
Abstract
Scholars in discourse studies have defined legitimation as the justification (and critique) of powerful institutions and their practices. In moments of crisis, legitimation tactics often shift. This article considers how such shifts are incited by unauthorized information leaks. Leaks, I argue, constitute freshly available texts that reveal privileged institutional information presented in a specialized rhetorical style. To explore how leaks are harnessed by institutional critics, I examine the 2013 Snowden/National Security Agency (NSA) crisis. Combining corpus analysis with discourse analysis, I explore how Snowden’s NSA leaks affected the online writing of the American Civil Liberties Union (ACLU). I also consider overlaps between the rhetorical patterns in the leaked NSA documents and those in the ACLU’s post-leaks writing. Findings from my analysis of legitimation and style categories suggest that, prior to the leaks, ACLU writers primarily used a character- and narrative-based style to delegitimize the NSA’s policies as illegal and secretive, and to push for their reform. After the leaks, though, the ACLU mainly used an informationally dense style rife with academic terms and vocabularies of strategic action, portraying NSA surveillance as massive and complex. As the documents moved from the NSA’s secret, technical discourses to public, critical discourses, the latter came to resemble the former rhetorically. These findings raise crucial questions about how critics can make use of leaks without necessarily relegitimizing institutional power.
Introduction
On June 6, 2013, The Guardian published the first ever full-text disclosure of a classified document describing U.S. government surveillance (Greenwald, 2013a), one of many documents leaked by former National Security Agency (NSA) contractor Edward Snowden. Back in 2005, the New York Times (henceforth Times) had revealed information about a post-9/11 NSA surveillance program (Risen & Lichtblau, 2005), but the Times did not publish any classified documents. By contrast, The Guardian published a top-secret Foreign Intelligence Surveillance Court (FISC) order. 1 The order required Verizon to turn over copies of its customers’ phone call metadata 2 within a 3-month period to the NSA, on behalf of the Federal Bureau of Investigation (FBI; Greenwald, 2013a). Thus, unlike previous controversies faced by the U.S. intelligence agencies, the 2013 crisis explicitly centered on textual evidence: public recontextualization of privileged institutional texts. Clearly not intended for public audiences, these texts nevertheless supplied crucial public evidence of secret institutional practices. This evidence was made available via entextualization, that is, Edward Snowden’s act of “rendering discourse extractable,” and allowing it to be (in more than one sense) “lifted out of its interactional setting” (Bauman & Briggs, 1990, p. 73). Thus entextualized, the NSA’s internal institutional discourse could be reported upon, defended, and criticized in public—and the specialized language of the NSA could be infused into these debates.
The Snowden-leaked FISC order was not only politically significant but also unusual in terms of its rhetorical and linguistic style. For example, It is hereby ordered that [Verizon] shall produce to the National Security Agency (NSA) upon service of this Order, and continue production on an ongoing daily basis thereafter for the duration of this Order . . . an electronic copy of the following tangible things: all call detail records or “telephony metadata” created by Verizon for communications (i) between the United States and abroad; or (ii) wholly within the United States, including local telephone calls. (“Verizon Forced to Hand Over,” 2013)
This excerpt features extreme case formulations (Pomerantz, 1986) in the phrases “ongoing daily basis,” “all call detail records,” and “wholly within the United States.” It also contains informational and academic lexis and syntax, for example, “production,” “duration,” “tangible,” “telephony metadata,” and “communications”; the cohesion-marking words “and” and “or”; and even the cohesion-marking punctuations colon, semicolon, and bracketed roman numerals. As analyzed below, other leaked documents, such as those describing the Agency’s PRISM, Upstream, and XKEYSCORE programs, exhibited similar linguistic and stylistic features. More remarkably, these specialized features actually reappeared in public critiques of the programs. Ironically, the NSA’s technical language was partly adopted by those interested in discrediting the NSA’s legitimacy.
The Snowden/NSA case suggests that leaks can enact a special form of legitimation crisis (Habermas, 1975), which is to say, a crisis over whether powerful institutions’ actions adhere to “the system of laws, norms, agreements, or aims agreed on by (the majority of) the citizens” (Martin Rojo & Van Dijk, 1997, p. 528). Past studies of legitimation discourse have examined moral and factual contestations between powerful institutions’ defenders and critics (Van Leeuwen & Wodak, 1999). But as this study reveals, leaks can alter these dynamics by publicizing secret institutional texts and encouraging their circulation. In so doing, they may not only provide new evidence of problematic institutional practices but also unearth specialized institutional genres and linguistic forms, making these available for reuse. By widely circulating such genres and forms, leaks have the potential to disrupt and transform (de)legitimation discourse and thus enable new moral arguments and rhetorical styles to emerge.
The present study seeks to describe this rhetorical disruption and transformation. I specifically ask, “How did Snowden’s leaks reshape the delegitimation tactics of the NSA’s critics?” I explore this question using a corpus of NSA-related blog entries published online by the American Civil Liberties Union (ACLU), one of the Agency’s fiercest institutional foes. In addition to pursuing issues of legitimation and recontextualization, I also consider lingering methodological questions about corpus analysis—specifically, how to see the big picture of natural language data without losing sight of microscopic (con)textual detail (Aull & Lancaster, 2014; Hyland, 2010). Following Aull and Lancaster’s (2014) call for “more context-informed corpus linguistic analysis” (p. 175), I present a context-informed method of corpus construction (Anthony & Baker, 2015). Specifically, I conduct a large-scale keyword and style analysis of my entire corpus, as well as a close discourse analysis of 60 representative texts. For the former, I use the tools Stylo (Eder et al., 2016) and DocuScope (Ishizaki & Kaufer, 2012). For the latter, I adopt an approach I call Legitimation Category Analysis, building off of past discourse studies of legitimacy categories (e.g., Cap, 2008; Oddo, 2011; Van Leeuwen, 2007).
This study helps clarify the effects of the leaked NSA documents on the ACLU’s delegitimation discourse, revealing significant shifts in rhetorical style and moral argumentation. Prior to the leaks, ACLU writers primarily used a character- and narrative-based style to delegitimize NSA surveillance as illegal and secretive; afterward, they mainly used an informationally dense style rife with academic terms and vocabularies of strategic action, portraying NSA surveillance as massive, indiscriminate, and technically complex. I attribute this shift in rhetorical strategy to the leaked documents’ numerous extreme case formulations and copious technical details. Overall, my findings raise questions about how critics can make use of leaks without, to some extent, relegitimizing institutional power.
Legitimation, Leaks, and the 2013 NSA Crisis
This article explores how the 2013 Snowden leaks marked a rupture in the NSA’s legitimation and delegitimation, rhetorical tactics used to support or challenge NSA practices. But just what is meant by the terms legitimation and delegitimation in this context? For Jürgen Habermas (1979), “legitimacy means that there are good arguments for a political order’s claim to be recognized as right and just” (p. 178). Habermas terms such arguments legitimations, which concern whether “institutions are fit to employ political power in such a way that the values constitutive for the identity of the society will be realized” (p. 183). As Van Leeuwen (2007) points out, the same values and standards used to legitimize institutions can also be used “to de-legitimize, to critique” (p. 92).
