
Abstract
Vehicle volume serves as a critical metric and the fundamental basis for traffic signal control, transportation project prioritization, road maintenance planning, and more. Traditional methods of quantifying vehicle volume rely on manual counting, video cameras, and loop detectors at a limited number of locations. These efforts require significant labor and cost for expansions. Researchers and private sector companies have also explored alternative solutions, such as probe vehicle data, although this still suffers from a low penetration rate. In recent years, along with the technological advancement in mobile sensors and mobile networks, the quantity of mobile device location data (MDLD) has been growing dramatically in spatiotemporal coverage of the population and its mobility. This paper presents a big-data driven framework that can ingest terabytes of MDLD and estimate vehicle volume over a larger geographical area with a larger sample size. The proposed framework first employs a series of cloud-based computational algorithms to extract multimodal trajectories and trip rosters. A scalable map matching and routing algorithm is then applied to snap and route vehicle trajectories to the roadway network. The observed vehicle counts on each roadway segment are weighted and calibrated against ground truth control totals, that is, annual vehicle-miles traveled and annual average daily traffic. The proposed framework is implemented on the all-street network in the State of Maryland using MDLD for the entire year of 2019. The results demonstrate that our proposed framework produces reliable vehicle volume and also its transferability and generalization ability.
Keywords
Vehicle volume measures the amount of traffic traveling through a roadway segment within a specific period of time. It serves as a critical metric and the fundamental basis for various transportation applications including traffic signal control, transportation project prioritization, and road maintenance planning. Traditional methods of quantifying vehicle volume rely on manual counting, video cameras, and loop detectors at a limited number of locations, a practice that requires significant human labor and a high cost for further expansion ( 1 – 5 ). Researchers and private sector companies have also explored alternative solutions such as probe vehicle data, although this still suffers from low penetration rate ( 6 – 10 ).
Since the early 2000s, along with technological advancement in mobile sensors and mobile networks, the quantity of mobile device location data (MDLD) has been growing dramatically in coverage and size, with broader spatiotemporal coverage of the population and its mobility. A series of research studies has demonstrated the usefulness of MDLD for enhancing the traditional travel survey and revealed its potential to substitute surveys ( 11 , 12 ). At the same time, obtaining travel statistics solely based on MDLD is also worth investigating to reduce human labor and cost. However, MDLD do not include any ground truth information such as trip origins and destinations, travel modes, and trip purposes. This requires computational algorithms to be developed and validated against the existing travel surveys. More importantly, unlike travel surveys which collect information from representative samples to obtain population-representative statistics, MDLD are collected from all available mobile devices with uneven data quality.
This study was conducted as part of the “Vulnerable Road User Density Exposure Dashboard” project (https://mti.umd.edu/sdi), an interactive dashboard that utilizes MDLD to provide data and insights into multimodal volume and safety risk exposure of vulnerable road users (e.g., pedestrians, bicycles) at intersections and roadway segments within Maryland. In this study, we present a big-data driven framework that ingests terabytes of MDLD and estimates vehicle volume for all roadway segments. First, a series of cloud-based computational algorithms are applied—including but not limited—to a trip and tour identification algorithm to mine travel behavior information and a travel mode imputation model that imputes multimodal trajectories from MDLD. A map matching and routing algorithm is then applied to snap and route vehicle trajectories to the roadway network. The observed vehicle counts on each roadway segment are weighted to match the annual vehicle-miles traveled (AVMT) by county, urban/rural status, and functional classes. Further, a random forest regression model is used to calibrate the weighted vehicle volume against the annual average daily traffic (AADT) acquired from loop detectors. The proposed framework is implemented on the all-street network in the State of Maryland using MDLD data for the entire year of 2019, and can be applied for every state in the USA. The framework is scalable, and the data sources proposed for weighting and calibration are generally available across the USA.
Literature Review
Application of MDLD in Transportation Research
The appearance of MDLD in the transportation industry started in the 1990s. From the mid 1990s, researchers began installing Global Positioning System (GPS) data loggers in vehicles to supplement travel surveys ( 13 – 15 ). With high-frequency in-vehicle GPS data, this approach can significantly improve the accuracy of travel surveys by recording the exact locations of origin and destination as well as times of departure and arrival. However, only a few vehicles can be sampled with this technique, a drawback that limits its capability. Similarly, wearable GPS, which was introduced in the early 2000s, allowed respondents to report non-vehicle travel modes but still suffered from issues of small sample size ( 16 , 17 ). Since the 2010s, private sector entities such as INRIX and RITIS have also started to incorporate probe vehicle data into their commercial products ( 18 – 21 ). Nonetheless, the low penetration rate (i.e., 2%–10%) of this commercial probe vehicle data remains the core challenge with respect to drawing the whole picture of travel patterns.
As mentioned above, despite having high precision, traditional MDLD usually suffer from small sample size, which significantly limits the usefulness of the data. Since mobile devices such as smartphones and tablets have become more popular, MDLD generated from these devices have a greater potential for being used in transportation applications. These new types of MDLD, namely cellular data and location-based service (LBS) data, offer more extensive spatiotemporal coverage and larger sample size. The cellular data are generated through communication between cellphones and cell towers ( 22 ) and can be further categorized into call detail record (CDR) and sightings ( 11 ). The CDR data can only capture the cell tower location, whereas the sightings provide the exact latitude and longitude values. Both types of cellular data have been widely applied to research topics such as travel behavior, human mobility, and social networks since the year 2000 ( 23 – 31 ). Despite the large volume of data, cellular data are limited by their spatial and temporal resolution, which is determined by the density of cell towers and users’ cellphone usage levels ( 32 ). On a positive note, however, the collection of cellular data requires less advanced mobile devices and can raise fewer user privacy concerns. LBS data provide the exact locations generated when a mobile application updates the device’s location with the most accurate sources, based on the existing location sensors such as Wi-Fi, Bluetooth, cellular tower, and GPS (11, 23–25, 33, 34). Many applications have been developed using the LBS data. For instance, a recent smartphone-enhanced travel survey conducted in the USA used a mobile application, rMove developed by Resource Systems Group (RSG), to collect high-frequency location data and allow the respondents to recall their trips by showing the trajectories in rMove ( 35 – 38 ). Additionally, Airsage leveraged LBS data to develop a traffic platform that can estimate traffic flow, speed, congestion, and road user sociodemographics for every road and time of day ( 39 ). Further, the Maryland Transportation Institute (MTI) at the University of Maryland (UMD) developed the COVID-19 Impact Analysis Platform (https://data.covid.umd.edu) to provide insight into the impact of COVID-19 on mobility, health, economy, and society across the USA ( 40 – 43 ).
Vehicle Volume Estimation Methods
Estimating Vehicle Volume With Loop Detectors
Loop detectors are widely used to record traffic volumes and occupancy levels. These sensors are usually buried under the pavement to detect the induction change from the presence of a vehicle. Kwon et al. developed an algorithm using data from single loop detectors to estimate truck traffic volumes ( 1 ). The results showed a 5.7% error compared with the ground truth highway data. Loop detector data were also applied together with probe vehicle data to estimate queue length ( 44 ) and vehicle volume at a city-wide scale ( 45 ). Although proven to be efficient in estimating vehicle volume, the high cost of installation and maintenance of loop detectors limits their capability of being scaled up to cover the entire transportation network. Therefore, loop detector datasets are often incomplete and mostly unavailable at minor arterials and local streets.
Estimating Vehicle Volume With Probe Vehicle Data
In the past two decades, MDLD have gained significant attention and have been utilized for estimating various traffic characteristics including vehicle volume. With the development of MDLD, estimating vehicle volume at the city scale became a reality. Probe vehicles can record their trajectory data with high granularity (i.e., 1 Hz). Based on the trajectory data obtained from probe vehicles, a wide range of methods can be used by researchers to solve transportation problems. Zhao et al. proposed novel methods to estimate queue length and vehicle volume based on the probability theory without prior information about the penetration rate or queue length distribution ( 6 ). Guo et al. estimated vehicle volume and queue length at signalized intersections and proposed a new framework to optimize traffic signal control operations ( 7 ). Sekuła et al. applied several machine learning and neural networks to estimate historical hourly vehicle volume between sparsely located sensors based on probe vehicle data ( 8 ). Shockwave theories were also applied to probe vehicle data by a few studies ( 9 , 10 ).
