
Abstract
Objective:
To date, the integration of artificial intelligence (AI) in healthcare has expanded rapidly, offering new tools for patient education and communication. In prostate cancer (PCa), where information needs are high and emotionally sensitive, AI-driven chatbots (CB) may enhance patient engagement. This study aims to compare the performance and perceived quality of responses from CB versus urologists (URO) to common PCa-related inquiries.
Methods:
We conducted a cross-sectional analysis of 20 frequently asked PCa general questions. Responses were generated by two AI-based CB and four certified URO in a simulated clinical messaging setting, without direct patient interaction. Expert reviewers first assessed each response for medical accuracy and completeness. Then, five blinded non-medical evaluators rated the responses using Likert scales to evaluate completeness (1–5), empathy (using a five-item adaptation of the Jefferson Scale), and overall preference.
Results:
A total of 600 responses were evaluated. Accuracy and completeness scores were comparable between CB and URO responses, according to experts’ evaluations (p = 0.45 and p = 0.12). However, CB responses scored significantly higher in completeness and empathy (both p < 0.001) for non-medical evaluators. Moreover, a statistically significant preference for overall CB-generated responses over those from urologists, was demonstrated (p < 0.001).
Conclusions:
While CB responses were as accurate as those from URO, they outperformed in completeness and empathy. These results suggest that AI-based CB could serve as effective tools in enhancing patient communication and satisfaction and may be a valuable complement to urologist-led care in clinical practice.
Introduction
In today’s digital era, the widespread availability of medical information on the internet has significantly transformed the healthcare landscape. 1 Health organizations have embraced innovative technologies across the entire spectrum of care, from diagnosis to treatment and follow-up, while patients are increasingly turning to online platforms to better understand their medical and surgical options. 2 However, the reliability of such information varies greatly. To address this issue, professional societies like the American Urological Association (AUA) and the European Association of Urology (EAU) have developed patient-centered educational content grounded in their official clinical guidelines.3,4 These include accessible resources and high-quality videos created by various working urological groups, designed to make complex surgical information more understandable to the general public. 5
Despite the value of these resources, direct interaction with healthcare providers remains essential throughout a patient’s care journey. In this context, the rise of artificial intelligence (AI)-powered chatbots marks a new frontier in digital health. 6 These tools, which are both accessible and easy to use, offer support and health information in real time. Therefore, the accuracy, consistency, and quality of chatbot-generated responses must be rigorously assessed to ensure they are trustworthy.7,8
In this panorama, prostate cancer (PCa) is a matter that exemplifies the intersection of technological innovation and patient communication. 9 The use of novel technologies has revolutionized PCa care, including concerns about diagnosis, staging, treatments with the rise of robotic surgery, 10 post-operative complications, post-surgical quality of life, including sexual and urinary functions, 11 often outweigh patients’ fears about cancer recurrence, above all during active surveillance. 12 Despite the growing role of AI in healthcare, 13 there is a lack of focused research evaluating how accurately and empathetically AI chatbots respond to PCa-related questions.
While several studies have highlighted the limitations of chatbots in specialized medical fields14,15 and in PCa care, 16 none have specifically compared their performance to that of human experts in delivering PCa information. Therefore, this study aims to assess and compare the accuracy, consistency, quality of information, and patient preference regarding responses from chatbots (CB) and urologists (URO) to common PCa-related inquiries.
Methods
We conducted a cross-sectional comparative analysis to evaluate the quality of general and no-specific responses to PCa-related questions provided by AI CB and board-certified URO. A total of 20 clinically relevant questions were developed, covering 4 key domains (Table 1):
Diagnosis
Treatment options
Perioperative complications
Postoperative follow-up
Twenty prostate cancer-related questions divided in categories administrated to chatbots and urologists.

These questions were selected to reflect common patient concerns and were framed in layperson-friendly language to simulate real-world patient inquiries. Responses to each question were generated independently by two widely used AI-powered CB (Chatbot 4 and GeminiPro), as well as by four experienced URO (⩾5 years of expertise in prostate cancer management). All responses were collected in a simulated clinical messaging environment that mirrored asynchronous communication, without any direct interaction with patients, and neither AI nor URO respondents were provided with additional patient context beyond the phrased question.
