
Abstract
Objective
Clinical practice guidelines support evidence-based care but are often underused due to complexity, time constraints, and navigation challenges. We investigated whether a conversational agent (chatbot) using an open-weight large language model (LLM) with retrieval-augmented generation (RAG) could provide guideline-consistent answers for bipolar disorder management based on the full 2018 Canadian Network for Mood and Anxiety Treatments (CANMAT) and ISBD guidelines, comparing against a system using only the base LLM.
Method
We developed a multi-step RAG-based chatbot that retrieves relevant guideline sections and generates responses using Llama 3.3 70B. Twenty-one clinical vignettes spanning all guideline sections were created. Six expert psychiatrists generated queries and were presented with paired responses without labels from 2 systems: one using the base Llama 3.3 70B model, the other RAG-enhanced. Responses were rated for guideline consistency on a 3-point scale, and were analyzed using mixed-effects ordinal logistic regression.
Results
Experts evaluated 126 responses, of which 110 (87.3%) were rated as correct as or more correct than the baseline system. The RAG system produced 80 answers (63.5%) rated fully consistent with the guidelines versus 24 (19.0%) for baseline, and only 10 answers with major deviation (7.9%) versus 48 (38.1%) for baseline. Ordinal regression showed RAG responses were significantly more likely to be more correct (OR = 9.1, 95% CI [5.3-16.3], P < 0.001), which was consistent across all raters. Preference ratings favoured RAG answers in 78.7% of cases. Performance varied by vignette, with some errors in both retrieval and reasoning.
Conclusion
The use of RAG with an open-weight model helped produce answers consistent with the CANMAT guidelines across vignettes that required adapting or combining guideline text, suggesting a proof-of-concept of a bipolar guideline chatbot. We identified areas to improve results and evaluation. Future work should explore additional retrieval strategies and LLMs, and test in more naturalistic settings.
Plain Language Summary Title
Evaluation of an AI system to answer treatment questions from bipolar disorder medical guidelines.
Plain Language Summary
We evaluated the effectiveness of an AI system at answering treatment questions from the bipolar disorder medical guidelines.
Introduction
Bipolar disorder is a prevalent and chronic psychiatric condition that presents a significant public health challenge globally, 1 with a lifetime prevalence rate of bipolar I at 0.87% and bipolar II at 0.57%.2,3 Its management is complicated by the illness's recurrent, multi-phased course, characterized by periods of wellness interrupted by episodes of mania, hypomania, and depression, along with its lifelong nature and high rates of comorbidities. 4 Clinical guidelines, such as those developed by the Canadian Network for Mood and Anxiety Treatments (CANMAT) and the International Society for Bipolar Disorders (ISBD), 5 aim to enhance care through evidence-based recommendations. These guidelines were developed using a rigorous overview of evidence, combined with expert clinical opinion, to produce pragmatic, hierarchical recommendations organized by treatment lines and levels of evidence. Previous evidence has shown that physicians' adherence to the CANMAT/ISBD guidelines can improve patient outcomes. 6 Despite the availability of clinical guidelines, their use in practice remains inconsistent,7,8 leading to suboptimal outcomes such as ineffective medications and inadequate consideration of comorbid conditions. Multiple barriers may play a role, including limited time and clinician skill, 9 guideline complexity, 10 challenges in applying recommendations to specific clinical scenarios,11,12 and difficulty navigating the documents. 13
To address these barriers, previous studies have examined digital tools such as C-IMPACT BD, a web application that provides rule-based recommendations from the CANMAT bipolar guidelines and has been shown to increase use of first-line therapies. 14 Recent advances in artificial intelligence offer additional opportunities to overcome barriers to guideline implementation. In particular, conversational agents, or “chatbots,” allow users to pose questions in natural language and receive support for treatment decisions. 15 These chatbots use large language models (LLMs) to answer questions. These models have been trained on language content from across the internet and may include knowledge relevant to clinical decision making, 16 though this information can be incomplete or incorrect, or drawn from more general sources such as internet forums. However, a challenge limiting their direct application in clinical settings is the generation of inaccuracies. These errors may arise from incorrect, biased, or outdated information, or as “hallucinations,” where the model fabricates content. 17
Retrieval-augmented generation (RAG) 18 is a technique that can improve the accuracy of chatbot systems.19,20 When a query is submitted, the RAG framework retrieves relevant information from domain-specific sources such as clinical guidelines, then passes the query, retrieved content, and system instructions to the LLM to generate a response. Initial studies have shown that this technique can reduce hallucinations and improve factual relevance.21,22 Examples of this approach in clinical settings are emerging, with LLMs being integrated with specialized texts and guidelines for managing specific conditions, such as thyroid disease, 23 liver disease24,25 and anticoagulation protocols for gastrointestinal procedures. 26 Because LLMs have a limited context window (the maximum text they can process at once), they cannot always include an entire guideline in a single prompt. 27 When context windows are smaller, RAG or a related technique is needed for retrieving relevant sections from large documents. Even with larger context windows, RAG helps focus responses on the most pertinent content rather than overwhelming the model with unnecessary text.
