
Abstract
Freight transportation modeling often struggles with data limitations, especially in accurately representing complex supplier selection processes and their impact on network flows. This research addresses this critical gap by developing a large-scale, calibrated agent-based model for supplier selection, complemented by a probabilistic heuristic for international shipments. Our approach integrates trade relationships between industry sectors, transportation costs, and a supplier-rating model adapted from existing literature. The model’s core objective is to minimize the discrepancy between modeled and observed commodity flows while ensuring a close match to regional shipping distance distributions. Implemented and tested across four major U.S. metropolitan areas—Atlanta, Chicago, Dallas–Fort Worth, and Los Angeles—the model demonstrates high fidelity in replicating observed freight patterns. Key findings reveal consistent alignment with national shipping distance trends and highlight significant spatial variations in commodity trade assignments and demand across the study regions. This behaviorally informed and transport-sensitive framework is designed to approximate real-world decision making, providing a robust tool for policymakers and planners to evaluate targeted interventions, assess infrastructure investments, and enhance supply chain resilience in the face of disruptions.
Keywords
Introduction
Freight transportation is a critical enabler of global commerce, facilitating the large-scale movement of raw materials, intermediate goods, and finished products across complex supply chains. These supply chains link producers, distributors, and consumers through multimodal networks that span local, national, and international scales. Tackling such complexities and achieving efficiency in global and domestic supply chains is vital to ensure the smooth flow of goods and to avoid economic disruption. In the United States, for instance, an estimated 20.2 billion tons of freight, valued at over $18 trillion, moved across the transportation network in 2023, that is roughly 55.5 million tons a day ( 1 ). However, these movements also generate significant negative externalities, including traffic congestion and infrastructure degradation ( 2 , 3 ). The transportation sector is a critical backbone of the U.S. economy, accounting for a significant percentage of the Gross Domestic Product (GDP) and total logistics costs. Heavy-duty trucks, in particular, serve as the primary mode of freight movement, transporting the vast majority of the nation’s shipment value and tonnage.
In recent years, the vulnerability of global supply chains, particularly to disruptions in freight transportation systems, has become increasingly apparent. High-profile incidents have highlighted how bottlenecks can severely affect the movement of goods and economic stability. The COVID-19 pandemic, for instance, exposed structural weaknesses in logistics systems, as lockdown and labor shortages led to port congestion, vessel delays, and container imbalances, ultimately resulting in widespread supply shortages. Similarly, the 2021 blockage of the Suez Canal—a vital artery for global maritime trade—halted the passage of hundreds of ships and was estimated to delay approximately $400 million worth of cargo for each hour of the obstruction ( 4 , 5 ). These events underscore the strategic significance of freight transportation and the necessity for advanced modeling tools that can simulate supply chain dynamics and anticipate the ripple effects of potential disruptions.
Freight transportation is inherently a derived demand, driven by the need to move goods from production to consumption locations. This characteristic highlights the importance of understanding the structure of supply chains and the flow of goods from their origins to their destinations, including the logistics and routing choices in between. Changes in production sources can have a significant impact on transportation networks by altering logistics flows, modal shares, and traffic composition. Conversely, the condition and capacity of transportation infrastructure can influence sourcing decisions, for instance, port congestion or deteriorating network performance may discourage sourcing from specific regions. Additionally, the push for supply chain resilience and nearshoring strategies has begun to reshape global sourcing behavior. For instance, evolving trade dynamics have recently altered U.S. import patterns. In 2023, Mexico overtook China as the United States’ top trading partner ( 6 ), signaling a structural shift in freight origins These shifts carry significant transportation implications. Nearly 40% of Chinese imports to the U.S. enter via the ports of Los Angeles and Long Beach ( 7 ), whereas most imports from Mexico enter through Texas by truck and rail ( 8 ). As sourcing patterns evolve, they necessitate reevaluation of infrastructure investments, highlighting the need for freight modeling tools to accurately assess network-level impacts.
Effectively addressing the network-level impacts of freight movement requires modeling tools capable of capturing the decision-making behavior of individual freight agents, particularly with regard to sourcing and logistics choices. Recently, agent-based modeling (ABM) has been used in the freight domain as a means of simulating such complex interactions. In contrast to traditional aggregate or deterministic models, freight ABMs represent suppliers, shippers, carriers, receivers, and end consumers as autonomous agents with unique objectives and behavioral rules. These agents interact with each other and with their physical and policy environment in ways that give rise to emergent system-level outcomes. This approach enables the modeling of heterogeneous preferences, adaptive behaviors, and decentralized decision making. As a result, freight ABMs are especially well suited to exploring how logistical decisions—such as supplier selection, carrier choice, shipment size, transport mode, and routing—are shaped by evolving conditions including infrastructure constraints, regulatory policies, technological innovation, and interactions with passenger traffic on shared networks.
While freight ABMs encompass a wide range of logistics behaviors, this study focuses specifically on the sourcing choices of freight agents, namely, supplier selection and commodity assignment. These sourcing choices represent a foundational decision in supply-chain operations, shaping not only procurement outcomes but also influencing freight demand and the spatial distribution of goods movement. From a transportation modeling perspective, these choices determine the origins of commodity flows, which in turn affect network usage, traffic patterns, and infrastructure conditions. Opting for suppliers located near demand centers can minimize vehicle miles traveled (VMT), fuel consumption, and associated economic burdens. However, in many cases, commodities are available only from geographically distant or cost-advantaged regions, necessitating long-haul shipments and greater reliance on national freight corridors. These trade-offs highlight the importance of explicitly incorporating supplier selection into freight ABMs to better simulate real-world logistics dynamics and evaluate the system-level consequences of sourcing behavior.
This research presents a large-scale calibrated ABM of supplier selection and commodity assignment that integrates trade relationships between industry sectors and transportation costs. This is done using an agent-based and activity-based model for both passengers and freight known as POLARIS. The model aims to emulate a more realistic representation of how receiver businesses choose their suppliers and how commodities flow between each pair of suppliers and receivers, compared with previous models (including earlier versions of POLARIS Freight). This is being achieved by accounting for a receiver’s own benefit from maximizing their perception of the selected supplier’s rating using a supplier rating model from the literature ( 9 ). Additionally, the model seeks to account for unobserved factors by ensuring that the inter-zonal flows are matched and the shipping distance distribution gap is reduced. By linking micro-level attributes of shipping cost and supplier rating with macro-level freight patterns, the model offers a good representation of freight flows between agents and allows modeling and analysis of the impacts of freight transportation on infrastructure planning and supply-chain resilience. In this paper, the model is implemented in four metropolitan areas: Atlanta, Chicago, Dallas–Fort Worth (DFW), and Los Angeles (LA), along with a heuristic to select importer and exporter establishments in these four areas.
The rest of this paper is organized as follows. The Literature Review section provides details on traditional supplier selection models, supplier selection in freight ABMs, and the research gap and contributions. The section, Research Framework and Data Sources out the supplier and commodity selection module within POLARIS Freight and points to relevant data sources that are used in such studies. The Methodology section provides model notations and algorithmic details for both domestic and international trade models. The Results and Discussion section presents findings for the four metropolitan areas. Finally, findings, limitations, and policy implications are explained in Conclusion section.
Literature Review
This section gives a brief summary of research work done in freight ABMs and supplier selection modeling in the literature.
Traditional Supplier Selection Models
Supplier selection is a well-described problem in supply chain management and operations research, with a rich body of literature addressing how receivers choose from among potential suppliers. Originally supplier selection models used minimum cost as the most important criteria. However, later research started to include other attributes such as geographic location ( 10 , 11 ), quality ( 12 ), delivery ( 10 ), performance history ( 13 ), reputation ( 10 , 11 , 13 ), risk ( 12 ), service levels ( 12 ), production capacity ( 10 ), technology ( 11 , 12 ), and so forth. These models generally fall into multi-criteria decision making (MCDM) and mathematical optimization. MCDM techniques such as the Analytic Hierarchy Process (AHP) ( 14 , 15 ), Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) (16–18), Analytic Network Process (ANP) ( 17 , 19 ), Data Envelopment Analysis (DEA) ( 18 , 20 ), among others, are widely used to capture subjective preferences and trade-offs. On the other hand, optimization-based approaches—including single- and multi-objective linear programming ( 19 , 21 ), goal programming ( 19 ), and mixed-integer programming—have been applied to more quantitative supplier selection scenarios. A comprehensive review of these supplier selection models is presented in multiple papers including (22–24).
Supplier Selection in Freight Agent–Based Models
While traditional supplier selection models focus on procurement efficiency, freight ABMs aim to simulate the behavior of suppliers and receivers within transportation systems. In recent years, freight ABMs have been gaining traction as more researchers started developing different ABMs, including Freight Activity Microsimulation Estimator (FAME) ( 25 ), MASS-GT ( 26 , 27 ), CRISTAL ( 28 ), SynthFirm ( 29 ), and POLARIS (30–32).
