
Abstract
Ridehailing services (e.g., Uber or Lyft) may serve as a substitute or a complement—or some combination thereof—to transit. Automation as an emerging technology is expected to further complicate the current complex relationship between transit and ridehailing. This paper aims to explore how US commuters’ stated willingness to ride transit is influenced by the price of ridehailing services and whether the service is provided by an autonomous vehicle. To that end, a stated preference survey was launched around the US to ask 1,500 commuters how they would choose their commute mode from among choices including their current mode and other conventional modes as well as asking them to choose between their current mode and an autonomous mode. Using a joint stated and revealed preference dataset, a mixed logit model was developed and analyzed. The results show that ridehailing per se might not be a significant competitor to transit, especially if it is integrated with transit as a first-/last-mile service. The total share of transit (transit-only riders plus those who use transit in connection with first-/last-mile ridehailing) remains substantially flat as set against conventional ridehailing services, even if ridehailing fares decrease. On the other hand, when the ridehailing price is significantly reduced by automation, our analysis suggests a decline in total transit ridership and an increase in ridehailing, especially for solo ridehailing. Also, it was found that autonomous pooled ridehailing might not be as appealing to commuters as autonomous solo ridehailing.
Ridehailing services (e.g., Uber or Lyft) may serve as a substitute or a complement—or some combination thereof—to transit. The emergence of autonomous vehicles may further complicate this already muddled relationship, by changing both the price of travel and the nature of the in-vehicle experience. This paper examines how US commuters’ stated willingness to ride transit is influenced by the price of ridehailing services and whether the service is provided by an autonomous vehicle.
Prior research paints a mixed picture on the interactions of ridehailing and transit. On the one hand, transit riders could use ridehailing to overcome the first-/last-mile problem caused by public transit’s fixed-route nature, and to serve trips in off-peak times when transit is less convenient. Examining US National Household Travel Survey data, Wu and MacKenzie ( 1 ) found that “although less than 1% of [taxi or ridehailing] trips involved a direct transfer to or from transit, one-third of all tours containing [taxi or ridehailing] also included transit.” Hall et al. ( 2 ) found that Uber is a complement for the average transit agency, increasing transit ridership by 5% after 2 years in the US. On the other hand, ridehailing is an alternative mode of travel, and riders might leave public transit for this new mode, as ridehailing increases the convenience and reduces the cost of taking a taxi-like service ( 2 , 3 ). Greenwood and Wattal ( 4 ) show that UberX provides a 20% to 30% reduction in prices relative to traditional taxis. While ridehailing fares are typically higher than public transit fares, riders will substitute ridehailing service for public transit if the service is fast enough and convenient enough to offset its additional cost.
To that end, it is anticipated that the autonomous vehicle (AV) technology may further improve the economics of ridehailing by reducing the operational costs, and therefore adversely affect the ridership, revenue, and general viability of public transportation systems ( 5 – 7 ). As shared autonomous ridehailing grows, it is likely to draw some of the market share of public transit, unless planned on a mutually complementary basis ( 8 ). Using stated preference (SP) data, Levin and Boyles ( 9 ) developed a nested logit model for mode choice prediction among three modes of (1) driving an AV and paying for parking at the destination, (2) driving an AV and repositioning it back to the origin, and (3) transit. They found that parking cost was the main incentive for choosing transit, and that the avoidance of parking costs through AV round-trips resulted in both an increase in AV round-trips relative to one-way and parking trips and a decrease in transit demand.
Researchers have begun to investigate integrated AV and transit solutions ( 10 – 12 ). The idea of integrated AV and transit systems was illustrated by Lenz and Fraedrich ( 13 ) as “broadening service options of public transport” by providing multimodal service in less dense areas. Liang et al. ( 10 ) used an integer programming model to maximize the profit of AVs as a last-mile connection to train trips, while Yap et al. ( 14 ) developed a mode choice model for last-mile services using SP data. Their estimated mode choice model showed that on average, first-class train travelers prefer AVs over bus/tram/metro as the last-mile connection. Vakayil et al. ( 11 ) developed an AV and transit hybrid system and emphasized its potential for reducing total vehicle miles traveled and the corresponding negative externalities such as congestion and emissions.
Other researchers including Shen et al. ( 12 ) have used agent-based simulation assuming fixed modal splits between buses and AVs to explore the idea of supporting bus operations and planning with complementary AV services. They simulated first-/last-mile trips to and from a train station in Singapore and found that integrating shared AVs with transit improves system performance. Also, Moorthy et al. ( 15 ) estimated the benefits of using shared AVs for first-mile service to the airport in Ann Arbor, Michigan as up to 37% energy savings. Pinto et al. ( 16 ) assessed the impact of a suburban first-mile shared-ride AV (SAV) transit feeder system on transit and SAV demand using a simulation-based approach. Alemi and Rodier ( 17 ) studied first-/last-mile connections using travel demand data from the San Francisco Bay Area. They observed that nearly 31% of the existing single-occupant work trips could be shifted to public transit by using a ridehailing service as an access mode.
Empirical models of mode choice involving AVs and transit have not been adequately studied and developed. The extent and nature of interactions between AVs and transit are also understudied. Existing research on autonomous ridehailing systems ( 18 – 23 ) has provided little insight into the future of transit systems.
This study aims to measure the extent to which commuters may replace transit with ridehailing (i.e., solo and pooled ridehailing), versus the potential to encourage new riders to use transit by providing a first-/last-mile connection service (i.e., transit plus ridehailing). This paper contributes to the literature through building a framework to study the potential impact of autonomous ridehailing services on transit market share, considering both transit-only travel and transit linked by ridehailing services for the first/last mile. Moreover, it estimates and applies a mode choice model to examine how these relationships may be affected by automation-driven price reductions in ridehailing services. An SP choice experiment is conducted and a joint SP–RP choice model is developed. The choice sets considered include car and transit along with three ridehailing modes for a commute trip: solo ridehailing, pooled ridehailing, and transit plus ridehailing in which ridehailing services provide a first- and/or last-mile connection to transit. The effects of vehicle automation were elicited by including it as an attribute of ridehailing and car alternatives in the experimental design.
This paper is organized as follows. In the next two sections, the survey, data collection process, and modeling methods are explained. Then, the model results and analysis are presented. The final section of the paper summarizes the findings and offers suggestions for future studies.
Survey Design
To study the mode choice behavior of individuals, data usually come from one or both of two sources: revealed preference (RP) data, which refer to situations where the choice is made and observed in real choice situations; and stated preference (SP) data, which refer to situations where a choice is made in hypothetical situations ( 24 – 28 ). Although it necessarily involves hypothetical choices, SP data can be used to cover wider variations of attribute levels, and it is especially useful for choices that include new alternatives, whereas RP is limited to studying alternatives and attributes already represented in a marketplace.
In this study, the survey consisted of three parts: socio-economic characteristics, information about the respondent’s typical commute trip, and mode choice behavior in hypothetical scenarios featuring emerging transportation modes.
In the first section of the survey, respondents were asked about their age, gender, driver’s license holding, transit pass holding, education, disability status, occupation, and parking situation at their workplace. They were also asked about their household’s income, size, numbers of full-time and part-time workers, number of members younger than 18, rental or ownership status, and number of vehicles owned.
The second section of the survey asked respondents several questions about their commute trip on a typical workday, including the departure time, number of intermediate stops and number of transfers along the trip, and their primary commute mode.