While RAG-based applications are emerging in related areas—including mental health support, 28 psychiatric documentation, 29 and depression detection 30 —to our knowledge, RAG systems have not yet been studied for providing treatment recommendations in mental health using clinical guidelines. We identified one study that examined a chatbot for decision support in bipolar disorder treatment. 31 This study did not use RAG; it augmented the chatbot's prompt with an excerpt from the U.S. Veterans Administration 2023 guidelines on bipolar depression, 31 and only tested recommendations for that mood state. Their augmented model prioritized expert-recommended medications 50.8% of the time, compared with 23.0% for the unaugmented model. The study used a proprietary, closed-weight model, GPT4-turbo, through OpenAI.
In this work, we investigate the use of RAG to provide treatment recommendations for bipolar disorder, covering all sections of the 2018 CANMAT guidelines, the world's most cited guideline for bipolar disorder. Our question set spans all mood states, both bipolar disorder types I and II, and addresses complex considerations such as age, comorbidities, side effects, special populations, and medication history. These vignettes often required reasoning that could not be satisfied by returning guideline text verbatim, as they involved synthesizing information from multiple sections and reconciling competing factors. We believe this reflects the complexity of treating mental illnesses like bipolar disorder and distinguishes our approach from prior guideline-based RAG systems, which have largely focused on simple knowledge retrieval.25,32,33 As opposed to prior work 31 that used proprietary models, we examined the use of an open-weight LLM, which offers advantages in privacy, interpretability, and reproducibility. We hypothesized that our RAG system would outperform the base LLM for all expert raters, despite raters generating their own queries from vignettes, introducing variation in wording. This work aims to inform future applications of RAG systems in psychiatry and other areas of medicine where recommendations must integrate multiple data points from guidelines and patient-specific queries.
Methods
Vignette Evaluation
We designed our evaluation based on recent assessments of clinical chatbots,25,26,31–33 asking expert raters to generate queries from clinical vignettes and score responses for consistency with the CANMAT 2018 guidelines. Six psychiatrists were initially recruited through the CANMAT network. All were guideline experts, either as co-authors or through regular clinical and educational use, and each had at least 10 years of experience treating bipolar disorder (range: 10-30 years). Raters received an orientation that included a walkthrough of a warm-up vignette, which was not scored. Due to an error, one participant did not receive most of the introduction and did not complete the warm-up case; this individual was excluded, and a seventh rater was subsequently recruited.
To avoid the risk of overfitting, where questions might be tailored to produce optimal answers for a fixed set of questions, we asked raters to write their own queries based on the provided vignettes rather than using the original wording. This approach also enabled evaluation of a more naturalistic and broader range of queries, as even minor differences in phrasing can significantly influence responses from systems using LLMs.34,35
To minimize courtesy bias, particularly because participants were recruited within the same network, raters were asked to blindly evaluate responses from 2 versions of the chatbot: one using RAG and one without, which we will refer to as the base model. We did not disclose how the 2 versions differed, only informing participants that they would be comparing 2 chatbot systems. The order in which responses appeared (left or right) was randomized for each vignette.
We created our primary scoring criterion by adapting recently used scoring criteria26,33:
As a secondary outcome, we also asked participants to choose between the 2 responses by judging overall preference, considering readability, contextual applicability, and clarity in expressing complex clinical concepts, also based on a recent study. 36 The purpose of this was to provide an initial investigation as to whether a RAG system adversely affected these usability aspects.
Clinical Vignettes Development
We developed 21 vignettes simulating clinical scenarios encountered by clinicians treating bipolar disorder, adapting the format from Perlis (2024)31 to include patient demographics, diagnostic history, presenting symptoms, medication history, and social/functional context. Three vignettes were created for each of the 7 sections of the 2018 CANMAT guidelines (excluding the introduction and conclusion). Vignettes are summarized in Table 1, with an example provided in Supplemental Table S1. To ensure clarity in age-related cases, older adult patients were assigned ages in the 70s, adolescents between 13 and 17 years, and all other cases between 20 and 59 years, with a mix of genders. The complexity of each vignette was intended to reflect questions that a community psychiatrist might reasonably pose in practice. Scenarios were designed to require integration of multiple guideline components (e.g., combining recommendations for bipolar I maintenance with strategies to mitigate weight gain) or to adapt the guidelines to the clinical scenario, such as excluding previously failed medications. However, the degree of complexity and reasoning varied depending on how raters formulated their queries, particularly for cases 1 and 4.
Clinical Vignettes.
