
Abstract
Mobility analysis is a crucial element in the research area of transportation systems. Forecasting traffic information offers a viable solution to address the conflict between increasing transportation demands and the limitations of transportation infrastructure. Predicting human travel is significant in aiding various transportation and urban management tasks, such as taxi dispatch and urban planning. Machine learning and deep learning methods are favored for their flexibility and accuracy. Nowadays, with the advent of large language models (LLMs), many researchers have combined these models with previous techniques or applied LLMs to directly predict future traffic information and human travel behaviors. However, there is a lack of comprehensive studies on how LLMs can contribute to this field. This survey explores existing approaches using LLMs for time series forecasting problems for mobility in transportation systems. We provide a literature review concerning the forecasting applications within transportation systems, elucidating how researchers utilize LLMs, showcasing recent state-of-the-art advancements, and identifying the challenges that must be overcome to fully leverage LLMs in this domain.
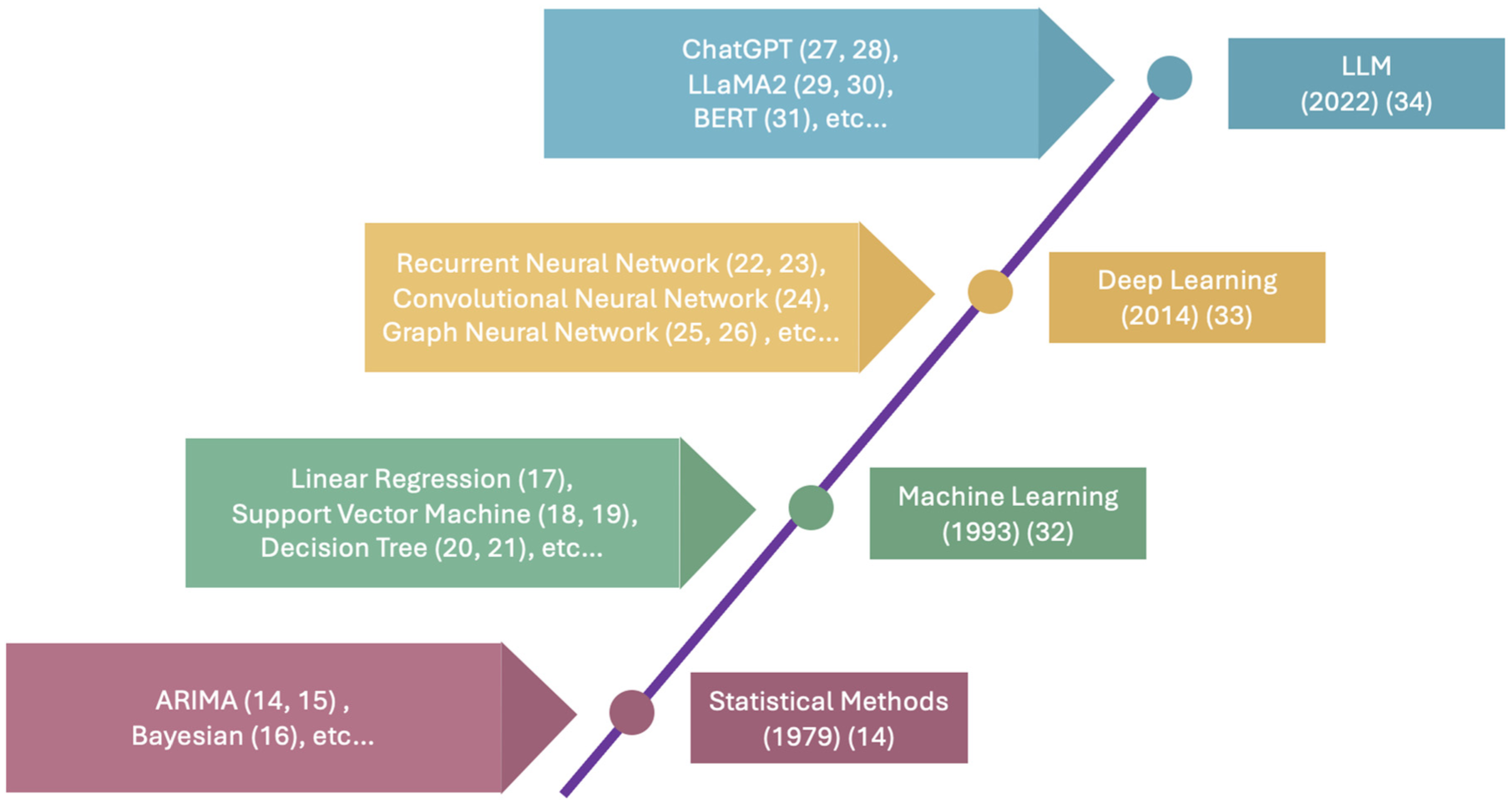
Forecasting the mobility of vehicles and pedestrians is crucial for planning and optimizing transportation systems that enable the movement of people and goods within and across different areas ( 1 – 3 ). Traditionally, statistical models have been widely used for transportation system forecasting, focusing on factors such as population growth, urban development, and changes in infrastructure. Common methods include the autoregressive integrated moving average (ARIMA) model, Bayesian approaches, and others. Recently, there has been a notable shift toward leveraging deep learning techniques in this domain ( 4 – 7 ). Deep learning models are extensively employed in modern scientific research and engineering ( 8 – 10 ). They particularly excel at identifying complex patterns in mobility data, offering insights into traffic flow and public transit demand with high accuracy ( 11 – 13 ). The developmental timeline of these advancements is illustrated in Figure 1.
The development of large language models (LLMs) has introduced a new paradigm for quantitative problem solving in various domains ( 35 – 37 ). These models, exemplified by the generative pretrained transformer (GPT) series, have significantly affected research areas ranging from sentiment analysis, machine translation, and text summarization in natural language processing (NLP), as well as data augmentation, predictive modeling, big data analytics, and statistical learning to complex data analysis ( 38 – 40 ). LLMs stand out for their ability to process and interpret large datasets in a sophisticated manner, closely mirroring human cognitive abilities ( 41 ). This capability makes them particularly promising for applications in understanding diverse and complex data streams ( 42 – 44 ).
Recently, the application of LLMs in time series forecasting has garnered increasing attention and progress ( 45 – 47 ). Two primary approaches have emerged in this domain: first, researchers have developed specialized time series foundation models inspired by LLM architectures ( 48 , 49 ), as well as multimodal foundation models capable of time series analysis ( 50 ). Second, investigators have explored the adaptation of pretrained LLMs for time series forecasting through various methods, including fine-tuning ( 51 ), reprogramming ( 52 ), and zero-shot inference ( 53 ). LLMs distinguish themselves from traditional methods by their advanced reasoning and contextual understanding capabilities, which allows for deciphering complex patterns in data, and their flexibility in transfer learning, which minimizes the need for retraining, especially when the downstream data size is limited. Moreover, their scalability makes them suitable for real-time analysis, and their ability to handle multimodal data is invaluable for integrating diverse data sources. LLMs also offer the potential for enhanced interpretability and customization, which are essential for practical applications where understanding the model’s reasoning is crucial. These capabilities collectively highlight the potential of LLMs to revolutionize complex, multimodal forecasting tasks in various real-world settings.
