
Abstract
Block programming has been suggested as a way of engaging young learners with the foundations of programming and computational thinking in a syntax-free manner. Indeed, syntax errors—which form one of two broad categories of errors in programming, the other one being logic errors—are omitted while block programming. However, this does not mean that errors are omitted at large in such environments. In this exploratory case study of a learning environment for early programming (Kodetu), we explored errors in block programming of middle school students (N = 123), using log files drawn from a block-based online. Analyzing 1033 failed executions, we found that errors may be driven by either learners’ knowledge and behavior, or by the learning environment design. The rate of error types was not associated with the learners’ and contextual variables examined, with the exception of task complexity (as defined by SOLO taxonomy). Our findings highlight the importance of learning from errors and of learning environment design.
Keywords
Introduction
Block programming has been suggested as a way to engage young children with the basic foundations of programming—and computational thinking at large—without the hassle of writing actual code (Sáez-López et al., 2016; Weintrop & Wilensky, 2015; Zhang & Nouri, 2019). Using a simple graphical interface, which is most commonly based on drag-and-drop interactions, learners can quickly and easily construct a computer program from basic blocks just like they would build a structure from little Lego bricks. Not surprisingly, the popularity of block programming has grown, and it is now used by millions of children and teens around the globe employing platforms like Scratch (https://scratch.mit.edu), Hour of Code (https://hourofcode.com), or Tynker (https://www.tynker.com). One of the prominent advantages—and promises—of using block programming is that learners are not prone to syntax errors, which characterizes novice and often also expert) programmers (Jackson et al., 2005; McCall & Kölling, 2015).
Errors may be beneficial for learners, in particular when they are responded with an effective corrective feedback, which allows students to reflect upon their attempts to solve a problem and to identify preconceptions (Metcalfe, 2017). Thus, error detection and error-driven teaching have been suggested as effective practices in teaching programming and computational thinking (Harrison & Hanebutte, 2018; Koehler, 2020; Nalaka & Edirisinghe, 2008). To support such methods, a deep understanding of novice programmers' errors should first be established; indeed, much has been studied in this context over the last decades (Chan Mow, 2012; Gladwin, 1987; Jackson et al., 2005; Ko & Myers, 2003; McCall & Kölling, 2015; Shooman, 1975). Despite the great importance of errors when learning to program, and despite the rising popularity of block programming, research in the field of block programming errors is still in its infancy. This is the gap we aimed to bridge in this exploratory research, that will serve as a first step towards furthering research in this field. We do so in a case study of a single learning environment for early programming (Kodetu).
Hence, the main purpose of the current study was to identify and classofy types of errors of young students in block programming, and to test for associations between these types and characteristics of the task and the learner. To meet this goal, we set up the following research questions: 1. What are the types of errors of young students in block programming and what is their distribution? 2. What are the associations between the types of errors and the following task characteristics? a. Level; b. Computational thinking concept; c. Difficulty. 3. What are the associations between the types of errors and the following learner characteristics? a. Gender; b. Programming experience.
As this is—as far as we are aware of—the first study to focus on the identification and categorization of errors in block programming, we have no solid basis for setting up hypotheses for the types of errors, their frequencies, and their relationships with the various research variables. Therefore, we took an exploratory, bottom-up approach, using a large dataset of student errors. The rest of the paper is arranged as follows: In the section below, we will review the relevant literature about novices' errors in programming and about the ways in which block programming languages have been implemented in computer science education, and will lay down the theoretical framework for defining task difficulty in computer science education; we will then give full details about the methodological aspects of the reported study, followed by a description of our findings; finally, we will discuss the findings and their implications.
Literature Review
A computer program is a set of commands, written in a designated language, readable by a computer, and aimed at performing a specific task. Therefore, an error in programming normally takes one of two main forms: either preventing the computer from successfully running a code, or allowing it to run the code, however, with an undesired outcome. Broadly speaking, there are three common types of errors in programming: syntax, semantic, and logic (or logical) errors (Hristova et al., 2003; McCall & Kölling, 2015). Syntax errors are mistakes in the spelling, punctuation, and order of words in the program, e.g., using a capital letter when one is not needed, or omitting a semi-colon at the end of a command when it is required. Semantic errors refer to the meaning of the code, e.g., not declaring a variable before using it (in languages that require a declaration), or trying to assign a real number to a variable that is defined as integer only. The third type, logic errors, refers to mistakes in the logical structure of the program, e.g., using a wrong logical operation or calculation, sequencing operations in the wrong order, or repeating a command or a set of commands the wrong number of times.
Notably, syntax and semantic errors are strongly associated with the design specific to the programming language in use, hence their frequency is language-dependent (Grandell et al., 2005; McIver, 2000a), while logic errors are usually language-independent and have more to do with the programmer’s reasoning. As our research is focused on block programming, which was originally introduced to reduce syntax and semantic errors, we are mostly interested in logic errors. The following sub-sections review the relevant background to logic errors and block programming.
Errors in Programming
Logic errors are the most common errors for novice programmers. Analyzing about 300,000 function implementations of learners of introductory programming MOOCs, Smith and Rixner (2019) found that logic errors accounted for about half of the total errors in students' codes. Furthermore, while syntax and semantic errors usually cause compilation or runtime failure and maybe spotted and fixed using feedback from the development environment (Becker et al., 2016; Marwan et al., 2019; Qian & Lehman, 2019; Staub, 2021), logic errors are more difficult to debug, hence tend to remain in the code (Smith & Rixner, 2019).
