
Abstract
In a distributed system framework, spatial crowdsourcing (SC) is a highly important area of research where task allocation to task executors (TEs) is an important step. Tasks are requested by a task provider and are allocated by an SC platform to TEs. However, TEs may submit the allocated task as late as possible, known as procrastination. Plenty of research works are available on task allocation in SC, whereas few research works are found that address procrastination. In a bipartite graph setting, a procrastination-aware scheduling is proposed. A recent work uses ChatGPT for procrastinating agents. Balanced distribution of tasks has not been addressed there. Recently, an algorithm was proposed that distributes tasks in a balanced manner in different slots to mitigate procrastination in SC. Here, we propose a quality-aware task allocation mechanism in an SC environment that combines a data science approach with a reinforcement learning-based approach. Once TEs are allocated tasks, we have proposed an AI-enabled (learning-the-variance) algorithm to distribute the tasks into slots with a more balanced distribution than any of the existing algorithms to mitigate procrastination. Our procrastination prevention mechanism outperforms existing methods, which is shown by extensive simulations. Analytically, it is shown that the proposed mechanism maintains a balanced distribution.
Introduction
When a large set of tasks is (task and job will synonymously be used) to be accomplished from a crowd is generally termed as crowdsourcing. 1 Mobile crowdsourcing (MCS), an extension of crowdsourcing, harnesses sensory and mobile devices to accomplish crowdsourcing tasks. 2 In MCS, a few tasks in some locations may not get enough task executors (TEs), 3 and such a lack of TEs or agents is the reason for the inception of location-based crowdsourcing or spatial crowdsourcing (SC). In SC, TEs are allocated tasks with location information and a deadline (spatio-temporal constraint) to complete the tasks. For example, on-demand food delivery 4 and transportation 5 services, traffic information collection, 6 etc.
At an abstract level in SC, we have task providers (TPs) who disseminate the tasks to the TEs through a platform, constrained by deadlines and specific locations.7–11 Henceforth, TPs, TEs, and the platform will be assumed as agents (even if it is not explicitly mentioned in the context) in their usual sense.
As per recent research, SC is a highly important area of research in a distributed system framework.12,13 There are multiple features of SC that reveal its distributed nature, which are discussed below.
In a distributed system, nodes or computing devices are distributed over a network and can act independently without the involvement of a central server. Similarly, TPs and TEs in SC as nodes, spread over different geographical locations, can perform task requests and task execution independently, bypassing the need for a central SC platform. However, the SC platform is needed only to match TP and TEs and assign tasks to TEs. It means, a TP can request tasks to the TEs, and each TE can execute the assigned tasks in a parallel manner and independently. The nodes in a distributed system are connected through a network. In the same way, a TP and a TE or two different TEs in SC can communicate with each other for task assignment, payment, rewards, etc., over mobile networks or the internet.
The nodes in SC can play the dual role of TP and TE, and each node can directly communicate with a subset of the other nodes. For such a direct communication, the connection (edge) between any two nodes is established if the distance between those two nodes is within a threshold value, and those nodes are called neighbours. A node that acts as a TP node can provide/float tasks to its neighbour TE nodes. The TE nodes may agree to accept the request or forward the requested tasks to their neighbour TE node(s). In this way, SC, in a sense, is general enough to be mapped to (has a connection with) a P2P Network,14,15 where a node in SC can act as both TP and TE, but one at a time, and can send task requests to the TEs through the SC platform. The TEs who agree upon executing the tasks accept and execute the tasks. During task execution, the TEs act as peers and cooperate with each other for exchanging information, validating results, etc.
In an SC environment, a time-constrained agent, when assigned tasks with a deadline at a specific location, may delay submission of the assigned task, which is termed as procrastination16–19 in behavioural economics.20,21 This late submission of tasks or procrastination may be problematic for TP in many applications. So, there are two benefits if the prevention of procrastination is achieved. One immediate benefit will be for the TP, as she will be getting the completed tasks at certain intervals instead of getting all the tasks in tandem as late as possible. As a result, the TP will have sufficient time to process the submitted tasks at their end. Secondly, the quality of the accomplished task will be maintained as the task will be carried out uniformly throughout the period given to the TE.
In the literature, there are a few research works that address the issue of procrastination. One procrastination-aware scheduling is proposed in a bipartite setting in Wang et al. 22 In their work, they have matched a set of jobs to several slots (a.k.a schedules, defined in Section 3). Each slot has a certain time limit and is constrained by a cost threshold. This method of matching jobs to different slots is not balanced. Due to such unbalanced matching, some slots will be matched with less number of jobs (NOJ) and some will be matched with more jobs. In this case, the slot with less NOJ is prone to procrastination. 20
Arakawa et al. 23 address the fact that if one agent procrastinates, then the agent will be helped through a large generative model as an API to give them some kind of continuation so that they can continue their work. But, they haven’t addressed the fact that how the tasks are to be distributed in a balanced manner.
In a recent work, 24 a poly-time job distribution algorithm in different slots in the SC environment is proposed to prevent procrastination. In that paper, the job allocation into slots is balanced to some extent. But a more balanced allocation of jobs into different schedules could be achieved.
In this paper, we propose two AI-enabled methods for task allocation and procrastination prevention, presented in two phases. In the first phase, we have proposed a quality-aware task allocation (QATA) algorithm. This algorithm first selects
Mainly, by load balancing, it is meant as balancing the NOJ in different schedules or slots. In our paper, we have balanced the schedules or slots in terms of the cost of the jobs. However, along with considering the cost, balancing with NOJ is also considered while comparing with NOJ in UCSMPP and OFFPSP.
Recent research on task allocation addresses dynamic appearance of tasks and workers,28–30, multi-objective optimization, 31 heterogeneity and collaboration, 32 etc. But, to the best of our knowledge, the problem of task assignment, along with procrastination prevention, has not been addressed in SC.
Our main contributions in this paper are summarized below: We have proposed two methods (we have used the term methods or algorithms synonymously) in this paper – (i) for task allocation and (ii) for the prevention of procrastination. A data science approach (CMS) is used for QATA, as it is faster in finding top-performing TEs (as the time complexity is linear). Along with CMS, an MAB-based approach is taken to address the cold start problem. The proposed approach for QATA has achieved a maximum task allocation to the TEs with a higher quality score. In the second method, we have proposed an AI-enabled (learning-the-variance) algorithm to prevent procrastination by uniformly distributing the assigned tasks into several slots with equal deadlines. We have compared our proposed procrastination prevention algorithm with the current state-of-the-art (SOTA) algorithms from the perspective of the distribution of tasks within a given time horizon and found that our proposed method has achieved a better balanced distribution of jobs than SOTA. We have also shown analytically that our proposed algorithm maintains the balanced distribution.
The remaining part of the paper is arranged in the following order. Relevant and recent literature is given in Section 2. The system model is furnished in Section 3. Sections 4 and 5 discuss the proposed algorithm and the analysis, respectively. Section 6 presents the simulation of the second proposed work, and it is compared with the relevant existing works in Section 7. The conclusion and future works are discussed in Section 8.
Literature review
One of the best explanations of procrastination is presented by George Akerlof et al., 20 where he procrastinated for a long time in sending a parcel to his friend in the USA. A detailed discussion is given in the archived version of this paper. 33
A number of research works could be found in the direction of load balancing and time-constrained task scheduling in crowdsourcing and in other computational models. Some of them are, Mukhopadhyay et al.,8,34 Meitei and Marchang, 35 Al-Muqarm and Hussien, 36 Feng and Xiao, 37 Zhao et al., 38 and Zhou et al. 39 These works have focused either on scheduling with load balancing as in 35 or scheduling with deadline in Mukhopadhyay et al.,8,34 Feng and Xiao, 37 Zhao et al., 38 Zhou et al., 39 or both Al-muqarm and Hussien. 36 Also, learning algorithms are employed for ground truth inference 40 and task allocation 41 in SC. None of these works has addressed procrastination.
