
Abstract
Statistical Analysis of Square Contingency Tables - Social-professional Homogamy in France II. The Contribution of Association Models: Contrary to correspondence analysis (CA), log-multiplicative association models are only known by a restricted audience in France. This second article uses the latter technique to analyze a socioeconomic homogamy table (based on the two-digit catégories socioprofessionnelles of the spouses) from the INSEE Labour Force Surveys conducted between 2003 and 2010. It illustrates the strong resemblance between the two approaches, and highlights the advantages brought by the greater flexibility of association models. They provide a view of the social space both more accurate and easier to interpret than CA, in particular by giving special status to endogamous couples (in which the spouses belong exactly to the same group). They also allow us to analyze specifically men-women asymmetries which emerge from the choice of a spouse (hypergamy), an essential issue poorly apprehended by classical methods.
Les modèles d’association, comme les modèles log-linéaires dont ils constituent un prolongement, offrent une grande souplesse de construction qui permet notamment d’étendre la logique qui présidait à l’invention de l’analyse des correspondances sur table incomplète. Introduits par Leo Goodman il y a plus de trente ans (Goodman, 1979), et aujourd’hui désignés le plus souvent comme des modèles RC (pour row-column association) 1 , ils consistent dans leur version la plus simple à attribuer des scores aux lignes et aux colonnes d’une table. L’écart à la situation d’indépendance, mesuré ici en termes d’odds ratios, est alors modélisé par le produit des scores correspondant respectivement à la ligne et à la colonne de la case (se référer aux Annexes 1 et 2, pour des précisions concernant les équations du modèle et une comparaison avec l’analyse des correspondances). Ce modèle simple d’interprétation peut s’étendre par l’ajout d’un nombre libre de dimensions 2 . La lecture des dimensions ainsi obtenues est alors similaire à celle des axes d’une analyse des correspondances (cf. le premier article de cette série).
Les apports de ce type de modèle par rapport à l’analyse des correspondances sont multiples 3 . En ce qui concerne l’analyse d’une table d’homogamie, leur premier intérêt est qu’il est possible de modifier le modèle de base afin qu’il ne reflète plus seulement la situation d’indépendance, mais celle de quasi-indépendance décrite plus haut. Dans ce cas, le modèle de base décrira déjà parfaitement les effectifs de la diagonale de la table ; les scores d’association ne seront plus contraints par l’association observée dans ces cases. En pratique, cela signifie que les coefficients diagonaux s’ajusteront afin de corriger les associations prédites par le modèle sur la diagonale, de manière à ce qu’elles correspondent exactement aux observations. Les scores d’association seront donc choisis de manière à refléter au mieux l’association hors-diagonale ; ils décriront une partie de l’association sur la diagonale, mais à titre d’« effet secondaire » seulement. Cette solution, in fine assez proche de l’algorithme utilisé par l’analyse des correspondances sur table incomplète, remplit les exigences requises pour la représentation d’un espace social à partir de l’homogamie socioprofessionnelle observée : seules les distances entre groupes doivent présider à la construction des axes, l’endogamie d’un groupe devant être représentée séparément.
D’autres propriétés des modèles d’association méritent aussi notre attention. Nous avons déjà souligné que le nombre de dimensions présentes dans le modèle est fixé par avance, au contraire de l’analyse des correspondances, où autant d’axes sont calculés que la reconstitution parfaite de la table en nécessite. Cette particularité est intéressante à deux titres. Tout d’abord, elle permet de vérifier, à l’aide de différents indicateurs statistiques, combien de dimensions doivent être interprétées, et d’éliminer celles qui ne sont pas statistiquement significatives au regard des effectifs de la table. Ceci permet de se prémunir contre des interprétations abusives d’axes non significatifs, mais aussi, dans l’autre sens, d’exclure sans états d’âme des axes qui présenteraient en analyse des correspondances un aspect erratique difficile à interpréter. D’autre part, une fois le nombre de dimensions fixé, le modèle synthétise au mieux dans les axes représentés l’ensemble de l’information de la table, grâce à l’ajustement des paramètres inclus dans le modèle de base. Lorsque deux dimensions seulement sont retenues, le plan représenté résume le mieux possible l’ensemble de l’information, permettant de saisir l’ensemble des associations en un seul regard. Cette propriété a pour contrepartie la non-imbrication des axes : l’ajout d’un axe au modèle est susceptible de modifier les scores sur les axes d’ordre inférieur (Caussinus, 1986).
Enfin, une caractéristique intéressante des modèles d’association tient à ce qu’il est possible, lorsque les catégories en lignes et en colonnes possèdent des modalités communes, de forcer les scores des deux dimensions à être égaux lorsqu’ils décrivent une même modalité (les scores sont alors dits symétriques, ou homogènes, entre lignes et colonnes). Dans le cas de l’homogamie, cela signifie que le modèle suppose une homologie parfaite entre les positions socioprofessionnelles des hommes et des femmes : une fois tenu compte de la répartition entre hommes et femmes dans les différentes PCS (distributions marginales de la table), on fait l’hypothèse qu’il n’existe pas, par exemple, de tendance des ouvriers à se mettre en couple avec des employées plutôt que le contraire, au-delà de ce qui est rendu nécessaire par la contrainte de disponibilité des conjoints.
Le cadre souple de la modélisation des tables de contingence nous permet de tester cette hypothèse à partir des données observées. Si elle est vérifiée, l’interprétation des résultats en est largement simplifiée, puisqu’une seule série de points doit être analysée, gain appréciable dans notre cas où le nombre de catégories est élevé, et où les positions correspondant aux hommes et aux femmes n’ont pas présenté en analyse des correspondances de différences interprétables. En outre, cette hypothèse peut aussi être utilisée à titre de simplification, avant de passer à une étude détaillée et systématique des différences entre lignes et colonnes à l’aide d’un autre modèle – ce que nous présenterons plus bas.
Identifier un espace commun aux deux sexes - Les modèles d’association lignes-colonnes
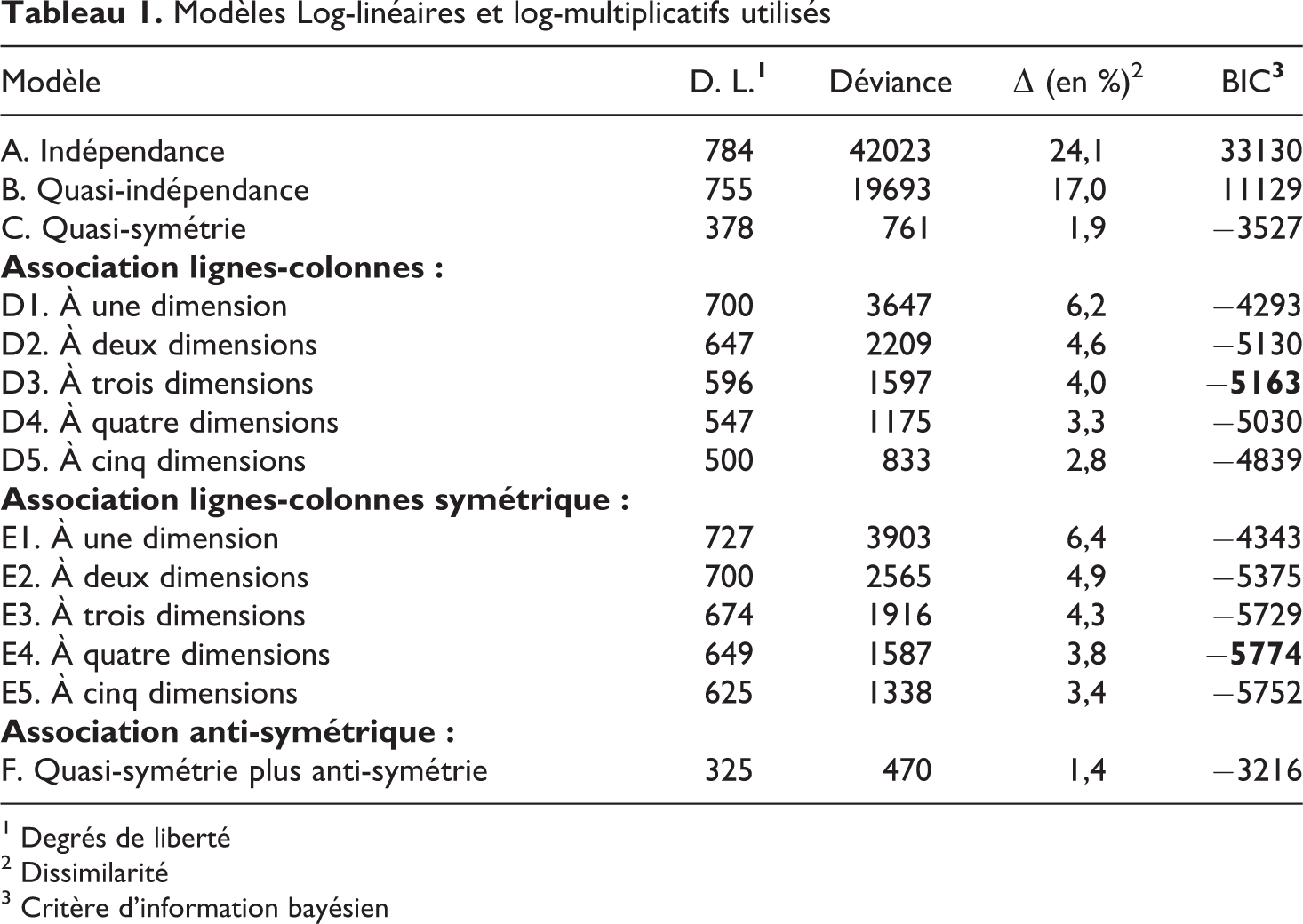
L’application de ces modèles à notre table d’homogamie socioprofessionnelle illustre cette situation (Tableau 1) 4 . L’hypothèse d’indépendance peut clairement être rejetée (modèle A), ce qui n’est pas étonnant : un tel modèle « classe dans une mauvaise cellule » 24 pourcent des couples (déviance de 42023 pour 784 degrés de liberté, soit une probabilité infinitésimale d’observer nos données avec un tel modèle selon le test du rapport de vraisemblance). Le simple fait d’exclure la diagonale de la table de l’hypothèse d’indépendance améliore déjà beaucoup la description de la table (modèle B) : l’indicateur BIC (critère d’information bayésien, cf. Raftery, 1995) baisse de manière importante, indiquant que ce modèle est à préférer à celui d’indépendance (modèle A), en tenant compte du nombre de paramètres utilisés par le modèle. Cette observation confirme l’importance de l’endogamie dans les comportements de choix du conjoint ; elle n’interdit cependant pas de tenter de décrire mieux la partie hors diagonale de la table, la probabilité d’observer nos données avec un tel modèle étant toujours extrêmement faible.