Thus, scholars in Critical Discourse Studies have sought to understand how legitimation and delegitimation strategies help shore up institutional power and respond to institutional crises (Cap, 2008; Martin Rojo & Van Dijk, 1997; Oddo, 2011; Van Leeuwen, 2007; Van Leeuwen & Wodak, 1999). As Martin Rojo and Van Dijk (1997) note, however, legitimation is not merely a speech act such as an accusation or an apology; it is a complex, unfolding process that also occurs through nondiscursive institutional actions, for example, enacting laws (legislative legitimation) and deciding court cases (judicial legitimation). Such legitimation shifts tend to occur in response to crises, when it is most pivotal to maintain, disrupt, or reestablish legitimacy (Habermas, 1979, pp. 178–179). For example, Piotr Cap (2008) analyzes a memorable legitimation shift: the Bush Administration’s changing justifications for the Iraq War. According to Cap, after the postinvasion discovery that Saddam Hussein’s regime did not actually have weapons of mass destruction (WMDs), Bush et al. shifted their rhetoric to emphasize the ideological threat of Hussein’s Iraq. This was a departure from Bush’s prewar legitimation rhetoric, which had emphasized the physical threat of Iraq’s (nonexistent) WMDs (Cap, 2008, pp. 37–38). Thus, the administration sought to forestall public skepticism of the Iraqi threat by strategically redefining it. Cap’s work shows that legitimation strategies may shift in response to public perceptions, including those resulting from newly leaked information. A related example is WikiLeaks’s Iraq War releases in 2010, which likely accelerated the 2011 withdrawal of U.S. troops by exposing particularly gruesome U.S. war crimes (Gallagher, 2013). However, as the recent history of the NSA proves, not all leaks have the same potential to incite and constitute new (de)legitimations.
Prior to 2013, leaks of NSA information had only limited political effects, in part because they had emerged entirely from secondhand reports. For example, in 2005, the Times revealed that shortly after 9/11, the NSA began collecting data about U.S. citizens’ phone calls and emails. Drawing on conversations with anonymous sources (“Nearly a dozen current and former officials . . . discussed [the program] with reporters”), the Times reported that the program had caused turmoil within the government (Risen & Lichtblau, 2005). 3 Ultimately, though, there were few Congressional hearings in response to the revelations, and soon enough “domestic spying seemed to fall off the [public] radar” (Rozen, 2009, p. 33). In fact, in 2008, the Congress passed the FISA (Foreign Intelligence Surveillance Act of 1978) Amendments Act (FAA), which authorized the program that the Times had exposed (Wittes, 2011). By contrast, the 2013 leaks led to legislation aimed at curbing NSA power: the 2015 USA Freedom Act (Nakashima, 2015).
In the realm of judicial legitimation, too, the pre-2013 reporting did not provide justiciable evidence. In response to the 2008 FAA’s passage, the ACLU sued the government on constitutional grounds (“Amnesty v. Clapper,” 2015), and in February 2013, the Supreme Court ruled against the ACLU’s standing to sue (“Amnesty v. Clapper,” 2015), arguing that the plaintiffs had attempted to “manufacture standing . . . based on hypothetical future harm” (Clapper v. Amnesty International USA, 2013). Indeed, such harm was “hypothetical” and “future”-oriented because of a lack of documentary evidence. Yet after the Snowden leaks, multiple rulings declared NSA surveillance illegal (Savage, 2015).
The new laws and court decisions were in part due to the sheer volume of new information in the leaked documents. As noted above, the documents revealed NSA collection of metadata about all Americans’ phone calls (Greenwald, 2013a). They also exposed two Internet surveillance programs, PRISM and Upstream (“NSA slides explain,” 2013). PRISM collected data from major U.S. internet platforms such as Facebook and Google, and Upstream directly tapped underseas cables and other parts of the global Internet to intercept and search “Americans’ international Internet communications—including emails, chats, and web-browsing traffic” (Gorski & Toomey, 2016). The documents thus revealed the sheer scope and variety of NSA programs.
However, the documents’ significance goes beyond just the information they provided. In short, various aspects made them more recontextualizable than earlier leaks. Recontextualization, as defined by Linell (1998), is “the dynamic transfer-and-transformation of something from one discourse/text-in-context” to another (pp. 144–145). But when and why do such transfers-and-transformations occur? Oddo (2018) argues that various “formal, semantic, and cultural” aspects (p. 3) make some texts more “worthy of recontextualization” (p. 25) than others. In the case of leaks, I argue that three key factors determine whether they are deemed valuable evidence and, thus, recontextualizable information likely to incite a crisis. These factors hinge on whether they are
primary institutional sources (culturally valuable),
contradictory of past institutional claims (semantically valuable), or
formatted as digital files (formally valuable).
These three aspects made the 2013 leaks more transformative than the 2005 Times disclosure, and in what follows, I offer examples of how (unlike the 2005 Times story) the leaks’ cultural, semantic, and formal features helped boost their circulation and prevent their suppression.
The 2005 Times reporting was based on verbal conversations with anonymous government sources, which are open to competing government claims that the sources are unrepresentative, misinformed, manipulative, or not credible. Conversely, the Snowden-assisted reporting was based on primary, written sources: documents used to administer the programs. The Snowden-leaked documents are institutional genres such as court orders, instruction manuals, and training slide presentations. Such texts must by pragmatic necessity be accurate, as they are used for ongoing Agency business. This primary sourcing made the stories more recontextualizable, as the documents bore the stamps of “immediacy” and “officialdom” (Oddo, 2018, p. 227).
Moreover, whereas the Times’s sources’ language could not be extensively compared with previous public statements, the leaked documents contained copious written descriptions of NSA activities. Once revealed, these NSA activities often implied previous falsehoods in the public record. For example, in March 2013, Director of National Intelligence James Clapper was asked publicly if the NSA collected “any type of data at all on millions or hundreds of millions of Americans,” and he answered, “No, sir. Not wittingly” (Dwyer et al., 2013). But the FISA court order leaked on June 6, 2013, revealed that the NSA had, in fact, intentionally sought “all call detail records or ‘telephony metadata’ created . . . for communications (i) between the United States and abroad; or (ii) wholly within the United States, including local telephone calls” (“Verizon Forced to Hand Over. . .,” 2013). This and other semantic contradictions lent the documents an element of scandal and drama, further increasing their recontextualization potential (Oddo, 2018, p. 227).
Finally, whereas the 2005 Times leak was solely recontextualized as a news story, the 2013 leaks were also made publicly accessible as digital files. This imbued the documents with “prepared-for detachability” (Bauman & Briggs, 1990, p. 74). For example, as artifacts of an internal institutional culture, the files feature jargon-laden technical language and internet slang, jokes, and braggodocio (Gellman, 2020, pp. 187–220). While the former may have made recontextualization problematic from the point of view of accommodation (Fahnestock, 1998), the latter likely made it attractive as a “human interest story.” Furthermore, many files are multimodal digital texts, whose visual design features serve to emphasize important information: official logos of agency divisions and participating technology companies, section headings and diagrams, bolding and highlighting, and so on. This information would have stood out as reporters and publics accessed the files. The files are also mainly in .pdf format, making them convenient to read, store, organize, analyze, and share. All of these formal elements set the stage for publics to view the documents as real and legitimate, to pay attention to their contents, and to recirculate them.
In March 2015, a Pew Research study found that 87% of respondents had heard about NSA surveillance, with 31% having heard “a lot” about it (Shelton et al., 2015). Granted, polls conducted in 2005 in the immediate aftermath of the Times’s NSA reporting also found high levels of public interest in the issue, with one finding that “75 percent said they have been following the issue very closely or somewhat closely.” However, the same poll found that “only 29 percent said the issue will be ‘extremely important’ to them in the 2006 elections” (“Poll finds U.S. split over eavesdropping,” 2006). In addition, the Times reporting did not have as lasting an effect on internet discourse: Google searches in November 2020 for “Bush wiretapping,” “Bush eavesdropping,” and “warrantless wiretapping” return no more than 1.5 million results (for “warrantless wiretapping” 4 ), whereas searches of “Snowden NSA” and “Snowden files” return over 5.9 million and 4.8 million results, respectively. Overall, it seems reasonable to conclude that the Snowden leaks circulated much more widely than the information the Times reported.
