both with a happy and with a sad vocal timbre (i.e., happy word and happy vocal timbre, happy word and sad vocal timbre, and so on) such that a total of 72 experimental items were recorded. The 20 fillers consisting of neutral words were recorded with a neutral vocal timbre.
Experimental items were counterbalanced across two lists (that is, a word appeared with a happy timbre in one list and with a sad timbre in the other) such that each list contained all the experimental words only once. There were equal numbers of each item type (i.e., happy word–happy timbre, happy word–sad timbre, etc.) in each list. Fillers were constant across lists. In this way, a total of 56 items was presented in each list. Half of the participants were randomly assigned to one list, and half to the other list.
The musical phrases were delivered in a different random order for each participant using the DMDX experimental program (Foster & Foster, 2015) through 40 mm AudioSonic headphones. Words were only presented aurally. Participants were instructed to indicate if the target word was happy or sad by selecting a key on the keyboard. The valences were represented on the keyboard with a large smiley face representing happy on one key (F on the keyboard), and a large sad face representing sad on another key (J on the keyboard). To control for handedness, the order of happy and sad keys was reversed for half the participants in each list. Participants could only indicate happy or sad responses; therefore, it was expected that neutral items (fillers) should be randomly categorised as happy or sad. Participants were told to keep their fingers on the keys at all times. Reaction times were measured from the onset of the target word.
Results
Figures 2 and 3 show the reaction times and number of errors, respectively, of these within word comparisons according to word valence and condition.
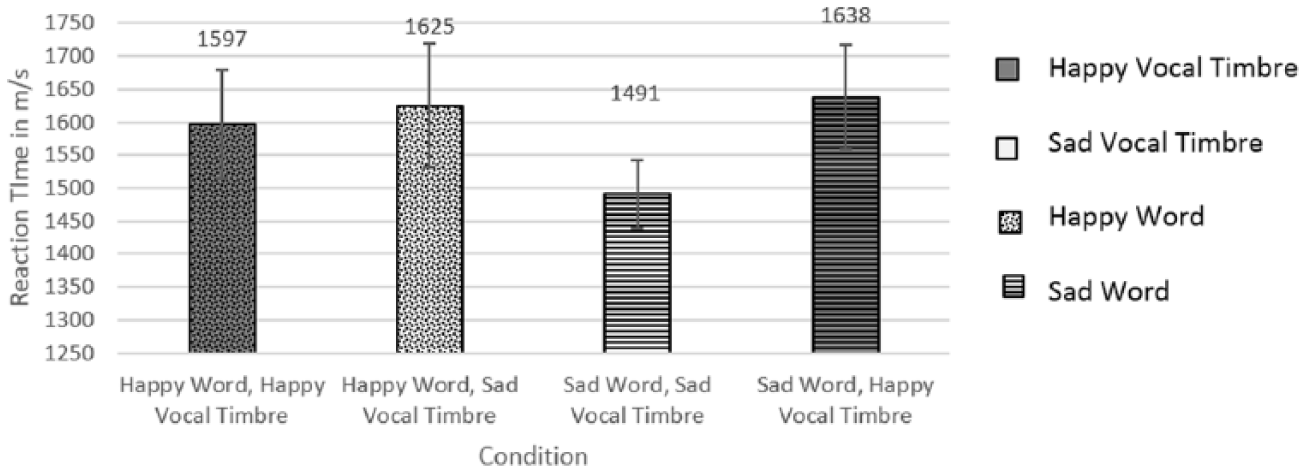
Reaction times for matched and mismatched conditions.