In transportation systems, time series forecasting represents a fundamental analytical task that often requires processing temporal data alongside diverse contextual information. The multimodal nature of transportation data, encompassing structured temporal sequences (e.g., traffic flow, speed, and occupancy data) and unstructured contextual information, presents an ideal use case for LLM applications ( 54 ). This contextual information may include real-time traffic incident reports, regulatory notifications from transportation authorities, visual data from traffic surveillance systems, and meteorological conditions affecting road networks. The inherent capability of LLMs to process and synthesize diverse data types while maintaining temporal coherence makes them particularly suitable for transportation forecasting tasks. For instance, LLMs can simultaneously analyze historical traffic patterns while incorporating relevant external factors such as scheduled events, weather forecasts, or infrastructure maintenance schedules, which is a task that traditionally required multiple specialized models ( 55 ). Furthermore, the sophisticated pattern recognition and transfer learning capabilities of LLMs suggest their potential to address common challenges in transportation forecasting, such as handling nonlinear relationships, accounting for seasonal variations, and adapting to evolving urban mobility patterns. The NLP capabilities of LLMs also offer the possibility of generating interpretable forecasts accompanied by contextual explanations, which could significantly enhance decision-making processes in transportation management systems ( 30 , 56 ).
However, the specific application of LLMs in time series forecasting in transportation and urban systems has not been thoroughly explored in the existing literature. While there are studies on LLM applications in time series analysis ( 52 , 57 – 59 ) and deep learning’s broader impact on transportation ( 4 , 60 , 61 ), a focused examination of LLMs in this context is missing. This gap indicates a significant opportunity for in-depth research on the use of LLMs for advanced traffic predictions and transportation infrastructure planning.
Our survey seeks to address this gap by presenting a comprehensive exploration of the potential of LLMs in forecasting tasks in transportation systems. We will discuss two key sets of techniques—data processing and model framework—that demonstrate the versatile applications of LLMs in both transportation and human mobility forecasting contexts. Through reviewing current research and practical applications, our work aims to highlight the transformative potentials that LLMs offer to improve the efficiency, safety, and sustainability of transportation systems, while also generating transportation and mobility planning solutions. By contributing a concentrated analysis on the role of LLMs in transportation and human mobility forecasting, we aspire to stimulate further research and innovation in this domain, as well as facilitate a richer integration of LLMs with transportation systems and human mobility planning strategies.
Background
LLMs
In recent years, there has been a significant transformation in the field of NLP, primarily driven by the advent and evolution of LLMs. In 2018, the introduction of bidirectional encoder representations from transformers (BERT) by Devlin et al. ( 62 ) marked a significant advancement in pretraining language representations. BERT established a new benchmark for state-of-the-art performance across a multitude of language understanding tasks by leveraging bidirectional training in a novel way. The release of GPT-3 in 2020 further expanded these capabilities by introducing and demonstrating the effectiveness of few-shot learning ( 63 ). These advancements provide a guideline on how to further improve LLM performance. In addition to the preceding models, many new LLMs, like LLaMA ( 64 ) and Mixtral ( 65 ), have also been developed, and applied to various tasks ( 66 ).
LLMs have seen diverse applications across various time series fields, including finance ( 66 ), healthcare ( 67 , 68 ), traffic management ( 69 ), and videos ( 70 , 71 ), demonstrating their versatility beyond traditional text-based tasks ( 9 , 46 ). For instance, in the financial domain, researchers have leveraged LLMs to surpass conventional models like ARMA-GARCH by employing techniques such as zero-shot/few-shot inference and instruction-based fine-tuning, highlighting LLMs’ capability for enhanced predictive accuracy ( 66 ). In healthcare, innovations like GatorTronGPT focus on medical research, including biomedical NLP, showcasing the potential of LLMs in processing and interpreting complex medical data ( 67 ).
The application of LLMs to traffic problems exemplifies their ability to analyze and forecast time series patterns in mobility and transportation data, further underscoring the transformative impact of LLMs across diverse research areas and practical applications.
Forecasting Tasks in Mobility Analysis
Time series prediction is a vital component of intelligent transportation systems because of its ability to provide predictive and timely information that benefits society at large. Normally, mobility forecasting tasks are often categorized as a type of time series prediction problem ( 72 , 73 ) and deep learning techniques are the most popular approaches today. In this survey, we mainly focus on four types of time series forecasting problems: traffic forecasting, human mobility forecasting, demand forecasting and missing data imputation.
Traffic Forecasting
Traffic forecasting focuses on predicting future traffic conditions, such as vehicle flow, speed, and congestion levels, on transportation networks. Here, the term “traffic” refers to the collective movement of various modalities, including vehicles, bicycles, and pedestrians, across road networks or urban areas. Accurate traffic forecasts are essential for effective traffic management, infrastructure planning, and mitigating congestion in intelligent transportation systems.
The traditional approaches for traffic forecasting are usually based on time series analysis. These methods model traffic data as time-dependent sequences to identify patterns and make future predictions. The ARIMA model is a widely used technique in this category. And there have been comprehensive studies on applying ARIMA models to forecast short-term traffic flow, demonstrating their effectiveness in capturing temporal dependencies in traffic data ( 74 , 75 ).
Recently, the machine learning-based models, especially deep learning methods, have become more popular in the field of traffic forecasting because of their strong performance. For instance, recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, are used to model complex temporal patterns in traffic data, achieving high accuracy by capturing long-term dependencies in traffic flow ( 22 ). In addition, the graph neural networks (GNN) approaches are well suited to traffic forecasting problems because of their ability to capture spatial dependency, and there has been comprehensive studies summarizing the GNN paradigms in the traffic domain ( 76 ).
Human Mobility Forecasting
Human mobility forecasting, in contrast, focuses on predicting the movement patterns of individuals or crowds over time and space. While traffic forecasting emphasizes aggregate flows on transportation networks, human mobility forecasting is more centered on modeling individual-level or group-level movements across broader spatial and temporal contexts. Understanding and forecasting human mobility is essential for urban planning, transportation management, and public health interventions.
Among the traditional statistical methods, Markov chains (MC) are popular probabilistic models that predict future human locations based on the current state and transition probabilities. For instance, Lu et al. ( 77 ) proposed and implemented a series of MC-based models for human forecasting, demonstrating their effectiveness in capturing sequential movement behaviors.
Similar to traffic forecasting, deep learning methods have been widely applied in the field of human mobility forecasting ( 78 ). For example, in T-CONV ( 79 ), the authors leveraged convolutional neural networks (CNNs) to model trajectories as two-dimensional images, and adopted multilayer CNN to combine multiscale trajectory patterns to achieve precise prediction. In addition, Xue et al. ( 80 ) proposed MobTCast, which is a transformer-based model for human mobility forecasting, leveraging auxiliary trajectory forecasting to enhance accuracy.
Demand Forecasting
Traffic demand forecasting denotes the process of predicting the size of crowds or the number of vehicles traveling in a given location at a specific time in the future.
