
Abstract
Accurate segmentation of stenosis in X-ray angiography (XRA) images is crucial for the objective assessment of stenosis severity and subsequent treatment planning in coronary artery disease. Current clinical practice primarily relies on subjective visual evaluation, which suffers from significant inter-observer variability. In this work, we propose a deep learning model enhanced with a novel Hybrid Context-Aware Attention (HCA) module. HCA employs a parallel dual-pathway design that integrates global inter-channel attention and grouped multi-scale spatial aggregation. This integration enhances feature discriminability and spatial-context modeling, leading to more accurate and anatomically consistent stenosis segmentation in XRA. Evaluated on three independent datasets, our method achieves competitive performance against existing approaches across multiple metrics, demonstrating consistent leading performance. Ablation and attention visualization studies further confirm the contribution of the designed module to reducing segmentation errors and enhancing focus on stenotic regions. These findings demonstrate that the proposed model is an effective and generalizable approach for stenosis segmentation in XRA, with the potential to support standardized assessment in clinical practice.
Introduction
Accurate assessment of coronary artery stenosis is fundamental for the diagnosis of coronary artery disease and the planning of interventional therapies. 1 In clinical practice, X-ray angiography (XRA) is the preferred modality for stenosis evaluation and revascularization planning, due to its accessibility and real-time imaging capabilities.2,3 However, the current clinical workflow relies heavily on visual estimation of stenosis from XRA images. This subjective approach introduces significant inter-observer variability, which can directly affect treatment decisions and patient outcomes.4,5 The growing adoption of robot assisted percutaneous coronary intervention (PCI) further underscores the need for automated, precise, and quantitative stenosis analysis.6–9 Despite progress, accurate automatic stenosis segmentation remains highly challenging due to complex vascular morphology, non-uniform contrast enhancement, vessel overlap, and subtle stenosis appearances.
Recent studies have proposed various methods to address these issues. Han et al. 10 proposed a transformer-based framework for stenosis detection in coronary XRA sequences, using spatio-temporal feature extraction and long-range dependency modeling. Wang et al. 11 proposed an enhanced YOLO model for detecting and classifying coronary artery stenosis in XRA. Molenaar et al. 12 used a U-Net with a ResNet-101 encoder to segment coronary arteries in XRA and detect stenosis via vessel diameter profiling. While several methods can effectively identify lesion regions,13–16 they often lack the pixel-level delineation needed to quantify key morphological features such as vessel diameter. Since these measurements are essential for clinical assessment, recent research has shifted toward pixel-level stenosis segmentation. The 2023 ARCADE Challenge introduced the coronary artery stenosis segmentation task based on XRA and publicly released a large-scale annotated dataset. 17 For this task, Lee et al. 18 achieved top performance using a semi-supervised YOLOv8 m model. Subsequently, Abedin et al. 19 proposed DenseSelfMA-Net, which employs a DenseNet121 encoder and integrates Self-ONN into multi-scale attention modules in the decoder for enhanced feature representation. Lalinia et al. 20 further improved the Swin UNETR model by integrating adapter-efficient tuning and vessel-aware processing. Despite these advances, current methods still face limitations in accuracy and lack thorough validation across independent multi-center datasets.
To address these challenges, we build upon the adaptability of the YOLO series in related medical imaging tasks,21–24 and propose an enhanced deep learning model for automated coronary stenosis segmentation in XRA. The model is designed to improve both accuracy and generalization across diverse datasets. The main contributions of this study are as follows:
We propose a novel Hybrid Context-Aware Attention (HCA) module. Integrated into a YOLOv11-based segmentation architecture, it jointly captures channel-wise dependencies and multi-scale spatial context to enhance relevant features and suppress noise, thereby improving localization accuracy. We provide comprehensive multi-center validation. Extensive experiments on three independent datasets demonstrate the model's superior and consistent segmentation performance compared to state-of-the-art methods.
Materials and methods
Datasets
To evaluate the model's performance across diverse data sources, we used three coronary XRA image datasets: two public datasets and one local dataset.
Local dataset: This dataset comprises 557 XRA images from 254 patients (182 male, 72 female; mean age 63 ± 10 years) at a local hospital, with approval from the institutional ethics committee. For each patient, trained radiologists selected 1–3 angiographic sequences (from eight standard views) that clearly displayed stenosis in one of the major coronary branches: the left anterior descending (LAD), left circumflex (LCX), or right coronary artery (RCA). From each sequence, 1–2 key frames with optimal contrast opacification were extracted, resulting in a final set of images with resolutions ranging from 512 × 512 to 1016 × 1016 pixels. Importantly, while the frames selected for annotation follow clinical practice, the underlying angiographic sequences were collected consecutively without preselection. The dataset covers a wide range of clinical conditions, including single-, double-, and triple-vessel diseases, varying stenosis severity (mild, moderate, severe), and morphology (focal, diffuse), as well as diverse angiographic views including left anterior oblique, right anterior oblique, cranial, caudal, and others.
ARCADE-stenosis dataset: We utilized a subset of the public ARCADE dataset, 17 which contains 1500 coronary XRA images (512 × 512 pixels), each annotated with at least one stenotic region. The dataset is officially split into 1000 training, 200 validation, and 300 test images. To ensure clinical diversity, it maintains a balanced distribution of lesions across the three major coronary arteries (LAD, LCX, RCA), with all stenotic regions annotated using polygonal labels.
ICA-stenosis dataset: This subset was derived from the public ICA dataset. 25 From the initial 616 images, we applied exclusion criteria based on clinical relevance and image quality: images without significant stenosis (n = 179), with occlusion (n = 2), overlapping vascular structures (n = 15), pseudostenosis due to RCA curvature (n = 4), or poor image quality (n = 36) were removed, yielding a final set of 380 images for evaluation.
Data annotation
Under cardiology expert guidance, trained radiologists performed pixel-level annotations of coronary stenosis for the local and ICA-stenosis datasets using ITK-SNAP 3.8.0. 26 Representative ground truth annotations from the public ARCADE-stenosis dataset and the local dataset are shown in Figure 1.