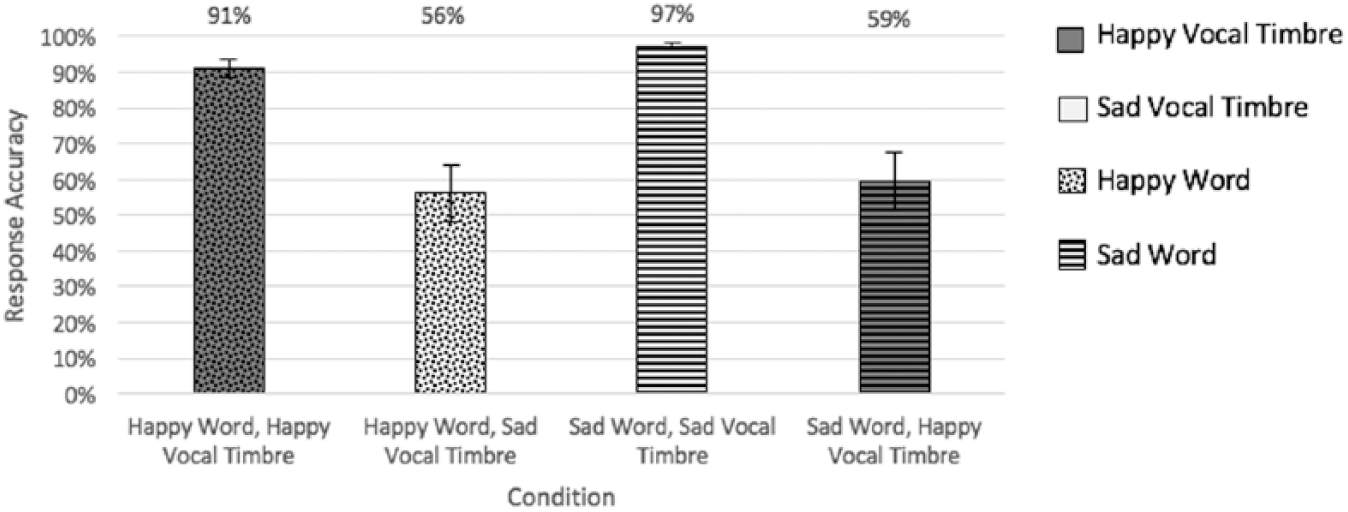
Percentage of correct responses for matched and mismatched conditions.
Two separate 2 (happy vs. sad words) × 2 (happy vs. sad timbres) repeated measures analyses of variance (ANOVA) were used to see whether there were differences in either reaction times or error rates for emotionally charged words sung with a matched or a mismatched emotional vocal timbre.
In the case of reaction times (RTs), as expected, there was no main effect of timbral valence as responses to sad and happy timbres overall were not significantly different, F(1, 19) = 1.806,p = .195,
Pairwise comparisons were used to further investigate response times to the two types of words separately. Results showed that response times to sad words when sung with a happy vocal timbre were significantly longer as compared to response times to sad words sung with a sad vocal timbre, t(19) = 2.484, p = .022. On the other hand, response times to happy words sung with a happy vocal timbre were not significantly different to those sung with sad vocal timbre, t(19) = -0.345, p = .734.
In the case of response accuracy, there was no main effect of timbral valence, F(1, 19) = .373, p = .549,
As expected, visual inspection showed that neutral filler items were responded to randomly with 49% of neutral items being responded to as happy, and 51% being responded to as sad.
Discussion
The current study investigated whether vocal timbre could act as a prime, impacting on emotional perception of sung words. The above results show that emotionally charged words were recognised more accurately when sung with an emotionally matched vocal timbre than with an emotionally mismatched one. They also show that sad words were recognised faster when sung with a matching sad timbre. On the other hand, happy emotionally charged words were not recognised faster when sung with an emotionally congruent vocal timbre. The finding of an impact of non-linguistic features (vocal timbre in this case) on perception of sung words is in line with the results from the emotional tone of voice priming paradigm.
Emotional valence and word categorisation speed
While these results do show the predicted effect of vocal timbre on the speed at which the valence of sung words is recognised, the effect seems to be restricted to sad words. This somewhat unexpected finding could be explained by negativity bias.
Already in the comparison test performed by expert musicians, it was observed that happy vocal timbres were not as clearly happy as sad vocal timbres were sad: it was found that the sad vocal timbres used in the final reception test were most accurately identified as being similar to the vocal timbre they were replicating (74% of the time as opposed to 31% for happy words). In principle, it could be due either to the sad timbre offered as an example being easier to replicate for the singer or to the sad timbres replicated being easier to identify for the musicians that performed the subsequent comparison task. In either case, given that these were all experienced musicians, it points to the possibility that sad vocal timbres contain more salient characteristics than happy vocal timbres (e.g., more throaty, rough, breathy sounds). In fact, sadness and tenderness/love have been identified as some of the most expressive qualities in music performance (Juslin, 2001, p. 317). If so, it should not be so surprising that the effect on reaction times was most marked for sad words in the general population.
