
Abstract
The integration of artificial intelligence in libraries can have a wide impact on the evolution of information access and management. It allows both the streamlining of internal processes and the transformation of the way users interact with information resources, thereby enhancing effectiveness and operational efficiency while enriching the user experience. This article presents the experience of incorporating several artificial intelligence techniques in the Library of the National Congress of Chile and describes three initiatives: (1) publishing legislation as linked open data with Semantic Web technologies, combining machine-readable comprehension with high standards of interoperability; (2) maintaining the history of legislation via the automatic tagging of legislative documentation with natural language processing; and (3) predicting law approval based on the current political context using machine learning. The use of these technologies has allowed the library to offer a wide variety of knowledge management services, providing useful and timely information for parliamentary work as well as automated human-based repetitive tasks for the efficient use of public resources.
Keywords
Introduction
Artificial intelligence (AI) is being widely used to facilitate automation and support various human tasks, and its integration in libraries is having a significant impact on the evolution of information access and management. The techniques that are being increasingly used include natural language processing, intelligent search engines or multimodal discoverers, and physical or virtual robots. The use of these techniques allows internal processes to be streamlined and also transforms the ways users interact with information resources, thereby enhancing operational efficiency and effectiveness while enriching the user experience.
In more legislative-specific cases, AI tools are being used to process session video records, analyse legislative documents, build citizen engagement tools, and support legal and parliamentary advice (see, among others, Ben-Porat and Lehman-Wilzig, 2020; Chalkidis et al., 2017; Elsawy and Shehata, 2023; Fitsilis, 2021; Gagnon and Azzi, 2022; Klapwijk et al., 2021; Oksanen et al., 2019). In line with this global trend, the Library of the National Congress of Chile (Biblioteca del Congreso Nacional de Chile or BCN), a parliamentary library with significant citizen engagement, is committed to maintaining the highest standards of quality and efficiency in the generation and use of a wide range of products and services.1 Technological tools have played a crucial role, improving productivity processes and enabling the continuous expansion of services for Congress members and staff as well as the general public.
This article describes three altogether different AI applications at the BCN, each using different technologies: (1) the publication of linked open data on legislation using Semantic Web technologies that combine machine-readable comprehension (vocabularies, ontologies and Shape Expressions) with high standards of computational expressivity and interoperability, which has delivered over 52 million Resource Description Framework (RDF2) triplets for public use; (2) the creation of the History of the Law and Parliamentary Labour systems with the automatic tagging of legislative documentation using natural language processing, machine learning, linked data/linked open data and the Akoma Ntoso (AKN) extensible markup language (XML) standard, reducing document processing times by 37.5%; and (3) the implementation of an approval predictor for individual laws using a logistic regression model that takes information from the current political context, achieving an 86% accuracy rate. Developing these projects with AI-based technology has allowed the BCN to offer a wide range of knowledge management services, providing useful and timely information to the parliamentary community, legal community and citizens at large.
Towards a Semantic Web-based library
The Semantic Web
The Semantic Web emerged around the year 2000. It is based on the idea of extending the link between two existing pages on the (non-semantic) Web, which lacks a meaning other than a simple connection (in hypertext markup language (HTML) the <a href> tag), to a link that has a specific machine-readable meaning. This could make it possible to create intelligent agents, capable of navigating, understanding and solving human problems by exploring the Web. To achieve this, the Semantic Web proposes a technological stack based on two fundamental elements derived from the traditional Web. The first is the concept of a Uniform Resource Identifier (URI), which is basically a resource identifier from an abstract point of view (like an identity or passport number for a person) and is slightly different from a Uniform Resource Locator (URL), which locates documents. This means that a single resource can have one URI but several URLs, depending on the representations of the resource. For example, if an article is published at a URI, accessing it can provide a machine-readable representation for an application, while a human user might obtain a readable copy in their language. The second element is RDF, which is a declarative format that allows for the description of a resource defined by a URI through attributes and relationships with other resources; it can be implemented in multiple syntaxes, such as JavaScript Object Notation (JSON), XML or comma-separated values (CSV). The idea behind URIs and RDF is that both data and data models (vocabularies, taxonomies and ontologies) can be described in the same format and under an interoperability model based on hypertext transfer protocol (HTTP).
With these aspects resolved, the creator of the World Wide Web, Tim Berners-Lee (2006), proposed the Web of Data and linked open data, promoting the international adoption of data publication standards using Semantic Web technologies at the government level. The Linked Open Data Cloud project grew from 12 open linked data sets in 2007 to 1314 data sets in 2023.3
Motivation for libraries
There are multiple justifications for making linked open data available in a public-sector library:
Public data facilitates study and research; Open systems facilitate external contributions; Public data belongs to citizens, as it is financed through taxes; Public data builds trust by promoting information transparency.
The first Semantic Web project at the BCN aimed to publish the database of Chilean legislation as linked open data (where legislation is the set of rules, laws and decrees that define the legal order). Most nations have mechanisms for the publication of legislation: official gazettes or bulletins, or a government publishing office, for example. In Chile, the legal fiction of knowledge was sadly true because the official gazette was not freely accessible; approved laws mainly amended previous texts rather that providing the consolidated the texts in force; and accessing older legislation was very challenging.
To address this, the BCN launched the Ley Chile (‘Chile Law’) website in 2008, which contains the full text of legal norms, including their different versions, amendments and related information such as bills and jurisprudence; a search engine; and several tools for use and interoperability. While the primary objective of this website was to address the issue of legal certainty, it provides current texts to Congress and citizens at large.
In 2024, the website averaged 80,000 visits daily – a high number given its specialized content and a Chilean population of around 17 million Internet users. Well aware of the public value of this database, since 2011 the BCN has provided access to Ley Chile as linked open data through the BCN Open Data Portal (datos.bcn.cl) (Cifuentes-Silva et al., 2011).
Semantic Web infrastructure
The BCN Open Data Portal (datos.bcn.cl) portal provides linked open data generated by Congress that belongs to several collections and originates from diverse sources. To achieve this, it implements a computing infrastructure with several elements.
RDF triplestore
A key aspect of a technological infrastructure for the Semantic Web is a database engine that not only allows for the proper storage and management of data but also enables querying for intra-organization use and public availability. In this scenario, the appropriate component is an RDF store (Hertel et al., 2008), which can be implemented either as a native RDF database or a relational database with RDF and SPARQL (recursive acronym for SPARQL Protocol and RDF Query Language) mapping components. There are three desired characteristics. First, it should provide a query interface in the SPARQL language, the de facto standard query language in the Semantic Web. Second, it should have the ability to store information in structures called graphs (represented by a URI), which allows for the grouping of RDF triples in a similar way to a table in a relational database. Strictly speaking, a data tuple or quad is composed of four elements: the three parts of an RDF triple (subject, predicate, object) plus the graph it belongs to. And third, it should have the ability to execute federated queries by accessing other public databases through what is defined in the SPARQL 1.1 Protocol (World Wide Web Consortium, 2013). In the case of the BCN, the implementation of this part of the technological stack utilizes the OpenLink Virtuoso RDF database.
Linked Data Frontend
A Linked Data Frontend is an essential tool that enables the HTTP publication of all URIs existing in the RDF triplestore. The main idea is that the tool receives HTTP requests to URIs defined in a mapping file (commonly a regular expression associated with a SPARQL query). At that moment, it connects to the RDF database and retrieves all RDF triples corresponding to the resource associated with the URI. Then, through content negotiation (HTTP 303 code), it delivers the data representation that best fits the HTTP request (one of the RDF syntaxes, which can vary between HTML, RDF + XML, RDF + JSON and many others). For the BCN OpenData Portal (datos.bcn.cl) project, we implemented the WESO-DESH tool, an open-source Linked Data Frontend written in Java that integrates RDFa (RDF in Attributes) into its HTML view.
Data models
For the publication of open data, it is essential to describe the model that shapes the data in such a way that it can be understood. From the technological stack of the Semantic Web, tools are provided that allow expressiveness at different levels.
Vocabularies and ontologies
An ontology is a formal specification of a representational vocabulary for a shared domain, encompassing classes, relations and other objects. In short, it is an explicit specification of a conceptualization (Gruber, 1993). In the field of the Semantic Web, ontologies enable the description of the semantic aspects of a data model through technologies such as RDF, RDF Schema4 and web ontology language (OWL),5 facilitating the specifications for sharing and reusing data.
To implement ontologies and vocabularies associated with own data sets, it is ideal to reuse other schemas (vocabularies and ontologies) that define properties or classes that are semantically equivalent to our domain model. This is mainly because there are multiple general-purpose and specific vocabularies that have been around for a long time and are well known within the community, making their use for describing data models natural and easy to understand. If the elements of the domain model we need to model have not been modelled before, or if we define a specific use case, it will be necessary to design an ontology that allows us to model the problem domain. To design and be able to reuse the data, there are several ontology-matching techniques available that enable reuse (Giunchiglia et al., 2005; Jean-Mary et al., 2009; Kalfoglou and Schorlemmer, 2003). It is also important to consider the principles of reuse, do not reinvent and mix freely (Bizer et al., 2008). At a technical level, it is ideal to use OWL (World Wide Web Consortium, 2012), RDFS (RDF Schema) (Guha and Brickley, 2014) or a combination of both. RDFS allows for the expression of classes, properties, hierarchies, domains and the range of properties, as well as other elements such as defining sequences. On the other hand, OWL enables the description of higher levels of expressiveness, such as transitive relations, set operations, negations, quantifiers, cardinalities and other property attributes.
