
Abstract
Fundamental research has indicated that (a) difficulties in reading are linked to a deficit in phonemic awareness and word reading and (b) in French, decoding and word reading are based on the syllable as a functional unit. A software program involving two tasks, namely, phonemic discrimination and grapho-syllabic segmentation, was proposed to poor readers aged from 7 to 12 years in order to stimulate their reading skills. Two experiments were set up during which the children were trained for a total of 10 hours. In Experiment 1, conducted at home, we observed meaningful progress in phonemic awareness and decoding after training only in the poorest readers. In Experiment 2, which was conducted at school, we observed significant short- and medium-term effects on phonemic awareness, decoding, and word reading. These encouraging results support the use of evidence-based practices based on tools validated by means of experimental research in ecological situations.
Keywords
The question of the contribution made by digital technology to and its effectiveness in learning at school in general (Chauhan, 2017), and with regard to reading in particular, has been the object of several meta-analytic reviews (Archer et al., 2014; Cheung & Slavin, 2012, 2013a, 2013b). It seems, even though it is not always clearly stated, that the software or apps are often designed on the basis of results taken from basic research into reading difficulties. It is within this context that a new software program intended for French-speaking children experiencing reading difficulties has been developed. The aim is to test its effectiveness on the reading performances of poor readers. In the framework of evidence-based reading interventions, it is important to test and validate the tool before proposing them as a way of assisting poor readers.
Introduction
What Does Research Tell Us About the Causes of Difficulties in Learning to Read?
Learning to read consists in becoming capable of matching phonological and semantic representations to the groups of letters (graphemes) that make up a word. Some children exhibit a deficit in the system responsible for the mental representation of the sounds of words that disrupts the learning of the grapheme–phoneme correspondences (Snowling, 2000). Many longitudinal studies have shown that this deficit predicts later difficulties in reading before formal reading instruction starts (Caravolas et al., 2012; Puolakanaho et al., 2007). Indeed, some poor readers experience significant difficulties in tasks that call on phonological capabilities that involve the mental representation and manipulation of the sounds of speech. More specifically, access to phonemic awareness goes a long way to explaining the ability to learn to read (Castles & Coltheart, 2004; Melby-Lervåg, Halaas Lyster, & Hulme, 2012). A phonological deficit is not only a consequence of the deficient learning of reading but may also preexist this as longitudinal follow-ups of children as of nursery school, and in some cases even as of birth, have shown (Gallagher, Frith, & Snowling, 2000; Lyytinen et al., 2004; Scarborough, 1990; Van Alphen et al., 2004).
It has now been clearly established that training that focuses on the systematic teaching of the grapheme–phoneme correspondences is the most effective (Bus & van Ijzendoorn, 1999; Ehri et al., 2001; Hatcher, Hulme, & Snowling, 2004). The meta-analysis performed by Galuschka, Ise, Krick, and Schulte-Korne (2014) suggests that this is the only type of training whose effectiveness in children with reading difficulties has been statistically confirmed.
The debate concerning which interventions are the most effective for children with reading difficulties persists to this day. According to theoretical models of reading development, children move from slow letter-by-letter decoding to the extraction of units that are larger than phonemes (Ehri, 2005; Seymour & Duncan, 1997).
Grapho-Syllabic Processing During Learning to Read
When they start to learn to read, children associate the segments from the orthographic sequence with the known segments of the oral sequence. They use their knowledge of the structure of spoken language and look, when confronted with writing, for the sequences of letters that correspond to oral units (Goswami & Bryant, 1990). Before learning to read, French-speaking children identify and manipulate oral syllables (Ecalle & Magnan, 2002, 2007) unlike English-speaking children (Duncan, Seymour, Colé, & Magnan, 2006). When reading pseudowords aloud, French-speaking children in first grade segment the groups of letters by trying to find the known oral syllables (Bastien-Toniazzo, Magnan, & Bouchafa, 1999). This observation of the establishment of a relationship between the written and oral modes via syllables during early reading has led to the emergence of the hypothesis that grapho-syllabic processing lies at the root of the decoding that is deployed in order to identify written words. Using a visual adaptation of the oral word-initial phoneme detection task (Mehler, Dommergues, Frauenfelder, & Segui, 1981), Colé, Magnan, and Grainger (1999) revealed a syllabic compatibility effect in good readers at the end of first grade. This effect was shown through shorter detection times when the target corresponded to the first syllable in the word (detect PA in parole or PAR in pardon) than when it did not (detect PAR in parole or PA in pardon). The transition from a grapho-phonemic procedure to a grapho-syllabic procedure might be explained through its lower cognitive cost, in particular with regard to operations involving the assembly of units during the conversion process (it is less costly, e.g., to assemble )mar)+)di) than )m)+)a)+)r)+)d)+)i)). These results have been confirmed using the same paradigm (Maïonchi-Pino, Magnan, & Ecalle, 2010a, 2010b) and, in particular, have shown an impact of syllabic frequency. Similarly, Doignon and Zagar (2006) used a letter detection task in a situation of illusory conjunctions and showed that children at the end of first grade perceive phonological syllables in letter sequences, while Chetail and Mathey (2009) revealed a syllabic congruency effect in readers in second grade in a colored lexical decision task. Using the illusory conjunction paradigm, Maïonchi-Pino, De Cara, Ecalle, and Magnan (2012a, 2012b, 2015) studied the influence of the sonority and position of the consonants on syllable-based segmentation strategies within two-colored bisyllabic pseudowords with the structure CVC.CVC (TOL.PUDE). The results suggest that children are sensitive to an optimum organization based on sonority at the syllabic boundaries (sonority profile with a sonorous coda and an occlusive onset) which favors automatic syllable segmentation. A more recent study using an audiovisual pseudoword recognition task (Maïonchi-Pino et al., 2015) undertaken among 140 children subdivided into five academic levels (from first to fifth grade) has confirmed that the syllable is a prelexical phonological unit that is rapidly available to learner readers and has emphasized the modulating role of syllable frequency and sonority in segmentation strategies.
