
Abstract
Accurate three-dimensional (3D) vehicle detection in roadside light detection and ranging (LiDAR) point clouds is critical for intelligent transportation systems, as it enhances traffic efficiency, strengthens safety management, and supports vehicle–road-cloud collaboration. This paper addresses key challenges in this context: uneven point cloud density, limitations of single-modality representations (voxel-based feature diffusion, pillar-based vertical information loss), and inefficient long-range dependency modeling. We propose VPMambaNet, a novel model integrating three core innovations: (1) a voxel–pillar hybrid representation with dual-path architecture, leveraging voxels’ vertical detail preservation and pillars’ efficient coverage of sparse regions; (2) the hybrid scan state space module, a cascaded state-space module with Hilbert and cross scans for hierarchical local-to-global modeling with linear complexity; (3) the neighborhood attention extension-based voxel–pillar fusion module, enabling progressive cross-modal integration. Experiments on DAIR-V2X-I show VPMambaNet outperforms state-of-the-art methods by 1.11%–2.21% in average precision across difficulty levels, with stronger gains in complex scenarios. Ablation and qualitative analyses validate its robustness to sparse point clouds, long-range targets, and annotation noise. VPMambaNet provides an efficient, accurate solution for roadside 3D vehicle detection, directly supporting practical transportation applications such as real-time traffic monitoring and autonomous driving collaboration.
Keywords
Introduction
Roadside perception systems, as a critical component of intelligent transportation systems (ITS), enable accurate and efficient vehicle detection in complex, large-scale traffic environments, thereby improving traffic operational efficiency and enhancing road safety management. Leveraging its inherent perspective advantages, roadside perception can provide extended sensing capabilities beyond the line of sight. Through the vehicle–road-cloud collaborative system, it delivers critical information that onboard sensors of both autonomous and conventional vehicles cannot access ( 1 ). Compared with cameras and radar, light detection and ranging (LiDAR) has garnered increasing attention in three-dimensional (3D) vehicle detection because of its unique ability to capture spatial positioning and 3D geometric structural data. With the emergence of widely adopted autonomous driving benchmarks ( 2 – 4 ), numerous 3D detection models ( 5 – 7 ) have continuously advanced the state-of-the-art (SOTA) performance. However, the roadside LiDAR has a unique viewing angle, and the collected point clouds have a wider spatial coverage, with radial density decaying exponentially with distance instead of uniform high density. At present, most existing SOTA methods for 3D object detection are originally designed for on-board scenarios, and their feature modeling methods do not match the characteristics of roadside point clouds. As a result, these methods have low efficiency in modeling long-range sparse targets in roadside scenarios, and it is difficult to achieve competitive performance when directly migrated to roadside scenarios.
Although several 3D detection approaches tailored for roadside scenarios have been proposed following the recent release of roadside perception benchmarks ( 8 ), these methods primarily rely on image data from the benchmark for 3D detection. Such vision-centric roadside methods ( 9 , 10 ) focus on image-based bird’s-eye view (BEV) representation for 3D detection, but lack the precise spatial geometric information provided by LiDAR, leading to poor robustness in complex traffic scenarios with occlusion and low light. Therefore, the research on LiDAR-based roadside 3D vehicle detection needs to be explored further. The mainstream LiDAR-based 3D detection methods can be divided into four categories according to different point cloud representation and encoding strategies: (1) voxel-based methods, (2) pillar-based methods, (3) point-based methods, and (4) point–voxel hybrid methods. Each has its own distinct advantages and inherent limitations in roadside applications. Voxel-based methods (e.g., VoxelNeXt ( 11 ), VoxelRCNN [ 12 ]) quantize point clouds into regular 3D voxels and capture vertical geometric details via sparse convolution, but generate many empty voxels in the far-field sparse regions of roadside scenes, leading to severe feature diffusion and computational redundancy ( 13 ). Pillar-based methods (e.g., PillarNet [ 14 ], PillarNet++ [ 15 ], CenterPoint-P [ 16 ], PillarNeXt [ 17 ], SST [ 18 ]) project point clouds into two-dimensional (2D) pillars to reduce computational costs and improve modeling efficiency in sparse regions, but completely lose vertical spatial structure information, which limits the detection accuracy of occluded and multi-scale vehicles in dense near-field roadside scenes. Point-based methods (e.g., PointRCNN [ 19 ]) extract features directly from unstructured raw point clouds, which can theoretically retain fine-grained spatial information to the greatest extent. However, when processing large-scale roadside point clouds, such methods suffer from sparse point cloud feature loss and high computational complexity, resulting in extremely low efficiency in modeling long-range sparse targets. Point–voxel hybrid methods (e.g., PV-RCNN [ 20 ]) integrate the advantages of raw point and voxel representations to enhance feature richness, but face extremely high computational and memory overhead (e.g., 17.2 GB of GPU memory is required in our experiments), which is incompatible with the real-time deployment requirements of roadside infrastructure. Recently, the state space model (SSM) has attracted significant attention because of its ability to capture long-range dependencies with linear computational complexity. As an SSM-based detector, PillarMamba ( 21 ) introduces Mamba ( 22 ) to realize linear-complexity long-range dependency modeling, but it relies on single-pillar representation and cannot make up for the loss of vertical information, and its recursive scanning mechanism damages the local continuity of roadside point clouds. Based on the above analysis, 3D vehicle detection using roadside LiDAR point clouds must address two interrelated core challenges, which are the root cause of the limitations of existing methods: first, the inherent defects of point cloud data itself, including natural sparsity and unstructured distribution; second, the unique characteristics of roadside point clouds—namely, ultra-large spatial coverage and exponential radial density decay with distance, leading to severe inhomogeneity between dense near-field and extremely sparse far-field regions. In summary, none of the existing methods can simultaneously solve the three core pain points of LiDAR-based roadside 3D vehicle detection: the inherent defects of single-modality representation, the contradiction between efficient long-range dependency modeling and local information preservation, and the effective fusion of heterogeneous features for roadside inhomogeneous density point clouds.
To address these pain points in a unified framework, we propose VPMambaNet, a dedicated roadside 3D vehicle detection model. In addition to adopting the dual representation of voxel and pillar, the model incorporates two key innovations: the hybrid scan state space module (H3SM) and the neighborhood attention extension-based voxel–pillar fusion module (NA-VPF). Specifically, to overcome the limitations of single data representations, we introduce a hybrid voxel–pillar representation for quantizing roadside point clouds and employ a dual-path architecture to synergistically exploit the strengths of both representations. For the BEV feature maps generated from voxels and pillars, we propose H3SM to model long-range dependencies through a cascaded Hilbert ( 23 ) and cross scanning design, enabling multi-scale feature processing and addressing local information loss and discontinuity, thereby achieving hierarchical processing from local to global. To facilitate feature interaction and fusion between voxel and pillar representations, we designed NA-VPF, which performs multi-stage feature fusion with linear complexity. Specifically, the module first enhances the bidirectional interaction of voxel and pillar features on their respective BEV maps. Then, it establishes cross-feature interactions between the two BEV maps using neighborhood cross-attention (NCA), while applying neighborhood attention (NA) to the pillar-based BEV features. Finally, heterogeneous features are integrated into a unified representation for 3D vehicle detection. Extensive experiments on the DAIR-V2X-I dataset demonstrate that our model significantly outperforms existing roadside 3D vehicle detection approaches across all evaluation metrics.
