
Abstract
This study demonstrates the feasibility of utilizing machine learning (ML) for routine identification of sand particles. Identifying different types of sand is necessary for various geotechnical exploration projects because understanding the specific sand type plays an important role in estimating the physical and mechanical properties of the soil. To accomplish this, dynamic image analysis was employed to generate a substantial volume of sand particle images. Individual size and shape descriptors were automatically extracted from each particle image. The analysis involved use of 40,000 binary particle images representing 20 different sand types, and a corresponding six size and four shape descriptors for each particle (400,000 parameters). Six ML models were trained and tested. The work demonstrates that using size and shape features the models efficiently identified up to 49% of individual sand particles. However, when clusters of particles were considered in conjunction with a voting algorithm, classification accuracy significantly improved to 90%. Among the ML models studied, neural networks performed the best, while decision tree exhibited the lowest accuracy. Finally, the use of size consistently outperformed shape as a classification parameter but combining size and shape parameters yielded superior results across all sands and classifiers. These findings suggest that ML holds much promise for automating sand classification using ordinary images.
Keywords
The identification and categorization of soils not only play a vital role in the fields of geotechnical, geological, and hydrological engineering but also contribute to well-informed decision-making for construction, agriculture, and environmental activities ( 1 , 2 ). Traditionally, the sieve analysis method has been the conventional means of ascertaining the distribution of sand particle sizes within geotechnical engineering. However, this method is labor-intensive and time-consuming, and provides results of limited accuracy, especially for particles smaller than 300 µm ( 3 ). Additionally, the process becomes more intricate when attempting to characterize particle shapes. The classic method for shape classification involves the utilization of the Krumbein-Sloss chart, which relies on visually comparing particles with reference images, making the process both cumbersome and susceptible to subjectivity ( 4 , 5 ).
Supervised machine learning (ML) algorithms employ an automatic inductive approach to recognize patterns within data and establish connections between these patterns and their corresponding labels. Inductive reasoning involves drawing general conclusions from specific observations or examples. In the context of supervised ML, the term “inductive” signifies that these algorithms learn from specific labeled examples provided in the training data. They generalize patterns and relationships from the observed data to make predictions or classifications on new, unseen data. In simpler terms, the inductive approach of supervised ML involves learning from specific instances to make broader generalizations about how new, similar instances should be categorized or predicted. Once these relationships are learned, they can be applied to similar data to assign labels to new data points. This technique has been introduced for the automated identification and classification of mineral and volcanic ash particles and the spatial prediction of shallow landslides ( 6 – 8 ). However, most of these studies focused on large area scene analysis, such as geographic maps or plant leaves, which means it would not be suitable for the classification of sand type ( 9 , 10 ). None of these studies employed images where individual particles are visible. In addition, in some cases these studies employed complex stereo-images ( 11 ).
Dynamic image analysis (DIA) has been utilized for capturing images of individual particles, ranging in quantity from 1,000 to 1,000,000 particles ( 3 ). Recent advancements in image segmentation hold the promise of enabling the identification of individual particles within a standard sand image captured by a camera or a soil probe, such as a vision cone ( 12 ). However, DIA operates by capturing individual images of a moving specimen, creating a substantial collection of separate particle images. This obviates the need for segmenting the region of interest, resulting in a sizable image dataset suitable for statistical analysis and application in computer-vision-based soil classification. Moreover, DIA furnishes engineering descriptors for size and shape that can effectively represent sand characteristics across various scales ( 13 ). Lastly, a pre-trained ML classifier can produce identification results for a new specimen by utilizing the same class of image features used during training.
This research paper delves into the application of ML methods in the realm of sand classification. One of the primary goals of this study is to investigate the precision and efficiency of categorizing sand particles using various ML classifiers, all while utilizing engineering size and shape descriptors. This approach enables the accurate classification of individual sand particles to a satisfactory degree. Prior studies by the authors first involved the use of size and shape descriptors as features in ML, and identified which features are independent of each other ( 13 ). This first step was carried out using six sands. Next, the authors explored using seven different ML algorithms for classification of nine sands ( 14 ). In this work, we employ shape and size descriptors as features and vastly increase the difficulty of the classification task by extending the sands being classified to 20 using the six best-performing classifiers. In prior research, it was established that ML techniques, specifically neural networks (NN), could effectively identify 75% of sand particles by relying on size and shape descriptors across nine distinct sand types ( 14 ). The current study aims to evaluate the effectiveness of ML-based sand classification in tackling a considerably more intricate classification task. To accomplish this, a dataset featuring 20 distinct sand types was compiled and employed to train six distinct ML models. The analysis was conducted using 2,000 binary particle images for each sand type, which were obtained through DIA (i.e., images were black and white with no grayscale). The work demonstrates that ML-based classification of sand can be carried out swiftly, non-destructively, and precisely, at levels consistent with what can be expected from manual classification by a trained engineering geologist.
ML thus has the potential to alleviate the workload of geologists and engineers while enhancing accuracy by automating tasks that would otherwise be impractical because of the extensive time and effort required to process the vast amount of information.
Features Used for Sand Classification
Sand particles can be characterized as numerical values within ML models. These values must correspond to distinctive features that enable differentiation of various objects. Desirable features must be informative, discriminating, and independent, to permit effective analyses in ML models.
Engineering size and shape descriptors have long been used for particle classification ( 15 ). However, their use has been limited by the difficulty and labor-intensive nature involved in acquiring them manually. In recent years, micro-computed tomography, and especially DIA, have made acquiring this information feasible for large datasets.
DIA offers the opportunity of providing many size and shape features that can be used for classification with ML. The method employs a high-frame-rate camera combined with a pulsed laser to image millions of individual particles in a short time (
3
). DIA feeds specimens into a hopper that disperses particles to the imaging unit at a constant rate. A vibrating tray is used to help separate the particles (Figure 1). Particles fall through a 50 cm-long shaft into the imaging plane. As particles travel through the imaging plane, particle shapes are captured at a frame rate of up to 175 frames per second with a 4-megapixel (
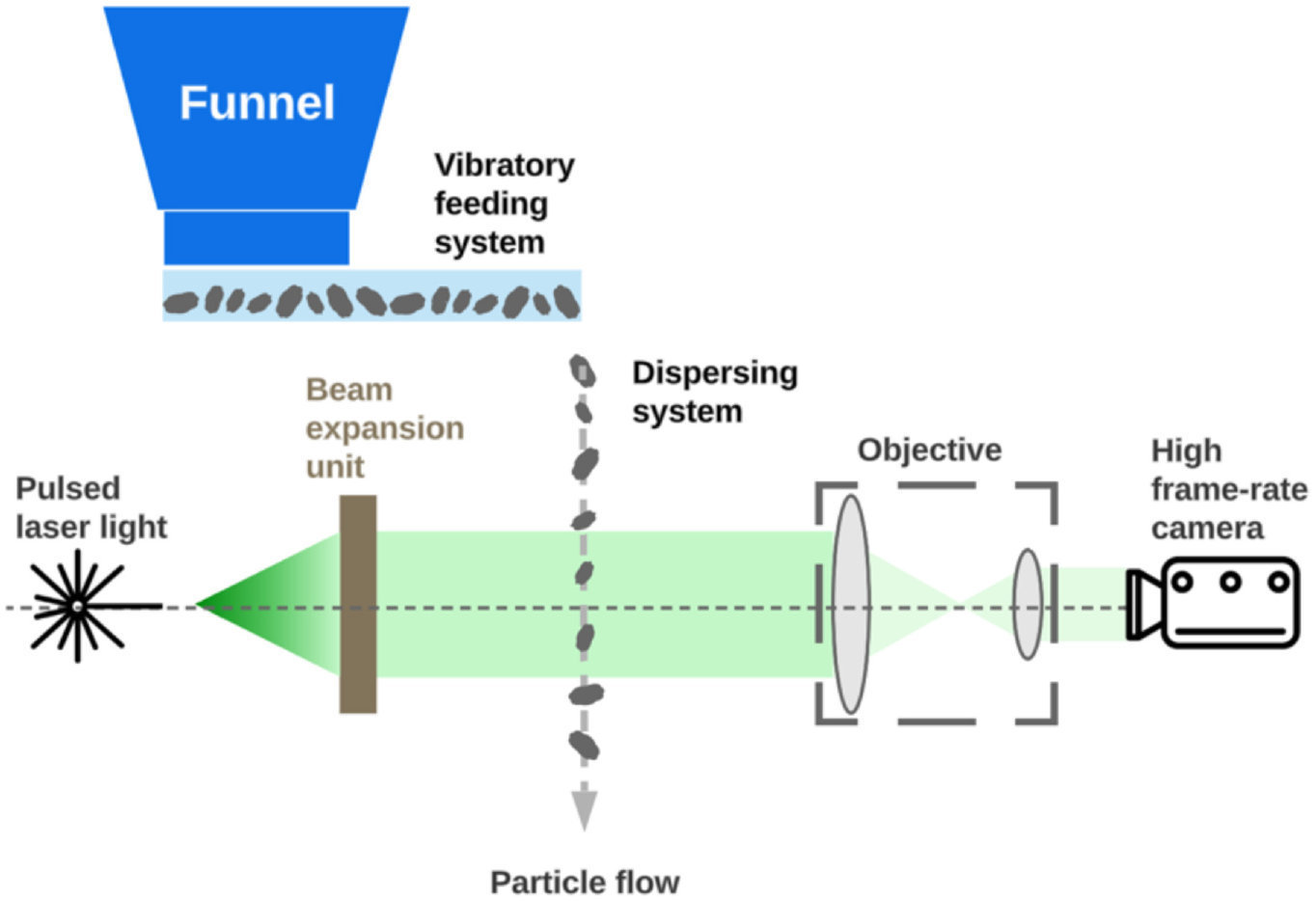
Schematic of dynamic image analysis device.
