
Abstract
The purpose of this study was to examine the generalizability and dependability of scores produced by Sentence Order Fluency, a novel approach to progress monitoring of reading comprehension. Analyses were conducted to evaluate the performance of three alternative scoring methods—Absolute Correct, Pairs Correct, and Levenshtein Similarity—as well as test length and levels of aggregation (the numbers of passages or paragraphs used to calculate scores). Absolute and Pairs Correct scores performed similarly and appeared to show greater generalizability than Levenshtein Similarity scores. Students contributed more variance than probes in most models. Minimally sufficient levels of reliability for progress monitoring decisions could be possible using scores based on administration of 2 passages or 6 paragraphs using Pairs Correct scores. Levenshtein Similarity appeared to require a greater number of probes to obtain comparable reliability, suggesting limited practical value relative to other scoring procedures.
Progress monitoring of academic skills is a mainstay of data-based decision-making in multi-tiered systems of support (MTSS, e.g., Tindal, 2013). Measurement strategies devised as progress monitors for reading comprehension can be divided into those in which data are collected after a student is done reading (“offline” measures; Van den Broek & Espin, 2012), or those in which data are collected while a student is reading (“online” measures). Two chief differences between these approaches are in the aspects of comprehension being measured, as well as the amount of time required for test administration. Examples of “offline” measurement strategies include oral, or written retelling of information students recall from texts, or also strategies in which students respond to questions (i.e., multiple choice items) or make judgments about texts (i.e., sentence verification tasks). Satisfactory validity evidence has been documented for such measures in multiple studies, but researchers have also documented insufficient reliability for instructional decision making (e.g., Roberts et al., 2005), or administration or scoring procedures that limit feasibility of use for progress monitoring (e.g., Alonzo et al., 2007; Fuchs & Fuchs, 1992).
Online measures generate data during reading, which can increase feasibility or ease of use in schools. Maze may be the best-known example of an online measure of aspects of comprehension. In this task, students read text in which every 7th word has been removed and replaced with a set of three alternatives: a word that would make sense in the context of the sentence, as well as two distractors. The accuracy and rate at which students can complete maze has been interpreted as an indicator of their overall proficiency in comprehension of similar text. Although maze data have been positively correlated with comprehension (e.g., Marcotte & Hintze, 2009; Shin & McMaster, 2019), and may be sensitive to growth in reading skill beyond fluency or decoding for adolescents (Tichá et al., 2009), evidence suggests that the aspects of comprehension measured directly by maze are limited to the sentence level (January & Ardoin, 2012; Muijselar et al., 2017; Parker et al., 1992).
Sentence Order Fluency
Sentence Order Fluency (SOF; Lekwa et al., 2025) was proposed as an online measure of comprehension for spans of text greater than one sentence that could be used for the purpose of progress monitoring. In this timed task, students are presented with short texts in which the order of sentences within each paragraph has been randomized. Students then write numbers next to sentences to suggest a coherent sequence. The intended outcome of this task is an estimate of students’ accuracy and automaticity in generating coherent mental representations of information encoded in text (e.g., Van den Broek & Espin, 2012). For students to offer accurate and rapid responses to SOF paragraphs, they must be able to access lexical information for individual words, including their meaning within context (e.g., Perfetti, 2007), understand meanings of individual statements (sentences; e.g., Perfetti et al., 2005), and use information from the text and from background knowledge to detect and evaluate alternative coherence relationships among non-adjacent sentences. Aspects of each of these processes have been identified as potential sources of difficulty in comprehension in theory (i.e., Kintsch & Kintsch, 2005; Van den Broek & Espin, 2012) and documented in empirical evidence (e.g., Cromley & Azevedo, 2007; Oakhill et al., 2003; Perfetti et al., 2005).
Research Priorities for Development of Progress Monitors
Lynn Fuchs (2004) outlined three stages of research and development through which the validity and usefulness of a measure for progress monitoring can be established. These stages include research on the psychometric qualities of the measure’s scores at single points in time (stage 1), the reliability and validity of the slope (stage 2), and the instructional utility of the measure (stage 3). Multiple types of evidence from a variety of sources are necessary at each stage. See, for example, the progress monitoring standards of the National Center on Intensive Intervention (National Center on Intensive Intervention [NCII], n.d.), which emphasize technical adequacy (e.g., reliability, sensitivity, and other aspects of validity), repeated measurement of student performance, and links to instructional decision-making.
The priority at this early stage of development of SOF as a progress monitoring strategy is Fuchs’s Stage 1—and correspondingly NCII’s technical adequacy criteria—focusing on establishing the psychometric qualities of SOF scores at single points in time. This body of evidence is a necessary foundation for examining growth over time and instructional utility in subsequent stages. Specifically, for SOF to provide data that are useful for measuring growth in aspects of reading comprehension, there needs to be evidence that scores at single points in time are sufficiently reliable and sufficiently related to the construct of interest.
