
Abstract
This paper investigates the use of an elicited consideration set in a mathematical model of choice and consideration set formation. It proposes an econometric formulation by allowing unrestricted correlations among alternatives in the consideration set formation and a flexible substitution pattern in the choice model. Data from a stated preference (SP) survey is used where the SP choice tasks were followed by an elicitation of the consideration set while responding to the SP experiments. As opposed to the latent choice set formation approach, the elicited consideration set reduces the computational burden for model estimation. Empirical models reveal the benefit of modeling choice in conjunction with consideration of the set formation. It is evident that overlooking the probabilistic consideration set results in the over-estimation of the effects of key choice attributes, for example, travel time and generalized cost. Estimated correlations among alternatives in the consideration set formation revealed rich patterns of complementary and supplementary relationships among the alternatives that would not be possible to observe otherwise. However, it is also clear that the relationship in the consideration set formation may not be fully translated into substitution patterns in the choice model; that is explained by the error-component mixed logit model.
Keywords
The choice set is an important pre-requisite of any discrete choice model. In the case of revealed preference (RP) choices, the choice set is implied by the availability of alternatives. For example, in the case of a RP mode choice model, the number of alternatives available to an individual is implied by the feasible mode alternatives for the trip under investigation. In the case of stated preference (SP) choices, the choice set is explicitly mentioned in the choice task. In both cases (implicit choice set in RP and explicit choice set in SP), the classical discrete choice modeling practice considers deterministic choice sets. However, it is true that all alternatives may not be always considered by all individual choice makers. Major discrepancies between the modeler’s assumed choice set and the actual choice maker’s considered choice alternatives would have serious consequences that may make the choice models invalid or at least useless. In this paper, we distinguish “choice set,” which is the set of alternatives assumed by the choice modelers, from the “consideration set,” the actual set of alternatives considered by the choice maker while making a choice. We focus on developing a probabilistic consideration set for the discrete choice model. However, it is impossible to know the actual consideration set of an individual choice maker unless we ask about it.
Historically, inaccessible information on a consideration set as well as the possible wide variation in size and combinations of consideration sets by different choice makers has encouraged researchers to consider a probabilistic choice set for discrete choice modeling. The ground-breaking work of Manski ( 1 ) established the probabilistic choice set formation model, where he considered that the actual choice of a discrete alternative is conditional on the probability of a specific choice set that includes that alternative. However, possible explosions of the combinations of choice alternatives in the probable choice sets that pre-condition the choice-making leave the original formulation of the probabilistic choice set of Manski apparently impractical. Later, a few other researchers proposed a simplifying assumption stating that the inclusion of an alternative in the choice set is independent of the inclusion/exclusion of any other alternatives ( 2 , 3 ). Such an independent availability (IA) assumption makes the computation of probabilistic choice set formation a feasible proposition.
Although the IA assumption simplifies the choice set formation model greatly, there still remains a huge obstacle in practical application of such models. Even with a slight increase in the total number of feasible alternatives (J), the possible number of choice sets grows by 2J. As a result, the computational burden of estimating a joint model with choice set formation remains a costly issue in discrete choice modeling exercises. However, a viable alternative approach to consider a latent choice set is to actively collect data in the consideration set from survey respondents. Such an approach is known as “consideration set elicitation” and it can greatly reduce the computational burden of estimating a joint choice model with a probabilistic consideration set formation. However, the IA assumption still remains necessary to manage the probabilistic consideration set formation and therefore limits the behavioral interpretations of estimated model parameters. The application of mixing distribution in an IA-based model formulation (mixed-IA) can further overcome such limitation. In addition, mixing distribution in the choice model utility function (error-component) in the context of mixed-IA-based consideration set formation can unravel a multidimensional relationship among choice alternatives in consideration set formation stages, as well as discrete choice-making stages. This paper presents such an econometric model with a probabilistic consideration set formation, where the consideration sets are elicited by the respondents. The paper is inspired by Swait ( 4 ), but we used a more flexible error correlation patterns in both the consideration set and the discrete choice model. For the empirical investigation, we used data from a SP survey on commuting mode choices in the Greater Toronto and Hamilton Area (GTHA). The survey collected the elicited consideration set directly from the respondents after the SP choice tasks. The SP choices and the elicited consideration set data were used for estimating the discrete choice model with consideration set formations.
The paper is organized as follows. The literature review presents a brief literature review on elicited consideration sets and choice modeling with consideration set formation. The next section presents the econometric formulation of the proposed model. The data for empirical evidence section briefly explains the dataset used for empirical investigation. The next section presents a discussion on the empirical models. The paper concludes with summaries of key findings and recommendations for further research.
Literature Review
The choice set of discrete choice models has been a critical issue guiding the formulation of such models since the beginning. Luce’s ( 5 ) choice axiom and later McFadden et al.’s ( 6 ) generalization of logit models are based on deterministic choice sets. The effects of such assumptions on the choice set were not clear until Manski ( 1 ) proposed the probabilistic choice set formation model. Later, the works of Williams and Ortúzar ( 7 ) proved that strict deterministic choice set assumptions in discrete choice modeling can have serious implications on choice model mis-specifications. However, an empirical model of choice set formation was not possible until Swait ( 2 ) and Swait and Ben-Akiva ( 8 ) presented a practical but simplifying assumption (IA) on choice set formation. The IA assumption made it possible to manage many alternatives in a probabilistic choice set formation. Since then, the application of IA or its variants has been used for joint models of discrete choice with probabilistic choice set formations ( 9 ). Ben-Akiva and Boccara ( 10 ) further extended the IA-based probabilistic choice set formation model by incorporating random constraints and ordered availability options. All of these approaches are for implied choice set formation, where all feasible alternatives are considered and all possible random choice sets are generated for model estimation.
The premise of the implied “choice set” is apparently the unobserved and uncertain/random combinations of alternatives that the modeler thinks are feasible to a specific choice context. A related, but more direct, concept is the “consideration set,” which replaces the “choice set” by a set of alternatives that the choice maker seems to consider. Finn and Louviere ( 11 ), Roberts ( 12 ), and Roberts and Lattin ( 13 ) used the concept of the consideration set as the set of alternatives that the choice makers are aware of and have positive evaluations about. Roberts and Lattin ( 13 ) collected data on an elicited consideration set to explicitly model the consideration set jointly with a choice model. Gensch and Soofi ( 14 ) also used elicited consideration set information to model probabilistic consideration set formation based on entropy-based latent thresholds.
Horowitz and Louviere ( 15 ) stressed that consideration sets are indicators of preferences and thus do not have any additional benefit in joint modeling with the choice model. However, they certainly recognize the importance of collecting an elicited consideration set directly from the survey respondents. In contrast, Roberts and Lattin ( 16 ) do not fully agree with Horowitz and Louviere ( 15 ). Their reviews of published research work on consideration sets clearly highlight the benefit of investigating the consideration set. In reality, choice makers may have different rules in selecting the consideration set as opposed to making a choice. That is, the compensatory rule for the consideration set may induce a non-compensatory rule for choice-making, or vice versa.