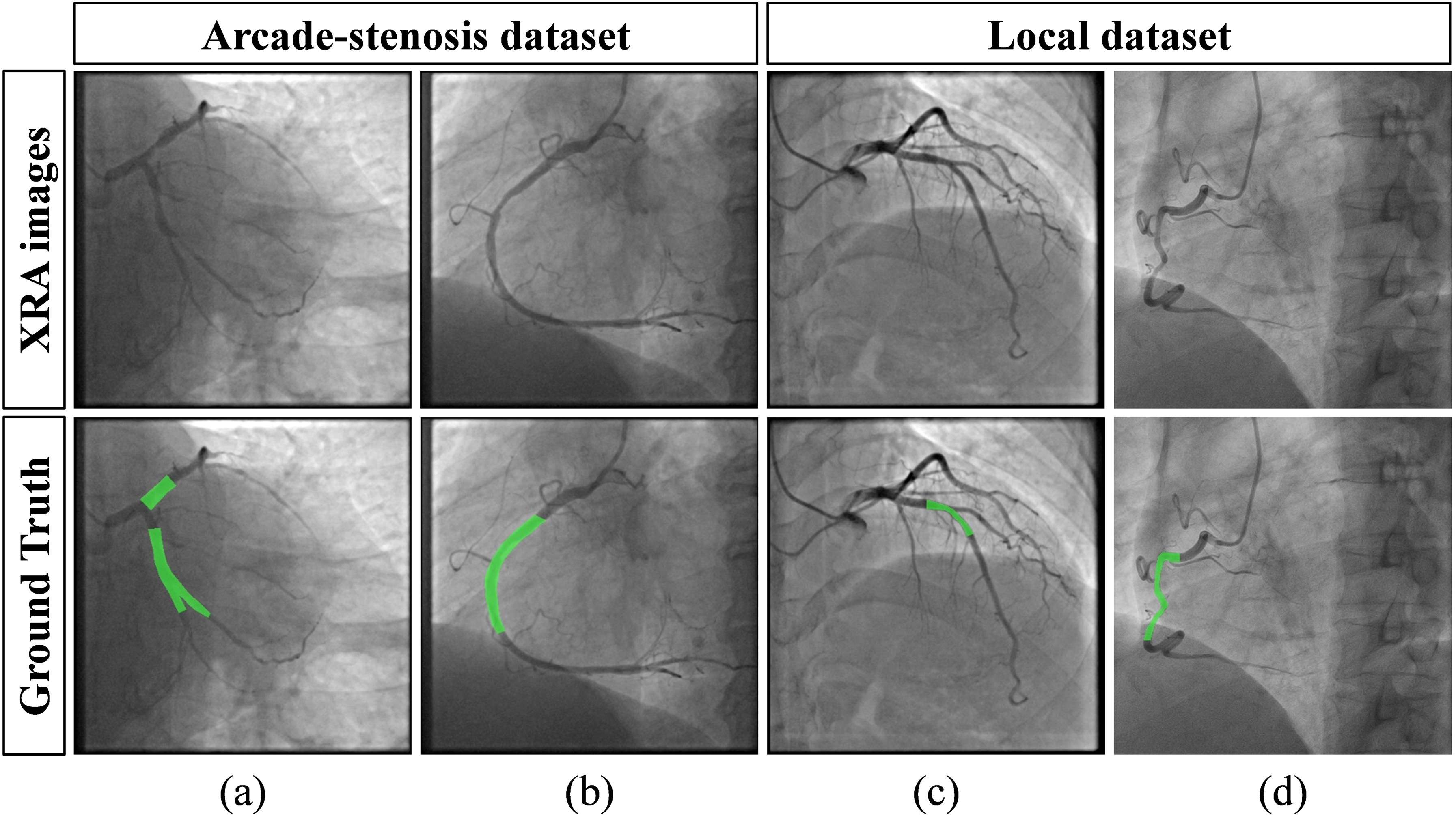
XRA images and corresponding stenosis annotations. (a, b) Examples from the ARCADE-stenosis dataset showing annotated lesions in the left and right coronary arteries, respectively. (c, d) Corresponding examples from the Local dataset (see online version for color distinctions).
Method overview
The overall workflow of the proposed method is illustrated in Figure 2. It consists of three main stages: preparation of multi-center datasets, development and training of a stenosis segmentation model, and comprehensive evaluation of the model across all datasets with multiple evaluation metrics.
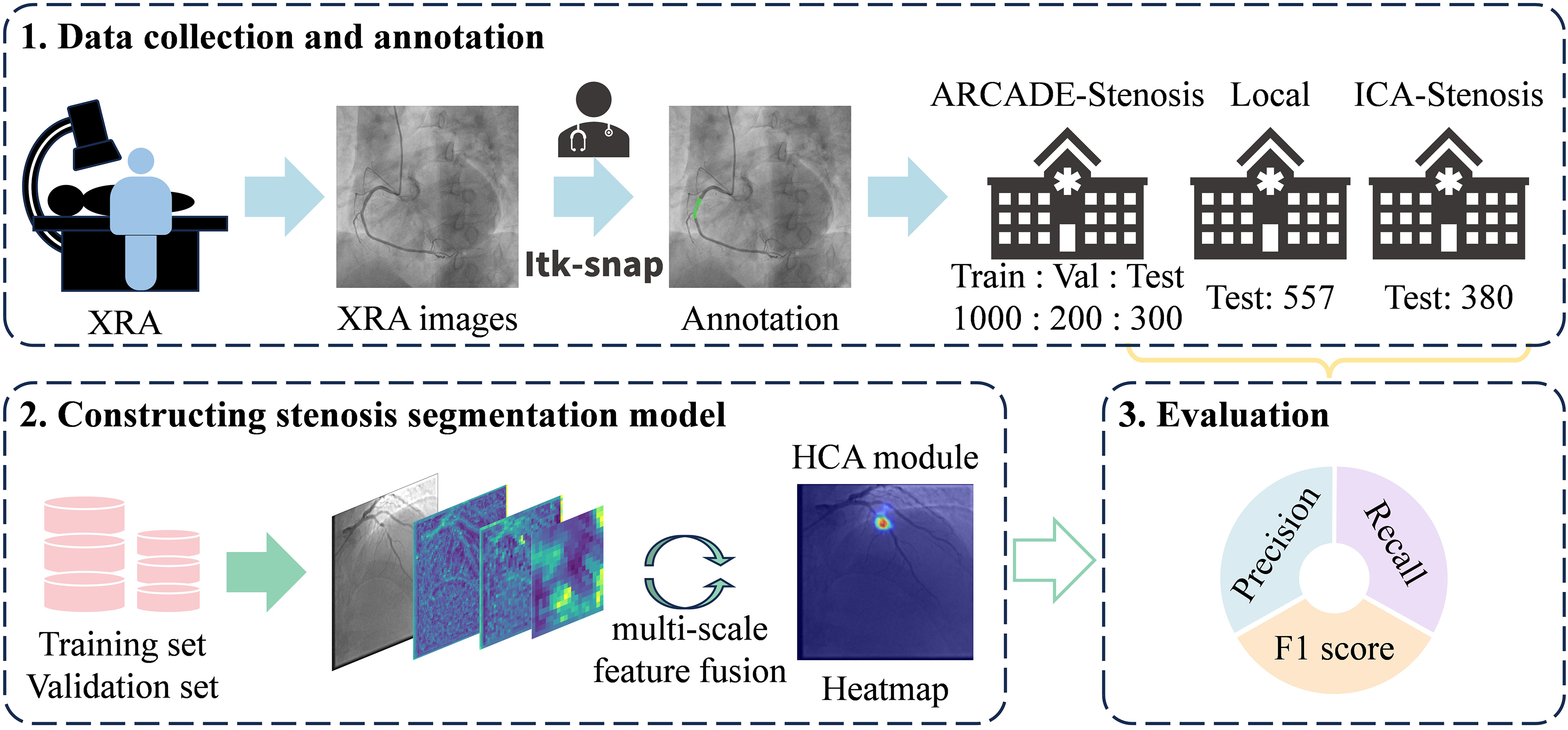
The workflow of this study.
Network architecture
The architecture of the proposed model, as shown in Figure 3, comprises three main components: the backbone, the neck, and the head. The backbone serves as the primary feature extractor, transforming the input image into a hierarchy of multi-scale feature maps through successive downsampling. The neck fuses and refines these multi-scale features before forwarding them to the head. The head simultaneously generates a bounding box and a segmentation mask for each target based on the refined feature. To enhance feature discriminability, we design the Hybrid Context-Aware Attention (HCA) module and place it between the neck and the head. This placement allows the module to operate on fused multi-scale features, directly refining task-relevant representations before final prediction while avoiding interference with earlier feature extraction or fusion processes. This module adaptively refines features by jointly modeling global channel dependencies and multi-scale spatial context, thereby highlighting stenosis-relevant regions while suppressing irrelevant backgrounds and healthy vessel patterns.