The FAME ( 25 ) models supply chains at an aggregated firm level. FAME aggregates firms based on their locations, type, and size to generate firm-type synthetic populations. The model uses a fuzzy rule–based model for supplier selection, where the rules depend on categorical variables for size and proximity of suppliers and receivers. MASS-GT ( 26 , 27 ) follows a top-down approach, where they synthesize shipments from aggregated origin–destination (O-D) flows, and then assign them to a given receiver followed by a given supplier. The receiver probabilistic assignment is a function of the probability of a shipment being used by a specific industry sector and the firm sizes within this sector. While the supplier assignment is a function of the probability of a shipment being sent by a specific industry, sector and the firm sizes within this sector are weighted by the transportation cost. SynthFirm ( 29 ) synthesizes firms and uses a market-clearing mechanism based on shipping distances and values estimated from the Commodity Flow Survey (CFS) data.
CRISTAL ( 28 ) models long-term, medium-term, and short-term horizons to capture supply chain behaviors in depth. Long-term decisions include how many goods to produce and how many goods are needed, fleet and warehousing decisions, and trade partnerships including supplier selection. The medium-term decisions include setting up order frequencies and tour generation, while the short-term decisions include powertrain and routing choices. The supplier selection model in CRISTAL is a multinomial logit model (MNL) where the utility associated with a given supplier out of a candidate set of suppliers is based on the following supplier attributes: if it is located in the same region (internal); if it is a foreign supplier; employment; and great circle distance (GCD) from the receiver location. The parameters were not estimated based on collected survey data, their values were based on a fuzzy logic model from a report of Cambridge Systematics ( 33 ).
POLARIS ( 30 ) is an agent-based and activity-based model for both passengers and freight. The passenger modules of POLARIS synthesize the population and their activities, estimate activity destinations, and resolve conflicts between activity start times. POLARIS also estimates mode choice and routing decisions, and simulates passenger cars, transit, ride-hailing services, and so forth. The POLARIS Freight module ( 31 , 32 ) is mostly an enhanced version of CRISTAL. POLARIS Freight uses the core modules of CRISTAL and improves the structure of models with updated models and collected data. POLARIS Freight also adds other freight modules such as passing through freight loaded and empty demand, service trip demand, on-demand deliveries (ODD) for meals and groceries, and port allocation among others. POLARIS Freight offers the additional benefit of interacting with the passenger demand, so e-commerce and ODD demands are a function of the synthesized population attributes, and directly affect the shopping and eat-out activities of the households. Moreover, it allows the co-simulation of freight and passenger trips which account for their inter-dependencies and interactions on the traffic network and their en route switching decisions as a result of congestion. The current paper proposes a large-scale supplier selection model to replace the utility-based model of CRISTAL existing in POLARIS Freight.
Another important ABM study ( 9 ) that strongly relates to this research, combined a decision-making framework with computational techniques for supplier selection. The authors introduced a hybrid agent-based computational economics and optimization model, demonstrating how behavioral rules and optimization techniques can be integrated to simulate decentralized procurement decisions. The authors used fuzzy logic and genetic algorithms to explore large solution spaces. This paper is particularly important for our current research, since we adapted the supplier rating utility model developed in Pourabdollahi et al. ( 9 ) based on collected survey data to account for factors such as reliability, financial credibility, and capacity.
Research Gap and Contributions
The integration of supplier selection into freight ABMs remains an open challenge. Despite their sophistication, traditional supplier selection models often abstract away the behavioral aspects of individual agents when selecting suppliers and the flow calibration which is critical from a transportation systems perspective. Conversely, supplier selection in most freight ABMs, including previous iterations of POLARIS Freight and CRISTAL, relies on exogenous assignments or unconstrained utility maximization. By introducing strict calibration discipline to macroscopic trade targets and an optimization-based decomposition that scales to millions of candidate pairs, this framework directly removes the limitation of uncalibrated trade flow assignments, ensuring decisions are both informed by network conditions and constrained by actual zonal commodity flows. Moreover, international trade flows are often ignored or aggregated on a zonal level with little regard for which specific businesses act as importers or exporters and which ports serve as the points of entry. Not all models consider detailed supplier attributes, such as reliability, credibility, or capacity, when modeling procurement decisions. This limits the ability of freight ABMs to represent a more realistic picture of the transportation component of supply chains to effectively evaluate infrastructure investments, policy shifts, or supply chain resilience strategies.
This research aims to bridge these two domains by introducing a calibrated, large-scale supplier selection and commodity assignment model into a freight ABM context. Specifically, the primary objectives of this study are to: i) move beyond exogenous supplier assignment by developing an optimization-based framework that accounts for firm-level behaviors, including reliability ratings and capacity constraints; ii) ensure that the modeled supplier–receiver pairings reproduce observed macroscopic patterns, specifically regional shipping distance distributions and zonal commodity flow volumes; and iii) overcome the limitations of zonal aggregation by establishing a heuristic to assign import/export flows to specific domestic establishments based on port throughput and industry sector data. Our contribution is threefold:
Optimization-based supplier selection and commodity assignment: We introduce a linear programming formulation that selects supplier–receiver pairs by commodity for domestic trade based on shipping cost, supplier production capacity, receiver consumption needs, commodity compatibility, and supplier rating, adapted from Pourabdollahi et al. ( 9 ), which models indirectly the cost of commodity, reliability, and financial credibility.
Heuristic international assignment: We develop a probabilistic heuristic that selects importers and exporters for international shipments, grounded by individual port flows and a mapping between the commodities and the sectors of the North American Industry Classification System (NAICS).
Model calibration and large-scale implementation: The model components are tested on four metropolitan areas in the United States, Atlanta, Chicago, DFW, and LA, and calibrated to match observed trade patterns and commodity flows. The model is integrated within POLARIS, yielding additional benefits from using synthesized freight agent attributes.
Research Framework and Data Sources
The data inputs for this model include various public data sources and POLARIS model outputs, as shown in Figure 1.
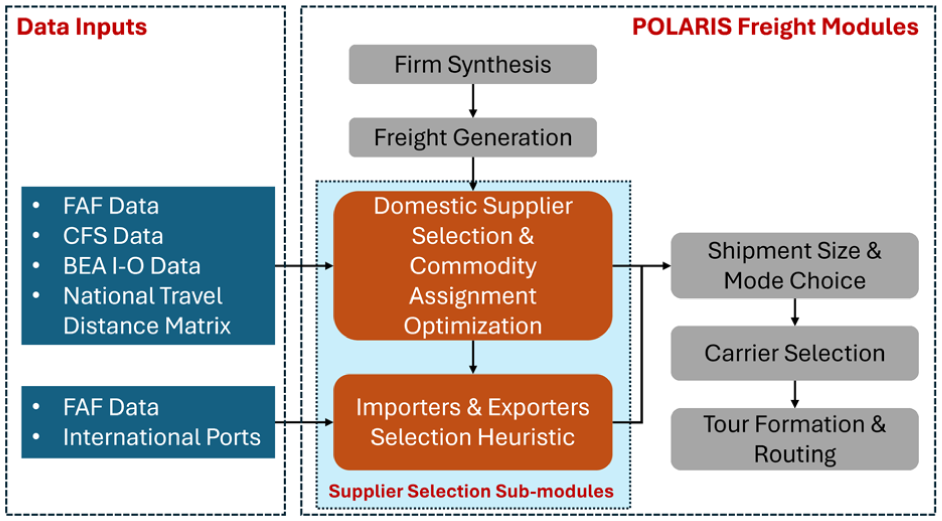
Supplier and commodity selection module within POLARIS Freight.
Public Data Sources
The Bureau of Economic Analysis input–output data ( 34 ) contain information on make-use interactions between industry sectors. These interactions capture how sectors produce commodities for others, consume commodities produced by other sectors, and the volume of trade that occurs among them. This data source is used in the model to identify potential sectors that can supply commodities to the industry sector of the receiver. In the absence of observed firm-to-firm logistics relationships, these make-use tables serve as deterministic structural constraints governing the feasible pairings between firms belonging to different NAICS codes.
Freight analysis framework (FAF) data ( 8 ) map the commodity flow tonnage among 140 FAF zones, including: 132 domestic FAF zones (representing major metropolitan areas by state and rest of their states) and eight foreign FAF zones (representing countries such as Canada and Mexico, sub-continents, or whole continents). This data source is used in the model to provide the zonal commodity flows to be matched by the model. The commodities are classified according to the two-digit Standard Classification of Transported Goods (SCTG) codes.
Commodity Flow Survey (CFS) public use file (PUF) data ( 35 ) represent a sample from survey data for shippers exporting or shipping commodities domestically including the shipment weight and distances along with weight factors for the sample. This data source is used in the model to provide a shipping distance distribution for each city to be matched by the model. The commodities are classified according to the two-digit SCTG codes.
