
Abstract
Large Language Models (LLM) have the capacity to quickly produce passages of varying lengths, complexity, genres, and topics, which could be useful for teachers of mono- and multilingual students with reading-specific learning disabilities, specifically relating to monitoring oral reading fluency (ORF). This study addressed one primary research question with two sub-questions.
Keywords
Grade-level reading passages are used in special education for students with reading-specific learning disabilities (RD) to assess fluency, indicate overall reading proficiency, generate long-term learning goals for Individualized Education Programs (IEPs), monitor student progress toward their goals (Fuchs, 2017; Fuchs & Fuchs, 2011), and use for instructional practice (e.g., repeated oral reading; Hudson et al., 2020; Rasinski et al., 2009). Artificial intelligence (AI) has the potential to allow teachers to generate reading passages of varying lengths, complexity, genres, and topics within seconds, specifically via Large Language Models (LLMs; Sidwell et al., 2024; Yuan & Hart Barnett, 2026). Thus, teachers may no longer be restricted to reading passages provided by a specific curriculum, intervention, or repository. The LLMs can also produce passages in Spanish, which may be particularly useful for the growing number of multilingual learners (MLs) with RD (Luft Baker et al., 2022). Therefore, LLMs may be especially useful for teachers of culturally and linguistically diverse students with RD, especially as it relates to reading assessment and data-driven planning for special education via oral reading fluency (ORF).
RD
Approximately 75% to 80% of students receiving special education services under the category of Specific Learning Disability demonstrate significant struggles with reading, making RD the most common form of learning disability (Learning Disabilities Association of America [LDA], n.d.). Furthermore, 76% of MLs in the United States report their native language to be Spanish (National Center for Education Statistics [NCES], 2024), and nearly 16% of MLs receive special education services, with approximately 45% of these students receiving services under the category of Specific Learning Disability (NCES, 2024; Office of Special Education, 2022). Models of instruction for MLs can generally be placed into one of two types: English-only, in which MLs receive all instruction and support in English, or bilingual, in which there is some degree of ongoing instruction and support across languages (Burr et al., 2015). Research suggests that bilingual models of instruction are the most effective, especially for maintaining native-language literacy skills (Serafini et al., 2020; Steele et al., 2017). Regardless of the model, best practice for MLs is that assessment is done in both English and the student’s home language (Francis et al., 2019; Luft Baker et al., 2022). Thus, there is a need for quality Spanish reading assessments.
According to the Simple View of Reading, reading comprehension is the product of word identification fluency (i.e., reading fluency) and language comprehension (Gough & Tunmer, 1986). Thus, difficulties with either fluency or language comprehension result in difficulties with reading comprehension. Furthermore, Automaticity Theory (LaBerge & Samuels, 1974) argues that one must read text with effortless accuracy in order to preserve the cognitive attention necessary for reading comprehension. Thus, the transfer of word-level decoding skills to passage-level reading fluency is essential to reading comprehension. For students reading alphabetic orthographies more transparent than English (e.g., Spanish), timed passage-reading rate predicts reading comprehension better than word-level decoding measures (Florit & Cain, 2011). Reading-specific learning disabilities, including dyslexia, are most often characterized by significant struggles with accurate and fluent word identification and reading (Chard et al., 2002; LDA, 2025). As such, a large focus of instruction and assessment for students with RD, especially in the elementary grades, is reading fluency (Hudson et al., 2020). Fluency is composed of automaticity (the speed at which words are read), accuracy (reading words correctly), and prosody (reading with appropriate rhythm and pace; Rasinski et al., 2009). While prosody is a key component of fluency, the majority of assessment and instruction focus upon automaticity and accuracy (Rasinski et al., 2009).
Data-Driven Planning and ORF
Data-driven planning is one of the four domains of the High-Leverage Practices for Students with Disabilities (HLPs), and the pillar HLP for the domain is HLP 6: Use student assessment data, analyze instructional practices, and make instructional adjustments that improve student outcomes (Lembke et al., 2022; McLeskey et al., 2022). The iterative process described by HLP 6 is often referred to as data-based individualization (DBI; Lembke et al., 2022) or data-based decision-making (Filderman et al., 2018). Research supports the use of DBI for students with RD (Filderman et al., 2018). Data-based individualization is a recursive process that entails using data to (a) establish a student’s present level of performance, (b) generate an ambitious long-term goal, (c) support hypothesis generation to drive intervention design, (d) regularly (i.e., weekly or bi-weekly) monitor a student’s progress toward their goal(s), and (e) drive timely decisions regarding whether to modify the intervention or goal(s) according to the student’s response to instruction (Filderman et al., 2018; Lembke et al., 2022). Data are the engine that drives DBI, and ORF is often the primary data for upper-elementary students with RD.
Oral reading fluency is a type of curriculum-based measurement (CBM; Deno, 1985), and like other CBMs, it has several methodological requirements (Fuchs, 2004). First, it must result in quantifiable data that are reliable and valid. While validity is a broad construct, it is often examined as criterion-related validity in CBM research (Fuchs, 2004). Thus, a given score on a CBM must be acceptable in terms of the extent to which it predicts current and future performance on a meaningful academic outcome.
Second, CBM must be sensitive to student learning, or growth, over time to be useful for progress monitoring (Fuchs, 2004). The CBM is administered frequently (i.e., weekly or bi-weekly), scores are plotted on a graph, and a reliable slope is generated over a brief time period (e.g., 10 weeks) that is indicative of the student’s learning trajectory. There are different types of CBM that can be used across a variety of domains (e.g., reading, writing, mathematics), but we will focus on reading. If a reading intervention is working for a student, their graphed CBM data should indicate a positive slope that is steep enough for the student to meet their goal. Alternatively, if the intervention is not working, then CBM data will indicate a flat slop, a negative slope, or a positive slope that is not steep enough for the student to meet their goal (Lembke et al., 2022). In the former case, the intervention is maintained. In the latter, the intervention should be modified according to a teacher’s data-driven hypothesis. As progress monitoring may occur weekly or bi-weekly, teachers need a large number of CBM forms.
Although there are different types of CBM for reading, such as phoneme segmentation fluency, ORF is a CBM frequently used for IEP goal generation and progress monitoring for students with RD in the elementary grades (Fuchs & Fuchs, 2011). Oral reading fluency consists of a grade-level reading passage, of which the student is instructed to read as much as they can in 1 minute, and teachers count the number of words read correctly as well as overall accuracy (Fuchs & Fuchs, 2011). Grade-level texts are key because students are expected to learn more complex reading skills as they progress across grades, and the texts are expected to mirror this increase in complexity (National Governors Association Center for Best Practices & Council of Chief State School Officers, 2010). The grade level of passages used is determined by a student’s performance as opposed to the grade the student is in. Teachers use ORF guidelines (see Fuchs & Fuchs, 2011) to determine which grade-level passage a student should have their learning goals written for and be progress-monitored on. Because students with RD often read at one or more grade levels below their actual grade, selecting the appropriate grade level for ORF is critical to its use within DBI (Fuchs & Fuchs, 2011; Lembke et al., 2022).
Appropriately Leveled Reading Passages
Given that ORF is often used to inform IEP goal generation, progress monitoring, and instructional decision-making, appropriately leveled passages are central to high-quality ORF (Amendum et al., 2018). Appropriately leveled texts across languages (English, Spanish) are also essential, as best practice indicates MLs should be assessed and monitored across languages (Luft Baker et al., 2022). We apply the term leveled text to refer to a grade-level (e.g., Grade 1, Grade 2) text that should require grade-appropriate reading skills for an individual to read with acceptable fluency in alignment with the Common Core State Standards (CCSS; National Governors Association Center for Best Practices & Council of Chief State School Officers, 2010). How texts should be evaluated for complexity has not been agreed upon by the field (Benjamin, 2012), but the CCSS defines complexity across three elements: (a) quantitative, (b) qualitative, and (c) reader/task factors. The quantitative element is often expressed as a readability score drawn from a formula that accounts for features like word length, sentence length, unique words, and text cohesion (Amendum et al., 2018). Common readability scores include Lexile, Flesch-Kincaid Grade Level (FKGL), and Flesch Reading Ease. The FKGL and Flesch Reading Ease are computed based on the average length of words (syllables) and length of sentences within a text; these Flesch metrics correlate with Lexile scores and are valid predictors of average time it takes to read a passage (McNamara et al., 2014), making them useful measures of ORF passages.
The qualitative element captures aspects of a text that go beyond mechanical features of words and sentences. For example, while a poem may have a low readability score (no complex sentences or difficult to read words), it may be difficult for many readers due to text structure and the use of figurative language. Qualitative factors include the meaning or purpose of text, alignment of the text with the reader’s prior knowledge, language features (literal vs. figurative), text structure (linear vs. non-linear), and the presence of visual supports (e.g., diagrams), which are especially relevant for informational texts (National Governors Association Center for Best Practices & Council of Chief State School Officers, 2010). Finally, reader and task factors refer to what the reader brings to the text and their purpose for reading the text.
