
Abstract
Conventional methods for visual assessment of civil infrastructures have certain limitations, such as subjectivity of the collected data, long inspection time, and high cost of labor. Although some new technologies (i.e., robotic techniques) that are currently in practice can collect objective, quantified data, the inspector’s own expertise is still critical in many instances because these technologies are not designed to work interactively with a human inspector. This study aims to create a smart, human-centered method that offers significant contributions to infrastructure inspection, maintenance, management practice, and safety for the bridge owners. By developing a smart mixed reality (MR) framework, which can be integrated into a wearable holographic headset device, a bridge inspector, for example, can automatically analyze a certain defect such as a crack that he or she sees on an element, and display its dimension information in real-time along with the condition state. Such systems can potentially decrease the time and cost of infrastructure inspections by accelerating essential tasks of the inspector such as defect measurement, condition assessment, and data processing to management systems. The human-centered artificial intelligence (AI) will help the inspector collect more quantified and objective data while incorporating the inspector’s professional judgment. This study explains in detail the described system and related methodologies of implementing attention guided semisupervised deep learning into MR technology, which interacts with the human inspector during assessment. Thereby, the inspector and the AI will collaborate/communicate for improved visual inspection.
The Federal Highway Administration provides annual statistics on structurally deficient bridges. According to 2017 statistics, 54,560 bridges are structurally deficient among a total number of 615,002 bridges ( 1 ). Utilizing novel technologies for better management of such aged and deteriorated civil infrastructures is becoming more critical. Although the existing status of the U.S. civil infrastructure is well documented, there is slow progress in improving this status. Structural systems have aged to an extent that critical decisions about repair or replacement now need to be made. To prevent the impending degradation of civil infrastructure, utilizing novel technologies for periodic inspection and assessment for long-term monitoring has recently become more critical ( 2 ). Although the inclination to use conventional inspection methods still persists, advanced sensing technologies have the ability to better understand the current condition with more resolution and accuracy ( 3 ). Conventional methods for visual assessment of infrastructures have certain limitations, such as subjectivity of the collected data, long inspection time, and high cost of labor. On the other hand, imaging technologies allow collecting quantified data and performing objective condition assessment. These techniques are now receiving a breakthrough improvement with the employment of state-of-the-art artificial intelligence (AI) models. Instead of postprocessing of the collected inspection data, an AI system can detect damage in real-time and analyze for condition assessment at a reasonable accuracy. The main objective of the AI integrated mixed reality (MR) system described in this paper is to assist the inspector by accelerating certain routine tasks such as measuring all cracks in a defect region or calculating a spall area. In this system, the human-centered AI interacts with the inspector instead of completely replacing the human involvement during the inspection. This collective work will lead to quantified assessment and reduced labor time while also ensuring human-verified results. Even though this study focused on concrete defect assessments with particular focus on concrete bridges, the methodology can be expanded for other types of structures.
Concepts
Virtual, Augmented, and Mixed Reality
Virtual reality (VR) is a computer simulated reality that replicates a physical environment or imaginary world through an immersive technology. VR replaces the user’s physical world with a completely virtual environment and isolates the user’s sensory receptors (eyes and ears) from the real world ( 4 ). The VR is observed through a system that displays the objects and allows interaction, thus creating virtual presence ( 5 ). Nowadays, VR headsets have gained vast popularity especially in the gaming industry. Augmented reality (AR), on the other hand, is an integrated technique that often leverages image processing, real-time computing, motion tracking, pattern recognition, image projection, and feature extraction. It overlays computer generated content onto the real world. An AR system combines real and virtual objects in a real environment by registering virtual objects to the real objects interactively in real-time ( 6 ). The beginning of AR dates back to Ivan Sutherland’s see-through head-mounted display to view three-dimensional (3D) virtual objects ( 7 ). The initial prototype was only able to render a few small line objects. However, AR research has recently increased dramatically and now it is possible to visualize very complex virtual objects in the augmented environment. The recent developments of AR/VR technology have helped companies produce holographic headsets that benefit MR technology, in which one can experience a hybrid reality in which physical and digital objects coexist and interact in real-time. The term mixed reality was originally introduced in a 1994 paper entitled “A Taxonomy of Mixed Reality Visual Displays” ( 8 ). In the paper, a virtuality continuum (VC), in other words an MR spectrum, was explained in detail. A schematic representation is shown in Figure 1.
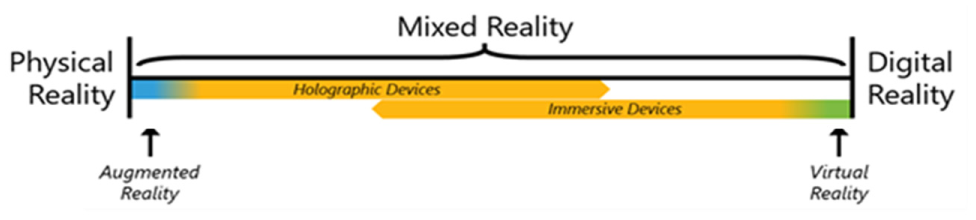
MR spectrum and device technologies ( 9 ).
The MR technology has breakthrough applications especially with successful deployment of 3D user interfaces such as in computer-aided design, radiation therapy, surgical simulation and data visualization ( 10 ). The next generation of computer games, mobile devices, and desktop applications also will feature 3D interaction ( 11 ). There are also some other research efforts into using MR technology in the construction industry and in maintenance operations. Kamat and El-Tawil discuss the feasibility of using AR to evaluate earthquake-induced building damage ( 12 ). Behzadan and Kamat investigated the application of the global positioning system and three-degree-of-freedom (3-DOF) angular tracking to address the registration problem during interactive visualization of construction graphics in outdoor AR environments ( 13 ). Vision based mobile AR systems are widely used in 3D reconstruction of scenes for architectural, engineering, construction, and facility management applications. Bae et al. developed a context-aware AR system that generates 3D reconstruction from a 3D point cloud. Important research into the use of AR in infrastructure inspection has also been carried out by several researchers ( 14 ). Researchers in the University of Cambridge are currently collaborating with Microsoft to develop an effective bridge inspection practice in which the data collected from the field are visualized in an MR environment in the office ( 15 ). Moreu et al. developed a conceptual design for novel structural inspection tools for structural inspection applications based on the HoloLens device ( 16 , 17 ). The experiments conducted with the HoloLens for taking measurements and benchmarking the obtained measurements are shown in the study. The proposed methodology takes yet a further step and combines AI implementation with MR technology. In this system, the embedded AI architecture not only predicts the location/region of cracks and spalling on the infrastructure in real-time along with condition information but also augments the information in the holographic headset for improved human inspector–AI interaction.