Computer engineering, data scientists and AI specialists were likely involved in the training process of the AI, using large amounts of medical data to ensure that the chatbot produced appropriate answers and subsequently the chatbot was designed to include a level of “humanization” in its responses, aiming to reply in a supportive and understanding manner.
To assess the quality of the responses, a panel of three independent expert urologists (⩾10 years of expertise in PCa management), evaluated each answer based on two main criteria: accuracy and completeness, according to a Likert Scale from 1 to 5. Accuracy was defined as the degree to which the response aligned with current clinical guidelines and evidence-based practices, while completeness referred to how thoroughly each response addressed the components of the question, including clarity, structure, and thematic relevance.
Following expert evaluation, a second assessment was carried out by a group of five non-medical participants (without any personal or family history of PCa), selected to represent typical patients or lay users. These evaluators were blinded to the source (CB vs URO) of each response and were instructed to assess each answer based on three main dimensions:
-
-
- Additionally, they indicated their
Statistical analysis
Descriptive statistics were presented as median (IQR) for non-parametric data. Comparisons among the two groups were conducted using Pearson Chi squared or Wilcoxon test for normally distributed variables or for variables that did not meet the normality assumption. All analyses were conducted using SPSS version 27 (IBM Corp., Armonk, NY, USA). A p-value <0.05 was considered indicative of statistical significance.
Results
Two CB and 4 URO answered each 20 patients-centered questions, with a total of 120 responses generated. Afterward, these responses were assessed by a group of five non-medical volunteers, who were blinded to the authorship of each answer to minimize bias, evaluating 600 answers.
As shown in Table 2, expert urologists rated both CB and URO responses as sufficiently accurate and complete to be presented to non-medical volunteers. No significant differences were found between the two groups in terms of these two parameters (p = 0.45 and p = 0.12, respectively).
Expert urologists’ evaluations of responses on Likert scale for answer accuracy, and completeness between chatbots and urologists.
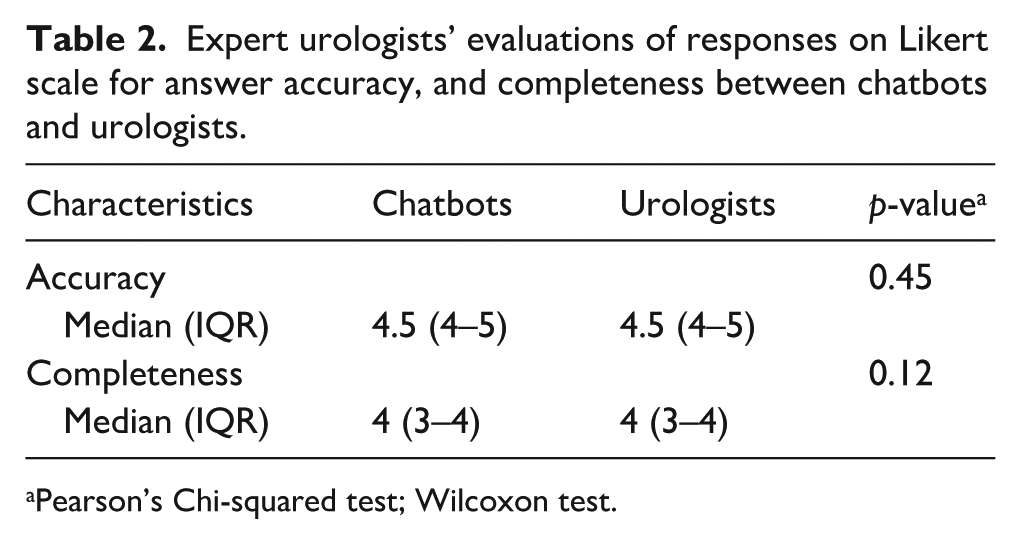
Pearson’s Chi-squared test; Wilcoxon test.
Conversely, as summarized in Table 3, concerning trust and satisfaction, CB responses received significantly higher scores, considering them completer and more empathetic compared to those from URO (all p < 0.001).
Non-medical volunteer evaluations of responses on Likert scale for answer accuracy, completeness, empathy and preference ranking between chatbots and urologists.