Data from the original pilot study (Lekwa et al., 2025) of 119 students in 4th, 5th, and 6th grades in the mid-Atlantic U.S. offered evidence supporting interpretations of SOF scores as indicators of students’ comprehension of text, as opposed to students’ abilities to decode or identify words within text. Specifically, SOF scores exhibited significantly stronger correlations with scores from a traditional, standardized test of reading comprehension (r = .67) than with oral reading fluency scores (r = .47). Moreover, SOF uniquely explained 16% of the variation in traditional comprehension scores after controlling for students’ reading fluency and accuracy; the measures, together, explained 62% of this variation. Although these results were consistent with intended interpretations of SOF data, SOF scores exhibited reliability estimates (intra-class correlations) ranging from .62 to .76. This was mostly insufficient for progress monitoring, for which reliability indices of .70 or greater are desired (Ysseldyke et al., 2023). Examining proportions of variance attributable to characteristics of individual SOF probes or scoring procedures might help explain the limited reliability observed in the pilot sample and might suggest strategies to boost reliability.
Factors That Influence Reliability of SOF Scores
Two design features that may influence reliability are test length (i.e., the quantity of examinee behavior sampled or the number of items or distinct tasks completed as the basis for calculating a score) and scoring procedures (i.e., how performance is quantified). Longer assessments sample more behavior and tend to yield more reliable scores than shorter ones (Crocker & Algina, 1986). Such sampling can be increased either by administering more items at a single time point or by using multiple probes (analogous to alternate forms). Reliability may also vary as a function of scoring procedures, particularly to the extent that they produce sufficient variation between examinees or within examinees over time (e.g., Hier et al., 2020; Pierce et al., 2010). The present study included examination of both features in the context of SOF.
Test Length
One approach to increasing behavioral sampling in SOF is to vary the number of items or tasks students complete as the basis for calculating a single score. Scores in the original SOF pilot study (Lekwa et al., 2025) were calculated based on students’ performance across three narrative passages, each three paragraphs in length. Students were given 4.5 minutes to re-order paragraphs for each narrative passage, for a total testing time of 13.5 minutes per SOF administration. Yet items, in this approach to reading assessment, are essentially individual paragraphs on an SOF probe. This distinction might be consequential because performance across paragraphs is likely to be relatively independent, as coherence judgments for one paragraph are unlikely to be related to, or depend on, coherence judgments in adjacent paragraphs. It might be possible that basing scores on responses to some number of paragraphs, rather than full passages, is a more efficient way to achieve sufficient reliability—an issue that has been explored in prior research on measures for screening and progress monitoring (e.g., Ardoin et al., 2004; January et al., 2018; Mercer et al., 2012).
Alternative Scoring Procedures
Three scoring procedures were examined in the SOF pilot study, each representing a different balance between ease of calculation and precision: the count of sentences sequenced in their original positions (Absolute Correct), the number of sentences placed adjacent to their original sentence neighbors (Pairs Correct), and a string similarity index calculated by Levenshtein distance (Levenshtein Similarity; Levenshtein, 1966). The first score, Absolute Correct, is the easiest to implement, but the accuracy of this score could be limited, as several sentences within a paragraph can be sequenced correctly, but outside of their original position. An alternative is to calculate the number of correct sentence pairs in each passage or paragraph. While this requires more effort if scoring is to be completed by hand, the interpretation of Pairs Correct is straightforward and unambiguous. The final alternative scoring procedure, Levenshtein Similarity, is an index of the similarity between two strings of values (the order suggested by the examinee compared to the actual order for the passage or paragraph). It was hypothesized that this score would offer somewhat more credit than absolute correct or correct pairs for near-misses, or responses that approximated but did not fully match original placements or pairings. Each of these procedures exhibited slightly different relationships with Gates MacGinitie Reading Test—4th Edition (GMRT-IV) Comprehension scores in the original pilot study (Lekwa et al., 2025). It remains unknown whether the three scoring procedures lead to equivalent or different levels of reliability.
Research Questions
The purpose of this study was to use framework of generalizability theory (Brennan, 1992) to explore the degree to which students, versus other systematic factors or random error, contribute variance to SOF scores, and to better understand strengths and weaknesses of alternative SOF scoring methods in efficiently generating data that are adequate indicators of differences in student reading comprehension, while also sufficiently reliable for instructional decision-making. I conducted this study to address the following four research questions: (1) What proportion of the variance in SOF scores is attributable to students? (2) Does the generalizability of SOF scores differ as a function of test length when length is operationalized as full passages versus individual paragraphs? (3) To what extent does the generalizability of SOF scores depend on score calculation methods? (4) Upon how many passages or paragraphs should scores be based to obtain data that are sufficiently reliable for instructional decision-making?