Commonly used size descriptors include equivalent projected circle (EQPC) diameter (de), maximum and minimum Feret diameter (dFmax and dFmin), maximum inscribed circle and minimum circumscribed circle diameters (dins and dcir) and perimeter equivalent circle diameter (PED). These size descriptors can measure dimensions of irregular particles in multiple manners (Figure 2). Similarly, shape descriptors are able to capture global and intermediate scales of particle morphology. Four independent shape descriptors were identified by Li and Iskander, to represent: 1) proportion of axis (aspect ratio [AR]), 2) convexity (Cx), 3) smoothness of the perimeter (sphericity [S]), and 4) roundness of corners (Wadell roundness [R]) ( 13 ). In general, the values of shape descriptors range from 0.0 to 1.0, corresponding from an infinitely irregular particle to a perfect circle, respectively.
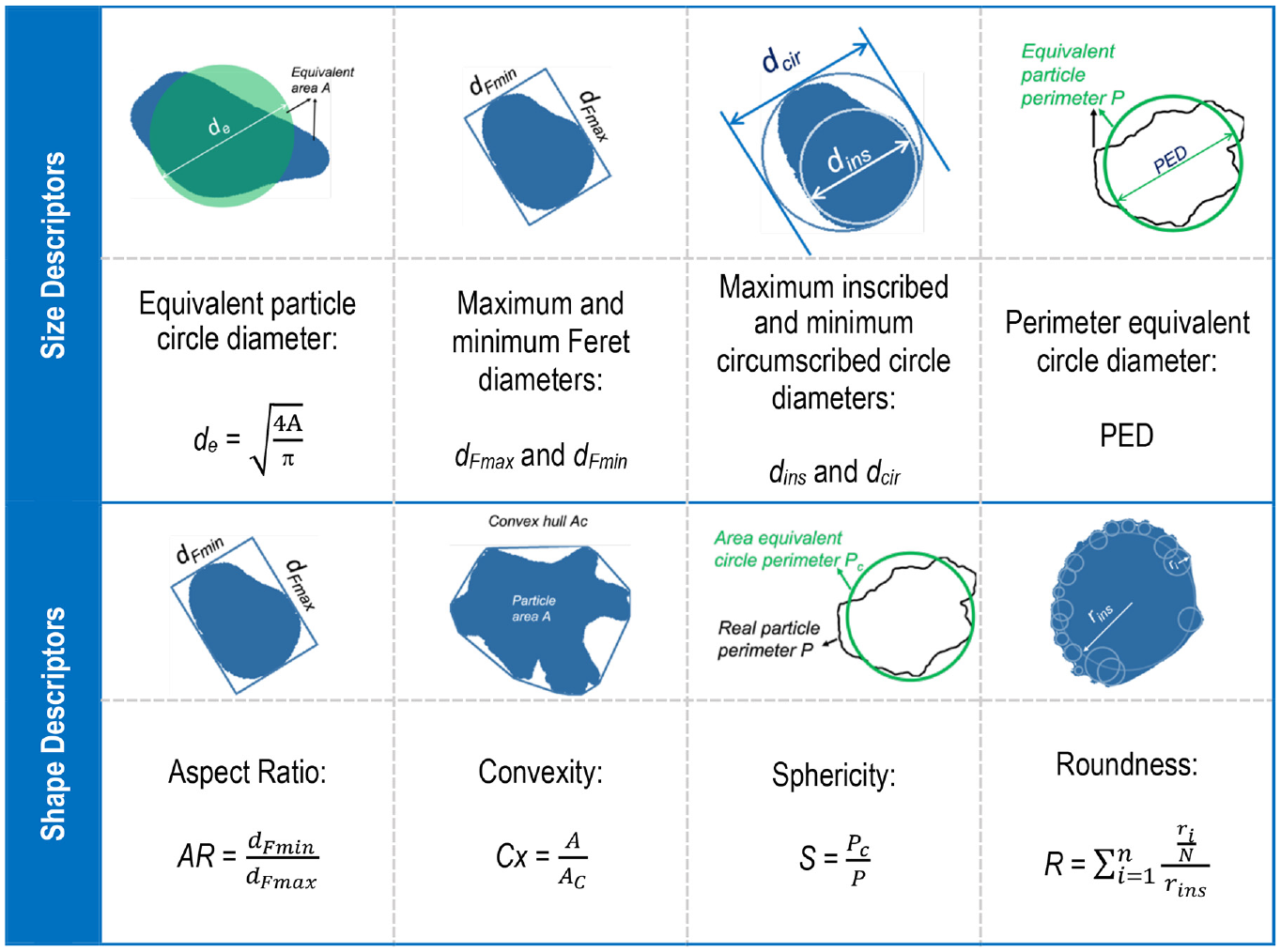
Particle size and shape descriptors.
These four shape and six size parameters were selected because: 1) they were previously shown to be independent of each other, 2) they are sufficient for classification analysis using ML, and 3) prior work has demonstrated that the highest classification accuracy was achieved when all 10 parameters were employed in the ML models ( 14 ).
Sands to Be Classified
Twenty sand specimens were utilized for analysis in this study. These sands were selected to cover a diverse range of sizes and shapes, effectively representing the intricate nature of sands encountered in classification scenarios. Details of the EQPC and Feret sizes, and shape descriptors, are available in Table 1. The information in Table 1 was acquired by the authors using DIA apparatus. These materials can be categorized as shown in Table 1.
Statistics of Shape and Size Descriptors Employed
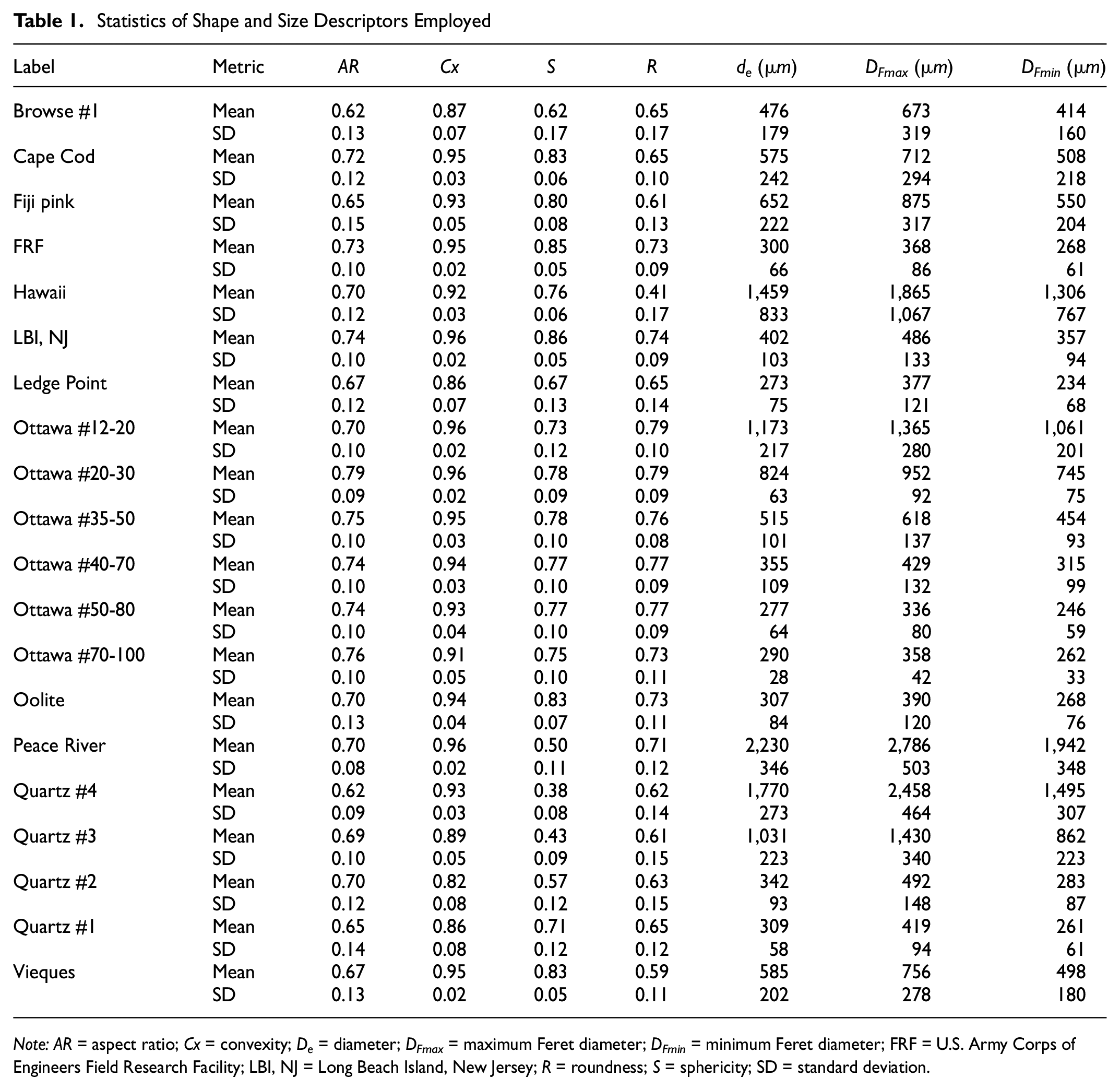
Note: AR = aspect ratio; Cx = convexity; De = diameter; DFmax = maximum Feret diameter; DFmin = minimum Feret diameter; FRF = U.S. Army Corps of Engineers Field Research Facility; LBI, NJ = Long Beach Island, New Jersey; R = roundness; S = sphericity; SD = standard deviation.