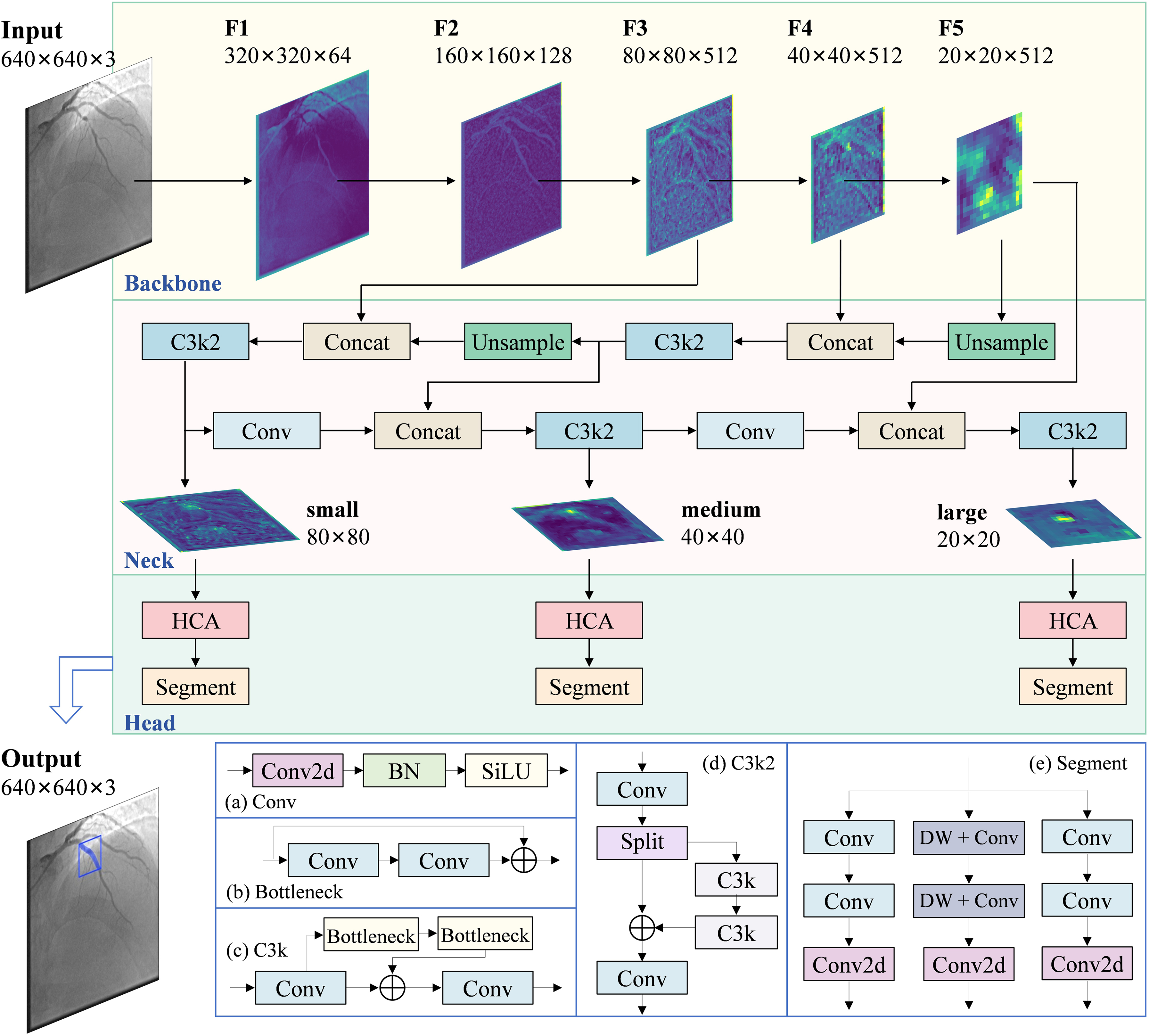
The overall architecture of the proposed model, consisting of three components: the backbone, the neck, and the head. (a)-(e) detail the inner structures of the Conv, Bottleneck, C3k, C3k2, and Segment blocks, respectively.
Hybrid context-aware attention module
Stenosis occupies a minimal area in coronary XRA images, resulting in a severe class imbalance that biases models towards the majority background class, leading to reduced sensitivity and accuracy. To address this, we propose a Hybrid Context-Aware Attention (HCA) module. As shown in Figure 4, the HCA comprises two parallel branches: the Channel-Context Modeling (CCM) branch and the Spatial-Scale Modeling (SSM) branch. The CCM branch captures global inter-channel dependencies to enhance discriminative features, while the SSM branch models multi-scale spatial-contextual correlations to focus on relevant structures. Their outputs are fused to adaptively highlight stenosis-relevant patterns and suppress irrelevant backgrounds. This parallel design allows the model to simultaneously refine features from both dimensions without compromising either, enhancing sensitivity to small stenosis regions while suppressing irrelevant backgrounds.
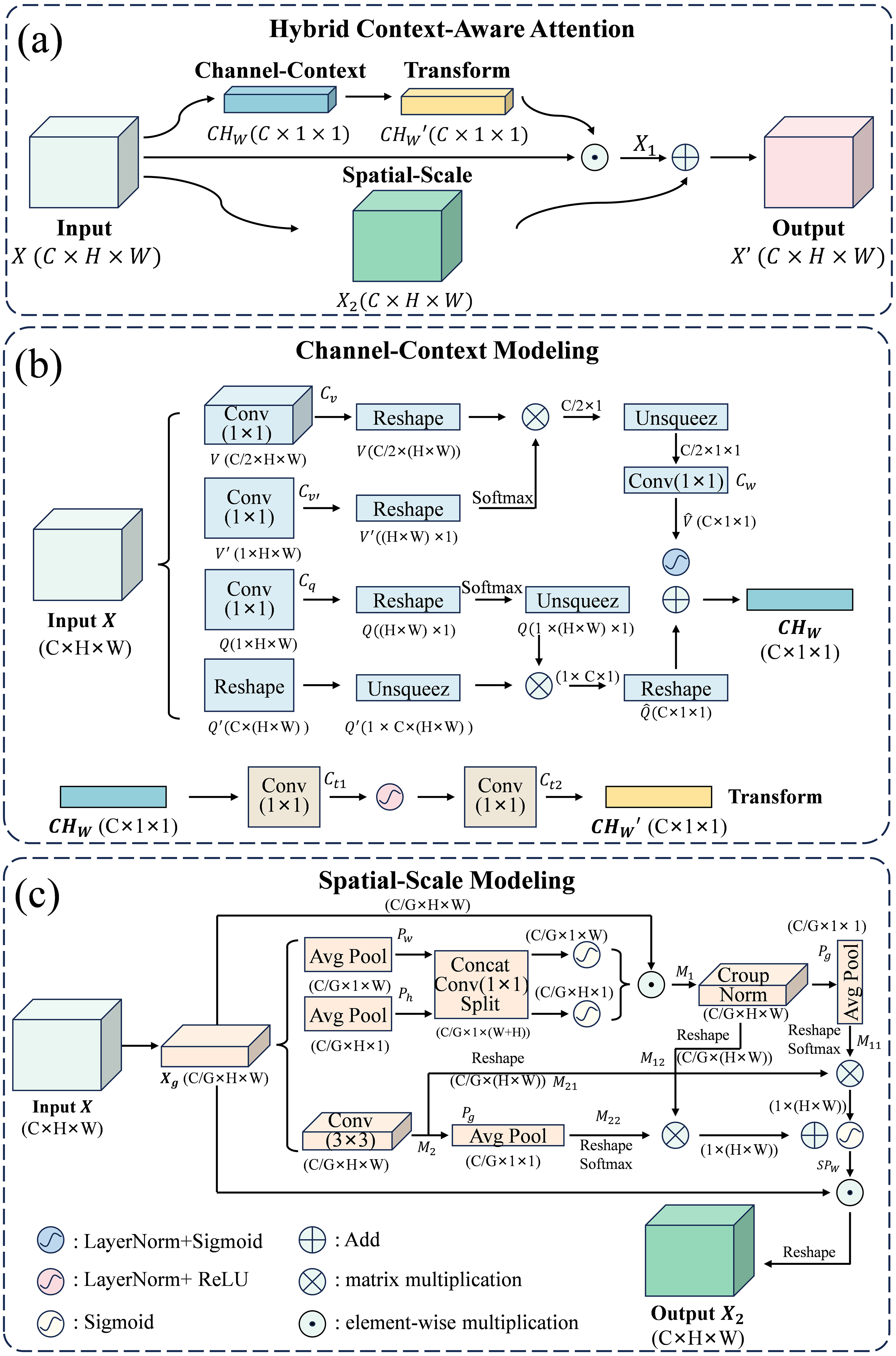
The proposed Hybrid Context-Aware Attention (HCA) module for feature refinement. (a) Overall structure. (b) Channel-context modeling (CCM) branch. (c) Spatial-scale modeling (SSM) branch.