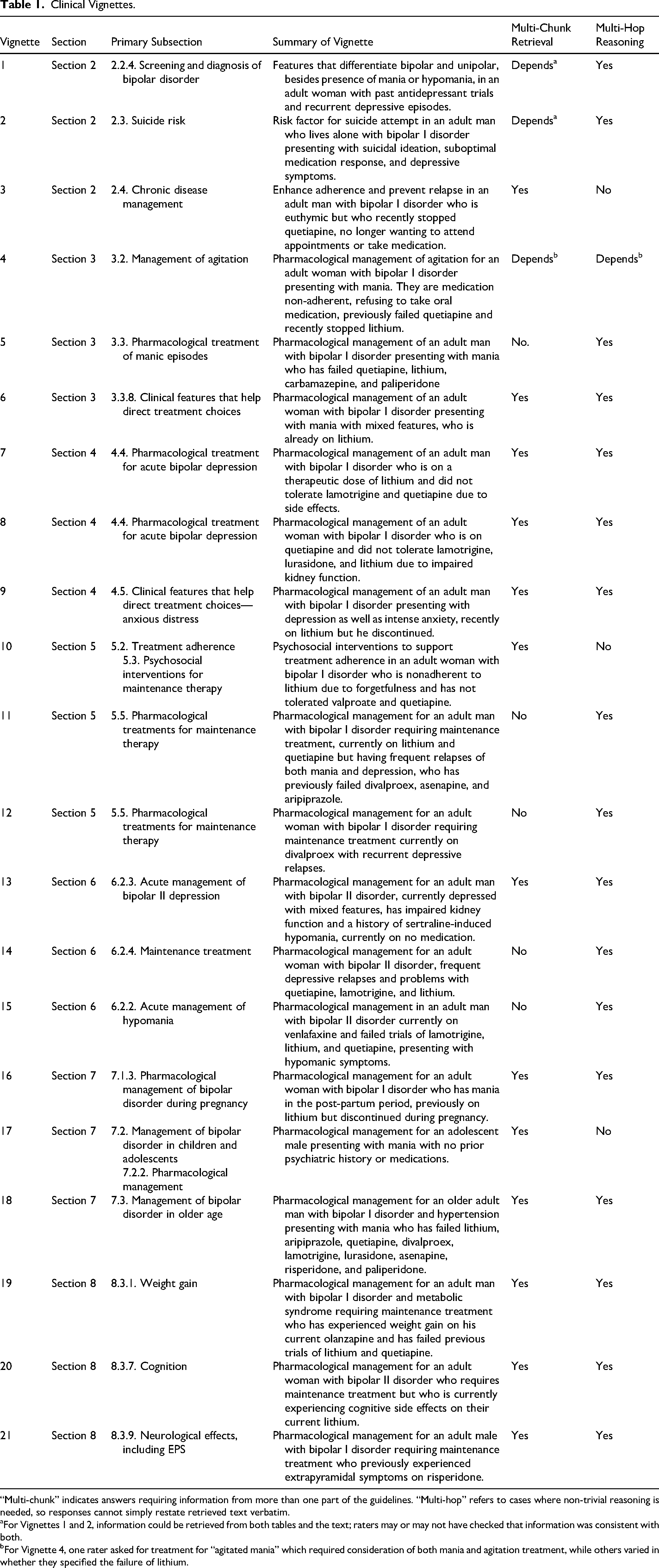
“Multi-chunk” indicates answers requiring information from more than one part of the guidelines. “Multi-hop” refers to cases where non-trivial reasoning is needed, so responses cannot simply restate retrieved text verbatim.
For Vignettes 1 and 2, information could be retrieved from both tables and the text; raters may or may not have checked that information was consistent with both.
For Vignette 4, one rater asked for treatment for “agitated mania” which required consideration of both mania and agitation treatment, while others varied in whether they specified the failure of lithium.
Chatbot Design
Document Preparation and Retrieval
We created a database of guideline content by scraping the CANMAT 2018 bipolar disorder website, converting paragraphs, tables, and figures into text. Each chunk was annotated with its section, subsection, and any referenced tables or figures to support downstream filtering.
Our system uses a multi-step RAG pipeline (Figure 1). First, user queries are classified into 1 of 5 categories: bipolar I mania, bipolar I depression, bipolar I maintenance, bipolar II, or general query. This classification, performed by a lightweight Mistral 7B model, 37 restricts the subsequent vector search to relevant guideline sections.
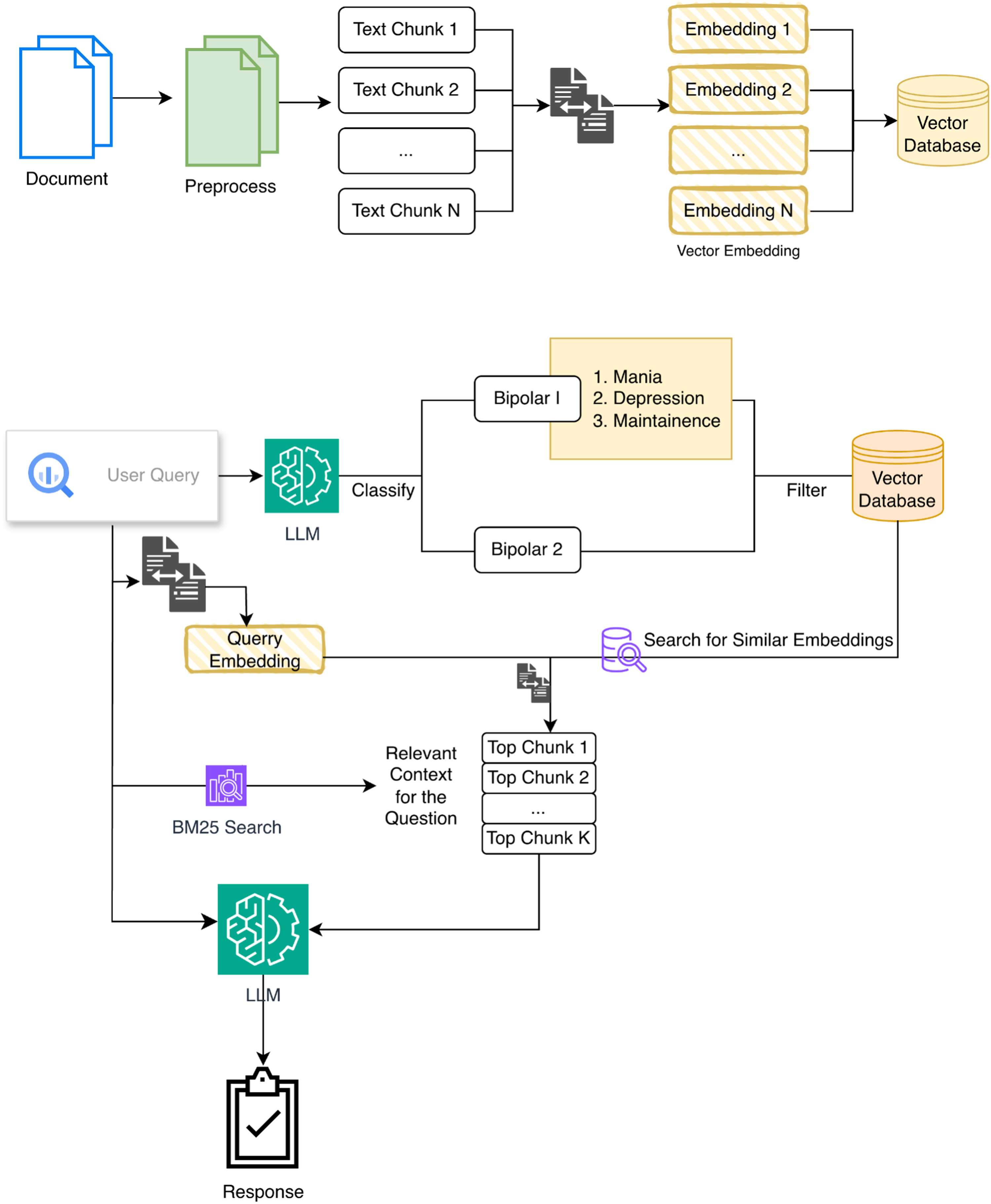
Diagram of our multi-step retrieval-augmented generative system.
To improve retrieval accuracy, we implemented a hybrid approach that combines dense and sparse methods: embedding-based search (Qwen/Qwen3-Embedding-0.6B) 38 for semantic similarity and BM25 39 for exact keyword matching. Section headers are boosted during BM25 scoring. When a query includes header terms such as “cognition,” “treatment,” or “adverse effects,” scores for chunks in that section are multiplied by 2. References to tables or figures in retrieved sections are appended to the context for final response generation.
Response Generation Using an LLM
For answer generation in our RAG system, we employed Llama 3.3 70B, which was the most capable open-weight model available at the study's inception. Llama 3.3 70B has demonstrated performance comparable to leading commercial models released around the same time, such as GPT-440,41 showing similar scores on benchmarks such as GPQA, Math 500 and BFCL, 42 though results vary by task.
Prompt design was refined through collaboration between team members with expertise in computer science and psychiatry (Supplemental Table S2). The system prompt instructed the model to use only the retrieved context when reasoning and answering questions, reducing hallucinations. We used the Chain-of-Thought 43 technique in prompt engineering to improve LLM reasoning. The prompt guides the LLM to first gather patient attributes, such as disorder subtype, mood state, population, and then apply hierarchical reasoning to decide the treatment line needed, exclude medications based on comorbidities, side effects, evidence level, or user preferences, reflecting a clinician's decision-making process.
