
Abstract
Consequential validity (often referred to as “test fairness” in practice) is an essential aspect of educational measurement. This study evaluated the consequential validity of the Research-Based Early Mathematics Assessment (REMA). A sample of 627 children from PreK to second grade was collected using the short form of the REMA. We conducted two sets of analyses with different foci (item- or scale-level) for validation: differential item functioning (DIF) and consequential validity ratio (CVR) analyses. The analyses focused on the demographic subgroups of gender, English Language Learner status, and race/ethnicity. We found a low percentage of DIF items (less than 3%) and high CVRs (ranging from 96 to 98%). Both findings support the consequential validity and thus “fairness” of the REMA.
Keywords
Introduction
Early mathematics cognition has been shown to be a fundamental cognitive ability that substantively influences students' success in multiple academic domains (e.g., science, technology, engineering, and math [STEM] as well as literacy skills, Clements & Sarama, 2011; Duncan et al., 2007; Purpura et al., 2017) including important long-term outcomes (e.g., high school achievement, Watts et al., 2014). Due to an increased amount of attention devoted to early mathematics, researchers have recognized the need for high-quality math assessments for young children, especially assessments that provide a comprehensive and consistent evaluation from preschool through the primary grades. In response to this critical need, Clements and colleagues (Clements et al., 2008/2019a have conducted empirical studies to develop and validate the Research-based Early Mathematics Assessment (REMA), an instrument that measures the early mathematical competency of children from 3 to 8 years of age. In addition to the original full version, a short-form version of the REMA (i.e., REMA-SF) has been developed and validated to have a shorter assessment time and a higher level of efficiency during its administration (Dong et al., 2021).
Consequential validity, or the degree of score uses and interpretations that can support justified and fair decisions (Messick, 1995), has been recognized as an essential aspect of testing practices by many researchers and psychological professionals (e.g., AERA/APA/NCME, 2014; Dumas et al., 2022; Iliescu & Greiff, 2021). The REMA is a major measurement tool in early childhood research, and previous studies have demonstrated its internal and external validity using a variety of methods (Clements et al., 2008b; Dong et al., 2021). However, the consequential validity and fairness of the REMA has not been comprehensively investigated. Given that the justification of a measure’s consequential validity usually requires multiple sources of supporting evidence (Messick, 1995; Mislevy, 2018), the current study conducts two sets of analyses with different foci (item- or scale-level) to produce evidence and evaluate the consequential validity of the REMA.
Methods
Participants
The data used in this study were derived from the Development and Research in Early Mathematics Education (DREME) Network study (Coburn et al., 2018). The analytic sample consists of longitudinal math data for 627 children from PreK spring to second grade-Fall. These children were students at two large public-school districts in the western United States: 51.0% were female, and 30.5% were identified as English language learners (ELLs). Regarding their race or ethnicity, 66.1% of children were Hispanic, 9.3% were African American, 13.7% were Asian and Pacific Islander, 4.4% were non-Hispanic White, .8% were American Indian or Alaskan Native, and 5.6% were multiracial.
Measures
The data in the present research were collected using the REMA-SF. In the previous development study of the REMA-SF (Dong et al., 2021), multiple sources of validity evidence were established, such as sufficient content coverage, clear unidimensionality, good model-data-fit indices, as well as satisfying reliability and separation. Moreover, in the same investigation, this evidence was well-replicated to an external sample, which demonstrates that the validity of the REMA-SF is generalizable (i.e., cross-observer validity).
The REMA-SF consists of 80 items ordered by their Rasch difficulty parameters. Measuring young children’s math cognition can be challenging because children’s attention spans are relatively short; therefore, the administration of the REMA-SF applied a start, basal, and stop rule. Children began the assessment at the designated start points for each grade level. A basal level was established in which children received at least three consecutive items correctly, and they stopped after three consecutive errors. To avoid the confounding effect of language on children’s math scores, ELLs may receive the test in an alternative language version (e.g., Spanish). This also supports the consequential validity of the measure, particularly the interpretation of the construct scores.
The REMA-SF assesses correctness for each item and records students' strategies (i.e., problem-solving processes) when those are observable, and strategies were recoded into three levels of sophistication. Given that the strategies children use in solving mathematical problems are a critical component and reflection of their math learning (e.g., Biddlecomb & Carr, 2011; Fennema et al., 1998), both correctness and strategy codes (133 indicators in total) were used for scoring children’s math competency via a unidimensional partial credit Rasch model. We found a person reliability of .93 and a separation of 3.58 in this sample, which indicates that the REMA-SF scores were highly reliable (Wright & Masters, 1982). The strategy items allow a better differentiation among students with various levels of math competency (Clements et al., 2008b; Dong et al., 2021), and provide more effective and specific feedback regarding children’s learning to stakeholders (e.g., teachers) compared to item correctness only. Such cognitive-process feedback derived from children’s test scores can be perceived as major evidence for consequential validity (Iliescu & Greiff, 2021), because it may positively contribute to instruction and children’s future learning outcomes (e.g., amplify the effect of differentiated instruction or set more accurate learning goals for each child).