RDF data shapes
RDF data shapes are another aspect of the Semantic Web stack that provide a method to describe and validate RDF data; they describe the shapes or topology of a node group in the context of a specific RDF graph, extend the expressivity of data specification, and fill a validation space not covered by ontologies and vocabularies. Shape Expressions (Prud’hommeaux et al., 2014) and Shapes Constraint Language (SHACL; Knublauch et al., 2017) are the most widely accepted proposals to define and validate the topology of RDF graphs, and although SHACL has become a World Wide Web Consortium recommendation, Shape Expressions is being used in many different scenarios (Cifuentes-Silva et al., 2020; García-Gonzalez et al., 2020; Labra Gayo et al., 2014; Solbrig et al., 2017; Thuluva et al., 2018) due to its concise, human-readable syntax and an increasing set of open-source and community tools that are currently being developed. Shapes, vocabularies and ontologies must be described based on an HTTP URI, which can later be treated in abbreviated syntax as a namespace or prefix.
Documentation portal
A documentation portal provides indispensable functions for the data sets published by an organization, including:
Data description – this allows for detailed descriptions of the ontologies, vocabularies and shapes that structure the data, which is essential for correct interpretation. It also enables the description of the data set's content, purpose, origin and lifecycle elements (such as creation and modification dates), as well as the source or provenance of the data, helping users understand the value and potential applications of the data. Additionally, it is useful to describe the URI patterns of the exposed RDF graph, providing an even greater level of understanding of the data set. Interoperability mechanisms – these allow for a description of the technical specifications according to which the data is published, including data formats, URIs and publication standards. They encompass the existence and access methods of the SPARQL endpoint or APIs (application programming interface), available content negotiation mechanisms, and the presence or absence of data dumps associated with the various published data sets and periods. Promotion of the use of open data – this can be achieved by publishing manuals or user guides that explain how to query and use the data, either through SPARQL examples or direct access via the URIs where the data is exposed. Provision of a communication channel with the community – this allows for the establishment of a link between the organization and the data user community, where channels such as contact forms, forums or mailing lists related to the data can be set up. At the same time, it enables the publication of data usage terms and news about updates to the available data.
The Semantic Web in use
The first set of linked open data published by the BCN was the data sets of Chilean laws in 2011 (Cifuentes-Silva et al., 2011). The main idea behind this implementation was to conduct a proof of concept to validate the technology and explore its potential uses. The work involved designing an ontology of laws associated with the Chilean model and then generating RDF triples for all the existing laws in the Ley Chile database. Additionally, an update tool was installed to keep the data up to date as new laws were published. This included an RDF graph that allowed for the linking and navigation of the laws across their various versions, relating them to the different organizations that generated them and, in the case of international treaties, linking them to their respective countries (connecting these to their URIs in DBpedia and Wikidata), among other things. All this was published in URIs that were not only unique but also readable, opting for the use of hierarchical URIs. Although only the basic metadata of the laws (such as title, date, creating organization, modification date, type of law and link to the XML text) was published at the time, the experience proved useful for the interoperability and availability of the data for other state agencies and the public, as well as for conducting proof-of-concept tests with SPARQL and considering the possibility of mixing this data with other data. In this first project, 300,000 laws were published in RDF – equivalent to 8 million RDF triples. As of June 2024, there were 748,000 laws in RDF and 13.7 million RDF triples.
Then, we defined an ontology of legal norms and a namespace prefix for the ontology, which was related to the particular context of the national reality.6 We considered a structure that was extensible to others domains, such as Parliament, education or health. This ontology has been written using both RDF Schema and OWL, making it possible to apply inferences, through an ontology reasoner, to RDF graph. Another important feature of the ontology is that it has been composed using previous ontologies and data sets, such as Simple Knowledge Organization System (SKOS) (Bechhofer and Miles, 2009), Dublin Core (Baker, 2000), Friend Of A Friend (FOAF) (Brickley and Miller, 2007), Geonames,7 Organization8 and DBpedia.9
By utilizing the Geonames and DBPedia ontologies, we were able to link data from the legal norm graph to external record sets – specifically, international treaties and countries. This task was challenging due to the significant amount of manual labour required. Finally, the ontology was stored in the RDF store to enable inferences, as already published on the Web using RDF/XML and Turtle syntax text files. The documentation was published in both Spanish and English.
During the same year, 2011, the BCN began to develop its first projects based on linked open data. These projects aimed to facilitate interoperability within the BCN's systems and enable citizens to reuse data and access all products and services based on URIs. Two of these projects were strategic for the BCN's definitive implementation as a Semantic Web-based Library: the History of the Law system, which aimed to collect, process and publish all of the documents generated during a law's legislative processing, and the Parliamentary Labour system, which aimed to compile all of the legislative activity carried out by a parliamentarian during the exercise of their office as registered in the printed media of the legislative power, such as parliamentary motions, session journals or commission reports. For the implementation of both systems, a diverse set of ontologies was implemented and several data sets were published
Parliamentary biographies
This data set comprises two main elements. The first is an ontology – the biographies ontology – which provides a model of classes and properties in RDFS and OWL, and is defined based on the FOAF, Dublin Core and Time ontologies, allowing for the description of people, political parties and other related concepts, such as events (birth, death) and political position (senator, deputy, president).10 The second element is the data, which is published as linked open data in RDF and provides basic information about each person, their periods of membership of political parties and parliamentary positions held since 1810. By June 2024, the database contained 5296 people related to the political history of the country. Figure 1 displays, at the top, a portion of the biographies ontology model associated with the person entity and, underneath, the data for Gabriel Boric, Chile's president, in an RDF representation (HTML + RDFa).
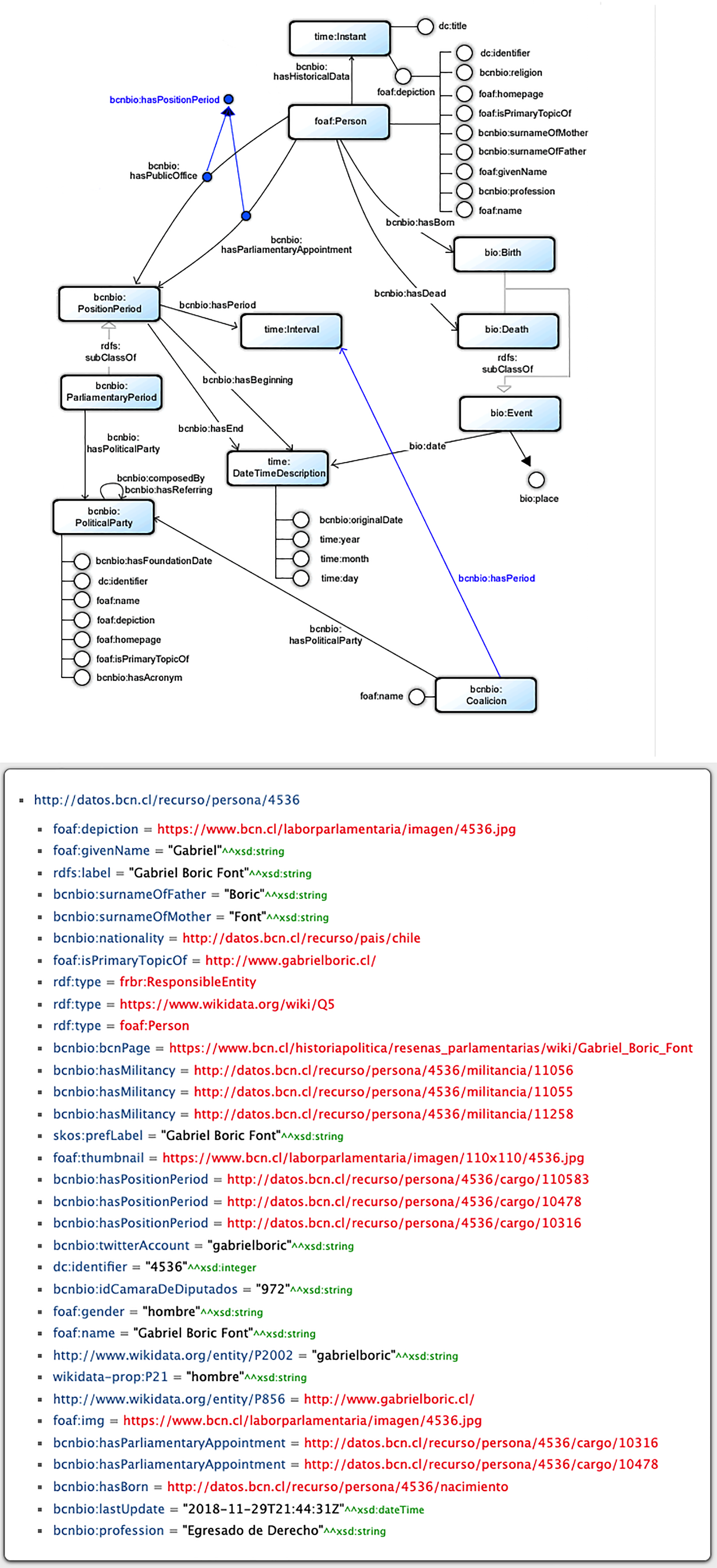
Parliamentary biographies data set: part of ontology model (top) and person in RDF (bottom).