The contributions of this paper are summarized as follows:
We propose a novel roadside point cloud 3D vehicle detection model, VPMambaNet, which introduces a hybrid quantization strategy combining voxels and pillars within a dual-path architecture. This design specifically addresses the intrinsic limitations of single representations—namely, the restricted feature diffusion in voxel-based modeling and the vertical information loss in pillar-based modeling—thereby establishing a more effective feature foundation for long-range dependency modeling and cross-modal fusion.
We develop a cascaded state space module, H3SM, that hierarchically integrates Hilbert and cross scanning mechanisms. While preserving linear computational complexity, H3SM effectively mitigates the loss and interruption of critical local information caused by conventional recursive scanning approaches, enabling efficient modeling that transitions from local details to global dependencies. This makes it particularly suitable for capturing long-range correlations in large-scale roadside point clouds.
We further present the NA-VPF, which achieves complementary fusion of voxel and pillar features through a three-stage progressive strategy: bidirectional feature interaction enhancement, neighborhood-aware attention feature interaction modeling, and heterogeneous feature integration. This approach ensures linear computational complexity while generating a unified and robust feature representation. Extensive experiments on the DAIR-V2X-I dataset demonstrate that VPMambaNet outperforms existing roadside 3D vehicle detection methods with regard to detection accuracy and overall performance.
Methods
We first provide a brief overview of the overall model architecture, followed by a detailed description of the key modules H3SM and NA-VPF.
Overall Architecture
The architecture of VPMambaNet is illustrated in Figure 1. From an overall structural perspective, VPMambaNet adopts a dual-path hybrid voxel–pillar architecture. The design philosophy of this architecture is deeply coupled with the key characteristics of roadside LiDAR point clouds—high density in near-field regions, sparsity in far-field regions, and radial density decay with distance—and is also an optimization targeting the inherent defects of single-modality representations. On the one hand, the dual-path architecture can simultaneously leverage the advantages of voxels (preserving vertical geometric details in dense regions) and pillars (enabling efficient modeling in sparse far-field regions) to achieve feature modeling for vehicle targets across the full range of roadside distances. On the other hand, compared with the point–voxel hybrid architecture used in PV-RCNN, the voxel–pillar dual-path design avoids the high computational cost brought by point-based feature extraction and supports parallel feature extraction for both representations, making it more suitable for large-scale roadside scenarios.
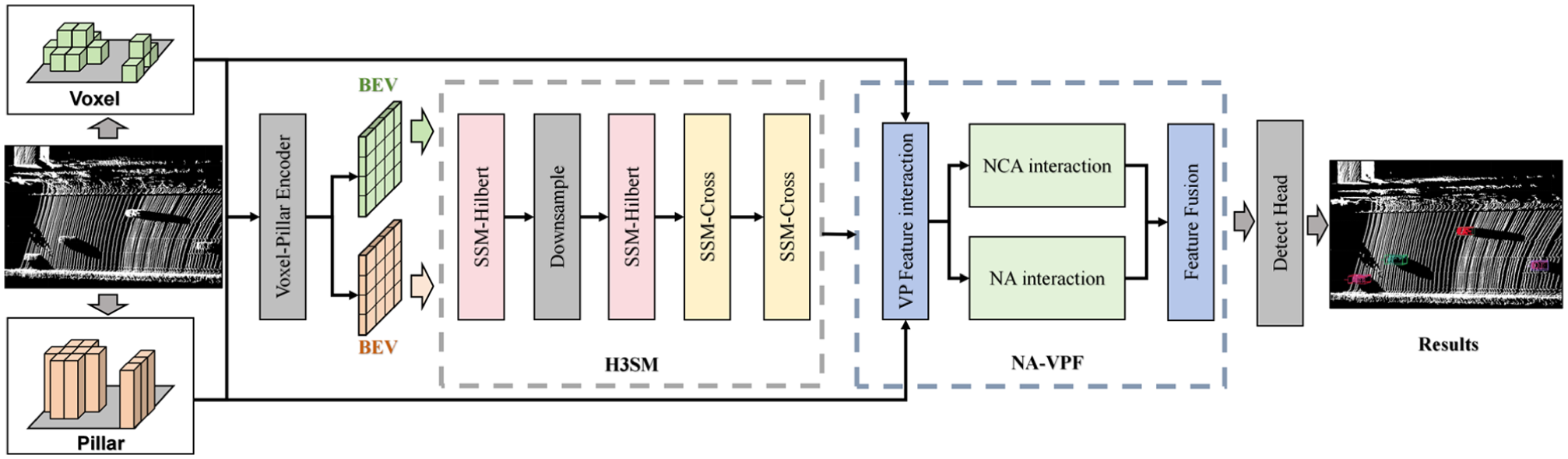
Architecture of VPMambaNet. The model processes point clouds through a dual-path voxel–pillar encoder to generate BEV features. Features are enhanced by the H3SM module for long-range context modeling and fused by the NA-VPF module for cross-modal integration, finally fed into a Center Head for three-dimensional box prediction.
Specifically, VPMambaNet consists of four main components: the voxel–pillar encoder, the H3SM module, the NA-VPF module, and the detection head. Given an input point cloud, it is first quantized into voxels and pillars on the x–y plane using the same resolution. The voxel–pillar encoder then extracts voxel and pillar features and generates corresponding BEV feature maps. These BEV features are subsequently fed into the H3SM module. Within H3SM, the original-scale BEV features are first transformed into a sequence via Hilbert scanning and processed using a bidirectional (forward and backward) SSM to extract features. The resulting feature map is then downsampled, and the Hilbert scanning and bidirectional SSM operations are repeated once. Next, two rounds of cross scanning combined with bidirectional SSM operations are performed. Finally, the processed features are output separately for the voxel and pillar branches. The NA-VPF module then performs feature interaction and fusion between the voxel and pillar branches. Specifically, the initial voxel and pillar features from the encoder are first integrated into each other’s feature maps through pooling and broadcasting operations. Subsequently, NA is applied to the pillar feature map, while NCA is used with the pillar feature map as query and the voxel feature map as key/value to facilitate cross-modal interaction. The resulting features are then combined with the original features via residual connections to form a unified and robust feature representation. This fused feature is fed into the detection head to produce the final vehicle detection results.
