
Abstract
Deep reinforcement learning has seen significant progress in traffic signal control. However, existing research still lacks the ability to effectively capture the correlation of road network information and the perception capability of traffic signal states. To address this gap, we propose a multi-intersection traffic signal control method that integrates a graph attention network, named the graph attention network-deep deterministic polcy gradient (GAT-DDPG) algorithm. This algorithm incorporates the restart random walk into the attention mechanism, exploring graph information through global random walks, reducing reliance on local nodes, and enhancing the model’s comprehensive understanding of graph structure features, thereby improving the modeling capability of traffic network structures. Moreover, the algorithm can automatically identify and extract key features from the complex data of the traffic network without manual intervention, adapting to different traffic network topologies, and can update and adjust the traffic signal control system in real-time to accommodate actual traffic flow and congestion situations. Experimental results indicate that the GAT-DDPG algorithm reduces average vehicle travel time significantly across three real road networks (Hangzhou and Jinan in China, and New York, U.S.) and two synthetic road network datasets. Additionally, it demonstrates optimal convergence speed and performance in these real datasets, attributed to its capability to capture global information and deeply comprehend the intricate structures of traffic networks. The research proves that this model has significant advantages in the field of traffic signal control, improving the operational efficiency of urban area intersections. Future work will incorporate additional road environment factors to better adapt to complex urban traffic.
Keywords
With the rapid development of urbanization, the issue of traffic congestion is increasingly prominent, leading to a series of challenges such as fuel consumption, environmental pollution, and others, resulting in significant economic and social losses ( 1 – 3 ). Addressing traffic congestion could involve expanding infrastructure or optimizing traffic signal control methods. Among these measures, effective control of traffic signals appears particularly crucial.
Traditional fixed-time traffic signal control methods, which set fixed durations for green and red lights, are unable to adjust flexibly based on actual traffic conditions, leading to traffic congestion, unpredictable travel times, and energy wastage. To address these issues, the field of traffic management has developed an increasing number of efficient adaptive traffic signal control methods ( 4 ). Adaptive traffic signal control methods can adjust the signal light control strategy in real-time according to the current road traffic conditions to reduce traffic congestion and improve traffic efficiency ( 5 ). Currently, there are various adaptive traffic signal control methods, such as those based on fuzzy logic ( 6 – 9 ). However, these methods tend to have poor robustness and are susceptible to external environmental influences. Additionally, methods based on genetic algorithms require pre-defined traffic scenarios, making it difficult to respond to real-time changes in traffic conditions and achieve real-time traffic light control ( 10 ). Methods based on immune network algorithms can search for better solutions but have slow convergence speeds and require many iterations ( 11 ). Methods based on cellular automata typically rely on static traffic flow models, making it difficult to acquire and apply real-time traffic data ( 12 ). This may lead to suboptimal performance, especially in highly dynamic traffic environments. Therefore, further research is needed to develop traffic light control methods that are more robust, real-time, and efficient.
With the wave of artificial intelligence, the application of deep reinforcement learning (DRL) in the field of traffic signal control is becoming increasingly widespread ( 13 – 17 ).
A signal timing algorithm based on DRL was proposed, which learns Q-functions from traffic states and performance outputs, solving modeling and optimization problems through deep Q-networks (DQN) ( 18 ). This method significantly outperforms traditional approaches in finding better signal timing solutions. The DQN algorithm was applied to an adaptive traffic light timing system, directly controlling phase durations and defining the action space as all possible phase durations, thereby avoiding the issue of uncertain phase durations before the end of a phase ( 19 ). The multi-agent DQN algorithm was proposed and applied to traffic signal control, addressing the curse of dimensionality problem in traffic networks with high traffic volumes and interference ( 14 ). Additionally, a model and data-driven integrated reinforcement learning approach enhances system stability ( 20 ). A general framework for multi-intersection control using reinforcement learning employs a parameter-sharing training scheme, achieving strong generalization capabilities ( 21 ).
Focusing on policy-based methods, the proximal policy optimization (PPO) algorithm was applied to traffic signal control and compared with DQNs and double DQNs (DDQN). The results showed that the PPO policy outperformed DQN and DDQN in traffic signal control ( 22 ). The regional-grid advantage actor-critic algorithm, based on the advantage actor-critic algorithm, was proposed to enhance traffic signal control performance by sharing policies and locally discounted states with neighboring agents ( 23 , 24 ).
Different traffic signal control methods demonstrate different advantages under various simulation scenarios and levels of road network complexity. Existing research has indicated that DQN exhibits good performance in single-intersection road scenarios but may not achieve optimal solutions in large-scale road networks ( 25 ). In comparison, algorithms based on the actor-critic (AC) architecture show more pronounced advantages in complex road network studies ( 26 , 27 ).
Despite the progress made by these DRL-based algorithms in traffic signal control, there is still a need for further improvement in capturing the relevance of road network information and enhancing state perception ( 28 – 30 ). Graph neural networks (GNNs) can better capture the correlation of road network information, but research integrating GNNs with DRL for traffic signal control remains relatively limited, with existing studies still having some shortcomings.
The inductive graph reinforcement learning algorithm, based on graph convolutional networks (GCN), adapts to new road networks and traffic situations by learning effective control strategies while leveraging fine-grained vehicle data. However, it has limitations in optimizing global performance ( 31 ). A model based on graph-structured data state representation uses an end-to-end framework, employing GNNs for traffic network representation learning and Q-learning for policy learning, enhancing policy transferability but only considering isolated intersections ( 32 ). The hierarchical graph representation learning algorithm integrates the current step state of multiple agents and the previous multiple step states of each agent, facilitating the generation of optimal final embeddings. Nonetheless, the representation capability of the traffic network state remains inadequate ( 33 ). A graph-based DRL algorithm uses arbitrary signal phases as actions to achieve flexible traffic flow control and can be directly applied to intersections of any geometric shape. However, it only considers lane nodes without accounting for more detailed graph structures ( 34 ).
The main contributions and limitations of previous studies are summarized in Table 1.
Main Contributions and Limitations of Previous Studies

Note: AC = Actor-Critic; DQN = Deep Q-Networks; GAT = Graph Attention Network; GCN = Graph Convolutional Networks; GNN = Graph Neural Networks; MADQN = Multi-Agent DQN; PPO = Proximal Policy Optimization; RGA2C = Regional-Grid Advantage Actor-Critic.
Therefore, in this paper, we delve into the control of traffic signals using the DRL approach with an AC architecture. To acquire the status information of relevant vehicles more accurately, we construct a model that represents states as graph-structured data, aiming to effectively model the interrelationships among features induced by the spatial structure of intersections. Simultaneously, we propose a fusion algorithm that incorporates GNNs into the deep deterministic policy gradient (DDPG) algorithm. Through this centralized control algorithm, we further enhance the capability to capture correlations in road network information and improve state awareness, resulting in a significant enhancement in decision-making for traffic signal control.
The experimental results demonstrate that our model exhibits superior performance in complex urban traffic networks with multiple intersections. This not only further validates the effectiveness of the proposed algorithm but also provides strong support for addressing urban traffic signal control problems.
The contributions of this paper are as follows:
1) We propose a graph attention network-deep deterministic polcy gradient (GAT-DDPG) algorithm. Modeling the traffic signal control problem as a graph-based state representation Markov decision process (MDP), enabling the learning of graph-structured data. By utilizing latent graph features, it learns complex decision-making for traffic signal control, thereby enhancing DRL’s perception of the urban road network state.
2) We devise a fusion algorithm that combines the attention mechanism with random walk with restart (RWR). This fusion modifies the weight calculation formula of GAT, incorporating the node importance ranking from the RWR algorithm. As a result, the algorithm directs increased attention toward highly significant nodes. Leveraging the available node importance information enhances GAT’s capability in graph data modeling.
3) We conduct experiments on synthetic road networks as well as large-scale real road networks containing hundreds of traffic signals. The experimental results demonstrate that, compared with the original DDPG and other methods, the proposed GAT-DDPG method shows significant improvements in both convergence and learning effectiveness.
Traffic System Modeling
In this section, the traffic signal control problem is redefined as a novel MDP, and the states, actions, and rewards are defined accordingly. The objective is to make autonomous decisions about which phase the intersections in the road network should be in, aiming to reduce lane pressure and improve traffic flow rate.
Markov Decision Process (MPD)
The MDP model consists of a state set
We model the traffic signal control problem as an MDP based on a graph-based state representation. GAT is employed to efficiently process the information of nodes and edges into embedded vectors while considering their topological relationships. In the entire MDP process of DRL, the agent receives the current decision action
State Representation by Graph
We represent the geometric features of urban traffic networks (note that this research applies to systems where traffic travels on the right-hand side of the road) using graphs, and embed traffic state data into the graph to represent the states of the target MDP. Each individual decision-making process state is composed of real-time information from local sensors. As it does not encompass all the information of the global MDP but only a portion of the urban traffic network, it is also referred to as partially observable.
Four types of node are defined in the graph: vehicles, lanes, intersections, and traffic signal controller (TSCer). The defined edge types are as follows:
Each node is connected to itself by an edge.
Each node is connected bidirectionally to other nodes of the same type.
Each lane node is connected bidirectionally to all vehicle nodes on that lane.
Each lane node is connected bidirectionally to other lane nodes at the same intersection.
Each TSCer node is connected bidirectionally to intersection nodes. (The phases of TSCer nodes influence the direction of vehicles at the intersection, and the intersection node information includes information from all TSCer nodes within the intersection.)
The global state is encoded as
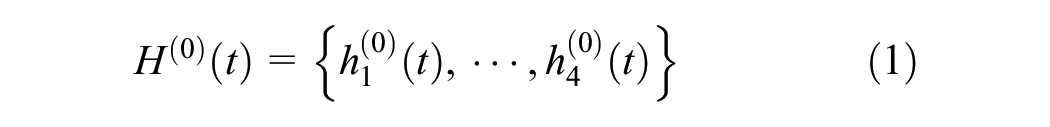
where
superscript (0) = the node features of the input graph (initial node features, refer to the original data obtained from local observations).