The first data load was collected from an institutional wiki (based on MediaWiki) where biographical reviews of the main political actors in the history of the country are stored, archived and maintained. This institutional wiki, developed in 2010, contained RDFa metadata, which was extracted and transformed into RDF. This was accomplished using a model of dereferenceable URIs, allowing seamless navigation through various types of resources. Although a large amount of data was normalized during this process, due to the fact that the wiki did not have a validation mechanism for the inputs, there have been minor errors related to the formats and some inconsistencies in the information, such as duplicate periods of militancy or dates in different formats, which have been progressively corrected manually. Currently, the data-editing process is carried out directly on the RDF triplestore, and most of the databases of the various systems at the BCN use the parliamentarians’ URIs for interoperability.
Geography
The geography ontology provides a model of classes and properties in RDFS and OWL that describes geographical entities from the different models of territorial division existing in the Chilean political administration.11 It defines the distribution of regions, provinces and communes (administrative), as well as the divisions by district and constituency (electoral). This model allows, among other things, one to solve the problem of the different territorial distributions of the country over time – for example, when a region was divided into two – as well as define the different electoral divisions, which vary according to how the electors are distributed in the country over time. Currently, the linked open data set associated with this domain model covers the historical geographical distributions of the country and their relationships (country, region, province, commune), as well as the current electoral distribution (electoral district and senatorial constituency).
Bills and legislative resources
This data set comprises the data on bills as well as the legislative resources ontology12 and Congress model,13 which have been presented in detail in a previous study (Cifuentes-Silva et al., 2023, 2024). A bill is a document that is submitted to the National Congress to propose a legal text and is debated by Congress with the aim of creating a new law. In Chile, a bill can be introduced either by the executive branch (referred to as a presidential message) or by a member of Congress (known as a parliamentary motion). The data set of bills contains information such as basic metadata (title, bill number, submission date, status, URL to the text); access to its processing in the Senate's tracking system; details of each stage it has undergone; and the votes associated with the bill. For bills that have been enacted into law, it also includes a link to the law in the Ley Chile system.
The legislative resources and Congress ontologies, both implemented in RDFS and OWL, model a wide variety of concepts and relationships associated with the work of the National Congress, including the definition of bills, votes, document structures, elements of the legislative process, and many other abstractions necessary for automating tasks associated with the law-making process. These ontologies are widely used in several internal applications due to their breadth, and indeed both serve as the foundation for the metadata of XML documents processed in the open standard for legal documents, AKN. Finally, the legislative resources ontology is also modelled using a schema developed in Shape Expressions.14
National budget
As presented in Cifuentes-Silva et al. (2020), the national budget data set is based on an ontology that represents the Chilean budget law, published annually; the relationships between different state agencies that receive and allocate budget amounts to dependent agencies; and the budget execution of each of them.15 Among the main vocabularies and ontologies used for building this model are SKOS, RDFS, Dublin Core, OWL and the core vocabulary. Also, for this data model, Shape Expressions is implemented. In structural terms, the budget law has a hierarchical composition of seven main levels, what is reflected in the ontology. The first level explains in an aggregated form the national budget; the next three levels coincide largely with state agencies that use public funds; and the last three levels describe the internal composition of the budget within an organization. Each of the elements presented in each level has an associated number defined in the law – for instance, Chapter 16 for the Ministry of Health.
In this way, the data model is composed of two main types of RDF classes: metamodel classes, such as budget execution, budgetary entity and budget entity, which model common behaviour for domain business classes and are useful for describing domains and ranges in RDF properties, and domain business classes, such as national budget, batch, chapter, programme, subtitle, item and allocation, which can give meaning to data and establish constraints, such as the usage of the owl:oneOf property.
Regarding the data, the content of the data set is updated monthly according to budget execution and can be consumed via the SPARQL endpoint, by content negotiation in other formats or through the monthly dumps available on the API website.16
Other data sets and models
Since the publication of the first data set as linked open data at the BCN, several models have been implemented and used transiently or partially in different projects. They include the following:
Communal reports ontology – classes and properties (in Turtle and RDF/XML) that describe indicators from official sources on the demographic, social, educational, economic, municipal and citizen security data of each commune in Chile. This ontology is described in datos.bcn.cl portal. Transparency ontology – classes and properties (in RDFS and OWL) to depict the hierarchies and labour relations among functional units and officials within the BCN. It was used for RDFa markup in an earlier transparency website.
Results
The BCN has established itself in Latin America as a library that is built on an open technology stack, where Semantic Web technologies play a crucial role in the publication and availability of open data for free use, as well as the creation of products based on these technologies. As of June 2024, more than 52 million RDF triples had been published with a sustained growth rate, along with nine ontologies and domain-specific vocabularies, production systems, and numerous technological tools that utilize the data and models. Furthermore, over time, this philosophy of providing data openly and freely for third-party use has become ingrained in the organizational culture, and many new projects use and produce data that is available as linked open data.
Limitations
Notwithstanding the foregoing, it is important to highlight some of the most significant limitations of this work:
Although the complete data set of legal norms of the state was published in RDF, it contained only the basic metadata of the norms and a link to the XML version, not the triples associated with their content or normative structure. These could be highly useful for implementing applications and performing analysis with graph-based tools. This omission was due to the fact that a single norm can generate thousands of triples by itself, not to mention updated versions of norms that are automatically composed from the text of amending norms or other linkages. Some of the initiatives associated with RDFa mentioned in the study are no longer available as web pages. This is due to the technological replacement of applications, coupled with a shift in focus from interoperability to usability. In the case of the biographies wiki, RDFa was initially used for populating and structuring person-related data. However, RDFa is no longer used to mark biographical entries. Instead, the RDF representation of person entities is now directly derived from the internal parliamentary database. Linking to external data sets, such as Wikidata, is performed manually on a resource-by-resource basis, without automated mechanisms to streamline the process. A wide variety of data sets and web services not based on Semantic Web technologies were not included in this work.
Natural language processing of legislative documents
To discuss natural language processing, it is necessary to provide context on the projects that drove this technology at the BCN.
History of the law and parliamentary labour
At the beginning of 2012, the development of the History of the Law and Parliamentary Labour projects began (presented in detail in Cifuentes-Silva and Labra Gayo, 2019), which would expand the catalogue of products and services that the BCN offers to the public and the National Congress.
A ‘history of the law’ is a collection of all the documents generated during a law's legislative processing – from the initiative that gave life to a bill to its discussion in Congress, the reports of the parliamentary committees that studied it and the transcripts of the debates in the session rooms – gathering their traceability within the legislative process. It allows one to gauge the so-called ‘spirit of the Law’, enabling its interpretation in a precise way in relation to the scope and sense that was given to the norm when it was legislated. This legal instrument is particularly useful both for judges when preparing judgements and for lawyers when they use certain rules to support their arguments.
Similarly, ‘parliamentary labour’ is a compilation of all the legislative activity carried out by a parliamentarian during the exercise of their office, as registered in printed media belonging to the legislative power, such as parliamentary motions, session journals or commission reports.
Until 2011 in Chile, both tasks were undertaken by legal analysts and only for specific requests, by manually processing each document related to a law. The objective of the History of the Law and Parliamentary Labour projects was to establish a technological infrastructure support mechanism and the necessary processes for the semi-automated elaboration of the history of the law, covering all the laws of the republic, and make it available to the public through both open data and a public-access web portal.
For the electronic and semi-automated elaboration of both document collections, it was necessary to have a granular database that registers all the documents of the legislative process that make reference to bills or parliamentarians, allowing for the later extraction and selectively recovery of what was discussed around a bill that would become law, as well as what a certain legislator said in any context. For this reason, the Organization for the Advancement of Structured Information Standards (OASIS) standard for legal documents, AKN (Palmirani and Vitali, 2011), was used for the construction of these projects, since it provides electronic representations of parliamentary, normative and judicial documents in XML using semantic markup and annotation of textual documents through linked open data, and allows the addition of semantic marks on the text, which in turn enables the precise identification of the location of parliamentary interventions, the presence of debates around a bill, the processing phases and many other types of metadata.
Data sets
To create the History of the Law and Parliamentary Labour systems, we used several data sets.
Legislative process documents
This data set includes basic metadata schema (URI, title, date, originating chamber, document type, etc.) and document contents in text (TXT) and XML (AKN version) formats. There are several document types in different formats. The legislative process has, chiefly, session logs, which include attendance records, a transcription of the discussion on the floor (parliamentarians’ speeches), and often several of the documents presented during the session, such as official letters, bill proposals (motions or messages) or communications. Another important document type is the committee report, which provides an extended summary of what occurred in a session of a committee; it has a structure similar to a session log but focuses on issues within the remit of the committee.
Each document type, depending on its time period and originating chamber, has different drafting rules and structures, which have evolved over time. At the extreme, older documents use an outdated Spanish orthography (that of Andres Bello).17 The documents’ format also varies according to time period. Documents from before September 1973 (when Congress was dissolved) were only available in physical format – that is, on paper – therefore processing them required digitization. Documents from 1990 onwards are digital, in formats like .doc, .pdf, or even .xml, thus allowing for the processing of the file itself.