Rule-based models are traditional approaches for demand forecasting. For example, Zhao et al. ( 81 ) presented three such models aimed at performing traffic demand forecasting with big data. The total sample demand distribution model uses comprehensive population data to predict travel demand across regions, eliminating the need for traditional sample surveys and parameter estimation, which are required in older gravity models. The transportation integration model merges several stages of traffic forecasting—such as trip distribution, mode choice, and traffic assignment—into a unified approach, allowing for real-time data integration to more accurately predict shifts in traffic patterns and congestion. Finally, the nonmotorized demand forecasting model targets demand forecasting for nonmotorized modes like walking and cycling. This model uses high-resolution spatial data to improve prediction accuracy, addressing the limitations of traditional models that often overlook or inadequately predict nonmotorized travel demand.
The utilization of textual information in traffic demand forecasting has been explored in some deep learning studies. For instance, two deep learning architectures, DL-LSTM and DL-FC, were proposed in Rodrigues et al. ( 82 ) that improved time series forecasting accuracy by leveraging text information in addition to original time series data. These two deep learning architectures demonstrate significantly reduced forecast errors in the context of taxi demand prediction.
Missing Data Imputation
Imputation is also a critical study in traffic data studies. For various reasons, such as broken devices or lack of stable measuring equipment, some pieces of data in a whole traffic system may be missing. Therefore, performing traffic data imputation to recover missing data is usually a necessary task in traffic research ( 83 ).
In the early days, popular approaches for missing data imputation included traditional traffic prediction models, interpolation-based methods, and statistical learning-based methods ( 84 ). Traffic prediction models like ARIMA and Bayesian networks predict missing data using historical information. As a result, these models cannot fully utilize data collected after the missing point. Interpolation-based methods are divided into two subgroups: temporal-neighboring methods and pattern-similar methods ( 85 ). These methods assume that traffic patterns are highly similar, limiting their application to very stable or regular situations. Statistical learning-based methods mainly include principal component analysis-based techniques such as probabilistic principal component analysis (as noted by Qu et al. [ 86 ]). A comparative experiment among these methods was conducted by Li et al. ( 85 ). The study found that the performance of different methods varies with the missing data pattern and ratio.
In recent years, deep learning models have been applied to traffic data imputation. Generative adversarial networks generate realistic data through a generator-discriminator setup, improving imputation performance. GNNs, especially those using diffusion-based convolution methods, have shown good results in learning both space and time patterns in traffic data. Recent work by Huang et al. used a model that learns from both graph structure and node data to fix missing traffic data and find sensor faults. It worked better than older Graph Convolutional Network (GCN) models on messy and uneven traffic datasets ( 87 ). CNNs have also been directly applied for this purpose, as shown by Zhuang et al. ( 88 ), whose model demonstrated better performance compared with the state of the art.
Methodology
In the evolving landscape of transportation and human mobility forecasting, LLMs have become critical tools, offering innovative perspectives and methodologies for analyzing various complex datasets such as sensor datasets, map datasets, traffic flow datasets, and route datasets, among others. This section dives deep into the various kinds of approaches to leverage LLMs within this domain, categorizing these approaches into two distinct sets of techniques: Processing (Tokenization, Prompt, Embedding) and Model Framework (Fine-tune, Zero-Shot/Few-Shot, Integration). As illustrated in Figure 2, which provides a general pipeline of LLM application for time series forecasting in transportation systems, the Processing techniques help users to create more LLM-friendly input data and manipulate LLM output data in various ways. The Model Framework section focuses on unblocking more potentials of LLMs for making more accurate predictions. Specifically, for Fine-tune and Zero-Shot/Few-Shot, we explore how to refine LLMs, while for Integration, we investigate better ways to fit LLMs into larger frameworks—considered an optional step in the overall pipeline. The final output of the pipeline can vary, including imputation, traffic chatbot, prediction, and more.
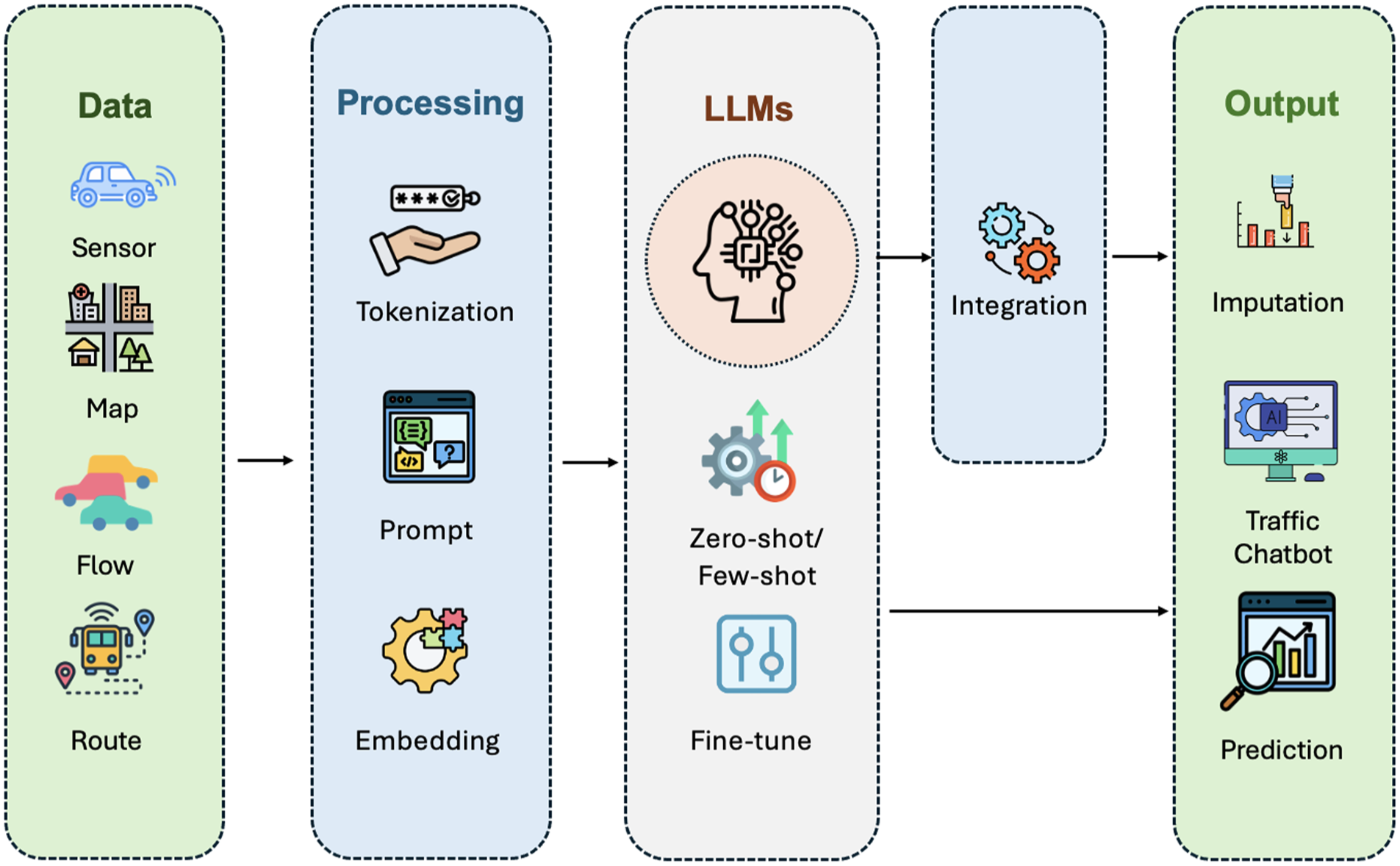
Overview of methodologies in LLM pipeline for time series forecasting in transportation systems.