Analysis Overview
The current study examines the consequential validity evidence from both the item and scale levels. The item-level evidence was generated from conventional differential item functioning (DIF) analyses with the Rasch model (Holland & Wainer, 1993). A DIF item that yields different score patterns over subgroups even when the overall latent score is held equal is perceived as an indicator of measurement bias (e.g., ELLs perform worse than expected on specific items). In this study, we assessed DIF on the REMA-SF over the following demographic subgroups: gender, ELL, and race/ethnicity (recoded into non-Hispanic white = 0, and racial/ethnic minorities = 1), and all DIF analyses were performed via Winsteps 4.6 (Linacre, 2021).
In contrast, the scale-level evidence was produced via the Consequential Validity Ratio (CVR, Dumas et al., 2022). Although recently formalized, this index was inspired by past regression-based methods for examining test fairness (e.g., Millsap, 2011). The CVR is designed to capture how well the scores from a given test can predict a criterion free from the undue influence of examinees' demographics. Statistically, CVR is the ratio of the effect size of a focal measure (e.g., REMA scores) to the total variance explained by the test scores and participant demographics combined

Results and Discussion
Item-level Consequential Validity Evidence from DIF Analyses
Summary of DIF Analyses Results.
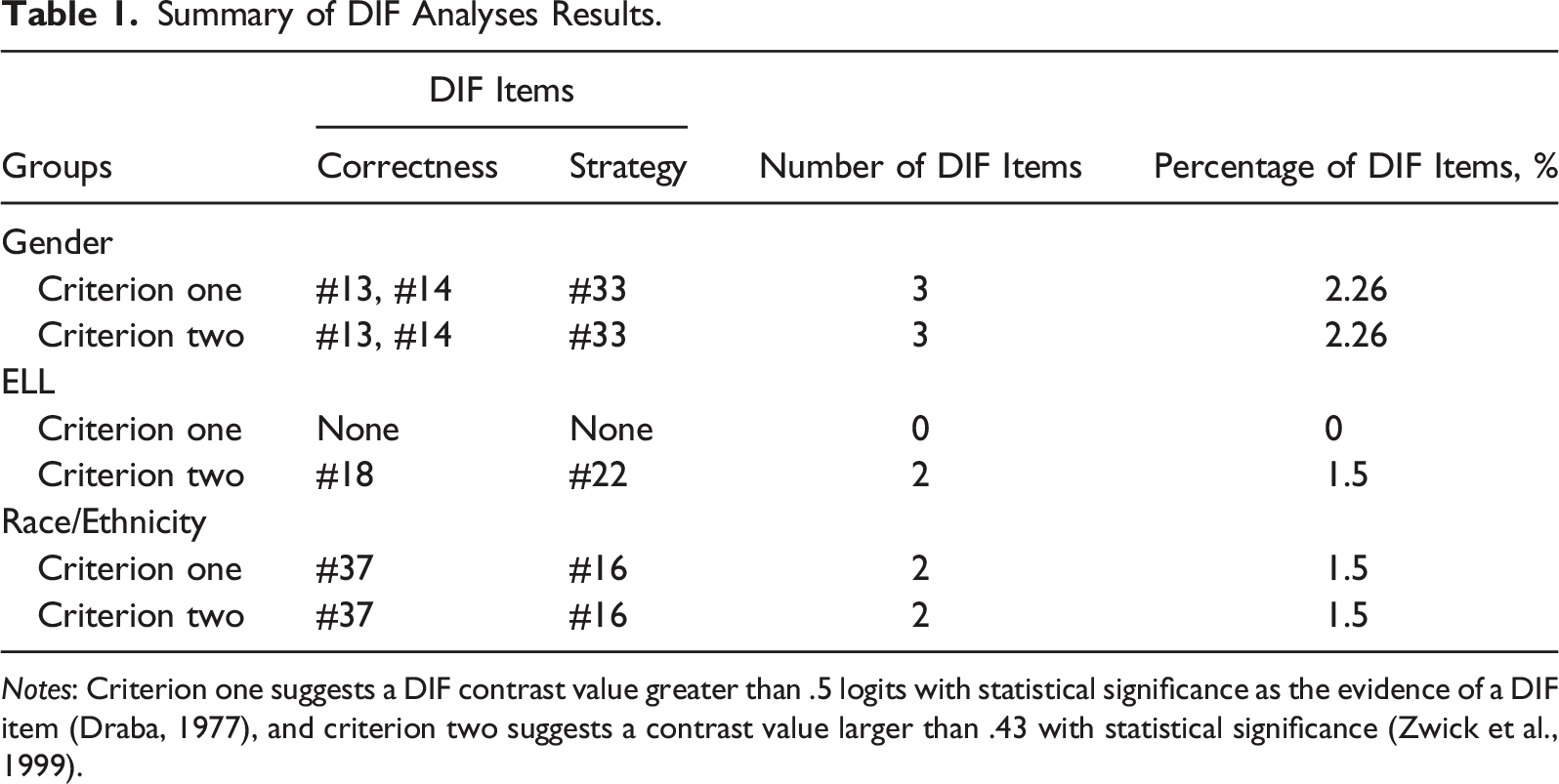
Notes: Criterion one suggests a DIF contrast value greater than .5 logits with statistical significance as the evidence of a DIF item (Draba, 1977), and criterion two suggests a contrast value larger than .43 with statistical significance (Zwick et al., 1999).
Moreover, Student’s t tests were used to examine statistical significance, and associated degrees of freedom were calculated via a joint approach (i.e., joint df; Satterthwaite, 1946; Welch, 1947). This study performed three DIF analyses (i.e., over gender, ELL, and racial groups). Notably, there are a total of 133 scoring indicators in the REMA-SF, so each set of DIF analyses tests 133 null hypotheses: indicator (1, 2, 3…, or 133) has the same difficulty for two groups. Such a large number of hypothesis tests might lead to Type I-error inflation. Instead of applying potentially overly conservative correction methods (e.g., Bonferroni correction), we set the alpha level to .01 to control Type I-error.
