
Abstract
The rescheduling of train timetables under a complete blockage is a challenging process, which is more difficult when timetables contain lots of trains. In this paper, a mixed integer linear programming (MILP) model is formulated to solve the problem, following the rescheduling strategy that blocked trains wait inside the stations during the disruption. When the exact end time of the disruption is known, trains at stations downstream of the blocked station can depart early. The model aims at minimizing the total delay time and the total number of delayed trains under the constraints of station capacities, activity time, overtaking rules, and rescheduling strategies. Because there are too many variables and constraints of the MILP model to be solved, a three-stage algorithm is designed to speed up the solution. Experiments are carried out on the Beijing–Guangzhou high-speed railway line from Chibibei to Guangzhounan. The original timetable contains 162 trains, including 29 cross-line trains and 133 local trains. The simulation results show that our model can handle the optimization task of the timetable rescheduling problem very well. Compared with the one-stage algorithm, the three-stage algorithm is proved to greatly improve the solving speed of the model. All instances can get a better optimized disposition timetable within 450 to 600 s, which is acceptable for practical use.
In the course of railway transportation, train operation is vulnerable to unpredictable factors such as bad weather conditions, human problems, and equipment failures. These factors may consequently lead to accidents of varying degrees, which are usually classified as disturbances or disruptions according to their impact. Under normal circumstances, the departure and arrival time of each train at each station are preset in the dispatching system, and this is called the original time.
As an accident occurs, some trains may not be able to complete the transportation task within the prescribed time because of its impact. In such cases, dispatchers will adjust the time of the affected trains to avoid delay propagation. Through their adjustments, the delay caused by a small disturbance can be recovered in a short time. However, for large disruptions, it is much more difficult for dispatchers to give a reasonable disposition timetable in a short time. In this case, an intelligent decision support system integrating optimization methods will be very useful to improve the dispatcher’s decision-making ability.
This paper focuses on the real-time timetable rescheduling problem under a complete blockage. In this scenario, all tracks in a certain segment are unavailable for trains until the disruption ends. The contributions of this paper are threefold.
First, we apply a mixed integer linear programming (MILP) model to a more complex train operation scene. In most recent studies, trains run from the same origin to the same terminus with the same stopping pattern. But in reality, different trains may have different origins, termini, and stopping patterns. Generally, if a train is late, the longer its route, the greater its resilience. But from the perspective of delay accumulation, under the same delay, a train with a longer route may accumulate more delays in its future operation. It complicates the process of timetable rescheduling. Moreover, in a railway network, there will be some cross-line trains. They may transfer the delay to other lines, causing more serious delays. In this paper, these situations are included in our scenario.
Second, when the end time of the disruption is known, we allow trains at stations downstream of the disruption to depart early to make full use of the buffer time. Zhan et al. (
1
) were the first to come up with this idea, and we apply their idea in our model with different constraints. A parameter
Last but not the least, a three-stage algorithm is designed to solve the MILP model. Since the MILP model may have numerous variables and constraints in our scenario, it sometimes may not be solved in a short time. Because of this, a three-stage algorithm is applied to improve the solving efficiency.
The rest of this paper is organized as follows. The next section gives an overview of the related literature. We present the problem description and the MILP model in the third section. In the fourth section, a three-stage algorithm is introduced. The fifth section presents our experimental setup and simulation results. Conclusions are drawn in the sixth section.
Literature Review
In recent years, the real-time railway rescheduling problem has been a hot topic in delay management. Cacchiani et al. ( 2 ) review the recovery models and algorithms for this problem. They conclude that the application of these models and algorithms in real-life railway systems can play an important role in increasing the quality of services. Timetable rescheduling is one of the most important research directions in the railway rescheduling problem. According to the accident type, existing studies can be divided into two categories: disturbances and disruptions. Since our focus is on disruption recovery, readers can refer to Qu et al. ( 3 ) for further reading, which reviews the methods of real-time railway traffic management under disturbances. In disruption recovery, Ghaemi et al. ( 4 ) describe the traffic level during a disruption as a bathtub with three phases: the traffic will decrease in the first phase, remain at a low level in the second phase and be restored to its original level in the third phase. Several optimization techniques are widely used to solve the three-phase traffic problem at microscopic and macroscopic levels.
At microscopic level, many studies use a detailed alternative graph model to consider the requirement of signals and switches, the headway reports, and the characterization of operations. Corman et al. ( 5 ) present a novel optimization framework for the multi-class rescheduling problem, which is designed to preserve solution quality from the higher priority classes and neglect lower priority classes. After that, they develop two heuristic algorithms to provide a set of feasible non-dominated schedules of the bi-objective rescheduling problem ( 6 ). Caimi et al. ( 7 ) embed a complex central railway station area in a closed-loop discrete-time system, to assign precomputed blocking-stairways to trains while respecting resource-based clique, connection, platform, and consistency constraints with the objective of maximizing customer satisfaction. Chu and Oetting ( 8 ) propose a microscopic method to estimate the feasibility of pre-defined dispatching measures in case of certain disruptions. Pellegrini et al. ( 9 ) develop a model in which the infrastructure is represented with fine granularity to assess the impact of the granularity of the representation of the control area. Ghaemi et al. ( 10 ) extend it with the short-turning measures that trains approaching the blockage cannot proceed according to their original plans and have to short-turn at a station close to the disruption on both sides. Because of the magnitude of the model details, these microscopic models can only deal with the work of relatively small areas.
To improve the efficiency of decision-making, many scholars have begun to use an event–activity network to formulate the train operations, without taking signals and switches into account. Veelenturf et al. ( 11 ) propose an integer linear programming (ILP) model to handle large-scale disruptions at a macroscopic level by adjusting the departure and arrival time of trains at stations. Meng and Zhou ( 12 ) propose a stochastic programming model for single-track railway lines that takes the uncertainty of the disruption duration into account. Their model reschedules the timetable dynamically by a rolling horizon approach. Louwerse and Huisman ( 13 ) present a MILP model suitable for a partial and a complete blockage and based on Netherlands Railways. Measures of delaying trains, canceling trains, and reversing trains at stations adjacent to the blockage are taken to reschedule trains. Zhan et al. ( 1 ) also formulate a MILP model to arrange for the affected trains to stop at stations during a disruption and produce a disposition timetable for trains to resume operation after the disruption, considering headway and station capacity constraints. After that, they extend their model to a case of a partial segment blockage and compare three practical train rescheduling strategies based on a real-world instance in China ( 14 ). To reduce passenger inconveniences during disruptions, Binder et al. ( 15 ) integrate passenger rerouting and timetable rescheduling into an ILP model where limited vehicle capacity is taken into account. Ghaemi et al. ( 16 ) consider the interaction of traffic on both sides of the blockage and apply a MILP model to find the optimal short-turning solutions. In their model, blocked trains can return to their origin station by taking over train services in the opposite direction. Zhu and Goverde ( 17 ) propose a MILP model where more short-turn station candidates and more stopping patterns are given for each train. From their test results, these macroscopic models can solve the rescheduling problem of a large-scale disruption very well, and still take plenty of time to get an optimal timetable when there are too many trains needing to be adjusted.
Most of the studies above are tested on lines with a few trains or select part of the all-day timetable to simulate. When facing a line with lots of trains or an all-day timetable, their methods may not give feasible results in a short time. Some European scholars have recently tried to use short-turning measures to narrow the scope of the disruption ( 10 , 16 , 17 ), except for Meng et al. ( 12 ) and Zhan et al. ( 1 , 14 ). In Meng et al. ( 12 ) and Zhan et al. ( 1 , 14 ), their test lines are railway lines in China, where trains operate with seat reservations for passengers. After passing their origins, they must continue to their termini and cannot return to their origin by taking over the passenger services in the opposite direction. Because of the train seats having been sold in advance, the cancelation of trains will result in major changes of passenger itineraries. In this paper, we extend the mathematical model originally described by Zhan et al. ( 1 ) and the timetable is only rescheduled by retiming and reordering measures. Our model is built to solve the three-phase traffic problem of an all-day timetable at once. Because we do not use short-turning and canceling measures, coupled with numerous trains operating on our test line, the scope of a disruption will be wider. So we propose four new strategies to reschedule trains and a brand-new three-stage algorithm to accelerate the solving speed. Simulations are carried out on the Beijing–Guangzhou high-speed railway line with 29 cross-line trains and 133 local trains.
Problem Description and Model Formulation
Problem Description
During railway operation, the performance of infrastructure will be affected by unexpected factors. When the facilities in one or more segments cannot guarantee the safe passage of trains, it will cause a disruption. If a complete blockage occurs, trains cannot pass through the blocked segment until the blockage is completely repaired. The affected trains have to stop at a nearby station during the disruption.
It should be noted that the high-speed railway line we consider here has two tracks in each segment, with one track for each direction. Trains in different directions run independently in each segment. In China, we call the train going away from Beijing the “down train” and the train in the opposite direction the “up train”; up trains are numbered even and down trains are numbered odd. In this paper, down trains are taken as our rescheduling object.
An example of this problem is shown in Figure 1. The blue line consists of seven stations and six segments. In particular, station 6 is a hub station where trains can run to another line. Five trains are running on it during the blockage, with the same high speed.