Thus, empirical studies indicate the importance of the syllable as the sublexical unit that bridges phonology and lexical entries, thereby facilitating word recognition fluency. Similar results have been found with Finnish children (Hautala, Aro, Eklund, Lerkkanen, & Lyytinen, 2012; Häikiö, Hyönä, & Bertram, 2015) and with Spanish children (Alvarez, Garcia-Saavedra, Luque, & Taft, 2017; Jiménez, García, O’Shanahan, & Rojas, 2010).
These results have led researchers to test the hypothesis according to which intensive training in grapho-syllabic segmentation should help poor decoders improve the decoding procedure and enable them to identify written words better. The medium- and long-term effectiveness of grapho-syllabic training on the decoding of written words has been revealed both among poor decoders in first grade (Ecalle, Kleinz, & Magnan, 2013; Ecalle, Magnan, & Calmus, 2009; Kleinsz, Potocki, Ecalle, & Magnan, 2017) and among poor decoders in secondary school (Potocki, Magnan, & Ecalle, 2015).
The positive effects of syllable-based reading interventions have been shown in other alphabetical languages such as Dutch (Wentink, Van Bon, & Schreuder, 1997), English (Bhattacharya & Ehri, 2004; Diliberto, Beattie, Flowers, & Algozzine, 2009), Spanish (Jiménez et al., 2007), Finnish (Heikkilä, Aro, Närhi, Westerholm, & Ahonen, 2013; Huemer, Aro, Landerl, & Lyytinen, 2010), and German (Müller, Richter, Karageorgos, Krawietz, & Ennemoser, 2017).
Research Questions
To summarize, this set of works suggests that (a) phonemic awareness is one of the capabilities that is essential for learning to read; (b) the syllabic units can be thought of as intermediate, fundamental units via which the written word decoding process becomes more efficient; and (c) training that targets grapho-syllabic processing improves word decoding performance. The aim of the current work, which was undertaken during two studies, was to test the effectiveness, among two groups of poor readers, of a software program involving two forms of processing: first phonemic discrimination and then grapho-syllabic segmentation. Moreover, we tested the effect of training in two ecological conditions: at home and at school.
Method
In the following two experiments, one was conducted at home under the control of parents and the other at school under the control of teachers with the same basic experimental design. After a baseline established between t0 and t1, which were the times of assessment during the pretests, a period of training was administered to the children. They were then evaluated again at t2 to examine the potential impact of training on word reading and associated skills. There was an interval of 5 weeks between each assessment session. However, in Experiment 2, the medium-term effect of training was examined with a fourth assessment session. All the tasks were taken from a normalized reading assessment battery (BALE; Jacquier-Roux, Lequette, Pouget, Valdois, & Zorman, 2010) in order to compute z-scores.
Experiment 1: Training at Home
Participants
Fourteen children (5 girls, 9 boys) from 7.2 to 10.7 years, schooled in normal primary classes, were recruited from speech-therapy practices. They were all poor readers, as confirmed by their speech therapists. However, we also checked their initial level in reading (see later). A letter was sent to them and their parents explaining the purpose of the study and its design and indicating their right to withdraw from the study. They all gave their consent and made a commitment to follow the training attentively.
Assessments: material and procedure
With regard to the skills that were evaluated three times, the linguistic material changed at t2 but the tasks did not. The expected effect of training could therefore not be due to a test-retest effect. All the tasks were administered by an experimenter.
Reading test (t0). The initial level of reading was assessed using the Alouette test (Lefavrais, 2004). The children had to read a short text in 3 minutes. We considered an index of speed and accuracy.
RAN: Rapid Automatized Naming (t0)
The children had to name as quickly as possible a series of 25 pictures consisting of five items (familiar words) arranged randomly in five lines on a page. The time was taken into account.