Given the mixture of usage of NAICS industry sectors and SCTG commodities in the above data, and that businesses—that is, suppliers and receivers—are typically classified using NAICS codes, it is crucial to use a mapping between the two classifications. It is important to mention, however, that there is no standard way of mapping one NAICS to many commodities that can be used for all businesses with the same NAICS code, since businesses from the same industry sector can produce different mixtures of commodities. Acknowledging this limitation, we opted to use one of the mappings in the literature developed in Pourabdollahi ( 36 ). In addition, we aggregated the 42 SCTG codes into 15 groups shown in Table 1. This aggregation helps in reducing the problem size. However, it comes at the expense of capturing the detailed behavior of the supply chains of individual commodities.
Commodity Grouping Used

POLARIS Model Outputs
While this model is capable of independently addressing the supplier selection problem, implementation within POLARIS can offer significant advantages. This integration allows access to different attributes for businesses through POLARIS’s firm synthesis and freight generation modules, as shown in Figure 2. This integration can also enable future dynamic feedback between sourcing decisions and network conditions that can be translated into modified shipping costs.
Firm synthesis: This module synthesizes parent firms and their member establishments (business locations) along with their characteristics based on proprietary data samples to match control totals from public data sources. The synthesized attributes include three-digit NAICS industry sectors, U.S. county, employment, fleet, revenue, and so forth.
Freight generation (FG): This module uses the firm synthesis outputs, FAF data, and NAICS commodity mapping to estimate the production capabilities and consumption demand of each establishment. The production and consumption of establishments are computed based on tonnage rates per employee, where rates differ based on FAF zones and NAICS.
Given the estimated production and consumption capacities of external establishments, we randomly sample from each external zone enough establishments to cover that zone’s total supply and demand to/from the study region. This helps reduce the problem size, where a given receiver will not use all possible national suppliers as potential suppliers. Therefore, for a given study region, all internal establishments within the region are considered. However, only a portion of the external domestic establishments are used. This is a trade-off as it reduces the problem size but at the same time limits the selection pool of external suppliers.
International ports: For the international shipment heuristic, POLARIS disaggregates import and export FAF flows from the zonal level to individual ports using ports and land borders information and capacities from Bureau of Transportation Statistics ( 37 ). These ports are used as points of entry and exit for import and export flows for the businesses in the study region.
These POLARIS Freight module interactions are summarized in Figure 2, where the POLARIS model outputs feed into the supplier selection and commodity assignment problem, resulting in annual trade flows between suppliers and receivers. These trade flows include information on the quantity of tonnage traded annually, type of commodities traded, and trade type. The trade type depends on the type and location of supplier and receiver: import, export, regional, domestic inbound (external–internal), and domestic outbound (internal–external). Shipment size and mode choice logit models depend on such information to estimate shipping chain decisions.

POLARIS Freight modules interactions.
Methodology
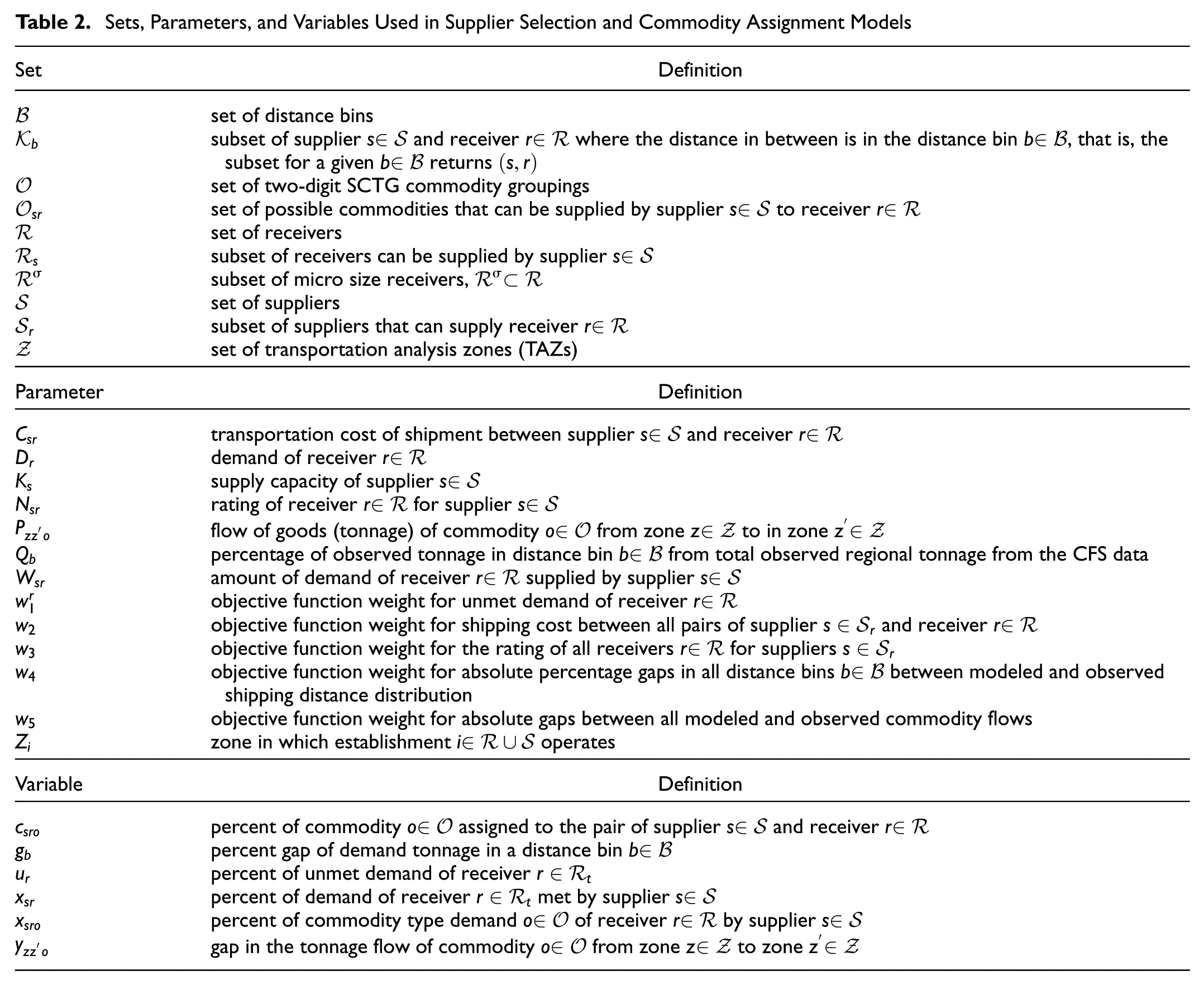
In this section, we first begin with formulating a linear programming model to solve the supplier selection and commodity assignment problems jointly. Since commercial solvers struggle with computationally modeling this problem at the target area scales, we decompose the problem into two phases, addressing the supplier selection problem first, and solving the commodity assignment problem next. Table 2 provides definitions for the sets, parameters, and variables used in this section. To facilitate readability, the model adheres to the following structural logic: uppercase Roman letters denote parameters (e.g.,