Modèles Log-linéaires et log-multiplicatifs utilisés
1 Degrés de liberté
2 Dissimilarité
3 Critère d’information bayésien
Nous introduisons donc les modèles d’association lignes-colonnes à une, puis plusieurs dimensions, en mettant toujours la diagonale de côté. Ces modèles sont des extensions du modèle de quasi-indépendance (modèle B), et sont imbriqués les uns dans les autres, ce qui nous autorise à comparer leurs degrés de liberté, leurs déviances ainsi que leurs indices de dissimilarité pour mesurer leurs apports successifs 5 ; nous nous fonderons cependant sur l’indicateur BIC pour sélectionner le modèle qui représente le meilleur compromis entre simplicité et qualité de la description des données : de manière générale, le modèle présentant la valeur du BIC la plus négative doit être retenu.
Des cinq modèles lignes-colonnes testés (D1 à D5), c’est celui à trois dimensions qui correspond à ce critère, avec un BIC de -5163 (une valeur négative du BIC indique que le modèle est à préférer, étant donné sa faible complexité et sa qualité de description des données, au modèle saturé, qui décrit par définition parfaitement la table). Ce modèle classe de manière incorrecte seulement 4 pourcent des couples, soit un gain de 13 points par rapport au modèle de quasi-indépendance. On peut néanmoins noter que le recours à une seule dimension suffit à expliquer près de 11 points de plus que la quasi-indépendance, alors que l’ajout d’une deuxième dimension ne permet de classer correctement que 1,6 points supplémentaires. L’espace matrimonial des catégories socioprofessionnelles s’ordonne donc clairement selon une hiérarchie principale, les oppositions suivantes étant secondaires (ce que l’analyse des correspondances sur table incomplète avait déjà montré).
Mais ce constat peut être nuancé par l’introduction des modèles d’association lignes-colonnes symétrique, dans lesquels les positions des hommes et des femmes sont supposées équivalentes (modèles E1 à E5). Ces cinq modèles présentent en effet tous, pour un même nombre de dimensions, une valeur du BIC inférieure aux modèles précédents, signe que les asymétries entre positions des hommes et des femmes, si elles existent, ne sont qu’un déterminant secondaire de l’homogamie socioprofessionnelle ; elles méritent de toute façon un traitement à part, ainsi que nous l’avons déjà soutenu.
Le meilleur modèle selon l’indicateur BIC est celui postulant une association symétrique à quatre dimensions (E4), ce qui signifie qu’il est possible – et nécessaire – d’étudier au moins ces quatre dimensions, sans risque de commenter abusivement des associations qui ne seraient en fait que du bruit dans les données : l’homogamie socioprofessionnelle se structure aussi selon des lignes d’ordre secondaire sur lesquelles il n’est pas inintéressant de se pencher.