Hybrid Scan State Space Module
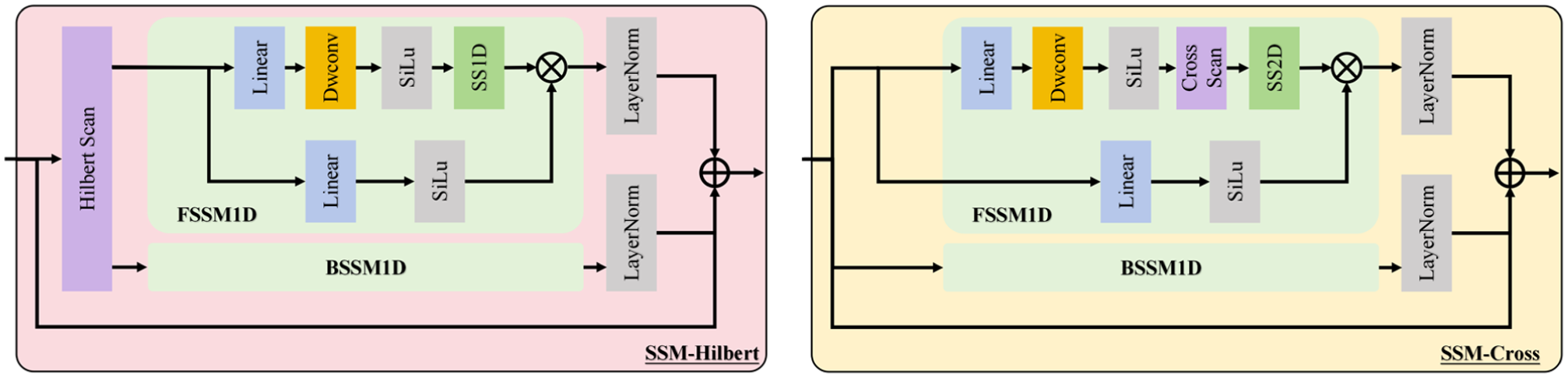
Given the SSM’s ability to model long-range dependencies with linear computational complexity and an efficient global receptive field, we explored its application in roadside point cloud processing. However, roadside point cloud scenes are characterized by extensive spatial coverage, uneven density distribution, and extreme scale variation. Direct application of conventional SSM-based methods would therefore lead to spatial continuity interruption and loss or disruption of critical local information. To address these challenges, we propose the H3SM, which integrates Hilbert and cross scanning in a cascaded and hierarchical manner. This hybrid scanning strategy not only enables effective long-range dependency modeling for large-scale roadside point clouds but also restores spatial continuity. By processing features at multiple scales, H3SM mitigates the loss and interruption of key local information. H3SM comprises two core components: the SSM-Hilbert block and the SSM-cross block. These blocks employ distinct scanning strategies—Hilbert scanning and cross scanning—to extract both local and global contextual information from BEV feature maps. Their structural designs are tailored to meet the specific requirements of different feature processing stages.
SSM-Hilbert Block
The core of SSM-based feature modeling lies in capturing dependencies within serialized one-dimensional (1D) sequences. For 2D BEV feature maps, the choice of scanning strategy directly determines whether the spatial adjacency of 2D features can be preserved during serialization, which is critical for perception in roadside scenarios. In the SSM-Hilbert block, we adopted the Hilbert curve as the serialization strategy. Compared with raster or Z-order curves, the Hilbert curve, as a space-filling curve, exhibits superior local retention characteristics. Meanwhile, within the cascaded architecture, the Hilbert curve can flexibly adapt to BEV feature maps of different scales, ensuring consistency in spatial feature modeling across scales—a capability that conventional fixed scanning strategies can hardly achieve. For the input feature map, elements are mapped to positions along the Hilbert curve and sorted accordingly to form a sequential input. However, because of the large size of the feature map, even with Hilbert curve-based space filling, proximity and local geometric structure losses are inevitable during serialization. To address this, we employed a bidirectional SSM for sequence feature extraction and replaced the standard 1D convolution in the original SSM with a depthwise separable convolution to preserve spatial continuity and model local geometry. Specifically, for the serialized input feature F, the SSM-Hilbert block performs the following steps:

where FSSM1D and BSSM1D represent the forward SSM and backward SSM, respectively, both using SS1D. Their basic structures are the same, with only the scanning direction of the sequence being different, as shown in Figure 2. For each forward or backward processing, the 1D sequence first uses LayerNorm to stabilize the feature distribution, then uses linear projection to increase the dimension and expand the feature expression ability, then uses Depthwise separable convolution (DWConv) to introduce local inductive bias and enhance local feature extraction, and then uses the state equation to model long-range dependencies. The discrete step size Δ in Equation 3 is implemented as a learnable parameter. The state metrics
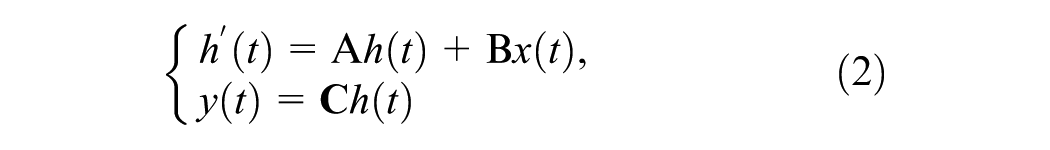
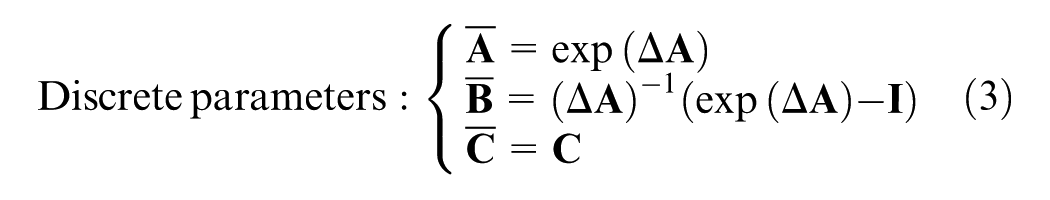


The Hilbert curve is constructed at different orders for feature maps of different scales to ensure a bijective mapping between 2D coordinates and the 1D Hilbert index. The order of the Hilbert curve determines the resolution of the space-filling grid: a standard k-order Hilbert curve can fully fill a
Architecture of the Hybrid Scan State-space Module (H3SM). The module cascades two SSM-Hilbert blocks and SSM-cross blocks. Features are processed at multiple scales and merged to achieve hierarchical local-to-global modeling.
SSM-Cross Block
Compared with SSM-Hilbert blocks, SSM-cross blocks have some differences in network structure design, mainly because of the difference in scanning strategies. In SSM-cross blocks, we constructed a bidirectional SSM and residual connection structure to enhance the model’s attention to distant sparse targets in the cross-scan strategy and reduce the forgetting of historical relationships caused by cross scanning. The specific structure of the network is shown in Figure 2. For the input feature
Overall Processing Flow
The complete H3SM structure includes two SSM-Hilbert blocks and two SSM-cross blocks. The four cascaded blocks form a hybrid scanning architecture that resolves the core conflict between local detail preservation and global long-range dependency modeling in roadside scenes. Hilbert scanning excels at retaining local spatial continuity and fine-grained geometric features, whereas cross scanning (horizontal and vertical bidirectional scanning) has natural advantages for capturing long-range dependencies along the road’s forward and lateral directions. In contrast to single-scan strategies, this cascaded design enables hierarchical feature modeling from local details to global context, which is especially well suited for roadside scenarios containing both dense near-field objects and sparse far-range targets. The overall processing flow is as follows. Starting from the input BEV feature map
Neighborhood Attention Extension-Based Voxel–Pillar Fusion Module
The hybrid voxel–pillar representation effectively addresses the challenges of multi-scale conflicts and insufficient information complementarity in vehicle detection from roadside point clouds. Voxel-based representations preserve vertical structural details and local features in high-density regions, whereas pillar-based representations enable efficient modeling in sparse regions. However, the voxel and pillar features are heterogeneous features with different spatial encoding characteristics, and direct concatenation or element-wise fusion will lead to feature redundancy, semantic conflict, and loss of complementary information. Therefore, we designed a three-stage progressive fusion strategy, NA-VPF, which gradually realizes the alignment and deep integration of heterogeneous features from shallow bidirectional interaction to deep cross-modal attention modeling and finally to heterogeneous feature fusion.
