
Abstract
Competition among individuals is a natural mode of determining who is fittest. While in nature, economics, and sports, it is common to infer ability or aptitude from the outcome of competitions, our knowledge on its effects in regard to psychological/educational assessment is scarce. In the present pilot study, we explore a measurement approach for assessing individual differences in interpersonal, face-to-face competitions, based on a set of cognitively demanding, competitive, fast-paced, two-opponent tasks. For initial task evaluation, we conducted comprehensive reliability and construct validation analyses, considering cognitive ability, motivation, and personality measures. Moreover, using structural equation models we conducted a simultaneous factorization of the tasks with the other validation measures. The results suggest that the newly developed tasks measure both cognitive ability (intelligence) as well as a competition-specific component. The competition-specific component was positively associated with experience in competitive gaming and negatively correlated with neuroticism. While the pattern of validities was promising, the measurements’ reliabilities were yet unsatisfactory. Implications for future research as well as the design of competition-based measurements are discussed.
Introduction
Interpersonal competition, in which two or more persons strive for a goal, which cannot be shared, is a natural mode of human interaction. Situations fitting this pattern occur frequently in various professional and private settings. Furthermore, competition is a common element of games as well as an effective gamification element in learning settings (e.g., Sailer & Homner, 2020).
While specific characteristics of the situation as well as the type of goal may differ, succeeding in competitive situations is often considered as an indicator of success in general. This conclusion appears natural, because––from an evolutionary perspective––asserting oneself in competitions for resources is widely considered as an essential aspect for the “success” of a species (e.g., Christiansen & Loeschcke, 1990).
Although competition is not the only way in which success may be achieved, it is, nevertheless, a dominant mode in specific situations. Particularly in professional settings––such as in the fields of military, law, economy, or sports––succeeding in interpersonal competitions can account for a large proportion of professional success in general.
Clearly, the probability of succeeding in competitive situations differs between individuals. To some extent, these differences may be attributed to factors that are independent from the competitive nature of a situation, such as abilities or traits required for a specific operation or task. However, some contributing factors may be specific to competitive settings. While there is some evidence pointing to the unique influences of competitive elements on performance in interactive dyads (Munkes & Diehl, 2003), further information on their structure, suitable measurement approaches, as well as the actual relevance are not available.
In general, despite some singular results (Berge et al., 2015), little is known about competition-specific individual performance differences. Previous research has focused more on individual differences with respect to preferences for competitive situations (Balafoutas et al., 2012; Ross et al., 2003) or differences in competition motivation (Franken & Brown, 1995). In fact, neither theoretical foundations nor measurement approaches addressing competition-specific individual differences are yet well-developed. However, we consider it essential to gain a deeper understanding of the potential impact of such individual differences because competition is often a natural element inherent in situation in which human performance is assessed. This understanding is not only necessary for a more profound comprehension of the construct, but also for assessing its actual relevance, which is currently unclear as well.
The present study, therefore, aims to address this lack of knowledge by investigating an operationalization approach based on a set of competitive two-opponent tasks. Because neither structure nor measurement approaches are established, this study is intended as a pilot study that explores these two aspects simultaneously.
Competition-Specific Measurements
Clearly, a necessary step for investigating competition-specific individual differences is the development of viable measurement approaches. However, this poses particular challenges, because of the absence of a well-defined theoretical foundation. For one, a competitive situation is always interwoven with specifics tasks or operations that might require different sets of abilities or skills. Whether or not they might interact with competitive features is unclear. Moreover, properties of the competition situation itself might affect outcomes. Specifically, the consequence of winning or losing, whether competitions are face-to-face or not, and the number of competing individuals/parties may yield different effects, limiting the generalizability of singular settings. Also, it is important to consider the measurement’s suitability for standardization.
As guiding principles for selecting specific features for measurement development, we focused on (a) what might be relevant from the perspective of psychological/educational assessment, (b) which operationalization is economic and therefore viable, and (c) how measurements might relate to non-competitive approaches.
With regard to relevance, we consider it desirable to measure success in direct (face-to-face), dyadic, and cognitively demanding tasks, because various daily interactions comprise these components. It appears, furthermore, unlikely that these components are easily addressed by conventional tests.
With regard to operationalization, there are several options. One might, for instance, consider an observational approach, rating the success in actual competitive situations. However, objectivity and economic feasibility might be limited. An approach allowing for more standardized measurements may be found in the intersection of board games and test gamification.
In the context of board games, cognitively demanding dyadic competitions have long-since been a traditional mode. Chess, for instance, has (at least in public perception) been considered as a suitable training as well as assessment tool for strategic and military thinking (Burgoyne et al., 2016). Equally important, board games usually comprise standardized instructions and scoring rules and their materials can be similar to those of cognitive ability tests, which facilitates contrasting competitive and non-competitive measurements.
Introducing game-like attributes (such as points, leaderboards or competition) to an assessment or test context has gained some popularity in the past years and is referred to as gamification (e.g., Deterding et al., 2011; Rabah et al., 2018). As Armstrong et al. (2016) point out: “A gamified assessment is not a stand-alone game, but it is instead an existing form of assessment that has been enhanced with the addition of game elements” (p. 672). Commonly, gamification strategies are used for enhancing participants’ motivation and engagement (e.g., Berg, 2021; Cechanowicz et al., 2013; Looyestyn et al., 2017; Sailer & Homner, 2020) rather than for assessing their differential impact. Consequently, while gamification has been considered in many studies (e.g., Dicheva et al., 2015; Koivisto & Hamari, 2019; Rabah et al., 2018; Sailer & Homner, 2020), validations of individual differences due to game-like components are virtually nonexistent. However, the differential perspective is certainly important, because it is likely that measures are considerably altered by gamification (Landers et al., 2020). In addition, in application-oriented settings, little attention is paid to the psychometric properties of gamified assessments although these are the basis for any successful use (Armstrong et al., 2016; Nikolaou et al., 2019).
We conjecture that combining features of competitive board games, such as alternating moves with an opponent including an objective-based scoring-system, with cognitively demanding operations that relate to contents of standardized test procedures, could be a viable measurement approach for competition-specific individual differences (Lumsden et al., 2016). However, merely using existing games, such as Scrabble, as a measurement approach might be problematic for different reasons. For one, single matches often take a long time and are therefore uneconomical. Moreover, instructions are often complex and their presentation is not standardized between games. Also, cognitive components related to gameplay, such as figural, verbal, or numeric content domains, are usually not clearly and definably implemented and may be confounded with other features of the game. Accordingly, for the present study, we decided to create three separate tasks that are more suitable for assessment. In these tasks, two opponents compete in a face-to-face manner. Task contents were either predominantly figural, verbal, or numeric, relating to the content domains typical in intelligence tests (Jäger, 1984; Valerius & Sparfeldt, 2014). Other features, such as instructions, duration and other materials (as far as feasible) were matched.