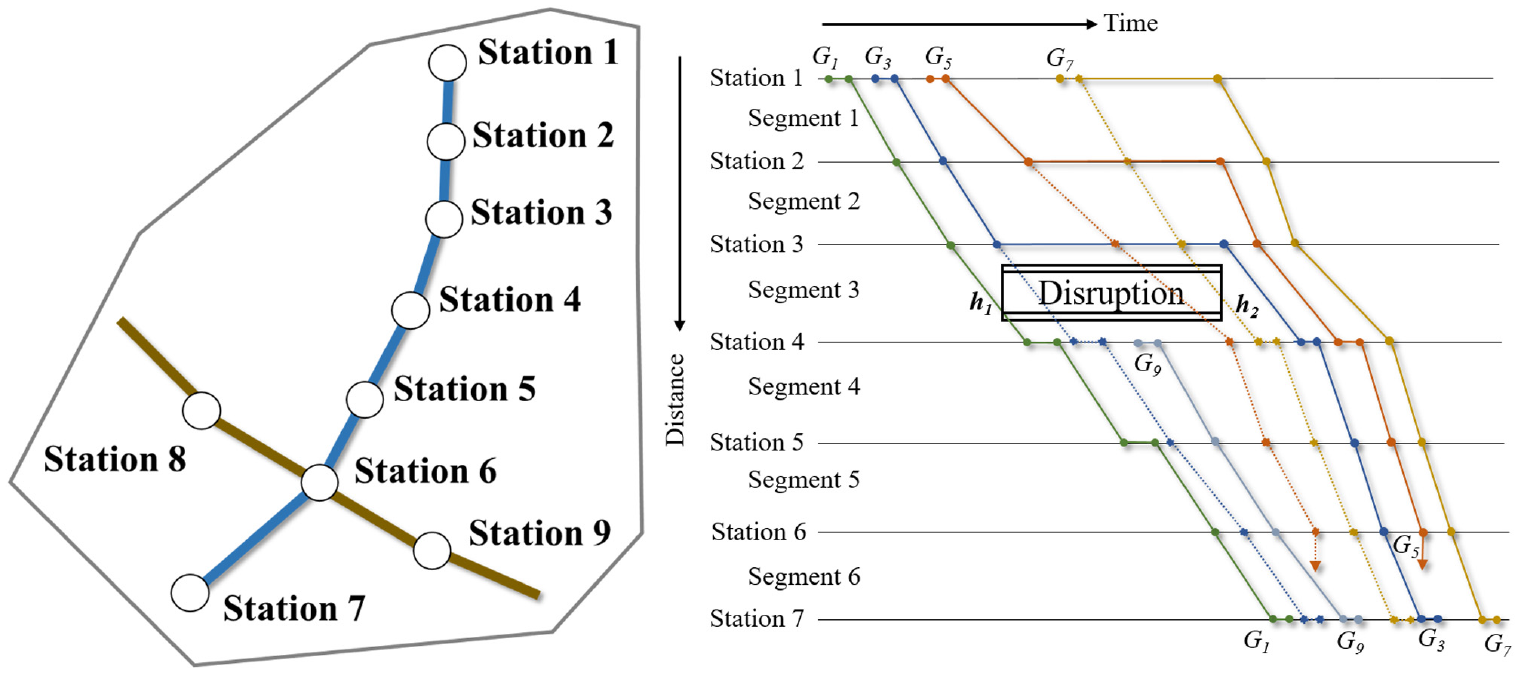
An example of train dispatching under a complete blockage.
Model Formulation
Assumptions
In the case of complete blockages, rescheduling the train timetable is a complicated process. To simplify the problem modeling, some assumptions are made, which do not affect the problem generality.
Before the disruption occurs, trains operate according to the original timetable. The event time is specified in minutes.
When a disruption occurs, trains that have entered the blocked segment can pass as planned.
After the disruption occurs, each track in stations for the down/up direction can be used by each down/up train, and each track has at least one platform for passengers to alight/board.
Methods of canceling trains will not be taken into account. The original timetable will be retimed and reordered to minimize train delays.
The origin and terminus of the railway line have enough tracks for trains to operate.
For a better understanding of this paper, the decision variables and parameters are listed in Table 1.
The Decision Variables and Parameters Used in the Model

Model Basics
The train rescheduling problem can be formulated by an event–activity network, with
In addition, the segment (
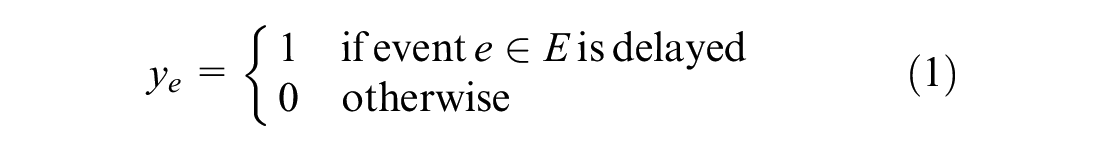
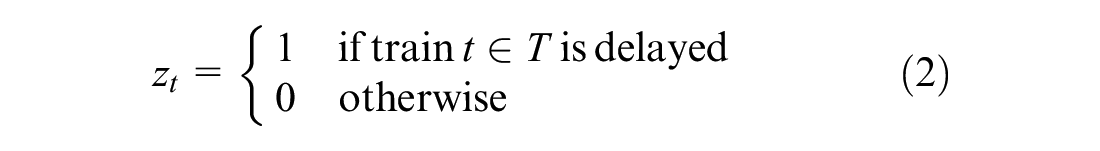
Two types of penalties are introduced to adjust the impact on delayed train numbers and the total delay time. The parameter
The basic model of the timetable rescheduling problem is as follows:
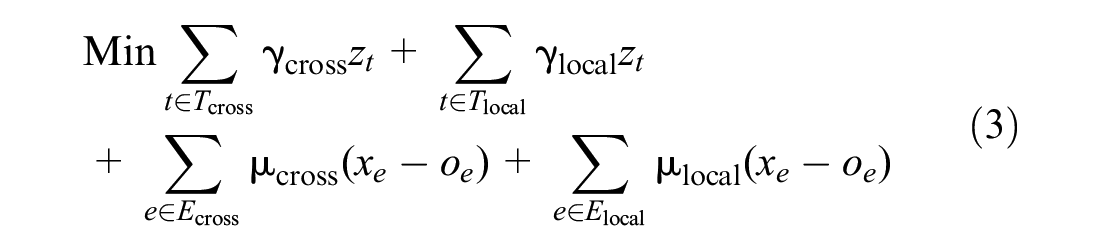
subject to

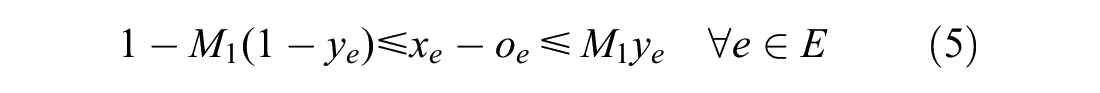
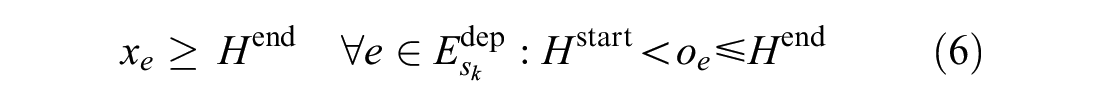
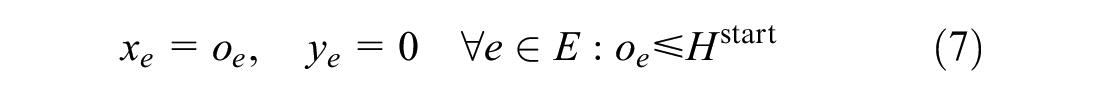
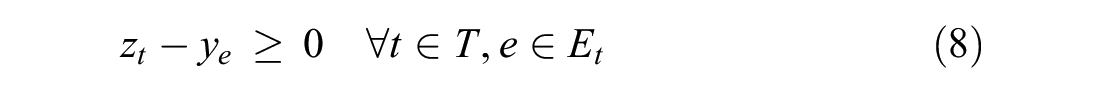

The objective function Formula 3 minimizes the number of delayed trains and the total delay time. Formula 4 ensures that any event cannot occur before its original time. Formula 5 ensures the relationship between the binary variable
Additional Constraints
To ensure the safety of passenger services, more constraints need to be added. These constraints can be divided into four categories, namely station capacity constraints, activity time constraints, overtaking rule constraints, and rescheduling strategy constraints. Recall that we extend the model in Zhan et al. ( 1 ), using the same constraints of activity time, train overtaking, and station capacity. We propose four rescheduling strategies based on complex scenarios, and brand-new strategy constraints are added in our model.