By enabling effective interaction and fusion between these two representations, the proposed NA-VPF module enhances the robustness of complex roadside scenes, achieves full-scale coverage of vehicle targets, and maintains a favorable trade-off between computational efficiency and detection accuracy. Specifically, NA-VPF consists of three key components: bidirectional feature interaction enhancement, neighborhood-aware attention feature interaction modeling, and heterogeneous feature integration, as shown in Figure 3. These components work in a progressive manner to achieve deep feature integration. The detailed implementation is as follows:
(1) Bidirectional Feature Interaction Enhancement
We first constructed a voxel–pillar index matrix C in the x–y coordinate space based on the BEV feature maps of voxels and pillars. Let the voxel coordinate be
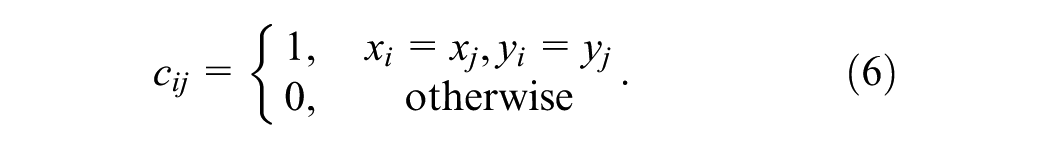
Based on this index matrix, voxel features are processed via max pooling and 2D submanifold convolution before being mapped to corresponding pillar locations. Similarly, pillar features are broadcast and processed through 2D submanifold convolution before being integrated into the voxel feature space. The mapping operations are defined as:
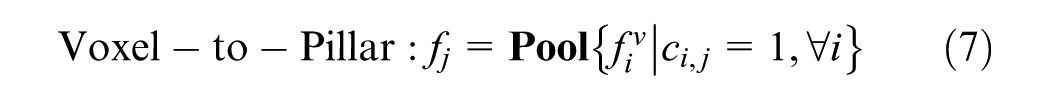
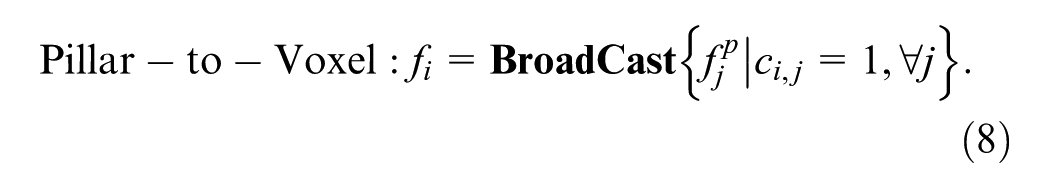
Finally, the resulting sparse features are compressed along the height dimension and concatenated with the BEV feature maps obtained from H3SM to form the enhanced feature representation.
(2) Neighborhood-Aware Attention Feature Interaction Modeling
After bidirectional feature enhancement, we modeled the interaction between the two BEV feature maps. Given the large spatial scale and high background noise in roadside BEV feature maps, we propose using NCA to capture cross-representation interactions. Considering that pillar BEV features offer higher computational efficiency and robustness in long-range sparse regions, whereas voxel BEV preserves 3D geometric details and spatial context, we used pillar BEV features as queries and generated keys and values from voxel BEV features. This allowed NCA to model the interaction between voxel and pillar features effectively. Additionally, to enhance local fine-grained associations, we applied NA to the pillar BEV features.
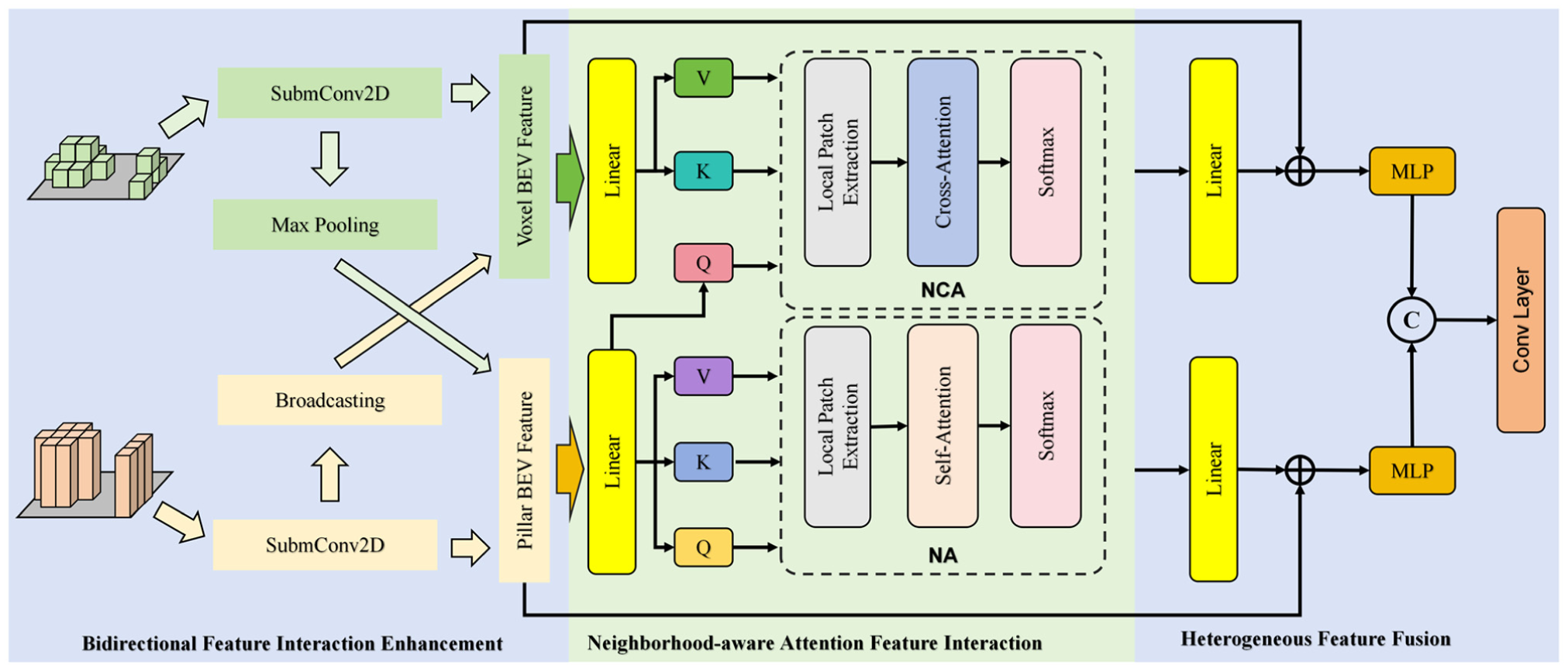
Architecture of the voxel–pillar fusion module (NA-VPF). The fusion is performed progressively: (1) bidirectional interaction exchanges features between voxel and pillar BEV maps; (2) neighborhood attention modeling uses NCA and NA to capture cross-modal and local interactions; and (3) heterogeneous fusion integrates features to produce the unified output.
We choose NA and NCA instead of global self-attention, mainly based on two considerations. First, the computational complexity of global self-attention is
Specifically, the pillar BEV feature map was linearly transformed to generate queries, whereas the voxel BEV feature map was transformed to produce keys and values. For each query, a neighborhood index set was generated based on its spatial location. The similarity between the query and all keys within the neighborhood was computed, and the corresponding values were weighted and fused:
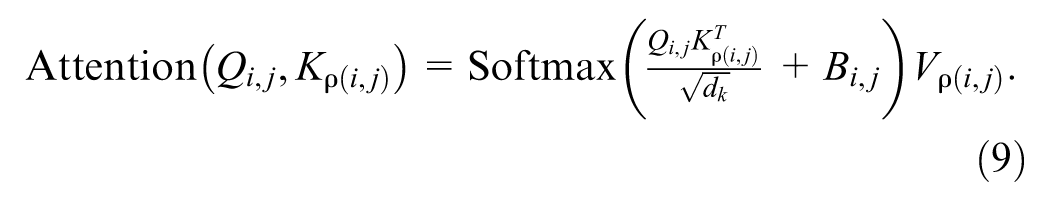
For the pillar BEV features, queries, keys, and values were obtained via linear transformations. The similarity between the current query and each key within its neighborhood was calculated. Invalid pillars with no point cloud data were masked out to avoid noise interference, and the values were then weighted and fused accordingly. To ensure computational efficiency and maintain spatial consistency, we kept the neighborhood window size uniform across all feature maps.