We refer to the new tasks as cognitive dyadic measurements (CDM). Essentially, CDM are closely related to conventional dyadic board games. Their tasks are restricted by clear rules, defining potential actions, their sequences, and scoring. For obtaining multiple measurements within a limited time frame, single matches have strict time limits. Individual scores are obtained as average scores over multiple CDM matches, whereby each match is treated as the equivalent of one test-item, however, instead of the item content, only the opponent changes. More specific details about these features and the reasons for selecting them are given in the “Methods” section.
While CDM may only represent one of various measurement options, we think that their relation to both, board games and traditional ability tests, may be particularly useful. Specifically, their close relation to cognitive operations may facilitate analyzing competition-specific individual differences, by enabling us to isolate them statistically from cognitive ability. Furthermore, CDM allow for a high standardization and, because of their relation to board games, they offer a rich source of inspiration for task development.
Properties of CDM-Type Measures
While dyadic competitions are a well-established mode of assessment in other fields, they are only rarely used for cognitive/psychological measurements. In fact, competitive settings in general are scarce in this context. Exceptions are (group) discussions as part of assessment centers or, to a minor extent, gamified test materials with a competitive component.
This raises the question what specific properties CDM might have and whether the apparent neglect of such approaches might be justified. The amount of information for answering these questions is rather limited. However, some properties may be inferred from the board game and gamification literature.
Clearly, CDM are only useful if they yield incremental validity over already established measures. Because of the CDM’s cognitive component, a substantial amount of their variance may be explained by general mental ability (GMA). However, this assumption is not supported by prior evidence. On the contrary, cognitively demanding competitive games yielded only small correlation with GMA. A meta-analysis by Burgoyne et al. (2016) reports that correlations between GMA and chess scores are averagely 0.25. This result was roughly equivalent in experienced and unexperienced player collectives. A singular non-chess result by Lim and Furnham (2018), who considered the verbal game Taboo, reported a similarly small correlation with Raven’s progressive matrices of 0.33.
One might conjecture that these small correlations with GMA might result from the fact that test item content and competitive (game) tasks do not bear a strong resemblance. However, this conjecture appears unlikely because games without a human opponent usually yielded medium to large correlations with GMA (e.g., Buford & O’Leary, 2015; Quiroga et al., 2016; Sobczyk et al., 2015). Quiroga et al. (2015) even argue convincingly that typical game contents may be a viable replacement for conventional GMA measures, reporting a correlation of r = .93 between latent variables representing GMA and game scores.
So why do games with human opponents yield such poor correlations with GMA, although typical game tasks appear to represent GMA quite well? We conjecture that this may either be the result of (a) a lack of reliability or (b) differing construct validity.
Reliabilities may be comparably decreased because a computer opponent may act more standardized and, therefore, more reliable than continuously changing (and also developing) human opponents. Differences in validity, on the other hand, may be attributed to the additional social component in face-to-face competitions.
To the best of our knowledge, previous research on measures obtained in face-to-face competitions did not report reliabilities. One reason for this might be that most measures of internal consistency are not applicable to a competitive assessment situation, having opponents instead of items, including the partially dynamic way in which opponents are chosen.
With respect to validity, results, other than correlations with GMA, are rare.
Nomological Net
The forced social comparison, which is an essential component of competitions (e.g., Johnson & Johnson, 1989), suggests that opponents who are confident in social situations and who are motivated by competition, might have an advantage in competitive games (Berge et al., 2015). Accordingly, it has been suggested that personality traits associated with positive and stable emotion, such as high emotional stability or low neuroticism, might have a positive effect on competitive task performance (e.g., Lobel et al., 2014). While neuroticism may also have an impact on the performance in other tests, correlations are often small (r = −.08 to r = −.12 for measures of intelligence) and non-significant (e.g., Freund & Holling, 2011). In stressful situations, correlations are comparably increased but still largely insignificant (Dobson, 2000).
Moreover, test anxiety has been reported to reduce positive emotions and engagement during competitive games (Hong et al., 2015). Test anxiety has also repeatedly been negatively associated with performance in (cognitive) tests in general (Cheng et al., 2014; Hembree, 1988; Gaye-Valentine & Credé, 2013). Whether this relation differs between competitive and traditional test settings is uncertain.
Motivational variables may also account for some proportion of game success. Specifically, competition motivation has been regarded as an independent motivation facet (Tauer & Harackiewicz, 1999). However, its effect on success in competitive tasks is unclear. In addition, achievement motivation may also be related. For instance, achievement motivation was significantly higher in professional female chess players as compared to a non-professional collective (Vollstaedt-Klein et al., 2010).
Of course, results pertaining to gaming (particularly chess) may not apply directly to CDM. However, we conjecture that the setting and the type of measurement should be sufficiently similar to generalize the listed findings to some extent. Accordingly, we assessed the aforementioned other constructs in order to map a potential nomological net. Specifically, we assessed the Big-5 personality dimensions, test anxiety, competition as well as achievement motivation in addition to GMA. While relation with other board games might also have been interesting for establishing the nomological net, we did not include them in our study for the same reasons that have be outlined in the “Competition-specific Measurements” section.
The Present Study
The present study investigates CDM as an approach for assessing individual performance differences in a competitive setting. Specifically, we conducted a comprehensive first evaluation, including analyses of reliability and construct validity. For the construct validation, we hypothesize that CDM scores have substantial correlations with (a) task related measures and (b), beyond that, with measures that address the competitive component. Specifically, based on the results presented in the previous subsection, we expect (a) positive correlations of CDM scores with GMA as well as (b) positive correlations with competition and achievement motivation, and negative correlations with test anxiety and neuroticism.
Note, that while finding the expected pattern of validities does not unambiguously constitute that CDM measure a competition-specific component, it would substantiate the assumption’s plausibility. In turn, not finding any plausible validities beyond GMA would cast doubt on the feasibility of measuring competition-specific individual differences, at least for the present CDM.