In speech, negative prosodies have also been found to be more salient than positive ones in relation to accuracy in word discrimination: “independent of emotional meaning, words with happy prosody were rated less accurately than words with neutral or angry prosody” (Schirmer & Kotz, 2003, p. 1139). Clearly, negative/sad emotional prosodies/vocal timbres are highly salient. Therefore, it is likely that these emotions are easier to categorise and may also impact word perception to a greater extent than their positive, high arousal counterparts (e.g., happy prosodies/vocal timbres), as has been found here.
The reason why negative valences such as sadness appear to be more salient and more easily identified is likely to be related to the phenomenon known as negative bias. Negative bias has been observed across many disciplines for some time (Rozin & Royzman, 2001). It refers to the “asymmetry in the way in which people handle evaluatively positive and negative phenomena” (Lewicka, Czapinski, & Peeters, 1992, p. 425), with a tendency for negative experiences (thoughts, emotions, etc.) to be felt more acutely than positive ones (Baumeister, Bratslavsky, Finkenauer, & Vohs, 2001). This negative bias has been explained as the result of evolutionary pressures which would benefit increased awareness of potentially dangerous stimuli (Hansen & Hansen, 1988; Rozin & Royzman, 2001).
In the case of this reception test, it may be that participants are impacted to a greater extent by the sad vocal timbre, intensifying its effect on sad words. This would explain why participants were quickest (by over 100 m/s) in identifying word valence when both word and vocal timbre were sad (i.e., negative) (see Figure 2). At any rate, the salience of sad vocal timbres observed here is in line with research cited above which suggests that negative emotional signals are likely to have more of an impact on emotional perception than positive ones.
This explanation for the lack of happy word RT effect together with the pattern of results (see Figure 2) suggests the RT differences between the matched and mismatched valence conditions could be the result of the congruent timbral valence facilitating recognition of the word’s valence: the more recognisable sad timbre is thus associated with a larger effect on the congruent sad words. If the effect was the result of the incongruent timbres interfering with the recognition of the word’s valence, it should have been the sad words that were less affected when being sung with a less incongruent timbre. However, in the absence of a neutral timbral condition, we cannot extract a definitive conclusion in this regard.
In sum, it is clear that timbral valence can influence the speed at which words are processed, at least for some words and in some circumstances. In particular, it is the more negative valences that show the greatest effect, and this may have to do both with sad timbres possibly being more salient and with a more general cognitive negative bias.
The mechanism by which such an effect takes place is beyond the purview of this study. However, we can speculate that sad timbres may predispose the listener to a state of mind in which the perceived likelihood and magnitude of a negative experience occurring is heightened (Rozin & Royzman, 2001). This negative emotional vocal timbre may heighten the listeners’ sensitivity to further cues for “sadness”, which may in turn facilitate the episodic representation of compatible sad words making their valence easier to recognise (in a similar way to Krestar & McLennan’s suggestion that “attention to a particular nonlinguistic feature like ETV may allow episodic representation to dominate” [2013, p. 1800]).
Emotional valence and word categorisation accuracy
As well as an effect on categorisation speed, we also found an effect of timbral valence on word categorisation accuracy: people were more likely to make mistakes when the timbral valence mismatched that of the word. This effect on accuracy had not been predicted. However, it is well-known that, whenever people have to work under time pressure, a trade-off between speed and accuracy can ensue (Rinkenauer, Osman, Ulrich, Müller-Gethmann, & Mattes, 2004; Wickelgren, 1977). Under these circumstances, participants can sacrifice accuracy to work as quickly as possible, or sacrifice speed to work more accurately. As participants were instructed to work as quickly as possible in this experiment, this may have resulted in a sacrifice of accuracy in favour of speed.
But why would words be miscategorised at all? One possibility is that participants were (sometimes) responding to the valence detected in the timbre instead of that of the word. The emotion expressed in the vocal timbre may create an expectation of the valence of accompanying words that, when violated in mismatch cases, is more likely to elicit an incorrect response. That is to say, participants may be so influenced by the vocal timbre and the emotion expressed therein that, in mismatched conditions, a conflict is induced between responding to the emotion elicited by the timbre and that evoked by the meaning of the word itself.
Alternatively, the effect on accuracy may be due to the emotional charge of the timbre imbuing the word itself making it “feel” more (or less) happy or sad than it would in normal circumstances. This would, in turn, make the word less readily identified as happy or sad when sung with a mismatched emotional timbre and, thus, more easily misidentified. In other words, this effect could be due to the emotional valence of the words being altered to accord with the emotional valence created by the timbre.