The third section of the survey administered an SP experiment. For this part, various choice scenarios were developed, and in each scenario the respondents were asked to choose between commute modes. The survey included five transportation modes: car, transit, transit plus ridehailing for the first/last mile, solo ridehailing, and pooled ridehailing. Each of these modes could be presented as conventional (i.e., human-driven) or autonomous in the choice scenarios.
Since respondents might have different perceptions about ridehailing modes, a brief explanation of the ridehailing services was given to the respondents before starting the third part of the survey. The general concepts of ridehailing and driverless ridehailing were explained to respondents as follows:
In a
The three specific mode alternatives that include ridehailing were explained to the respondents as follows:
In the
In a
In a
To create the SP choice scenarios, each mode was characterized by several attributes including travel time, waiting time, travel cost, and parking fee. Travel cost for car is the energy (gas or electricity) cost, calculated based on the fuel economy of the car owned by the respondents (they reported year, make, and model of their car in the first part of the survey) and the trip distance as calculated between their home and workplace locations through the Google Distance Matrix API. A gasoline price of $2.74 per gallon and an electricity price of $ 0.13 per kWh were assumed. In cases where the respondent did not own a car, we used an average fuel economy of 20.5 miles per gallon as the basis for the energy cost of the car alternative. The fuel economy information for different vehicles can be found at https://www.fueleconomy.gov/. Travel times for the car and transit alternatives were also obtained from the Google Distance Matrix API. To generate the travel time of the transit plus ridehailing alternative, the estimated transit travel time was multiplied by a fraction (selected from among 0.5, 0.7, and 0.9 according to an experimental design), as this alternative is expected to have a shorter travel time than the transit-only alternative.
The combination of various attribute levels in each choice situation was determined through an orthogonal experimental design. The attribute levels used in the experimental design of the survey are presented in
Attribute Levels/Values Used to Characterize Alternatives in Stated Preference Scenarios
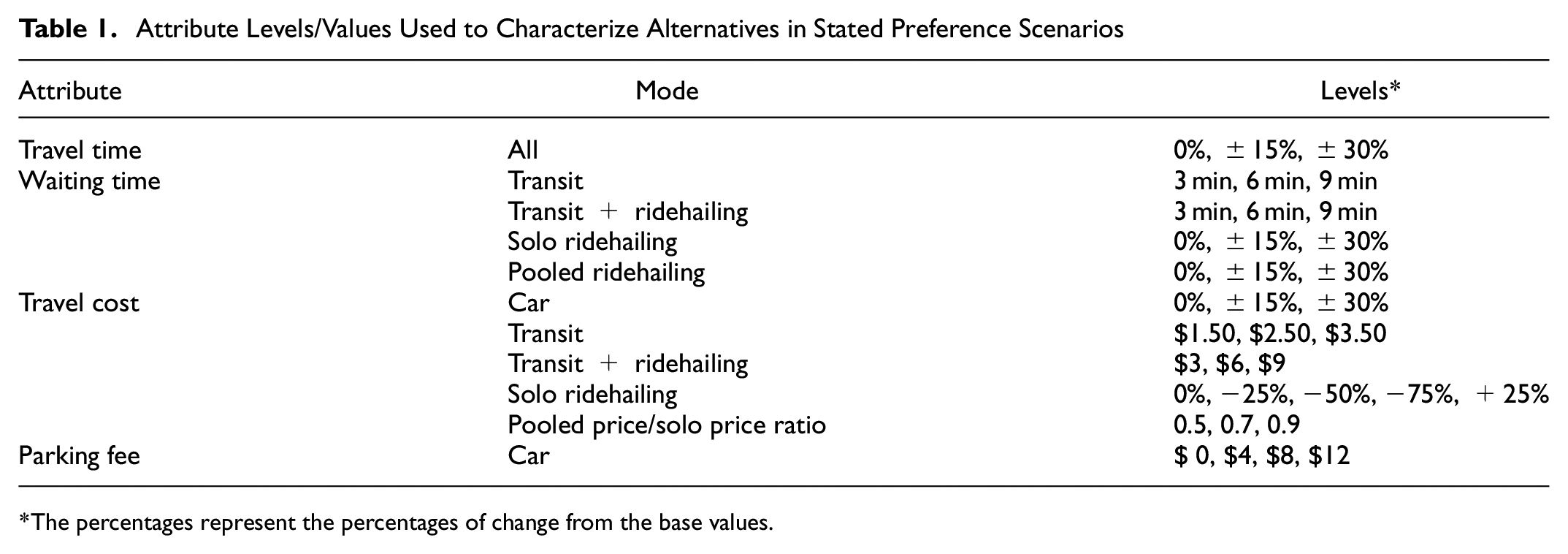
The percentages represent the percentages of change from the base values.
Data Collection
Because of the large number of alternatives and their associated attributes, we conducted a random sampling approach to reduce respondent burden. We used a fractional factorial experimental design to develop a balanced and orthogonal set of 9,000 choice scenarios including 6,000 choice scenarios with conventional vehicles in block sizes of four, and 3,000 choice scenarios with AVs in block sizes of two. These scenarios were then partitioned randomly into sets of six. We checked the balance and orthogonality of the resulting design and found that the main effects and two-way interactions were unconfounded. The “AlgDesign” R package was used to generate the fractional orthogonal designs.
Each respondent was presented with a total of six scenarios. In scenarios 1 to 4 they had to choose between conventional modes. Each respondent was presented with three or four alternatives per scenario and was asked to choose the preferred alternative for his/her daily commute trip from home to work. If someone reported driving as their current mode, they did not get a pure transit alternative, and if they were currently a transit commuter, they did not see a driving alternative. All ridehailing services were shown to each respondent, except that the transit plus ridehailing mode was displayed only if respondents’ commute trip took longer than 30 min by transit or included a transfer. The modes shown in scenarios 1 to 4 were the same in each case but with different attribute levels.
In scenarios 5 to 6, respondents chose between two modes only. One was their current commute mode (e.g., driving) and the second mode was randomly selected from the other four modes (e.g., solo ridehailing, pooled ridehailing, transit, transit plus ridehailing). One of these two modes was randomly displayed as autonomous (For the case of transit, its autonomous version would be transit plus autonomous ridehailing). The modes shown in scenario 6 were the same as those shown in scenario 5 but with different attribute levels.