For further analyzing a potential competition-specific component, we used structural equation models (SEM). Specifically, applying a bifactor approach (Eid et al., 2003; Johnson et al., 2004; Valerius & Sparfeldt, 2014), we separated the information of the CDM into a content-specific factor, representing the cognitive component, and a method-specific factor, addressing the competitive component. Moreover, based on results of the previous construct validation, we investigated the validity of the competitive component.
To the best of our knowledge, the present study is the first investigating performance in cognitively demanding competitive tasks, which have been specifically designed for psychological assessment. It is also the first study conducting a broad construct validation (e.g., DiStefano & Hess, 2005) for competitive success beyond measures of cognitive ability or directly related constructs. Thus, in addition to evaluating CDM as an assessment approach, the present study might provide useful information on potential predictors for competitive success.
Method
In the following, the three newly developed CDM as well as design and variables of our validation study are outlined.
General CDM Construction
Four Steps of Test Construction According to Wilson (2005).

In addition to the general decision that CDM are conducted in a dyadic and face-to-face manner and that they relate to the three content domains (verbal, numeric, and figural) that are common in both tests and games (e.g., Jäger, 1984; Valerius & Sparfeldt, 2014), several specific decisions with respect to design were required, which are outlined in the following.
General CDM format
We decided for a matrix layout, because it is common in intelligence tests and board games. Figure 1 gives an example for each of the three CDM respectively. Exemplary constellations for the figural, verbal, and numeric CDM (from left to right).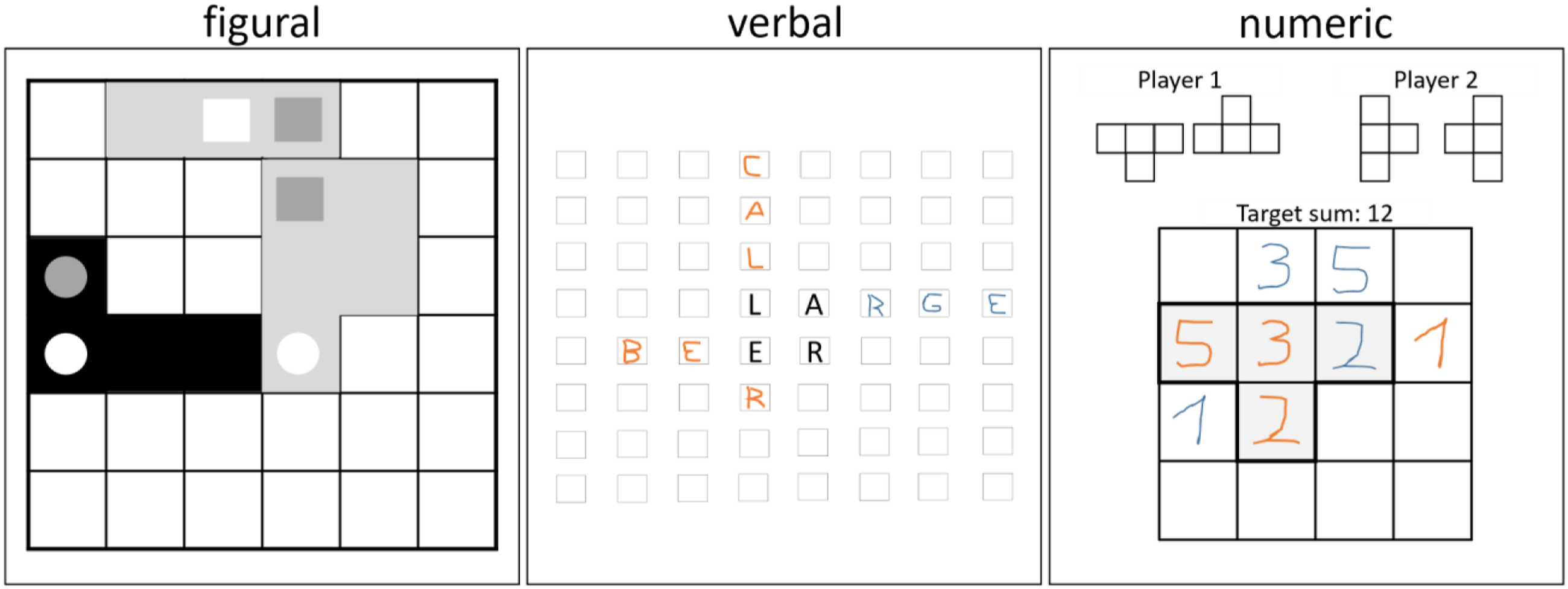
Time limits
Matches, as well as individual moves were restricted by predefined time limits. This was necessary to allow for an organized and simultaneous CDM administration in a round-robin design as well as time-efficient testing. While the time limits automatically introduce a speed component, we tried not to pronounce this component too much, providing enough time for reflected moves.
Stochastic properties
Results should not be stochastically determined early within a match and starting players should not have an advantage. Hereby we relayed on traditional guidelines for test construction (Eid & Schmidt, 2014).
Reward
We did not give any additional incentive beyond being declared “match winner.” We conjecture that in this way an intrinsic motivational component may contribute to individual outcomes. For the sake of standardization, we decided against additional reward, because their impact could differ across contexts and would be hard to control for in this particular study design. We did, furthermore, not provide win-lose information beyond single matches because this was practically unfeasible.
Instructions
Instructions were generated with particular care to ensure that differences in scores were due to differences in ability and not in knowledge of rules. For each CDM, instructions took between 15 and 20 min. Materials included (i) a written sheet with rules, (ii) instruction videos, (iii) training rounds, and (iv) a chance for participants to ask final questions.
Time limits as well as stochastic properties were optimized successively during the construction process by repeatedly putting the CDM to the test. Furthermore, a small preliminary study was carried out with N = 6 participants who played the first versions of the CDM and were asked to “think aloud” while doing so. Observed misinterpretations of rules as well as the results of subsequent interviews with each of the participants provided valuable insights in their understanding of the instructions, helping us to revise some of them.
The Three CDM
Figural CDM
The figural CDM used a 6 × 6 matrix field. Next to the matrix lay an assortment of tiles of different forms, fitting the matrix field size. Each participant was given an identical set of tiles, differing in color only (red vs. blue). On these forms a selection of symbols was printed determining rules for connecting them. An example is given on the left panel of Figure 1. There were five different sets of tiles, which were rotated between rounds.