Logic errors are commonly caused by faulty algorithmic design or with misconceptions regarding the very structure of programming tasks (Ettles et al., 2018). Therefore, reducing such errors usually involves engaging students with algorithmic thinking and with the fundamental concepts of programming, like the way loops are structured or the way variables represent specific values (Agbo et al., 2019; Grover & Basu, 2017). Brennan and Resnick (2012) defined such concepts—including sequences, loops, parallelism, events, conditionals, operators, and data—as the basic dimension of computational thinking which emerges when engaging with bock programming. Algorithmic thinking, in which problem-solving is done in a systematic, step-by-step manner, is considered as a cornerstone of computational thinking as a higher-order thinking skill (Shute et al., 2017). Some meta-cognitive practices are part of Brennan and Resnik’s second dimension of computational thinking, specifically, being incremental and iterative, testing and debugging, reusing and remixing, and abstracting and modularizing.
Therefore, identifying and correcting logic errors may involve meta-cognitive skills (Ginat & Shmallo, 2013), and following that notion, error-detecting has been suggested as a powerful pedagogical tool in programming teaching (Nalaka & Edirisinghe, 2008). Due to the unique cognitive and meta-cognitive skills involved in the process of debugging logic errors and due to the distinctive role these types of errors play in the field of computer science education, attempts have been made to focus on reducing as much as possible the burden of engaging with other types of errors. As a result, the use of block programming languages has become popular.
Block Programming
Learning to program is a complex task, which involves both general algorithmic thinking knowledge and particular knowledge of the specific programming language in use. In order to reduce the hassle of this task, visual programming languages—which have learners focus mostly on the logical foundation of programming—have been developed. In visual programming, users face a graphical interface that presents them with the available commands, with each command designed as a block (hence the term ‘block programming’); using drag-and-drop, users can construct a program by creating a sequence (or sequences) of blocks. This way, writing a code is similar to building a Lego construction from individual blocks, and syntax errors are eliminated, as commands are a priori written and are capable of being joined together only when it makes sense (Kelleher et al., 2002; Maloney et al., 2010).
The most popular block programming languages are Scratch (https://scratch.mit.edu; developed in MIT Media Lab), Alice (http://www.alice.org; developed by the late Prof. Randy Pausch of Carnegie Mellon University), and Google’s Blockly (https://developers.google.com/blockly). Notable, block programming languages can be powerful tools for “real” programming; indeed, one can use them to build complex virtual or physical artifacts, e.g., with MIT’s App Inventor (https://appinventor.mit.edu), BBC’s micro:bit (https://microbit.org), or Lego Mindstorms.
Block programming, more than conventional text-based programming, may motivate students to learn “real” programming; furthermore, knowledge and experience gained with block programming may facilitate learning the more advanced material in text-based programming (Armoni et al., 2015; Ouahbi et al., 2015). As such, block programming languages have been suggested as a great means to promote learners' understanding of programming and of computational thinking at large (Fagerlund et al., 2021; Lye & Koh, 2014; Montiel & Gomez-Zermeño, 2021). Many learning environments have used block programming in a game-based design that adds some motivational aspects to the learning process (Tatar & Eseryel, 2019; Theodoropoulos & Lepouras, 2020).
Importantly, learning in block programming environments has been found to be associated with learner characteristics, in particular gender (Eguíluz et al., 2017; Funke & Geldreich, 2017; Hsu, 2014; Seraj et al., 2019)—however, not necessarily in terms of learning progress or success, but rather in different patterns of use or behavior—and prior coding experience, which was associated with either an appreciation of the block programming affordances or less enjoyment from practicing it (Bakali et al., 2018; Eguíluz et al., 2017; Menounou et al., 2019; Weintrop & Wilensky, 2015).
Certainly, using block programming languages does not fully eliminate errors, however, it keeps space mostly for logical errors (Socratous & Ioannou, 2020), which emphasizes the fact that algorithmic thinking is the core skill to be acquired while using such languages. As for the importance of learning from errors, for both students and teachers (Metcalfe, 2017; Rach et al., 2013; Tulis et al., 2016), it is important to understand which errors are most common in such programming languages. This is the focus of the current research.
Using Taxonomies of Learning in Computer Science Education
Taxonomies of learning are classifications of desired learning objectives or learning outcomes. Bloom’s Taxonomy is probably the most known of them. The original taxonomy (Bloom et al., 1956) referred to six hierarchical levels of educational objectives sorted in increasing order by complexity, namely knowledge, comprehension, application, analysis, synthesis, and evaluation. Later, it was revised by one of the original taxonomy’s designers, and it is now common to refer to the following six levels: remember, understand, apply, analyze, evaluate, and create (Anderson & Krathwohl, 2001). Both versions of Bloom’s Taxonomy have been used in the field of computer science education, mostly for assessing learners' knowledge (Masapanta-Carrión & Velázquez-Iturbide, 2018). For example, Ullah et al. (2020) have defined the following six assessment criteria, based on the original Bloom’s Taxonomy: define the syntax of each structure used in a program (knowledge), explain each structure used in a program (comprehension), apply each structure used in a program as per the required output (application), breakdown the program by using nested structures or multiple structures of the same topic (analysis), synthesize the problem by using an appropriate structure of each topic of the program (synthesis), and, judge problem criteria and choose the most effective structure of the topic for problem solving (evaluation). Other proposed teaching and learning strategies, based on the revised taxonomy, are learning by typing (remember), learning by appreciating examples (understand), learning by modifying open sourced codes (apply), learning by partial coding (analyze), learning by debugging (evaluate), and learning by problem solving (create) (Lai et al., 2020).