Sets, Parameters, and Variables Used in Supplier Selection and Commodity Assignment Models
Joint Supplier Selection and Commodity Assignment
Let
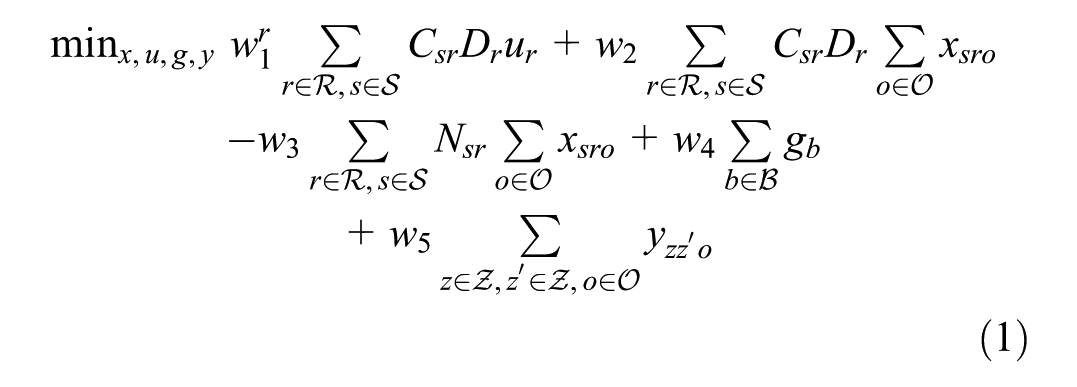
where
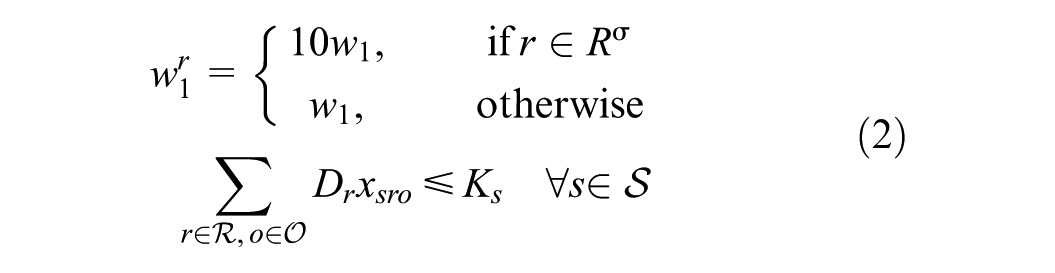
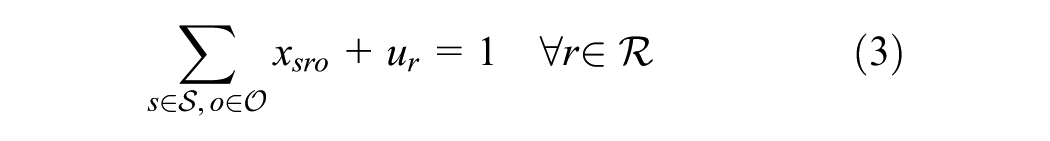
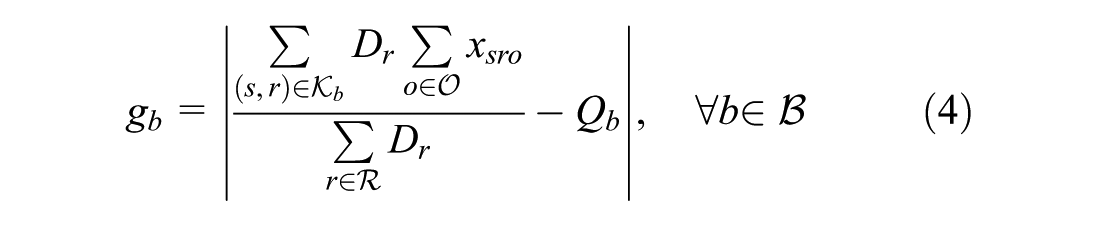
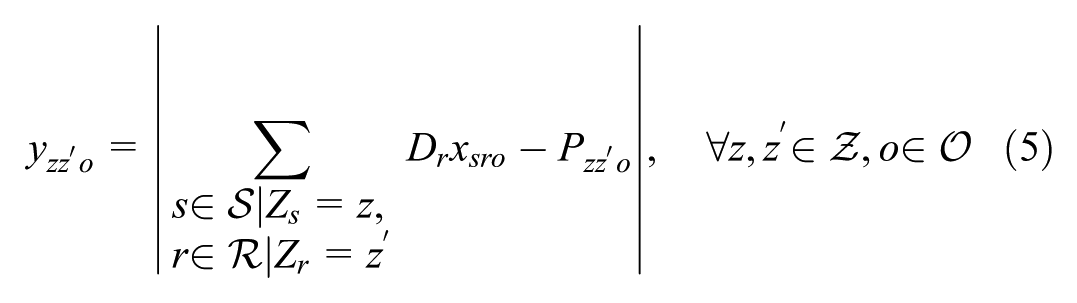
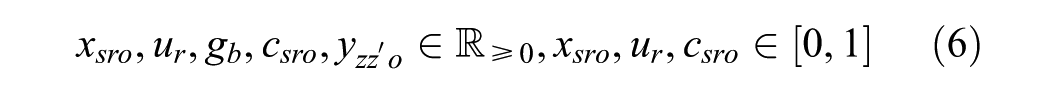
In objective function 1, we minimize the weighted cost of: i) unmet demand; ii) the transportation cost for met demand; iii) supplier–receiver rating factor; iv) the percentage gap in demand tonnage in distance bins; and v) the gap in the inter-zonal commodity tonnage flow. It is important to note that the components of objective functions possess vastly different orders of magnitude (e.g., total transportation cost versus percentage-based flow gaps). To prevent the larger magnitude terms from mathematically dominating the optimization, the problem is solved using a hierarchical (lexicographic) multi-objective framework. Implemented via the setObjectiveN feature in the Gurobi solver (
38
), this approach optimizes objectives sequentially based on strict priority levels rather than a simultaneous weighted sum. Priority is assigned in the following order: (1) minimizing unmet demand to ensure system stability; (2) minimizing the deviation from observed shipping distance distributions; and (3) minimizing transportation costs and maximizing supplier ratings. The normative choice to prioritize calibration over cost minimization ensures that the model bounds theoretical micro-economic efficiency within the realities of observed macroeconomic behavior. This sequential structure often creates binding trade-offs where the solver intentionally bypasses a highly rated, low-cost local supplier if selecting them would cause the aggregate shipping distance distribution to violate the observed regional patterns. Ultimately, this method inherently handles scaling disparities without requiring heuristic normalization. This sequential solution method inherently handles the scaling disparities without requiring heuristic normalization of the input data. To prioritize micro size receivers denoted by
Collectively, the objective function captures the tension between theoretical efficiency and empirical realism. The terms related to transportation cost (
While the model is formulated using percentage flows (
Supplier Selection Model
The joint model, though linear and seemingly simple, is not scalable for the problem sizes tackled in this paper because of the very large number of potential combinations for the
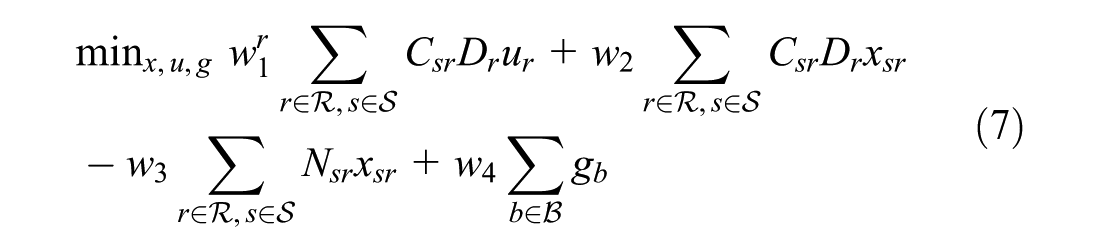
where
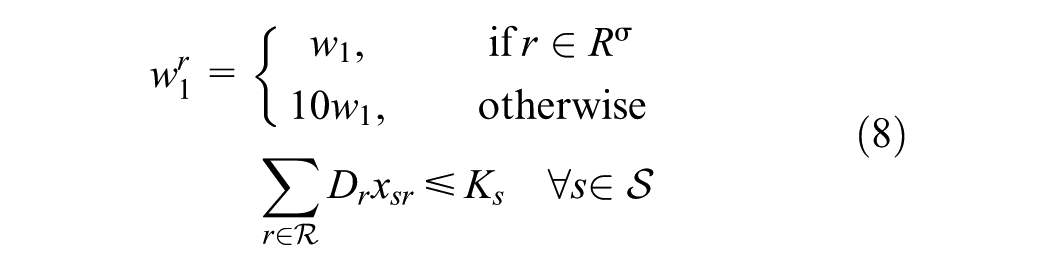
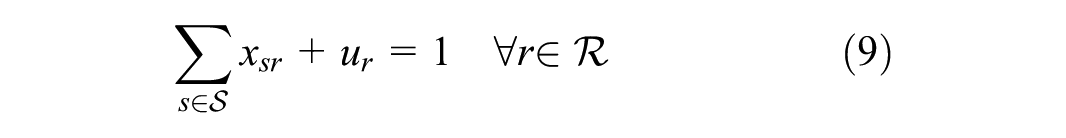
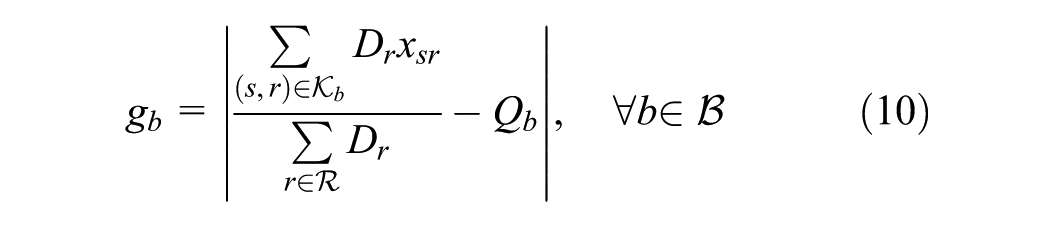
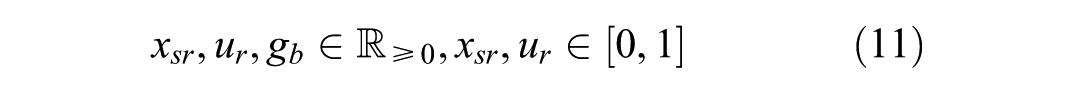
In objective function 7, we minimize the weighted cost of: i) unmet demand; ii) transportation cost for met demand; iii) supplier–receiver rating factor; and iv) percentage gap in demand tonnage in distance bins. Note that, here, we condense variable
Commodity Assignment Model
Now that we have solutions to
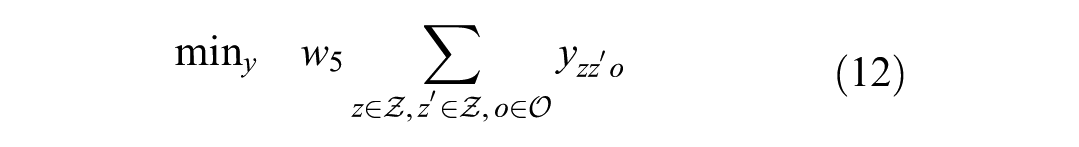
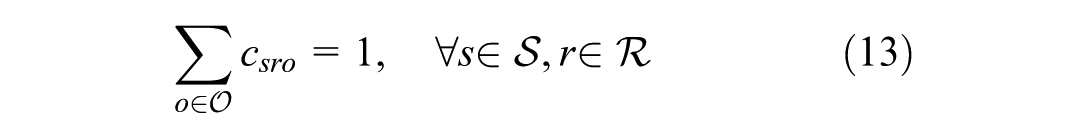
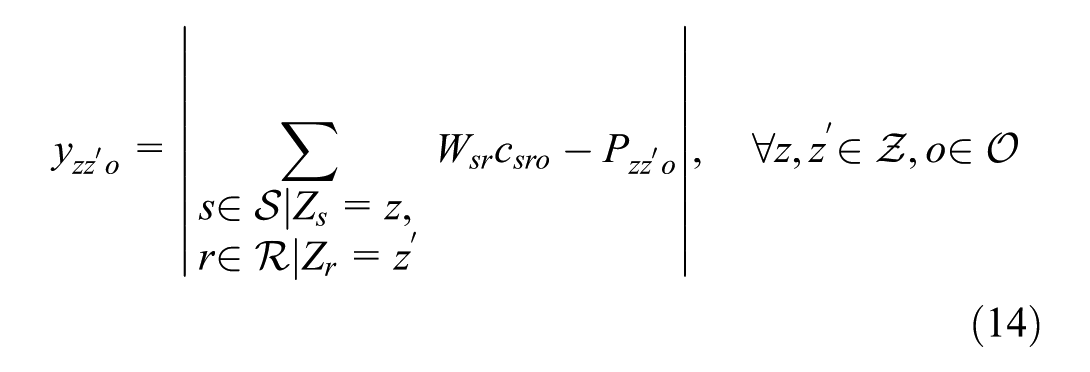
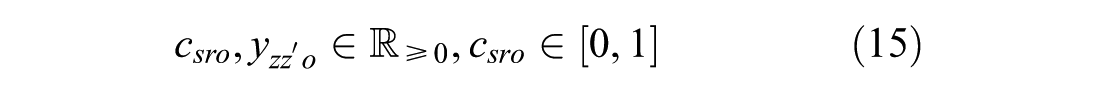
Objective function 12 minimizes the gap in the tonnage flow of commodities flowing between zones. Constraints 13 ensure integrality of assignments for commodity types to
For the supplier rating, Pourabdollahi et al. ( 9 ) proposed using the following proxies to substitute in the ordered logit model estimated based on the collected real data: the unit value of the commodity from FAF data as a proxy for cost/price; production capacity as a proxy for capacity/reliability; and the annual value of commodities as a proxy for credit/financial condition (which can be substituted with estimated revenues from the firm synthesizer). For the shipping cost, a travel distance and time matrix were estimated through the POLARIS router module. In this paper, the cost was used as distance between shippers and receivers which accounts for network conditions. However, the cost can be also calculated based on routed travel time or a combination of both.
International Heuristic for Importer and Exporter Establishments Selection