An item was identified as DIF when the contrast value was over the mentioned criterion and yielded statistical significance. From Table 1, we found three DIF items (2.26% of the items) over gender groups and two DIF items over racial/ethnic groups (1.5%), and the DIF results based on the two criteria were consistent. There was no DIF item over ELL groups with criterion one, but two DIF items (1.5%) were identified based on the second criterion. Overall, the number or percentages of DIF items are minimal in the REMA-SF, which means that the overwhelming majority of items in this measure work similarly across different subgroups. Furthermore, the small amount of DIF items does not necessarily indicate the items are of bad quality but could have reflected differences in the construct meaning across populations (Church et al., 2011). For example, one strategy item showed DIF over gender groups. Many studies have documented substantial gender differences in strategy use in the context of early mathematics (e.g., Carr & Jessup, 1997; Fennema et al., 1998; Zhu, 2007). In other words, children from different gender groups, even with the same math ability, may have a different probability of using a certain type of strategy, which results in the occurrence of DIF.
Since the original version of the REMA was developed, it has been widely used in early mathematical research (e.g., Weiland & Yoshikawa, 2013). The item-level evidence demonstrates the consequential validity of the REMA, which can support the justifications of its score interpretation and use (e.g., comparing children’s early math scores across gender, language, or racial groups). For the very small number of items that displayed DIF, applied researchers are advised to be cautious of those REMA items in cases where they are testing students from the affected demographic groups. Almost no DIF items were detected over ELL groups, which shows the benefits of administrating alternative language versions of the REMA to students with different language backgrounds. The DIF results from this work may provide essential clues and promising directions for future assessment revision (e.g., adapting detected DIF items into specific demographic groups or coding strategy sophistication level conditionally).
Scale-Level Consequential Validity Evidence from CVRs
To calculate the CVRs, we needed to choose focal and criterion measures. The measured math performance in this study is longitudinal, but the design of the REMA (e.g., start, basal, and stop rule) enables children to take different items of the measure at different timepoints, instead of taking the exact same items or parallel forms repeatedly. We therefore tested predictive relations between mathematics ability at two adjacent measurement occasions. In this way, the earlier math scores served as the focal measure, and the later scores served as the criterion measure.
Summary of Effect Sizes for Predictive Models and CVRs.