Methods
Sample
This study was completed in a Kindergarten–12th grade charter school in the Mid-Atlantic U.S. The school distributed consent forms to parents of all 6th graders after IRB review and approval of this study within the lead author’s institution. This study’s sample (a sub-sample of the original pilot) comprised a group of 63 students in the 6th grade. This sub-sample was the focus of this study given that these 6th graders completed the same set of 9 SOF probes over three weekly sessions, whereas 4th and 5th grade participants only completed 3 SOF probes each. Students were 61% Asian, 24% Black, 13% White, and approximately 1% Native American and Hawaiian/Pacific Islander, respectively; 53% of the sample was female. Although socio-economic data were not available for individual students, a total of 28% of this school’s students were eligible for free and reduced-price lunches.
Measure
The SOF probe set examined in this study was created using text from easyCBM Passage Reading Fluency (PRF) probes at the 6th grade level (Sáez et al., 2010). Each PRF probe was a short fictional narrative consisting of between 16 to 26 sentences and 250 to 300 words. Individual sentences from each PRF passage were copied and pasted into a spreadsheet in their original order, which was taken, for purposes of this research, to be the most coherent arrangement of the sentences. Sentences were then numbered to record their original order and their randomly assigned order within scrambled paragraphs as determined by a random number generator. Each SOF paragraph was constrained to have at least 4, and no more than 7 sentences. The original first sentence of the first paragraph of each narrative was always listed and identified as the first sentence “for free” to offer students a starting point. Each SOF probe was printed on a single 8.5″ by 11″ page in 11-point Times New Roman font.
Procedures
All 9 SOF passages were administered between April and June 2023, in a whole-group format by the author. Data were collected in a partially nested design, with students each completing the same nine SOF probes nested within three weekly testing occasions (see Webb & Shavelson, 2005, for an example). Although this study’s second research question concerned test length or aggregation and SOF generalizability, it is important to note that actual administration procedures were not manipulated: the same passages were given in the same order to all participating students at each weekly SOF testing session, for a total of 9 passages completed per student. For this reason, effects related to time (such as practice, skill growth, and fatigue) or order effects are not separable from probe effects in this dataset. Group administration started with a short introductory activity to ensure students understood the sentence ordering task. In this activity, the author explained the task, modeled the task as students watched, and led the students through two practice paragraphs. Students were then given 4.5 minutes to complete each SOF passage.