For 90 s, participants alternately placed their tiles on the matrix. Tiles of a respective color needed to be connected to each other. In addition, participants had to adhere to specific symbol matching rules. The participants were asked to try to restrict the number of tiles the opponent was able to place and to use as many of their own tiles as possible. The participant who was able to place the last tile won. To keep our presentation concise, we included the matching rules in the electronic supplementary materials of this article.
Verbal CDM
The verbal CDM used a 6 × 8 matrix field (see middle panel of Figure 1). Four letters were already given in a 2 × 2 arrangement in the middle of the matrix (a new combination for each match). Participants had to alternately add single words to the fields in a fixed 15 s time frame using pens of different color to distinguish originators. Each match had six rounds.
Valid words and combination had to satisfy a set of specific rules. If a participant failed to add a word within 15 s, the other participant was declared the winner. If a participant was faster than 15 s, the opponent had, nevertheless, to wait her/his turn. The participant who added the last valid word won. If, however, the sixth round was also completed successfully, a bonus round was used to determine the winner. In this round both participants were allowed to insert a word. The participant who first added a valid word was declared the winner. To keep our presentation concise, we included the extended rules in the electronic supplementary materials of this article.
Numeric CDM
The numeric CDM used a 4 × 4 matrix. Participants were asked to alternately insert integers from 1 to 5 into the fields. One match took 80 s. The goal of each participant was to reach a predefined sum of integers within a certain arrangement of fields. The target value for the sum score was changed for each match, ranging from 8 to 16. The arrangement of fields for the first participant resembled a “T,” that is, three horizontal fields plus the field below the second field in line, as well as its 180-degree rotation (see right panel of Figure 1).
Participants were asked to try to reach more sum scores than the opponent by selecting strategically sensible integers. Again, to keep our presentation concise, extended rules are included in the electronic supplementary materials of this article. In contrast to the two previous CDM, the evaluation of results was performed by a program instead of the participants themselves to ensure accuracy.
Scoring procedure
For each CDM, an average person score was calculated. Specifically, the score was the mean of the single match outcomes, coding a won match with +1, a draw with 0, and a lost match with −1. Thus, a person score ranging from −1 to +1 was obtained. Using the mean instead of the sum was necessary to account for differences in the number of matches between sessions.
Clearly, similarly to grading on a curve or scores in assessment centers, this scoring approach is group normative. Thus, individual scores always depend on the average ability of the competitors.
Participants
Participants were recruited from the undergraduate students at the department of Psychology of a mid-sized German university. We based a prior sample size estimation on detecting true correlation coefficients of 0.30 on a two-sided α-level of 5% and a power of 80%, requiring a minimum of 85 complete cases. Adjusting for multiple testing was not conducted because the present study is an exploratory correlation study. We used a correlation of 0.30 as reference because prior studies investigating relations of GMA and competitive board game success seldom reported larger values (e.g., Burgoyne et al., 2016; Lim & Furnham, 2018). Anticipating dropouts, we decided to invite 100 students to participate in five sessions of 20 participants each.
For assigning students to the five appointments, they were asked to select feasible dates from a predefined schedule. Afterward, each of the participants was randomly assigned to one of the selected dates. If the number for an appointment was larger than 20, superfluous participants were randomly excluded.
The number of actually participating students for each of the five sessions was 18, 16, 17, 19, and 21, respectively, that is, overall 91 students participated. For sessions 1 and 4, each missing participant was excused. For sessions 2 and 3, two of the missing participants were not excused respectively. One participant missing in session 2 participated in session 5 instead.
Of the 91 participants, 87 completed an additional online survey containing several validation measures. Of these participants 72 (82.76%) were female. The mean age was 20.82 years (SD = 2.55). 11 participants (12.64%) were left-handed. All participants were German native speakers. Demographic variables did not differ significantly between the five sessions, based on a significance level of 5%.
Procedure and Variables
The study was split into an online survey, in which participants completed a series of questionnaires and tests, and five separate group session in which the CDM were conducted. For matching results from the two parts, participants generated a person-specific eight-figure code (ID) to ensure anonymity of results.
Online survey
Tests and Questionnaires Used in the Online Survey.
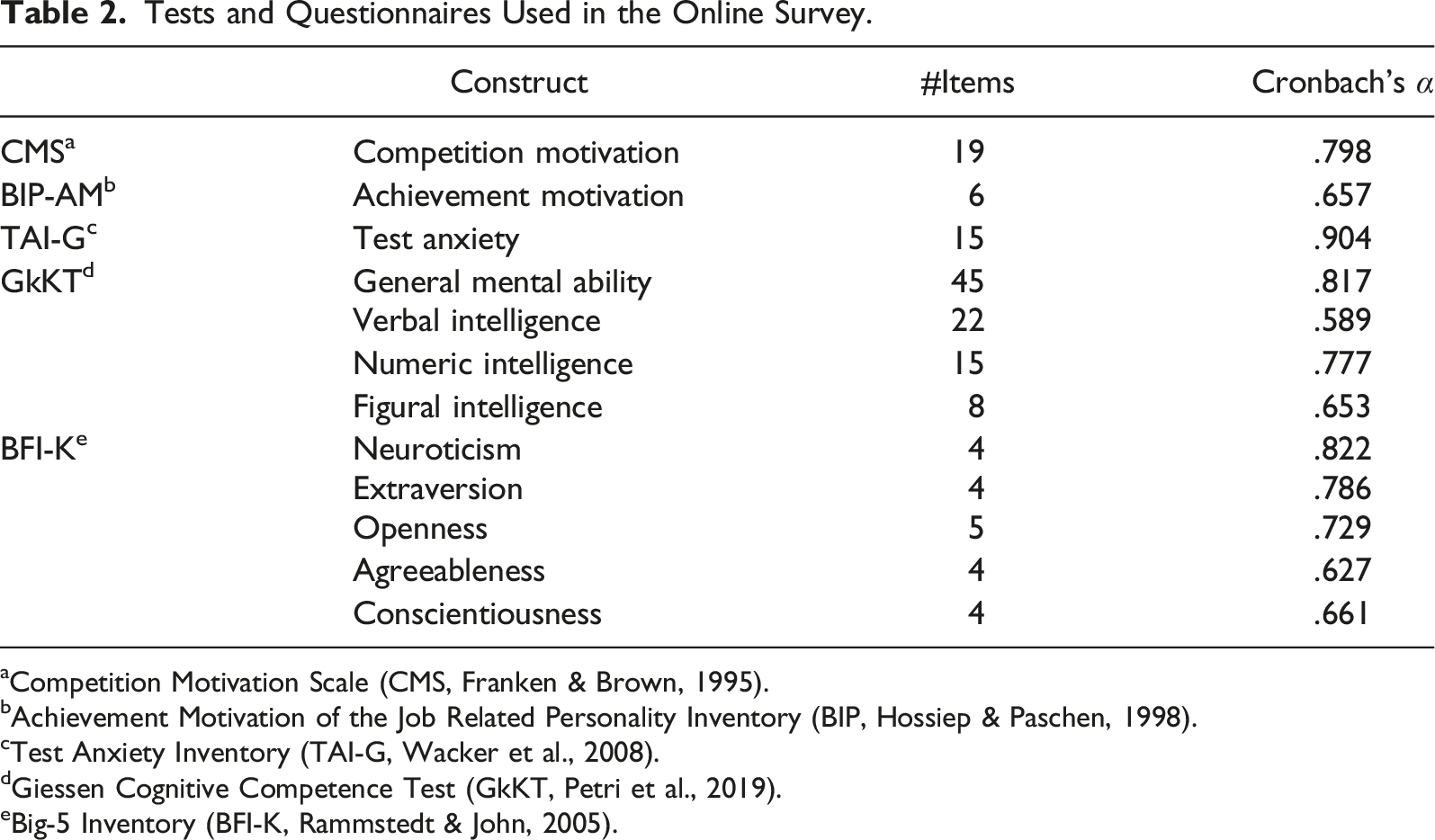
aCompetition Motivation Scale (CMS, Franken & Brown, 1995).