The major issue with supplier selection modeling in international trade lies in the lack of information on foreign establishments. Without their attributes, it is not feasible to solve the same supplier selection problem. Another complicating factor in international trade stems from the type of commodities, size, and business models of importers/exporters, which cannot be modeled easily given the data limitations.
This probabilistic heuristic was developed specifically to address the unique challenge of linking aggregate port-level data with disaggregate firm-level agents in the absence of ground-truth micro-data. While it relies on established principles of flow disaggregation, the specific procedural logic is bespoke to the available data structure. A key advantage of this tailored approach is computational efficiency, as demonstrated in the results.
Algorithm 2 shows the heuristic used for selecting importer and exporter establishments for international shipments. The main inputs for this heuristic are: i) imported and exported tonnage by commodity type at each major port for each internal county; ii) internal establishments for a given metropolitan area; iii) production and consumption NAICS commodity matrices; iv) size threshold or percentage of importer/exporter establishments; and v) lower and upper bounds of the trade volume for a given importer/exporter. The size threshold for establishments is based on the assumption in Holguín-Veras et al. ( 39 ) that it is mostly large-sized establishments that are involved in large volumes of international trade (neglecting international packages). Trade volume ranges are used as soft constraints on the quantity of goods imported and exported by a given establishment to avoid over-allocation of goods to fewer establishments. The lower bound used in this study was a fully loaded truck once annually, while the upper bound was assumed to be four fully loaded trucks daily. These bounds are inputs to the algorithm, so they can be changed with modeler discretion. These bounds act as soft constraints, since establishments who exceed the range are not eliminated from the potential importer/exporter set to deal with instances of the limited number of large sized businesses in a given county. Conversely, establishment trade volume by port can be below the range in case of low-throughput ports. Assigning tonnage proportionally to the size of the importer/exporter is an alternative solution to this issue.
Import and Export Shipments Heuristic

Once the importers/exporters set is defined, for both trade types (imports and exports) and for each commodity, a port is chosen from the ports list. The NAICS of the importer/exporter is chosen based on the probability that this given NAICS produces or consumes this commodity. An establishment that belongs to the selected NAICS is chosen randomly and is assigned a flow within the specified range unless the port’s remaining tonnage is less than the lower bound. The shipment information is stored and the process is repeated till all the international trade volume has been assigned.
Results and Discussion
The developed models were implemented in the metro areas of Atlanta, Chicago, DFW, and LA. Figure 3 shows the geographical regions of each study area, while Table 3 lists the run times for the algorithms used. It is important to provide a breakdown of the total computational effort. The times reported in Table 3 represent the core optimization and heuristic phases. However, the data preparation phase, which generates the set of potential supplier–receiver pairs and calculates their respective attribute matrices, remains computationally intensive. Even with the usage of distributed multi-threading across multiple workstations, this pre-processing step accounted for approximately 60% to 70% of the total end-to-end execution time. Consequently, a primary opportunity for future research lies in accelerating this data generation phase beyond standard CPU parallelization. Future efforts could leverage GPU-accelerated computing to handle these large-scale matrix operations or employ spatial indexing heuristics (e.g., KD-trees) to efficiently prune the candidate set before cost calculation, offering a greater marginal return on speed. All optimization-related computations were carried out on a single Intel® CoreTM i9-14900K CPU @3.20 GHz workstation with 128 GB of RAM and 24 cores. Problem instances were solved by using the Python 3.10.11 interface to the commercial solver Gurobi 11.0.3 ( 38 ).