(3) Heterogeneous Feature Fusion
For the features extracted via NCA and NA, we employed a dual-path residual fusion strategy to preserve both the original feature information and the enhanced attention-based interactions. This approach avoids information loss through residual connections. Specifically, the NCA-enhanced features were linearly transformed and then fused with the voxel BEV features via a residual connection to prevent the dilution of fine-grained voxel details. Similarly, the NA-enhanced features were linearly transformed and fused with the pillar BEV features via a residual connection to retain accurate spatial localization and avoid over-smoothing. Finally, the two residual outputs were concatenated and fed into a convolutional layer to achieve heterogeneous feature fusion between voxels and pillars, resulting in the final output feature representation.
Results
To comprehensively evaluate the performance of the proposed model, we conducted extensive training and validation experiments on the DAIR-V2X-I dataset, benchmarked its performance against existing SOTA methods, and performed in-depth quantitative analysis. To further illustrate the model’s effectiveness in real-world roadside detection scenarios, we also carried out qualitative visual analysis on three datasets: DAIR-V2X-I, A9-Dataset, and our self-developed roadside dataset.
Dataset
The DAIR-V2X-I dataset is a specialized roadside sensing subset of the DAIR-V2X dataset ( 8 ), comprising 10,084 frames of synchronized roadside images and point clouds. The dataset is partitioned into training, validation, and test sets at a ratio of 5:3:2. To ensure fair comparison with existing methods, we adopted the KITTI evaluation metrics for performance assessment. An average precision (AP) matrix, comprising 40 position points, served as the evaluation metric for the model. The evaluation criteria were categorized into easy, moderate, and challenging levels based on the extent of truncation and occlusion. For vehicle detections, the threshold for rotational intersection over union (IoU) was set at 0.5.
Model Setting
This section provides a concise overview of additional model components, including the detection head and loss function. The selection of the detection head involved a trade-off between accuracy, speed, and architectural compatibility. Although alternative heads exist, such as the anchor-based head in PointPillars ( 24 ) or the two-stage head in PV-RCNN ( 20 ), they present certain limitations for our single-stage framework. The anchor-based detection head requires many predefined anchor boxes, resulting in numerous redundant proposals that increase both computational and memory overhead. Furthermore, the design of hyperparameters of this type of detection head is challenging and significantly affects detection performance, particularly in estimating 3D orientation, where effectiveness remains limited. In contrast, the CenterPoint ( 16 ) detection head eliminates the need for predefined anchor boxes by directly predicting object centers through a center point heatmap. This approach avoids the complexity and potential suboptimal configurations associated with manually setting anchor box scales, aspect ratios, and other parameters. Moreover, since each object corresponds to a single positive sample via heatmap prediction, the reliance on non-maximum suppression as a post-processing step is reduced, thereby decreasing redundancy and computational burden. Therefore, this single-stage detection network adopts the detection head from CenterPoint, which enables end-to-end training and inference for the entire architecture. In summary, compared with PointPillars, CenterPoint offers superior accuracy and more robust orientation estimation. In contrast, PV-RCNN’s two-stage design is architecturally incompatible with our efficient, single-stage pipeline. Thus, the CenterPoint detection head provides the optimal balance of high accuracy and deployment efficiency for our roadside detection task. The loss function is also directly inherited from CenterPoint to ensure consistency in optimization objectives. For the DAIR-V2X-I dataset, the detection range was defined as [0.0 m, 102.4 m] along the horizontal direction and [−5.0 m, 5.0 m] along the vertical direction. The pillar quantization resolution was set to [0.2 m, 0.2 m], and the voxel resolution was configured as [0.2 m, 0.2 m, 0.3 m] across the x, y, and z dimensions, respectively.
Experimental Detail