La lecture des deux premières dimensions du modèle (Figure 1), fait apparaître des résultats globalement en accord avec ceux obtenus grâce à l’analyse des correspondances sur table incomplète (Figure 3 du premier article). On retrouve sur l’axe horizontal une hiérarchie très proche ; mieux : les résultats surprenants se trouvent ici confirmés, concernant le rattachement de certaines catégories d’employés (5x) aux classes moyennes, la position extrême des professeurs et professions scientifiques (34) et des professions libérales (31), ou encore la proximité des employés des services directs aux particuliers (56) avec les ouvriers qualifiés. Cette première dimension est de loin la plus importante, avec un coefficient d’association intrinsèque (équivalent de la part de variance expliquée par un axe en analyse des correspondances) de 0,56, soit 4 fois la valeur correspondant à la deuxième dimension.
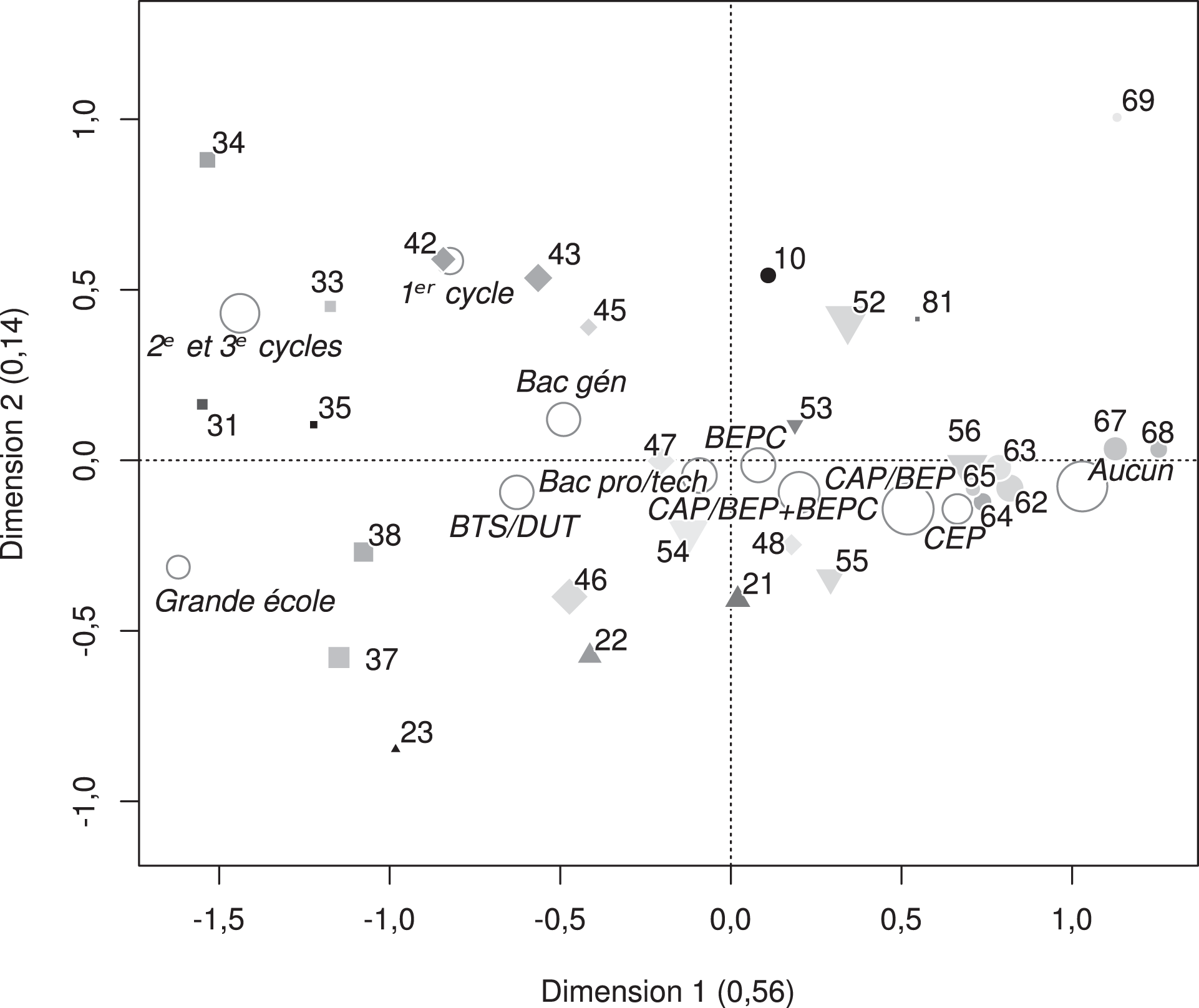
Les deux premières dimensions du modèle d’association lignes-colonnes symétrique retenu L’aire des points est proportionnelle aux effectifs des catégories correspondantes hommes et femmes confondus (sauf pour les diplômes), la teinte de gris à la tendance à l’endogamie de la catégorie (le noir équivalant à l’endogamie la plus forte de tous les groupes). Les niveaux de diplôme sont placés en modalités supplémentaires (voir Annexe 2). Entre parenthèses figure le coefficient d’association intrinsèque de chaque dimension
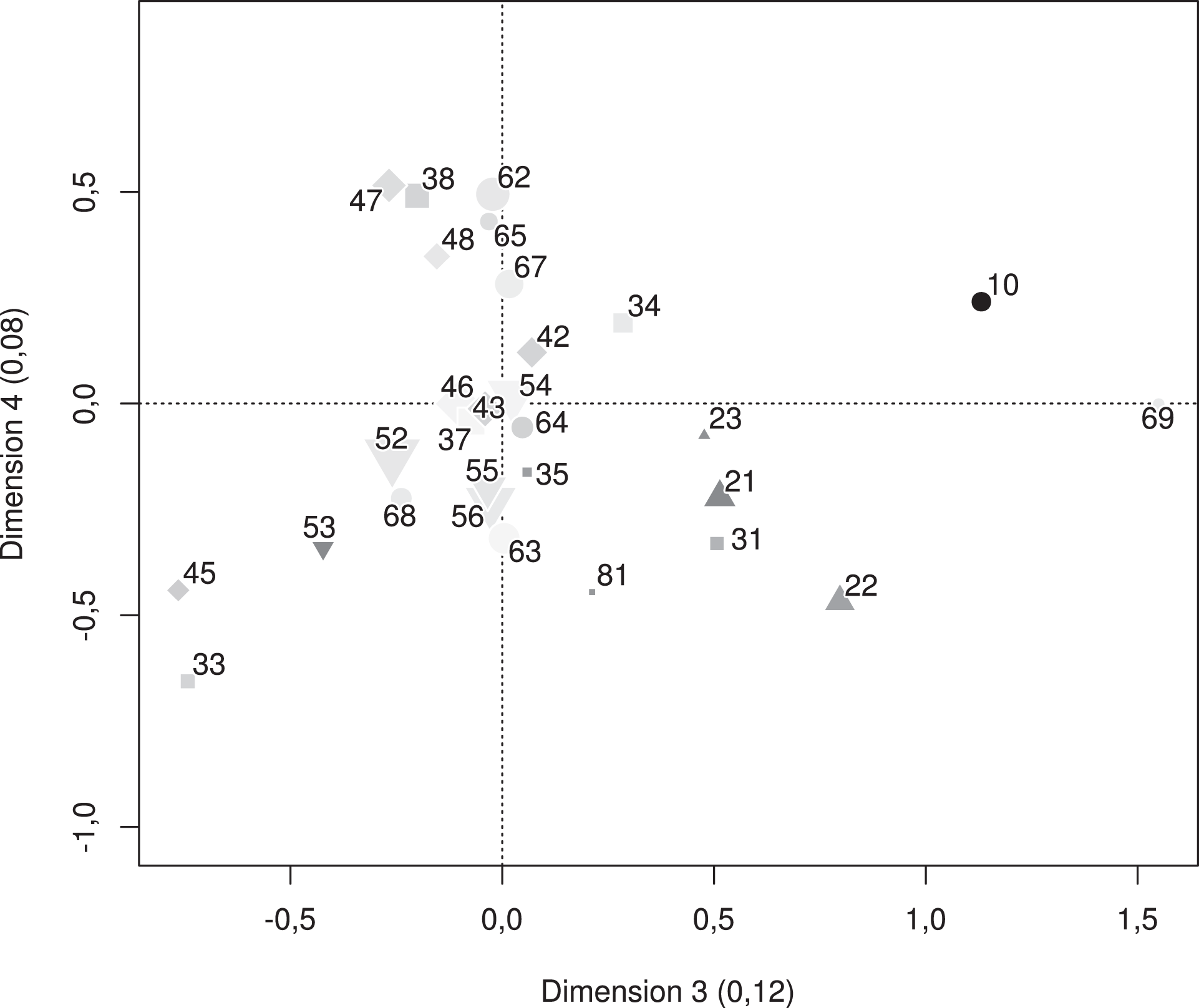
Dimensions 3 et 4 du modèle d’association lignes-colonnes symétrique retenu L’aire des points est proportionnelle aux effectifs des catégories correspondantes hommes et femmes confondus, la teinte de gris à la tendance à l’endogamie de la catégorie (le noir équivalant à l’endogamie la plus forte de tous les groupes). Entre parenthèses figure le coefficient d’association intrinsèque de chaque dimension
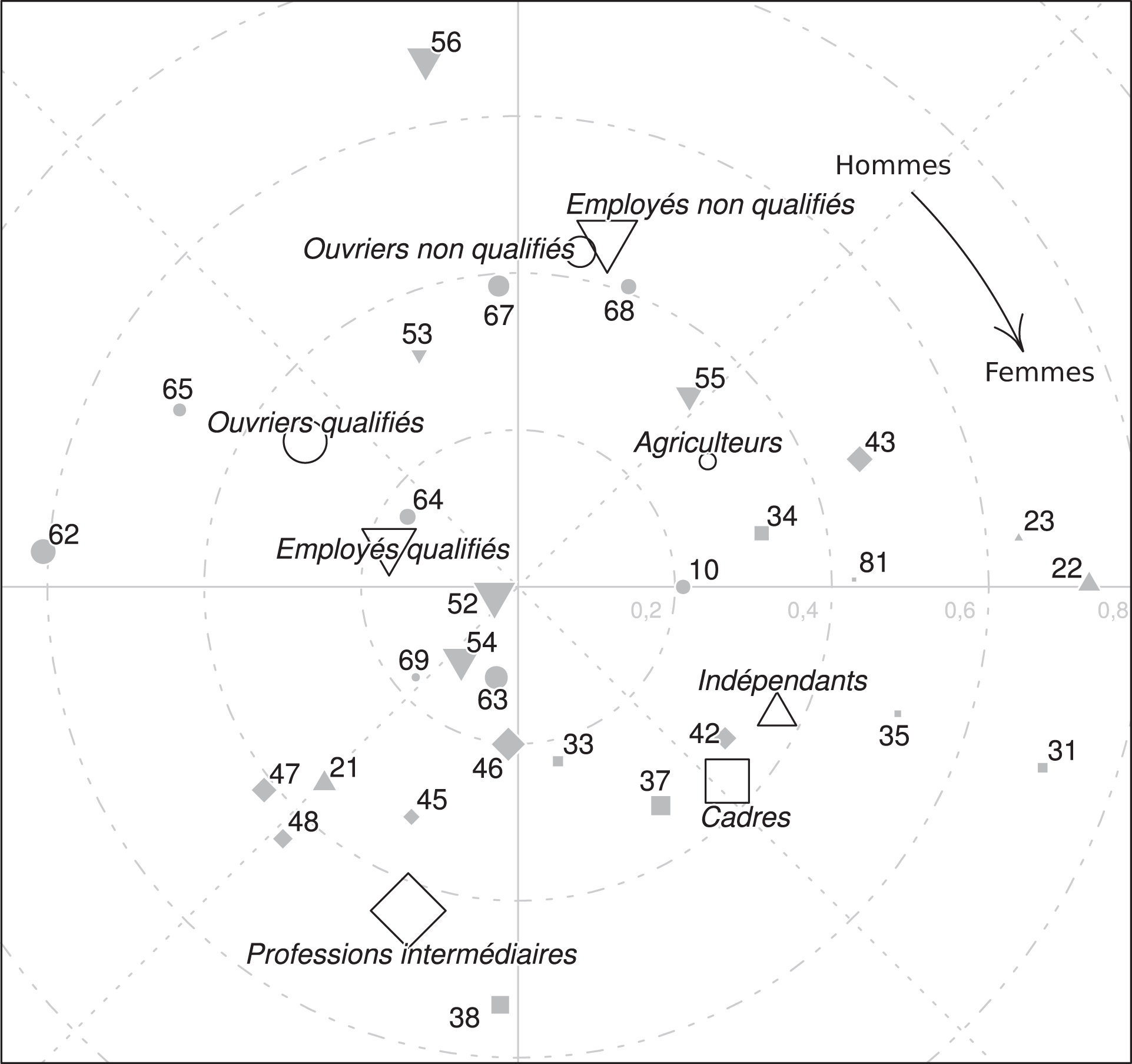
Les deux dimensions du modèle d’association anti-symétrique L’aire des points est proportionnelle aux effectifs des catégories correspondantes hommes et femmes confondus. Les catégories agrégées sont placées en modalités supplémentaires (cf. Annexe 2). Tous les points sont significativement différents de l’origine au seuil de 5 pourcent à l’exception des points centraux 10, 52, 63 et 64, ainsi que des points 34 et 35 (intervalles de confiance normaux fondés sur 300 itérations de bootstrap)
Le deuxième axe correspond lui aussi de près à celui déjà commenté plus haut : l’opposition entre secteur privé et secteur public est bien la seconde dimension qui organise les échanges matrimoniaux. À la différence des résultats obtenus plus haut à l’aide de l’analyse des correspondances sur table incomplète, on ne retrouve pas du tout d’effet Guttman : les points sont bien répartis sur les deux dimensions, et la dispersion dans le bas de la hiérarchie est plus forte qu’elle ne l’était précédemment.