Following these developments, many other researchers investigated the consideration set model with or without choice models. Chiang et al. ( 17 ) used a simulation technique to combine a consideration set simulation that feeds into a choice model without any elicited consideration set information. Swait ( 18 ) proposed an econometric formulation that can model the consideration set and choice in an integrated fashion that does not require an elicited consideration set while maintaining a close link between the expectation from a consideration set and a following choice. Cascetta and Papola ( 19 ) highlighted the importance of the probabilistic choice set formation approach to avoid choice model mis-specification and proposed a fuzzy logic-based approach called the implicit availability/perception (IAP) model. Their model also does not take elicited consideration information. Başar and Bhat ( 20 ) used the IA-based joint model of a consideration set and choice for modeling airport choice in the San Francisco Bay Area, organically proposed by Swait and Ben-Akiva ( 8 ). Swait and Erdem ( 21 ) investigated factors that affect the inclusion of alternatives in a consideration set. They used separate models for the consideration set and the discrete choice and found that the same factor may have different effects on consideration set inclusions and the discrete choice. Swait and Erdem used an IA-based joint model of consideration set formation and choice for investigating brand effects. They found differential effects of brand credibility on consideration set formation and discrete choice.
The above paragraph cites researches that tackled the consideration set, but in almost all of the cases the consideration sets are the modeler-defined choice sets in RP contexts. The use of elicited consideration information in an econometric model of consideration and choice model is rare, especially in the transportation literature. Nurul Habib et al. ( 22 ) estimated a mode choice model for travel demand management policy evaluation that used SP data with an elicited consideration option for carpooling. Instead of all alternatives, they considered a probabilistic consideration of only one alternative (carpool). Salisbery and Feinberg ( 23 ) used SP data to jointly investigate a consideration set formation and discrete choice. However, instead of using explicitly collected elicited consideration information, they inferred the consideration set from elicited ranking of alternative choices. Hensher and Ho ( 24 ) investigated the effects of different combinations of alternatives in consideration sets on the discrete choice model by using SP data. However, they also did not have elicited consideration set information and thus they used arbitrary combinations for investigation.
It is Swait who strongly argued for an elicited consideration set in the SP survey and subsequently proposed a joint model of consideration set formation and choice (2, 4). His hypothesis has proven that consideration set formation and the choice model may differ in alternative-specific constants, scales, and SP attribute parameters. He argues that these issues need to be empirically tested by using appropriate model formulations. He used the IA-based joint model of RP consideration set formation and choice, and further proposed an approximate formulation to overcome the IA assumption. The proposed approximation uses a reduced form mixing distribution in the RP consideration set inclusion utility function, but it can only induce complementary (positive correlation) effects between the alternatives.
A few recent papers looked at the impact of the consideration set on discrete choice. When the chosen alternative is not found in the stated consideration set, then the latent consideration set is commonly used to tackle this situation ( 25 ). In this case, the authors found that a two-stage model outperforms traditional mixed logit models ( 25 ). Another recent study explored the effect of both stated consideration set formation and visual consideration set formation ( 26 ). It is found that the stated consideration set suffers from endogeneity. The study experimented with the impact of visual consideration set formation using eye-tracking experiments and found that the visual consideration set provides different results in a few specific cases. Another study proposed a consider-then-choose model and found that the consider-then-choose model outperforms traditional discrete choice models, which do not include consideration set formation data ( 27 ).
In this paper, we extend this concept to SP choice contexts ( 4 ). However, we proposed a full-scale mixing distribution in the IA-based model that can capture both supplementary and complementary effects in the probabilistic consideration set formation model. In addition, we also induce the error-component of a mixed logit model for the choice model to investigate how the relationships in consideration set formation translate into the choice model substitution patterns. The next section briefly explains the econometric formulation of the model.
Modeling of Choice and Choice Set Formation
The econometric structure of the proposed model takes the original IA-based model of consideration set and choice proposed by Swait and Ben-Akiva and Swait (3, 4, 8). It considers that the consideration set in a non-empty set of choice alternatives and inclusion of an alternative j is approximated by a univariate binary logit model. The following equation explains the core model:

where

where
It is assumed that
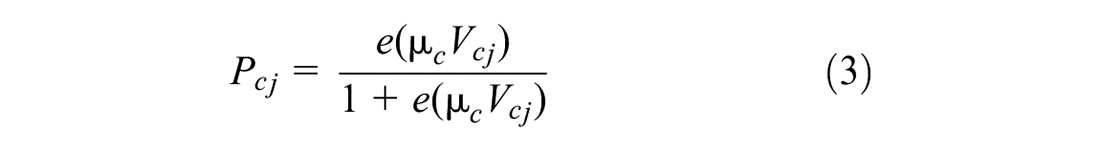
Under the IA assumption, the probability of eliciting a set of alternatives as a consideration set, “Con,” takes the following form (2, 3):
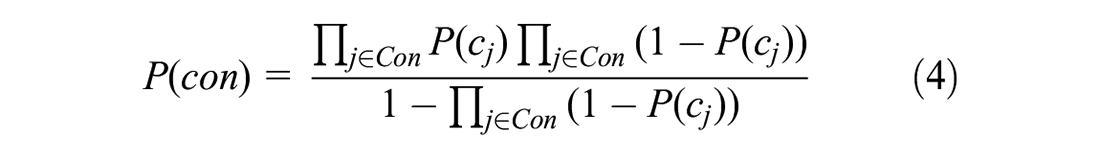
For the conditional choice model, it is assumed the
Under such an assumption, the choice of an alternative j conditional on it being in the consideration set “Con” takes the well-known multinomial logit (MNL) form as follows:
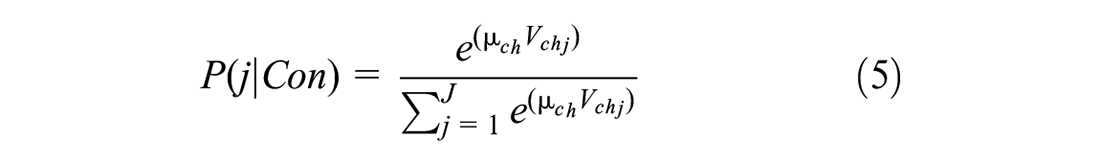
where
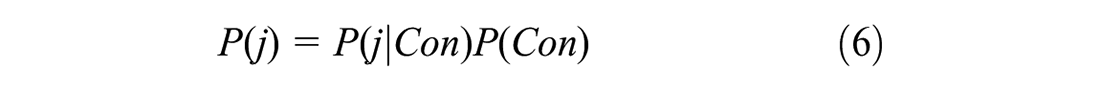
This is a closed form formulation of SP choice and elicited consideration set formation. The notable distinction of this formulation, compared to that originally proposed by Swait ( 2 ) and Swait and Ben-Akiva ( 3 ), is that only the elicited alternatives are considered in choice set formation. The original formulation takes all feasible alternatives in the choice set and considers that the choice set is somewhat latent. Our formulation considers that the consideration set is elicited and therefore can be modeled explicitly. However, whether the scale of the consideration set inclusion utility function and other parameters are similar to those in the conditional choice utility function or not needs to be empirically investigated.
