
Abstract
Background:
Heart disease is the leading cause of death worldwide and predicting it is a complex task requiring extensive expertise. Recent advancements in IoT-based illness prediction have enabled accurate classification using sensor data.
Objective:
This research introduces a methodology for heart disease classification, integrating advanced data preprocessing, feature selection, and deep learning (DL) techniques tailored for IoT sensor data.
Methods:
The work employs Clustering-based Data Imputation and Normalization (CDIN) and Robust Mahalanobis Distance-based Outlier Detection (RMDBOD) for preprocessing, ensuring data quality. Feature selection is achieved using the Improved Binary Quantum-based Avian Navigation Optimization (IBQANO) algorithm, and classification is performed with the Deep Long-Term Recurrent Convolutional Network (DLRCN), fine-tuned using the Adaptive Botox Optimization Algorithm (ABOA).
Results:
The proposed models tested on the Hungarian, UCI, and Cleveland heart disease datasets demonstrate significant improvements over existing methods. Specifically, the Cleveland dataset model achieves an accuracy of 99.72%, while the UCI dataset model achieves an accuracy of 99.41%.
Conclusion:
This methodology represents a significant advancement in remote healthcare monitoring, crucial for managing conditions like high blood pressure, especially in older adults, offering a reliable and accurate solution for heart disease prediction.
Keywords
Introduction
Cardiovascular diseases (CVDs)1,2 remain the leading cause of death worldwide, contributing significantly to global mortality rates across various demographics. These conditions encompass multiple disorders, including arrhythmias, coronary artery disease, and heart failure, all of which affect the heart and vascular system. The rising prevalence of CVDs highlights the critical need for effective diagnostic tools and predictive models 3 that can aid in early detection and intervention, thereby improving patient outcomes and reducing the overall burden on healthcare systems.
The early detection of heart disease is difficult due to the complexity of cardiovascular conditions, which necessitate advanced diagnostic tools and extensive expertise. Although traditional diagnostic methods are commonly used, they often struggle to deliver accurate and timely predictions, leading to treatment delays and increased patient risk. Cardiac diseases continue to pose a significant public health challenge globally, highlighting the need for timely and precise diagnosis.
The investigation of CVD is critical because it continues to be a primary cause of death globally, accounting for roughly 17.9 million 4 fatalities each year, according to the World Health Organization (WHO). 5 Conventional diagnostic techniques, like angiography, are costly, carry considerable risks, and often result in low detection rates and slow convergence. Traditionally, the diagnosis of CVDs has relied heavily on the manual evaluation 6 of clinical symptoms, patient medical history, and a variety of diagnostic tests such as electrocardiograms (ECG), echocardiograms, and stress tests. While these conventional methods have played a crucial role in CVD, they have notable limitations. Manual evaluation is often time-consuming, susceptible to human error, 7 and can miss subtle indications of disease progression. Furthermore, conventional diagnostic tests frequently fail to collect the dynamic changes in a patient's condition, resulting in delays in both diagnosis and treatment. The emergence of machine learning (ML) 8 and DL 9 has brought about a transformative shift in the field, offering advanced tools to enhance the accuracy and efficiency of cardiovascular disease prediction and diagnosis.
Emerging technologies such as the artificial intelligence (AI), machine learning (ML), Internet of Medical Things (IoMT), and deep learning (DL) are transforming the medical diagnostic landscape, allowing for faster and more accurate prediction of cardiovascular diseases. IoMT combines real-time data from wearable devices, electronic health records (EHR), and medical images to create an effective framework for early detection of cardiac diseases. Federated learning improves data privacy by allowing for distributed model training, while edge computing lowers latency through local data processing. Hybrid models that incorporate XGBoost, Bi-LSTM, and fuzzy logic improve diagnostic accuracy in complex scenarios. Furthermore, graph convolutional networks (GCN) and time-frequency domain analysis can help detect diseases like pulmonary hypertension more accurately. Current research aims to improve system performance, reduce computational complexity, and ensure scalability across various healthcare settings, particularly in resource-constrained environments. Efforts focus on enhancing algorithms, increasing efficiency, and rendering advanced diagnostic tools more accessible and practical for broad implementation.
Initial approaches utilized supervised learning techniques such as Decision Tree (DT), 10 Support Vector Machine (SVM), Random Forest (RF), Naive Bayes (NB), Logistic Regression (LR), 11 Artificial Neural Network (ANN), and K-Nearest Neighbour (KNN). These models significantly improved upon manual evaluation by automating the analysis process and reducing human error. However, they also encountered challenges, including bias, overfitting, and difficulties in handling complex, large-scale datasets effectively. The hybrid approaches combine the strengths of multiple ML techniques. A notable development is the integration of XGBoost with Long Short-Term Memory (LSTM)12,13 networks. XGBoost excels at handling structured data and extracting important features, while LSTM networks are adept at analyzing time-series data and capturing temporal relationships that are crucial for cardiovascular disease analysis. This hybrid approach has shown promising results, significantly improving the early detection of CVDs by leveraging both structured data analysis and temporal sequence learning.
The integration of IoT 14 devices with edge computing has further revolutionized healthcare monitoring systems. IoT devices, such as wearable sensors and smart watches, periodically collect real-time physiological data such as heart rate, ECG readings, and blood pressure. Edge computing reduces delay and energy consumption, allowing for timely interventions and continuous health monitoring. Current heart disease prediction methods face significant challenges that limit their effectiveness. Many conventional models depend on a narrow range of clinical variables, leading to oversimplified assessments that overlook the complex nature of heart disease risk. Additionally, these techniques often fail to accommodate diverse patient demographics, resulting in biases and decreased accuracy. The reliance on historical data also raises concerns about data quality and completeness. Furthermore, many existing algorithms do not utilize advanced analytical techniques, such as machine learning, which could better identify intricate patterns and relationships among risk factors. Thus, there is an urgent need for more robust and versatile prediction models that utilize comprehensive datasets and innovative analytical approaches. Despite these advancements, significant challenges remain in ensuring data accuracy, security, and privacy. The sensitive nature of medical data necessitates robust privacy-preserving algorithms, especially when dealing with large volumes of data for real-time responsiveness. 15
Moreover, extensive clinical validation is crucial for advancing CVD prediction models. Many current models have shown excellent performance in controlled research environments but require rigorous testing and validation in real-world clinical environments to enhance reliability and efficiency. This involves expanding datasets to include more diverse patient populations and conditions and continuously updating models based on new data and clinical insights.
Recent progress in cloud and edge computing has significantly improved the reliability and availability of applications, especially in healthcare. A significant application of this is the development of a CVD prognosis model employing customized neural network architecture, DLRCN, supported by the IBQANO feature selector and Robust Mahalanobis Distance-based Outlier Detection for preprocessing.
This study seeks to address these challenges by introducing a cutting-edge methodology for heart disease prediction. This approach combines advanced data preprocessing, feature selection, and deep learning techniques specifically designed for IoT sensor data. This method not only advances the capabilities of heart disease detection, but also emphasizes the potential of integrating advanced deep learning techniques with IoT systems to provide accurate, reliable, and real-time healthcare solutions. This study addresses a highly relevant and current healthcare challenge: the accurate prediction of heart disease, which remains a leading cause of death globally. The integration of IoT-based data and advanced deep learning models for real-time illness prediction aligns with ongoing advancements in healthcare technology, making the research particularly timely.
Problem statement and motivation
Traditional diagnostic systems for CVD often suffer from inaccuracies and delays, hindering effective patient management and early intervention. Early methods using techniques showed improvements, but they faced issues such as bias, overfitting, and difficulty managing complex, large-scale datasets. This proposed work aims to improve the detection accuracy, efficiency, and real-time capabilities of heart disease prediction systems. Hybrid approaches combining ML and DL, such as XGBoost integrated with LSTM networks, have shown promise. Additionally, the combination of IoT devices and edge computing has revolutionized healthcare monitoring systems by reducing delay and energy consumption while enabling real-time data processing and timely interventions. These advancements aim to create more responsive and effective healthcare solutions, enhancing patient outcomes and decreasing the burden on healthcare systems.
This research highlights its innovation by integrating advanced preprocessing methods, sophisticated feature selection algorithms, and a hybrid DL framework to improve heart disease prediction. Utilizing clustering-based data imputation and normalization, as well as robust Mahalanobis distance-based outlier detection, the suggested work maintains high data quality by effectively managing missing data and outliers. Using the IBQANO algorithm to choose features makes it much easier for the model to find the most important ones, which improves the accuracy of its predictions. The DLRCN created in this research merges convolutional and recurrent layers, enabling the capture of both temporal and spatial patterns in the data. Furthermore, the implementation of the ABOA for dynamic hyperparameter tuning ensures the model achieves optimal performance. This thorough methodology, validated extensively on multiple datasets, not only shows superior accuracy and reliability compared to existing models but also addresses critical issues such as data quality, feature redundancy, and complex temporal dependencies in medical datasets.
This proposed research makes a meaningful contribution to heart disease prediction by combining advanced data preprocessing methods, sophisticated feature selection techniques, and a hybrid deep learning model specifically designed for IoT-based sensor data. Although machine learning has been utilized for predicting heart disease in prior studies, this work differentiates itself by integrating CDIN, RMDBOD, and the IBQANO algorithm with the DLRCN, which is further optimized using the ABOA. These enhancements allow the model to effectively manage complex high-dimensional datasets, resulting in higher accuracy and reliability compared with existing approaches. Therefore, although the application of machine learning to heart disease prediction is not entirely new, the unique combination of methodologies employed in this study represents a significant advancement in the field.
Develop an advanced methodology for heart disease prediction using IoT sensor data by leveraging the DLRCN-ABOA algorithm. To increase the accuracy, efficiency of CVD prediction models. Implement preprocessing methods with CDIN to manage missing data and RMDBOD to identify and handle outliers. Sophisticated feature selection method for optimal selection of features using IBQANO algorithm. The hybrid deep learning framework to capture both spatial and temporal characteristics in the data using DLRCN. Implement the ABOA for dynamic hyperparameter tuning to ensure optimal performance. Validate the proposed methodology extensively on multiple datasets to achieve superior accuracy and reliability.
The arrangement of the suggested work is detailed as follows: Section II presents a survey on existing methodologies, setting the context for the current study. In Section III, we describe the suggested algorithm in detail, explaining the innovative approach and techniques used in the research. Section IV gives the results and discussion, analyzing the outcomes of the suggested method. Finally, Section V offers conclusions and explores the future scope of the proposed work, highlighting potential directions for further research.
Related works
Despite significant advancements, several challenges remain. Existing models often fail to ensure data accuracy, security, and privacy, especially when handling large volumes of data for real-time responsiveness. 16 There is also a need for more robust validation of these models in clinical settings, as well as the incorporation of advanced privacy-preserving algorithms. 17 Future research should focus on integrating more sophisticated wearable technologies, expanding datasets for better model validation, and exploring multi-modal data integration for comprehensive and proactive healthcare management. Addressing these gaps will be crucial for further enhancing the efficiency and scalability of CVD prediction models in real-world applications. In recent years, advancements in the integration of AI, the IoT, 18 and edge computing 19 have significantly impacted healthcare, especially in disease prediction, monitoring, and diagnosis. This review explores the evolution of these technologies in healthcare, detailing various approaches and methodologies.