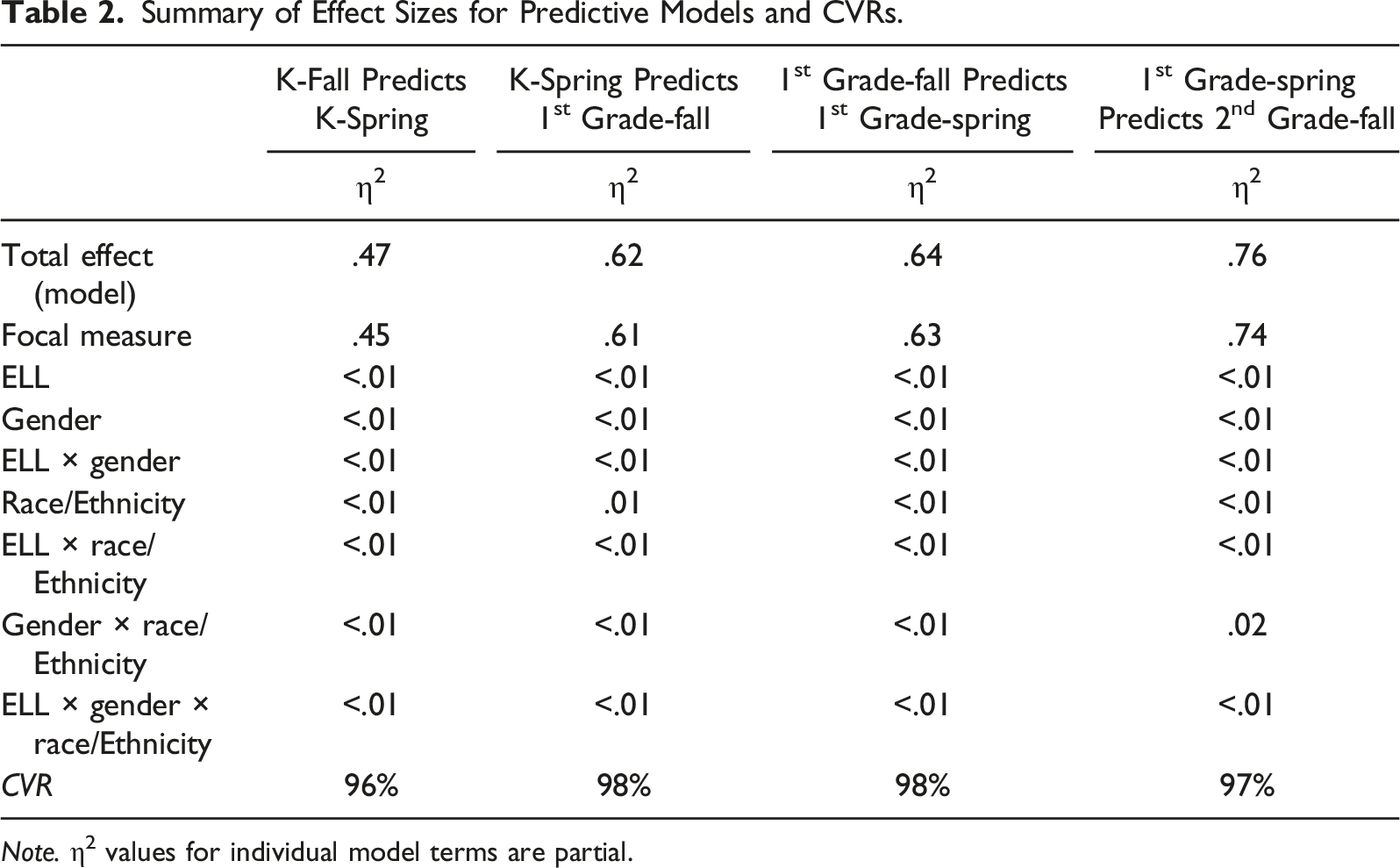
Note. η2 values for individual model terms are partial.
Scale-level consequential validity evidence is often produced via structural equation modeling-based analyses (e.g., multigroup confirmatory factor analysis). However, it can be methodologically challenging to execute such procedures for measures with many scoring items (e.g., 133 scoring variables in the REMA-SF), resulting in the omission of scale-level evidence in general practice. The current study applies a new and efficient method (i.e., CVRs) to produce scale-level evidence for the justification of consequential validity. Notably, although CVRs are straightforward to calculate and relatively easy to interpret, they are not recommended to be used to replace or skip over other necessary validation efforts (Dumas et al., 2022), such as the DIF analyses shown in this study.
In conclusion, both item-level and scale-level validity evidence shows that the inferences drawn from the REMA scores can be made in the same way across demographic groups, and the consequential validity and fairness of the measure is supported.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Heising-Simons Foundation (Grant # 2020-1777).