Estimating Vehicle Volume With MDLD
Many studies have been conducted focusing on estimating traffic flow and detecting congestion using cellular data ( 46 , 47 ). Xing et al. utilized CDR with Time Difference of Arrival (TDOA) positioning technique to estimate multimodal traffic volumes on different types of urban roadways by identifying three modes of travel: drive alone, carpooling, and bus ( 48 ). The results showed that, compared with the ground truth vehicle volume obtained from license plate recognition cameras, the mean relative error was in the range of 17.1% to 25.7%, depending on the roadway type. Despite significant advances in positioning techniques, cellular data still suffer from low accuracy issues, whereas LBS data have a noticeable advantage from utilizing different sources to accurately locate the user—a feature that has resulted in an increased usage of this type of data by researchers and the private sector for estimating vehicle volume. Fan et al. developed a computing framework alongside a heuristic map matching algorithm to estimate vehicle-miles traveled (VMT) and AADT for the State of Maryland using INRIX data. The results showed an R 2 of 0.878 when fitting the estimated AADT with the ground truth AADT ( 49 ). Moreover, several state agencies conducted rigorous evaluations of vehicle volume obtained through traditional methods as well as from MDLD obtained by private sector companies. They found the latter to be a promising source for supplementing current surveys and traditional methods ( 50 ).
Big-Data Driven Vehicle Volume Estimation Framework
Overview of the Framework
In this study, we propose a big-data driven vehicle volume estimation framework, which offers the capability of efficiently estimating vehicle volume ingested from terabytes of MDLD. Figure 1 shows the proposed framework. The proposed framework is built on Amazon Web Services (AWS). MDLD and all supporting data are stored in Simple Cloud Storage (S3). All algorithms are developed based on Apache Spark, which uses resilient distributed datasets (RDD), and are coded in PySpark using the Elastic MapReduce services. In the cloud environment, MDLD are spliced into RDDs given the number of executors ( 43 , 49 ). At the same time, all external data sources (i.e., K-dimensional tree, network, routing engine) are broadcast into all executors for master and core nodes. The same algorithms are applied to each RDD along with the broadcasted variables, and the results are aggregated and outputted into S3.
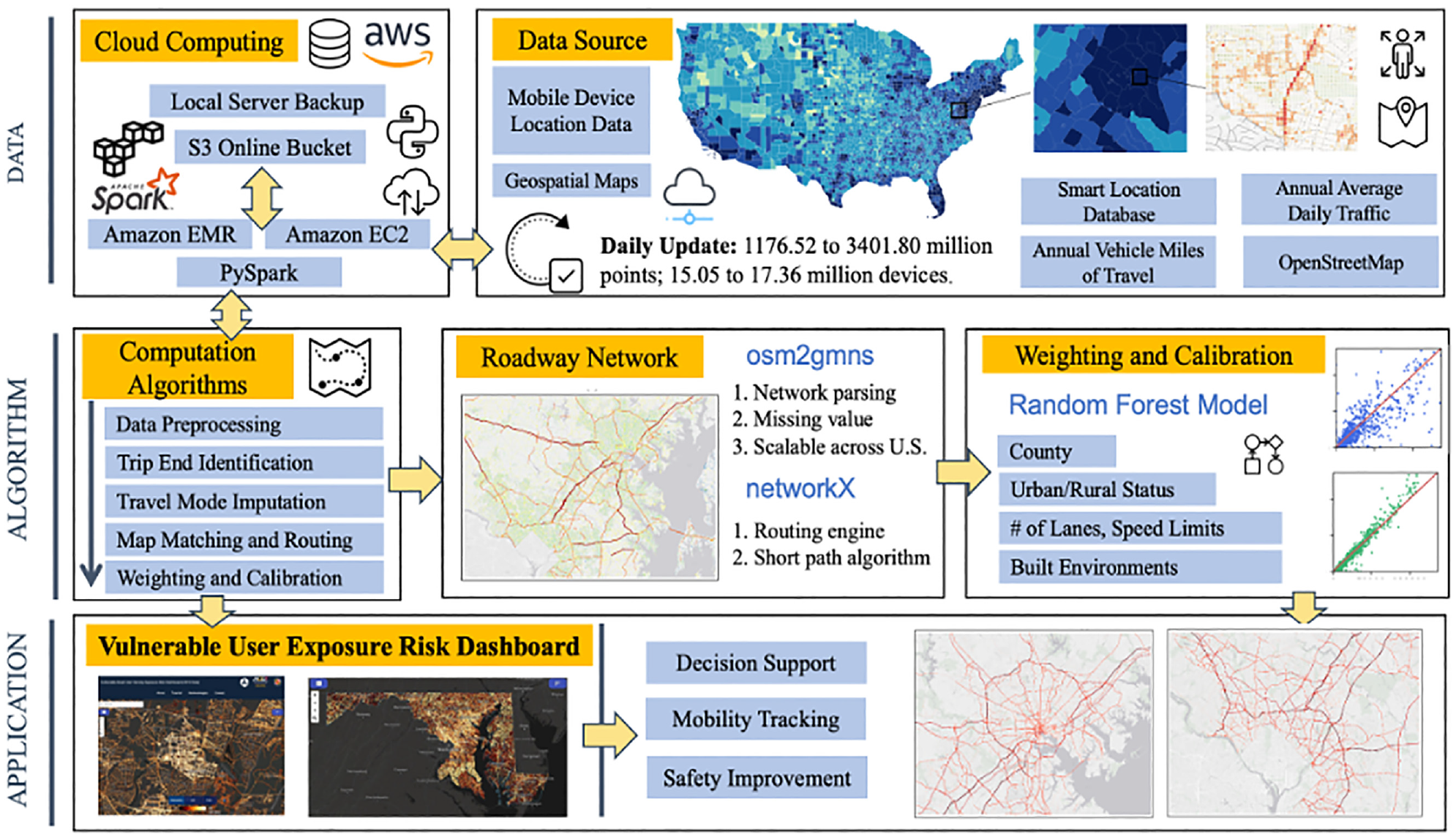
Diagram of big-data driven vehicle volume estimation framework.
Trip End Identification and Travel Mode Imputation
A trip is the basic unit of analysis for almost all transportation applications. However, MDLD usually do not contain any trip-related information. Therefore, in this study, a trip end identification algorithm is used to extract trip-level information from the MDLD, including trip start location, trip end location, departure time, and arrival time. Then, a travel mode imputation model is further applied to infer four travel modes—namely, air, drive, rail, and nonmotorized modes—based on heuristic rules and a random forest model. Detailed descriptions of the trip end identification algorithm and the travel mode imputation model can be found in the following references ( 12 , 51 ).
Map Matching and Routing
To ensure flexibility and scalability of our map matching and routing method across the entire USA, we extract the drivable network from OpenStreetMap (OSM) using the latest open-source Python package osm2gmns. The osm2gmns package can parse roadway network data from OSM and output networks to csv files in the General Modeling Network Specification format. It provides customized and practical functions to facilitate traffic modeling. Functions include complex intersection consolidation, movement generation, traffic zone creation, short link combination, and network visualization. More details about osm2gmns can be found here: https://osm2gmns.readthedocs.io/en/latest/
To match each location sighting to our OSM network, the OSM network is first parsed and converted into the routable formats, where roadway segments are represented by links and nodes. With the network topology, we use the networkX package to build a shortest path-based routing engine. We then transform the latitude and longitude of the start node and end node for each link to the plane coordinate (in meters), and then calculate link direction (degree) using the arctan value between the two nodes. The travel direction between consecutive sightings is also calculated. Similar to the method for link direction calculation, the coordinates of each sighting are converted to plane coordinates, then the degree is calculated using the arctan value between consecutive sightings. A spatial index structure, K-dimensional tree (K-D tree), is built using the link geometric nodes (i.e., link nodes). Then, for each sighting, we search all link nodes that are within 100 m. The 100 m threshold is selected to balance the algorithm efficacy and the computing speed. If we increase the value, more candidate links will be considered but this will require more computing resources. If we decrease the value, we might not be able to find a candidate link when the observation is sparse. To validate, we calculate the distance between consecutive link nodes using the Maryland OSM network as an example. Results indicate that more than 95% of the link nodes are within 100 m of their neighbors, as shown in Figure 2. Therefore, using the 100 m value as the radius for searching candidate nodes is reasonable.