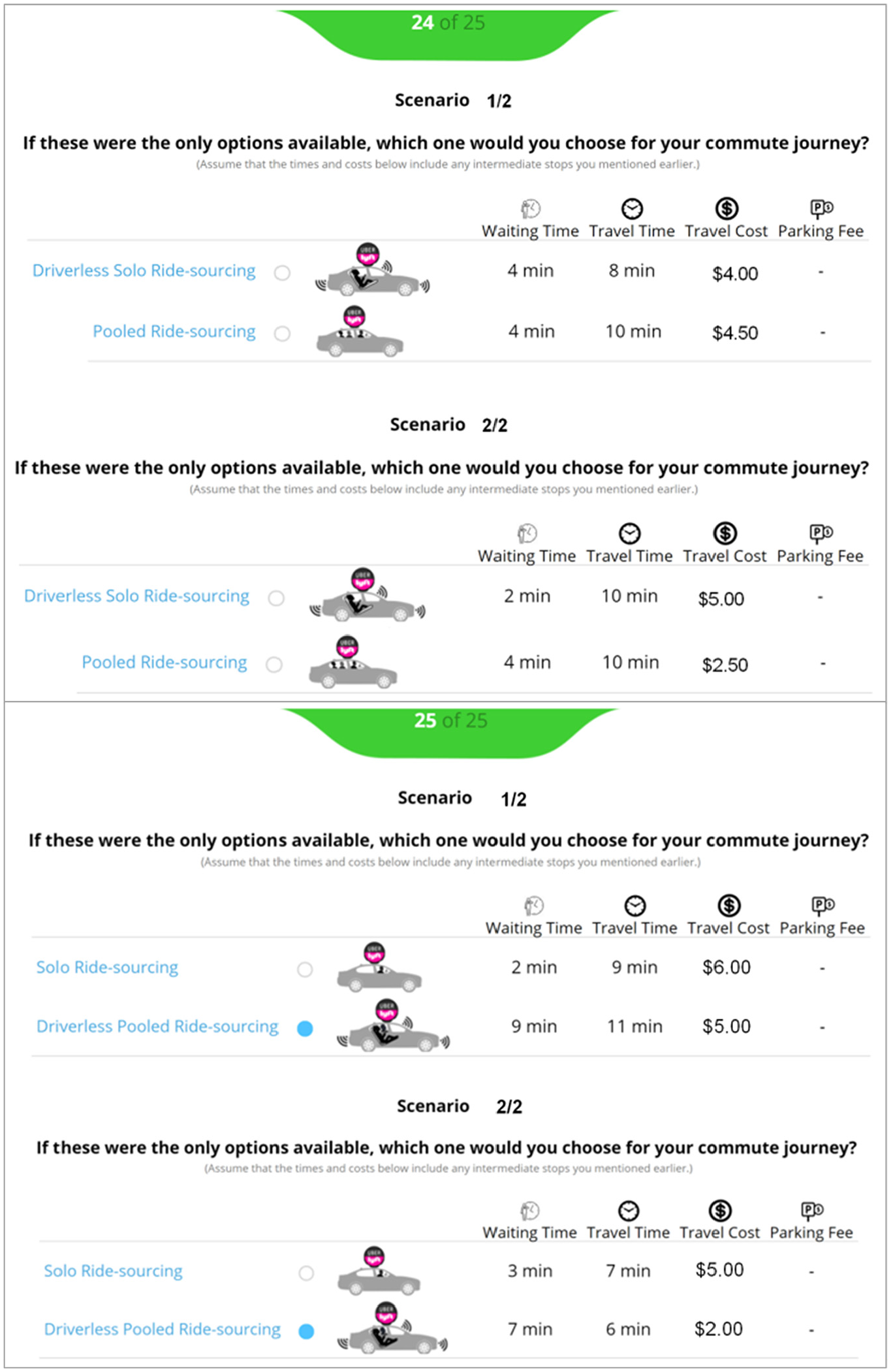
Examples of two sets of scenarios 5–6 shown to two different respondents.
The survey was implemented on Amazon Web Services (AWS) and was administered on Amazon’s Mechanical Turk (MTurk). MTurk is an online crowdsourcing marketplace that makes it easier for individuals and businesses to outsource their processes and jobs to a distributed workforce who can perform these tasks virtually. This could include anything from conducting simple data validation and research to more subjective tasks like survey participation, content moderation, and more. To have high-quality data, only the respondents with approval rates of 95% or higher on at least 100 previously completed MTurk tasks were qualified to take this survey. Although MTurk is widely used for data collection, the sample could be biased by MTurk respondents perhaps being younger, more educated, and more familiar with technology applications ( 29 – 33 ). The use of SP–RP analysis can help to reduce the impact of this bias on estimates, by bringing predicted market shares closer to actual market shares ( 25 , 28 ).
The survey was released in March 2019 on a nation-wide scale with a target sample size of 1,500 respondents, distributed proportionally to the population living in each of the four continental US time zones. This generated a total of 9,000 SP observations. To control data quality, we applied established quality-control techniques to identify and filter out data of low quality. In our experiment, low-quality data may result from several concerns. A particular concern with respondents being paid to complete a survey is that some may respond without giving adequate consideration to questions, or even randomly. To address these concerns, we conducted a consistency check across the sample to check for inconsistent responses. Also, we flagged the respondents with very long or very short survey completion times. Finally, after dropping respondents with current modes of walk or bike because of their low share, unemployed respondents, and those working from home, 6,753 observations were retained.
The geographic distribution of all the respondents who participated in the survey is displayed in
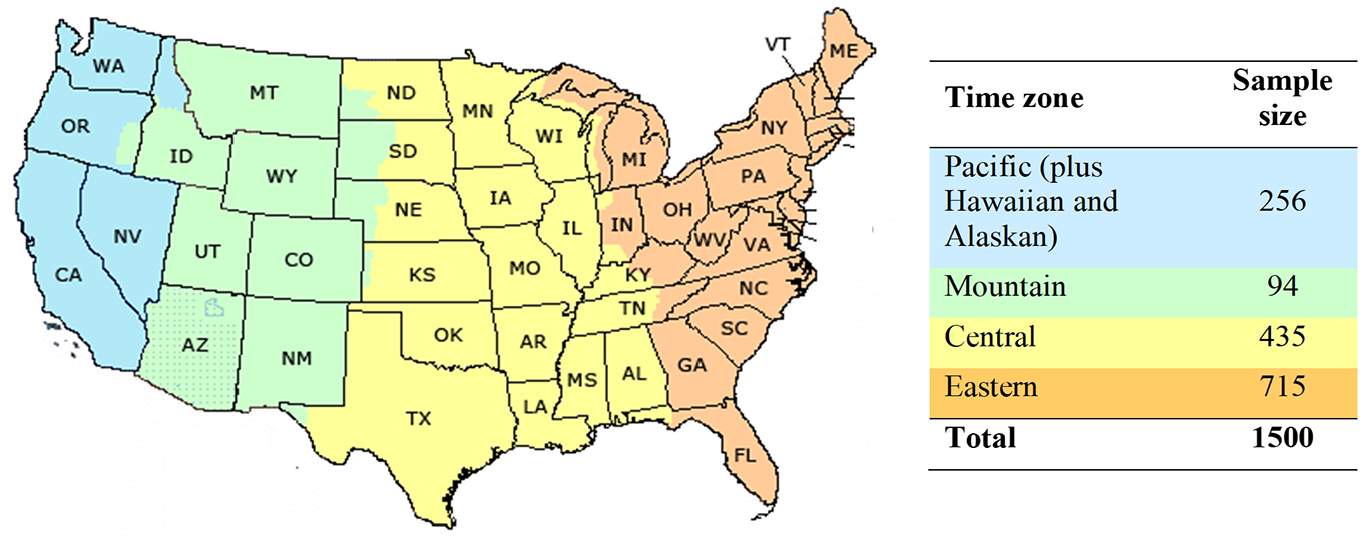
Geographic distribution of the respondents around the US.
