
Abstract
On-demand intra-city freight logistics (ICFL) has recently emerged as a new freight service, where shippers can submit their shipping requests using smartphones and be matched to drivers in real time based on their locations and drivers’ availability. A major challenge faced by on-demand ICFL platforms is the shortage of vehicles during peak demand periods. Cargo pooling, the cargo version of carpooling, offers as a promising way to increase supply: cargoes heading in the same direction would share the cargo compartment of the same vehicle and be serviced simultaneously, which is achieved by careful sequencing of the pickup and delivery locations of the cargoes. We investigate models for cargo pooling for on-demand ICFL and quantify its benefit, which is new to the literature. The major difference between existing studies on ICFL and ours is that we no longer assume that demands are known beforehand. Instead, the demands arrive gradually throughout the day and we need to periodically match requests to drivers and re-optimize vehicle routes. We formulate the matching problem as a dynamic pickup and delivery problem with three-dimensional loading and time window constraints. To solve this model, we develop an algorithm based on large neighborhood search and tree search. The algorithm is tested with real freight data in a city in the Yangtze River Delta. Results show that the algorithm can reduce the total cost by 21.4% and reduce the total vehicle miles traveled by 36.0%.
Keywords
The widespread use of smartphones has created a variety of on-demand services, for example, on-demand food delivery and on-demand ride hailing. Recently, intra-city freight logistics (ICFL) has also become on-demand, where a shipper can submit their shipping request—the pickup and delivery locations, the earliest pickup time (EPT) and the latest delivery time (LDT), and the type and dimension of the cargo—using smartphones and being matched to drivers in real time based on their locations and drivers’ availability. It is reported that the ICFL market in mainland China increased from 893.1 billion CNY (132.4 billion USD) in 2017 to 1,319.9 billion CNY (195.7 billion USD) in 2021, with an average annual compound growth rate of more than 10% ( 1 ). Furthermore, from 2017 to 2021, the market penetration rate of on-demand ICFL increased from 0.6% to 2.9%, and is expected to reach 19.8% by 2025 ( 1 ).
On-demand ICFL differs from other kinds of freight services in several ways. (i) It is on-demand because the shipping requests are received throughout the day and need to be matched to drivers in real time. Requests stay valid unless they cannot be matched with drivers within a time limit. (ii) It is intra-city because the pickup and delivery locations are within the urban area of a city. (iii) The cargo typically weighs between 30 kg and 500 kg and can be anything from furniture and luggage bags to hardwood floors and grocery/fruit pallets. (iv) The cargo needs to be picked up and delivered during the day, typically between 8:00 a.m. and 8:00 p.m. (v) The cargo is transported using cargo vans or small pickup trucks, as shown in Figure 1. This is because many Chinese cities prohibit medium-sized to large trucks from entering urban areas as a way to alleviate congestion during the day, which makes cargo vans and small trucks the only choices for ICFL. For ease of discussion, we use the term vehicles to refer to both cargo vans and small trucks used in ICFL. (vi) The cargo in a single shipment often does not take up the entire cargo compartment of a vehicle. The six characteristics of on-demand ICFL make it a crucial component of urban logistics. In comparison with other freight services, on-demand ICFL excels in meeting the personalized, on-demand freight needs of customers.

Intra-city freight logistics (ICFL) relies on cargo vans and small trucks to transport cargoes.
A major challenge faced by on-demand ICFL platforms is the shortage of vehicles during peak demand periods. At present, on-demand ICFL platforms provide dedicated services to shippers. A vehicle is dispatched to fulfill shipping requests one at a time and the vehicle will not pick up a new shipment until the shipment onboard has been delivered. This means that the cargoes are transported in a point-to-point way without intermediate stops and no two requests co-exist in the cargo compartment of a vehicle. Consider the example shown in Figure 2a. At 12:45 p.m. there are two shipping requests, where the pickup and delivery locations of the first one are indicated as P1 and D1, respectively. Its EPT and LDT are 1:00 p.m. and 1:30 p.m., respectively. The pickup and delivery locations of the second one are P2 and D2, respectively. Its EPT and LDT are 1:10 p.m. and 1:40 p.m., respectively. The travel times between P1 and P2, between P2 and D1, and between D1 and D2 are all 15 min. Assume that there is only one vehicle available and it is located at O, the platform can only take one of the two shipping requests while rejecting the other one.
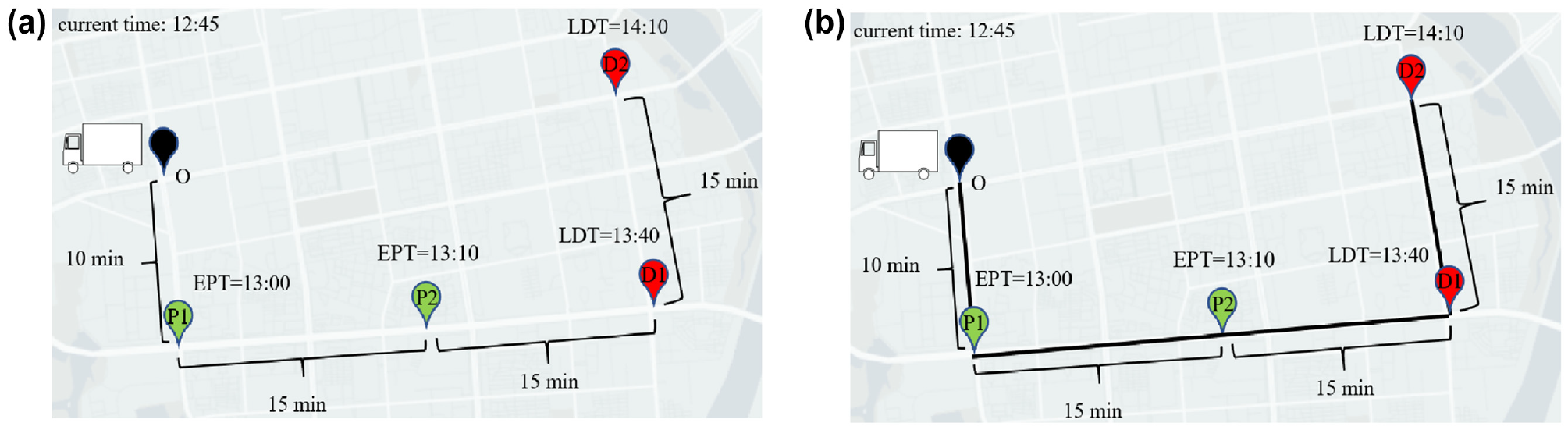
Cargo pooling can effectively increase supply and serve more requests: (a) when the platform provides dedicated services to shippers, only one shipping request can be served and (b) when the platform offers cargo pooling, both shipping requests can be served.
Cargo pooling, the cargo version of carpooling, has recently emerged as a way to increase supply during peak demand periods: cargoes heading in the same direction share the same cargo compartment and are serviced simultaneously, which is achieved by careful sequencing of the pickup and delivery locations of multiple cargoes. This offers a great opportunity to better utilize the capacities of the vehicles and serve more shippers. Let us continue with the example shown in Figure 2a. When cargo pooling is allowed, the platform can use the single vehicle available to accommodate both shipping requests following the black pickup/delivery route shown in Figure 2b. Under cargo pooling, since the vehicles need to make intermediate stops to pick up and deliver cargoes, the transportation time of a single request may increase. However, the utilization of the cargo compartments of the vehicles is improved and the total distance traveled is also reduced. As the transportation time for a single request may be prolonged with cargo pooling, the logistics company offers a lower price for this service as compensation. This allows shippers to take advantage of cost savings for the transportation of their cargo.
Though cargo pooling is a quite new service, similar ideas have appeared in other experiences of pooling in freight logistics in different regions of the world. Montoya-Torres et al. ( 2 ) studied a situation where three companies distributed goods to their stores. They compared the situation of the three companies delivering their goods separately and one company delivering all the goods in the form of cargo pooling. They used real data from the city of Bogotá, Colombia, for simulation. Pan et al. ( 3 ) introduced goods pooling strategies in supply chain transportation. Their model was tested with real data for 12 weeks of two French retailers and significantly reduced the CO2 emissions. Kay et al. ( 4 ) demonstrated the economic impact of consolidation on transportation costs. The real data sets they used were produced using real city and town coordinates and population densities of Turkey. Therefore, there has been research on cargo pooling all over the world since 2010, but the situations mentioned above are all different from on-demand ICFL.
In this research, we quantify the value of cargo pooling in on-demand ICFL. The studies that are most closely related to our work are those on cargo pooling under static ICFL, where all shipping requests are received before any vehicle is dispatched. This problem is usually modeled as a pickup and delivery problem (PDP) with side constraints, which include: (i) capacity constraints, which measure whether a group of cargoes can fit into the cargo compartment of a vehicle. When only the weights of the cargoes are considered in the capacity constraints, they are called the cardinality constraints; when the dimensions of the cargoes are considered in the capacity constraints, they become the three-dimensional loading (3D-Loading) constraints; and (ii) time window constraints, which specify the time intervals when a cargo can be picked up from the origin and when it can be delivered to the destination. Table 1 compares our research with existing studies and illustrates the differences. Männel and Bortfeldt ( 5 , 6 ) investigated the PDP with 3D-Loading constraints. They assumed that the cargoes should strictly meet the first-in-last-out rule. Wu et al. ( 7 ) improved a hybrid heuristic algorithm for solving PDPs with 3D-Loading constraints without time window constraints. Dupas et al. ( 8 ) developed a mathematical model using combinatorial configurations approach for the PDP with 3D-Loading constraints. Stamadianos et al. ( 9 ) proposed a decision support system for the PDP with 3D-Loading constraints, considering multiple criteria. Our work is also remotely related to studies on the vehicle routing problem (VRP) with side constraints, where goods are transported between depots and customers. Gendreau et al. ( 10 ) was the first to look at the VRP with 3D-Loading constraints. Bortfeldt and Homberger ( 11 ) and Reil et al. ( 12 ) studied the VRP with 3D-Loading and time window constraints and developed a two-stage heuristic. Moura ( 13 ) presented a mixed integer linear programming model that characterized the 3D-Loading VRP with time windows.