Another common taxonomy of learning is the Structure of the Observed Learning Outcomes (SOLO) (Biggs & Collis, 1982). As its name suggests, SOLO Taxonomy classifies learning based on learners' responses. Assuming that learning becomes more complex as it progresses, this taxonomy refers to five phases. At its lowest level, it defines a pre-structural phase, in which a learner fails to demonstrate the required knowledge; next, during the unistructural level, a learner picks up only one or a few aspects of the task with which they are engaged; then, during the multi-structural level, they may pick up several aspects, however, without connecting them to each other; when integration of different aspects occur, the learner gets to the relational level; finally, when generalization and transfer of that acquired knowledge are achieved, the learner gets to the extended abstract level.
Just like Bloom’s Taxonomy, SOLO is alo domain-independent and has been implemented in the field of computer science education. Whalley et al. (2011) have offered an implementation of SOLO taxonomy for the assessment of code writing; their framework includes the following stages that describe to students' codes: substantially lacking knowledge of programming constructs or is unrelated to the question (pre-structural), representing a direct translation of the specifications (unistructural), representing a translation that is close to a direct translation (multi-structural), providing a valid well-structured program that removes any redundancy and has a clear logic structure (relational), and finally, using constructs and concepts beyond those required in the exercise, that improve the solution (extended abstract). Since the development of that version of the SOLO Taxonomy, it has been used to assess students' solutions in programming in various contexts (Ginat & Menashe, 2015; Izu et al., 2016; Lister et al., 2006; Seiter, 2015). As our study is focused on classifying students' errors, that is, our data consists of students' learning outcomes, we preferred SOLO Taxonomy over others. Overall, as computational thinking and programming tasks involve cognitive processes that cover the full range described by SOLO, this taxonomy is suitable for studying such skills (Selby, 2015). Indeed, SOLO has been also used in the broader context of computational thinking, for designing and evaluation learning tasks (L. Lin et al., 2017; Parmar et al., 2022). Recently, Kaspersen et al. (2021) explicitly demonstrated how a computational thinking program can promote young learners across all the dimensions of Brennan and Resnick’s (2012) framework by addressing all levels of SOLO taxonomy. Importantly, Kasperson et al. emphasized that each of Brennan and Resnick’s dimensions (concepts, practices, perspectives) could be promoted at each of SOLO levels (unistructural, multistructural, relational, and extended abstract).
Importantly, both Bloom’s and SOLO taxonomies—although originally aimed at classifying learners' cognitive level or solution complexity—have also been used to classify learning tasks. This is usually done by mapping a task based on its desired solution, or as Petersen et al. (2011) put it, by “the characteristics of a response to which they would award full marks” (p. 632). This is similar to the case of the broader terms, “higher-order thinking” and “lower-order thinking”, which traditionally refer to learner’s skills or practices, and have also been used to characterize tasks based on the thinking level required to solve them (Haleva et al., 2021; Mohd Darby & Mat Rashid, 2017; Osadi et al., 2017; Rubin & Rajakaruna, 2015). We adopt this use, and will categorize the tasks in our studied learning environment based on SOLO Taxonomy; by doing so, we ignore the pre-structural level of the taxonomy, as each of the classified problems require some knowledge to correctly solve it.
Methodology
Our exploratory case study is based on a secondary analysis of log files drawn from students' use of an online learning environment for basic concepts in programming (Hershkovitz et al., 2019). Log files have been previously used to study errors in programming (Rodrigo et al., 2013; Seo et al., 2014; Thompson, 2006; Yarygina, 2020); mostly, such studies have referred to cases in which programs did not run completely successfully—either due to compilation error or run-time error—that is, generally focusing on syntax or semantic errors. Our approach is different, as we—while studying block programming, in which such errors are not possible—refer only to logic errors. Hence, our data include submitted codes that ran successfully but did not result in the expected outcome. Therefore, we had to manually classify the submitted codes for understanding the reason for not achieving the desired goal.
Population and Data Collection
The data we analyzed were collected in April 2017 from a population of N = 123 primary school Spanish students, 10–12 years old (51% boys and 49% girls–63 and 60, respectively). About half of the participants did not have any previous experience with coding (63 of 123, 51%). The students arrived to an outreach activity organized by the Faculty of Engineering of the University of Deusto (Bilbao, Spain), and participated in a workshop about technology, programming, and robotics. During this workshop, the students used Kodetu for about 50 minute, engaging with a module consisting of 15 challenges, increasingly ordered by level of difficulty. Before playing this game, participants had completed a short online questionnaire, in which they self-reported on a few background variables (gender, age, coding experience).
Learning Environment: Kodetu
Kodetu (http://kodetu.org) is a web app built using Google’s Blockly (https://developers.google.com/blockly) for teaching basic programming skills (Eguíluz et al., 2017). This platform has been recently used to assess the acquirement of computational thinking, as well as creativity in programming (Eguíluz et al., 2017; Guenaga et al., 2021; Israel-Fishelson et al., 2021). Each of Kodetu’s challenges presents the user with a maze in which an astronaut should get to a marked destination. Guiding the astronaut to her destination is done via a block-based code which the user is editing. Moving to the next challenge is possible only upon completion of the current challenge.