Phonemic awareness (t0, t1, t2)
Two tasks were administered during each session. At t0 and t1, the first task was a phonemic segmentation task in which the children were asked to give the number of phonemes in a word pronounced by the experimenter (/8); in the phoneme deletion task, the children had to delete the initial (/10) or the final (/10) phoneme in words pronounced by the experimenter and then to produce the new phonological form (feuille → euille). At t2, in the phonemic discrimination task, the children had to say whether two syllables began with the same sound (mi-ri; fa-fa; /14). The second task consisted in merging the first phonemes of two words in a single syllable (bonne-année →)ba); /10). The z-scores were calculated on the global score for each session.
Decoding (t0, t1, t2)
The children had to read aloud a series of 20 pseudowords. A new list was proposed at t2.
Regular word reading (t0, t1, t2)
The children had to read aloud a series of 20 isolated high-frequency words. At t2, the 20 new words were low-frequency words.
Irregular word reading (t0, t1, t2)
Same task as earlier.
Fluency (t0, t1, t2)
The children had to read aloud a short text (Mr. Petit) in 1 minute. The score corresponded to the number of words read minus the errors. At t2, they had to read a new short text (Le Géant égoïste).
Training: material and implementation
The aim of the software (ChassymoDys) is to stimulate the ability to perform phonemic discrimination and construct ortho-phonological syllables which are known to be the functional units in word reading. First of all, the child saw a written syllable on the screen and then heard it. Then, two oral words with two phonemes that were phonetically close in the target syllable were orally presented (ex: Screenshots from the ChassymoDys software.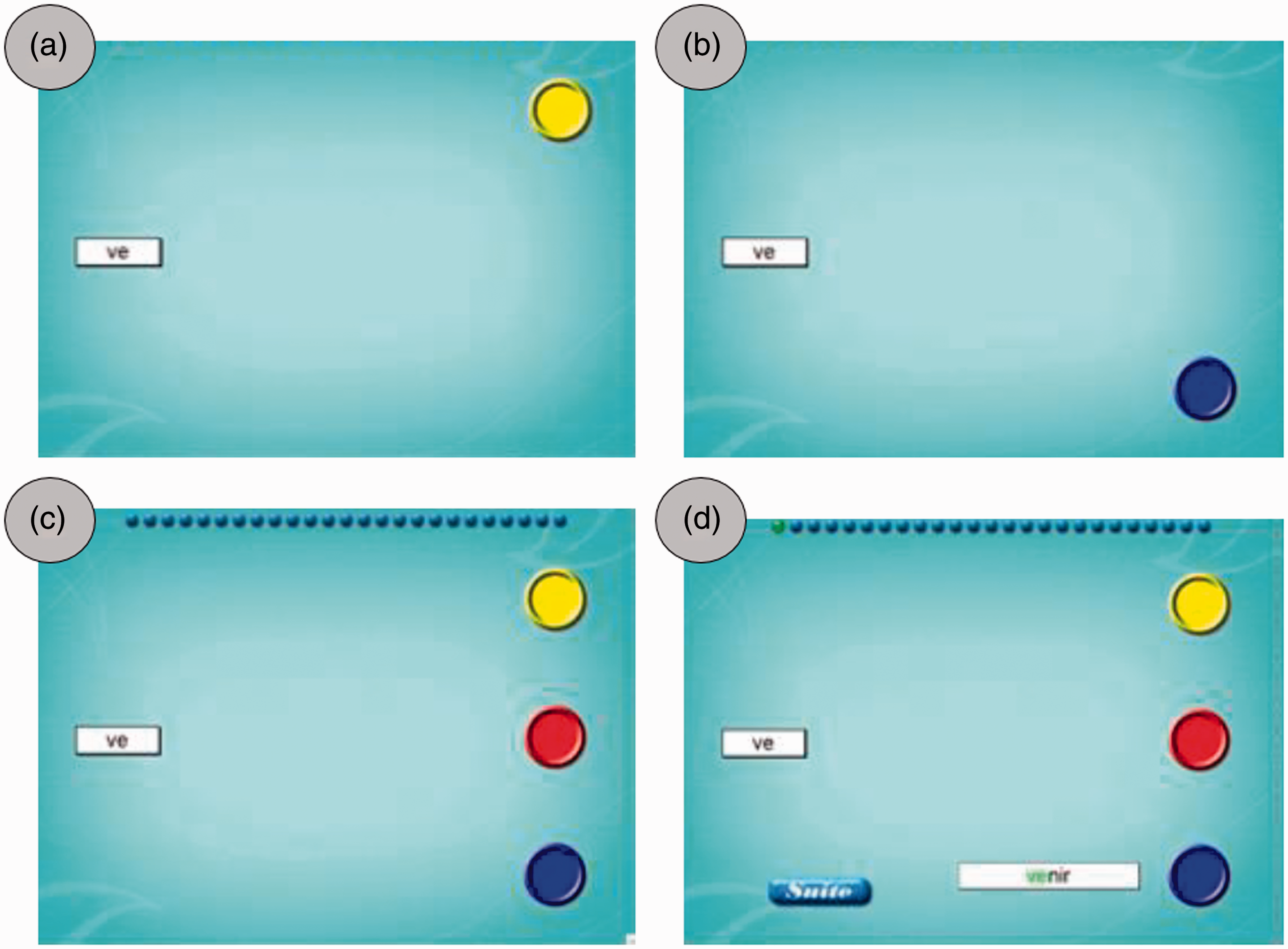
The software contains 24 modules of increasing difficulty as a function of the structure of the syllable (CV, CCV, and CVC) and the type of word, that is, bi- or tri-syllabic. These modules are organized into six subgroups, with the word frequency diminishing from the first group to the last. Each module contains 25 items which are presented in a random order. For every item, the order of presentation of the two words varies in a random way. The position of the target syllable in the word also varies (initial, final in bi-syllabic items, and also median in tri-syllabic items).