Détail intéressant, le point correspondant au baccalauréat général se situe ici du côté positif de l’axe 2 : ceci pourrait constituer un argument en faveur de l’interprétation en termes de structure du capital – culturel contre économique. Mais la situation des BTS et DUT, dans la moitié inférieure du plan, n’a pas changé, et le point correspondant aux grandes écoles s’est même éloigné de l’origine de l’axe. Notons par ailleurs que le point correspondant aux diplômes du premier cycle universitaire est situé légèrement plus haut que celui correspondant aux diplômes des deuxième et troisième cycles, alors qu’il est le signe d’un moindre capital culturel.
Enfin, l’observation selon laquelle les divergences de diplôme sur l’axe 2 ne se développent que dans la partie supérieure de l’échelle sociale se trouve confirmée. L’opposition entre les employés civils et agents de service de la fonction publique (52) et les employés de commerce (55), deux catégories situées au même niveau sur le premier axe, mais opposées selon le deuxième, illustre ce fait : ces deux catégories sont très similaires en termes de diplômes des conjoints (28 pourcent des premiers qui vivent en couple et hommes et femmes confondus, contre 31 pourcent des seconds, sont titulaires d’un diplôme supérieur ou égal au baccalauréat technique, professionnel ou général). Il semble donc que l’interprétation en termes d’opposition public/privé soit ici encore la seule capable de rendre compte de cet axe, les oppositions de diplôme, si elles sont bien visibles, n’étant qu’une conséquence secondaire d’une distinction essentiellement fondée sur le secteur d’activité.
Le modèle d’association lignes-colonnes met encore plus clairement en évidence cette lecture, en écartant de l’origine du deuxième axe les catégories les plus marquées comme relevant du secteur public ou du secteur privé, et en positionnant les catégories mixtes, comme les ouvriers (6x) ou les techniciens (47), sur l’origine de l’axe. Mis à part les agriculteurs (10), les ouvriers agricoles (69) et les professions libérales (31), dont les spécificités ont déjà été évoquées, la distinction entre secteurs est parfaitement retracée par la deuxième dimension.
Conformément encore à ce que nous observions avec l’analyse des correspondances sur table incomplète, la troisième dimension (Figure 2) ne reflète pas non plus l’opposition entre capital économique et capital culturel. Cette dimension est en revanche différente de celle identifiée avec cette dernière technique, puisqu’elle oppose ici les catégories d’indépendants (agriculteurs, 10 ; artisans, commerçants et chefs d’entreprise, 2x ; professions libérales, 31) aux professions du secteur public (cadres, 33 ; professions intermédiaires, 45 ; employés, 52), et de manière secondaire aux cadres et professions intermédiaires du secteur privé (37, 38, 46) ou relevant des deux secteurs (47, 48). Les professeurs et professions scientifiques (34) se trouvent ici en position d’intermédiaires, du fait de leur forte proximité, déjà notée, avec les professions libérales (31). L’apport des modèles d’association par rapport à l’analyse des correspondances est en tout cas visible, l’interprétation de ce troisième axe étant ici bien plus aisée que dans le premier article (Figure 4), en particulier grâce à l’élimination – temporaire – des divergences hommes-femmes. Alors que la dimension 2 opposait secteur privé et secteur public, la dimension 3 oppose les indépendants au secteur public, la combinaison de ces deux dimensions d’importance comparable identifiant toutes les configurations de statut d’emploi.
Association modélisée par l’analyse des correspondances (AC) et les modèles lignes-colonnes (RC)
La quatrième et dernière dimension est plus inattendue. Elle oppose d’un côté des professions à caractère technique ou industriel (ingénieurs et cadres techniques d’entreprise, 38 ; techniciens, 47 ; contremaîtres, 48 ; ouvriers de type industriel, 62 et 67 ; ouvriers qualifiés de la manutention, du magasinage et du transport, 65), à des professions du secteur public (cadres de la fonction publique, 33 ; professions intermédiaires administratives de la fonction publique, 45), de l’artisanat (artisans, 21 ; ouvriers de type artisanal, 63 et 68) ou du commerce (commerçants, 22 ; employés de commerce, 55). La position des agriculteurs (10), des professeurs et professions scientifiques (34) et des instituteurs (42), du côté de l’industrie, mérite d’être soulignée. Cette opposition est de relativement faible ampleur (coefficient d’association intrinsèque de 0,08, soit environ sept fois plus faible que la première dimension), mais elle est bien réelle étant donné la nette réduction de la valeur du BIC. Elle peut s’interpréter en termes d’univers de rencontres, les professions proches sur cet axe ayant pour la plupart des chances de se rencontrer dans le cadre de leur activité, ou du fait de proximités géographiques.
Analyser l’asymétrie hommes-femmes - Les modèles d’association anti-symétrique
Jusqu’à présent, nous avons considéré que les positions des hommes et des femmes sur les dimensions étudiées étaient interchangeables. Cette hypothèse reposait, pour l’analyse des correspondances, sur des corrélations et un examen visuel, et, pour les modèles d’association lignes-colonnes, sur des tests statistiques plus élaborés. Cette seconde voie nous a montré que l’asymétrie entre les positions des hommes et des femmes n’était absolument pas le facteur déterminant des associations observées, justifiant ainsi que nous nous concentrions sur la structuration générale de l’espace socioprofessionnel. Néanmoins, l’indicateur BIC, s’il permet d’identifier le modèle qui synthétise au mieux les caractéristiques des données observées, notamment en présence d’échantillons de taille importante, n’autorise pas à affirmer que le modèle retenu décrit correctement toutes les tendances présentes dans les données. S’en tenir à la valeur du BIC présente en effet le risque de négliger des effets qui, pour être secondaires, n’en sont pas moins réels (Weakliem, 1999; Raftery, 1998).
Dans le cas de l’homogamie, l’asymétrie hommes-femmes étant un aspect que la théorie sociologique incite fortement à investiguer (Guichard-Claudic et al., 2009), il est nécessaire de vérifier à l’aide d’autres procédures s’il est possible d’en dire quelque chose à partir des données dont nous disposons, aussi faible que soit l’effet : le choix d’un modèle doit être guidé par l’usage interprétatif qui en sera fait, un critère statistique unique ne pouvant répondre à cette question d’ordre scientifique (Gelman et Rubin, 1995). Plus précisément, il est possible de recourir à des modèles imbriqués, en ajoutant des éléments au meilleur modèle désigné par l’indicateur BIC, ce qui permet de tirer le meilleur de chaque modèle (Gelman et Rubin, 1999: 7) : l’association nette des marges observée dans une table d’homogamie se décompose toujours parfaitement en une composante symétrique, résumée ici par les modèles à association symétrique, et une composante anti-symétrique, représentant les écarts à l’association symétrique 6 . Il est donc possible d’étudier séparément la composante asymétrique des données en complément des modèles déjà utilisés, et sans entrer en concurrence avec les interprétations déjà proposées.
Cette méthode de décomposition des tables a été initialement proposée en combinaison avec l’analyse des correspondances (Constantine et Gower, 1978; Greenacre, 2000), avant d’être appliquée aux modèles d’association (Yamaguchi, 1990; van der Heijden et Mooijaart, 1995; de Falguerolles et van der Heijden, 2002), ce qui illustre encore la proximité entre les deux approches. Néanmoins, la méthode d’étude de l’asymétrie d’une table fondée sur l’analyse des correspondances ne permet de décomposer que l’asymétrie brute, c’est-à-dire les écarts à l’indépendance lorsqu’on suppose égales les distributions socioprofessionnelles respectives des hommes et des femmes. En plus de cette méthode, les modèles d’association proposés par van der Heijden et Mooijaart (1995) permettent d’étudier l’asymétrie nette, soit celle observable une fois tenu compte du fait que les professions occupées par les hommes et les femmes diffèrent : c’est celle qui nous intéresse le plus ici, dans la logique des analyses effectuées plus haut (voir l’Annexe 2 pour l’équation de ce modèle).