Arakawa et al. 23 (as mentioned in Section 1) have addressed procrastination using a large generative model. However, how to prevent such procrastination by balanced distribution of tasks within a time horizon has not been discussed.
Wang et al. 22 have proposed an algorithm called Procrastination-aware-Scheduling for Tasks (OFFPSP). This algorithm has distributed a given set of jobs into a number of schedules (slots) based on a threshold set for each schedule, but not in a balanced manner. With these unbalanced schedules, the TP may face the same problem (will not get ample time) as stated earlier.
In Debnath et al., 24 one procrastination preventive algorithm (UCSMPP) in the SC environment is proposed, where all the allotted jobs to the TEs are re-ordered according to their cost. From this ordered job list, jobs are pair-wise (first and last jobs, second and second last jobs, and so on) assigned to the corresponding schedules (slots). This way, all the jobs with higher cost are distributed among all the schedules, and those schedules become balanced in terms of cost (TC and AC) and NOJ. This algorithm shows a better balancing effect than in Wang et al. 22 But this balancing effect could be improved, and that improvement has been proposed in our paper.
Debnath et al. 24 only address the problem of procrastination by balancing the allocation of tasks into slots using a novel classical algorithmic approach, but do not address the prior task assignment problem, that is, the tasks to be assigned to the TEs before the prevention of procrastination. In this paper, first, we have proposed a task assignment method with the combination of CMS and MAB, then addressed the problem of procrastination with a variance-based learning method. Such a combination of CMS and MAB approach for task assignment and a variance-based learning approach to address procrastination has not been applied in the SC literature to the best of our knowledge. In the sense that the task must be assigned to the TEs first, and then the possible procrastination is to be addressed, it is a more realistic approach than the approach proposed in Debnath et al. 24 in the SC scenario.
Another concept of behavioural economics is loss aversion, which states that the participating agents perceive loss more seriously than the equivalent profit. There are a few research works on this aspect of behavioural economics in MCS and/or SC scenarios. Some of them are Li et al.42,43 and Liu et al. 44 in crowdsourcing and Liu et al. 45 in other computational models. This loss aversion-aware SC is another important research direction one can pursue.
System models
Notations and their usage
Our proposed algorithm first allocates tasks to the currently available TEs. After the allocation, when agents start executing the tasks, they may procrastinate, that is, the TEs may submit the allocated tasks on the last day or penultimate day, which may cause problems to the TP. In this model, our proposed algorithm pinpoints the prevention of procrastination by scheduling those allocated tasks in a balanced manner for an arbitrary
Objective
There are two objectives of our proposed model. Given any
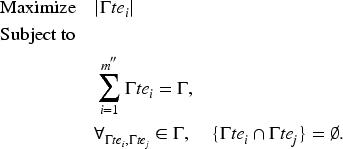
Given a set of jobs
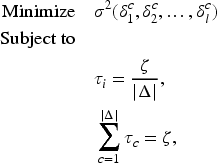
Proposed algorithms
In this section, we shall describe the algorithms proposed in this paper. First, the proposed task assignment algorithm is discussed, and then the proposed procrastination prevention algorithm is explained in detail.
Task assignment
The proposed method of task allocation first requires the TP to float task requests to its neighbouring TEs. If these TEs are not willing to participate in task assignment or require more TEs, they are required to forward the request to their neighbouring TEs. If the neighbouring TEs of TP refuse to forward the tasks, a game-theoretic setting may be considered by incorporating a tit-for-tat strategy, where if they don’t forward the task request, they will be penalized when they participate in future task assignments. Now, when the TP receives a list of TEs along with their quality scores, it gives the set of tasks and the received list of TEs along with their location to the SC platform. In this list, a TE might appear more than once with her quality score. A quality score for an agent
Phase 1: CMS
In the first phase of the first proposed approach, the platform finds the
Regarding CMS, the following mechanism is used. First, two parameters

Now, the count of

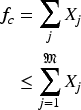
So
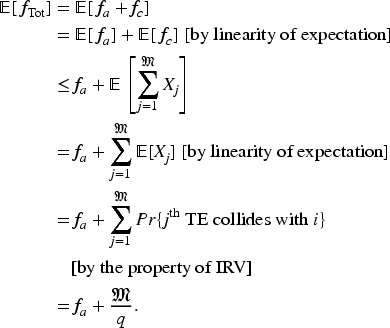

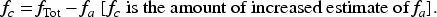
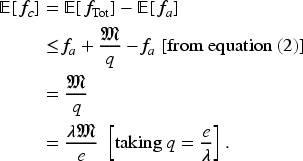
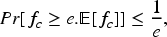
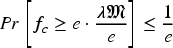




Space is also an important parameter here. The amount of space required is:
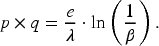
In the second phase, we propose a reinforcement learning (RL)-based approach to select the remaining TEs and allocate tasks to them. RL involves an agent that learns from its environment, where the environment could be known or unknown to the agent. The environment can be represented as a set of states. The agent interacts with the environment by taking an action to change its current state to another state. There can be multiple actions associated with a state, and each action has a probability. The sum of all the probabilities of such actions is 1. Taking one of these actions, an agent transitions to a specific state. For each state change, an agent receives a reward, which can be positive or negative and is unknown to the agent; however, the agent is not guided on which action to take (see Figure 1). The agent’s objective is to find out the action that yields maximum rewards.
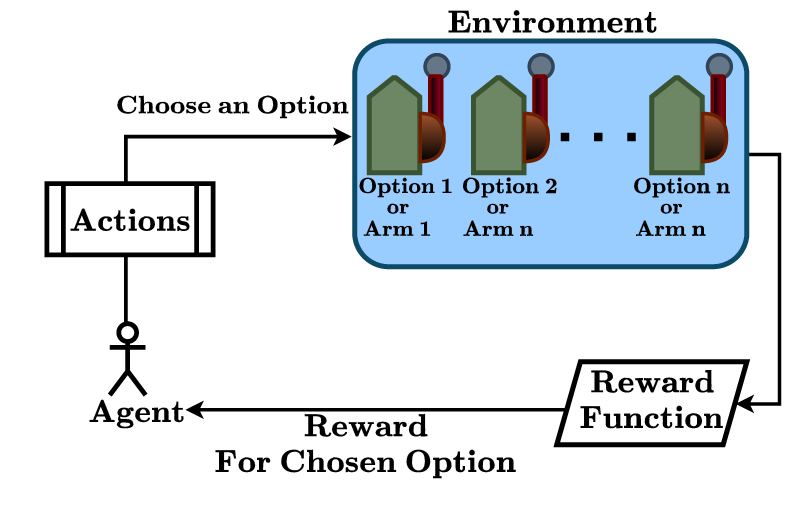
Block diagram of reinforcement learning.
MAB is one kind of RL method where there are
In
Mapping RL to MAB.