Comparison Between Existing Studies and Our Research
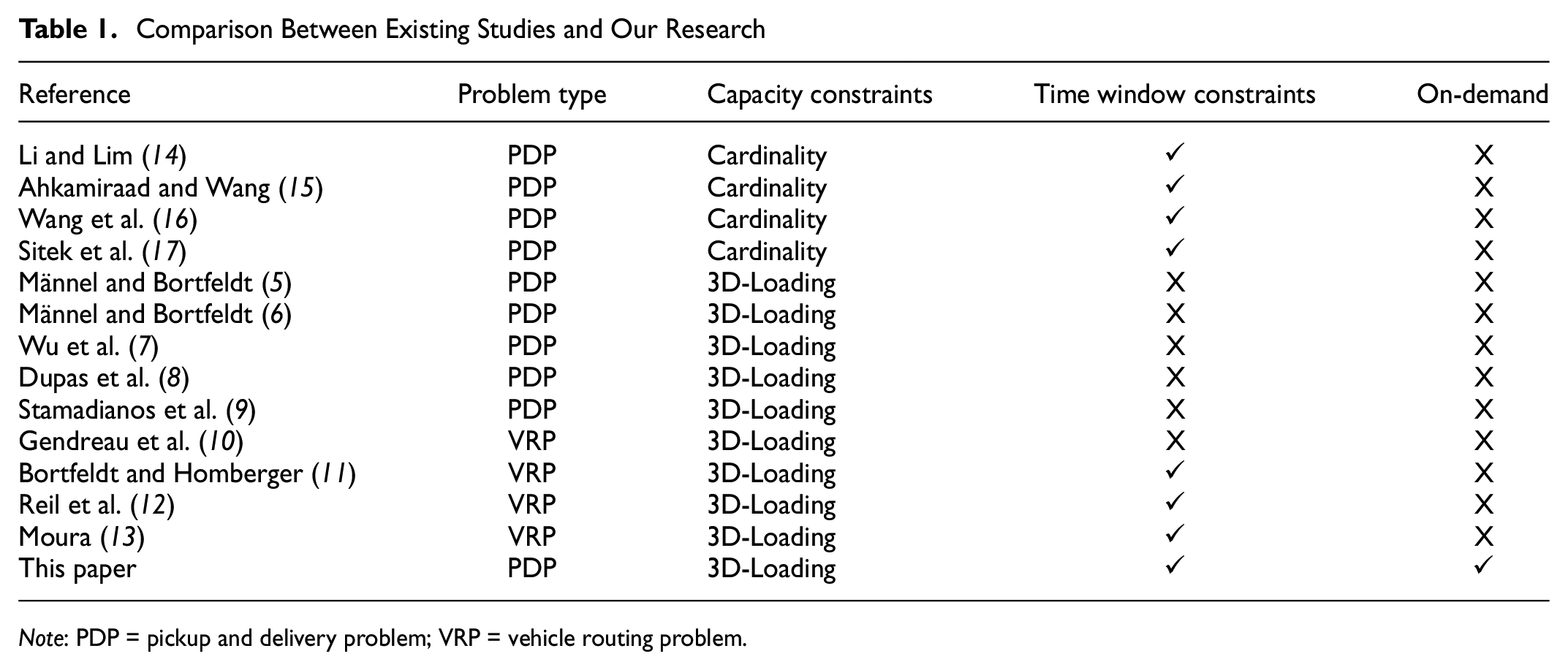
Note: PDP = pickup and delivery problem; VRP = vehicle routing problem.
We are the first to investigate cargo pooling in on-demand ICFL, which is new to the literature. The major difference between existing studies on ICFL and ours is that we no longer assume that demands are known beforehand, which is referred to as the static ICFL. Instead, the demands arrive gradually throughout the day and we need to periodically match requests to drivers and update vehicle routes. In each match, we take as input the demands received since the previous match as well as those that were received before the previous match but are still valid, the availability of the vehicles (their respective locations and the remaining capacities of the cargo compartments), and the pickup/delivery routes assigned to vehicles in the previous match. We then output vehicle routes and the storage plans of the cargoes inside the cargo compartments of the vehicles. We formulate the problem as a dynamic PDP with 3D-Loading and time window constraints. Existing researches tend to adopt heuristic algorithms to solve the PDP with 3D-Loading constraints ( 5 , 6 , 8 , 10 , 16 , 18 , 19 ). Since our problem is more complex because of the time windows, dynamic property, and larger scale of data, we adopt a hybrid heuristic algorithm. For PDPTW, which is a special case of dynamic PDP with 3D-Loading and time window constraints, Ropke and Pisinger ( 20 ) and Bent and Van Hentenryck ( 21 ) achieved outstanding results especially for larger instances through neighborhood search methods, while the method of tabu search was proved to be very successful for smaller instances by Li and Lim ( 22 ). Our hybrid heuristic algorithm is composed of a modified large neighborhood search algorithm by Männel and Bortfeldt ( 5 ) and Ropke and Pisinger ( 20 ) and a tree search algorithm by Chen et al. ( 23 ). The algorithm is tested with real freight data in a city in the Yangtze River Delta, China. Results show that cargo pooling can reduce the overall cost by 21.4% and reduce the total vehicle miles traveled by 36.0%. We summarize the contributions of our research as follows:
We are the first to investigate cargo pooling in on-demand ICFL, where demands are gradually received during the day.
We model the problem as a dynamic PDP with 3D-Loading and time window constraints, and develop a solution approach that periodically optimizes the pickup and delivery routes of vehicles.
The algorithm is tested with real freight data in a city in the Yangtze River Delta.
The remainder of this paper is organized as follows. In the next section, we introduce our notation and terminology. In the “Problem Definition” section, we present the definition for the cargo pooling problem. In the “Solution Approach” section, we develop a solution algorithm based on large neighborhood search and tree search. The “Numerical Experiments” section presents the dataset description, experimental setup, main results, analysis of the main results, and sensitivity analysis. The final section concludes the discussion and outline possible future research directions.
Notation and Terminology
In on-demand ICFL, customers submit shipping requests to the platform “24/7” and expect to be matched to a driver in real time. When a shipping request is received, its status is set to open. Once it is matched to a driver, its status becomes matched. If a shipping request cannot be matched to a driver in a given amount of time, for example, 30 min, it is rejected. On the side of the platform, it periodically, for example, every 10 min, invokes a matching procedure. Each time before the matching procedure is called, the platform gathers the following inputs: (i) the shipping requests that are open, which include those received since the previous matching and those that were received before the previous matching but have not been matched; (ii) the availability of the vehicles, including their locations and the remaining capacities of the cargo compartments; and (iii) the existing pickup and delivery routes assigned to the vehicles. The matching procedure then re-optimizes the pickup and delivery routes assigned to the vehicles as well as the way cargoes are stored in the cargo compartments of the vehicles.
The goal of this research is to develop a matching, or a re-optimization, model to facilitate cargo pooling. Now, let us define our notations. Suppose that there are
Let us suppose that there are
Each time we re-optimize, we need to determine the vehicle’s route plan which can be described with the following parameters.
In the re-optimization, to minimize the total cost, we need to optimize the route of vehicle
Problem Definition
In each re-optimization, the problem can be modeled as a PDP with 3D-Loading and time windows constraints (3L-PDPTW) which has an initial solution with unbreakable structure. To introduce these problems better, we divide the discussion into two parts. The first part introduces the 3D-Loading Problem and the second part introduces the 3L-PDPTW.
3D-Loading Problem
Checking whether a vehicle is able to load the cargoes when it arrives at a pickup point is a 3D-Loading problem. Let
Define the vertical direction as the Z axis, the short-side direction of the compartment as the X axis, and the long-side direction as the Y axis. Cargoes can only rotate around the Z axis, so they can only have two orientations. Parameters
To determine the relative position between cargo
Then
Orientation constraints: Cargoes can only rotate around the Z axis.
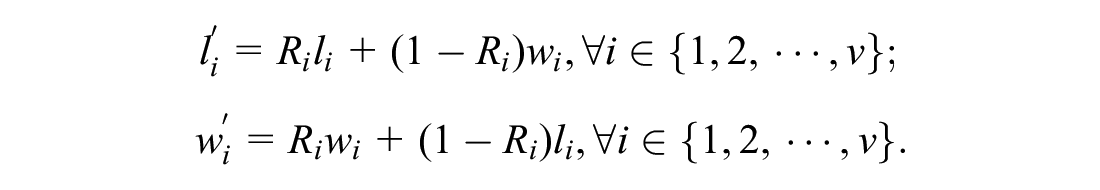
Nonoverlapping constraints: Cargoes cannot overlap. If
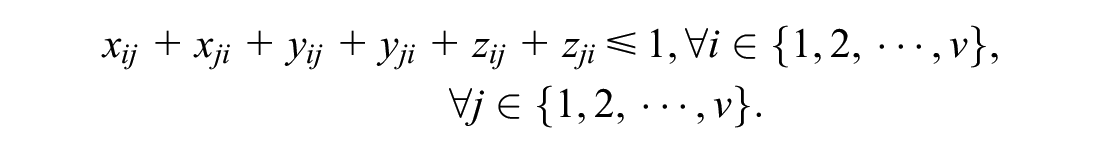
Supporting constraints: If a cargo is placed on the top of another, the upper surface of the lower cargo must fully support the lower surface of the upper cargo. That is, if
No exceeding constraints: The cargoes cannot exceed the compartment in the three directions of the X, Y, and Z axes. Take the X axis as an example. Let
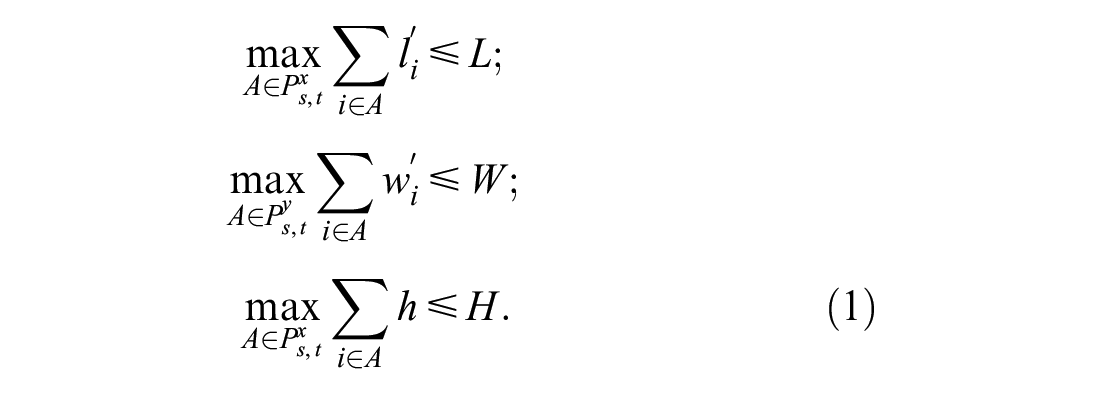
Loading order constraints: The cargoes placed earlier cannot be on top or in front of a cargo placed later.