Rappelons qu’un des apports des modèles d’association est de permettre la mesure de l’importance respective des dimensions symétrique et anti-symétrique de l’association, ainsi que leur significativité statistique : étant donné la très faible ampleur de l’asymétrie observée dans nos données, un recours à la seule analyse des correspondances n’aurait pas permis de s’assurer de la significativité des effets observés.
Le modèle que nous utilisons décrit l’association anti-symétrique nette par une paire de dimensions, qui s’ajoute à un modèle quasi-symétrique décrivant parfaitement l’association symétrique de la table nette de la structure de ses marges. Son apport doit donc être mesuré par comparaison à ce dernier modèle, qui classe déjà correctement 98,1 pourcent des couples (Tableau 1): la marge de progression, et donc l’asymétrie observée, sont faibles. Ce premier constat nous amène à relativiser la critique selon laquelle l’étude quantitative de l’homogamie a trop souvent tendance à négliger les différences entre hommes et femmes : le modèle de quasi-symétrie montre que, une fois contrôlées les différences de composition socioprofessionnelle des populations des hommes et des femmes, la part des comportements de choix du conjoint qui peut être attribuée à des rôles sexués se révèle très faible. En d’autres termes, si asymétries il y a, et si – notamment – la femme a plus souvent un statut inférieur à celui de son conjoint que l’inverse (phénomène de l’hypergamie), cela est dû beaucoup plus à une contrainte de disponibilité des conjoints qu’à des préférences individuelles ; ou encore, au fonctionnement du marché du travail qu’à celui du marché matrimonial.
La faiblesse de l’asymétrie nette des marges n’interdit cependant pas son étude. Le modèle tenant compte de l’asymétrie classe correctement 0,5 pourcent supplémentaires des couples par rapport au modèle de quasi-symétrie, ce qui revient à diminuer d’un peu plus d’un quart la valeur de l’indice de dissimilarité par rapport à ce modèle. L’importance de nos effectifs assure que les deux dimensions décrites par le modèle sont significatives (le coefficient d’association intrinsèque est significativement différent de 0 à la probabilité critique de 0,008).
L’interprétation de la Figure 3 qui présente les résultats de ce modèle diffère, malgré une ressemblance apparente, de celle des plans issus d’une analyse des correspondances ou d’un modèle d’association lignes-colonnes. L’interprétation de tels graphiques ne doit plus être réalisée sur la base d’oppositions observées axe par axe (coordonnées cartésiennes), mais par rotation autour de l’origine, en combinant l’étude de la distance des points à l’origine à celle de l’angle formé par les segments reliant deux points à l’origine de la figure (coordonnées polaires).
En effet, la distance des points à l’origine mesure la plus ou moins forte asymétrie hommes-femmes de la catégorie par rapport à l’ensemble des autres catégories : plus un point est éloigné du centre, plus il est globalement contrasté du point de vue des conjoints que choisissent les hommes de cette catégorie par rapport à ceux que choisissent les femmes de cette même catégorie. L’angle formé par deux points reliés à l’origine indique alors quels sont les groupes associés aux membres d’une catégorie selon leur sexe : dans le sens indiqué par la flèche, se trouvent les groupes associés aux hommes de la catégorie ; dans le sens inverse, ceux associés aux femmes de la catégorie. Enfin, un groupe connaît son asymétrie maximale avec les groupes dont les points forment un angle droit avec le sien ; il présente au contraire une association symétrique et des choix similaires avec les points qui forment un angle nul avec le sien ; et enfin une association symétrique, mais des choix opposés, avec les points qui forment un angle de 180° avec le sien (ceux qui lui sont diamétralement opposés). Ces critères sont résumés par une figure plus intuitive à manier : plus l’aire du triangle reliant deux points à l’origine est grande, plus deux points présentent une forte asymétrie ; la comparaison du sens de l’angle avec celui indiqué par la flèche donne le sens de l’asymétrie.
Cette représentation, qui peut sembler peu naturelle (mais quelle analyse mathématique l’est avant d’être rendue évidente par l’habitude de la pratique ?), répond en fait à une exigence simple qui est intrinsèque à l’analyse de l’asymétrie nette d’une table : au contraire des analyses en termes d’axes utilisées plus haut, il n’est ici pas possible d’opposer des groupes sur des échelles reliant deux extrêmes. Dans l’analyse des asymétries hommes-femmes, même nette des marges de la table, on étudie un jeu à somme nulle : les proportions d’hommes et de femmes étant fixées, toutes les catégories étant (dans une certaine mesure) mixtes, et tous les individus étudiés étant en couple, il est nécessaire que les hommes et les femmes de chacun des groupes, dont ceux au statut social le plus bas ou le plus élevé, prennent un conjoint dans des directions opposées, de manière à ce que les échanges s’équilibrent. Ainsi, lorsque l’on effectue un mouvement circulaire autour de l’origine du graphique, on n’arrive jamais à une extrémité : avec qui se mettraient alors en couple les individus du sexe que la position extrême de leur groupe isole ?
Pour illustrer ce problème logique par une image sociologique plus évocatrice, s’il est un fait que les femmes cadres présentent un taux de célibat bien supérieur à la moyenne, alors que c’est le contraire pour les hommes, c’est le signe qu’à un « extrême » de l’échelle sociale, le mécanisme d’hypergamie des femmes aboutit à des incompatibilités qui empêchent purement et simplement la mise en couple pour de nombreuses femmes. Néanmoins, une fois ce phénomène contrôlé par la prise en compte des marges, il reste que des hommes et des femmes cadres sont bel et bien en couple, et qu’ils ne font pas les mêmes choix en matière de conjoint. Si l’on s’en tient au modèle traditionnel de l’hypergamie féminine, on s’attendrait selon un type idéal à ce que les hommes choisissent des femmes de statut légèrement inférieur sur les dimensions identifiées plus haut (professions intermédiaires, employées de bureau…) ; mais les femmes cadres n’auraient d’autre choix que de rester célibataires. Cette proposition n’est clairement pas réaliste, et le modèle d’association anti-symétrique permet justement de décrire le comportement matrimonial des femmes cadres qui vivent effectivement en couple.
Un premier aperçu de la figure est donné par les points correspondant aux catégories agrégées, projetées en supplémentaire sur la Figure 3. Il apparaît que les hommes cadres ont tendance à prendre une conjointe parmi les professions intermédiaires plus souvent que le cas inverse ne se produit, une fois contrôlée l’influence des marges de la table ; il en va de même pour les professions intermédiaires par rapport aux employés qualifiés, à ces derniers par rapport aux ouvriers qualifiés, et finalement pour les ouvriers qualifiés par rapport aux ouvriers et employés non qualifiés 7 . Cet enchaînement correspond à l’échelle de statut déjà dégagée plusieurs fois : il illustre la persistance d’une tendance à l’hypergamie des femmes ou à l’hypogamie des hommes parmi ces catégories, et démontre l’actualité de cette théorie.
Cependant, comme nous l’avons vu, une hiérarchie parfaite est impossible, puisque l’homme ouvrier ou employé non qualifié et la femme cadre doivent dans notre table trouver des conjoints : si la hiérarchie occupait tout le cercle, cela indiquerait que ces deux profils très éloignés bouclent le circuit en se mettant en couple ensemble. Ce mécanisme existe, puisque le point correspondant aux cadres (ainsi que celui correspondant aux indépendants) est plus éloigné de celui correspondant aux ouvriers non qualifiés dans le sens des aiguilles d’une montre que dans le sens inverse. Mais il n’est pas le seul à jouer. En effet, nous n’avons pas encore couvert tout le spectre des catégories agrégées : les points correspondant aux indépendants et aux agriculteurs se situent en-dehors de l’arc de cercle déjà décrit, et font donc le lien entre les deux extrêmes. Les femmes cadres prennent plus souvent des conjoints parmi les indépendants que l’inverse n’arrive, les femmes indépendantes font de même avec les employés et ouvriers non qualifiés.
Ce tableau, identifié à partir des catégories agrégées, résume-t-il fidèlement ce que l’on observe au niveau détaillé ? La hiérarchie traditionnelle, qui se déroule dans le sens des aiguilles d’une montre, est stable : partant des hommes des professions intellectuelles, l’on suit de manière relativement ordonnée l’échelle de statut dégagée par les analyses précédentes, pour arriver finalement, à l’opposé, aux personnels des services directs aux particuliers (56) et aux ouvriers non qualifiés (67 et 68), qui constituent incontestablement le bas de la hiérarchie. Les plus nettes ruptures, séparant des ensembles de catégories aux comportements très contrastés, s’effectuent entre les professions intermédiaires (4x) et les ouvriers qualifiés (62, 64, 65), puis entre ces derniers et les ouvriers et employés non qualifiés (56, 67, 68). Notons au contraire la relative concentration d’un groupe incluant la plupart des professions intermédiaires (4x), les catégories supérieures des employés (de la fonction publique, 52 administratifs d’entreprise, 54), et les artisans (21), et auquel se rattachent de près les cadres au sens strict (du public, 33 ; du privé, 37 et 38).