bAchievement Motivation of the Job Related Personality Inventory (BIP, Hossiep & Paschen, 1998).
cTest Anxiety Inventory (TAI-G, Wacker et al., 2008).
dGiessen Cognitive Competence Test (GkKT, Petri et al., 2019).
eBig-5 Inventory (BFI-K, Rammstedt & John, 2005).
CDM session
The CDM session took about 3 hours in which participants competed in a round-robin design. 1 The time was divided into three blocks of similar duration. First, the figural, then the verbal and finally the numeric CDM were conducted.
During the entire study, three investigators were present.
Each of the sessions was conducted uniformly between 9:00 and 12:00 a.m. They took place in seminar rooms, in which tables were spaciously arranged in an oval shape. For the very first round of every CDM, the seating arrangement was randomly selected. Opponents were seated on opposite sides of separate tables. The materials required for the first CDM were positioned in front of them. Prior to the subsequent two CDM, they were replaced while participants were allowed a 5 min break.
Opposite sides of the tables were color coded in blue and red respectively in order to facilitate further instructions. This included all materials as well as pens used for score notation. Participants on the red table side had the first move. Colors were arranged in order to balance the privilege of having the first move.
Additionally, participants were given a rating sheet for documenting CDM evaluation and their pulse rate. The latter was self-assessed prior to the CDM and in the middle of each of the CDM, within a time frame given by the instructor. The CDM acceptance evaluation questionnaire (adapted from the acceptance questionnaire by Kersting, 2005) contained five six-categorical items measuring comprehensibility of instructions and experienced strain during measurements, using two items each, as well as an overall quality rating of the CDM.
Quality Assurance
To ensure the quality of the data, we took several precautions. After data entry, 10% of the cases were randomly selected and cross checked. Moreover, we conducted several plausibility checks. For instance, we checked whether the number of times participants had the first move was balanced, as well as whether there were no repeated ID combinations within games. We also checked whether the average game score of the three games was 0.0 for each of the five session, which was determined by the design of score calculation.
Results
In the following, distributional properties, acceptance ratings, reliability, and validity of the CDM are considered. Moreover, results of structural equation models (SEM), analyzing a competition-specific component, are presented.
All analyses were performed using R (R Core Team, 2021). The SEM were fitted using the R-package lavaan (Rosseel, 2012).
CDM Scores
CDM scores were restricted to a range of −1 (all rounds lost) to +1 (all rounds won). The observed scores of the figural CDM ranged between −0.67 and 0.67, for the verbal CDM between −0.71 and 0.86, and for the numeric CDM between −0.38 and 0.54. The distribution of scores was close to normality, which may be concluded from the QQ-plots displayed in Figure 2. QQ-plots of person scores of the three CDM.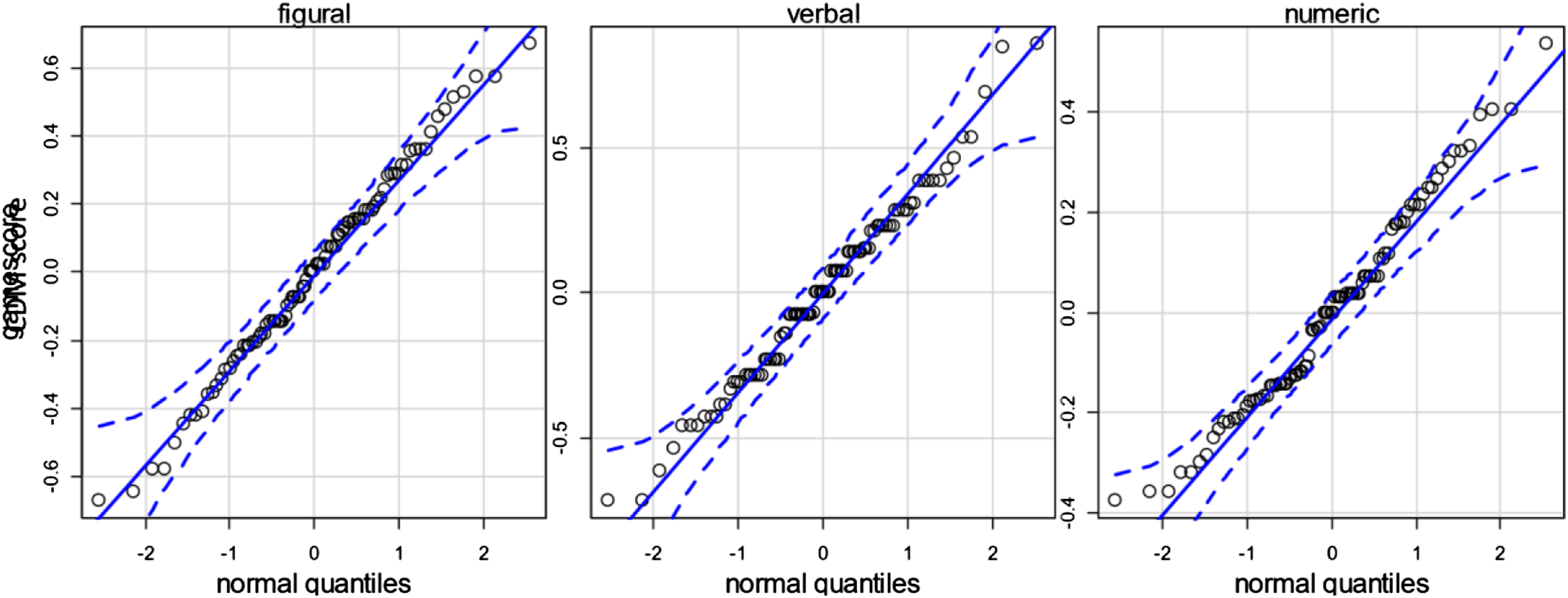
Acceptance Evaluation
Mean and Standard Deviation of CDM Acceptance Evaluation Scores.