This data set includes all the session logs from both Congress chambers from 1965 to 1973, and from 1990 onwards, and all the committee reports, messages, motions and official letters, as preserved for the history of the law, for all laws from 1990 and many decrees issued between 1973 and 1990.
Named entities
The second data set has data on several named and interrelated entities. It is used for tagging and referencing operations within XML documents, configuring processes in the processing workflow, and supporting delivery and query functions. The most relevant entity sets are as follows:
People – this set enables the identification of parliamentarians and the creation of the Parliamentary Labour system. It includes metadata according to the biographies ontology, which covers basic information (first name, last name), known name, nationality, public positions held in Congress and the executive branch, birth and death (including place and date), links to other resources (such as social media), a Wikidata URI, gender, a thumbnail image URL and political affiliation (including political parties and periods of membership). Organizations – a set that includes the state agencies involved in the legislative process, such as the chambers of the National Congress, ministries and other entities like the governing junta (the ruling body from 1973–1989) or the Constitutional Convention of 2020. Political parties – a set that contains information on political parties, including a description, their logo, founding date and founders. Other data sets – there are data sets for sessions and legislatures, allowing for the timely identification and differentiation of session documents; a dataset for describing the legislative phases, defining the constitutional and regulatory procedures for each law making process; and a dataset for bills, among others.
Document structure elements
Each document type is defined by a hierarchical structure of sections, composed of various instances of the ‘SeccionEstructural’ class. These different collections of data enable the dynamic configuration of an XML editor based on the type of document being edited, while also allowing other applications to navigate the document's structure according to the defined subsections.
Automatic markup of XML documents
Possibly one of the most tedious tasks, requiring the most human time and effort, is identifying and marking in a text both the structural sections (such as chapters or subchapters) and named entities, and their association with specific identifiers. A more efficient option is implementing a component that automates this task, with humans only reviewing the marking done by the algorithm. We will call this tool the automatic marker, which transforms a plain-text unformatted document into an XML document with AKN schema.
This problem has already been addressed using machine learning (Akhtar et al., 2004), textual visual properties (Burget, 2007), content-associated patterns (Bolioli et al., 2002) and combinations of rules (Abolhassani et al., 2003). We used three methods:
Knowledge engineering – the manual implementation of rules or ad hoc algorithms. We used regular expressions and exact matches to detect structural elements and identify entities in the text. The quality is verified with a document sample and a complete list of entity descriptor labels. The model’s precision and effectiveness depend on the quantity and quality of the rules implemented. Machine learning – pre-labelled documents divided into training and test sets. Training documents are fed to classification algorithms that use pattern recognition (e.g. Hidden Markov models, Naive Bayes, conditional random fields or neural networks) to yield a classification model, and the quality is verified with metrics (such as precision, accuracy, recall and the F-measure (Baeza-Yates and Ribeiro-Neto, 2011)) on the test sets. The most commonly used marking components are entity recognizers (e.g. Stanford Named Entity Recognizer,18 spaCy and OpenNLP). Hybrid approach – combining both approaches. Complex structural marking is executed with knowledge engineering, taking as its input machine-learning-recognized entities (restricted to key sections to improve marking efficiency and precision).
In the History of the Law project, the complexity and detail involved in marking legal documents with multiple tasks (i.e. detection and disambiguation of named entities, structural recognition of document parts and specific formatting) required the implementation a four-component pipeline.
Named-entity recognizer
A named-entity recognizer finds mentions of nouns or ‘entities’ in the text (e.g. dates or figures written in narrative prose) and identifies the entity type of each. We use a customized version of the Stanford Named Entity Recognizer, implemented by a conditional random field (CRF) classifier, which enriches the input text with recognized entities, possible entity types (see Table 1) and confidence scores. As a training corpus, we used session documents that had been manually labelled with 64,727 words, each with a type. To evaluate the deployed model, we used tenfold cross validation (90% training, 10% testing). The named-entity recognizer detected on average 97% of the entities in the text and correctly assigned their type in 89% of cases.
Types recognized by named-entity recognizer and number of entities in the knowledge base.

Mediator
The mediator assigns the URI associated with an entity mentioned in the text, performing entity linking or disambiguation, similar to DBpedia Spotlight (Mendes et al., 2011), AGDISTIS (Usbeck et al., 2014) or WikiME (Tsai and Roth, 2016). The mediator is based on a RDF triplestore, accessible through a SPARQL endpoint that stores information ranging from basic descriptions (e.g. names or text descriptors, dates) to more complex structures (e.g. membership periods, event occurrences), all associated with entities of the types described in Table 1.
The simplest case involves sending a label via representational state transfer (REST) as a parameter, with the mediator returning a list of suggestions in JSON format, structured as ‘URI, label, score’ and ordered by decreasing score. To improve accuracy, parameters such as the entity type or a session identification number can be added. Additionally, the mediator can operate by receiving an XML file with recognized entities as input. It will return an XML file where it adds a URI and label attributes to each entity, assigning the URI with the highest calculated score for each case, provided this score meets or exceeds a configurable threshold.
To enhance the tool's precision, context data can be assigned to narrow down the set of possible alternatives when selecting the URI for each label to be identified. Since this tool is used to disambiguate entities in documents of the National Congress, useful context data may include the session date, the chamber of the document, the session number or the legislative period. To evaluate and refine its accuracy, the first set of session journals from the 1965–1973 period was processed using the named-entity recognizer system, which assigned URIs to the entities identified in the text. These assignments were manually reviewed both individually and through an aggregated view that highlighted anomalies (e.g. persons identified who did not belong to the parliamentary period). This process enabled the fine-tuning of the filtering algorithms associated with contextual information. As a result, a tool was developed that currently operates with an error rate of less than 1% in its productive use.
Structural marker
We define the structural detection of text as the task of identifying groups of consecutive strings that, to a human reader, correspond to elements such as titles, subtitles, paragraphs, sections (groups of paragraphs under the same heading or subheading), chapters, annexed documents integrated into a text, enumerations and lists. Additionally, given the context of application in documents containing parliamentary debates, we define a special type of structural element called an intervention (speech), which describes what is spoken by a person and can consist of one or more consecutive paragraphs. The structural marker is the tool that performs structural detection by adding marks to the text to indicate the beginning and end of each structural element. In our case, the marks added to the processed text output are in XML format.
The primary strategy for detecting structural and hierarchical sections in text documents combines the use of regular expressions with the application of rules that encapsulate programming logic, triggered when specific regular expressions are detected. This approach is particularly practical for documents generated by the National Congress, as they generally adhere to standardized drafting rules. The tool can identify first-, second- and third-level structural sections; sequences of elements based on numbered and unnumbered lists (including nested ones); and parliamentary speeches.
Given that the documents to be processed mainly consist of political debates, the primary element to be recognized is a block called participation. This block is composed of one or more speeches involving the actor who is moderating the session (usually the President of the Chamber); an actor who emits the participation (the primary speaker); and potentially other actors, who interrupt. In this composite block, it is essential to automatically identify the participation author, which necessitates an analysis of the speeches to detect the underlying structures of participation and implement a rule with automaton characteristics. This particular implementation is needed because participation, in structural terms, is unique as it lacks a conventional title and body structure, and is embedded within other recognized structural sections of the debate.
Technically, the structural marker receives plain text with or without entities as input. From this text, a DocumentPart object is generated, containing a property with the full text and an empty list of DocumentPart objects (subparts). The process involves running specific rules depending on the document type and the depth level of the DocumentPart object. Each rule processes the text of a DocumentPart object and returns all identifiable DocumentPart objects, adding them to the subparts list. The final task is to serialize the object in XML format.
XML converter to AKN schema
This component takes the XML output from structural marking, entity recognition, and entity linking and yields an XML in AKN format, editable by tools like the Language Independent Markup Editor,19 LegisPro,20 AT4AM,21 Bungeni,22 xmLegesEditor23 or LEOS.24 To convert raw XML into AKN, we first tried extensible stylesheet language transformations (XSLT), but the required style sheets to identify entity references and group them as headers (essential to AKN) were too complex. Given the diversity of the document structures, we took a programmatic approach that takes the input XML file, generates a document object model (DOM)-like representation and traverses it to convert each raw node to AKN XML. Figure 2 shows a fragment of a session document in plain text and its equivalent in AKN XML, where references are made to entities defined in URIs.