In the module used by our participants there were 15 challenges, presenting the user with basic concepts of programming, namely, sequencing (Challenges 1–7), repetition (Challenges 8–10), and conditioning (Challenges 11–12). Within each concept, Challenges were sorted by an increasing order of difficulty. The Challenges were as follows: Challenge 1 introduced a very simple forward-path coding. Challenges 2–3 introduced a single rotation, using a “turn [right/left]" block, in different path points. Challenges 4–6 combined more than one rotation in different combinations, and Challenge 7 was a long maze intended to show the hard manual work required to lead the astronaut through the path step by step. Challenge 8 introduced the concept of loops, presenting the learners with a “repeat until destination” block, with the learners being limited to write a 2-block solution, in order to force them to use that block; code length was limited from that point on. Challenges 9–10 enhanced the use of loops. Challenges 11–12 presented the concept of conditionals, with a simple if-statement, using an “if path [ahead/to the left/to the right]" block, allowing to check whether a path existed before moving, and Challenges 13–14 introduced the concept of more complex conditionals, with an “if path [ahead/to the left/to the right]/else” block. Finally, Challenge 15 posed the classic problem of a general maze (difficult even for experienced coders). Those challenges are presented in Figure 1. Kodetu challenges; figure taken from Eguíluz et al., 2017, p. 257.
Classifying Kodetu Challenges Based on SOLO Taxonomy
Classifying Kodetu challenges based on SOLO taxonomy.
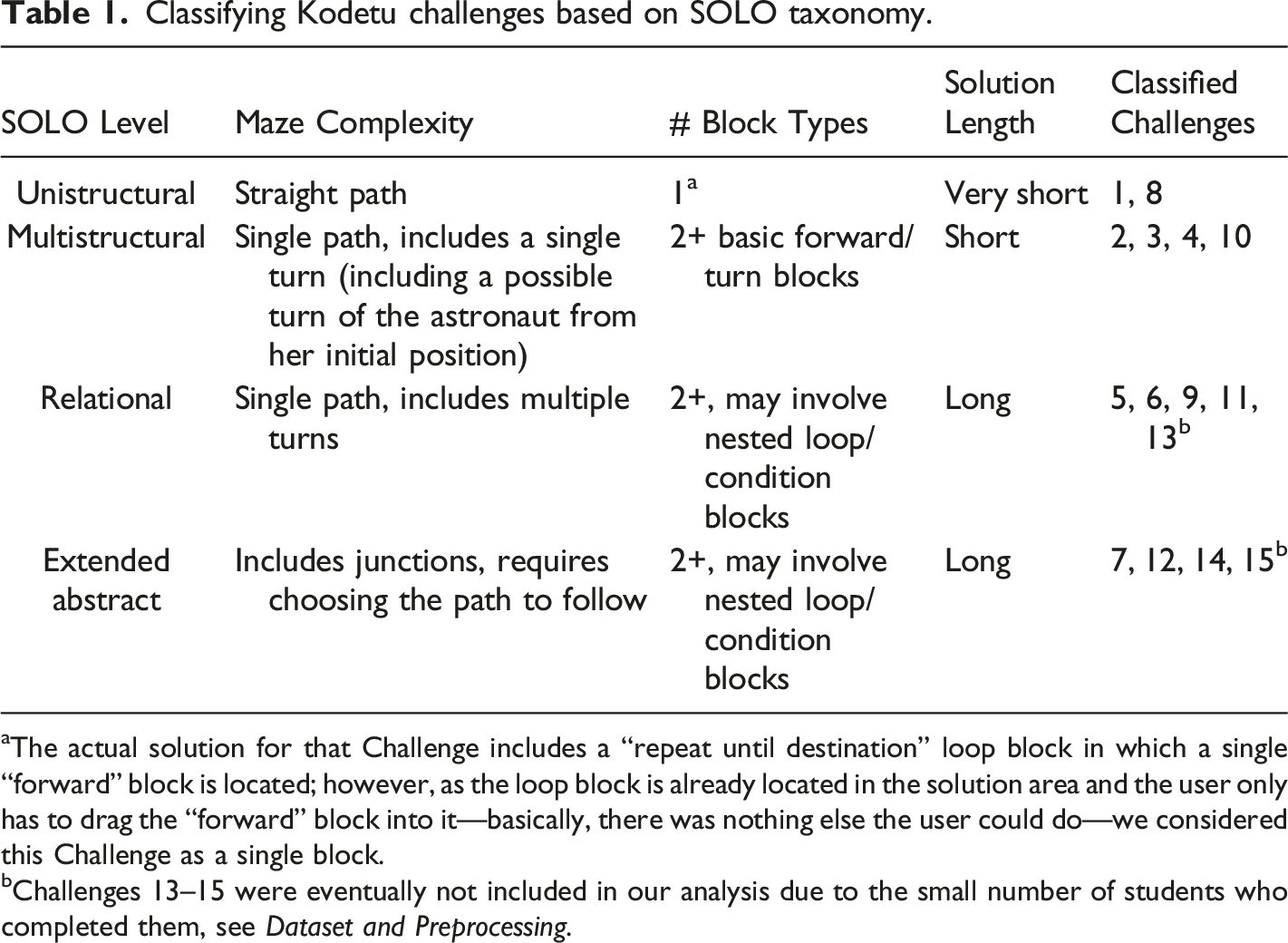
aThe actual solution for that Challenge includes a “repeat until destination” loop block in which a single “forward” block is located; however, as the loop block is already located in the solution area and the user only has to drag the “forward” block into it—basically, there was nothing else the user could do—we considered this Challenge as a single block.
bChallenges 13–15 were eventually not included in our analysis due to the small number of students who completed them, see Dataset and Preprocessing.
Dataset and Preprocessing
The full log file included over 100,000 rows, each representing an action taken by a user, including its timestamp, the challenge in which it was taken [1–15], the code associated with this action, and a result indication. Logged actions included each block dropping in the editing area, either dragged from the blocks menu or from within the editing area. In cases where actions did not reflect code execution, the result field took the value “unset”; otherwise, it took one of the following values: “success” – the astronaut got to her destination; “failure” –the astronaut stopped before getting to her destination; “timeout” – the astronaut got into an infinite loop; “error” – the astronaut fell off the path into the void. For the purpose of this study, we filtered out the logged actions that reflected non-executions, leaving us with 2679 total executions. This left us with 1033 failed executions (39%), that is, cases where the astronaut started moving and did not get to her destination.