Overview of Deep Learning Approaches in Damage Detection and Analysis
For more than a decade, researchers have been investigating employing the techniques of the computer vision field to analyze cracks, spalls, and other types of damage. The early approaches mostly used edge detection, segmentation, and morphology operations. Yet, the recent advances in AI have yielded very promising accuracy and possessed a wide range of applicability. A review paper on computer vision based defect detection and condition assessment of concrete infrastructures emphasizes the importance of sufficiently large, publicly available, and standardized datasets to leverage the power of existing supervised machine learning methods for damage detection ( 18 ). According to the study, learning based methods can be reliably used for defect assessment. For the processing of defect images, many researchers in the literature implemented convolutional neural network (CNN) to perform automatic crack detection on concrete surfaces. Combined with transfer learning and data augmentation, CNN can offer highly accurate input for structural assessment. Yokoyama and Matsumoto developed a CNN based crack detector with 2,000 training images ( 19 ). The main challenge of the detector was that the system often classified stains as cracks. Yet, the detection was successful for even very minor cracks. Similarly, Jahanshahi and Masri developed a crack detection algorithm, though theirs uses an adaptive method from 3D reconstructed scenes ( 20 ). The algorithm extracts the whole crack from its background, whereas the regular edge detection based approaches just segment the crack edges; it thereby offers a more feasible solution for crack thickness identification. Adhikari et al. used 3D visualization of crack density by projecting digital images and neural network models to predict crack depth, necessary information for condition assessment of concrete components ( 21 ).
For detection of spalls and cracks, German et al. used an entropy based thresholding algorithm in conjunction with image processing methods in template matching and morphological operations ( 22 ). In addition to detection of local defects of structures, there are also studies on identifying global damage to the structures. Zaurin et al. used motion tracking algorithms to measure the midspan deflections of bridges under live traffic load ( 23 ). Computer vision is also used to process ground penetration radar (GPR) and infrared thermography (IRT) images that are useful to identify delamination formed inside concrete structures. Hiasa et al. processed the IRT images of bridge decks taken with high-speed vehicles ( 24 , 25 ). In identifying damage, many different techniques are useful for specific purposes. However, a more generalized deep learning approach is introduced in this study so that the methods can be expanded toward identifying almost any type of damage if sufficient amount of training data is available.
The CNN models are mostly composed of convolutional and pooling layers. In the convolutional layers, the input images are multiplied by small distinct feature matrices that are attained from the input images (corners, edges, etc.) and their summations are normalized by matrix size (i.e., kernel size). By convolving images, similarity scores between every region of the image and the distinct features are assigned. After convolution, the negative values of similarity in the image matrix are removed in the activation layer by using the rectified linear unit (ReLU) transformation operation. After the activation layer, the resultant image matrix is reduced to a very small size and added together to form a single vector in the pooling layer. This vector is then inserted into a fully connected neural network in which actual classification happens. The image vectors of the trained images are compared with the input image and a correspondence score is calculated for each classification label. The highest number will indicate the classified label. A summary of the described procedure is shown in Figure 2.
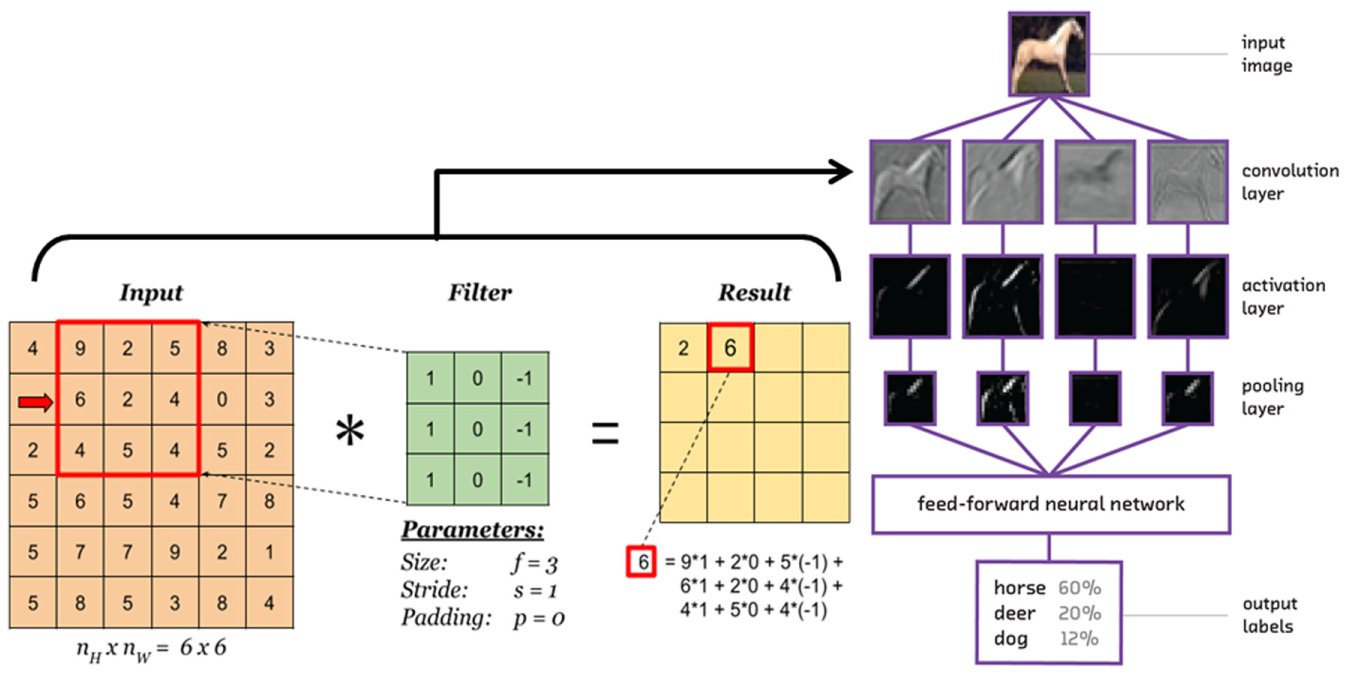
Description of a simple convolutional neural network (CNN).