Station Capacity Constraints
Suppose train
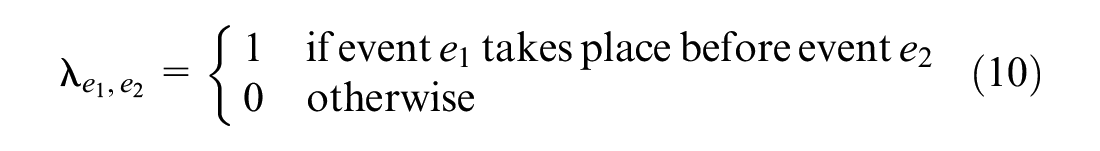
By comparing the arrival time of train
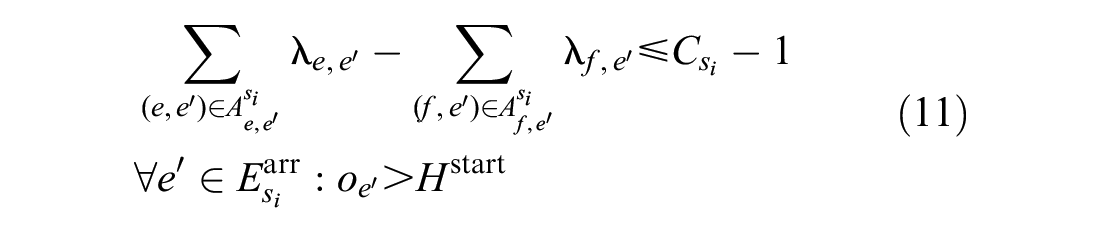
Activity Time Constraints
These constraints include minimum operating time constraints and minimum headway time constraints. Formulas 12 to 16 are added to the model.

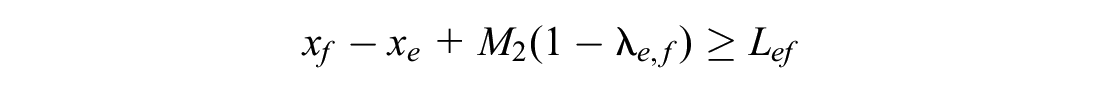
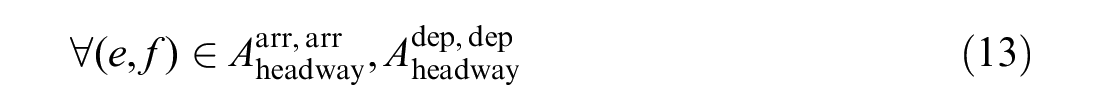
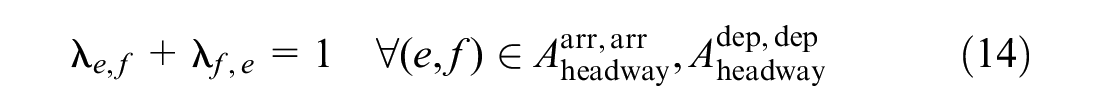
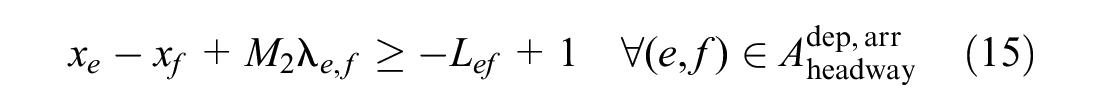
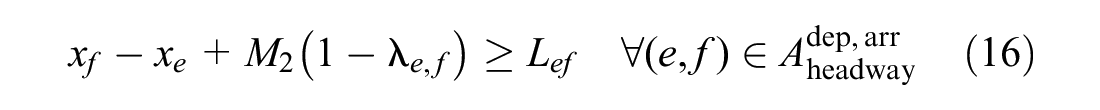
Formula 12 ensures that any train meets minimum operating time constraints. If event
Train Overtaking Constraints
As mentioned earlier, there is only one track in segments for trains running in the same direction. One train can only overtake another train at a station, not in a segment. To meet this requirement, the constraints on train overtaking are as follows:

Formula 17 means that the order in which two trains arrive at the next station must be the same as the order in which they leave the previous station. It should be noted that
Rescheduling Strategy Constraints
We set four strategies to reschedule trains. First of all, make blocked trains stop at stations as much as possible and avoid them staying in segments for too long. So during the rescheduling process, we set the maximum running time of the trains in each segment to the planned running time in their original timetable. Although this measure will increase the total delay time, it will better ensure the safety of passengers. Note that, in dense traffic lines, not all trains can meet this limit. A special case is shown in Figure 2, which shows a part of the timetable used in this paper. At the beginning of the blockage, three trains enter the segment between station 11 and station 12. Since there are only two tracks in station 12 for trains to stop, train
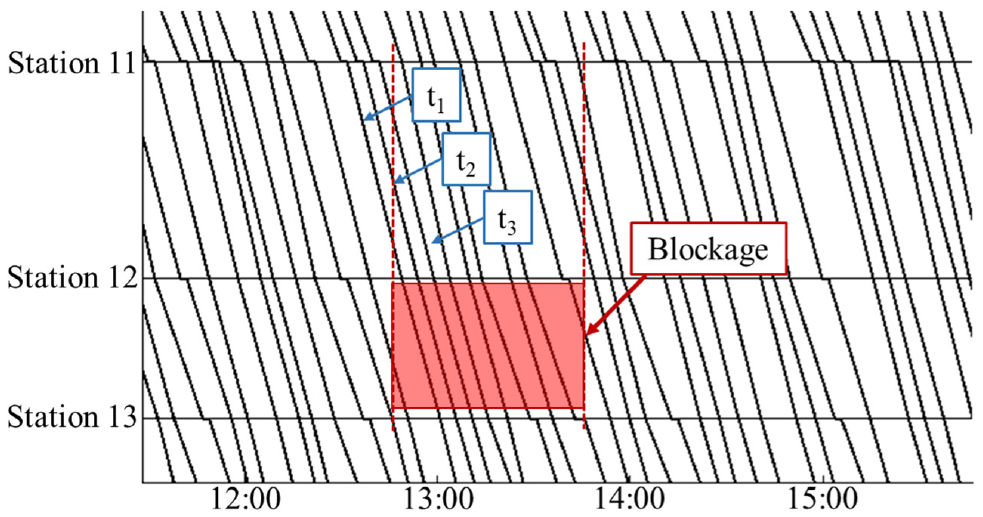
A special case that not all trains running in one segment can stop at the stations ahead.
Second, blocked trains at stations downstream of the blocked segment can depart early when the end time of the disruption is known. In reality, the end time is uncertain at the beginning, but we can get it in advance before the disruption is over. We introduce a parameter
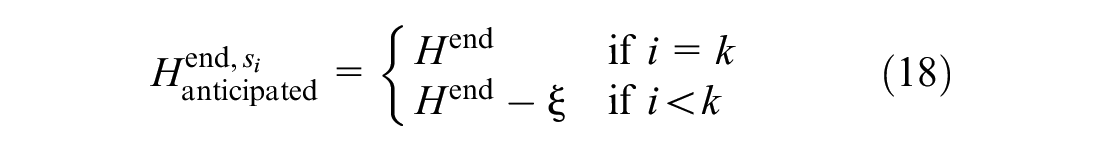
At the anticipated end time, blocked trains are allowed to leave their stations for the next one, utilizing these early departure times to resume normal operations more quickly.
Third, before the disruption is completely repaired, a delayed train cannot affect the subsequent punctual trains. If train
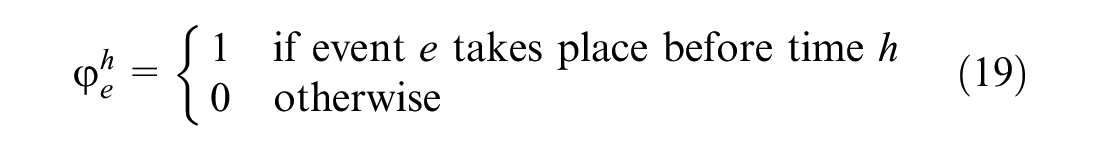
Formulas 20 to 21 represents the constraints of variable
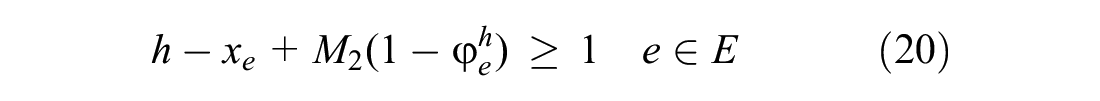
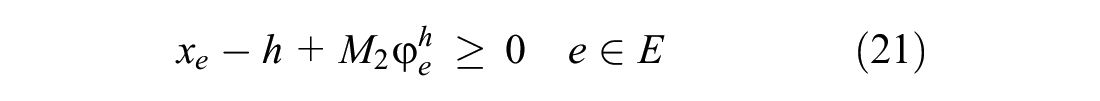
Formulas 22 to 24 are added to the downstream stations of the blocked segment to meet the third strategy.