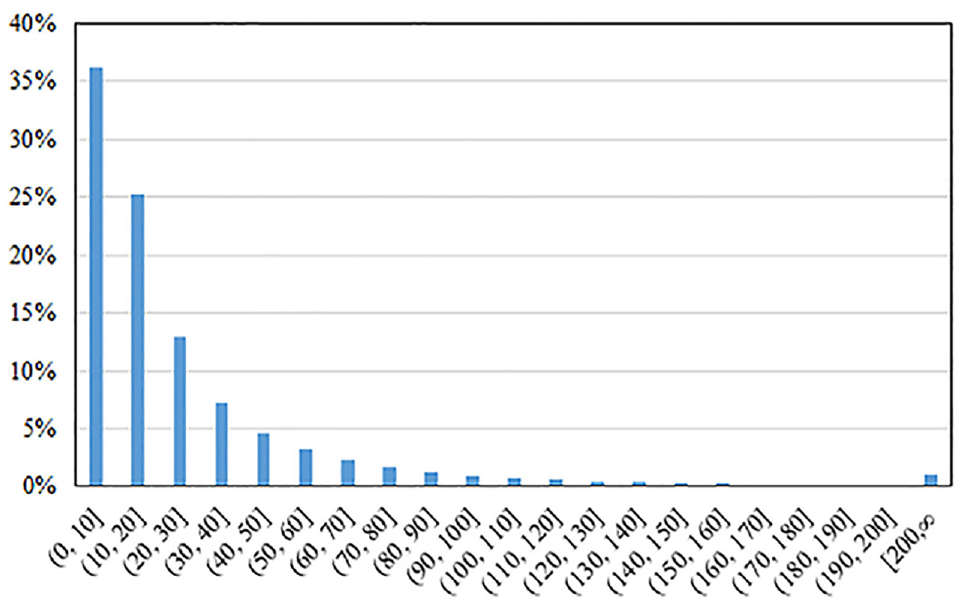
Distribution of distance between link nodes in the OpenStreetMap network.
As the next step, for each sighting, we compare its travel direction to all candidate links (see Figure 3 for details). The closest link with an absolute travel direction difference smaller than 30 degrees will be selected as a valid matched link for the sighting. This 30 degree threshold is selected mainly to avoid the sighting being matched to the link in the opposite direction. In common cases, the degree difference between the travel direction and the link direction should be approximately zero. Here, we use a 30 degree threshold to consider the uncertainty of location accuracy in MDLD. After the matched link for each sighting is found, given the observed link sequence, the routing engine can fill the gap between consecutively observed links and retrieve the complete route. Another layer of reasonable checks is conducted at the routing stage. For each pair of consecutive sightings that are snapped to links, the routed distance is calculated by summing the link length of all the links traveled between the two sightings. Two reasonableness checks are carried out:
If the routed distance is greater than the cumulative distance between the two sightings snapped to links by 2,000 m or more, we consider the route invalid.
The travel time on these links will be calculated based on the timestamp difference between the two sightings. With the routed distance and travel time, the average travel speed on these links can be calculated. If the speed exceeds 50 m/s (i.e., 112 mph or 180 km/h), we assume that one of the two sightings is matched to the wrong link.
If either of these two violations is observed, we apply a trial-and-error process by removing the latter sighting and performing the routing using the next sighting snapped to the network until it does not violate the 2,000 m threshold or the 50 m/s threshold ( 52 ). A simple example of the map matching and routing method is illustrated in Figure 3.
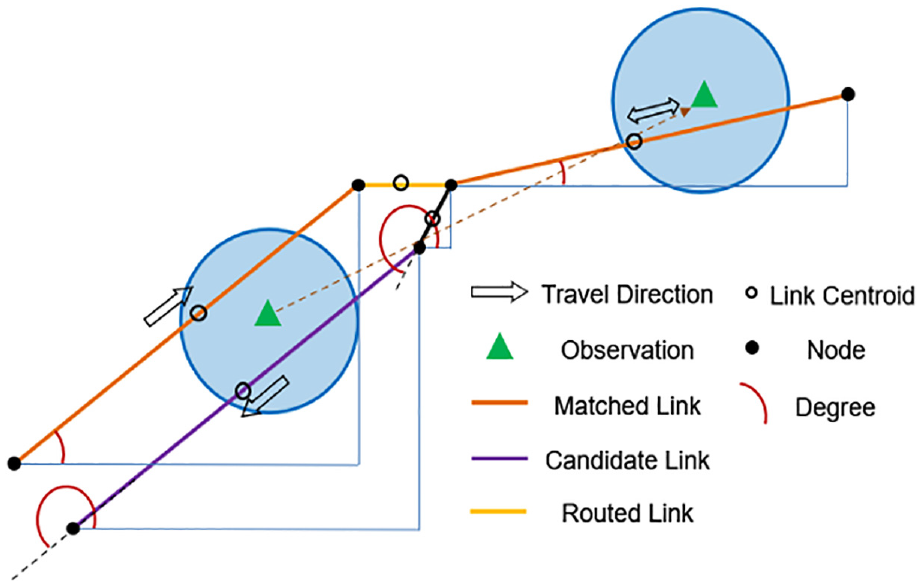
Example of map matching and routing.
Weighting
After map matching and routing, we collect routes for all vehicle trips and aggregate them by links to obtain the observed vehicle volume for each link. Afterward, we develop a link-based weighting method to match the AVMT in the region. We classify each link by county, urban/rural status, and functional classes and calculate the link weight using the formula below:
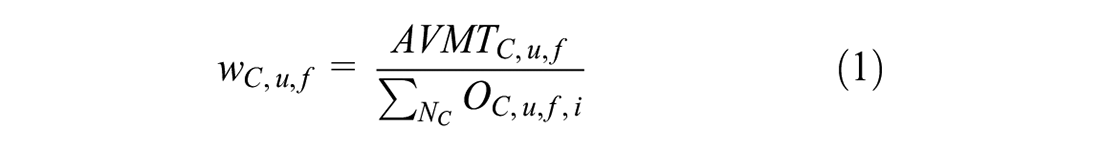
where
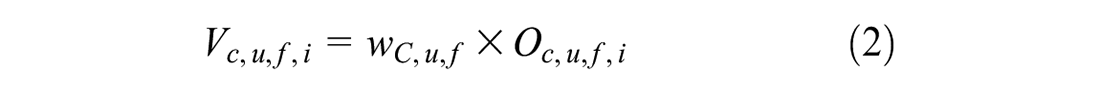
where
Volume Calibration
The weighted vehicle volume is further calibrated to match the ground truth AADT collected from loop detectors at a limited number of locations. In this study, we use the random forest regression to calibrate the weighted vehicle volume against the AADT to obtain the final vehicle volume. During the calibration process, a 10-fold cross-validation process is used to fine-tune the random forest regression hyperparameters with 90% training data. The fine-tuned models are then applied to the 10% testing data.
Case Study: The State of Maryland
Data
MDLD and the Study Area
This study used MDLD data obtained from MTI. MTI has integrated and cleaned the raw MDLD from multiple data vendors and built a national MDLD data panel that consists of more than 270,000,000 monthly active users and represents movements across the USA (40–43, 51). Figure 4 shows the density of location sightings covering locations within and outside of the boundaries of the State of Maryland. In this study, we used all MDLD data that are observed in the State of Maryland for the entire year of 2019. The MDLD is processed on a daily basis and the results are aggregated to produce an annual total result.