For our evaluation, we maintained nearly identical prompts for the RAG and baseline versions to isolate the effect of retrieval augmentation; the only modification was removing instructions related to utilizing the retrieved context in the baseline model, as it operated without access to retrieved documents. The complete prompts are provided in Supplemental Table S2.
Cloud Deployment and User Interface
The user interface of the chatbot consists of a standard chat window with the CANMAT bipolar guidelines displayed alongside (Figure 2(a)). Responses include the retrieved “chunks,” linking to the relevant subsections of the guidelines.
(a) Our chatbot in standard mode, linking to relevant parts of the guidelines which can be viewed. (b) Our Chatbot as seen during our evaluation.
For the interface of the chatbot used in the evaluation, links to the subsections were not included so as not to differentiate the responses further from the base model. Our evaluation interface displays responses side by side and lists 3 rating options for each answer, as well as a button to choose the preferred response (Figure 2(b)). During the evaluation, response generation latency was approximately 2 to 3 seconds per query, which raised no concerns among reviewing clinicians.
We deployed our system on Amazon Web Services (AWS) through our institution's AWS account. The chatbot itself is hosted on AWS Amplify, and it is built using Node.js. The vector search runs directly in the user's web browser. All LLM inference tasks are handled by AWS Bedrock and embedding model inference by a 6 GB GPU SageMaker endpoint. Further architectural details are available on our GitHub repository.
Statistical Analysis
We analyzed rating outcomes using a mixed-effects ordinal logistic regression model implemented in the R package brms. 44 This approach was selected because the ratings (i.e., wrong, inaccurate, and correct) are inherently ordered, and the model accommodates this structure without collapsing categories into binary outcomes. Including random intercepts for participants and vignettes accounts for variability in rater tendencies and vignette difficulty, thereby improving the generalizability of the findings. The cumulative logit link estimates the effect of rating method (RAG vs. baseline) on the odds of being in a higher category, under the proportional odds assumption. We summarized these predictions to characterize individual-level tendencies, providing mean posterior probabilities and 95% credible intervals for each rater under both conditions. This approach allows us to assess whether the observed group-level effect of RAG versus baseline is consistent across participants—details in Supplemental Material S1.