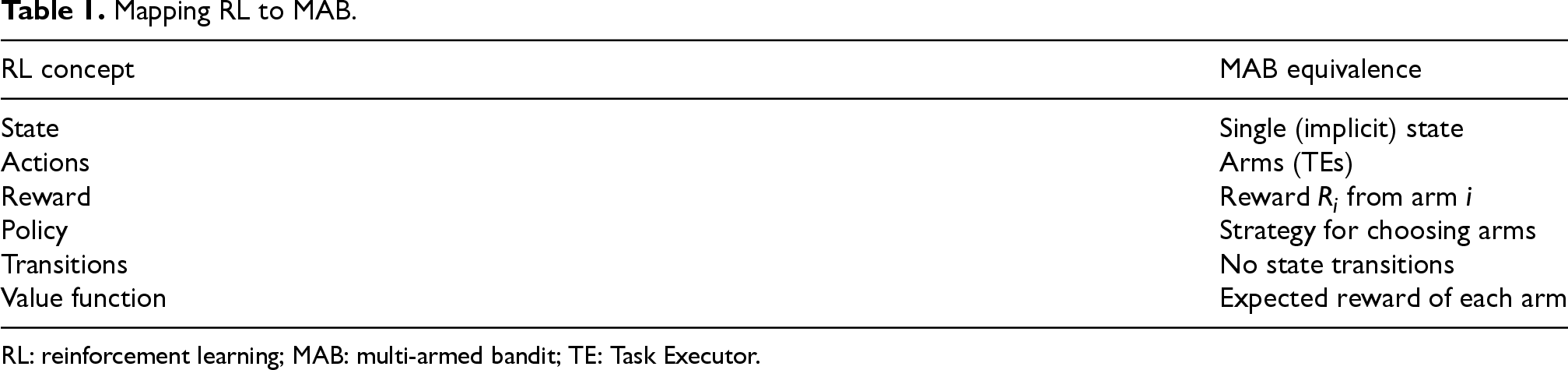
RL: reinforcement learning; MAB: multi-armed bandit; TE: Task Executor.
In the proposed task assignment method, we have used CMS for selecting the top
We provide the algorithm in Algorithm 1 followed by a numerical example.
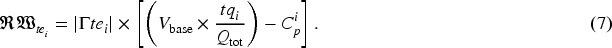
It is to be noted that for sustainability, the platform needs some operational cost, and because of that, the platform requires some reward. Here,
The policy in our proposed algorithm for the platform is a

QATA (Algorithm 1) allocates tasks using a combined approach based on CMS and MAB for selecting TEs and a common approach (proportionate ratio based on quality score) for assigning tasks to the TEs. Lines 2 to 12 find
Then Algorithm 1 returns the list of TEs assigned with the tasks to the next proposed algorithm, procrastination preventive scheduling of jobs: a balanced perspective (PPSJBP).
The list of TEs (
Prevention of procrastination
In this section, we have discussed the proposed algorithm called PPSJBP. The algorithm, PPSJBP, is based on minimizing the variance of all the schedules based on TC that is, all the jobs are distributed among the schedules in a balanced manner based on TC. When all schedules are balanced, all jobs with a higher cost will uniformly be distributed into different schedules. Thus, the accumulation of higher-cost jobs into one schedule will be prevented. As mentioned earlier in Section 1 that in the case of an unbalanced distribution of jobs, there may be fewer NOJ in any schedule with high cost. With less NOJ, the participating agents might have a mindset of Akerlof’s story
20
and hence the participating agent will be prone to procrastination. But when the jobs are distributed into the schedules in a balanced manner, there is no scope for such a mindset which leads to the prevention of such delay, that is, procrastination. This algorithm is presented here for an arbitrary TE
Schematic diagram of PPSJBP
Figure 2 shows the flow diagram of our proposed algorithm. The set of tasks assigned to any 
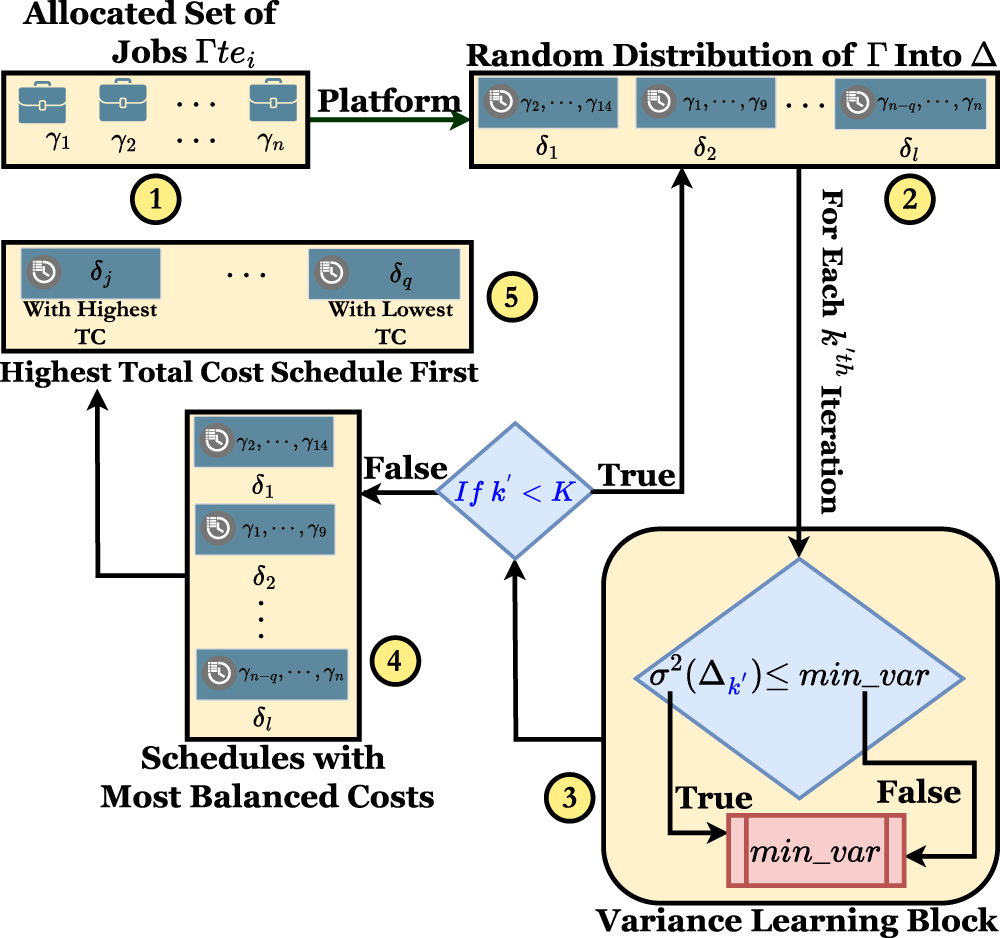
Flow diagram of the proposed algorithm, procrastination preventive scheduling of jobs: a balanced perspective (PPSJBP).

Line 1 initializes
However, based on the simulation, we have observed that the value of
In CMS, along with heavy hitters (TEs), a few non-heavy hitters (who are not very far away from the heavy hitters) may also creep in (false positive cases). For the task assignment phase, this is not a big issue, as non-heavy hitters are also close to the heavy hitters. However, in PPSJBP, we had to assign exact tasks in exact slots; otherwise, variance minimization could be troublesome. We have addressed this variance minimization by the learning-the-variance method (PPSJBP). The time complexity of PPSJBP is
Analysis of the proposed algorithms
This section analyses QATA in terms of expected reward and regret bound, and PPSJBP in terms of balancing effect.