Machine-Sorted Sands
The following machine-sorted sediments were purchased from a materials supplier (Figure 3). All machine-sorted sands are poorly graded.
Dynamic image analysis images of 10 machine-sorted sands employed in this study.
Natural Sediments
Natural sand sediments were collected by the authors in an ad hoc process from a variety of beaches, suppliers, and research test sites (Figure 4).
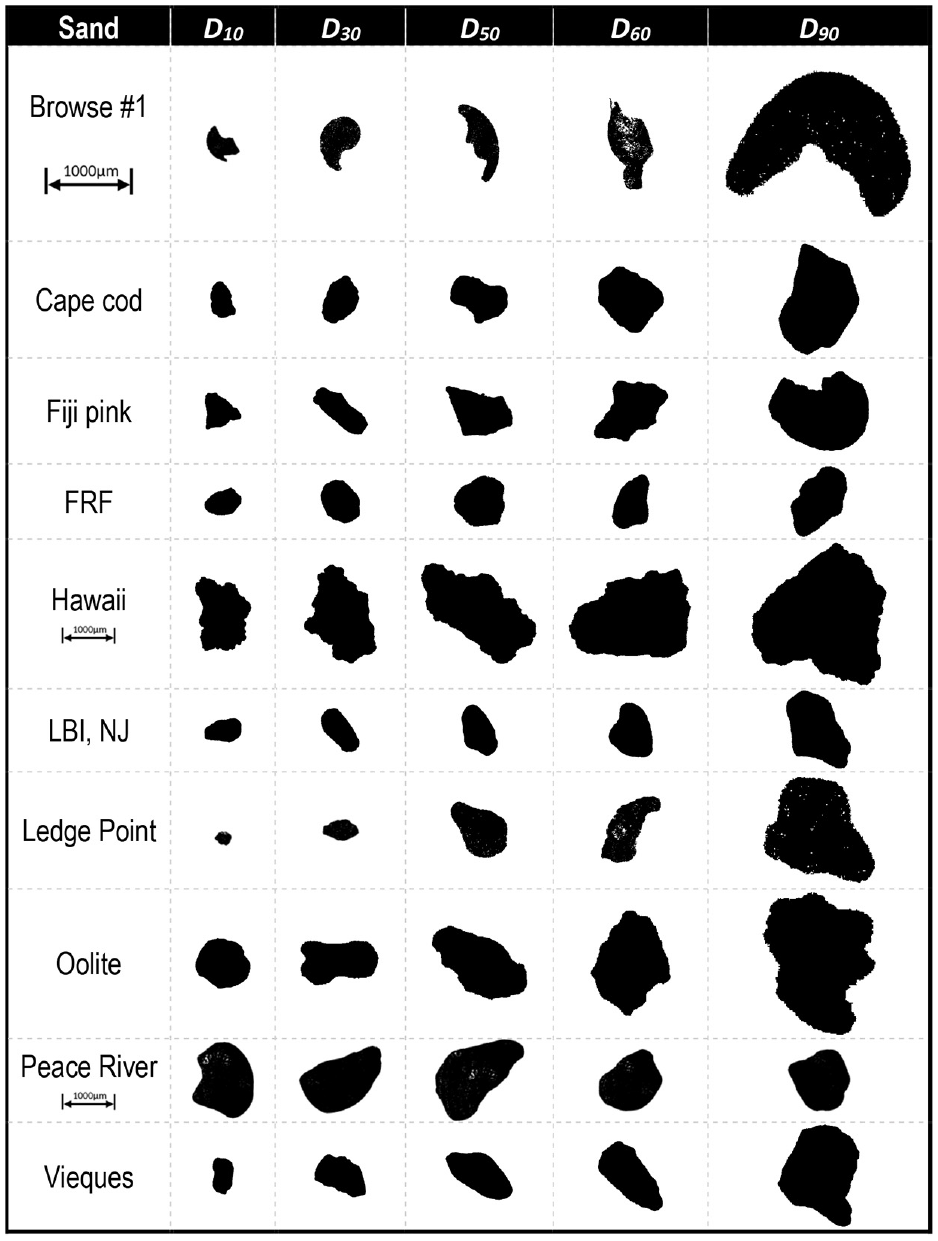
Dynamic image analysis images of 10 natural sands employed in this study.
Statistical Analysis of Dataset
A total of 2,000 particle images were captured by DIA for each type of sand, which resulted in a dataset consisting of 40,000 binary images. A QICPIC (Sympatec, Clausthal-Zellerfeld, Germany) equipped with an M7 camera lens was employed for capturing binary images with a resolution of 4 µm/px. Therefore, sand particles smaller than 200 µm were excluded from consideration since their image resolution was less than 50 pixels wide, which is not sufficient for meaningful analysis.
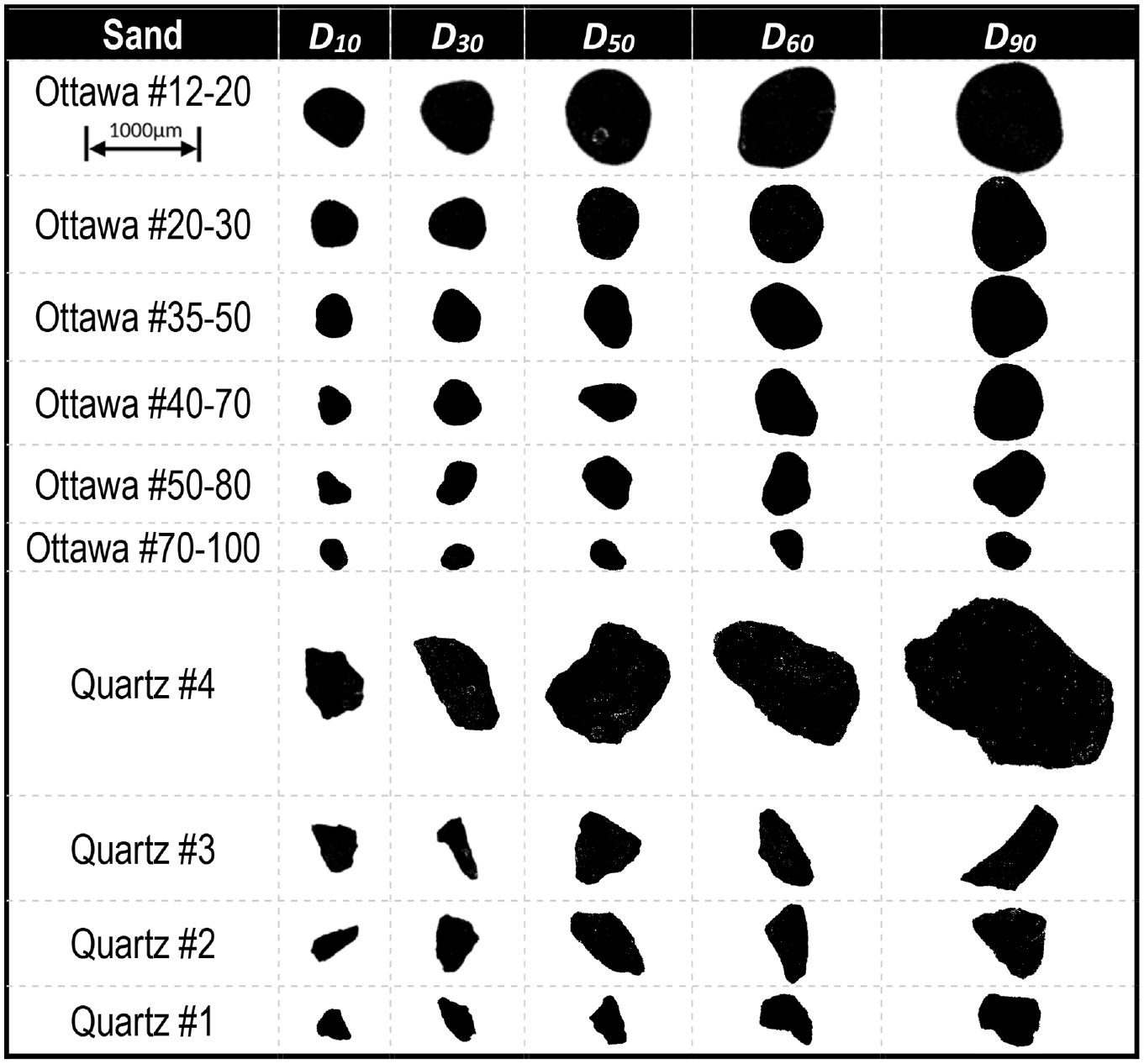
Representative DIA particle images of the 20 sands are shown in Figures 3 and 4. The cumulative particle size distributions of the 20 tested sands were computed from the EQPC diameter, illustrated in Figure 5. The distributions were represented using volume percentage for each sand. Volume distributions are believed to represent mass distributions obtained from sieve analysis as long as the material possesses a uniform specific gravity throughout the specimen.