It is important to highlight that our dataset included erroneous submissions only, that is, submissions that did not result in successfully complete the task. We chose to include successful submissions that may have been inefficient. For example, a code in which the sudent guided the astronaut to redundantly turn right and immediately left before following further steps. Such solutions are not considered as erroneous if the astronaut did get to her destination, and as was previously shown, ineffective solutions may have positive impact on student performance (Rangie et al., 2018)
Research Process
Error classification was done in a bottom-up approach while reading the codes submitted in the erroneous runs. This was done by the two authors in an iterative process and while keeping on full agreement. Each erroneous code could have included multiple “atomic errors”, where each one was classified into a single error category. After categorizing the errors observed in the log file, we ran statistical analyses to test for associations between the frequency of error types, the variables characterizing the task (level, computational thinking concept, difficulty) and the learner (gender, programming experience).
Findings
Types of Errors
Classifying the erroneous codes resulted in seven types of errors, presented here in descending order by their overall frequency.
Decomposition (369 of 1033, 35.7%), refers to cases where the erroneous code was a result of decomposing the problem into smaller problems that were then wrongly recomposed, either by order or insufficiently. For example, in Challenge 11, a correct solution involves a “Repeat Until Destination” loop, an “If Path to Left” condition, and “Forward” steps, in the following order: “Repeat Until Destination (If Path to Left (Left), Forward)", the following erroneous solution would be classified under this category: “If Path to Left (Left), Repeat Until Destination (Forward)".
Counting (288 of 1033, 27.9%), referring to cases where the number of the astronaut steps used in the code was smaller or larger than required. For example, in Challenge 2, where a correct code would be “Forward→Forward→Right→Forward”, the following code falls under this category: “Forward→Right→Forward".
Repetition (276 of 1033, 26.7%), referring to cases where the code within a repetition block was wrong, or where the to-be-repeated code was not used within a repetition block. For example, in Challenge 9, where the loop should include “Forward→Left→Forward→Right”, the following code falls under this category: “Repeat Until Destination (Forward→Left)”. Note that loops were first presented in Level 8.
Orientation (233 of 1033, 22.6%), referring to cases where the astronaut was guided to turn to a wrong angle. For example, in Challenge 3, where a correct solution could be: “Right→Forward→Forward”, an erroneous code classified under this category is: “Left→Forward→Forward”.
Premature (202 of 1033, 19.6%), referring to very short codes which formed the beginning of an expected solution. For example, in Challenge 4, where a correct solution could be: “Right→Right→Forward→Forward→Forward”, the following code falls under this category: “Right→Right”. These erroneous runs could be found by testing the solution step-by-step.
Conditionals (196 of 1033, 19.0%), referring to cases where a condition—or the code within it—was wrongly used. For example, in Challenge 11, where the condition should include “If Path to Left (Left), Otherwise Forward”, a use of “If Path to Left (Forward), Otherwise Left” would fall under this category. Note that conditionals were first presented in Level 11.
Redundant (56 of 1033, 5.4%), referring to longer-than-expected codes which were a result of keeping redundant blocks in the editing area. For example, in Challenge 3, where a correct solution could be: “Right→Forward→Forward”, it is possible that a student had tried the following erroneous code: “Left→Forward→Forward” (which would be classified under “Orientation” below), and upon realizing their mistake, added a “Right” block at the beginning without omitting the “Left”, to form the following erroneous code that falls under this category: “Right→Left→Forward→Forward”.
Associations between Types of Errors and Task Characteristics
For each task, we computed the frequency of types of errors and then ran a few analyses to test for associations between these frequencies and level number, the difficulty of the task (based on SOLO taxonomy), and the computational thinking concept represented by that task.
Level Number
Frequencies of error types by level of the game.
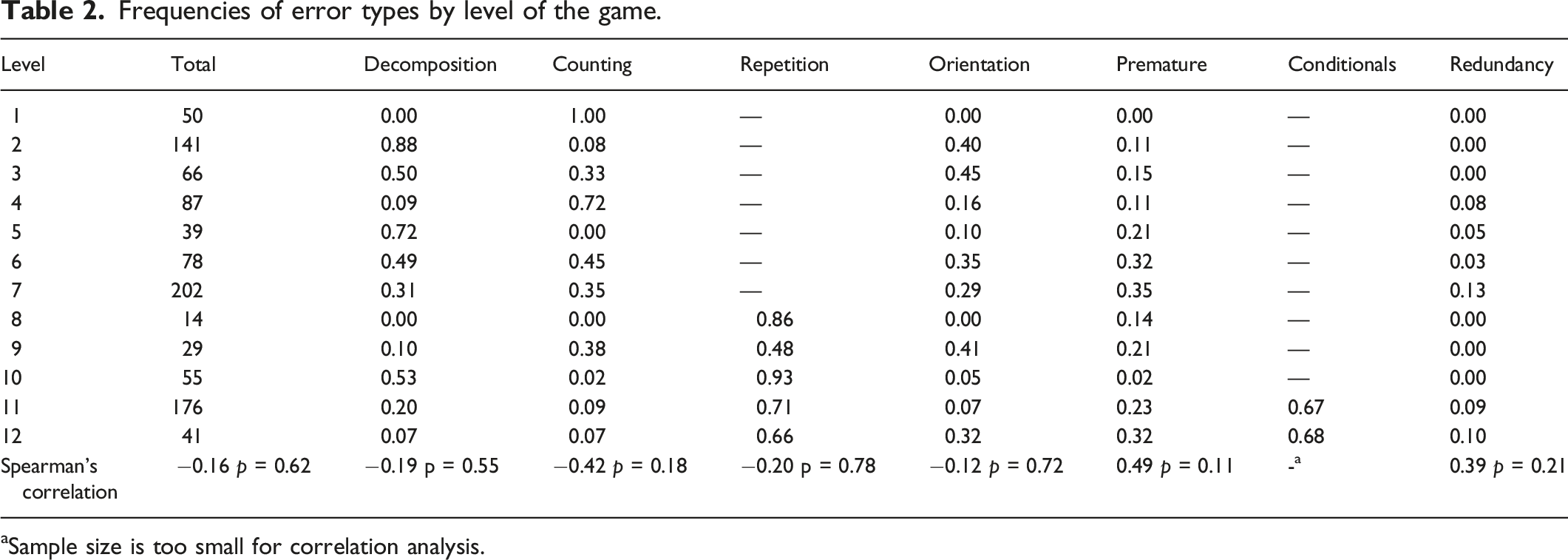
aSample size is too small for correlation analysis.