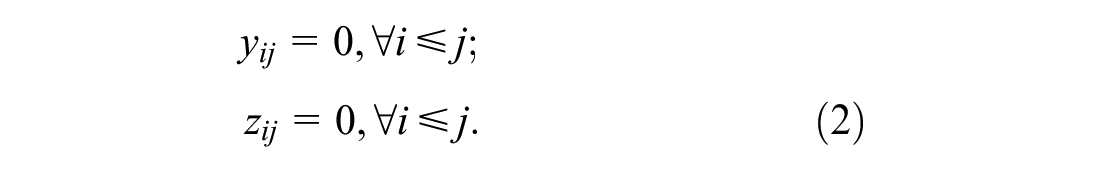
PDP with 3D-Loading and Time Windows Constraints
In every re-optimization, as shown in “Notation and Terminology,” we need to optimize the route of vehicle
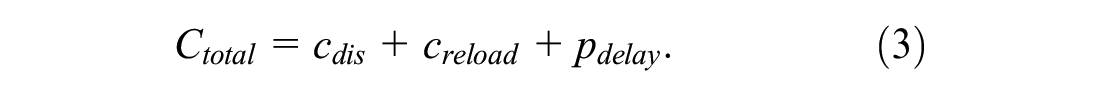
These three parts will be introduced in turn. We first introduce the cost of distance. We use Manhattan distance to approximate the actual distance between pickup and delivery locations, which is widely adopted in the literature (
24
,
25
).
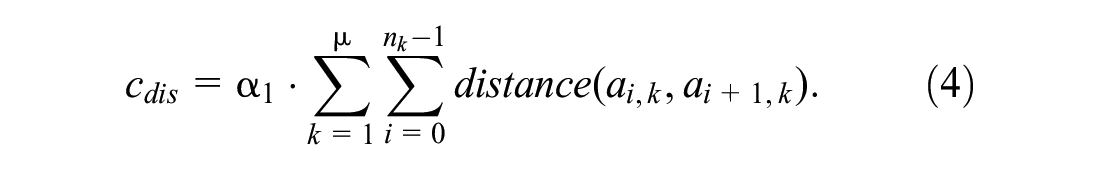
We then introduce the cost of reloading. As shown in Figure 3, there are four cargoes in the compartment. We assume that all cargo vans can only be opened on one side which is marked in the figure. There are no other cargoes that are closer to the door or are on top of cargo
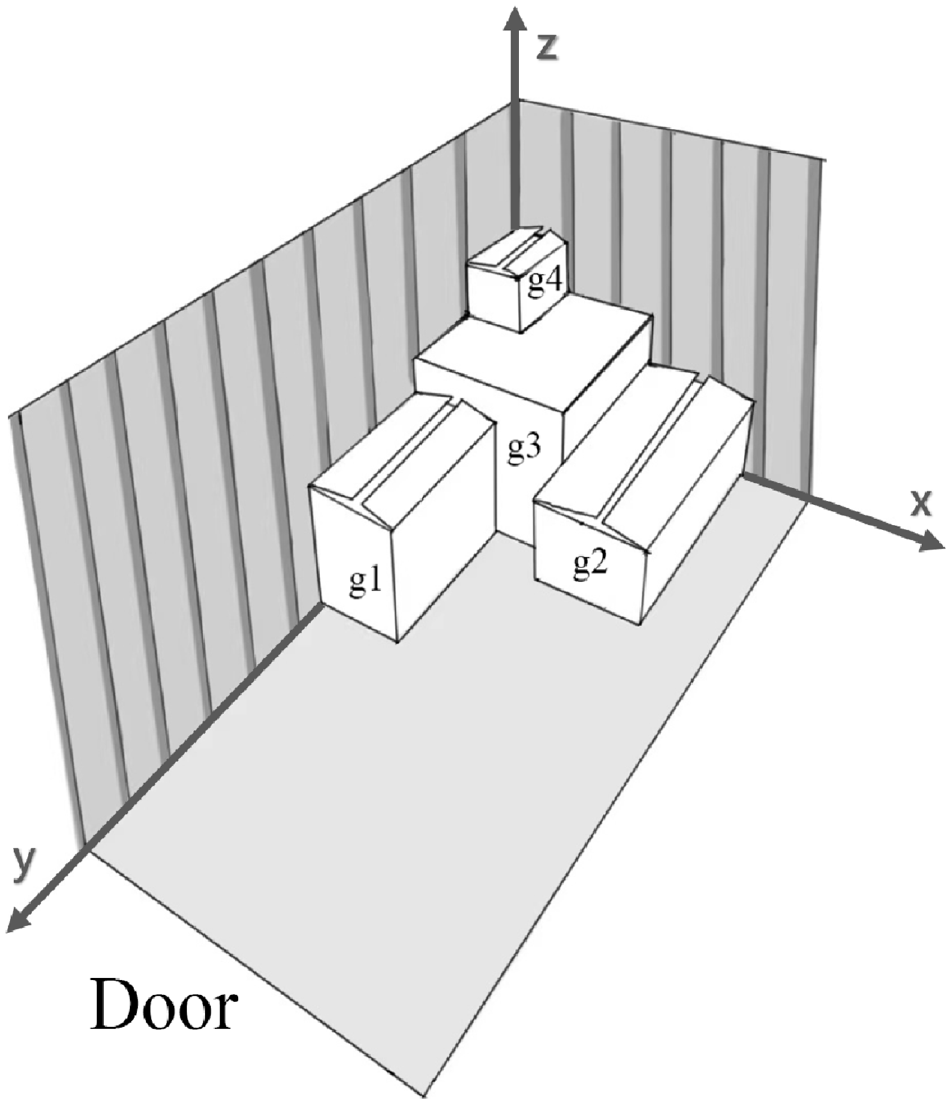
Illustration of possible placement of four cargo items in the cargo compartment.
We assume that any cargo put in the van later will definitely block the cargo put in the van earlier. This assumption is from the research of Männel and Bortfeldt ( 5 ). Essentially, considering reloading is a trade-off between the cost of distance and the cost of reloading. Ignoring reloading may give route planning more freedom, thereby reducing cost of distance. Conversely, making the route shorter may result in more reloading effort.
Let function
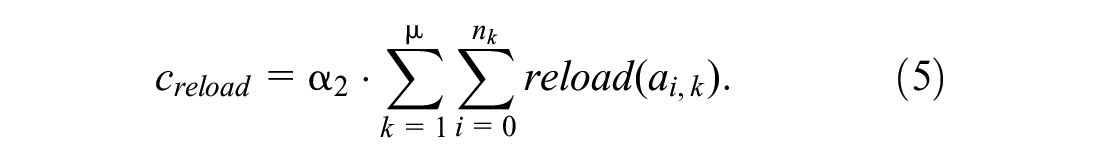
The last part of the cost function is the penalty for late delivery. In essence, cargo pooling is a way to reduce the total cost by properly extending a single request’s transportation time. For a shipper, cargo pooling may result in extended transit times, increasing the likelihood of missed delivery deadlines. It essentially penalizes the objective function if the delivery of a cargo cannot be made before its LDT. The goal is to produce a pickup/delivery schedule that tries to respect the LDTs of the cargoes, so we need to take the delay penalty into consideration. Constant
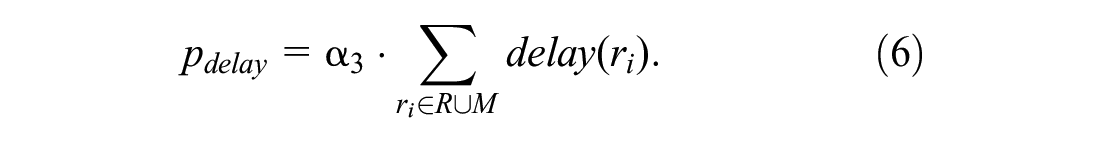
After introducing the cost function, we introduce the constraints of our model. The constraints and rules of our problem are listed as follows:
No missing constraints: All requests should be delivered.
3D-Loading constraints: Each time a vehicle arrives at a pickup point, we should check whether cargoes can be loaded into the vehicle. This kind of checking can be modeled as a 3D-Loading problem, see section 3D-Loading Problem for details.
Weight constraints: Each time a vehicle arrives at a pickup point, we should check whether the sum of the cargoes’ weight will exceed the vehicle’s maximum weight capacity.
Maximum travel distance constraints: Each vehicle has a maximum travel distance. The total distance of a single trip of a vehicle should be less than the maximum travel distance.
Driving hour constraints: As is required by State Council of the PRC ( 26 ), after driving for 4 h, the driver of a vehicle must take a break of 20 min.
Maximum requests constraints: Each type of vehicle has a maximum number of requests that it can take at the same time.
Last-in first-out rules (LIFO): To avoid reloading, cargo that is later loaded into the vehicle should be unloaded first, as this avoids repeated movement of cargoes. If reloading is necessary, we add the cost of reloading to the cost.
Time windows rules: Each request should have an EPT and an LDT, and the vehicle should arrive at the designated location in these time windows. If a timeout is necessary, we add penalty for late delivery to the cost.
Solution Approach
To cope with on-demand requests, we need a dynamic algorithm to do cargo pooling repeatedly. And in each time period, we carry re-optimization with the information known. In this section we first introduce the framework of the algorithm, then introduce two algorithms used in cargo pooling: large neighborhood search (LNS) and tree search (TS).
Overall Solution Approach: Framework of Algorithm
According to the model, the service hours of a day are divided into many 10 min intervals called time periods. In each time period, we perform re-optimization of cargo pooling. The process of the algorithm for cargo pooling is shown in Figure 4. In each re-optimization, we input: (i) the open shipping requests, (ii) the availability of vehicles, and (iii) the existing pickup and delivery routes. Then we perform re-optimization for cargo pooling with LNS and TS to obtain a new pickup and delivery route. The detailed optimization model is shown in the dotted box. After constructing the initial solution, if a specific number of consecutive unimproved iterations is not reached, the model will keep searching the neighborhood of the current solution. The routing part in the red dotted box is used to find a better solution, and the 3D-Loading part in the blue dotted box is used to ensure the feasibility of the solution. After re-optimization, we record the completed requests and update: (i) the open shipping requests, (ii) the availability of the vehicles, and (iii) the existing pickup and delivery routes. We then pass them to the next period. After finishing the last time period, we can use the data of all the completed requests to calculate the total cost and vehicle miles traveled to evaluate the benefits of on-demand cargo pooling.