A period of five successive weeks of training was proposed to the children and their parents and could take the form of either 30 minutes or 2 × 15 minutes of training for 4 days per week to make a total of 10 hours. Adherence to the schedule was monitored by the computerized recording of the number of items that were processed by the children and by a follow-up sheet indicating the duration of the training sessions, which was filled in by the parents. In this way, our aim was to verify that the software had been used as intended in the home context.
Results
The results are presented in two different sections in order to respond to two questions: (a) What is the global effect of training in the four domains of phonemic awareness, decoding, word reading, and fluency? (b) What are the characteristics of individual differences before and after training?
Effect of training
z-Scores (Mean (SD), Range) at t0, t1, t2, and Results of Wilcoxon Test.

Note. RAN = rapid automatized naming.
aThe Wilcoxon tests compare the two differences d1 (d1 = t1−t0) and d2 (d2 = t2−t1).
First, we observe that almost all the z-scores were negative, confirming that the children were (very) poor readers. However, one child in the initial reading test unexpectedly had a null z-score. However, his z-scores in the four domains were low, so he was retained for this study. Moreover, we observed some positive z-scores for phonemic awareness, which might be due to the work performed with these children by their speech therapists, who mainly focused their interventions on stimulating this domain. An examination of the data ranges reveals other positive z-scores, indicating large individual differences between these poor readers, as expected. Finally, none of the results of the nonparametric analyses were significant.
With regard to the individual differences
To examine this issue, we first observed the links between initial performance at t0 and the gain in performance after training (d2) and then examined the progress curves in two contrasted groups.
Matrix of Spearman Rank Order Correlations Between Initial Performances at t0 and Gain in Performance After Training (d2) (N = 14).

Note. Alo = Alouette test; RAN = rapid automatized naming; PA = phonemic awareness; Dec = decoding; RWR = regular word reading; IWR = irregular word reading; Flu = fluency; t0 = initial performance at t0; d2 = gain of performance between t1 and t2 after training.
*p < .05.
We formed two groups based on their z-scores in the Alouette reading test at t0. We distinguished between very poor readers (VPR; z ≤ −1,7; n = 7) and poor readers (PR; z ≥ −1.6; n = 7). Their progress curves are presented in Figure 2. We again used the Wilcoxon test to examine whether d2 was significantly greater than d1 in each group. First, we can observe that the two groups differed on z-scores, with PR having better scores than VPR in all the tasks. In phonemic awareness, the performance gains after training in both groups were not statistically significant. We can also observe that the scores in the two groups were similar at t2, with the VPR group making more progress (d2 = +2.5; sd = 2.9) than the PR group (d2 = +1; sd = 1.3). In decoding, the performance gain with training in the VPR group (d2 = +1.7; sd = 1.8; vs. d1 = 0.4; sd = .05) was at the limit of significance (Z = 1.86, p = .06). All the other results of the nonparametric tests were nonsignificant (p > .10). In summary, only in phonemic awareness did the VPR group seem to benefit from the training more than the PR group.