Utsha et al. 20 presented a lightweight convolutional neural network (CNN) model for valvular heart disease (VHD) screening using phonocardiogram (PCG) signals. Designed for mobile device deployment, this model utilizes self-supervised learning (SSL) to leverage unlabeled data, thereby enhancing accuracy and robustness. The mobile application prototype demonstrated near real-time performance, making it suitable for scalable VHD screening. The Long Short-Term Memory (LSTM) network performs better than the other deep learning models, with an accuracy of 98.74%, precision of 99.95%, and recall of 99.86%. However, the proposed algorithm's effectiveness is limited by the accuracy of ECG signal analysis, which can be affected by external noise and interference. 20
Devi et al. 21 proposed Self-Improved Jellyfish Optimization (SI-JFO) with LSTM networks to enhance heart disease detection using IoT, the proposed framework offering a novel approach that optimizes LSTM hyperparameters more effectively, leading to substantial improvements in accuracy and computational complexity. The SI-JFO algorithm's self-improvement mechanism enables dynamic adaptation during optimization, avoiding local minima and enhancing global search capabilities. Additionally, the framework leverages the African Vulture Optimization Algorithm (AVOA) for feature selection, ensuring that only the most essential features are utilized and further boosting performance. The framework has been extensively evaluated using datasets such as the Public Health Dataset, achieving an impressive accuracy of 99.56%, outperforming traditional methods such as Grey Wolf Optimization (GWO), Whale Optimization Algorithm (WOA), and Particle Swarm Optimization (PSO). Furthermore, it achieved 99.75% precision and 99.63% recall, demonstrating its potential to transform IoT-based healthcare systems by improving heart disease detection accuracy and efficiency. However, the optimization method may require extensive hyperparameter tuning, which can be time-consuming and resource-intensive. 21
Ramkumar et al. 22 proposed a smart IoT-enabled CVD prediction system utilizing an LSTM model. The Kalman filter is used to remove unwanted noise and address missing data in collected datasets. The feature extraction process uses a combination of Lion and Krill head optimization techniques. The smart healthcare system, which is based on LSTM and Recurrent Neural Networks, has an impressive accuracy of 99.99%, outperforming existing smart heart disease prediction systems, including traditional methods. However, this proposed monitoring system may face data privacy and security issues, particularly when handling sensitive patient information. 22
Munagala et al. 23 proposed a Fuzzy- LSTM model to offer a new IoT-enabled approach for heart disease prediction. The proposed model is improved through Population and Fitness-based Harris Hawks Optimization (PF-HHO). It achieved a remarkable accuracy of 95.89%, consistently outperforming other models and demonstrating superior performance across various metrics, establishing it as an exceptionally effective solution for the early detection and continuous monitoring of cardiac conditions. Nonetheless, if not properly managed, the Fuzzy-LSTM model may encounter overfitting problems, which could reduce its predictive accuracy. 23
Gupta et al. 24 presented an intelligent healthcare monitoring system that utilizes edge computing and a CNN for the early prediction of health conditions, including fall detection. This system employs local edge servers to enable fast data processing. The CNN-based method demonstrated enhanced precision and recall while ensuring reduced processing times relative to alternative techniques such as SVM, ANN, and KNN. The efficacy of the suggested algorithm can be assessed through precision and error rate metrics, attaining an accuracy of 99.23% relative to alternative methods. The dependence on deep learning for health monitoring may result in interpretability challenges, hindering healthcare professionals’ trust in the predictions. 24
Liao et al. 25 proposed a multilayer perceptron (MLP) neural network optimized with a genetic algorithm (GA) was used. The model includes a fuzzy inference system and a multidirectional long-term memory (Mu-LTM) approach to enhance heart disease prediction accuracy. Designed to handle large volumes of patient data, this system enables precise and timely predictions, supporting proactive healthcare management. A sophisticated healthcare system utilizing Mu-LTM (multidirectional long-term memory) for accurate monitoring and forecasting of heart disease risk attains a specificity of 97.99%, an accuracy of 97.89%, a coverage error of 97.94%, and a sensitivity of 97.96%,. This optimization method may neglect specific factors influencing heart disease prediction, potentially resulting in incomplete evaluations. 25
Baseer et al. 26 proposed an integrated IoMT and AI-based model utilizing CatBoost and TabNet for coronary artery disease prediction was proposed. This model leverages real-time physiological data from connected medical devices and employs advanced AI algorithms for feature selection and predictive accuracy. The model significantly outperformed existing models. The experimental results demonstrated a prediction accuracy surpassing 90%, employing both medical data and environmental variables via the IoMT. A notable limitation identified was the considerable computational resources required due to the complexity of the deep learning model, which may be impractical in low-resource environments or for real-time processing on edge devices. 26
Malwade et al. 27 utilized federated learning to predict heart diseases by training a global model on IoT-based EHRs without centralizing the data. The server aggregates these updates to refine the global model iteratively, ensuring continuous improvement while preserving data privacy and security. The experimental findings demonstrated an accuracy rate of approximately 88%, accompanied by a significant reduction in latency for data processing in distributed systems. Nonetheless, challenges persist, including the increased complexity of managing communication among diverse nodes and the difficulties in integrating heterogeneous data sources, which may negatively impact performance in practical applications. 27
Ge et al. 28 utilized deep learning methods and time-frequency domain features to identify pulmonary hypertension linked with heart disease. Their novel approach makes use of time-frequency domain transformations to improve feature extraction, resulting in higher disease detection accuracy. The experimental results show a success rate of around 85%, which is particularly useful for early-stage identification. However, one significant limitation is the reliance on high-quality, labeled data, which can be difficult to obtain in real-world clinical settings, potentially limiting its use in resource-constrained or general practice environments. 28
Alzakari et al. 29 proposed a hybrid model integrating LSTM and XGBoost networks for the early prediction of CVDs. Utilizing the UCI Heart Disease dataset, the hybrid algorithm efficiently captures temporal relationships and intricate connections within the data, outperforming traditional methods. The experimental results demonstrated an accuracy increase of up to 93%, with the system successfully handling large datasets from remote healthcare systems. However, one significant limitation is its reliance on stable internet connections and cloud infrastructure, which may make it unsuitable for areas with poor network coverage or scarce resources. 29
Ramesh et al. 30 presented the Hybrid Gradient Boosted Decision Tree with Random Forest (HGBDTRF) algorithm utilizes ensemble learning to improve the prediction accuracy of heart disease prediction. This hybrid approach combines the strengths of gradient-boosted decision trees (GBDT) and random forests (RF) to improve predictive performance. The process involves training GBDT to identify key features and applying RF to classify them. When applied to large datasets, the experimental results showed a 91% accuracy, outperforming traditional models such as RF and GB. However, limitations include increased model complexity and longer training times, which may impede real-time implementation, particularly in mHealth or edge computing scenarios. 30
Gao et al. 31 created MedGCN, Cross-Fusion graph convolutional network (CF-GCN) model that uses IoT-edge computing to look at unstructured clinical diagnostic reports in real time. The model combines OpenAI's GPT-4 with a CF-GCN to predict disease and diagnoses. By utilizing unstructured Clinical Diagnostic Reports (CDRs) from patients with various vascular obstructive diseases, MedGCN achieves a highest accuracy and efficiency. The simulation results revealed an 89% prediction accuracy, demonstrating the model's ability to train complex, unstructured clinical data. However, one significant limitation is the need for large training datasets and edge computing infrastructure, which may not be available in all healthcare settings. 31
Mandava 32 proposed a hybrid DL system, MDensNet201-IDRSRNet, was introduced for efficient CVD prediction. The system combines Modified DenseNet201 for feature extraction and the Improved Deep Residual Shrinkage Network (IDRSNet) for classification. The experimental results showed an highest 94% accuracy, indicating the potential for large-scale implementation in hospital settings. Nonetheless, the main limitation is the high computational power required to run the hybrid model, which poses a challenge for low-power IoT devices and real-time applications in rural or remote healthcare settings. 32
Lai et al. 33 developed the Edge Intelligent Collaborative Privacy Protection (EICPP) solution integrates federated learning and edge computing to enhance accuracy and protect privacy. The KubeFL framework supports health monitoring through a device-edge, cloud-layered federated learning model. The EICPP framework demonstrated a balance between accuracy and privacy protection. The experimental results showed a 95% effectiveness in protecting data privacy while maintaining the system's computational performance. However, one significant limitation is the complexity of the encryption and decryption processes, which could result in increased latency, especially in real-time healthcare applications where rapid diagnosis is critical. 33
Kanza et al. 34 proposed an IoT-based health monitoring system integrates fuzzy logic and ML for early detection and personalized assessment of CVD. The system collects patient data through sensors, processes it using fuzzy logic to evaluate symptoms, and employs ML models, particularly RF, to predict CVD risks. This approach offers a comprehensive and user-friendly solution for early diagnosis and proactive health management. The experimental results showed a detection accuracy of 90%, which is especially useful for early-stage diagnosis. However, the study has limitations, such as the need for high-quality IoT sensor data and accurate calibration, which can be difficult to obtain in underdeveloped areas with limited access to advanced technology and infrastructure. 34 This research illustrates the potential of combining AI, IoT, and edge computing technologies to develop intelligent healthcare systems that offer high accuracy, real-time analysis, and enhanced privacy protection. Table 1 represents the analysis of recent methodologies.
Comparative analysis of recent methodologies.
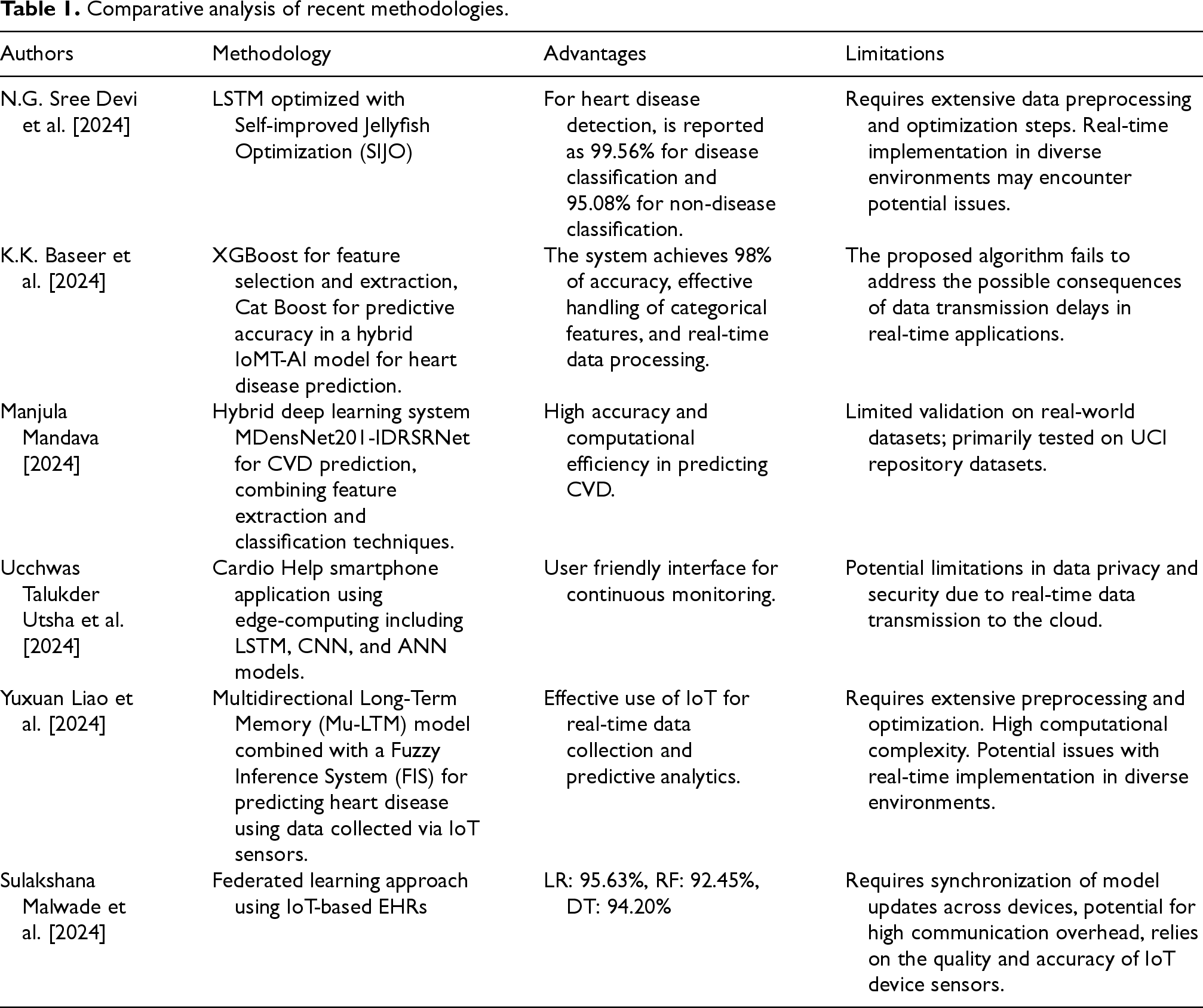
Comparative analysis of recent methodologies.
The lightweight convolutional neural network introduced by Ma et al. may encounter difficulties in attaining optimal performance in more intricate situations, potentially affecting the accuracy of valvular heart disease screenings. Elsedimy et al. 4 emphasize that their methodology is significantly dependent on precise parameter tuning for the SVM, a process that can be time-intensive. Moreover, the efficacy of quantum-behaved PSO may diminish when utilized on highly intricate datasets, potentially reducing the precision of cardiovascular disease forecasts. The computational demands of the enhanced quantum CNN may limit its real-time applications, making it unsuitable for deployment in resource-constrained environments. Zhou et al. observe that the combination of the grasshopper evolutionary algorithm and SVMs is limited by its reliance on high-quality datasets, which are not always readily available.