Summary of the Demographic Statistics of the Final Sample
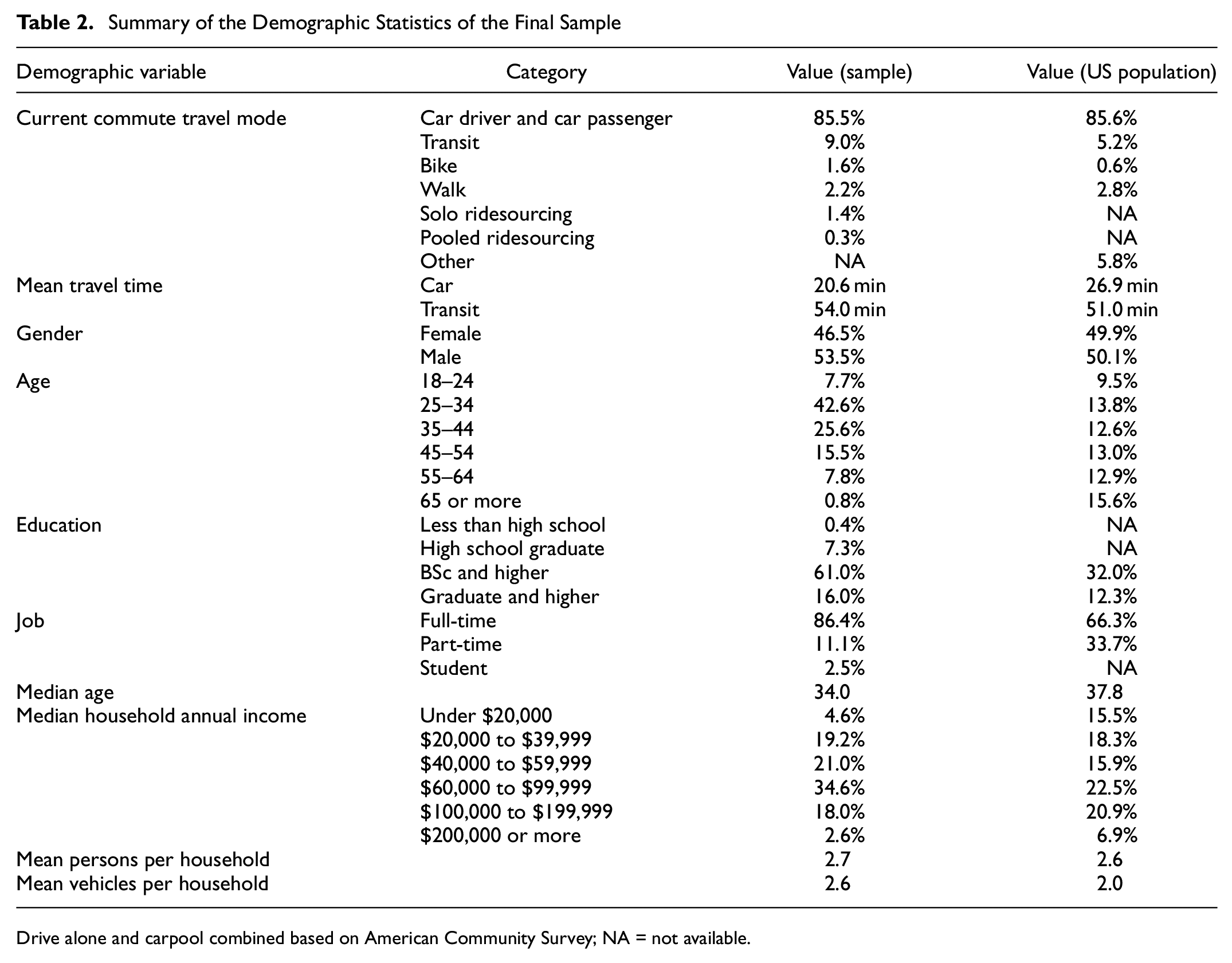
Drive alone and carpool combined based on American Community Survey; NA = not available.
Methods
A model developed based on pure SP data is prone to over- or under-estimating market shares because of hypothetical bias ( 25 ). The inclusion of RP data ensures that estimation is anchored to observed behavior, resulting in more realistic market share predictions.
Although the “nested logit trick” is the most common approach to pooling RP and SP data, it cannot account for correlations between repeated observations of the same respondent, such as in the six repeated choices made by each respondent in this study. More importantly, joint SP–RP estimation can cause a “state dependence” effect, defined as the impact of actual choice data (RP) on the individual’s stated choices (SP data) ( 34 ). Habit persistence or inertia in seeking an alternative may lead to a positive effect of state dependence, while a negative effect may result from the desire for variety or from latent dissatisfaction associated with the current alternative ( 34 ).
Most SP–RP studies ignore state dependence and adopt fixed parameters in pooling SP–RP data. This study has accommodated such unobserved heterogeneity in the state dependence effect of the RP choice on SP choices based on the approach suggested by Bhat and Castelar ( 34 ): see section 19 of ( 25 ) for more detail.
To model the mode choice behavior of commuters, using the joint SP–RP data, a mixed logit (MXL) model was built that can account for an error structure between alternatives including unobserved preference heterogeneity, correlated choice sets, SP–RP scale difference, and state dependency.
The mixed logit model develops as the vector form of the individual-specific parameter, βi. We begin with the basic form of the MXL model, with alternative-specific constants, αji, and attributes, xji, for individuals i in choice setting t and a choice set comprising several alternatives including the qth and the jth:
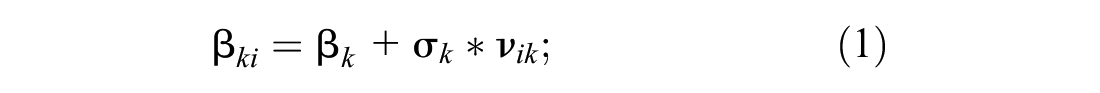
and
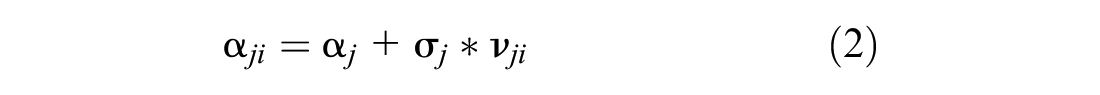
where
βk is the population mean;
vik is the individual-specific heterogeneity, with mean 0 and standard deviation 1;
σk is the standard deviation of the distribution of βiks around βk; and
αji represents the choice-specific constants.
The elements of βi are randomly distributed across individuals with fixed means. The vjkis are the source of the heterogeneity as individual and choice-specific unobserved random terms.