The CCM branch processes the input
In parallel, the SSM branch splits the input X into G groups along the channel dimension. For each group
Loss functions
The proposed model's loss function integrates four components for joint optimization: classification loss
Following the baseline implementation,
24
the weighting coefficients are set to
Here, the classification loss
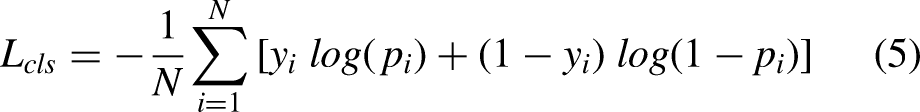
The bounding box loss
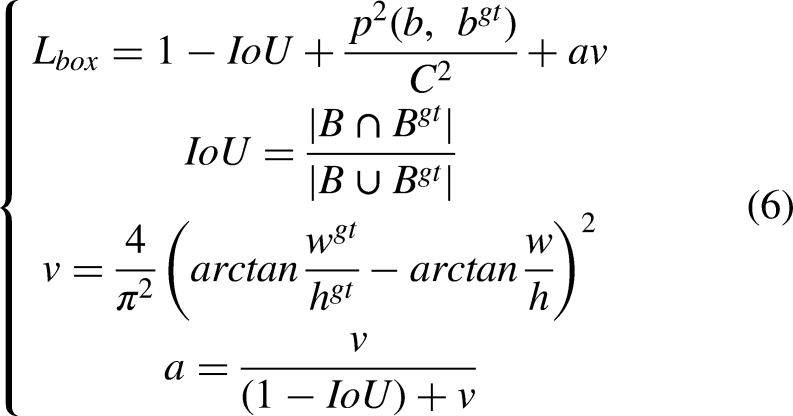
To further refine regression, we employ Distributional Focal Loss
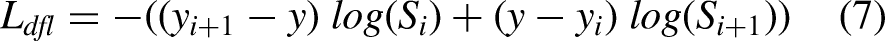
Finally, the mask loss
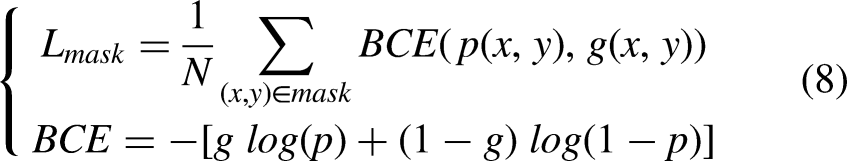
Implementation details
The model was trained, validated, and tested on the pre-split ARCADE-stenosis dataset (1500 images). To assess generalization, performance was further evaluated on two test sets: an independent local dataset and a second public coronary stenosis dataset. All XRA images were uniformly preprocessed by resizing to 640 × 640 pixels, converting to RGB, scaling to [0, 1], and normalizing using the mean and standard deviation to ensure input consistency. Model weights were initialized from COCO pre-trained checkpoints. 29 Extensive online augmentation was applied during training, including random rotation (±45°), scaling (0.5 to 1.5), horizontal flipping, HSV adjustments (hue: ±2.7°; saturation: 0.3 to 1.7; value: 0.6 to 1.4), translation (max shift ratio: 0.3), random cropping (crop ratio: 0.8), and median blur (7 × 7 kernel). We used SGD with a base learning rate of 0.01, weight decay of 5 × 10−4, and a cosine annealing scheduler with warm restarts. Training ran for 100 epochs with a batch size of 4, implemented in PyTorch 2.0.0 on a server with four NVIDIA RTX 4090 GPUs.
Evaluation metrics
Model performance was evaluated using six standard evaluation metrics. Precision, Recall, F1 score, and IoU are computed at the pixel level, while HD95 and ASSD are boundary-based metrics computed from segmentation boundaries. 30 For each image, true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN) are counted by pixel-wise comparison between the prediction and the ground truth. Based on these values, the corresponding evaluation metrics for the image are computed. The final reported result is the average of these per-image metric values across the entire test set.
Precision, Recall, F1 score, and IoU are region-based metrics that reflect overall segmentation accuracy. Precision reflects the proportion of predicted stenosis regions that overlap with ground truth. Recall indicates the proportion of actual stenosis regions that are correctly detected by the model. The F1 combines both metrics to provide a balanced assessment of the model's overall performance. IoU measures the normalized overlap between predicted and ground-truth stenosis regions. Their definitions are:

HD95 (95% Hausdorff Distance) and ASSD (Average Symmetric Surface Distance) are introduced as boundary-based metrics to assess the geometric accuracy of segmentation boundaries. HD95 quantifies the boundary distance error by calculating the 95th percentile of the set of all minimum distances between the predicted boundary points and the ground-truth boundary points (in both directions). ASSD measures the average distance between the predicted and ground-truth boundaries. They are defined as:
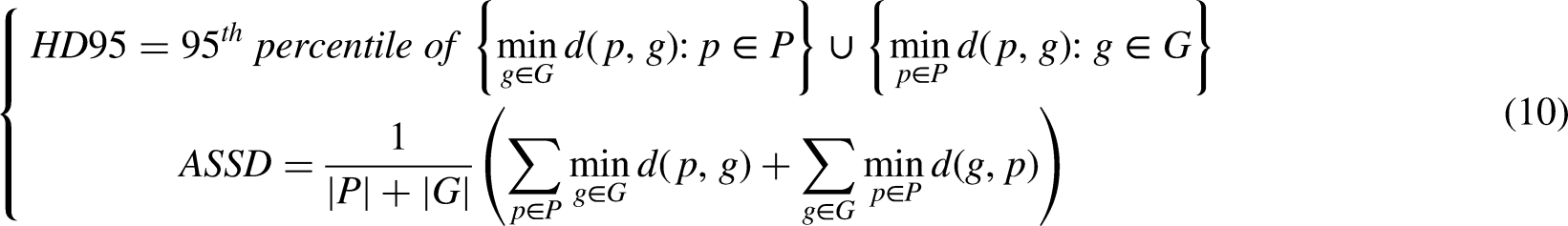
Statistical analysis
The Wilcoxon signed-rank test was performed to compare the proposed model with each comparative method, based on the results from five repeated runs with different random seeds. Comparisons were made using F1, Precision, Recall, IoU, HD95, and ASSD on each test set separately. Given the limited number of runs, the non-parametric test was adopted without assuming normality of the distribution. Statistical significance was defined as p < 0.05, and the reported results are presented as mean ± standard deviation.