Computational Thinking Concept
Frequencies of error types by computational thinking concepts.

aSample size is too small for correlation analysis.
Task Difficulty
Frequencies of error types by SOLO-based difficulty.
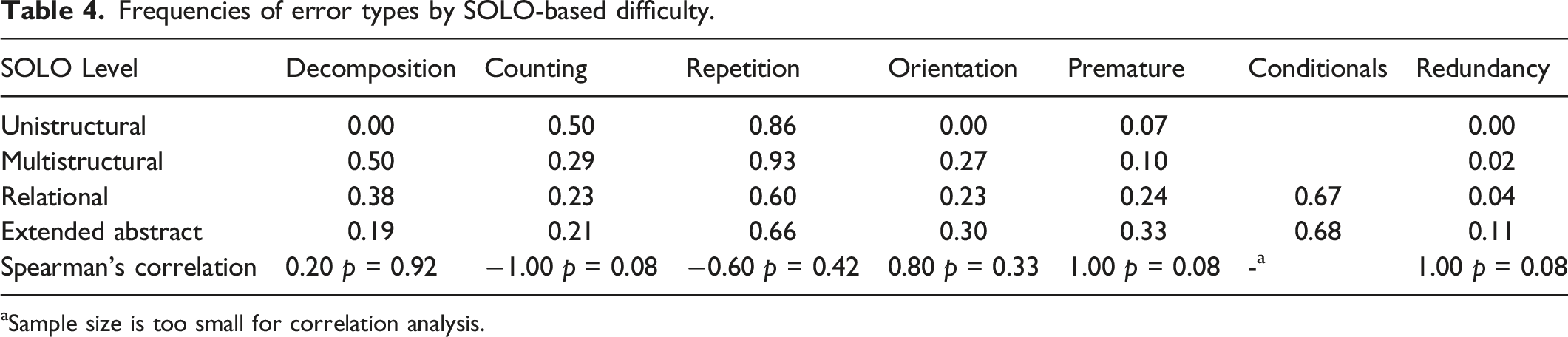
aSample size is too small for correlation analysis.
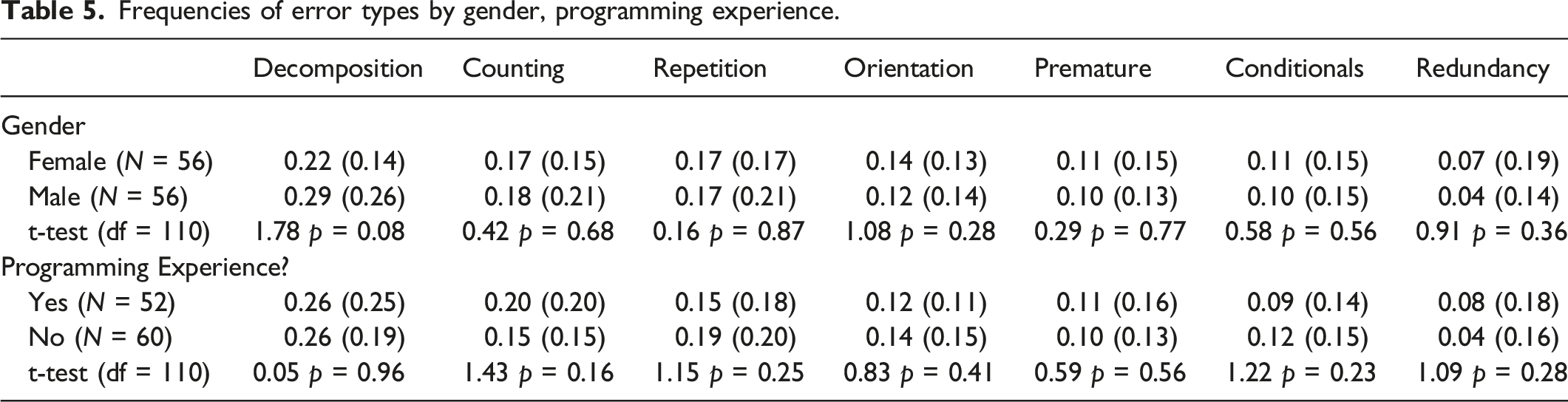
Associations between Types of Errors and Learner Characteristics
For each student, we calculated the rate of each type of error from their own total erroneous submissions. Then, we compared between female and male frequencies for each type of error separately, using t-test; similarly, we compared rates of type of error between participants with and without programming experience.
Frequencies of error types by gender, programming experience.