We implemented the proposed network in PyTorch and trained each model for 40 epochs using the AdamW optimizer combined with the one-cycle learning rate scheduling strategy ( 25 ). The initial learning rate was set to 0.0003. To enhance generalization and prevent overfitting, we employed standard data augmentation techniques during training, including random flipping, random rotation, random scaling, and random translation. All training and inference experiments were performed on an RTX-4090 GPU with a batch size of 1.
Overall Results
Evaluation on DAIR-V2X-I Val Set
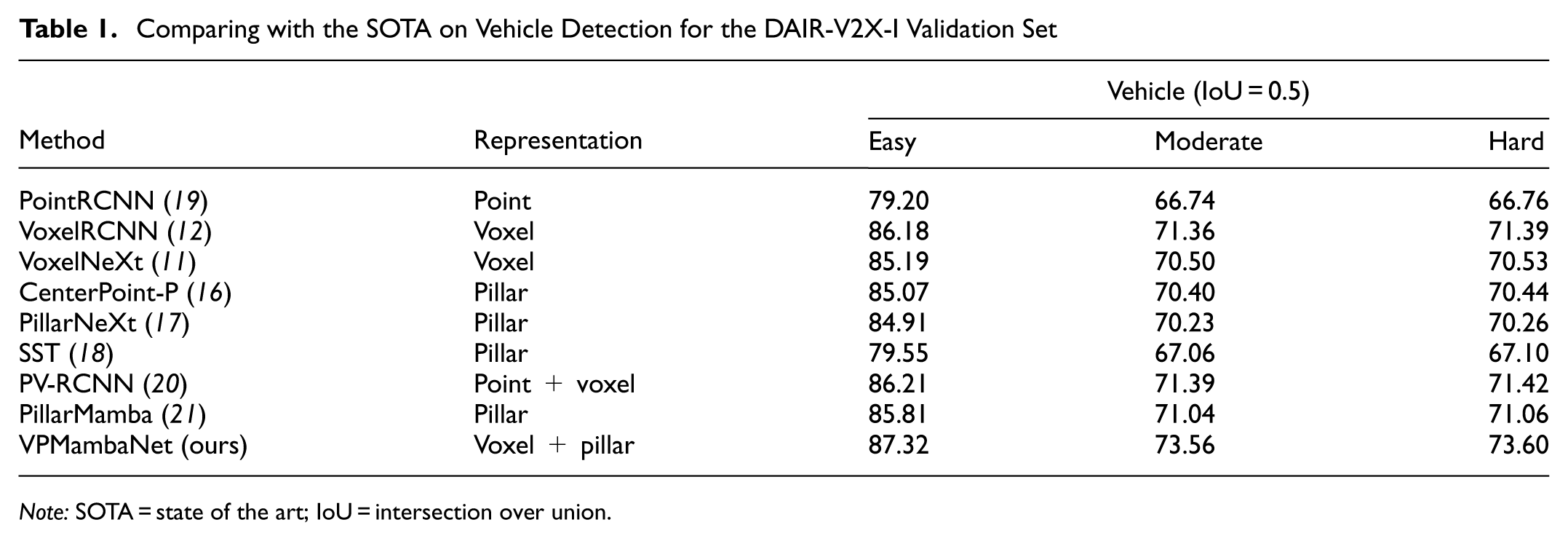
We conducted a comprehensive comparison between VPMambaNet and existing SOTA methods for 3D vehicle detection from roadside point clouds. The experimental results are summarized in Table 1. Quantitative analysis demonstrates that VPMambaNet achieves the best overall performance, with detection accuracies of 87.32%, 73.56%, and 73.60% on the easy, moderate, and hard difficulty levels, respectively. These results surpass the second-best method by 1.11–2.21 percentage points, with particularly notable improvements observed in medium- and high-difficulty scenarios. This confirms VPMambaNet’s strong adaptability to complex roadside environments. From the perspective of data representation performance, single-point representation methods (e.g., PointRCNN [ 19 ]) exhibit the lowest accuracy, trailing the best results by approximately 7–8 percentage points. This highlights the limitations of raw point cloud processing in addressing the sparsity and uneven density characteristics of roadside scenes. Single-voxel representations (e.g., VoxelRCNN [ 12 ]) generally outperform single-pillar methods (e.g., PillarMamba [ 21 ]), yet both suffer from inherent modality-specific drawbacks: restricted feature diffusion for voxels and loss of vertical structural information for pillars. In contrast, hybrid representations demonstrate clear superiority. Specifically, VPMambaNet’s voxel–pillar combination outperforms PV-RCNN’s point–voxel hybrid and top-tier single-modality methods by 1.14–2.54 percentage points, underscoring the complementary strengths of voxel-based vertical detail preservation and pillar-based sparse region coverage. With regard to difficulty adaptability, VPMambaNet shows greater performance gains in moderate and hard scenarios (2.17–2.54 percentage points) compared with easy scenarios (1.11–1.51 percentage points), indicating its enhanced robustness in detecting distant and low-density targets. This aligns well with the design objectives of the H3SM module, which addresses local information loss and interruption, and the NA-VPF module, which enhances cross-modal complementarity. From the perspective of model innovation, the key contributors to performance improvement include: (1) hybrid representation compensating for the limitations of single-modal inputs, (2) H3SM’s hybrid scanning mechanism enabling efficient modeling of long-range dependencies and local features, and (3) NA-VPF’s cross-modal fusion achieving deep integration of complementary features. The synergistic effect of these components endows VPMambaNet with strong scene-specific adaptability to roadside environments characterized by uneven density and multi-scale object distributions, ultimately leading to a significant performance breakthrough.
Comparing with the SOTA on Vehicle Detection for the DAIR-V2X-I Validation Set
Note: SOTA = state of the art; IoU = intersection over union.
Efficiency Evaluation
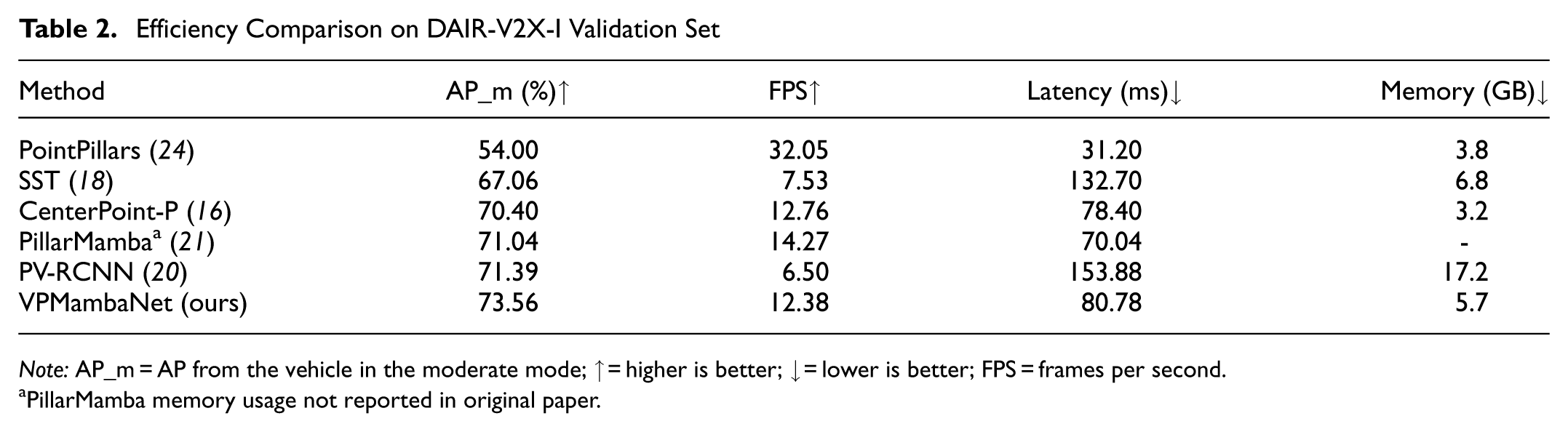
Efficiency evaluation is shown in Table 2. To assess the practical efficiency of VPMambaNet in real-world roadside infrastructure, we evaluated inference throughput, per-frame latency, and GPU memory usage on an RTX 4090 GPU with a batch size of 1. VPMambaNet achieved a throughput of 12.38 frames per second (FPS) with an average latency of 80.78 ms per frame and a peak GPU memory consumption of 5.7 GB. Although slower than lightweight approaches such as PointPillars (32.05 FPS), our method significantly outperformed it by 19.56% AP. Compared with the recent SSM-based detector PillarMamba (71.04% AP, 14.27 FPS), VPMambaNet delivered 2.52% higher accuracy with comparable latency. Notably, it also outperformed high-accuracy but computationally heavy models such as PV-RCNN (71.39% AP) while using less than one-third of the GPU memory (5.7 GB versus 17.2 GB). These results confirm that our method indeed achieves a favorable accuracy–efficiency trade-off, making it well suited for practical roadside deployment scenarios.
Efficiency Comparison on DAIR-V2X-I Validation Set
Note: AP_m = AP from the vehicle in the moderate mode; ↑ = higher is better; ↓ = lower is better; FPS = frames per second.
PillarMamba memory usage not reported in original paper.