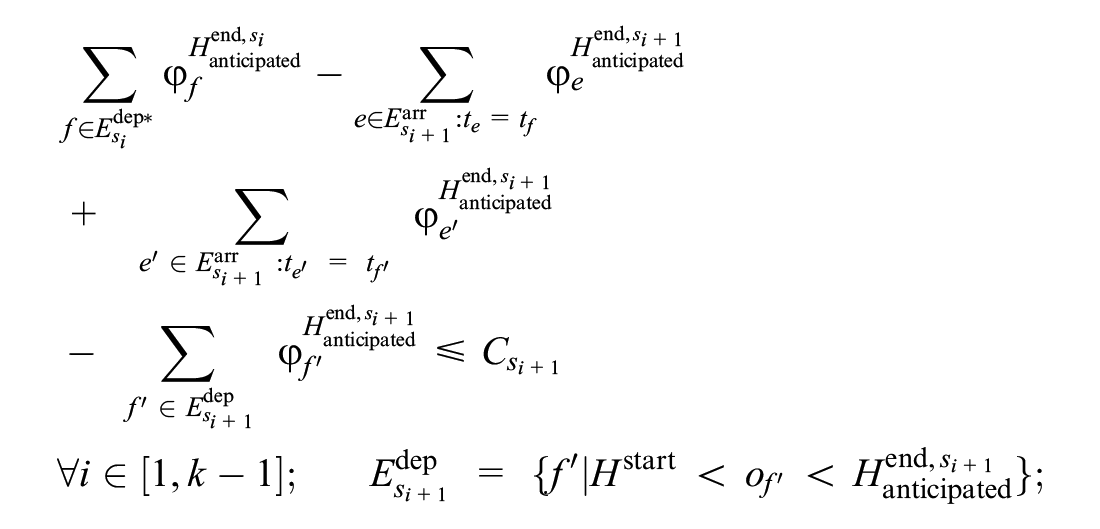
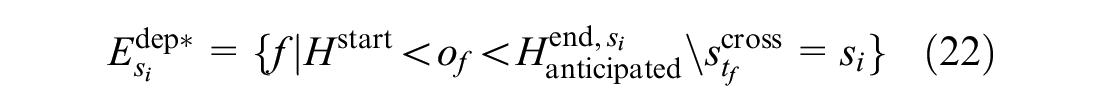
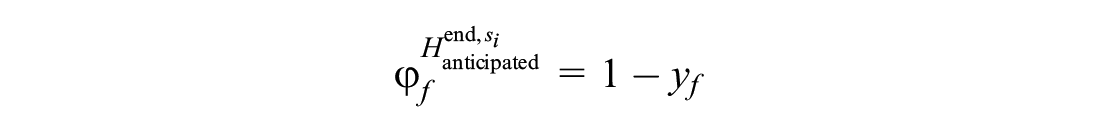
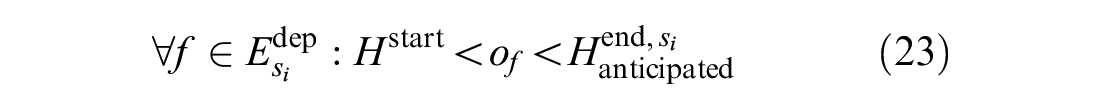
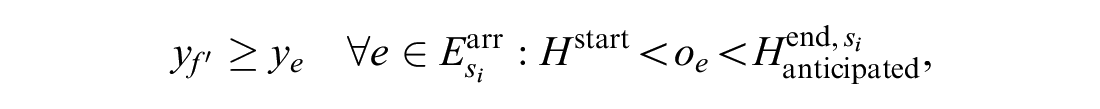
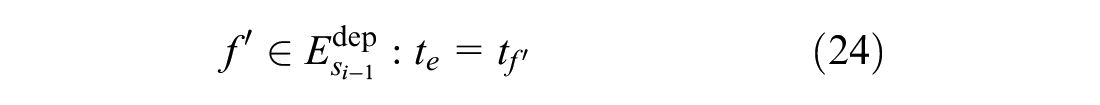
Formula 22 ensures that before the blockage ends, one of the affected trains can leave its current station only when at least one track is free at the next station. In Formula 22,
Last but not the least, to avoid delay propagation, those cross-line trains that arrive at their handover stations on time during the rescheduling process must be sent to other lines on time. Formula 25 ensures that the fourth strategy is met.
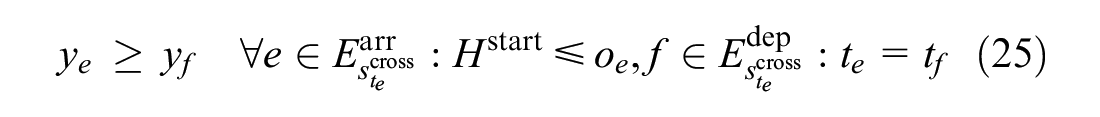
This ensures that when
Valid Constraints
When a train departs from a station before a certain point in time, its arrival event at that station must also occur before that point in time. Accordingly, when a train arrives at a station after a certain point in time, its departure event at that station will also occur after that point in time. Although these constraints are implied in the above constraints, we explicitly add these constraints here to strengthen the formulation, which helps us to improve the solution speed. These constraints are as follows.
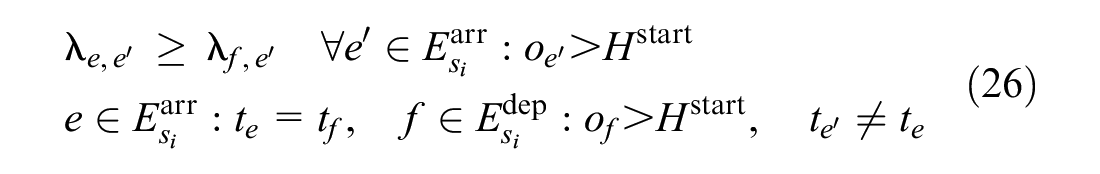
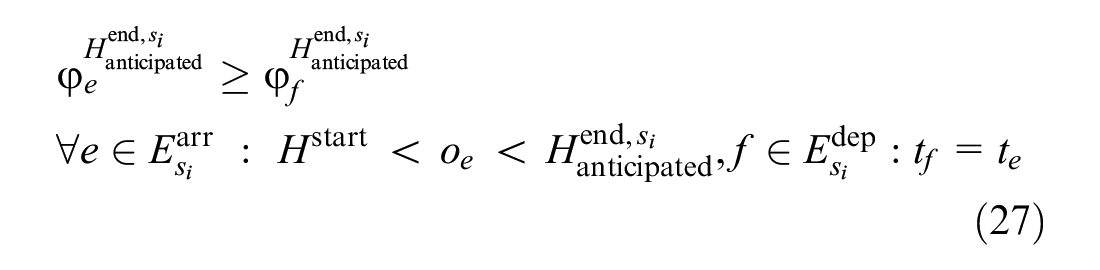
Formula 26 is added in each station and Formula 27 is added in the downstream stations of the blocked segment. In Formula 26, if
Three-Stage Algorithm
Because of the excessive number of trains in a day, having too many variables and constraints in the model makes it difficult to solve. Thus, how to improve the solving ability of the model becomes another focus of this paper.
Source of Ideas
When a disruption occurs, many events need to be rescheduled. If the number of trains that need to be rescheduled can be reduced, it will have a positive influence on the solution of the problem. Let us imagine the worst situation, that dispatchers do not make any adjustments under a disruption. Under this situation, trains may still operate according to the fixed order in their original timetable. Following this rule, a feasible timetable can be obtained, whereby delayed trains can be extracted for optimization. Because it is the worst situation and the delay is propagated backward from train to train, the optimization of these delayed trains will mitigate the impact of delays and reduce the number of delayed trains. This means that the optimization result may only have a slight influence on those punctual trains in the feasible timetable. So we can merge the optimized timetable of delayed trains with the feasible timetable of punctual trains to get the disposition timetable. In this way, the original large-scale problem is simplified into a small-scale problem, and finally solved by optimizing the small-scale problem.
Computational Procedure
According to the above description, a three-stage algorithm is built. The overall process of the three-stage algorithm is shown in Figure 3.
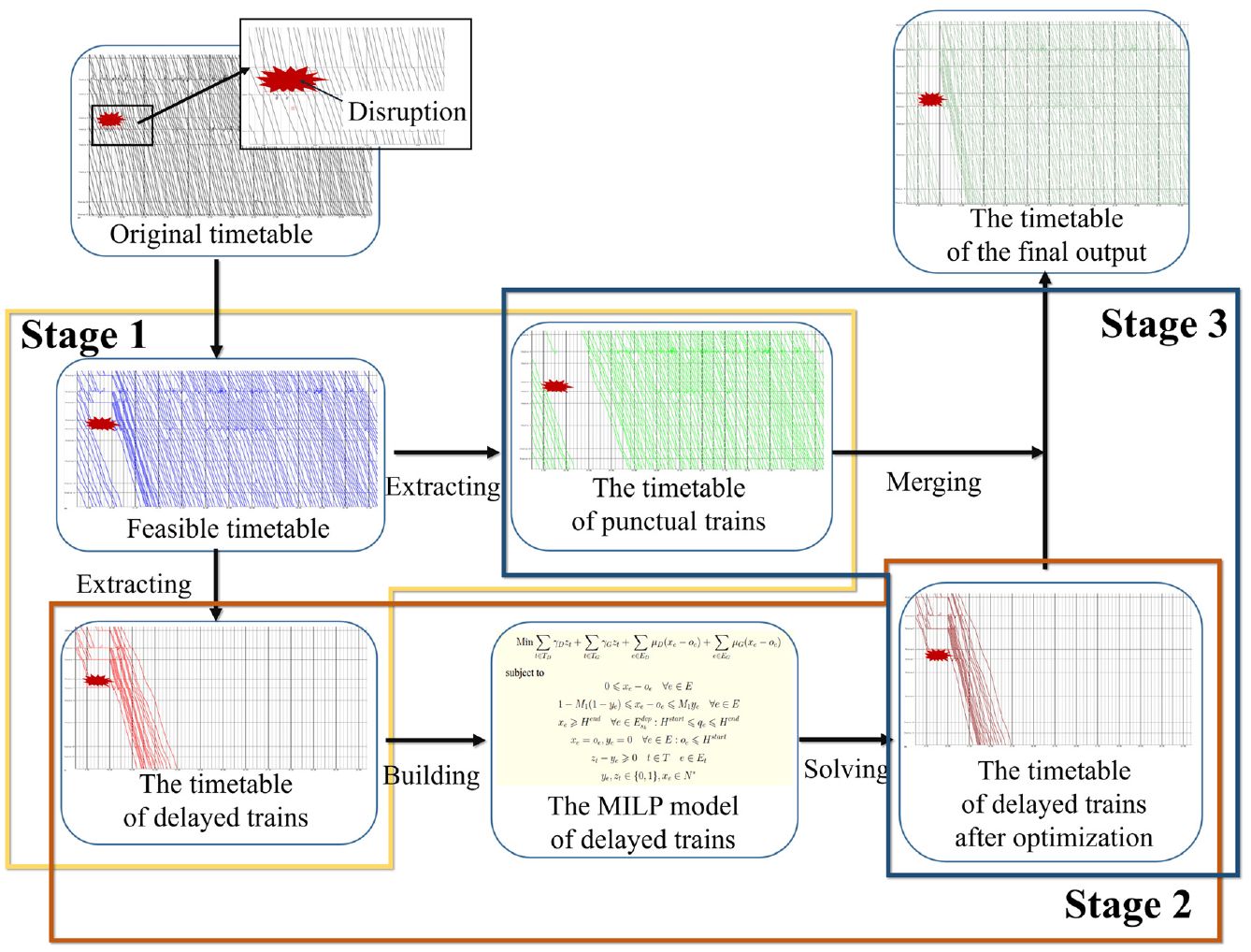
The flow chart of the three-stage algorithm.