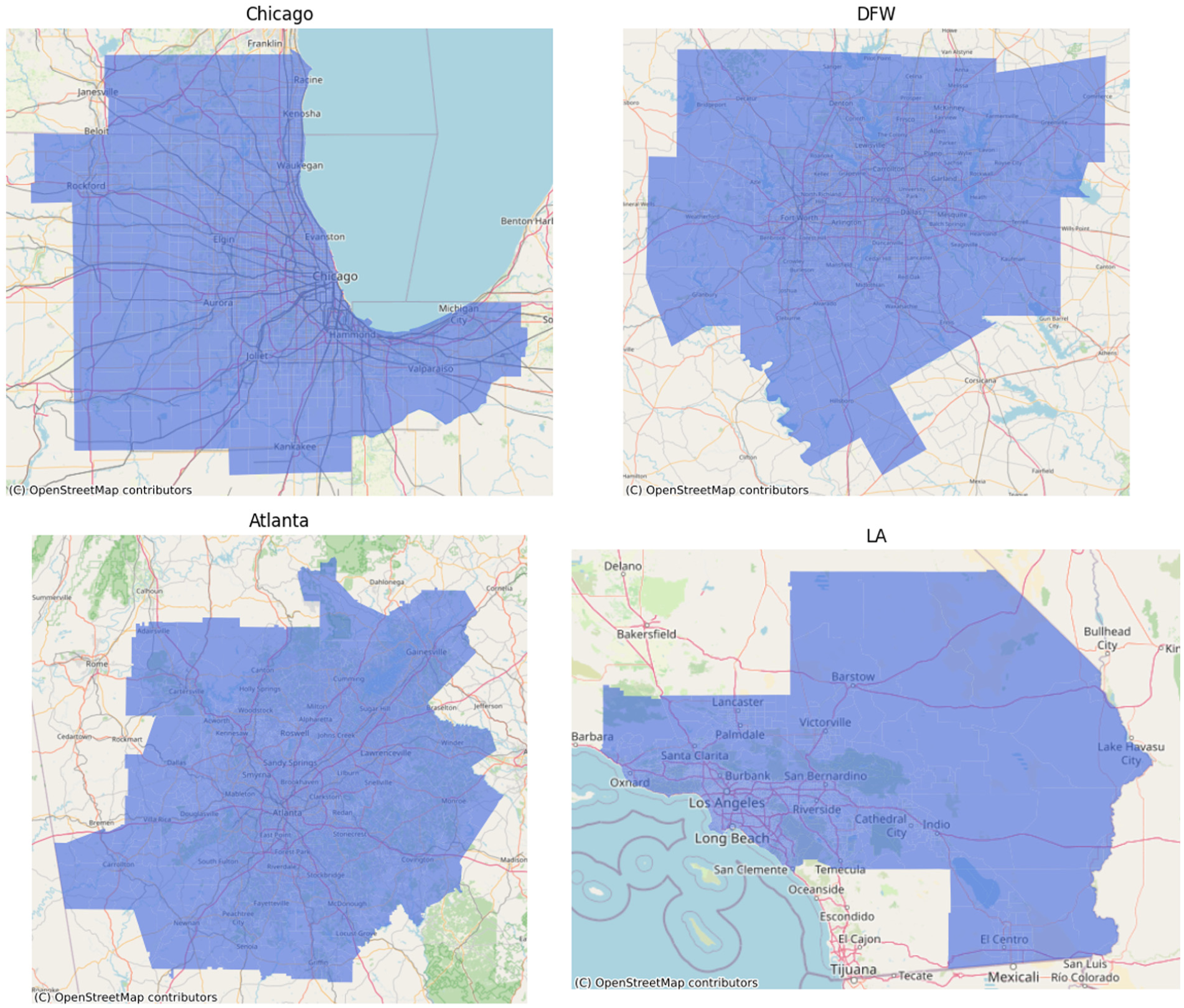
Modeled metro areas.
Solver and Heuristic Runtimes by Metro Area
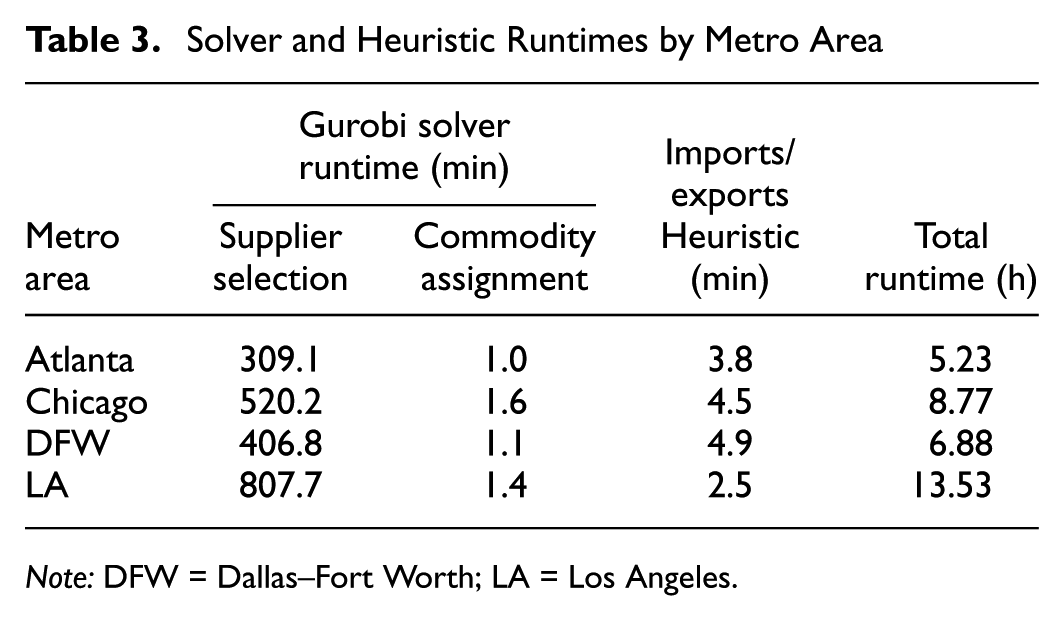
Note: DFW = Dallas–Fort Worth; LA = Los Angeles.
Table 4 summarizes: i) the annual demand in million metric tons; ii) the international trade share; iii) the number of modeled internal and external establishments; iv) the final number of assignments based on 2023 FAF non-pipeline flows; and v) the average number of domestic suppliers per receiver; vi) the average number of internal importers per port; and vii) the average number of internal exporters per port. To illustrate the computational burden, the total number of
Metro Area Key Statistics
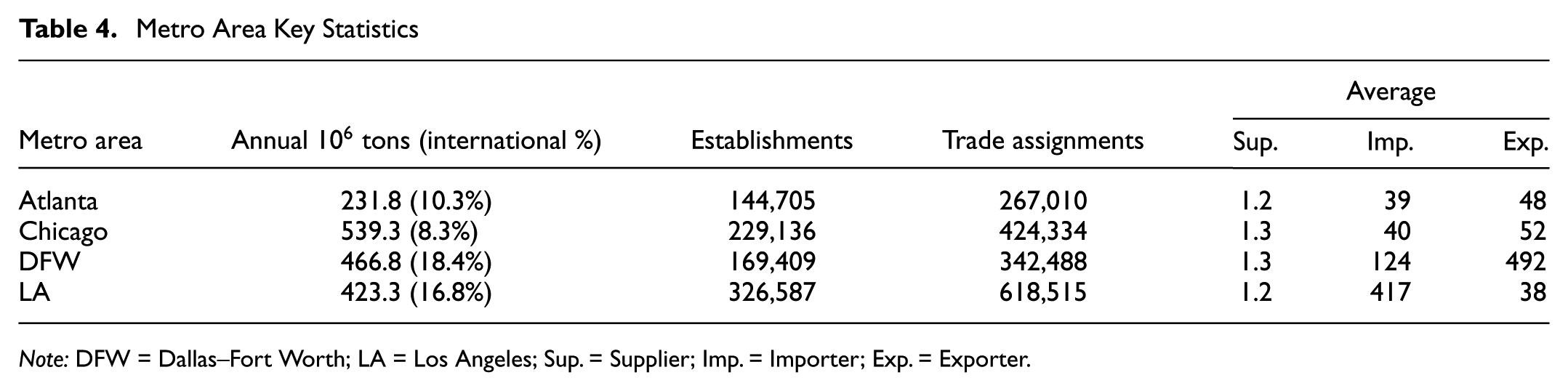
Note: DFW = Dallas–Fort Worth; LA = Los Angeles; Sup. = Supplier; Imp. = Importer; Exp. = Exporter.
Atlanta and Chicago had the lowest averages for the importers/exporters ratio, which is aligned with their lower share of international trade. Note that although Chicago generally has a very high import demand, this demand is mostly oil imported through pipelines which is not considered in this study because of the different nature of pipeline flows and their insignificance on the highway and railway networks. DFW had a high average number of exporters as it is a huge exporter metro area, while LA had a higher importer average for its high import volumes. The reported averages reflect the per-port values and are consequently affected by the presence of low-throughput ports. These results show that LA has a higher chance of being affected by import policies and disruptions, which would not only affect its position as a major gateway to the United States, but would also affect the large number of businesses in the import industry. Conversely, around 95% of DFW’s export tonnage are handled through points of entries within Texas itself, with almost 60% of the tonnage and 80% of exporters depending on Houston ports. These exporters are particularly vulnerable to disruptions during hurricane seasons, which have occasionally caused significant delays at the Port of Houston. This underlines the importance of modeling the supplier selection problem to quantify impacts of possible disruptions on these freight flows and study mitigating measures. Moreover, modeling these trade partnerships allows for the assessment of potential policies and scenarios on the transportation network, for example, the impact of increasing rail share for exports along the DFW–Houston corridor on the transportation network.