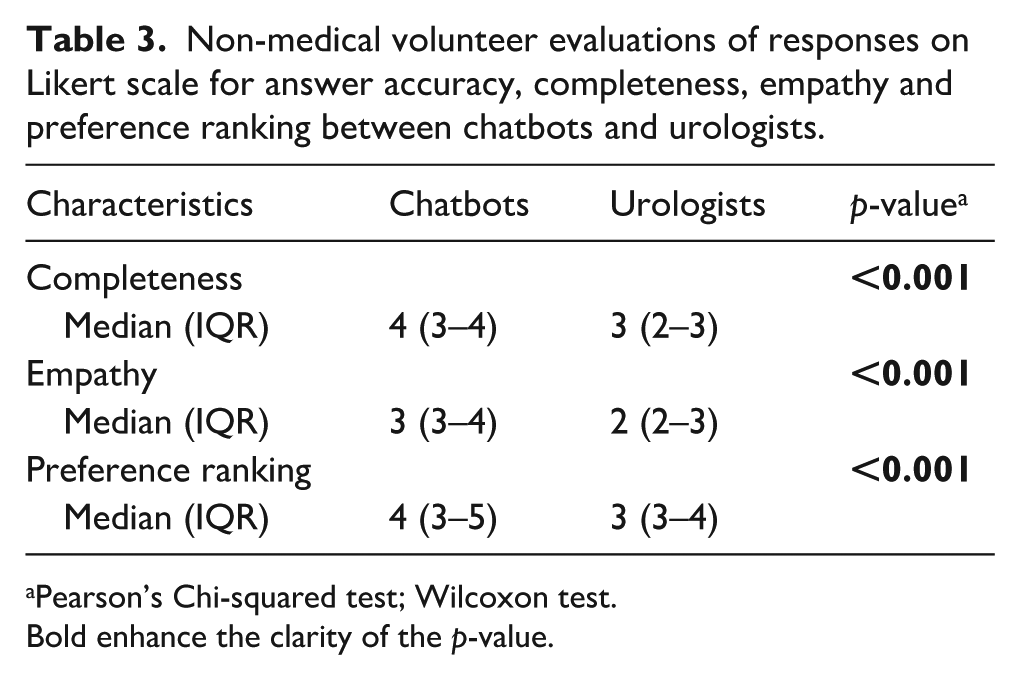
Pearson’s Chi-squared test; Wilcoxon test.
Bold enhance the clarity of the p-value.
Finally, the preference ranking for CB responses was significantly higher than for URO responses (p < 0.001), suggesting that while URO and AI CB are comparable in delivering accurate PCa information, CB may have an edge in communication style and comprehensiveness factors that can strongly influence patient perception and engagement.
Discussion
This study represents the first targeted evaluation of chatbot-generated responses in the context of PCa, a complex and emotionally charged condition that significantly impacts men’s physical and psychological well-being. 18 Seeing a physician and discussing treatment options following a diagnosis of localized or advanced PCa is a critical step in a patient’s care. For many, this may be their first interaction with the healthcare system, marking the beginning of a relationship with their urologist. 19 This phase of the cancer journey is particularly vulnerable to misinformation or disinformation, as patients often seek information urgently and from multiple sources. 20 Indeed, recent studies have highlighted the inconsistent performance of chatbots and AI platforms in urology and oncology, reporting limited actionability, incomplete sourcing, and a lack of personalization, thus raising concerns about their clinical utility.21,22
Based on these considerations, in the same way of Musheyev et al., 23 our aim was to assess whether CB can provide accurate, reliable, and patient-oriented information on PCa, potentially reducing anxiety and improving awareness of the disease and its broader context. We also sought to compare these AI-generated responses with those of expert urologists. Our findings contribute to the growing body of literature on the role of artificial intelligence in patient education and digital health communication, offering a more nuanced perspective. While accuracy was generally upheld, our results suggest that newer AI models may be evolving to more effectively replicate human-like empathy and comprehensive patient support, two critical components of cancer care, where emotional factors heavily influence decision-making, as reported in previous works. 24 This occur in a context in which patients’ perception of completeness of the responses from URO and CB is similar suggesting that both AI-powered CB and experienced urologists provided medically sound answers in terms of factual correctness.