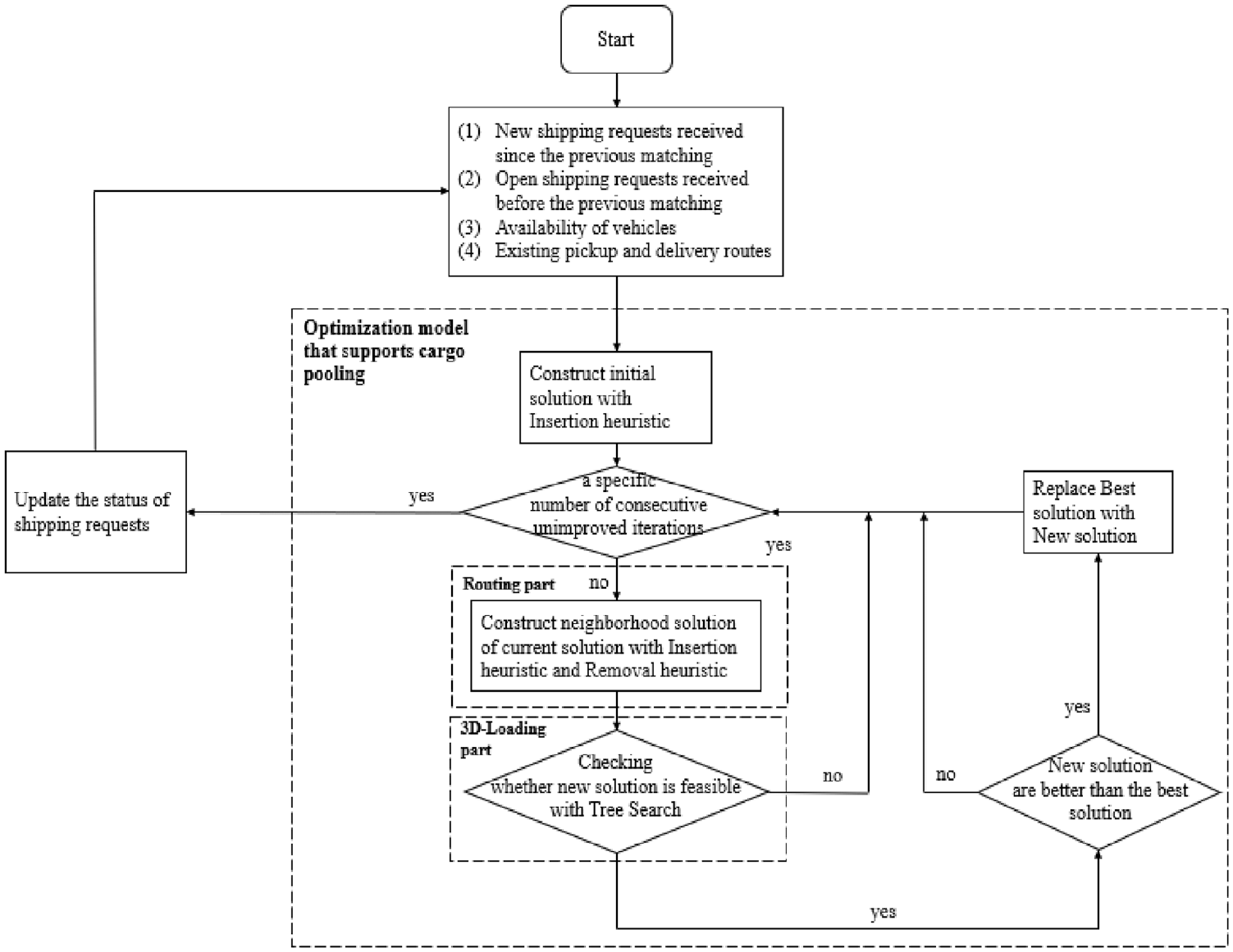
Solution framework for re-optimization.
We then introduce the detail of the state of vehicles and requests that will be rolling updated in each time period. Each request has four states: unassigned, assigned but not picked up, in transit, and delivered. If a request state is unassigned, it means this request has not been assigned to any vehicle and we can assign it to any vehicle that is available. If a request state is assigned but not picked up, it means that this request has been assigned to a vehicle but has not been started for pickup and we can still make adjustment to its pickup/delivery plan. If a request state is in transit, it means that this request has been assigned to a vehicle and this vehicle has already picked up the cargoes, then we must finish its delivery, but we still can adjust the delivery plan for other requests to change its transportation time. If a request state is delivered, it means that both the pickup and delivery of this request is done, we cannot do any removal or insertion to it. The state of vehicle
LNS Algorithm
We adopt the LNS algorithm developed by Shaw (
27
) to solve the routing part of 3L-PDPTW. The LNS algorithm is a widely used heuristic algorithm that keeps finding better solutions by searching the “neighborhood” of the current solution. In LNS, the neighborhood is implicitly defined by destroy and repair methods. The destroy method destroys part of the current solution, and then the repair method rebuilds the destroyed solution. The destroy method usually contains an element of randomness to destroy a different part of the solution each time the destroy method is called. The main processes are shown in Algorithm 1. We construct the initial solution with greedy insertion in Line 1 and set it as the candidate for best solution in Line 2. Between Line 4 and Line 10 we carry the LNS. In each iteration, we randomly choose removal heuristic and insertion heuristic to find the neighborhood of

In our study, we destroy our current solution
We use two kinds of insertion heuristic (greedy insertion, time insertion) and two kinds of removal heuristic (Shaw removal, random removal) in our model, which are introduced in this paragraph and the next two paragraphs. The Shaw removal, random removal, and greedy insertion methods are adopted from the adopted large neighborhood search heuristic devised by Ropke and Pisinger ( 20 ). Random removal randomly removes a request that has been assigned to a vehicle but has not been picked up. In on-demand cargo pooling, we track the state of each request and vehicle to mark whether they are available for removal and insertion. Therefore, we can only remove those requests that have been assigned to a vehicle but not been picked up. Greedy insertion traverses all the requests to be inserted, the vehicles to insert and the positions to insert, then selects one solution that causes the least cost increase. It is worth mentioning that this insertion is the most complex one, for it has to traverse all situations. Shaw removal removes the two assigned requests that are most similar between all assigned requests. The similarity between requests is calculated as follows:
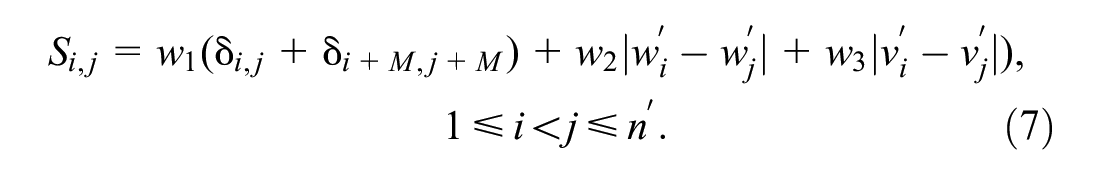
The
Besides these destroy and repair methods, we add time insertion, which inserts requests in chronological order. In this kind of insertion, we first sort all requests in order of LDT, traverse all the vehicles to insert and the position to insert, then select one solution that causes the least cost increase. Time insertion is similar to greedy insertion. Because of the lack of traversing of requests, time insertion can be done much faster than greedy insertion.
Tree Search
To solve the 3D-Loading problem, we adopt a TS algorithm developed by Chen et al. (
23
), which searches through a tree structure. Before introducing the algorithm, we first introduce the tree structure. Except for the root node, every node represents a kind of partial placement, the depth of node represents the number of cargoes this node has. For example, a node whose depth is four represents a kind of placement of
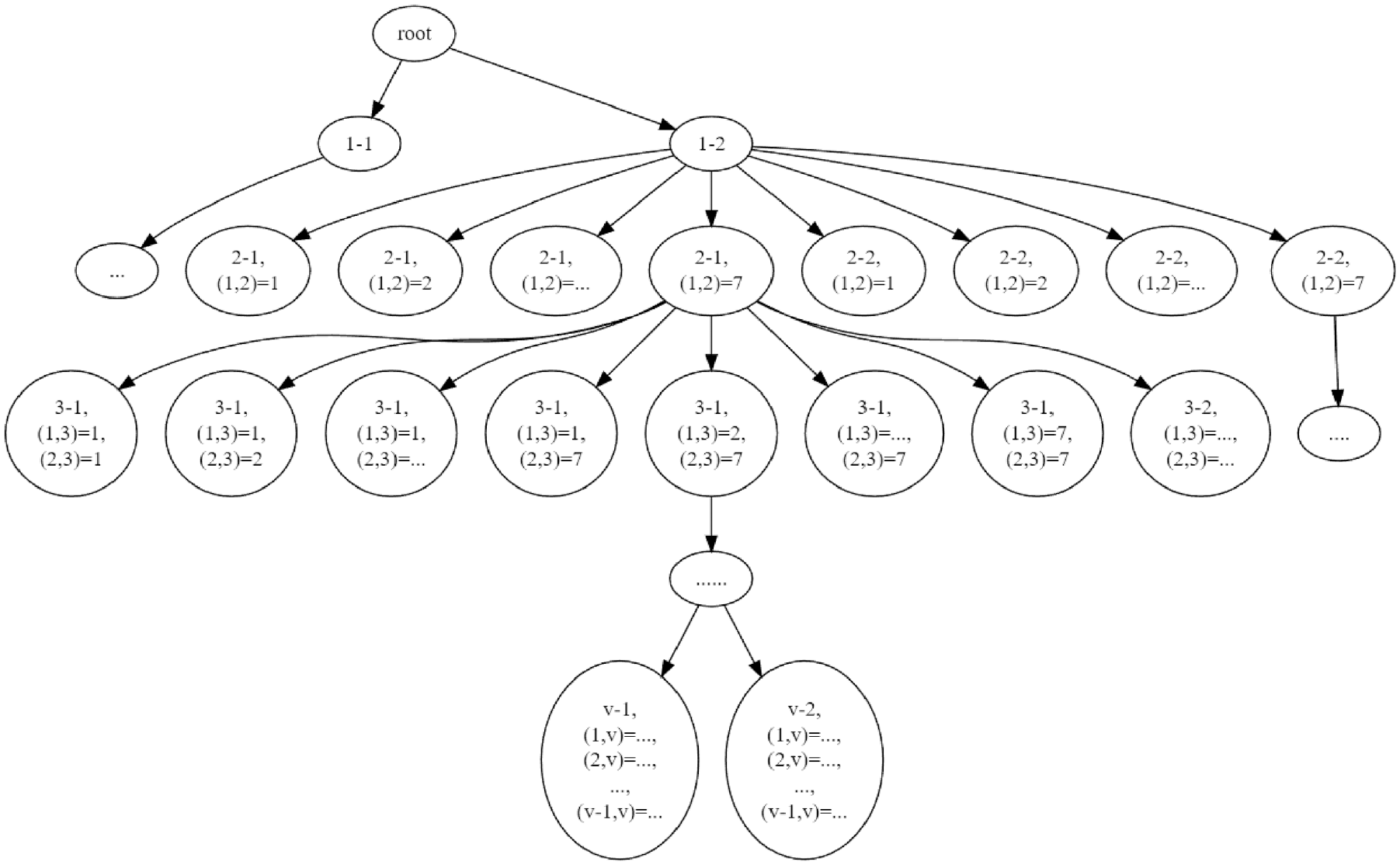
Illustration of the tree search algorithm.