Progress curves for VPR and PR in the four domains (†p < .10). VPR = very poor readers; PR = poor readers.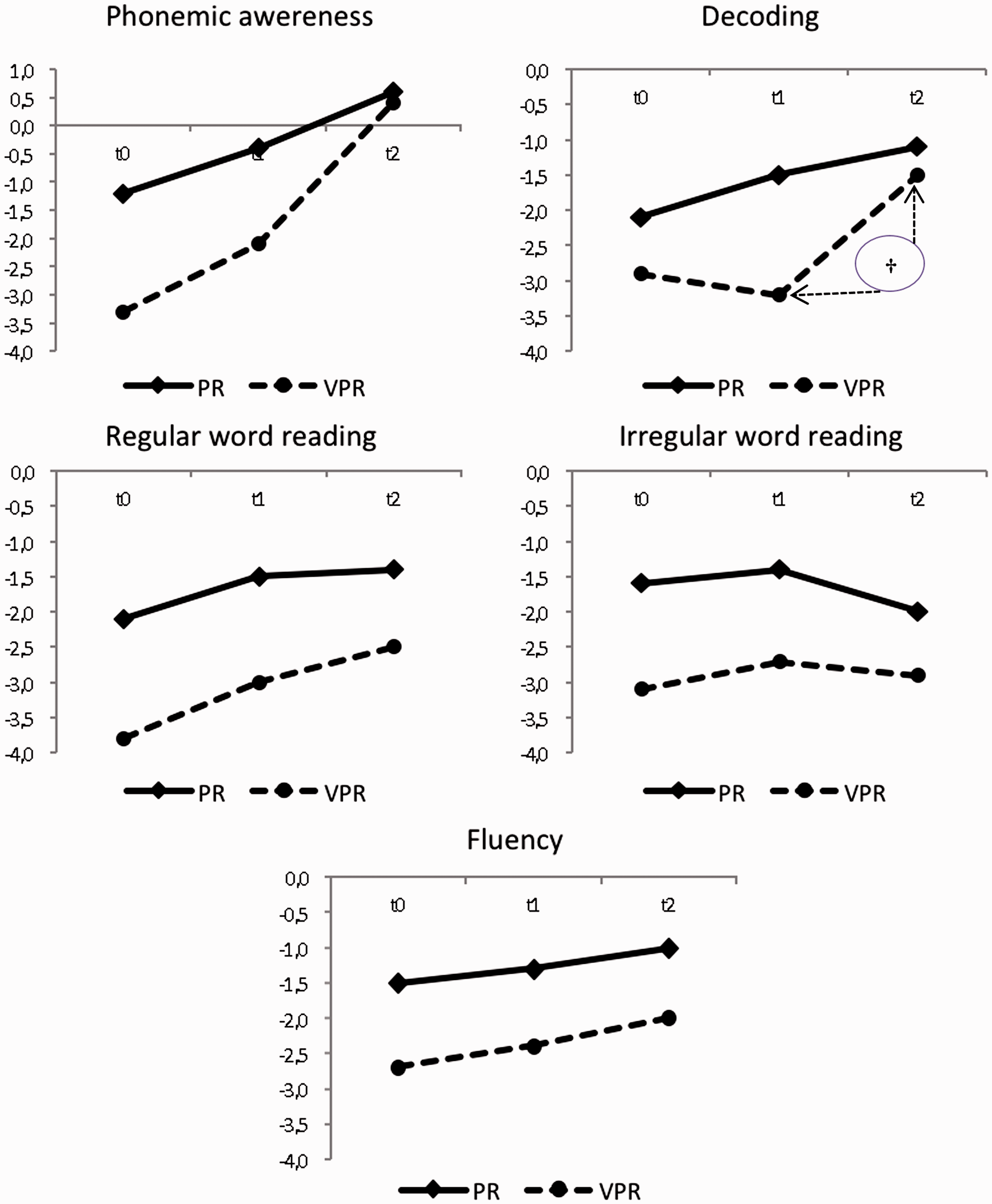
Experiment 2: Training at School
The same experimental design was used, with three assessment sessions (t0, t1, and t2) and a fourth one (t3) to examine the medium-term effect of training.
Participants
Sixteen children schooled in four classes for pupils with learning disabilities, so-called ULIS (Unités Localisées pour l'Inclusion Scolaire), participated in this study. In these Units for Educational Integration, children benefit from a differentiated education allowing them to follow a regular course, on the one hand, and receive targeted pedagogical interventions as a function of their difficulties, on the other. To examine the short-term effect of training, we analyzed the data obtained from 12 children (8 girls, 4 boys; aged from 8 to 11.9 years) for whom we had complete data for the first three assessment sessions. To examine the medium-term effect of training, complete data were available for 11 children (from t0 to t3). The teachers were willing to take part in this study and to implement the training within their own educational approaches.
Assessments and training
The same tasks from t0 to t2 were administered in the same conditions as in Experiment 1. The fourth session (t3) took place 2 months after the end of training with the same tasks as in t2.
Results
We present the results in three phases: (a) we examine the short-term effect of training in the 12 children assessed at three times by comparing the two mean performance differences, that is, the difference between t0 and t1 (d1) and between t1 and t2 (d2); (b) we present the links between the children’s initial performance at t0 and their performance gains after training; and (c) we examine the medium-term effect of training in 11 children by comparing the two mean performance differences, d1, which is the baseline, and d3 (d3 = t3 − t1), which corresponds to the evolution of performance at 2 months after the end of training.
Short-term effect of training
z-Scores (Mean (SD), Range Below) at t0, t1, t2, and Results of Wilcoxon Test (N = 12).

Note. RAN = rapid automatized naming.
aThe Wilcoxon tests compare the two differences d1 (d1 = t1−t0) and d2 (d2 = t2−t1).
Links between initial scores and gains
Matrix of Spearman Rank Order Correlations Between Initial Performances at t0 and Performance Gains After Training (d2) (N = 12).