Results
Segmentation performance and efficiency comparison
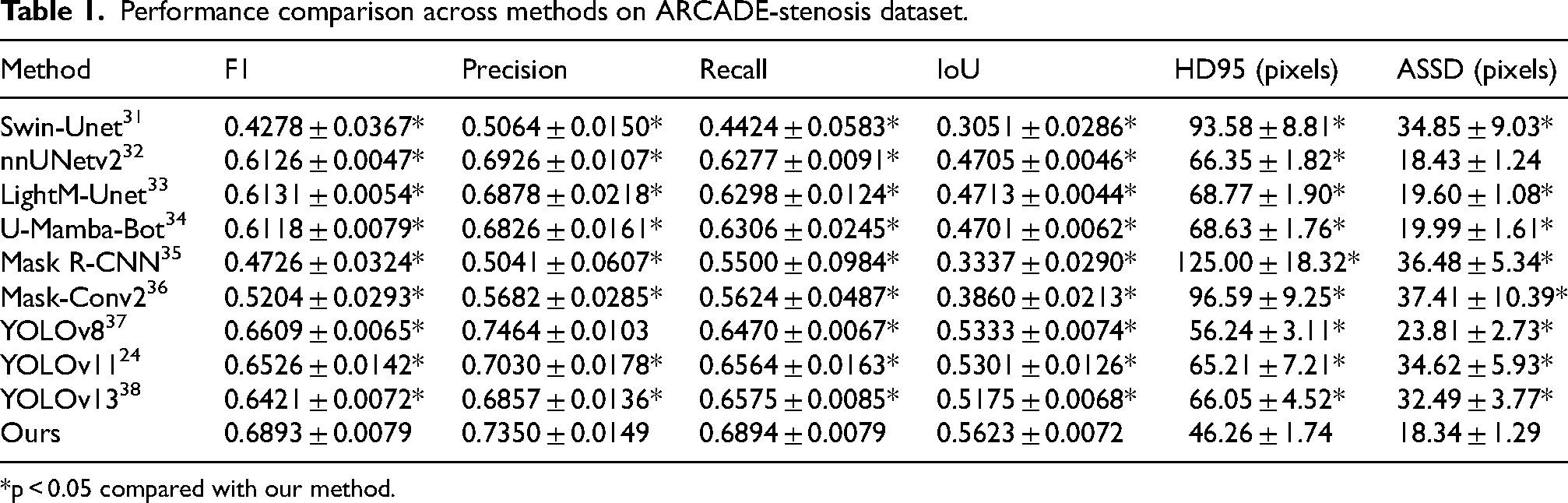
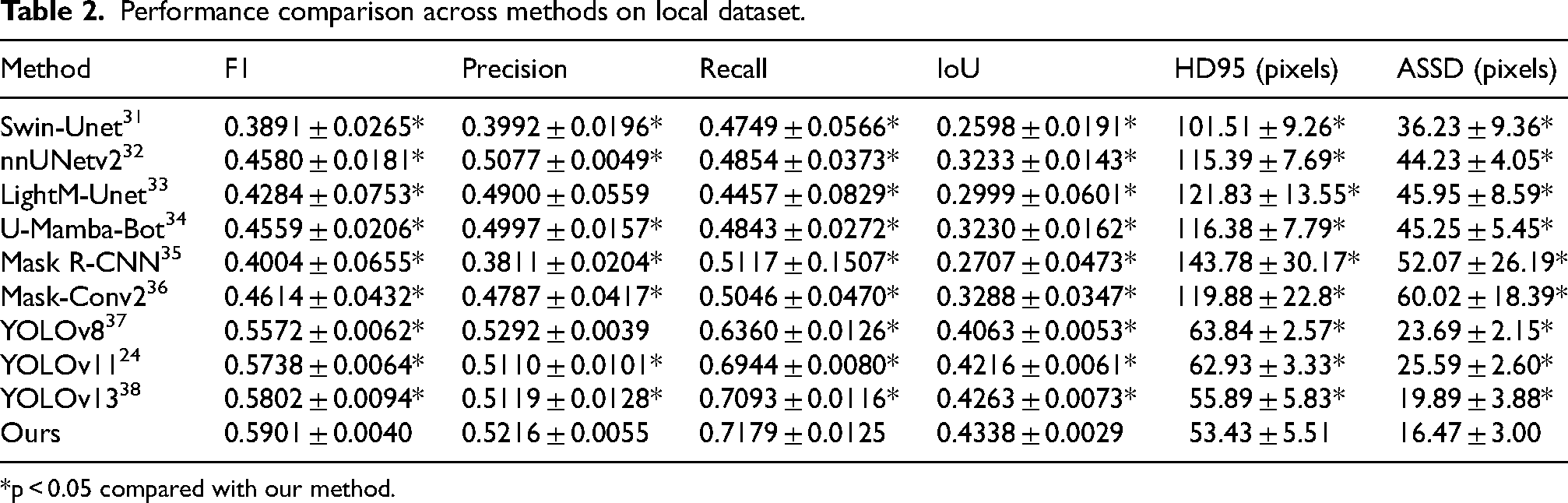
To evaluate the effectiveness of the proposed model, we conducted comparative experiments with various segmentation networks.24,31–38 All models were trained and evaluated under identical conditions, using the same dataset, preprocessing pipeline, data augmentation strategies, and training settings. All experiments were repeated five times with different random seeds, and the results are reported as mean ± standard deviation. As shown in Tables 1 and 2, our proposed method achieved better performance than most comparative approaches on the public ARCADE-stenosis dataset across both region-based metrics (F1: 0.6893 ± 0.0079, IoU: 0.5623 ± 0.0072) and boundary-based metrics (HD95: 46.26 ± 1.74 pixels, ASSD: 18.34 ± 1.29 pixels). On the local dataset, our method achieved the best performance across most metrics, including F1, Recall, IoU, HD95, and ASSD, with the only exception being Precision, where YOLOv8 was marginally higher. Wilcoxon signed rank test confirmed significant improvements across most comparisons. The only non-significant comparisons were Precision against YOLOv8 on both datasets, ASSD against nnUNet on ARCADE, and Precision against LightM Unet on the local dataset. Notably, F1 and IoU improvements were significant across all comparisons (p < 0.05), indicating more accurate stenosis localization. The proposed method also achieved an effective balance between accuracy and efficiency. As illustrated in Figure 5, it surpassed computationally heavy models such as U-Mamba-Bot and Mask-Conv2 in F1 score while requiring fewer floating-point operations (lower GFLOPs) and parameters (smaller model size). At the same time, it remained more accurate than lightweight models like LightM-Unet, which sacrificed performance for speed. These results confirm its ability to provide high performance with moderate computational demands.