It is worth pausing now to mention one factor that made the Snowden leaks less likely to incite a crisis. Bauman and Briggs (1990) identify four dimensions of “social power” affecting recontextualization: access, legitimacy, competence, and values. In brief, they argue that institutional power restricts people’s access to some texts; questions people’s right to legitimately repurpose them; interrogates people’s competence in understanding their contents; and exercises influence over texts’ “status” and “cultural capital” (pp. 76–77). While all of these issues manifested during the 2013 controversy, the strongest challenges made by the NSA and its defenders centered on the legitimacy of publicizing classified material and the competence of journalists and public audiences to understand it. However, these challenges were rendered problematic by the semantic and formal aspects of the leaks. Given the contradictions the leaks revealed, such as then-Director James Clapper’s “not wittingly” claim, publics were likely less inclined to embrace official critiques of leakers and journalists. Meanwhile, the leaks’ formal status as digital files enabled large communities of highly educated citizen journalists and activists to carefully analyze and research their contents. Consequently, the NSA and its public allies could not effectively censor the leaks or dissuade publics of their importance.
In short, the 2013 NSA leaks were greatly recontextualizable, and power dynamics that typically militate against recontextualization were largely overcome. Some of the leaks’ most important effects were on nondiscursive legitimation, including the legislative changes and court decisions mentioned earlier. But what were the leaks’ effects on public writing? After all, the documents are not simply evidentiary; they are also rhetorical texts, and as they were used in critical reporting and public debate, their “semantic aspects and communicative values [were] changed, due to the change of contexts” (Linell, 1998, p. 148). To what extent, then, did the leaks shape the discursive delegitimation tactics of the NSA’s critics, and how have such changes manifested at the level of critical writers’ rhetorical style and moral argumentation?
Data and Method
The present study sought to answer the question “How did the 2013 NSA leaks influence the rhetorical style and moral argumentation of the Agency’s institutional critics?” I specifically engaged this question by collecting all NSA-related blog entries published on the ACLU’s website through September 2018. 5 Using the entire corpus, I conducted DocuScope-based factor analysis (Ishizaki & Kaufer, 2012) and Stylo-based keyword analysis (Eder et al., 2016). And using a 60-text subcorpus, I conducted Legitimation Category Analysis. I deployed these methods to explore how the leaks may have influenced the ACLU’s employment of keywords, rhetorical style techniques, and legitimation categories in its writing about the NSA.
Corpora for Factor Analysis and Keyword Analysis
My full data set consisted of all webpages published at “https://www.aclu.org” tagged both “blog post” and “NSA surveillance,” as of September 2018. This resulted in 301 texts in total, all published between December 2005 and September 2018. The pre-leaks texts totaled 74, all published between December 2005 and June 2013; post-leaks texts totaled 227 (June 2013 to September 2018).
Selecting Subcorpora for Discourse Analysis
As Anthony and Baker (2015) note, “researchers can sometimes be criticised for ‘cherry-picking’ texts [to] illustrate a preconceived idea or point” (p. 273). Thus, I wanted to ensure that my subcorpora were representative of corpus-wide trends, including both (1) key style category differences pre- versus post-leaks identified by DocuScope (see “DocuScope and Rhetorical Factor Analysis” section) and (2) general content differences between the two periods. In addition, I wanted manageably sized subcorpora to facilitate a nuanced, line-by-line Legitimation Category Analysis.
To select texts representative of key style differences pre- versus post-leaks, I used DocuScope (Ishizaki & Kaufer, 2012) and Minitab to conduct a factor analysis. In brief, this procedure involved, first, processing all 301 texts using DocuScope (see “DocuScope and Rhetorical Factor Analysis” section); then, exporting DocuScope’s frequency counts; and, finally, importing the DocuScope data into Minitab for multivariate factor analysis. The factor analysis pointed me to texts most representative of corpus-wide DocuScope trends.
To select texts representative of general content differences, I conducted a corpus-wide keyword analysis. By “general content differences,” I mean words frequently used in one time period (e.g., pre-leaks) but infrequently used in the other period. I used the oppose( ) function in the R package Stylo (Eder et al., 2016), which ranks words by their relative keyness, 6 or the extent to which their frequency differences are greater than would be expected by chance. For the pre-leaks ACLU blog entries, the top eight keywords were sue, wiretapping, monitor, immunity, Bush, vote, request, and constitution. For the post-leaks period, they were metadata, disclosures, Snowden, search, bulk, mass, reform, and revelations. Thus, I determined which texts these keywords appeared in most often.
Combining these two methods of selection, I gathered 60 texts for close reading—30 each from the pre- and post-leaks periods. Each of the selected texts either scored highly on the DocuScope factor, exhibited a high prevalence of keywords, or did both things. 7 This procedure gave me confidence that my subcorpora were both representative and manageably sized.
Rhetorical Analysis Methods
As a close reading approach, I coded my pre- and post-leaks subcorpora for legitimation categories. In addition, as discussed above, I used DocuScope to analyze corpus-wide rhetorical style patterns.
Legitimation category analysis
In Critical Discourse Studies, various methods are employed to analyze legitimation. Van Leeuwen (2007) analyzes four common strategies: authorization (legitimacy derived from tradition, custom, law, or authoritative human sources), moral evaluation (legitimacy via implicit invocation of value systems), rationalization (legitimacy according to uses or ends of institutional action), and mythopoesis (legitimacy based on storytelling; p. 92). Other CDS scholars have analyzed Us versus Them categorization (Oddo, 2011) and threat construction (Cap, 2008). Still others have used their data sets to develop original categories (e.g., Martin Rojo & Van Dijk, 1997). I did the latter, following a reading strategy similar to Van Leeuwen’s (2007, p. 93).
As I read each text, I began by “first separating out the clauses and parts of clauses” (Van Leewuen, 2007) representing non-legitimatory content:
institutional action, especially surveillance activities and their legal and technical infrastructures;
institutions, typically the NSA and other government bodies;
institutional representatives;
other participants in, targets of, or opponents of institutional actions; and
“the settings and timings of these activities, and the tools and materials involved in them.” (p. 93)
These identified, I attended to “leftover” parts of each clause, scanning them for explicit and implied judgments—in other words, (de)legitimations.
To illustrate this process, below is a sentence from my corpus, text-formatted to highlight surveillance activities and legal and technical infrastructures (ALL CAPS); institutional actors cast in the ACLU corpus as “villains” ( Using SECTION 702, the strikethrough); institutional targets or opponents cast as “heroes” or “victims” (government copies, searches, and retains
For each (de)legitimation, I asked myself what standard it drew upon. I interpreted “vast” as appealing to a standard size of government power (smaller than “vast”), and “without ever obtaining a warrant” as appealing to standard legal procedures. Over time, I consolidated these into a set of categories. I categorized appeals to the fundamentally alarming (oversized, extraordinary, all-powerful) nature of certain government powers as
As I developed and applied these categories, I employed a collaborative coding strategy (Smagorinsky, 2008, p. 401): A second coder worked with me to verify all codes on a sample of texts (five texts pre-leaks, and five texts post-leaks), discussing and reaching agreement on how to interpret, code, and bracket each data segment. This collaborative discussion strategy resulted in deep agreement on codes in 1/6 of the texts selected for close reading. In the rest of my data, I consulted with my second coder on any “outliers” that did not seem to fit easily into the agreed-on categories. Of the full list, the categories that occurred most frequently are listed in Table 1.