The eighth edition of Dynamic Indicators of Basic Early Literacy Skills [DIBELS] (University of Oregon, 2023), known as Acadience, is a well-known producer of ORF available for free to teachers. We use the term DORF (DIBELS Oral Reading Fluency) hereon to refer specifically to ORF passages produced in the Acadience eighth edition. For this assessment, variation in student performance across ORF passages is well-established. Therefore, it is important to generate ORF passages that are relatively equitable in terms of complexity. Passages for DORF were written by established children’s authors from diverse backgrounds. The authors were instructed to generate both informational and narrative passages within a specified word length (175–225 for third grade) and Flesch–Kincaid (F-K) range (3.5–4.0 for third grade). As DORF is an indicator of overall reading ability, passages were evaluated for conceptual complexity to make final grade-level determinations and were then field-tested.
LLMs
Although there are several producers of research-validated ORFs available for teachers in English and, to a lesser extent, in Spanish, LLMs have been described as having the potential to allow teachers to generate ORF on demand that are appropriately leveled for DBI (Sidwell et al., 2024; Yuan & Hart Barnett, 2026). In turn, LLMs have been espoused as useful for generating ORF (Sidwell et al., 2024; Yuan & Hart Barnett, 2026), but little research has been conducted to examine the actual quality of passages LLMs generate (Ripoll et al., 2025).
Study Purpose and Research Question
Research supports the use of English-ORF for students with RD within a DBI framework (Fuchs & Fuchs, 2011). Theory (i.e., The Simple View of Reading) and empirical research provide support for using Spanish-ORF with native Spanish-speaking MLs in tandem with English-ORF (Keller-Margulis et al., 2012; Klingbeil et al., 2021). These practices necessitate many appropriate reading passages in both English and Spanish. Researchers have recommended LLMs as a method of ORF production (Sidwell et al., 2024; Yuan & Hart Barnett, 2026). However, we are unaware of any research examining the quality of ORF produced by LLMs, especially as it relates to use within a DBI framework for students with RD. Thus, the purpose of this study is to examine the quality of ORF generated in English and Spanish by readily available LLMs as compared to established ORF. Our main research question was:
We addressed the research question across two sub-questions as compared to validated third-grade ORF:
Method
For third-grade validated ORF, we identified Acadience eighth edition ORF (DORF) for English (23 passages) as well as their Spanish version (SP-DORF; Acadience Learning Inc, 2023) focusing on seven passages. These criterion passages were entered into Coh-Metrix (McNamara et al., 2014) for readability analysis, including word count, FKGL, and the five principal components of Coh-Metrix text readability (narrativity, syntactic simplicity, word concreteness, referential cohesion, and deep cohesion). These principal components allow a more robust picture of the difficulty of texts, as they are able to index (indirectly) genre features and factors that influence comprehension, beyond the superficial characteristics that are used in computing grade level (McNamara et al., 2014).
A Spanish-language natural language processing tool named MultiAzterTest was used for Spanish texts. MultiAzterTest calculates many of the same underlying metrics as Coh-Metrix but is able to evaluate texts in Spanish (Bengoetxea & Gonzalez-Dios, 2021). Metrics reported for Spanish texts include the number of words, Flesch readability ease score, textual lexical diversity, left embeddedness (a measure of syntactic complexity), content word overlap (a measure of referential cohesion), and the number of connectives (a measure of deep cohesion).
Publicly available free-to-use LLMs (ChatGPT, Claude) were employed to generate AI-comparison texts. Each model was prompted to produce 13 narrative and 10 informational third-grade-level texts (4 and 3 for Spanish; aligned with genre distribution in English and Spanish DORF). Prompts for the LLMs were modified across trial runs in order to yield text sets that were reasonably close to an FKGL between 3.5 and 4 (Center on Teaching and Learning, University of Oregon, 2023). Initial prompts followed the model provided in Sidwell et al. (2024), asking for a “reading passage that is narrative/informational using the 3rd-grade Dolch High Frequency Word list that is approximately 250 words long and at a 3rd grade level.” Prompts were altered to specify “a FKGL between 3.5 and 4” to improve grade-leveling. The text sets produced from these prompts are labeled Generic through the remainder of this article, as they did not specify any content or audience.
One of the potential benefits of LLM-generated ORF passages is the ability of educators to specify topics of interest and relevance to their students. Since these passages were not designed for any particular students, both LLMs were prompted to produce narrative passages “culturally responsive to today’s highly diverse elementary student body” and informational passages “about a diverse range of topics for today’s elementary schoolers; not just scientific topics” (without specific guidance, the LLMs only generated informational passages about the natural sciences). These passages are referred to subsequently as Diverse. Whether the passages resulting from this prompt contain topics that are interesting to a range of elementary students, and whether they accurately represent non-Anglo-European characters and cultures, is beyond the scope of the present research. Research suggests that open-ended prompting of LLMs generates narratives that subordinate and stereotype minoritized communities (Shieh et al., 2025); more research is needed to determine to what extent this algorithmic bias persists when prompted for cultural responsiveness. Here, the Diverse text sets serve primarily as examples of passage quality when LLMs are prompted with increased topic and audience specificity.
Text sets (23 texts per set in English; seven per set in Spanish) were examined via Coh-Metrix (RQ1a) and Leximancer (RQ1b). Analyses of variance (ANOVAs) were used to statistically compare DORF to LLM-generated passages according to FKGL and Coh-Metrix readability metrics. The FKGL of the text sets was compared using a Welch’s ANOVA with the Games-Howell post-hoc follow-up tests due to heterogeneity of variances in the dependent variable. The five principal components of Coh-Metrix readability were compared with one-way ANOVAs, with planned comparison follow-up tests using the Bonferroni correction to maintain a family-wise error rate (Keppel & Wickens, 2004). The planned comparisons follow a treatment versus control structure and compare the four LLM-generated sets to DORF. Descriptive statistics for English text sets are provided in Table 1. Due to the limited number of Spanish passages available in SP-DORF, no statistical comparisons were performed; descriptive statistics on readability are available in Table 2.
Means and Standard Deviations for English Text Sets.
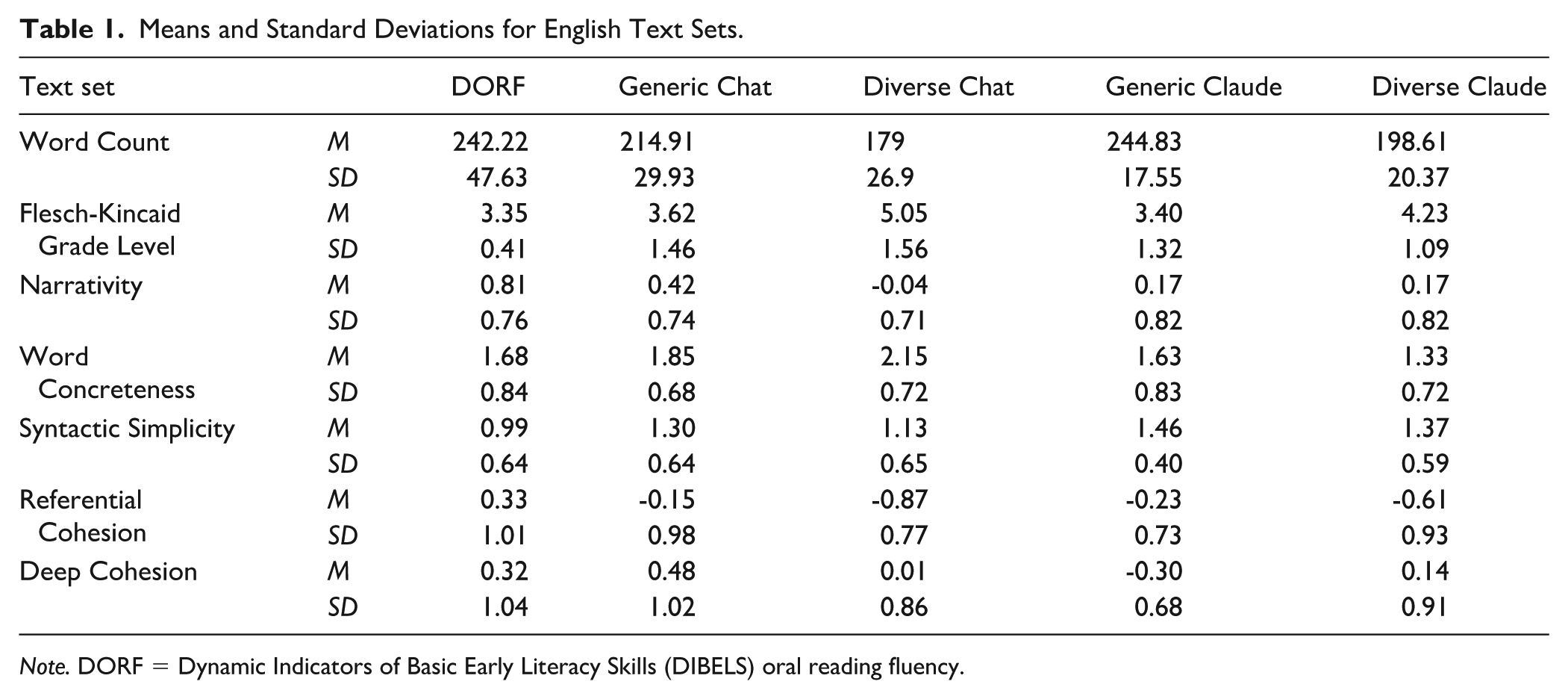
Note. DORF = Dynamic Indicators of Basic Early Literacy Skills (DIBELS) oral reading fluency.