Methodology
The proposed AI assisted infrastructure assessment using MR technology employs state-of-the-art methods and algorithms from interdisciplinary practices. Machine learning is used for robust detection of cracks and spalls on infrastructures, whereas human–computer interaction concepts are employed for improving the assessment performance by including the professional judgment of the human inspector. MR is an excellent platform to maintain this interaction because it augments virtual information into the real environment and allows the user to alter the information in real-time. In this proposed methodology, the bridge inspector uses an MR headset during routine inspection of infrastructure. While the inspector performs routine inspection tasks, the AI system integrated into the headset continuously guides the inspector and shows possible defect locations. If a defect location is confirmed by the human inspector, the AI system starts analyzing it by executing first defect segmentation, then characterization to determine the specific type of the defect. If the defect boundaries need any correction or segmentation needs to be fine-tuned, the human inspector can intervene and calibrate the analysis. The alterations made by the human inspector (e.g., change of defect boundary, minimum predicted defect probability, etc.) will be used later for retraining of the AI model by following a semisupervised learning approach. Thereby, the accuracy of AI is improved over time as the inspector corrects the system.
Another advantage of the system is that the inspector can analyze defects in a remote location while reducing the need for access equipment. Even though in some cases hands-on access is evitable (e.g., determining subconcrete defects), the system can still be effective for quick assessments in remote locations. If the defect location is far away or in a hard to reach location, the headset can zoom in and still perform assessment without needing any access equipment such as a snooper truck or ladder. The proposed framework is illustrated in Figure 3.
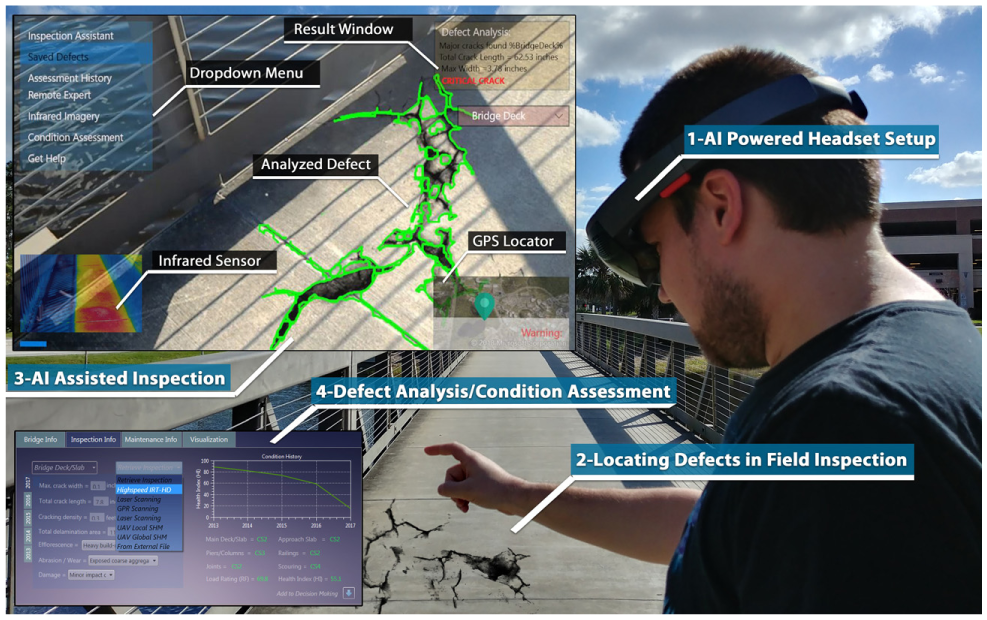
Visual representation of the AI powered MR system. (The headset user interface and analysis environment are shown for illustration purposes.)
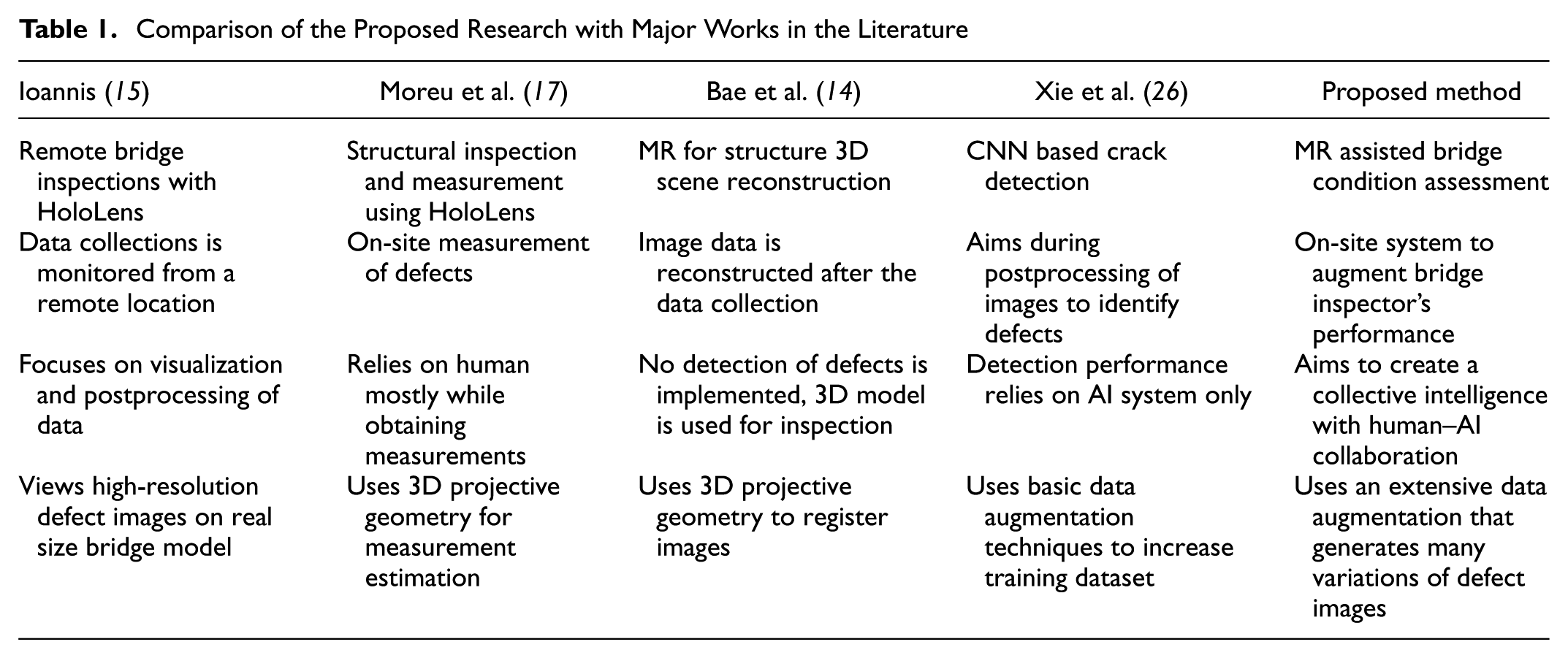
The proposed methodology of AI assisted infrastructure assessment using MR systems differs from the state-of-practice of current learning based approaches and mixed reality implementations in several aspects. Table 1 shows a comparison of the proposed method with major works in the research literature. The major difference of the proposed method from the current MR approaches is that the system performs automatic detection and segmentation of the defect regions using real-time deep learning operations instead of manually marking the defect regions in the MR platform. In this way, the system can save significant amounts of time in defect assessment as opposed to marking all these defects in the current MR implementations.