Legitimation Category Analysis Coding Scheme.
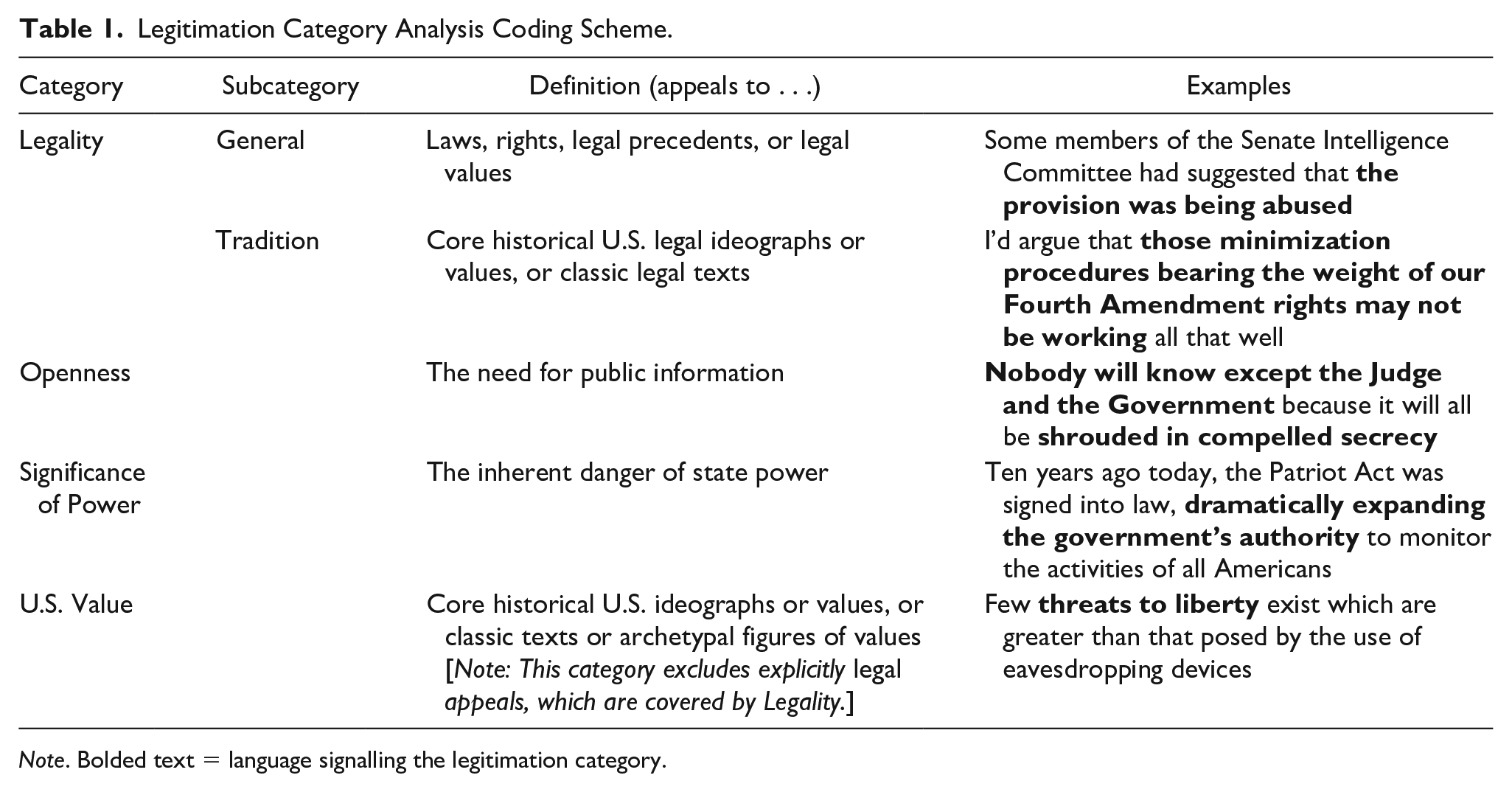
Note. Bolded text = language signalling the legitimation category.
Although the legitimation discourse studies cited earlier richly describe particular texts’ lexical and grammatical styles, none combines discourse analysis of legitimation categories and corpus analysis of rhetorical style features. My methods enable me to analyze how subcorpus-level legitimation and corpus-level style work in tandem, which past studies have not directly addressed.
DocuScope and rhetorical factor analysis
As an automatic text analysis tool, DocuScope is concerned with “uncovering how the writer’s small and recurring linguistic choices contribute to the whole text experience of the reader” (Ishizaki & Kaufer, 2012, p. 276). However, DocuScope is unlike most such tools (e.g., Stylo) in one crucial regard: It does not read texts as undifferentiated “bags of words.” Instead, DocuScope uses a dictionary to read texts for particular language action types (LATs; Ishizaki & Kaufer, p. 277), which represent categories of rhetorical style. Rhetorical style here is characterized by lexical and syntactic features designed to produce particular reading experiences. Some examples of DocuScope’s LATs are Academic Terms, Character, Citation, Description, Information, Inquiry, Narrative, Reasoning, Strategic, and Updates. See Table 2 for definitions and examples of DocuScope LATs most crucial to this study.
Docuscope Language Action Types and Examples.

Source. Adapted from Ishizaki and Kaufer (2012).
Note. LAT = language action type; FISA = Foreign Intelligence Surveillance Act of 1978; NSA = National Security Agency. Bolded text = language signalling the LAT.
Just like other text mining tools, DocuScope allows its results to be exported for statistical analysis. Specifically, multivariate factor analysis can help account for particular combinations of LATs in texts that are unlikely to have occurred together by chance. When DocuScope results are used for comparative factor analysis of two corpora, a statistically significant result, or factor, is defined by two poles. Each pole features a set of correlated LATs that is negatively correlated with another set of LATs. These may be interpreted as rhetorical styles distinguishing the two corpora.
For example, a rhetorical factor analysis of a research corpus and a news corpus might find a factor with positive correlations of Academic Terms, Citation, and Reasoning, and negative correlations of Character, Narrative, and Updates. The research articles would likely score positively on this factor, while the newspaper stories may score negatively. Thus, this type of analysis can help account for specific styles distinguishing writing in different disciplines (see, e.g., Ringler et al., 2018). In this study, however, I analyze specific styles distinguishing pre- and post-leaks ACLU blog entries.