Figure 4 illustrates the regional domestic shipping distance distribution for both observed and optimized flows. The observed and estimated weight percentages are recorded in Table 5, where
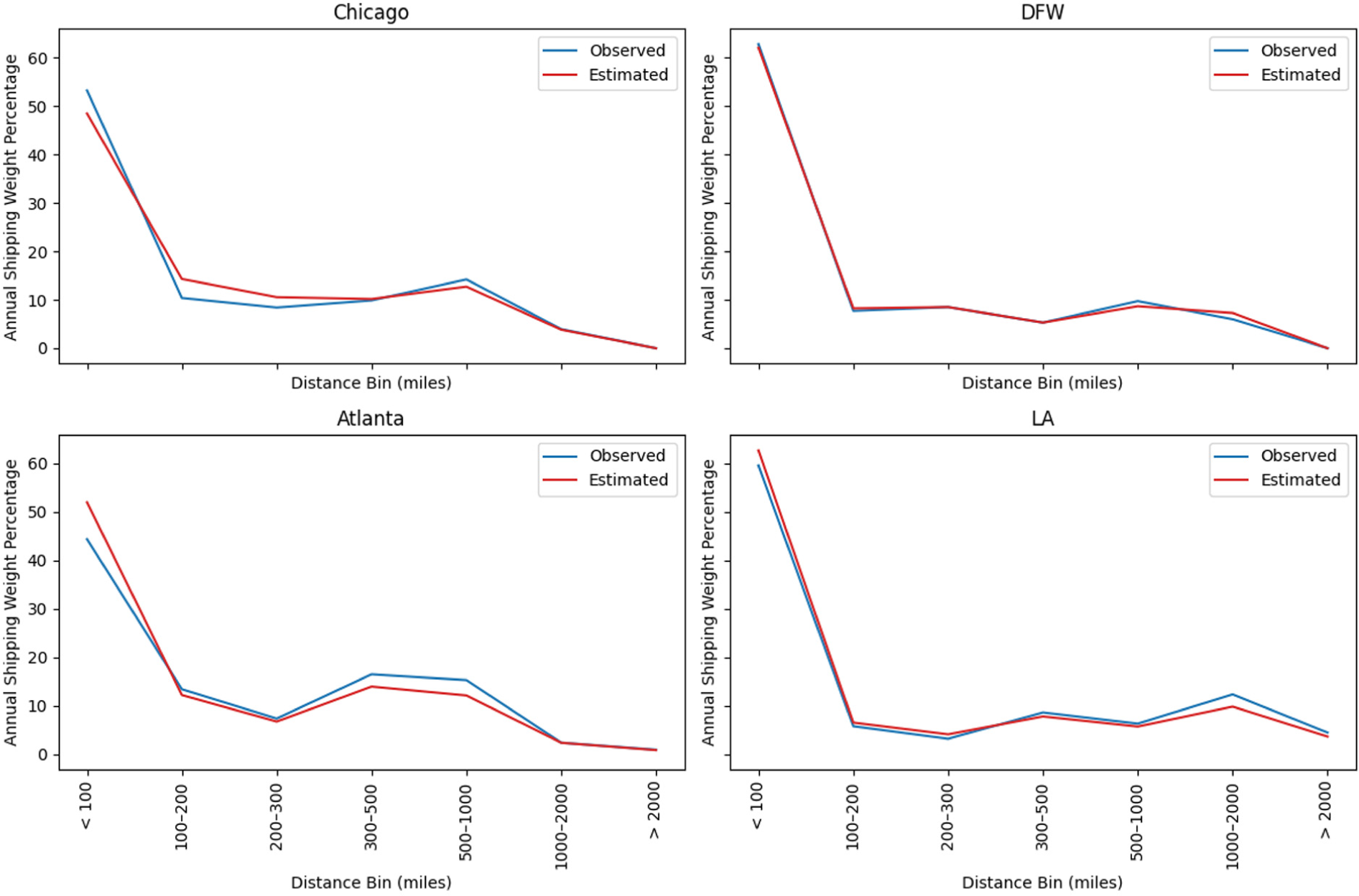
Shipping distance distribution.
Observed versus Estimated Distance Bin Percentage Shares
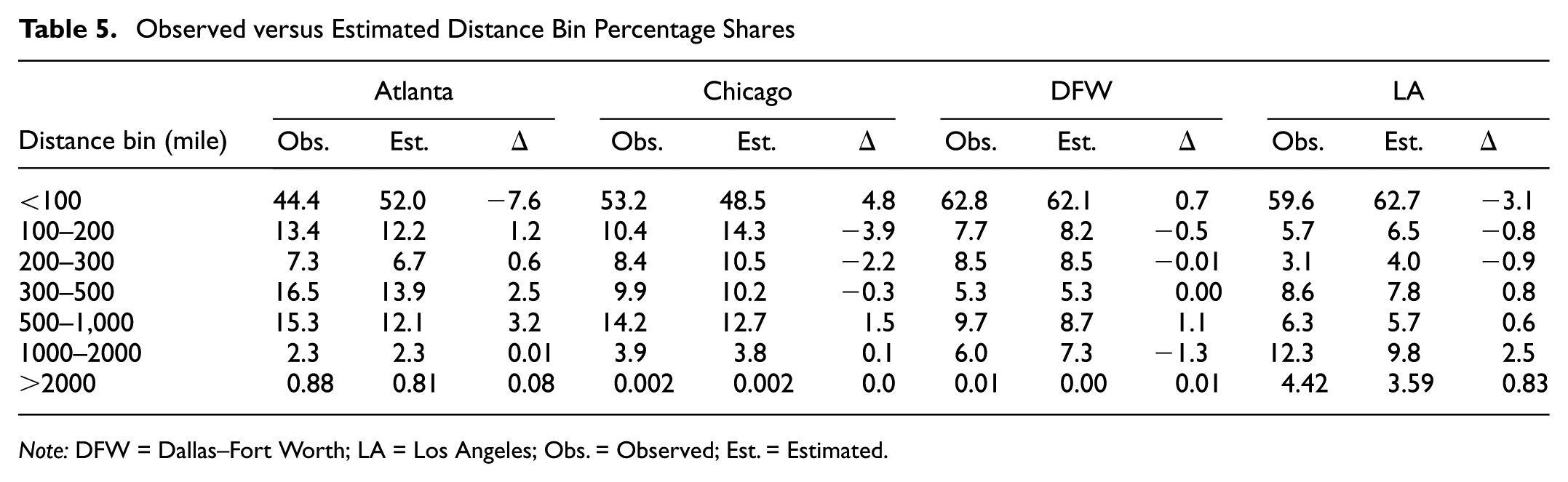
Note: DFW = Dallas–Fort Worth; LA = Los Angeles; Obs. = Observed; Est. = Estimated.
It should be noted that using smaller bins slightly increases the gaps. However, the major increase occurs in bins below 50 mi. This is a result of using establishments’ county centroids to calculate distance in this model and then comparing the results to actual observed distances from the CFS survey which, although it obscures the actual location of the supplier and receiver, reports the observed distances. Such differences might not affect the results of longer shipments but significantly affect shorter shipments. especially inter-county shipments. A possible solution to this issue is to use POLARIS disaggregated transportation analysis zones or locations, which can help reduce bias arising from large inter-county distances. Yet, improving the resolution of the model brings in further computational challenges contradicting the simplification approach that this study aimed to follow. It is worth mentioning that the gaps cannot be entirely eliminated since the model has multi-objectives and the priority was to ensure that receiver demands were met. Also, the external establishments sampled in the FG module in POLARIS do not consider the shipping distances, introducing an initial bias to the model.
Figure 5 depicts the analysis of the number of trade assignments and annual demand by commodity grouping (shown in Table 1), revealing significant spatial sector variations among major U.S. metropolitan regions. In Atlanta, Chicago, and LA, food and agricultural commodities—including processed foods—consistently represent both the largest share of trade pairs and the highest total demand. This dominance underscores the centrality of these commodities to urban consumption patterns, particularly given their primary end users in retail, restaurants, and food service sectors. DFW diverges from this trend, with petroleum products surpassing food commodities in both trade volume and aggregate demand. This reflects the DFW’s industrial structure and the major role of the petroleum sector in shaping freight flows.