Comparison of the Proposed Research with Major Works in the Literature
Data Collection Procedure and Defect Characteristics
Automated detection of defects in concrete structures requires training of each defect type individually, by processing many training images. First, commonly available infrastructure defects are determined and their condition assessment procedure is investigated using the infrastructure inspection guides ( 27 – 29 ). According to the reference guides, infrastructure defect types have been determined as shown in Figure 4.

Example defect images for each defect classification, showing (a) cracking, (b) rusting, (c) spalling, (d) efflorescence, (e) joint damage, and (f) delamination (detected by infrared).
Data collection is an important step in developing an AI system. The significant challenges of potential real life applications need to be evaluated carefully to collect suitable data for AI training. Preliminary work was conducted in the Civil Infrastructure Technologies for Resilience & Safety (CITRS) Lab at the University of Central Florida (UCF) to determine the important aspects of field data collection procedure. The effects of illumination, maximum crack width, target distance, and camera resolution were investigated in a laboratory environment. A set of synthetically generated crack images with different thicknesses, brightness, and pattern were printed on letter size paper and placed on a white platform. The experiment setup is shown in Figure 5.

Preliminary work on laboratory data collection held in Civil Infrastructure Technologies for Resilience & Safety (CITRS) Lab.
The proposed methodology focused on cracks and spalls for this study and the plan is to expand the system scope in the future with more defect types. The available defect images were gathered from various sources including industry partners, transportation agencies, and other academic institutions. Some of the data were only categorized but not annotated; a considerable portion of the data was annotated with bounding box pixel coordinates and a relatively small dataset was annotated for segmentation. An extensive data augmentation was, however, applied to the datasets to further increase AI prediction accuracy. The data augmentation included rotation, scaling, translation, and Gaussian noise. The annotation styles of all of the training datasets were unified and converted to Pascal VOC 2012 annotation format. The summary information for the training datasets is shown in Table 2.
Summary of the Training Datasets
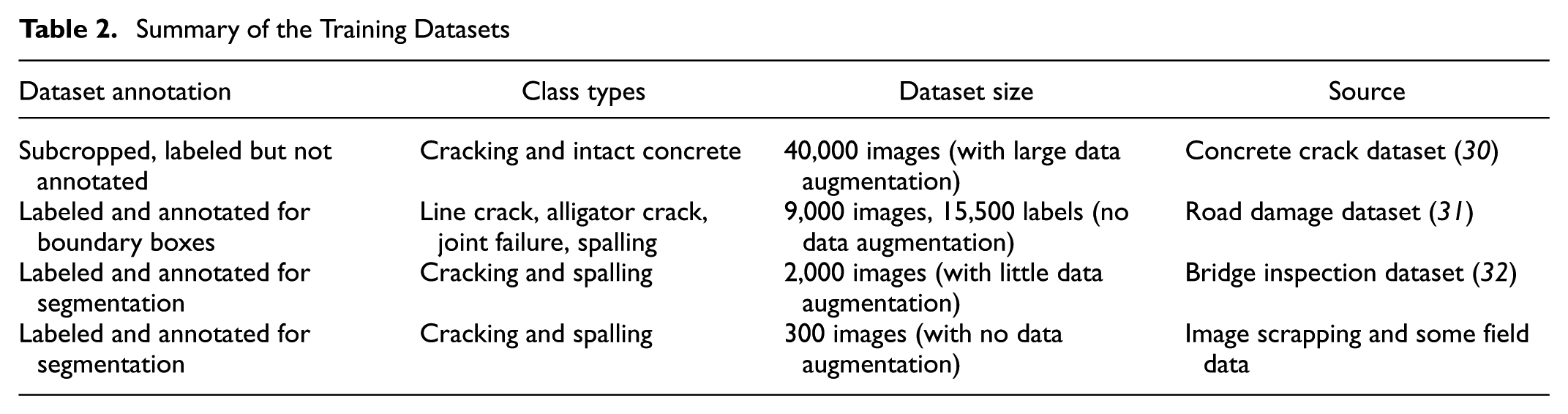
The training of the AI models was performed in the Newton Visualization Cluster operated by UCF Advanced Research Computing Center ( 33 ). The Newton Visualization Cluster includes 10 computer nodes with 32 cores and 192 gigabytes (GB) memory in each node; two Nvidia V100 graphics processing units (GPUs) are available in each compute node totaling 320 cores and 20 GPUs. The model training was performed on two clusters with total of four GPUs. A single training event was executed for 1 million steps (which takes approximately 75 h). The training was repeated multiple times to find optimal hyperparameters.