Each of the techniques presents a unique way to interact with or utilize LLMs. From the processing perspective, Tokenization means introducing innovative tokenization techniques for specific application scenarios. Prompt refers to performing prompt engineering to provide more contexts and instructions to LLMs for better outcomes. Embedding denotes utilizing LLMs as encoders that generate meaningful deep representations from original data for the downstream processes. From the model perspective, Fine-tune means dedicated fine-tuning processes which tailor models to specific forecasting tasks. Then, Zero-Shot/Few-Shot refers to directly querying pretrained LLMs without any examples or with several concrete examples, respectively, while not modifying the LLMs’ parameter weights. Finally, Integration denotes LLMs serving as an integral part of a larger infrastructure or pipeline. By illustrating these techniques, we aim to provide a comprehensive understanding of how LLMs can be effectively deployed to enhance mobility prediction modeling in transportation systems.
Data Processing
Tokenization
Tokenization is the process of breaking down raw textual data into a series of tokens as the input for querying LLMs, which makes data much more understandable and easier to analyze for LLMs.
Some tokenizers can be utilized in a notably straightforward way by directly breaking down the textual data into tokens, which is conceptually simple but still fairly effective, especially for time series data as a result of the limited informational breadth. However, tokenization could also be leveraged in more sophisticated ways. For example, Liu et al. ( 29 ) utilized a novel tokenizer, which defines timestamps at given locations as a token, and then embeds tokens by a spatial-temporal embedding layer. After that, the authors performed embedding fusion to generate inputs for a partially frozen attention (PFA) LLM.
Through tokenization, researchers can transform different types of traffic data into tokens which can be easily consumed by LLMs ( 53 ). While built-in tokenizers (e.g., Python NLTK) might usually be too generic, scientists can design tokenizers for specific applications. An appropriate tokenizer can be a great component to enhance the overall performance of LLM applications, especially for sophisticated sources like mobility data in transportation systems.
A typical example of tokenization technique, AuxMobLCast, proposed by Xue et al. ( 34 ), uses pretrained language encoders (e.g., BERT, RoBERTa, and XLNet) to encode the raw mobility prompts into two sets of tokens: (1) contextual tokens, carrying the contextual information such as temporal data, and (2) numerical tokens, containing the numerical human mobility information such as number of visits to a place-of-interest (POI). These two sets of tokens are ready to be learned simultaneously by the transformer-based decoder (e.g., GPT-2) later. In addition, the authors introduce the [CLS] token in the initial prompt and take the feature embedding of this special token as the input for a fully connected layer followed by a softmax layer, which empowers the framework to be able to perform the POI category classification.
Prompt
Prompt, or prompt engineering, means the process of structuring inputs to LLMs by providing more contexts and instructions in addition to original queries.
In the domain of LLM applications in transportation forecasting, prompt engineering can play an important role. For instance, Lai et al. ( 89 ) proposed LLMLight, a novel framework employing LLMs as decision-making agents for traffic signal control, which instructs LLMs with knowledgeable prompts containing real-time traffic conditions. Moreover, Xue et al. ( 90 ) introduced an innovative prompt mining framework in language-based human mobility forecasting, including a prompt generation stage based on the information entropy of prompts and a prompt refinement stage to integrate mechanisms such as the chain of thought.
Prompt engineering allows for the exploitation of LLMs’ vast knowledge bases and sophisticated understanding of spatiotemporal mobility patterns without the need for computationally intensive training processes, which makes it a great way for researchers to explicitly guide LLMs. With more contexts and instructions in prompts, LLMs can better understand the tasks assigned by researchers and generate outputs following the expected response formatting ( 91 ).
In Xue et al. ( 34 ), the mobility prompting introduced by the authors can transform numerical temporal sequences into natural language sentences allowing the existing language models of intelligent digital agents (e.g., Alexa and Siri) to be leveraged directly. Prompt engineering resolves a major drawback of the numerical model paradigms, which mainly focus on extracting and modeling structured numeric data and are less effective in dealing with other formats of data.
Embedding
Embedding is the strategy of utilizing LLMs as encoding models, which produce meaningful deep representations (i.e., embeddings) of input queries, instead of textual/numerical results, as outputs. The output embeddings are then leveraged as inputs for downstream procedures in the framework.
There are various applications for the embedding strategy in transportation research. In Xue et al. ( 34 ), a pipeline for predicting POI customer flows is proposed, which utilizes LLMs (e.g., BERT) as the encoder to produce feature embeddings for contextual and numerical tokens. Furthermore, LLMs can also be integrated into multimodal intelligent traffic systems by embedding text-based traffic information into feature vectors ( 92 ).
Through embeddings, LLMs can serve as robust and effective encoders, which can capture key information from textual traffic data and convert them into the desired formatting for downstream deep learning networks. Furthermore, the mobility data in transportation systems usually contains multiple sources of information, including texts, images, audio ( 93 ), and so on. And the embedding technique is a straightforward way for LLMs’ integration into sophisticated multimodal mobility forecasting frameworks.
The functionality of language models in graph transformer-based traffic data imputation (GT-TDI) is to serve as the information extractors from semantic descriptions of historical traffic data, and the language models will output embedded semantic tensors ( 31 ). Together with geographic edges, pattern edges, and incomplete traffic data, the semantic embedding from language models empowers GT-TDI’s ability to impute missing traffic data effectively.
Model Framework
Fine-Tune
Fine-tuning is the process of feeding a dataset containing task-specific examples to update the weights of parameters in pretrained LLMs through back-propagation.
Fine-tuned LLMs can effectively work with time series data, including mobility information in transportation systems. For instance, LLM4TS, an LLM-powered time series prediction framework, uses fine-tuned GPT-2 as its backbone model, which has good capability in interpreting temporal data ( 94 ). Moreover, Liu et al. ( 95 ) proposed STG-LLM, an innovative approach for spatial-temporal forecasting, which also leverages GPT-2 by fine-tuning a small number of its parameters to enable its understanding of the semantics of researcher-defined spatial-temporal tokens.
Fine-tuning can provide researchers with a customized LLM, which can be more accurate and effective for a given application domain with relatively low costs ( 96 ). In addition, fine-tuned LLMs can usually better understand inputs from researcher-designed tokenizers and be more likely to produce outputs in needed formats. Therefore, fine-tuning is a great approach to enhance the overall performance of small or generic LLMs in time series forecasting in transportation systems.
In GT-TDI, Zhang et al. ( 31 ) fine-tuned the pretrained language models with task-specific data (e.g., spatiotemporal semantic descriptions) to align them with the distribution of datasets in the traffic domain. With fine-tuned parameters, the language models are more capable of imputing incomplete traffic data. Similarly in AuxMobLCast ( 34 ), LLMs are fine-tuned for both sequence generation and auxiliary category classification tasks, and the joint training enhanced the proposed framework’s capability to perform human mobility forecasting.