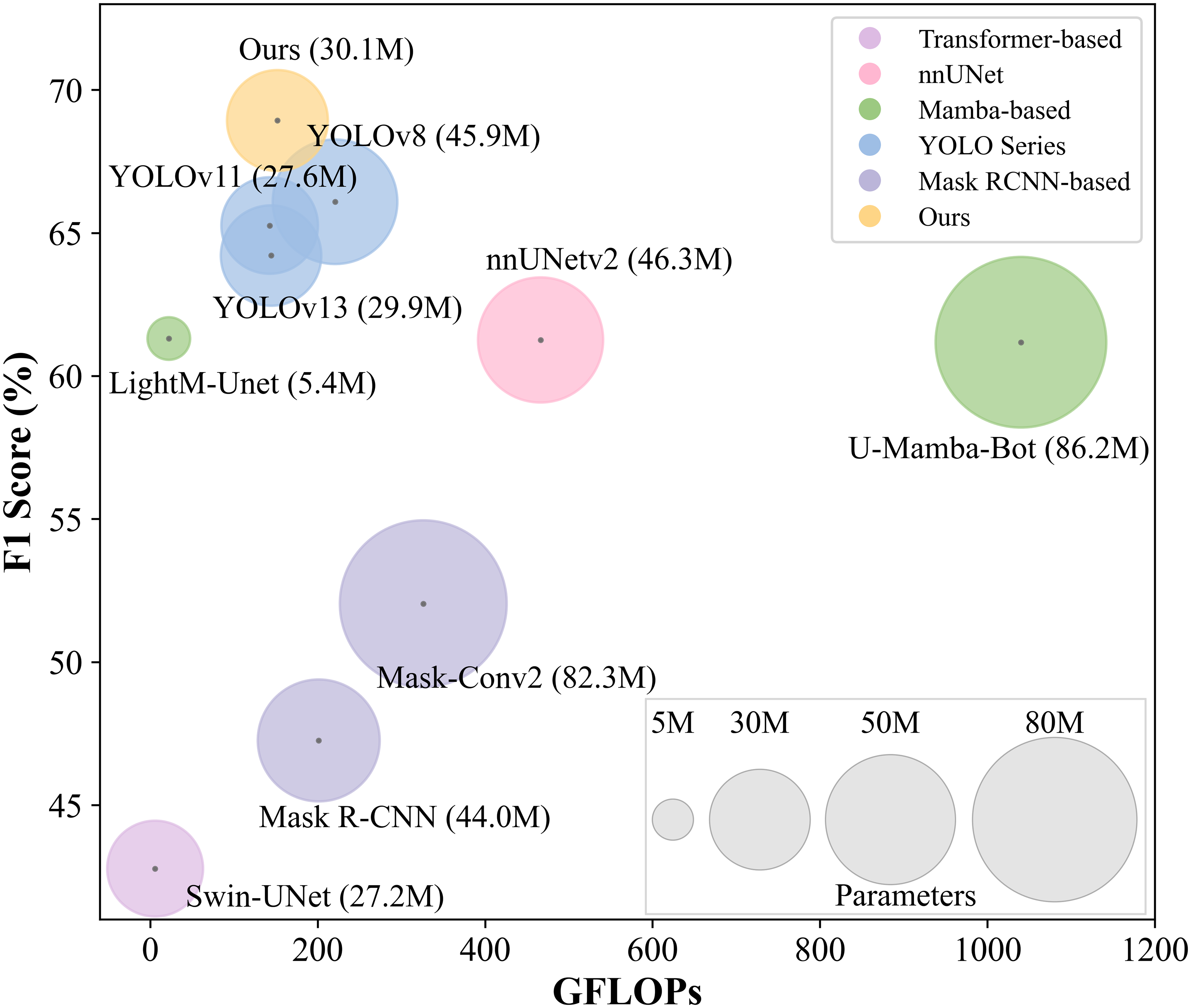
Relationship between model performance (F1 score), computational cost (GFLOPs), and model size on the ARCADE-stenosis dataset. Colors indicate model categories; bubble size represents model size (number of parameters); center point positions correspond to F1 score and GFLOPs values.
Performance comparison across methods on ARCADE-stenosis dataset.
*p < 0.05 compared with our method.
Performance comparison across methods on local dataset.
*p < 0.05 compared with our method.
Visual analysis
Figures 6 and 7 present segmentation results from different models on coronary XRA images. Visual evaluation indicates that our model provided competitive performance across diverse stenosis types, including focal, diffuse, bifurcation, and multi-vessel diseases. The model generated bounding boxes and segmentation masks in parallel based on shared feature representations. This approach effectively reduced interference from non-target areas, ensuring precise localization and anatomically consistent segmentation. In contrast, direct segmentation approaches such as nnUNetv2, Swin-Unet, and LightM-Unet often produced excessive fragmentation and false-positive predictions in non-stenosis regions, leading to a notable decline in accuracy. Compared to existing YOLO-series models, our model reduced segmentation errors and produced more complete stenosis segmentations.

Visualization comparison of segmentation results on ARCADE-stenosis dataset. Column 1 shows the ground truth; Columns 2–6 represent the outputs of different methods. Red boxes indicate segmentation errors (see online version for color distinctions).

Visualization comparison of segmentation results on local dataset. Column 1 shows the ground truth; Columns 2–6 represent the outputs of different methods. Red boxes indicate segmentation errors (see online version for color distinctions).
Ablation study
To evaluate the contribution of the HCA modules, we conducted ablation experiments using YOLOv11 as the baseline, with five repeated runs using different random seeds to assess model stability. Four model variants were evaluated: the baseline, the baseline with only the CCM branch, the baseline with only the SSM branch, and the baseline with the integrated HCA module. As summarized in Tables 3 and 4, the CCM branch consistently improved model performance across both datasets. On the ARCADE-stenosis dataset, it increased the F1 score from 0.6526 to 0.6759, reduced HD95 from 65.21 to 50.45 pixels, and reduced ASSD from 34.62 to 20.50 pixels. On the local dataset, it improved F1 from 0.5738 to 0.5809 and reduced ASSD from 25.59 to 20.21 pixels. The SSM branch showed improvement on the ARCADE-stenosis dataset, increasing F1 to 0.6712 and reducing HD95 to 52.73 pixels, but yielded slightly lower performance on the local dataset. Notably, the full HCA module combining both branches achieved the best overall performance across all metrics, with F1 reaching 0.6893 on ARCADE-stenosis and 0.5901 on the local dataset, indicating that CCM and SSM are complementary and their joint use produces a synergistic effect. The results across five repeated runs demonstrate the stability of the proposed model.
Ablation study results on ARCADE-stenosis dataset.

Ablation study results on local dataset.

Figure 8 presents representative segmentation results from the ablation study. The baseline model showed missed detections and false positives, particularly in regions of mild stenosis, complex branching, or low contrast. After integrating the HCA module, false positives in non-stenotic areas were effectively suppressed, while segmentation of focal and mild stenosis was improved. This led to enhanced localization accuracy, structural consistency, and a reduction in both missed detections and over-segmentation, producing more anatomically plausible results.
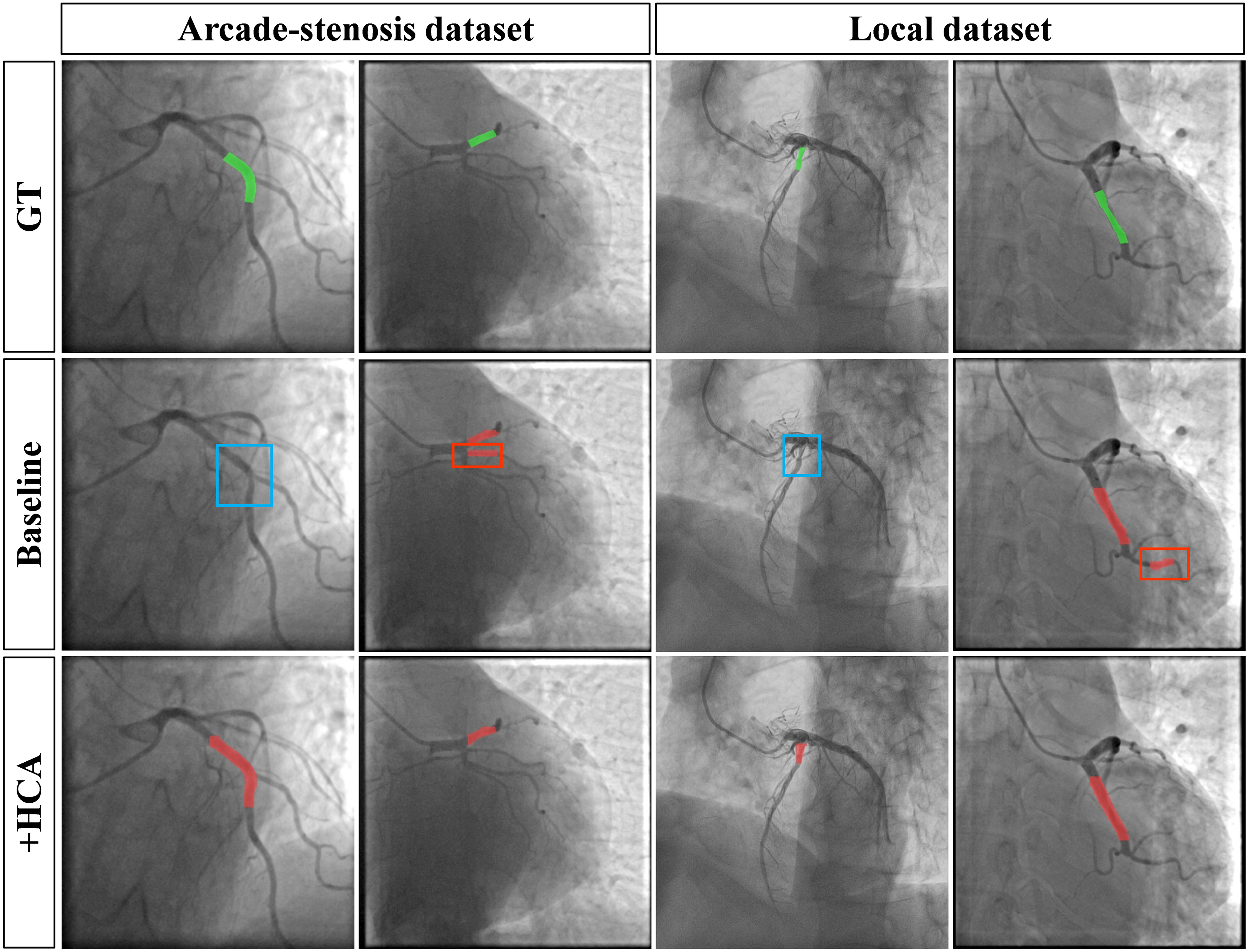
Visualization comparison of stenosis segmentation results in the ablation study. Blue and red boxes indicate false negative and false positive results, respectively (see online version for color distinctions).