Notes: Ratings ranged from 1 (not at all true) to 6 (absolutely true), and for “strain of tasks” from very low to very high.
Reliability
Split-Half Reliability of CDM Scores for Two Different Split-Types.

Validity
Correlations among CDM scores were generally small. The correlation between verbal and numeric CDM was r = 0.26 (p = 0.012), between verbal and figural CDM it was r = 0.17 (p = 0.098), and between numeric and figural CDM it was r = 0.18 (p = 0.085).
Pearson Correlation of CDM Scores and Validation Measures.
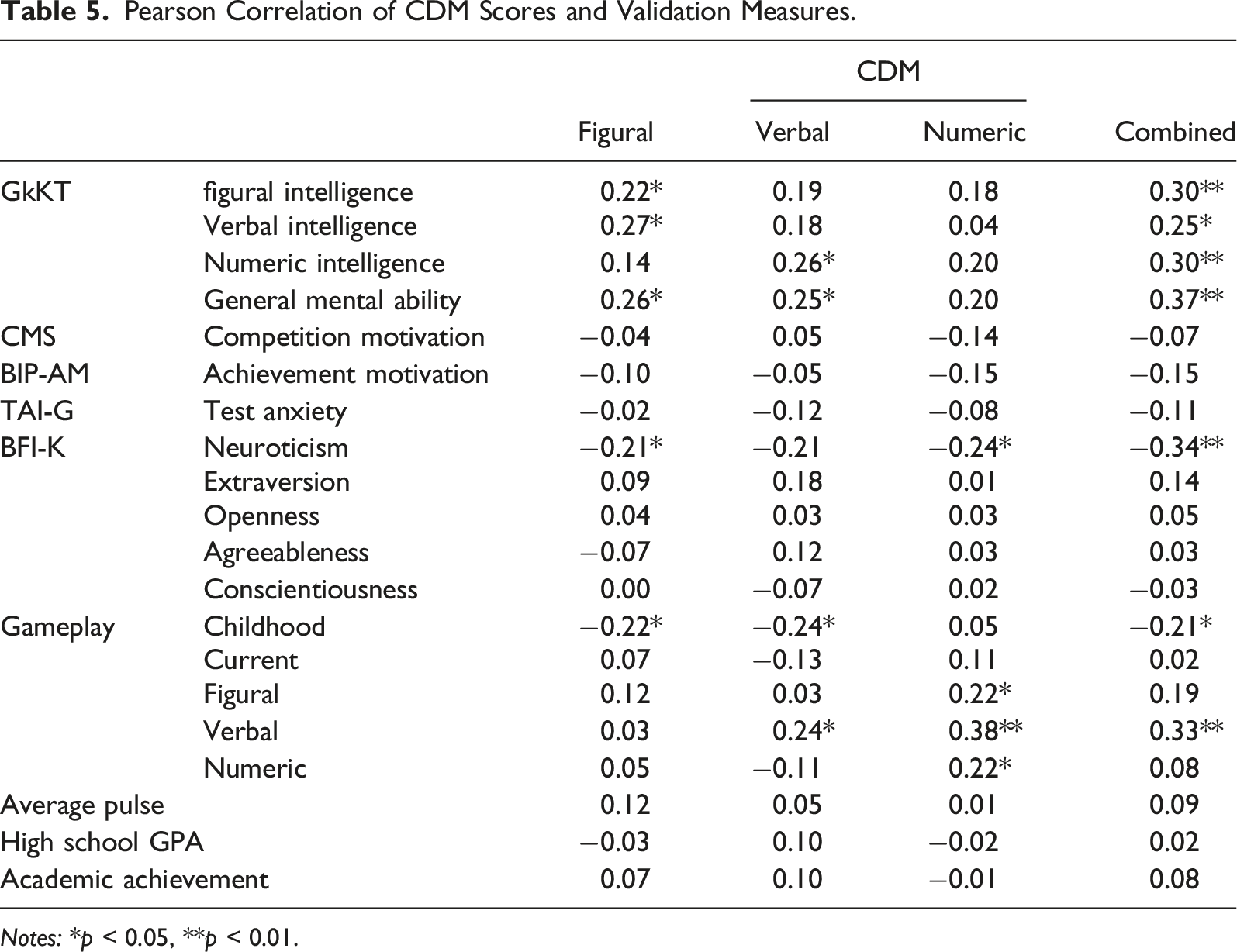
Notes: *p < 0.05, **p < 0.01.
Correlations with intelligence were small but significant. A maximum correlation of r = 0.37 (p < 0.001) was obtained for the combined CDM score and the measure of GMA. Single CDM and intelligence scores correlated homogeneously with each other, without yielding particularly increased coefficients for scores pertaining to matching content domains.
Contrary to our expectations, neither competition nor achievement motivation were related to CDM. However, it is notable that the correlations’ signs were continuously negative, implying that larger motivation scores were predictive for slightly decreased CDM scores. Similarly, test anxiety was not significantly related to CDM.
Considering correlations with the Big-5, only neuroticism yielded significant correlations. The generally negative correlations with neuroticism, ranging between −0.34 and −0.21, show that participants with higher values had slightly lower CDM scores.
