
Abstract
This study aims to develop machine learning (ML)-based homogenization models to efficiently predict the effective elastoplastic properties of short fiber-reinforced composites (SFRCs), reducing the reliance on computationally expensive micromechanical simulations. Sobol sampling is employed to generate training data by varying constitutive and microstructural parameters of representative volume element. Several ML models including artificial neural networks (ANN), support vector regression (SVR), random forest (RF), and extreme gradient boosting (XGB) are trained to predict homogenized stress-strain responses. A new approach is introduced that decomposes the stress-strain response into elastic and plastic components, allowing the ML models to learn these components separately and effectively. Additionally, the Taguchi method (L27 orthogonal array) is employed to minimize simulation runs and evaluate parameter sensitivity through ANOVA. The best-performing ML model is implemented in a finite element analysis (FEA) of an automotive component. Among all models, ANN demonstrated the highest accuracy in predicting the macroscopic elastoplastic response across a wide range of input parameters. Finally, the ANN-based elastoplastic material model is validated on a real-world macroscopic structure by implementing it into the finite element analysis of an automotive component. The results demonstrate that ML-based homogenization closely matches the traditional homogenization methods and also highlights its ability to effectively capture nonlinear material behavior.
Keywords
Introduction
In recent years, research on the prediction and modeling of the mechanical properties of composite materials has significantly increased. Due to their lightweight structure and high strength, composite materials are widely used in the automotive, aerospace, and industrial manufacturing sectors. However, the inherent anisotropy and nonlinear mechanical behavior arising from the interaction between fibers and the matrix pose significant challenges for accurately predicting their response under various loading conditions.1–3 Therefore, computational homogenization techniques have been developed to estimate the homogenized response of composites. Homogenized response refers to the effective macroscopic behavior obtained by averaging the heterogeneous microstructural properties of the constituents (e.g., matrix and fibers). This response captures how the composite behaves as a uniform material under external loading, based on detailed micro-level interactions. Voyiadjis and Deliktas 4 introduced a multilevel homogenization technique to obtain the effective properties of the heterogeneous crystalline structures. Representative Volume Element (RVE) analysis plays a crucial role in modeling the microstructural properties and their effects on the overall elastoplastic behavior of short fiber-reinforced composites (SFRC).5,6 The RVE is defined as being large enough to statistically represent microstructural heterogeneity while remaining significantly smaller than the overall structure. 7 These computational homogenization techniques facilitate the prediction of material performance without the need for costly and time-consuming experimental procedures.
The Mori–Tanaka method is a widely used homogenization technique for modeling the elastic and plastic properties of SFRCs.8,9 This method accounts for fiber-matrix interactions, allowing for the prediction of the effective elastic and plastic properties of the material. Furthermore, the J2 plasticity model is commonly employed to capture the nonlinear behavior of elastoplastic short fiber-reinforced composites.10–13 Additionally, various direct numerical simulation methods have been developed for computational homogenization. These include the full-field method, the mean-field method, and the Fast Fourier Transform (FFT) method. While finite element (FE)-based RVE analysis ensures high accuracy, it has disadvantages such as complex meshing requirements and high computational costs for intricate microstructures.14,15 Alternatively, mean-field models enable faster computations by considering the average strain and stress in each microstructural phase.16,17 On the other hand, the FFT method enhances computational efficiency by performing RVE analysis without requiring a stiffness matrix.18,19 Digimat MF analysis is one of the most popular and effective tools for predicting material behavior by simulating fiber orientation, distribution, and fiber-matrix interactions. The flexible framework of Digimat MF provides a versatile approach to analyzing the impact of microstructural properties on macroscopic material responses. 20 This software plays a key role in computational homogenization, particularly for predicting the mechanical behavior of SFRC. However, the high computational cost of RVE-based simulations presents a significant challenge, especially when dealing with complex material systems and large datasets. To address this issue, machine learning (ML) has emerged in recent years as a complementary approach. ML algorithms, trained on data obtained from detailed RVE analyses, have been proposed to enable rapid predictions of effective material properties and mechanical responses. These approaches are often highlighted for their ability to reduce computational time. 21
The emergence of data-driven approaches such as ML has opened new opportunities for developing reliable predictive material models. Unlike traditional methods that rely on empirical material modeling, this approach derives computational models directly from experimental data, bypassing the need for intermediate assumptions. With the growing availability of extensive datasets that characterize material behavior, there is a rising trend in leveraging data from analytical models, numerical simulations experiments, or hybrid sources. The capability to extract meaningful insights directly from data has attracted significant interest among engineers and researchers across diverse disciplines such as geotechnical engineering, 22 micro/nanostructual systems, 23 structural engineering, 24 and constitutive modeling. 25 This has particularly become possible due to advancements in computational hardware technologies. Recently, Mentges et al. 26 combined finite element analysis and orientation averaging to generate the training data. This data was used to train the micromechanics-based ANN for estimating the elastic properties of short fiber composites. The results demonstrated that a well-trained ML model can rapidly predict the elastic properties of the material with high accuracy. Tariq et al. 27 implemented various boosting ML algorithms to investigate the linear elastic properties of continuous fiber reinforced composite. They determined that XGB can effectively and accurately predict the homogenized behavior of composites with coefficient of determination (R2) values of up to 0.999. Recently, Chen et al. 28 trained an ANN model to predict the hyperelastic behavior of short fiber-reinforced rubber composites. Their results showed that the model’s predictions closely matched those of FE simulations while drastically reducing computational expenses. Xu et al. 29 combined backpropagation neural networks with micromechanical models to investigate the elastic properties of multilayer braided composites. By training the neural network on data from microscale micromechanical simulations, they achieved highly accurate predictions of the composite properties. Similarly, Ghane et al. 30 developed a multiscale ML framework to estimate the elastic behavior of woven composites. They utilized high-fidelity FE simulation data from a meso-scale model of a plain-weave fabric composite to train an ANN model. The ANN model provided a good balance between accuracy and efficiency in predicting microscale and mesoscopic parameters. El Said 31 used convolutional layers with Long Short-Term Memory (LSTM) layers to predict the stress response of laminated composites. By training the model on data from the RVE models database, he achieved accurate predictions of the nonlinear behavior of laminated composites. Le et al. 32 developed a computational homogenization approach that employs neural networks to model nonlinear elastic heterogeneous materials. Their technique demonstrated greater efficiency compared to the traditional nested multilevel FE2 method. Xue et al. 33 investigated the macroscopic elastic properties of composites materials with an ANN model trained on numerical results from fast Fourier transform method. They determined that ANN model can predict the elastic properties with high accuracy and improve the performance of existing homogenization models. Lourenço et al. 34 applied a range of physics-based constraints to a recurrent neural network model for learning elastoplastic behavior. Their study demonstrated that incorporating such constraints significantly enhances training efficiency, extrapolation capability, and predictive accuracy. Similar data-driven methodologies employing ML techniques to explore material behavior have been extensively studied, as evidenced by the research of Maharana et al., 35 Zhao et al., 36 Tariq et al., 37 Santos et al., 38 Mouloodi et al., 39 Tariq et al., 40 and Mahakur et al. 41
This comprehensive literature review highlights extensive research on utilizing ML techniques to predict material behavior. The researchers agree that ML models offer significant computational advantages over traditional numerical methods like finite element analysis or homogenization techniques. While ANNs have been widely employed to predict the homogenized elastic properties of composite microstructures, their application to capturing the nonlinear elastoplastic behavior of composites, particularly SFRC, remains limited. Furthermore, the adoption of advanced ML techniques such as ensemble learning methods, has been relatively limited in this domain, with most studies focusing on elastic properties rather than the more complex nonlinear plastic responses. This research identifies a critical gap in the systematic evaluation and comparison of advanced ML algorithms for predicting the homogenized nonlinear elastoplastic behavior of SFRC, which is essential for understanding the mechanical performance in composite materials under realistic loading conditions.
Therefore, the present study aims to evaluate the effectiveness of various advanced ML techniques in predicting the elastoplastic behavior of SFRC materials through homogenization, while significantly reducing computational complexity compared to conventional methods. The predictive accuracy of these ML models is validated by performing finite element analysis on a real-world automotive component, in which the predicted material model is compared against conventional numerical methods. The ML approaches considered in this work include ensemble learning-based models such as Random Forest (RF) and Extreme Gradient Boosting (XGBoost), alongside Artificial Neural Networks (ANNs) and Support Vector Regression (SVR). These models are trained on a dataset generated using Sobol sampling methods that systematically vary nine key micromechanical parameters for capturing the homogenized material response of SFRCs. The predictive performance of each trained ML model is assessed using statistical metrics such as R2, Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Square Error (RMSE), along with visualization tools like scatter plots and bar charts. Furthermore, a combination of Taguchi analysis 42 and ANOVA 43 is applied to quantify the influence of individual microstructural parameters on the homogenized material response. The predicted data from the most accurate ML model is then incorporated into finite element anlysis to simulate the behavior of a macroscopic automotive component, demonstrating its practical applicability and reliability in real-world engineering scenarios.
Mori–Tanaka method for short fiber-reinforced composites with an elastoplastic matrix
Modeling and simulating the behavior of short fiber-reinforced composites (SFRCs) with elastoplastic matrices requires the considering of both the matrix plasticity and fiber orientation. Homogenization methods are employed to predict the macroscopic mechanical response of composite materials. Homogenization involves analyzing the microstructural properties of a heterogeneous material to determine its homogenized macroscopic behavior.44,45
The Mori–Tanaka method is a well-established and extensively validated in the literature and has long been recognized as one of the most reliable micromechanical models for predicting composite properties. Many studies reports that Mori–Tanaka predictions closely match experimental measurements for a variety of composites. For example, Katouzian and Vlase 46 applied the Mori–Tanaka model to a carbon-fiber/epoxy laminate and noted that the “results obtained experimentally and their comparison with the theoretically obtained values show a good agreement.” Similarly, Stránský et al. 47 used Mori–Tanaka to predict the thermal conductivity of composite and stated that the model’s results were “corroborated by available experimental data.” More recently, Yan et al. 48 derived elastic-modulus predictions for concrete with recycled aggregate. Their Mori–Tanaka-based model produced values “in good agreement with the experimental results” and was notably closer to measurements. These examples, among many others, demonstrate that Mori–Tanaka homogenization reliably captures the true behavior of composites and align very well with laboratory measurements.
In this context, the Digimat MF software provides a powerful tool for homogenizing short fiber reinforced elastoplastic composites. 49 By considering microstructural parameters such as fiber orientation, distribution, and mechanical properties, Digimat MF can simulate the macroscopic elastoplastic behavior of the material. The software utilizes advanced homogenization methods, such as Mori–Tanaka and Eshelby, to accurately model the effects of fiber-matrix interactions and plastic deformation processes.50,51 Additionally, the models used to characterize elastoplastic behavior contribute to predicting the material’s response under various loading conditions. 52 This study focuses on the homogenization processes conducted using Digimat MF to ensure an accurate simulation of the mechanical properties of short fiber reinforced elastoplastic matrix composites.