Furthermore, the model's complexity may make implementation difficult in clinical settings. The RF-LRG algorithm developed by Kumar et al. faces challenges due to its reliance on edge cloud infrastructure, which could affect latency and accessibility in resource-constrained regions. The hybrid deep dense Aquila network proposed by Barfungpa et al. may also struggle with model interpretability, as its complexity can make the decision-making process difficult to understand. Srinivas et al. may face potential overfitting due to the complexity of the adaptive stacked residual CNN, which requires careful tuning to ensure the model generalizes well across diverse datasets. Devi et al. may face computational efficiency challenges, as optimizing long short-term memory using jellyfish optimization is resource-intensive, limiting practical real-time applications. Finally, Mandava 32 may encounter difficulties due to the high computational demands associated with the MDensNet201-IDRSRNet model, limiting its applicability in low-resource environments.
Methodology
In heart disease analysis, accurate preprocessing and advanced algorithms are vital for extracting meaningful insights and achieving precise predictions. This research as shown in Figure 1 explores a detailed methodology that employs sophisticated data preprocessing techniques, feature selection algorithms, and DL architectures to enhance the predictive effectiveness of heart disease classification models. The preprocessing phase utilizes CDIN and RMDBOD to prepare the data. For feature selection, the IBQANO is applied. The classification task is carried out using the DLRCN. Additionally, the ABOA is used to fine-tune the hyperparameters of the DLRCN model, ensuring optimal performance. This comprehensive approach effectively addresses the challenges of missing data, outliers, feature redundancy, and complex temporal dependencies in medical datasets, ultimately leading to more reliable and accurate prediction.
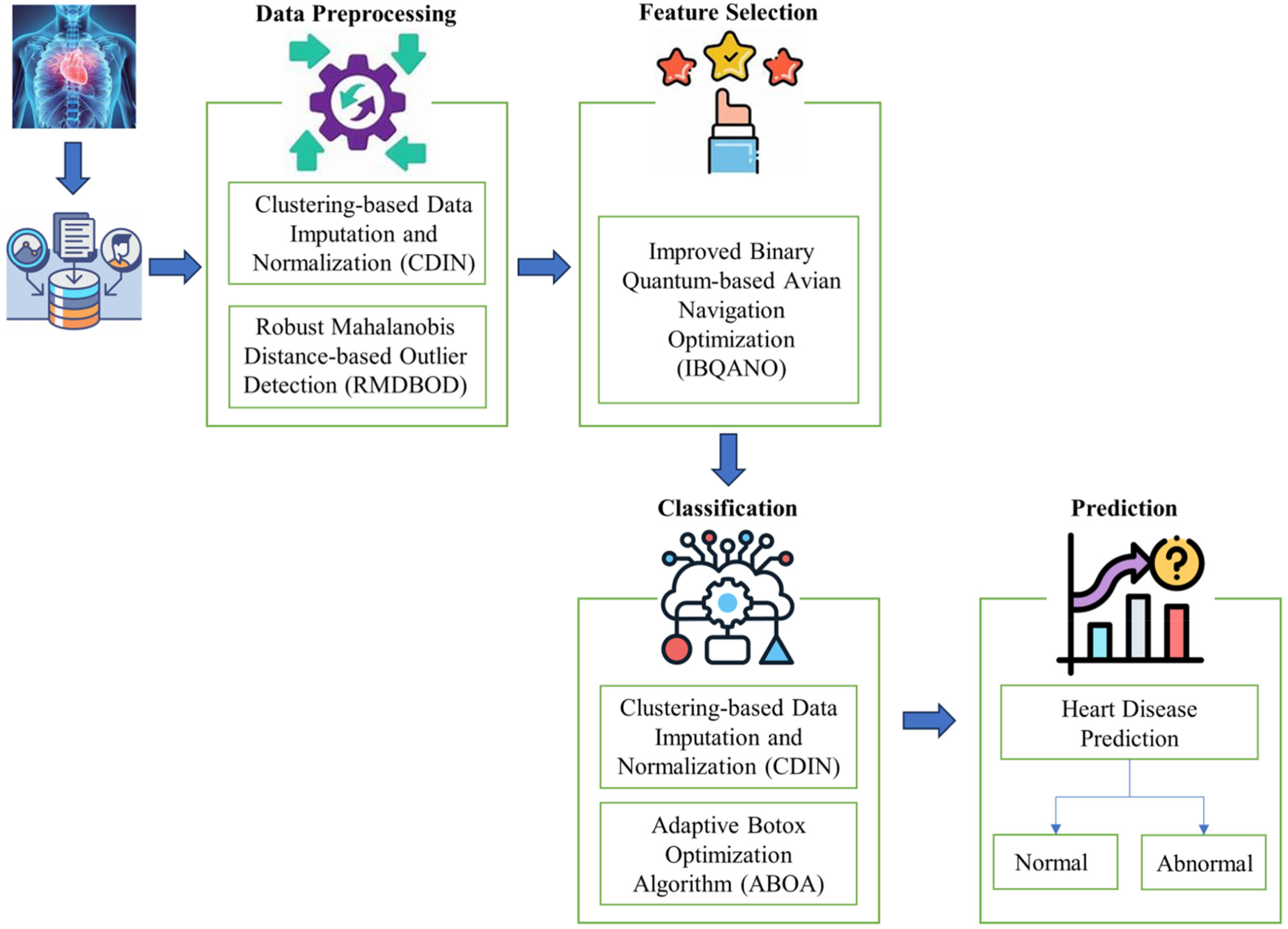
Proposed methodology for heart disease prediction.
The proposed heart disease prediction method presents a highly effective and innovative solution that surpasses traditional models in key performance metrics including precision, accuracy, F-measure, specificity, and sensitivity. By incorporating advanced data preprocessing techniques such as CDIN and RMDBOD, this approach ensures superior data quality and addresses issues related to missing data and outliers. Additionally, the application of the IBQANO algorithm for feature selection significantly boosts predictive performance. The DLRCN, optimized using the ABOA, excels in capturing both spatial and temporal patterns within the data, resulting in enhanced prediction accuracy.
Data Collection
IoT Sensors Physiological data, including heart rate, ECG readings, and blood pressure, were collected from wearable devices equipped with IoT sensors.
Data Transmission: Collected data are transmitted securely to a central processing unit via secure communication channels.
Data Preprocessing
CDIN: This technique addresses missing data by grouping similar data points into clusters. Imputation was performed within each cluster to fill in the missing values. The data were then normalized to ensure uniform quality across the dataset.
Let D be the dataset containing n samples and m features. For missing values in D, we define the imputation function I as follows:
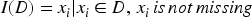
Normalize the dataset with Min-Max scaling:
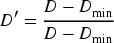
RMDBOD: Outliers in the dataset are identified and removed using this method, which enhances the overall accuracy of the model.
Calculate the mean (μ) and covariance (Σ) of the dataset:
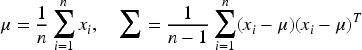
For each sample x, calculate the Mahalanobis distance:
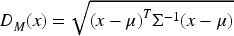
Detect outliers according to a specified threshold τ
Feature Selection
IBQANO: This algorithm is employed to select the most relevant features from the preprocessed data, ensuring that the model is optimized for performance.
Create a fitness function F to evaluate the chosen features:
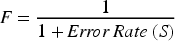
The IBQANO algorithm, which uses binary quantum encoding to efficiently explore feature combinations, should be used to optimize the feature subset S by maximizing F.
Model Training
DLRCN: The selected features are used to train this deep learning model, which is designed to capture both spatial and temporal patterns in the data.
DLRCN's architecture combines convolutional layers C for feature extraction and recurrent layers R for temporal pattern recognition.
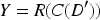
The output Y denotes the predicted probability of heart disease for each sample.
Hyperparameter Tuning
ABOA: The hyperparameters of the DLRCN were fine-tuned using this optimization algorithm to achieve the best possible model performance. Integrate ABOA to fine-tune the hyper-parameters of the DLRCN model, maximizing the prediction accuracy A:
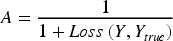
Adjust the weights W and biases B iteratively in accordance with the optimization criteria.
Prediction
Final Model Output: The trained model predicts the likelihood of heart disease based on the processed input data.
Data preprocessing is a foundational step in the data analysis pipeline, particularly in medical datasets where accuracy and completeness are paramount. Effective preprocessing techniques such as clustering-based data imputation and normalization and robust Mahalanobis distance-based outlier detection play a crucial role in preparing data. Clustering-based Data Imputation and Normalization is a sophisticated method designed to address the challenges of missing data through a two-phase approach: clustering and imputation, followed by normalization. In the clustering phase, the dataset is partitioned into distinct clusters using the K-means algorithm, which seeks to minimize the within-cluster variance. The K-means algorithm is iterative and optimizes the following objective function:
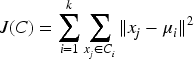
The imputation phase involves filling in missing values using statistical estimates derived from the data within each cluster. For a missing value 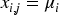
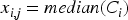
Min-Max Normalization:
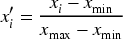
Z-score Standardization:
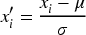
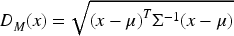
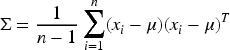

The IBQANO algorithm is a sophisticated method designed for binary optimization problems. It is particularly effective in feature selection tasks within medical datasets, such as heart disease prediction. By integrating the natural navigation behaviours of birds with quantum mechanics principles, this algorithm efficiently explores and exploits the search space to detect the optimal subset of features.
Avian Navigator Modelling:
V-echelon Communication Topology: This topology mimics the V-shaped flight formation of migratory birds, enhancing information exchange among search agents. It facilitates efficient communication, allowing agents to share valuable insights and converge towards optimal solutions. Quantum Focus Mechanism: This mechanism incorporates quantum principles to generate trial vectors, improving the algorithm's ability to explore the search space effectively. Short-term and Long-term Memory Structures: Each search agent has to store recent observations and long-term memory to retain historically best solutions. This dual-memory system helps balance exploration and exploitation. Quantum-based Navigation:
Mutation Strategies (“DE/quantum/I” and “DE/quantum/II”): Inspired by quantum mechanics, these strategies enable search agents to navigate the search space efficiently. Each flock is assigned one of these strategies based on the Success Probability Distribution (SPD) policy, which dynamically adapts to the search process. Qubit-crossover Operator: This quantum-inspired crossover mechanism enhances the diversity of the solutions generated.
The IBQANO's approach is summarized as:
Initialization: Randomly initialize N sets of search agents (binary vectors) in k separate geographic zones, each characterized by a random centroid. Each agent's position is encoded as a binary string representing a potential solution.
Flock Construction: Form k flocks by randomly selecting
Memory Setup: Establish short-term and long-term memory structures for each search agent. The long-term memory (
Formation of V-echelon Topology: Create the V-echelon communication topology for each flock, enabling efficient information exchange among search agents.
Assigning Mutation Strategies: Use the success graph to assign a mutation strategy to each flock based on the SPD policy. The mutation strategies, “DE/quantum/I” and “DE/quantum/II,” are designed to enhance the algorithm's exploration and exploitation capabilities.
Trial Vector Generation: Generate trial vectors for each search agent using the assigned mutation strategy:
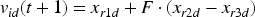
Where
Crossover: Perform crossover operations to create the trial vector 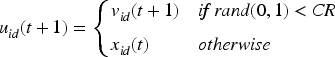
Selection: Choose trial vector:
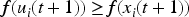
The vector with the better fitness value is retained for the next iteration.
Termination Check: Check if the termination condition (e.g., maximum iterations or convergence criteria) is met. If satisfied, terminate the algorithm; otherwise, return to step 2.
Display the Best Solution: Once the termination condition is met, display the best solution found by the algorithm.
The DLRCN is essential in this suggested work, combining convolutional and recurrent layers to identify complex spatial and temporal patterns in IoT sensor data. The convolutional layers excel at detecting spatial features like edges and shapes, which are vital for understanding heart disease indicators. On the other hand, the LSTM networks in the recurrent layers are very good at capturing temporal dependencies. This is very important for looking at time-series data where the order and context of data points are important. In this research, the DLRCN model, as shown in Figure 2, is utilized to process and analyze heart disease datasets, extracting complex features that traditional methods might overlook. The convolutional layers identify significant spatial features, while the LSTM layers capture temporal sequences, allowing the model to track how features change over time. This dual capability ensures a thorough analysis, leading to more accurate and reliable heart disease predictions. The DLRCN model makes predictions much better than earlier models because it combines these two powerful types of neural networks. Earlier models had trouble with temporal dynamics and spatial complexity.