An additional layer of individual heterogeneity can be applied to the model in the form of error components capturing alternatives-related influences. This is done by creating a set of independent individual terms that can be applied to the utility functions. This system allows us to create what is a model of random effects and, moreover, a very general type of alternative nesting. Let independent individual terms be ein (n = 1, . . ., N), normally distributed with mean 0 and standard deviation 1 (i.e., N[0,1]), and θn be the scale parameter (standard deviation) associated with these effects. Then, each utility function could be written as
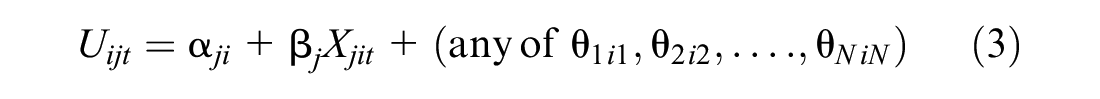
Assume a structure in a model with four utility functions as follows:
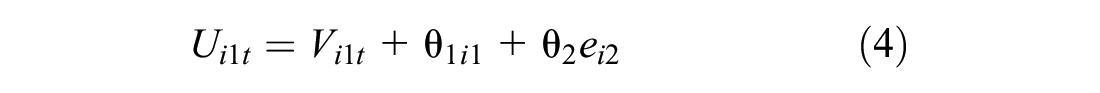
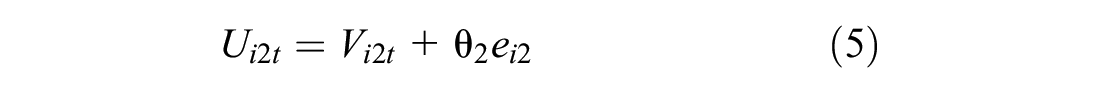
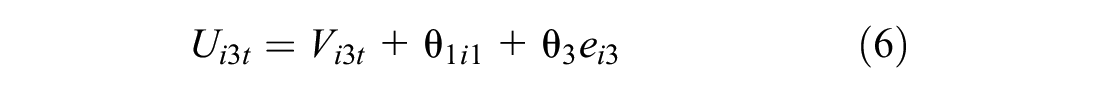
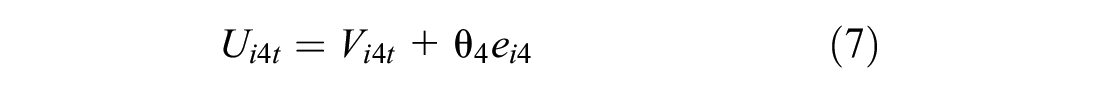
Therefore, there is a correlation between Ui1t and Ui2t and between Ui1t and Ui3t, while Ui4t has its own uncorrelated effect. The simplest way to allow different structures is to use binary variables, djn = 1, if the random term en occurs in utility function j and 0 otherwise.
Some specific characteristics of the model of interest in joint estimation with multiple datasets (i.e., SP and RP datasets) include the possibility of “state (reference) dependence” created in the SP data as a derivative of a market context of RP data; and the differences in the scale parameters for the SP data compared with the RP data. State dependence is defined by Bhat and Castelar ( 34 ) as

where δqt, RP = 1 if an RP observation, 0 otherwise, and φq is the state dependency parameter which can be fixed or random. For each SP alternative, this variable enters the utility function, with the ability to select a generic specification.
The scale parameter for the SP dataset relative to the RP dataset is obtained through the introduction of a set of alternative-specific constants (ASCs) that have a zero mean and free variance in the SP data while the scale for the RP dataset is normalized to 1.0 ( 35 ). The scale parameter is calculated using
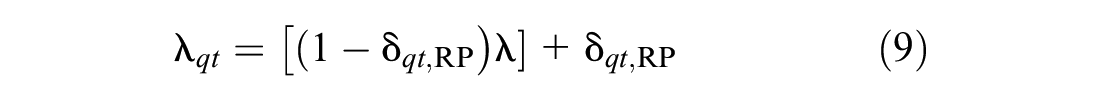
According to
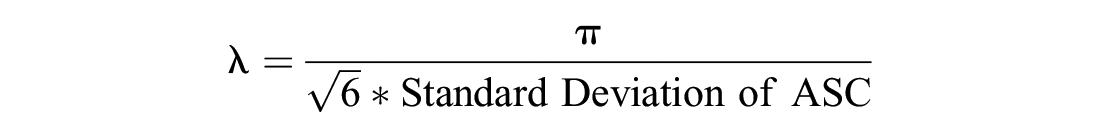
Then a model with error components for each alternative is identified. Unlike other specifications ( 36 ) that use the results to identify the scale factors in the disturbances of the utility functions, the logic is not used to identify the parameters on the attributes; and in the conditional distribution we are looking at here, the error components act as attributes, not as disturbances. Also, the θ parameters are estimated as if they are weights on attributes, not scales on disturbances. The parameters are identified in the same way that the βs are identified on the attributes.
As the error components are not observed, their scale is not identified. Therefore, the parameter on the error component is (δnσn) in which σn is the standard deviation. Given that the θ carries the magnitude and sign of the parameter on the component, the scale is normalized to 1 for estimation purposes as it is unidentified. Also, since the sign of δm is not identified, we normalize the sign to plus, and estimate |δm| with the sign and the value of σm normalized for identification purposes.
Results
Model Results
The results of the mixed logit model estimated in BIOGEME 3.2.5 are presented in
MXL Model Estimation Results
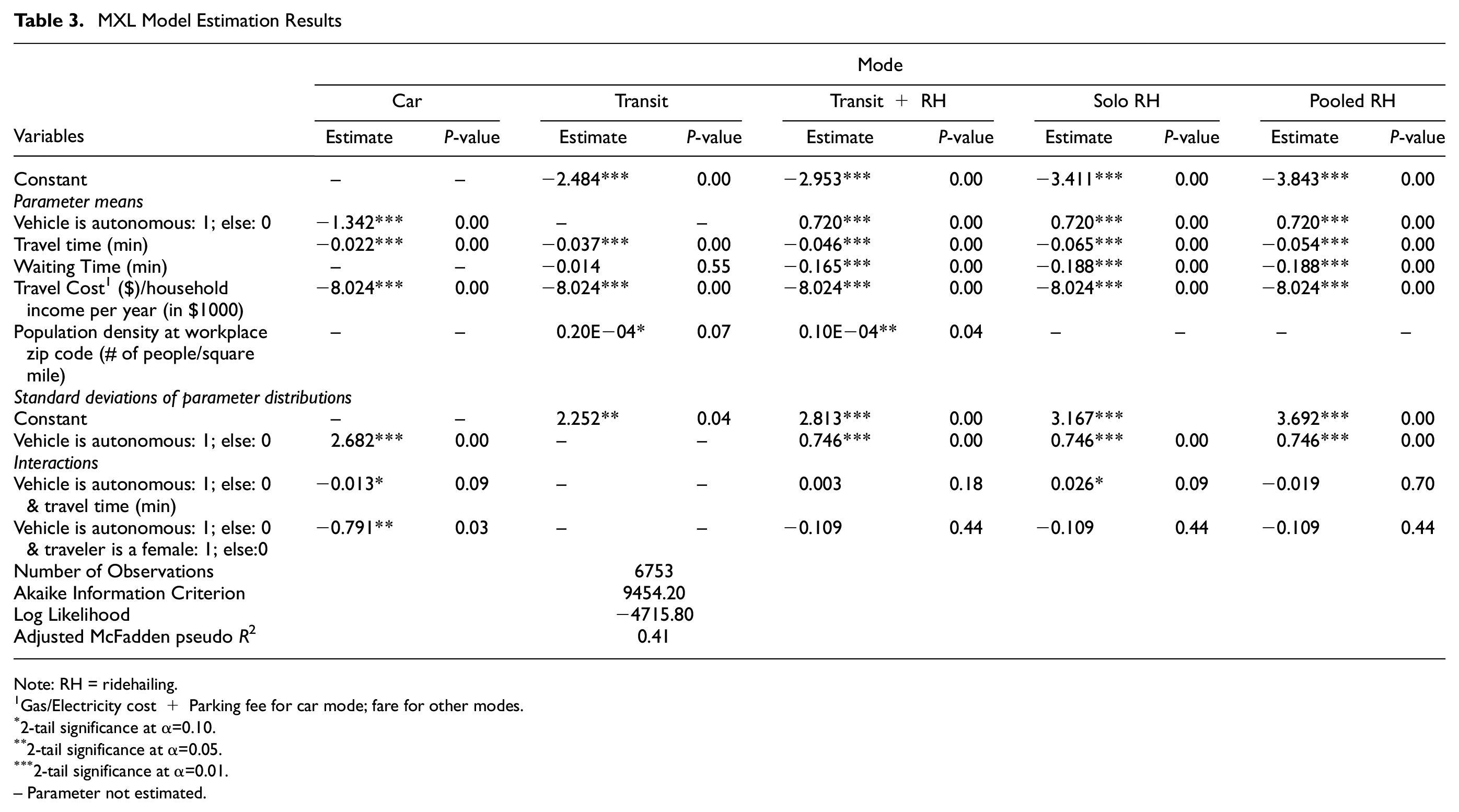
Note: RH = ridehailing.