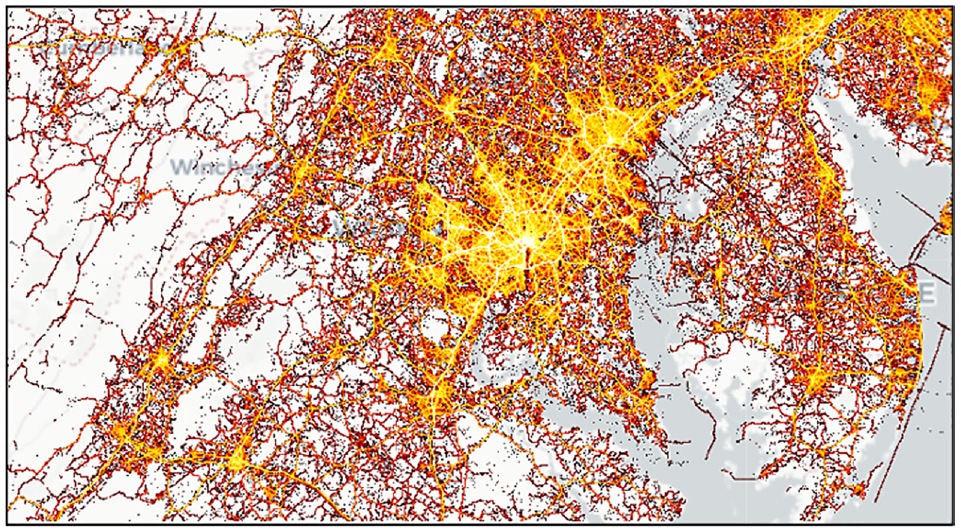
Mobile device location data around the State of Maryland.
OpenStreetMap Network
Using the osm2gmns package, we extracted a total of 634,516 drivable roadway segments within the State of Maryland. Information about the number of lanes and speed limits was recorded for only 111,835 roadway segments (17.6%) and 84,728 roadway segments (13.4%), respectively. As shown on the left-hand side in Figure 5, the missing values for the number of lanes and speed limits were estimated based on the corresponding values on nearby roadways in the same county, and with the same urban/rural status, and road functional classes. These two variables are further used as features in the vehicle volume calibration model.
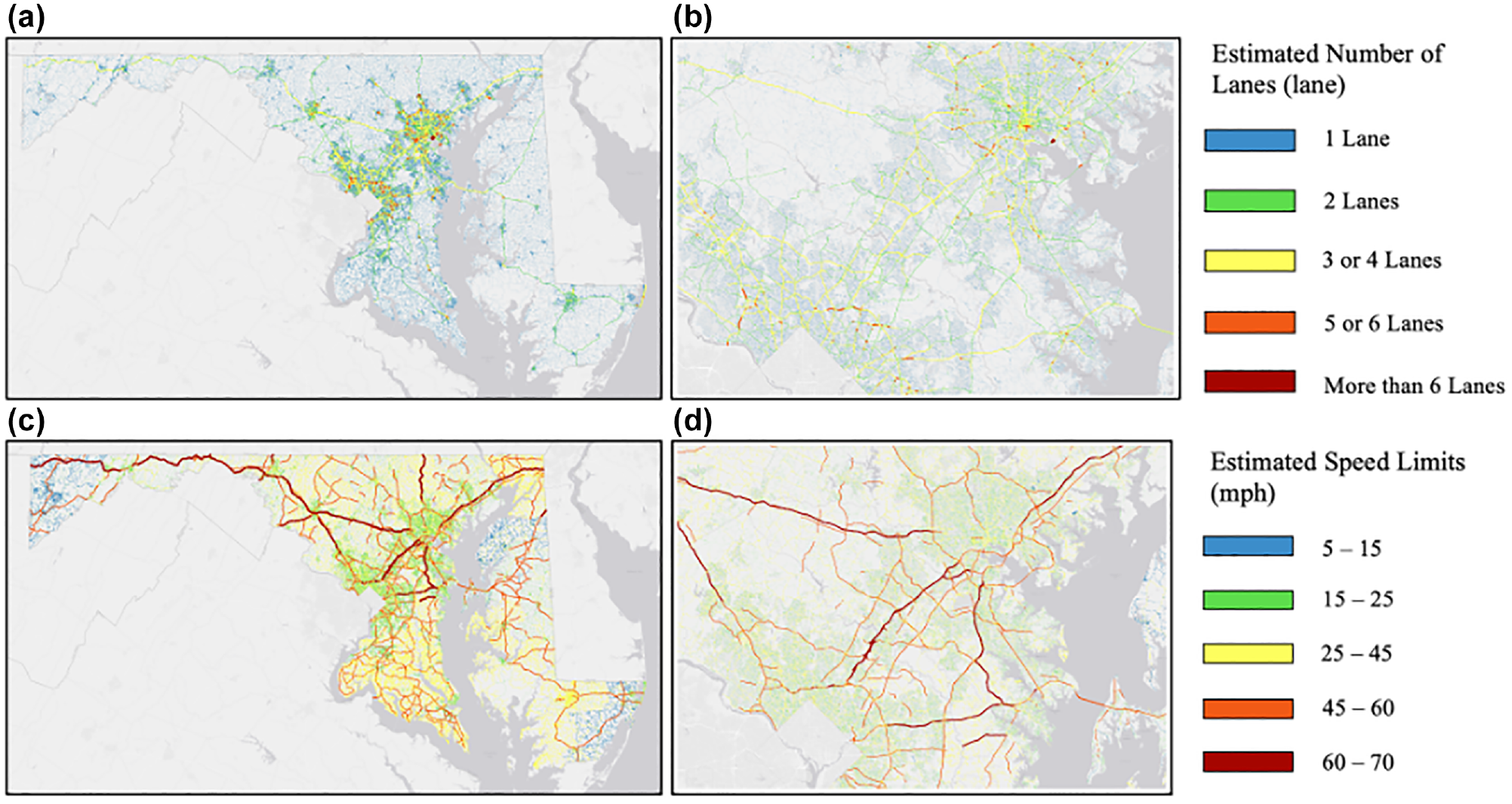
Number of lanes and speed limits in OpenStreetMap: (a) Estimated number of lanes in Maryland, (b) Estimated number of lanes zoom-in, (c) Estimated speed limits in Maryland, and (d) Estimated speed limits zoom-in.
AVMT Data
We use the VMT data from the Maryland Department of Transportation State Highway Administration (MDOT SHA) as a control total number to weight observed vehicle volume. Every year, MDOT SHA publishes an AVMT report by county and functional classification for the state, county, and municipal highway systems. This AVMT report features the current Federal Highway Administration’s Functional Classification Codes (1–7) and provides additional classifications (i.e., Urban, Rural, Principal Arterial and Other Freeways and Expressways, and Minor Collector). As discussed in the methodology section, the weights are generated based on county, urban/rural status, and functional classes. Here, 23 Maryland counties plus Baltimore City, urban or rural, and two function classes (highway and non-highway) are considered. We map the OSM link type to the FHWA Functional Classification Codes and generated the highway and non-highway classes. More specifically, “motorway,”“trunk,” and “ramp” are classified as highway (i.e., 1, 2 in FHWA class), and the other types are classified as non-highway (i.e., 3, 4, 5, 6, 7 in FHWA class). More details about the AVMT data can be found here: https://www.roads.maryland.gov/mdotsha/Pages/index.aspx?PageId=302
AADT Data
We use the AADT also from MDOT SHA to calibrate weighted vehicle volume against the ground truth at a limited number of locations. The AADT data consist of linear and point geometric features which represent the geographic locations and segments of roadway throughout the State of Maryland that include traffic volume metrics such as AADT. More details about the AADT can be found here: https://data.imap.maryland.gov/maps/77010abe7558425997b4fcdab02e2b64/about
Smart Location Database and Features for Volume Calibration
The Smart Location Database (SLD) is a nationwide geographic data resource for measuring location efficiency. The SLD is produced by the U.S. Environmental Protection Agency (EPA)’s Smart Growth Program. It provides more than 90 variables on land use and built environment characteristics such as population and employment densities, land use diversity, urban design attributes, destination accessibility, transit accessibility, and socioeconomic/sociodemographic characteristics at the census block group level. Most attributes are available for every census block group in the USA. In this study, we use SLD variables as features in the random forest regression to calibrate weighted vehicle volume to account for the effects of the built environment. The SLD variables used in this study are TotEMP, Pct_AO0, D1A, D1C, D3AAO, D3B, and D5AR:
TotEMP = total employment;
Pct_AO0 = percent of zero-car households;
D1A = gross residential density (housing units per acre) on unprotected land;
D1C = gross employment density (jobs per acre) on unprotected land;
D3AAO = network density by facility miles of auto-oriented links per square mile;
D3B = street intersection density (weighted, auto-oriented intersections eliminated);
D5AR = jobs within 45 min auto travel time, time decay (network travel time) weighted.