As shown in Figure 1, the aim of homogenization is to calculate the instantaneous effective stiffness tensor (C
eff
) at the macro level based on the mechanical properties of the microstructural components: It can be mathematically represented as Homogenization process of short fiber-reinforced composites.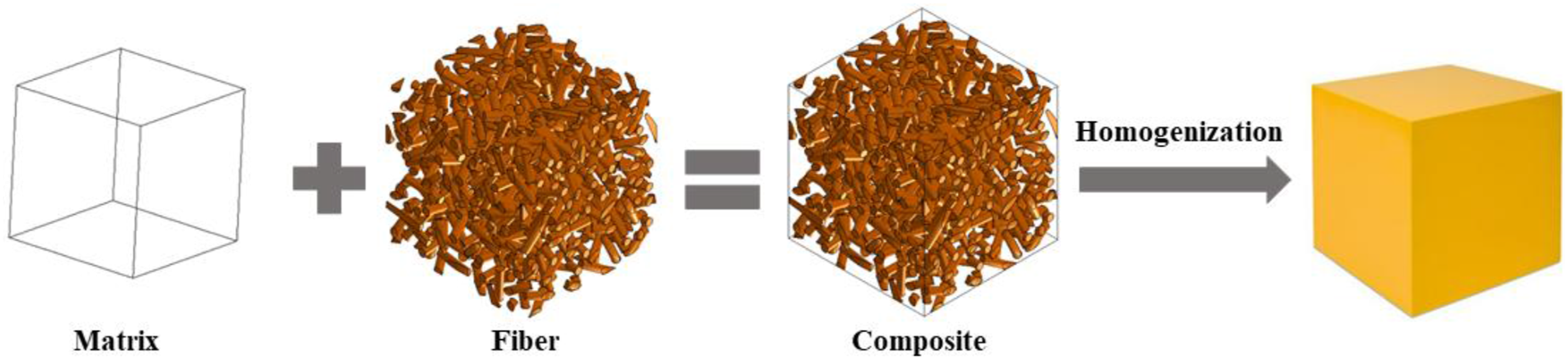

In this case, C
eff
stands for the effective elastic stiffness tensor that needs to be ascertained,
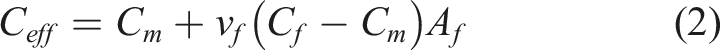
Here, v
f
is the fiber volume fraction, C
m
is the matrix’s stiffness tensor, and C
f
is the fiber’s stiffness tensor. The instantaneous stress concentration factor is defined as
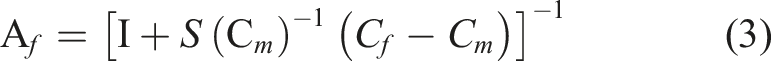
In this case, S stands for the Eshelby tensor and I for the identity tensor. The shape, aspect ratios, and orientation of the fibers employed in composite materials all affect the Eshelby tensor:
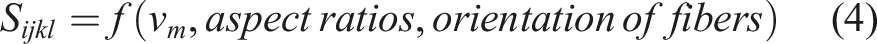
The Eshelby tensor for a general anisotropic material is calculated by the surface integral as shown in equation (5):
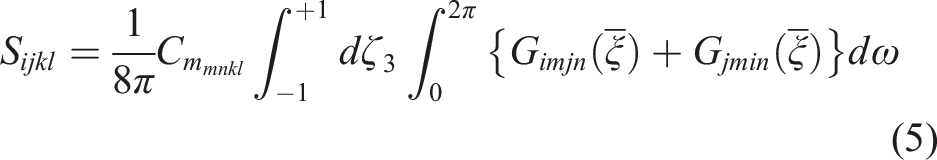
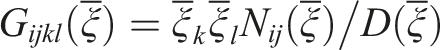
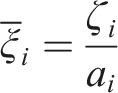
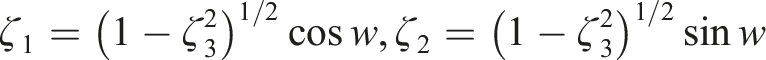
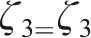
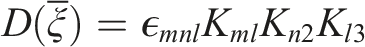
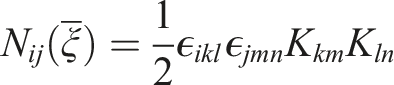

The permutation tensor is represented by
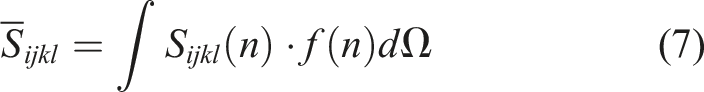
The Eshelby tensor for a certain fiber orientation is denoted by S
ijkl
(n). The probability density of fibers being orientated in direction n is described by the orientation distribution function (ODF), f(n). The differential solid angle across the unit sphere is denoted by dΩ. Another way to express the orientation-averaged Eshelby tensor is with the orientation distribution tensor:
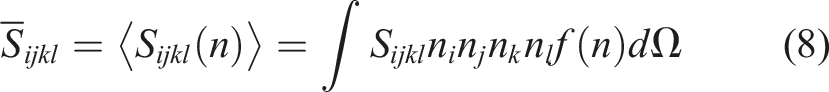
The tensor of orientation distribution, Θ, can be expressed as
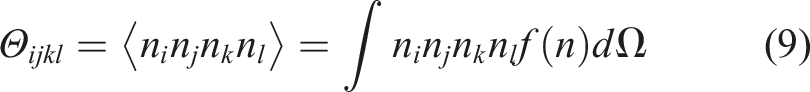
The unit vector n in this case indicates the fiber’s tiny direction. Software tools like Digimat evaluate this integration effectively using numerical methods and symmetry conditions. Advani and Tucker proposed an approach that uses the orientation distribution tensor O (or, more generically, a
ij
and a
ijkl
) to model the fiber orientation. The average of the fiber orientation for randomly oriented fibers is represented by the second-order orientation tensor, a
ij
, in this instance, and a
ij
= O. According to the Mori–Tanaka technique, the distribution of fiber orientation has a direct impact on the stiffness matrix’s constituent parts, which in turn effects the B coefficients that are employed in the Advani–Tucker formulation. Therefore, O is included in the stiffness tensor (C
ijkl
) calculation for randomly oriented fibers.
54
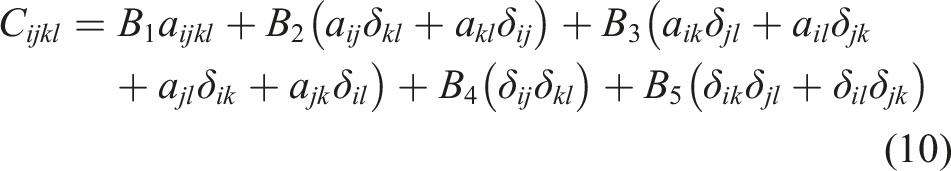
The fourth-order and second-order fiber orientation tensor components are denoted by the letters
In order to simulate short fiber-reinforced composites in a straightforward but accurate way, it is assumed that the matrix phase behaves elastoplastically and the fiber phase stays elastic throughout. According to this assumption, the stress state and internal state variables (such as damage, kinematic hardening, or isotropic hardening) determine the averaged concentration factors of the matrix phase. Different plasticity models have been proposed in the literature to describe plastic deformation in composite materials. Among these, the von Mises J2 plasticity model, which is based on the second invariant of the deviatoric stress tensor and assumes yield occurs when the distortion energy reaches a critical value, has been widely used to model the behavior of short fiber-reinforced polymers.56–58 This model can reasonably approximate the macroscopic yield behavior and strain hardening response of polymers using isotropic or kinematic hardening rules. While alternative constitutive models, such as those based on shear transformation zones for post-yield behavior in polymers59,60 or viscoplastic models for capturing brittle-to-ductile transitions in polycrystalline materials,
61
could be considered in other contexts, they primarily account for large deformations and time-dependent effects. Since this study does not involve such effects, the J2 plasticity model with nonlinear isotropic hardening was chosen to characterize the matrix behavior, ensuring a balance between accuracy and computational efficiency. Therefore, the J2 plasticity model with nonlinear isotropic hardening is adopted, and the incremental elastoplastic behavior of the matrix phase is defined by the following equation (11):
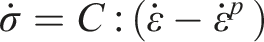
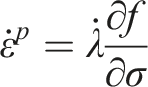
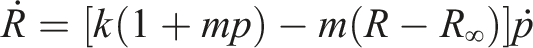
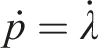
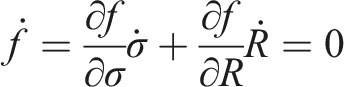
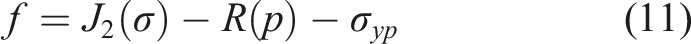
The formula is
Design of computational RVE experiments
Selection of input features
The behavior of glass fiber reinforced polypropylene (PPGF) composite under loading conditions is dependent on various material and structural properties that define an RVE model. Amongs these properties, elasticity modulus (E
m
) and Poisson’s ratio (
Training range of input parameters defined with their respective upper and lower limits.

Features sampling technique for input parameters
The quantity and quality of sample data are crucial for reliable conclusions drawn from simulations, machine learning, and experimental design. A regular grid of sample points can lead to overlap in high-dimensional spaces. To avoid this, a well-balanced and uniform sampling technique is needed. This study uses the Sobol sampling 62 algorithm, a low-discrepancy quasi-random method that ensures uniform coverage of high-dimensional feature spaces. Sobol sampling is effective for sensitivity analysis and optimization, offering better uniformity than random methods while remaining computationally efficient.63,64
The Sobol sampling method was used to generate a well-distributed design of experiments, ensuring comprehensive coverage of the design space. A base-2 quasi-random sequence with an exponent of 11 was employed, resulting in 211 = 2048 sample points. Each sample represents a unique combination of input parameters, that is, Ajustments of the components of orientation tensor.
A discrepancy of 6.15 × 10−5 was calculated to assess how evenly the generated samples are distributed across the parameter space. This low-discrepancy value indicates minimal clustering or gaps, ensuring an efficient exploration of the design space. Additionally, Principal Component Analysis (PCA) is used in this study to reduce the dimensionality of high-dimensional data and visualize its distribution. PCA is an unsupervised technique that transforms correlated variables into a new set of uncorrelated variables through an orthogonal transformation. This allows the data to be represented in a lower-dimensional space while preserving as much variance as possible.
