
Abstract
Car-following models, as the essential part of traffic microscopic simulations, have been utilized to analyze and estimate longitudinal drivers’ behavior for sixty years. The conventional car-following models use mathematical formulas to replicate human behavior in car-following phenomenon. The incapability of these approaches to capture the complex interactions between vehicles calls for deploying advanced learning frameworks to consider more detailed behavior of drivers. In this study, we apply the gradient boosting of regression tree (GBRT) algorithm to vehicle trajectory data sets, which have been collected through the Next Generation Simulation (NGSIM) program, to develop a new car-following model. First, the regularization parameters of the proposed method are tuned using cross-validation technique and sensitivity analysis. Second, prediction performance of the GBRT is compared to the world-famous Gazis-Herman-Rothery (GHR) model, when both models have been trained on the same data sets. The estimation results of the models on unseen records indicate the superiority of the GBRT algorithm in capturing the motion characteristics of two successive vehicles.
Drivers’ stochastic behavior renders more complexity, uncertainty, and non-linearity in transportation systems. Microscopic simulation architectures are key tools in replicating the stochastic nature of traffic conditions (1, 2). These frameworks allow traffic engineers to evaluate the performance of real-world traffic networks while considering the interaction between individual vehicles and various sections of roads such as signalized intersections. This results in reducing high expenditure on collecting field data and monitoring real transportation systems. In microscopic models, details of each vehicle’s motion characteristics such as speed, acceleration/deceleration, time and space headway are described with the help of behavioral models, including gap-acceptance, speed adaption, lane-changing, ramp metering, overtaking, and car-following models ( 3 ). Lateral and longitudinal interactions between vehicles are the two principal components for understanding the dynamic behavior of travelers in traffic microscopic simulators ( 4 ). Lateral behaviors, described by lane-changing models, comprise the decision to change lane, choice of target lane, and gap-acceptance ( 5 ). Car-following models reproduce the longitudinal behavior of vehicles, where the movement features of the following vehicle are restricted by the leading vehicle in the same lane. The focus of this study is on car-following models as the principal type of microscopic simulation model.
A growing trend towards developing car-following models began sixty years ago ( 6 ). Many classical car-following models have been constructed according to traffic flow theories and explicit assumptions. Examples of conventional car-following models range from the Gazis-Herman-Rothery (GHR) model ( 7 ), and safety distance or collision avoidance models ( 8 ), to desired measures (9, 10), optimal velocity models ( 11 ), linear models ( 12 ), cellular automaton models ( 13 ), and psycho-physical or action points models ( 14 ). The relative distance and speed between following and leading vehicles, and the speed of the following vehicle, as well as the driver’s perception/reaction time are the standard inputs, while the following vehicle’s acceleration/deceleration or speed are the main outputs in the car-following models. On the other hand, the rapid growth of data-driven approaches in addition to the availability of field data have led to a proliferation of deploying data mining techniques in transportation fields ( 15 ). In contrast to classical models, closed-form mathematical functions, calibrating, and manual errors are not concerns in data-driven techniques ( 16 ). The capability to extract more details on drivers’ responses as well as the flexibility to involve additional information (e.g., environmental effects and roadway geometry) are further benefits to using data-driven techniques in car-following models.
This study begins by reviewing car-following literature with a focus on models developed with the aid of data-driven approaches. It will then present the gradient boosting of regression trees (GBRT) algorithm and the GHR model in the Methodology section. Trajectory data sets and preprocessing procedures are described in the Data Description section, and in the Results and Discussion section, the optimal parameters of the proposed model are determined using sensitivity analysis and the cross-validation technique. The prediction performance of the proposed model is also compared with the GHR model in this section. The Conclusion summarizes the study.
Literature Review
As mentioned in the previous section, car-following models can be categorized into two main groups: conventional and data-driven models ( 4 ). A systematic review on the classical car-following models, their calibration, and evaluation have been reported by Brackstone et al. ( 6 ). Studies by Olstam et al. ( 3 ) and Panwai et al. ( 17 ) highlighted and compared the performance of classical car-following models in commercial traffic microsimulation packages, including AIMSUM with the safety distance model, MITSIM with the GHR model, and VISSIM and Paramics with the psycho-physical models. A group of conventional car-following models, such as GHR, Gipps, Cellular Automaton, S-K, Intelligent Driver, and Wiedemann, was assessed in terms of fundamental diagrams and vehicle trajectory data sets by Hamdar ( 18 ). A qualitative study by Saifuzzaman ( 19 ) described extension and improved versions of the classical car-following models from both engineering and human factor points of view. In accordance with the scope of the current study and the existence of holistic survey papers on classical car-following models, only the cutting-edge car-following models developed by data mining techniques are investigated.
Fuzzy logic, artificial neural network (ANN), and combinations of the two approaches, (e.g., locally linear neural-fuzzy models ( 20 )), have widely been utilized to simulate the future states of a vehicle in a car-following process. A number of studies have also tested the performance of other machine learning algorithms, including k-nearest neighbor ( 16 ), locally weighted regression ( 21 ), and support vector regression ( 22 ), for better understanding drivers’ dynamic behavior.
The reaction of a driver to a given stimulus stems from a set of ambiguous and vague driving rules rather than a deterministic relationship, which is typically enforced in the classic car-following models. To overcome such an issue, Kikuchi et al. ( 23 ), for the first time, presented a fuzzy inference system to simulate the driver’s action as a result of a fuzzy reasoning process determined by natural-language-based driving rules. In their study, the relative distance and speed between the two vehicles as well as acceleration/deceleration of the leading vehicle were fed as inputs into the GHR model. Each of the inputs was grouped into six fuzzy sets. A triangular membership function was assigned to each fuzzy set. Specifying a set of rules generates a set of outputs in fuzzy numbers. Then, averaging weighted outputs over the time, as the final output, leads to estimating the following-vehicle movement relative to the leading vehicle. More work in this context can be found in Wu et al. and Gao et al. (24, 25). The main challenge in developing such models was the determination of fuzzy sets and the corresponding membership functions, which are basic and essential concepts in fuzzy logic.