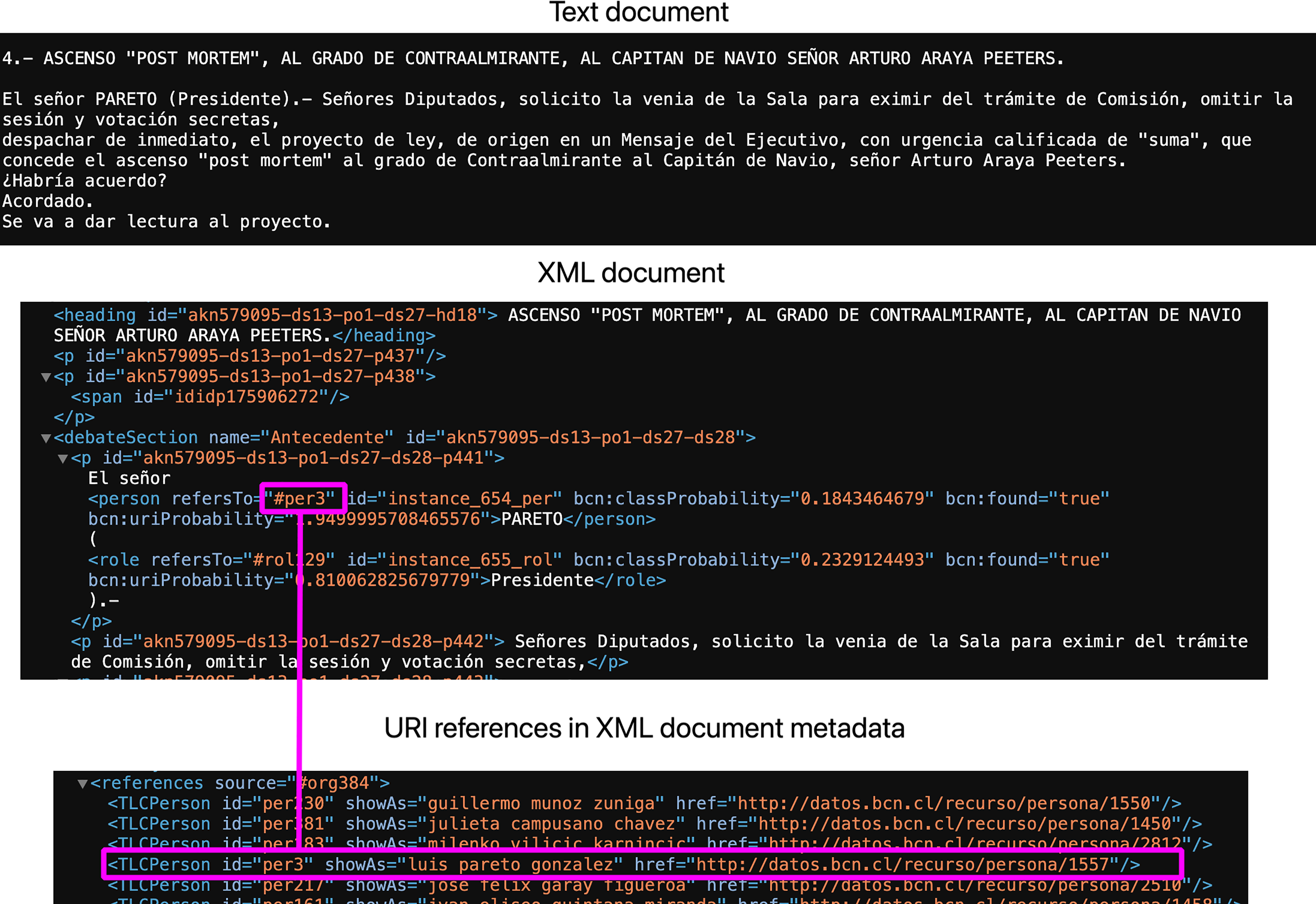
Text to XML markup with natural language processing.
Other natural-language-processing-based tools
There is a product derived from the History of the Law called the History of Law by Article, which exclusively documents everything that has occurred to a specific article or other normative unit during the law's legislative process. To create this product, various tools have been implemented to assist human analysts in their work. These tools operate together on two or more documents, allowing for cross-referencing between their sections, with the aim of subsequently compiling related information based on different criteria. These tools include:
A link generator – this operates on two consecutive versions of a bill's XML (consecutive in terms of modifications introduced during the legislative process) that have previously undergone automatic tagging. In the XML of each version, the basic normative units (such as articles, numerals, paragraphs or enumerated letters) are identified. The tool's function is to compare the normative units of both versions of the bill and establish text traceability for each unit. It determines whether a unit has been affected by text modifications, added, removed or moved. A reference generator – this operates on an XML version of a bill and a document containing discussions, such as a session journal or committee report. Its function is to automatically identify all sections of the discussion document where references are made to a specific normative unit, with the aim of compiling the associated debate for that unit across all documents where the law is discussed. An update generator – this operates on an XML version of a bill and an amendment document. An amendment is an instructive document that specifies changes to the normative units of a version of a bill, resulting in a new version of the bill once these changes are applied to the text. An amendment can include instructions such as ‘replace word X with word Y’, ‘remove point Z’ or ‘add article X’, for example.
To implement these tools, several techniques have been used, including XML tree traversal, text comparison using cosine distance, stopword removal, lemmatization, different types of tokenization, regular expressions and rules through programming classes (for details, see Gacitúa et al., 2016). The evaluation mechanism for all these tools followed the same approach, based on a comparison between manually labelled documents and the versions produced by the automated tools.
Constitutional History
This use case started with the History of the Law project. In late 2019, Chile experienced a ‘social outburst’ (Wikipedia, n.d.), characterized by large-scale civil protests across the country arising from dissatisfaction with the prevailing economic model. In an effort to quell the social unrest and address citizens’ demands through a structural legislative approach, most political parties in Congress settled on the Agreement for Social Peace and the New Constitution.25 A referendum was held to decide on the drafting of a new constitution; it received 78.27% approval and initiated the so-called 2020 Constitutional Process (Biblioteca del Congreso Nacional de Chile, n.d.). The BCN decided to document this process, similarly to the history of the law and parliamentary labour, and all the debates surrounding it in order to capture the spirit and foundations of each part of the drafting of the new constitution and the work of each person involved. Since all the technological infrastructure was already in place, a new website was launched containing the history of Chile's constitutions, as well as the history of constitutional processes that had not produced an approved draft.26
History of the Law
Once the AKN files have been annotated both automatically and manually, and have successfully passed the quality assurance phase, the publication process extracts the knowledge expressed in the document as RDF triples and tuples for a query database. All of the data extracted from the document during its publication in RDF (including structural sections, entities, parliamentary speeches and references to bills) is transformed into new RDF triples. These triples then complement the previously defined basic information in the RDF triplestore, making them available for querying at the SPARQL endpoint.
The publication process, packaged as a web service, implements a parser that traverses the XML tree of the AKN document looking for predefined structures within the document sections. Each type of document uses small data extractors per section, encapsulated in specific classes, allowing for reuse and specific implementations as needed. Subsequently, with the data extracted from all the XML documents in which a law is discussed (the history of the law) or a parliamentarian speaks (parliamentary labour ), the publication process generates a physical file, which is stored in a digital repository (DSpace) indexed by library specialists.27
The BCN launched the History of the Law28 and Parliamentary Labor29 portals in 2014 and, in 2020, the Constitution History portal. These platforms publish linked open data.
Results
By June 2024, the History of the Law system had processed 4143 laws associated with 49,030 documents, generating 520,219 participations from 1578 parliamentarians from 1965 onwards. Additionally, it has documented the history of all Chilean constitutions and constitutional proposals, as well as the work of the two recent constitutional conventions (2020 and 2022). The automated tagging has reduced the workload by 37.5% (Cifuentes-Silva and Labra Gayo, 2019), not to mention the impact it has had on the constant generation, updating and indexing of parliamentary labour document dossiers for each parliamentarian.
Limitations
Some of the most relevant limitations of this work are as follows:
Although session documents are processed in full text, relevant sections such as voting records are neither retrieved nor utilized. This is mainly because these records are directly consumed from web services provided by the chambers of Congress for integration into the database. Future plans, however, include incorporating this information, particularly for widely agreed-upon votes that do not record nominal votes but are of interest in the legislative process. Initially, the project included a wide range of features associated with detailed markup tasks that were mostly intended to be performed by human analysts, with the idea of enabling the development of other products and services in the future. However, due to limitations in access to both legal analysis and information technology development personnel, the system was consolidated around its core objective: building a record of the legislative history and parliamentary activities. To date, the system has not integrated tools based on large language models, which could improve the accuracy of processes such as the update generator or the reference generator. While the initial project envisioned linking metadata between intervention texts and session videos (using video subtitles based on the text of the interventions), this task has not yet been addressed. Although XML tagging processes could automatically identify additional information in the texts of legislative debate documents (e.g. subjects or free terms for indexing), this remains a pending task that could enable a wide range of new products and services.
Prediction of approval of laws
The crafting of legislation is a complex process that is influenced by various factors. While legislative initiatives often arise from citizen needs, many of them lack the necessary support within the legislative process to advance through processing and ultimately become law. This is partly due to the large number of projects in various subject areas; the time required for parliamentary debate in each case to gather diverse public opinions; and the sensitivity of establishing legal norms that govern society. Nevertheless, it is of great interest for both the executive branch and members of Congress to know the probability of whether a proposed bill will ultimately become law or not. This knowledge enables them to undertake the necessary political efforts to promote its processing and eventual enactment as law.
The third experience using AI corresponds to a law-approval predictor for bills processed in the National Congress of Chile, based on a logistic regression model. A logistic regression model is a statistical model that is used to predict the probability of a binary event – that is, an event that has two possible outcomes. It mathematically models the relationship between a dependent variable (the variable to be predicted) and one or more independent or predictor variables. A logistic regression model, in the context of AI, is a supervised learning technique that is used to solve binary classification problems by predicting the probability that an instance belongs to one of the two possible classes using the logistic function.
For this use case, the specific utilization of this type of model is based on several factors, including its high interpretability, which is essential in an advisory environment for members of Congress across all political sectors. In such a setting, there must be no political preference or biases, making it crucial for predictive models to be explainable and, ideally, simple. Additionally, the training data size is relatively small (fewer than 10,000 examples), making other models, such as deep learning, less suitable.