Analyses
A set of six mixed effects models was constructed to obtain variance components for generalizability and dependability studies for each scoring type (Absolute Correct, Pairs Correct, and Levenshtein) and each level of aggregation (by passages or by paragraphs). The first two score types are counts of correct responses. Variance components for models of these scores were estimated through generalized linear mixed effects models (GLMM) using the Poisson distribution with a log link and including random intercepts for students and corresponding facets of measurement; no significant overdispersion was detected. Distribution-specific variance,
Although data were collected following a partially nested design (students by SOF probes within measurement occasions), the corresponding multi-facet generalizability study revealed no systematic variation across measurement occasion—models resulted in singular fits, with random intercept variance for “occasion” equal to 0. Consequently, “occasion” was dropped from analysis, and models for research questions 1, 2, and 3 were adjusted to comprise 6 fully crossed single-facet generalizability analyses for each SOF score type at each level of aggregation (full passages or individual paragraphs). Three models examined generalizability and dependability for scores based on a number of entire passages (as in the original pilot study), and an additional three models were used to examine the same indices when scores are based on a number of paragraphs. Generalizability (


Question 4 was addressed with a set of decision analyses, in which generalizability and dependability coefficients were re-calculated, adjusting for increasing numbers of passages or paragraphs used to calculate scores. Profile confidence intervals were estimated for variance components (see Royston, 2007); parametric bootstrapping (1,000 samples) was used to calculate 95% confidence intervals for differences between student and probe variance components, as well as confidence intervals for estimates of
Results
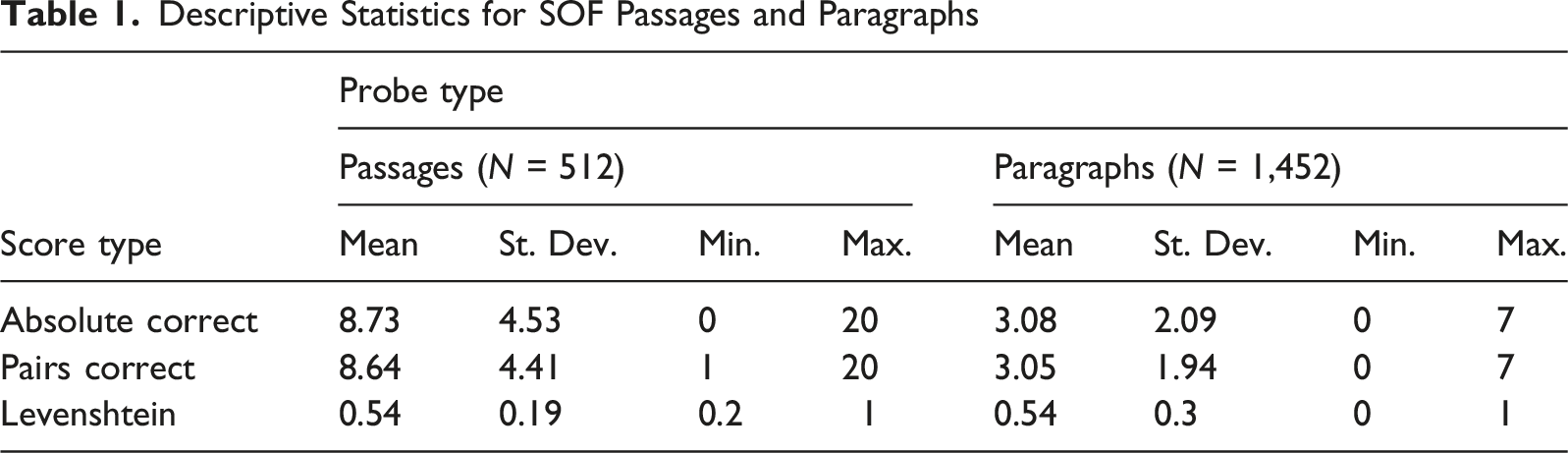
Descriptive Statistics for SOF Passages and Paragraphs
Research Question 1: Variation Attributable to Students
Generalizability Study Results for SOF – Passage Level
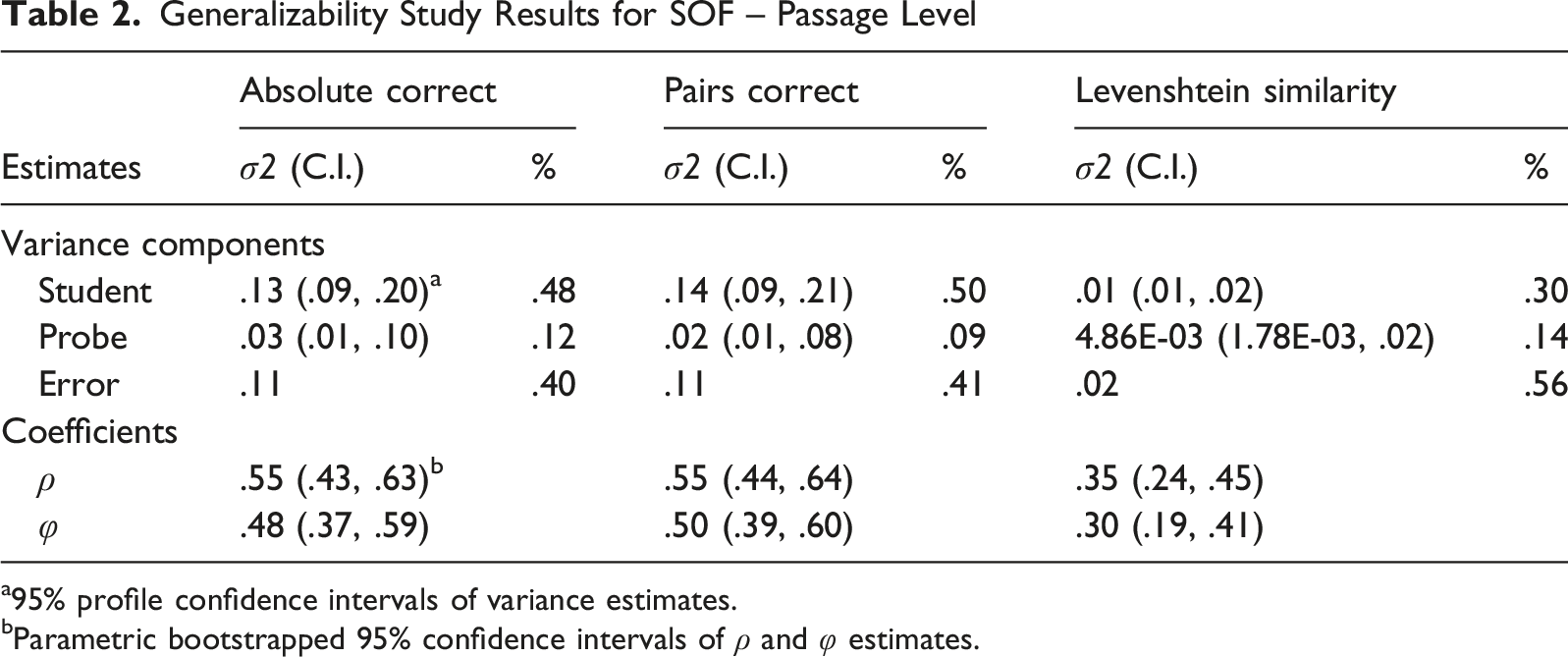
a95% profile confidence intervals of variance estimates.
bParametric bootstrapped 95% confidence intervals of ρ and φ estimates.