The edge type set is defined as
The node features are summarized in Table 2. “Current speed” represents the current velocity of vehicles (normalized), represented by the vehicle speed captured by lane sensors. “Position” denotes the relative position of vehicles on the lane. “Length” indicates the length of the lane in meters. “(EWA,
Nodes and their Corresponding Features
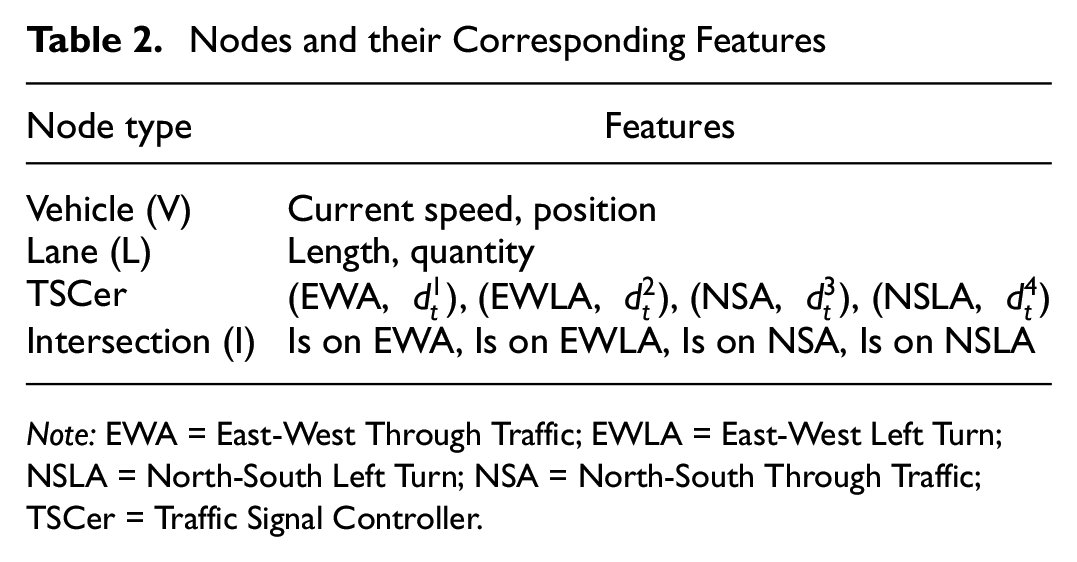
Note: EWA = East-West Through Traffic; EWLA = East-West Left Turn; NSLA = North-South Left Turn; NSA = North-South Through Traffic; TSCer = Traffic Signal Controller.
Action Space
We adopt a four-phase control scheme as illustrated in Figure 1, which offers advantages such as comprehensiveness, efficiency, adaptability, and safety. Compared with other methods, four-phase control is typically easier to implement and manage, and it demonstrates greater reliability in reducing congestion and improving efficiency. The phases transition in the order of east-west through traffic (EWA), east-west left turn (EWLA), north-south through traffic (NSA), and north-south left turn (NSLA). The phase set is defined as follows:
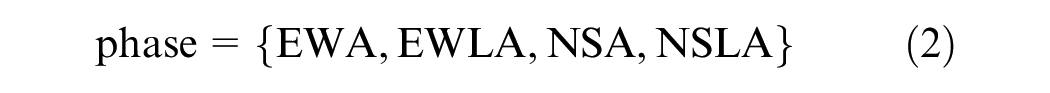
where
EWA = the east-west through movement traffic signal turning green (allowing vehicles on the east-west lanes to proceed through or make right turns),
EWLA = the east-west left-turn movement traffic signal turning green (allowing vehicles on the east-west lanes to make left turns),
NSA = the north-south through movement traffic signal turning green (allowing vehicles on the north-south lanes to proceed through or make right turns), and
NSLA = the north-south left-turn movement traffic signal turning green (allowing vehicles on the north-south lanes to make left turns).
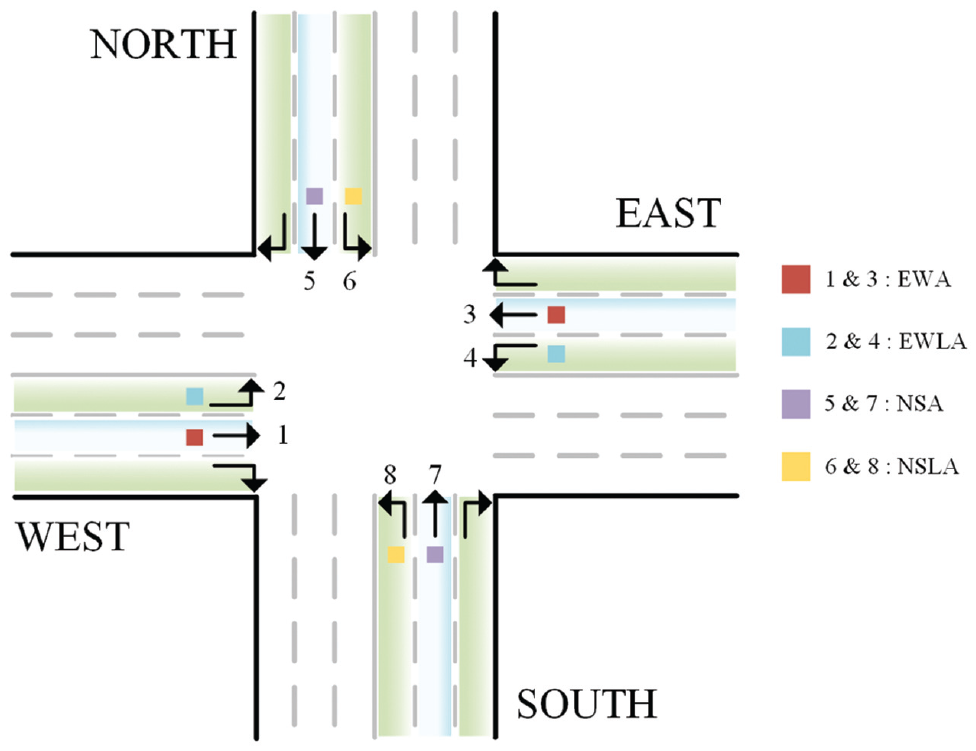
Schematic diagram of four-phase control scheme.
At each time step
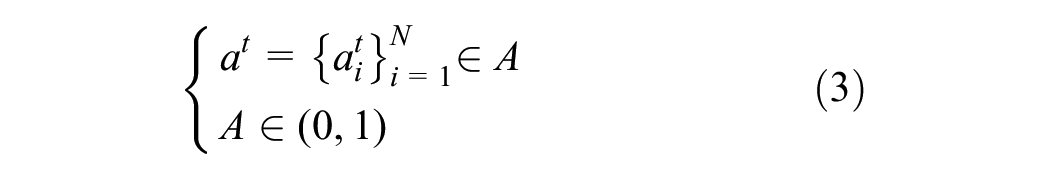
In the DDPG algorithm, actions are continuous, so in the application of traffic signal control, continuous action outputs need to be converted into discrete phase change decisions. This paper sets a threshold of 0.5: if the network output is greater than this threshold, the decision is to switch to the next phase (i.e.,
The phase transition process is illustrated in Figure 2, as exemplified. If the current traffic signal phase is the green light for the north-south direction, and the action selected at time step
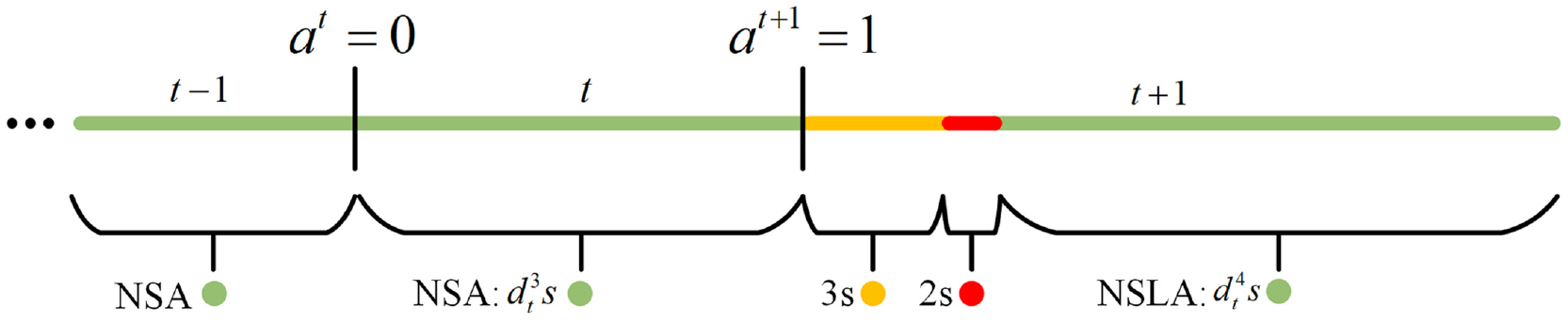
Signal light changes for different actions.