Stage 1: Generate a Feasible Timetable to Extract Delayed Trains
In Stage 1, to generate a feasible timetable, activity time constraints and station capacity constraints need to be met. Our goal is to allocate the event time according to the fixed order in the original timetable. Figure 4 gives the flow chart of the algorithm, which takes six steps.
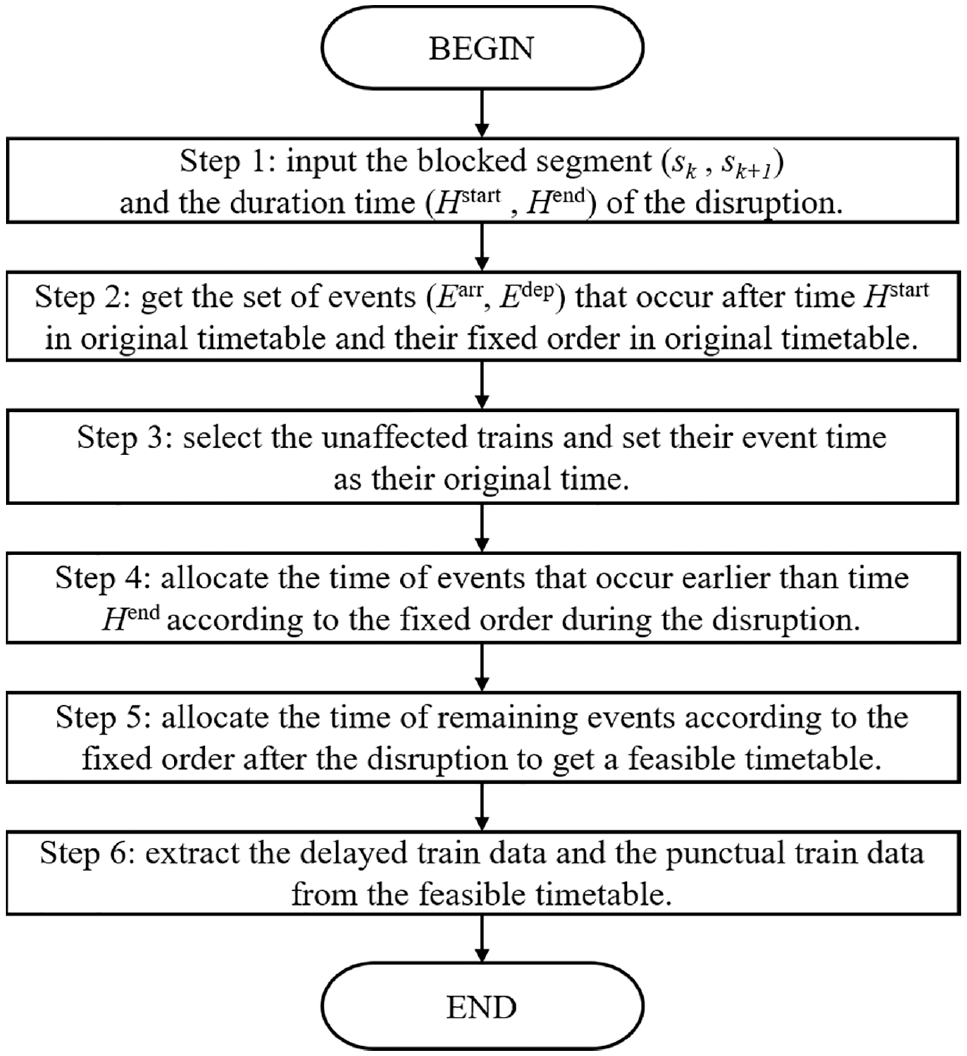
The generating algorithm in Stage 1.
Assume that the terminus of the line is station
Step 4 allocates event time from station
Let us take
Step 5 allocates the time of all remaining events from station
Continue to take Figure 1 as an example. At station 1, since we assume that the origin has enough tracks, all arrival events are set to their original time. Then, before setting each departure event time, the departure order needs to be changed. For example, for
Next, check these setting time to meet station capacity constraints. For each arrival event, get its sorting numbers in all arrival events and all departure events. Assume the sorting numbers of arrival event
At station 2, to meet the overtaking constraints (Formula 17), we first need to change the arrival order according to the adjusted departure order in station 1. After that, supposing event
Stage 2: Build a MILP Model and Optimize the Time of Delayed Trains
From Stage 1, the timetable of delayed trains is obtained. The objective of this stage is to optimize the time of the delayed trains. It should be noted that the set of delayed trains contains the last delayed train and all the trains before it, except for the unaffected trains in Step 3 of Stage 1. At Stage 2, the MILP model introduced in Section 3 using the data of delayed trains is built. To reduce the search space, the maximum time of each delayed event is set to the maximum time of these delayed events in the feasible timetable in Stage 1. Since the CPLEX solver (detailed below) has proven to be efficient in solving such problems, an optimized timetable of delayed trains is generated by it. Stage 2 ends.
Stage 3: Merge the Timetable of Delayed and Punctual Trains to Achieve the Final Timetable
As the timetable of punctual trains and the optimized timetable of delayed trains are obtained from Stage 1 and Stage 2, the task of Stage 3 is to merge these two timetables. At Stage 3, the optimized timetable of delayed trains is added into the timetable of punctual trains and the arrival and departure order of each station are updated according to the time of each event. As the optimized timetable may have a slight influence on the timetable of punctual trains, the next step is to judge whether the brand-new timetable satisfies activity time constraints (Formulas 12–14) and station capacity constraints (Formula 11). From station
Let’s take station
Experiments on Real-Time High-Speed Railway
The logic of the three-stage algorithm is coded in Python 3.7 and the MILP model is solved by IBM ILOG CPLEX 12.10 with default parameter values. All the experiments are running an Intel® Core™ i7-10875H Processor CPU @2.3GHz 16 GB RAM laptop.
Test Instances and Parameter Settings
The Beijing–Guangzhou high-speed railway line is one of the busiest lines in China and is reputed to be the longest high-speed railway line in operation in the world. The part of it from Chibibei to Guangzhounan is chosen as our test line, as shown in Figure 5. The test line contains 15 stations and 14 segments, which are marked as stations 1 to 15 and segments 1 to 14 following the order from Chibibei to Guangzhounan. For instance, Chibibei is station 1 and the segment between Chibibei and Yueyangdong is segment 1. Among them, Changshanan, Hengyangdong, and Guangzhounan are hub stations which connect other high-speed lines. In Figure 5, the number of tracks in each station is described on the right of each station location. The first number is the actual number of tracks in stations and the second number is the track number used in experiments. It is worth mentioning that the number of tracks in the origin or terminus is assumed to be enough for trains to operate. Therefore, the number of tracks in Chibibei or in Guangzhounan is set as 50.