The process of the algorithm is shown in Algorithm 2. In Line 1, we construct the tree

Numerical Experiments
To quantify the value of cargo pooling for on-demand city logistics, we conduct numerical experiments on real datasets and perform a sensitivity analysis on some parameters. Computational experiments are organized in the following four parts: dataset description, experimental setup, main result, and sensitivity analysis. All procedures are coded in the Python programming language using Visual Studio Code. All experiments have been conducted on a personal computer with five CPU and 12 GB RAM.
Description of Dataset
We use real demand data for the numerical simulations. Input to our model includes the set of shipping requests (origins, destinations, EPTs, LDTs, cargo dimensions, and estimated shipping charges). The cargo compartment dimensions of two types of vehicles are as follows: (i) length 1.8, width 1.3, height 1.1 and (ii) length 2.7, width 1.4, height 1.2. The freight requests are extracted from data collected in December 2021 in a city in the Yangtz River Delta, including an average of 16,000 requests per day. We have selected 508,391 requests information that chose the cargo pooling option for the numerical experiment. To gain a more intuitive grasp of the data, we randomly selected 500 requests and drew lines connecting all the pickup locations and delivery locations, as shown in Figure 6. The yellow points denote the pickup location and the red points denote the delivery point. The straight-line distance between the pickup point and the delivery point for almost all requests is less than 25 km.
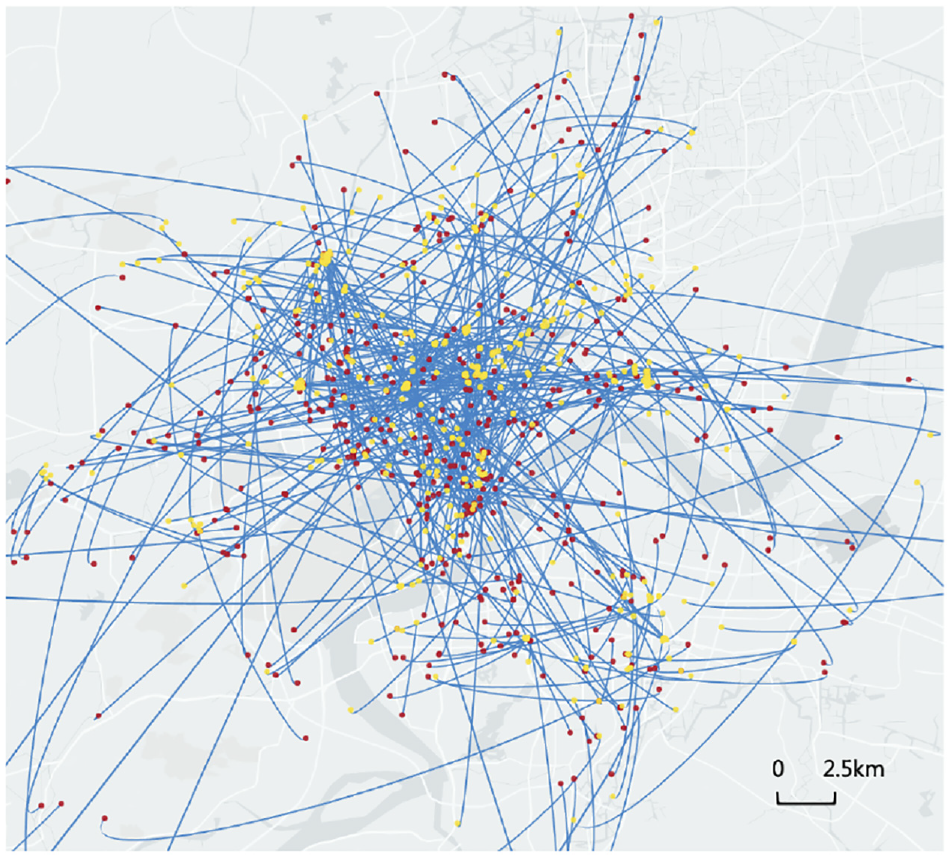
Geographical distribution of the sampling origin–destination pairs in our numerical tests.
To gain a better understanding of the datasets, we picked one of the days and plotted the results of number of requests received by time in percentage, as shown in Figure 7. Each data point on the line chart denotes the requests received in a 10 min interval, in percentage. We can tell that there are two peaks namely 10:00 in the morning and 14:00 to 15:00 in the afternoon. In addition, the histogram and cumulative distribution function of normalization results of transportation time in percentage are shown in Figure 8. We can tell that the vast majority of requests are delivered within an hour, a few requests take two hours to deliver, very few requests take more than two hours to deliver. Considering the business scenario, we mainly consider same-day and intra-city delivery. In data pre-processing, we eliminated requests that require more than a day for transportation and those with pickup and delivery points located in different cities. We then divided the remaining requests into time periods of 10 min each for input. It is worth mentioning that the LDT will be the actual delivery time. Since the actual time is too demanding for situation of cargo pooling, we will introduce the concept of time flexibility. In sensitivity analysis, we extend the LDT and repeat the experiment. The length of extended time is named the level of time flexibility.
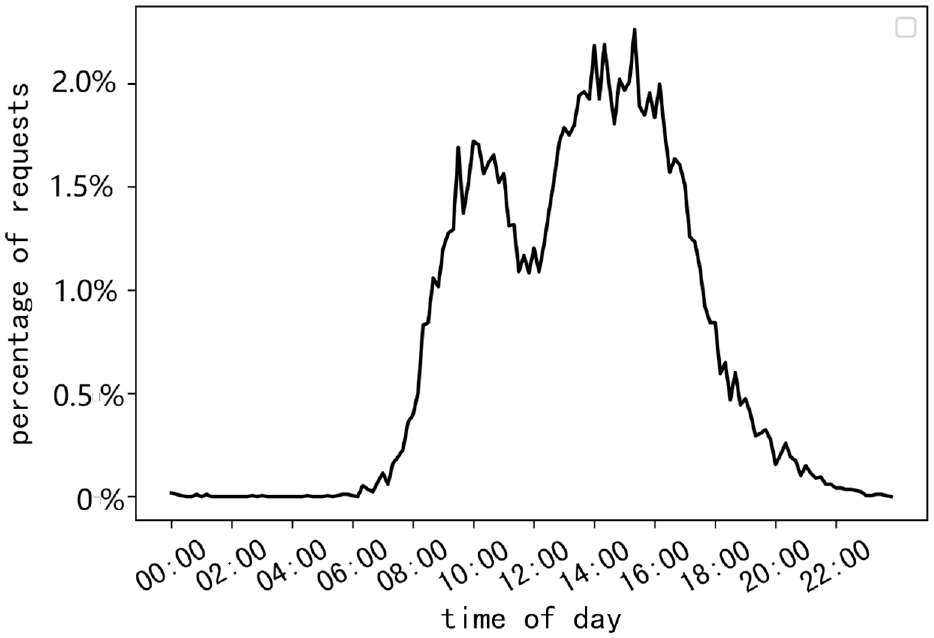
Distribution of the number of shipping requests received every 10 min.
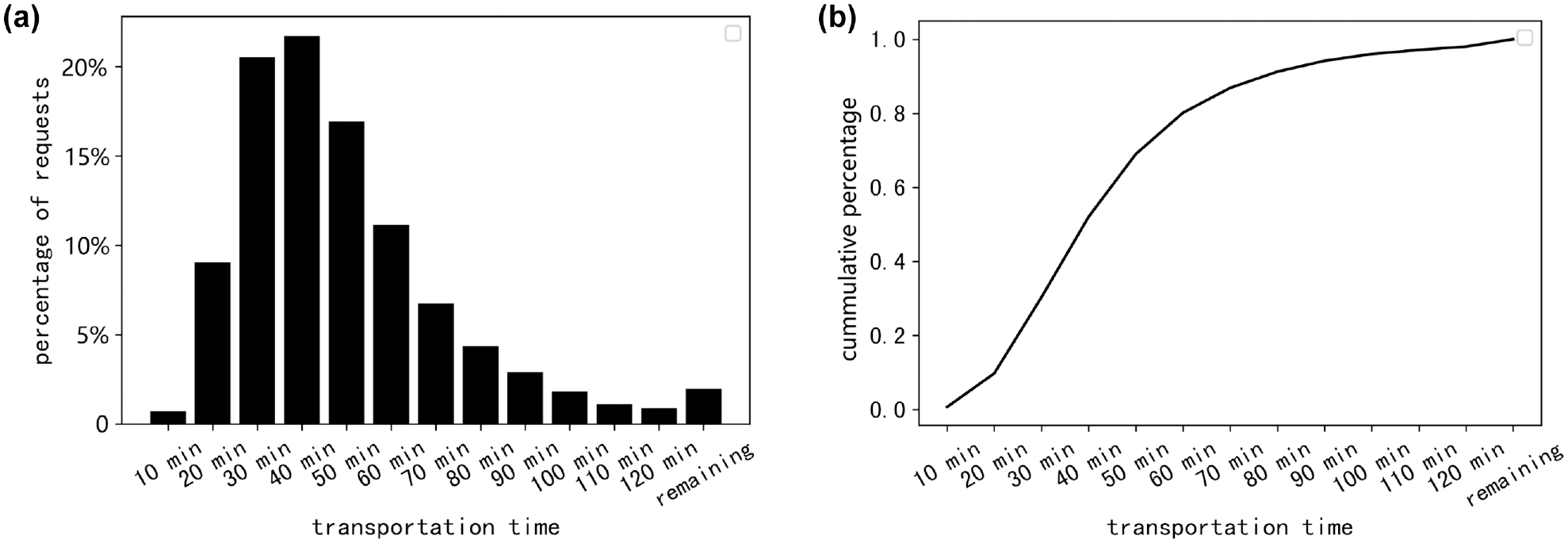
Descriptive statistics of transportation time: (a) distribution of the transportation times for completed shipping requests and (b) cumulative distribution of the transportation times for completed shipping requests.