Reward Scheme
We propose a calculation method based on lane-normalized pressure, using the pressure difference between all traffic phases at intersections as the algorithm’s reward. The normalized pressure formula is as follows:
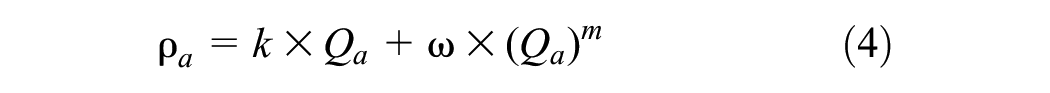
where
In Equation 4, when the queue length is small, the pressure growth is determined by
The normalized pressure value is in the range of [0,1], where a pressure value of 0 indicates that there are no vehicles queuing. When the queue length reaches the maximum capacity of the road, the pressure value equals 1, indicating that the road cannot receive any more vehicles from upstream roads. Let
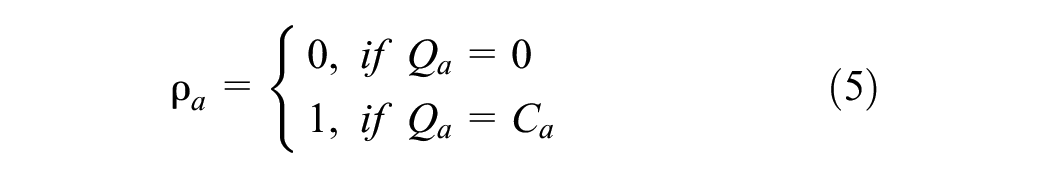
By substituting Equation 5 into Equation 4, the parameter
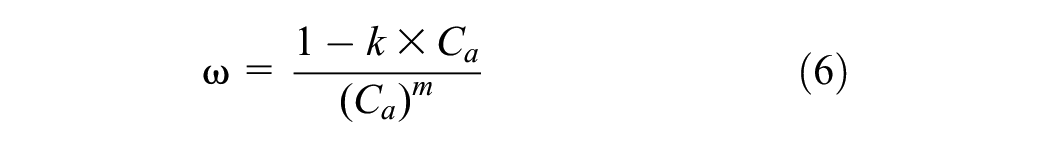
The normalization pressure formula obtained by substituting Equation 6 into Equation 4 is as follows:
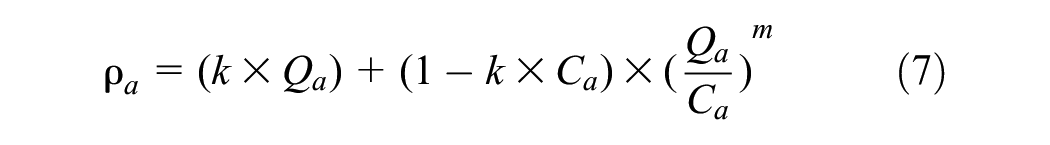
Assuming a lane’s maximum capacity
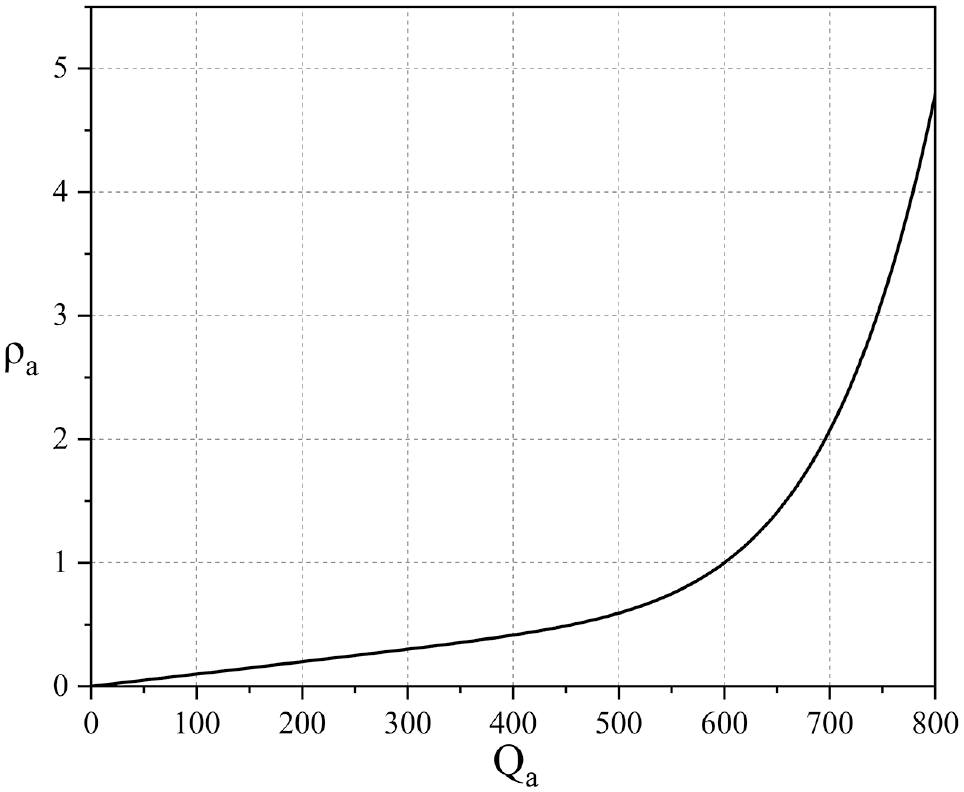
Plot of lane normalized pressure function.
The traffic phase pressure difference is defined as the difference between the entering lane pressure and the exiting lane pressure. The traffic phase
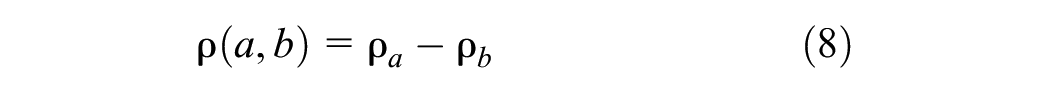
where
The pressure on intersection
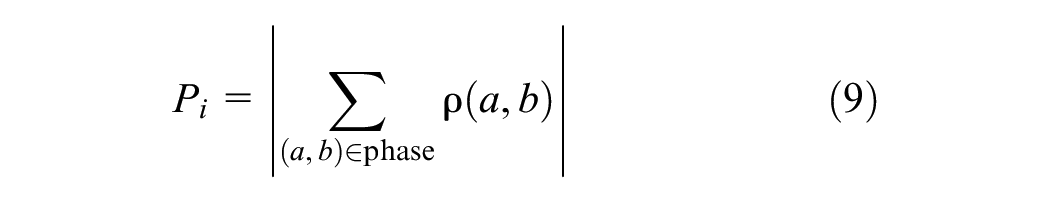
The pressure at the intersections is chosen as the reward for the reinforcement learning algorithm. A larger reward value indicates a smaller sum of pressures at the intersections. The reward function is defined as follows:

The rewards of the agents and their neighboring regions are combined using a weighted sum, and a spatial discount factor is introduced to make the rewards of agents in the neighborhood positively correlated with the distance between the two agents. The spatial discount factor is represented as follows:

where
The reward function for the intelligent agent is defined as the sum of the local reward obtained from the current local environment and the rewards obtained from all neighboring agents within its vicinity. This definition is based on the concept proposed in Chu et al. ( 23 ). It is specifically expressed as:

where
Methodology
In this section, we introduced the proposed GAT-DDPG algorithm, which uses GAT to represent the state and serves as the input for DRL. By employing neighborhood cooperation, the algorithm enhances the agent’s perception of the road network’s state, thereby improving the decision-making performance of DRL and enhancing the traffic signal control capabilities.
Deep Deterministic Policy Gradient (DDPG)
In traffic signal control, small variations in strategy can lead to significant fluctuations in traffic flow, making stability a crucial consideration. Despite the widespread application of the DQN algorithm in traffic signal control, it relies on approximating the Q-value function to indirectly formulate strategies ( 35 , 36 ). This indirect approach may pose challenges in maintaining stability. Therefore, we employ the DDPG algorithm to directly learn the policy function, thereby reducing the policy instability caused by approximation errors in the Q-value function ( 37 ).
The mean squared error between the estimated value and the target value is used as the loss function for the online critic network, as shown in Equation 13:
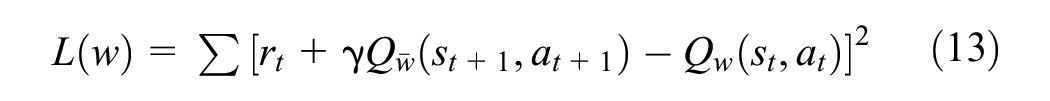
where
Online actor network updates its parameters by minimizing the following loss function:
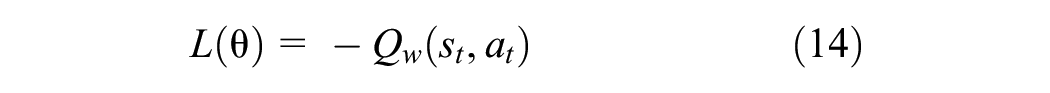
After training each mini-batch of traffic data, the parameters of the two target networks are softly updated based on the parameters of the two online networks, as shown in Equation 15:
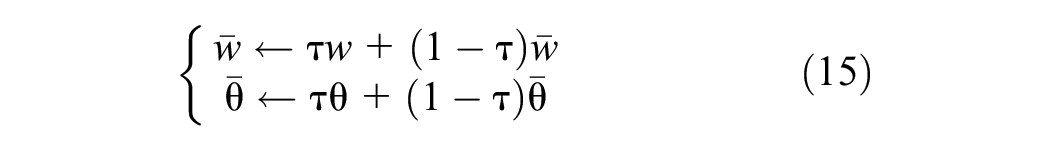
where
By continuously optimizing the parameters of the neural networks to select the optimal control strategy, traffic signal control can effectively reduce lane pressure and improve vehicle traffic efficiency.
Graph Attention Network-Deep Deterministic Policy Gradient (GAT-DDPG)
The representation of traffic signal states is crucial for the design and performance of control algorithms, as it directly affects the optimization effectiveness and real-time responsiveness of traffic signals. Many papers and systems on traffic signal control primarily adopt traditional state representations, such as traffic flow and vehicle density based on static features ( 38 ). Although this representation may be effective in certain cases, it often fails to comprehensively capture the complexities and diversities of modern urban traffic. Therefore, we introduce a novel approach by applying GAT to address this issue. GAT provides a new perspective for representing traffic signal states.