Data Availability
The code used for our chatbot and evaluation will be available on a public GitHub repository upon publication. Given the potential for automatic scraping systems to use any publicly available data to train LLMs, which may impact planned immediate short-term work, the vignettes and question–answer pairs will be made available upon reasonable request to the corresponding author within 2 years of publication.
Results
Our RAG system performed better than the base model on the clinical vignettes. In total, raters evaluated 126 responses, 80 (63.5%) of them from the RAG system were marked as fully consistent (correct), compared to 24 (19%) from the base model. Thirty-six RAG responses (28.6%) were marked as having minor deviations or omissions (inaccurate), compared to 54 (42.9%) from the base model. Ten RAG responses (7.9%) were marked as having major deviations (wrong), compared to 48 (38.1%) from the base model (Supplemental Table S3 and Supplemental Figure S1). The RAG system provided answers that were statistically significantly more likely to be more correct than the baseline model (OR = 9.1, 95% CI [5.3-16.3], P < 0.001). Across 84 ratings (66.7%), RAG provided an answer that was more correct than the base model, 26 (20.6%) had the same level of rating, and 16 (12.7%) less correct. In total, 110 (87.3%) of the RAG responses were rated as correct as or more correct than the baseline system. Mixed-effects ordinal logistic regression provided strong evidence that this advantage was consistent across individual raters, with posterior probabilities of superiority exceeding 0.99 for all 6 raters.
For our secondary analysis, overall, raters preferred the RAG response in 96 (78.7%) ratings out of 122 preference ratings. Raters did not provide preferences for 4 ratings. In the 26 ratings where the experts rated both answers as the same level of correctness, raters preferred 18 (69.2%) of responses from RAG. In the 16 ratings where the baseline was correct, the baseline responses were preferred.
For the RAG system, performance varied across vignettes. Some cases, such as Vignettes 1 and 4, had all 6 responses rated correct, whereas Vignette 9 had none marked correct and 5 rated inaccurate, with the base model performing better by producing 2 correct answers (Table 2). Vignettes 15 and 18 showed mixed ratings, with 3 responses marked correct, 2 inaccurate, and 1 wrong. In several cases (e.g., Vignettes 2, 3, and 19), both models achieved the same number of correct responses.
Chatbot Ratings for Each Vignette.
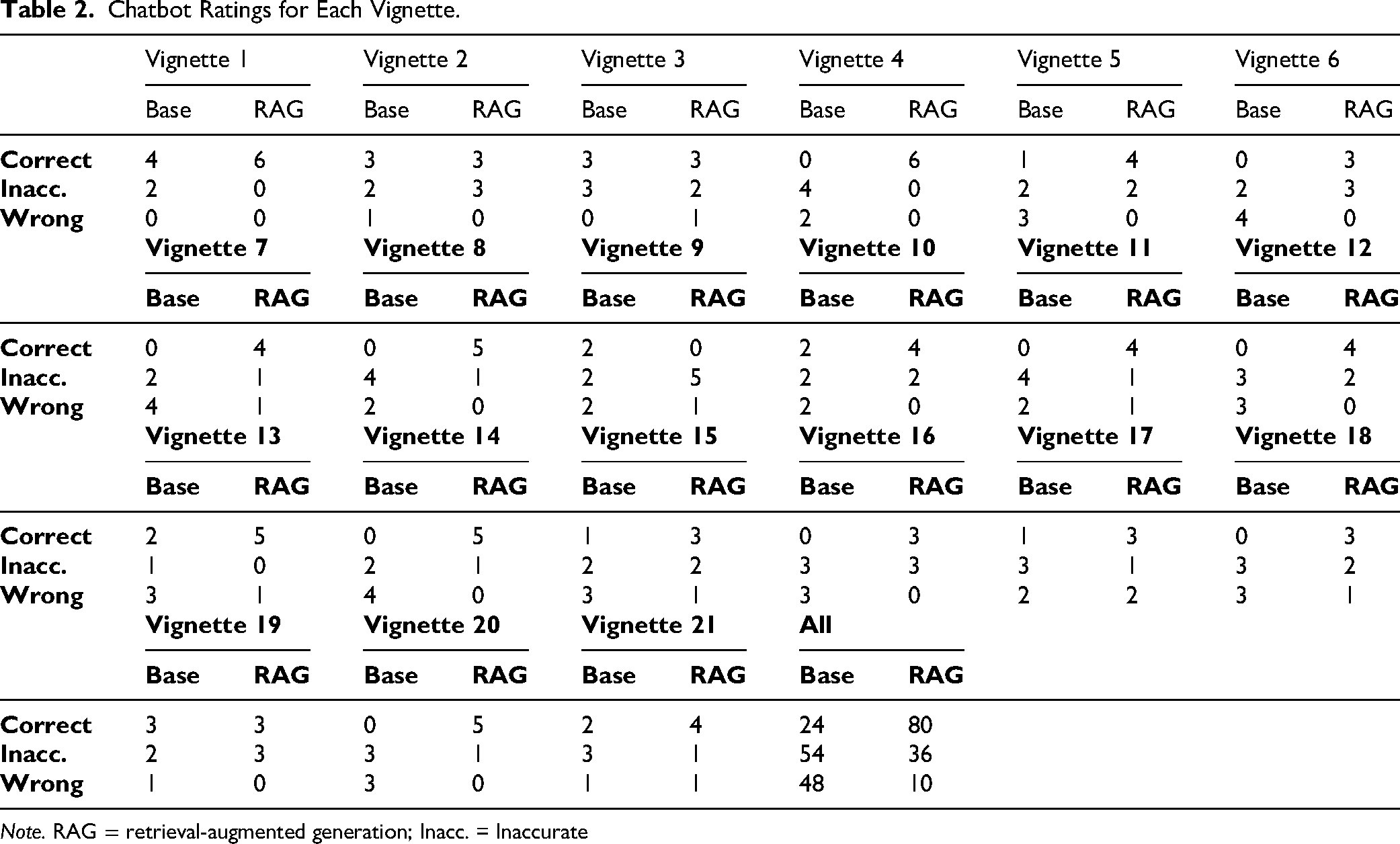
Note. RAG = retrieval-augmented generation; Inacc. = Inaccurate
We also observed variability among raters in how many responses they marked as correct. The strictest rater judged only 8 RAG responses as correct and marked 6 as wrong, whereas the most lenient rater marked 18 responses as correct and none as wrong (Figure 3).