The stochastic and non-linearity nature of human behavior and traffic streams call for more sophisticated models. ANNs have received the most attention in modeling car-following behavior in comparison with other data-driven approaches due to their remarkable ability to derive meaningful concepts from complicated and incomplete data sets. Hongfei et al. ( 26 ) introduced the application of ANNs in the car-following models for the first time. A two-hidden-layer back propagation ANN was applied to develop a car-following model, where the training and test data sets were collected by means of a five-wheel system in an open roadway condition. Moreover, the performance of other types of ANN architectures, including fuzzy adaptive resonance theory (ART) neural networks, radial basis function networks, and swarm algorithm, have been investigated. However, the results implied the superiority of the regular neural network compared to almost all other ANN training algorithms (27, 28). As ANNs require no pre-settings for considering the various combination of input variables or adding new features, the contribution of other factors, including the motion features of the preceding vehicle in front of the leading vehicle, can also be examined using ANNs ( 29 ). Unlike many studies that put the reaction time of the driver-vehicle unit as a constant value, a number of modified ANNs have been built to predict car-following behavior based on the instantaneous reaction delay (30, 31). Several studies have attempted to fuse ANNs with other approaches such as fuzzy logic and local linear regression models (4, 32).
Notwithstanding that several data-driven approaches for modeling car-following behavior have been postulated in literature, a lack of examining ensemble algorithms in this context has encouraged us to evaluate the capability of this class of machine learning algorithms. Since all variables in the context of car-following models are continuous, regression models are more reliable algorithms to build the relationship between the variables. Accordingly, the GBRT, as an effective type of ensemble algorithms, is deployed that takes advantage of predictive power, robustness to the noise by combining a set of base learners and minimizing the prediction error as learning proceeds.
Methodology
GHR Models
The general GHR model, proposed by Gazis, Herman, and Rothery at General Motors laboratory ( 7 ), is used as the basis of comparison for examining the performance of the GBRT-based car-following model. All GHR models express a general idea that a driver responds to a stimulus according to the following relationship: Response = function (sensitivity, stimulus), which is also known as the follow-the-leader theory of traffic. The response is always considered as the acceleration/deceleration of the following vehicle, which is a factor that can be easily controlled by drivers through accelerator or brake pedals. According to the follow-the-leader theory, it has been shown that there is a high correlation between the following driver’s response and the relative speed difference of the follower and leader vehicles. This results in considering relative speed as the stimulus in all versions of the GHR models ( 7 ). Therefore, the variations among GHR models is contingent on how to formulate the sensitivity term. While a variety of functional forms were proposed and evaluated as the sensitivity term, the general GHR model was introduced to cover all other types of GHR models:
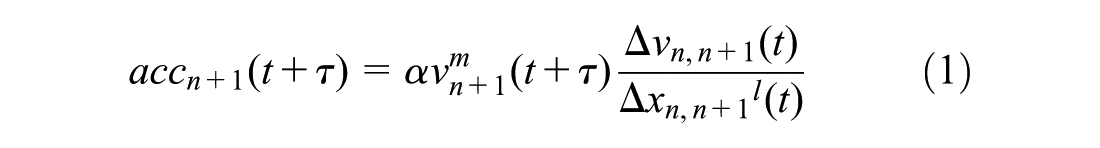
Denoting the current time as t,
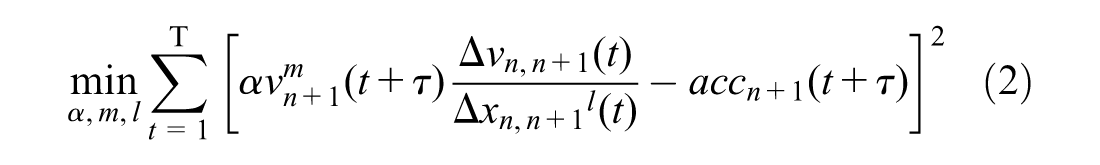
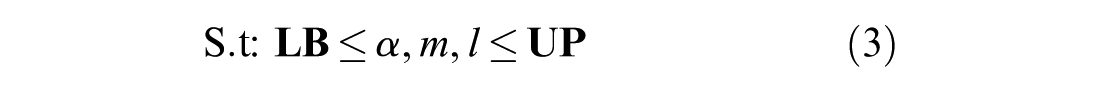
where T is the number of training instances. Equation 2 measures the sum of the squares of the errors between the estimated and true (observed) values of acceleration/deceleration. Equation 3 constrains the model parameters between the lower bound vector,
Gradient Boosting of Regression Trees
In this study, the response and explanatory variables of the proposed car-following model are considered similar to the GHR model. Accordingly, the acceleration/deceleration of the following vehicle at the time instant
The core idea in ensemble methods is to combine multiple base learners, which are usually called weak learners, to improve the accuracy and robustness of the final model. Two major questions need to be answered in ensemble methods: what type of weak learner should be used for the training process? How are weak learners trained and fused to yield the final model? Accordingly, ensemble algorithms fall into two main families: averaging and boosting methods. Each family follows a distinct procedure towards training and combining individual base learners ( 33 ). In the averaging methods, base learners are first built independently on randomly selected training instances, and then are averaged to generate the final model. Examples of this category are bagging and random forest methods. Naïve Bayes classifiers, decision trees, and neural networks are typically utilized as the machine learning techniques for training weak learners. In the boosting methods, weak learners are trained iteratively and in a stage-wise fashion to find a model that reduces the bias and variance of prediction. In each iteration, a strength weight is assigned to the weak learner that implies its prediction error rate; meanwhile, each training instance is reweighted by how incorrectly it was classified. The method of weighting training data and base learners distinguishes between boosting algorithms such as adaptive boosting and gradient boosting. The final model is the sum of the weighted weak learners ( 33 ).