GAT employs attention mechanisms to compute weighted sums of neighboring node features, making the weights of neighboring node features entirely dependent on the node features and independent of the graph structure. The core of GAT is the graph attention layer, which takes an input
As shown in Figure 4, to achieve sufficient expressive power for extracting higher-level features, a mapping with the parameter
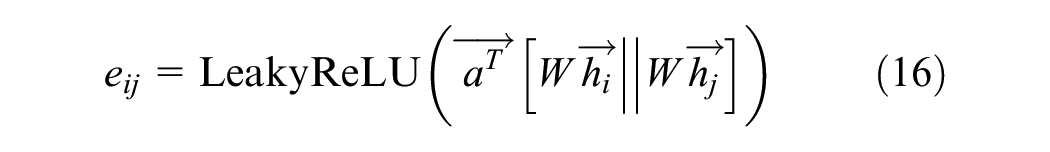
where
|| = vector concatenation.
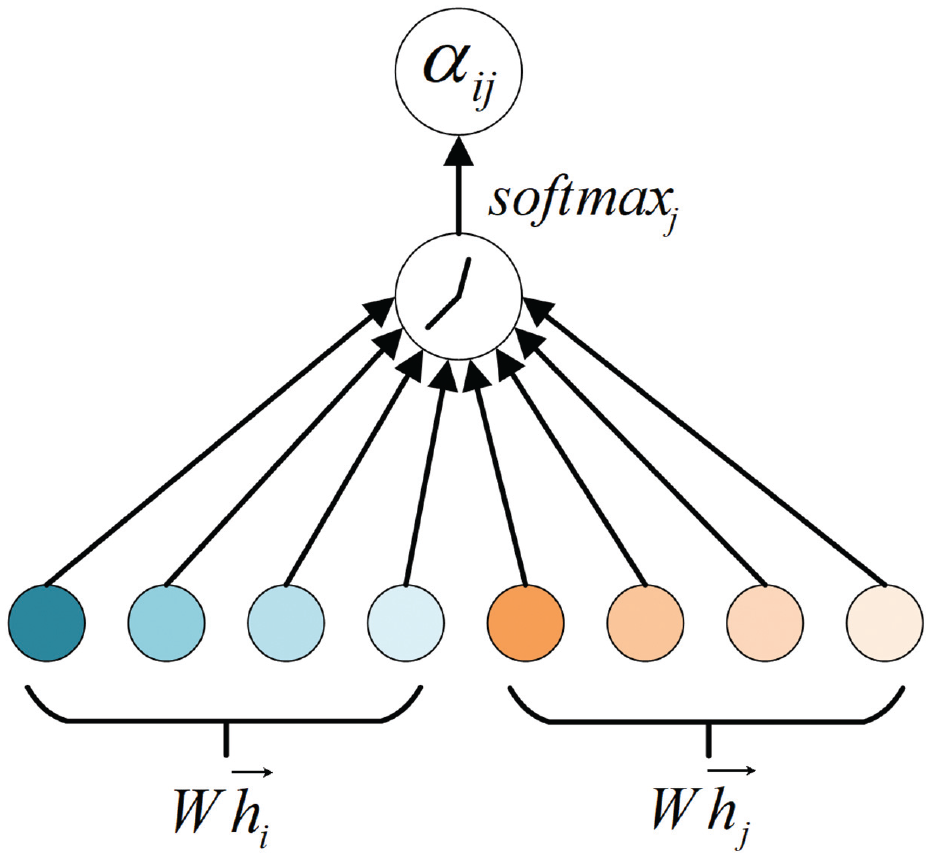
Node attention weights.
While GAT demonstrates good performance, it is highly sensitive to the structure of the input graph, often requiring different hyperparameter settings or adjustments to the model architecture for optimal performance with varying graph structures. This sensitivity limits the model’s generalization ability. Therefore, we propose a fusion algorithm of GAT and RWR. RWR explores the information of the entire graph by conducting random walks starting from multiple nodes, thus providing a more global perspective. This global information helps the model better understand the structural characteristics of the entire graph, reducing reliance on local neighbor nodes and, consequently, lowering sensitivity to the input graph structure. Using the RWR algorithm for node random walks, nodes are selected with a certain probability, and, through continuous random walks, the importance of nodes gradually propagates and accumulates. The algorithm is defined as follows:
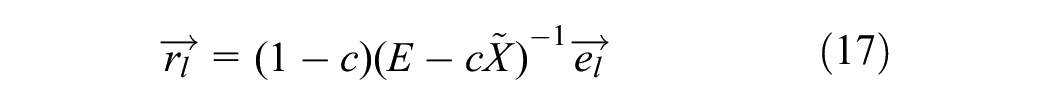
where
E = the unit matrix,
Introducing
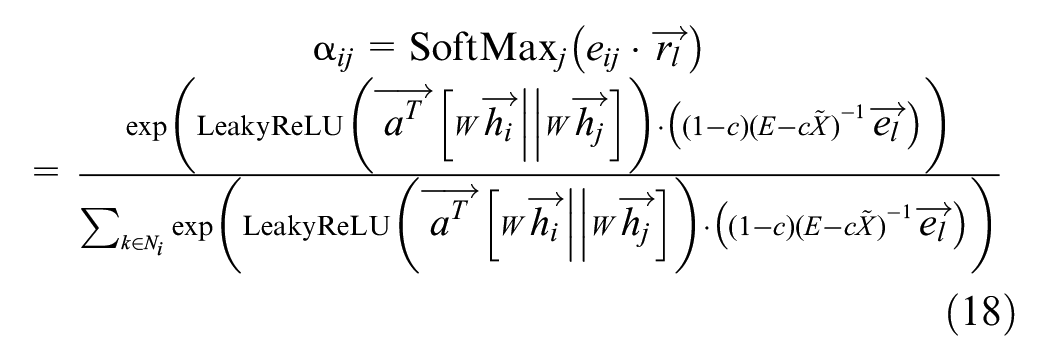
where
The output representation is obtained by linearly accumulating the neighborhood representations of nodes according to the attention weights, as follows:
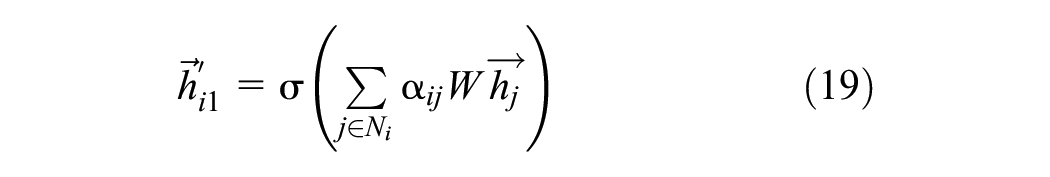
where
subscript
1
in
To ensure stable node representation through self-attention, we introduce a multi-head self-attention mechanism to enhance the model’s representational power. Specifically, using
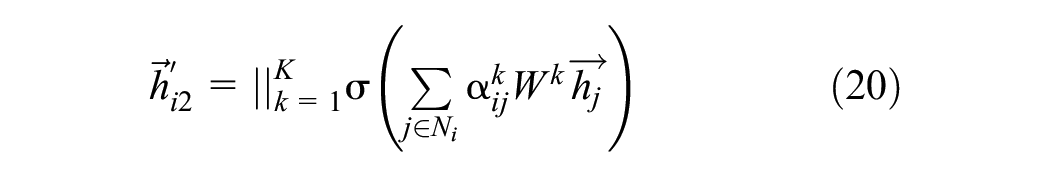
where
subscript
2
in
In the final layer of GAT, to avoid high-dimensional outputs arising from concatenation, averaging is used to fuse the results of multi-head attention, obtaining the final representation:
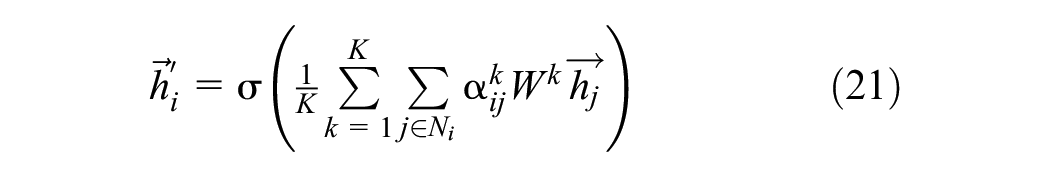
The GAT network structure used in this paper is illustrated in Figure 5. Firstly, the network employs an attention mechanism
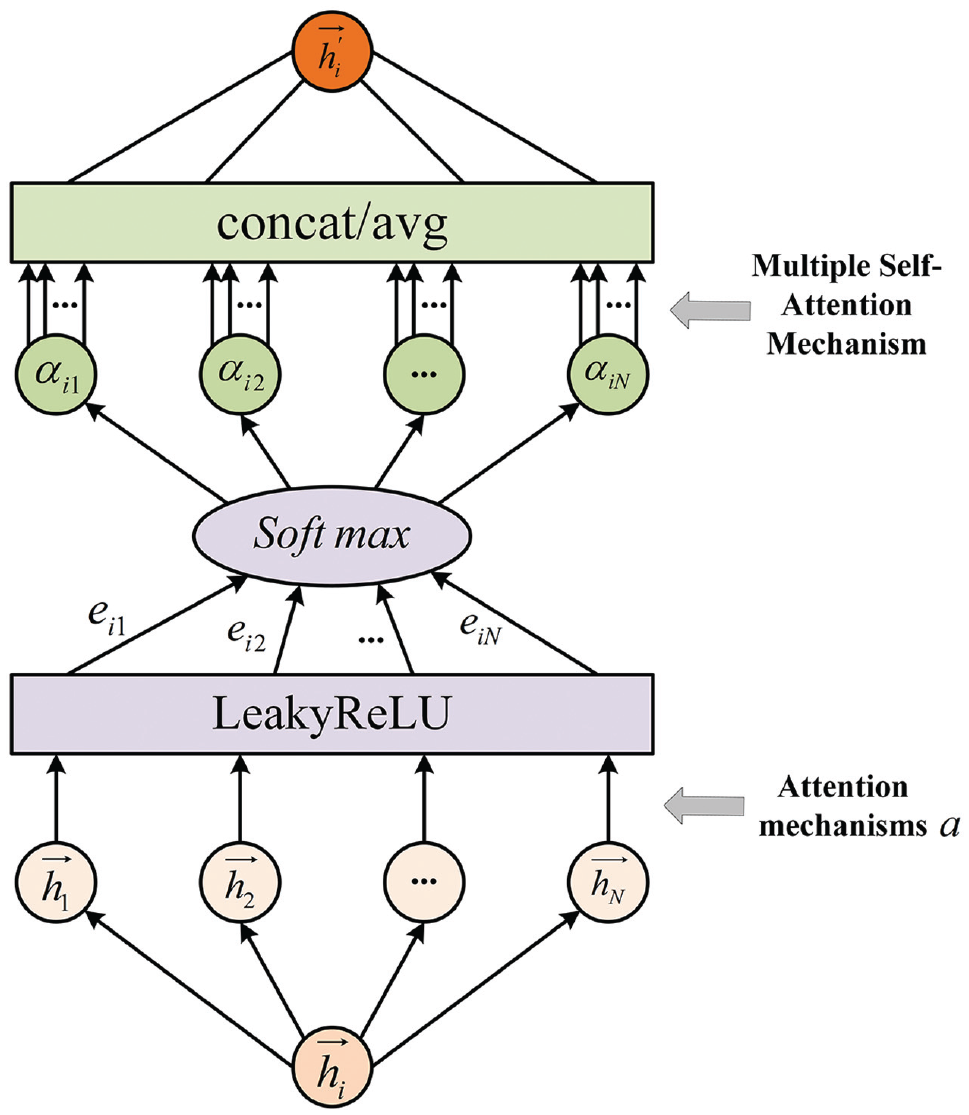
Network structure of the graph attention algorithm.