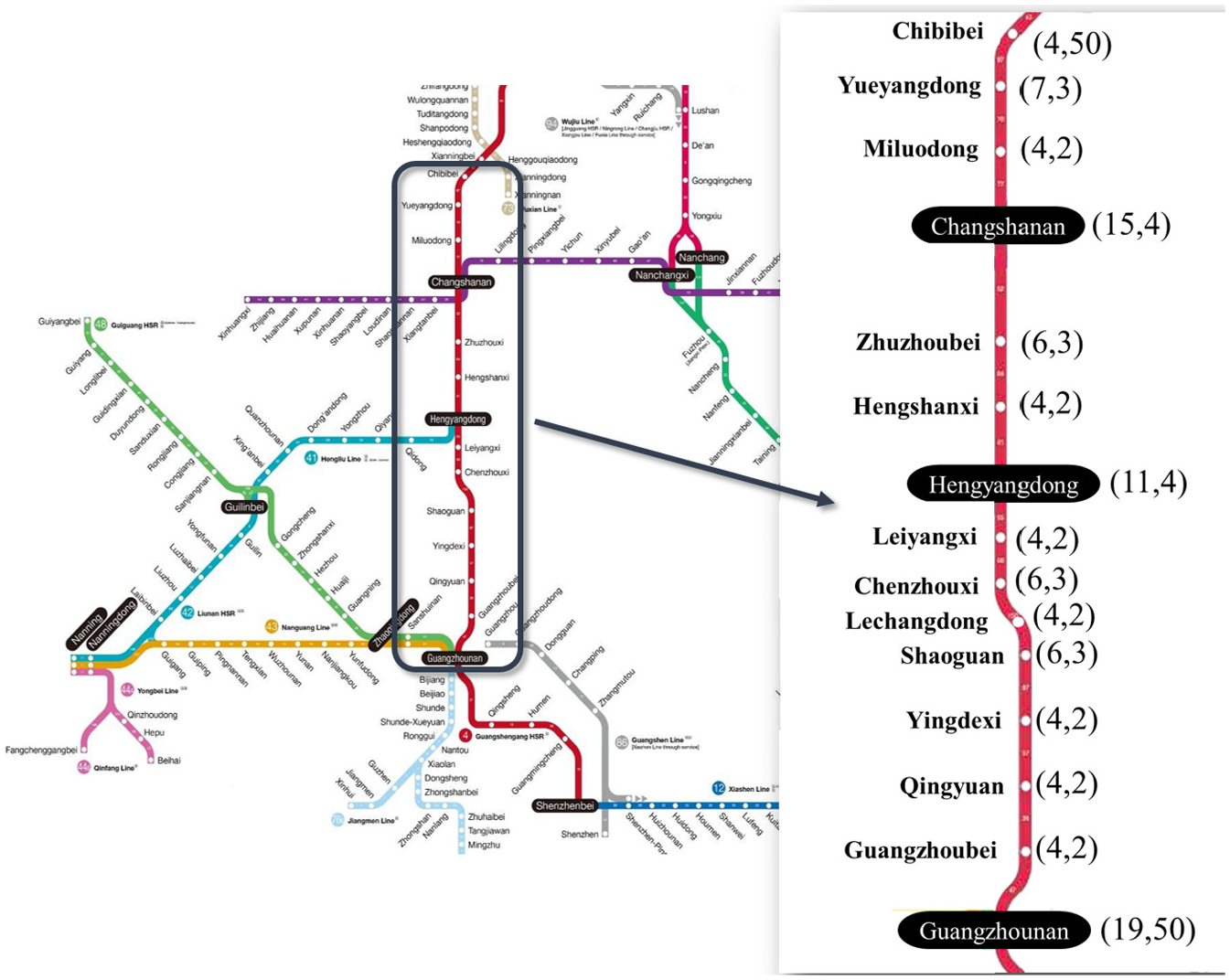
The Beijing–Guangzhou high-speed railway line from Chibibei to Guangzhounan.
The original timetable of the test line for July 2018, containing the data of 162 trains, is used. Three train route types are regarded as cross-line trains. As shown in Figure 6, black lines are local trains and blue lines are cross-line trains. There are 29 cross-line trains and 133 local trains in the original timetable.

The original timetable used in experiments.
Through the statistics of the historical records, the minimum running time in each segment is obtained. Table 2 shows the minimum running time used in experiments.
The Setting of the Minimum Running Time in Each Segment
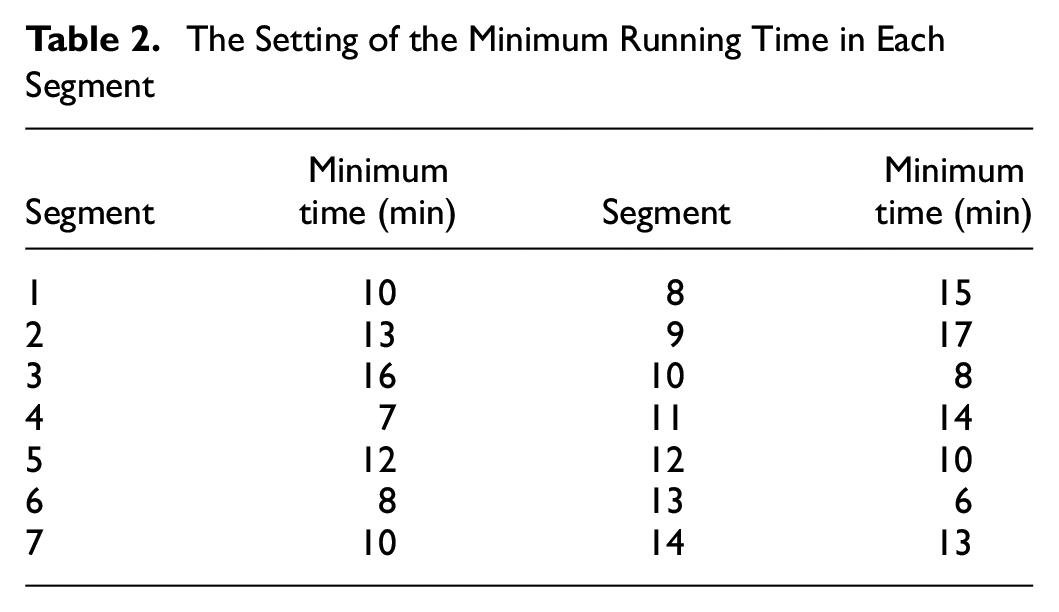
Our experiments choose several disruption scenarios with different start times, durations, and locations. 9:00, 12:00, and 15:00 are chosen as the start time of the disruption. The locations are set as segments 5, 8, and 11. There are three values for duration, 30 min, 45 min, and 60 min.
Simulation Results and Discussion
In this section, we describe the simulation results obtained by applying the three-stage algorithm. For comparison, another MILP model is constructed directly using the original timetable and solved by CPLEX; this is called the one-stage algorithm in the next sections.
Results of Various Disruption Scenarios
Figure 7 shows an example of the final timetable using the three-stage algorithm. In Figure 7, the blocked trains wait inside stations during the disruption. Since
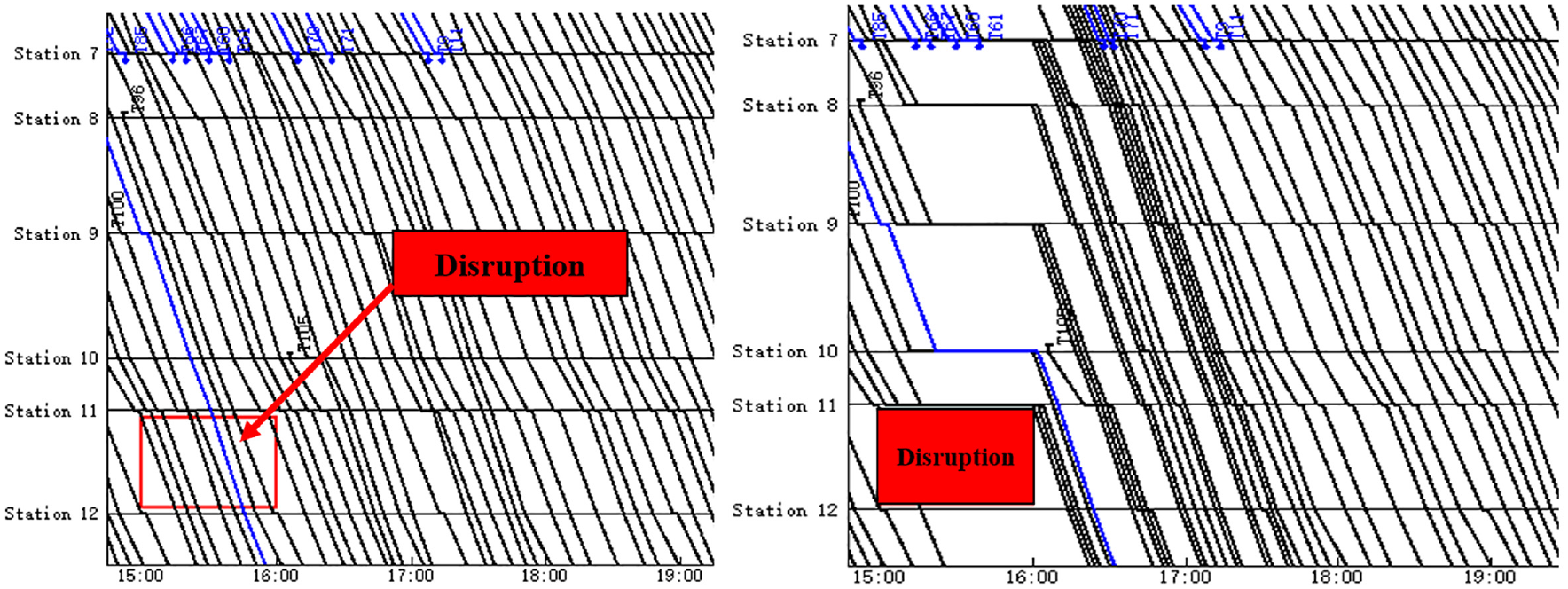
An example of the final timetable using the three-stage algorithm.