Analysis of Legitimation and Style in ACLU Blog Entries
In this section, I analyze how the 2013 leaks helped incite a new legitimation crisis for the NSA, as critics of that institution transformed their legitimation tactics in response to the newly leaked material. First, I examine what the ACLU’s legitimation tactics looked like before the pivotal leaks were made public, presenting my Legitimation Category Analysis (see “Pre-Leaks ACLU Legitimation Categories” section) and Rhetorical Factor Analysis (see “Pre-Leaks ACLU Rhetorical Factor Analysis Results” section) of 30 ACLU blog entries from before the leaks. Next, I study the leaked documents themselves, analyzing the documents most frequently referenced in post-leaks ACLU blog entries (see “Rhetorical Patterns in Snowden-Leaked NSA Documents” section). Finally, I investigate how the ACLU changed its legitimation tactics in apparent response to the leaks through my Legitimation Category Analysis (see “Post-Leaks ACLU Legitimation Categories” section) and Rhetorical Factor Analysis (see “Post-Leaks ACLU Rhetorical Factor Analysis Results” section) of 30 post-leaks ACLU blog entries. As described below, pre-leaks, the primary legitimation standards invoked were
Pre-Leaks ACLU Legitimation Categories
Legality
As shown in Figure 1, before the leaks, ACLU blog writers most often delegitimized the NSA through appeals to the law (
Thus, about
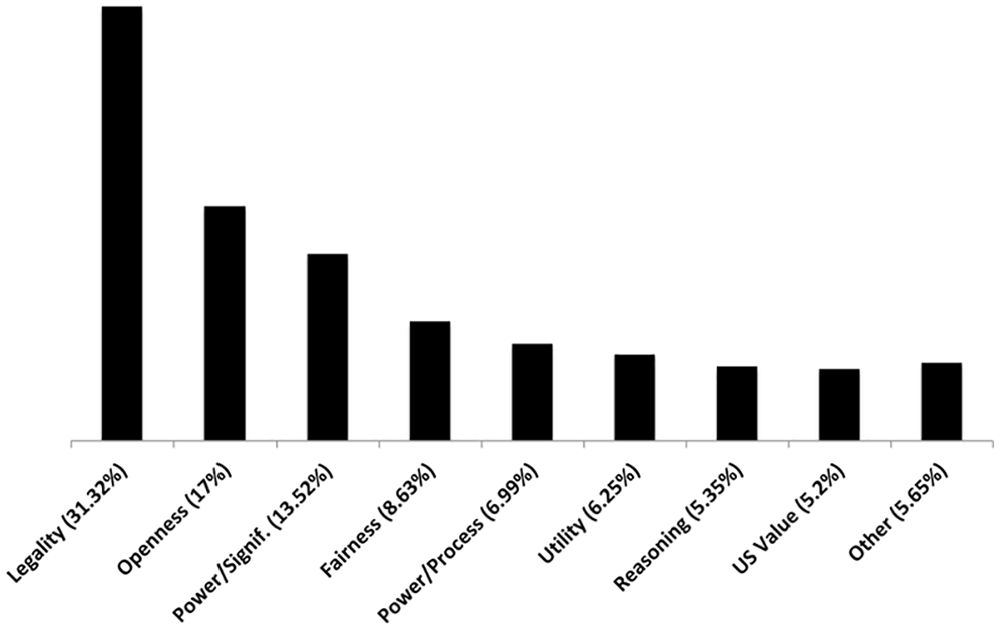
Distribution of legitimation category instances (N = 672) in pre-leaks ACLU blog posts. Prior to the leaks, Legality is the top category, followed by Openness and Significance of Power.
Traditional legality
Most appeals to traditional legality contain short, abstract phrases representing core legal ideographs (McGee, 1980), such as
<the Constitution> (and derivative modifiers, e.g., <[un]constitutional>, nominalizations, e.g., <constitutionality>, etc.);
<the Bill of Rights>, <the Fourth Amendment>, <the Fifth Amendment> (and its notion of <due process>); and
<right to privacy>/<civil liberties>.
The word <Constitution> and its variants appear in the ACLU’s pre-leaks texts
For instance, one entry from August 2008 argues that the immunity provided to NSA-cooperative telecommunications companies by the 2008 FISA Amendments Act is unconstitutional. The entire entry attempts to delegitimize the FAA as contrary to legal traditions, but the author also produces specific traditional legality arguments as follows: By retroactively removing those [customers’] rights [to sue the companies], the FISA Amendments Act have, in essence, deprived those plaintiffs of something of tangible value,
This excerpt draws upon particular terms and phrases (“taking,” “just compensation”) from the Fifth Amendment of the Constitution to delegitimize the policy. It also emphasizes the Constitution’s restrictiveness through the verb “allows” and the adverb “only.”
In the pre-leaks texts, constitutional rights are overwhelmingly portrayed as clear and firm sources of (il)legitimacy. For instance, one entry describes the 2001 Patriot Act as having “swept aside
General legality
In contrast to arguments that emphasize traditional U.S. constitutional law, ACLU arguments grounded in general legality employ keywords from a more abstract legal vernacular, which unsurprisingly includes
<law>/<[un]lawful>, <[il]legal>/<[il]legality>, and <statute>,
but also includes terms related to specific aspects of the legal process, such as
<warrantless> or <suspicionless>;
<probable cause>; and
<standing>.
In particular, <law> and its variants occur
Openness
For much of the post-9/11, pre-leaks era, the NSA as an institution was kept intentionally out of public view. Thus, the category I am calling
Implied in this category is the idea that people cannot protect their “individual rights and liberties” from policies and institutions that they do not know exist or that they do not understand. For example, the ACLU critiques the Department of Justice for not disclosing more information about NSA programs: “In order to have meaningful debate over government surveillance powers, we must be able to answer basic questions about the government’s current use of such powers” (2012-05-23). According to the openness standard, if a policy or institution is being deliberately closed off from public scrutiny and/or understanding, it is illegitimate.
Like appeals to legality, openness appeals often employ keywords, including
<secret> and <secrecy> (or <transparency>) and
related phrases such as <find out>, <basic information>, and <in the dark>.
Across all pre-leaks texts, <secret> and its variants appear
Using openness appeals, ACLU writers construe the U.S. public as a victim being denied their right to both know about and understand the NSA’s policies, as well as how these policies may be affecting the public’s other rights. For example, one writer critiques a Patriot Act–authorized program this way: “Section 215 and the “After four years, you’d hope that
Using phrases like “you’d hope,” counters like “but” and “only,” and negations (“haven’t”), this example implies that the public ought to be provided some knowledge of government policies that might potentially affect their basic rights, or failing that, the people’s duly-elected Congresspeople should be. The small number of people who understand this program and the rules that govern it make it illegitimate. In an earlier post that year arguing for corporate transparency, a blogger writes, “As citizens,
Overall, the ACLU’s appeals to legality and openness seem to assume that the NSA can and should be checked by a legitimate U.S. political system. In particular, ACLU writers’ legality appeals assume that the NSA is constrainable by courts that generally uphold the law and the Constitution, and that U.S. courts in fact generally do these things. These assumptions are further evidenced by the number of pre-leaks entries chronicling particular ACLU federal lawsuits and encouraging readers to support them. The ACLU’s openness appeals assume that NSA policies are generally knowable and understandable and that such knowledge is usable by publics for political action. In sum, the ACLU’s pre-leaks blog figures the United States as fertile ground for political action, and by emphasizing the NSA’s illegality and secrecy, the ACLU’s moral argumentation reflects a desire for concrete reforms toward greater public openness and legal redress.
Pre-Leaks ACLU Rhetorical Factor Analysis Results
This study explores overlaps between legitimation categories (e.g., legality and openness discussed above) and rhetorical style, considering how writers’ legitimation categories and rhetorical styles change along with the source texts that they draw on in their writing. Prior to June 2013, the ACLU was not as regularly citing primary government documents in its writing about NSA surveillance. Thus, it is important to clarify what the organization’s pre-leaks rhetorical style looked like in order to fully understand the changes that occurred after the 2013 leaks.
Following the procedure described earlier, I used factor analysis to distinguish the pre- and post-leaks ACLU entries based on their frequency counts of DocuScope LATs. There was a statistically significant difference between groups as determined by a one-way analysis of variance, F(1, 782) = 15.93, p = 0.
11
The pre-leaks factor correlated the DocuScope LATs of
Pre-leaks rhetorical style: Character and Narrative
During the pre-leaks period, ACLU staff writers employed
This style emphasized key players and dramatic scenes in the ACLU’s long war against the Bush Administration’s post-9/11 policies. For instance, one such scene was the 2008 FISA Amendments Act Senate debate (
As this excerpt shows, ACLU writers employed this style to develop heroic characters readers might identify with, such as Senator Dodd and the ACLU’s own attorneys and writers. They also identified villains, such as President Bush in the excerpt below, positioned as violating his oath of office and opposing “good Americans”:
and President Obama in the following, positioned as continuing the Bush administration’s questionable legal and secrecy tactics: For a full decade, the executive branch—first the
This style thus encourages readers to support and assist the ACLU and Dodd in their heroic struggles against villains like Bush and Obama.