Gas/Electricity cost + Parking fee for car mode; fare for other modes.
2-tail significance at α=0.10.
2-tail significance at α=0.05.
2-tail significance at α=0.01.– Parameter not estimated.
Several models were developed with different attributes including socio-economic variables, population density of home and workplace location, and interactions of different income bins and travel cost.
Random parameters in normal distributions have been employed for ASCs and for the automation attribute. Automation has been adopted as an attribute for car and for solo and pooled ridehailing modes including the ridehailing used for the first-/last-mile connection in transit plus ridehailing mode. The coefficients of automation were also assumed to be the same for all ridehailing modes (solo, pooled, and transit plus ridehailing). In addition, the coefficients of waiting time were assumed to be the same for solo and pooled ridehailing. Travel cost was divided by the midpoint of the income category reported by the respondent and was implemented as a generic variable with the same coefficient in all the utility functions.
All travel time parameters were found significant with negative signs for coefficients, which is consistent with intuition. The coefficients for waiting time also have negative signs, but waiting time is statistically insignificant for the transit alternative.
The results also showed that the population density at the respondent’s workplace location has a positive impact on choosing transit and transit plus ridehailing. This might be related to the higher level of transit accessibility in dense areas with a lot of parking and congestion issues, which makes non-car modes often more favorable in these settings.
Furthermore, several covariates were investigated as possible sources of heterogeneity around the means of the random parameter estimates. In effect, interacting random parameters with other covariates decomposes the heterogeneity observed within the random parameter, offering an explanation as to why that heterogeneity may exist (
25
). The random parameters for which a covariate was found to partly explain the variation in marginal utilities included car automation, car travel time, and travel cost for all modes. The statistically significant and negative parameter for the interaction term of the random parameter, car automation, and the covariate, gender of a traveler, suggests that female travelers are generally less willing to ride in AVs. Other variables including age and car ownership were also interacted with automation but were found to be statistically insignificant as sources of heterogeneity in our sample. Also, the interaction of the random parameter, car automation, with travel time attribute indicates that automation might lead to an increase in the average value of travel time savings (VTTS) for private cars and a decrease in the VTTS for solo ridehailing. The VTTS values implied by our results for each mode are reported in
Value of Travel Time Savings (VTTS)
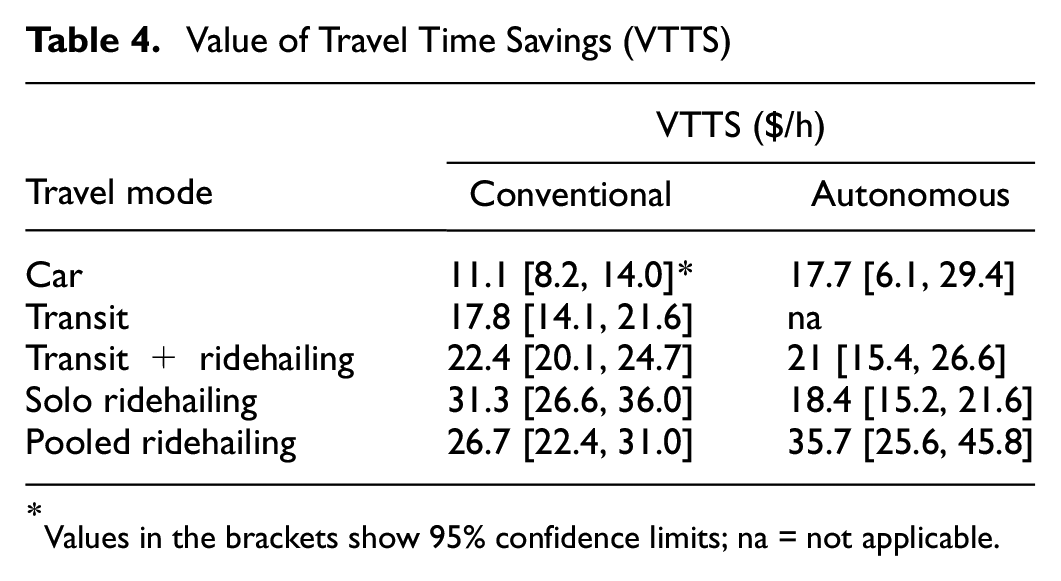
Values in the brackets show 95% confidence limits; na = not applicable.
The VTTS for autonomous ridehailing was found to be higher than that of a conventional car. This result is counterintuitive, as in theory it is believed that being freed from the need to drive would decrease the VTTS. However, a few other studies also found the same results ( 14 , 37 , 38 ), suggesting that since AVs are not yet commercially available, people are not familiar/comfortable enough with autonomous cars and their stated choices today may not reflect choices they make in the future. The VTTS for autonomous pooled ridehailing is higher than that of autonomous solo ridehailing. This may reflect concerns with sharing a ride in an autonomous car with strangers when no driver is present. Since we do not have the data necessary to test these hypotheses, we leave it to other studies in the future.
Sensitivity Analysis
After building the choice model, a sensitivity analysis was conducted to measure the impact of automation on the behavior of transit commuters. Automation and electric propulsion technologies are predicted to allow a substantial decrease in prices for all modes ( 39 ). Furthermore, automation is expected to affect the perceived cost of travel by drivers ( 37 , 38 , 40 ), and it is expected to reduce the travel time and waiting time by optimizing the efficiency of mobility services ( 19 , 41 , 42 ).
Therefore, this section explores the potential mode share effects of a decrease in the price, travel time, and waiting time of ridehailing in two scenarios. The ranges of decreases in the attributes are consistent with ranges of variable values covered in the experimental design in
Scenario 1
In this scenario, it is assumed that none of the modes are autonomous, and the effects of varying price, travel time, and waiting time of conventional ridehailing modes on the attraction of transit commuters are simulated. The baseline for this analysis is status quo; that is, when all modes are conventional, and they keep their current attribute values.