Based on this, we incorporate the RWR algorithm into GAT, enabling the model to more fully consider the long-distance dependency between nodes and the global topological characteristics of urban road networks, thereby enhancing the model’s generalization ability and robustness. The principle of the GAT-DDPG method is illustrated in Figure 6.
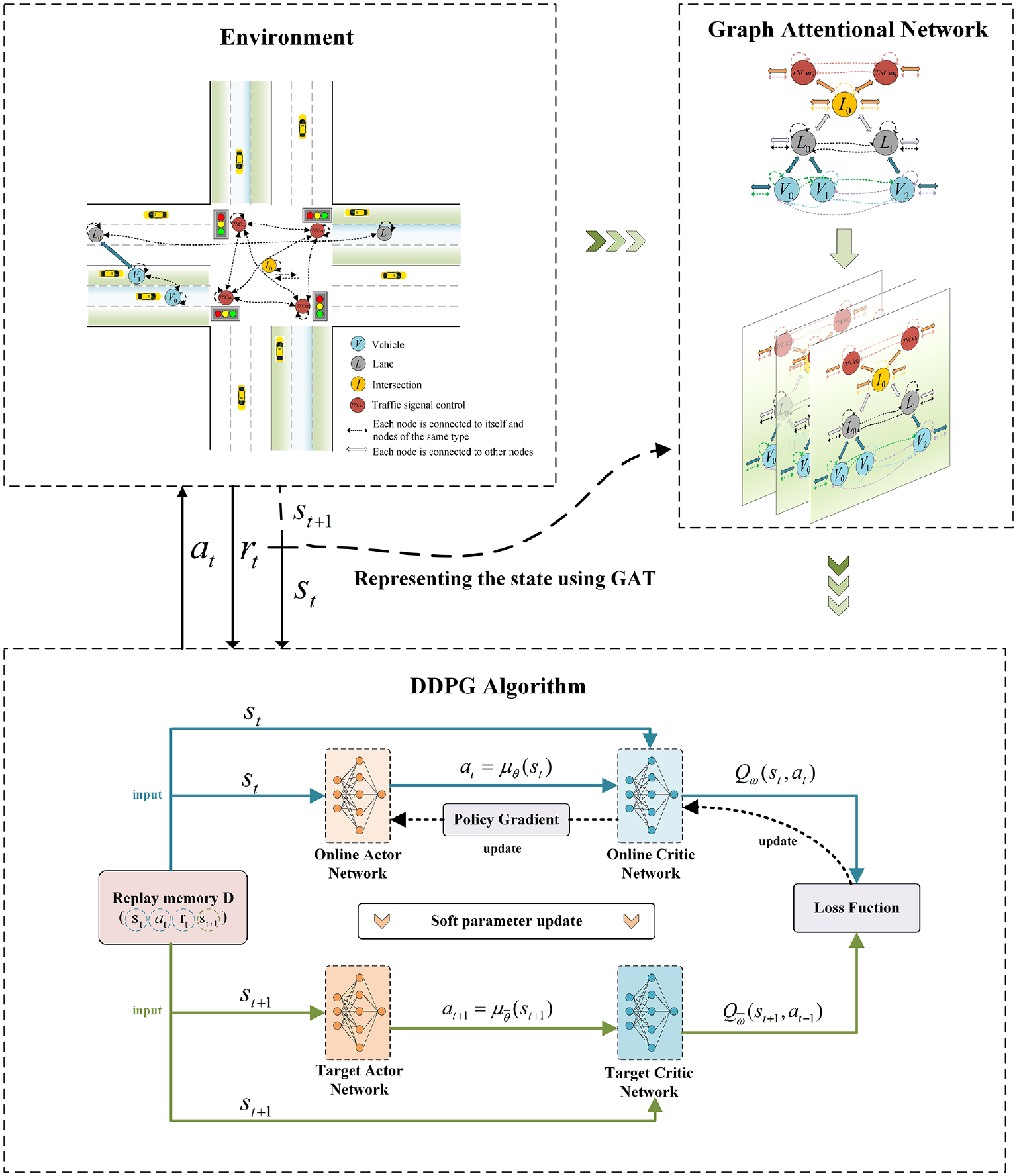
The structure of the graph attention-deep deterministic policy gradient (GAT-DDPG) algorithm.
GAT-DDPG effectively captures the complex relationships between nodes in traffic networks, enabling the model to better understand the topology and traffic flow patterns of the network. By integrating the RWR algorithm, the model’s capability to represent and generalize complex graph structures is enhanced. Using GNNs in the AC architecture of DRL, as state inputs, allows for learning complex decision-making in traffic signal control based on latent graph features. This enables the model to make decisions and optimizations in real-time traffic environments, facilitating flexible adjustments and responses to dynamic traffic conditions.
Unlike decentralized control, GAT-DDPG achieves centralized processing and analysis of traffic data across the entire area through a unified decision center. This enables the formulation of optimal signal control strategies based on a global perspective. Such global optimization effectively avoids traffic signal conflicts and enhances traffic flow.
Experiment and Evaluation
In this section, we conduct comparative analysis of the proposed algorithm with other methods in both synthetic road networks and real-world road networks. The experiments are conducted in the CityFlow simulation environment, an open-source platform widely used for traffic flow simulation research. Through these comparative experiments, the superiority of the proposed GAT-DDPG algorithm is demonstrated.
Datasets and Related Settings
We use three real datasets from New York, U.S., and Hangzhou and Jinan in China. The New York dataset comprises 196 intersections arranged in a grid format of 7 rows and 28 columns; the Hangzhou dataset consists of 16 intersections arranged in a grid format of 4 rows and 4 columns; and the Jinan dataset contains 12 intersections arranged in a grid format of 4 rows and 3 columns. In these real datasets, processed traffic data are inputted, including intersection identifiers, vehicle counts, traffic light status configurations, road identifiers, and road adjacency information, among others. Vehicle travel times are obtained by parsing vehicle trajectory data.
Meanwhile, the model was evaluated on two synthetic road datasets: a 3 × 3 traffic network and a 6 × 6 traffic network. The synthetic datasets comprise both one-way and two-way traffic data. In the two-way lanes, there are four possible directions: west to east, east to west, north to south, and south to north. On the other hand, one-way lanes only have two possible directions: west to east and north to south.
In the experiments of this study, the mild traffic flow for the 3 × 3 synthetic road dataset is 626 vehicles per hour (vph) (i.e., 626 vehicles generated per hour), the moderate traffic flow is 1,071 vph, and the heavy traffic flow is 2,340 vph. For the 6 × 6 synthetic road dataset, the mild traffic flow is 1,021 vph, the moderate traffic flow is 2,426 vph, and the heavy traffic flow is 4,680 vph. Other relevant settings are shown in Table 3.
Other Relevant Settings
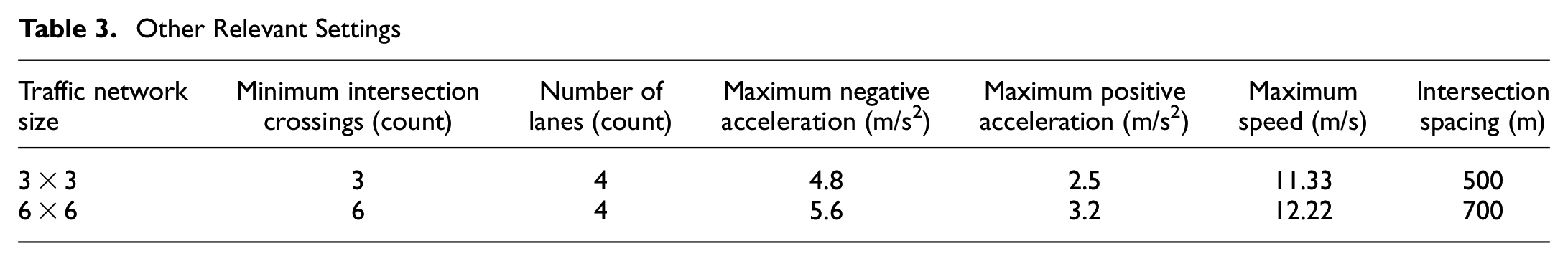
The study conducted 200 episodes of model training. Throughout the training process, a batch size of 32 was employed, with each training cycle utilizing 1,000 samples. Additionally, the study set the maximum capacity for storing past experiences to 10,000. The target Q-network was updated every five training cycles, with a discount factor
Compared Algorithms and Metrics
We use average travel time (ATT) as the primary metric for evaluating algorithm performance; this is computed as the ATT (in seconds) of all vehicles between their entry and exit from the controlled area. Compared with other metrics that focus more on specific regions or nodes, such as average queue length or queue length per lane, ATT covers the entire journey from start to finish. This provides a comprehensive reflection of the overall performance and efficiency of the traffic system. Optimizing signal timings to reduce congestion and delays is a core objective of traffic signal control systems. ATT, as a performance metric, intuitively reflects the effectiveness of signal timing and provides robust support for optimization decisions.