Table 3 shows the results for different instances, including the results of the one-stage algorithm. The instance
Results of Different Disruption Scenarios Using One-Stage or Three-Stage Algorithm
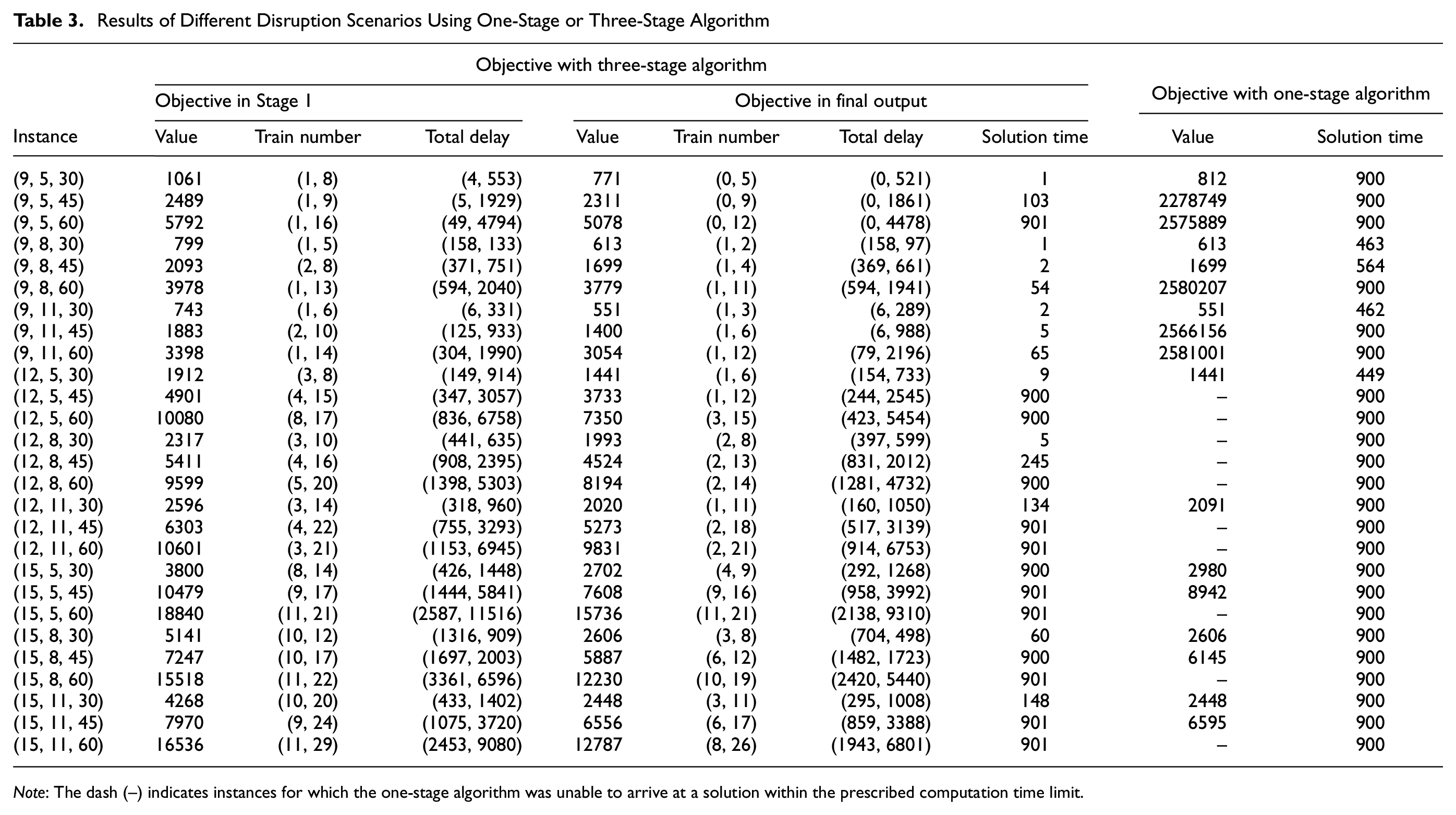
Note: The dash (–) indicates instances for which the one-stage algorithm was unable to arrive at a solution within the prescribed computation time limit.
Among these instances, there are 10 instances solved by the one-stage algorithm where no feasible result can be obtained within the limited computational time, which are marked as “–.” As the results shown in Table 3, our algorithm can produce optimized results under any circumstances, but in some cases one-stage algorithms cannot. Comparing the objective of the three-stage algorithm with the objective in Stage 1, these results indicate that the other two stages greatly optimize the feasible solution. A comparison of the data results using the two different algorithms shows that our algorithm can generate a superior objective value under the same time limit or generate the same optimal value with less solving time. This proves that the proposed algorithm performs well in the problem of timetable rescheduling and reduces the search space, which makes it easier to find good search results.
Computational Time Limits of CPLEX
To further illustrate the effectiveness of the three-stage algorithm, we choose instances with a solution time of up to 900 s and test them under different computational time limits. The computational time is limited to 150, 300, 450, 600, and 900 s. The results of Stage 1 are added to the graph for comparison. Figure 8 shows the results of these 13 instances.
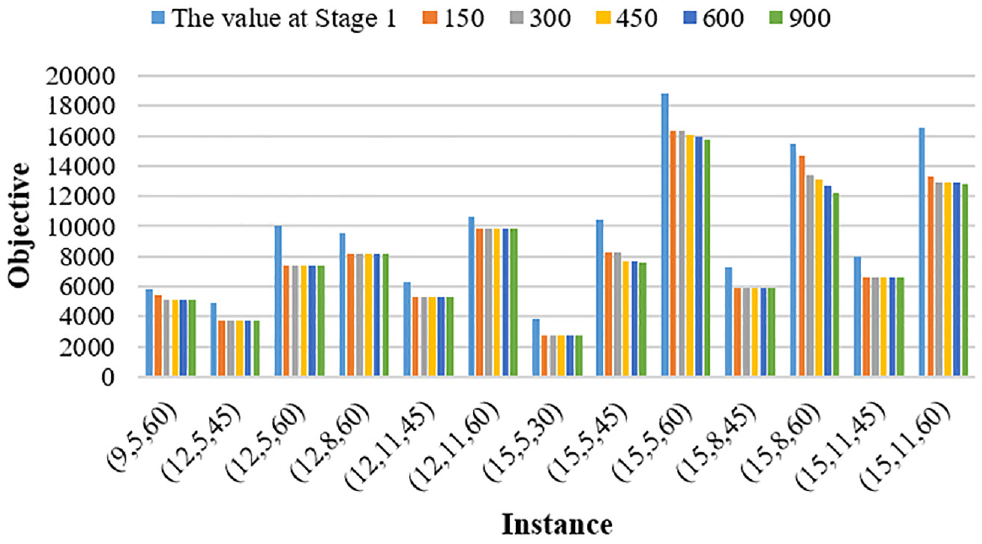
The objective of the three-stage algorithm under different computational time limits of CPLEX.
In Figure 8, we can see that all instances get a optimized objective in 150 s, which is much better than that at Stage 1. This fully proves the high efficiency of the remaining process of the three-stage algorithm. Moreover, except for the instances (15, 5, 60) and (15, 8, 60), most of the instances can achieve a better optimized solution within 450 to 600 s, and when the time limit increases, the objective value will not drop. In instances (15, 5, 60) and (15, 8, 60), the scale of the problem is too large to be solved in a short time, and the objective value will still slightly decrease as the time limit increases. This phenomenon is unavoidable in the face of large-scale problem solving. It is worth mentioning that our algorithm is an exhaustive search method. In fact, we will get a feasible result in each instance, which may be replaced soon by a better result over time. In these two instances, our three-stage algorithm can produce a feasible result within 150 s, while the one-stage algorithm cannot obtain a feasible solution within 900 s, which further proves that our method can solve large-scale problems well. To sum up, taking the scale of the problem into account, all instances using the three-stage algorithm can get a good solution within 450 to 600 s, which is acceptable for practical use.
The Building Time of the MILP Model
The solution time in Section 5.2.1 is without the building time of the MILP model. In this section we discuss the building time of different MILP models. We construct the MILP model using Python 3.7. Figure 9 shows the model building time when using different algorithms.
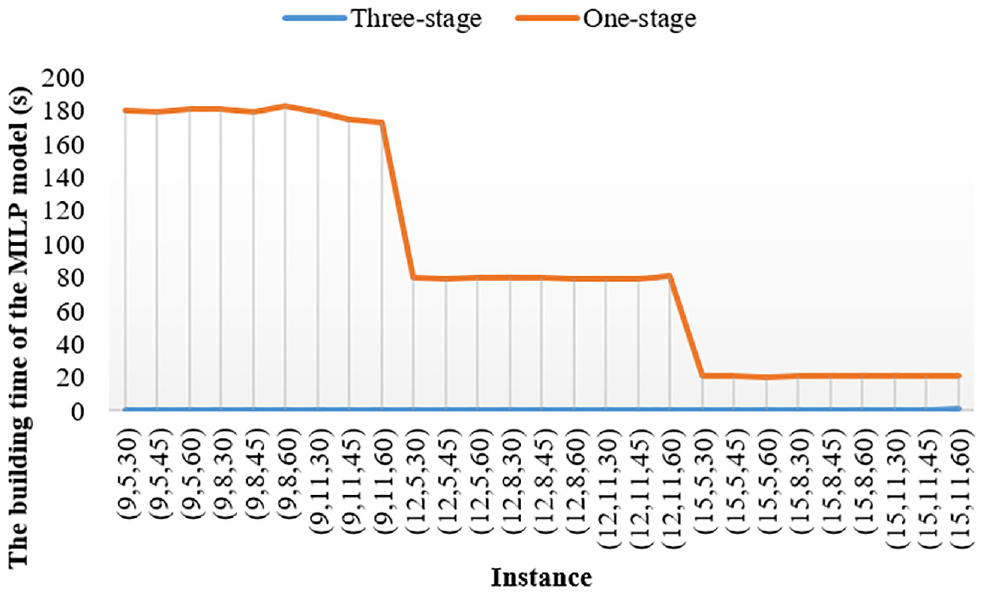
The building time of the mixed integer linear programming (MILP) model using different algorithms.