This aligns with emerging research suggesting that even artificial expressions of empathy can enhance user experience and foster trust, particularly when real-time access to physicians is limited.25,26 Our study highlights that AI has the potential not only to deliver clinically valid content but also to simulate the compassionate, patient-centered communication that strengthens adherence to medical advice. Moreover, our results are consistent with findings in other fields, 27 where instruments like the Modified DISCERN, EQIP, and PEMAT have been employed to evaluate AI-generated content.28,29 Although we did not use EQIP or Flesch-Kincaid metrics in this study, the high completeness scores assigned to CB responses suggest that the structure and depth of information may, in some cases, surpass traditional expert responses, potentially due to time limitations or assumptions about patients’ prior knowledge in real consultations.
It is important to acknowledge that our simulated clinical environment cannot fully capture the dynamic, bidirectional nature of actual physician–patient interactions. Nevertheless, in line with those reported to Rodler et al., 14 evaluators noted that CB responses tended to include more background information, a broader range of treatment options, and clearer explanations, making them appear more comprehensive and informative. One possible explanation for the higher completeness and perceived empathy of CB responses could relate to the inherent limitations of human communication in clinical settings. Urologists, who often repeat the same information about diagnosis, treatment options, and prognosis to multiple patients and their families each day, may experience fatigue or cognitive overload. This repetitive strain, both mental and emotional, can unintentionally affect the depth or tone of their explanations, as reported in a previous study. 30 In contrast, CB do not experience fatigue and can deliver consistent, detailed, and empathetic responses regardless of the number of interactions. This fundamental difference may contribute to the perception that chatbot responses are more comprehensive and emotionally attuned.
Taken together, these findings suggest that AI CB could serve as powerful adjuncts in urological care, enhancing patient understanding, supporting clinical communication, and alleviating some of the informational burden on physicians. However, these tools are not intended to replace clinical professionals. Rather, they should be viewed as complementary resources that can provide clear, compassionate, and accessible information, particularly at emotionally vulnerable stages of the patient journey.
Limitations
This study has several limitations that should be acknowledged. First, the evaluation was conducted in a simulated messaging environment without direct patient interaction, which may not fully replicate the dynamic and nuanced nature of real clinical consultations. The static responses lacked the opportunity for follow-up questions or personalized dialog, potentially limiting the assessment of CB and URO adaptability. Third, we did not evaluate other important factors such as readability, source citation accuracy, or factual consistency using standardized tools like modified DISCERN or EQIP, or ChatGPT’s FKGL scores which have been reported as critical in previous AI health information studies. While our study prioritized empathy and completeness, future work should integrate readability metrics to provide a holistic view of CB utility in patient education.
Finally, the study focused exclusively on PCa-related general questions, which limits the generalizability of findings to more specific PCa questions and additionally clinical consultations allow for clarifications, follow-up questions, and individualized recommendations.
Notwithstanding these limitations, to the best of our knowledge, this is the first global research in urology comparing chatbots and physicians’ answers on PCa care. Future research are needed in order to incorporate specific questions and real patient feedback, dynamic conversational assessments, and comprehensive content quality metrics.
Conclusions
While AI-generated responses to PCa inquiries demonstrated comparable accuracy and completeness assessed by expert urologists, for non-medical volunteers, they significantly outperformed in terms of completeness and perceived empathy. Non-medical evaluators consistently preferred chatbot responses, highlighting the potential of AI tools to enhance patient communication, engagement, and satisfaction in the field of PCa. These findings suggest that AI-driven platforms may serve as valuable adjuncts in clinical settings, particularly for providing accessible, emotionally attuned, and informative responses to common patient concerns. As digital health continues to evolve, the integration of AI-generated messaging into urological practice could support more efficient patient education and complement traditional physician–patient interactions.
Footnotes
Ethical considerations
Not required. The study was conformed to the ethical guidelines of the 1975 Declaration of Helsinki without any changing in the standard practice.
Consent to participate
Indeed, all patients enrolled were requested to be involved, on a voluntary basis, in the study, signing a willing document of inclusion.
Author contributions
Conceptualization, L.C. and A.M‥; methodology, L.C. and A.M.; software, P.C.; validation, F.E. and R.P.; formal analysis G.R.; investigation, L.C. and A.M.; resources P.C.; data curation, F.E.; writing—original draft preparation, L.C.; writing—review and editing, L.C., A.M. and F.E.; visualization, F.E. and A.R.I‥; supervision R.P. and A.R.I. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.