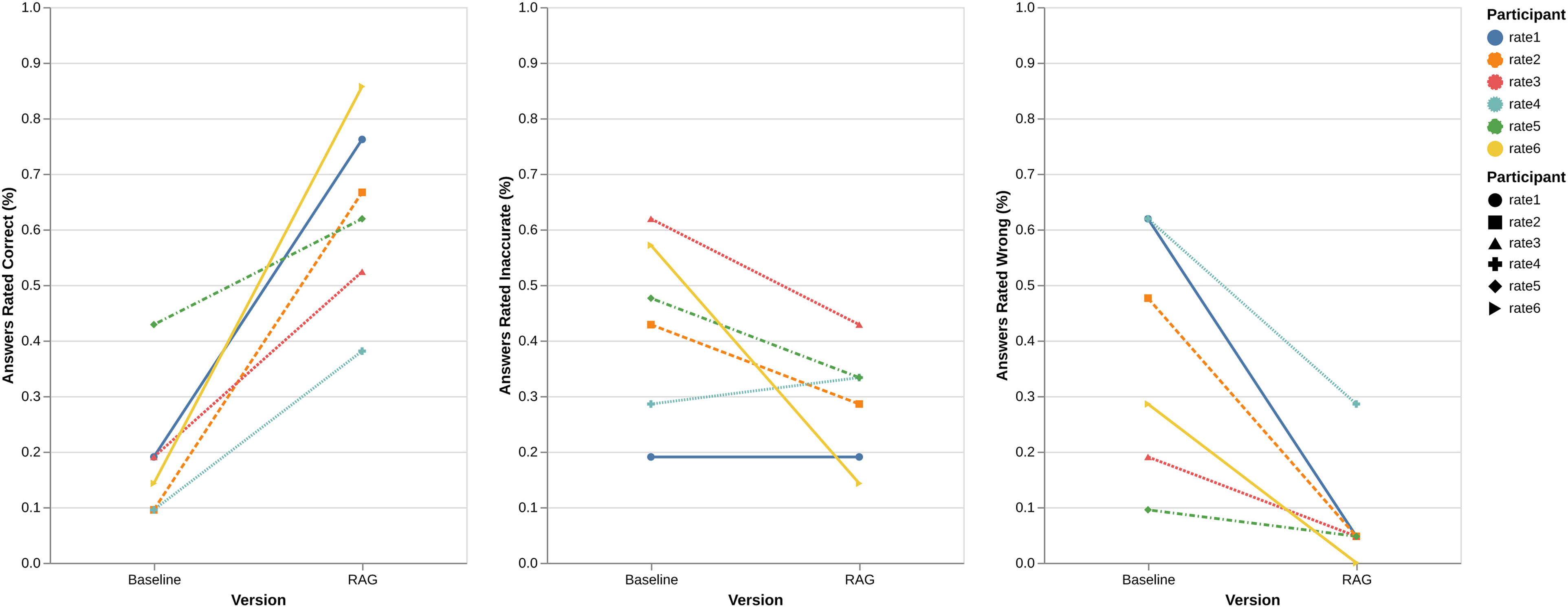
Comparison of ratings across 6 expert raters between the baseline and retrieval-augmented generation responses.
Of the 10 RAG-generated responses rated as wrong, 6 appeared to result from inadequate retrieval context—that is, the relevant sections retrieved from the clinical guidelines did not provide sufficient information to support a correct answer. Two of these errors occurred in Vignette 17, which involved managing mania in an adolescent patient, while the remaining errors were distributed across other vignettes. We have added more information on the errors in Supplemental Table S4, so that readers can evaluate their clinical safety implications.