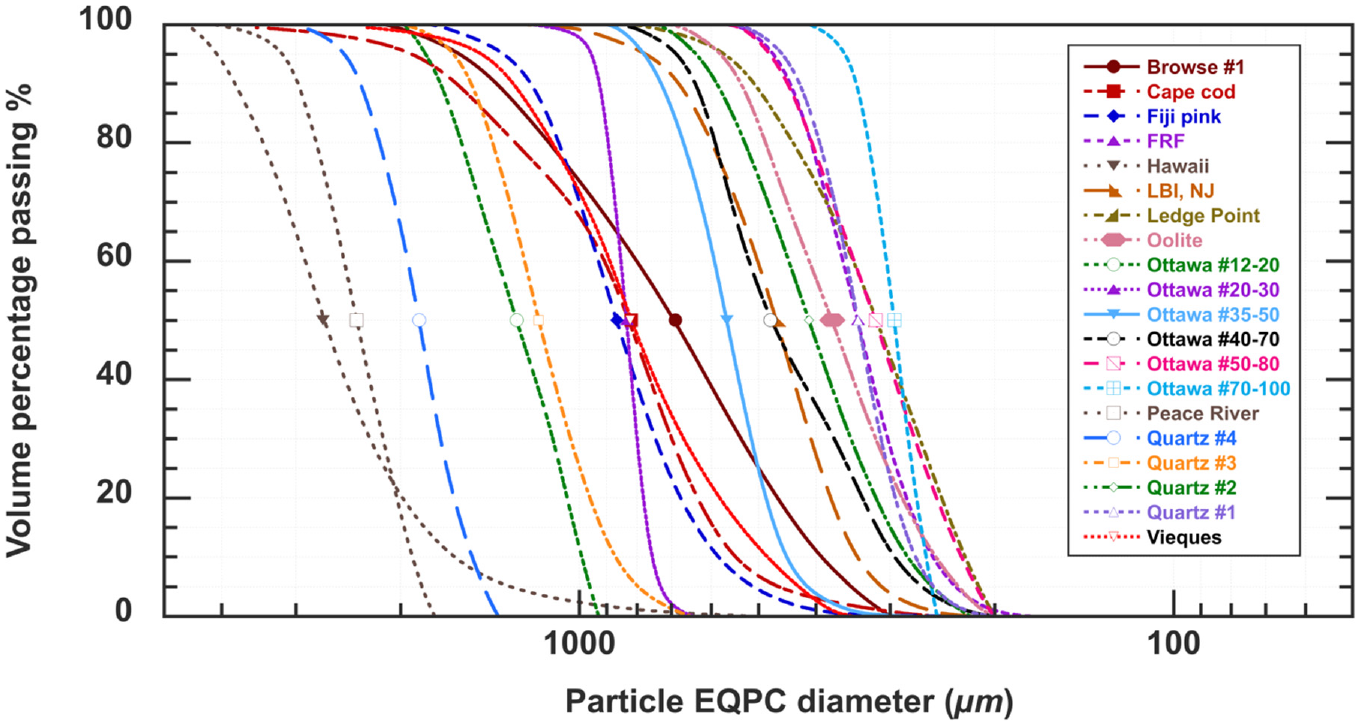
Particle size distribution of 20 classified sands.
All 20 sands are poorly graded, but they each possess a distinct size distribution. With the exceptions of Hawaii and Peace River sands, having D50 values of 2,375 µm and 2,701 µm, respectively, the chosen sands possess median particle sizes with D50 ranging from 316 µm to 1,861 µm. These sizes are categorized as fine-to-medium sands, while Hawaii and Peace River stand as the only coarse sands. Despite variations in particle size among the sands, identifying each sand solely by size would be challenging because of overlapping sizes across the various sands.
The statistical values of six typical size and four shape descriptors are presented in Table 1 for the 20 sands. All values are calculated using the size and shape descriptors obtained from DIA. A wide variety of shapes can be identified using the employed shape descriptors. The employed shape descriptors allow for the identification of a diverse array of particle shapes. The distribution of S and R values spans from 0.3 to 0.8, while AR values tend to fall within the range of 0.62 to 0.79. Notably, Cx displays the smallest standard deviation, with values consistently exceeding 0.82. These Cx values imply the absence of concave features on all sand surfaces, whereas AR values indicate that particles maintain a moderate level of elongation. Nevertheless, subtle distinctions also emerge among particles of similar sand types but varying sizes. For instance, in the case of Ottawa sands, #20-30 exhibits larger shape values compared with #40-70, despite both sands being classified as rounded according to the Krumbein-Sloss chart method ( 4 ). Similarly, calcareous sediments such as Oolite, Fiji pink, Hawaii, Browse #1, and Ledge Point display irregular particle shapes because of significant concavities and convexities on their surfaces. However, the angularity varies across these sands. In summary, it can be concluded that visually classifying the 20 examined natural sands poses a considerable challenge when relying on subjective visual observations, owing to their overlapping shape and size descriptors.
Machine Learning (ML) Classifiers
Several ML models were explored for classification of sands based on their sizes and shapes. All ML analyses were implemented using readily available packages in Python®, as identified later. The following is a brief description of the ML models adopted in this work. More detailed description of these models is readily available in other papers ( 18 – 20 ). The classification task involves assigning one of 20 labels to each particle of sand, the labels being sand type (Table 1, Figures 3 and 4).
K-Nearest Neighbors (KNN)
K-nearest neighbor (KNN) classification algorithms make predictions about the class of a data point using a majority voting principle ( 21 ). Initially, the model is trained through by splitting the data into training and test sets. Next, the Euclidean distance is computed between the examined data points and the training dataset. In this process, K denotes the quantity of neighboring training points to incorporate into the classification process. The geometric distance dimensions are determined by the number of features present (with dimensions ranging from 4 to 60 in various analyses, encompassing up to six size and four shape attributes). The method presumes that instances within a dataset will generally exist in proximity to other instances that have similar properties. If the instances are tagged with a classification label, then the value of the label of an unclassified instance can be predicted based on the labels of its nearest neighbors. The distances from diverse shape and size parameters to the corresponding values in the particle being classified are thus utilized to classify individual particles. Consequently, the highest combined kernel densities were used for classification. The number of neighboring training points to be included in classification was taken in this study as K = 20, where 20 is the number of data points (i.e., particles) used for computing the nearest neighbor.
Support Vector Machines (SVM)
Support vector machines (SVM) have found extensive use in geotechnical applications for both classification and regression tasks, such as recognizing mineral grains automatically and predicting the axial load capacity of piles (
22
–
24
). The core principle behind SVM for classifying different entities involves identifying a hyperplane within the feature space. This hyperplane effectively separates distinct classes from one another. A crucial aspect is that the hyperplane should maximize its distance from the support vectors, which can represent diverse shape and size attributes, for instance. SVM classifiers face limitations when directly applied to classify multiple types of sands within a dataset. The approach involved classifying each individual type of sand against all other sands present. Consequently, this resulted in the creation of 190 binary sand classification models (
Decision Tree
Decision tree is widely used in ML to produce a treelike model of decisions ( 25 ). It creates a tree-like model where each internal node represents a test or condition on an attribute, and each leaf node represents a class label (in classification). The tree structure is designed to help make decisions based on input features and learn patterns from the training data. In this study, shape and size features are employed as decision nodes. To identify the most favorable splits, a cost function is utilized. For instance, when a decision tree commences its splitting process, it evaluates each feature in the training data. The prediction for a specific group is derived by calculating the mean of the responses from the training data inputs within that group. A Gini score was employed to decide the efficacy of a split ( 26 ). Gini score calculates the probability that a feature is misclassified. The model computes the discrepancy between the Gini score before a split and the average Gini score after the dataset split, based on the given attribute values. A good split thus reduces the Gini score. Decision trees are interpretable, easy to visualize, and capable of capturing complex relationships in data. However, they are prone to overfitting, especially if they grow deep and complex trees. To mitigate this, techniques such as pruning (removing unnecessary branches) and using ensemble methods such as random forests are often employed.
Random Forest
Random forest is an ensemble learning technique that leverages the strengths of multiple decision trees to achieve improved predictive performance and generalization ( 27 ). It is particularly effective in handling complex datasets with high dimensionality and noise ( 28 ). The algorithm’s fundamental idea is to create a “forest” of decision trees, each trained on a different subset of the data and employing a subset of the available features. While growing each individual tree, the algorithm only considers a random subset of features for each node split. This feature selection randomness further contributes to the diversity of the trees. Once all the trees are trained, they collectively make predictions for new data points. For classification tasks, each tree “votes” for a class, and the class with the most votes becomes the final prediction. This method is widely used in various ML classifiers and can provide robust and accurate predictions.