We also include urban/rural status, county code, link type, number of lanes, and speed limits as features in the calibration process.
Results
Overall Comparison
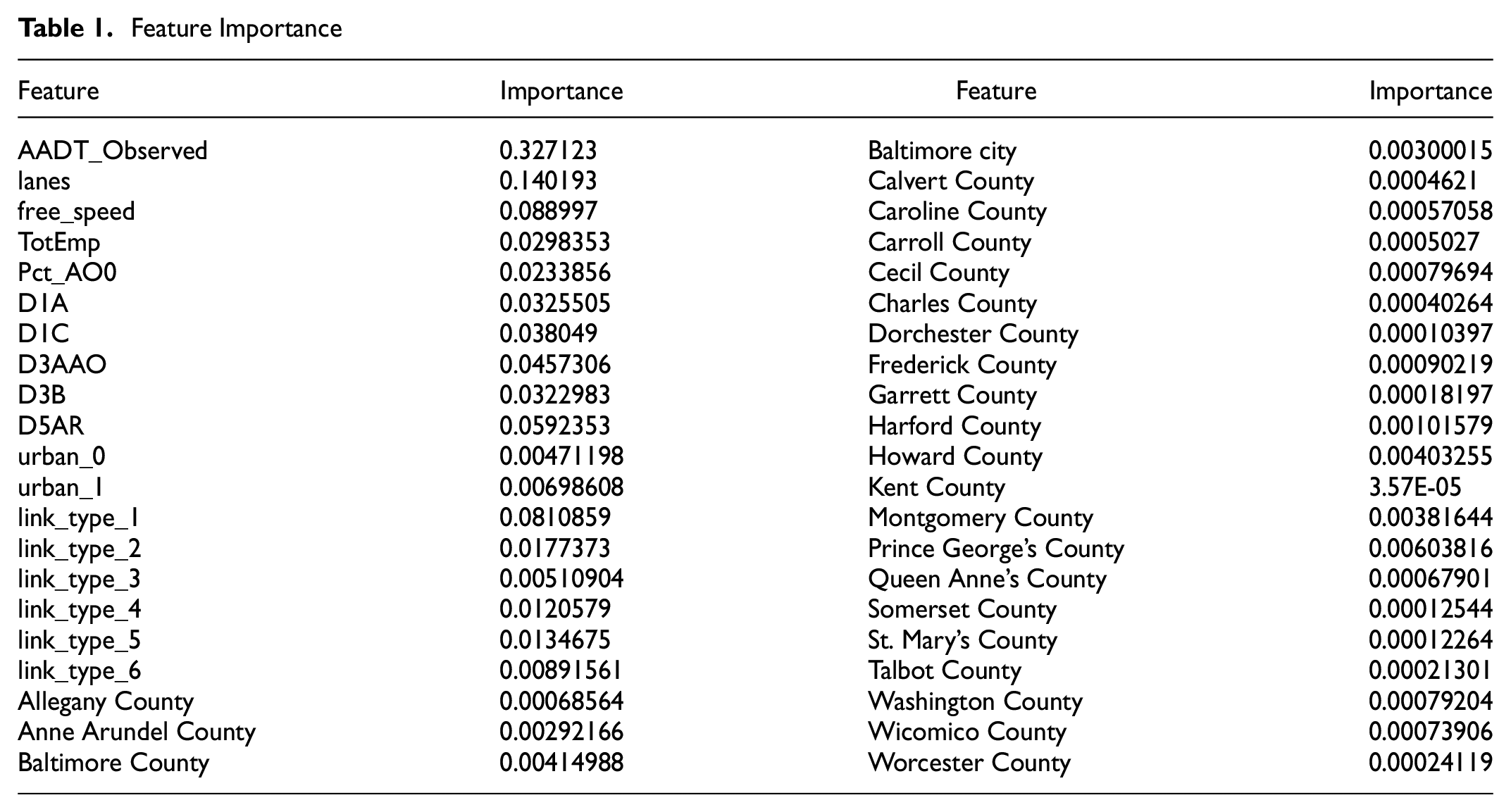
Figure 6 shows the weighting and calibration results for both training and testing sets. Table 1 shows the feature importance during the calibration process. The blue dots represent weighted volume comparisons and the green dots represent calibrated vehicle volume comparisons with MDOT SHA AADT. Figure 6, a and b, compares the weighted vehicle volume and calibrated vehicle volume with the MDOT SHA AADT in the training set respectively; Figure 6, c and d, compares the weighted vehicle volume and calibrated vehicle volume with the MDOT SHA AADT in the testing set respectively. As can be seen from Figure 6a, for the training set, the Pearson correlation value and the root mean square error (RMSE) between the weighted vehicle volume and the ground truth AADT are 0.746 and 7,912, respectively. These values are improved to 0.966 and 2,996 after calibration, as shown in Figure 6b. Similarly, for the testing set, the Pearson correlation and RMSE are improved from 0.764 and 7,548, to 0.854 and 5,701 respectively after calibration.
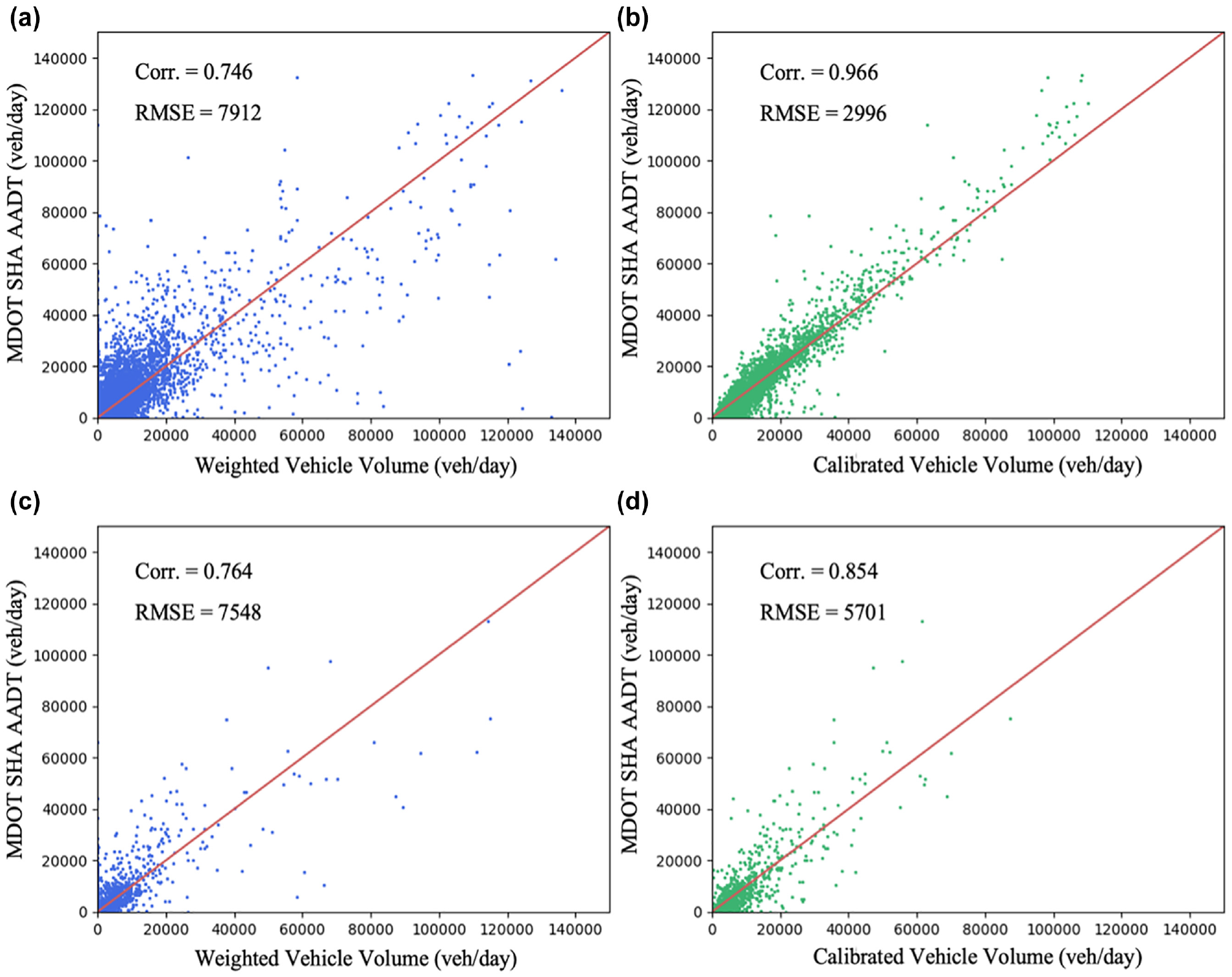
(a) Weighted vehicle volume in training set; (b) calibrated vehicle volume in training set; (c) weighted vehicle volume in testing set; (d) calibrated vehicle volume in testing set.