Analysis of QATA
The following analysis is motivated by Slivkins et al. 26 and Sutton and Barto. 46
The expected reward of the SC platform for 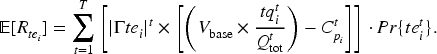
The reward of the SC platform for 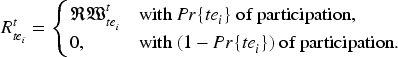
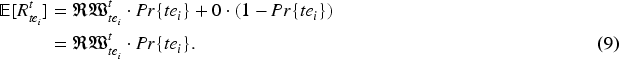


The following lemma is motivated by the proposition given in Slivkins et al. 26
The proposed algorithm based on the
First, we define the regret in the 
Consider 
Equation (13) states that the difference between the true mean 
This follows from the union bound.
47
The quantity 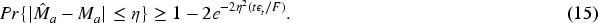
From equations (13) and (15), we obtain
Now, consider the case where a TE
In our paper, reward of a TE 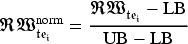
That means the regret at exploration with probability 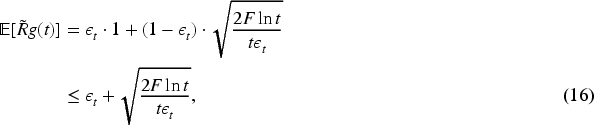
Substituting 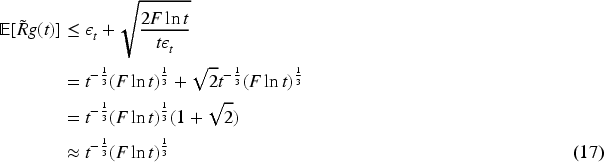
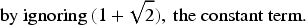

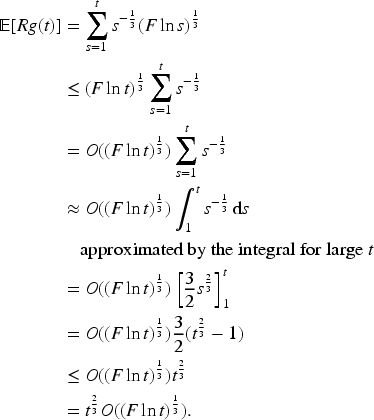
In the
The correct decay rate of
The following analysis is motivated by Upfal Eli
48
and Cormen et al.
49
The probability of allocation of all higher cost jobs (suppose Let us fix any arbitrary schedule
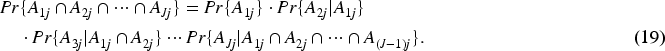
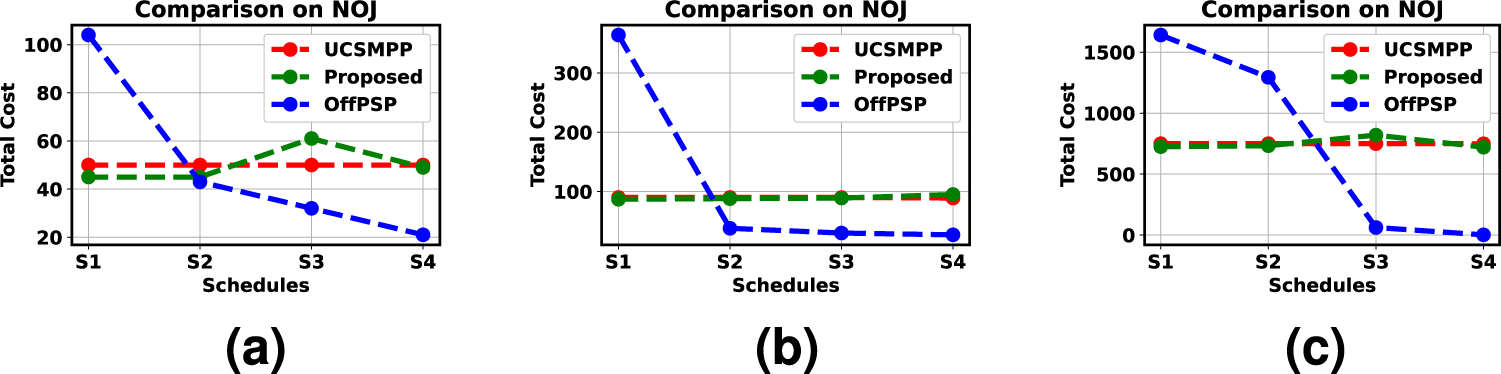
In PPSJBP, all the jobs are distributed into The expected NOJ to be assigned in a given schedule is We have here, The probability Comparison among UCSMPP, PPSJBP, and OFFPSP over the number of jobs in each schedule. (a) Synthetic, (b) Bus Driver Scheduling, and (c) KDD Cup 2015 datasets. We can find the probability We know that From the above discussion, we can see that a little deviation of any schedule from balanced job assignment has the probability upper bounded by 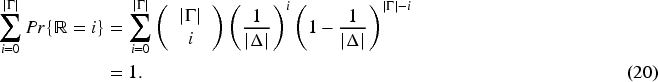

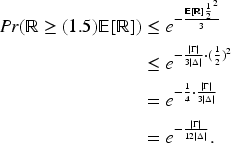
Now a connection will be established between finding our minimum variance with repetition and the online hiring assistant problem for stating our next analytical result. In the online hiring assistant problem, there are
The proof follows from the connection we have established above, that is, we need
Setup
The values extracted from the KDD Cup 2015 and BDD datasets are considered as the cost of jobs for the simulation of PPSJBP (mentioned above). The unit of job cost (
Synthetic dataset.

Synthetic dataset.
BDD dataset.

KDD Cup 2015 dataset.

If a TE or an agent in SC is assigned a set of jobs (with different costs) with a single and large enough time frame so that all the assigned tasks can be completed within the time frame, the TE might procrastinate. For example, a TE is assigned six jobs with costs 11, 11, 8, 7, 9, and 12 (in hours), with a 12-day time frame (considering 2 days to complete each job). As there is a single time frame, the TE procrastinates for, say, four tasks. So she has to execute four tasks in a single day instead of eight days. On the other hand, consider that a time frame of 4 days (a slot) is given for each pair of tasks (where the TC of all such pairs is balanced). In this case, the possible procrastination could be prevented because the TE has to submit each pair of tasks within 4 days. If the TC of each slot is not balanced, there is again a chance of procrastination (see Section 1 for more details).
There is no direct mapping or relationship of cost to procrastination behaviour for KDD Cup 2015 and BDD datasets. But, from the above discussion, we can infer that the cost can be mapped with procrastination on the basis of the data derived from KDD Cup 2015 and BDD datasets for simulation of our proposed method, PPSJBP. This mapping could be done for the TC of assigned jobs to any TE. This is because a TE might procrastinate when she is assigned jobs and deadlines to execute those jobs.
It is also to be mentioned that there is no bus (in BDD) or no student (in KDD Cup 2015) labelled with procrastination. That means these real datasets do not specify anything about procrastination. However, for our simulation regarding procrastination, getting the jobs and their costs (time) were the important ingredients. The KDD Cup 2015 and BDD datasets are providing the jobs and their corresponding costs. The ground truth labelling of which jobs procrastinated for how much time was absent in the KDD Cup 2015 and BDD datasets. If ground truth data were available, one further simulation in that direction could be done, along with our extensive simulation study with these real-world datasets. Depending on the availability of that ground truth dataset, that particular simulation is kept for our future work.