One caveat of the above approach is that the alternatives are independent of each other in consideration set formation. In reality, there may be a complementary or supplementary relationship among multiple alternatives. Similarly, the conditional choice model in this formulation considers that the alternatives are independent while choice-making. In reality, there may be various forms of substitution patterns among different alternatives. In this paper, we consider mixing distribution in the consideration set inclusion utility function to overcome the limitations of IA assumption. Similarly, we consider mixing distribution (error-component) in the discrete choice model to overcome the IID assumption. To do this, Equation 1 can be re-written as follows:
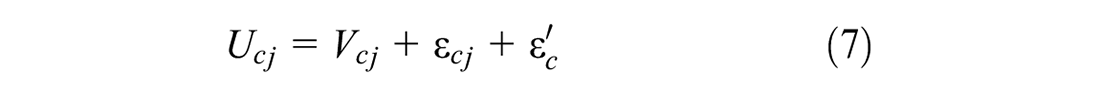
Here,
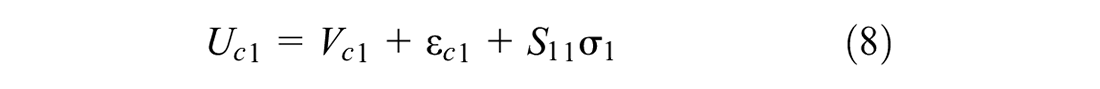
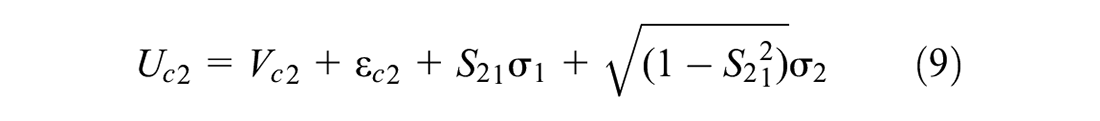
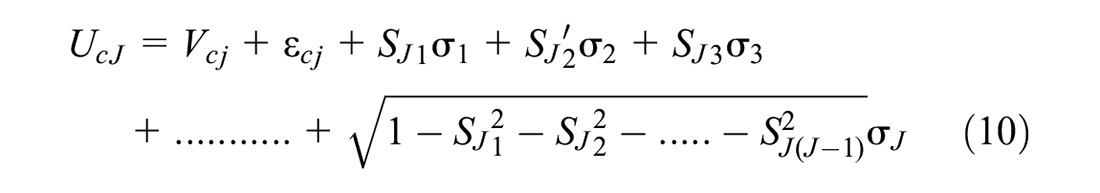
where S indicates the Cholesky factor (the lower triangular matrix of the full variance-covariance matrix); the subscript of S indicates two correlating alternatives;
Error correlation in the consideration set formation model can capture complementary or supplementary relationships between the alternatives (that are not captured by systematic utility functions), but it does not capture any substitution pattern among the choice alternatives. Under the IID assumption of the choice model formulation, alternatives remain completely independent from each other. Therefore, to capture the flexible substitution patterns, we induced error correlation in Equation 2 as follows:
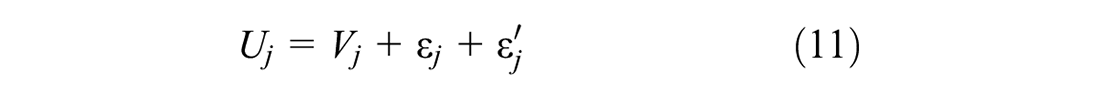
Here,
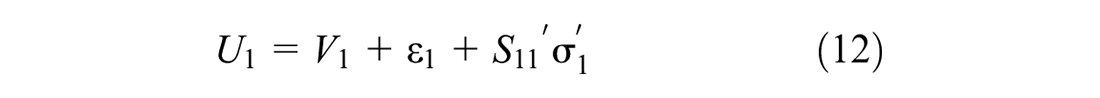
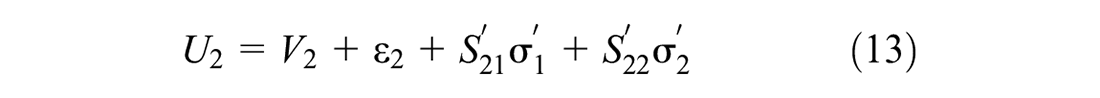
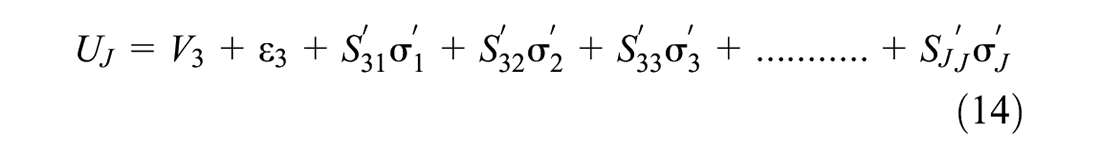
where
All of these random error correlation assumptions make the likelihood of the choice model and consideration set formation model a conditional function of the random errors
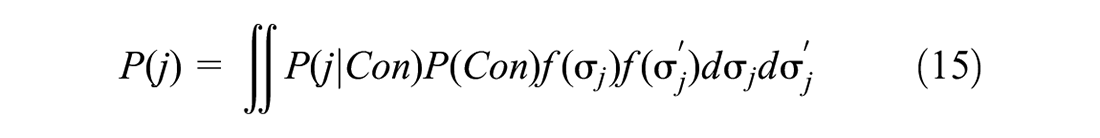
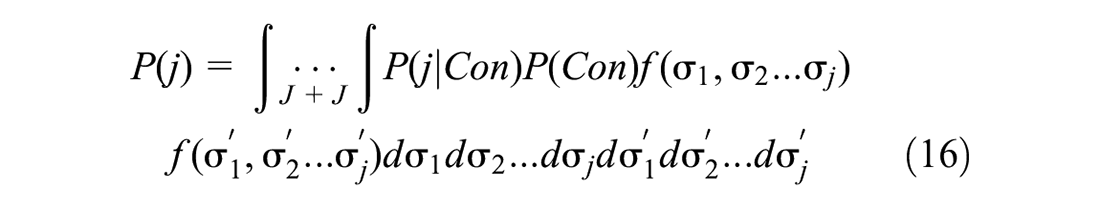
where
The first approach of consideration set elicitation is logically the better one, but it poses a considerable challenge in the following SP design. As different respondents may have different consideration sets, the SP design would have to be adaptive to the individual respondent-elicited consideration sets. Designing such adaptive SP tasks is computation intensive and may also require a longer time (than a standard survey) for survey completion. The second approach simplifies the data collection, as the SP tasks do not have to be adaptive to the elicited consideration set of a respondent. However, such post-SP elicitation of the consideration set can also be synonymous with elicited attendances of choice alternatives. The dataset used for empirical investigation in this paper used the second approach, which is explained in the following section.
Data for Empirical Investigation
Data for the empirical investigation has come from the SP survey conducted in the GTHA in 2014. The survey was conducted to evaluate alternative service strategies of a commuter transit service in the GTHA, called GO Transit. The survey was conducted among a randomly selected sample of commuters who commute long distances for whom GO transit services are feasible and are in competition with other local transit services as well as private automobiles. Non-motorized modes are not a feasible alternative for these types of commuters. The following nine alternative modes are the maximum number of feasible alternatives:
AD: auto driving;
AP: auto passenger;
LTW: local transit with walk access;
SPR: subway park ride;
SKR: subway kiss ride;
GTW: GO transit with walk access;
GPR: GO transit with park ride;
GKR: GO transit with kiss ride;
GLT: GO transit with local transit access.
The survey targeted several transit service attributes, and Table 1 presents the list of those attributes. D-efficient design is used that considers three levels for in-vehicle travel time and cost (base level, 50% increase, and 75% increase) and two levels for the dummy variables shown in Table 1 ( 29 ). For new variables, for example, parking charges at the GO station, 0 (base level), 4, and 8 dollars per day are considered. For access time, wait time, and so forth, the corresponding levels are the base level, 50% increase, and 50% decrease. These values are determined based on feasibility consideration and future expectations gained from discussions with the transit planning agencies in the region.