Means and Standard Deviations for Spanish Text Sets.
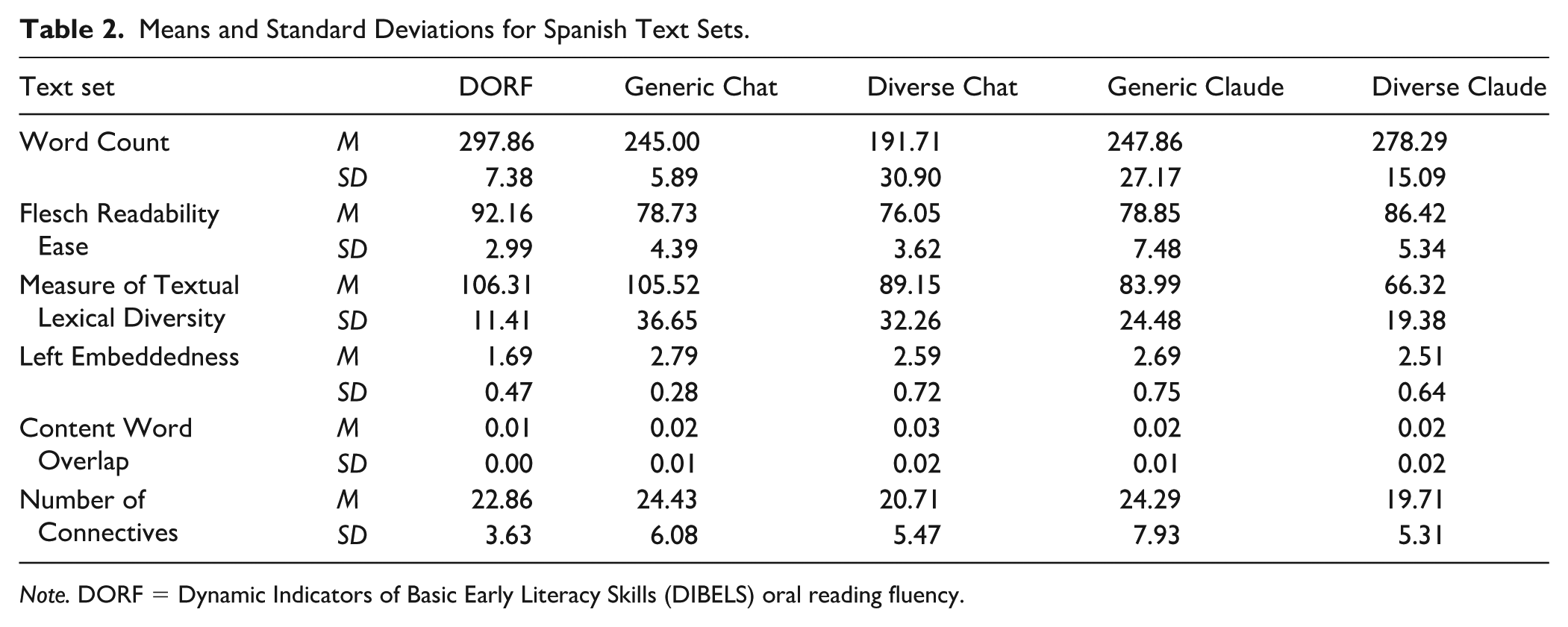
Note. DORF = Dynamic Indicators of Basic Early Literacy Skills (DIBELS) oral reading fluency.
To examine the conceptual diversity and co-occurrence for each data source (RQ1b), we relied on a text-mining software, Leximancer, which has been validated for content analytic purposes (Smith & Humphreys, 2006). We conducted a conceptual analysis of all text sets to examine the presence and frequency of themes—groups of related concepts that tend to appear together throughout text units of analysis. Leximancer’s algorithm identified core concepts, or themes, based on word frequency and co-occurrence, grouping them into themes based on conceptual proximity. Concepts were then ranked by connectedness, or the sum of co-occurrence relationships with other concepts, and mapped into thematic clusters, which enabled us to identify (a) the number of identified concepts, (b) the number of distinct theme clusters, (c) the top-ranked theme by frequency in text units (TUs), (d) the size of the dominant theme cluster and spread of secondary clusters, and (e) the connectivity score (sum of co-occurrence counts between the theme/focal concept and all other concepts) of the top theme. This analysis enabled us to assess the degree of thematic diversity (number of themes), dominance (distribution across TUs), and conceptual density (connectivity between the top theme and other concepts).
We also performed a relational analysis within each text set to examine the prominence of concepts that co-occurred and clustered around central themes. To assess the prominence of concepts associated with the top-ranking theme in each text set, we focused on co-occurring concepts with a prominence score between 1.0 and 2.99, indicating that these concepts co-occur with the primary theme more frequently than would be expected by chance, suggesting a meaningful relationship, and those with a score above 3.0, indicating that these co-occurring concepts have a strong, essential relationship. To further learn of the conceptual and linguistic composition of co-occurring concepts that showed a meaningful and strong relationship with the top-ranking themes, we coded each co-occurring concept for part of speech (e.g., noun, verb) and degree of concreteness (whereby concrete concepts refer to tangible, imageable referents; moderately concrete concepts refer to referents that may be visualized or understood with context; and abstract concepts are those that are less tied to sensory experiences).
For both the thematic and relational analyses, we compared patterns across the five English text sets and two Spanish texts. We focused our analysis on two of the five Spanish text sets to include the standardized assessment, SP-DORF, and the AI platform that generated the best-performing text sets in English.
Results
Quantitative Analysis of Readability for English and Spanish Text Sets
A Welch’s ANOVA comparing FKGL across text sets in English was significant: F(4, 49.66) = 8.69, p < .05, ω2 = 0.36 (all ANOVA results are available in Table 3). Among the Games-Howell post-hoc comparisons, four were significant: both the Diverse Chat (M = 5.05, SD = 1.56) and Diverse Claude (M = 4.07, SD = 0.82) had significantly higher average grade levels than the DORF criterion (M = 3.35, SD = 0.41). Diverse Chat also had significant pairwise differences from Generic Chat (M = 3.62, SD = 1.46) and Generic Claude (M = 3.4, SD = 1.32, p < −0.05). These latter differences between LLM-generated text sets indicated the LLMs are sensitive to specific prompting even within similar contexts (i.e., asking for 250-word narrative and informational third-grade passages).
ANOVA Results for Readability Statistics by Text Set.
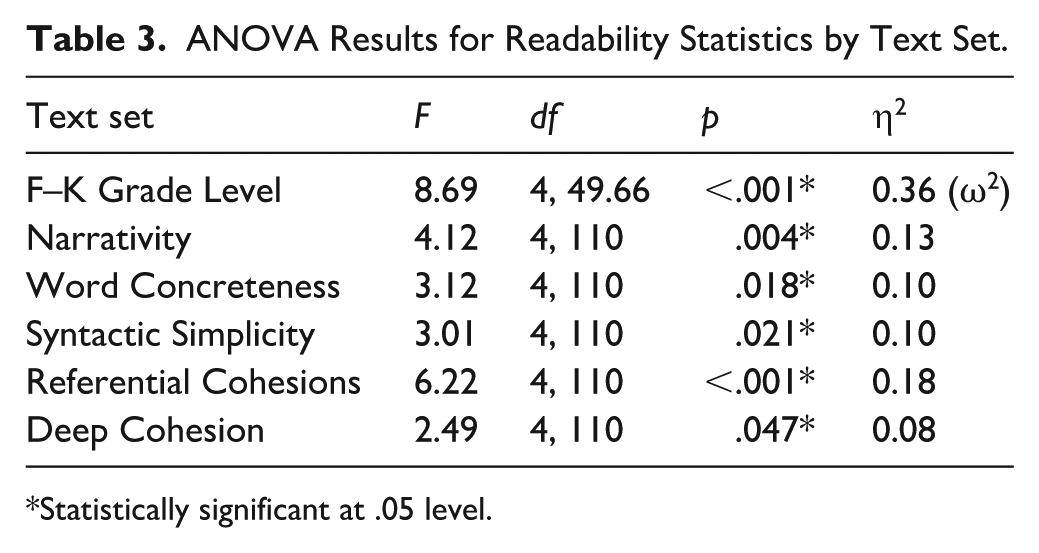
Statistically significant at .05 level.