Cross-Dataset Generalization Evaluation on the KITTI Dataset
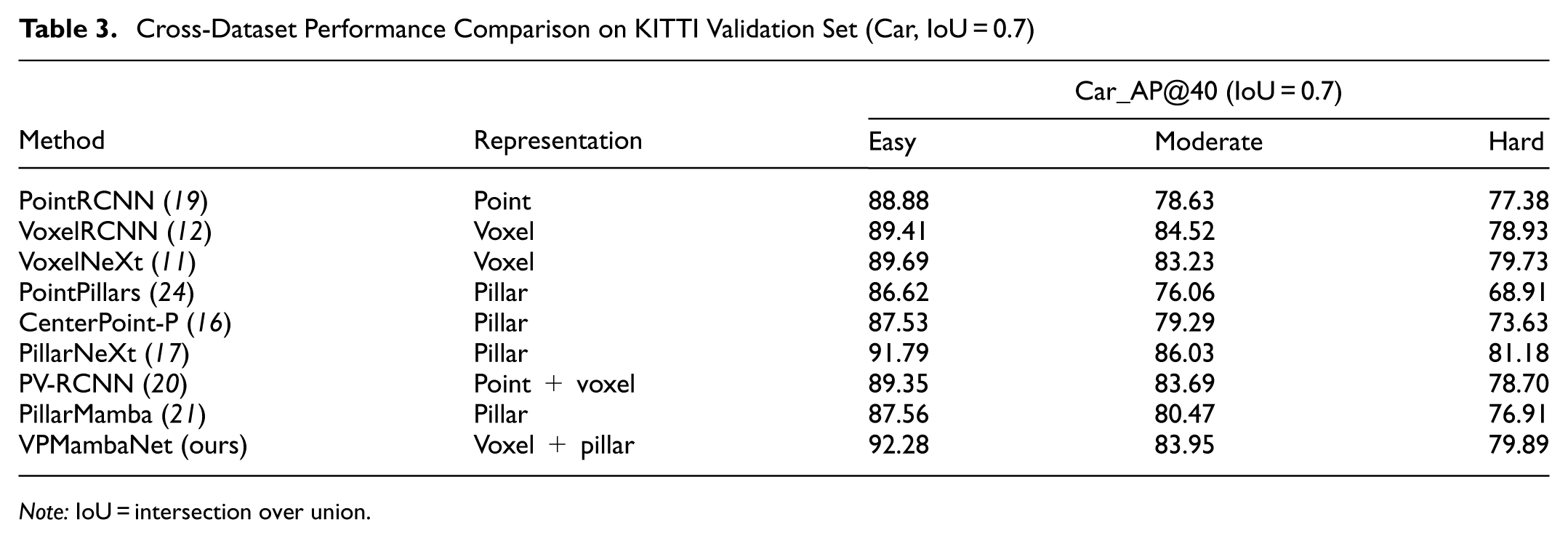
To further assess the generalization capability of VPMambaNet beyond roadside scenarios, we conducted extensive experiments on the KITTI dataset ( 26 ). KITTI is a widely adopted benchmark for onboard 3D detection, featuring dense point clouds and different object distributions compared with roadside datasets. This evaluation aimed to verify whether the proposed modules remained effective under domain shifts. We trained VPMambaNet on the KITTI train split (3,712 samples) for 80 epochs using the same hyperparameters as on DAIR-V2X-I, except for the detection range, which was adjusted to the KITTI standard: [0 m, 70.4 m] along the x-axis, [−40 m, 40 m] along the y-axis, and [−3 m, 1 m] along the z-axis. The voxel and pillar resolution were set as [0.05 m, 0.05 m, 0.1 m]. For models without publicly available KITTI experimental data, including VoxelNeXt, CenterPoint-P, PillarNeXt, and PillarMamba, we reimplemented and retrained them under the same settings. All models were evaluated on the KITTI val set (3,769 samples) with the official 40-point AP metric at IoU = 0.7 for the car category. Table 3 summarizes the performance on KITTI. VPMambaNet achieved 92.28% AP on the easy level, surpassing all compared methods by a noticeable margin. This demonstrates that our model excels in favorable conditions with dense point clouds and minimal occlusion. On the moderate and hard levels, VPMambaNet attained 83.95% and 79.89% AP, respectively. Although it trails the best performer, PillarNeXt (86.03% and 81.18%) on these more challenging subsets, it still outperforms other strong baselines such as CenterPoint-P (79.29%/73.63%) and PillarMamba (80.47%/76.91%). The relative dip in complex scenarios may be attributed to the inherent differences between roadside and onboard domains: KITTI features higher point density and smaller spatial extents, which do not fully leverage the long-range modeling strengths of H3SM designed for sparse roadside scenes. Nevertheless, VPMambaNet maintains competitive overall accuracy. The above cross-dataset results fully validate that VPMambaNet breaks the limitation of being only applicable to roadside scenes, and its core designs have strong universality and scalability, which can be extended to general 3D vehicle detection tasks.
Cross-Dataset Performance Comparison on KITTI Validation Set (Car, IoU = 0.7)
Note: IoU = intersection over union.
Qualitative Analysis
To further validate the detection robustness of VPMambaNet in roadside scenarios, we conducted qualitative visual analysis on three datasets: DAIR-V2X-I, A9-Dataset, and our self-developed roadside point cloud dataset. The visualization results are presented in Figure 4, where yellow boxes denote ground truth annotations and red boxes represent model predictions. Columns correspond to different test datasets, whereas rows represent diverse scene configurations within each dataset. On the DAIR-V2X-I dataset (first column), VPMambaNet successfully detected all vehicles in the scene with high precision in position, size, and orientation estimation. Notably, the model maintained stable detection performance even for distant targets. On the A9-Dataset (second column), which features sparse point clouds captured by a 64-line LiDAR, the model still achieved accurate vehicle detection across all test cases. Of particular interest is the second sub-figure, where the vehicle inside the white dashed box has a ground truth annotation (yellow box) that violates Germany’s right-hand traffic rule, indicating a factual annotation error. Despite this, the model correctly inferred the vehicle’s actual driving direction. Moreover, an unannotated vehicle within the yellow dashed box was also successfully detected by the model. In the case of our self-developed roadside point cloud dataset (third column), VPMambaNet again demonstrated precise detection capability. The same vehicle, marked by red dashed boxes in both sub-figures, was not annotated in the first sub-figure because of point cloud sparsity caused by long-range distance. Nevertheless, the model accurately detected it. By cross-referencing with the detection result in the second sub-figure, it is evident that the model’s estimation of the vehicle’s location, dimensions, and orientation in the first sub-figure aligns closely with reality. In summary, these visualization results further substantiate the robustness of VPMambaNet in real-world roadside environments. The model not only handles challenging conditions such as point cloud sparsity and distant targets but also effectively mitigates annotation noise, showcasing strong adaptability to practical deployment scenarios. Notably, while the aforementioned test datasets do not contain labeled adverse-weather sequences, our method shows consistent gains on distant and low-density targets—scenarios that closely mimic weather-induced degradation.

Visualization of vehicle detection by VPMambaNet across diverse datasets: (a) the DAIR-V2X-I dataset; (b) the A9-Dataset; and (c) our self-developed roadside point cloud dataset.
Discussion
In this section, we evaluate the effectiveness of three key components in VPMambaNet—the voxel–pillar hybrid representation, H3SM module, and NA-VPF module—on the validation set of DIAR-V2X-I (Table 4), using AP as the evaluation metric.
Evaluation Based on Ablation of Different Key Components in VPMambaNet

Note: H3SM = hybrid scan state space module; NA-VPF = neighborhood attention extension-based voxel–pillar fusion module; IoU = intersection over union.
Effectiveness of Voxel–Pillar Hybrid Representation
Experimental results comparing the use of voxels only (first row), pillar only (second row), and the hybrid voxel–pillar representation (third row) demonstrate that the voxel-only approach slightly outperforms the pillar-only approach. This confirms the advantage of voxels in preserving vertical structural details. However, simply concatenating voxel and pillar representations leads to performance degradation compared with using either modality alone, indicating that an unoptimized hybrid representation may introduce feature redundancy or conflict. These findings suggest that the hybrid representation must be integrated with dedicated feature modeling and fusion mechanisms—specifically H3SM and NA-VPF—to effectively exploit their complementary strengths.
Effectiveness of H3SM
Comparing the performance of the hybrid representation with H3SM (fourth row) and without H3SM (third row) reveals that incorporating H3SM leads to consistent improvements across all difficulty levels. Notably, the performance gains are approximately twice as large in the moderate and hard difficulty levels compared with the easy level. This indicates that the cascaded Hilbert and cross scan design in H3SM effectively mitigates the loss and interruption of critical local information in single-scan approaches, thereby enhancing the modeling of long-range dependencies for distant and low-density targets. These improvements provide essential support for robust feature representation.