Experimental Setup
In the experiment setup, we set the weights in Shaw removal as
For the case of our datasets, on one hand, during peak demand periods more than 350 requests arrive every 10 min, which is more than what is typical in existing studies. On the other hand, we need to let the shippers know in 1 min whether their shipping requests are accepted. Therefore, we have to make a trade-off between solution quality and running time. The logistics company usually sets a maximum number of requests for each type of vehicle when conducting cargo pooling during the actual operation. This is modeled above as maximum requests constraints. Maximum number of requests can reduce the number of visits for 3D-Loading checks and avoid doing insertion heuristics to a vehicle whose cargo compartment is almost full, which essentially is a trade-off between algorithm efficiency and running time.
The running time of re-optimization is crucial because the optimization system must assign new requests that arrive within each 10 min period, as well as unfinished requests from previous periods. During the system’s operation, customers and drivers are waiting for the results of cargo pooling, so we set a business requirement of 1 min. The main considerations are the waiting time of customers, computing resources, and responsiveness of the system.
To determine the most suitable maximum number of requests that can achieve a good solution in a suitable running time, we carry out the cargo pooling with different maximum number of requests. Then we record the average reduction in cost and the average running time. The results form Table 2. The two numbers in the first column represent the maximum numbers of requests of cargo vans and small trucks respectively. Because the length, width, and height of small trucks are larger than those of cargo vans, the maximum number of requests we set for small trucks is larger than for cargo vans. We select the maximum number of requests that provides the optimal cost reduction while ensuring the running time is less than 60 s. As marked in bold in Table 2, we choose (3,4) as the maximum number of requests, which means that cargo vans can deliver up to three requests at the same time, and that small trucks can deliver up to four requests at the same time. The following experiments were carried out under this setting.
Algorithm Efficiency and Running Time Under Different Maximum Number of Requests Without Time Flexibility
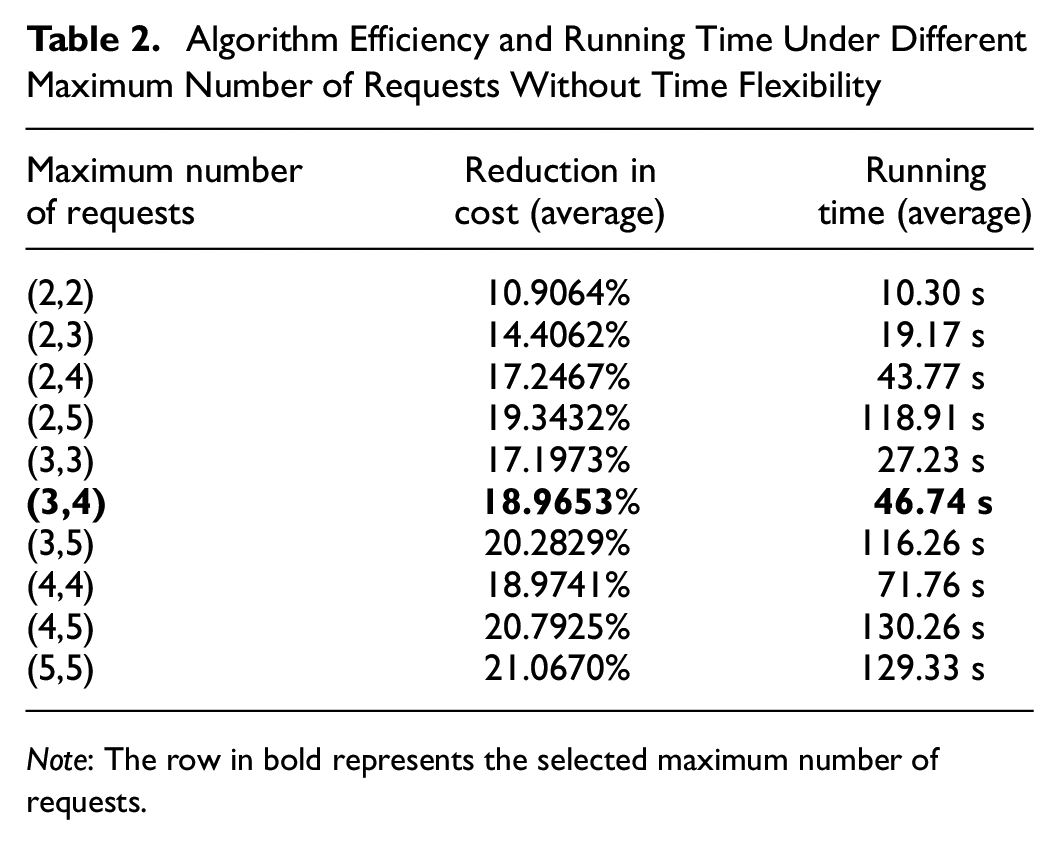
Note: The row in bold represents the selected maximum number of requests.
We also need to determine the probability of each operator being selected. Therefore, we conduct a sensitivity analysis on the probability of operator selection and record the percentage (pct.) reduction of total cost, the pct. reduction of vehicle miles traveled (VMT) and the running time. The results are shown in Figures 9 to 11, where “p1” denotes the probability that the Shaw removal is selected and “p2” denotes the probability that the greedy insertion is selected. From Figures 9 to 11, we can observe that the operator selection probability has little impact on the running time, but has a great impact on the algorithm effect. The largest pct. reductions of total cost and VMT occur when Shaw removal has a selection probability of 0.7 and greedy insertion has a selection probability of 0.9. The following experiments are carried out under this setting.
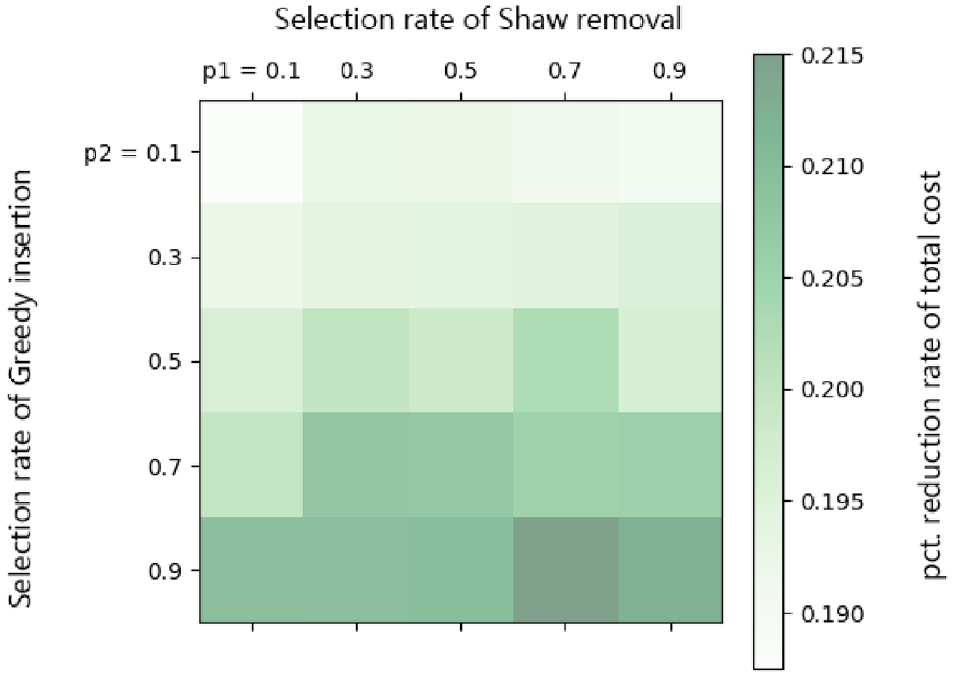
Percentage reduction of total cost under different probability of operator selection.
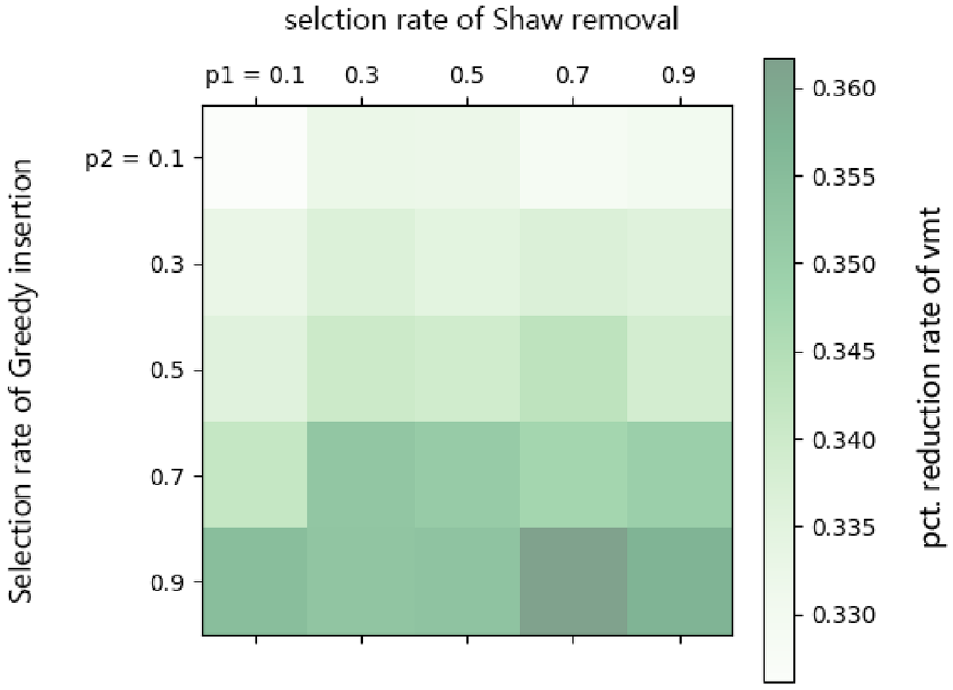
Percentage reduction of vehicle miles traveled (VMT) under different probability of operator selection.