One-way ANOVAs were used to compare DORF and LLM-generated text sets across the five principal readability components of Coh-Metrix (where higher values indicate more readable texts). There were significant differences among groups in all five of the readability metrics. The ANOVA comparing narrativity was significant: F(4, 110) = 4.12, p < .05, η2 = 0.13, and planned comparisons between the LLM-generated text sets and the DORF criterion indicated that Diverse Chat (M = −0.04, SD = 0.71), Diverse Claude (M = 0.16, SD = 0.82), and Generic Claude (M = 0.17, SD = 0.82) all differed significantly from DORF (M = 0.81, SD = 0.76). The higher mean narrativity z-score of the DORF set indicates higher readability. Word concreteness also differed significantly among the text sets: F(4, 110) = 3.12, p < .05, η2 = 0.10; however, none of the planned comparisons between the LLM-generated text sets and DORF were significant.
Syntactic simplicity also differed amongst groups: F(4, 110) = 3.01, p < .05, η2 = 0.10; Generic Claude (M = 1.46, SD = 0.40) was the only significant planned comparison with DORF (M = 0.99, SD = 0.64), with more syntactic simplicity. There were also significant differences in referential cohesion between text sets: F(4, 110) = 6.22, p < .05, η2 = 0.18; Diverse Chat (M = −0.87, SD = 0.77) and Diverse Claude (M = −0.61, SD = 0.93) both demonstrated lower referential cohesion than DORF (M = 0.33, SD = 1.01), suggesting they are more difficult to read. Deep cohesion also differed between groups: F(4, 110) = 2.49, p < .05, η2 = 0.08, although there were no significant planned comparisons between DORF and LLM-generated text sets.
Content Analysis of English and Spanish Text Sets
Content analysis via Leximancer of our text sets derived from DORF, ChatGPT, and Claude enabled us to extract themes (top concepts) based on word proximity and correlations as well as the prominence of concepts that co-occur with the themes.