A. Price
As shown in
B. Travel time and waiting time
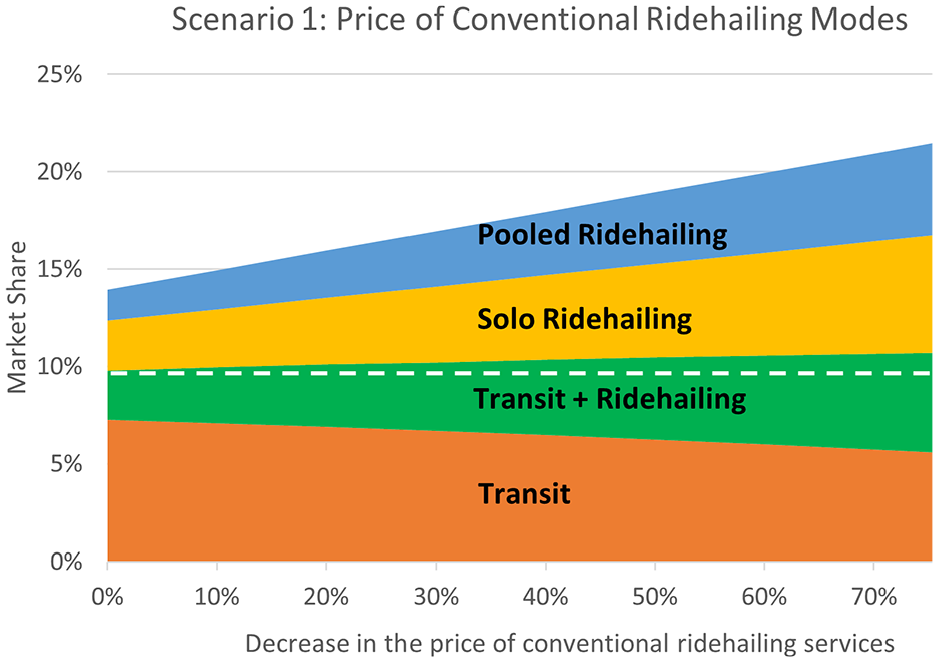
Change in the market share of transit and ridehailing modes as a result of decreased price of conventional ridehailing services.
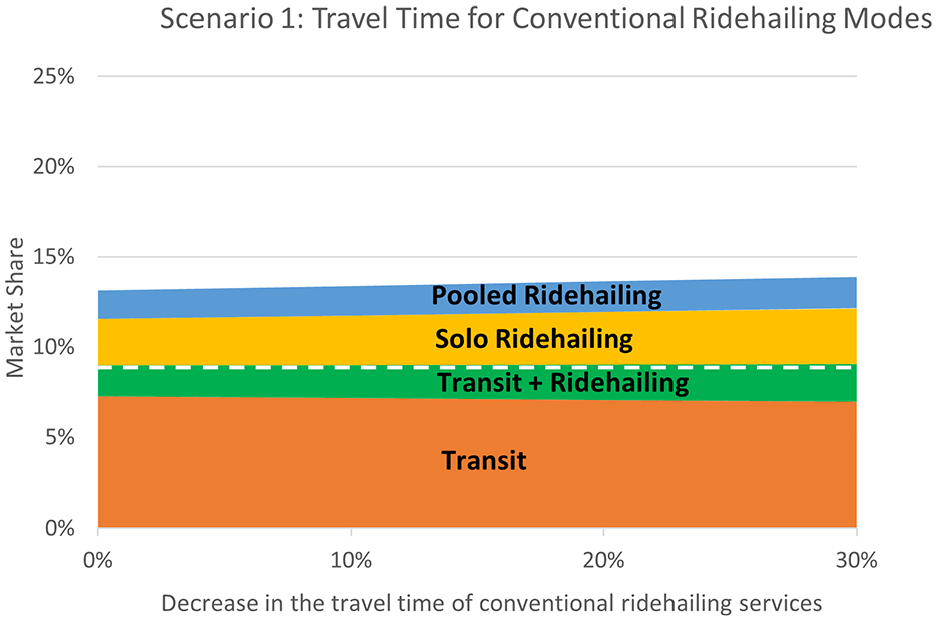
Change in the market share of transit and ridehailing modes as a result of decreased travel time for conventional ridehailing services.
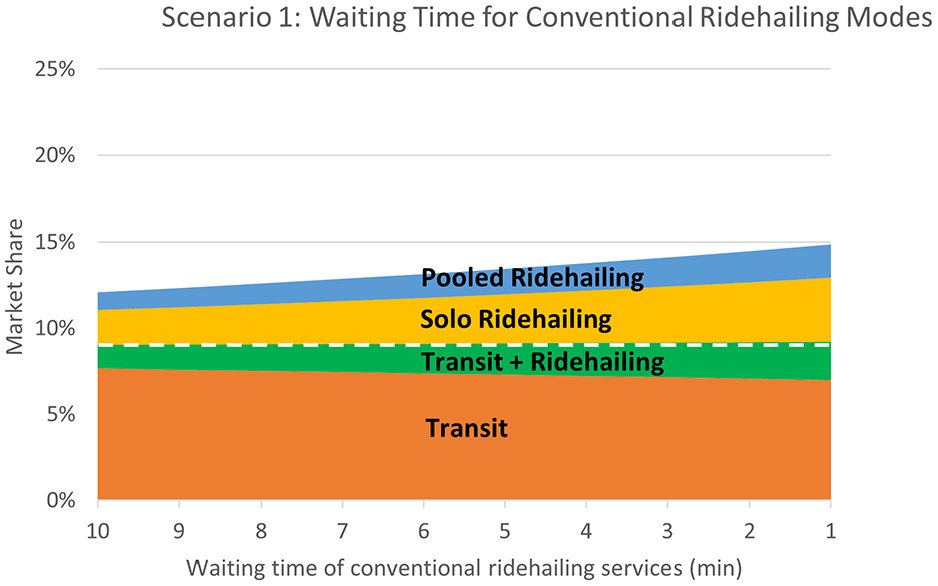
Change in the market share of transit and ridehailing modes as a result of decreased waiting time for conventional ridehailing services.
Scenario 2
In this scenario, all modes are assumed to be autonomous, and again the effects of varying the price, travel time, and waiting time of autonomous ridehailing modes on the market share of transit commuters are simulated. The baseline for this analysis is when all modes are autonomous, but they keep their other attributes at current levels.
A. Price
As can be seen in
B. Travel time & Waiting time
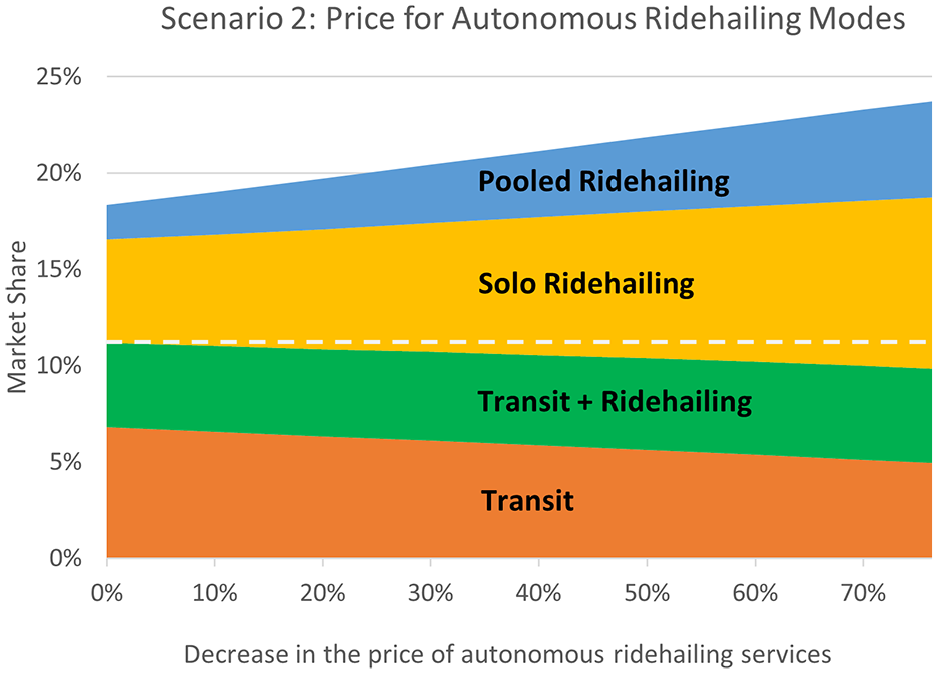
Change in the market share of transit and ridehailing modes as a result of decreased price of autonomous ridehailing services.