65
Here, PCA reduces the original 9-dimensional dataset to 2 dimensions, making it easier to assess the spread and uniformity of the Sobol-sampled data. This step ensures that the dataset is well-distributed before training ML models. A scatterplot of the dataset after PCA transformation is illustrated in Figure 3. The first principal component represents the most variance, while the second represents the next highest variance. The even spread of points in the plot indicates that the dataset is well-sampled across the entire feature ranges. Dimensionality reduction of input features using PCA.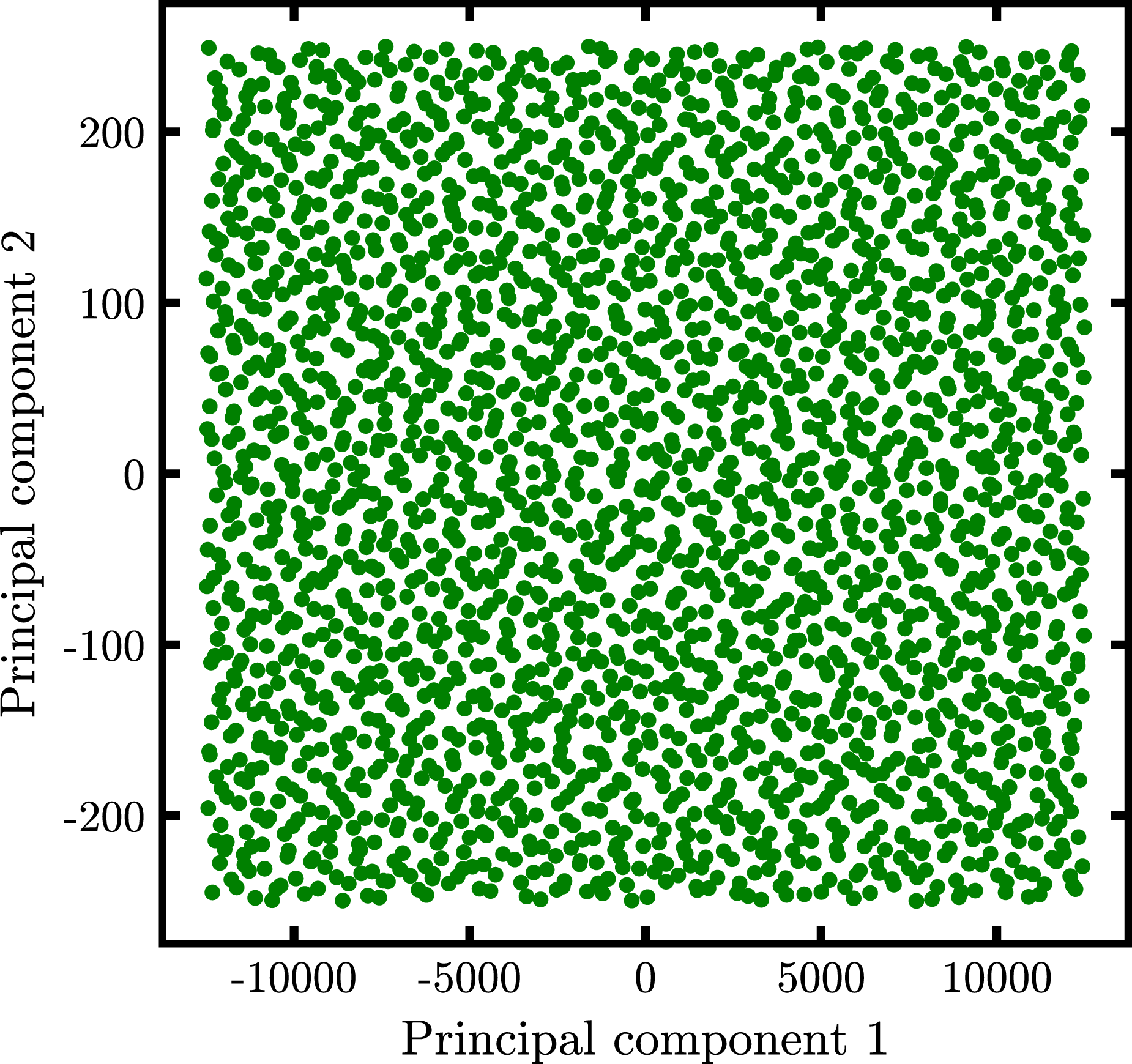
Generation of target data and preprocessing
The effective elastoplastic stress-strain curve of each PPGF RVE sample is determined using Mori–Tanaka homogenization theory implemented in DIGIMAT software. The material expert (MX) module available in DIGIMAT contains variety of materials calibrated with J2 plasticity models. The database of these materials are usually uploaded by different reliable industries. Nonetheless, each RVE analysis accounted for both microstructural characteristics and material properties of the fiber and matrix in all DOE samples. A 3% loading strain was applied to each RVE to evaluate its mechanical response under deformation. To efficiently handle multiple simulations, a Python script was written to automate the workflow. This script facilitated key tasks, including extracting input parameters from the DOE, generating RVEs, performing homogenization analyses, and storing the computed stress-strain curves as effective material response. Automating this process significantly reduced manual effort, improved consistency, and ensured a systematic evaluation of the homogenized mechanical behavior across different samples.
The homogenized stress-strain curve derived from the RVE analysis for a specific material sample incorporates plasticity in it. Therefore, to enhance the training of ML models, each stress-strain curve is decomposed into two distinct components, that is, the linear elastic region and the nonlinear plastic region. The linear elastic portion is characterized by a single scalar value of elasticity modulus (E
H
), which represents the homogenized material’s stiffness. Beyond the elastic limit, the nonlinear plastic region is more complex and requires a detailed representation. To achieve this, the plastic part of the stress-strain curve is interpolated at 11 evenly spaced points between 0% and 3% plastic strain, using an interval of 0.03%, as illustrated in Figure 4. This approach ensures that the ML model is trained to predict both the elasticity modulus and the stress values at these 11 interpolation points, effectively capturing the material’s transition from elasticity to plasticity. By decomposing the response in this way, the ML model gains a clearer understanding of both stiffness and nonlinear behavior, leading to improved accuracy and generalization when predicting the homogenized mechanical properties of new samples. Decomposition of nonlinear stress-strain curve and comparison of interpolated points with the simulated curve.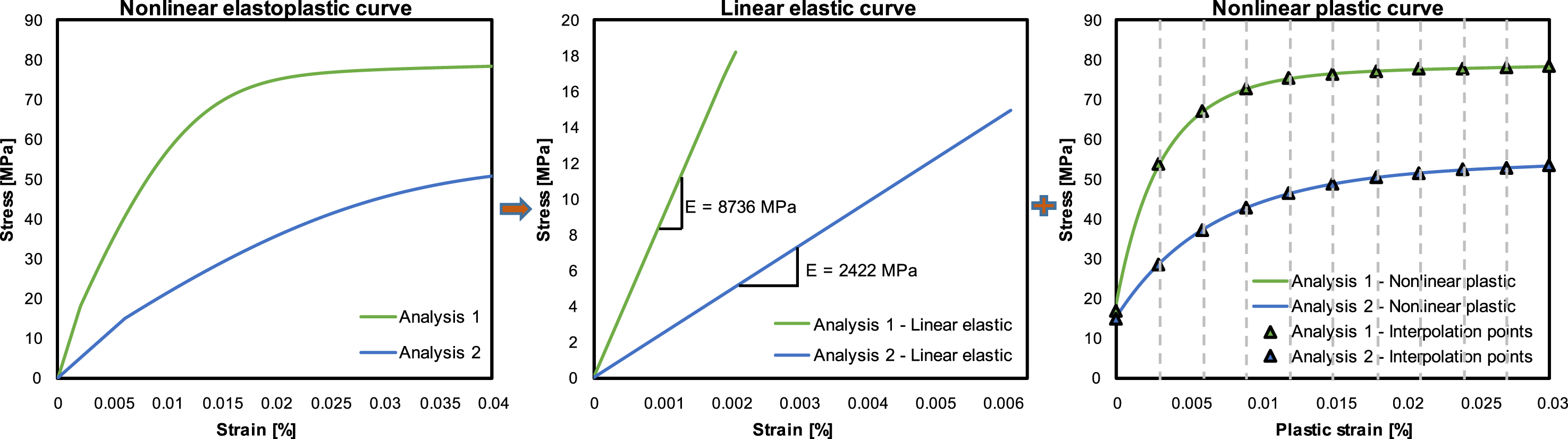
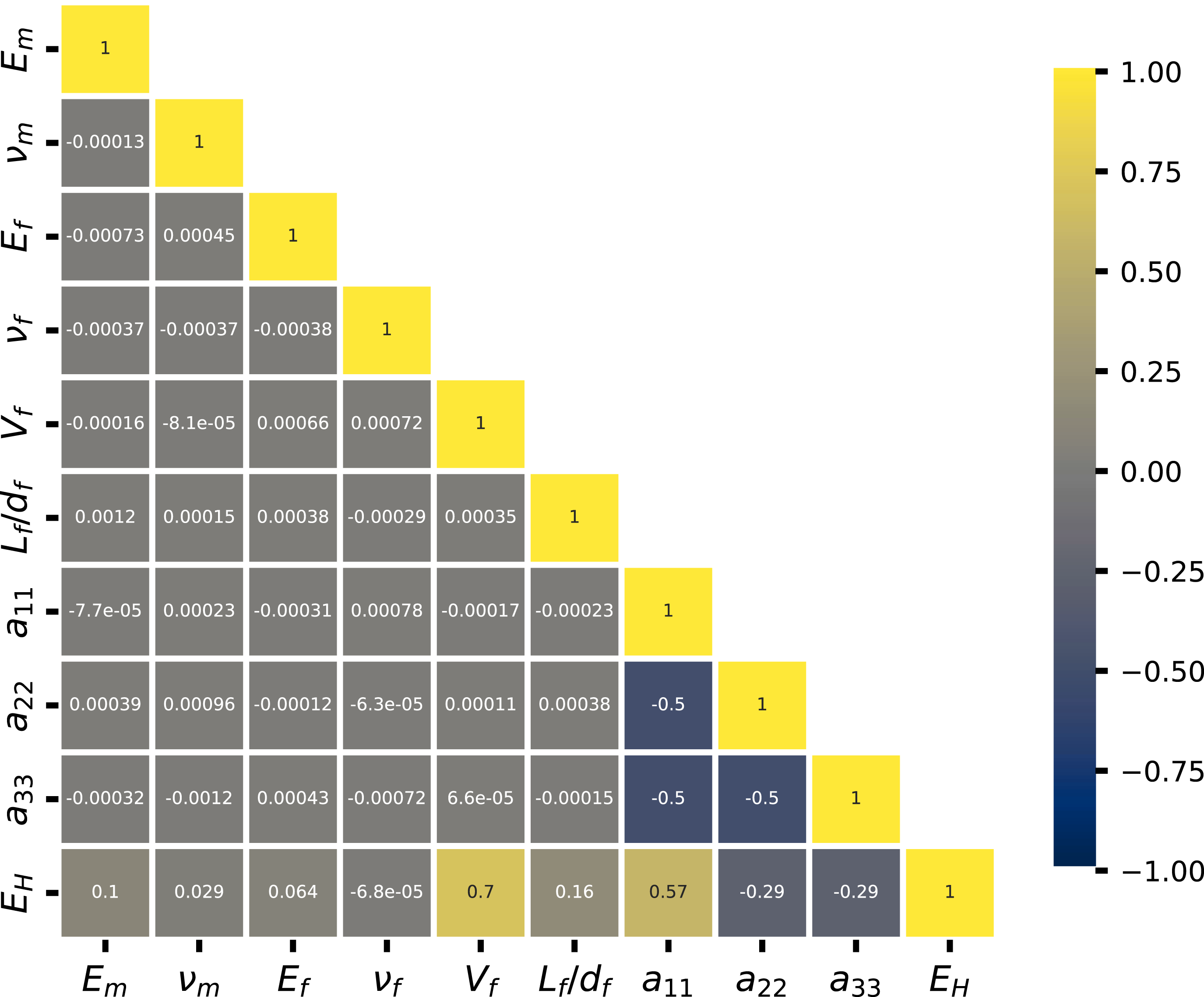
In this study, the Pearson correlation coefficient (PCC) was used to measure the linear relationship between input parameters and the homogenized elasticity modulus (E
H
). PCC values range from −1 to 1, where a value above 0.5 indicates a significant positive correlation, meaning both variables increase together. A value below −0.5 represents a strong negative correlation, where one variable increases as the other decreases. A PCC of 0 means no linear correlation, while values between −0.5 and 0.5 suggest a weaker or less noticeable relationship. The PCC is mathematically expressed as follows: Heatmap for the PCC between input parameters and homogenized elasticity modulus.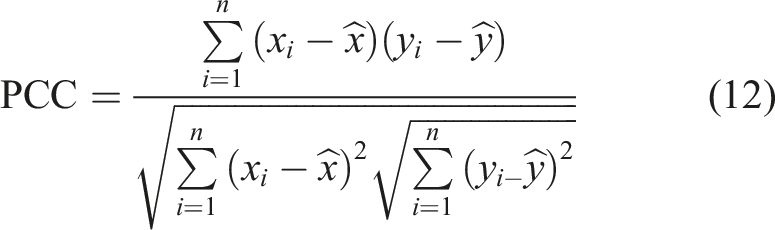
In machine learning, several data normalization or scaling methods are commonly used to improve model performance and training stability. These include min-max scaling, which transforms values to a range between 0 and 1, and standardization, which re-centers data around the mean with unit variance. Other techniques involve scaling data to lie within −1 and 1 or normalizing each sample’s feature values so they sum to 1. These methods help address issues like varying feature magnitudes and skewed distributions, ultimately ensuring more effective training and generalization. In this work, the dataset was scaled in a range of 0 to 1 using the min-max scaling formulation represented as,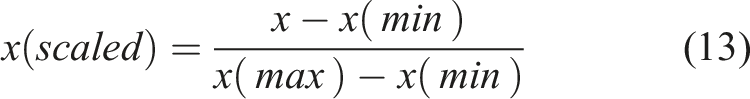
Here, x is the actual value, and x (max) and x (min) are the maximum and minimum values of a feature, respectively. After applying normalization, the dataset was split into training and testing sets to ensure effective model learning and evaluation. Approximately 80% of the data that consists of 1638 samples, was allocated for training, while the remaining 20%, comprising 409 samples, was set aside for testing. Model performance is assessed on the previously unseen data (i.e., testing set) to ensure that the predictions are not biased by the training data. In addition, model generalization and overfitting are monitored using evaluation metrics such as R2, MAE, MAPE, and RMSE on both the train and the test set.