As a style for expressing the unconstitutionality, illegality, and secrecy of NSA surveillance, character-driven storytelling is an effective one. For legal arguments to be persuasive, ascribing agency to specific people is wise; such individuals serve to personify the blameworthy behavior being legally charged. Further, the idea that specific people chose to conceal their actions raises the stakes on their lack of openness. In this regard, the ACLU’s pre-leaks style takes the popular pro-surveillance bromide, “if you’ve done nothing wrong, you should have nothing to hide,” and redirects it at the institutions governing U.S. surveillance policy.
Rhetorical Patterns in Snowden-Leaked NSA Documents
While the ACLU’s pre-leaks writing about the NSA depended on legality and openness legitimation categories, as well as character-driven, narrative-based style, the leaks that began in June 2013 provided new information about NSA policies in specialized rhetorical and linguistic styles. In this section, I briefly describe the new information and style patterns within the leaked documents.
Because the leaks were published in the mainstream press, they represented for ACLU writers an important legitimation resource: direct textual evidence of the NSA’s practices. In particular, ACLU writers most frequently referenced the following NSA programs first revealed in 2013:
The phone metadata collection program conducted under Section 215 of the Patriot Act (Greenwald, 2013a)
Internet surveillance operations under Section 702 of the FISA Amendments Act, particularly PRISM collection from Google, Facebook, and other tech platforms (Gellman & Poitras, 2013) and Upstream collection from underseas cables and other parts of the global internet (Timberg, 2013)
XKEYSCORE, an interface for accessing NSA data stores (Greenwald, 2013b)
Working backward from the ACLU blog entries, I located the leaked documents that provided evidence of these secret programs—the primary sources for the ACLU’s post-leaks critique. I already analyzed one leaked document—the Section 215 FISC order—in the Introduction section, so here I briefly analyze leaked documents about PRISM, Upstream, and XKEYSCORE. I contend that the style of these leaked documents is important because it appears to influence the writing style subsequently adopted by ACLU bloggers.
The first vital leak I analyze is a slidedeck, dated April 2013 and published in the Washington Post on June 7, 2013, that primarily describes the PRISM program, but also discusses Upstream (Gellman & Poitras, 2013). The slidedeck features copious academic, informational language and extreme case formulations. As shown in Figure 2, its first slide portrays PRISM as “used

First two slides of the April 2013 PRISM slidedeck leaked to The Washington Post. Higher resolution versions are available in Gellman and Poitras (2013).
There is also the extreme case formulation in Slide 2, “much of the world’s communications,” and an implied extreme case in “world’s telecommunications backbone.” Furthermore, Slide 2 uses academic register to provide informational context, for example, complex noun phrases like “International Internet Regional Bandwidth Capacity.” This register is reinforced by the international data flow visualization.
On July 10, the Washington Post published another slide discussing Upstream (“NSA slides explain. . .,” 2013), shown in Figure 3. Again, academic, informational register appears as technical terms: “fiber cables,” “infrastructure,” “data,” and “servers.” While there is less extreme case formulation in this example, the word bubble and left alignment place special emphasis on the directive “you should use both,” implying that NSA analysts use every tool at their disposal to collect information (see also Greenwald, 2014, p. 97).
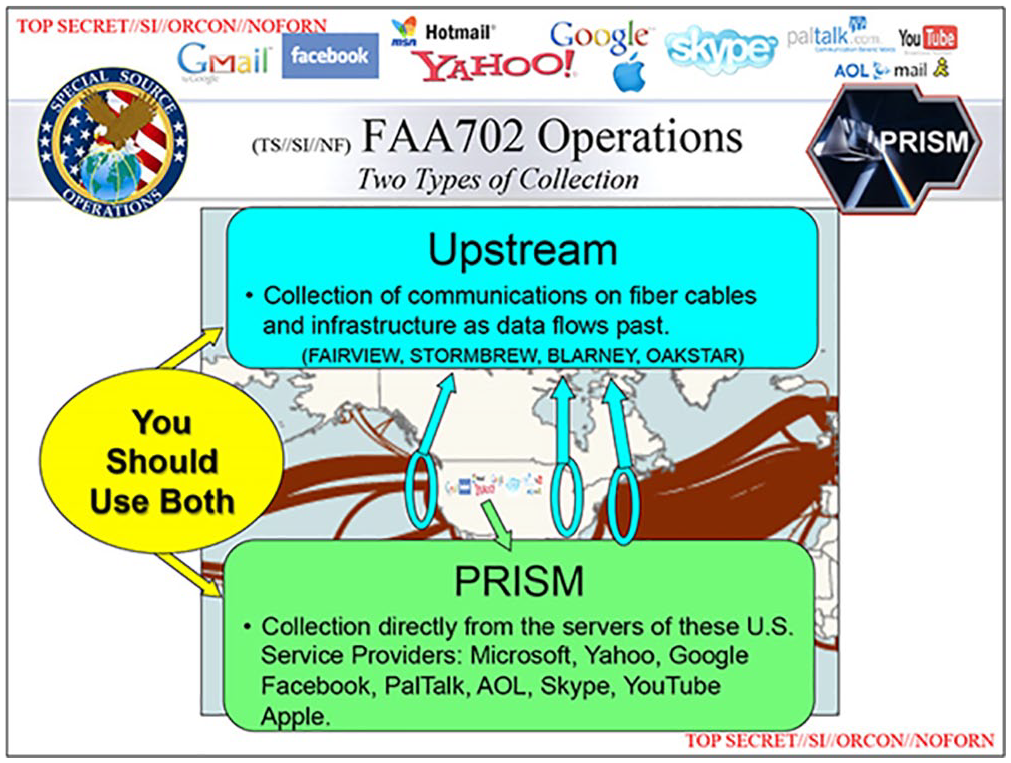
Slide from the April 2013 PRISM slidedeck describing Upstream and PRISM. Higher resolution version available in “NSA slides explain . . .” (2013).
Finally, on July 31, The Guardian published slides dated February 2008 describing XKEYSCORE. Here once more, extreme case formulations and technically complex vocabulary abound. As shown in Figure 4, the XKEYSCORE slides are rife with extreme cases, using “ALL” and “full-take” to indicate the completeness of the data sets that the tool can access.

Slides from the February 2008 XKEYSCORE slidedeck. Higher resolution version available in Greenwald (2013b).
The second slide in Figure 4 claims that the tool “indexes every e-mail address seen in a session” as well as “every file,” “phone number,” “webmail and chat activity,” indicating XKEYSCORE’s extreme level of user convenience. And the extremely technical language in these slides is ubiquitous, from “exploitation system/analytic framework” to “index” (as a verb), “meta-data,” “query,” “the standard N-tupple,” “client-side HTTP traffic,” and “machine specific cookies.”
Given their original contexts of use, these documents’ technical language and extreme case formulations make sense. They were for training highly educated analysts to run complex computational systems. And when written, they were expected to be kept entirely internal to the NSA. There was little worry that the extreme cases they described would cause public outcry, because public audiences would not encounter them. But soon enough, public audiences did encounter them (and “a public” may indeed have been constituted by them: cf. Warner, 2002). Journalists recontextualized these documents, leading to further recontextualization by the ACLU’s writers. So, to what extent did these rhetorical features appear in the ACLU’s public advocacy writing?