These explanations (timbre creating expectation and timbre imbuing the word meaning itself) would imply quite a strong pull of the emotional valence of vocal timbre if it can compete with a word’s intrinsic valence.
Curiously, despite the asymmetry in timbral valences (sad was sadder than happy was happy) and in contrast with the results of reaction times discussed above, the tendency for mistaken categorisation was the same for happy and sad words. One possibility is that what mattered in this case was whether the timbre was perceived as sad or not sad rather than sad or happy. The happy timbres used in the final reception task may not have been consistently found to resemble the happy timbre exemplar (31% of the time), but they were quite consistently recognised as not sad (82% of the time; similar to how consistently the sad timbres were recognised as clearly sad, 74% of the time). It is possible that, for the purposes of reacting quickly, it was the congruent timbre that was responsible for most of the effect by putting the listener in the right emotional state to activate compatible episodic word traces while, for the purpose of categorising, perceiving the timbre as either clearly sad or clearly not sad may have been enough to bias word responses. In that case, a happy word with a sad timbre would be as difficult to categorise as a sad word with a non-sad timbre.
What is clear, in any event, is that vocal timbre is contributing to the listener’s perception of the lyric’s emotional meaning and it does so in a consistent manner across this population of young to middle-aged Australians. This is just what was predicted. Therefore, that participants were more likely to misidentify word valences in mismatched cases across both happy and sad words supports the hypothesis that a timbre’s associated emotional valence affects the semantic processing of emotional words.
Implications and concluding remarks
In general, there is a lack of widely agreed-upon analytical techniques for vocal timbre analysis in popular vocal songs. The authors have elsewhere proposed analysing vocal timbre by considering how it may impact emotional perception of lyrics. Such an analytical technique requires reception testing to determine whether it would be robust (i.e., intersubjective, applicable beyond the idiosyncratic experience of the listener). The goal of the reception test presented in this paper has been to do just this.
The results of the reception test presented here demonstrate that vocal timbre does impact the emotional experience of lyrics and that the exploration of this experience may provide an avenue into vocal timbre analysis for popular vocal song.