Feature Importance
Vehicle Volume Validation by Link Types and Urban/Rural Status
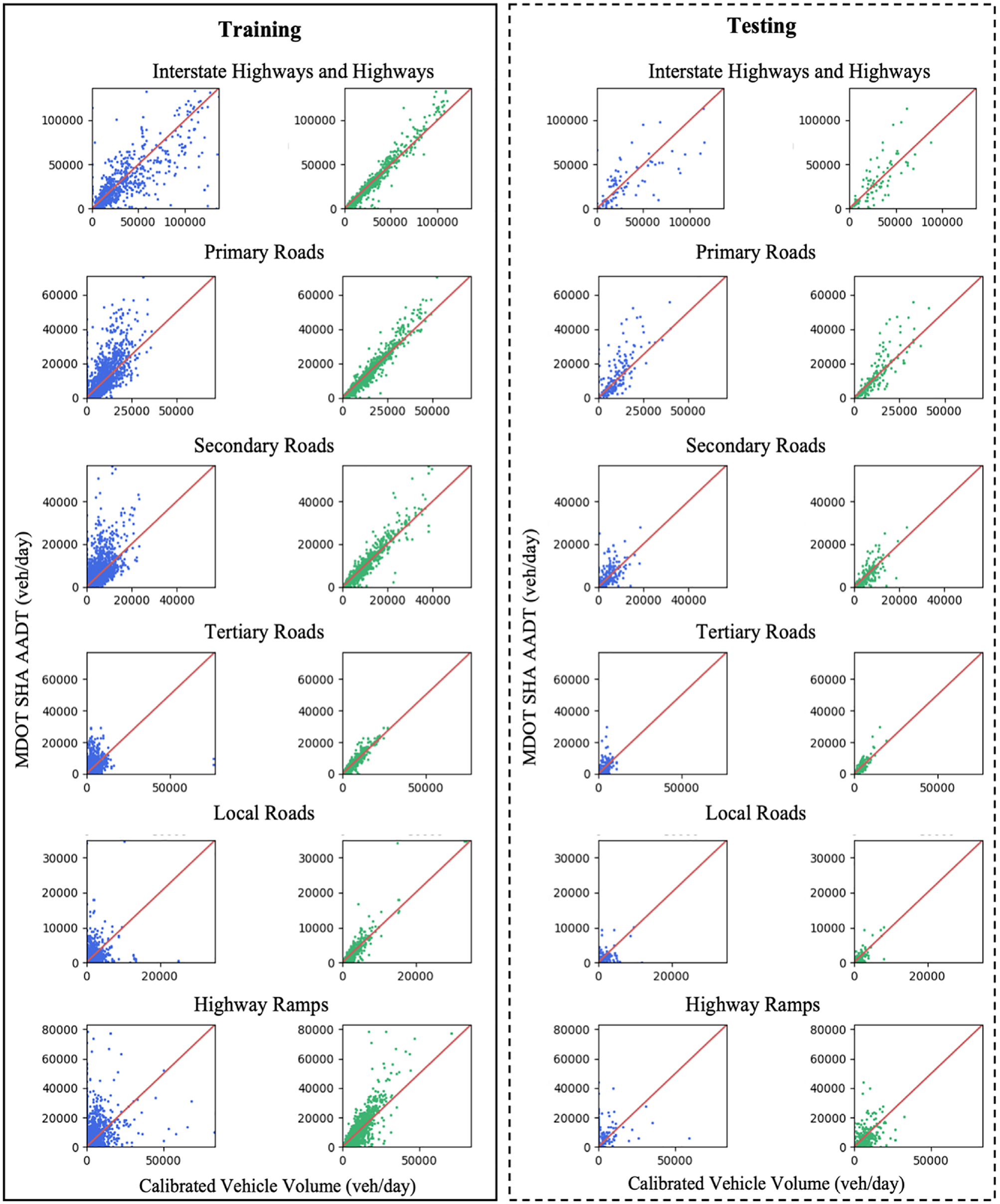
Figure 7 and Table 2 show the calibrated vehicle volume by link types for both the training and testing sets. For all link types, a good correlation (i.e., over 0.80) can be observed between the calibrated vehicle volume and the ground truth AADT, except for Local Roads and Highway Ramps in the testing set. The results indicate that our proposed framework can accurately estimate vehicle volume on higher-level roadways (i.e., Interstate Highways and Highways, Primary Roads, Secondary Roads), while concurrently maintaining high correlations for lower-level roadways (i.e., Tertiary Roads, Local Roads, Highway Ramps). The relatively weaker performance for the case of lower-level roadways can be attributed to limitations in technology. The MDLD only capture part of the daily trips of a device within the area with mobile network connections and higher-level roadways usually have a better coverage than lower-level ones. This variability might also result in capturing more travelers on highways and major arterials. In addition, the LBS data sample is more likely to include the active travelers that make more trips and/or longer-duration trips, such as long-distance travel for leisure or business purposes or long-distance commuting which usually happen on Interstate highways.
Comparison of volume calibration results by link type.