Les ouvriers se trouvent dans une position très asymétrique par rapport à ce groupe que nous dirons moyen, marquant l’importance de la distinction entre travail manuel et non manuel dans les identités sexuelles : les femmes ouvrières ont bien plus de chances de prendre un conjoint parmi les classes moyennes que leurs collègues masculins. Ce phénomène peut être illustré plus précisément par les coefficients d’association anti-symétriques (voir Annexe 3) concernant les ouvriers qualifiés de type industriel (62) : en prenant pour référence les hommes appartenant à cette catégorie, les coefficients négatifs indiquent que les cas dans lesquels un homme de cette catégorie est en couple avec une femme membre des professions intermédiaires (4x) sont moins nombreux que ceux dans lesquels c’est l’inverse, une fois contrôlée l’influence des marges de la table ; à l’inverse, les coefficients positifs indiquent que les cas dans lesquels un homme de cette catégorie est en couple avec une femme ouvrière (6x) ou employée des services directs aux particuliers (56) sont sur-représentés selon les mêmes critères. La position du point 62 sur la graphique résume bien cette situation.
Le reste du cercle présente un ordre moins net. Les catégories qui se situent entre les cadres et les ouvriers non qualifiés dans le sens contraire des aiguilles d’une montre sont très diverses : commerçants (22) et chefs d’entreprise (23), professeurs et professions scientifiques (34), professions intermédiaires de la santé et du travail social (43) et employés de commerce (55). Ces quelques catégories étant situées entre les deux extrêmes de la hiérarchie socioprofessionnelle, elles présentent une forte discordance de statut entre les hommes et femmes qui les composent : en effet, les premiers ont plus souvent tendance à prendre une conjointe au sein des catégories au statut le plus élevé de la société, quand c’est le contraire pour les secondes. Quel sens peut-on donner à cet assemblage de groupes apparemment disparates ?
Les catégories impliquées dans la hiérarchie traditionnelle, allant des cadres aux ouvriers et employés non qualifiés dans le sens des aiguilles d’une montre, suivent un modèle général dans lequel l’homme possède, plus souvent que l’inverse, un statut supérieur à celui de sa conjointe. Elles ont pour point commun de participer à une hiérarchie institutionnelle présente au sein des entreprises et des administrations : il semble donc que l’asymétrie dans le choix du conjoint suive pour ces catégories un principe profondément inégalitaire, qui soutient de manière frappante la théorie de l’hypergamie de la femme.
Les catégories qui ne s’inscrivent pas dans cette hiérarchie peuvent donc se définir en opposition à celle-ci : peu semblables du point de vue du statut, du secteur d’activité, du prestige ou encore de la féminisation, elles se caractérisent néanmoins toutes par un éloignement de l’organisation hiérarchique du travail. Les agriculteurs et les indépendants (2x) échappent par définition à ce type d’autorité. C’est aussi le cas des professions intellectuelles : professions libérales (31), professeurs et professions scientifiques (34), professions de l’information, des arts et des spectacles (35), constituent le sommet de la hiérarchie de statut mais ne font pas partie des professions de l’encadrement. De chaque côté des professions intellectuelles, les instituteurs (42) et les professions intermédiaires de la santé et du travail social (43) sont les seules professions intermédiaires qui se situent hors de la hiérarchie principale ; ce sont par ailleurs deux catégories qui échappent largement à l’organisation hiérarchique du travail, d’autant que cette dernière comprend des personnes exerçant en libéral. Finalement, en bas de l’échelle, les employés de commerce (55) et les ouvriers non qualifiés de type artisanal (68) sont plus souvent que les autres groupes d’employés et d’ouvriers intégrés dans un collectif de travail de petite taille avec une échelle hiérarchique courte (voire absente), allant de pair avec une faible formalisation des normes de travail (Gollac, 1989; Burnod et Chenu, 2001).
Ainsi, la circulation genrée des conjoints suit de près l’ordre hiérarchique institutionnel ; cette circulation est rendue possible par l’existence d’un circuit compensatoire, reliant les deux extrêmes de l’échelle de statut en passant par des catégories faiblement inscrites dans l’organisation hiérarchique du travail. Ainsi, les catégories extrêmes de l’échelle sociale s’échangent bel et bien des conjoints, dans une mesure à la fois faible et très asymétrique du point de vue du genre. Ce résultat ne fait au total que confirmer le principe au fondement des nomenclatures socioprofessionnelles, à savoir la grande valeur prédictive de caractéristiques purement professionnelles sur des comportements sociaux qui en sont a priori fort éloignés. Dans le domaine étudié, il n’en garde pas moins un parfum de scandale, tant la collision entre un univers professionnel explicitement hiérarchisé et un univers conjugal supposément égalitaire vient heurter l’approche romantique moderne de l’amour.
Conclusion
Une table d’homogamie, comme tout tableau croisé d’apparence simple, ne livre pas tous ses secrets sans des méthodes de questionnement appropriées. Nous espérons avoir démontré l’intérêt de recourir à des méthodes élaborées spécifiquement pour l’analyse de tables carrées, présentant les mêmes catégories en lignes et en colonnes. De telles données se rencontrent dans l’étude de l’homogamie et de la mobilité sociale, et plus généralement dans celle de tous comportements ou caractéristiques reproduits par des personnes différentes – comme des conjoints, des frères et sœurs ou des membres de deux générations successives –, ou encore par la même personne mais dans le temps – comme un vote, un choix résidentiel ou de consommation.
Trois phénomènes de natures différentes sont identifiables séparément dans une telle table, pour peu que des méthodes adéquates soient utilisées : une composante diagonale représentant l’identité des caractéristiques, ou la stabilité des choix ; une composante symétrique construisant un espace social des proximités et distances entre catégories ; une composante anti-symétrique, enfin, mesurant le changement des caractéristiques entre les deux individus ou points d’observation. Cette décomposition se révèle aussi d’un grand intérêt pour l’analyse de réseaux sociaux : la diagonale de la table est alors par définition dépourvue de sens (pas de contacts d’un individu avec lui-même), il est donc important de la mettre de côté pour ne pas perturber l’analyse du reste des cellules ; si le sens des liens est pris en compte dans les données, la décomposition de la table en une partie symétrique et une partie anti-symétrique permettra d’étudier de manière spécifique d’une part la proximité des différents individus, et d’autre part la circulation des contacts au sein du réseau.
En prolongeant le principe à l’origine de l’analyse factorielle, les modèles d’association nous ont permis d’affiner l’analyse en ne confondant pas les trois phénomènes déjà décrits, qui ont des interprétations sociologiques distinctes. L’étude de l’endogamie, correspondant à la diagonale de la table, a mis en évidence la plus forte tendance à l’entre-soi des classes supérieures en comparaison avec les classes populaires, mais surtout des indépendants (en particulier les agriculteurs) en comparaison avec les salariés. Une fois cet aspect mis de côté, nous avons été en mesure de dégager les lignes structurantes de l’espace social dessiné par les choix matrimoniaux correspondant aux différentes nuances de l’hétérogamie : une dimension hiérarchique reflétant le statut socioprofessionnel, d’importance nettement supérieure aux autres puisqu’elle explique les deux tiers de l’association nette observée 8 ; des dimensions secondaires mais non négligeables, dont la significativité statistique est assurée, opposant le secteur public et le secteur privé, les indépendants au secteur public, et enfin l’industrie aux autres activités.
Les différentes méthodes utilisées n’ont jamais été en contradiction, mais des nuances se sont fait jour, dues notamment au traitement symétrique ou non des positions des hommes et des femmes. L’utilisation de modèles log-multiplicatifs a révélé la relative faiblesse de ces différences sexuées une fois contrôlée la distribution des positions socioprofessionnelles : il n’apparaît dès lors pas complètement illégitime que nombre d’analyses les aient négligées. Néanmoins, l’étude spécifique de ces asymétries a finalement révélé la persistance du schéma traditionnel d’hypergamie de la femme, d’une ampleur relativement faible mais statistiquement et sociologiquement significative. L’examen des catégories détaillées révèle que celles qui sont intégrées à une hiérarchie institutionnelle reproduisent le plus fortement ce modèle inégalitaire de choix du conjoint.
Finalement, alors que nous nous sommes restreints ici à l’analyse d’une table à deux dimensions, les modèles RC-L déjà évoqués en introduction, permettent d’étudier des tables en trois dimensions ou plus, croisant par exemple la table d’homogamie étudiée ici avec une dimension temporelle ou spatiale. Les possibilités offertes par une telle spécification sont immenses : ces modèles permettent par exemple de mesurer l’évolution des différentes dimensions, symétriques mais aussi anti-symétriques, au cours du temps, et d’étudier ainsi les transformations de l’espace social identifié ici de manière très fine, alliant ainsi la richesse d’une analyse des correspondances à la puissance statistique des modèles log-linéaires et log-multiplicatifs. Le principe de l’association lignes-colonnes peut être généralisé de diverses manières pour décrire des tables de plus de trois dimensions, afin de synthétiser en un nombre réduit d’axes des données aussi complexes que nécessaire.