Discussion
This is the first study to evaluate the use of RAG for generating treatment recommendations for bipolar disorder based on the 2018 CANMAT guidelines. RAG combines an LLM with the retrieval of relevant guideline content to support answers that require synthesizing information rather than simple text lookup. Our goal was to design a system that could provide just-in-time answers to clinical questions across all mood states, bipolar disorder subtypes, and comorbidities, reflecting the complexity of real-world decision-making. Our findings indicate that the multi-step RAG system, built on open-weight models, produces answers that align with CANMAT guidelines at a substantially higher rate than the base model without RAG, which achieved only 19.0% correct responses and 38.1% with major errors. In contrast, RAG yielded 63.5% fully guideline-consistent responses and only 7.9% with major errors, demonstrating numerically better performance than a prior study assessing treatment decisions from an augmented GPT-4 Turbo model for bipolar depression alone, 31 though differences in study design limit direct comparison. We believe our study provides an initial demonstration of how RAG can be used with clinical guidelines in psychiatry for scenarios involving multiple considerations, such as age, previous medication responses, special populations, and comorbidities, providing directions for further improvement when seeking to design systems to help in complex clinical scenarios.
Our results provide an example of how RAG can support mental health treatment recommendations. The best performing vignette, Vignette 4, had all responses marked correct, likely because it required straightforward reasoning; the answer was simply the first-line treatment options for agitation without modification. However, one rater's query illustrated how phrasing can vary by asking for treatment for “agitated mania” rather than just agitation. The system interpreted this composite query and returned preferred treatments for both mania and agitation, demonstrating its flexibility in handling nuanced language. Other high-performing vignettes, such as Vignette 8 and Vignette 20, demonstrated the system's ability to generate recommendations based on scenario-specific factors. The former required adapting guideline tables on bipolar I depression treatment after excluding multiple failed medications, while the latter required integrating content from multiple sections discussing maintenance treatment for bipolar II and strategies to reduce cognitive symptoms. One rater judged the RAG system's performance as particularly strong, marking 85.7% of its responses as correct and the remainder as inaccurate, which underscores the potential of this approach, although outcomes may depend on query formulation and interpretation.
Evaluation of the RAG-based chatbot revealed 3 key challenges: variability in retrieval accuracy, limitations in multi-step reasoning, and inconsistencies between expert scoring and the system's design objectives. While most RAG responses were correct, the 7% with major errors seemed to have been related to retrieval issues, particularly in Vignette 17. This case required recommendations specific to the subsection on treating adolescents and youths. Despite the explicit instruction in the prompt for LLM to consider age factors, the retrieval component often failed to interpret numeric ages as indicators of youth, instead relying on explicit keywords such as “youth” or “adolescent.” When these were absent, the model defaulted to adult-specific recommendations. A substantial portion of errors appeared related to LLM weaknesses in multi-step reasoning. For example, in Vignette 9, the RAG chatbot appeared to struggle with balancing information retrieved from chunks on acute bipolar I depression, anxious distress, and comorbid anxiety. This sometimes led to incomplete responses, such as failing to recommend olanzapine–fluoxetine even though it is listed in the comorbid-anxiety subsection, likely because the acute-depression table designates it as a second-line option. In contrast, the baseline model, which was not constrained by specific retrieved chunks, recommended this combination more consistently, contributing to its superior performance on this vignette. Additionally, some responses were rated inaccurate or wrong because experts applied different rating standards or clinical judgment beyond the guideline scope, despite instructions to evaluate solely on consistency with the guideline. For instance, in Vignette 17, identical responses from the baseline model were rated “correct” by one expert and “inaccurate” by another, underscoring variability in scoring. Similarly, a rater judged a RAG response to Vignette 5 (Supplemental Table S1) as inaccurate because it suggested risperidone after paliperidone failure, noting that paliperidone is the active metabolite of risperidone—a clinically reasonable interpretation but not specified in the guidelines. This underscores a misalignment between system design and evaluation criteria: the chatbot was built for document-grounded reasoning, whereas experts often applied a physician standard, contributing to lower-rated accuracy. Future improvements could include integrating external clinical knowledge bases to better emulate clinical reasoning.
Future improvements should focus on 2 key limitations that can sometimes lead to errors in RAG systems: incomplete retrieval of relevant guideline sections and challenges with multi-step reasoning. Advanced RAG techniques and newer models could help address these issues. Our current search approach retrieves information in a single step, which makes it difficult to answer questions that require combining details from different sections of the guidelines. 45 Approaches such as PlanRAG 46 and self-correction 47 mechanisms, along with retrieval-enhanced embedding models, warrant exploration. To improve reasoning, 2 directions appear promising.
First, testing newer LLMs, including open-weight models such as gpt-oss 48 and state-of-the-art commercial systems like OpenEvidence, 49 GPT, 50 given its widespread adoption and direct relevance to the prior study. 31 This approach, combined with a structured clinical reasoning framework for prompt design, could enhance performance. Second, hybrid architectures that integrate rule-based components with LLMs may offer greater reliability. This strategy aligns with existing tools such as the C-IMPACT web application, 14 which provides rule-based recommendations for the CANMAT bipolar guidelines. Although C-IMPACT does not currently cover all scenarios tested in this study, it could be expanded. However, the upcoming update to the CANMAT bipolar guidelines would require ongoing rule development, highlighting the adaptability advantage of systems that minimize manual rule creation.