Comparison of Volume Calibration Results by Link Type
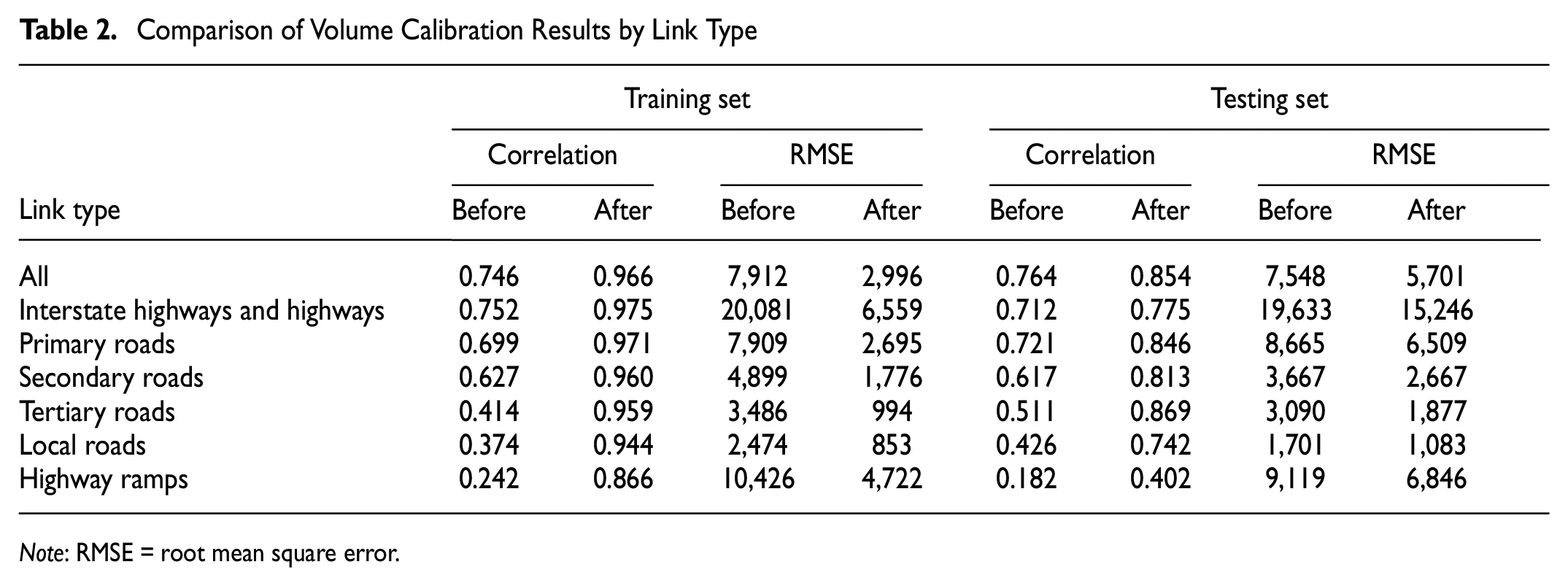
Note: RMSE = root mean square error.
Figure 8 and Table 3 show the calibration of vehicle volume by urban/rural status for both the training and testing sets. In summary, for both urban and rural roads, a good correlation (i.e., over 0.80) can be observed between the calibrated vehicle volume and the ground truth AADT, whereas a higher correlation can be observed for urban roads. The relatively weaker performance in rural roadways can also be attributed to the technology limitation mentioned above.
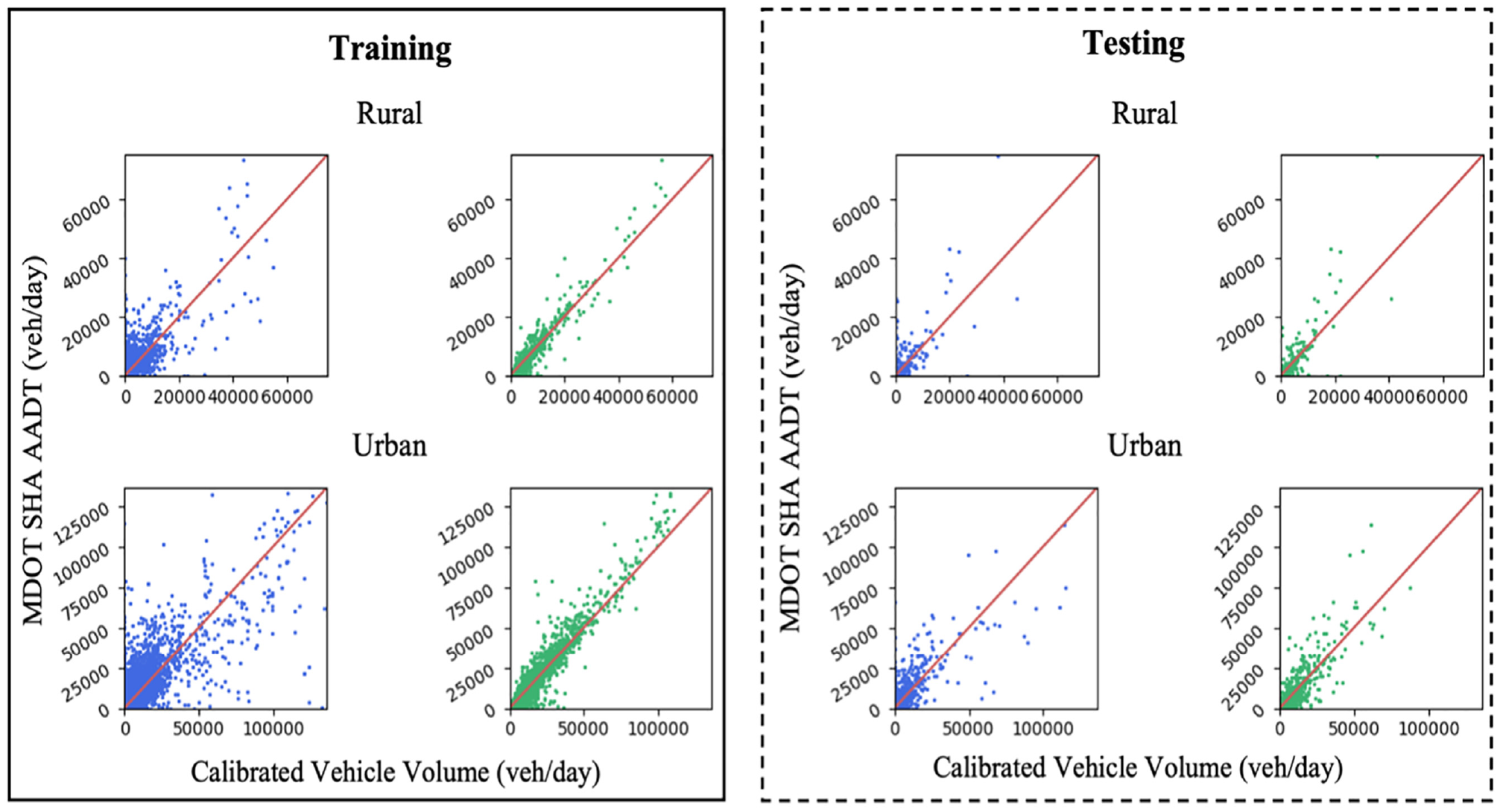
Comparison of volume calibration results by urban/rural status.
Comparison of Volume Calibration Results by Urban/Rural Status
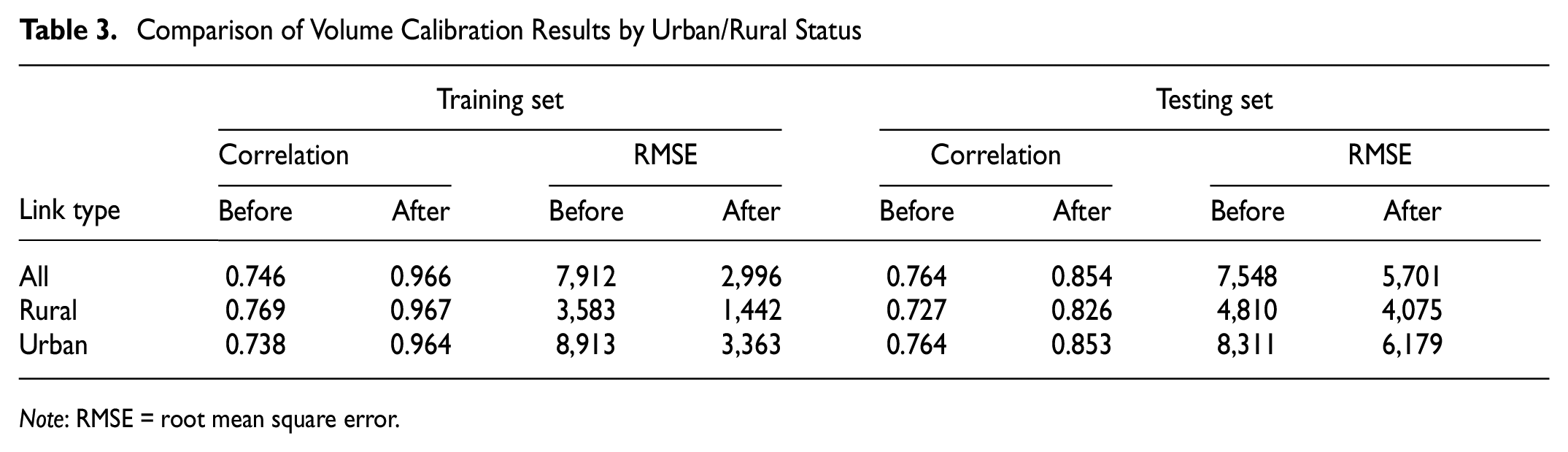
Note: RMSE = root mean square error.