Footnotes
Annexe 1 - Comparaison des équations de l’analyse des correspondances et des modèles d’association lignes-colonnes
Les traditions dont sont respectivement issus l’analyse des correspondances et les modèles log-multiplicatifs d’association ont chacune développé une approche mathématique, théorique et pratique bien affirmée, qui occulte la grande proximité des deux techniques du point de vue de la modélisation statistique. Ces ressemblances sont connues de longue date, et ont notamment été étudiées par Leo Goodman peu après avoir proposé les modèles d’association lignes-colonnes (Goodman, 1985, 1986), mais aussi par d’autres auteurs (Gilula et Haberman, 1986).
Leo Goodman étudie l’analyse des correspondances en tant que membre de la famille plus large des modèles de corrélation, sa particularité étant qu’elle calcule autant de dimensions que nécessaire pour reconstituer parfaitement la table (modèle saturé), là où les modèles de corrélation et d’association ne retiennent généralement qu’un nombre de dimensions réduit. Cette propriété permet à l’analyse des correspondances d’être estimée de manière assez efficace grâce à une décomposition en valeurs singulières aboutissant à l’optimum selon la méthode des moindres carrés, alors que les modèles de corrélation et d’association sont estimés selon un algorithme itératif plus intensif en calcul, via la méthode du maximum de vraisemblance. Il est donc tout à fait possible de réaliser une analyse des correspondances à l’aide de la méthode du maximum de vraisemblance, ce qui en fait un cas particulier de modèle log-multiplicatif, partageant de nombreux traits avec les modèles d’association.
Les modèles de corrélation, auxquels peut être assimilée l’analyse des correspondances, ont pour propriété de modéliser la proportion des effectifs de la table Pij correspondant à la cellule située à l’intersection de la ligne i et de la colonne j par une valeur mij définie de la manière suivante :
Dans cette équation, les paramètres Pi+ et P+j correspondent aux proportions marginales de la table, respectivement en lignes et en colonnes ; λm est la valeur propre associée à l’axe de rang m, et xim et yjm correspondent aux coordonnées (ou scores) respectives des catégories en ligne et en colonne sur cet axe. En tant que modèle saturé, l’analyse des correspondances classique retient toujours une valeur de M égale au rang de la table considérée, alors que les autres variantes choisiront généralement une valeur inférieure.
Les modèles d’association lignes-colonnes modélisent mij d’une manière d’apparence légèrement plus complexe :
L’ensemble des paramètres conserve la même interprétation, malgré le changement de notation : λm, xim et yjm sont respectivement remplacés par \varphim, μim et νjm. Les deux familles de modèles apparaissent donc très proches : à la situation d’indépendance, les proportions marginales lignes et colonnes Pi+ et P+j, ou les paramètres αi et βj suffisent à reproduire l’association observée, les parties restantes des deux équations sont donc égales à 1. Cela implique dans les deux cas que l’association prédite par les scores est nulle.
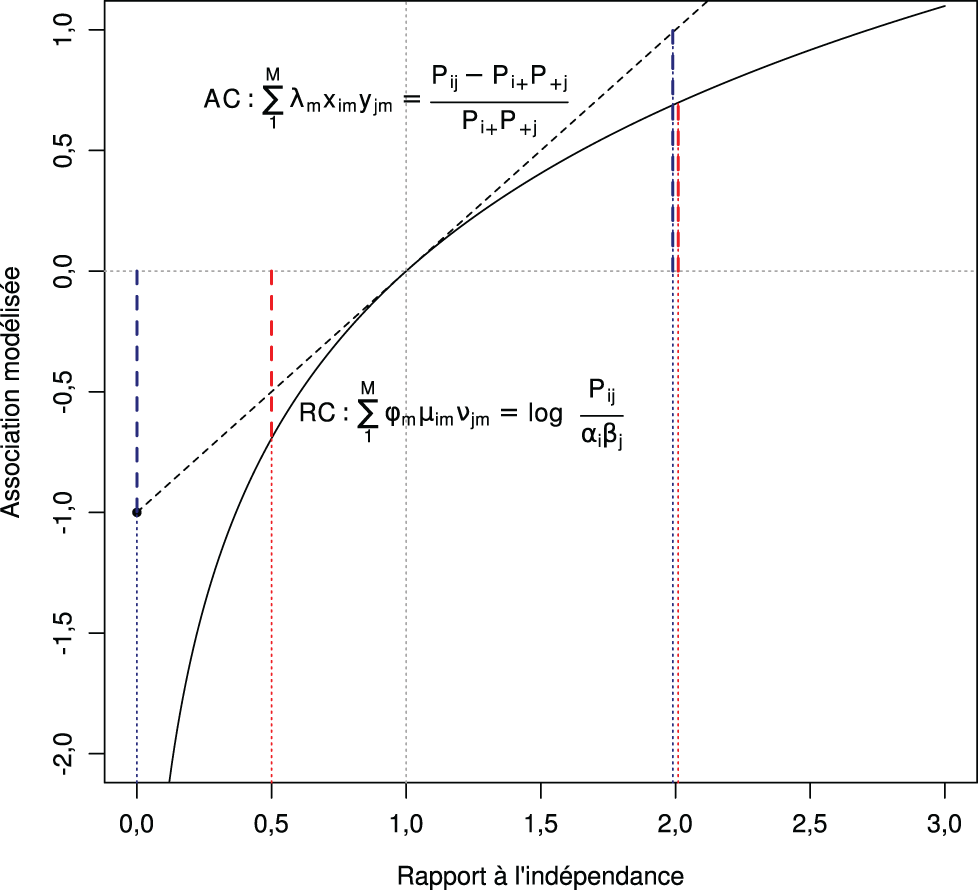
Plus généralement, lorsque l’association est raisonnablement proche de l’indépendance, les deux spécifications estiment des scores très similaires. Cela est lié au fait que la droite d’équation 1 + x est tangente à la courbe d’équation exp au point 0 (Figure 4) : autrement dit, pour des valeurs de x raisonnablement proches de 0, les deux fonctions prennent des valeurs très proches. Ce n’est que lorsque l’association observée diffère fortement de ce qui peut être expliqué par les paramètres marginaux que les deux familles de modèles donnent des résultats nettement différents – ce qui se lit sur la Figure 4 à l’écart entre la droite (analyse des correspondances) et la courbe (modèles d’association lignes-colonnes).
Une différence notable entre les deux méthodes tient à ce qu’en analyse des correspondances une sous-représentation (valeurs des abscisses inférieures à 1) n’est pas symétrique avec une sur-représentation (valeurs supérieures à 1) : en effet, une sous-représentation extrême correspond à une association égale au minimum à -1, alors qu’une sur-représentation extrême correspond à une association tendant vers plus l’infini ; une sur-représentation de 2 est l’inverse d’une sous-représentation infinie, correspondant à une abscisse de 0 (cf. traits verticaux pointillés sur la figure). Avec un modèle d’association, sous- et sur-représentation sont symétriques : une sous-représentation extrême correspond à une association tendant vers moins l’infini ; l’inverse d’une sur-représentation de 2 est une sous-représentation de 2, soit une abscisse de 1/2 (échelle multiplicative).
Il importe de noter que ces remarques ne s’appliquent qu’au cas où les deux modèles sont estimés à l’aide de la même méthode : moindres carrés ou maximum de vraisemblance. La pratique classique de l’analyse des correspondances recourt à la première méthode, le modèle étant saturé (tous les mij = Pij), ce qui implique que les paramètres marginaux sont égaux à la proportion des effectifs de la table situés sur la marge correspondante. Au contraire, les modèles d’association n’étant généralement pas saturés (les mij ne sont qu’une approximation des Pij), ils sont donc estimés par la seconde voie, plus souple, dans laquelle les paramètres marginaux prennent une valeur libre (celle qui permet de décrire le mieux les données observées avec le nombre de dimensions retenu). Les deux familles ont dans ce cas de nombreuses raisons de ne pas aboutir exactement au même résultat.
Annexe 2 - Équations des modèles d’association utilisés
En reprenant les notations utilisées dans l’Annexe 1, le modèle d’association lignes-colonnes s’écrit communément sous sa forme logarithmique :
Pour tous les modèles, nous rendons les scores identifiables en utilisant une normalisation avec pondération marginale : autrement dit, la somme pondérée des scores est nulle (contrainte de position) et la somme pondérée de leurs carrés est égale à 1 (contrainte d’échelle).