Zero-Shot/Few-Shot
Zero-shot and few-shot learning directly query LLMs without updating their pretrained parameters. The zero-shot technique only uses instructions in its prompts, while the few-shot technique contains several concrete examples in its prompts.
There are various zero-shot and few-shot applications in the domain of transportation systems. For instance, Li et al. ( 97 ) introduced UrbanGPT, an urban traffic spatiotemporal prediction framework, which also utilizes LLMs’ zero-shot reasoning. Furthermore, few-shot prompts can provide LLMs with more traffic domain knowledge contained in text descriptions, so that LLMs can better consider spatial-temporal factors and their interdependencies in traffic prediction tasks ( 30 ).
Modern LLMs have demonstrated strong performance at tasks defined on-the-fly without fine-tuning ( 63 ). The zero-shot technique can achieve great task-agnostic performance, while the few-shot technique can produce even better outcomes. Without the need for training, LLMs can already be a great ingredient in the development of time series prediction frameworks in transportation systems.
Without further fine-tuning or training, TrafficGPT directly leverages pretrained language models (e.g., GPT-3.5, ChatGLM3-6B, Qwen-14B-Chat, and InternLM-Chat-20B) to perform deductive reasoning, facilitated by the orchestration of the task request, the set of available traffic foundation models (TFMs), and the reasoning history in the prompts ( 98 ).
Integration
Integration means that an LLM serves as an integral component to process or produce informative intermediate results in a large framework.
LLM integration has been widely applied in the field of time series and spatiotemporal forecasting including traffic forecasting ( 99 ). For example, Ren et al. ( 100 ) proposed TPLLM, a traffic prediction framework which leverages GPT-2 as the base LLM to provide embedding inputs for downstream tasks, including traffic flow prediction, and traffic missing data imputation. In this framework, the pretrained LLM acts as an integral component that receives fused representations of temporal and spatial features and generates the final traffic prediction. This reflects the notion of integration, where the LLM not only performs sequence modeling, but also serves as the central reasoning module that operates on multimodal information. Specifically, temporal features from CNNs and spatial features from GCNs are combined and projected into the LLM’s input space, allowing the model to attend to spatiotemporal dependencies across all transformer layers. This early fusion strategy stands in contrast to traditional models that separate modality processing and rely on late fusion, and highlights the LLM’s ability to jointly reason over heterogeneous inputs. This integration enables a unified and parameter-efficient learning process for traffic forecasting. In addition, in the spatial-temporal large language model (ST-LLM), a framework introduced by Liu et al. ( 29 ), a PFA LLM is utilized for training on traffic feature datasets and inferring on new data to produce intermediate results for the downstream regression task to perform spatial-temporal prediction.
On the one hand, through integration with different types of models (e.g., computer vision, speech, etc.), LLMs can be leveraged effectively in multimodal forecasting tasks. On the other hand, LLMs’ capabilities could be augmented through integration, because LLMs can encode textual traffic data into insightful embeddings that can be easily consumed by other deep learning models.
In TrafficGPT, Zhang et al. ( 98 ) enabled iterative interactions between LLMs and the necessary TFMs to enhance LLMs’ understanding of operational contexts within the traffic domain. This integration allows TrafficGPT to leverage multimodal data as a source, providing more comprehensive support for various traffic tasks—a capability that cannot be achieved by either LLMs or TFMs alone. In addition, TrafficGPT enables multistep task planning through prompt-driven reasoning, allowing the LLM to iteratively select and coordinate TFMs based on user intent. This agent-style architecture supports complex traffic workflows, such as simulation-based control or data visualization, through dialogue and feedback, highlighting a form of integration centered on orchestration rather than embedding-level fusion. There are also more straightforward integrations of LLMs with other networks. A refined version of BERT, called TrafficBERT, was proposed by Jin et al. ( 101 ), and it has the ability to encode continuous traffic sequence data by taking linearly transformed inputs through stacks of transformer encoders. In the end, TrafficBERT is integrated with the final linear layer to generate predicted traffic sequences.
Applications
In this section, we present recent innovative deep learning applications of LLMs and foundation models in the mobility analysis of transportation systems across various fields, including traffic forecasting, human mobility, demand forecasting, and missing data imputation. We have summarized the methods proposed in these research works in the taxonomy in Table 1.
Taxonomy of LLM Applications in Forecasting Tasks in Transportation and Urban Systems
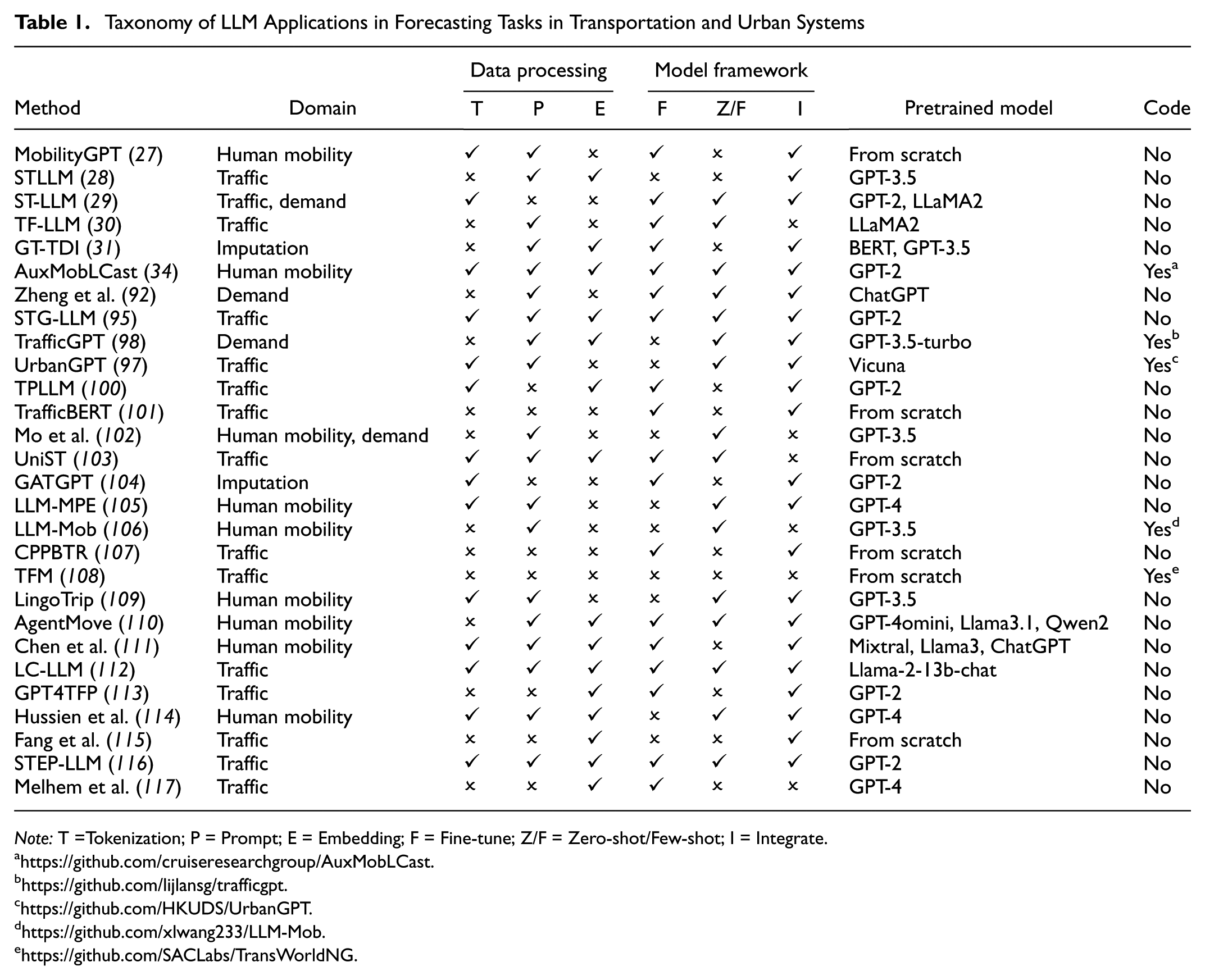
Note: T =Tokenization; P = Prompt; E = Embedding; F = Fine-tune; Z/F = Zero-shot/Few-shot; I = Integrate.