We have presented the results of simulation of the proposed algorithm in different directions, which are (i) comparison between a set of schedules with minimum variance and other randomly chosen sets of schedules, (ii) by varying
Comparison between set of schedules with minimum variance and other randomly chosen sets of schedules
This simulation shows the comparison between a set of schedules with minimum variance and other randomly chosen sets of schedules. For this simulation, we have chosen four different sets of schedules at random, which have high variance and compared with minimum variance set of schedules where
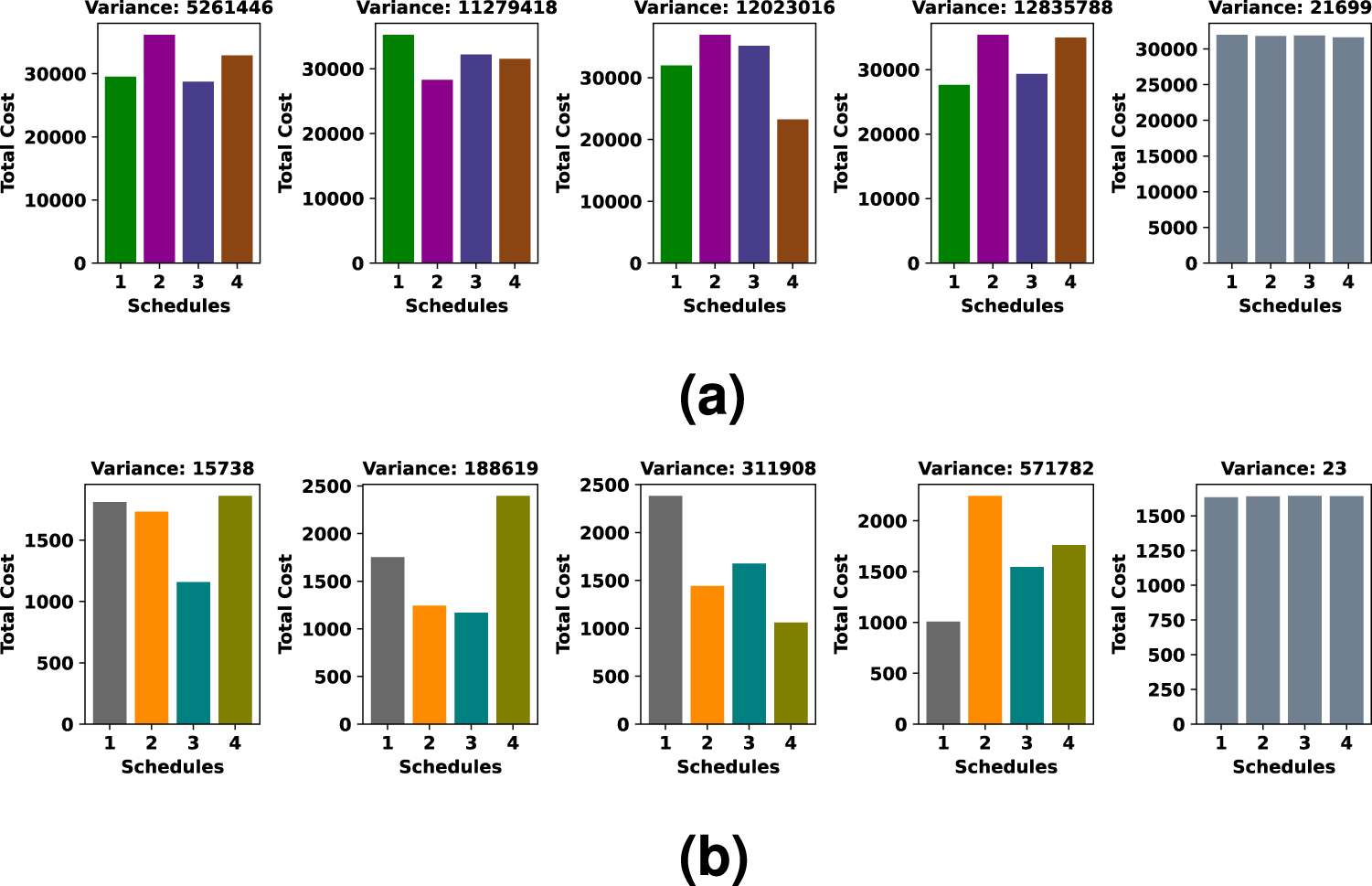
Comparison between a randomly chosen set of schedules with the minimum variance set. (a) Comparison using Bus Driver dataset and (b) Comparison using KDD Cup 2015 dataset.
This simulation establishes the fact that the proposed algorithm is able to allocate all jobs into the schedules in the most balanced manner according to their costs. It follows Lemma 3, which states that the probability of accumulation of all higher cost jobs into a single schedule is very less. We claim this because when the set of schedules with minimum variance is achieved after
The purpose of this simulation is to show that if we vary

Balanced sets of schedules by varying
This simulation shows the comparison when the schedules are dispensed with and without ordering of TC (from Figures 6(a) to 6(c)). In each figure, the plots on the left-hand side and right-hand side show with and without ordering, respectively. In the right-hand side of Figure 6(a), we can see that if schedule 3 is dispensed before schedule 4, the verification time for schedule 4 would comparatively be less than schedule 3 because schedule 4 is heavier than schedule 3. The left-hand side of the same figure shows that the schedule with the largest cost, that is, schedule 4, is dispensed first, then schedule 1, and so on, which provides more time for verification of comparatively heavier schedules after submission of tasks. In this simulation, the minor difference among the costs of each schedule is scaled so that the dispensing of schedules with and without ordering could be clearly understood.
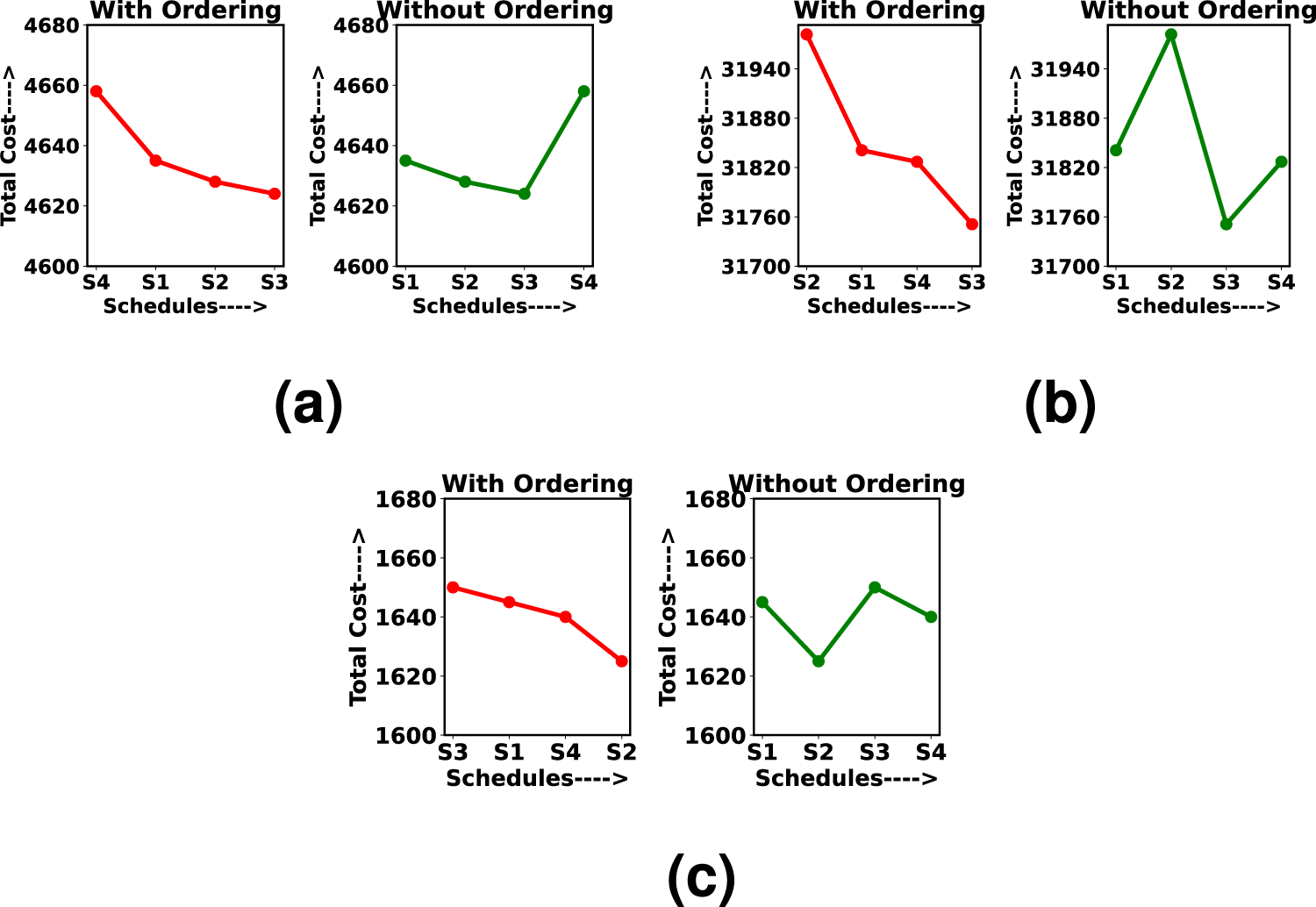
Comparison between with and without ordering of dispensing schedules. (a) Synthetic dataset, (b) Bus Driver dataset and (c) KDD Cup 2015 dataset.