It can be seen from the experimental results that the building time of the one-stage algorithm is much longer than that of the three-stage algorithm. From the building time of the one-stage algorithm, we can find that the building time is inversely proportional to the start time of the disruption. The earlier the disruption occurs, the more trains are affected and the longer the building time is. This phenomenon shows that it is necessary to narrow the rescheduling range of trains. Since the average building time of 27 instances using the three-stage algorithm is 0.2 s, while that using the one-stage algorithm is 92.7 s, our algorithm can efficiently reduce the complexity of the problem.
Effect of Penalty Values
To evaluate the effect of penalties to the model solution, four value sets are selected for (
Final Results with Different Penalty Values
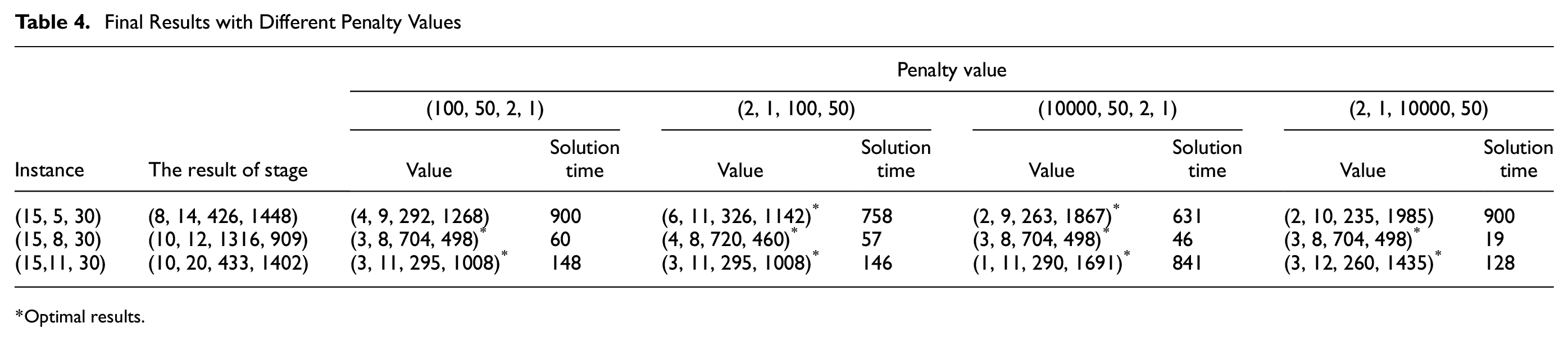
Optimal results.
From the statistics in Table 4, because these penalties change the search direction during the solution process, different penalty sets in each instance lead to different solution times. In theory, when the number of delayed trains and the total delay time are given different weights, the final result will also be different, just like the results of instance (15, 5, 30). In instance (15, 5, 30), when the delay time of the cross-line trains is given more weight, the final result will be less delay time of the cross-line trains, and more delay time of the local trains, and vice versa. However, the results of the first penalty set and the third penalty set in instance (15, 8, 30) are the same. This is because the number of delayed cross-line trains can no longer be reduced in the final result. Giving more weight to delayed cross-line trains will not change the optimal result. In addition, the results of the third penalty set and the fourth penalty set in instance (15, 8, 30) are the same too. It is because the optimal result has no room to reduce the number of trains and the weight change between local trains and cross-line trains in delay time is not enough to change the delay values. Moreover, the results of the first penalty set and the second penalty set in instance (15, 11, 30) are also the same. This is because neither the weight change in the train number between local trains and cross-line trains nor the weight change in the delay between local trains and cross-line trains is enough to change the final output. When the weight of the delayed number of cross-line trains or the weight of the delay time of cross-line trains continues to increase, such as the third penalty set and the fourth penalty set in instance (15, 11, 30), the final result can be changed. Therefore, it can be concluded that when there is room for adjustment in the final result, the higher the train number penalty, the fewer delayed trains; the higher the delay penalty, the less the delay. But to obtain the expected results, the appropriate weight should be carefully selected.
Function of Anticipation Abilities
In the MILP model, the time when the blocked trains can depart from stations is related to the parameter
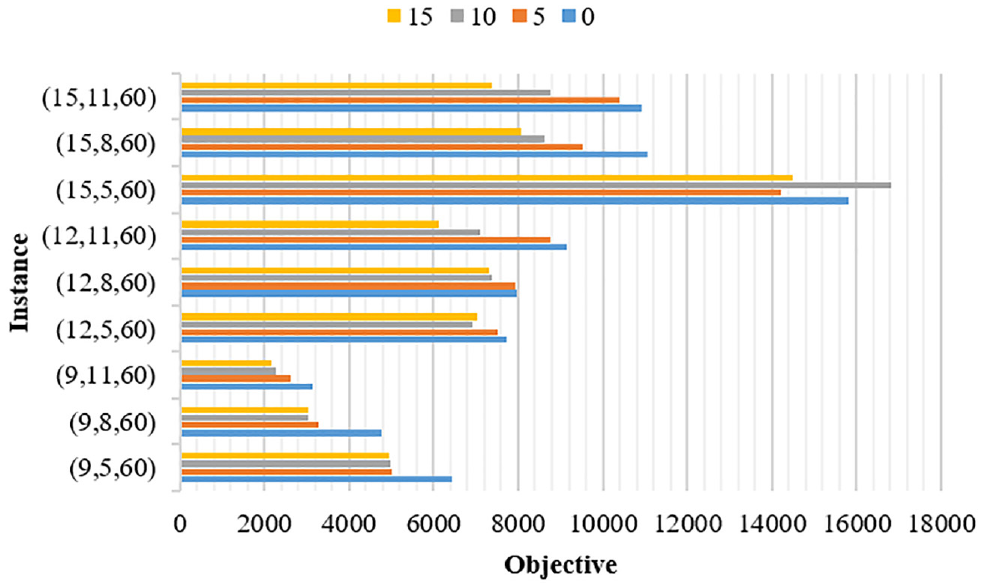
The objective in the final output using different anticipation abilities.
From Figure 10, it can be seen that in most cases, if the anticipation ability is greater, the objective value is better. Therefore, when facing with a large disruption, a great anticipation ability can help blocked trains quickly get back to normal. But there are exceptions. The results with the values of 15 min and 10 min in instance (15, 5, 60) are greater than that with the value of 5 min, and the result with the value of 15 min in instance (12, 5, 60) is greater than that with the value of 10 min. It is worth mentioning that all the results in these two instances are non-optimal solutions. So when enough solution time is given, the final result with a greater anticipation ability must be better. However, in a certain period of time, the greater the anticipation ability, the more choices for train selection, which increases the search space. In these instances, a better solution cannot be generated within 900 s.
Conclusions
In this paper, we developed a macroscopic real-time rescheduling approach for high-speed railway under a complete blockage. Aiming at minimizing the total delays and the number of delayed trains, a MILP model is proposed to generate a disposition timetable under the constraints of station capacities, activity time, overtaking rules, and rescheduling strategies. Our rescheduling strategy is that blocked trains must wait inside stations until the disruption ends, and when the exact end time of the disruption is known, trains at stations downstream of the blocked station can depart early. The model is applied on the part of Beijing–Guangzhou high-speed railway line from Chibibei to Guangzhounan with several disruption scenarios. There are in total 162 trains in the original timetable, combining 133 local trains and 29 cross-line trains. Since it is difficult to solve the MILP model directly in a short time, a three-stage algorithm is designed to accelerate the solution process.
Simulation results prove that our proposed method can handle the real-time timetable rescheduling problem under a case of complete blockage very well. Our approach has a higher solution efficiency and can meet different rescheduling requirements by changing penalties. Because all instances can obtain a better optimized disposition timetable within 450 to 600 s, our approach is acceptable for practical use. It is also found that a better anticipation ability can accelerate the recovery process, but may increase the search space, resulting in a failure to find a better solution within the specified time.
Several directions for further research are available. First, we find that the anticipation ability is very important for disruption recovery, which is not explored in this paper. Some research on the uncertainty of the disruption end time would be very meaningful if carried out to improve the anticipation ability. Second, we only consider the delays that occur on one line in this paper. However, in a railway network with cross-line trains, delays will spread to other lines as well. It is significant to build a method from the network level and study the strategy of using shared platforms for trains in different directions. Finally, trains that run from the same origin to the same terminus may have different routes to choose in a railway network. The measure of rerouting can be taken into account to solve the real-time rescheduling problem.
Footnotes
Acknowledgements
Thanks to our project partners for their useful contributions.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Bowen Gao, Decun Dong, Dongxiu Ou; data collection: Bowen Gao, Yusen Wu; analysis and interpretation of results: Bowen Gao, Yusen Wu; draft manuscript preparation: Bowen Gao, Yusen Wu, Dongxiu Ou. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Research Program of Comprehensive Support Technology for Railway Network Operation (No.2018YFB1201403), the Research Program of Shanghai Science and Technology Committee (No.18DZ2202600), and the National Natural Science Foundation of China (No.52172329).