Traffic Forecasting
Traditional statistical methods typically treat traffic forecasting as time series problems ( 2 , 72 ). One of the common approaches is to utilize autoregressive models (e.g., ARIMA) to predict time series. After the advent of deep learning, RNN-based and knowledge-based methods were introduced in times series forecasting ( 2 , 72 , 118 ). For instance, Ma et al. ( 119 ) explored deep learning methods in this field through the combination of a deep restricted Boltzmann machine with RNN to model and predict the evolution of traffic congestion. Using GPS data, this method achieves high prediction accuracy, providing valuable insights for congestion mitigation. Furthermore, focusing on scalability and efficiency, Monteil et al. ( 120 ) compared multiple deep learning models with simpler predictors for long-term, large-scale traffic predictions, emphasizing the importance of prediction accuracy, training time, and model size.
However, RNN-based methods are hard to learn long-term temporal dependencies, and it is difficult for domain knowledge-based methods to model temporal dependency automatically. A pioneering approach in this realm, pretrained bidirectional temporal representation (PBTR), can overcome the limitations of these methods. PBTR utilizes the transformer encoder to predict crowd flows in gridded regions and demonstrates exceptional capability in modeling long-term temporal dependencies within an encoder-decoder framework, significantly enhancing prediction accuracy ( 107 ). Furthermore, the traffic transformer model demonstrates the potential of deep learning architectures in modeling time series and spatial dependencies in traffic forecasting, significantly outperforming traditional models ( 121 ).
Building on the achievements of previous deep learning models, the application of LLMs further underscores the potential of innovative approaches in the domain of traffic forecasting. For instance, TrafficBERT uses transformers for traffic flow prediction, outperforming traditional statistical and deep learning models. It efficiently utilizes large-scale traffic data and employs multihead self-attention to navigate the complexities of various road conditions without necessitating road-specific or weather data ( 101 ). Moreover, the application of LLMs extends to the generative graph transformer (GGT) model, designed for city-scale traffic forecasting. Treating traffic flow and interactions as sequences, GGT comprehends and predicts complex traffic patterns, facilitating more dynamic and accurate predictions of traffic conditions, thereby aiding in improved traffic management and planning ( 108 ).
Recent innovations in LLM application include STLLM, which integrates LLM with a mutual information maximization paradigm of cross-view to capture implicit spatiotemporal dependencies and preserve spatial semantics for traffic flow in urban areas ( 28 ). In addition, Liu et al. ( 95 ) proposed STG-LLM, which adapts LLMs for spatial-temporal forecasting through a spatial-temporal graph tokenizer and adapter, bridging the comprehension gap between complex spatial-temporal data and LLMs. Furthermore, Guo et al. ( 30 ) proposed TF-LLM, an innovative approach to generate interpretable traffic flow predictions, which leverages LLaMA2 to process multimodal traffic data, including system prompts, real-time spatial-temporal data, and external factors to make predictions and provide explanations about traffic flow. Finally, Ren et al. ( 100 ) introduced TPLLM, a traffic prediction framework based on pretrained LLMs, which demonstrates the efficacy of combining LLMs with convolutional and graph convolutional networks for traffic prediction, especially in scenarios with limited historical data.
Collectively, these studies underscore the transformative potential of deep learning and LLMs in traffic forecasting, offering innovative solutions for managing and understanding complex transportation systems.
Human Mobility
LLMs have become pivotal tools in contemporary research aiming to understand and forecast the complexities of human mobility dynamics, surpassing traditional models. Wang et al. ( 106 ) introduced LLM-Mob, a novel method using LLMs for accurate and interpretable human mobility prediction by leveraging language understanding and reasoning capabilities, along with new concepts which capture both short-term and long-term human movement dependencies and context-inclusive prompts to improve the accuracy of predictions. In addition, LLMs can be integrated to forecast human mobility and visitor flows to POI by utilizing a variety of information, such as numerical values and contextual semantic information, as components in natural language inputs ( 34 ). Furthermore, LLM-MPM, a framework for human mobility prediction under public events, shows the unprecedented ability of LLMs to process textual data, learn from minimal examples, and generate human-readable explanations ( 105 ).
In addition to the direct application of LLMs on human mobility prediction, researchers have also introduced generative models inspired by LLMs. For instance, Haydari et al. ( 27 ) proposed a geospatially aware generative model, MobilityGPT, to capture human mobility characteristics and generate synthetic trajectories. Leveraging a gravity-based sampling method to train a transformer for semantic sequence similarity, MobilityGPT can ensure its controllable generation of semantically realistic geospatial mobility data to reflect real-world characteristics.
Demand Forecasting
Numerous LLM applications have been proposed in the domain of demand forecasting. For example, Liu et al. ( 29 ) introduced the ST-LLM designed for traffic demand prediction, incorporating a spatial-temporal embedding module to learn the spatial locations and global temporal representations of tokens before embedding fusion and feeding into LLMs. ST-LLM can effectively predict taxi and bike demands to enable efficient allocation and scheduling of vehicles. Moreover, Mo et al. ( 102 ) highlighted a shift toward utilizing LLMs’ reasoning abilities for complex predictions in travel demand and behavior studies without traditional databased training. By carefully crafting prompts with travel characteristics, individual attributes, and domain knowledge, the study demonstrates that LLMs can predict travel choices accurately and provide logical explanations for the predictions. Tested against standard models, such as multinomial logit and random forests, the LLM approach shows competitive accuracy and F1-score.
Inspired by general LLMs, there are also domain-specific LLMs trained from scratch in traffic studies. Yuan et al. ( 103 ) introduced UniST, a universal model for urban spatiotemporal prediction, addressing the need for a versatile model capable of adapting to various urban scenarios with different spatiotemporal features. UniST leverages elaborate masking strategies for generative pretraining and employs spatiotemporal knowledge-guided prompts to align and utilize shared knowledge across different scenarios effectively. This approach enables UniST to perform well in diverse prediction tasks, including demand forecasting, demonstrating its universality and effectiveness through extensive experiments across multiple cities and domains, notably excelling in few-shot and zero-shot settings.