A brief study is given for hyperparameter
The Bus Driver Scheduling dataset with 359 data is considered for this study. We have randomly selected 100 tasks and considered
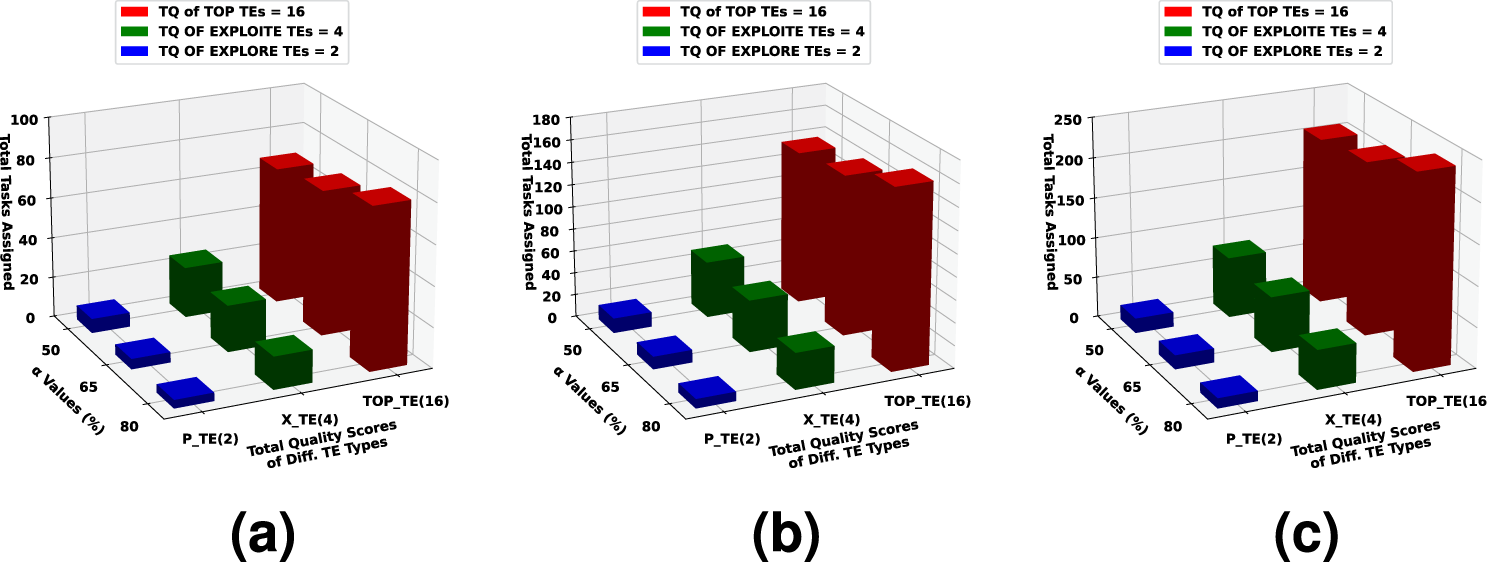
Number of tasks assigned with parameter
The
A similar study is carried out for randomly selected 200 tasks and 300 tasks from the same dataset, and the same set of
Our proposed algorithm (PPSJBP) is compared with OFFPSP, 22 which used a threshold-based algorithm to allocate jobs to every schedule (without balancing), but our proposed algorithm has generated balanced (in terms of TC and NOJ) schedules without any threshold (this gives a general flavour to our proposed algorithm as threshold-based allocation is somewhat imposing extra restriction on the allocation of jobs to the schedules). In OFFPSP, a job is allocated to a schedule if the ratio of marginal utility to the cost (utility/cost) of that job is maximum compared to all other jobs. If the utility of the last allocated job is higher than that of the other jobs, the last job is kept, and the other jobs are discarded. These discarded jobs have not been processed further (as per the algorithm presented in Wang et al. 22 ). This creates a disparity in the job allocation process, and it is also observed that OFFPSP may not perform efficiently in terms of balancing the scheduled jobs. We have considered the uniform utility for all jobs for the simulation. We have also compared PPSJBP with UCSMPP proposed in Debnath et al. 24 Even though UCSMPP has shown a better balancing effect than OFFPSP, PPSJBP has achieved a better balancing effect than UCSMPP.
Setup for comparison
We have (1) threshold for
Based on TC per schedule
In this simulation, shown in Figures 8(a) to 8(c), we have compared PPSJBP, UCSMPP, and OFFPSP in terms of TC of each schedule. We see that PPSJBP has produced a better-balanced effect in distributing jobs into schedules compared to both UCSMPP and PPSJBP.
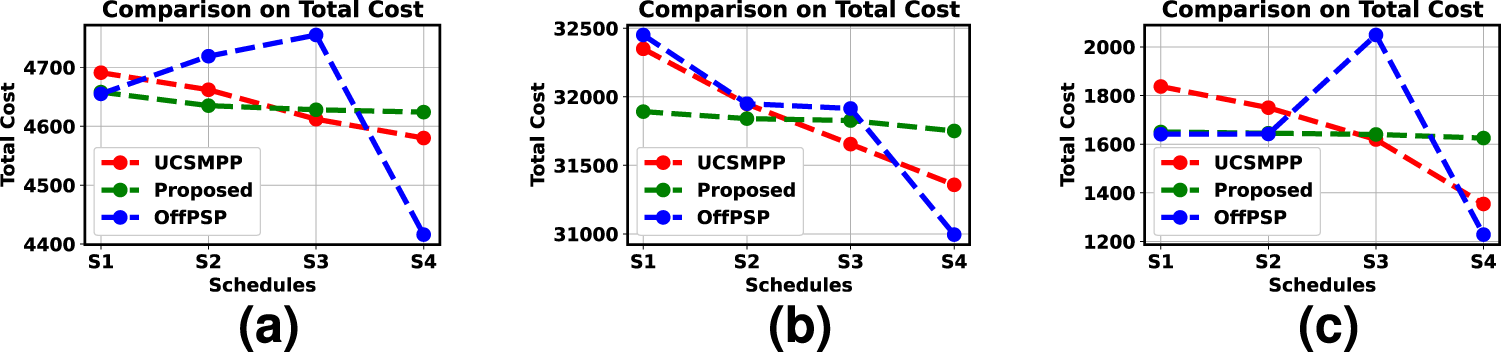
Comparison among UCSMPP, PPSJBP, and OFFPSP over total cost of each schedule: (a) Synthetic, (b) Bus Driver Scheduling and (c) KDD Cup 2015 datasets.