Theoretical background of various ML models
In this study, four ML models are evaluated to determine the most effective algorithm for predicting the homogenized elastoplastic stress-strain response of PPGF composite materials. The selected models include Random Forest (RF), Extreme Gradient Boosting (XGB), Artificial Neural Network (ANN), and Support Vector Regression (SVR). A brief overview of each model is provided in the following sections.
Random forest (RF)
RF is an ensemble learning method that combines multiple decision trees to create a more robust predictive model. Instead of relying on a single decision tree, RF builds many trees using different random subsets of the dataset, then averages their predictions. This approach, known as bootstrap aggregating or bagging, helps reduce overfitting and makes the model more resilient to noise and outliers. The RF prediction can be expressed as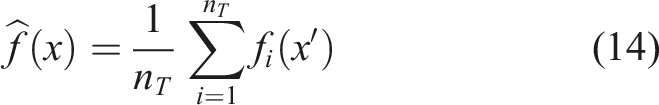
Extreme gradient boosting (XGB)
XGB is an advanced version of the traditional Gradient Boosting algorithm, designed for high efficiency, scalability, and predictive accuracy. It constructs an ensemble of decision trees by optimizing a loss function using gradient descent while incorporating both L1 (Lasso) and L2 (Ridge) regularization to enhance generalization and prevent overfitting. The algorithm iteratively builds trees, refining predictions by minimizing errors from previous iterations. A key advantage of XGB is its ability to reduce processing time through optimized computations, making it suitable for both regression and classification tasks. The inclusion of a regularization term in the objective function helps control model complexity, reducing the risk of overfitting and improving overall performance. Its objective function is represented as follows: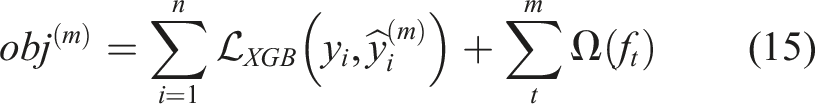
Artificial neural network (ANN)
ANNs are computational models inspired by the structure and functioning of the human brain that are designed to recognize patterns from complex data. ANNs consist of interconnected layers of artificial neurons, including an input layer that receives data, one or more hidden layers that process information, and an output layer that generates predictions. Each neuron processes incoming signals using weighted connections, applies an activation function, and passes the result to the next layer. Through iterative learning, often using backpropagation and optimization techniques like stochastic gradient descent, ANNs adjust their weights to minimize prediction errors. Due to their ability to model nonlinear relationships and extract meaningful patterns from raw data, ANNs are widely used in diverse fields such as image and speech recognition, financial forecasting, medical diagnosis, and engineering applications. ANNs have gained significant popularity with the rise of deep learning architectures, demonstrating state-of-the-art performance in tasks involving large-scale and high-dimensional datasets. 68
Support vector regression (SVR)
SVR is a machine learning technique designed for predicting continuous values in regression tasks. Unlike traditional regression methods that minimize the error between predicted and actual values, SVR aims to find a hyperplane that best fits the data where the margin between the hyperplane and the support vectors (data points closest to the hyperplane) is maximized. It uses kernel functions (e.g., linear, polynomial, or radial basis function) to map input data into higher-dimensional spaces, enabling the modeling of complex nonlinear relationships. The optimization problem in SVR can be formulated as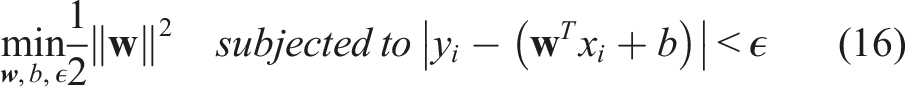