In this study, we envision utilizing the GBRT algorithm, which was initially developed by Friedman ( 34 ), for estimating the car-following model. The key goal in the GBRT algorithm is to fit a regression tree at each step to the difference between the observed response and the aggregated prediction of all learners grown previously. As indicated by the name of the algorithm, the decision trees algorithm with a fixed size is chosen as the weak learner.
Suppose the training data set contains N samples of (yi,
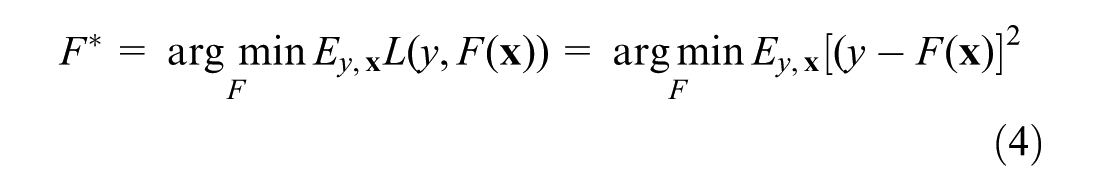
Notwithstanding that many forms of loss functions exist in the literature, the squared-error loss function is chosen in Equation 4 due to the superior computational properties of the least-square algorithm for minimizing the squared-error loss function (
34
). The GBRT algorithm seeks to find the function
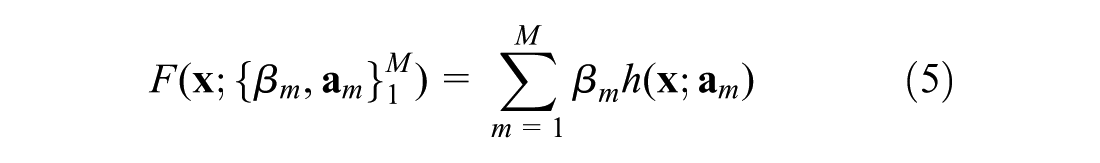
where M is the number of weak learners, and β is the corresponding weight for each learner.
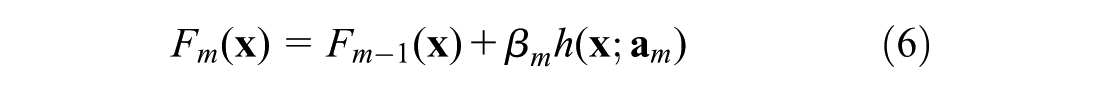
Thus, at each step m, the estimator
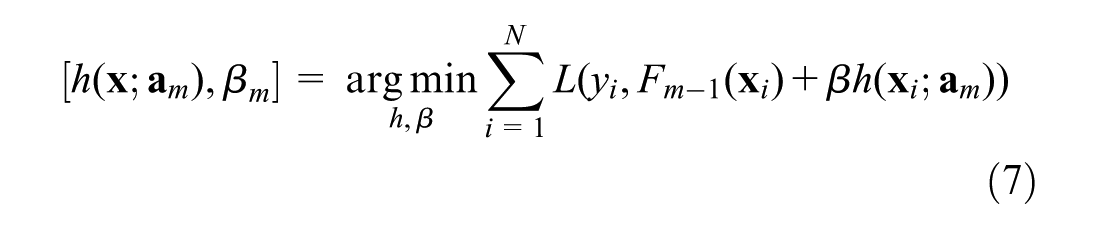
where the loss functions in Equations 4 and 7 are the same. As Equation 7 is a hard optimization problem, one way to more easily resolve the problem is to apply the gradient descent algorithm. Considering Equation 6 and given the estimator
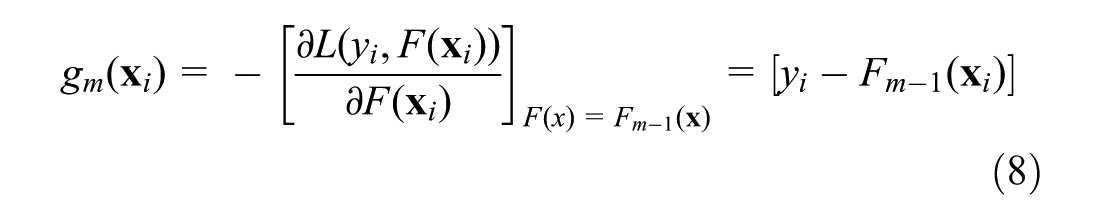
where the right-hand side is computed by substituting the squared-error loss function. Hence, at each step m, the regression tree
The step size, βm, is calculated by solving the one-dimensional optimization problem using Equation 9:
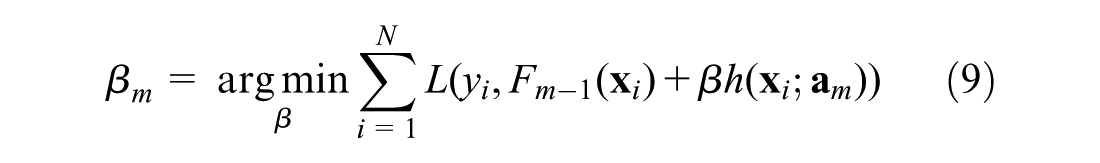
It should be noted that solving Equation 9 can be thought of as finding the optimal step size in the gradient descent algorithm.