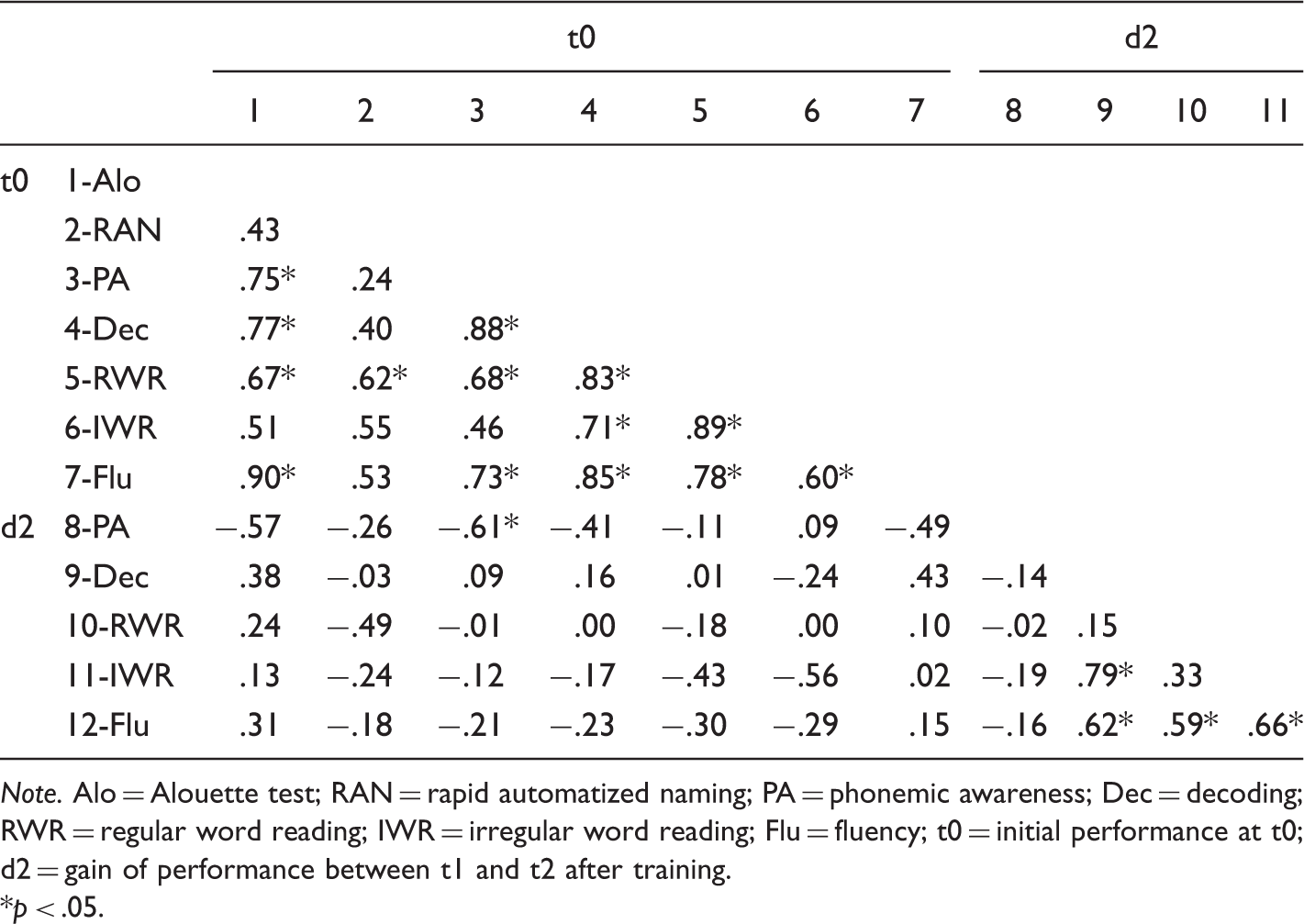
Note. Alo = Alouette test; RAN = rapid automatized naming; PA = phonemic awareness; Dec = decoding; RWR = regular word reading; IWR = irregular word reading; Flu = fluency; t0 = initial performance at t0; d2 = gain of performance between t1 and t2 after training.
*p < .05.
Medium-term effect of training
The potential medium-term effect was again analyzed using Wilcoxon tests to compare d1 and d3. In phonemic awareness, we observed that the performance continued to increase between t2 and t3 (Figure 3), with the medium-term gain being significant (Z = 2.4, p = .02), d3 = 2.2 greater than d1 = −.03. Despite some regression of the scores at t3 in the other domains, the gain was always significant in decoding (Z = 2.04, p = .04), d3 = 2 greater than d1 = 0.3, and in irregular word reading (Z = 2.85, p = .004), d3 = 1.8 superior to d1 = 0. However, we observed no significant effect on regular word reading or fluency.