Thematic Analysis of English Text Sets
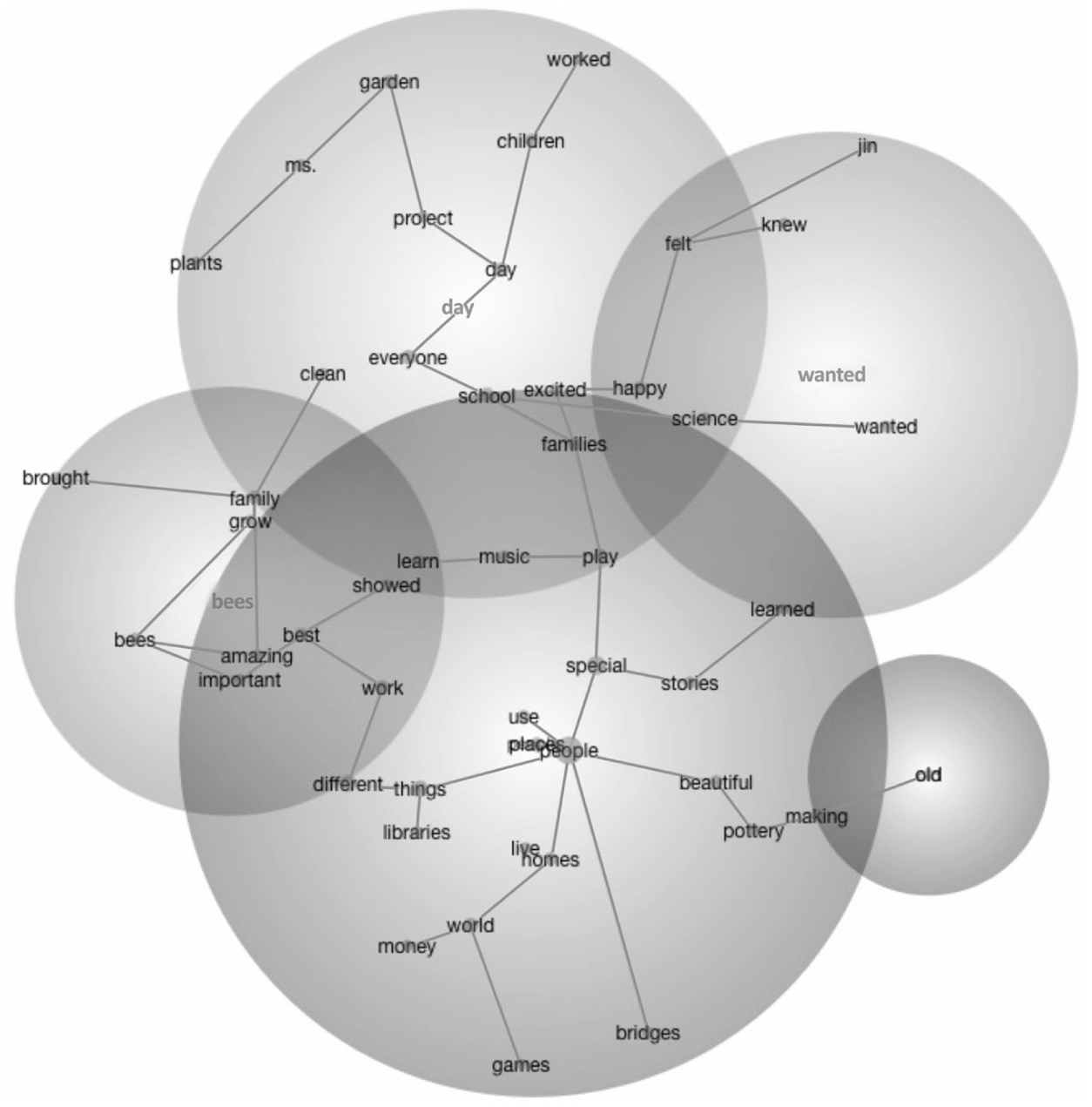
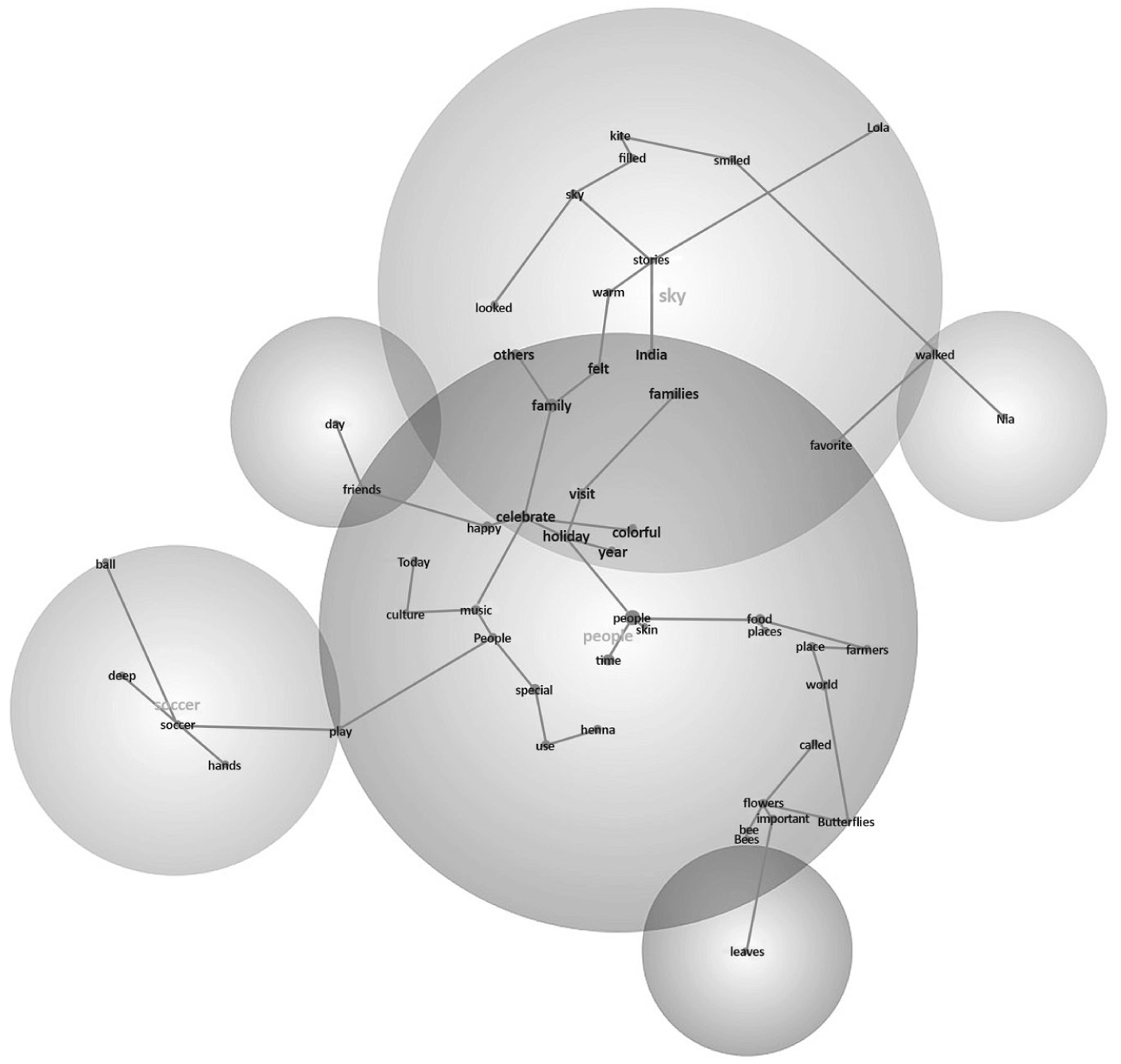
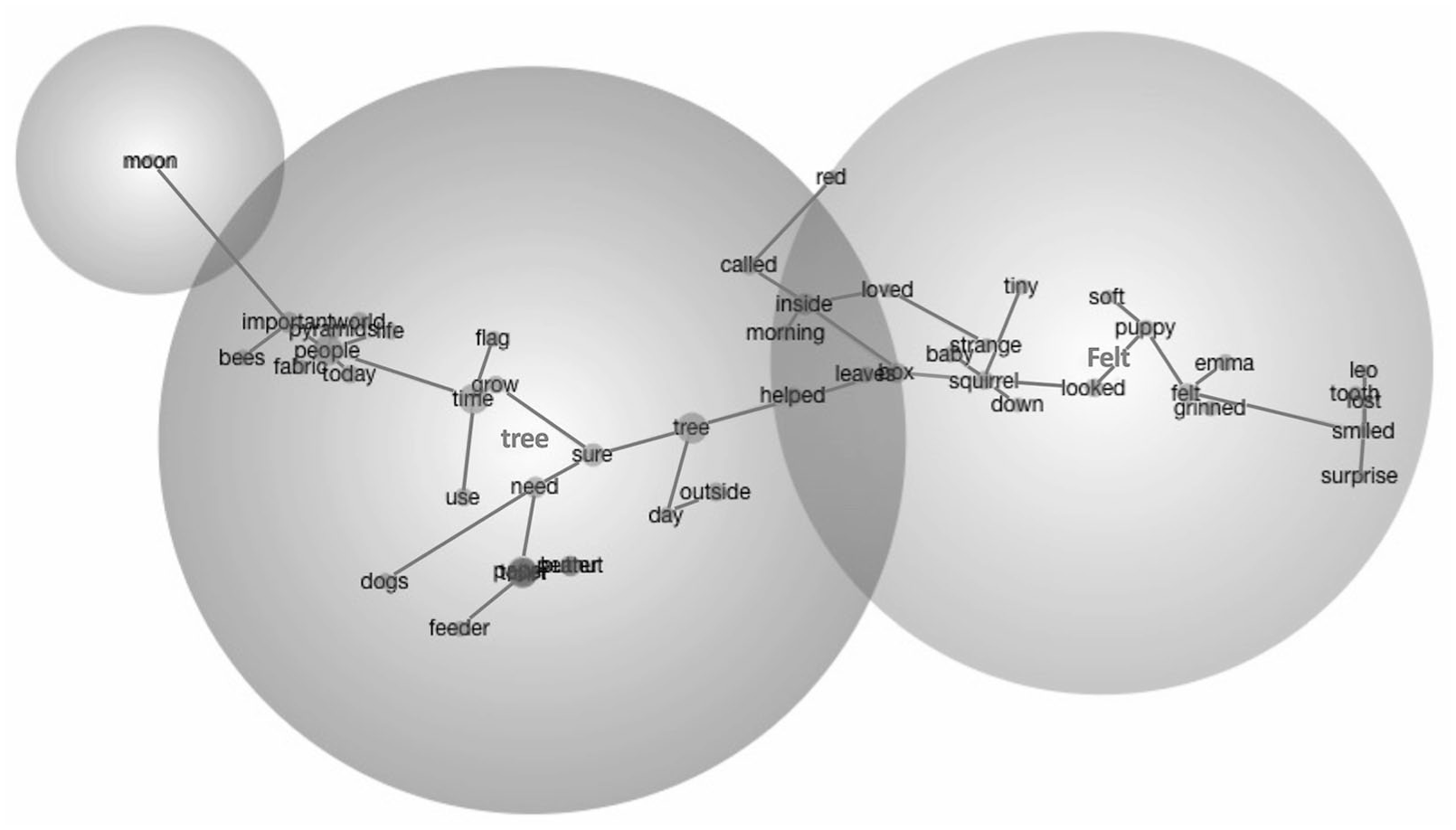
In terms of thematic spread, DORF, Diverse Chat, and Diverse Claude text sets exhibited the greatest variety, each splitting into five distinct theme clusters. As such, this suggests that the content in these sources (DORF, Diverse Claude, and Diverse Chat) is distributed across more distinct topics, or concept groupings, and has more collections of words that travel together across texts than Generic Claude and Generic Chat. For DORF (see Figure 1 for theme clusters), 43 concepts were grouped into four themes; there is a dominant theme of “tree” (118 TUs) followed by a moderately sized cluster (“inside” in 42 TUs) and two conceptually less clustered themes (“dad” and “thought” in 19 and 7 TUs, respectively). Diverse Claude text sets (see Figure 2) generated 46 concepts grouped into five themes, with two highly clustered themes (“people” in 142 TUs and “day” in 83 TUs) with moderately (“bees” in 26 TUs) and less clustered themes (“wanted” and “old” in 11 and 7 TUs, respectively). As such, DORF and Diverse Claude reflected repetitive and/or structured passages with the same underlying concepts, given the concentrated and moderately clustered themes. Unlike DORF and Diverse Claude, Diverse Chat (see Figure 3) produced 50 concepts underlying five themes, with one clearly dominant theme (“people” in 121 TUs), with several smaller clusters (“flowers” in 30 TUs; “sky” in 13 TUs; “day” in 7 TUs; and “skin” in 5 TUs), reflecting a strong conceptual focus (and still showing greater thematic variety than Generic Claude and Generic Chat).