The GBRT algorithm steps are summarized as follows:
Initialize the approximation function
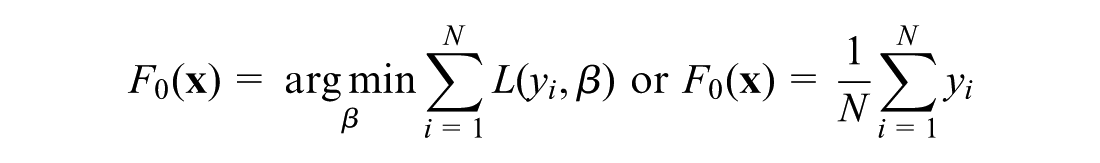
For Calculate the pseudo-responses: Fit the regression tree Calculate the step size βm using the line search: Update the model:
End the algorithm.
Regularization Parameters
Regularization is a process used in an attempt to prevent the overfitting problem in statistical models by explicitly controlling the model complexity and constraining the fitting procedure ( 34 ). Overfitting occurs when the model is extremely complex with too many parameters. A large number of parameters engenders the learning process to be performed through memorization of the training data set rather than understanding the concepts and attributes inside the data. An overfitted model perfectly predicts only on training examples due to the memorization but has a poor predictive performance on the unseen data. For the GBRT model, adding too many weak learners with over-complex trees as well as the high speed of learning are the main sources of overfitting, which call for introducing regularization parameters to control the issue.
The value of M, the number of weak learners, is one of the regularization parameters that regulates the expected loss reduction over the training data. Moreover, handling the speed of learning through a shrinkage process has been found to be an efficient approach for avoiding complexity and overfitting, particularly in additive models ( 34 ). The shrinkage strategy can be obtained by incorporating the learning rate ν, which scales the contribution of each weak learner, as shown in Equation 10. Thus, the additive model in the second step of the algorithm is replaced by:
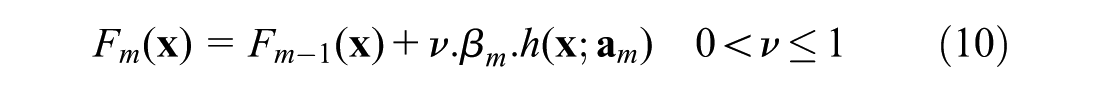
The parameters M and ν interact strongly with each other. Thus, the value of each affects the other. Accordingly, a sensitive analysis that considers both parameters simultaneously needs to be performed for determining their optimal values. Model evaluation techniques such as cross-validation is deployed to compute and compare the generalization error under each combination of M and ν.
The size of regression trees, denoted as D, is another regularization parameter that controls the overfitting problem. The tree depth is defined by tuning parameters like the maximal number of decision splits and/or the minimum number of observations required to be at a leaf node. The decision tree is usually overfitted on the data set with a few samples but a large number of features. Fortunately, the current data set contains a large number of samples with only three features, which reduces the possibility of generating overfitted trees. Even though the size of trees has a slight impact on the overfitting problem due to the mentioned characteristics of the car-following data set, we compute its optimal value by performing a sensitivity analysis. So we not only obtain the highest decrease in the test error but ensure that the important structures of the ultimate model are captured ( 35 ).
It is worth mentioning that, in this paper, the driver’s reaction time (τ) is not an explanatory variable in both GHR and GBRT models; instead, it is used as a constant value in the models. Indeed, its value affects the order of predictor variables with their corresponding response variable. For example, the triple
Data Description
The proposed car-following model is developed and tested based on vehicle trajectory data sets collected by the Federal Highway Administration (FHWA) under the NGSIM program. The NGSIM program aims to collect high-quality data on vehicle motion parameters over a time window for which driver behavior and interactions with traffic objects are inferred through microscopic modeling. The data in this study are selected from the northbound traffic on I-80 in Emeryville, California, recorded on April 2005. The NGSIM I-80 data set contains three subsets recorded in three time periods: 4:00 to 4:15 p.m., 5:00 to 5:15 p.m., and 5:15 to 5:30 p.m. Deploying seven video cameras installed on a tall building, the trajectory data was recorded at the one-tenth-of-second resolution. A variety of vehicle trajectory features have been extracted and provided in each data set, including acceleration, speed, location coordinates, ID of the preceding and the following vehicle of the subject vehicle, type and length of the vehicle, and space and time headway with respect to the leading vehicle.
However, the NGSIM data include measurement errors in computing location coordinates, which in turn produce the unrealistic large speed and acceleration values. Raw data has also been affected by high-to-medium-frequency disturbances due to speed transitions, which need to be modified. Several studies in literature have proposed techniques to rectify errors in the raw data before being used in traffic flow theory problems (36, 37). In this study, the proposed multistep filtering procedure in the References ( 36 ) is applied to the NGSIM data to create reconstructed reliable trajectory data. First, the data points out that their absolute acceleration/deceleration exceeds a certain threshold value, which is 3 m/s2 within this scope, and are detected as unrealistic values. Using a filtering technique such as natural cubic spline interpolation, new longitudinal locations of outliers are interpolated between a sequence of non-outlier points before and after the outliers. The outlier speed and acceleration are then calculated from the new distance locations through the basic equations of motion. Secondly, a low-pass filter is utilized to remove the random error component from speed and acceleration profiles. Further details on the vehicle-trajectory-reconstruction procedure can be found in the References ( 36 ).