Neural Networks (NNs)
NNs also known as Artificial Neural Network (ANN) are a classifier of ML model inspired by the structure and functioning of the human brain ( 29 ). They are designed to recognize patterns and relationships in data, making them particularly powerful for tasks such as image and speech recognition, natural language processing, and more. NNs consist of interconnected layers of nodes, also known as neurons, that process and transform input data to produce desired outputs. The basic building blocks of an NN are neurons. Neurons receive inputs, perform computations, and produce outputs. Neurons are organized into three types of layer. NNs have achieved state-of-the-art results in various fields but require substantial amounts of data and computation power for training. Advances in hardware and artificial intelligence techniques have enabled the development of more complex and efficient NN architectures, contributing to the rapid progress of deep learning research ( 30 , 31 ).
Ensemble Voting
Ensemble voting is a technique that involves combining distinct ML classifiers, each with its own unique concept, and leveraging a majority vote strategy to predict class labels. Ensemble voting is particularly useful when individual models perform well on different subsets of data or when they excel in different aspects of the task. It is a way to harness the power of diversity and collaboration to achieve better overall results. In majority voting, the anticipated class label for a specific sample corresponds to the class label that represents the most frequently occurring (mode) prediction across the individual classifiers. In this study, the five individual classifiers SVM, KNN, random forest, decision tree, and ANN were employed as an ensemble.
Results and Discussion
Five individual ML classifiers and the ensemble voting methods were employed for sand classification. In this study, 20 sands dataset with 40,000 (
Test Accuracy and Efficacy of Different Machine Learning Models
Note: NA = not available.
Feature scaling in ML is one of the fundamental techniques used for data pre-processing. It improves the performance and robustness of ML algorithms, such as KNN and SVM, by making uniform the Euclidean distance of size and shape features under consideration ( 33 ). Therefore, normalization and standardization were applied in the present study, as follows:
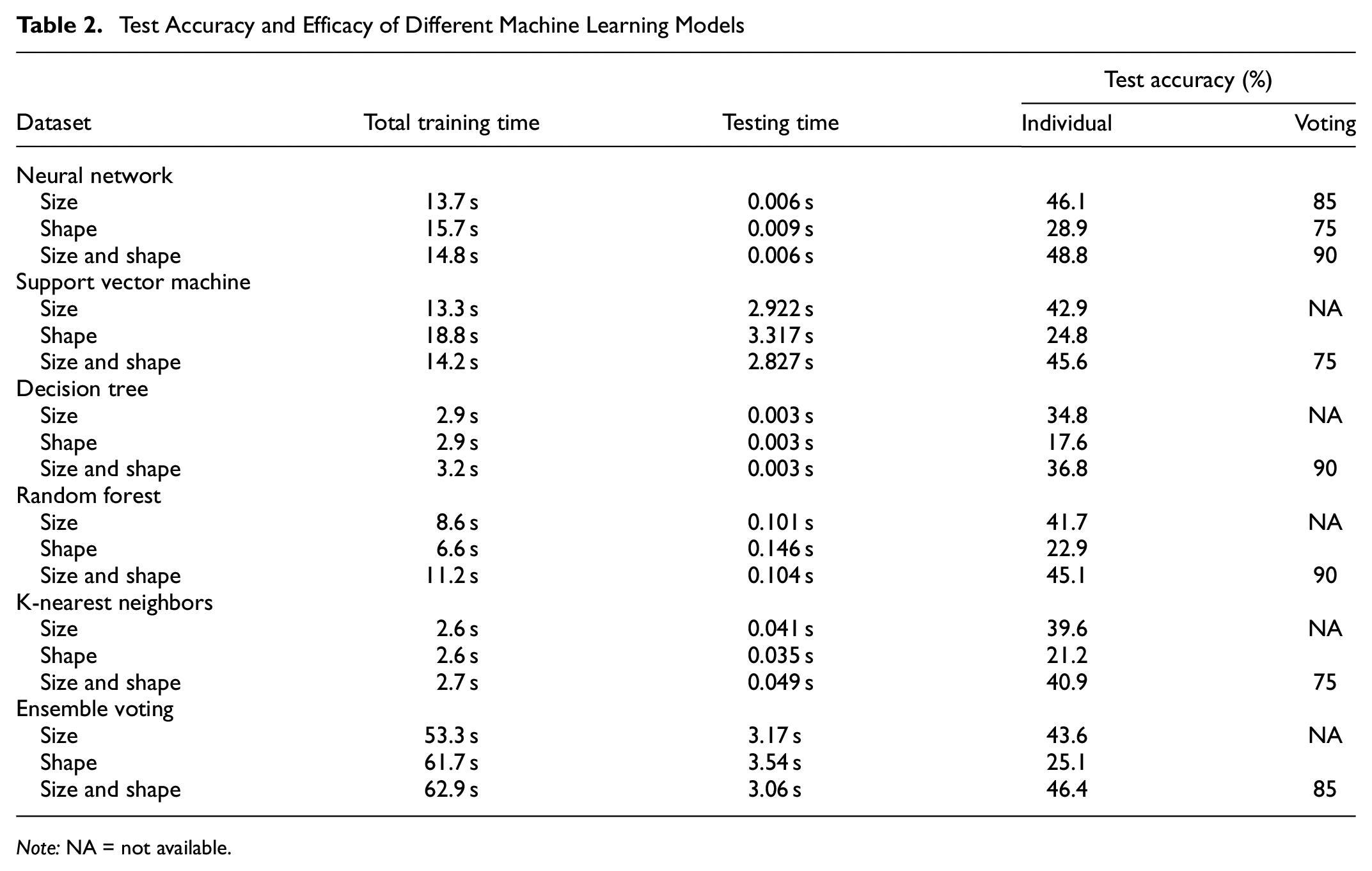
The performance of each classifier for sand particle classification was evaluated using mean accuracy, as shown in Table 2. Classification accuracy is defined as the ratio of the correctly predicted number of individual particles to the total number of sand particles. A 10-fold cross-validation was employed, by randomly splitting the dataset into 10 subsets, so that the test accuracy was performed using one subset (
In general, sand classification using size descriptors alone tends to yield better accuracy compared with using shape descriptors alone, across various ML classifiers. The average classification accuracy was 41.5% versus 23.4%. The reason is that the selected sands have a larger size variability compared with shape variability. The highest classification accuracy of 46.1% was achieved by employing an NN classifier using size-related features. On the other hand, when relying solely on shape features, the mean accuracy remains lower, falling within the range of 17.6% to 28.9%. When both size and shape features are combined in the ML models, the classification accuracy improves to 36.8%–48.8% using all classifiers. The greatest classification accuracy was observed using NNs with 48.8% of individual particles correctly classified. Engineering shape descriptors alone cannot differentiate the 20 examined sand particles well within the ML models. However, it is essential to combine size and shape descriptors together to reach the maximum accuracy. Finally, decision tree exhibited the lowest accuracy of 34.8%, 17.6%, and 36.8% using size, shape, combined size and shape together, respectively. Thus, the decision tree model is not suggested for solving individual sand classification problem.
Surprisingly, the application of ensemble methods did not significantly enhance classification accuracy compared with individual classifiers. For instance, the ensemble voting approach produced a slightly lower outcome than the individual NN classifier, yielding an overall accuracy of 43.6%, 25.1%, and 46.4% compared with 46.1%, 28.9%, and 48.8% using size, shape, size and shape together, respectively (Table 2).
Training time and testing time are also summarized in Table 2. All analyses were efficiently carried out on a personal MacBook Pro computer with an Apple M2 chip with 16 GB memory. The efficiency of the analyses can be attributed to the analyses employing numerical values representing shape and size features, rather than particle images. All algorithms were implemented using Python sklearn packages and were completed within a few seconds to 1 min. There is not a significant difference between using the number of features for classifying sands, but the ensemble voting method takes the longest computation time because of the necessity of iterating through each individual classifier. However, the maximum required time for training was 63 s.