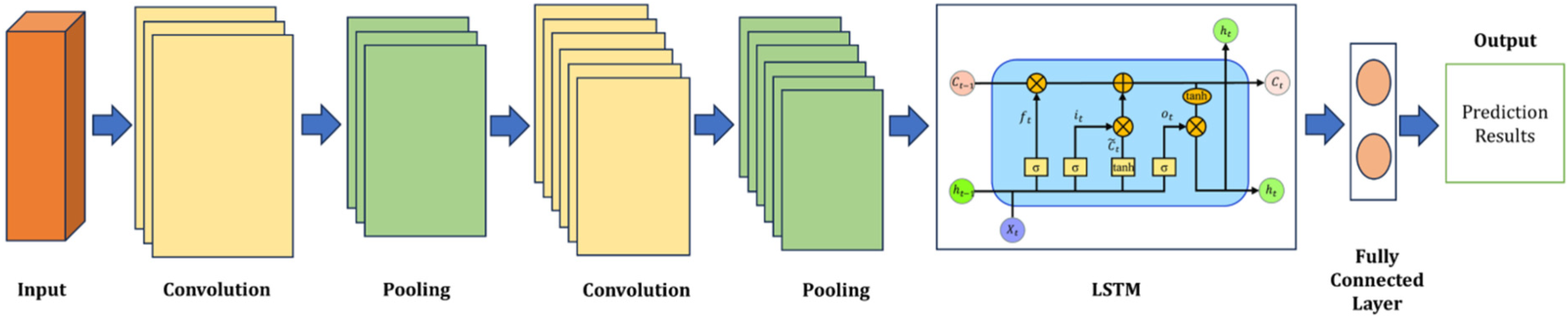
Proposed DLRCN structure.
The DLRCN performs classification tasks on time-series data. The DLRCN model architecture was carefully designed to exploit both spatial and temporal patterns in the time-series data. The architecture began with convolutional layers, which are adept at extracting spatial features from the input data. These layers apply a series of convolutional filters to detect local patterns and structures, such as edges and shapes, within the data. This spatial feature extraction is crucial for understanding the underlying characteristics of the time-series data. Following the convolutional layers, max-pooling layers were introduced to down-sample the feature maps.
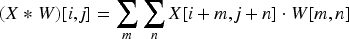
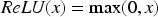
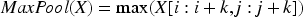
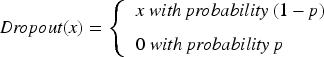






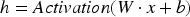
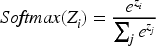

The ABOA is a unique technique inspired by the precise method of administering Botox injections to smooth out wrinkles. This concept is adapted to optimize the hyperparameters of the DLRCN model. The idea behind ABOA draws from the method of injecting Botox into specific facial muscles to induce localized muscle relaxation, which smooths the skin. In optimization terms, this translates to strategically updating decision variables (hyperparameters) to enhance the model's performance.
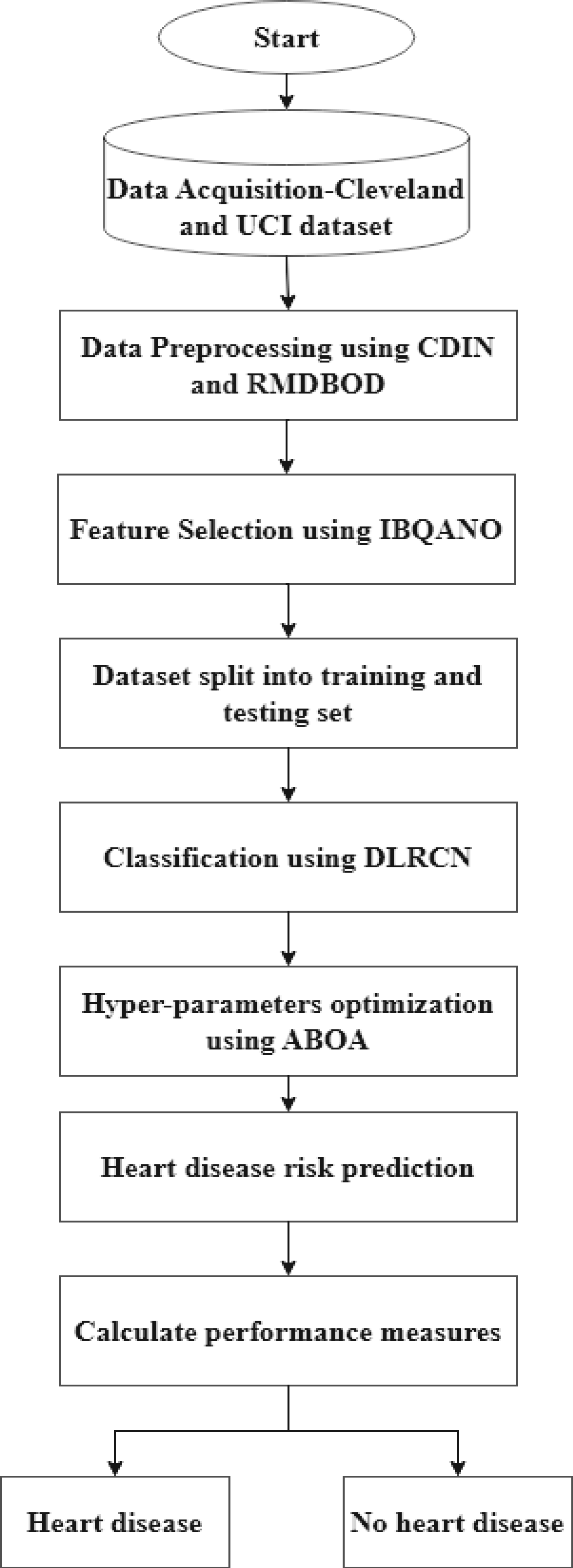
Flowchart of the proposed algorithm.
In this work, ABOA is critical because it dynamically adjusts the DLRCN model's hyperparameters for optimal performance. ABOA fine-tunes the model parameters by imitating the Botox injection process, ensuring that the DLRCN effectively captures both spatial and temporal patterns in the data. This optimization process not only improves the model's predictive accuracy but also ensures robustness and generalization across various datasets. The innovative use of ABOA in this research highlights its effectiveness in surpassing traditional hyperparameter tuning methods, offering an advanced solution for heart disease prediction.
The Adaptive Botox Optimization Algorithm (BOA) is inspired by the strategic process of administering Botox injections to enhance facial aesthetics by smoothing out wrinkles. This concept is adapted to optimize the hyperparameters of the DLRCN model. The idea behind ABOA draws from the method of injecting Botox into specific facial muscles to induce localized muscle relaxation, which smooths the skin. In optimization terms, this translates to strategically updating decision variables (hyperparameters) to improve the model's performance.
Algorithm Initialization:
ABOA operates as a population-based optimizer, leveraging the collective search capabilities of its participants to generate viable solutions for optimization problems.
Initialization:
Randomly initialize a set of search agents (candidate solutions) in the decision space. Each agent's position is represented as a vector:
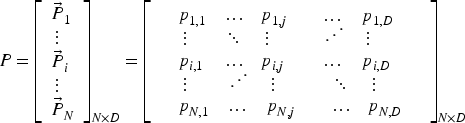
Each agent's position is initialized using:

Fitness Evaluation:
Evaluate the objective function for each ABOA member, forming a vector of objective function values:
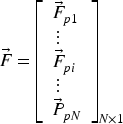
Position Update:
Determine the number of decision variables (muscles) requiring Botox injection:
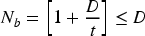
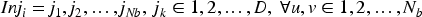
Botox Injection:
Compute the amount of Botox injection for each population member:
New Position Calculation:
Update the position of each ABOA member:
If the objective function value improves, replace the previous position:
This research introduces an innovative framework for heart disease classification. The use of the Deep Long-Term Recurrent Convolutional Network (DLRCN) and Figure 4. shows the Adaptive Botox Optimization Algorithm (ABOA) for hyperparameter tuning ensures robust performance, offering a cutting-edge solution for reliable heart disease prediction.

Flowchart of the adaptive botox optimization algorithm.
The proposed methodology leverages a range of foundational techniques to enhance the accuracy and reliability of heart disease predictions. The methodology includes advanced preprocessing techniques such as CDIN along with RMDBOD. These methods are essential for handling missing data and detecting outliers within medical datasets, ensuring that the data input into the model are of high quality, thereby reducing the chances of prediction errors. For feature selection, the methodology employs the IBQANO algorithm. This algorithm is highly effective in identifying the most pertinent features from complex datasets, which is critical for enhancing the model accuracy and minimizing computational requirements. By combining principles from quantum mechanics with avian navigation patterns, IBQANO efficiently explored the search space to determine the optimal subset of features for heart disease prediction. The core of the proposed methodology is the DLRCN, which is designed to capture both spatial and temporal patterns within the IoT sensor data. The convolutional layers of the DLRCN are adept at identifying spatial features such as edges and shapes, whereas the LSTM layers are skilled at recognizing temporal dependencies, making the model particularly effective for analyzing time-series data. This dual-layer architecture ensures comprehensive analysis of the data, leading to more accurate predictions. Additionally, the ABOA was used for the dynamic tuning of the DLRCN model hyperparameters. Drawing inspiration from the precision of Botox injections for targeted muscle relaxation, ABOA strategically adjusts the hyperparameters to optimize the performance of the model across various datasets. This approach offers an improvement over traditional hyperparameter-tuning methods, ensuring that the model remains both accurate and robust.
For this research, two distinct heart disease datasets the University of California (UCI) Repository Statlog Heart Disease Database and the Cleveland Heart Disease Database were utilized. The performance of the proposed heart disease algorithm evaluated with existing algorithms models includes CNN, RNN, Bi-LSTM, and DBN on the UCI and Cleveland datasets. By incorporating these advanced techniques, the proposed methodology effectively addresses key challenges, such as data quality, feature redundancy, and the complexity of temporal dependencies in medical datasets. This holistic approach leads to more reliable and accurate heart disease predictions, as evidenced by significant performance improvements over existing models, particularly when applied to the Cleveland and UCI heart disease datasets. This research evaluated the performance of the proposed models by comparing their results against various existing algorithms. The comparative analysis focused on metrics such as accuracy, precision, F-measure, specificity, sensitivity, BER, Kappa, SNR, and execution time. The proposed models demonstrated significant improvements in all these metrics, outperforming traditional machine learning methods and other deep learning approaches. The simulation was conducted using Python, with TensorFlow and Keras for deep learning tasks and Scikit-learn for data preprocessing and evaluation.
Parameters and formulas







For this research, two distinct heart disease datasets were utilized as shown in Table 2: the University of California (UCI) Repository Statlog Heart Disease Database and the Cleveland Heart Disease Database. 27 The attributes and characteristics of these datasets are outlined below:
Dataset description of UCI repository statlog and Cleveland heart disease database.
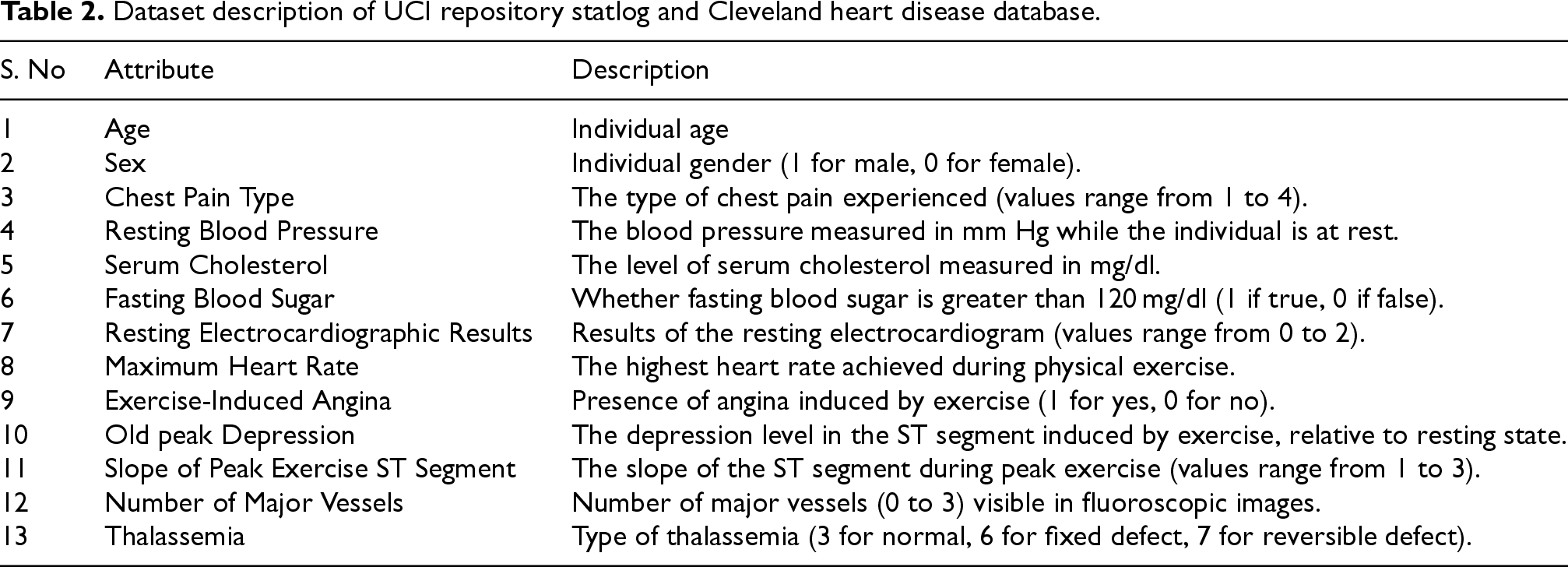
Dataset description of UCI repository statlog and Cleveland heart disease database.