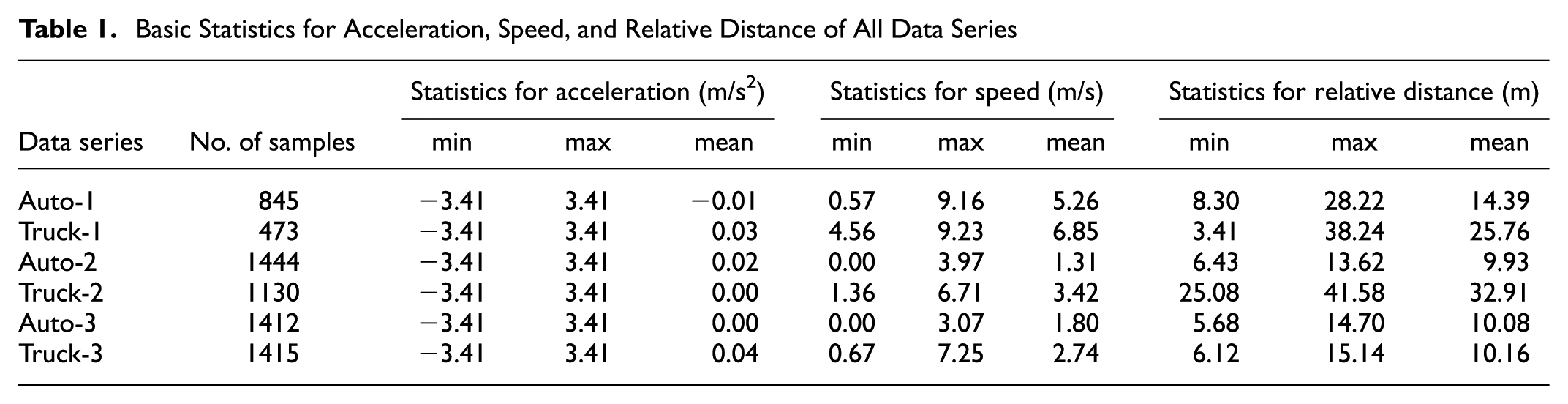
In this study, a total of six data series, two from each subset, are utilized for the analysis. In each of the three subsets, two pairs of following and leading vehicles that have the highest number of data points were selected. The following vehicle in one pair is an Auto, and in the other is a Truck vehicle. Each pair builds one data series that ends up with the total six data series, named Auto-1, Truck-1, Auto-2, Truck-2, Auto-3, and Truck-3. Summary statistics of the acceleration, speed, and relative distance of the following vehicle in the original data series are provided in Table 1. Using the above-mentioned filtering procedure, the reconstructed data of speed and acceleration profiles for Auto-2 data series, as the data series with the maximum number of samples, are plotted against the original NGSIM data in Figure 1. The proposed car-following algorithm and the corresponding analysis are applied to all data series.
Basic Statistics for Acceleration, Speed, and Relative Distance of All Data Series
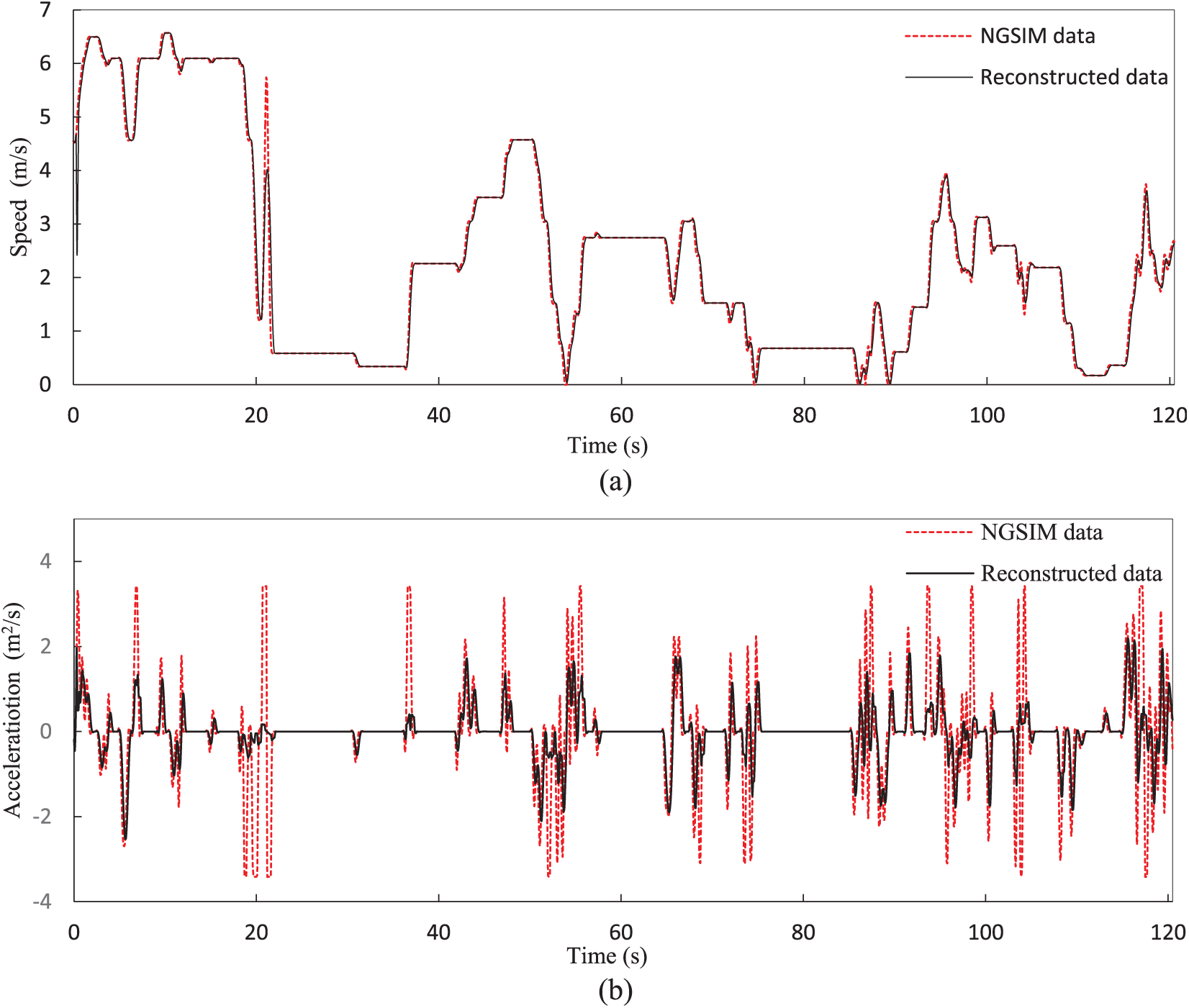
Comparison between the NGSIM and reconstructed data of speed and acceleration profiles for the Auto-2 data series: (a) speed profile and (b) acceleration profile.