Further evaluation will be needed to test iterative improvement. Our methodology highlighted challenges related to rater availability and variability. Most raters required more than 2 hours to complete 21 ratings, making it impractical to compare different system outcomes and continuous optimization. It also reflects a structural trade-off: standardizing questions across raters would improve comparability but reduce ecological validity, while cross-rating design for inter-rater reliability would further strain rater availability. Future studies should explore ways to provide robust evaluations while reducing the time burden on guideline experts, who are often clinician-scientists with limited availability. One option is to develop marking rubrics for vignettes, allowing less experienced raters, such as psychiatry residents, to complete evaluations with an expert available to resolve disagreements. Rubrics could also support automated evaluation, although human oversight would likely still be necessary. To avoid overfitting, rubrics should accommodate variability in queries and could be created after external clinicians generate the queries rather than the chatbot development team.
Beyond the limitations noted above, other limitations should be considered. Examining the impact of gender, stage of training, and other equity considerations on responses was beyond the scope of our study, but will be an important future direction. Future work should also examine how applying the current approach to guidelines of varying quality, precision, and structure might affect accuracy. While we believe our study was based on scenarios with more complexity than many others in RAG studies so far, they still represent simplifications compared to real-world patients, and our evaluation solely evaluated single-turn question answering, deferring the evaluation of real-world, dynamic multi-turn conversations to future work. Future studies could evaluate multi-turn interactions using simulated clinical dialogues in which information is disclosed incrementally, reflecting the iterative nature of real psychiatric consultations. Additionally, our system was only designed to achieve guideline concordance, not clinical optimality; future iterations could be improved to approach clinical optimality by integrating post-2018 evidence, off-guideline clinical nuances, and updated pharmacological data.
Despite these limitations, our study provides a foundation for further use of RAG chatbots to support decision-making in mental health, while highlighting multiple directions for improvement. Although our results showed that responses still contained minor and occasional major deviations from the guidelines, future work could examine how a chatbot with this level of performance functions in more naturalistic settings, such as with clinicians at varying career stages or trainees who lack guideline expertise. A prior study in bipolar depression found that community-based clinicians selected optimal medication choices for only 23.1% of vignettes, whereas a simple prompt-augmented chatbot using GPT-4 Turbo achieved 50.8%. 31 This preliminary evidence suggests that even imperfect systems may meaningfully improve care, though direct comparison with human clinicians remains an important empirical question warranting further study. In the future, explainable AI 51 could enhance such tools by highlighting relevant guideline text and reasoning, enabling error checking and supporting clinician education. Ultimately, we believe this work advances efforts to integrate AI into clinical workflows, supporting evidence-based care for individuals with bipolar disorder and other conditions.
Supplemental Material
sj-docx-1-cpa-10.1177_07067437261457232 - Supplemental material for A Chatbot for the Management of Bipolar Disorder: Using Retrieval-Augmented Generation With an Open-Weight Large Language Model to Answer Clinical Questions Based on the CANMAT and ISBD 2018 Guidelines for Bipolar Disorder: Un dialogueur pour la prise en charge du trouble bipolaire : utiliser la génération augmentée par récupération avec un grand modèle de langage (GML) à poids ouverts pour répondre aux questions cliniques fondées sur les lignes directrices de 2018 de CANMAT et de l'ISBD relatives au trouble bipolaire
Supplemental material, sj-docx-1-cpa-10.1177_07067437261457232 for A Chatbot for the Management of Bipolar Disorder: Using Retrieval-Augmented Generation With an Open-Weight Large Language Model to Answer Clinical Questions Based on the CANMAT and ISBD 2018 Guidelines for Bipolar Disorder: Un dialogueur pour la prise en charge du trouble bipolaire : utiliser la génération augmentée par récupération avec un grand modèle de langage (GML) à poids ouverts pour répondre aux questions cliniques fondées sur les lignes directrices de 2018 de CANMAT et de l'ISBD relatives au trouble bipolaire by Yash Mali, Zejiao Zeng, Kayoung Heo, Grace Zhang, Antarip Kashyap, Jincheng Chen, Kamyar Keramatian, Gayatri Saraf, Marco Solmi, Edwin Tam, Sagar V. Parikh, Ayal Schaffer, Serge Beaulieu, Raymond Ng, Lakshmi N. Yatham and John-Jose Nunez in The Canadian Journal of Psychiatry
Footnotes
Acknowledgments
Technical guidance, project coordination, and computing resources were provided by the University of British Columbia Cloud Innovation Centre.
ORCID iDs
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the AWS.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Marco Solmi has received honoraria/has been a consultant for AbbVie, Angelini, Bausch Health, Boehringer Ingelheim, Pharmascience, Lundbeck, Otsuka, Teva. Marco Solmi holds shares of MESAS, S2M. Serge Beaulieu reports research grants, personal fees, and/or nonfinancial support from Abbvie, Boehringer-Ingelheim, CIHR, DiaMentis, Idorsia, Eisai, Janssen, and Otsuka-Lundbeck. Sagar V. Parikh is the Medical Director for the National Network of Depression Centers and reports research grants paid to his institution from Aifred, Compass Pathways, and Janssen; and consulting fees from Boehringer Ingelheim and Otsuka. Ayal Schaffer reports consulting fees and honoraria from AbbVie and Otsuka. Lakshmi N. Yatham reports research grants and/or personal fees from Abbvie, Alkermes, Allergan, Dainippon Sumitomo, Gedeon Richter, GSK, Intracellular Therapies, Merck, Sanofi, and Sunovion. All other authors have no conflicts of interest to declare.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.