The following presents the design and results of a law-approval predictor implemented for the Chilean legislative process.
Data sets
For the implementation of the predictor, data was used from 14,738 bills introduced to Congress since 1990, along with their processing details, political parties and the actors involved in the legislative process. This data was obtained from the open data portals of the National Congress and supplemented with exogenous variables calculated ad hoc. The development of the predictor utilized three sources of data:
Linked open data from the BCN – as mentioned earlier, the open database of the BCN provides information about parliamentarians from 1990 to the present, including their terms in office, personal details, start and end dates, and the positions they have held. It also includes information about bills introduced from 1990 to the end of 2022, their authors and their political parties. Opendata Congress XML database – an XML service database that provides records of the processing of bills, which is updated daily. This data is published by the Senate from the bill-processing system. Exogenous database – a database created specifically for this purpose, containing a list of election years and a table of the political parties, with a Political Trend Index based on the author's perceptions.
The Political Trend Index differentiates the political tendencies of the parties on a scale from −1 to +1, where −1 represents a more left-wing ideology and +1 corresponds to a more right-wing ideology (see Figure 3). According to the authors’ perceptions, the Communist Party of Chile (Partido Comunista de Chile) would have an index of −1, while the Republican Party of Chile (Partido Republicano de Chile) would have a value of +1. The chart shows the political parties in vertical axis, and the political trend index in horizontal axis.
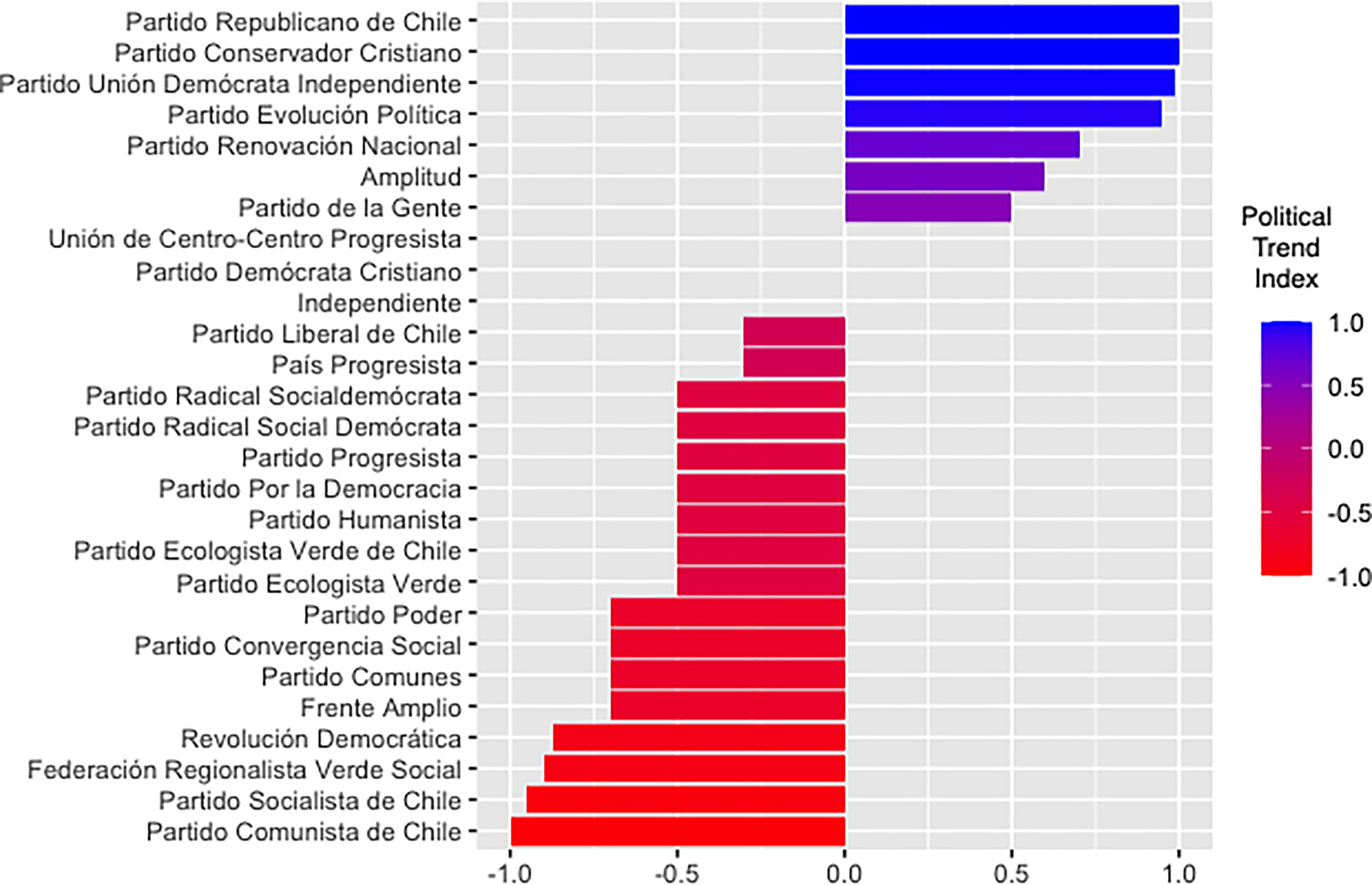
Political Trend Index of parties based on authors' perceptions.
The main idea behind this index is to convey the political trend value to parliamentarians affiliated with the party in various circumstances, whether as authors of a bill, the President of the Republic (who holds executive power) or the President of the Chamber of Deputies or the Senate, who have direct influence over the prioritization of bill discussions. Figure 4 shows the Political Trend Index applied to the positions of President of the Republic, President of the Senate and President of the Chamber of Deputies from 1990 to 2024 (vertical axis represents PTI). The idea behind this index is to have an indicator that differentiates and systematizes political support during a bill's processing period, which will be translated into a limited set of features for regression analysis.
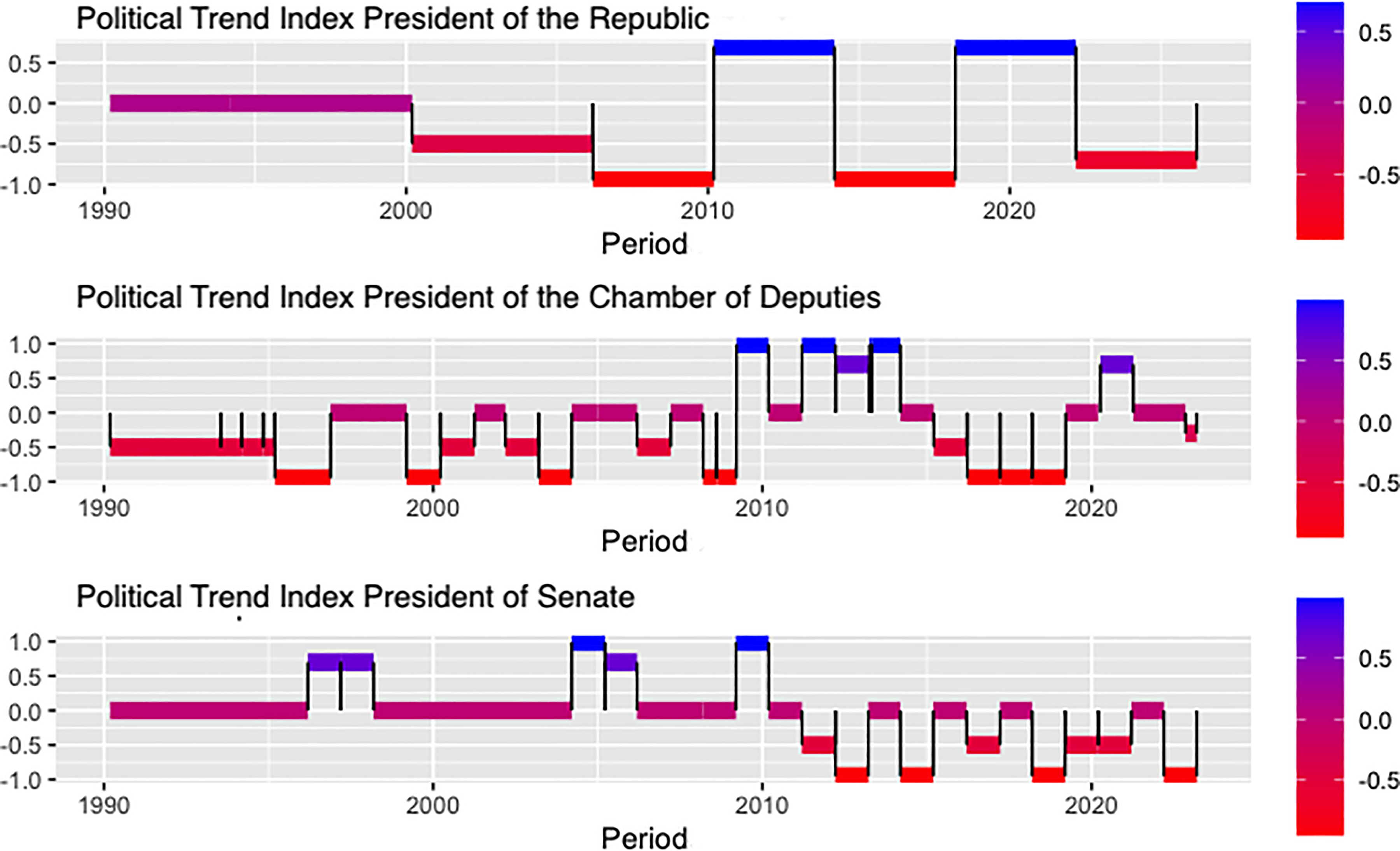
Political Trend Index of distinct roles based on authors' perceptions.