Real-Time Damage Detection
For real-time detection of damage, a lightweight architecture that can run on mobile central processing units (CPUs) was selected. SSD: Single Shot MultiBox Detector (SSD) is a relatively new, fast pipeline developed by Liu et al. ( 34 ). SSD uses multiboxes in multiple layers of convolutional network and therefore has an accurate region proposal without requiring many extra feature layers. SSD predicts very fast while sacrificing very little accuracy, as opposed to other models in which significantly increased speed comes only at the cost of significantly decreased detection accuracy ( 35 ). The network architecture of the original SSD model is shown in Figure 6.
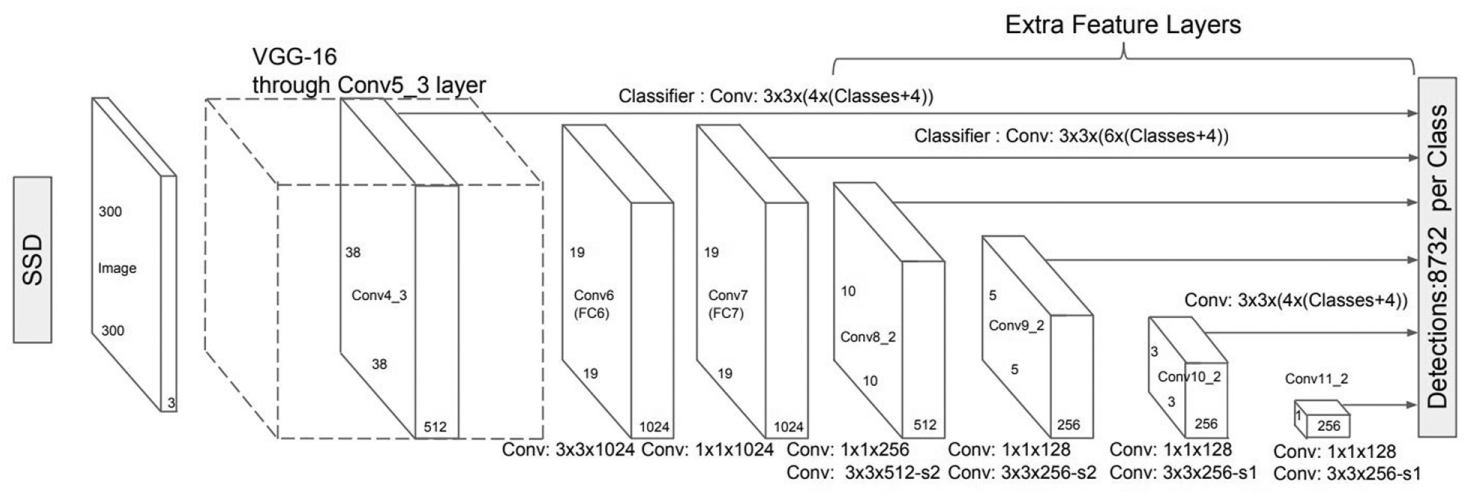
Original SSD network architecture ( 34 ).
The original SSD paper uses VGG-16 as a base architecture. VGG has become a widely adopted classifier after it won the 2015 ImageNet competition ( 36 ). Although newer classifiers such as MobileNetV2 offers much faster prediction speeds at similar accuracy in a 15 times smaller network ( 35 ), VGG is a better choice to benefit transfer learning in this study (because of the extensive hardware and memory requirement of MobileNETv2). Transfer learning allows employing the weights of already trained networks by fine-tuning only certain classifier layers based on the size of the available dataset. Figure 7 shows challenging cases in which the damage detection algorithm from real-world images shows promising results.

Damage detection on real-world images, showing (left) spalling in multiple locations at different depth and (right) alligator crack detected at large angle on wetted concrete surface.
Attention Guided Segmentation
For concrete defect assessment, it is not enough to just detect the damage in a bounding box; the damage also needs to be segmented from intact regions to perform defect measurement. Therefore, another AI model is implemented in parallel to the SSD to perform segmentation of the damage regions. Popular segmentation models such as FCN, UNet, SegNet, and SegCaps ( 37 ) were investigated; however their architectures were found to be too large for the small annotated dataset used in this study. To overcome this problem, the VGG weights that were retrained in SSD architecture were used in a relatively small, customized segmentation architecture inspired by the SegNet model ( 38 ). The SegNet model architecture is shown in Figure 8.
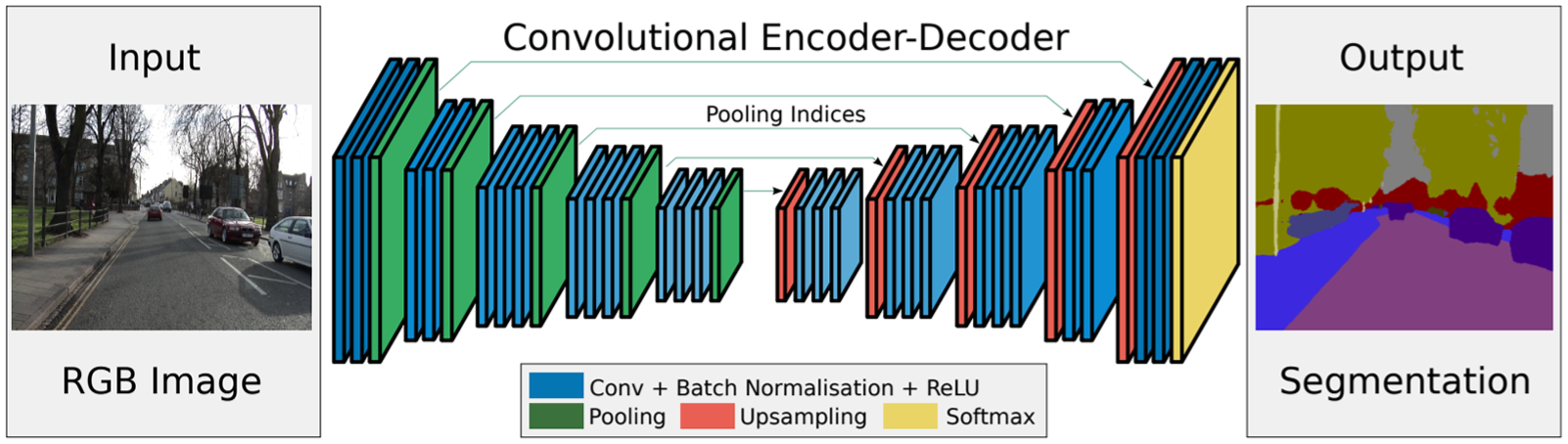
Illustration of the SegNet architecture ( 38 ).