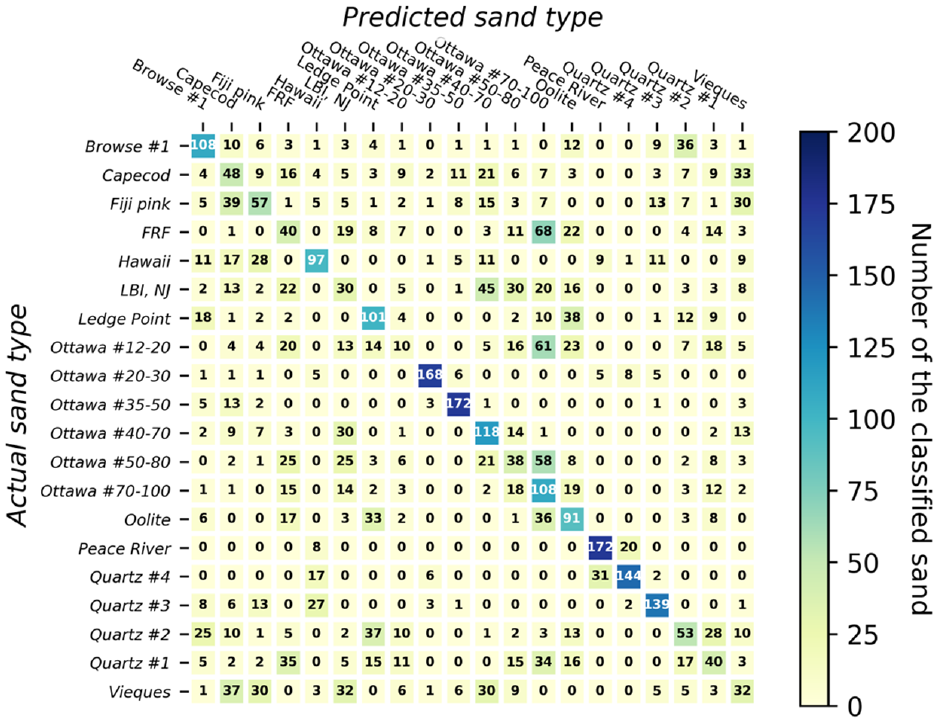
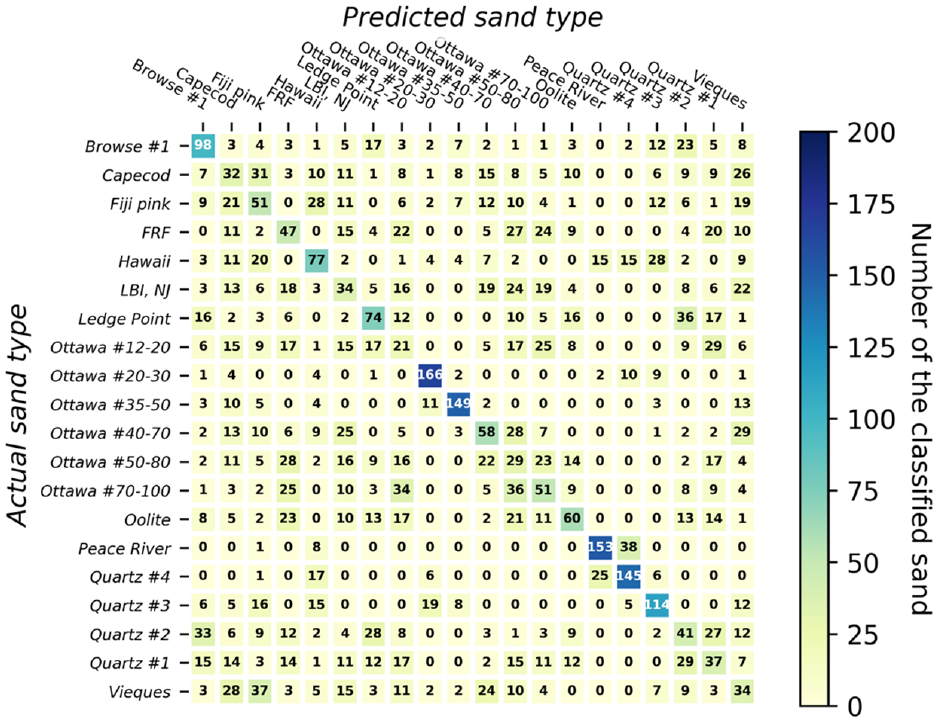
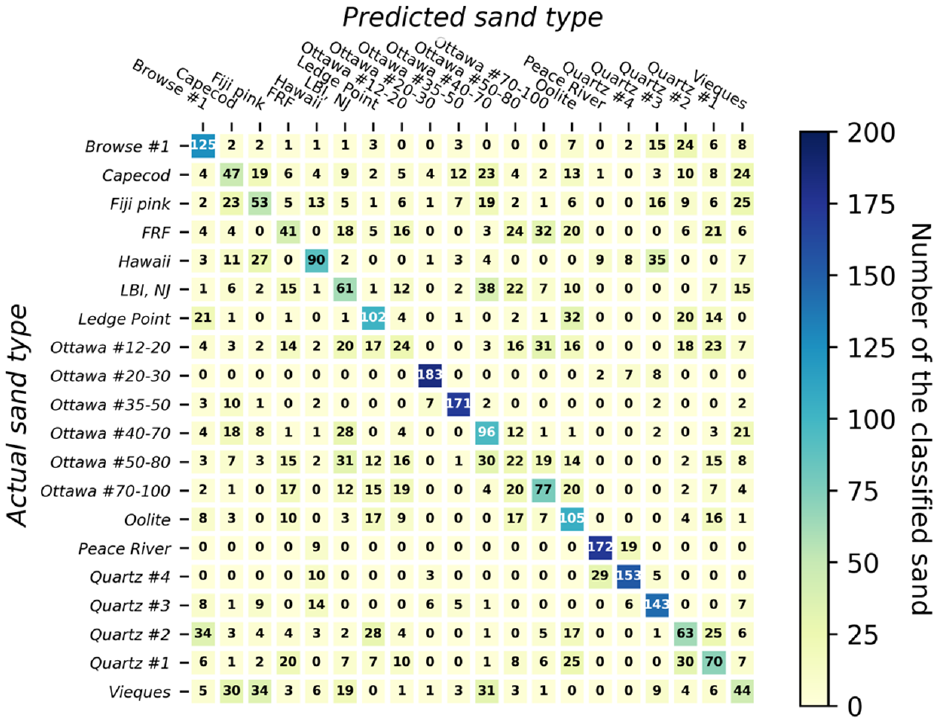
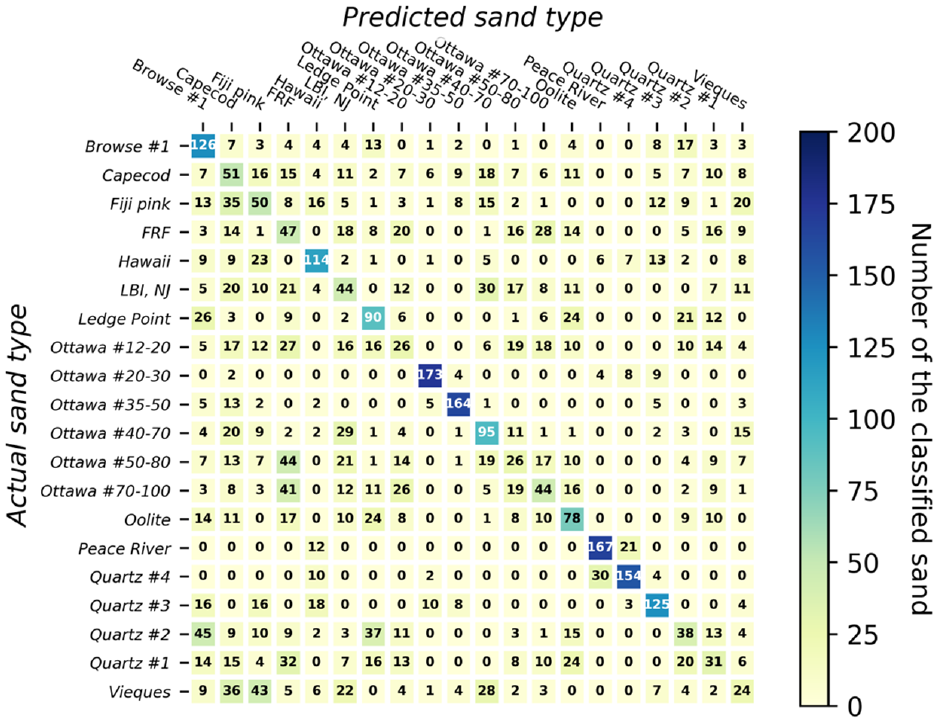
A confusion matrix, often referred to as an error map, serves as a visual representation that illustrates the performance of an ML algorithm. The matrix depicts the number of accurately classified particles corresponding to each specific type of sand within a dataset of 20 types of sand. Each row of the matrix corresponds to the actual sand type of instance, while each column corresponds to the predicted sand type. In this study, the matrix comprises a grid with dimensions of
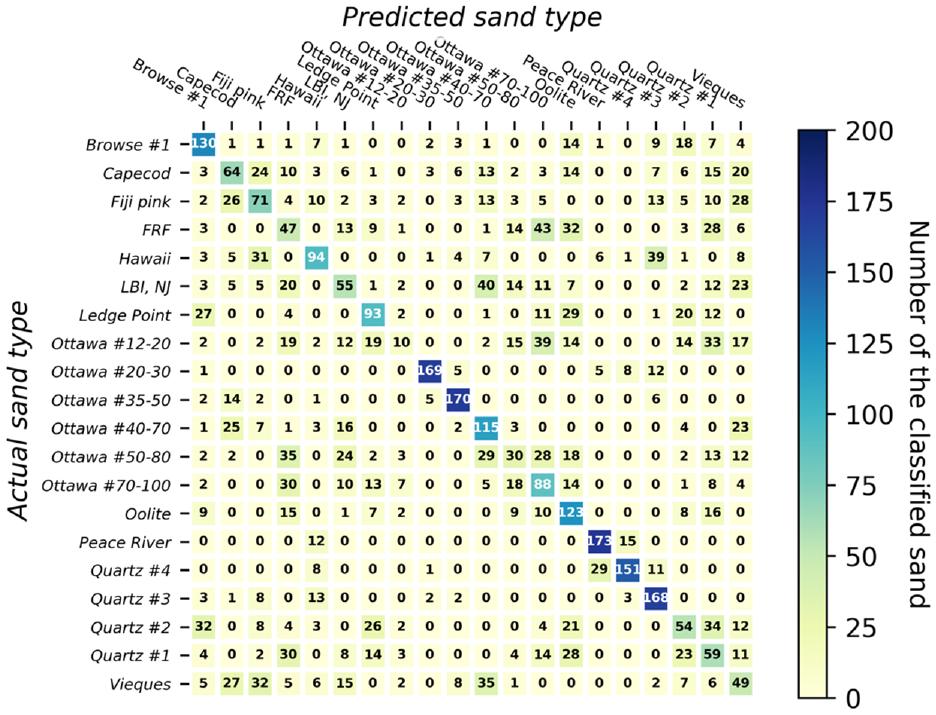
Predicted classification accuracy for 4,000 individual sand particles using neural networks employing size and shape descriptor data of each particle.