Stated Preference Attributes to Capture Strategies Under Investigation
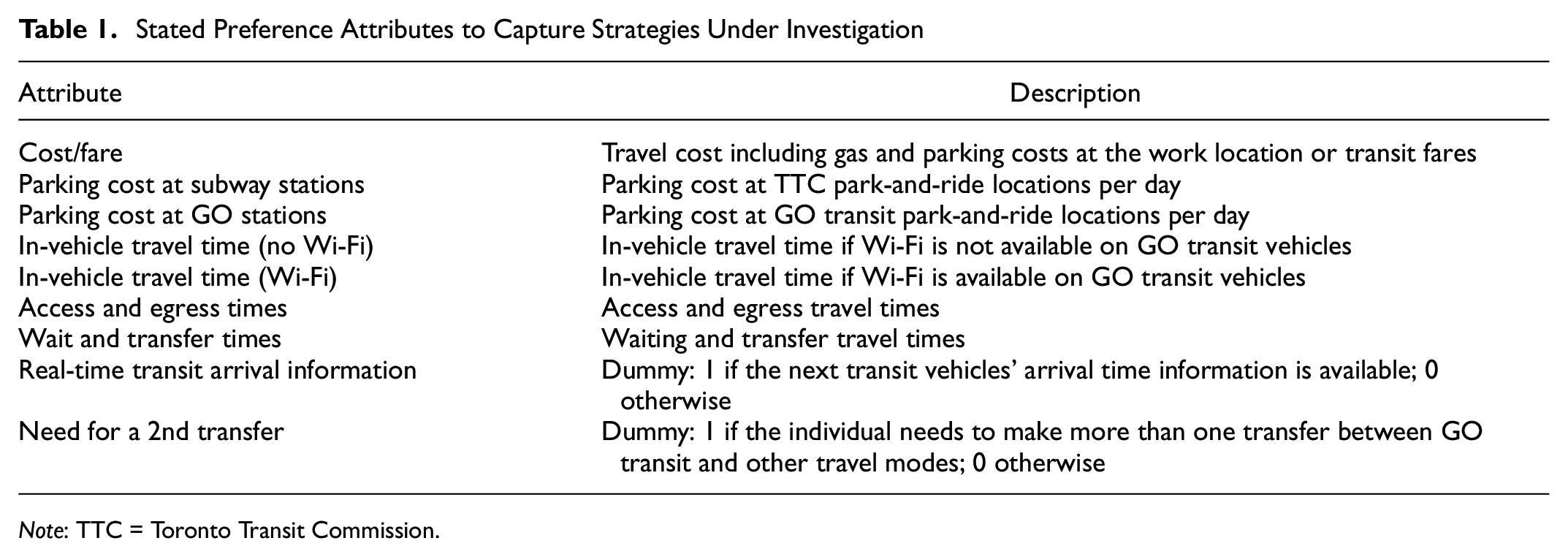
Note: TTC = Toronto Transit Commission.
Mahmoud et al. ( 30 ) explained the details of survey methodology, sampling, and other issues related to this survey. The survey was coded in a web-based adaptive survey format. Respondents gave input of home and work locations at the beginning of the survey and that information is used to specify the feasible choice set as well as actual level-of-service attributes for the SP scenarios. Respondent-specific customized level-of-service attributes are imputed from pre-stored origin–destination-based level-of-service attribute tables generated by an operational traffic assignment model that is being used by the planning agencies in the GTHA.
Once the feasible choice set is identified, six corresponding SP scenarios with customized attribute values were presented. Several alternative sets of SP scenarios were pre-designed based on the D-efficient design approach ( 29 ). Figure 1 shows a typical SP scenario for a respondent with eight feasible alternatives. The SP choice tasks of the survey are followed by the option to elicit the consideration set by the respondents. The respondents elicited the alternatives that they considered in the SP choice tasks.
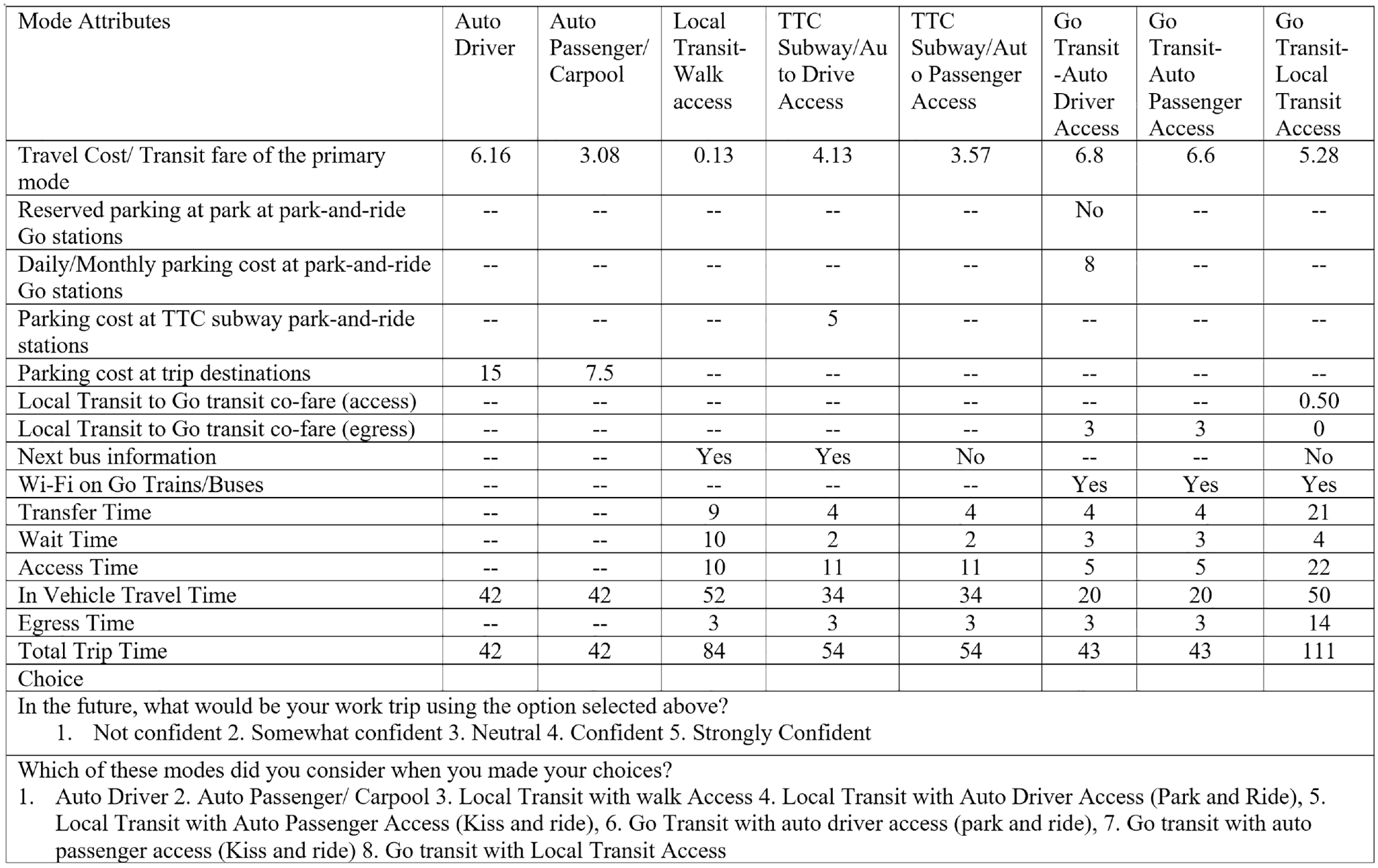
A sample stated preference scenario with feasible alternatives of the survey.