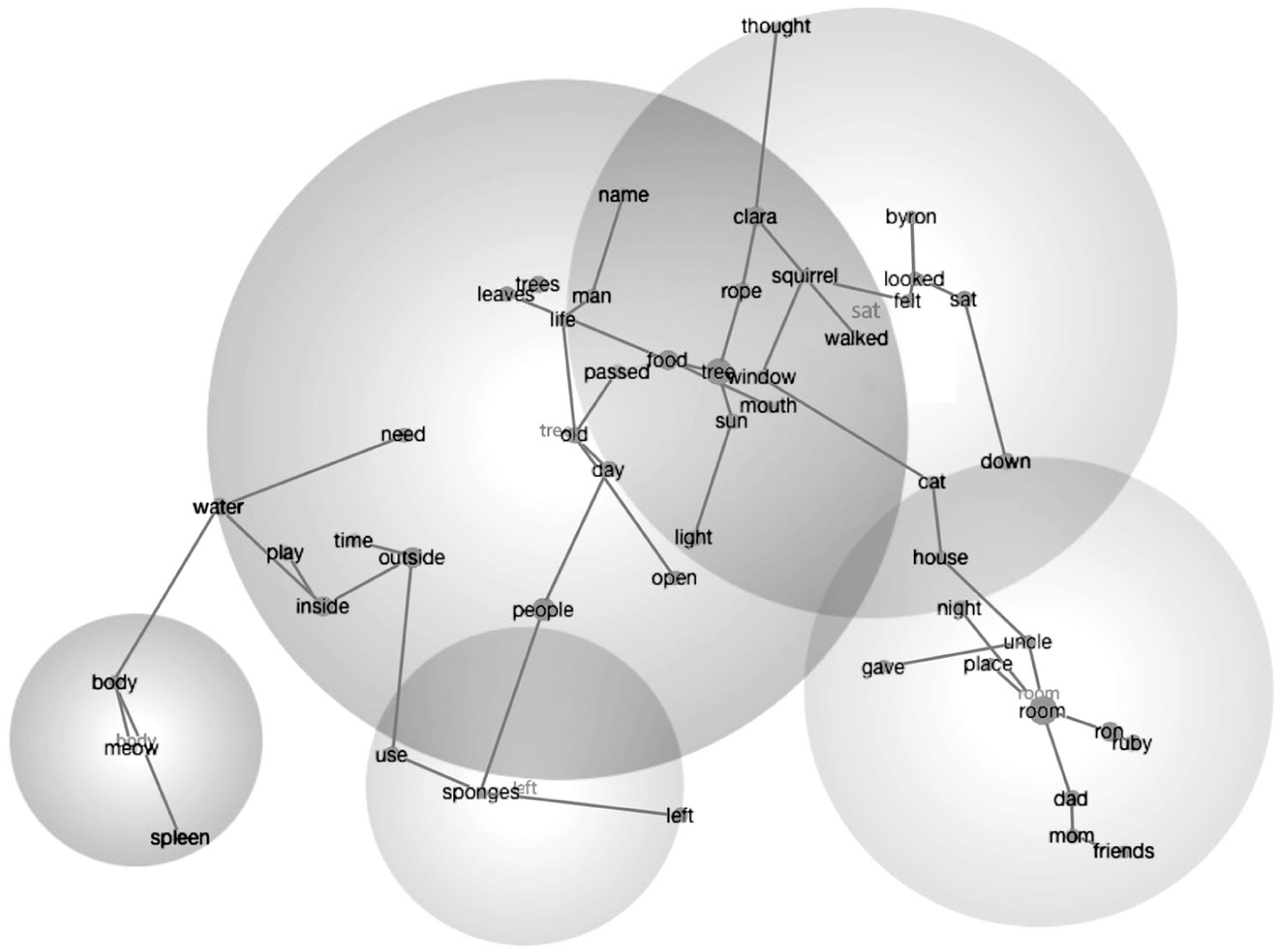
Leximancer concept cloud for English DORF.
Leximancer concept cloud for Diverse Claude.
Leximancer concept cloud for Diverse Chat.
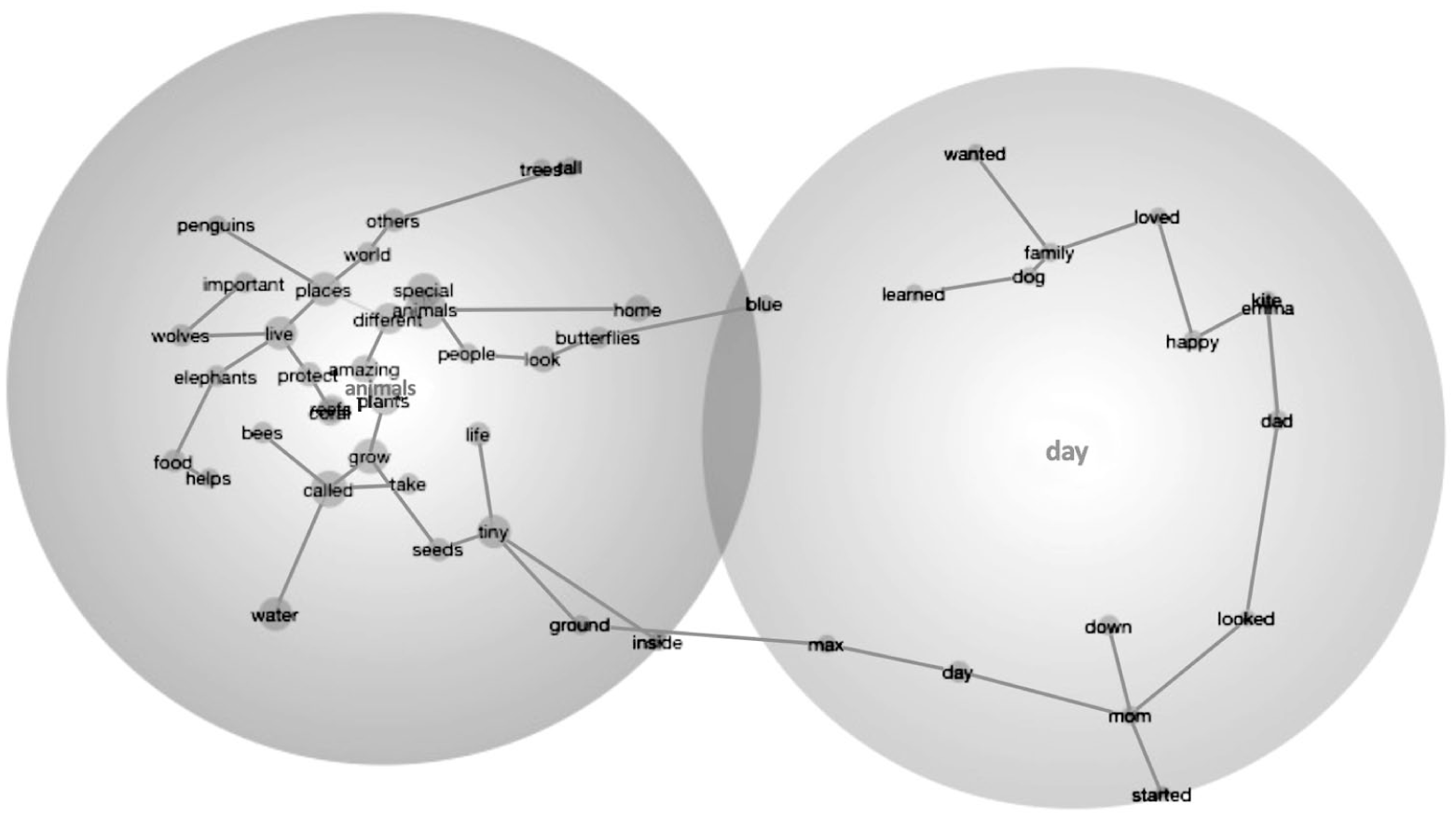
Generic Claude (see Figure 4) and Generic Chat (see Figure 5) text sets generated 47 and 49 underlying concepts, respectively, underlying only two theme clusters. These text sets showed the least thematic diversity, indicating that the content focused on a couple of core concepts/themes. Generic ChatGPT focused on the concepts of “tree” and “felt” (in 110 and 33 TUs, respectively), with a marginal focus on “moon” (in 8 TUs), whereas Generic Claude focused on “animals” and “day” (in 172 and 21 TUs, respectively).
Leximancer concept cloud for Generic Claude.
Leximancer concept cloud for Generic Chat.
Across the five text sets, the Claude-generated and Generic Chat text sets tended to produce the highest prevalence (or hits) of a theme across TUs, with top themes, such as “animals,” “tree,” and “people,” appearing in between 142 to 194 TUs. In contrast, top themes in Diverse ChatGPT and DORF texts, while similarly centered on “people” and “tree,” showed lower recurrence, with 118–145 associated TUs, indicating comparatively less concentrated conceptual clustering. As a separate but related finding, the text sets in Generic ChatGPT, Generic Claude, and Diverse Claude not only have the highest prevalence among their top themes, but also these themes were highly interconnected with other concepts, showing connectivity scores of 516, 1,071, and 693, respectively, indicating the strongest conceptual density among each top theme cluster across the text sets.
Relational Analysis of Top Theme and Co-Occurring Concepts in English Text Sets
In our relational analysis across the five data sources, text sets varied in the number of associated concepts and the proportion of strong versus meaningful co-occurrence relationships. The concept of tree was the most prominent theme in both DORF and Generic ChatGPT, while people emerged as the top theme in Diverse ChatGPT and Diverse Claude, and animals were most prominent in Generic Claude.
In DORF, tree co-occurred with 24 prominent concepts. Of these, 12 showed a strong, essential conceptual link (prominence > 3.0) including man, place, night, trees, leaves, and day. The remaining 12 co-occurring concepts (e.g., old, down, light, people, walked) demonstrated moderate, meaningful relationships (prominence > 1.0) with the top theme. Similarly, Generic Claude featured animals as the top theme, with 26 co-occurring concepts. This dataset also showed a balanced distribution, with 13 concepts strongly linked to animal (e.g., live, wolves, home, places, amazing) and 13 meaningfully related co-occurring concepts (e.g. special, ground, wanted).