Generalizability of SOF—Paragraph Level
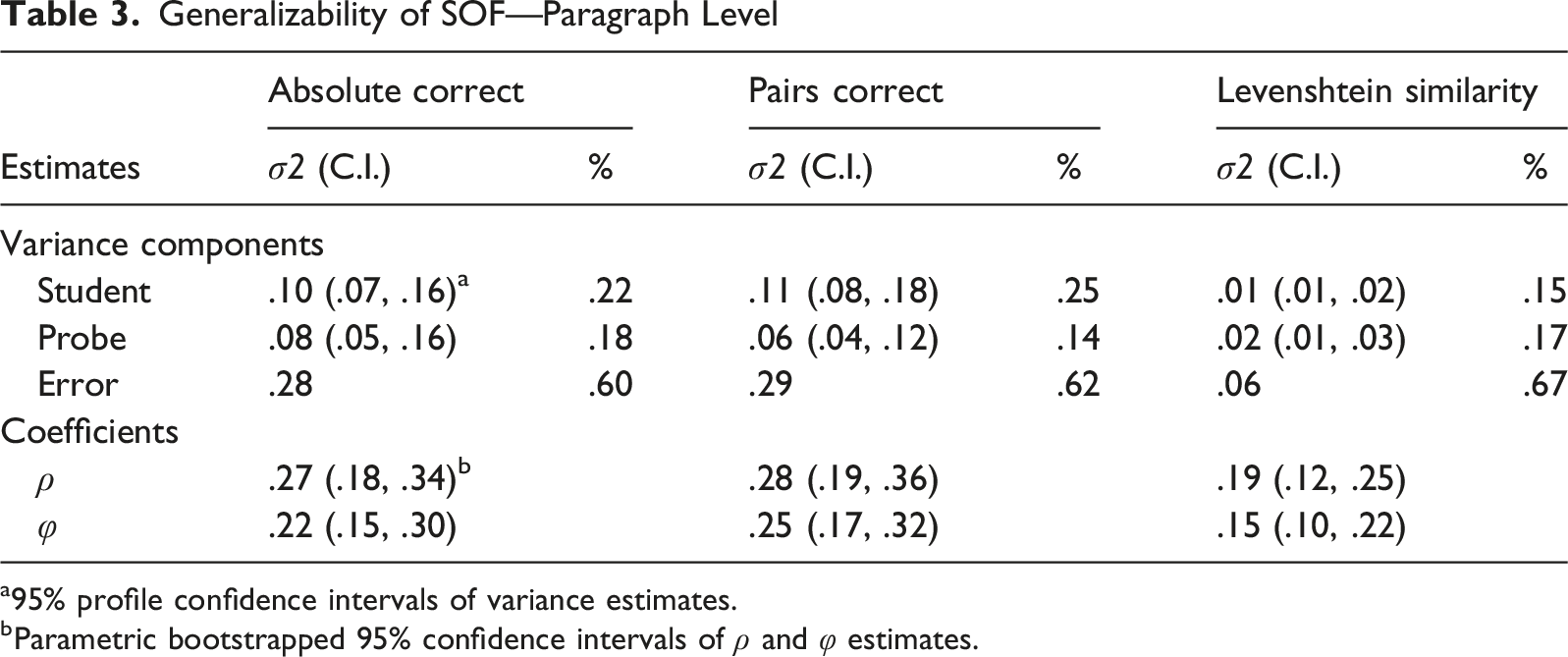
a95% profile confidence intervals of variance estimates.
bParametric bootstrapped 95% confidence intervals of ρ and φ estimates.