Lorsque le modèle contient plus d’une dimension (i.e. M > 1), des contraintes interdimensionnelles doivent être appliquées :
Sous un tel modèle, le logarithme de l’odds ratio construit à partir des catégories i et i’, j et j’ s’écrit :
Il est donc proportionnel au produit des écarts entre les scores des lignes et des colonnes considérées : le coefficient d’association intrinsèque φm donne la mesure de l’ampleur des odds ratios sur la dimension correspondante.
Le modèle d’association lignes-colonnes avec paramètres diagonaux s’écrit :
le dernier terme désignant la fonction indicatrice prenant la valeur 1 pour les cellules de la diagonale de la table (i = j), et 0 pour les autres cellules.
Le modèle d’association lignes-colonnes symétrique avec paramètres diagonaux s’écrit donc :
Enfin, le modèle d’association anti-symétrique a pour équation (seul le modèle à une double dimension, pour lequel W = 1, est utilisé) :
L’introduction de modalités supplémentaires dans des modèles d’association se fonde sur la construction de deux tables croisant modalités actives et modalités passives respectivement pour les lignes et les colonnes : les scores correspondant aux modalités actives sont fixés aux valeurs obtenues dans le modèle original, et ceux correspondant aux modalités passives sont estimés sous cette dernière contrainte. Un nouveau modèle est alors estimé soit sur les deux tables (lignes et colonnes passives) prises séparément, soit sur une table combinant les deux sous la forme suivante :
où Vide représente une table de mêmes dimensions I×J que la table originale, mais dont les valeurs sont uniquement des zéros structurels, qui n’affectent aucunement le modèle et servent simplement de remplissage. Lsup représente la table de dimensions I’×J croisant lignes supplémentaires et colonnes actives. Csup représente la table de dimensions I×J’ croisant lignes actives et colonnes supplémentaires.
Dans le cas le plus simple du modèle d’association lignes-colonnes asymétrique, on est alors ramené à deux modèles log-linéaires (et non plus log-multiplicatifs), le modèle d’association lignes et/ou celui d’association colonnes (Wong, 2010: 10-23). En utilisant la table présentée ci-dessus, l’équation du modèle n’est pas modifiée, mais les paramètres μi et νj sont contraints à leurs valeurs obtenues dans le modèle original en ce qui concerne les modalités actives (i ≤ I et j ≤ J) : les scores nouvellement introduits, correspondant aux modalités supplémentaires (I < i ≤ I + I’ et J < j ≤ J + J’), sont estimés librement.
Dans les cas plus complexes des modèles d’association lignes-colonnes symétrique et anti-symétrique, l’estimation des scores correspondant aux modalités supplémentaires repose sur le même principe. La différence tient, dans le modèle d’association symétrique, à ce que les scores des modalités actives et supplémentaires sont contraints à être les mêmes pour les lignes et les colonnes : μi = νj pour tout i et j. Dans le modèle d’association anti-symétrique, les scores μi et νj des modalités actives sont contraints de la même manière que dans le modèle d’association asymétrique. Dans le cas du modèle anti-symétrique, cette contrainte n’est pas appliquée, mais les mêmes scores μ et ν s’appliquant alternativement aux lignes et aux colonnes, la comparaison des lignes et des colonnes a lieu naturellement.
Il est important de noter que les scores des modalités supplémentaires ne sont identifiables dans chacun de ces modèles qu’après imposition d’une contrainte, qui est dans notre cadre que la somme pondérée de ces scores est nulle (cf. équation ci-dessus ; la seconde contrainte concernant la somme des carrés n’est pas nécessaire). Ceci signifie que, contrairement à l’analyse des correspondances, le score d’une modalité supplémentaire d’un modèle d’association n’a de sens que relativement aux autres modalités supplémentaires utilisées. Ainsi, dans la Figure 3 ci-dessus, le point supplémentaire correspondant aux agriculteurs n’occupe pas exactement la même position que le point actif correspondant à la catégorie 10, pourtant strictement identique à la précédente : en effet, dans ces deux cas, la modalité est comparée à des classifications différentes, fournissant des informations qui ne sont pas équivalentes. Pour être interprétable, une modalité supplémentaire doit donc être introduite en même temps qu’un ensemble de modalités avec lesquelles la comparer, qui recouvre typiquement la même population que les modalités actives.
Annexe 3 - Paramètres d’association anti-symétriques
| Homme | Femme | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 52 | 53 | 54 | 55 | 56 | 62 | 63 | 64 | 65 | 67 | 68 | 69 | 81 | |
| 52 | |||||||||||||
| 53 | 0,37 | ||||||||||||
| 54 | 0,09 | −0,88 | |||||||||||
| 55 | −0,04 | −0,43 | −0,05 | ||||||||||
| 56 | −0,12 | 0,21 | −0,19 | 0,19 | |||||||||
| 62 | −0,10 | 0,42 | −0,10 | 0,03 | 0,57 | ||||||||
| 63 | −0,07 | 0,22 | −0,01 | −0,03 | −0,26 | 0,04 | |||||||
| 64 | −0,28 | 0,00 | 0,29 | 0,09 | 0,07 | −0,02 | −0,12 | ||||||
| 65 | −0,02 | 0,06 | −0,33 | −0,29 | 0,08 | −0,14 | −0,28 | −0,10 | |||||
| 67 | 0,04 | −0,25 | −0,11 | 0,09 | 0,01 | −0,29 | −0,03 | −0,02 | −0,16 | ||||
| 68 | 0,01 | 0,19 | −0,14 | 0,03 | −0,24 | −0,23 | −0,09 | 0,08 | −0,14 | 0,03 | |||
| 69 | −0,01 | −0,42 | 0,29 | 0,18 | 0,22 | 0,23 | −0,06 | 0,27 | 0,37 | −0,02 | −0,26 | ||
| 81 | −0,28 | 0,10 | −0,47 | −0,44 | 0,01 | 0,01 | −0,17 | −0,23 | 0,05 | −0,51 | −0,34 | −0,20 | |
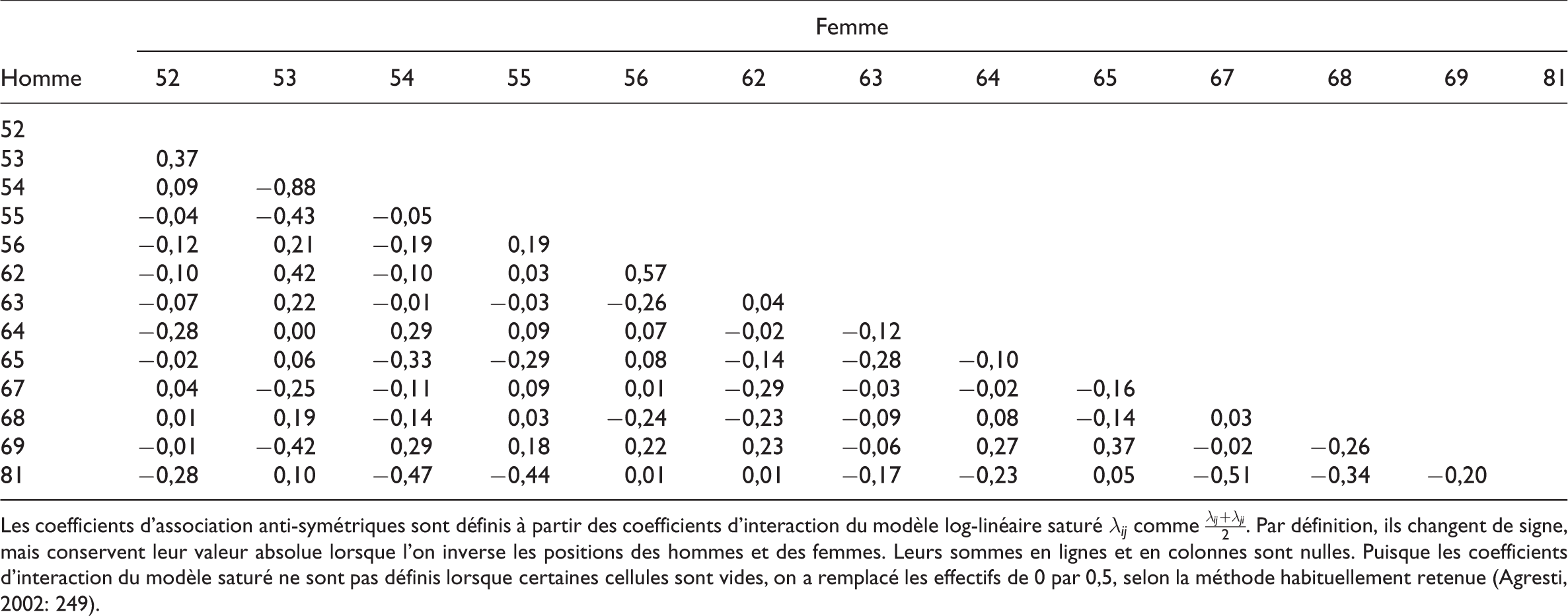
Les coefficients d’association anti-symétriques sont définis à partir des coefficients d’interaction du modèle log-linéaire saturé