The compared algorithms encompass traditional traffic signal control methods and reinforcement learning (RL)-based traffic signal control methods, outlined as follows:
Traditional Traffic Signal Control Methods
Fixedtime ( 39 ): Use fixed timings with random offsets, employing pre-determined schemes for traffic cycle lengths and phase times. This method is widely applied when traffic flow is steady.
Maxpressure ( 40 , 41 ): Chooses phases that maximize pressure. Maximum pressure only requires local information, as intersection control depends solely on queue lengths on adjacent road segments.
RL-Based Decentralized Traffic Signal Control Approach
CGDRL (Coordinated Deep Reinforcement Learners) ( 42 ): A DRL-based approach to multi-intersection signal control using joint action modeling involves collaboration through the design of a coordination graph to optimize joint actions between two intersections.
IntelliLight ( 43 ): A DRL method that demonstrates good performance in two-phase signal control. It does not consider neighboring information, with each intersection controlled by an individual agent. The agents do not share parameters and are updated independently.
GCNN (Graph Convolutional Neural Networks) ( 44 ): A multi-intersection traffic signal control method based on RL and GCNN, using GCNN to directly extract geometric road network features and employing model-free RL methods to adaptively learn policies.
CoLight ( 45 ): A multi-intersection signal control method based on GAT. It considers not only the spatiotemporal impact of adjacent intersections on the target intersection but also models adjacent intersections without indexing.
MA2C (Multi-Agent Advantage Actor-Critic) ( 23 ): A DRL-based multi-intersection traffic signal control method uses the same states and rewards as IntelliLight and employs a fully scalable decentralized multi-agent reinforcement learning algorithm. This method considers neighbor information, enhancing observability.
MDQN (Multi-Agent Deep Q-Networks) ( 46 ): A DRL-based approach for multi-intersection signal control. It considers neighbor information and incorporates this information into the loss function of the DQN. Each agent selects the optimal action to control the intersection by obtaining local lane state information.
FRAP (Flip and Rotation invariant All Phase) ( 47 ): A DRL method based on the intuitive principle of mutual competition in traffic signal control. When conflicts occur between two traffic signals, priority is given to the one with greater traffic movement, that is, higher demand.
DDPG ( 48 ): A DRL method that optimizes deterministic policies by simultaneously learning policy and value function networks. It is suitable for continuous traffic signal control tasks.
RL-Based Centralized Traffic Signal Control Approach
GAT-DDPG: Learns from graph-structured data, incorporating neighboring node information and their significance, while leveraging latent graph features to comprehend the intricate decisions associated with traffic signal control.
Performance Comparison
In this study, we have demonstrated the exceptional performance of the GAT-DDPG method through validation on synthetic datasets, including 3 × 3 and 6 × 6 traffic networks, as well as three real-world datasets. The specific results are presented in Table 4.
Performance Comparisons on Both Synthetic and Real-World Datasets

Note: CGDRL = Coordinated Deep Reinforcement Learners; DDPG = Deep Deterministic Policy Gradient; FRAP = Flip and Rotation invariant All Phase; GAT-DDPG = Graph Attention Network-Deep Deterministic Policy Gradient; GCNN = Graph Convolutional Neural Networks; MA2C = Multi-Agent Advantage Actor-Critic; MDQN = Multi-Agent Deep Q-Networks.
For the 3 × 3 traffic network, when compared with the DDPG algorithm, our approach shows a 6.25% improvement in ATT under light traffic conditions, a 6.32% improvement under moderate traffic conditions, and a significant 12.53% improvement under heavy traffic conditions.
In the case of the 6 × 6 traffic network, similarly compared with the DDPG algorithm, our method achieves a 9.84% enhancement in ATT under light traffic conditions, a 12.01% improvement under moderate traffic conditions, and an impressive 14.09% improvement under heavy traffic conditions.
Furthermore, in the real-world datasets of cities with heavy traffic flow such as New York, Hangzhou, and Jinan, this method also achieves significant improvements in ATT for vehicles. Compared with the DDPG method, our approach results in a 13.31% improvement in ATT in the Hangzhou dataset, a 15.12% improvement in the Jinan dataset, and a remarkable 17.76% improvement in the New York dataset.
Based on comprehensive data analysis, we can conclude that our method exhibits superior performance enhancements under heavy traffic flow conditions. Particularly in more complex environments with multiple intersections and nodes, as in the case of 36 intersections, under heavy traffic conditions, our method shows the highest performance improvement, reaching 14.09%. This clearly demonstrates the effectiveness of the GAT algorithm combined with the RWR algorithm in enhancing urban road network state perception and overall performance.
Our research findings highlight that adopting the GAT-DDPG approach can significantly enhance the ATT of vehicles under various traffic flow conditions, especially in complex urban road networks, where performance improvements are most pronounced.
In intricate and complex traffic environments, traffic signal control remains at the core of real-world traffic management and is one of the critical challenges currently needing to be overcome. The outstanding performance of the GAT-DDPG algorithm in simulating complex environments effectively verifies its potential efficiency and reliability in real-world complex traffic environments. This remarkable adaptability positions GAT-DDPG with tremendous potential and value in addressing urban traffic bottlenecks and optimizing traffic network layouts.
Convergence Comparison
Self-Convergence Comparison
As depicted in Figure 5, we provide a visual representation of the self-convergence of our algorithm in 3 x 3 and 6 x 6 traffic networks for both unidirectional and bidirectional heavy traffic scenarios. To make it easier to present the data, we took logarithms of the ATT.
In Figure 7a, it can be observed that, in the case of a 3 × 3 traffic network with unidirectional heavy traffic, the algorithm reaches a converged state at the 5th training iteration, and the logarithmic values of ATT stabilize around 4.08. In Figure 7c, for the 6 × 6 traffic network with unidirectional heavy traffic, the algorithm successfully achieves convergence by the 4th training iteration, and the logarithmic values of ATT stabilize around 3.53. This represents a performance improvement of 13.48% compared with the unidirectional heavy traffic scenario in the 3 × 3 traffic network.
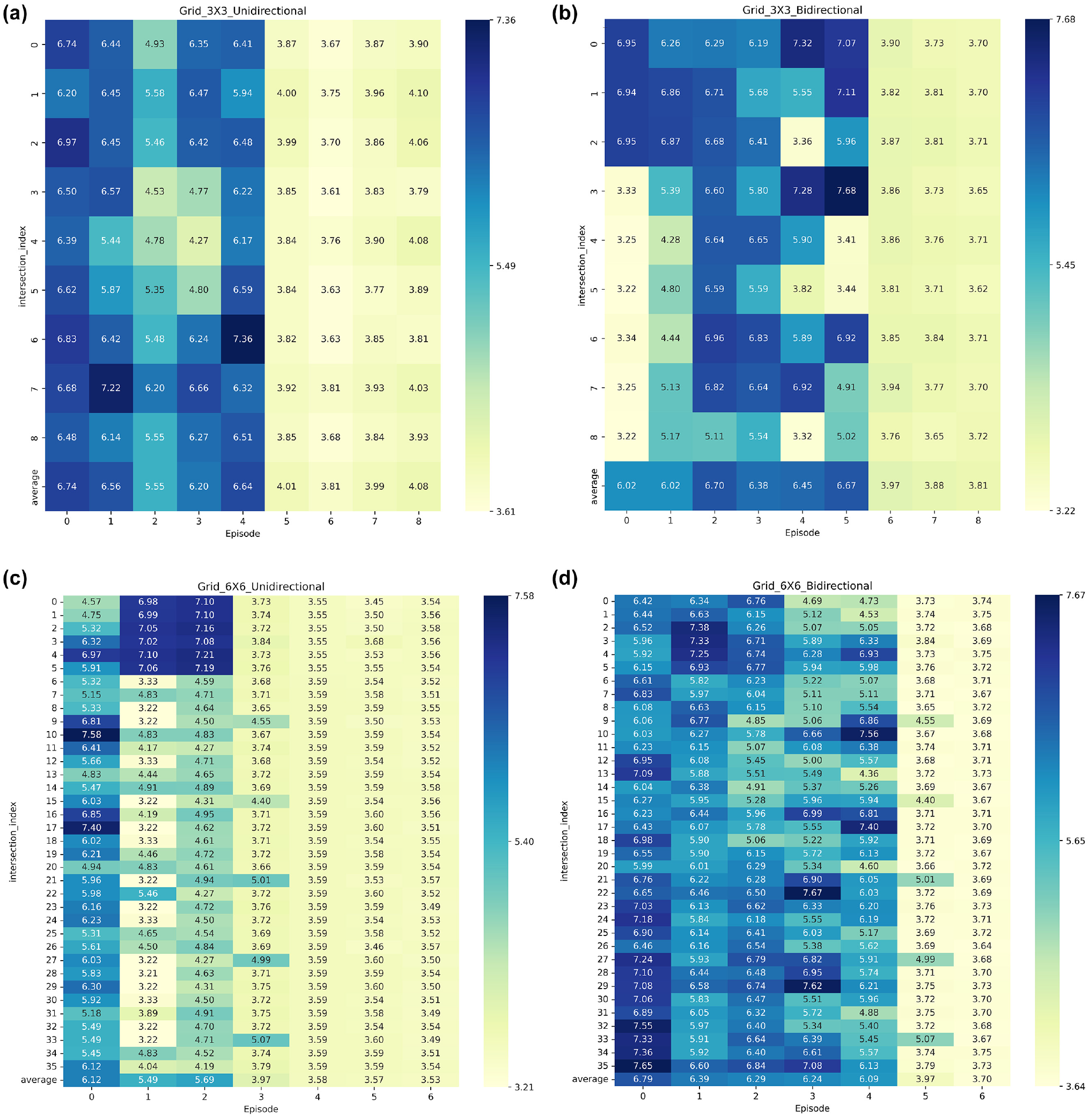
Self-convergence of the graph attention-deep deterministic policy gradient (GAT-DDPG) algorithm in synthetic datasets for both unidirectional and bidirectional heavy traffic scenarios: (a) 3 × 3 grid unidirectional, (b) 3 × 3 grid bidirectional, (c) 6 × 6 grid unidirectional, and (d) 6 × 6 grid bidirectional.