Post-Leaks ACLU Legitimation Categories
Significance of power
As shown in Figure 5, after the leaks a large plurality of the ACLU’s delegitimation appeals (
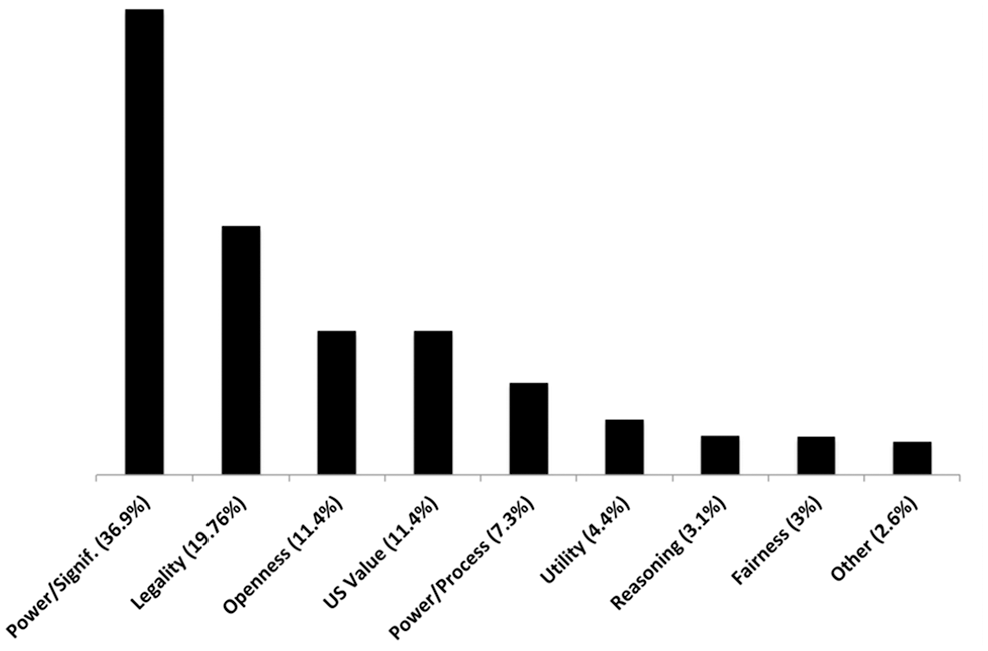
Distribution of legitimation category instances (N = 997) in post-leaks ACLU blog entries. Significance of power accounts for a plurality of all categories invoked.
Using this kind of appeal, ACLU staff attorneys argue that the NSA and its programs are, essentially, too large to exist. Far beyond being unconstitutional, illegal, and overly secretive, NSA surveillance is ubiquitous, all-encompassing, and world (or society) altering. It represents an unacceptable new monopoly on domination.
As with traditional and general legality as well as openness, this type of appeal is often triggered by the presence of common ideographs and stock phrases such as <
<vast>, <massive>, <dragnet>, and <broad>
and the extremism and novelty of the program:
<extraordinary>, <significant>, and <unprecedented>.
The biggest shifts in keyword frequencies occurred for words signaling size. Across all pre-leaks texts, <mass> and its variants (including <massive>) occurred only
In the ACLU’s view, the NSA’s massive power is problematic in part due to its technical complexity. In conveying this, many of the ACLU’s delegitimation appeals appear in and around technical terms, as shown in the following examples (
The provision has been used to . . . search
The NSA could . . . [better] isolate the communications of its targets based on metadata—such as email addressing information—rather than searching the
The government could still [surveil]
As these examples show, understanding the significance of the NSA’s current powers also requires understanding technical language such as “search,” “metadata,” “traffic,” “selectors,” and “IP address.”
As in the NSA’s own documents, technical terms in ACLU writing are often accompanied by extreme case formulations (Pomerantz, 1986), for instance, in the phrases “
These claims of omnipotence are reinforced by large numbers and quantifiers, which the leaked documents also contain (see “Rhetorical Patterns in Snowden-Leaked NSA Document” section). For instance, words ending in “illion” (e.g., millions of calls, trillions of bits of data) are much more common in the post-leaks corpus. Such words occurred only about
Post-Leaks ACLU Rhetorical Factor Analysis Results
As noted in my earlier overview of factor analysis results (see “Pre-Leaks ACLU Rhetorical Factor Analysis Results” section), the post-leaks ACLU texts are statistically distinct from the pre-leaks texts in that the average pre-leaks text scored significantly higher on the factor pole correlating DocuScope LATs of
Post-leaks ACLU rhetorical style: Informational, academic, strategic
Stylistically, the post-leaks ACLU entries contain more informational lexis and syntax (e.g., cohesion markers, quantifiers, comparisons, and stative verbs), academic lexis (infrequent nouns, adjectives, and adverbs that are abstract and specialized), and strategic lexis (particularly words related to espionage). This style is thickly descriptive, using higher-register language to analyze information about the NSA’s techniques—often referring directly to the NSA documents.
Rhetorically, this style serves to do more explaining and informing, as opposed to facilitating reader action. ACLU bloggers emphasize the conceptual challenges raised by NSA surveillance: its magnitude, complexity, and opacity. Whereas the pre-leaks period was more episodic, containing obvious series of posts surrounding events like the FISA Amendments Act debate in 2008 and the 10-year anniversary of 9/11, the post-leaks ACLU blog engages the issue of NSA surveillance as though it were an ongoing research topic.
For example, an early post-leaks blog entry titled “A Guide to What We Now Know About the NSA’s Dragnet Searches of Your Communications” explains the tool XKEYSCORE ( The Times’s front-page story raises questions
In a strategy of accommodation (Fahnestock, 1998), the writer uses informational lexis to compare XKEYSCORE to things that “we all use every single day on the web,” such as “search engines.” These comparisons may help readers envision what the highly complex program looks like. The writer also draws language directly from the Guardian-published XKEYSCORE document, citing the phrase “nearly everything a typical user does on the internet” (Greenwald, 2013b); through this act of citation, too, the program is engaged in a manner similar to a research topic. By contrast, pre-leaks ACLU writers approached NSA surveillance less as a technical issue to explain than as a political issue to affect through action.
Two later entries do similar explanatory work, one for FAA surveillance programs and another for the Upstream program. In “Questions Congress Should Ask About Section 702,” the ACLU writer explains the NSA’s “backdoor searches” ( Members of Congress
The writer uses an em dash to introduce a definition, and then, after employing a phrase rich in academic terms—“search Section 702 databases for information using US person identifiers”—inserts the informational phrase “for example” before a simple illustration. Across these entries, informational lexis is often used to unpack terms that DocuScope registers as academic, serving to accommodate the higher-register style of the leaks for public audiences.
Finally, the post “Unprecedented and Unlawful: The NSA’s ‘Upstream’ Surveillance” explains Upstream. To do so, the writer uses citation and reported speech (
To help readers understand this complicated program, the writer appeals to the expertise of both David Kris and the FISA Court. Much like the definition, illustration, and comparison employed above, these speech reports provide explanation through academic and informational lexis. But in addition, the speech reports implicitly delegitimize the NSA’s actions by positioning their sources (a former Assistant Attorney General; the Department of Justice court overseeing NSA surveillance) as potentially opposing the program.
Overall, this style of academically informing readers about government strategies serves to linguistically enact significance of power delegitimation. Because the highly-technical NSA programs depend upon specialized knowledge and limited access, there is an asymmetrical power/knowledge relationship between NSA officials and those whose data they collect. In the ACLU’s writing, this relationship is enacted by higher-register lexis and syntax as well as technical terms. Thus, in explaining and critiquing NSA programs, the ACLU’s style is at the same time inflected by them. As noted earlier, this style change somewhat necessarily shifts the writing’s focus from facilitating political action (as in the pre-leaks texts) to facilitating technical understanding. In the final section of this article, I go over some critical questions raised by this post-leaks style shift.