Interestingly, participants with a higher frequency of competitive gaming in childhood achieved slightly decreased figural and numeric CMD scores, as indicated by the negative correlations of r = −0.22 (p = 0.038) and r = −0.24 (p = 0.024) respectively. Experience with verbal games, on the other hand, was predictive of increased scores in the verbal and numeric CDM, yielding correlations of r = 0.24 (p = 0.027) and r = 0.38 (p < 0.001) respectively. Finally, neither pulse rate nor high school GPA or the self-assessment of academic achievement were significantly related to CDM. An overview of the correlations is given in the electronic supplementary materials of this article.
Latent Factor Structure
For isolating a competition-specific factor from the CDM scores, we fitted a sequence of three hierarchically nested SEM. Note that, due to model-identification constraints, we did not include specific latent variables pertaining to verbal, numeric, and figural content (e.g., Johnson et al., 2004; Valerius & Sparfeldt, 2014).
Model 1 considers a bi-factorial structure in which CDM scores are connected to general mental ability (GMA) and an orthogonal competition-specific factor. Specifically, indicators of GMA are the three intelligence scores as well as the CDM scores. The CDM scores are also indicators of the second factor denoted as “competition.” The model structure and parameter estimates are displayed in Figure 3. Model structure and standardized parameter estimates of the three SEM for extracting and explaining the competition-specific component of the CDM. Significance levels: ∗ = p ≤ .05 and ∗∗ = p ≤ .01 (GPE = gameplay-experience).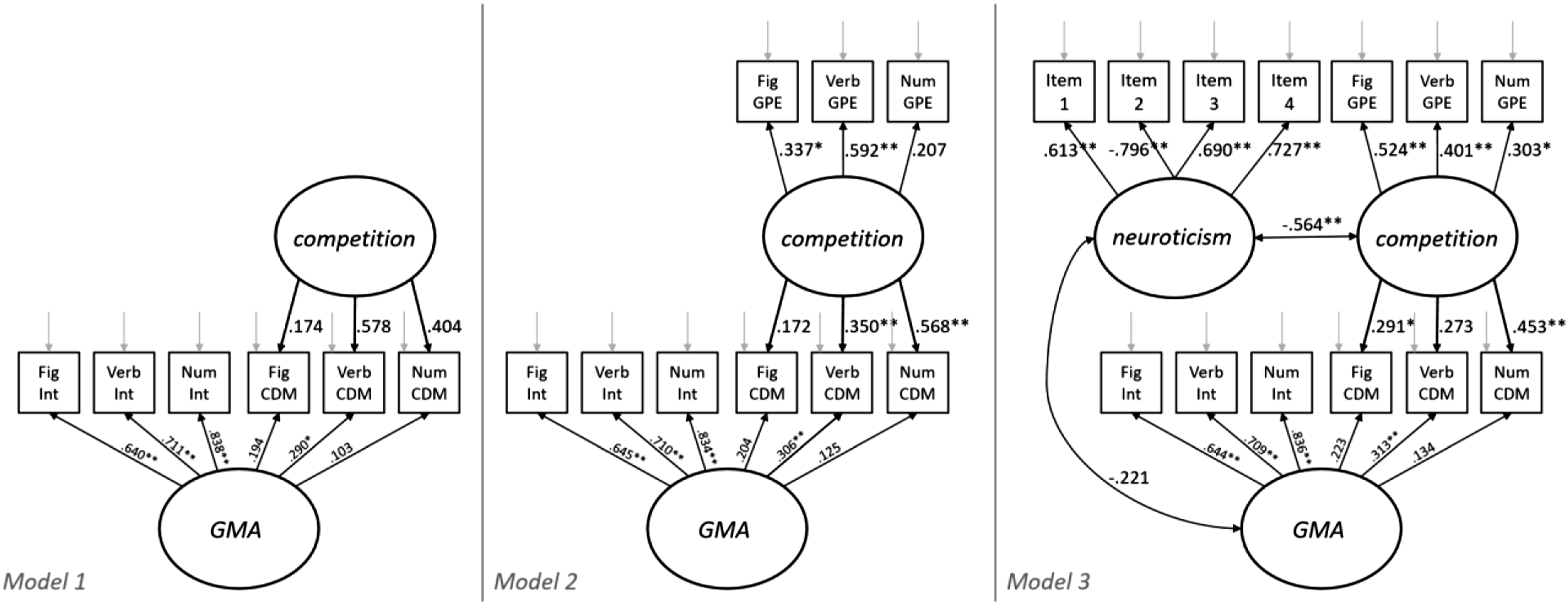
Model 1 fits the data very well, yielding a model test of χ2(6) = 3.340 (p > .05) as well as RMSEA = .000 with a 90%-confidence interval with limits of .000 and .096, CFI = 1.000, and TLI = 1.086. Loadings pertaining to CDM scores are consistently positive.
Accordingly, both model fit and parameter estimates support the bi-factorial solution for CDM scores. However, the loadings pertaining to the CDM score are consistently small, which is in accordance with the generally small validities outlined before. Specifically, only the verbal CDM yields a significant association with GMA.
Model 2 adds the three competitive gameplay experience variables (GPE) as indicators to the competition factor as compared to model 1. By including these indicators, it can be examined whether the systematic variances among CDM scores (that are independent from GMA) relate to a competition-specific component. Indeed, the updated model closely fits the data, yielding χ2(24) = 22.676 (p > .05) as well as RMSEA = .000 with 90% confidence limits of .000 and .080, CFI = 1.000, and TLI = 1.021. Thus, it is plausible to assume that the second factor measures a competition-specific component. Overall, the model’s parameter estimates that were already contained in model 1 do not change significantly (see Figure 3).
Model 3 introduces neuroticism as a third factor, using the four corresponding BFI-K items as indicators. By linking neuroticism to GMA and competition, the plausibility of the corresponding correlations can be considered with respect to factorial validity. Again, the fit is very good, yielding χ2(59) = 59.368 (p > .05), RMSEA = .008 with 90% confidence limits of .000 and .065, CFI = .998, and TLI = .999. The correlation between neuroticism and competition is strongly negative, yielding a significant value of −.564 matching the expected relation. In turn, the correlation between GMA and neuroticism is non-significant, yielding a small negative value of −.221.
All of the models support the assumption that CDM measure both competition-specific and GMA-related information. However, while the connection to the competition component is substantial, yielding significant loadings for all three CDM scores in at least one of the models, the connections to GMA is consistently weak for two of the CDM. Only, the verbal CDM yields consistently significant standardized loadings on GMA.