As a unique approach for damage segmentation, an attention guided technique is proposed in this paper. A sequential connection is created between detection and segmentation models. First, images are first fed into the damage detection pipeline and when the bounding box is verified by the human inspector, damage segmentation is executed only for the region inside the detected bounding box. This approach significantly improves the accuracy of segmentation and successfully prevents outliers. Figure 9 shows qualitatively how attention guided segmentation is superior to segmentation without attention guidance. In the figure, the segmentation model is first executed for the entire image, yielding inaccurately segmented regions. In the second image, only the bounding box region is fed into the segmentation pipeline, resulting in much higher accuracy.

Effectiveness of attention guided segmentation shown in red highlighted areas, showing how (left) segmentation results in some false positive results and (right) attention guidance readily removes misclassified pixels.
Human-Centered AI and Semisupervised Learning
The human–computer interaction in MR technology will allow human–AI collaboration for benefiting collective intelligence. In the proposed AI models for damage detection and segmentation, the prediction threshold values in the inference mode are adjusted by the human inspector through the MR system. This type of hybrid AI can easily outperform a traditional AI on its own ( 39 ). This type of hybrid system is commonly seen in autonomous vehicle technologies, the health industry, and video game AI engines. When coupled with semisupervised learning, hybrid AI can perform impressively well.
During a bridge inspection, asking the human inspector to modify the prediction threshold will help improving the accuracy of the detection and determination of the boundary region of the segmentation. In Figure 10, real-time damage detection is not showing one of the spall regions to the inspector when the prediction threshold is set to 0.5; when the inspector adjusts the value to 0.2, the missing spall region is also detected. (The value represents the probability of accurate prediction.)

Example of human–AI collaboration in the proposed methodology, showing how (left) detection AI on its own misses a spall, whereas (right) human-assisted AI detects all spalls with a threshold adjustment by the inspector.
Similarly, the human inspector can also fine-tune the segmentation boundary by adjusting the prediction threshold. Thus, the damage area can be calculated at higher accuracy. The fine-tuned segmentations along with the corresponding bounding box coordinates are recorded for future retraining while benefiting from semisupervised learning. Some example results of human–AI collaborative damage detection and segmentation are shown in Figure 11.

Example results of human–AI collaborative damage detection and segmentation.
Pose Estimation and Geometry Calculation
The condition assessment methodology based on the AI system’s damage analysis will require answers to questions such as how wide a crack is, which one of two or more bridge piers is closer, or what the camera height, rotation, or focal length is. This information is required for identifying actual measures of defects for accurate assessment of infrastructures and also for augmenting a certain object onto 3D view or highlighting defects in an MR headset. Using projective geometry and camera calibration models, it is possible to correctly project objects onto 3D, achieve scene reconstruction, and accurately predict the actual dimension of the objects. However performing transformations in 3D spaces requires use of four-dimensional (4D) projective geometry instead of conventional 3D Euclidian geometry ( 40 ). The projection matrix allowing camera rotation is defined as

where
x = image coordinates,
K = intrinsic matrix,
R = rotation matrix,
t = translation,
X = world coordinates.
The projected coordinate vector x is calculated by multiplying the world coordinates by the rotation and translation free projection matrix. The coordinate parameters are then put into a system of equations as in
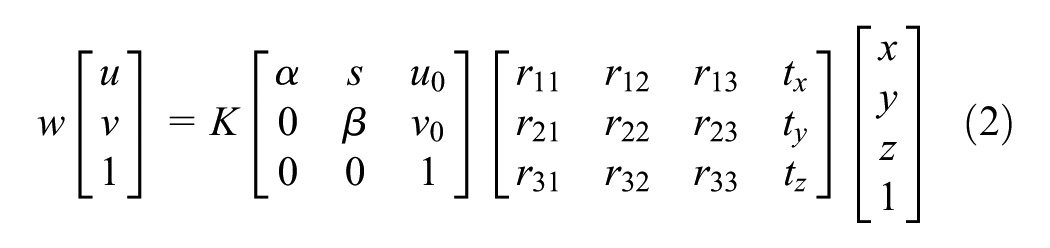
The local coordinates on the image plane are represented by u and v; w defines the scale of the projected object.
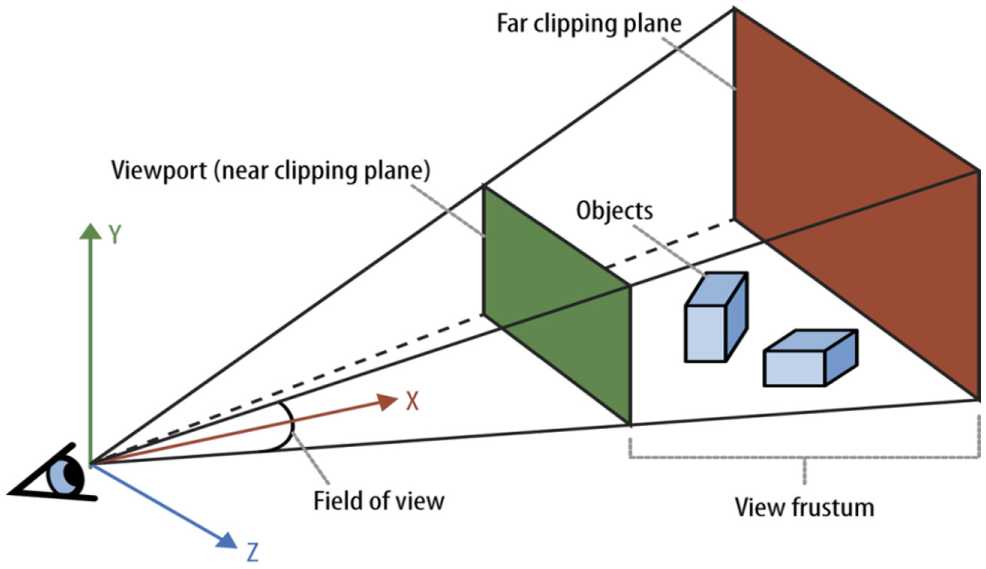
Camera, viewport, and projection of real-world objects onto two-dimensional image plane ( 41 ).