Comparison of different attention mechanisms
To evaluate the effectiveness of the proposed HCA module, we compared it against several representative attention modules, including GC, 39 PSA, 40 EMA, 41 and DarkIR, 42 within the same baseline framework under identical training conditions. All experiments were repeated five times with different random seeds to ensure stability, and the reported results are the averages. We retained the default structures from the original papers to evaluate plug-and-play performance. As summarized in Tables 5 and 6, the HCA module achieved the best F1, Precision, Recall, IoU, HD95, and ASSD scores among all evaluated attention mechanisms on both datasets. These results demonstrate the effectiveness of the HCA module within the YOLOv11 framework under unified training settings. Figure 9 further shows that the high-activation regions (red) in the HCA Grad-CAM visualizations exhibit the closest overlap with the ground truth, indicating precise localization. Meanwhile, the low-activation regions (blue) effectively suppress responses in complex vascular bifurcations and background interference, demonstrating improved specificity.
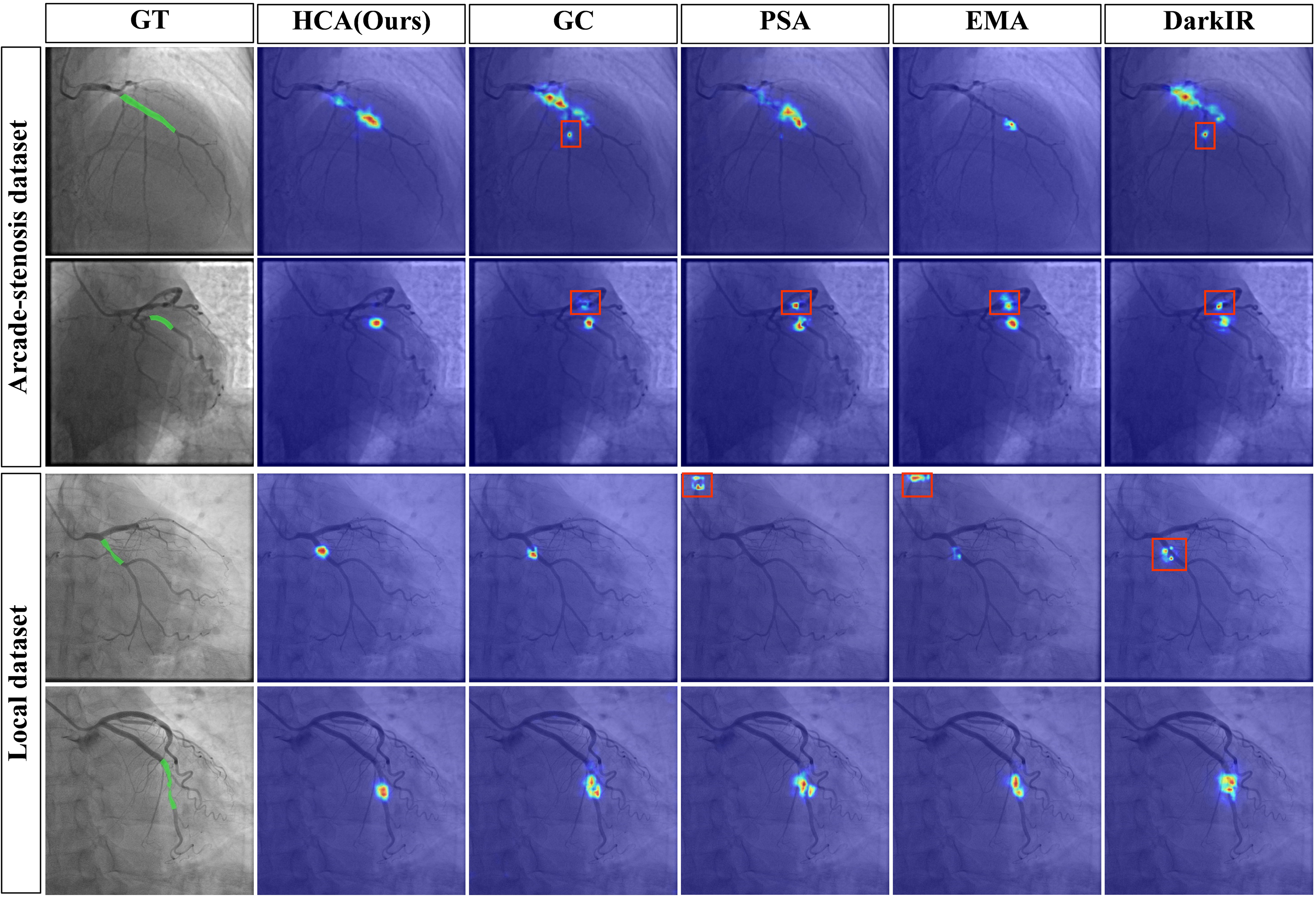
Comparison of Grad-CAM from different attention modules. The first column shows the ground truth; subsequent columns display attention activation maps (red: high, blue: low). Red boxes indicate erroneous activations in non-stenosis regions (see online version for color distinctions).
Performance comparison of different attention mechanisms on ARCADE-stenosis dataset.

Performance comparison of different attention mechanisms on local dataset.

External test
To further test the generalization and clinical applicability of the proposed method, we evaluated it on the public ICA-stenosis dataset using the model trained solely on ARCADE-stenosis data. All experiments were repeated five times with different random seeds. As shown in Table 7, our method achieved the best F1 score, Recall, IoU, and boundary metrics among all compared approaches, with a competitive Precision. Statistical testing confirmed significant improvements across most metrics, except for Precision. This demonstrates its better generalization capability compared to other methods.
External validation on the ICA-stenosis dataset.