Results and Discussion
The model evaluation process for the proposed GBRT-based car-following model is implemented in two steps. First, the regularization parameters (v, M, D, τ) are optimized using 5-fold cross-validation to ensure a good fit of data. In the second stage, using the optimal values found in the first stage, the performance of the GBRT model is compared with the optimum GHR model that has been optimized based on Equations 2 and 3. It should be noted the optimal reaction time is also determined for the GHR model to have a fair comparison. As mentioned in the Methodology section, the data instances that are fed into both algorithms vary according to the reaction time (τ) value. Such a time dependency between consequent data instances hinders splitting them randomly into the training and test sets. Consequently, in this study, the first 80% of each data series is selected as the training data set while holding on to the remaining 20% of the data as the unseen records to be used only in the second step of the model evaluation process. Both steps are consecutively implemented in each of the six data series separately and their results are reported.
First Step: Regularization Parameters
In the sensitivity analysis for computing regularization parameters, 5-fold cross-validation is utilized to obtain the average prediction error. Due to the inherent time dependency between the explanatory and response variables of the consequent data samples, unlike general cross-validation, each fold is not created randomly. While the test set is still held on to for the second step of the evaluation, the training set is subdivided into five subsets in such a way that the first 20% of the training portion of each data series constitutes the first fold, the second 20% forms the second fold, and so forth.
A matrix with different combinations of v and M is designed for simultaneously optimizing the learning rate and the number of weak learners. The vectors
Figure 2 illustrates how the GBRT prediction error is influenced by various combinations of (v, M) for the data series Auto-2 and Truck-2, as the data sets with the highest number of samples. Each line represents the variation of the average MSE for a particular value of v over the full range of the vector
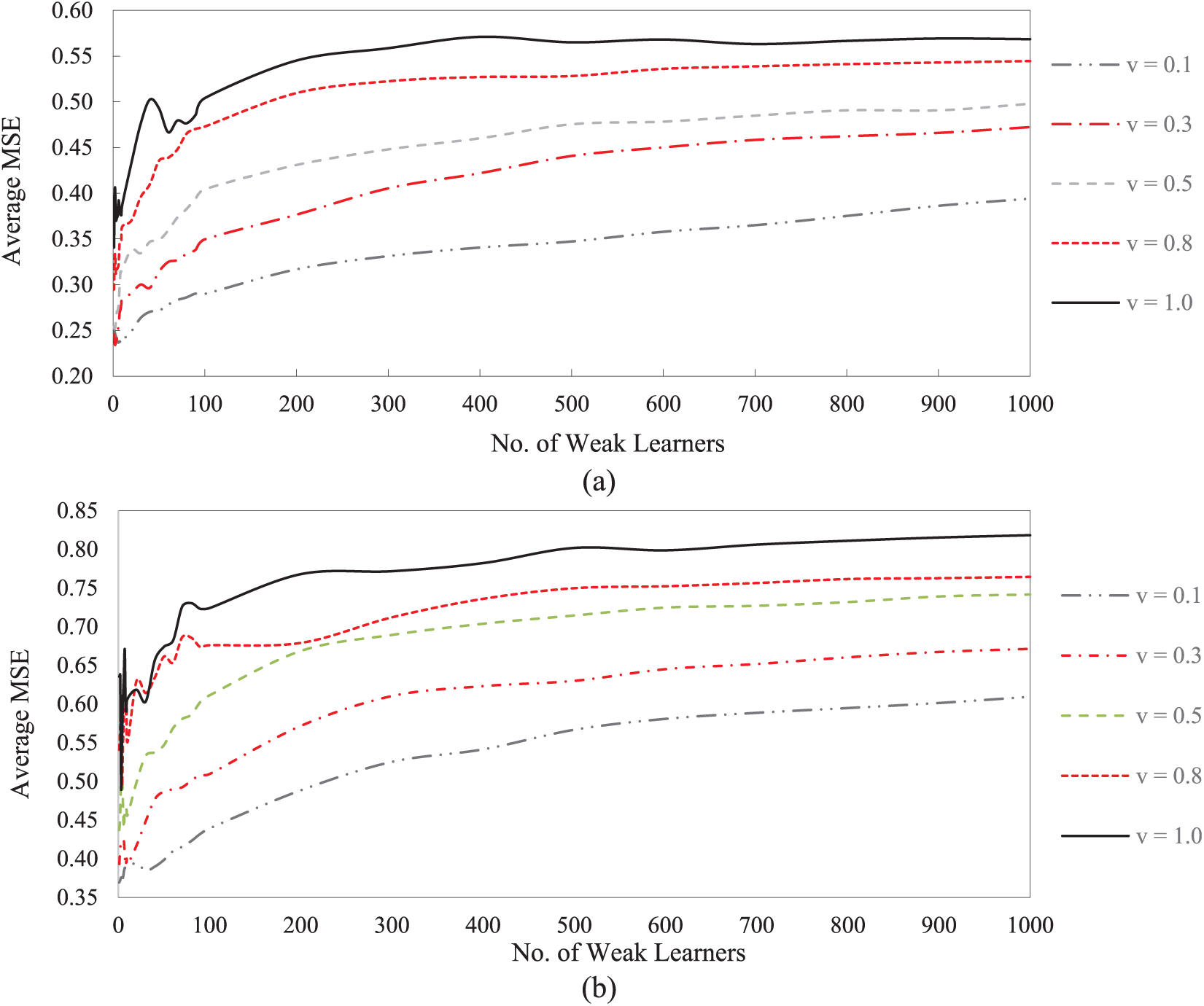
Average MSE for the GBRT model upon various combinations of the number of weak learners (M) and the learning rate (v) for two data series: (a) Auto-2, (b) Truck-2.