Missing Data Imputation
Several studies represent how LLMs help traffic spatial-temporal imputation tasks. In Zhang et al. ( 31 ), GPT-3.5 is applied to generate human-like texts to fine-tune a BERT-based text model, which generates traffic semantic tensors from the semantic descriptions. This method enhances the accuracy of filling in missing and updating inaccurate traffic data, demonstrating the capability of LLMs in interpreting complex spatial-temporal traffic patterns. Another study, GATGPT by Chen et al. ( 104 ), also claims its effectiveness in spatial-temporal imputation tasks, which leverages pretrained LLMs with a graph attention network for spatial-temporal imputation. This method is designed to efficiently handle missing data in multivariate time series by capturing both spatial and temporal dependencies.
Challenges and Outlook
In this section, we discuss the limitations of current research and potential further research directions in the field of mobility forecasting in contemporary transportation systems with LLMs.
Interpretability and Explainability
Traditional time series models, such as ARIMA and Kalman filters, have been widely used for traffic forecasting as a result of their simplicity and ability to model short-term temporal dependencies. However, they often struggle to capture complex, nonlinear, and long-range patterns that are common in real-world transportation systems. More recently, deep learning models, including RNNs, LSTMs, and GNNs, have significantly improved forecasting accuracy by learning intricate spatiotemporal dependencies. Nevertheless, these models typically operate as “black boxes,” offering limited transparency into their decision-making processes and lacking inherent mechanisms for providing human-understandable rationales.
In the transportation domain, the need for interpretability is particularly critical. Unlike traditional computer science or artificial intelligence research, the studies in traffic forecasting do care about integrating transportation science and how transportation domain knowledge helps forecasting models generate interpretable results. Therefore, it is crucial not only to make accurate forecasts for transportation systems but also to understand why a model made a particular forecast or decision, to better arrange traffic and understand human mobility patterns.
LLMs offer new paradigms that can address both performance and interpretability challenges in transportation forecasting. LLMs can also support interpretability during earlier stages like data processing and model integration. For example, improved tokenization methods can keep important traffic-related information, like road types, time periods, or congestion levels, clearly separated in the input, making it easier to track how each part of the data affects the output. When LLMs are used to create embeddings, the resulting representations can help identify which parts of the data the model pays most attention to. In addition, when LLMs are integrated into larger systems, they can explain their predictions in plain language or through structured outputs, making the overall process easier to understand. These features, especially when combined with explainable AI (XAI) tools such as attention heatmaps or example-based explanations, can make transportation forecasting models more transparent and useful for real-world decision-making. Beyond achieving strong forecasting performance, LLMs provide enhanced interpretability and explainability. Interpretability refers to LLMs’ ability to infer causal relationships while producing forecasting results ( 122 ). Explainability infers that LLMs can generate and showcase human-like thought processes in natural language, such as chain of thought ( 123 – 125 ). LLMs are suitable for both improving the performance of forecasting models and facilitating the interpretability and explainability for forecasting results in transportation domain.
However, at this point, most existing papers only present extensive experiments to demonstrate the effectiveness of the proposed methods, but ignore the interpretations of results and the explanations of the thought processes ( 34 , 101 ). This practice not only underutilizes the unique ability of LLMs, but also makes it difficult for researchers to understand the incentives and rationales for LLMs behind LLMs producing certain results.
In addition, currently many LLM-powered frameworks did not integrate with domain knowledge in transportation very well. For example, Ren et al. ( 100 ) introduced TPLLM, an LLM-based traffic prediction framework, which leverages the sequential nature of traffic data, similar to that of language. However, TPLLM does not incorporate established transportation-specific theories or models, such as traffic flow theory ( 126 ) and traffic assignment models ( 127 ), which might be crucial for more interpretable traffic predictions. In Jin et al. ( 101 ), TrafficBERT, a BERT model pretrained with large-scale traffic data, is proposed to forecast traffic flow on various types of roads. However, TrafficBERT mainly treats traffic data as general spatiotemporal time series information, and does not include much transportation-specific background.
Therefore, a promising future direction for research in the transportation forecasting domain is to utilize LLMs to build interpretable and explainable modules with more emphasis on transportation domain knowledge. Such modules can be very beneficial for analyzing the inference results and diagnosing errors or unexpected behaviors. In addition, the interpretability and explainability of LLMs will make the overall framework much more transparent by providing human-understandable rationales.
Privacy Concerns about LLM-Powered Transportation Frameworks
Privacy is a key bottleneck for collecting real-world data in transportation systems ( 128 ), and it is also a major concern for wider utilization of LLMs ( 129 ). Therefore, even though the strong generalization ability is an important advantage of LLMs ( 130 ), in the transportation domain, researchers may still face obstacles because of the lack of publicly available datasets suitable for fine-tuning general-purpose LLMs into transportation-specific LLMs.
First, it is challenging to protect data privacy in intelligent transportation (ITS) devices, which are crucial for collecting transportation data. This is because, to ensure data security and integrity, ITS devices rely on secret keys ( 131 ). However, many ITS devices lack the capability or resources to securely store and manage secret keys generated for secure communication or data transfer, making the privacy of collected traveler data vulnerable ( 132 ).
Second, LLMs may leak private information and compromise data privacy ( 129 ). One reason is that LLMs are memorizing training data, and it has been proven that extracting sensitive information from them is a practical threat ( 133 ). Furthermore, LLMs may have the ability to correctly infer private information, meaning that even if users only provide publicly available data, LLMs can still sometimes infer and disclose users’ correct private information ( 134 ). Research also suggests that LLMs should be trained only on data explicitly produced for public use ( 135 ).
Third, intensively interactions with LLMs and providing private data to query LLMs in transportation systems make it even more difficult to maintain data privacy. Many LLM-powered transportation models require private or sensitive information, including but not limited to real-time traffic flow videos, mobility data, temporal information, vehicle sensory data, and even conversational data from nearby vehicles ( 34 , 98 ).
Recently, advancements have been made in maintaining data privacy for LLMs and forecasting frameworks in transportation systems, particularly through the use of differential privacy. For instance, an efficient differentially private stochastic gradient descent mechanism was proposed, which can be applied to fine-tune LLMs and has theoretical privacy guarantees ( 136 ). Zhang et al. ( 137 ) introduced a privacy-preserving federated learning approach for traffic speed forecasting, utilizing a differential privacy-based adjacency matrix to protect topological information. In addition, another privacy-preserving blockchain-based framework for traffic flow prediction has been proposed, which stores model updates from distributed vehicles on the blockchain and leverages a differential privacy method with a noise-adding mechanism to enhance location privacy protection ( 138 ). Furthermore, LLM agents can also incorporate homomorphic encryption schemes and attribute shuffling mechanisms to safeguard user privacy ( 139 ). Finally, many of the transportation companies have been using databases and cloud planforms from big techs like Oracle and Microsoft, there have been mature solutions for protecting data privacy and security between the companies, the LLM application could be developed based on those mature solutions.
Cost and Legality
Application development based on LLMs is significantly more costly than traditional model development. As the most advanced AI technique, LLM development requires substantially more computational resources, such as hundreds or thousands of GPUs/TPUs, compared with traditional models ( 140 ). The financial cost for LLM application development and maintenance can therefore be prohibitive. In addition, hybrid professionals with expertise in both transportation and AI are required for LLM application development. Unfortunately, transportation professionals are often not proficient in LLM technologies, meaning companies will need to invest heavily in hiring new qualified staff or training current staff to effectively use LLMs. To address these challenges, traditional transportation companies may have to work closely with IT giants that specialize in LLM development to access computational resources and collaborate on application development.