Research Question 2: Aggregating Performance Across Sets of Passages or Paragraphs
There were meaningful differences in the
Research Question 3: Reliability for Different Scoring Procedures
Resulting estimates of
Research Question 4: Number of Probes Required
Figure 1 depicts the numbers of passages and paragraphs estimated to be required as a basis for scores to be used in progress monitoring (with desired levels of reliability displayed as the region within the gray bar in each graph). The dashed vertical line represents the amount of text (3 passages, or 9 paragraphs) that is often presented to students when measures of oral reading fluency are used for screening purposes (e.g., Shinn, 2002). Results suggest that minimally acceptable levels of reliability could be achieved using any of the three score types, although Absolute Correct and Pairs Correct scores would require approximately half the amount of text required by Levenshtein Similarity scores. Absolute and Pairs Correct Scores based on 4 passages or 12 paragraphs approached levels of reliability useful for screening decisions, and levels of reliability that would be minimally suitable for progress monitoring after 2 passages or 6 paragraphs. Decision study results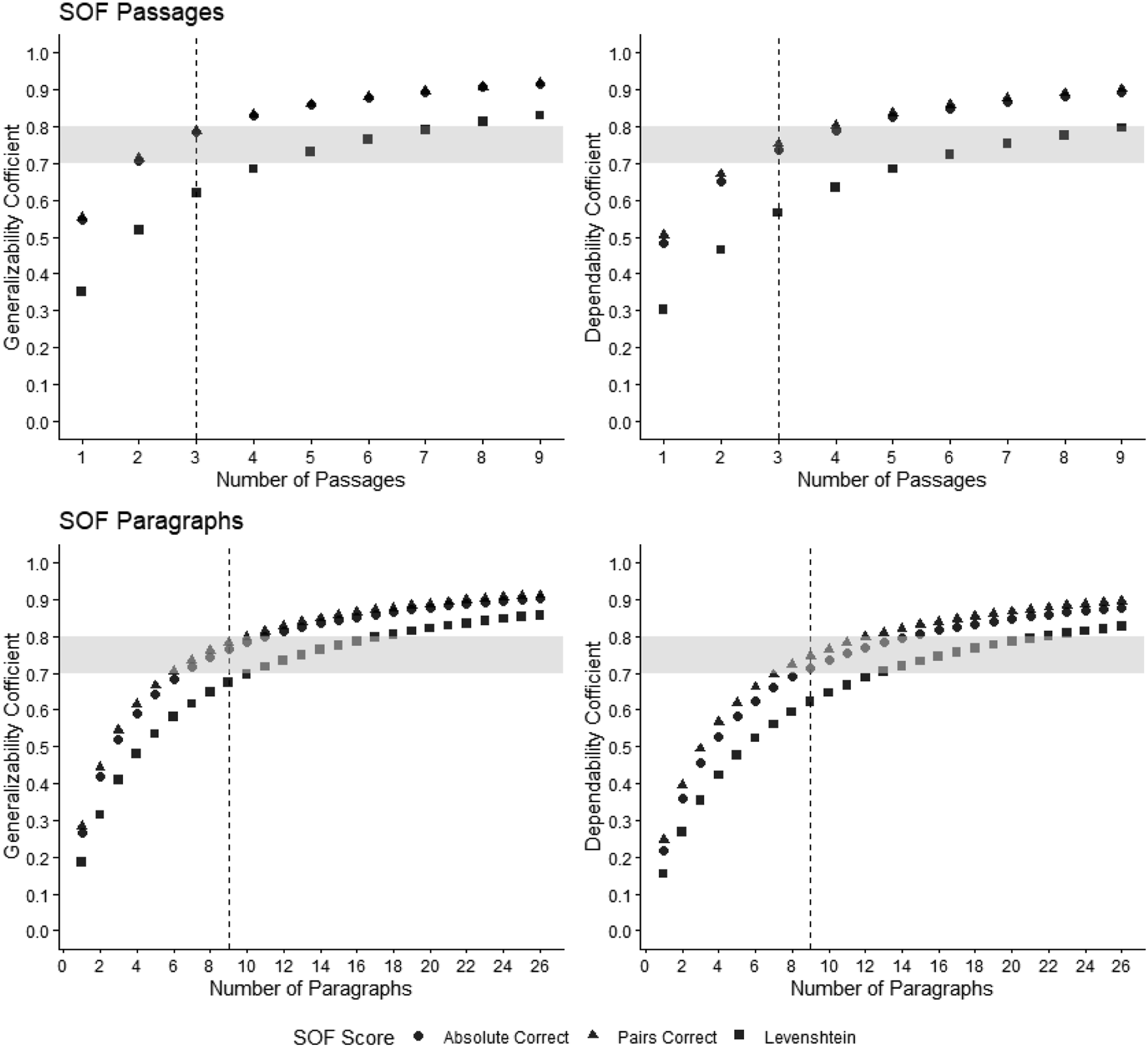
Discussion
Although the results of Lekwa and colleagues’ (2025) initial pilot study supported the hypothesis that SOF scores represent variation in comprehension more than they represent basic reading skills, they exhibited insufficient reliability for instructional decision making. The purpose of this study was to explore sources of variation in SOF data that might suggest avenues for improvement—specifically, to ascertain the degree to which students versus probes or measurement error contribute to variation in SOF scores—and to determine whether aggregation of performance across passages or paragraphs could improve generalizability and dependability of SOF data.