Progress curves in the four domains from t0 to t3 (N = 11; *p < .05; **p < .01).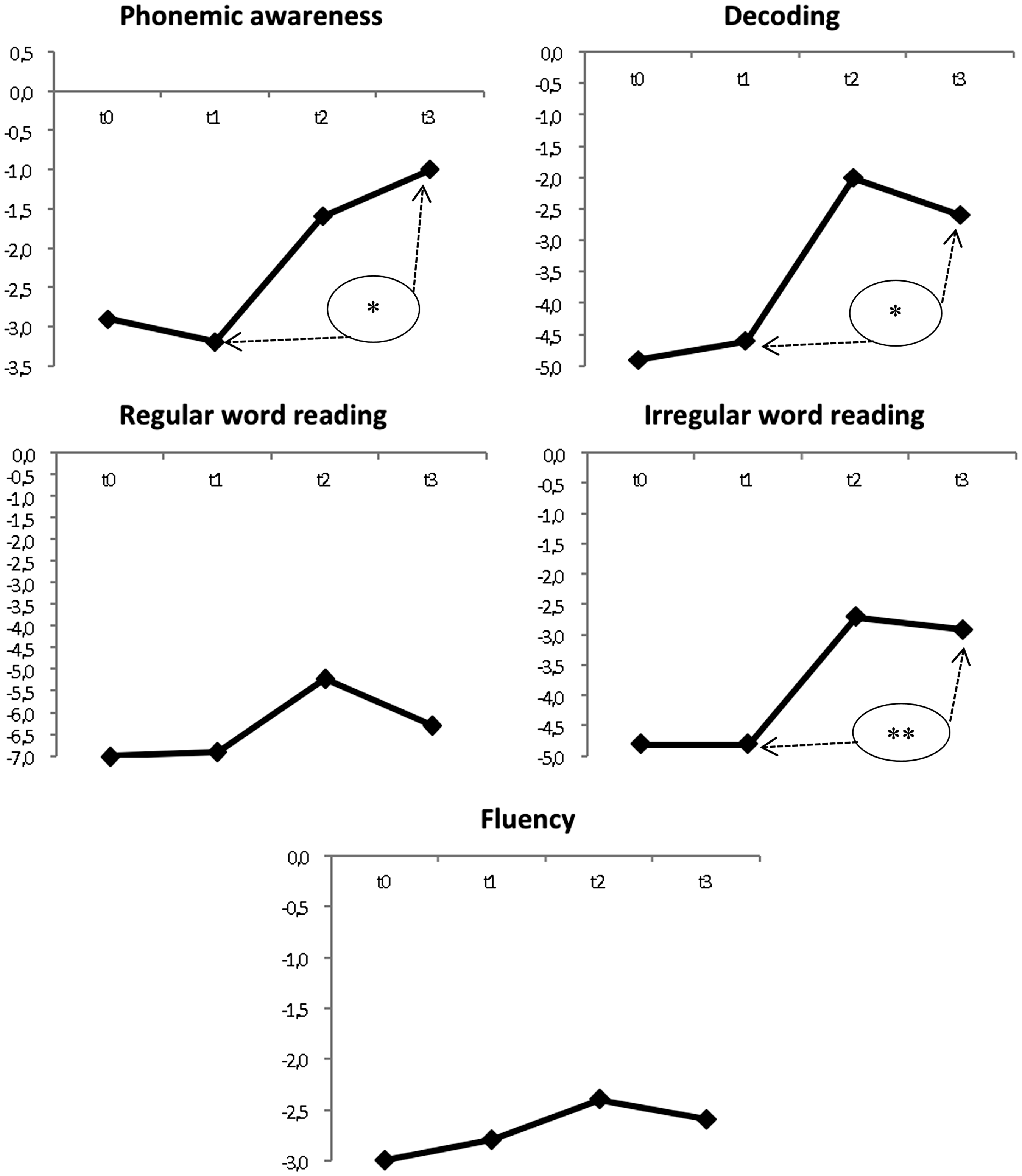
Discussion
The aim of this study was to test a new software solution designed in the light of scientific arguments resulting from work on learning to read and the associated difficulties. Two important elements were adopted: On the one hand, to promote the learning of grapheme–phoneme correspondences, it is necessary to stimulate phonemic awareness and, on the other, word reading in French is based on the syllable as functional unit. With the software solution, ChassymoDys, used in the two studies, young poor readers are called on to perform two successive tasks: a phonemic discrimination task and another task that involves grapho-syllabic processing. The two studies conducted here, one at home and supervised by the child’s parents and the second in class under the supervision of the teachers, made it possible to examine the progress of young poor readers in response to the effect of training in standardized reading and phonemic awareness tasks which confirmed the significant developmental delay in the poor readers recruited for this study.
Experiment 1 did not reveal any global effect: The children did not progress in response to the effect of training in the different tasks proposed to them. However, we observed that the mean phonemic awareness score became normal (z = 0.5) at t2. In addition, an examination of the individual differences revealed posttraining performance gains that were negatively associated with initial performance; in other words, the lower the initial scores at t0 were, the greater the gains were. This led us to observe progress in two contrasted groups. Two results should be emphasized: the group of very poor readers made more progress in decoding (increase in the curve between t1 and t2) and phonemic awareness (statistically at the limit of significance), in which the performance gain was greater than that in the group of poor readers. This means that the software seems to have accurately targeted some of the major difficulties in very poor readers, with the evidence indicating an effect in the various conditions used in the proposed training. In the case of poor readers, we may expect a longer period of training to be necessary in order to observe a significant effect (see later).