Discussion
The present study was conducted to set a sensible starting point for systematic research exploring individual differences in cognitively demanding competitions. We developed three cognitive dyadic measurement (CDM) tools, combining features of cognitive ability tests with a competitive component. The new CDM were evaluated considering acceptance, reliability as well as construct validity, including structural equation models (SEM) for distinguishing content- and competition-specific components.
Overall, acceptance and understandability of instructions of CDM tasks were rated very highly by the participants. The strain of CDM tasks was rated moderate to low.
Reliabilities of CDM scores were rather low, yielding coefficients between .350 and .553. Validities did partly match our hypotheses: As expected, GMA scores yielded small to moderate positive correlations with CDM scores. The size of these validities was close to values reported in the few previous studies investigating competitive board games (e.g., Burgoyne et al., 2016; Lim & Furnham, 2018). The numeric, verbal, and figural CDM did not yield distinctly increased correlations with GMA measures with corresponding content. This might be due to relatively large standard errors of correlation coefficients due to sample size and the fact that all CDM were presented in a matrix format, which may have introduced an identical figural component to all scores.
Furthermore, as hypothesized, neuroticism was negatively correlated with CDM scores. Additional positive validities were observed for competitive gameplay experience. Contrary to expectations, neither test anxiety, nor competition or achievement motivation correlated significantly. However, the affected test power due to the low reliabilities of CDM scores needs to be taken into account.
The SEM results suggest that systematic variances among CDM are well explained by two components: GMA and a competition-specific component. While loadings on these components were only small to moderate, the loading pattern of the other indicators and the correlations among latent variables support the substantive interpretation.
Critical Considerations
The present results––while providing useful information with respect to the CDM approach as well as personality attributes beyond GMA that appear to be relevant for succeeding in competitions––should only be considered as preliminary. Because CDM represent only one specific type of competition measurement and validation variables were restricted to psychological constructs, generalizations of the present results may be overly optimistic.
While the SEM supports a bi-factorial solution for the CDM, it cannot be precluded that other constructs (such as memory, concentration, or crystallized intelligence) may explain additional CDM variance. Although previous literature does not indicate that other cognitive abilities beyond GMA are relevant (e.g., Quiroga et al., 2015), it might be worth conducting a more comprehensive validation, considering the small validity coefficients in the current sample. Moreover, validating the latent competition variable with competitive gameplay experience may be considered critically. While this variable certainly includes competition-specific aspects, other alternative interpretations might be plausible as well. Future research should include a wider selection of different competition indicators for a more comprehensive validation of this aspect.
On a different note, the small sample size, although sufficient for verifying substantial correlations, led to a reduced precision of coefficients. Particularly, because of the comparably small validity coefficients, future studies should increase sample size. This also holds true for the SEM. While the fit indices indicate that the models fit well, their reduced precision needs to be considered with caution. Thus, any specific results should be considered as preliminary until they have been validated in larger samples. However, before more extensive data collections are conducted, the measures’ limitations with respect to reliability should be resolved.
Desiderates for Further CDM Development
Clearly, the usefulness of CDM is reduced due to their limited reliabilities. While they may be attributed in part to restrictions of range due to the student sample, the adequate reliabilities of the GMA measures show that better coefficients could have been obtained. We conjecture that the dynamic features of CDM are among the central reasons. Specifically, having a human opponent who can develop during the course of the measurement and, for instance, change strategies, might inevitably result in increased measurement error.
While these dynamic features are difficult to control directly, there are options to partially improve reliabilities. One option is to increase the number of matches. An acceptable reliability of 0.80 for the verbal task, which had a reliability of approximately 0.55 based on averagely 17 matches, would require 56 matches based on the Spearman-Brown prediction formula. If one match takes 2 minutes, about 2 h would be required.
Also, some of the negative effects on reliability may be lessened by an extended training phase. If all participants have a substantial amount of training, there might be less development within the actual measurement phase and, therefore, the sequence of opponents would be less influential. Moreover, a training phase would reduce the impact of gaming experience differences. However, it has to be noted that we already provided comprehensive instructions and a short training phase, which, in total, took 15–20 min per CDM.
Another option for improving reliability is to improve the CDM tasks themselves. The difference in reliability between the three CDM clearly shows that the type of task matters. While all CDM were used correctly by the participants, we observed that the time limit for each round might have had an impact. Particularly in the numerical CDM, several participants inserted the numbers rather hastily, requiring less than half of the available time. Consequently, differences in ability might not have been given the chance to manifest appropriately. The verbal CDM, having the highest reliability, decelerated the process somewhat by setting a fixed 15-second period for entering a single word. However, this remains a conjecture because multiple influencing factors are confounded.
Another difference between the three CDM was the inter-connectedness of moves. In the verbal CDM, it often appeared sufficiently challenging to insert a new word, ignoring its strategical impact on the opponent’s moves. In the figural CDM, the effects of moves were more interwoven. With placing a tile, participants were able to restrict the opponent’s and to keep their own options. In the numeric CDM, we perceived the inter-connectedness most strongly, because collecting points depended on the results of multiple rounds. We think that the larger the inter-connectedness of moves is, the more complex and/or random the scores may be. While this conjecture is supported by the pattern of reliabilities, further evidence is needed for verification.
Outlook and Recommendations
The present pilot study pursued two objectives: creating measurement approaches as well as extracting and validating a competition-specific component. With respect to the first objective, we think that while the CDM have provided valuable results, they are not yet suited for individual assessment, because of their reliabilities. While we provided some suggestions for improving them, it might be particularly challenging to improve CDM up to the quality standards of traditional test procedures. Additional studies examining the relation between the three newly developed CDM and existing board games (e.g., Scrabble) could be considered another next step of exploring the nomological net.
With respect to extracting a competition-specific component, we are confident that CDM can be useful. Analyzing the validity of the competitive component may provide new insights into the nomological network that appears to play an important role for success in competitive situations. However, further research is certainly required for substantiating our understanding of the competitive component.
In addition to the simple win-lose-scores, CDM may also provide valuable behavioral information. While––for the sake of participants’ anonymity––we did not collect person-specific behavioral observations, such an addition might be valuable. Also, a more detailed assessment of previous gameplay experiences may be beneficial, allowing to analyze more specific relations, such as, for instance, between “Scrabble” and the verbal CDM.
Besides the practical desiderates for CDM revision, we hope that the present study sets a starting point for systematical research on the effects that game-like attributes (like a competitive component) have on the assessment of abilities or traits required for a specific operation or task as it appears unwarranted not to pay attention to potential effects it can have on the assessment.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.