The projection calculations are held automatically in AR platforms. After a crack or spall region is detected and accurately segmented from the scene, an image target is automatically created in the platform environment. The image targets work with feature based 3D pose estimation using the calculated projection matrix ( 42 ). The projection matrix can be calculated by following the stereo camera calibration procedure provided by the headset manufacturers. In the calibration, camera intrinsic and extrinsic parameters such as camera focal length, location, and orientation of the camera are estimated using the headset sensor’s gyroscope and head-position-tracker. After a successful calibration, simple proportioning of image pixel size to a known real-world dimension (camera offset from eye focus is known) is used to calculate the area of a spall or length of a crack. Figure 13 shows calibrated image targets in the AR platform.
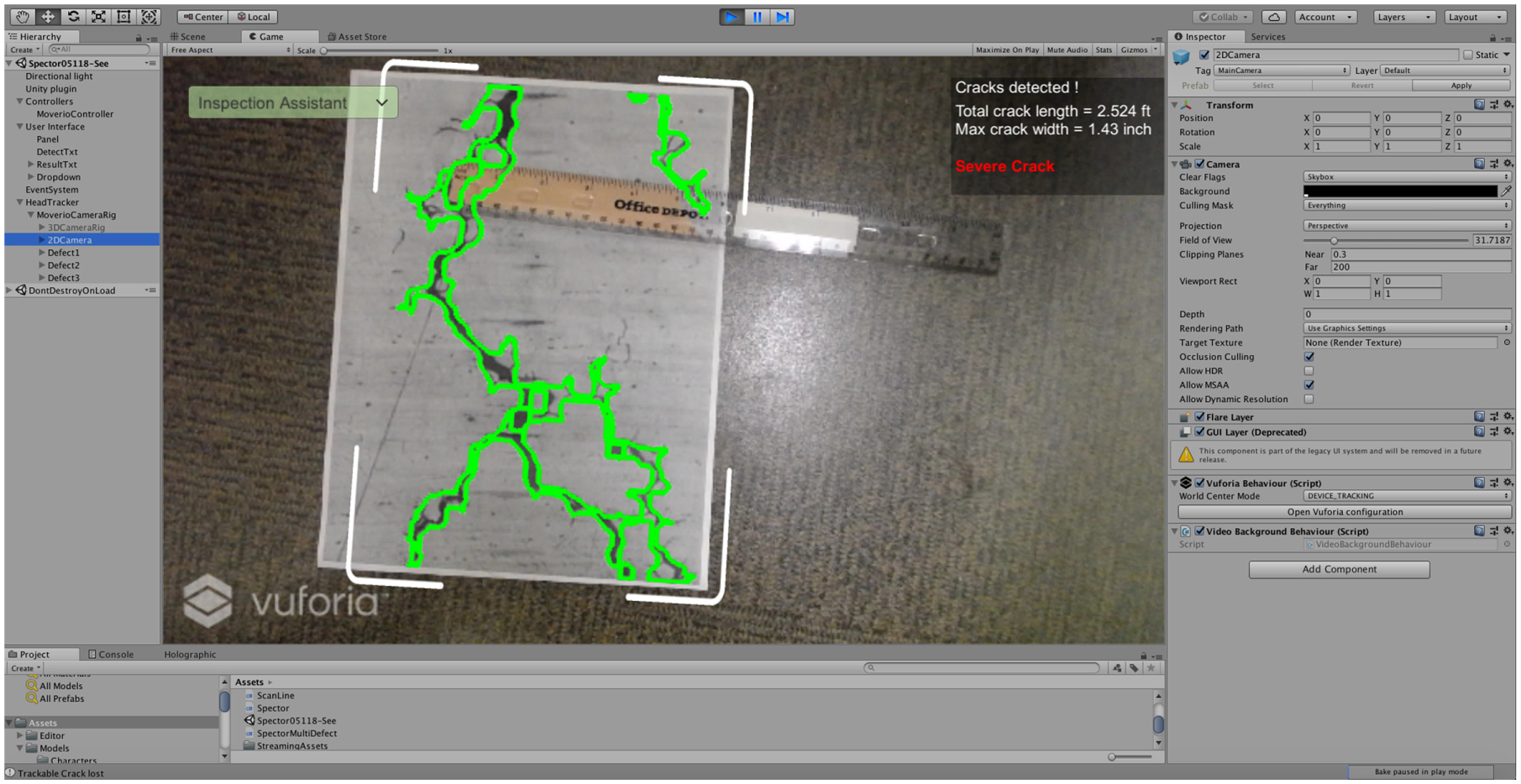
Calibrating image targets using AR platform. (The calibration was performed in Unity using Vuforia library. A ruler was used to compare estimated maximum thickness.)
Condition Assessment of Concrete Defects
The inspector will have the chance to investigate a certain defect in more detail if the condition information of the defect is shown to that inspector in real-time. For example, when a crack condition is shown in the headset interface as “severe crack” according to AASHTO guidelines, the inspector will want to perform a comprehensive crack assessment. This type of assistance to the inspector will lead to more objective and accurate inspection practice. The condition assessment methodology in this study aims to implement a quantified assessment procedure in which the limit values are interpreted from major inspection guidelines. The condition state limits and the recommended actions stated in FDOT, AASHTO, and FHWA inspection guidelines are therefore investigated. In the AASHTO bridge inspection manual ( 27 ), all elements have four defined condition states. The severity of multiple distress paths or deficiencies is defined in the manual for each condition state with the general intent of the condition states as below. The feasible actions associated with each condition are also shown.
CS 1: Good → do nothing/protect.
CS 2: Fair → do nothing/protect/repair.
CS 3: Poor → do nothing/protect/repair/rehab
CS 4: Severe → do nothing/repair/rehab/replace
The AASHTO manual provides somewhat quantifiable condition limits for cracking and delamination. Yet, other deterioration modes are mainly based on subjective decisions of visual inspection. The limits condition criteria for AASHTO are tabulated in Table 3.
Inspection Condition Limit Criteria of AASHTO Bridge Deck Elements

Note: na = not applicable.