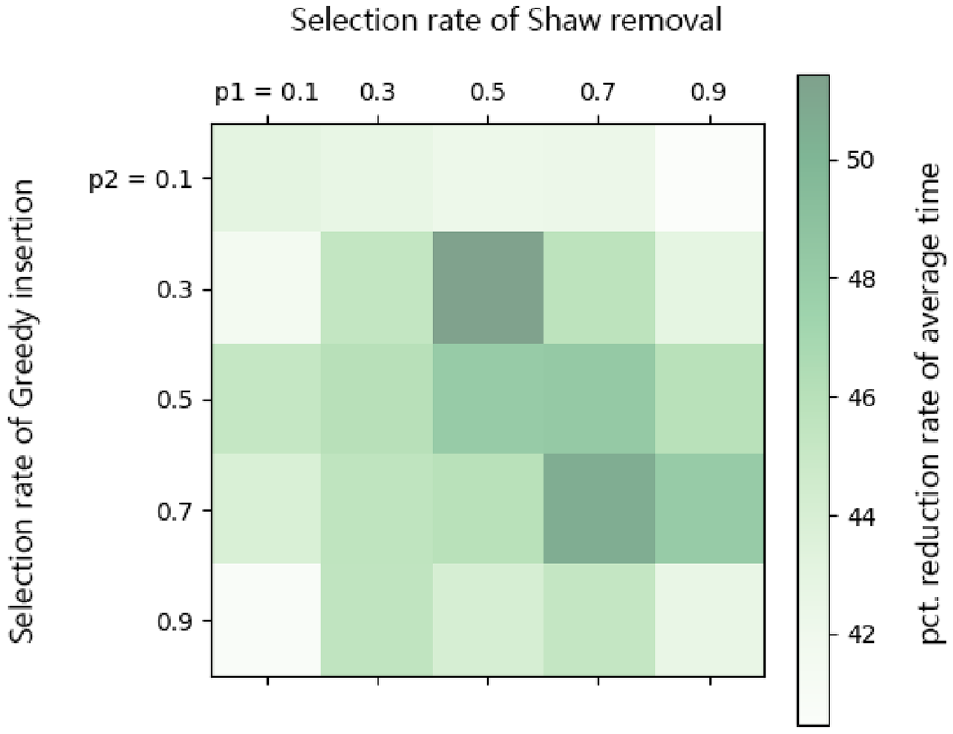
Running time of re-optimization under different probability of operator selection.
Main Results
In this section, we perform cargo pooling in on-demand ICFL. The detailed results of each small time period are shown in the Table 3. The table lists the results of each static cargo pooling, including the number of requests received, cost of distance with and without cargo pooling, penalty for late delivery with and without cargo pooling, number of reloading, total cost with and without cargo pooling, VMT with and without cargo pooling, percentage of total cost reduction and percentage of VMT reduction.
Detailed Results of Each Small Time Period Without Time Flexibility
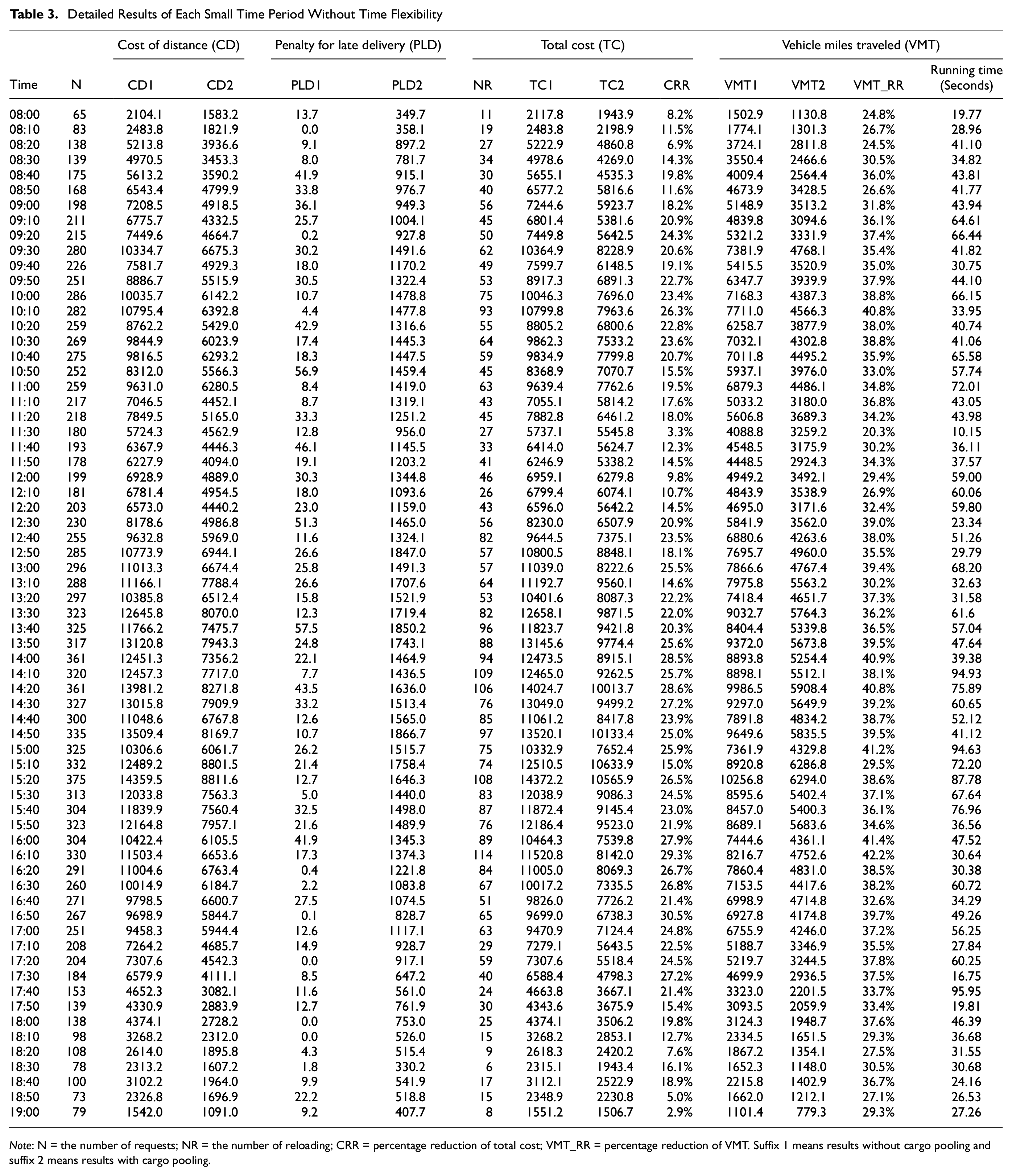
Note: N = the number of requests; NR = the number of reloading; CRR = percentage reduction of total cost; VMT_RR = percentage reduction of VMT. Suffix 1 means results without cargo pooling and suffix 2 means results with cargo pooling.
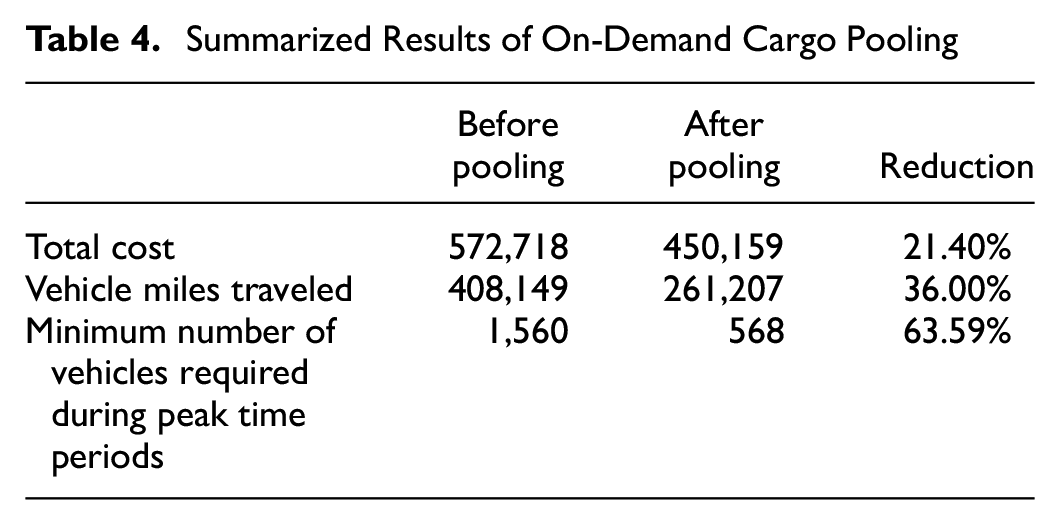
A summary of the results in Table 3 is shown in Table 4. We extracted some parameters that are of most interest in this study, including total cost with and without cargo pooling, percentage of cost reduction, VMT with and without cargo pooling, percentage of VMT reduction and minimum number of vehicles required with and without cargo pooling. The minimum number of vehicles required is equal to the maximum number of vehicles used to fulfill all delivery requests across all periods.
Summarized Results of On-Demand Cargo Pooling
To better quantify the value of cargo pooling for on-demand city logistics, we divide the results in Table 3 into peak periods and off-peak periods, and check the value of cargo pooling at the two time periods respectively. If the number of requests arriving within 10 min is greater than 250, this period is called peak period. If not, it is called off-peak period. The results are summarized in Table 5. The average NR denotes the average number of reloading.