A consumer panel is used for recruiting people for the survey. A total of 11,380 randomly selected individuals from the panel were invited, while only 2466 qualified to be participants. Out of all qualified individuals, 961 attempted the surveys, but only 704 respondents completed all parts of the survey.
Data from all of these 704 respondents are used in this study. Preliminary data investigation reveals that not all respondents considered all feasible alternatives presented in the SP choice tasks. In fact, the average number of alternatives considered is 2.5, while the median number of considered alternative is 2 and the maximum number of considered alternative is 7. On an average, only 50% of feasible alternatives are considered by the respondents for making choices.
It is worth noting that not all individuals considered all feasible alternatives, even in the case of SP choice scenarios where (unlike RP contexts) all alternatives are clearly specified. For example, if there are two alternatives in the universal choice set, then the consideration set can include either one or two alternatives and not always two alternatives. Also, there is considerable variation in considering various subsets of feasible alternatives for actual choice-making. This justifies the assumption of the consideration set formation model and also the assumption that information in the elicited consideration set facilitates a model of choice and choice set consideration. The following section presents the empirical models.
Empirical Investigation
For the empirical investigation, we parameterized the utility functions in the space of willingness-to-pay as follows:
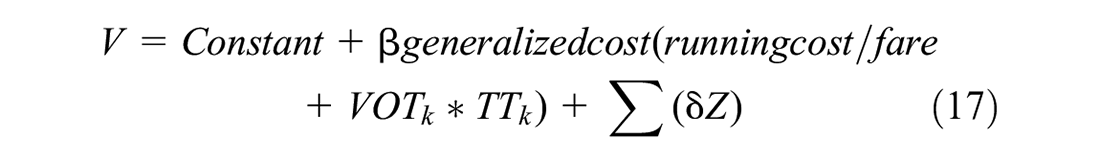
where V refers to systematic utility function of the choice model or consideration set inclusion model;
In Equation 16,
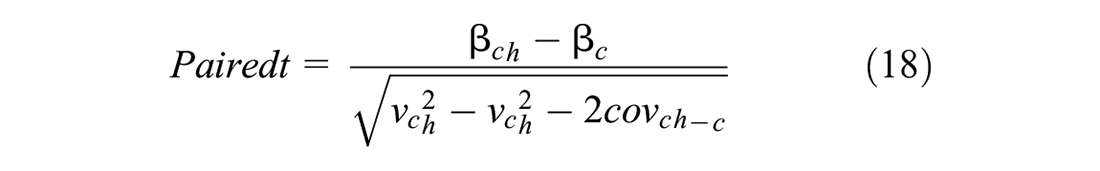
where
Stated Preference (SP) Attributes to capture strategies under investigation
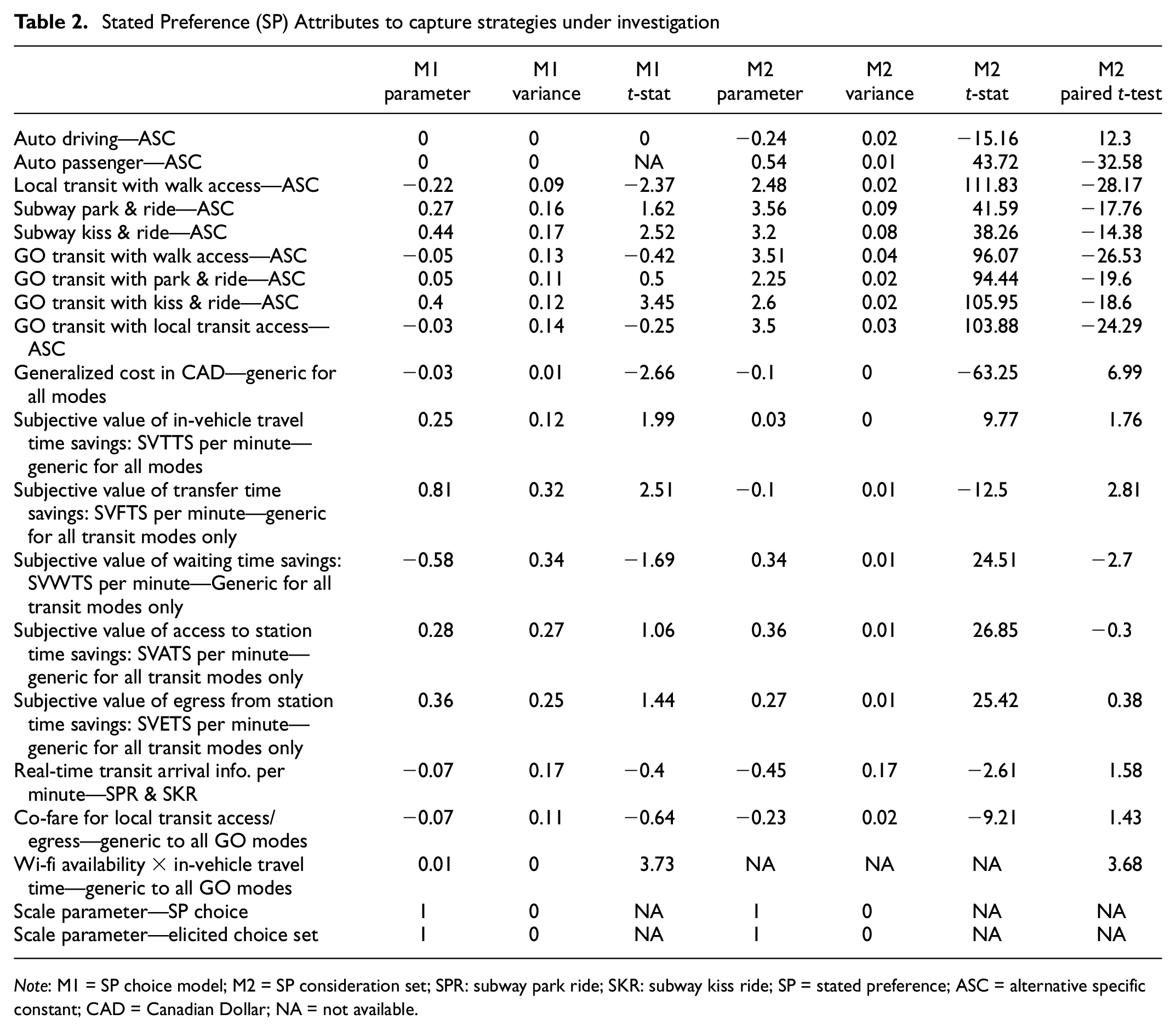
Note: M1 = SP choice model; M2 = SP consideration set; SPR: subway park ride; SKR: subway kiss ride; SP = stated preference; ASC = alternative specific constant; CAD = Canadian Dollar; NA = not available.
The value of paired t equals 1.64, which indicates a one-tailed confidence limit of 95%. It is clear that the choice model and consideration set inclusion models are significantly different with respect to alternative choice specific constants. The generalized cost and subjective value of in-vehicle travel time savings (SVTTS) have significantly different coefficients in the choice model and consideration set inclusion model. The subjective value of transfer time savings (SVTFS) has a counter-intuitive sign in the consideration set inclusion model and the subjective value of waiting time savings (SVWTS) has a counter-intuitive sign in the choice model. The subjective value of access to station time savings (SVATS) and the subjective value of egress time from station savings (SVETS) do not show any significant differences in the two model components. The effects of real-time transit arrival information are estimated with a counter-intuitive sign. The necessity for co-fare payment between two transit services in the study area does not show significant different effects in the two model components. Finally, Wi-Fi availability in interaction with total in-vehicle travel time seems only to have an impact on the choice model component.