The condition assessment guides are used as reference in the MR system. An example implementation of the condition assessment methodology is shown in Figure 14.
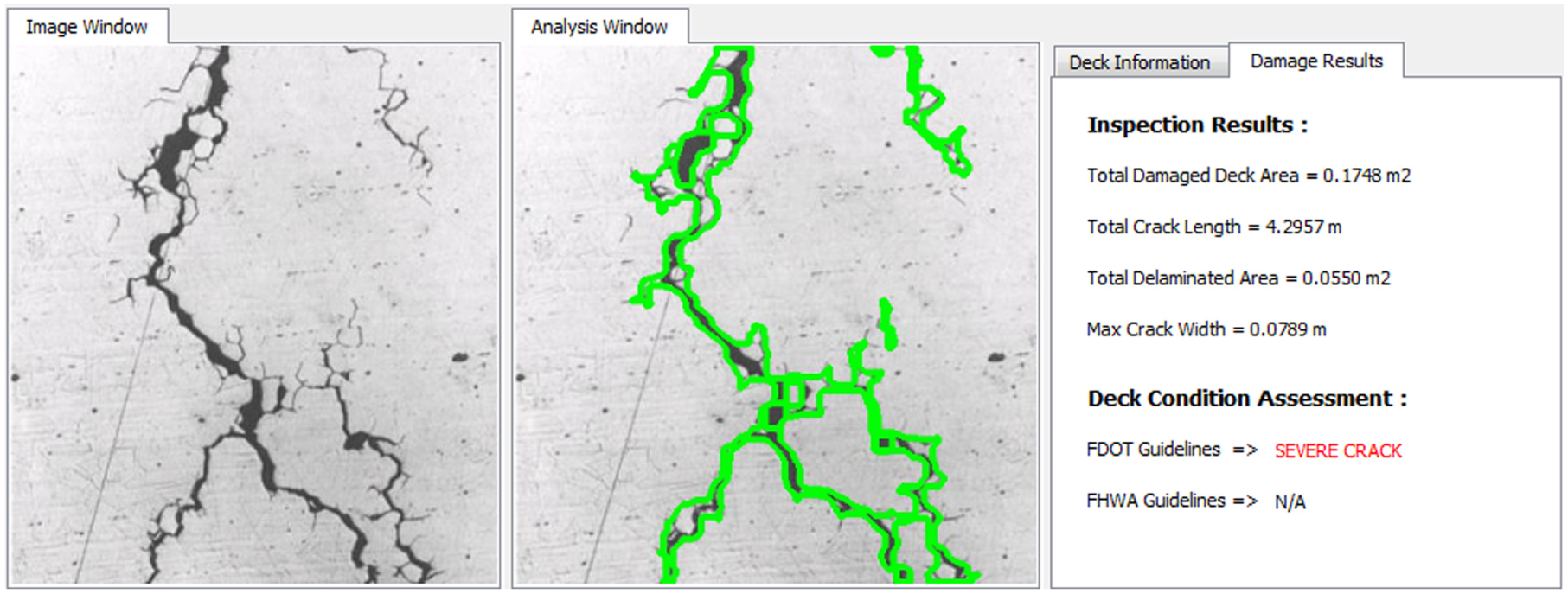
Example implementation of the condition assessment methodology.
Conclusions
This study aimed to integrate and demonstrate novel AI detection and segmentation algorithms into an MR framework by which a bridge inspector, for example, can benefit from this system during his/her routine inspection/assessment tasks. The inspector can analyze damage in real-time and calculate its condition state without needing to perform any manual measurement. The methods described in the paper explain how a framework for collective human–AI intelligence can be created and how it can outperform the conventional or fully automated concrete inspections. The human-centered AI asks only minimal input from the human inspector and gets its predictions verified before finalizing a damage assessment task. This kind of a collaboration layer between human expert and AI is the unique approach of this study. Furthermore, the AI system follows a semisupervised learning approach and consistently improves itself with use of verified detection and segmentation data in retraining. The use of semisupervised learning addresses successfully the problems of small amounts of data in AI training, which are particularly encountered in damage detection applications for which a comprehensive, publicly available image dataset is unavailable. This work aimed to achieve the following scientific contributions with real life implementations for bridges and other structures:
Current scientific approaches have employed various learning based methods for automatic detection of concrete defects while replacing human involvement in the process. However, the developed method aimed to merge the engineer/inspector’s expertise with AI assistance using a human-centered computing approach, thus yielding more reliable civil infrastructure visual assessment practice.
In machine learning based approaches, the availability of training data is the most critical aspect of developing a reliable system with good accuracy in recognition. Yet, in infrastructure assessment, creating a large image dataset is a particularly challenging task. The proposed method therefore used an advanced data augmentation technique to generate synthetically a sufficient number of crack and spall images from the available image data.
Utilizing non-destructive evaluation (NDE) methods effectively in bridge decision making has recently gained importance in bridge management research with the growing number of vision based technologies for infrastructure inspections (i.e., camera based systems, unmanned aerial systems, infrared thermography, ground penetrating radar). This study proposed a method to collect more objective data for infrastructure management while also benefiting from inspectors’ professional judgment. In the short term, the proposed method can serve as an effective data collection method and in the long term, as AI systems become more reliable approaches for infrastructure inspections, the proposed system will be a more feasible approach.
The AI assisted MR inspection framework presented will be expanded in many ways in a future study. First, a multichannel analysis method will be investigated to fuse multiple sources of data (i.e., imagery data and infrared thermography). This new method will bring more capabilities such as detecting and analyzing subconcrete delamination and steel corrosion. Second, more defect types will be trained for the AI system; it will be possible to use the methods for steel and composite structures.
Footnotes
Acknowledgements
The authors would like to express their gratitude to Prof. Joe LaViola, and also Mr. Kevin Pfeil, doctoral student, from the department of Computer Science at UCF for invaluable discussions and feedback.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: EK, FNC, UB; data collection: EK; analysis and interpretation of results: EK, UB; draft manuscript preparation: EK, FNC, UB. All authors reviewed the results and approved the final version of the manuscript.
The Standing Committee on Artificial Intelligence and Advanced Computing Applications (ABJ70) peer-reviewed this paper (19-05705).