Results in Peak Periods and Off-Peak Periods
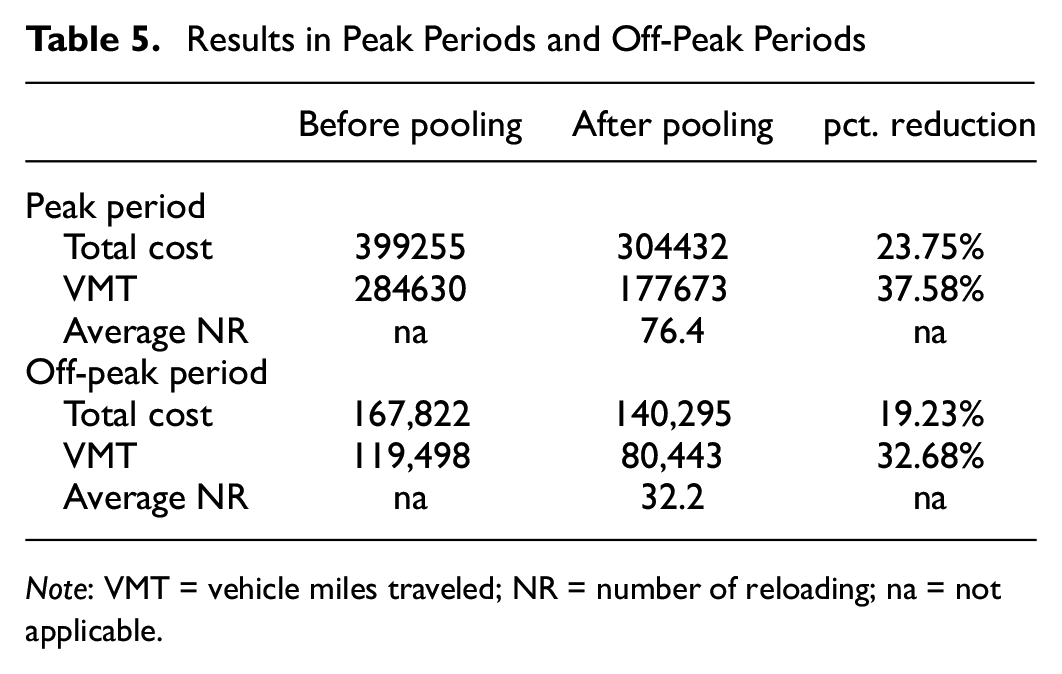
Note: VMT = vehicle miles traveled; NR = number of reloading; na = not applicable.
We also compare situations where we allow reloading in the problem versus when we offer LIFO and no reloading. The results are shown in Table 6.
Comparison Between LIFO and Reloading

Note: LIFO = Last-in First-out.
Analysis of Main Results
Based on Tables 3 and 4, it is evident that cargo pooling results in significant reductions in both daily cost (21.40%) and VMT (36%). These findings demonstrate that cargo pooling can effectively reduce the cost of logistics companies in on-demand ICFL, as compared with the traditional point-to-point service model. Furthermore, the traditional model would require at least 1,560 vehicles to fulfill all requests during peak periods, whereas cargo pooling reduced this number to 568, thereby increasing supply during high demand periods. These improvements highlight the substantial benefits of cargo pooling over the traditional point-to-point service model in on-demand ICFL. Consequently, for logistics companies with high business volumes, cargo pooling can help meet more requests, reduce costs, and maintain competitiveness in the on-demand ICFL market.
According to Table 5, cargo pooling results in a 19.23% reduction in total cost during off-peak periods, while during peak periods it can reduce total cost by 23.75%. These findings demonstrate that the greater the number of requests, the more significant the total cost reduction achieved through cargo pooling. A similar trend is observed for VMT reduction, with cargo pooling reducing VMT by 32.68% during off-peak periods and 37.58% during peak periods. This is because a larger number of requests provides more opportunities for request consolidation, enabling more efficient cargo pooling. This principle underscores the importance of cargo pooling for rapidly growing or large logistics companies that receive a significant volume of on-demand requests.
It can be seen from Table 6 that cargo pooling with LIFO can reduce VMT by 30.95%. But cargo pooling with reloading can reduce VMT by 36.00%, which is much bigger. As for the total cost reduction, the difference between the two situations is not significant. The differences between the situation with LIFO and with reloading are: (i) the LIFO rule limits the freedom of path choice, so the VMT in the situation with LIFO will be longer; (ii) allowing reloading will cause extra labor cost and longer staying time. The experimental results are in line with our expectations. The pct. reduction of VMT in the reloading situation is 30.95%, which is less than the 36.00% reduction of VMT in the LIFO situation. But with the extra labor cost and penalty for late delivery caused by longer staying time, the pct. reductions of total cost in these two situations, 20.74% and 21.40%, show little difference. This presents logistics companies with the option of whether to permit reloading. The ideal choice will depend on factors such as the company’s staff salary level and other relevant considerations, which should be determined through simulation.
Sensitivity Analysis on Time Flexibility
In this section, we experiment with on-demand cargo pooling under different levels of time flexibility. As introduced before, we adjust the time flexibility through extending the time windows of delivery. We choose 10 min, 20 min, and 30 min as three different levels of time flexibility.
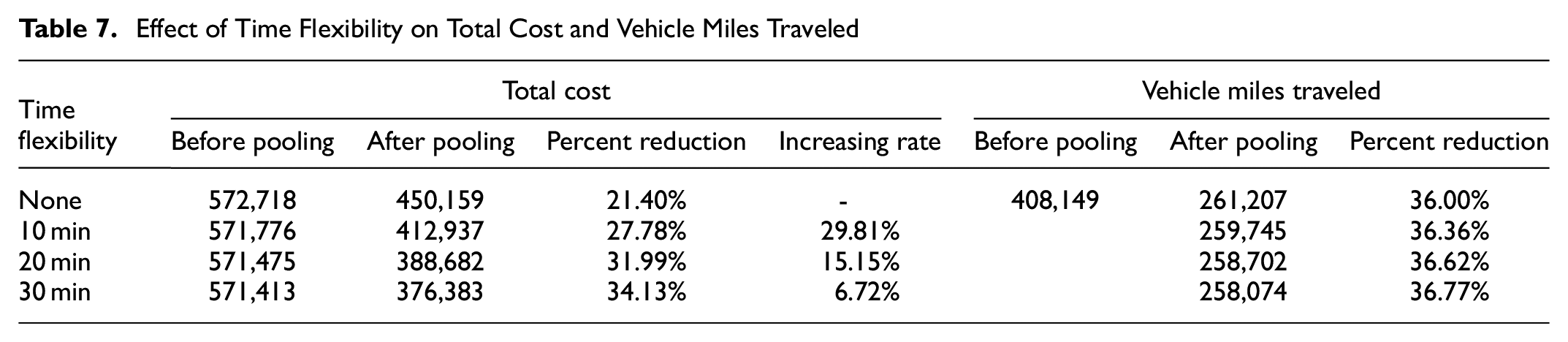
A summary of the on-demand cargo pooling under different levels of time flexibility is shown in Table 7. Except for the increasing rate of pct. of cost reduction when time flexibility increases, other parameters are the same as in Table 4. It can be seen that the total cost reduction can increase with the increase of the level of time flexibility. But as the level of time flexibility increases, the increase in cost reduction gradually becomes slower, from 29.81% to 15.15% and 6.72%. This means that there is a saturation threshold for time flexibility, which means the maximum of the delay caused by cargo pooling. As introduced at the beginning of this paper, cargo pooling is a way to reduce total cost and total VMT by extending the delivery time of a single request. Adding time flexibility can reduce the impact of extended time on a single request. Sensitivity analysis for time flexibility can help logistics companies better assess the reduced customer experience and cost reduction brought about by cargo pooling. However, it is difficult to reduce VMT by time flexibility, and it is the stable optimization of the logistics system by cargo pooling. Furthermore, the impact of time flexibility on the minimum number of vehicles required is shown in Table 8. The reduction in minimum number of vehicles required is also stable as time flexibility changes. It is worth mentioning that the minimum number of small trucks required plus the minimum number of cargo vans required is larger than the minimum number of vehicles required in total. This is because of
Effect of Time Flexibility on Total Cost and Vehicle Miles Traveled
Effect of Time Flexibility on Minimum Number of Vehicles Required

Conclusion and Future Work
In this study, we aim to address the issue of vehicle shortage during high demand periods by investigating the benefits of cargo pooling in on-demand ICFL. We establish a dynamic PDP with 3D-Loading and time window constraints for cargo pooling in on-demand ICFL and develop a dynamic algorithm for the solution. Through a simulation experiment utilizing real-world freight data, we demonstrate that cargo pooling can significantly reduce both the distance traveled by cargo vans and the overall cost. Additionally, we examine the effect of varying levels of delivery time flexibility and find that while time flexibility has a significant impact on cost reduction, it has a minimal effect on total VMT. Our research provides valuable insights for logistics companies in determining the value of cargo pooling and can serve as a reference for their cargo pooling practices.
However, our research still has some limitations. In our future research, we will improve our model in the following aspects:
We will develop a predictive model and take the randomness of requests into consideration. In each optimization period, we will experiment with cargo pooling with historical requests, newly arrived requests, and predicted requests.
Our static part is modeled as 3L-PDPTW, which takes a long time to solve. We do not take into account the running time of the program in this paper. In practice, new requests and routes can only be assigned to vehicles after the program has finished running. And within these minutes, the states of the vehicles and the requests may also change.
In this study, we assume that all customers accept the cargo pooling service. In the future, we will model a shipper’s choice between cargo pooling and conventional point-to-point service and develop a hybrid cargo pooling model.
Besides the model limitations, logistics companies are also faced with some barriers to implement the cargo pooling in on-demand ICFL:
1. Since the dimensions of cargoes can be irregular, it can be difficult for shippers to describe the cargo sizes adequately and accurately, which may lead to failure of the cargo pooling exercise in practice;
2. There is risk of cargoes being taken out by mistake or broken when reloading;
3. Not all customers are willing to accept cargo pooling—the platform needs to offer a choice between cargo pooling and standard service;
4. In current operations, there is no punishment to the driver if late delivery occurs;the pricing strategy needs more research.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: S. Cao, H. Jiang; data collection: Z. Lei, L. Zhao, S. Cao; analysis and interpretation of results: Z. Lei, H. Jiang, S. Cao, L. Zhao; draft manuscript preparation: Z. Lei, H. Jiang. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is funded by the National Natural Science Foundation of China under grant no. 72361137005 and by Tsinghua University-DiDi Joint Research Center for Future Mobility.