Figure 3a, b delineates how accuracy of the GBRT model is influenced by changing the size of the decision trees (D) and the reaction time (τ), respectively. The average MSE is computed for each value of D and τ with the analogous approach to the v and M. As depicted in Figure 3a, the average MSE for almost all data series declines slightly by setting D = 3. However, the variation in MSE remains constant for values of D > 3. Accordingly, the D = 3 is selected as the optimum value of the decision tree depth. Such a plateau stems from that fact that the car-following model contains only a few features. As a consequence, the possibility of facing the overfitting problem decreases even if the decision trees become over-complex by increasing the value of D. Furthermore, as depicted in Figure 3b, the GBRT prediction performance remained approximately constant over the reaction time interval although the lower values of the reaction time work better for some of the data series such as Auto-1 and Auto-2. It is clear that the optimal value of the reaction time is an essential characteristic of the driver in a given data set rather than the learning algorithm, which may be distinct for other data sets. Since the scope of this study is to tune the GBRT parameters instead of determining a reliable reaction time interval for all possible data sets, we use the exact optimal value of the reaction time obtained for each data series. In summary, as mentioned in the Methodology section, the most effective regularization parameters for the GBRT-based car-following models are (v, M) while the (D, τ) do not significantly impact on controlling the degree of fit to the data.
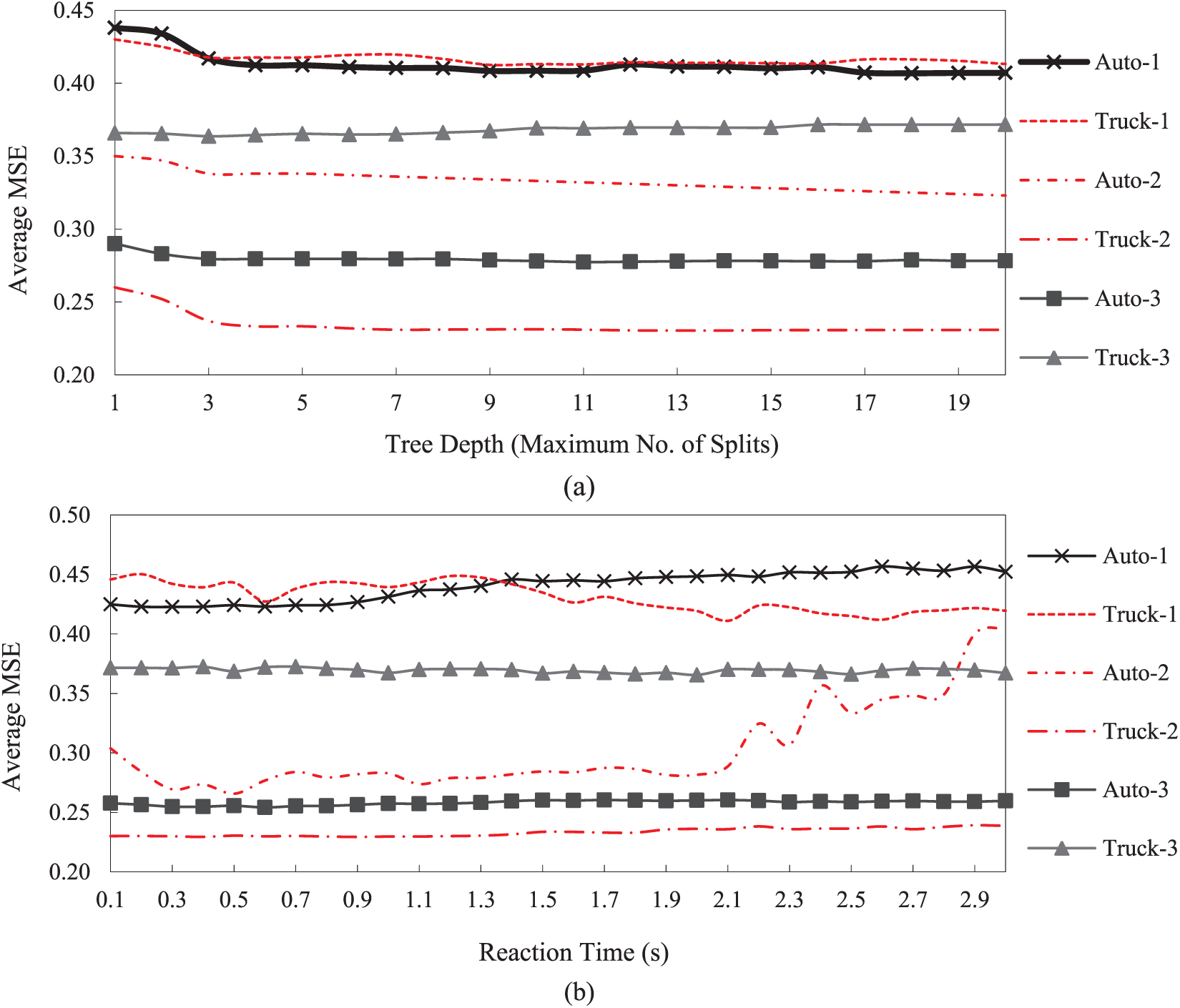
Average MSE of the GBRT model upon different values of: (a) Tree Depth (Maximum Number of Splits), (b) Reaction Time(s).