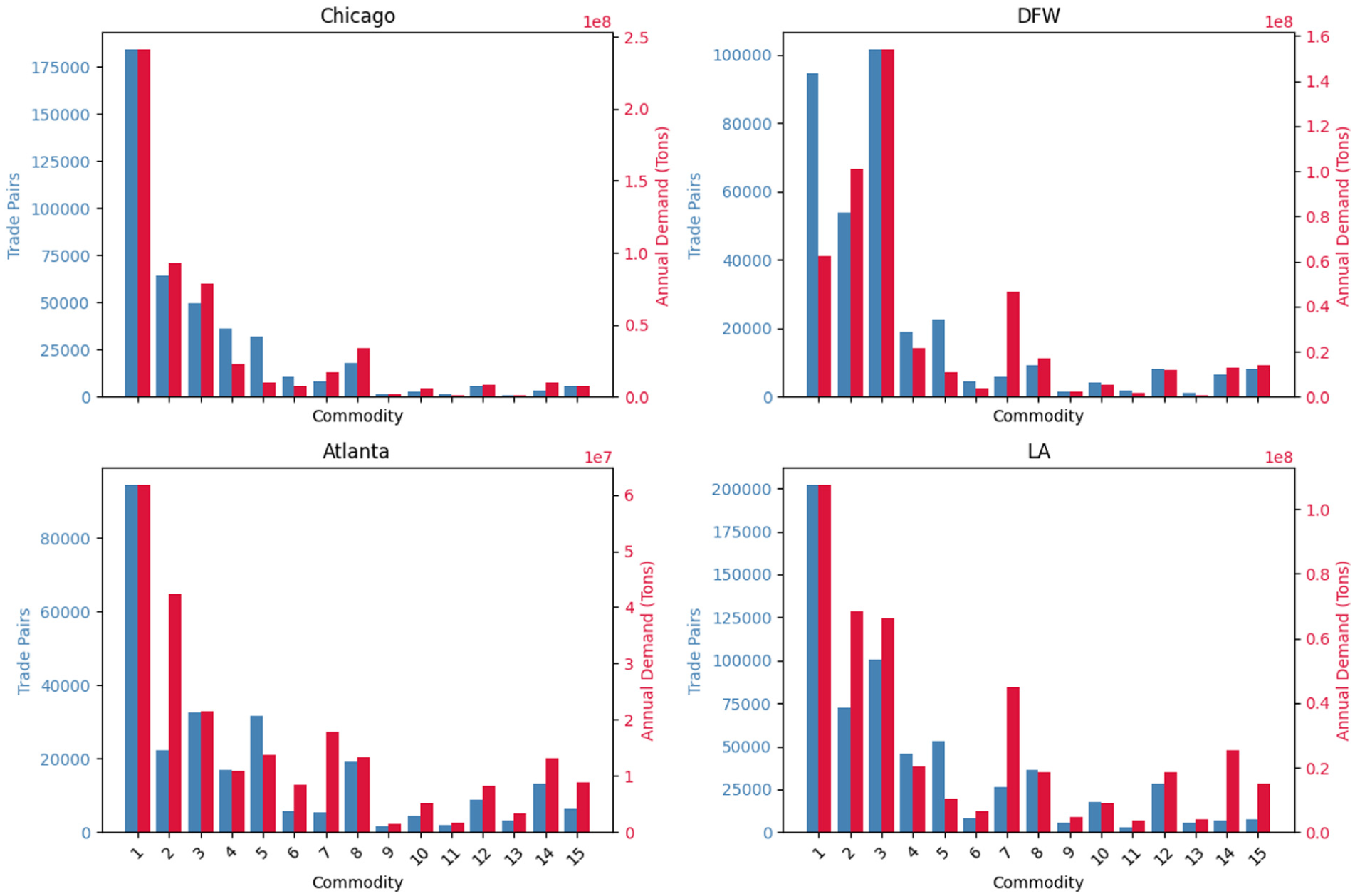
Trade assignments and demand by commodity type.
Population size is the key driver of total food commodity demand. Chicago and LA, the most populous metro areas in this study, exhibit the highest aggregate demand for food products. The number of businesses of NAICS 722—Food Services and Drinking Places—can be used as a proxy to analyze the dominance of the food commodity group. For instance, Chicago, with the highest demand tonnage and approximately 19,000 food and drinking places, averages 1,310 annual tons per trade pair. In contrast, LA, despite a high total demand, has nearly 34,000 such establishments, resulting in a lower average of 532 tons per pair. Atlanta and DFW, with 11,000 and 14,000 establishments respectively, display intermediate averages 654 and 662 tons per pair, reflecting both their relatively smaller populations and lower total demand. These findings suggest that while demand for food commodities scales with metropolitan population, the average demand per trade pair is inversely related to the number of establishments as a result of higher market competition.
Finally, commodities such as leather, textiles, electronics, and office furniture consistently show the lowest trade volumes across all regions, indicating their relatively minor contribution to volume, and consequently to freight flows on the transportation network. These results show that a detailed understanding of commodity-specific trade dynamics provides a better modeling tool suited to study the appropriate targeting policies for a given metropolitan area.
Conclusion
The freight transportation field often suffers from data limitations, which constrain modeling capabilities, making researchers rely on publicly available aggregated data to infer the actual behaviors and operations of freight stakeholders. One such challenge arises in the supplier selection problem, where data on actual bidding processes and firm-level decision making are rarely accessible, making it difficult to accurately represent market conditions. This research addresses the supplier selection process by modeling receiver behavior to maximize perceived supplier ratings. Importantly, it achieves this by decreasing the discrepancy between modeled and observed commodity flows. The overarching objective is to produce a more behaviorally realistic and transport-sensitive representation of supplier selection outcomes, particularly of their impact on transportation network flows. To achieve this goal, this paper has proposed a supplier selection and commodity assignment model that seeks to match shipping distance distribution while ensuring a match in the inter-zonal commodity flows. In addition, the paper has also proposed an international shipments heuristic that matches commodity flows individual ports with establishments. The developed models were implemented on a large scale on four metropolitan areas in the U.S.: Atlanta, Chicago, DFW, and LA. The model results showed a close match between the estimated and observed shipping distance distributions for all study regions.
The implications of the proposed models are far-reaching, providing a critical tool for studying targeted policies and understanding complex freight dynamics. By capturing the nuanced decisions of individual freight agents, the model enables a deeper exploration of how changes in sourcing patterns, influenced by factors such as trade policies, infrastructure investments, or even disruptions, translate into real-world transportation network impacts. For instance, the model can be used to assess the network-level consequences of cost fluctuations on specific imported goods by simulating shifts in supplier selection, evaluating changes in VMT, and quantifying their effects on congestion and network reliability. Conversely, it can inform strategic infrastructure planning by predicting how new or improved corridors might alter logistics choices, attract new suppliers, or facilitate more efficient movement of goods. Furthermore, the ability to simulate supplier–receiver relationships at a micro level within POLARIS ABM makes this model invaluable for analyzing supply chain resilience strategies. It can help identify vulnerabilities within existing supply chains, simulate the cascading effects of disruptions (e.g., port closures, infrastructure failures), and evaluate the effectiveness of mitigation measures such as diversifying supply sources or rerouting commodity flows. This granular insight into trade partnerships offers policymakers a powerful analytical framework to proactively address emerging challenges and optimize the performance of urban and national freight systems.
A critical distinction must be made with regard to the scalability of the joint versus decomposed formulations. In the joint formulation, the number of decision variables (
However, for a unified national-scale implementation where the network size increases dramatically, the exact decomposition approach may still face tractability limits. Addressing this national scalability will likely require future research into heuristic solution methods or hierarchical regional decomposition strategies to trade off a marginal degree of optimality for necessary computational speed.
Despite its significant contributions, this research acknowledges several limitations that offer clear avenues for future work. A key consideration is that while the commodity assignment problem is made feasible through decomposition, the current approach does not explicitly guarantee an optimal commodity assignment from a global perspective, given its sequential nature after supplier selection. Future efforts could explore iterative or more integrated solution methodologies to enhance optimality. Another limitation stems from the spatial aggregation of shipping costs; currently, distances between establishments are based on county centroids, which, especially in large or geographically diverse counties, may not accurately reflect actual travel distances. A refined approach would involve leveraging the more precise POLARIS locations and zones, or even exact establishment coordinates, to calculate transportation costs, thereby increasing the model’s accuracy. Additionally, the initial set of external establishments generated by the FG module in POLARIS introduces a potential bias, as these are sampled without explicit consideration of their optimal shipping distances. Future enhancements to the FG module could integrate spatial optimization to yield a more representative initial population of external trade partners. The present shipping cost calculations do not explicitly account for network congestion. However, a major future direction involves integrating the model with the POLARIS Freight multimodal router, which is currently under development. This integration would allow for dynamic feedback, where simulated congestion levels on the network would influence shipping costs, leading to more realistic and adaptive supplier selection decisions in subsequent simulation iterations. Finally, using the heuristic for imports and exports, although warranted because of the impracticality of getting data on foreign suppliers and receivers, introduces a limitation with regard to parameter sensitivity. The resulting allocation of international flows is inherently sensitive to the assumed lower and upper trade bounds; tightening these bounds forces the flow across a larger pool of establishments, while relaxing them concentrates trade among a few dominant actors. Despite this sensitivity in baseline allocation, the heuristic remains a robust tool for capturing the relative domestic impacts of supply shocks, such as port disruptions. Addressing these limitations will further enhance the model’s fidelity, computational efficiency, and practical utility for advanced freight planning and policy analysis.
Footnotes
Acknowledgements
Melissa Rossi, a DOE Office of Energy Critical Minerals and Energy Innovation (CMEI) manager, played an important role in establishing the project concept, advancing implementation, and providing guidance.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Abdelrahman Ismael, Taner Cokyasar; data collection: Abdelrahman Ismael, Taner Cokyasar; analysis and interpretation of results: Abdelrahman Ismael, Taner Cokyasar; draft manuscript preparation: Abdelrahman Ismael, Taner Cokyasar. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based on work supported by the U.S. Department of Energy, Office of Science, under contract number DE-AC02-06CH11357. This report and the work described were sponsored by the U.S. Department of Energy (DOE) Transportation Technologies Office (TTO) under the Integrated Transportation and Energy Cross-Sectoral System of Systems at Scale (ITES4), an initiative of the Energy Efficient Mobility Systems (EEMS) Program.