Tool design
With this data, an initial database of bills was created with 23 features, including the current status of the bill (enacted as law, rejected, in process, archived); date-related characteristics (such as separating the year and month for each date into different features); the identification of events that could affect legislative processing, such as determining if a year was a presidential election year or not (assuming this could affect the processing of certain types of bills); the number of days since entry into processing or since the last movement in Congress; and 13 characteristics based on political trends measured from various perspectives (sums, averages, etc.).
The primary idea behind using these variables was to characterize the political landscape and determine if a particular bill could be approved, assuming that the actors involved in the process coincided in some way due to their political tendencies. Thus, in line with the aforementioned principle, political trend values were applied to characteristics such as authors, the President of the Republic, the President of the Senate and the President of the Chamber of Deputies at the time of the bill's entry into processing, as well as at the time of the last processing recorded in the Senate's processing system. Having defined the first set of characteristics, three groups of projects were generated:
Bills that became law (enacted) – all bills that were transformed into law and have critical information in the database (dates and status). Bills that could still become law (in process) – all bills with critical information in the database and currently with an ‘in process’ status. Bills that did not become law (rejected) – all bills that were not excluded in the first stage and were not in the ‘enacted’ or ‘in process’ categories. This category includes archived bills and unconstitutional bills, among others.
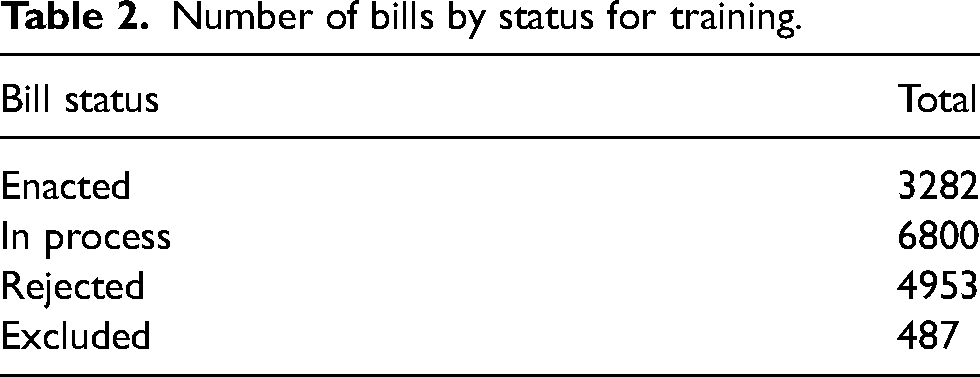
Additionally, a fourth group was excluded from the exercise due to having too much missing or inconsistent data. The purpose of identifying these groups is to implement a set for training the logistic regression model (enacted + rejected) and another set to predict whether a bill will become law (in process) later. Table 2 provides the totals by project type.
Number of bills by status for training.
Results
With the prepared data, a logistic regression model was trained in R.30 Initially, 23 preliminary features were considered for the model. During the regression analysis, the Akaike Information Criterion technique was used for feature selection, transitioning from the initial model with 23 features to a simplified and optimized final model with 9 features, all of which were statistically significant (p < .001). Of the discarded features, more than 10 exhibited high correlation (multicollinearity) and were therefore removed, primarily to avoid issues of accuracy and sensitivity in predictions with new data. Other discarded variables showed low statistical significance and were therefore also removed. Table 3 provides a detailed description of the features of the final logistic regression model.
Features of the final logistic regression model.

The final model shows a classification accuracy of 86.23%, with a 95% confidence interval of (0.8546, 0.8697), a sensitivity value of 0.89 and a specificity value of 0.82. Additionally, it is worth mentioning that the cut-off point for the regression is set at 0.38, which is the threshold at which the prediction changes from approval to rejection.
As a testing mechanism for the model’s functionality and accuracy, simulations were conducted to mimic shifts in political trends among various actors associated with characteristics related to the Political Trend Index. These changes directly influenced the calculated probability of a bill’s approval, aligning with the expected outcomes.
Figure 5a presents a comparison between the actual cases and the values provided by the regression model for the training data (vertical axis shows number of elements and x axis the predicted value) and Figure 5b displays the confusion matrix of the predictor using the training data.
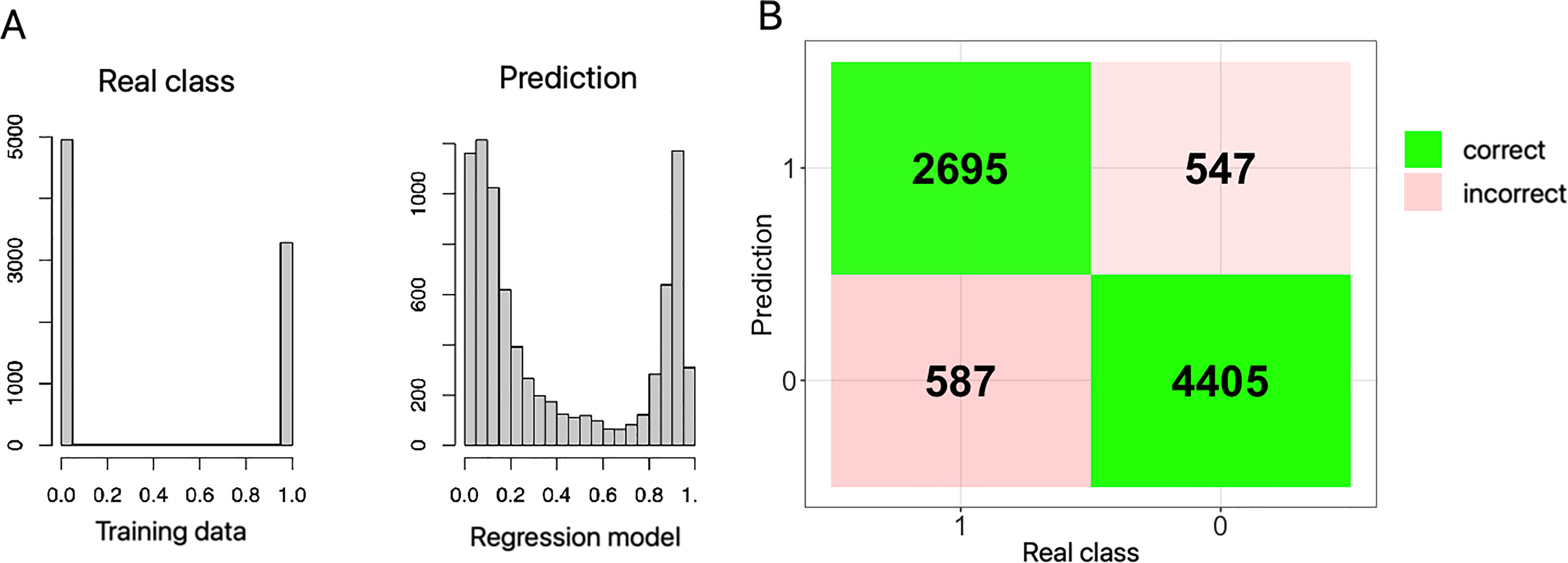
A: Comparison between real data and prediction - B: Confusion matrix for Law predictor
Limitations
While the model demonstrates acceptable performance, it is not without limitations, which include:
The absence of some key features, such as identifying whether a bill is designated as urgent legislation – a prerogative of the executive branch – or whether it pertains to a topic of current political debate. The use of an arbitrarily defined Political Trend Index by the authors, which may affect the accurate representation of the data and the results obtained. Future work in this area could include a dynamic calculation of real Political Trend Index values based on voting distances (greater differences among voters imply larger distances), which are observed between different political parties, potentially segmenting the Political Trend Index by topic.
Law-predictor prototype
Figure 6 shows the user interface of the first functional prototype of the predictor. It features a line graph where two zones are differentiated on the vertical axis: one for approval (green) and one for rejection (red). The horizontal axis shows the evolution of the prediction over time according to changes in the political context, as well as information related to the bill. Additionally, a thermometer-type graph indicates the current probability of approval.