A chief priority in initial stages of the development of a progress monitoring instrument is the establishment, or improvement of, the instrument’s psychometric properties for scores at single points in time (e.g., Fuchs, 2004), including evidence that the instrument measures the intended construct, and that it can produce data with sufficient reliability to support instructional decision-making. Ysseldyke, Chapparo, and Van Der Heyden (2023) recommend reliability of at least .70 for purposes of progress monitoring, and at least .80 for purposes of screening or instructional planning. The SOF task in its current form might produce scores that can achieve these criteria, but only if scores are based on administration of multiple probes, including the added costs in time and effort from students and possibly from those responsible for scoring as well. Results of the current study suggest considerable room for improvement.
These results are nearly commensurate with those of earlier generalizability studies conducted on measures designed for progress monitoring, such as studies of curriculum-based measurement (CBM) of math computation fluency (Christ et al., 2005; Hintze et al., 2002), written expression (Keller-Margulis et al., 2016), and other measures of reading such as maze (Mercer et al., 2012) and oral-retell fluency (Sudweeks et al., 2003). In those studies, as in the current study, levels of generalizability and dependability often fell below the desired minimum of .70, appearing within the approximate range of .30 and .60. Yet other studies of progress monitors, such as measures of oral reading fluency, have yielded generalizability and dependability indices for single probes well above .70 (e.g., Christ & Ardoin, 2009; Hintze et al., 2000). Whereas measures of oral reading fluency generate a larger sample of students’ reading behavior in shorter times—perhaps explaining comparatively stronger generalizability findings—researchers have also used methods to limit probe-specific variation (e.g., Ardoin & Christ, 2009; Christ & Ardoin, 2009). The results of the current study suggest there may be value in creation and field-testing of a large set of SOF texts, and in careful selection of a subset of texts that, together, produce scores with the smallest standard error of measurement.
Estimates of “probe” variance in this study are not direct estimates of variance due to probes—they are instead confounded with facets such as testing occasion and probe order. However, results suggested little to no variation across each of the three weekly SOF sessions, leaving open the possibility that a meaningful amount of variation in SOF performance is related to features of the probes themselves; identification of such features could be useful in further improvements to this method of assessment. For example, the correct first sentence of the first paragraph was identified for students at the top of each easyCBM passage, whereas the orders of sentences in subsequent paragraphs were fully scrambled. This design choice was made based on speculation that the task might otherwise be too difficult. Yet it is possible that this feature reduced load on students’ working memory capacities and introduced systematic variation when scores were based on performance across individual paragraphs. Whether this feature adds to or detracts from reliability of SOF scores is a question that requires additional research.
Alternatively, research might also focus on identification of textual and linguistic characteristics of SOF probes that interact with student reading comprehension skill levels. Such relationships might strengthen or weaken the extent to which SOF scores discriminate between levels of skill in reading comprehension. These characteristics might include such factors as the number and length of sentences per paragraph, indices of lexical diversity (type-token ratio; Anggia & Habók, 2023); text cohesion (e.g., Dahl et al., 2021) and text coherence (McNamara et al., 1996), as readers with different skill levels, cognitive abilities (i.e., working memory), first languages, and background knowledge may respond differently to texts.
Improving the Reliability of SOF Scores
Results of the current decision study (specifically, those for the fourth research question) suggest two strategies that might help optimize reliability, while retaining efficiency. First, there appears to be limited value in the Levenshtein string similarity index as a scoring method. The variance components estimated for these data in the current study are potentially inaccurate, as evidenced by lack of support for assumptions around residual distributions, meaning that actual levels of generalizability and dependability could be higher or lower than observed. Regardless, given results of the original pilot (in which each of the three scoring methods yielded equivalent effect sizes), plus the risk that the complexity Levenshtein scoring procedure detracts from the measure’s ease of use, Pairs Correct, moving forward, appears to be the optimal choice.
Second, SOF scoring might best be accomplished by aggregating performance across single paragraphs instead of full passages. The correct sequence of sentences within each paragraph, in the pilot version of SOF, was independent of the correct sequence of any adjacent paragraphs. There might not be a strong rationale, then, for creating SOF probes out of multi-paragraph narratives. Although SOF scores based on single paragraphs had weaker generalizability and dependability than scores based on full passages, scores based on sets of paragraphs could more efficiently achieve acceptable reliability levels than scores based on a number of multi-paragraph passages (see Figure 1). Questions remain, however, about optimal paragraph length and structure.