Step 2: Comparison between GBRT and GHR Models
First, we optimize the parameters of the GBRT and GHR models for establishing a fair comparison between the two predictive models, as one of the salient objectives in this study. Then, for having a robust comparison, the fitted models are examined on the test samples of each data series, which have not been deployed in the training process. For the test portion of each data series, the acceleration of the following vehicle is estimated with both techniques and the corresponding MSEs are reported as shown in Figure 4.
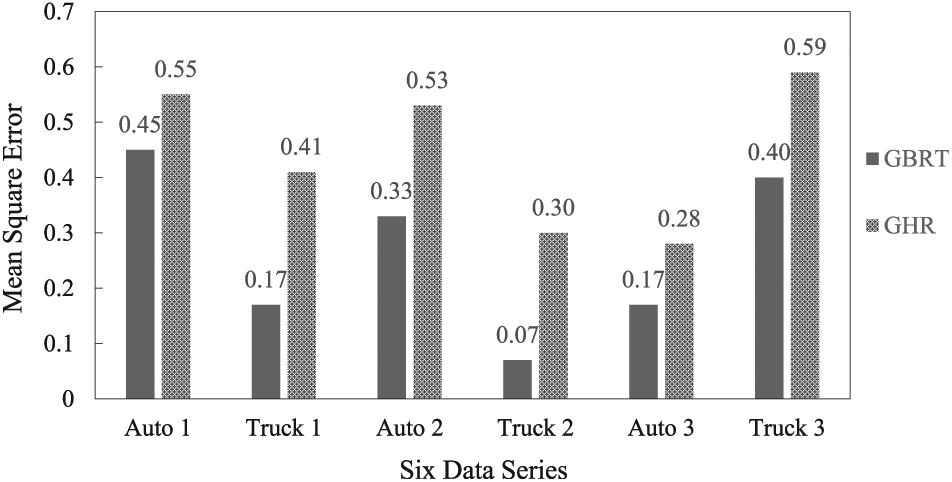
Performance comparison between the GBRT and GHR models based on MSE, as the good
The comparison between the two models proves the superiority of the GBRT model in all data series, regardless of whether the auto or truck is the follower vehicle. The primary reason for the superiority of GBRT originates from the fact that such models are unrestricted in growth according to the relationship among the variables. However, constraining the interdependency between features of the car-following behavior to a pre-defined structure lessens the GHR power to capture more aspects of driver behavior.
Conclusion
With the emergence of advanced data-driven approaches and technologies for collating the massive vehicle trajectory data sets, the sophisticated car-following models can be developed so as to alleviate the shortcomings of the classical car-following models, such as restriction to mathematical equations and inability to incorporate additional effective factors. With the help of data mining techniques, there is no need to define the functionality form of the model. This is a practical benefit particularly in the complex traffic flow condition where building an appropriate model is almost impossible. Furthermore, data-driven approaches give room to researchers to investigate the effect of new factors on car-following behavior, including other kinds of the microscopic and macroscopic parameters, weather conditions, leading vehicle types, time of day or week, road geometry, and the motion inputs related to the vehicles other than the leading vehicle.
In this study, the GBRT algorithm was presented to reproduce the response action of the following vehicle in accordance with the motion characteristic of the leading vehicle. Data sets for the analysis were captured from the NGSIM program. Data preprocessing techniques were applied to the raw data to remove random error measurements and obtain a reliable data source. To ensure a promising model, first, the regularization parameters of the model were determined. Second, the optimal GBRT and GHR models were trained on the same training set. The prediction results of applying both models to the unseen test data demonstrated the superiority of the proposed GBRT algorithm compared to the well-known GHR model.
As a future research direction, it would be interesting to simultaneously capture other drivers’ stochastic behavior. Using advanced machine learning algorithms, lateral and longitudinal behaviors of a vehicle can be simulated by integrating the lane-changing, car-following, and gap-acceptance concepts. Furthermore, outstanding frameworks for replacing the traditional models with the data-driven approaches in the commercial microsimulation packages such as VISSIM and CORSIM should be provided.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: Research Supervision: Dr. Montasir Abbas; study conception and design: Sina Dabiri, Dr. Montasir Abbas; data collection: Publically Available; analysis and interpretation of results: Sina Dabiri; draft manuscript preparation: Sina Dabiri. All authors reviewed the results and approved the final version of the manuscript.
The Standing Committee on Artificial Intelligence and Advanced Computing Applications (ABJ70) peer-reviewed this paper (18-01813).