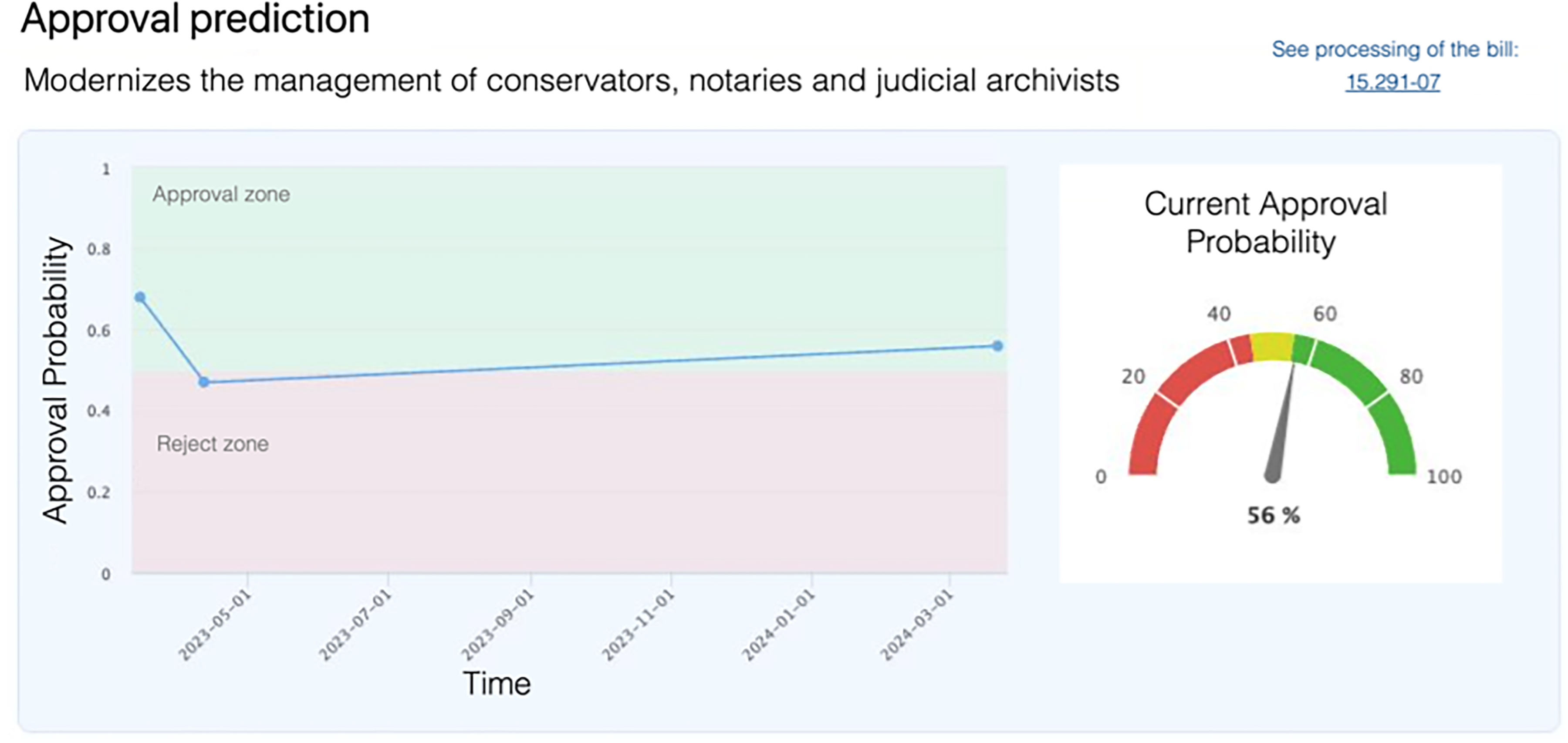
Law-predictor user interface.
This tool still has restricted access as we are in the process of improving the validation and user interface.
Related work
Although this work explores various lines of development in AI implemented at the BCN, there have been similar experiences worldwide, which can offer different approaches to enrich the discussion. Below, international cases that are analogous to each of the experiences described are presented.
In the field of parliamentary linked open data and libraries, we find the ParliamentSampo system (Hyvönen et al., 2022), a linked open data service and semantic portal designed to investigate political culture and language in the Finnish Parliament. Based on a knowledge graph containing nearly one million parliamentary speeches (from 1907 to 2021) and data about Members of Parliament, it utilizes the Parla-CLARIN format for analysis and application development, aiming to enhance transparency in political decision-making for diverse user groups. Hyvönen et al.’s (2022) article provides an interesting analysis of the speeches but does not focus on the details of open data models, and while mentioning them, does not delve into the process of generating open data.
The study by Koryzis et al. (2021) analyses the digital transformation of parliaments today, highlighting trends towards open data, standardized processes and participatory inclusion. Based on surveys conducted with parliamentarians and parliamentary professionals from 25 countries across five continents, it proposes a transformational framework that identifies essential tools for sharing information and knowledge. One of the most relevant findings related to our case study is the recognition of technological aspects with high utility and maturity associated with the use of linked open data, which are deemed more significant than the use of machine learning.
The article by Niu (2020) examines the diffusion and adoption of linked open data in libraries, revealing it as a decentralized and continuous process with significant reinvention. Through extensive analysis, it identifies three diffusion paths (inter-library, intra-library and inter-librarian) and highlights the roles of leading institutions, professional organizations, vendors and funders in facilitating adoption. The study underscores the importance of standards, tool reuse and commercialization in overcoming barriers such as resource limitations and steep learning curves. By mapping the stages of linked open data adoption, this research offers a comprehensive framework to guide libraries in embracing linked open data for enhanced interoperability and knowledge-sharing.
Also in the field of the Semantic Web and linked open data technologies, several advancements are reported in the literature on improvements both in access to the information provided to users and improvements in the impact on the internal functioning of the institutions that implement it. Among these are the use of Shape Expressions for ensuring the quality of linked open data (Candela et al., 2023); the replacement of MAchine-Readable Cataloging (MARC) standards with bibliographic framework (BIBFRAME), which is linked-open-data-based (Park et al., 2020; Samples and Bigelow, 2020) and ontology-based systems for processing scientific information in digital libraries (Malakhov et al., 2023); the use of Resource Description and Access (RDA) and Wikibase (the technological backbone of Wikidata) for managing named entities (Zapounidou et al., 2024); and the preservation and access of cultural heritage using Semantic Web technologies (Silva and Terra, 2024).
Gagnon and Azzi (2022) introduce the concept of ‘legislative intelligence’, which leverages AI and semantic analytics in parliamentary contexts to enhance citizen engagement through the semantic annotation of debates. Using natural language processing technologies, ontologies and knowledge graphs, these tools enable customized indexing, entity recognition and tailored recommendations for legislative critiques. Their study highlights an international open-source initiative aimed at developing legislative intelligence solutions, detailing its core functionalities and proposing a robust architectural framework.
In the context of natural language processing applied to legislative tasks, it is worth highlighting several underexplored areas. Notable advancements include the use of language models for tasks such as the automatic summarization of regulatory documents (Klaus et al., 2022) and multilingual legislative frameworks (Gesnouin et al., 2024; Zmiycharov et al., 2024). Additionally, retrieval-augmented generation models (Lewis et al., 2020) have been employed in tasks such as legal question-answering (Louis et al., 2024; Wiratunga et al., 2024) and the development of virtual assistants tailored to the legislative domain (Rafat, 2024).
In the realm of legislative prediction tools and similar applications, three notable experiences with different approaches deserve a mention:
Nay (2017) developed a legislative predictor for the United States Congress using word vectors and an ensemble model, achieving approximately 68% accuracy using only textual data and without incorporating additional contextual features. Bari et al. (2021) introduced a vote predictor for congressional members during legislative discussions, which serves as a basis for determining law approval and has an 80% accuracy rate. Katz et al. (2017) applied a model to predict votes in the United States Supreme Court, achieving 71.9% accuracy in predicting the votes of individual justices and 70.2% accuracy in case-outcome predictions.
Conclusions
The use cases presented in this article demonstrate the application of AI tools in a parliamentary library. We believe that it is important to showcase real cases, not only from the perspective of recent applications like large language models and retrieval-augmented generation, but also projects that highlight other technological facets that have contributed over time. These contributions span from AI to automation, process efficiency improvements and the development of new products.
From the perspective of both Semantic Web technologies and open data, which lay the groundwork for building systems based on knowledge graphs and enriched data, to the use of natural language processing for enhancing and streamlining computer-assisted human processes, as well as providing tools that encapsulate human reasoning to generate legislative predictions, AI has become fundamental in the BCN as a parliamentary library. This integration of AI-based technologies has been crucial in offering a broader and better catalogue of products and services to users.
The practice of publishing open legislative data can be highly beneficial in other cultural contexts, as it helps ensure legal certainty through open access to data and enables citizens to develop applications that make practical use of national legislation and legislative data. At the same time, open data also serves as a mechanism for promoting active transparency, facilitating direct access for the population and fostering trust in the government.
The creation of systems such as the History of the Law and Parliamentary Labour through the use of interoperability standards like AKN, AI tools such as natural language processing and automated archival systems within repositories constitutes a highly replicable framework for organizations that are responsible for providing information services related to archives and historical collections. The adoption of standards like AKN enables the use of widely available workflow management tools, accelerating the development of projects in similar environments.
Similarly, the legislative-approval predictor presented in this study is a tool that is highly replicable in other contexts, such as legislative bodies in different countries. It also provides general guidelines for designing similar tools in diverse scenarios where the dependent variable is the approval or rejection of a measure, based on a set of factors that may vary over time.
Supplemental Material
sj-css-1-ifl-10.1177_03400352251315844 - Supplemental material for Transforming parliamentary libraries: Enhancing processes delivering new services with artificial intelligence
Supplemental material, sj-css-1-ifl-10.1177_03400352251315844 for Transforming parliamentary libraries: Enhancing processes delivering new services with artificial intelligence by Francisco Cifuentes-Silva, Hernán Astudillo and Jose Emilio Labra Gayo in IFLA Journal
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.