In Figure 7b, for the 3 × 3 traffic network with bidirectional heavy traffic, the algorithm reaches a converged state by the 6th training iteration, and the logarithmic values of ATT stabilize around 3.81. In Figure 7d, for the 6 × 6 traffic network with bidirectional heavy traffic, the algorithm also achieves convergence by the 6th training iteration, with the logarithmic values of ATT stabilizing around 3.65. This represents a performance improvement of 4.20% compared with the bidirectional heavy traffic scenario in the 3 × 3 traffic network.
Comparing the convergence of the 3 × 3 traffic network and the 6 × 6 traffic network under the same traffic conditions, we can observe that the algorithm achieves better convergence in the complex traffic environment. Therefore, the algorithm proposed in this paper demonstrates superior performance in adapting to complex traffic scenarios.
Comparing the convergence of the 6 × 6 traffic network with bidirectional heavy traffic flow to the convergence of both unidirectional and bidirectional heavy traffic flow in the 3 × 3 traffic network, we observe that, despite the more complex bidirectional heavy traffic flow environment in the 6 × 6 network, it achieves a convergence speed, similar to that of the 3 × 3 network, under unidirectional heavy traffic flow conditions. Moreover, the logarithmic values of ATT can converge to around 3.65, which represents the optimal performance across the three traffic environments. This discovery further validates the superior performance of our proposed algorithm in scenarios with more intersections and complex traffic conditions. It also signifies the effectiveness of our algorithm in enhancing road throughput and better adapting to real-world urban road scenarios.
The experimental results depicted in Figure 7 illustrate the rapid convergence of the data. This phenomenon could potentially stem from the relatively large gradient descent step size during the initial stages, causing parameters to swiftly traverse the parameter space and, thus, accelerating the convergence speed. As training progresses, the learning rate may gradually decrease, leading to smaller steps in parameter updates, thereby inducing the model’s performance improvement to gradually stabilize.
Comparative Convergence Analysis of Algorithms
Convergence speed is an important metric for evaluating the performance of an algorithm. In reinforcement learning, we usually want the algorithm to converge quickly because it can reduce the training time and the computational cost. An algorithm with good convergence can accurately approximate or even reach the optimal policy in a shorter period of time, and can operate stably and find the optimal solution under different environmental conditions. This is especially critical in the real-world traffic environment, which is complex, changing, and full of uncertainties.
As shown in Figure 8, we compared the learning curves of GAT-DDPG against four other DRL methods. The evaluation was conducted on three real datasets, revealing that GAT-DDPG significantly outperformed other baseline methods in the time taken to reach a threshold and the final learned performance. GAT-DDPG initiated with optimal performance, reached the targeted performance at the fastest pace, and concluded with optimal convergence.
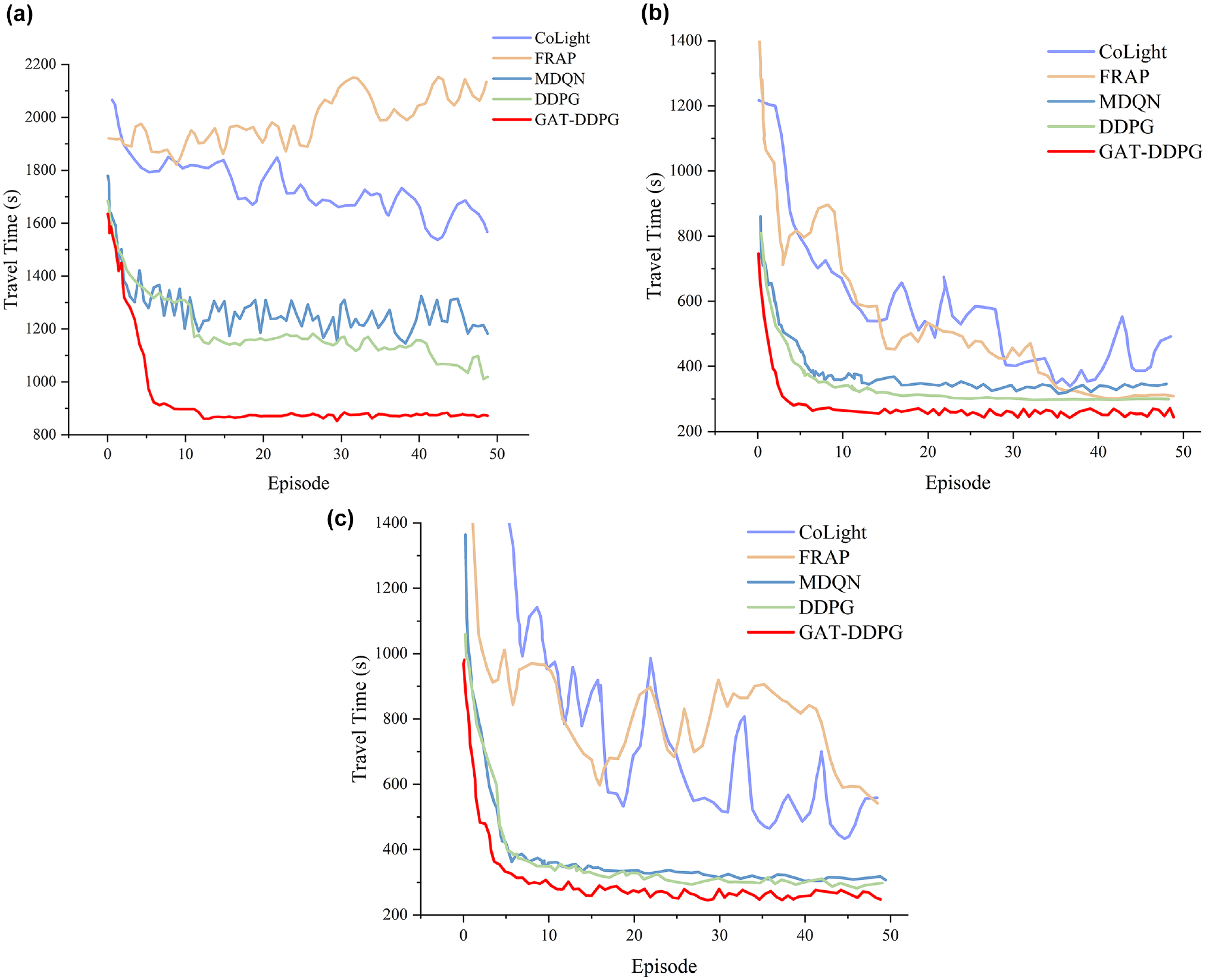
Convergence of the global graph attention-deep deterministic policy gradient (GAT-DDPG) and the other four algorithms during the training process: (a) New York, (b) Hangzhou, and (c) Jinan.Note: DDPG = Deep Deterministic Policy Gradient; FRAP = Flip and Rotation invariant All Phase; MDQN = Multi-Agent Deep Q-Networks; GAT-DDPG = Graph Attention Network-Deep Deterministic Policy Gradient.
Importantly, the attention GAT-DDPG pays to neighborhood information and importance during learning did not lead to a deceleration of model convergence. On the contrary, it accelerated the speed at which the model approximated the optimal policy. This underscores the efficacy and superiority of GAT-DDPG in tackling traffic signal control challenges.
Effectiveness Comparison
In Figure 9, the running times of GAT-DDPG and four other methods are compared on three real datasets and four synthetic datasets. “Running time” refers to the time required for the model to converge during training. To ensure fair evaluation, all methods were assessed using the same hardware. Because of the model’s complexity, GAT-DDPG initially requires more training time. However, after approximately 20 iterations, it achieves significant results, as depicted in Figure 8. The reduction in the number of iterations substantially shortens the overall running time, as illustrated in Figure 9. This demonstrates the effectiveness of the GAT-DDPG model, enabling flexible adjustment and rapid response to dynamic traffic conditions, thereby achieving faster decision convergence.