One potential way to mitigate costs is to leverage open-source LLMs, which are increasingly available and can substantially reduce licensing fees. However, open-source models may introduce additional challenges related to security, performance reliability, and legal compliance, as compared with commercially available closed-source models. Transportation agencies and companies must carefully weigh these trade-offs when selecting LLMs for their applications.
Another issue is that transportation data sources in industry may not be sufficient or readily accessible for application development. Although many important data sources, such as environmental and traffic condition data, originate from roadside cameras and sensors installed by government institutions, much of these data are collected, maintained, and managed by private data companies under contract. This introduces another layer of complexity concerning data accessibility, licensing fees, and legal agreements, particularly when using such data for LLM-driven applications. Even though governments have invested heavily in infrastructure, accessing high-quality, large-scale datasets remains one of the biggest challenges for intelligent transportation systems ( 141 ). Therefore, companies must collaborate not only with government agencies but also with private data providers, necessitating stringent data privacy and security measures to protect sensitive information. Navigating these legal frameworks is essential to ensure compliance with privacy rights and data protection laws. Furthermore, technical challenges related to data interoperability and standardization remain significant: different agencies and companies often use varying formats and protocols for data collection and storage, making seamless aggregation and analysis difficult. Establishing common standards and protocols is crucial for maximizing the utility of transportation data in LLM applications.
In addition to financial and data-related challenges, the computational intensity of LLMs poses practical limitations for real-time traffic forecasting applications. Deploying large models in real-time environments demands extremely low latency and high efficiency, which can be difficult to achieve. Emerging techniques such as model pruning, quantization, and knowledge distillation offer promising solutions by reducing model size and inference time while maintaining acceptable accuracy. Incorporating these efficiency improvements can help make LLM deployment more feasible and cost-effective for real-world intelligent transportation systems.
Insufficient Open Data Resources
Despite the importance of open data in transportation research, the availability of datasets in this field remains quite limited. Although most studies listed in Table 1 utilize publicly available datasets, these datasets are primarily confined to specific geographical areas such as California (PeMS managed by Caltrans), New York City, and Chicago ( 97 , 103 , 142 ). Alternative sources, such as the Beijing taxi trajectories utilized by Duan et al. ( 107 ), require significant data preprocessing, while the SUMO dataset employed by Wang et al. ( 108 ) is suitable only for highly specific tasks. Furthermore, certain datasets, such as the Foursquare New York City (FSQ-NYC) dataset referenced by Wang et al. ( 106 ), are no longer accessible because of inactive download links. The current situation in limited available transportation datasets underscores that current research is predominantly concentrated on a few locations, leaving much of the world without accessible traffic data.
Another challenge is that most of the existing datasets consist of mainly numeric data and lack textual data, limiting their compatibility with LLMs. The few datasets containing free text are typically collected for specific research purposes. For instance, the Barclays Center event data collected by Liang et al. ( 105 ) was specifically scraped from the official website for a focused case study and is not part of a standardized database that could be utilized for other studies.
One key advantage of LLMs is their ability to directly process a wide range of input formats, including free text, images, tabular data, and sensor feeds. In contrast, traditional models typically require clean, structured numerical inputs and may discard valuable contextual or semantic information during preprocessing. This flexibility allows LLMs to leverage open data sources such as raw textual reports, public APIs, and crowdsourced content—many of which were previously underutilized in transportation research because of format incompatibility.
To support broader applications of LLMs in transportation, more attention should be given to alternative open data sources beyond traditional sensor-based feeds. First, crowdsourced mobile data, including fitness apps like Strava, bike-sharing system data, application-based location traces (e.g., from Yelp), and cellular signal data, offers high spatial and temporal coverage at relatively low cost. These data sources have been shown to significantly improve the accuracy of demand models for pedestrian and bicycle traffic ( 143 ). Second, fixed infrastructure sensing systems such as inductive loop detectors, weigh-in-motion stations, and traffic cameras provide consistent, high-quality flow and vehicle type data. Many of these datasets are available through DOT open data portals (e.g., PeMS in California, or PennDOT’s TSMO data system). Third, advanced traveler information systems (ATIS) aggregate real-time feeds such as incident reports, weather alerts, construction zones, and live travel times. Platforms like RITIS (Regional Integrated Transportation Information System) and OpenDataPhilly provide structured APIs or downloads that LLMs could potentially process and interpret.
There is a critical need to develop more open-source datasets for transportation forecasting with consistent standards across regions. This would enable LLMs trained on data from one location, such as NYC, to be readily applied to other cities like Philadelphia or Boston. Public databases should also be updated regularly to ensure that the available resources remain functional. Furthermore, to enhance the effectiveness of LLMs in this domain, datasets should incorporate more associated multimodal data or retain embedded original free text content, allowing for more versatile and in-depth analysis across diverse tasks and applications in transportation systems.
In addition to addressing the preceding challenges, several promising real-world applications could be explored in future research. For example, LLM-powered virtual traffic analysts could assist traffic control centers by summarizing incident reports, recommending signal timing adjustments, or translating sensor feeds into human-readable alerts. Multilingual LLM agents could support traveler information systems by dynamically generating traffic updates and detour instructions in multiple languages for international travelers. In demand-responsive transit, LLMs could analyze event schedules, social media trends, and real-time location data to forecast short-term demand surges and optimize dispatch decisions. Furthermore, LLMs trained on crowdsourced cyclist and pedestrian data could support planning for safer, more inclusive active transportation infrastructure. These concrete use cases highlight the potential of LLMs not only to improve prediction performance but also to enhance communication, accessibility, and responsiveness in modern transportation systems.
Conclusion and Future Work
We present a comprehensive and up-to-date study of LLMs and their variants tailored for the analysis of forecasting problems in transportation and human mobility scenarios. By introducing a new taxonomy, we categorize and assess prominent techniques in each domain, highlighting their respective strengths, limitations, and practical applications. We aim to not only describe the current landscape but also provide a structured perspective that could serve as a foundational reference for future work in this emerging field.
Looking forward, we see numerous research opportunities to advance the use of LLMs in forecasting tasks in transportation systems. Key areas include the development of interpretable models that integrate theories in transportation domain, the establishment of privacy-preserving techniques suitable for LLMs in real-world deployments, and the creation of standardized, open-source datasets that support cross-regional transportation applications. We aspire for this survey to act as a spark, igniting further interest and sustaining a deep-seated enthusiasm for research in LLMs and their uses in transportation systems.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Zijian Zhang, Yujie Sun, Zepu Wang; data collection: Zijian Zhang, Yujie Sun, Zepu Wang; analysis and interpretation of results: Zijian Zhang, Yujie Sun, Zepu Wang, Yuqi Nie, Xiaobo Ma, Ruolin Li, Peng Sun; draft manuscript preparation: Zijian Zhang, Yujie Sun, Zepu Wang, Yuqi Nie, Xiaobo Ma, Ruolin Li, Peng Sun, Xuegang Ban. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by NSFC Grant (62250410368).