The final specifications of the model consider separate coefficients in the choice model and consideration set formation for alternative-specific constants and the SVTTS. The SVTFS is only considered in the choice model and the SVWTS is only considered in the consideration set inclusion model. The same coefficients of the SVATS and SVETS and the effects of the co-fare option are used in both the choice and consideration set formation models. Tables 3 and 4 presents three empirical models side-by-side. The first one is the choice model with correlated consideration set formation and the error-component discrete choice model; the second one is a model with an uncorrelated consideration set formation model and the MNL choice model, and the third one is the choice model without any consideration set (deterministic choice set). Goodness-of-fit values of all three models are expressed by the adjusted rho-squared value, which compared the fit of the final model against the corresponding null (equiprobable) model after correcting for the number of parameters in the final model. As these three models have very different types of likelihood functions, the adjusted rho-squared values are not one-to-one comparable. However, it is clear that the proposed models have large improvements in fitting observed data against their null model counterparts. Alternative-specific constants are lower in the proposed model than in the choice model only, which indicates a better explanatory power of the SP attributes in the proposed models.
Model of Choice and Choice Set Inclusions
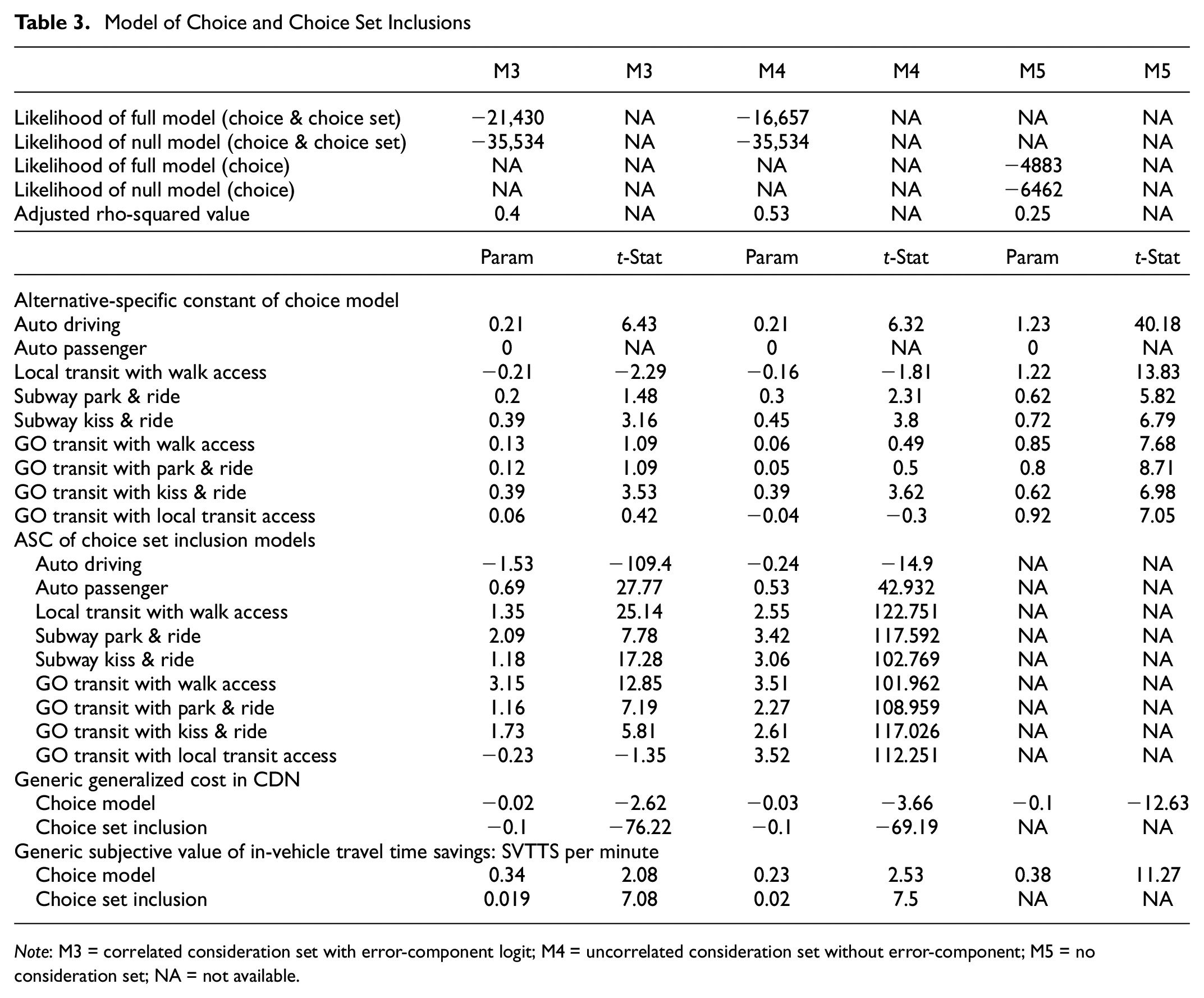
Note: M3 = correlated consideration set with error-component logit; M4 = uncorrelated consideration set without error-component; M5 = no consideration set; NA = not available.
Model of Choice and Choice Set Inclusions
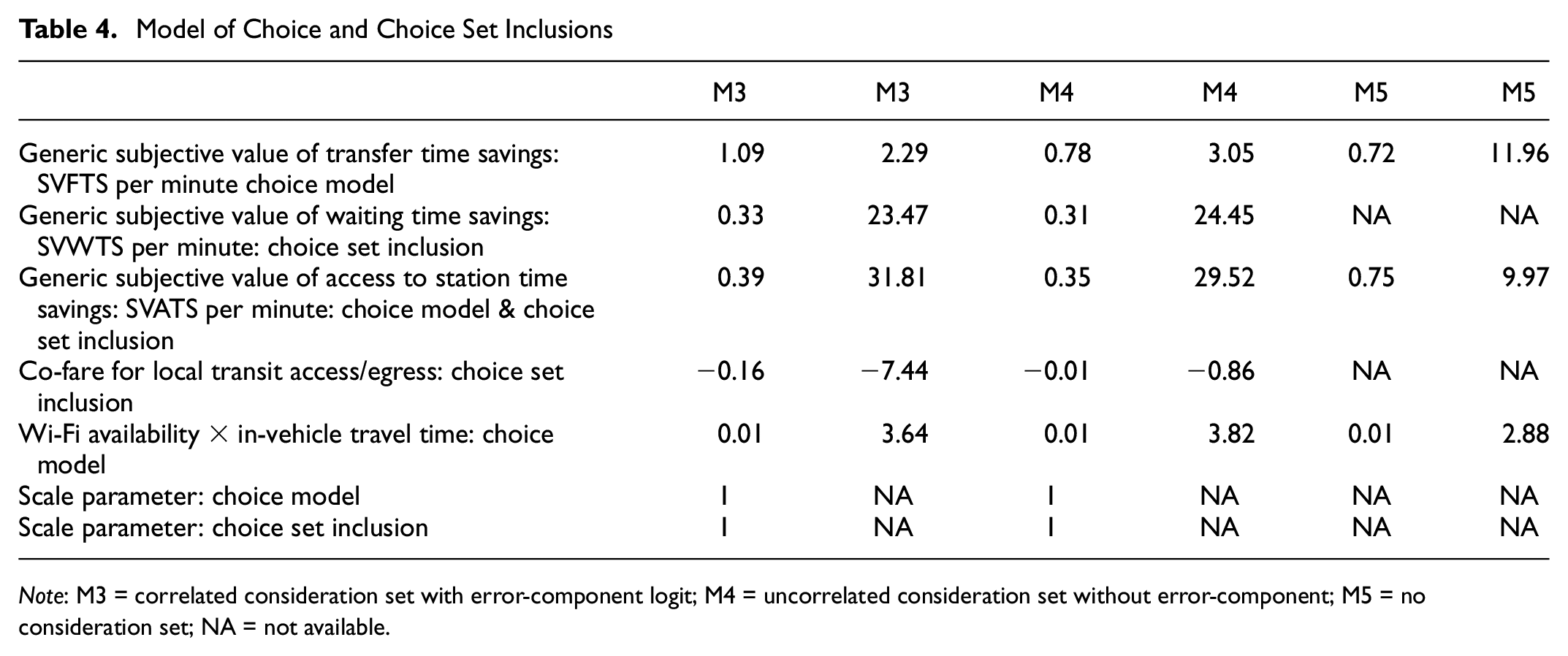
Note: M3 = correlated consideration set with error-component logit; M4 = uncorrelated consideration set without error-component; M5 = no consideration set; NA = not available.