The dataset comprises 13 attributes recorded from 270 subjects. Among the subjects, 150 are classified as negative (i.e., no heart disease, normal), while the remaining 120 are classified as positive (i.e., heart disease, infected). Notably, this dataset is complete, with no missing values present.
Cleveland heart disease database
The dataset includes data from 303 subjects, featuring 79 raw attributes. For this study, only 13 attributes were selected, with one attribute serving as the output class. Due to the presence of missing values, data from six subjects were excluded, resulting in a final dataset of 297 subjects for analysis. The individuals with heart disease are denoted by a label of ‘1’, while those without heart disease is labelled ‘0’. 35
Experimental setup
The experiments were performed on a system featuring an Intel Core i7 processor, 32GB of RAM, and an NVIDIA GTX 1080 GPU. The implementation was executed using Python, utilizing TensorFlow and Keras for deep learning tasks and Scikit-learn for data preprocessing and evaluation. Table 3 show the simulation parameters table.
Simulation parameters.

Simulation parameters.
This Table 4 outlines the essential hyperparameters used in training the classification model. The activation function is Sigmoid, which is suitable for binary classification as it outputs probabilities. The optimizer selected is Adam, chosen for its effectiveness and adaptability, with a learning rate set at 0.001 to provide consistent and steady updates to the model's parameters. Binary Cross Entropy is used as the loss function, fitting for binary classification tasks. The model training is conducted over a maximum of 50 epochs with a batch size of 32, balancing between training efficiency and model stability. Additionally, a validation split of 20% is utilized to evaluate the model's performance on unseen data during training, helping to prevent overfitting.
Hyperparameter configuration for model training.

Hyperparameter configuration for model training.
Figure 5(a) illustrates the training and testing accuracy, as well as the training and testing loss, over 50 epochs for the Cleveland Heart Disease dataset. The graph shows the training and testing accuracy, where both curves exhibit a steady increase as the epochs progress. Initially, there is a rapid increase in accuracy, which gradually tapers off as the model approaches higher levels of accuracy. By the end of the 50 epochs, both the training and testing accuracies are nearly converged, with values of 99.72%, indicating excellent model performance and generalization. Figure 5(b) depicts the training and testing loss, both of which exhibit a significant decrease as the epochs progress. Initially, there is a sharp drop in loss, indicating that the model is learning effectively. As training continues, the loss values for both training and testing datasets continue to decrease, with slight fluctuations towards the later epochs. By the end of the training period, the loss of 0.023% is a very low value, demonstrating that the model has effectively minimized errors and overfitting has been controlled.
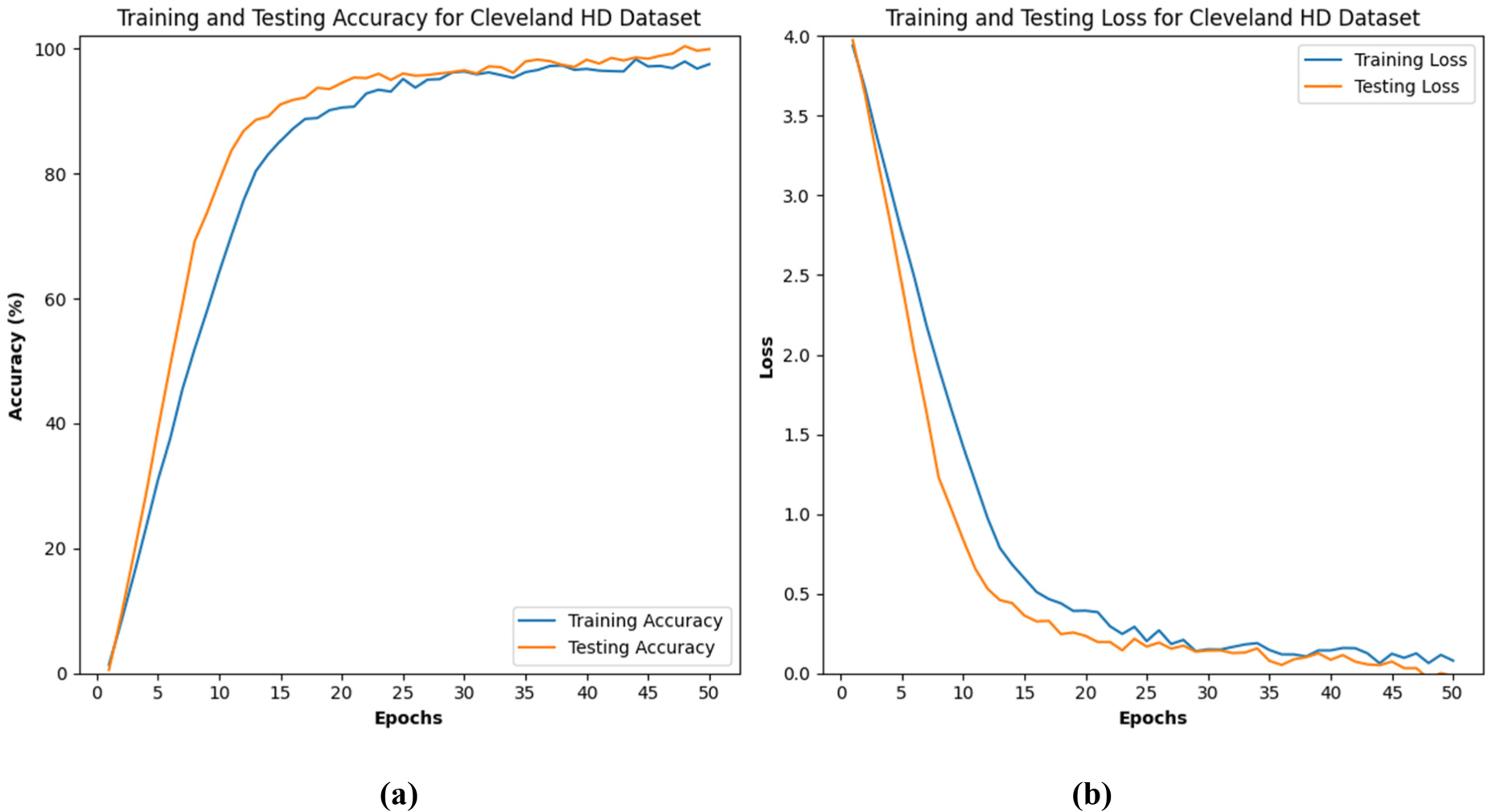
(a) and (b) represents the training and testing accuracy of Cleveland HD dataset.
The Figure 6(a) and (b) shows the training and testing performance of a model on the UCI Repository Statlog Heart Disease Dataset over 50 epochs. The accuracy plot indicates rapid improvement initially, with both training and testing accuracies stabilizing and converging near 99.41% by the end. The loss plot shows a sharp decrease in both training and testing losses initially, stabilizing around epoch 25, with minimal loss values by the end. Overall, the model demonstrates strong learning and generalization capabilities.
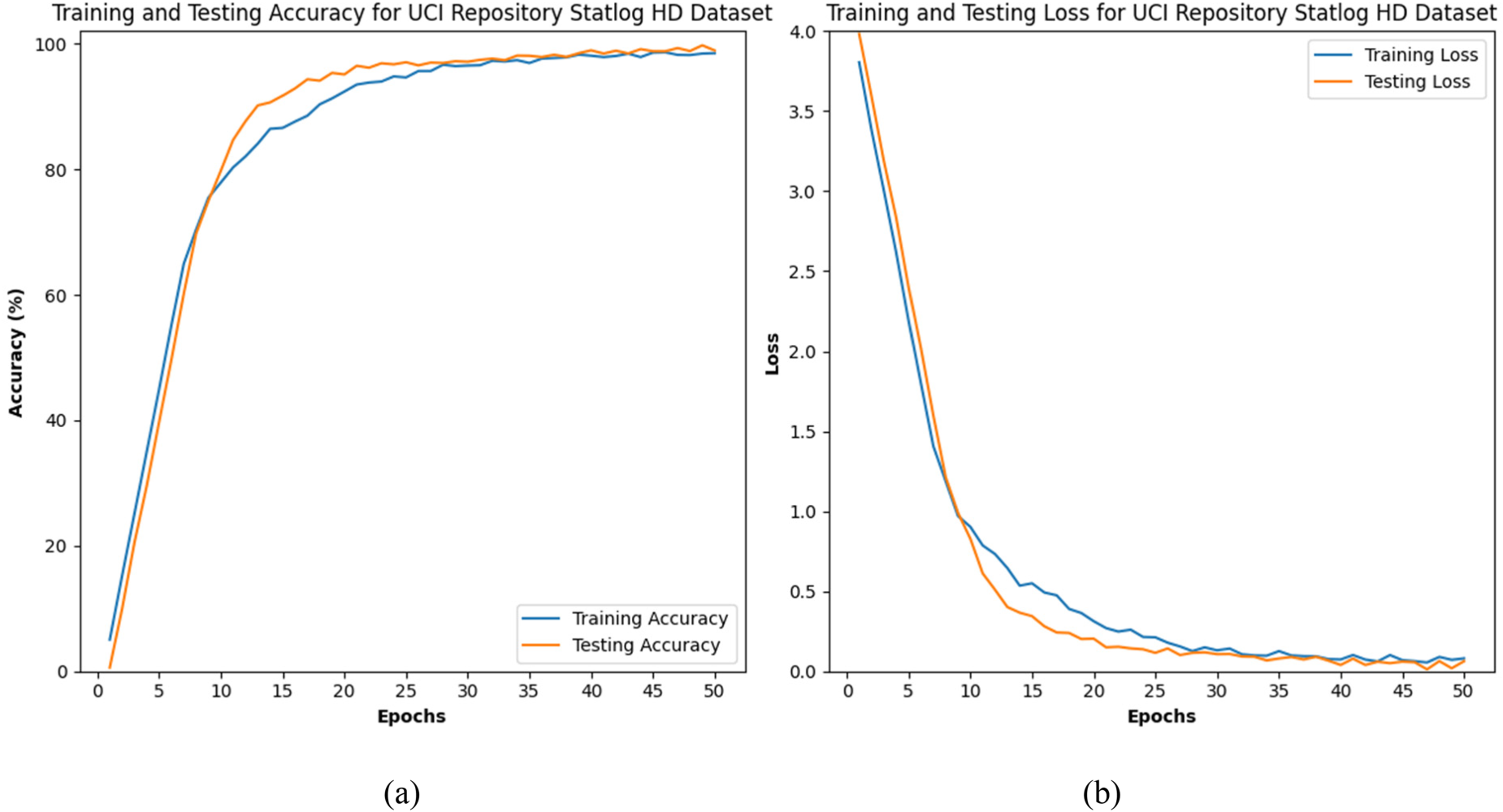
(a) and (b) represents the training and testing accuracy of UCI HD dataset.
The comparative analysis as shown in Figure 7 and Table 5 of various models for heart disease classification is illustrated in the figures and table. The evaluated models include CNN, RNN, Bi-LSTM, DBN, and the proposed models on the UCI and Cleveland datasets. The proposed model on the Cleveland dataset attained the highest accuracy at 99.72%, followed by the proposed model on the UCI dataset with 99.41%. In contrast, the traditional models exhibited lower accuracies, with both Bi-LSTM and RNN achieving 97.12%, CNN at 95.02%, and DBN at 98.45%. Precision results further demonstrate the superior performance of the proposed models. The Cleveland dataset model achieved a precision of 99.66%, and the UCI dataset model reached 99.35%. The traditional models, such as CNN, RNN, and Bi-LSTM, showed precision values of 96.07%, 97.87% and 97.54%, respectively, while DBN had a slightly lower precision of 96.79%.