Technical Language in Post-Leaks Style and Legitimation
So far, I have observed technical language across the post-leaks ACLU entries, especially in discussions of technologies under NSA surveillance: the internet, phone networks, social networking websites, and so on. DocuScope coded much of this technical language as academic terms and informational and strategic lexis, and I also found technical language in many instances of significance of power delegitimation. But just how representative was this overlap between style and legitimation? To answer this question, I first looked for technical words/phrases within instances of the three key post-leaks DocuScope LATs; these words/phrases are displayed in Table 3. Then, I reread all stretches of text I had coded as significance of power legitimation, and checked each one for DocuScope-coded technical terms within a one-sentence radius. In this way, I was able to compare the two subcorpora vis-à-vis their respective total significance of power legitimation categories near these DocuScope LATs.
Technical Words/Phrases Within DocuScope LATs.

Note. LAT = language action type.
I found that the proportion of significance of power legitimations near DocuScope-coded technical terms shifted from about
While significance of power was a substantive category pre-leaks, its stylistic expression was substantively less technical than its post-leaks variant. As with the post-leaks findings described above, this appears to suggest a shift in the ACLU’s writing from a largely political register to a more technical, specialized register. As discussed further below, this is most likely a consequence of ACLU writers regularly recontextualizing material from the leaked NSA documents. Regardless of the cause, though, the move from facilitating political action to explaining technical information may have consequences for the prospects of further surveillance policy reform.
Discussion and Conclusions
The 2013 NSA leaks represented a special form of legitimation crisis, one that was incited—and partly constituted—by newly publicized, formerly classified textual evidence. Edward Snowden entextualized a corpus of highly technical, top-secret documents and extracted them from the hierarchized, ordered, internal discourses of the intelligence community. This allowed them to be recontextualized in the more horizontal, disordered, external discourses of the news media and public debate. By warranting a new legitimation crisis and helping to shape its linguistic form, the leaks provided resources for new kinds of arguments and new styles of writing about NSA surveillance programs. This study’s primary purpose was to detail how these new arguments and styles manifested in NSA critics’ writing.
Thus, I combined micro-level discourse analysis of legitimation strategies with macro-level corpus analysis of rhetorical styles, modeling a mixed-methods approach that few previous scholars have adopted. One limitation of this approach is that, in drawing boundaries around my corpora and subcorpora, and in deriving frequencies of linguistic and rhetorical patterns from individual texts, I necessarily omitted some nuances: from individual variation in authorial styles to subtle changes in contexts from text to text. However, this limitation was mitigated to some extent by the institutional nature of my corpora. In addition, I sought to contribute to corpus studies by modeling a defensible and transparent method for selecting representative texts (Anthony & Baker, 2015). In these ways, this study has hopefully demonstrated the importance of methodological pluralism, transparency, and precision in studies of written online discourse.
Using Legitimation Category Analysis and Rhetorical Factor Analysis, I found that prior to the leaks, the staff attorneys writing for the ACLU’s website primarily delegitimized NSA surveillance on grounds of traditional and general legality as well as openness. They argued that NSA surveillance is illegal, unconstitutional, and overly secretive. They used a character- and narrative-based style to name and describe specific heroes and villains, telling dramatic stories about intense post-9/11 surveillance policy debates. This style emphasized human agency and heroism, with the apparent goal of inspiring readers to unite with their fellow citizens to reform the surveillance system.
Then, Edward Snowden leaked secret NSA documents, which contained extreme case formulations (“all call detail records,” “wholly within the United States,” “ALL unfiltered data”) and copious technical information. Afterward, the ACLU’s online writing shifted toward delegitimation primarily on grounds of significance of power. This legitimation category portrayed NSA programs as enormous, unrestrained, and pervasive: as “mass” and “bulk” surveillance. In style, post-leaks ACLU bloggers drew on academic, informational, and strategic syntax and lexis. In short, both the ACLU’s moral frameworks and its writing style became much more technical. The apparent goal was no longer advising readers about how they might enact specific reforms, but rather cultivating an attitude of shock—teaching readers the scope of the problem without necessarily inspiring them to fix it.
Overall, these findings suggest that when the secret NSA documents entered the public sphere, the rhetorical features of ACLU writing changed. As analyzed in the “Rhetorical Patterns in Snowden-Leaked NSA Documents” section, the documents bear similar features to the ACLU’s post-leaks writing: The NSA is direct about the extreme nature of its powers, and it explains them using copious technical jargon and academic language. As ACLU writers repeatedly recontextualized new batches of the documents, they carried over these semantic and stylistic features. Thus, paradoxically, the leaks reshaped the ACLU’s rhetoric in ways that downplayed citizens’ political agency, even as new legislation and court rulings were beginning to constrain the NSA’s power (see “Legitimation, Leaks, and the 2013 Snowden/NSA Crisis” section). Facilitating such reforms through citizen action was a core ACLU mission before the leaks, but afterward, the organization seems to have shifted toward more abstract rhetorics of analysis and theorization. In this way, legislative and legal discourses on the NSA were shifting somewhat toward change, while the ACLU’s online writing was shifting somewhat toward stasis.
What explains this discrepancy between legislative and legal actions on the one hand and the ACLU’s writing on the other, and what were its political effects? For example, what other rhetorical tactics might the ACLU have employed post-leaks? Perhaps the organization could have focused more heavily on the narratives of particular activists and investigative journalists, that is, those who face constraints from the NSA’s and other institutions’ surveillance policies yet are still fighting to reform such policies. Conversely, perhaps the ACLU’s tactics described here were necessary to convey the leaks’ full significance. A key limitation of the present analysis is its focus on a single organization—albeit, a very significant one in the area of surveillance reform. Accordingly, future scholarship around the 2013 leaks’ rhetorical effects might consider comparing the tactics of traditional, politically connected advocacy organizations like the ACLU to those of other, potentially more radical and racially conscious digital rights and privacy organizations (e.g., the Center for Media Justice).
Ultimately, the tactical questions raised by my findings are crucial because, in addition to inciting legitimation crises, those who disclose and recontextualize leaks also help determine the public response to such crises. As rhetorical scholars have recently noted, liberal and left-wing political groups often use “fact-checking” and other tactics that seem to emphasize their status as gatekeepers of objective reality; unfortunately, these tactics have not succeeded in mobilizing mass publics toward change (Cloud, 2018). Relatedly, the present study shows that subtle choices, such as how to quote and evaluate textual evidence, can make the difference between an active public organizing for reform and an overwhelmed public simply trying to understand the technical nature of a problem. To be sure, by publicizing the leaks and interpreting their meaning, the NSA’s critics at the ACLU won the battle. But given that the NSA’s specialized rhetoric lives on and even proliferates in ACLU discourse, the Agency’s broader war for social power still persists—inviting further exploration from the perspective of writing and discourse studies.
Footnotes
Acknowledgements
The author would like to thank John Oddo, David Kaufer, and Andreea Ritivoi, who each provided helpful feedback on drafts of this work. He is also grateful to the two anonymous reviewers and to editor Chad Wickman for their useful comments and suggestions. Additionally, he thanks the Andrew W. Mellon Foundation for selecting him for a Digital Humanities fellowship just prior to this research process, as well as G. Ryan Sablosky, who provided invaluable programming suggestions. Finally, he wishes to thank Alaina Foust for her advice and support.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.