Considering that the proposed model has more theoretical strength over the choice model with the deterministic choice set, it is clear that the latter gives different parameter sets compared to those in the choice model components of the proposed models. Also, the accommodation of multivariate correlations among the alternatives in the consideration set formation and error-components in the choice model does not affect marginal rates of substitutions of choice attributes by any large margin. However, significant differences in attribute effects in the choice model and consideration formation model are clear in many key attributes of commuting mode choices.
Overall, commuter sensitivity to generalized cost is over-estimated by the choice model if it is estimated considering a deterministic choice set. Also, commuters are more sensitive to generalized cost while considering an alternative in the consideration set compared to making a choice of the alternative. The SVTTS is higher for making a choice than considering an alternative in the consideration set. Interestingly, it seems that commuters in the GTHA are concerned about waiting time for transit being included in the consideration set, but not while making a choice. A possible explanation is that the major transit mode options that are mainly of commuter transit services or rail-based systems have well-defined schedules except a few (e.g., buses and street cars). Schedule compliances of such services are more systematic than random. In such case, waiting time is more or less predictable and perhaps commuters can plan to arrive at stations at a time to avoid long waiting times. Therefore, waiting time is a factor to consider an alternative in the consideration set, but not a very significant one while making a choice.
The SVTTS for M1 is 15 dollars/hour. A recent study estimated the mode choice model using the study area’s data and reported that the value of travel time savings is 14.244 dollars/hour ( 31 ). That study also estimated a generic travel time and cost for all transit modes, auto drive, and auto passenger. The two values are relatively close. For M2 and M3, we could use different model specifications to get a more robust SVTTS. However, we kept all the exact model specifications to compare them more straightforwardly.
Access time to transit is equally perceived in consideration set inclusion and choice-making. Also, it seems that overlooking stochastic consideration set formation causes an over-estimation of the SVATS. The same is true for the SVETS, but it is clear that commuters are more sensitive to access time to transit stations than the egress time from the transit stations. The co-fare requirement for multiple transit users has a negative influence in transit mode consideration and transit mode choice from a consideration set. However, it is clear that considering correlations among alternatives in consideration set formation and discrete choice makes this parameter statistically significant. Currently, no transit system in the GTHA (except for a few buses) has a Wi-Fi option for commuters to use. Therefore, the option of having Wi-Fi was used as one of the attributes of SP scenarios. Intuitively, having a Wi-Fi option becomes statistically significant only when we interact with transit in-vehicle travel time. This implies that Wi-Fi becomes more useful if the transit in-vehicle travel time is longer. Interestingly, this interaction has a similar coefficient in both proposed models and the choice model with the deterministic choice set. This indicates that effects of Wi-Fi availability while in the transit vehicle are not affected by consideration of deterministic or stochastic choice sets.
Based on estimated Cholesky factors of error correlations, we estimated the covariance matrices and then the correlation coefficients among random errors in the consideration set and the choice model. The estimated Cholesky factors and t-stat values are presented in Tables 5 and 6. A positive correlation between two alternatives in the consideration set formation model indicates a complementary effect, which means that if one is considered then the other is also likely to be considered. A negative correlation between two alternatives in the consideration set indicates a supplementary relationship, which means that if one is considered then the other one is less likely to be considered. In the case of the error-component logit model of discrete choice, the induced correlations capture substitution patterns (preference heterogeneity) as well as heteroskedasticity. Since we have nine alternatives; we have a 9 by 9 correlation matrix, which is difficult to read from a table. It is clear that the proposed model captures the multidimensional relationship between the alternatives in the consideration set formation and in discrete choice.
Estimated Cholesky Factor and t-Stat for the Choice Set Formation Model.
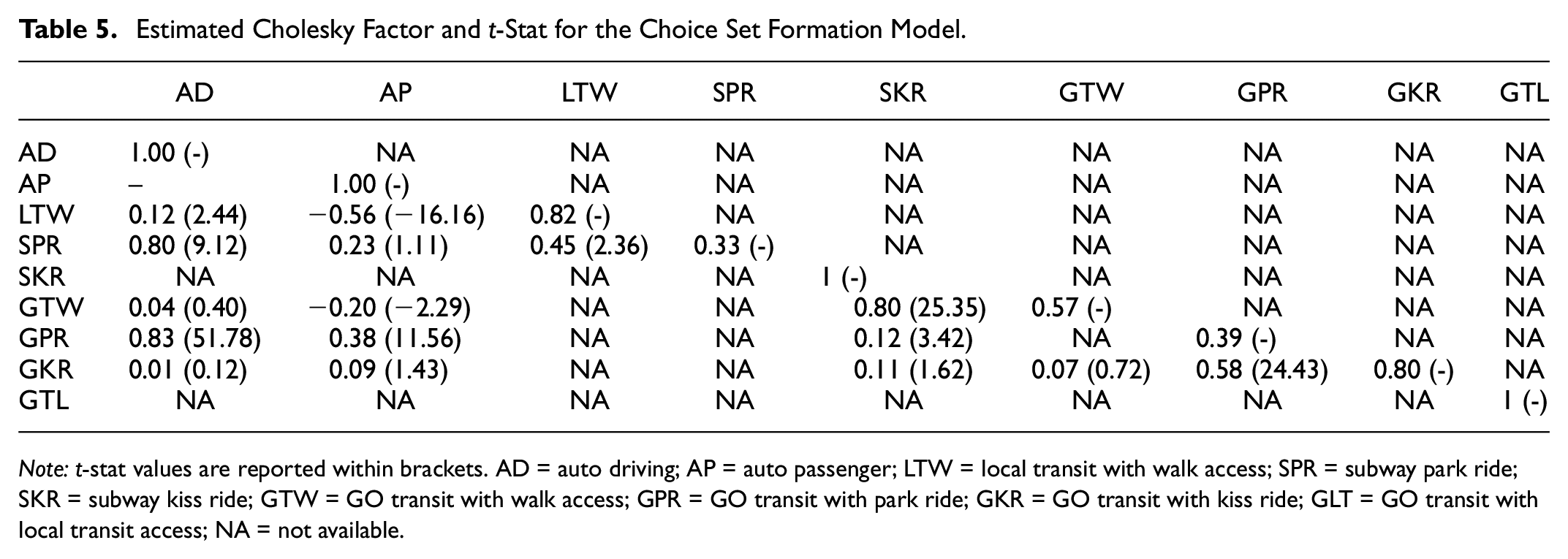
Note: t-stat values are reported within brackets. AD = auto driving; AP = auto passenger; LTW = local transit with walk access; SPR = subway park ride; SKR = subway kiss ride; GTW = GO transit with walk access; GPR = GO transit with park ride; GKR = GO transit with kiss ride; GLT = GO transit with local transit access; NA = not available.