Predicted classification accuracy for 4,000 individual sand particles using support vector machine employing size and shape descriptor data of each particle.
Predicted classification accuracy for 4,000 individual sand particles using decision tree algorithm employing size and shape descriptor data of each particle.
Predicted classification accuracy for 4,000 individual sand particles using the random forest algorithm employing size and shape descriptor data of each particle.
Predicted classification accuracy for 4,000 individual sand particles using the K-nearest neighbor algorithm employing size and shape descriptor data of each particle.
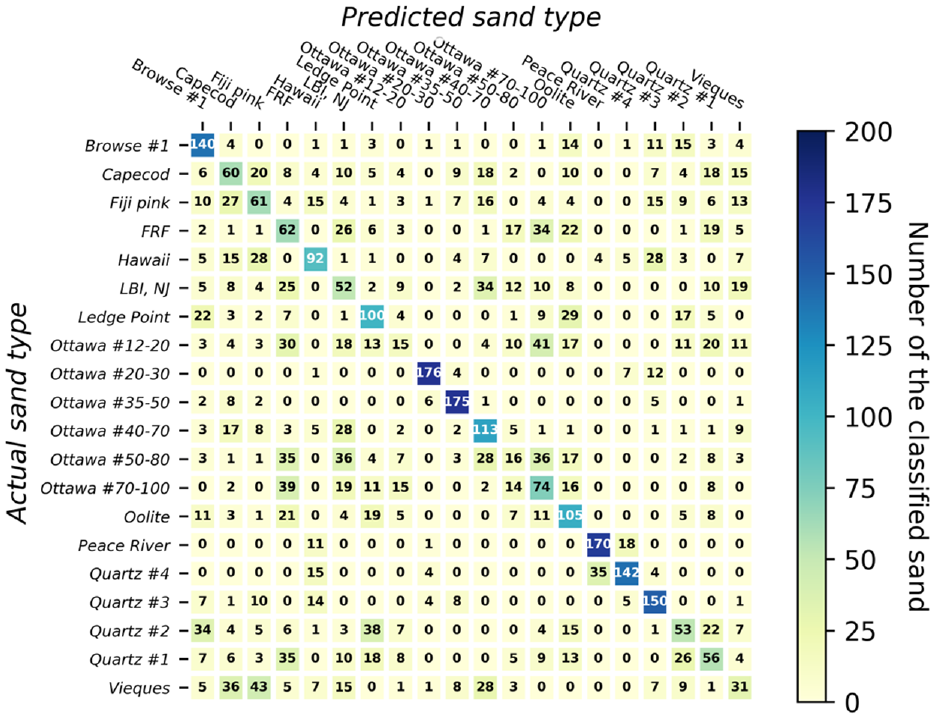
Predicted classification accuracy for 4,000 individual sand particles using the ensemble voting algorithm employing size and shape descriptor data of each particle.
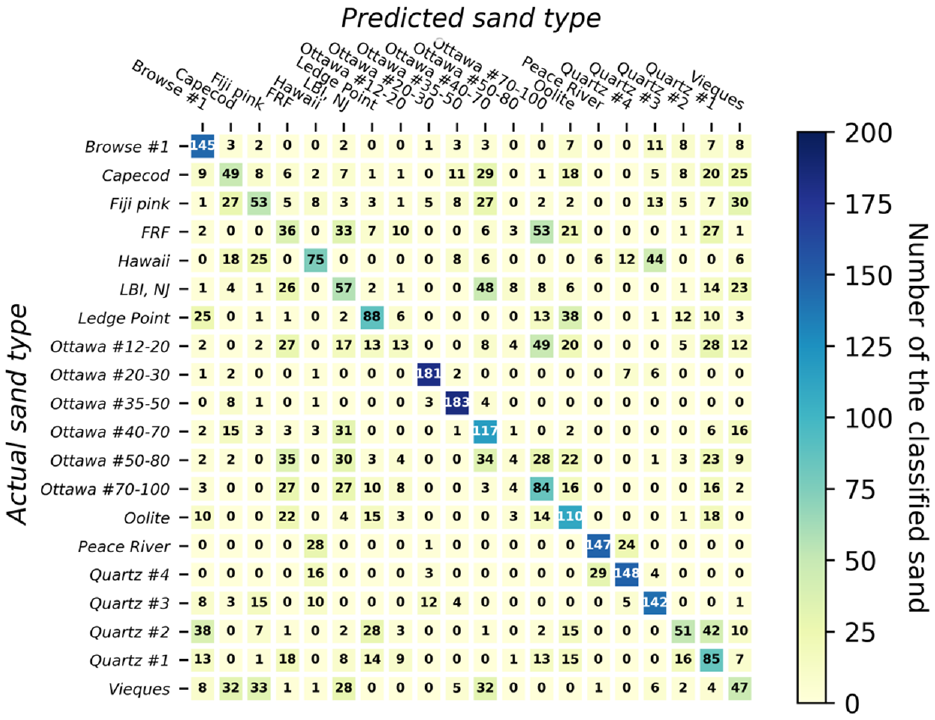
Predicted classification accuracy for 4,000 individual sand particles using neural networks employing size descriptor data of each particle only.
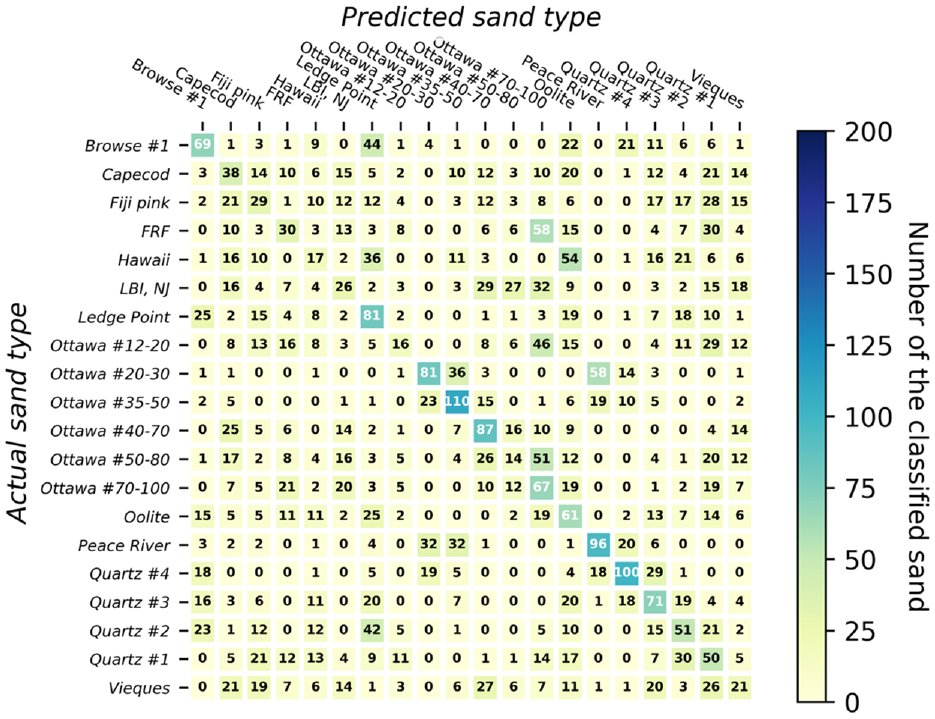
Predicted classification accuracy for 4,000 individual sand particles using neural networks employing shape descriptor data of each particle only.
In Figures 6–13, the numbers within each cell represent the number of classified particles falling into each respective category. The numbers on the diagonal of each matrix indicate the particles that were correctly identified for each sand type. Given that there were 200 particles of each sand type in the testing dataset, a perfect prediction would result in 200 particles along each diagonal. Values outside the diagonal indicate incorrectly classified sands, along with their corresponding misclassifications. For instance, the first row of the confusion matrix shown in Figure 6 indicates that, for Browse #1 sand, 130 (65%) out of 200 particles were correctly classified. However, 9%, 7%, 4.5%, 3.5%, and 2% were misclassified as Quartz #2, Oolite, Quartz #3, Quartz #1, and Vieques, respectively. Importantly, this does not imply a mixture of these sands within the specimen; it solely highlights the misidentification and the incorrect labels assigned.