Description of the automobile component and its finite element modeling
The elastoplastic material model predicted through ML-based homogenization is validated on a real-world macroscopic structure by implementing it into the finite element analysis of an automotive component. Specifically, the validation is performed on the cover part of the top mount, which serves as a crucial link between the vehicle’s chassis and suspension strut (Figure 6). The top mount plays a vital role in enhancing ride comfort by absorbing road-induced impacts and dampening vibrations, preventing them from being transmitted to the vehicle. As a key component of the suspension system, it contributes to the overall stability and performance of the automobile. Cover part of the top mount used for validation model in this study.
The structural model of the cover component was imported into Abaqus software with its actual geometry and dimensions. In the finite element modeling process, the part was assigned the homogenized elastoplastic material properties obtained from the ML model. To simulate realistic boundary conditions, the bottom surface was fully constrained in all degrees of freedom (DOF 1, 2, 3). A vertical load of 16 kN was applied to the top face, while lateral movements were restricted in the remaining degrees of freedom (DOF 1, 2), as illustrated in Figure 7. Finite element model of the cover part with boundary and loading conditions.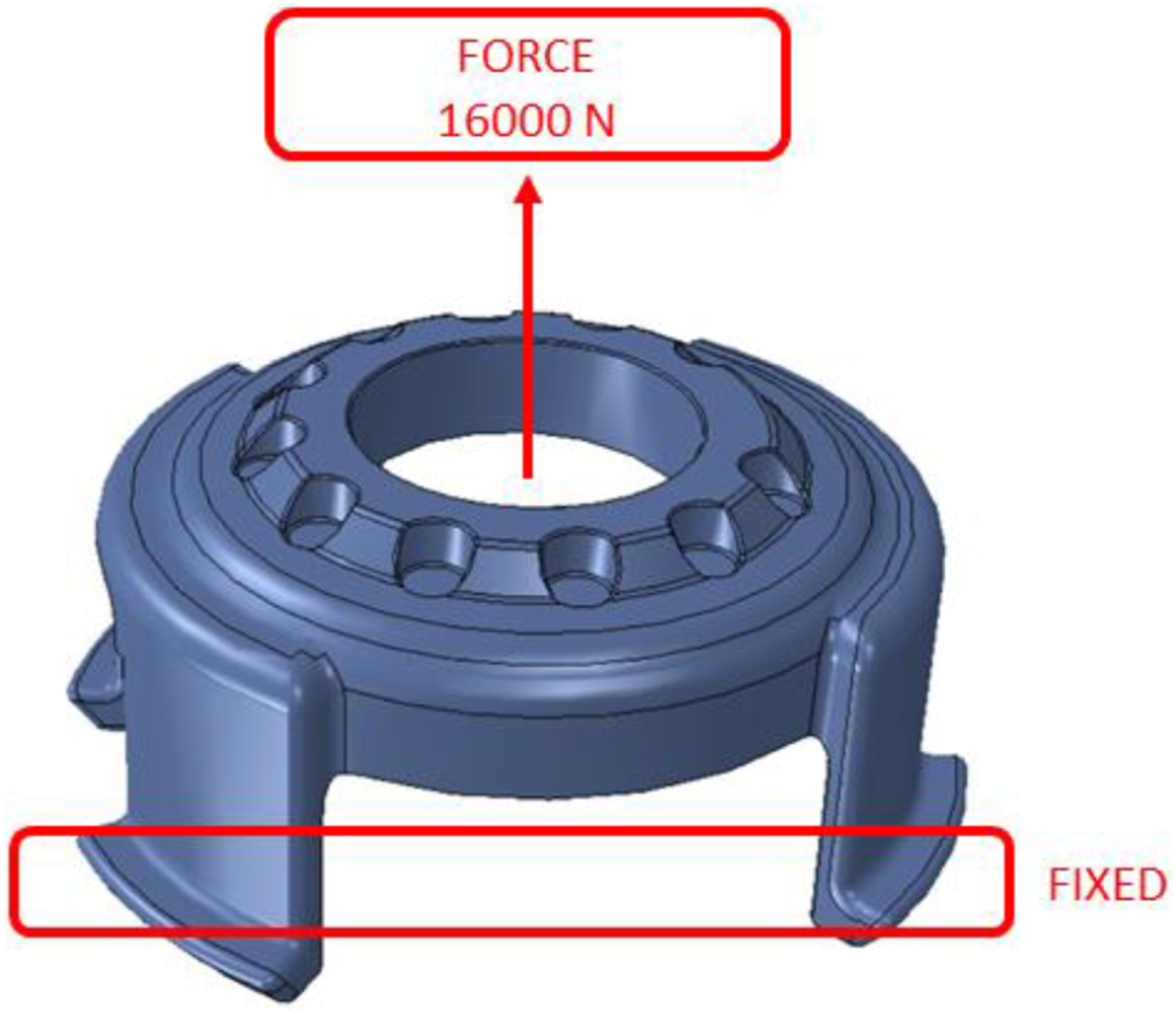
To ensure an optimal balance between computational accuracy and efficiency, a mesh convergence study was carried out using 10-node quadratic tetrahedral elements (C3D10). As illustrated in Figure 8, both the maximum von Mises stress and displacement values exhibit high sensitivity to mesh refinement between 6 mm and 5 mm, with the maximum stress increasing by approximately 18%. This substantial variation highlights the inadequacy of coarser mesh in capturing the mechanical response with sufficient accuracy. Conversely, for mesh sizes finer than 5 mm (i.e., 4 mm, 3 mm, and 2 mm), the relative changes in stress and displacement drop below 1%, indicating convergence of the solution. This behavior is supported by Figure 8(b), which presents the percentage change between successive mesh refinements. Based on a convergence threshold of 1% relative change, a mesh size of 4 mm was selected as the optimal discretization, offering the suitable balance between numerical precision and computational cost. Mesh sensitivity analysis of the automobile component with (a) variation of maximum stress and displacement with different mesh sizes ranging from 7 mm to 2 mm and (b) relative percent change in maximum stress and displacement between successive mesh refinements.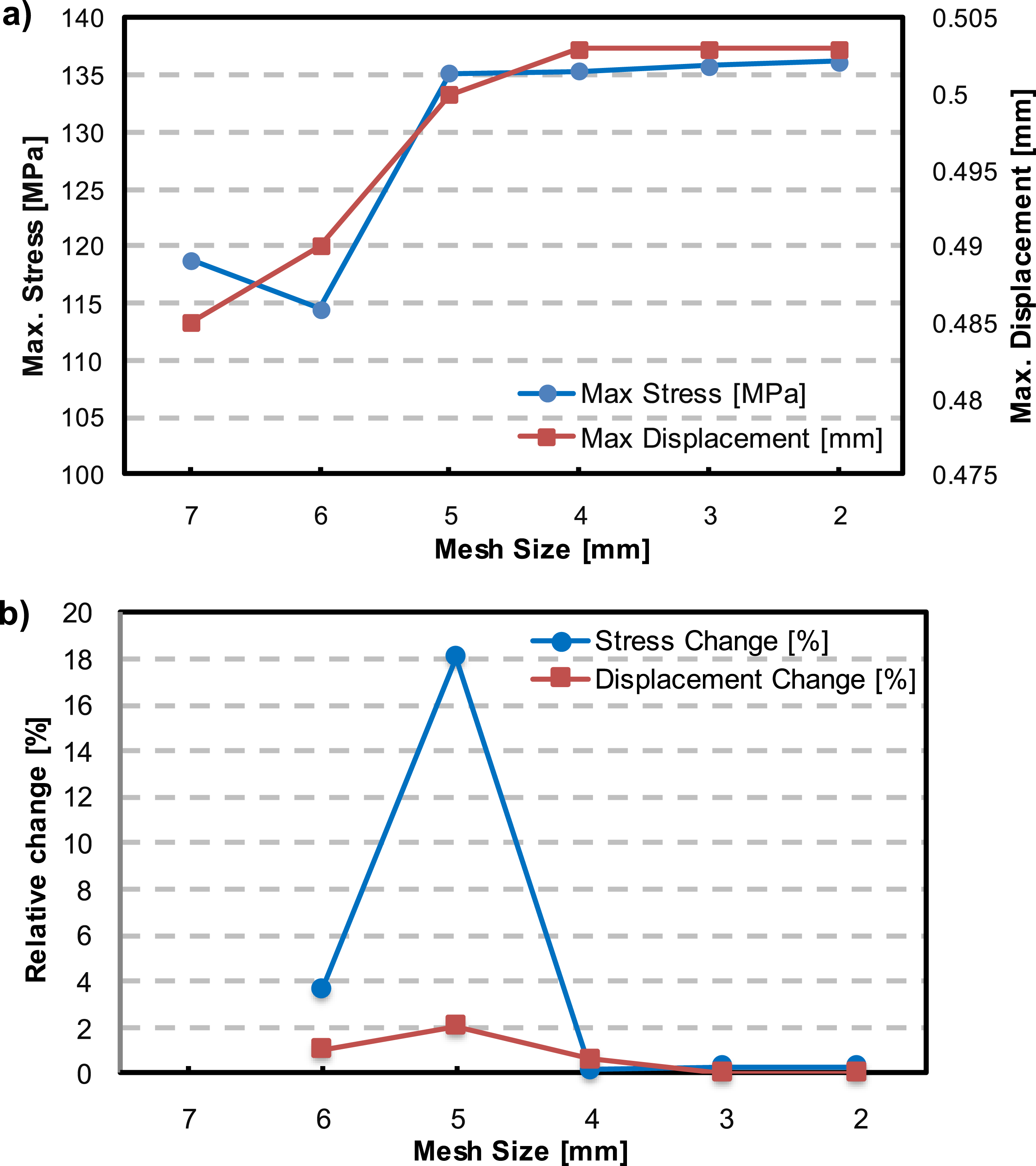
Modeling results and discussions
Optimal model confgurations
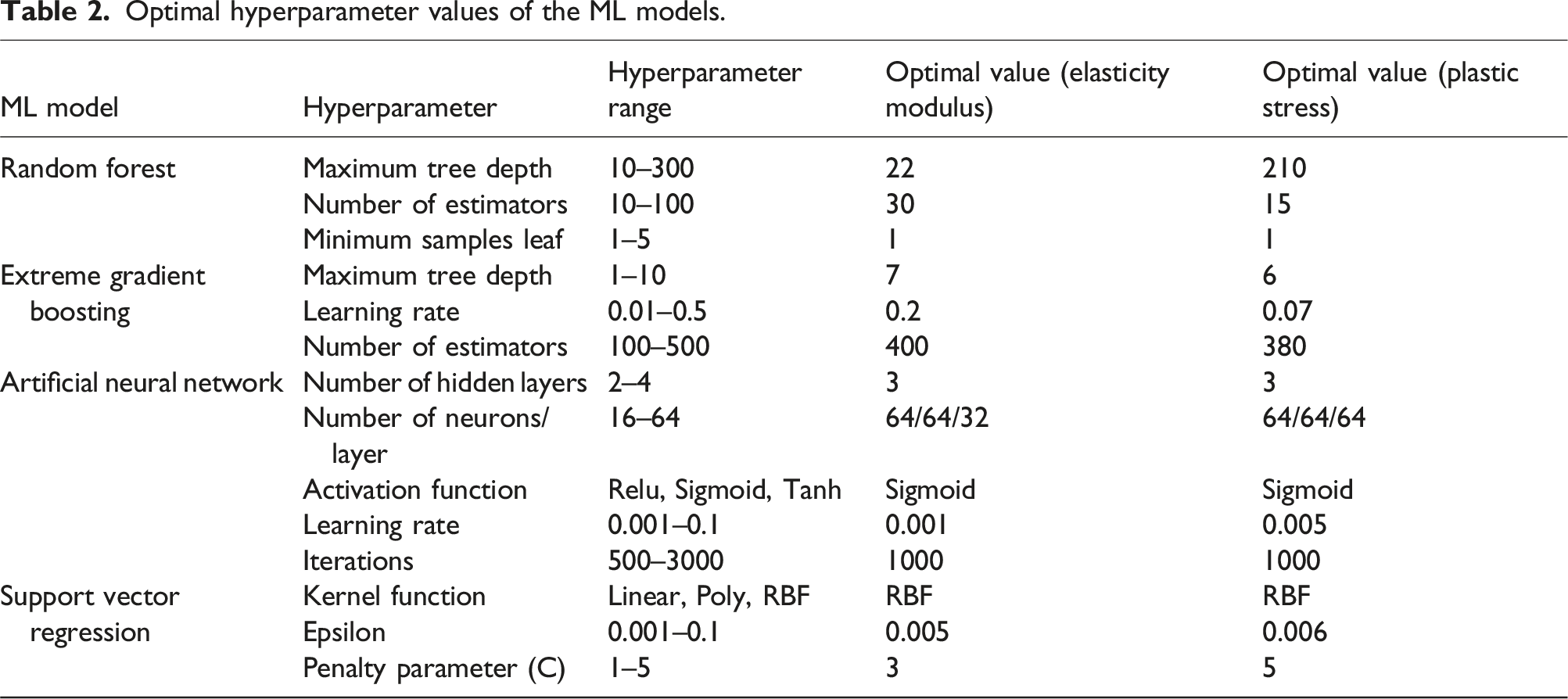
Optimal hyperparameter values of the ML models.
Prediction performance evaluation of all trained models
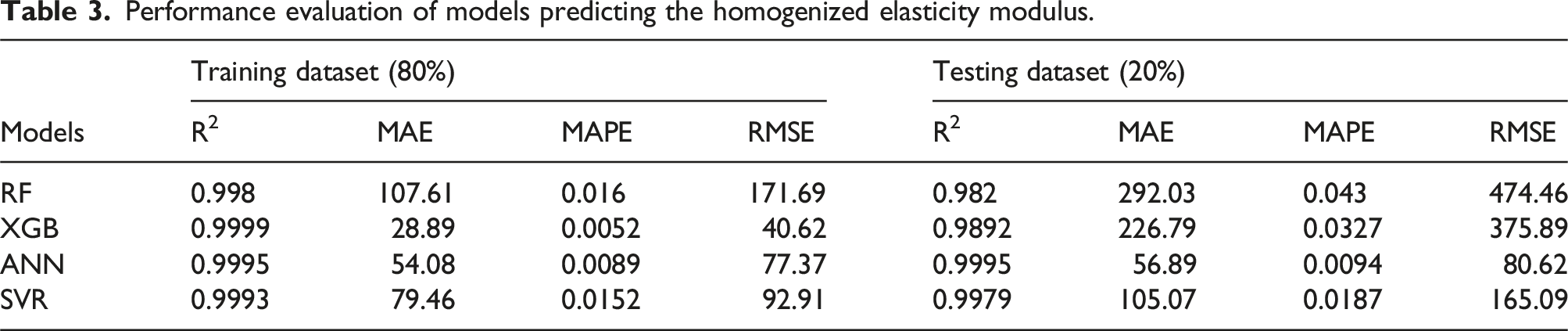
Performance evaluation of models predicting the homogenized elasticity modulus.
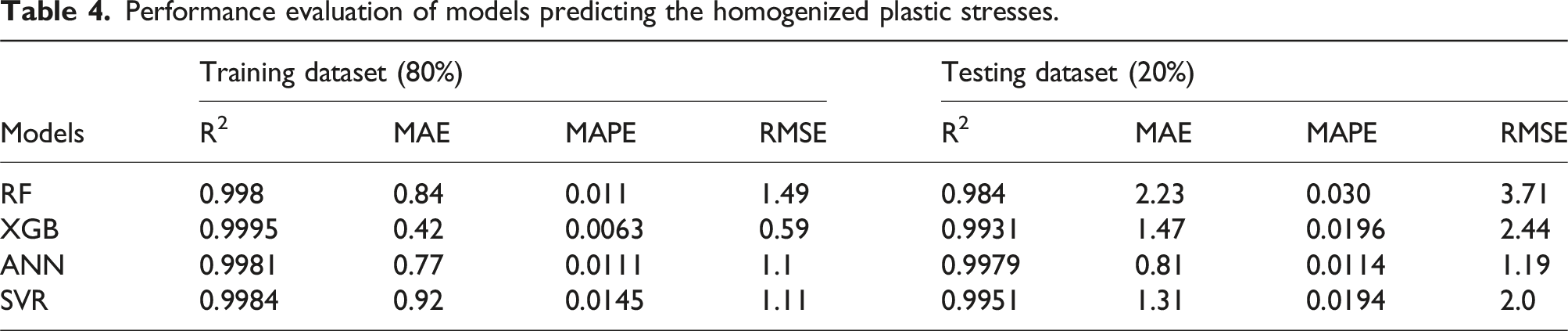
Performance evaluation of models predicting the homogenized plastic stresses.