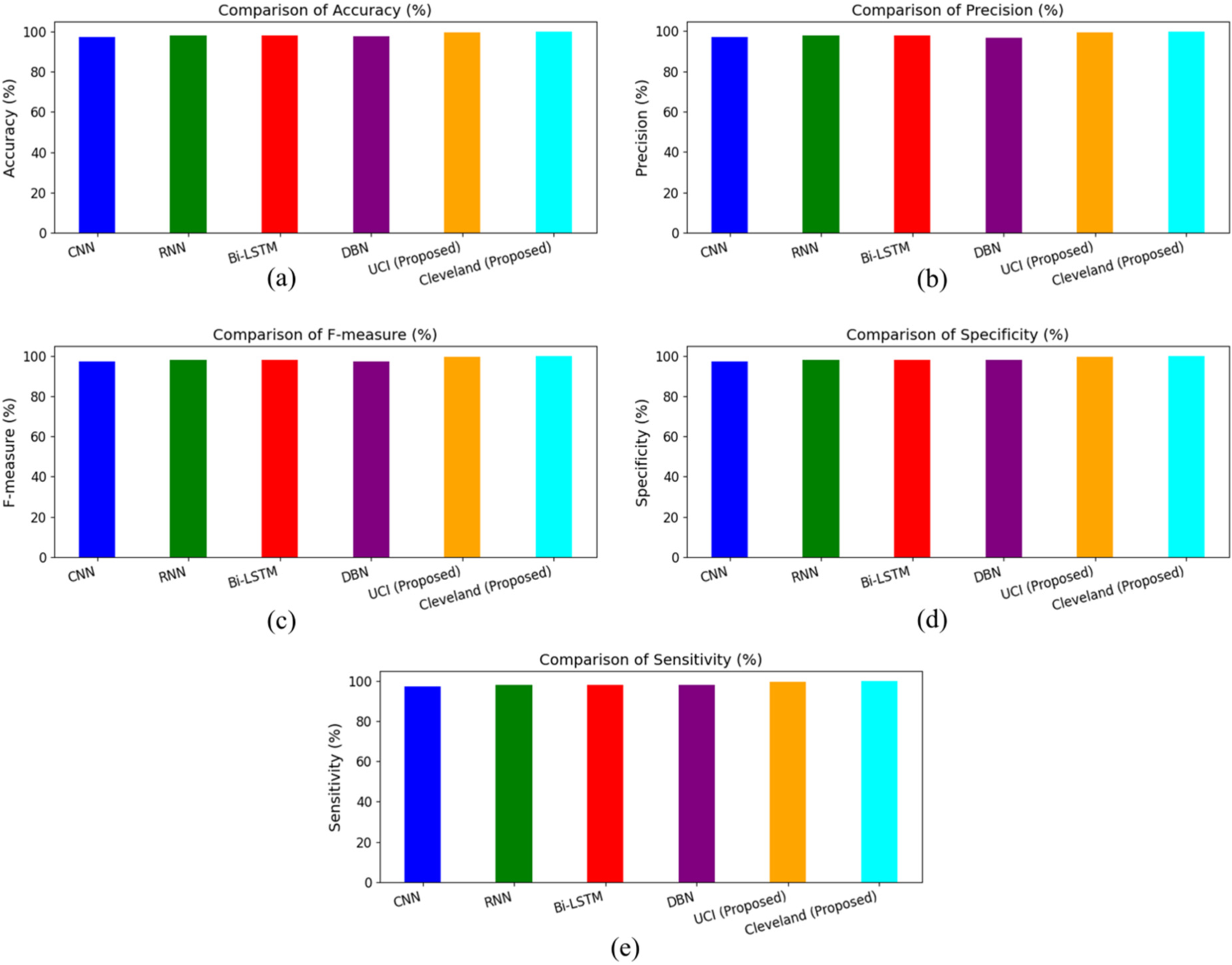
Comparative performance analysis of models based on key metrics.
F-measure values also highlight the robustness of the proposed models, with the Cleveland dataset model achieving 99.69% and the UCI dataset model achieving 99.38%. Among the traditional models, Bi-LSTM and RNN both attained 97.89%, 96.82, CNN achieved 95.04%, and DBN reached 97.24%. Specificity results for the proposed models, with the Cleveland dataset model showing 99.67% and the UCI dataset model showing 99.36%. Traditional models displayed lower specificity, with CNN at 94.21%, RNN at 97.92%, Bi-LSTM at 97.47%, and DBN at 97.76%. In terms of sensitivity, the Cleveland dataset model led with 99.71%, followed closely by the UCI dataset model at 99.39%. Traditional models showed lower sensitivity values, with CNN at 97.02%, RNN at 97.92%, Bi-LSTM at 97.87%, and DBN at 97.76%. The proposed models on the UCI and Cleveland datasets significantly outperformed the traditional models (CNN, RNN, Bi-LSTM, DBN) across all evaluation metrics. This demonstrates the effectiveness of the proposed approach in enhancing accuracy, precision, F-measure, specificity, and sensitivity for heart disease classification.
The comparative analysis as shown in Figure 8 and Table 6 of various models for heart disease classification, focusing on metrics such as BER, Kappa, SNR, and execution time, is detailed in the figures and table. The models evaluated include CNN, RNN, Bi-LSTM, DBN, and the proposed models on the UCI and Cleveland datasets. The proposed model for the Cleveland dataset achieved the lowest BER at 89.00%, followed by the UCI dataset model at 90.00%. Traditional models showed higher BERs, with CNN at 97.34%, RNN at 95.44%, Bi-LSTM at 93.1%, and DBN at 92.01%. The Kappa statistic values highlight the superior performance of the proposed models. The Cleveland dataset model achieved the highest Kappa value at 99.00%, followed by the UCI dataset model at 98.00%. Among traditional models, CNN had a Kappa of 94.2%, RNN at 90.33%, Bi-LSTM at 88.45%, and DBN at 82.1%.
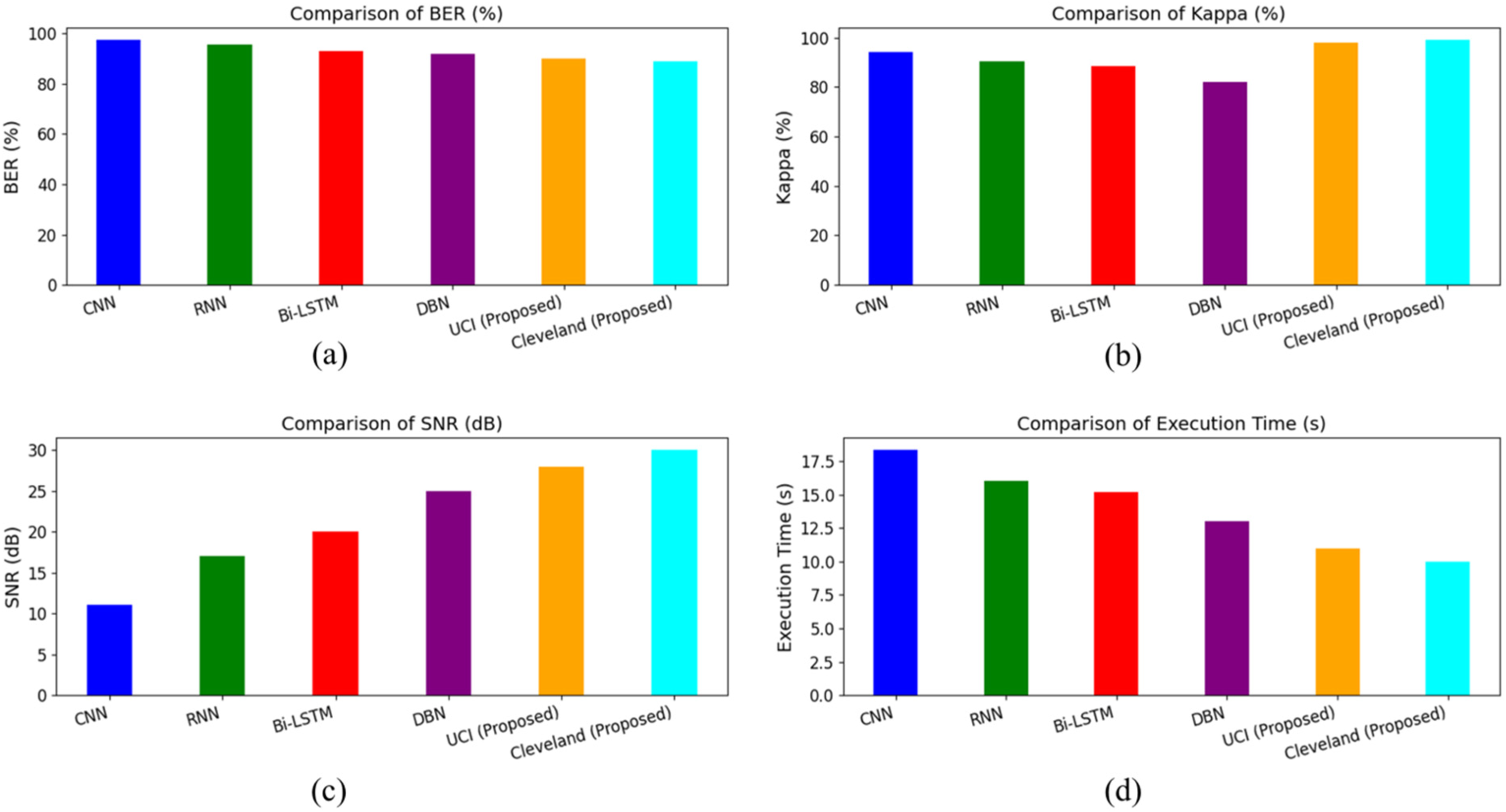
Performance metrics analysis: BER, kappa, SNR, and execution time.
The SNR results favor the proposed models, with the Cleveland dataset model achieving the highest SNR at 30 dB, followed by the UCI dataset model at 28 dB. Traditional models showed lower SNR values, with DBN at 25 dB, Bi-LSTM at 20 dB, RNN at 17 dB, and CNN at 11 dB. In terms of execution time, the proposed models demonstrated faster performance. The Cleveland dataset model had the shortest execution time at 10 s, followed by the UCI dataset model at 11 s. Traditional models exhibited longer execution times, with CNN at 18.33 s, RNN at 16.01 s, Bi-LSTM at 15.22 s, and DBN at 13.01 s. The proposed models on the UCI and Cleveland datasets significantly outperformed the traditional models (CNN, RNN, Bi-LSTM, DBN) across all evaluated metrics, including BER, Kappa, SNR, and execution time. This demonstrates the effectiveness of the proposed approach in enhancing accuracy and efficiency for heart disease classification.
The Table 7 shows the analysis of model performance metrics reveals that the proposed models, particularly the Cleveland (Proposed) model, exhibit superior effectiveness compared to traditional models. Both UCI (Proposed) and Cleveland (Proposed) models demonstrate outstanding performance across all evaluation metrics, including Negative Predictive Value (NPV), Positive Predictive Value (PPV), True Negative Rate (TNR), True Positive Rate (TPR), Area Under the Curve (AUC), and Matthews Correlation Coefficient (MCC). Notably, the Cleveland (Proposed) model achieves the highest AUC (99.47%) and MCC (93.34%), indicating its exceptional ability to distinguish between positive and negative cases and overall classification accuracy. In contrast, traditional models such as CNN, RNN, Bi-LSTM, and DBN, while performing well, do not reach the high benchmarks set by the proposed models.
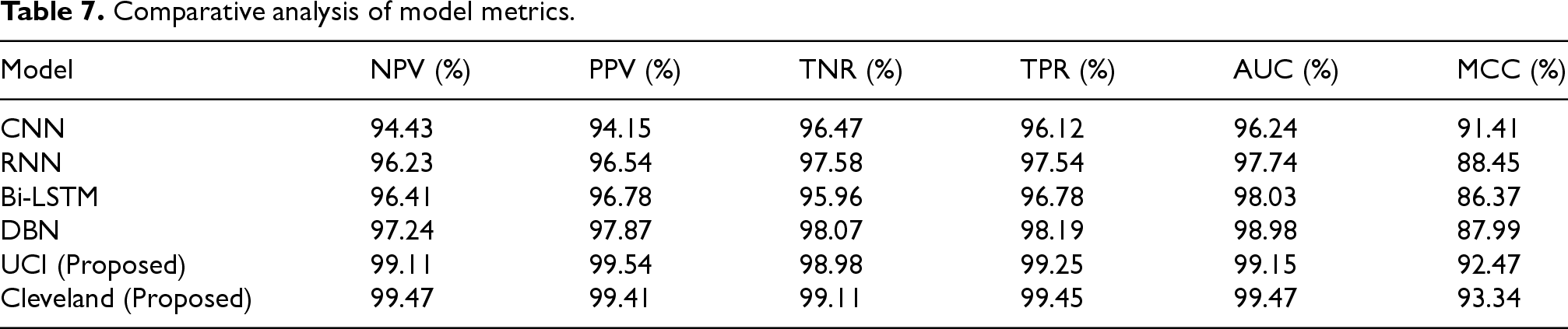
The presented results as shown in Figure 9 and Table 8 provide a detailed evaluation of various models for heart disease classification, using five key performance metrics: accuracy, precision, F-measure, specificity, and sensitivity. The proposed models, UCI and Cleveland, exhibit superior performance across all these metrics when compared to existing methods. In terms of accuracy (Figure a), the Cleveland model achieves the highest score at 99.72%, closely followed by the UCI model at 99.41%. This represents a notable improvement over other model such as those by Ramkumar et al. (98.99%) and G. Rajkumar et al. (98.01%). Similarly, for precision (Figure b), the Cleveland and UCI models lead with 99.66% and 99.35% respectively, showcasing their enhanced ability to correctly identify positive cases. The F-measure (Figure c), which balances precision and recall, again highlights the Cleveland model at the top with 99.69%, followed by UCI at 99.38%. This trend of the proposed models outperforming others continues in specificity (Figure d), where Cleveland and UCI achieve 99.67% and 99.36% respectively, demonstrating their effectiveness in correctly identifying negative cases. Finally, regarding sensitivity (Figure e), the Cleveland model scores the highest at 99.71%, with UCI following at 99.39%. This underscores the proficiency of the proposed models in accurately detecting true positive cases, thereby minimizing missed diagnoses of heart disease. Thus, the proposed UCI and Cleveland models consistently outperform existing methods across all measured metrics, highlighting their robustness and reliability in heart disease classification. This thorough evaluation confirms the efficacy of the proposed approaches in providing superior diagnostic performance.