Figure 9 visualizes the calibrated vehicle volume averaged from the entire year of 2019 (represented as AADT) on the all-street network in the State of Maryland. It can be seen that the Interstate highway and the highway skeletons can be clearly identified from the map. Major arterials also stand out from the map. Figure 9b zooms into the Washington DC area, where I-495, I-270, I-95 and the Baltimore/Washington Parkway are clearly seen. Figure 9c zooms into the Baltimore area, where I-395, I-695, I-795, I-95, and I-70 are all captured. Figure 9d zooms into Hagerstown, MD, which is a city in Washington County, MD near the border of Pennsylvania. The I-70, I-81, and MD-40 are all captured, demonstrating the ability of our proposed framework to produce reliable results in rural areas.
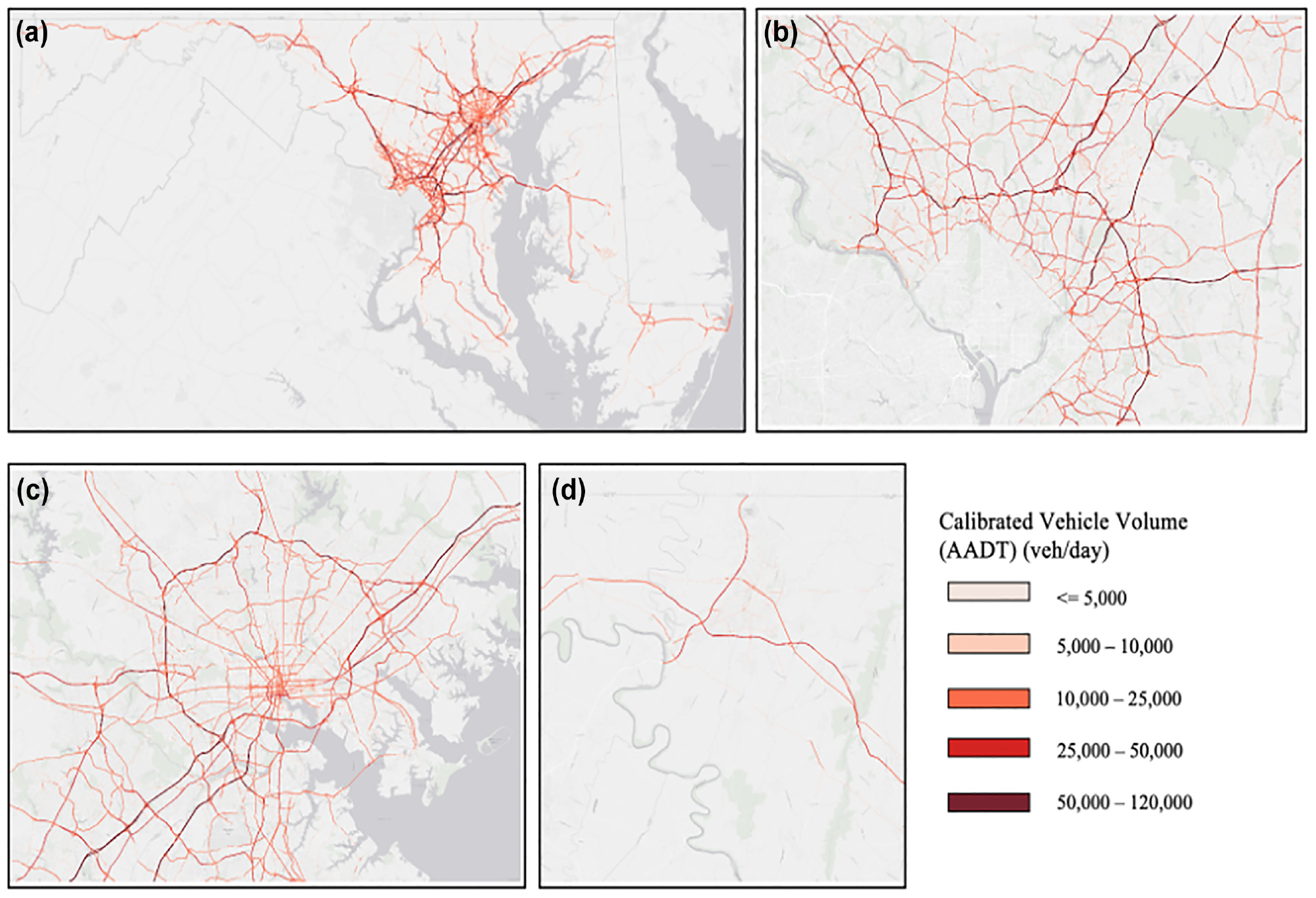
Visualization of calibrated vehicle volume: (a) the State of Maryland, (b) Washington DC, (c) Baltimore City, (d) Hagerstown, MD.
Discussion and Conclusion
This paper presents a big-data driven framework that is able to ingest terabytes of MDLD and estimate vehicle volume based on MDLD. The proposed framework first employs a series of cloud-based computational algorithms to extract vehicle trajectories. A map matching and routing algorithm is then applied to snap and route vehicle trajectories to the road network. The observed vehicle counts on each road segment are weighted and calibrated against the control total, that is, AVMT, and data collected from real-world loop detectors. The proposed framework is implemented and validated on the all-street network in the State of Maryland using MDLD data from 2019. After weighting and calibration processes, high correlation and low RMSE values are observed between our vehicle volume estimates and the ground truth data. To further improve the proposed framework, especially to tackle the challenges in estimating vehicle volumes for local and rural roads, a dedicated data collection process is suggested to enrich the real-world observations to support weighting and model calibrations.
The framework proposed in this study and the study findings have practical implications. For instance, estimated vehicle volume based on MDLD can be leveraged in safety risk exposure analysis and can support traffic signal controls ( 53 – 55 ). In particular, the proposed estimation method can particularly be beneficial for safety risk exposure and crash analysis with respect to vulnerable road users (e.g., pedestrians and bicyclists). Data on pedestrian and bicyclist exposure have traditionally been collected through surveys or count collections at sample locations ( 56 , 57 ). In addition to being costly and labor intensive, these conventional data collection methods are susceptible to subjectivity and may yield inaccurate data. Consequently, the collection of high quality and readily available data on pedestrian and bicyclist exposure is considered as a limitation in safety analysis ( 55 , 58 , 59 ). As exposure data are crucial for contextualization of crash analysis and prioritization of safety countermeasures ( 56 ), utilization of high quality and consistent exposure data is imperative. When it comes to safety analysis, using MDLD for volume estimation—as performed in this study—provides a tremendous advantage over using data obtained from traditional volume estimation methods. This is because of the potential of the MDLD to produce more reliable exposure data. Employment of such high-fidelity exposure data (i.e., MDLD-estimated volumes) as input for safety and crash analyses can lead to more accurate results and guide data-driven, evidence-based policy decision making to improve the safety of all road users including the most vulnerable ones.
Footnotes
Acknowledgements
This study was conducted as part of a collaboration among the Maryland Department of Transportation State Highway Administration (MDOT SHA), Maryland Transportation Institute (MTI) at the University of Maryland College Park, and Shock, Trauma and Anesthesiology Research (STAR) Center at the University of Maryland Baltimore through sponsorship from the Safety Data Initiative from the U.S. Department of Transportation (U.S. DOT).
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: M. Yang, W. Luo, C. Xiong, Y. Ji; data collection: M. Yang, M. Ashoori, J. Mahmoudi, G. Zhao., S. S. Namadi, Y. Ji; analysis and interpretation of results: M. Yang, J. Mahmoudi, W. Luo, J. Lu; draft manuscript preparation: M. Yang, W. Luo, M. Ashoori, J. Mahmoudi, G. Zhao, S. S. Namadi, A. Kabiri, S. Hu. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.