The learning curves for the ANN model presented in Figure 9(a) and (b) illustrate the training and validation loss evolution for predicting the elasticity modulus and nonlinear plastic stress, respectively. In both cases, the loss values exhibit a consistent decreasing trend across 1000 iterations, indicating effective learning and convergence of the model. The y-axis, plotted on a logarithmic scale of mean squared error (MSE) in MPa, shows that the errors decrease from an initial order of 10−2 to approximately 10−5 by the end of the iterations, suggesting a substantial reduction in prediction error over time. Notably, the validation loss curves closely overlap with the training loss curves throughout the process, which is a positive sign of good generalization and an absence of overfitting. If any indications of overfitting had emerged, appropriate mitigation techniques such as early stopping, L2 regularization, or dropout would have been considered to enhance the model’s generalization performance. The presence of some noise in the curves, particularly in the validation loss, could indicate minor instability or sensitivity to the data, though this does not appear to undermine the overall trend. Overall, these curves suggest that the ANN models are well-trained and robust for predicting both elasticity modulus and nonlinear plastic stress. ANN learning curves for (a) elasticity modulus and (b) nonlinear plastic stress.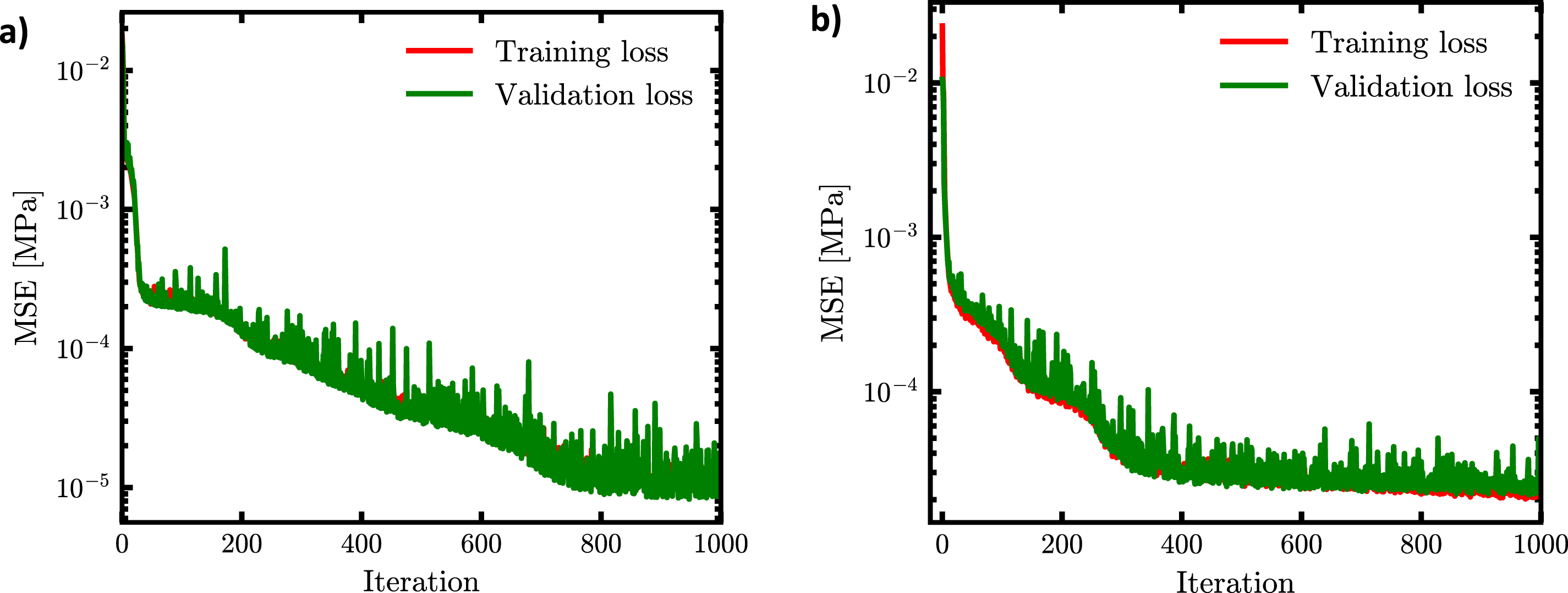
The scatter plots in the Figure 10 compare the predicted homogenized elasticity modulus E
M
against the actual values for four trained ML models including RF, XGB, ANN, and SVR. In these plots, the 45° diagonal line (y = x) called as ideal fit line represents the perfect prediction accuracy if the data points lie very close to it with no scattering. Among the models, ANN exhibits the highest predictive accuracy as its data points align almost perfectly with the ideal fit line, with all predictions falling within the ±5% error bounds. The density of predicted points on the ideal fit line highlights the consistency and reliability of ANN model in predicting the E
M
. SVR also performs well with predictions closely following the ideal fit line and only a few outliers slightly exceeding the 5% error margins, particularly at higher E
M
values. In contrast, RF and XGB demonstrate greater dispersion with a significant number of data points deviating beyond the error bounds. The higher scattering in RF and XGB predictions highlights their limitations in capturing the underlying patterns in the data, leading to reduced predictive accuracy. Comparison of predicted versus actual homogenized elastic modulus (E
H
) for different ML models: (a) RF, (b) XGB, (c) ANN, and (d) SVR. The black line denotes the ideal fit (y = x), while dashed lines represent ±5% error bounds to assess prediction accuracy. The predictions are based on the full set of RVE input parameters: 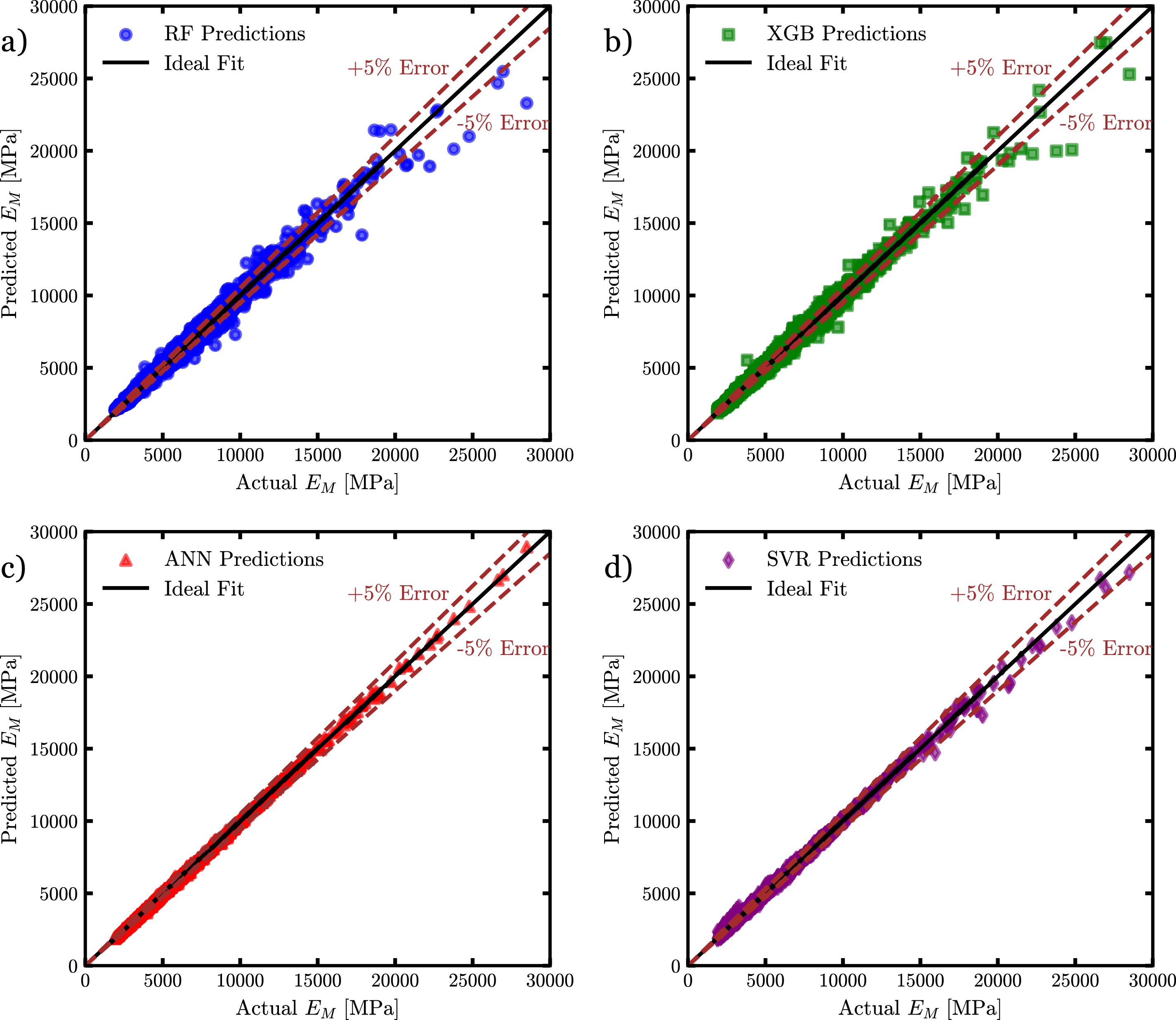
Figure 11 presents plastic stress-strain curves predicted by the trained ML models alongside the actual curve derived from the Mori–Tanaka homogenization method. The microstructural parameters for obtaining these results are as follows: Comparison of actual and ML predicted plastic stress-strain curves for short fiber-reinforced composites. An inset zoom highlights differences in the high-strain regime.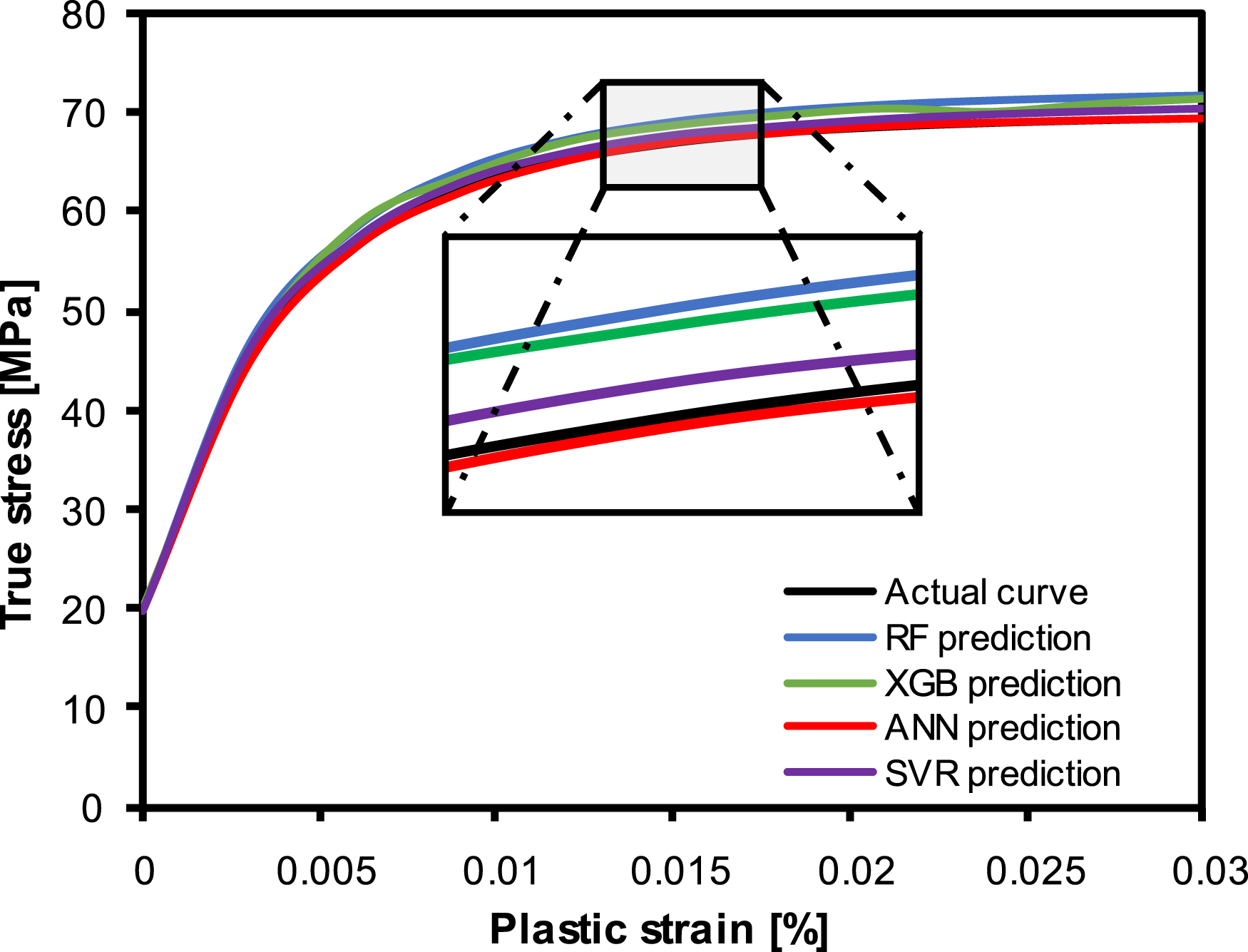
Computational performance of ANN model
In addition to accuracy and generalization, computational efficiency is a crucial factor in evaluating the practicality of homogenization methods. Therefore, the prediction runtime of the proposed ML-based homogenization approach with the conventional Mori–Tanaka mean-field method is compared. The ANN training was performed using a workstation equipped with an 12th Gen Intel® Core™ i9-12,900H processor, 64 GB RAM, and an NVIDIA RTX A2000 GPU. The complete training process of the ANN model using the Adam optimizer and network architecture presented in Table 2 required about 12 minutes to converge for 2048 RVE-based samples. Once the ANN model is trained, it can predict the homogenized material properties of SFRC in less than one second per sample, owing to their purely algebraic forward-pass computation. In contrast, the Mori–Tanaka method requires constructing an RVE, which involves defining the microstructural geometry, assigning material properties, and performing simulations. This process typically takes approximately 3–4 minutes per sample, depending on the complexity of the RVE and computational resources. Therefore, while the training phase of the ML model involves a one-time computational cost, it is orders of magnitude more efficient than running large number of high-fidelity simulations. This comparison highlights the significant runtime advantage of ML-based homogenization. The ability to obtain instantaneous predictions without the need for repeated simulations makes the ML approach particularly well-suited for parametric studies, uncertainty quantification, and real-time structural analysis workflows.