We have also compared PPSJBP with OFFPSP and UCSMPP in terms of AC (from Figures 9(a) to 9(c)) and NOJ (from Figures 3(a) to 3(c)). In both cases, PPSJBP outperforms OFFPSP while it behaves almost similarly to UCSMPP. This is because UCSMPP has distributed the jobs into each schedule deterministically, whereas in PPSJBP, the jobs are assigned randomly. Another reason is that we have adopted a similar method of dividing the overall deadline (
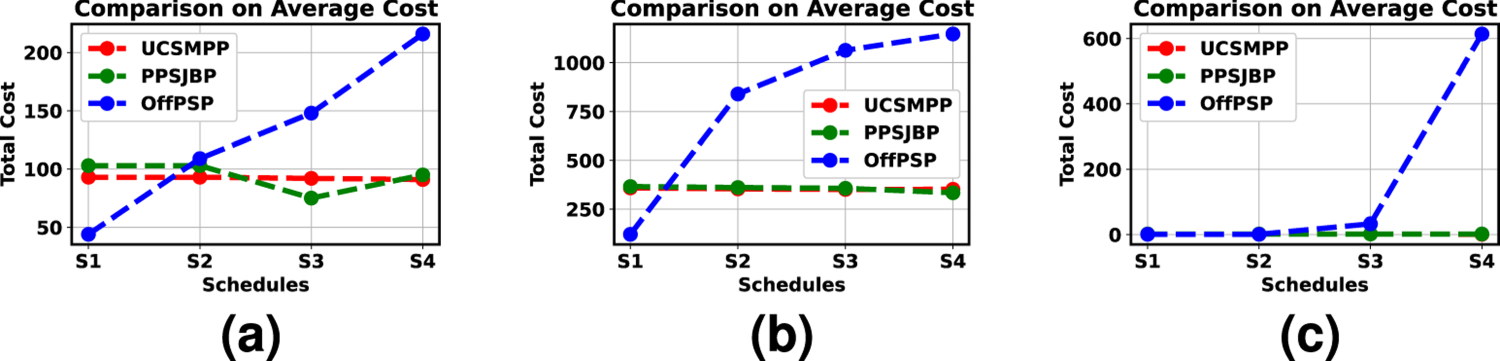
Comparison among UCSMPP, PPSJBP, and OFFPSP over AC in each schedule: (a) Synthetic, (b) Bus Driver Scheduling and (c) KDD Cup 2015 datasets.
This section shows the CTE of TC, AC, and NOJ on OFFPSP, UCSMPP and PPSJBP by comparing their behaviour over CTE. We have shown the comparison of CTE in two segments. First segment uses the sum of TC, AC and NOJ of each schedule and shows that PPSJBP has better balancing effect than the other two (Figures 10(a) to 10(c)). In the second segment, we have calculated the variance of the summation of TC, AC and NOJ of all the schedules for each dataset and drawn the comparison by taking 100% of values of TC, AC and NOJ (Figure 11(a)) and then by taking 75% and 50% of values of TC, AC and NOJ (Figures 11(b) and 11(c)). The purpose of such partial consideration of values of TC, AC and NOJ is to show that the variance over a summation of partial values of TC, AC and NOJ for each schedule also produces a better balancing effect for PPSJBP than OFFPSP and UCSMPP (Figures 11(b) and 11(c)).
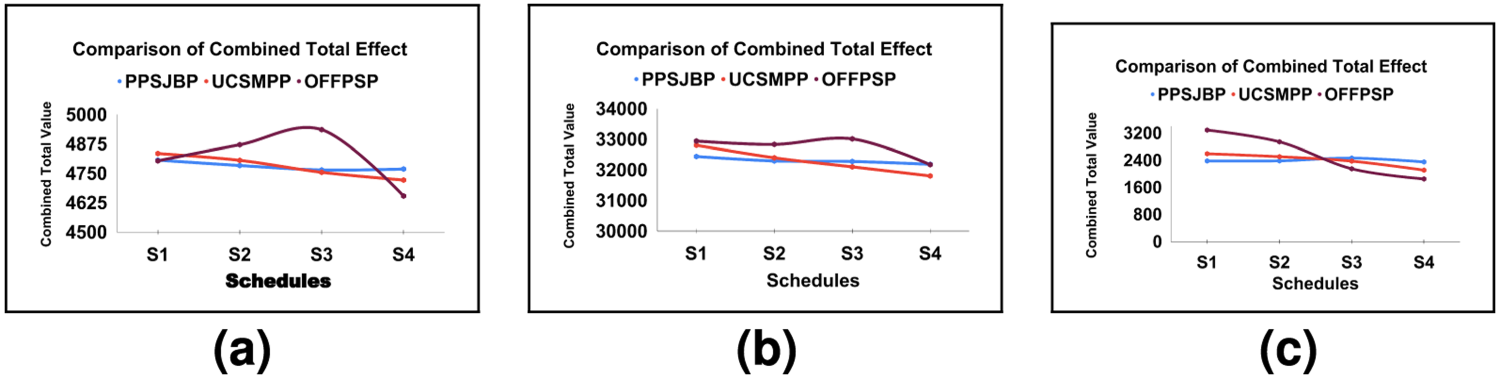
Comparison among UCSMPP, PPSJBP, and OFFPSP over combined total value: (a) Synthetic, (b) Bus Driver Scheduling and (c) KDD Cup 2015 datasets.
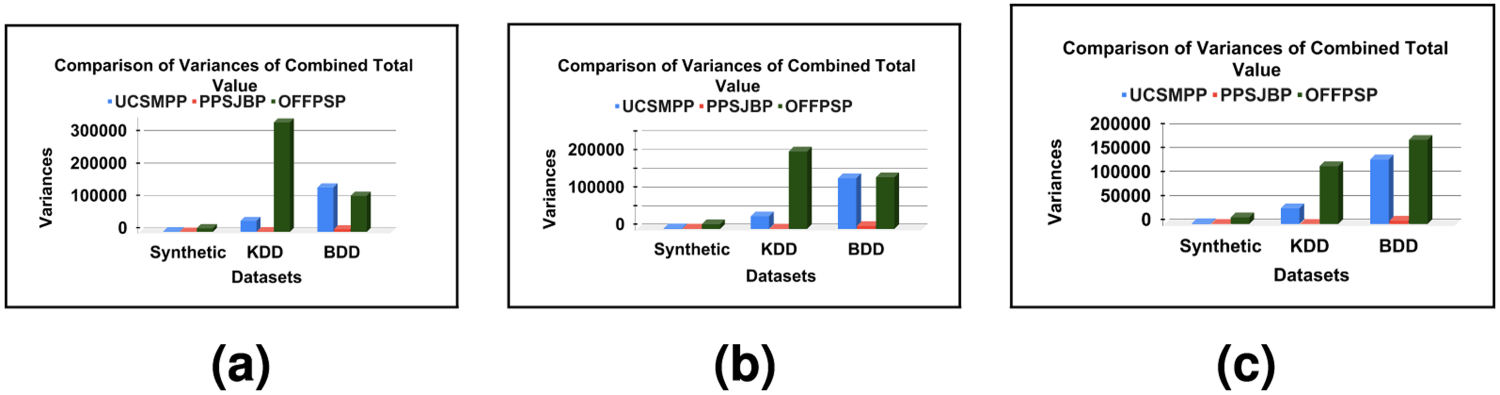
Comparison over variances of combined values with varying proportion: (a) 100% proportion, (b) 75% proportion and (c) 50% proportion.