Limitations
First, it was not possible in the original pilot study, from which these data were obtained, to administer all nine SOF passages for 4th and 5th graders. Future research with a larger sample spanning a wider range of age or grade levels will be beneficial. Moreover, students in this sample represented a broad range of reading skill levels (as reported in the original pilot study, the median GMRT-IV comprehension score for students in this sample was near the 50th national percentile rank). For SOF to be useful as a method for measuring progress in the context of reading intervention, it will be necessary to demonstrate the reliability and validity of estimates of skill at single points in time, as well as estimates of the slope, based on samples comprising students experiencing comprehension difficulties.
Second, the fact that students completed the 9 SOF probes in the same order across testing occasions is a major limitation of this study’s design. As noted above, this resulted in confounding between probe variance and any effects related to change in performance over time, or to order of administration. Yet, with the short intervals between testing occasions in this study (one week) and the range of reading skills among participating students, systematic variation in SOF performance over time might still have been difficult to detect if probe selection had been randomized or counterbalanced. Because of the intended end-use of SOF, which is progress monitoring, it will be important in future research to avoid this confound and enable better evaluation of change in students’ skills over time.
Third, the amount of time allowed for SOF completion (4.5 minutes) was likely too long, as a number of students completed their probes with time to spare. As a result, pilot SOF scores might not discriminate well between skills of students at the higher end of the scale, and the data analyzed in this study are not complete indicators of students’ silent reading or comprehension fluency. It is possible that this restricted student variation, as the students who finished early could have received scores equal to students who took the full 4.5 minutes to complete the same amount of text.
Finally, although the linear model (with normally distributed residuals) appeared to result in a better fit based on visual analysis of residual plots, models of Levenshtein Similarity scores never adequately met distributional assumptions and estimates of the relative magnitude of residual or distribution-specific variance to other variance components are not interpretable.
Future Research
The process of completing the SOF task is not identical to typical reading, and judgments of the relative coherence of various possible sentence pairings might require more working memory than students would otherwise use to comprehend narrative texts. Whether SOF taxes students’ working memory above and beyond the level required for successful comprehension warrants examination. Because the task requires students to hold and work with information about multiple sentences simultaneously, performance of students with limited working memory could be negatively impacted, which potentially reduces the validity of scores it produces. SOF, in the current study, was administered in a paper-and-pencil format, but use of a digital testing format in future research would enable students to click and drag sentences into position, possibly reducing extra burden on working memory.
The easyCBM texts used in the SOF pilot study were designed for the purpose of measuring students’ oral reading fluency and were not intentionally written such that each paragraph followed a specific flow of ideas or required a specific kind of inference. Some passages appeared to function more effectively for SOF than others. For example, some passages, such as 6.2 (see Table 2 in Lekwa et al., 2025) appeared to be substantially more difficult than other passages. This could have increased variation due to probe characteristics or error variation and could have decreased variation due strictly to differences between students. Unique texts, on their own, represented between 9% and 18% of the total variation in SOF scores in the current study (depending on method used, or span of text scored). This is not inconsequential and suggests that performance on one probe cannot be expected to generalize fully to all other probes. As noted above, it would be beneficial to understand how specific characteristics of texts might increase the degree to which SOF scores discriminate between different reading comprehension skill levels. Then, based on findings of such analyses, it would be beneficial to design original texts for use in SOF measurement that exhibit those characteristics.
Finally, additional attention to estimation of variance components for non-Gaussian data may be warranted. Analyses described above were originally carried out using linear mixed effects models. Upon evaluation of model fit, analyses were completed again using generalized linear models. The decision to use generalized linear mixed models to estimate variance components in this study was motivated by the fact that although progress monitoring data often meet assumptions required for analysis with linear models (i.e., normal residual distributions), the underlying processes that generate such data may best be described with non-Gaussian distributions. Most measures designed for the purpose of progress monitoring yield scores that are essentially counts of correct responses, or rates of a specific behavior within a span of time; variance for such data is conceptually and mathematically distinct from variance under the normal distribution. Sensitivity analysis revealed that generalizability estimates obtained from the GLMMs displayed above ranged between 8 and 10 points higher than those obtained from corresponding linear models. It might be helpful in future measurement research to examine conditions under which such differences become consequential for researchers and end users.
Conclusion
SOF, as designed and administered in the original pilot study (Lekwa et al., 2025) did not produce scores with sufficient reliability for instructional planning. Results of this study suggest directions for future research. Changes to SOF format and design might be able to yield data with sufficient reliability for instructional decision-making, especially if scoring is based on counts of sentences restored to their original positions (Absolute Correct) or counts of correct sentence pairs (Pairs Correct). However, additional research will be required to identify modifications that could boost psychometric qualities, thereby reducing administration times required for sufficiently reliable and valid data.
Footnotes
Author Note
The current study was supported with grant funding from the Rutgers University Research Council. The positions and opinions expressed in this article are solely those of the author.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Research Council, Rutgers, The State University of New Jersey.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.