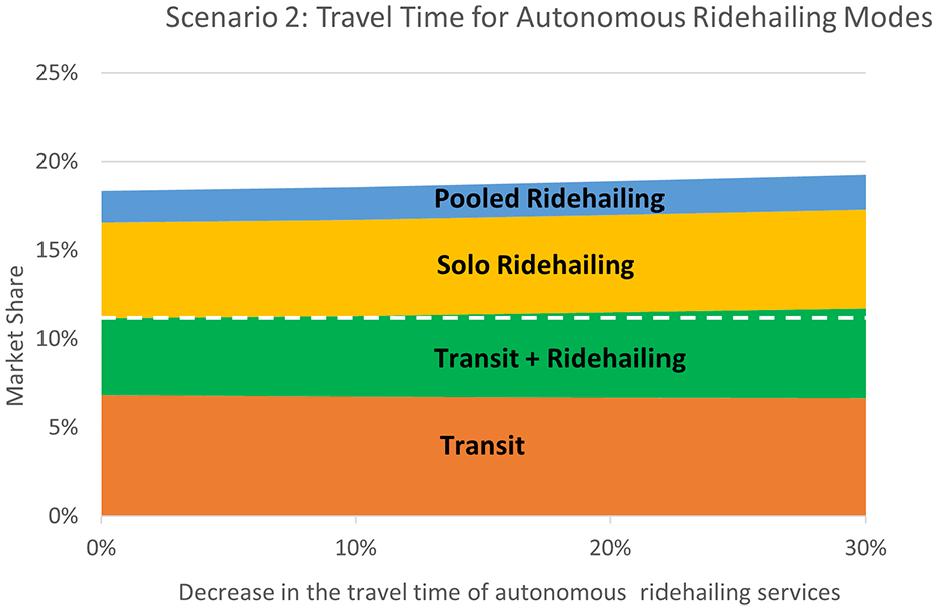
Change in the market share of transit and ridehailing modes as a result of decreased travel time for autonomous ridehailing services.
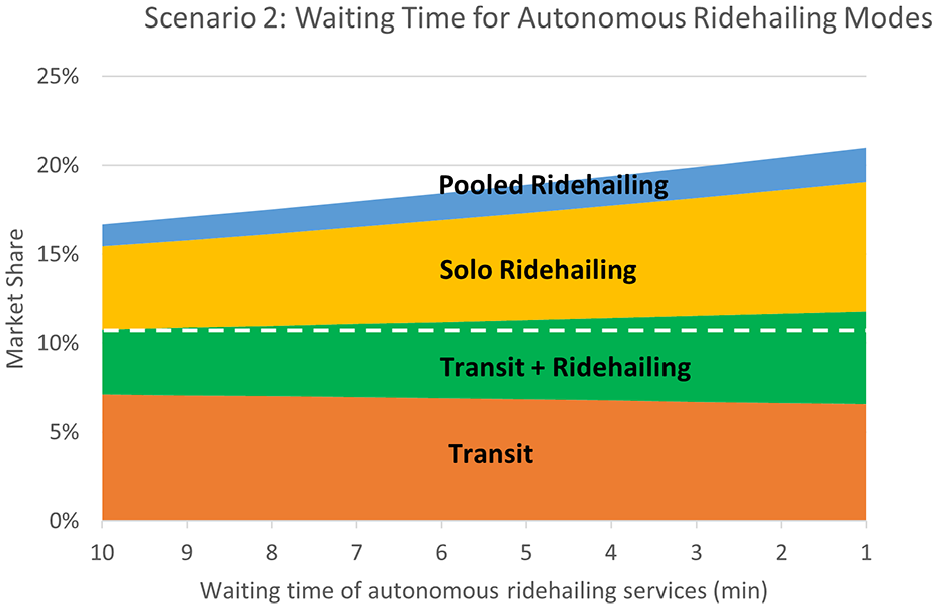
Change in the market share of transit and ridehailing modes as a result of decreased waiting time for autonomous ridehailing services.
In
In
Furthermore, comparing
According to
As can be seen in
Conclusions
In this study, we explored how the automation of ridehailing might affect transit market share. To understand how the changes in the commute mode shares depend on the characteristics of transportation modes, a survey was designed and distributed nationally that consisted of three parts: socio-economic questions, actual mode choice questions (i.e., RP data), and hypothetical mode choice questions (i.e., SP data). In the third part, various choice scenarios were developed that included five transportation modes: car, transit, transit plus ridehailing for the first/last mile, solo ridehailing, and pooled ridehailing. To model the behavior of commuters a mixed logit model was employed using joint SP–RP data, considering car as the reference mode.
The model results indicated that travel cost, waiting time, and travel time decrease utility of all modes, and higher population density at the work location increases the utility of transit and transit plus ridehailing modes. In addition to the choice model analysis, we also built and analyzed different scenarios, assuming different prices, waiting time, and travel times for ridehailing services as well as assuming the services being autonomous or conventional.
It was found that ridehailing per se might not be a significant competitor to transit, especially if it is integrated with transit as a first-/last-mile service. With conventional ridehailing services, the total transit mode share (transit-only riders plus those who use transit in connection with ridehailing for first/last mile) remains largely flat even if ridehailing fares decrease. On the other hand, if automation significantly reduces the price of ridehailing services, our analysis suggests a decline in total transit ridership and an increase in ridehailing, especially for solo ridehailing in commute trips. This could lead to major challenges with traffic congestion and emissions. Ridehailing services already face taxation and other regulations by cities, and additional policies may be needed in a future with autonomous ridehailing to offset the effects of automation-enabled labor cost reductions. The results also suggest that the better services by ridehailing companies to minimize travelers’ waiting time and travel time may not negatively affect the total transit market share, regardless of the service being conventional or autonomous. The results also imply that autonomous pooled ridehailing might not be as attractive to commuters as autonomous solo ridehailing, which could be an important insight for transportation network companies (TNCs).
In future studies, it will be interesting to include other modes such as walking and biking to figure out the shift between those and ridehailing services, as automation is introduced and/or prices change. Also, future studies could focus on the attitudes of individuals toward autonomous pooled ridehailing to gain insights about the reluctancy or willingness of people to the automation of this mode. Since the workplace population density was found to have a positive and statistically significant effect on choosing transit and transit plus ridehailing modes, it would be desirable to examine how other land use attributes such as employment density and land use diversity affect the choice between transit and ridehailing services, particularly given the future availability of AVs. Finally, we should note that the data for this study were collected a year before the COVID-19 pandemic hit the US, and so the data and market share estimates might not reflect current or near future attitudes toward ridehailing and/or transit services.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was provided by Toyota Motor Engineering & Manufacturing North America Inc.