Estimated Cholesky Factor and t-Stat for Error-Components in Choice Model
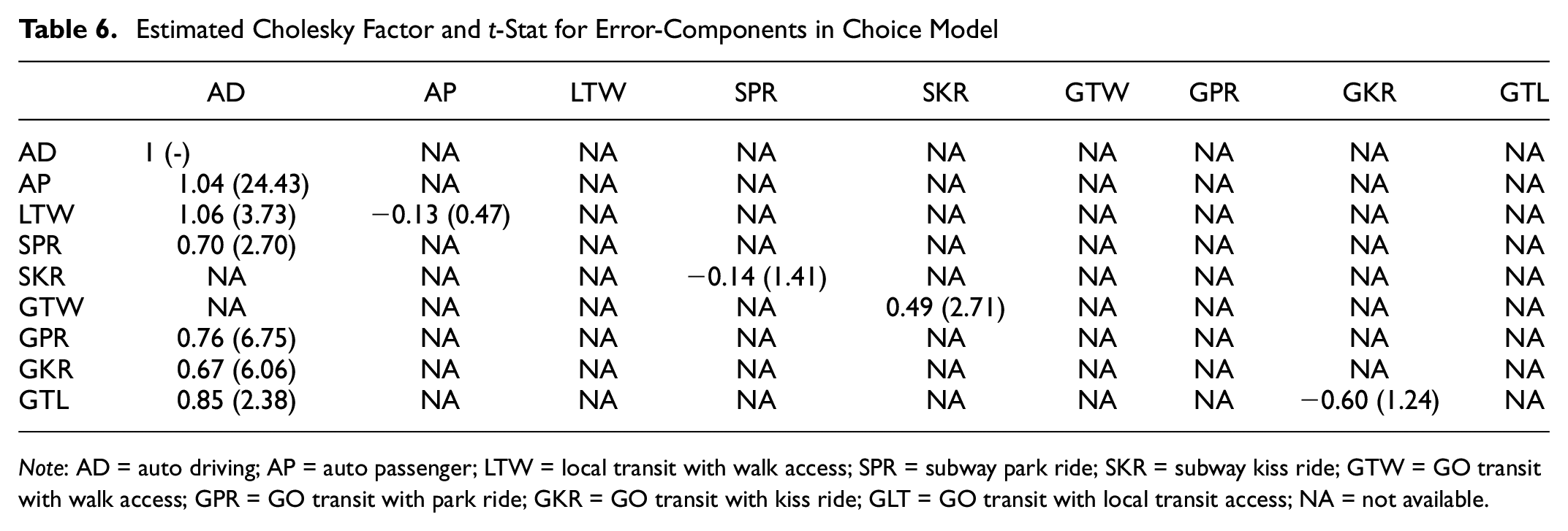
Note: AD = auto driving; AP = auto passenger; LTW = local transit with walk access; SPR = subway park ride; SKR = subway kiss ride; GTW = GO transit with walk access; GPR = GO transit with park ride; GKR = GO transit with kiss ride; GLT = GO transit with local transit access; NA = not available.
Alternatives have more complementary than supplementary relationships in consideration set formation and multiple (cross-nested) substitution patterns in choice-making. The “auto driving” alternative has a complementary relationship with all alternatives except with “auto passenger,”“subway kiss ride,” and “GO with local transit access.” However, “auto driving” has a positive substitution with all alternatives except “subway kiss ride” and “GO with local transit access.”“Auto driving” is the most dominant and flexible mode. Its popularity is reflected in such relationships. Interestingly, although auto driving seems to have no relationship with “auto passenger” in the consideration set formation stage, it has the highest substitution relationship in the choice-making stage. The same is true for “auto driving” and “GO with local transit access.” The “Auto passenger” mode has a supplementary relationship with transit with walk access modes in the consideration set formation stage, but it has either substitution or no relationship in the choice-making stage. However, the “auto passenger” model maintains a consistent relationship with transit with park ride and kiss ride options in the consideration set formation (complementary relationship) and choice-making stage (positive substitution). Relationships among kiss ride and park ride options of transit modes are also consistent in the consideration set formation and choice-making stage.
Overall, it is clear that the relationship between alternatives may change from the consideration set formation stage to the choice-making stage. The mixed error formulation used in this paper can unravel such complicated relationships and, of course, the availability of elicited consideration set data facilitates such investigation.
Conclusion and Recommendations for Future Research
This paper investigates changes in preference structures from consideration set formation and choice-making. It estimates a model of consideration set formation by using elicited consideration information along with modeling the discrete choices.
From the practical perspective and policy implications, only a choice model is sufficient. However, the goal of this study is to present the elicited consideration set information collected directly from the survey respondents, which greatly reduces the computational burden of such a model. The contribution of the paper is threefold. Firstly, it presents an innovative model of choice and consideration set formation with an unrestricted complementary/supplementary relationship between different alternatives in the choice set formation and complete substitution patterns among the alternatives in discrete choice.
Secondly, it demonstrates that the use of elicited consideration set information collected directly from the survey respondents greatly reduces the computational burden of the model. Thirdly, the empirical investigation of the paper reveals significant differences in various attributes of commuting modes in considering the alternatives as commuting modes and the final choice of an alternative for commuting.
An empirical application of the proposed model for the commuting mode choices of cross-regional commuters in the GTHA reveals many behavioral details that are difficult to observe otherwise. It seems that different attributes have different types of influences on choice and choice set inclusion utility functions. Some of them have similar effects on both and some have effects only on either one. Most interestingly, it is clear that neglecting a probabilistic consideration set makes the choice model over-estimate key parameters, for example, sensitivity to generalized cost and subjective value of time savings. Wide ranges of complementary and supplementary effects are visible among alternative travel modes in the consideration set formation model. It is also clear that the complementary/supplementary relationships among alternatives in the consideration set do not fully translate into similar substitution patterns in the choice model. Strong substitution between some alternatives is clear in the choice model, but there is no relationship in the consideration set and vice versa. This confirms the idea that the elicited consideration set is also some form of choice data, and modeling it together with choice-making can unravel the complex and multi-stage relationship between discrete choice alternatives in consumer choice-making behavior.
The proposed methodology can be extended in various ways. Firstly, we used a small dataset where the elicited consideration set is smaller than the actually feasible sets. This restricted us from estimating any other forms of a discrete choice model for the choice model component than a MNL. Our error-component modeling approach overcomes the IID assumption of the MNL, but we believe, for the larger dataset and wide ranges of choice alternatives, nested logit or generalized EV modes could also be tested. The proposed model is tested for a SP dataset, but it can also be used for RP data if elicited consideration data can be collected in the RP context. However, we believe that the process of consideration set elicitation may have an influence on data quality. It is imperative that we should investigate alternative methods fro the consideration elicitation process and empirically compare those. These are considered as recommendations for further research.
One limitation of this study is that the modeling framework requires computational resources to minimize the model run time. It is worth noting that the two models can be estimated separately since there is no correlation between
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Z. Rashedi; data collection: Z. Rashedi; analysis and interpretation of results: Z. Rashedi, M.S. Hasnine; draft manuscript preparation: Z. Rashedi, M.S. Hasnine K. Nurul Habib. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by an NSERC Discovery Grant and partially supported Howard University start-up grant.