Discussion
In this exploratory case study, we analyzed students' (N = 123) unsuccessful submissions in block-based programming. Based on an analysis of log files drawn from a single online learning environment (Kodetu), we identified seven types of errors. We will first point out that the overall rate of failed submissions in our study (37%) lies within the extremely wide range found in previous studies—often referred to the rate of failed compilations—which may get to as high as 90% (Blikstein, 2011; Ettles et al., 2018; Pettit, 2014; Rivers et al., 2016). Importantly, we should recall that the learning environment studied here is based on block programming, which was originally developed to decrease the complexity of coding and the number of potential errors (Jackson et al., 2005; McCall & Kölling, 2015). Indeed, syntax errors are amongst the most common errors for novice programmers (Ahadi et al., 2018; Fu et al., 2017; Hristova et al., 2003), while the type of errors we point out are non-syntactic. Reducing syntax errors is important, as they can substantially impact on the experience of learning to program, and choosing the right programming language is therefore important (Mciver, 2000b).
Two Categories of Errors: Driven by Learner, Learning Environment
Overall, we identified seven types of errors, which we can classify into two broad categories, as these errors were either mostly driven by the learner’s knowledge and behavior or in the learning environment design.
Learner-Driven Errors
The first category, which is mostly learner-driven, relates to two dimensions in Brennan and Resnick’s (2012) framework of studying CT, namely concepts and practices, and to their acquisition and implementation by the learners.
Concepts are the cornerstones of engaging with CT; in block-based programming, concepts are mapped to blocks. Indeed, in the learning environment we studied here, there are blocks that—when joined together—control an astronaut’s path and guide her to her destinations. Besides blocks that control movement—i.e., moving forward and turning—there are blocks that correspond to CT concepts of loops and conditionals. Indeed, we identified errors that correspond to incorrectly constructing these structures, which we classified under “repetition” and “conditional” types of errors. The prominence of these types of errors while using a rather intuitive programming interface, emphasizes students’ misconceptions of basic CT concepts, such as loops and conditionals (Grover & Basu, 2017), although they are probably less prevalent in block programming compared to text-based programming (Mladenović et al., 2018). Therefore, it is recommended to explicitly teach about CT concepts using other tools and methods, including unplugged activities (Caeli & Yadav, 2020; Delal & Oner, 2020).
CT practices refer to the ways in which learners think and learn, therefore depicting the “how?” of the learning process, rather than just the “what?” (Brennan & Resnick, 2012). The “decomposition”, “premature”, and “redundant” types of errors fall under this broad category, as they most probably derived from implementing (or incorrectly implementing) problem-solving practices. Specifically, “decomposition” errors may be related to the practice of modularizing, that is, building something large by first building its smaller parts; “premature” errors may be a result of being incremental, that is, trying to run codes prematurely in order to follow the resulting path step by step; and “redundant” errors may be associated with either of these practices.
Notably, the characteristics of a programming language and the design of a learning environment for programming may shape novices’ practices of coding (Weintrop & Wilensky, 2018). This should be emphasized to educators, who could in turn explicitly help students foster such practices (Kong et al., 2017). Furthermore, CT practices should be continuously assessed, alongside with CT concepts, in order to have a more comprehensive understanding of students’ progress; only this will allow supporting them. In that sense, our approach of focusing on student errors may be taken as a metaphor to a pedagogical practice of learning from errors; that is, educators should encourage a culture where it is ok to make mistakes, as such mistakes would reveal misconceptions, knowledge gaps, and unfruitful programming practices from which students could grow (Basu et al., 2020).
Learning Envirovnment-Driven Errors
The second category of errors has mostly to do with the design of the learning environment, and holds those errors related to counting and orientation. These errors can be seen as inherent to the given learning environments, as guiding the astronaut to her destination—a task that by its very definition requires counting and turn-making—is the learners’ goal. That they were evident in over 50% of the erroneous codes we analyzed, demonstrates the crucial impact of the user interface in block-based programming. To put it simply, a large portion of student errors, when being presented with the foundations of programming, was a result of misunderstanding or misinterpreting visual cues, that have little to do with programming concepts or practices per se.
These findings echo previous studies of teaching young children to program by means of using friendly and seemingly-intuitive environments—either virtual or physical—that demonstrated how visual-spatial cues may hinder learning (Simões Gomes et al., 2018; Tony Andrew Lowe, 2018). Therefore, the obstructing mechanism may be related to visual-spatial skills, which were previously found to be positively associated with learning (Mathewson, 1999; Morrison, 2004; Salmerón & García, 2012). Within the context of teaching programming to young learners, it is common to engage them with problem-solving that requires visual-spatial abilities (e.g., in Code.org, CodeMonkey, or CodeCombat), hence these abilities should be taken into consideration while designing such learning environments and while using them for teaching. Identifying these types of errors has a large contribution to the understanding of novices’ errors in block programming, and extends previous attempts to classify such errors (e.g., Emerson et al., 2020).
Associations Between Error Type and Personal and Task Characteristics
We found no associations between error type and learner characteristics, specifically gender and prior coding experience. Previous studies indicated on differences in the ways by which children with prior coding experience engage with programming or computational thining tasks, and that such experience may impact their preferences towards certain types of programming language (Bakali et al., 2018; Menounou et al., 2019; Weintrop & Wilensky, 2015). To these, our findings add the important notion that types of errors do not necessarily correlate with prior coding experience, which highlights the importance of the very design of the learning environment.