An important observation is that, in nearly all cases, the majority of particles within each row can be accurately classified, as illustrated in Figures 6–13 and Table 2. In particular, NN, decision tree, and random forest can classify 90% of 20 sand clusters using both size and shape. This performance is much better than classifying individual particles, as the accuracy rates for classifying individual particles were only 48.8%, 36.8%, and 45.1% for NN, decision tree, and random forest, respectively. On the other hand, as far as SVM, KNN, and ensemble voting are concerned, even though their accuracies are 75%, 75%, and 80%, respectively, their classification accuracy for sand clusters remains significantly better than classifying individual sands (which achieved accuracy of 45.6%, 40.9%, and 46.4%, respectively). Consequently, the probability of correctly classifying a sand cluster utilizing any of the six ML classifiers with both size and shape attributes is approximately 90%, according to the conducted tests.
When employing both size and shape features, NN demonstrated the highest classification accuracy compared with other classifiers. Additionally, utilizing a voting approach separately for size and shape features significantly improved the classification accuracy for individual sands (for size from 46.1% to 85%, and for shape from 28.9% to 75%). This demonstrates that ML has a remarkable ability to automatically classify sand clusters.
Some of the sands were identified with a very high accuracy by all models and some of them were not. For instance, Ottawa #20-30 and #35-50 and Peace River were consistently identified with the highest accuracies for all ML models, with an accuracy around 80%, while most of the natural soils and Ottawa #12-20 and Quartz #1 and #2 were not captured well. This is not related to the spread of the size and shape parameters. The relative standard deviation (standard deviation normalized by mean) of all parameters shown in Table 2 is presented in Table 3. The relative standard deviation of de and dFmax of the Vieques, for instance, is 35%–37%, while Peace River sand is around 16%–18% for the same parameters. One would expect the classification accuracy to improve with the decrease in the relative standard deviation, but that is not the case. A comparison between Vieques and Peace River (best- and worst-performing natural samples) suggests that the classification accuracy is not related to the relative standard deviation. Indeed, correlation between the relative standard deviation of the size or shape parameters with the best NN classifier suggests no correlation with R 2 <5% (not shown). Thus, ML algorithms are identifying relationships that are not evident through conventional statistical analyses.
Relative Standard Deviation (SD) of Shape and Size Descriptors Employed
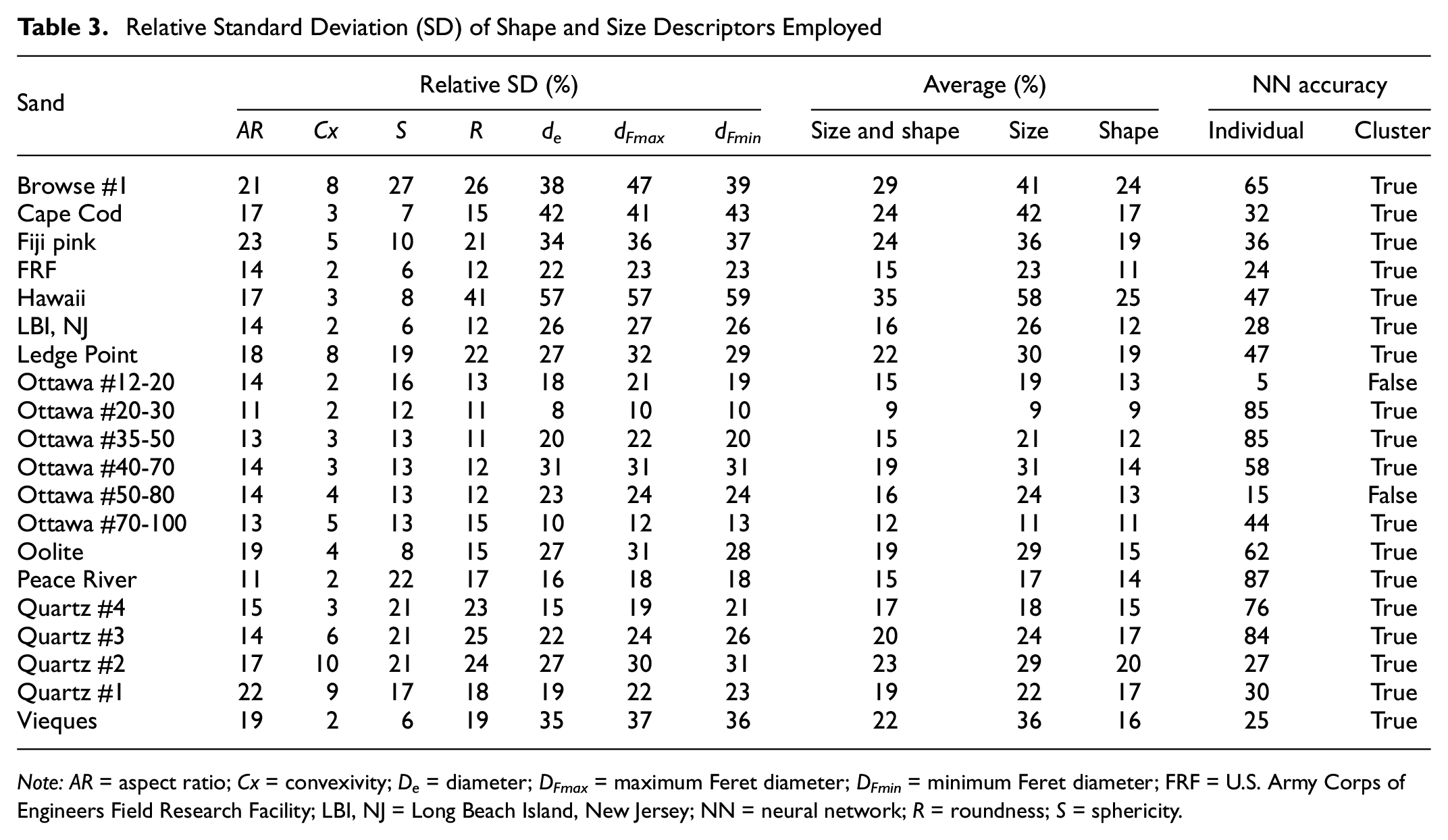
Note: AR = aspect ratio; Cx = convexivity; De = diameter; DFmax = maximum Feret diameter; DFmin = minimum Feret diameter; FRF = U.S. Army Corps of Engineers Field Research Facility; LBI, NJ = Long Beach Island, New Jersey; NN = neural network; R = roundness; S = sphericity.
It is possible to employ a voting algorithm where, when presented with a cluster of sand particles and their individual classifications, the predominant class within the cluster can be confidently identified as the sand type for that particular cluster. By comparing the highest count of sand particles classified within each row to the count of particles classified along the diagonal of the same row, comparing the greatest number of sand particles classified in each row with the number of particles classified along the diagonal of the same row is a metric for correct classification of a group of particles.
The problem at hand is an image classification problem which lends itself to analysis using convolution neural networks (CNN) ( 30 ). However, CNN is relatively time-consuming, and the proposed ML approach is much faster, from a numerical standpoint. The proposed ML models rely on engineering size and shape descriptors provided directly by the DIA software, eliminating the need for original images that CNNs requires. CNNs often demand extensive computational resources, taking approximately 2 h for training 50 epochs on a high-performance computing cluster. In contrast, our proposed ML models proved highly efficient as far as training time is concerned, requiring only a few minutes on a personal computer. Finally, our past research suggests that the classification accuracy of the majority of sand particles achieved with ML models is only slightly lower (10% lower) than CNN, demonstrating the effectiveness of ML for scaling up the work.
Conclusions
The feasibility of employing sand particle size and shape descriptors along with ML algorithms for sand classification has been demonstrated. Engineering size and shape descriptors were employed as features for sand particle classification using individual and ensemble ML models. The classification results show that the size and shape features are efficient and robust to identify up to 49% of individual sand particles, using parameters batch extracted from binary images. However, classification accuracy improved to 90% when clusters of particles were employed along with a voting algorithm. The next section provides a concise overview of the specific findings.
Among the ML models explored, NN provided the best performance for classifying 46.1%, 28.9%, and 48.8% of sand particles using size, shape, and size and shape descriptors, respectively.
For all the classifiers considered, size outperformed shape as a parameter for classification. However, use of combined size and shape parameters produced superior results for all sands and all classifiers.
Decision tree was the least accurate ML classifier and its use for soil classification is not warranted at this time.
A voting algorithm yielded a classification accuracy of 75%–90% for the 20 sands considered. It is noteworthy that engineering geologists commonly employ sand clusters in classification practice, and it is indeed unlikely that anyone would classify a particle of sand visually using a single particle. Thus, the performance of the voting regime is consistent with the accuracy attained by manual classification.
This work provides a basic and necessary step toward automatic machine classification of soils. In the future, the training dataset can be expanded from 20 to potentially hundreds of types of sand and enable quick soil classification on-site, during site investigation activities, using a smartphone equipped with a high-resolution camera. Indeed, reliable and speedy methods for segmentation of particles from images are also required, but research on these methods is ongoing (12).
These results suggest that ML promises to become commonly employed for classification of sand from ordinary images. Once appropriate segmentation algorithms are developed, and large libraries of sand particles are assembled, individual particles can be classified with approximately 40%–50% accuracy, and a voting algorithm can be used to classify the material based on the classification of the majority of individual particles. This method allows for automatic sand/particle classification which may eventually assist engineers on-site to quickly determine geotechnical properties of soil formations that would presently be analyzed in laboratories.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: M. Iskander, L. Li; data collection: L. Li; analysis and interpretation of results: L. Li, M. Iskander; draft manuscript preparation: L. Li. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.