From this point, some preliminary analysis of vocal timbre in popular vocal songs needs to be conducted to identify areas in the technique that require further research. The impact of repeated listenings will also require further exploration – i.e., if/how does our perception of emotional vocal timbres/lyrics change as we grow more familiar with a song? There are also other questions about listening and recording environments that should be addressed in the future.
Clearly, the development of an analytical technique for vocal timbre that is centred on the perception of emotional meaning will be an ongoing process. However, this article presents evidence to support the idea that we could analyse vocal timbre by considering its emotional impact on lyrics.
In sum, the impact of timbre on the emotional perception of sung words is a significant finding. It supports the stated hypotheses which could form the basis of further analysis of vocal timbre: first, that vocal timbre seems to contribute to the emotional experience of song and, second, that vocal timbre seems to contribute to the emotional experience of a song in an intersubjective way. Therefore, approaching vocal timbre analysis by considering how timbre impacts emotional perception of lyrics may be robust and yield intersubjective results.
Footnotes
Appendix
List of happy, sad, and neutral words used for stimuli in main test.
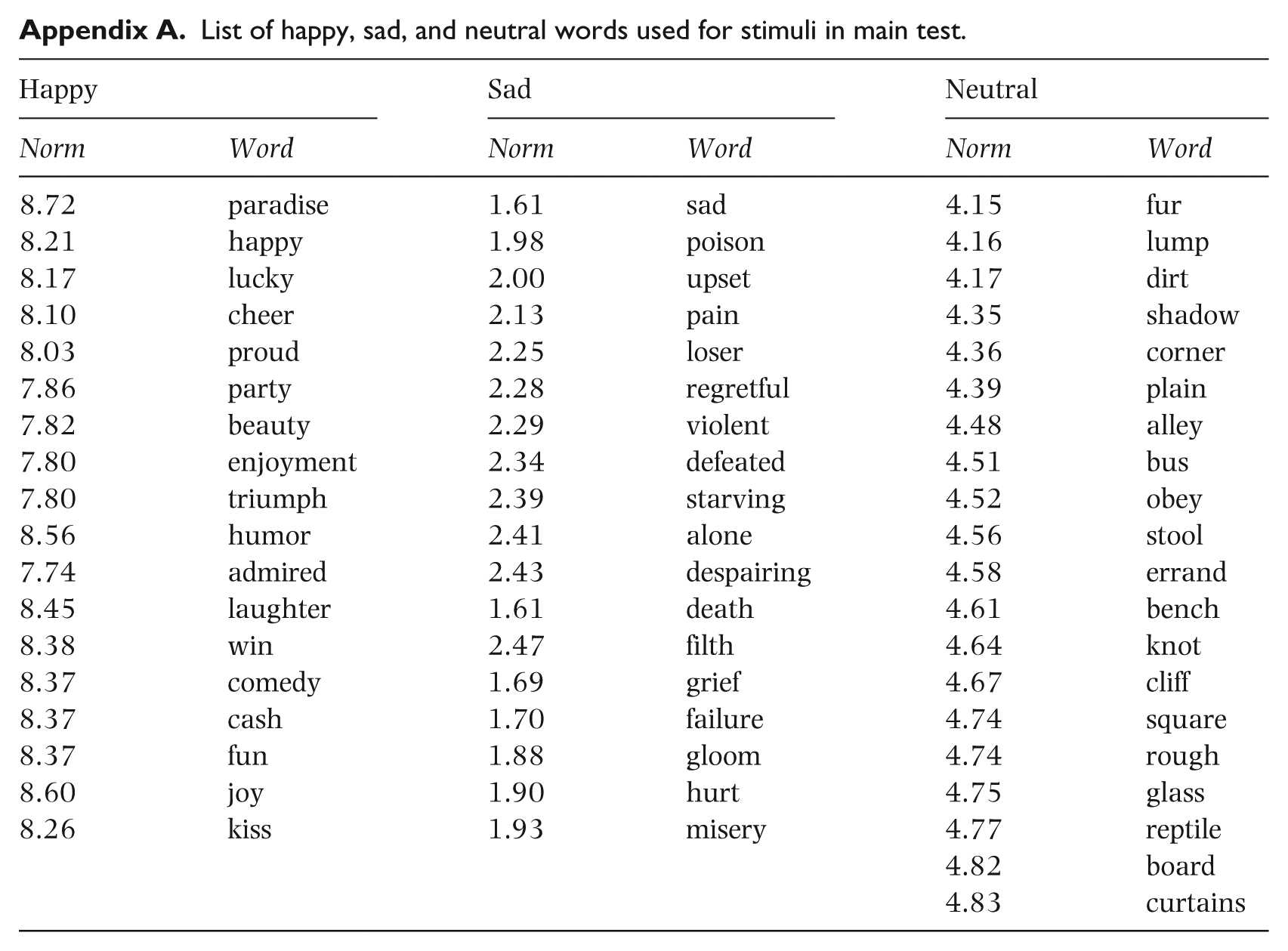
| Happy |
Sad |
Neutral |
|||
|---|---|---|---|---|---|
| Norm | Word | Norm | Word | Norm | Word |
| 8.72 | paradise | 1.61 | sad | 4.15 | fur |
| 8.21 | happy | 1.98 | poison | 4.16 | lump |
| 8.17 | lucky | 2.00 | upset | 4.17 | dirt |
| 8.10 | cheer | 2.13 | pain | 4.35 | shadow |
| 8.03 | proud | 2.25 | loser | 4.36 | corner |
| 7.86 | party | 2.28 | regretful | 4.39 | plain |
| 7.82 | beauty | 2.29 | violent | 4.48 | alley |
| 7.80 | enjoyment | 2.34 | defeated | 4.51 | bus |
| 7.80 | triumph | 2.39 | starving | 4.52 | obey |
| 8.56 | humor | 2.41 | alone | 4.56 | stool |
| 7.74 | admired | 2.43 | despairing | 4.58 | errand |
| 8.45 | laughter | 1.61 | death | 4.61 | bench |
| 8.38 | win | 2.47 | filth | 4.64 | knot |
| 8.37 | comedy | 1.69 | grief | 4.67 | cliff |
| 8.37 | cash | 1.70 | failure | 4.74 | square |
| 8.37 | fun | 1.88 | gloom | 4.74 | rough |
| 8.60 | joy | 1.90 | hurt | 4.75 | glass |
| 8.26 | kiss | 1.93 | misery | 4.77 | reptile |
| 4.82 | board | ||||
| 4.83 | curtains | ||||
Ethical approval
Ethical approval for this project was given by the University of New England Human Research Ethics Committee (reference numbers: HE15-186, HE14-190, and HE16-306).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Australian Postgraduate Award, the Faculty of Humanities, Arts, Social Sciences and Education, University of New England (Australia).