As for gender, previous studies had demonstrated how girls and boys manifest differently the way they construct block-based programs (Funke & Geldreich, 2017; Hsu, 2014). When measuring achievementsin programming tasks, boys and girls do not necessarily differ from each other (Abdullah et al., 2021; Vasilopoulos & van Schaik, 2018; Zha & Billingsley, 2021). Indeed, a large-scale, log-based study of the same system used here (i.e., Kodetu), covering 3355 primary- and middle-school students, has shown some complex associations of behavior within the system and gender, prior coding experience (Eguíluz et al., 2017). Therefore, our findings of no associations between gender and error types may not be surprising.
Also, we pointed out the lack of associations between error types and game level or concept taught, contrary to previous large-scale analyses that suggest a performance decrease in both block-based and text-based learning environments for programming as the game progresses (Eguíluz et al., 2017; Israel-Fishelson & Hershkovitz, 2020); That is, our study adds to the existing literature the notion that as learners progress in a learning process, they may find it more difficult and hence submit more erroneous solutions, but the very mechanisms that drive these failed submissions do not necessarily change profoundly. This makes us reiterate the notion of learning from mistakes, which we highlighted above, as a means to change learners’ behavior meaningfully. Therefore, while using self-paced learning environments, learners may benefit from some human- or machine-led guidance.
The only attribute that was found to be associated with the type of error was the task complexity, as defined by SOLO taxonomy (Biggs & Collis, 1982). While counting errors decrease as tasks become more complex, premature and redundancy errors increase. Importantly, the tasks classified at the higher levels of SOLO taxonomy, compared with those at the lower levels, are not necessarily characterized by shorter paths of the puzzles they present, hence the decrease in counting-related errors is not explained by the maze length, and may be easily explained by their familiarity with the learning environment in which all tasks are designed similarly.
The increase in premature and redundant types of errors—which, as we explained above, are related to CT practices—may indicate that students modify their problem-solving strategies as tasks become more complex, probably working incrementally to a larger extent and trying to break down the problem to smaller, simpler ones. As previously suggested, students implement various strategies of problem solving in programming, either textual of block-based, and it is the changes in these strategies, and not merely the strategies themselves, that are more indicative on learning (Blikstein et al., 2014; Kesselbacher & Bollin, 2019). In a sense, our findings echo Breland et al.’s (2013) ideitnfication of learning pathways of novice programmers; their findings demonstrated a shift from exploring to tinkering to refinement, which may be associated with the increase we suggest in the use of a systemic way of problem-solving.
Therefore, identifying these changes sheds new light on the mechanisms that help students transfer from visual to procedural programming (Yetunde, 2018), and emphasizes the importance role of block-based programming in strengthening the very foundations of CT (Repenning, 2017; Sáez-López et al., 2016). Achieving this desired goal was probably a result of the learning environment made of a series of seemingly-similar tasks, which made the learners first familiar with the environment and its user interface, and then led them towards the learning goal in small steps. This is indeed a desired design principle of digital learning games, and at large of any learning experience (Diniz et al., 2015).
Nevertheless, for increasing the impact of this supportive design, it is advised to make explicit the implementation and development of CT practices. This may be achieved by guiding students through reflecting upon their problem-solving strategies, as was previously demonstrated in various domains (Cengiz & Karataş, 2015; C. H. Lin & Liu, 2012; Mason & Singh, 2016). Within the context of self-paced online learning environments, such a reflective process could be guided by a virtual agent (Egbert et al., 2021; Moechammad Sarosa et al., 2021).
Limitations
This study is not without limitations. We analyzed data from a single learning platform (Kodetu), and therefore our findings may be influenced by unique characteristics pertaining to this platform. Our analysis also focused on a dozen tasks which refer to a limited set of CT concepts, namely, sequence, loops, and conditionals. It is of great importance to study all CT concepts (Barr & Stephenson, 2011; Brennan & Resnick, 2012). Moreover, the analysis was focused on students from a single country (Spain)—which has specific educational, cultural, and technological characteristics—and on a specific age group. Therefore, it is advised to replicate this study in other learning environments, and in other geographical and cultural settings. Another limitation lies in the mechanism of progressing in the learning environment studied, that is, the need to successfully complete a task before moving on to the next one. This design principle may reduce errors that would otherwise arise because students have had training and have gained experience in previous tasks. It is possible, therefore, that more open, exploratory learning environments would yield other types of errors, or at least other frequencies of the types we found, and therefore encourage replicating this study is such environments. Still, we believe that we add an important unique contribution to the literature, and that our study has valuable implications.
Conclusions and Implications
In this study, we characterized students’ errors in block-based programming. We found two broad categories of errors, driven by either learners’ knowledge and behavior or by the learning environment design. Testing for associations between error types and personal and task characteristics, we only found such a link between error types and SOLO-defined task complexity, suggesting that it may indicate the development of problem-solving strategies as a result of the design of the learning environment.
This study has a few important implications, of which we will highlight three. First, identifying types of errors may lead to the improvement of CT acquisition processes while using block-based programming. With no syntax involved, educators could use student errors as learning opportunities to strengthen students’ understanding of the foundations of CT, that is, to promote a culture of learning from errors. Second, identification of error types may help support learners with formative feedback, and if errors are detected and recognized automatically in real-time, this could serve to offer students insightful, helpful support. Third, design characteristics may have a crucial impact on learners’ progress—hence, being a key component in assessment processes—and should be taken into consideration by developers and designers of learning environment, as well as by educators and policy makers.
We recommend to further explore patterns of error in block programming and the relationship between them and content- and task-characteristics.
Footnotes
Acknowledgments
The authors would like to thank to the members of DeustoLearningLab at the University of Deusto for their ongoing collaboration and their continuous support. Special thanks to Prof. Mariluz Guenaga (Director), Dr Pablo Garaizar, and Andoni Eguíluz.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.