Taguchi and ANOVA method for the evaluating SFRC performance
This section employs the Taguchi method to analyze the behavior of a SFRC materials during homogenization and implements ANOVA technique to investiagte the signicance of various RVE parameters on the response of interest. The Taguchi method is a robust statistical approach that utilizes orthogonal arrays to systematically design experiments. This allows for the evaluation of multiple factors with a significantly reduced number of trials compared to traditional full factorial designs. 69 By strategically selecting parameter combinations, this method ensures a balanced and efficient assessment of factor effects while minimizing experimental costs and material waste.70,71 Taguchi method is widely adopted in manufacturing industries to enhance the process optimization and quality improvement by identifying optimal conditions with minimal resources.
Taguchi L27 (39) orthogonal arrays and the calculated homogenization response of RVE.
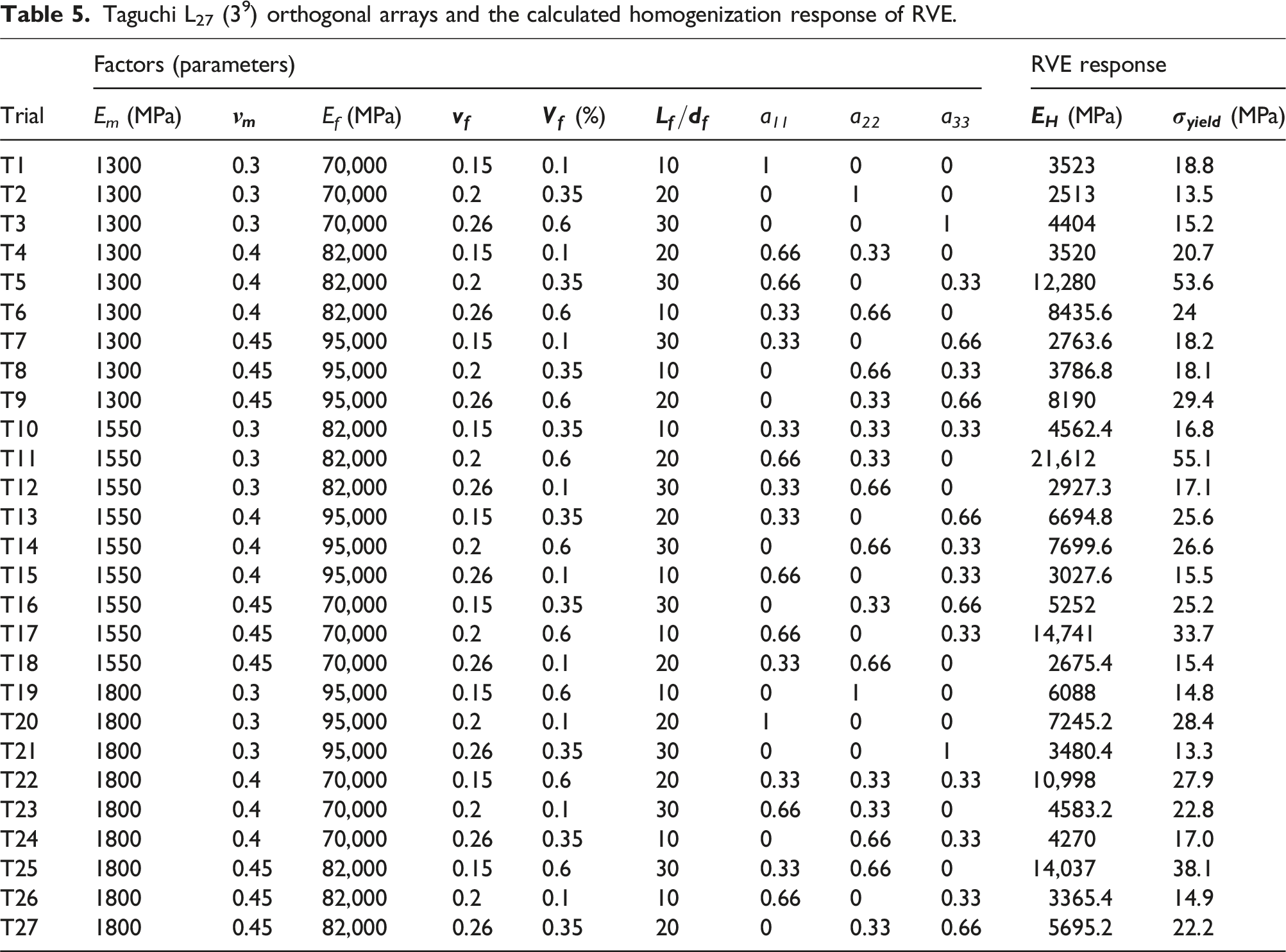
These orthogonal arrays are utilized for conducting the homogenization analyses of short fiber reinforced composite materials. In the homogenization analysis, the elastic modulus (E
H
) and yield stress (
A statistical tool like ANOVA is used to analyze the effect of each parameter in a Taguchi L27 orthogonal array on a response variable. This will help determine how each of the nine RVE parameters influences the elastic modulus (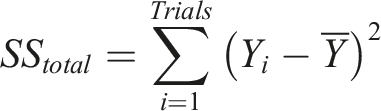
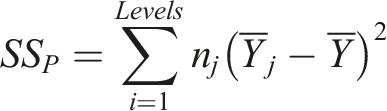
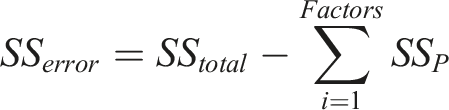
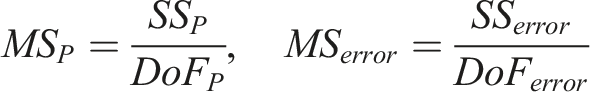
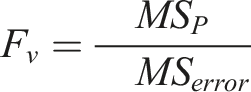
ANOVA analysis results for the homogenized elasticity modulus (
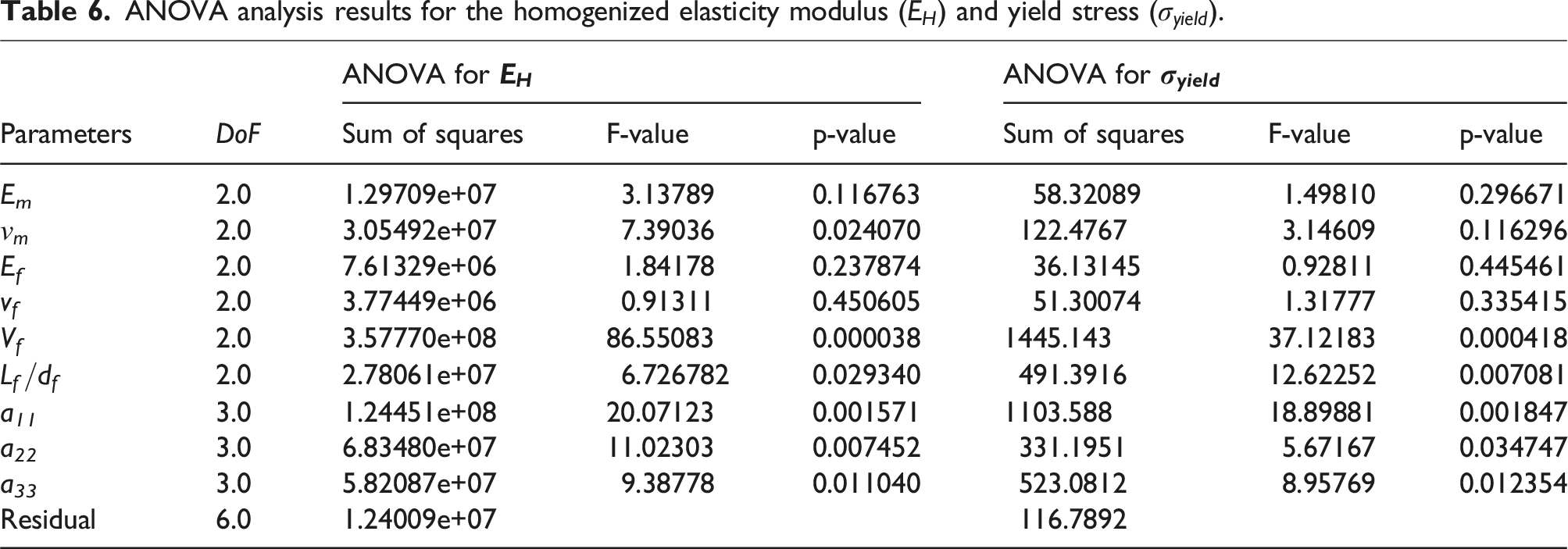
For the
Overall, these results align with the fundamental principles of composite material behavior, where fiber volume fraction, distribution and orientation dictate the overall mechanical performance, both in terms of stiffness and elastoplastic strength. It can be noted that the statistical significance of the fiber elasticity modulus (E
f
) in the ANOVA results is low, although it is known that E
f
physically contributes to composite stiffness. The apparent statistical insignificance arises primarily from the specific range of input parameters considered in this study. The variations in E
f
were relatively narrow compared to those of other parameters such as fiber V
f
and
Finite element analysis of automobile cover part based on different homogenization approaches
Three trials from the Taguchi L27 arrays presented in Table 6 are selected based on performance diversity, parameter coverage, and engineering relevance. The homogenization of these trials is carried out using the traditional Mori–Tanaka-based mean-field homogenization and ML-based homogenization techniques. Subsequently, homogenized material data from both approaches is implemented into Abaqus software to carry out the finite element analyses of an automobile cover part. The finite element results as per both homogenization schemes are compred to illustrate the accuracy of ML-based homogenization.
The trials selected for further finite element analysis of the cover part are T1, T5 and T11. Trial T1 represents the lowest stiffness (E H = 3523 MPa) and yield strength (σ yield = 18.8 MPa), reflecting a baseline material configuration (V f = 0.1, E f = 70,000 MPa). This trial is useful for cost-driven applications with lower material requirements. Trial T5 with an intermediate fiber volume fraction (V f = 0.35) balances moderate stiffness (E H = 12,280.6 MPa) with high strength (σ yield = 53.6 MPa), highlighting the impact of high aspect ratio (L f /d f = 30) and fiber orientation (a 11 = 0.66). This trial captures a typical performance scenario and helps illustrate the composite behavior when reinforcement is at an average level. Trial T11 exhibits the highest stiffness (E H = 21,612 MPa) and yield strength (σ yield = 55.1 MPa) due to high fiber volume fraction (V f = 0.6), high fiber elasticity modulus (E f = 82,000 MPa) and favorable fiber alignment (a 11 = 0.66). This trial represents the upper bound of the composite performance that is ideal for simulating high-stress regions. The nonlinear elastoplastic stress-strain data is computed for the selected trials (T1, T5, and T11) using the Mori–Tanaka (MT) mean-field homogenization and ML-based homogenization techniques. The obtained homogenized data is then used to calibrate the plasticity model in Abaqus. Since ANN performed best among all the ML models tested in this study, it is used for predicting the homogenization response of the SFRC composites. The macroscopic mechanical behavior of the material is obtained by carryıng out finite element analysis of the automotive component with material data obtained from MT homogenization and ANN-based homogenization techniques.