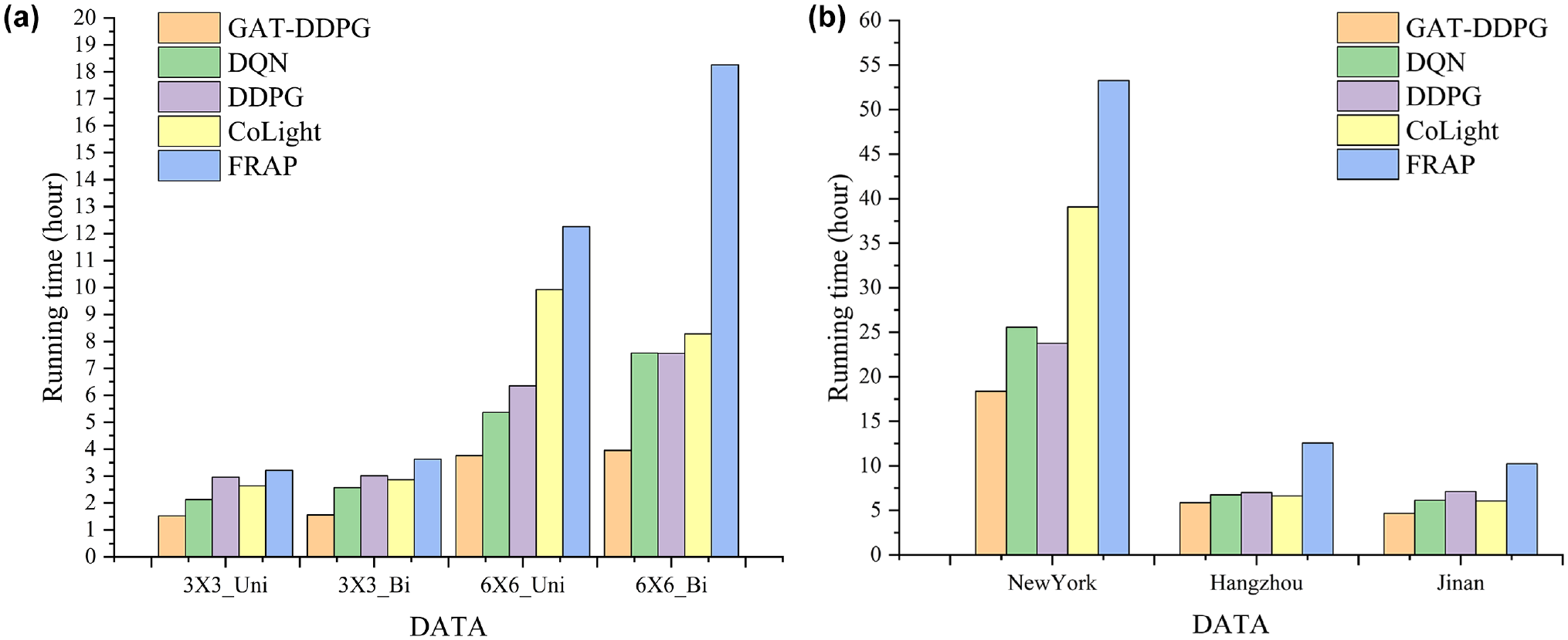
Running times for different models: (a) synthetic datasets and (b) real datasets.Note: DDPG = Deep Deterministic Policy Gradient; DQN = Deep Q-Networks; FRAP = Flip and Rotation invariant All Phase; GAT-DDPG = Graph Attention Network-Deep Deterministic Policy Gradient.
Simultaneously, we considered model variants and conducted ablation experiments to validate the effectiveness of each module:
DDPG: Retains the DDPG component for learning traffic network states while removing the GAT algorithm component to assess the impact of GAT on model performance.
GCN-DDPG: Replaces GAT, used for learning traffic network states, with GCN to evaluate the impact of GAT on model performance.
GAT-DDPG-noRWR: Retains the GAT component for learning traffic network states and only removes the RWR algorithm component to assess the impact of RWR on model performance.
Figure 10 compares the results of ablation experiments on three real datasets. From the experimental results, it can be concluded that integrating GAT into the DDPG model effectively improves model performance, reducing the ATT of vehicles. Simultaneously, incorporating the RWR module effectively enhances the model’s convergence speed, which is crucial for enhancing training efficiency and performance stability, especially when dealing with large-scale and complex traffic network data.
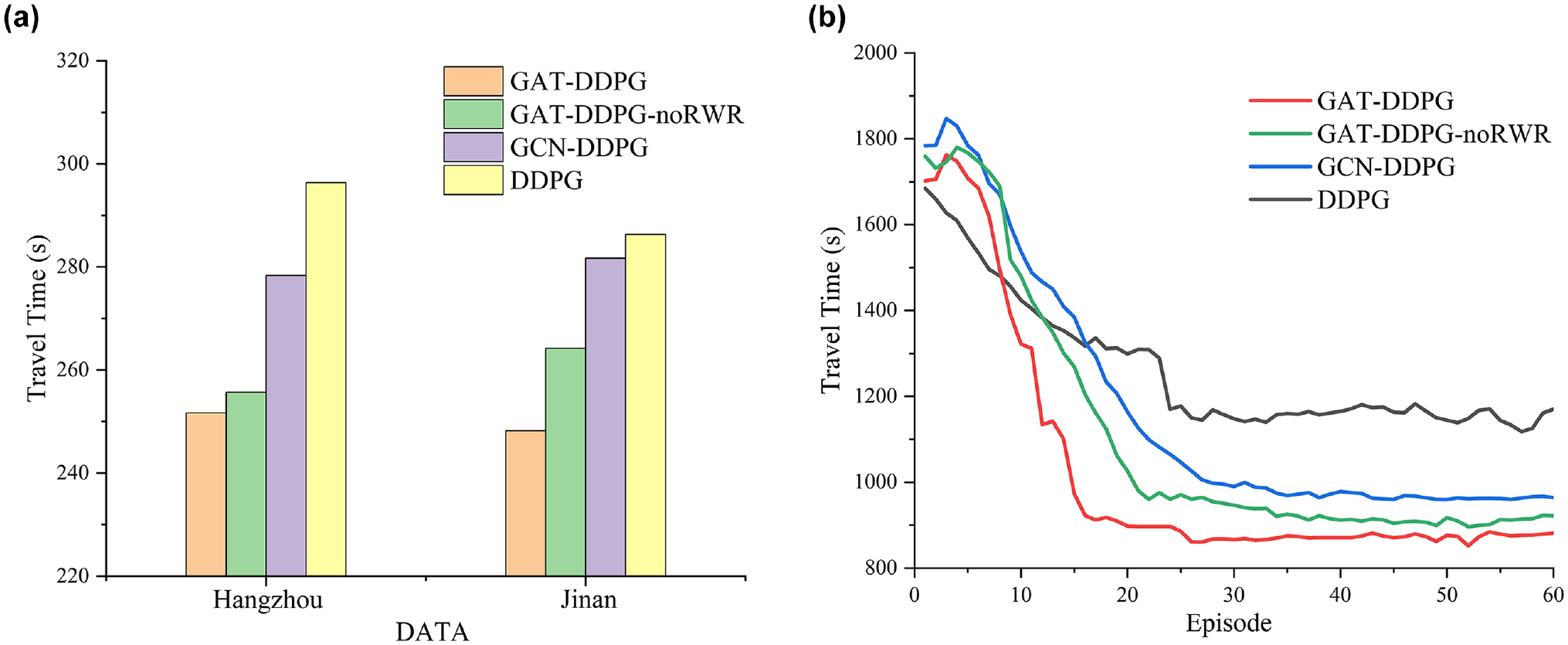
Ablation experiment: (a) Hangzhou and Jinan, and (b) New York.Note: DDPG = Deep Deterministic PolicyGradient; GAT-DDPG = Graph Attention Network-Deep Deterministic Policy Gradient; GAT-DDPG-noRWR = Graph Attention Network-Deep Deterministic Policy Gradient without Random Walk with Restart; GCN-DDPG = Graph Convolutional Network-Deep Deterministic Policy Gradient.
Conclusion
Accurately capturing and comprehensively representing traffic states remains a major challenge in the current traffic signal control domain. Since the traffic condition of an intersection is often profoundly affected by multiple intersections in its vicinity, this intricate interdependence greatly increases the complexity and difficulty of state acquisition. To address this challenge, we propose an innovative GAT-DDPG algorithm.
Specifically, GAT-DDPG uses GAT’s unique attention mechanism to accurately identify and measure the complex relationships and interdependencies among different intersections in the traffic network. This capability allows GAT not only to capture direct influences between neighboring intersections but also to reveal potential indirect connections and interactions among intersections at a distance. Through this deep understanding of complex intersection relationships, GAT significantly enhances the perception capability of traffic network states. Additionally, GAT-DDPG integrates RWR technology, effectively reducing GAT’s reliance on local neighboring nodes and mitigating sensitivity to the input graph structure. This improvement provides a more comprehensive representation of traffic network states, enhancing the model’s generalization ability. Finally, the AC architecture of the DDPG algorithm enables more flexible and efficient traffic signal control strategies.
GAT-DDPG can potentially update and adjust the state of traffic signal control systems in real-time to adapt to actual traffic flow and congestion conditions. Importantly, it possesses powerful automatic learning capabilities that allow it to directly identify and extract key features from the complex data of traffic networks, without the need for human intervention to define or select the importance of features. This characteristic enables GAT-DDPG to better adapt to and handle various traffic network topologies.
We conducted comparative experiments with other algorithms such as MDQN, FRAP, and DDPG in synthetic road networks (including 3 × 3 and 6 × 6 traffic networks) and three real road networks: Hangzhou (16 intersections), Jinan (12 intersections), and New York (196 intersections), under heavy traffic flow conditions. The experimental results demonstrate that the GAT-DDPG algorithm consistently outperforms others across different complexities of traffic networks, affirming its robustness. Additionally, we conducted ablation experiments that further validate the significant role of algorithmic components in enhancing model training efficiency and stability. Furthermore, across the three real datasets with different traffic network structures, GAT-DDPG exhibited superior convergence compared with benchmark algorithms such as Colight, MDQN, FRAP, and DDPG. It rapidly adapts and achieves excellent performance on diverse datasets, underscoring its strong generalization capability.
The method proposed in this paper still has some limitations, mainly because it currently focuses only on vehicular traffic, ignoring key factors such as pedestrians and weather. To overcome these limitations, future research is planned to incorporate more diverse external data such as pedestrian behavior models as well as weather conditions, which may help to improve the performance of the model and make the algorithm more comprehensively adaptable to the complex and changing urban traffic environment.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Guoqing Yang, Xin Wen; data collection: Fuqiang Chen, Xin Wen; analysis and interpretation of results: Fuqiang Chen, Xin Wen; draft manuscript preparation: Xin Wen. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Tianjin Postgraduate Research Innovation Project (Approval Number: 2022SKYZ394, 2021YJSS336).