The other three data sources revealed that co-occurring concepts tended to be less strongly linked to the top theme. For example, in Generic ChatGPT, tree was linked to 22 concepts. A smaller subset of 6 co-occurring concepts (i.e., grow, need, night, squirrel, box, sure) was strongly linked, while the other 16 co-occurring concepts (e.g., important, world, paper, feeder, toilet) reflected meaningful associations. Similarly, in Diverse ChatGPT, the theme of people appeared with 34 prominent co-occurring concepts. Only three co-occurring concepts (i.e., holiday, henna, and stories) exceeded the 3.0 threshold for strong prominence, while the remaining 31 co-occurring concepts (e.g., culture, playing, celebrate, and music) showed meaningful relationships. Additionally, in Diverse Claude, people were again the top theme, co-occurring with 25 concepts. Of these, only three co-occurring concepts (i.e., live, homes, money) showed strong conceptual links, whereas 22 others (e.g., music, stories, school, world, different) reflected moderate relational prominence.
Together, these patterns highlight differences in how tightly each text set clusters concepts around its central theme. While some sources, like DORF and Generic Claude, demonstrated more balanced or densely connected thematic structures, the Diverse ChatGPT and Diverse Claude revealed broader, more diffuse networks of moderately related concepts.
In terms of levels of concreteness, DORF stands apart from the other text sets for its emphasis on highly concrete (i.e., 50% of co-occurring concepts) and minimally abstract concepts (i.e., 15%) co-occurring with the theme. Diverse ChatGPT uniquely reveals a high degree of abstract co-occurring concepts (53%), indicating a need for more interpretive/inferential thinking during oral reading. The Claude text balances both concrete and abstract co-occurring concepts, while Generic ChatGPT is more centered on moderately concrete co-occurring concepts than the other text sets. Across all five text sets, the highly concrete co-occurring concepts were overwhelmingly nouns.
Thematic and Relational Analysis of Spanish Text Sets
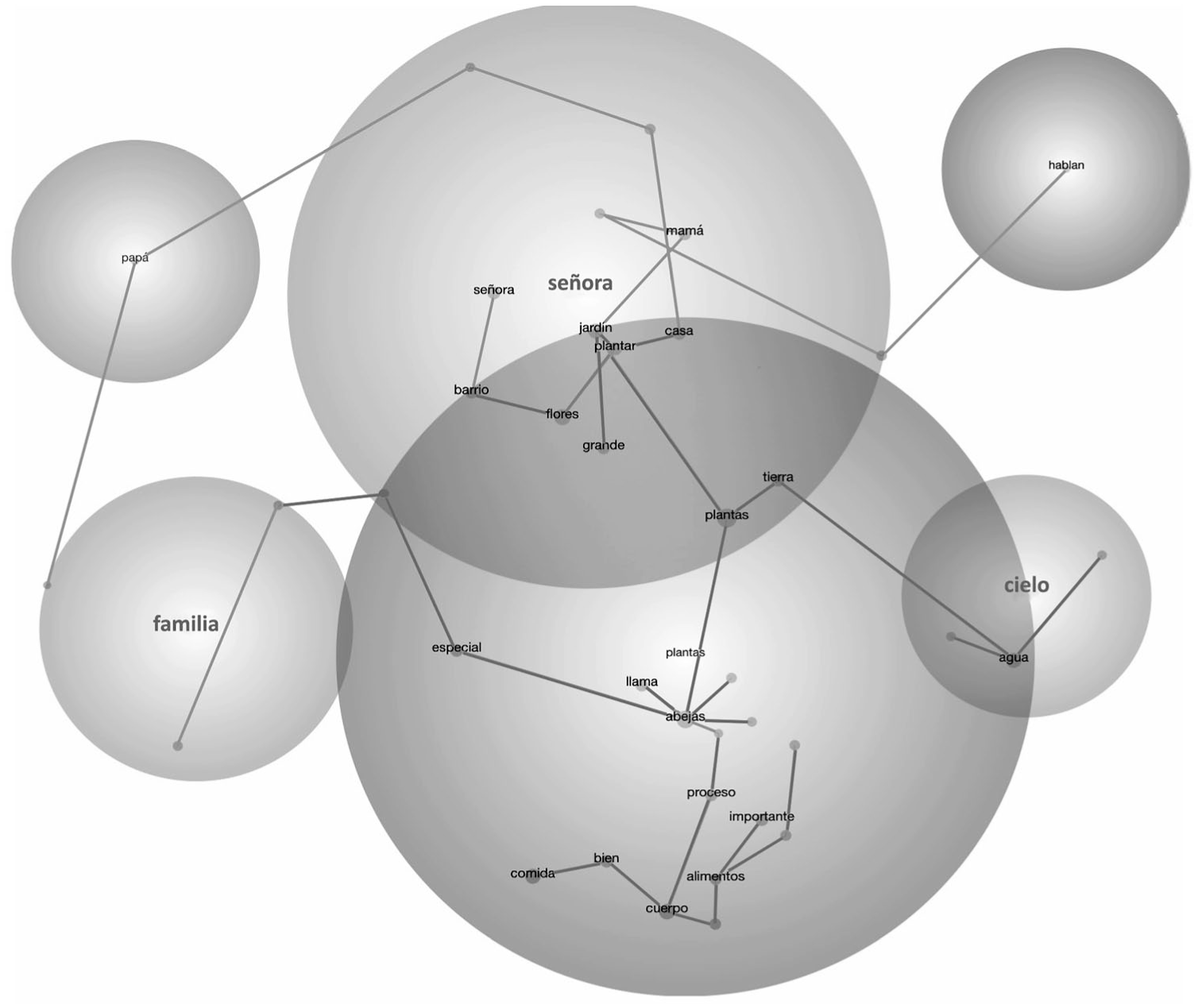
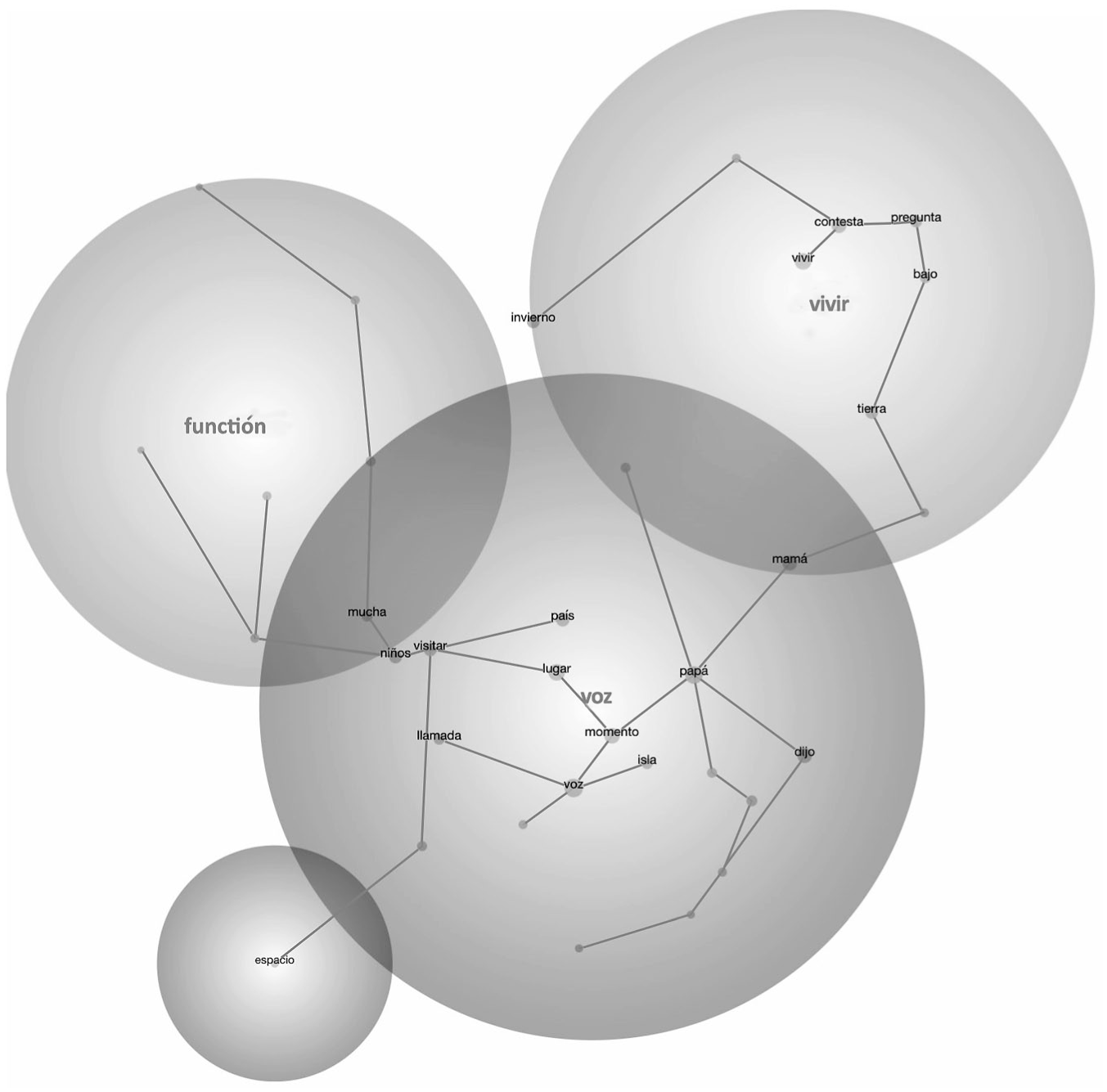
In terms of thematic spread for the Spanish text sets (SP-DORF and Diverse Claude), Diverse Claude ESP showed greater variety, splitting into six theme clusters, suggesting that the content in this source spans across more distinct topics than SP-DORF, which clustered into four themes. For Diverse Claude ESP, 38 concepts were grouped into six themes, with a dominant theme of “plantas” (plants) in 70 TUs, followed by two moderately (señora, familia [lady, family] in 18 and 10 TUs, respectively) and three less clustered themes (hablan, papá, cielo [speak, father, sky] in four TUs each; see Figure 6). The SP-DORF 33 concepts were grouped into five themes; there is a dominant theme of “voz” (“voice” in 44 TUs), followed by a moderately sized cluster (“vivir” [“to live”] in 19 TUs) and two conceptually less clustered themes (“espacio” [space] and “función” [function] in 5 and 3 TUs, respectively; see Figure 7). Across these two Spanish text sets, the Diverse Claude ESP tended to produce the highest prevalence (or hits) of a theme across TUs, with its top theme plantas (plants). Unlike SP-DORF, which somewhat concentrated on one dominant theme, Claude ESP showed more diffuse conceptual clustering.