The results of Experiment 2 clearly indicated a short-term effect of training on performance in phonemic awareness, decoding, and regular and irregular word reading. By contrast, we observed no effect on fluency. Furthermore, the data obtained 2 months after training again showed a significant medium-term effect on phonemic awareness, decoding, and irregular word reading. However, when we look at the performance curves, which indicate a fall-off in performance at t3, this effect is less marked. In addition, an examination of the correlation coefficients shows that word and pseudoword reading performance were positively linked. Finally, as in Experiment 1, the negative correlation coefficient observed between the phonemic awareness scores at t0 and the performance gains after training in the same task indicates that the children with the greatest difficulties in this domain were those who progressed most in response to the effect of training.
A number of points deserve to be discussed. First of all, the absence of any global training effect in Experiment 1 could be due to a training time that was less than that expected. Even though the parents had been well informed of the requirements concerning the training and the period of 30 minutes per day to be devoted to exercises with the software, we think it possible that this requirement was not always respected by the children when at home. To check whether this was indeed the case, we attempted to identify, on the basis of the time records (with the online monitoring of the time spent using the software), the time actually devoted to the software items. However, technical problems meant that we were not able to calculate this time accurately. Nevertheless, our initial estimates based on these, albeit incomplete, records suggest that our hypothesis is correct: It seems that some of the children did not spend as much time as they were asked in completing the software exercises. In Experiment 2, it seems that the teachers were more rigorous in ensuring that the requested amount of time was spent using the software. The second point relates to the absence of a training effect on fluency, in particular in Experiment 2, in which considerable effects were observed on word reading and phonemic awareness. This is not surprising given that the software does not specifically focus on the automation of the decoding and word reading procedure. A last point must be specified here: During the training time, the children received no instruction prompting them to respond quickly. In other words, fluency was not directly targeted. However, if progress in reading is observed after a training period, then we could also expect an effect on fluency. This hypothesis deserves to be examined in future studies.
The final point is that it is surprising to observe that the developmental delays (see the mean z-scores) in the reading of regular words were smaller than in the reading of irregular words. In effect, to read regular words, it is necessary to mobilize grapheme–phoneme correspondences (or a decoding procedure), whereas when reading irregular words, it is necessary to know the inconsistent letter–sound relations that form these words. We have no explanation for either this unexpected difference or for the following observation: The developmental delay in decoding was similar to that in irregular word reading, whereas we should have observed an almost identical delay in decoding and regular word reading.
One drawback of these two experiments is that the sample sizes were too restricted, while, as we have already said, we were also unable to measure the actual time that the children spend working with the items. Although clearly important, these two limitations do not invalidate the encouraging results observed in the very poor readers who received training, some in their homes and the others at school. Finally, the mixed results obtained in the first experiment, in contrast to the more convincing results obtained in the second, constitute an argument in favor of an intensive period of training which must be devoted to the dual processing proposed by the software: phonemic discrimination and grapho-syllabic segmentation. The ChassymoDys software had a real impact in both the short and medium term. Nevertheless, the fall-off in performance observed in the medium term (Experiment 2) argues in favor of extending the training period or resuming it after a pause. Indeed, the teachers indicated a decline in the commitment of certain children toward the end of the 5-week training period. Commitment and motivation are, in addition to the training time, variables that must also be taken into account when considering mechanisms designed to help children with reading difficulties.
Conclusion
This study provides some initial answers to questions relating to computer-based interventions underpinned by the dual principle of reinforcing phonemic discrimination abilities and developing the mental syllabary necessary for the process of identifying written words. This contribution is explicitly positioned within the framework of evidence-based practice. Our approach consists in designing software on the basis of theoretical hypotheses, testing this software experimentally with children with reading difficulties, and then undertaking its validation under ecological conditions.
The contribution of computer technologies within the framework of targeted interventions is undeniable, in particular when used to reinforce the mechanisms that need to become automated if they are to be effective, as in the case of written word identification. While computer-based tools designed to assist reading are moving forward fast, it has to be acknowledged that most of them are neither fully specified nor completely validated. Tools that form part of professional practice should be the object of cognitive (What is their effect on the targeted performance?) and ergonomic validation (How easy is the tool to use? How is it perceived and used by professionals?). Very few studies have addressed this latter point.
Finally, it is necessary to mention, as Cheung and Slavin (2012) clearly point out at the end of their meta-analysis, that the use of new technologies can play no magic role in improving the reading performance of children with difficulties. Despite this, their use provides a pedagogical aid for teachers and a high level of independence that allows children to overcome their difficulties (Hartley, 2010). When used in the home environment, they also make it possible to extend the learning time. Finally, following the tertiary meta-analysis by Archer et al. (2014), their contribution is all the more significant if the teachers have received training in advance and benefit from support during their use of these technologies in their teaching practice.
Footnotes
Acknowledgments
The authors thank the Master’s Degree students, Océane Géraud, and Justine Danjean, who participated in the data collection. They also thank the teachers, families, and children who agreed to take part in this study.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by ICE Institut Carnot Education—Region of Auvergne-Rhône-Alpes and by CNRS (Centre National de Recherche Scientifique) via PEPS (Projet Exploratoire Premier Soutien).