Effectiveness of NA-VPF
Comparing the model with only H3SM (fourth row) and the full model with NA-VPF (fifth row) shows that the inclusion of NA-VPF further improves performance across all difficulty levels, particularly in moderate and hard scenarios. The NA-VPF module achieves this improvement through its progressive fusion strategy combining “bidirectional interaction enhancement” and “neighborhood-aware attention feature interaction modeling,” which effectively integrates the vertical detail preservation of voxels with the sparse-region coverage of pillars. This strategy resolves the issue of feature heterogeneity within the hybrid representation and ultimately generates a more robust and unified feature representation, enabling the model to achieve a significant performance breakthrough.
Ablation on Impact of H3SM Parameter Sharing Strategy
Our default design shares a single H3SM across both voxel and pillar branches to reduce redundancy. To examine potential cross-branch interference, we compared three variants: shared (default), unshared (independent H3SMs), and partially shared (shared low-level layers, independent high-level layers). Results show that shared achieves the best efficiency without sacrificing accuracy (see Table 5). Unshared yields only 0.15% AP improvement but increases parameters by 38%, whereas partially shared yields negligible gains. This confirms that parameter sharing in our method enhances model compactness while preserving representational ability and without much cross-branch interference.
Ablation on H3SM Sharing Strategy
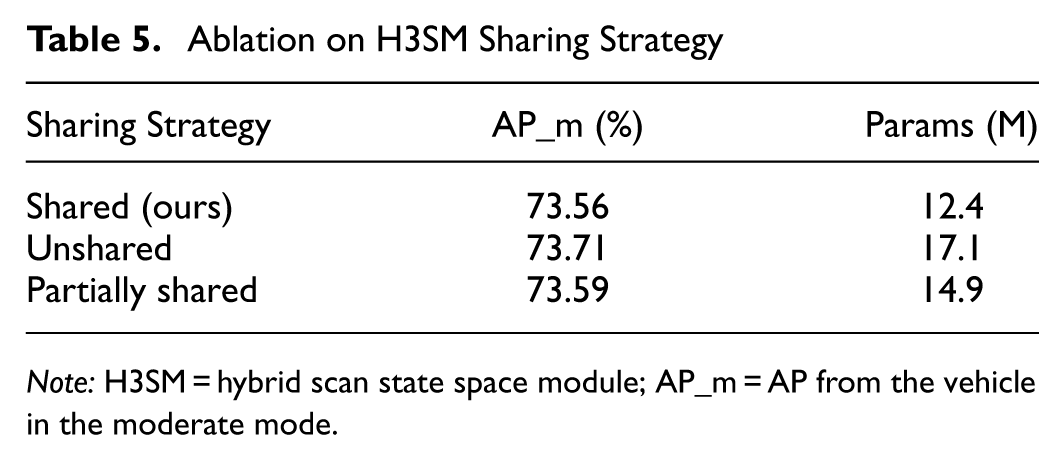
Note: H3SM = hybrid scan state space module; AP_m = AP from the vehicle in the moderate mode.
Analysis of Detection Effects at Different Distances
To rigorously validate that the overall performance gain of VPMambaNet stems from genuine improvement in long-range perception, we present a distance-ware comparison against representative baselines (Table 6). Although all methods achieve strong results within 30 m, the performance gap widens dramatically beyond 50 m, where point clouds become extremely sparse. Notably, VPMambaNet achieves 50.66% AP (>50 m), surpassing both pillar-based CenterPoint-P (+5.13%) and voxel-based VoxelRCNN (+4.49%). In contrast, the improvements in the 0–30 m and 30–50 m ranges are relatively modest (+1.15% and +0.37% over VoxelRCNN, respectively). This clear divergence in long-range performance confirms that our hybrid voxel–pillar representation and H3SM’s global context modeling effectively address the core challenges of roadside detection. Consequently, the SOTA result on DAIR-V2X-I is primarily driven by robustness in hard, safety-critical scenarios, not by dominance in near-field cases.
Distance-Wise Vehicle Detection Performance (Moderate, IoU = 0.5)
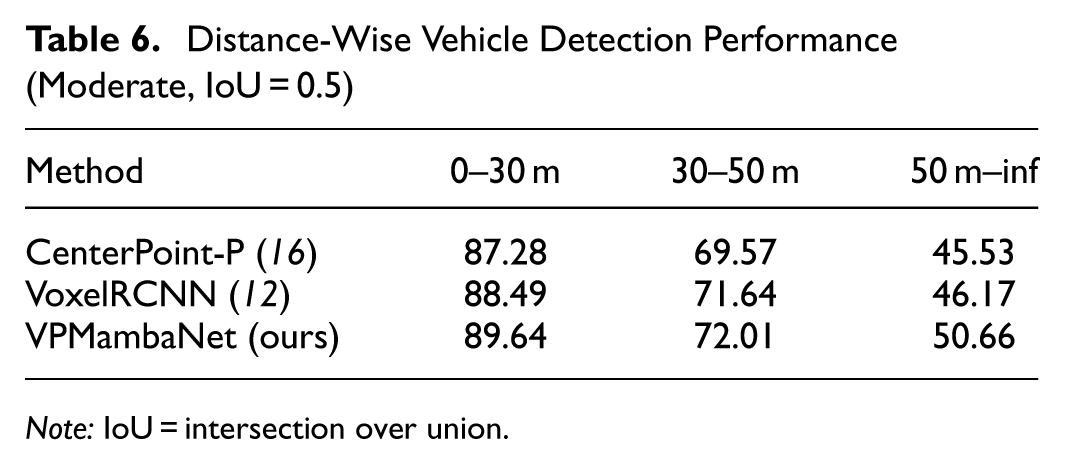
Note: IoU = intersection over union.
Conclusions
This paper proposes VPMambaNet, a novel model for 3D vehicle detection in roadside LiDAR point clouds, addressing key challenges: uneven density distribution, limitations of single-modality representations (voxel-based feature diffusion, pillar-based vertical information loss), and inefficient long-range dependency modeling. VPMambaNet integrates three core innovations: (1) a voxel–pillar hybrid representation with dual-path architecture, leveraging voxels’ vertical detail preservation and pillars’ efficient coverage of sparse regions; (2) H3SM, which enables hierarchical local-to-global modeling via cascaded Hilbert and cross scans with linear complexity; (3) NA-VPF, facilitating progressive cross-modal fusion through bidirectional interaction and NA. Experiments on DAIR-V2X-I show VPMambaNet outperforms SOTA methods by 1.11%–2.21% in AP across difficulty levels, with stronger gains in complex scenarios. Ablation and qualitative analyses validate each component’s effectiveness, confirming robustness to sparse point clouds, long-range targets, and annotation noise. VPMambaNet provides an efficient, accurate solution for roadside 3D vehicle detection. Given that the current dataset lacks labeled adverse-weather sequences, extending VPMambaNet to handle extreme weather scenarios is a key direction for future work, along with extending the model’s application to more scenarios to verify and improve its reliability.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: X. Xie; data collection: X.Li; analysis and interpretation: C. Zhao, Z. Chen; draft manuscript preparation: X. Xie. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Transportation Technology Project of Shaanxi Province (Grant No. 23-09X) and the Key Research & Development Project of Hebei Province (Grant No. 22375502D). Their assistance is gratefully acknowledged.