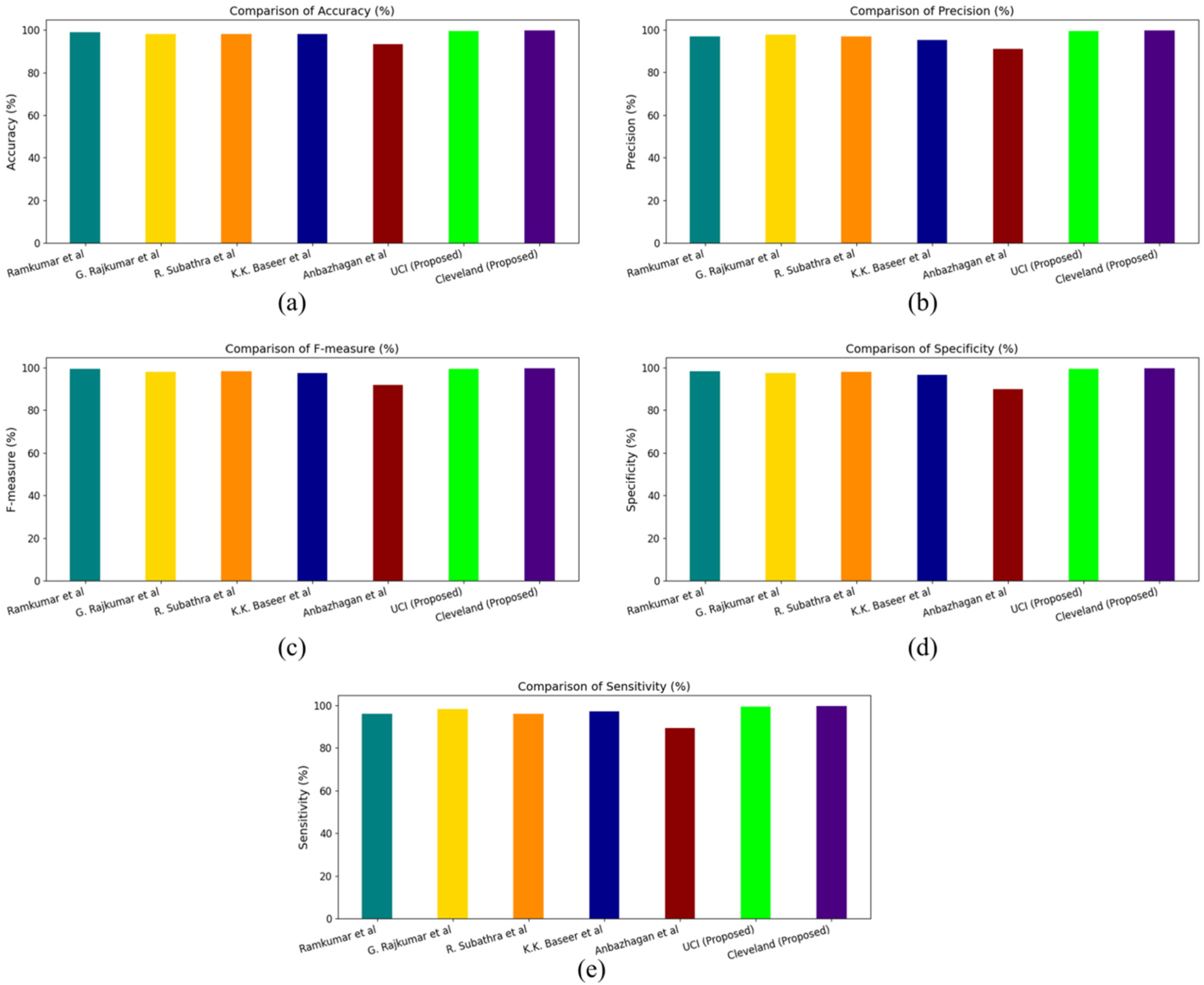
Performance analysis of state-of-the-art and proposed models.
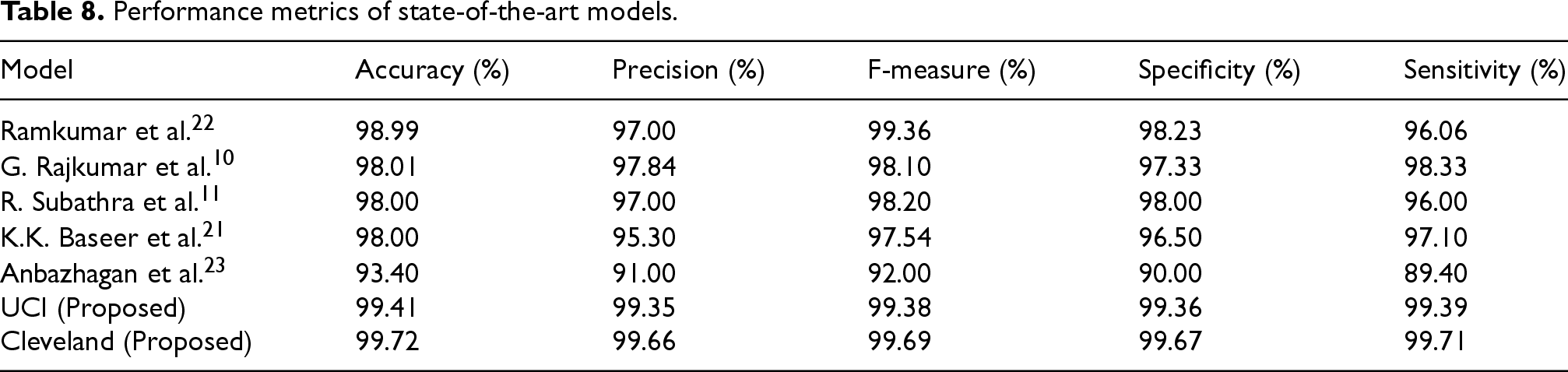
The Table 9 shows the performance analysis of the proposed models, UCI (Proposed) and Cleveland (Proposed), significantly outperform traditional machine learning algorithms. Among the conventional methods, Random Forest achieves the highest accuracy (96.10%) and precision (95.85%), while other models like SVM, Decision Tree, and Logistic Regression show lower metrics. K-Nearest Neighbours performs the least favourably. In contrast, the proposed models excel with UCI (Proposed) reaching an accuracy of 99.41% and precision of 99.35%, and Cleveland (Proposed) achieving even higher scores with an accuracy of 99.72% and precision of 99.66%. Both proposed models demonstrate exceptional specificity and sensitivity, highlighting their superior effectiveness and reliability in classification tasks compared to traditional algorithms.
Comparative analysis of performance metrics with existing deep learning methods.
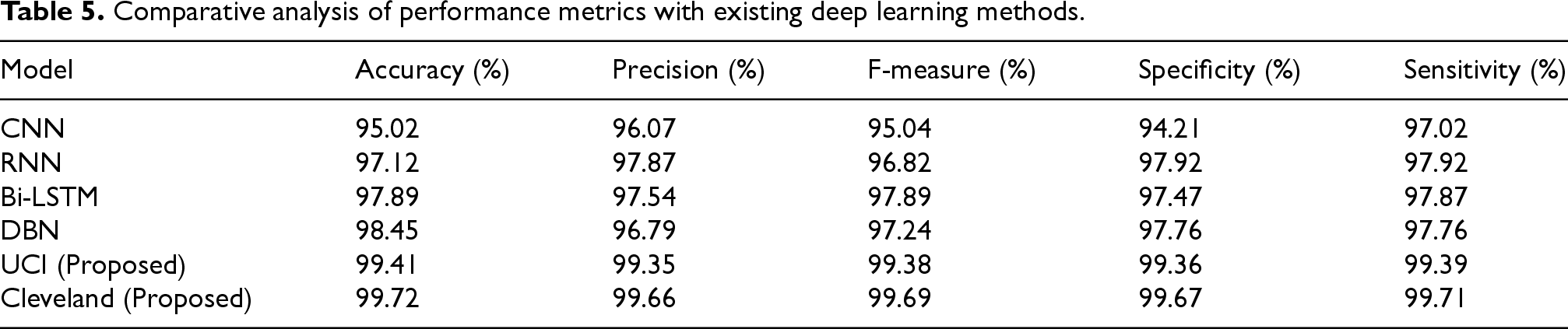
Comparative analysis of performance metrics with existing deep learning methods.
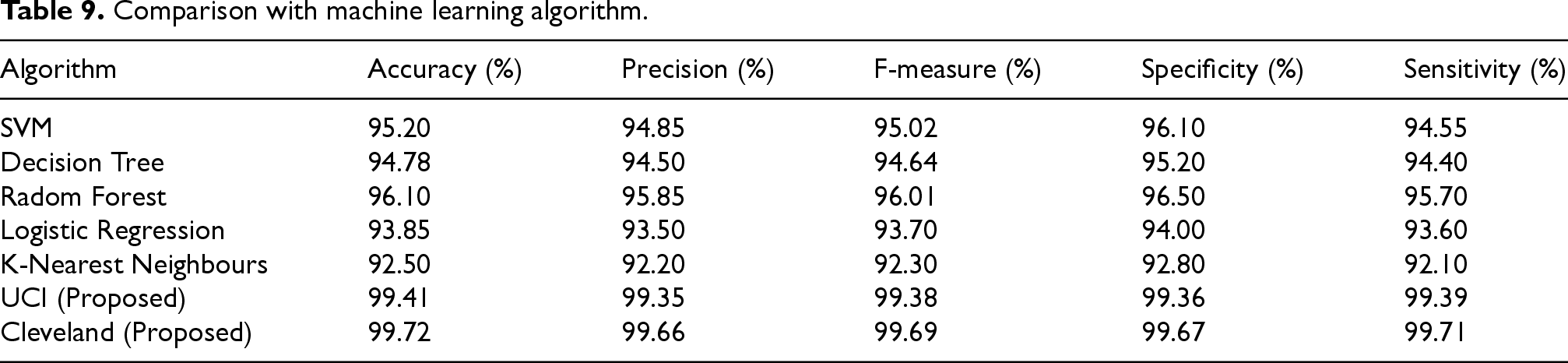
The performance evaluation as shown in Table 10 shows of various hybrid DL models illustrates a clear advantage for the proposed models, particularly in terms of accuracy, precision, F-measure, specificity, and sensitivity. Among the hybrid approaches, the Hybrid DenseNet – LSTM – DE model stands out with an impressive accuracy of 98.23% and precision of 97.98%, closely followed by the Hybrid CNN - PSO model, which achieves an accuracy of 98.05% and precision of 97.80%. Other hybrid models, such as Hybrid CNN - GA and Hybrid LSTM - ACO, also show strong performance but fall slightly short compared to these top performers. The Hybrid VGG – ResNet - GSA model, while performing well, shows relatively lower metrics compared to the top hybrids. In contrast, the proposed models, UCI (Proposed) and Cleveland (Proposed), achieve exceptional results with UCI (Proposed) reaching an accuracy of 99.41% and Cleveland (Proposed) surpassing all with an accuracy of 99.72% and precision of 99.66%. These proposed models significantly outperform the hybrid models, highlighting their superior effectiveness and robustness in classification tasks, and underscoring their advanced capability in achieving highly accurate and reliable results.
Performance comparison of different models.