As illustrated in Figure 12, the stress contour patterns of the cover part using the ANN-homogenized material exhibit a high degree of similarity to those obtained with the MT approach. This strongly supports the validity of the ANN model in capturing the material response effectively of the composite. Notably, stress concentration regions, particularly in areas of geometric discontinuities align well between the two approaches. In Trial T1, the MT homogenized method yields a maximum stress of approximately 99.21 MPa concentrated at the component’s legs, while the ANN-based method produces a nearly similar stress peak. Similarly, for Trial T5, both methods show a maximum stress around 171 MPa at the same critical regions, with minimum stresses in the central body. While in Trial T11, a maximum stress of about 168 MPa is observed in both methods. The slight variations observed in the stress values are within an acceptable range. This confirms the robustness of the ANN-based homogenization in accurately predicting the macroscopic stress response of composite materials. Stress contour plots of the cover part characterized with MT homogenized material model and ANN-homogenized material model for the three trials (i.e., T1, T5, and T11) selected from Taguchi orthogonal arrays.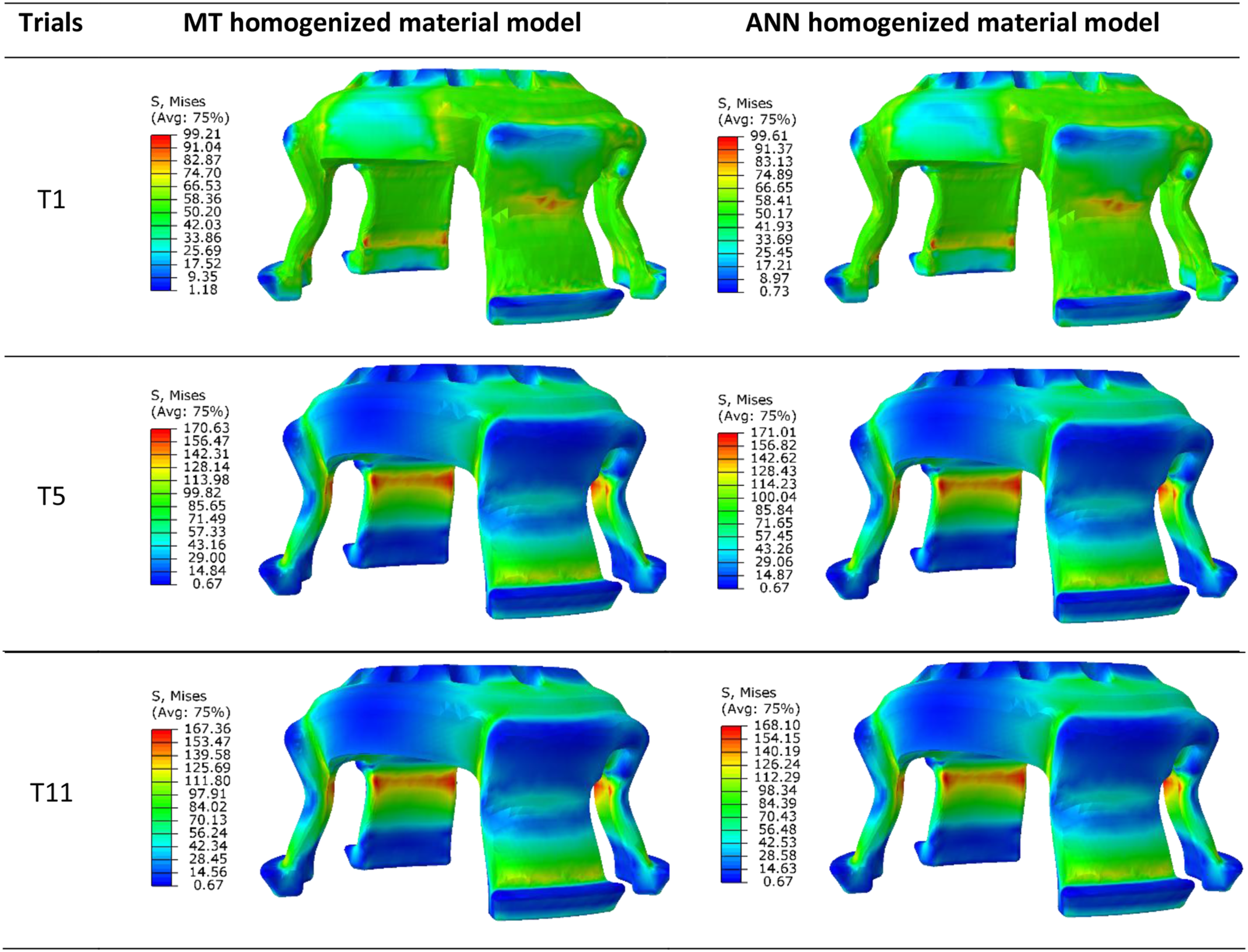
Figure 13 illustrates the stress-strain curves obtained from finite element analyses using Mori–Tanaka (MT) mean-field homogenization and the ANN-based homogenization technique for Trials T1, T5, and T11. The figure shows that for each trial, the ANN-based predictions exhibits a strong correlation with the MT-based results, capturing both the overall stiffness and nonlinear stress-strain behavior. Notably, Trial 1, which has the lowest fiber volume fraction (V
f
= 0.1) and aspect ratio (L
f
/d
f
= 10), exhibits the lowest stress levels across the strain range. In contrast, Trials 5 and 11 display significantly stiffer responses due to higher fiber content and fiber aspect ratios. The consistency between the ANN and MT results across different material parameter configurations highlights the ANN model’s ability to generalize well and accurately replicate the complex homogenized material behavior. Overall, this comparison validates the ANN-based homogenization technique as an efficient and reliable alternative to traditional mean-field methods without compromising accuracy in predictions. Comparison of stress-strain curves obtained from the finite element analysis of three trials with Mori–Tanaka (MT) and ANN homogenization technique.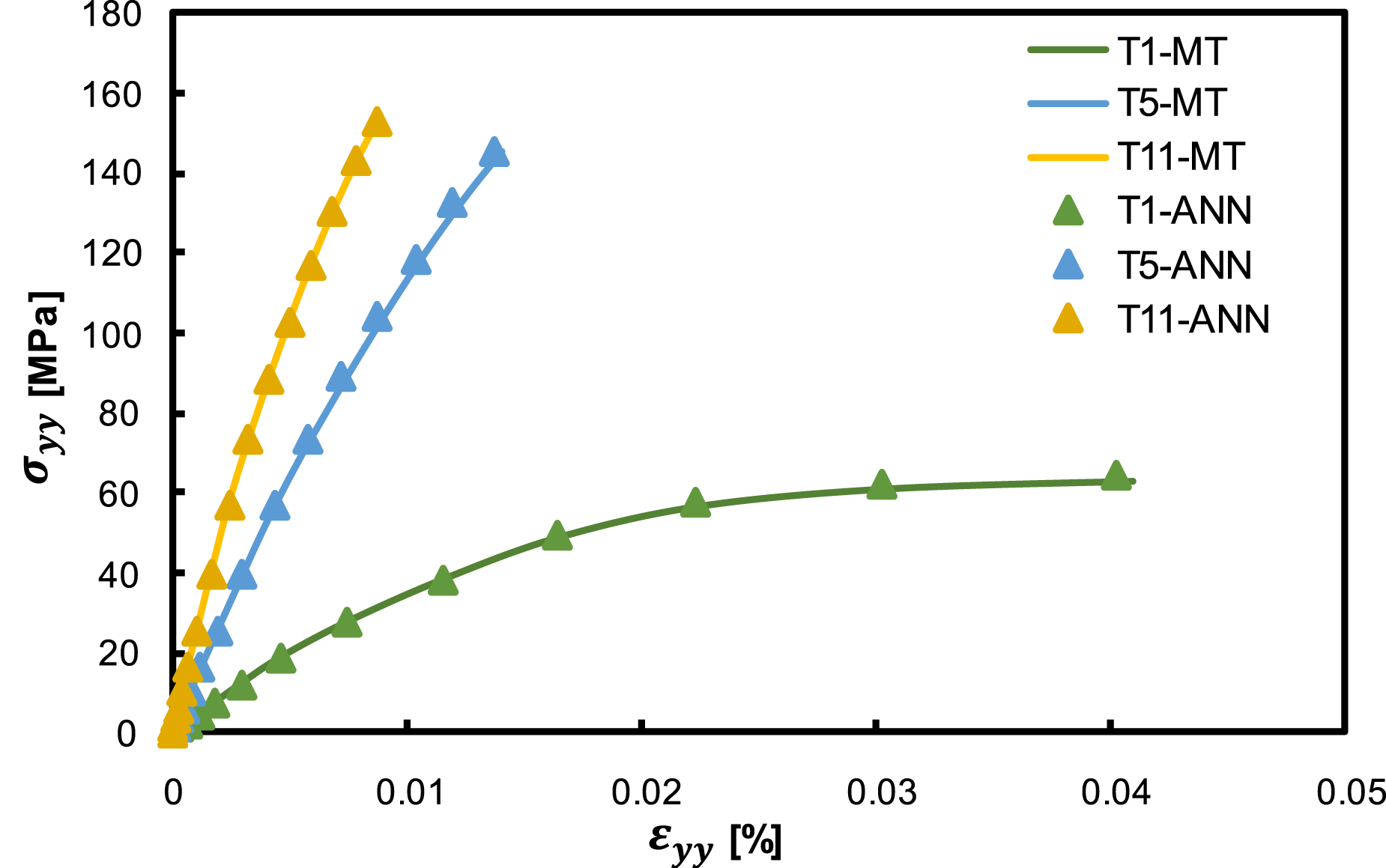
Conclusion
This study explores the potential of various advanced ML techniques including random forest (RF) and extreme gradient boosting (XGBoost), artificial neural networks (ANNs) and support vector regression (SVR) in predicting the homogenized nonlinear elastoplastic behavior of short fiber-reinforced (SFRC) composite materials. The training dataset was systematically generated using the Sobol sampling method, considering a wide range of microstructural parameters such as fiber and matrix elasticity modulus, Poisson’s ratio, fiber volume fraction, fiber aspect ratio, and fiber orientation tensor components. Additionally, Taguchi and ANOVA analyses were employed to quantify the influence of different microstructural parameters on the homogenized response of SFRC. The results revealed the most significant factors affecting the macroscopic elastoplastic behavior. The predictive performance of the ML models was evaluated using multiple statistical metrics, including R2, MAE, MAPE, and RMSE, along with visualization tools such as scatter plots and bar charts.
Among the models investigated, ANN demonstrated the highest predictive accuracy, with most predictions falling within a ±5% error range. These results underscore the ANN model’s ability to replace conventional homogenization techniques, offering a computationally efficient alternative while maintaining reliability in capturing the complex nonlinear behavior of composite materials. The effectiveness of ANN-based homogenization was further validated by integrating it into a finite element analysis of an automotive component, where the ANN-predicted material model produced results consistent with conventional numerical techniques. This close alignment validates the ANN-based homogenization’s capability to replicate the physics-driven Mori–Tanaka approach and its practical applicability in real-world engineering problems.
Overall, this study underscores the advantages of ML-driven approaches in predicting the homogenized behavior of composite materials, offering an accurate alternative to traditional numerical methods. The proposed methodology can facilitate rapid material design and optimization for engineering applications. In principle, the ML models can be extended to other types of composites such as particulate-reinforced, layered, or textile composites provided that a sufficiently diverse and representative dataset is available for the new material system and input features are adapted to capture the relevant micromechanical descriptors of the new composite (e.g., particle shape descriptors instead of fiber anisotropy). Similarly, while the trained models currently reflect predictions based on numerical homogenization using Mori–Tanaka, they could be adapted to predict results from alternative homogenization frameworks (e.g., self-consistent schemes, FE-based analysis, and FFT-based methods). However, this would require retraining the models on data generated via those methods. Future research can extend this work by exploring physics-informed architectures to enhance predictive capabilities further, as well as incorporating uncertainty quantification to improve the reliability of ML-based material models. It is also intended to extend this study by incorporating experimental results to further support the model validation.
Footnotes
Acknowledgments
The authors would like to thank Scientific and Technological Research Council of Turkey (TÜBİTAK) for their support within the scope of the International Cornet project (Project No: 123N452) and the SME user committee member YAMAS Rubber & Metal Solutions for providing the part information used in this research. We also sincerely thank TÜBİTAK for the scholarship awarded to the first author under the 2244 - Industrial PhD Program (Project No: 119C089).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was studied under funding of the TÜBİTAK-ARDEB 1071 International Cornet projects program (Project No: 123N452) and TÜBİTAK for the scholarship awarded to the first author under the 2244 - Industrial PhD Program (Project No: 119C089).
Data Availability Statement
Some or all data that support this study’s findings are available from the corresponding author upon reasonable request.