For statistical validation, we consider the proposed method PPSJBP, which gives a balanced distribution of tasks (in terms of cost) into slots with low variance, as the null hypothesis
Mann–Whitney
-test using four sets of samples.

Mann–Whitney
Earlier, we constructed a real-world dataset by distributing some assignment questions to a group of high school students (or crowdworkers) of standard VII to standard IX. It is distributed to observe if students procrastinate or not. Five students of standard IX were given assignments on
These samples are given in Tables 6 and 7, which show the procrastination behavior of students (crowdworkers). The pattern in the dataset shows realistically that crowdworkers procrastinate during the execution of their jobs.
School assignment: Procrastination 1.
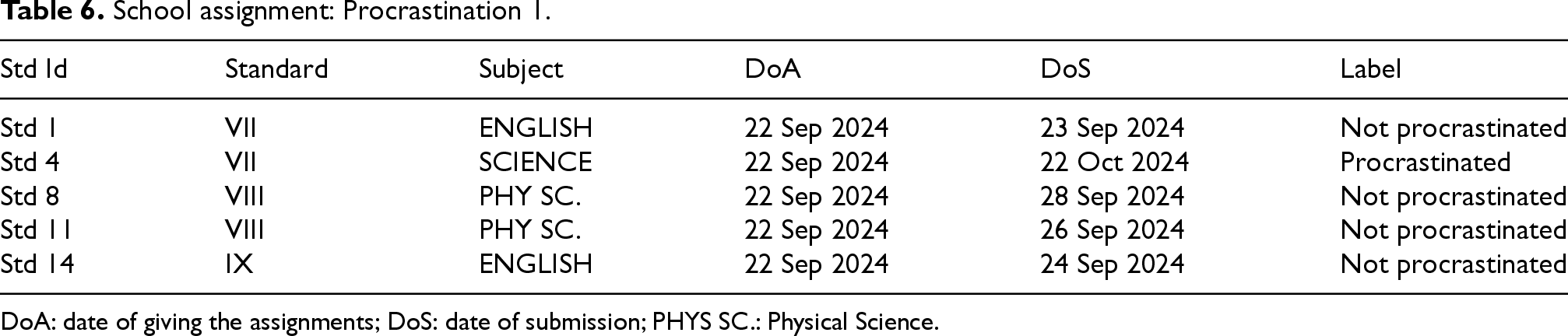
School assignment: Procrastination 1.
DoA: date of giving the assignments; DoS: date of submission; PHYS SC.: Physical Science.
School assignment: Procrastination 2.
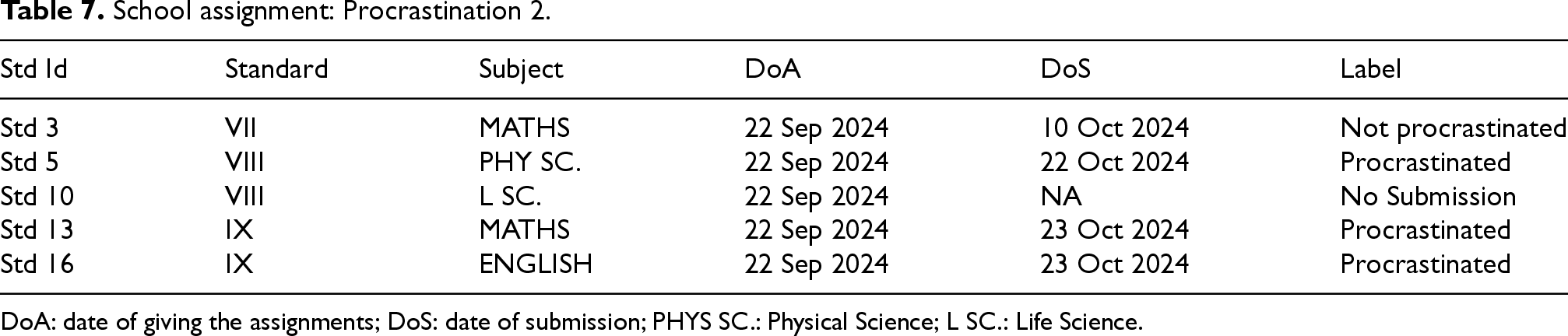
DoA: date of giving the assignments; DoS: date of submission; PHYS SC.: Physical Science; L SC.: Life Science.
In this paper, we have addressed the problem of task allocation and the prevention of procrastination of allocated tasks in SC. We have also shown that an SC environment can be mapped to a distributed network. To address the issue of task allocation, we have proposed a method to find top-performing TEs using a data science approach (CMS) and allocated a subset (
To address the second problem,, that is, to prevent procrastination, we have proposed a novel method named PPSJBP, which distributes jobs into different schedules (in the most balanced manner) as per their TC to avoid procrastination in SC applications. Every schedule is given an equal time frame by subdividing the total time frame so that the on-time and efficient completion of jobs is guaranteed. Another aspect of PPSJBP is that the schedules that are finally given to the agents are presented in non-increasing order of their TC. The benefit of this is twofold: (1) the agents will have less burden as they will be going down the line to execute jobs in several schedules and (2) the TP will have ample time to work on the little bit heavy schedule as it is submitted earlier. So PPSJBP is relying on two facts: aligning the jobs into the schedules by a randomized repetitive procedure (balancing), and rearranging the set of schedules with minimum variance in non-increasing order of the cost of each schedule (benefiting TP). We have compared our scheme with the existing algorithms with synthetic as well as real datasets through extensive simulation, and it is observed that our proposed method outperforms the existing one in terms of balancing effect. Also, we have shown analytically that our proposed algorithm maintains the balanced distribution. There could be many other directions to the prevention of procrastination. One direction could be to use Platform-centric data about agents to avoid procrastination in a better way. Another direction could be to give incentives to the agents on the way of performing the task to avoid procrastination. Such an incentive-based system integrated with a game-theoretic setting could be another viable option to motivate TEs to avoid procrastination in an SC environment. In a dynamic or real-time scenario, tasks and TEs appear/arrive dynamically or in an online fashion to the platform. Similarly, when a TE completes task execution, she can leave the platform immediately, or she can also leave if she is unassigned to a task, after a certain amount of time (wait time). This is also applicable to a task. In case of dynamic arrival, there is no prior information to the platform about TEs or tasks before their arrival to the platform. Our future work, as a third future direction, will be extended to address such a dynamic nature of both TE and tasks.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Code/data availability
The code for the implementation of the proposed method, PPSJBP, will be available upon request.
Studies not involving humans or animals
This article does not contain any studies with human or animal participants. There are no human participants in this article, and informed consent is not required.