Leximancer concept cloud for Spanish Diverse Claude.
Leximancer concept cloud for Spanish DORF.
Among these two text sets, SP-DORF demonstrated strong semantic association and coherence around the top theme voz [voice], with 9 out of 11 co-occurring concepts (e.g., baja, función, piloto, teatro [fall, function, pilot, theater]) showing a strong conceptual link to this theme, and the remaining 2 co-occurring concepts (lugar, dijo [place, said]) showing a meaningful but weaker connection to this theme. In contrast, Diverse Claude ESP’s top theme of plantas [plantas] included 16 co-occurring concepts overall. Of these, 12 co-occurring concepts (e.g., jardín, plantar, casa, tierra, alimentos [garden, to plant, home, soil, food]) demonstrated strong associations, and four co-occurring concepts were meaningfully related to plantas (e.g. agua, llama, mamá, libros [water, call, mother, books]). Although Diverse Claude ESP had a greater number of linked concepts to the central theme, the relative proportion of strongly connected concepts was higher in SP-DORF, indicating tighter conceptual cohesion around its top theme.
In terms of levels of concreteness, both Spanish text sets were comparable for their emphasis on highly concrete (i.e., 55% or more of co-occurring concepts) and minimally abstract concepts (i.e., 6% or less) co-occurring with the theme. Like the English text sets, the majority of co-occurring concepts were also nouns.
Discussion
The purpose of this study was to examine the quality of third-grade ORF generated by two commonly available LLMs, ChatGPT and Claude, as compared to established ORF in Spanish and English. Regarding quantitative quality, we found the LLMs generated passages of high variability across languages, regardless of prompt. For example, the standard deviation of FKGL for all English LLM-generated passages exceeded 1.00, while the standard deviation for DORF was 0.41 (see Table 1). Given that ORF is intended to establish goals and progress monitor students within a specific grade level, we consider an FKGL standard deviation of greater than 1.00 to be unacceptable. For Spanish, SP-DORF had a Flesch Readibility Ease standard deviation of 2.99, while LLMs had a standard deviation range of 3.62 to 7.48. Flesch Readability Scores above 90 are considered elementary texts; the average readability of all Spanish LLM-generated texts was lower than 90, producing texts more appropriate for middle school audiences than the 3.5 to 4 grade band that was prompted for. Furthermore, we found several significant differences in readability between DORF and the LLM-produced ORF. Given the high-stakes nature of ORF for students with RD (e.g., IEP goal setting), we suggest practitioners use an established form of ORF instead of LLM-generated ORF when possible.
A principal area of focus in this study was to examine the thematic structures across our various data sources. Recognizing that readers must construct mental models of texts to make connections across a text, we aimed to understand the level of cohesion in terms of the thematic/conceptual composition across text sets, given that such cohesion can support reading speed and comprehension (Graesser et al., 2011). As such, ORF passages can therefore include cohesive devices, such as repeating closely related words and concepts that allow readers to link ideas across sentences (Tortorelli, 2019). Our content analyses revealed that English text sets from DORF, Diverse Claude, and Diverse ChatGPT demonstrated a wider thematic spread with a greater number of underlying concepts clustering around central themes or with greater collections of words that travel together across texts. These text sets present diverse themes, allowing readers to encounter a broader array of interconnected ideas across all three data sources. Among these data sources, which showed greater thematic spread, it was Diverse Claude that demonstrated the strongest conceptual density when we analyzed the prevalence of the top theme across data sources; in other words, the top theme was highly interconnected with other concepts across texts. However, our relational analysis enabled us to identify DORF and Generic Claude as having stronger links between concepts that co-occurred with their top themes.
We observed the same patterns in our thematic and relational analyses for the Spanish text sets whereby Diverse Claude ESP showcased greater thematic spread, and SP-DORF exhibited stronger links between co-occurring concepts and its most prevalent theme. Therefore, prompting to request culturally responsive passages on a range of diverse topics does achieve focal, densely clustered concepts regardless of whether passages are in English or Spanish, but standardized ORFs (DORF and SP-DORF) are more promising in producing more tightly integrated passages given the stronger links between co-occurring concepts. Given the ease with which young students learn to read nouns and concrete words, semantically complex texts (e.g., including greater abstract terms) may be disruptive to students’ ORF (Mesmer et al., 2012). With this in mind, DORF (as well as SP-DORF) emphasized highly concrete co-occurring concepts, which may reduce comprehension-related hesitations and help to provide more reliable assessments of ORF.
Implications for Practice
The first implication from this study is that teachers should not use LLMs to generate ORF for use within a DBI framework for students with RD in English or Spanish. If a teacher must use an LLM to generate ORF, results indicate that teachers should use Claude (given its slightly more accurate grade-leveling) and specify length and FKGL in their prompting. However, teachers should verify that any LLM-generated ORF is appropriate according to FKGL (at minimum) and read the passage to check for coherence, the presence of stereotypes, and conceptual complexity. We should note that LLMs can be asked to evaluate the grade level of texts that they have produced, but the results are often inaccurate. While the possibility of specifying additional criteria for ORF text generation (such as about a topic that interests a particular student) is appealing, we do not recommend it at this time: We found that additional criteria (such as “responsive to a diverse student body”) decreased the accuracy of grade-leveling.
This brings us to the second major implication of this study: pre- and in-service teacher education needs to focus efforts upon providing teachers the skills necessary to effectively use and critically evaluate the output of AI. A focus on critical approaches to AI tools and AI-generated teaching materials is especially relevant to combat the dual threats of AI-hype and automation bias. While there is exciting potential of these novel technologies, teacher educator responses to them should be tempered with the knowledge that currently available LLMs are corporate products that are actively being sold to Grades K through 12 and higher education institutions. Additionally, pre-service and in-service teachers should be warned of automation bias or the tendency to believe in the veracity of information or conclusions reached by automated processes.
Limitations and Future Research
This research was preliminary, aiming to investigate the quality of ORF texts produced by LLMs. Out of a growing list of available AI tools, only two LLMs (ChatGPT and Claude) were examined, and only one validated criterion ORF was used (DIBELS). Additionally, the analysis of Spanish-language texts was limited by the small number of SP-DORF offered by Acadience. There was no technical adequacy examination of the LLM text produced (e.g., predictive validity). Finally, while our analysis did attend to conceptual and thematic diversity across text sets, we did not evaluate LLM-generated texts for reproduction of societal stereotypes, which have been documented through algorithmic reproduction of bias—a major concern when exposing students to LLM-generated instructional materials. Future research should address the above limitations and should also examine the impact of conceptual diversity (as quantified here) upon the technical adequacy of ORF for diverse learners (including reliability, validity, and sensitivity to growth). At this time, we see the most potential in using LLMs to generate brief reading passages for instructional (e.g., repeated oral reading) and formative subskill mastery assessment (e.g., accurate and automatic reading of 10 r-controlled vowel words embedded within a text), provided the teacher reads and confirms the quality of the text prior to use. Future research should investigate this line of text production by LLMs.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.