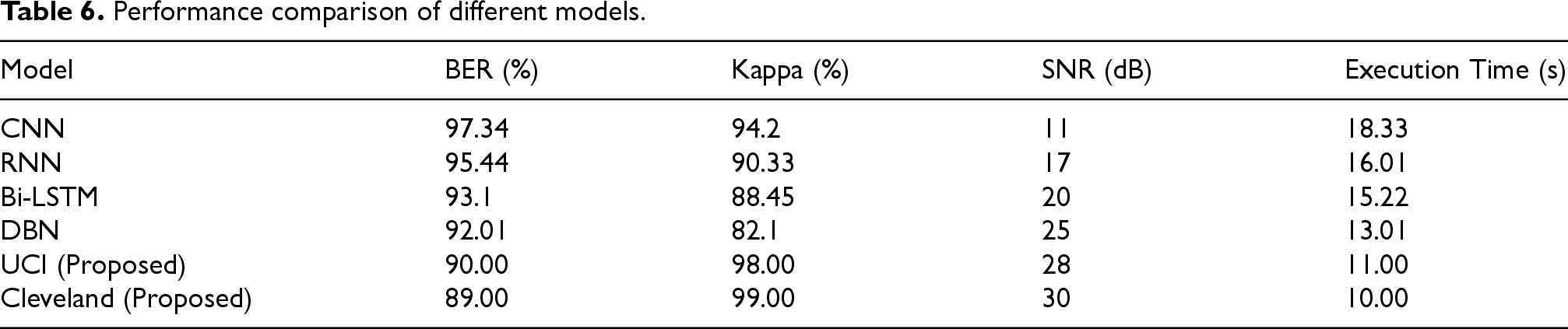
Comparative analysis of model metrics.
Performance metrics of state-of-the-art models.
Comparison with machine learning algorithm.
Comparison with hybrid optimization with deep learning algorithm
The computational complexity of various algorithms sheds light on the resources required for their execution as shown in Table 11. CNNs have a complexity of
Computational complexity.

Computational complexity.
RF algorithms exhibit a complexity of
This study thoroughly examined the proposed methodology for heart disease prediction using two widely recognized datasets: the UCI Repository Statlog Heart Disease Database and the Cleveland Heart Disease Database. These datasets were selected because of their comprehensive nature and frequent use by the research community, making them ideal for comparative analysis.
Case study 1: UCI repository statlog heart disease database
The UCI dataset included 270 samples, each characterized by 13 features, such as age, sex, chest pain type, resting blood pressure, and serum cholesterol levels. This dataset was split into training and testing sets, and the proposed DLRCN model, optimized with the ABOA, was applied. The results showed substantial improvements in key metrics, such as accuracy, precision, F-measure, specificity, and sensitivity, compared to traditional machine learning models and even some hybrid deep learning approaches. Notably, the model achieved an accuracy of 99.41%, which represents a significant enhancement over the previous methods applied to this dataset. For the UCI dataset, the proposed model recorded a BER of 90.00%. The Kappa value for this model was 98.00%. The SNR results were also favorable, with the UCI dataset model achieving an SNR of 28 dB. The use of CDIN and RMDBOD during preprocessing ensured high data quality, while the IBQANO algorithm effectively selected the most relevant features, contributing to the model's overall success.
Case study 2: Cleveland heart disease database
The Cleveland dataset, which contains data from 303 subjects and features similar to those in the UCI dataset, was used to validate the proposed methodology further. After pre-processing and feature selection, the DLRCN model was trained and evaluated using this dataset. The model achieved an impressive accuracy of 99.72%, surpassing the performance of the existing models in the literature. The integration of the ABOA for hyperparameter tuning is particularly effective in optimizing the performance of the model. This case study underscores the robustness and generalizability of the proposed methodology across various datasets. The Cleveland dataset, known for its complexity owing to missing values and noise, benefited significantly from the advanced preprocessing and optimization techniques employed in this research. The proposed model for the Cleveland dataset achieved the lowest Bit Error Rate at 89.00%. It also attained the highest Kappa value at 99.00%. Additionally, the model demonstrated superior Signal-to-Noise Ratio, reaching a peak of 30 dB.
The findings from both case studies highlight the potential of the proposed model for real-world applications, particularly in scenarios where data quality and feature relevance are critical. The consistently high accuracy achieved across different datasets suggests that this methodology can be effectively applied to other medical datasets, potentially leading to better diagnostic tools and improved patient outcomes.
Discussion
Overview of the proposed methodology
The approach developed for heart disease prediction in this study combines advanced pre-processing, feature selection, and deep learning techniques specifically designed for IoT sensor data. The methodology is innovative in its application of several sophisticated techniques such as CDIN and RMDBOD for preprocessing. These methods are crucial for ensuring data quality by effectively managing issues, such as missing data and outliers, which are common in medical datasets.
For feature selection, the IBQANO algorithm was employed. This algorithm is well-suited for binary optimization problems, making it particularly effective in identifying the most relevant features in medical datasets. The classification process is executed using a DLRCN, which integrates convolutional and recurrent layers to detect both spatial and temporal patterns in the data. This hybrid structure enables the model to process the complex dynamics found in the IoT sensor data. Additionally, the ABOA was used to fine-tune the hyperparameters of the model, further enhancing its performance.
Experimental parameters
The training of the DLRCN model was conducted with specific key hyperparameters, which are summarized below.
Activation Function: Sigmoid, chosen for its effectiveness in binary classification by producing probability outputs between 0 and 1. Optimizer: Adam, selected for its flexibility and efficiency in optimizing the model parameters. Learning Rate: Set at 0.001, providing consistent updates during training. Loss function: binary cross-entropy, suitable for binary classification tasks. Max Epochs: 50, balancing model convergence with training time. Batch Size: 32, optimizing the trade-off between training speed and model stability. Validation Split: 20% was used to assess the model performance on unseen data and reduce overfitting risks.
These carefully chosen parameters were instrumental in achieving the high accuracy levels reported in this study.
Experimental results and comparative analysis
The proposed models were evaluated using the Hungarian, UCI, and Cleveland heart disease datasets, showing considerable improvements over the existing methods. The Cleveland dataset model achieved 99.72% accuracy, whereas the UCI dataset model achieved 99.41% accuracy. This superior performance is a result of integrating advanced preprocessing techniques, feature selection, and the DLRCN model, which effectively captures the intricate patterns within the data.
Compared to traditional models, such as CNN, RNN, Bi-LSTM, and DBN, the proposed models outperformed them in all key metrics, including accuracy, precision, F-measure, specificity, and sensitivity. For instance, while the best traditional model (DBN) achieved an accuracy of 98.45%, the proposed Cleveland model achieved 99.72%, demonstrating the advantages of the proposed methodology.
The proposed methodology demonstrated clear superiority over existing techniques across several critical metrics, including accuracy, precision, F-measure, specificity, and sensitivity. The model achieved an impressive accuracy of 99.72% on the Cleveland dataset and 99.41% on the UCI dataset, outperforming traditional models, such as CNN, RNN, Bi-LSTM, and DBN. With precision values of 99.66% for the Cleveland dataset and 99.35% for the UCI dataset, the model effectively identified true-positive cases, thereby minimizing false-positives. In terms of specificity, the model excelled with values of 99.67% for the Cleveland dataset and 99.36% for the UCI dataset. This high specificity ensures the accurate identification of true negatives, which is crucial in reducing unnecessary treatments or interventions due to false positives. The model also showed strong sensitivity, with 99.71% for the Cleveland dataset and 99.39% for the UCI dataset, effectively minimizing missed diagnoses of heart disease.
Moreover, the proposed approach achieves a lower Bit Error Rate (BER) of 89.00% for the Cleveland dataset and 90.00% for the UCI dataset, which is notably lower than those of the traditional methods. The model's Kappa statistic, at 99.00% for the Cleveland dataset and 98.00% for the UCI dataset, indicated a high level of agreement between the predicted and actual classifications, reinforcing the reliability of the model. Additionally, the model achieved a superior Signal-to-Noise Ratio (SNR) of 30 dB for the Cleveland dataset and 28 dB for the UCI dataset, demonstrating its effectiveness in distinguishing relevant signals from noise, thus ensuring clearer and more accurate predictions. These enhancements across various metrics—accuracy, precision, specificity, sensitivity, BER, Kappa, and SNR—highlight the performance and reliability of the proposed methodology, establishing it as a highly effective solution for heart disease prediction.
Summary
This study introduced a comprehensive framework for heart disease prediction that utilizes advanced preprocessing techniques, feature selection algorithms, and a hybrid deep learning architecture. The proposed models deliver exceptional performance on benchmark datasets, significantly outperforming the existing methods in terms of accuracy and reliability. By integrating CDIN, RMDBOD, IBQANO, and DLRCN and leveraging the fine-tuning capabilities of ABOA, the methodology addresses critical challenges in heart disease prediction, such as handling missing data, reducing feature redundancy, and managing complex temporal dependencies.
The findings suggest that the proposed methodology offers a robust and accurate solution for heart disease classification, which could significantly enhance the diagnostic accuracy of remote healthcare monitoring systems. Future research should focus on validating these models with real-world clinical data, integrating them with electronic health record (EHR) systems, and exploring multimodal data fusion techniques to further enhance model performance and applicability in various clinical settings.
This study addresses a highly relevant and current healthcare challenge: the accurate prediction of heart disease, which remains a leading cause of death globally. The integration of IoT-based data and advanced deep learning models for real-time illness prediction aligns with ongoing advancements in healthcare technology, making the research particularly timely.
Conclusion
The results demonstrate that the proposed models, utilizing the UCI and Cleveland datasets, significantly outperform existing methods in all evaluated metrics, including accuracy, precision, F-measure, specificity, and sensitivity. Advanced preprocessing techniques like CDIN and RMDBOD ensure high data quality, while the IBQANO algorithm effectively selects the most relevant features. The DLRCN model, fine-tuned with ABOA, captures both spatial and temporal dependencies in the data, providing robust classification performance. This comprehensive approach addresses challenges such as missing data, outliers, and feature redundancy, resulting in more reliable and accurate heart disease predictions. On the Cleveland dataset, the proposed model achieves an accuracy of 99.72%, precision of 99.66%, F-measure of 99.69%, specificity of 99.67%, and sensitivity of 99.71%. The UCI dataset model also performs exceptionally well, with an accuracy of 99.41%, precision of 99.35%, F-measure of 99.38%, specificity of 99.36%, and sensitivity of 99.39%. These outstanding results highlight the potential of the proposed models to enhance diagnostic accuracy and reliability, offering a cutting-edge solution for heart disease classification. Future work should focus on validating the models with real-world clinical data, integrating them with EHR systems, enhancing explainability, and exploring multi-modal data fusion. Additionally, investigating real-time implementation, personalized medicine approaches and continuous learning mechanisms will ensure the models remain up-to-date and effective, ultimately contributing to better patient care and outcomes.
The study concludes that the proposed model outperforms existing approaches in terms of key metrics, and the results are supported by the data presented. The discussion of the model's performance is logical and consistent with the findings. While the proposed DLRCN showcases impressive performance over existing algorithms, it faces several significant drawbacks. Security concerns arise regarding the handling of sensitive patient data, necessitating robust measures to protect privacy. Additionally, the lack of real-world clinical validation poses a challenge, as laboratory results may not fully translate to practical healthcare settings. Furthermore, integrating the proposed models with existing EHR systems can be complex, requiring careful alignment with current workflows and data formats to ensure seamless adoption in clinical practice.
Future research should aim to validate these models in clinical settings, enhance their adaptability to a wider range of patient populations, and explore the integration of multimodal data to further improve their diagnostic accuracy and effectiveness. First, real-world clinical validation is essential. Future studies should focus on applying the proposed models to real clinical data from diverse patient populations, which would help ensure that the models are robust and generalizable across different demographics and clinical conditions. Second, integrating the proposed models with existing EHR systems could enable real-time predictions and automated alerts for healthcare providers, facilitating timely interventions and improving patient care through continuous data streams from IoT devices. Another promising direction is the fusion of multimodal data, such as combining physiological data with imaging data (e.g., ECG signals with echocardiograms), which can enhance the accuracy and reliability of heart disease predictions by providing a more comprehensive view of the patient's condition.
Additionally, as AI adoption in healthcare increases, the need for models that are not only accurate but also interpretable has become crucial. Future research should focus on developing methods that explain the predictions made by these models, ensuring that healthcare providers trust and understand the decision-making process. Furthermore, the proposed methodology can be extended to support personalized medicine by tailoring predictions to individual patients based on their unique characteristics and medical history, leading to more precise and effective treatment plans and improved patient outcomes. Finally, developing models that can continuously learn from new data and adapt to changes in patient conditions or population health trends is essential for maintaining the relevance and accuracy of predictions over time. These future directions not only highlight the potential for extending the current work, but also underscore the importance of ongoing innovation and adaptation in the field of AI-driven healthcare.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
All data analysed during this study are included in this article.