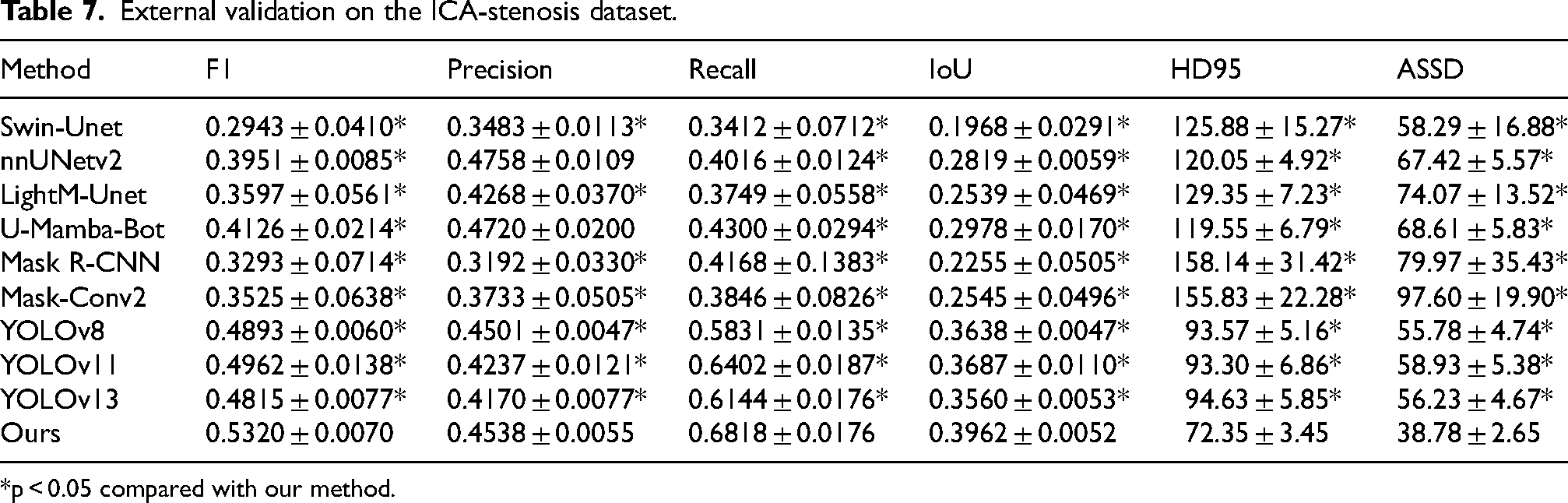
*p < 0.05 compared with our method.
Discussion
Accurate coronary stenosis segmentation is essential for objective assessment of stenosis severity. This study proposed an improved segmentation model enhanced with a Hybrid Context-Aware Attention (HCA) module, which refines features through dual complementary pathways. Comparative experiments demonstrated that the proposed model achieved competitive overall performance across multiple evaluation metrics on three multi-center datasets. On the public ARCADE-stenosis dataset, our model achieved the best overall segmentation performance. It also maintained this leading performance on both the local dataset and the external dataset, demonstrating consistent generalization.
The model's segmentation performance across multi-center data stems from the superior object detection ability of the YOLO framework. This strength is demonstrated by the leading results of this framework in the coronary stenosis segmentation task of the ARCADE Challenge. 43 Our experimental results confirmed that this framework selection led to higher segmentation accuracy. It achieved competitive performance against both traditional segmentation models such as U-Net and nnUNet, and recent competitive architectures like Mamba-based networks. Compared to two-stage architectures (e.g., Mask R-CNN) that perform detection before segmentation and thus suffer from inherent cascaded error propagation, our single-stage YOLOv11-based framework performs bounding box regression and mask segmentation simultaneously and in parallel from shared feature representations, avoiding this issue. To further enhance this ability, we integrated the HCA module into the YOLOv11 framework. Its CCM branch enhances feature discriminability through global inter-channel attention, while the SSM branch aggregates multi-scale context, enabling precise localization and effective background suppression. Grad-CAM visualizations show that HCA adaptively assigns higher weights to stenosis regions, emphasizing anatomically relevant structures. Ablation studies confirmed the module's contribution, as its inclusion consistently improves F1 scores and reduces errors in complex regions. The full integration of the HCA module provided the best overall performance.
A current semi-automatic method that incorporates expert input can achieve high boundary precision, 44 but it requires manual initialization and expert interpretation to locate the stenosis. To enable efficient clinical workflows, this study focused on fully automatic segmentation to support subsequent quantitative clinical assessment. The proposed model represents a substantive step in this direction, achieving competitive performance in segmenting stenotic lesions on multi-center datasets.
Several limitations of the proposed method require further investigation. First, while the model demonstrates consistent generalization across datasets, its segmentation performance declined on the external test sets. This decline primarily stems from the wide variation in coronary anatomy, including vessel tortuosity, branching patterns, and plaque morphology. Additionally, our model has only been evaluated on diagnostically optimal frames, and its performance on suboptimal frames (e.g., motion blur, poor contrast) has not been assessed. Therefore, training with larger and more diverse multi-center cohorts is essential to capture the full range of anatomical variations and ensure reliable segmentation in real-world practice. Second, the current segmentation remains at a coarse anatomical level, as it relies on polygon-level annotations from the public training datasets. While this level of segmentation is sufficient for lesion detection, it is inadequate for precise stenosis quantification, such as calculating the diameter stenosis percentage or minimal lumen area. To mitigate the impact of coarse annotations, we incorporated multiple loss functions during training to guide the model toward more accurate boundary delineation. However, coarse annotations still limit the upper bound of boundary segmentation performance. Pixel-level stenosis boundary annotation is required for clinically accurate measurements. Future re-annotation of the public dataset with pixel-level stenosis boundaries could improve the segmentation accuracy of our method. This would help establish a correlation between segmentation metrics and clinically actionable parameters, thereby facilitating automated stenosis quantification.
Conclusion
In this study, we proposed a deep learning model for coronary artery stenosis segmentation in XRA images, which integrates a novel Hybrid Context-Aware Attention (HCA) module. The dual-pathway design of HCA combines global inter-channel attention with grouped multi-scale spatial aggregation, thereby enhancing feature discriminability and spatial-context modeling in stenotic regions. Evaluation across three independent multi-center datasets demonstrated that our model achieved competitive segmentation accuracy compared to existing approaches. These findings validate the effectiveness of our architecture for stenosis segmentation and highlight its potential to support the development of future automated assessment tools. In the future, we will focus on improving segmentation precision for accurate quantitative measurement, expanding training data with multi-center cohorts to improve generalizability.
Footnotes
Acknowledgments
This work was supported by Guizhou Provincial Basic Research Program (Qiankehejichu-ZK[2021]478, Qiankehejichu MS[2026]563), the Youth Science and Technology Talent Growth Project of Common University in Guizhou Province (Qianjiaohe-KY[2021]180), the National Natural Science Foundation of China (81660298), and the Funding for the Excellent Reserve Talents in the Discipline of Affiliated Hospital of Guizhou Medical University (gyfyxkyc-2023-13).
Ethics approval
Ethical approval for this retrospective study was granted by the Ethics Committee of Guizhou Medical University (Approval No.: 2023-208), which also waived the need for informed consent due to the use of anonymized data.
Author contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, Guizhou Provincial Basic Research Program, Funding for the Excellent Reserve Talents in the Discipline of Affiliated Hospital of Guizhou Medical University, Youth Science and Technology Talent Growth Project of Common University in Guizhou Province, (grant number 81660298, Qiankehejichu MS[2026]563, Qiankehejichu-ZK[2021]478, gyfyxkyc-2023-13, Qianjiaohe-KY[2021]180).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The public dataset is accessible through the cited reference. The local clinical dataset and the associated analysis code are available from the corresponding author upon reasonable request, subject to privacy and compliance agreements.