
Abstract
Zell and Alicke (2009) have shown that comparisons with a few people have a stronger influence on self-evaluations than comparisons with larger samples. One explanation for this effect is that people readily categorize their standing in small groups as “good” or “bad,” which supersedes large-sample data. To test this explanation, we created a situation in which students learned that their performance ranked 5th or 6th out of 10 persons on a task. In each experimental session, two groups, each containing 5 people, were created by random assignment. Some students learned that their performance placed them last in one group of 5, and some learned that they were first in the other group of 5. In the other conditions, participants learned only that that they were 5th or 6th in the group of 10. Results showed that being last in the superior group led to lower self-evaluations than being first in the inferior group.
Self-knowledge is a dear and precarious commodity: difficult to obtain and sometimes painful when acquired. In a perfect informational world, people would have reliable and valid data from large samples on which to calibrate the extremity and worth of their habits, thoughts, preferences, skills, and desires. In the real world, self-knowledge is haphazard: One friend praises the poem that I wrote, but another lampoons it. One day I trounce my golf partners, and the next requires an expedition to find my golf ball in the woods. In this welter of confusing, contradictory, and incomplete feedback, it is no wonder that self-knowledge is often tenuous, inaccurate, and overly optimistic (Alicke & Sedikides, 2009).
One fundamental source of bias in self-knowledge and self-evaluation derives from social comparison opportunities for analyzing personal characteristics. Festinger’s (1954) social comparison theory was the first to highlight the importance of comparisons with other people for self-knowledge. Festinger emphasized the conditions that would make such comparisons useful and the types of comparisons that would be most informative. Whereas Festinger’s theory depicted a deliberate process of choosing comparisons and weighing their consequences, the subsequent history of social comparison research argues for a more spontaneous process (Blanton & Stapel, 2008). In short, comparisons are typically encountered rather than sought: They are less something we hanker after than something we cannot avoid.
The ubiquity and spontaneity of comparisons suggest that people will tend to assess their actions and outcomes with reference to whatever targets are available, regardless of their diagnosticity (Gilbert, Giesler, & Morris, 1995). In fact, local comparison information involving a relatively small group of available targets supersedes the effect of much larger and more valid sample data (Buckingham & Alicke, 2002; Zell & Alicke, 2009). One facet of this local comparison effect that educational and developmental psychologists have studied involves comparisons that arise in schools and their influence on students’ self-concepts (Davis, 1966). The most prominent investigations in this line of research have been conducted on the big-fish-in-a-little-pond, or frog-pond, effect (Huguet et al., 2009; Marsh & Parker, 1984; Marsh et al., 2008, in press; Seaton, Marsh, & Craven, 2009).
The frog-pond effect is the finding that high-performing students at academically inferior schools evaluated themselves more favorably than low-performing students at superior schools, after researchers statistically controlled for ability level. The frog-pond effect has been demonstrated in elementary, middle, and high school settings across more than 40 diverse countries (Seaton, Marsh, & Craven, 2009). Recently, we have conducted studies to expand the frog-pond effect into a general conception of local versus general comparisons (Zell & Alicke, 2009). We have shown, for example, that being the best or worst performer in a small group of 5 people influences self-evaluations more than information about one’s standing in a population of over 1,500 individuals. In fact, when local comparison information is available, it generally negates the effect of larger population data (Buckingham & Alicke, 2002). We believe, therefore, that the frog-pond effect is an important manifestation of the tendency for highly available local information to supersede more general comparison information, which we call the local dominance effect.
The local dominance effect has been widely demonstrated (Buckingham & Alicke, 2002; Zell & Alicke, 2009) but sparsely explained. On the basis of past research, an obvious guess about local dominance would be that people are relatively insensitive to large numbers and abstract base rates (Borgida & Nisbett, 1977; Kahneman & Tversky, 1973). However, we have shown that large-sample data are very influential when local comparison information is absent; it is the dominance of local over general comparison information that remains to be explained.
One explanation that we pursue in this work is that local comparisons entail perceptions of group membership and that people habitually evaluate themselves with reference to their group standing. This, of course, is the essential assumption of social identity theory (Tajfel & Turner, 1986), which we extend to the contrast between local and general comparisons. Local comparisons, especially with family members and small groups of peers, are the primary source of self-knowledge throughout early development. Children learn to categorize themselves in various ways: as the shyest member of their family, the fastest runner among their friends, a middling math student in their class, and so on. Although standardized tests and media depictions provide some experience with larger aggregates, the pervasive tendency to categorize oneself in relation to a few salient others remains the most influential mode of self-evaluation.
One way to demonstrate the importance of categorization in self-evaluation is to counterpose conditions in which an individual’s performance outcome varies only by whether it is defined in terms of its standing in a minimal group or a larger group. Consider the case of a student who learns that she is the fifth or sixth best performer among the 10 people who have completed a task, thus placing her in the middle of the pack. Now consider the same scores but this time defined in reference to separate groups of 5 students: In Group A, the student’s fifth-ranking score places her at the bottom of the pack, whereas in Group B, her sixth-ranking score places her at the top (i.e., everyone in Group A performs better than everyone in Group B). This is an extreme experimental analogue of the frog-pond situation, in which a student is either the lowest scorer in a superior group or the highest scorer in an inferior one, although the experimental situation has the advantage that the student knows exactly where she stands among all participants.
If local group categorizations matter, then the student who is the best member of the bad group should evaluate her or his performance more favorably than the student who is the worst member of the good group, despite having objectively worse performance (6th of 10 vs. 5th of 10). Another compelling finding would be to show that the student who places 5th in the good group evaluates himself or herself more negatively than the student who learns only that she is 5th overall, whereas the student who places 1st in the bad group evaluates herself more favorably than the student who learns only that she is 6th overall.
Method
Participants and design
One hundred students (67 female and 33 male) at a large Midwestern university participated in exchange for course credit in an introductory psychology class. Each experimental session contained 10 participants. Participants were randomly assigned to one of four feedback conditions (fifth, sixth, worst and fifth, or best and sixth), which yielded a 2 (rank: fifth or sixth) × 2 (grouped or ungrouped) between-subjects design.
Materials and procedure
Students were told that the research they were participating in focused on the effects of group membership on performance. The experimenter stated that some studies have found that people perform better in groups than alone, whereas others had found that people perform worse in groups than when alone. The purpose of the present study was ostensibly to help resolve these contradictory findings.
The 10 students were categorized into one of two 5-person groups (Group A or Group B) according to the letter they drew out of a hat. To ensure that there was no contact among group members, students were told that it was essential that they did not talk to any of the other participants, although they were encouraged to speak to the experimenters if they had any questions. After sorting the students into groups, we brought each group separately into a computer laboratory. Students in Group A were seated in a column on the right side of the room, and students in Group B were seated in a column on the left side of the room.
Participants then completed a lie detection test. The test required students to watch peers making videotaped statements and then to indicate, for each statement, whether they thought the peers were telling the truth or lying (Buckingham & Alicke, 2002). The video clips were displayed on a large projector screen, and participants indicated their responses privately at their computers using the MediaLab computer program (Jarvis, 2004).
After watching and responding to 15 video clips, students were provided with bogus feedback about their performance. All participants were told that they had correctly identified 9 of 15 statements as a truth or a lie and that this performance ranked 5th or 6th of the 10 people in the room. Then some participants were given additional information indicating that they ranked best or worst in their 5-person group.
After reviewing their feedback, students evaluated their performance (“How well do you think you performed on the lie detection test?”) and lie detection ability (“How would you rate your lie detection ability?”) on 7-point scales, ranging from 1, very poorly/bad, to 7, very well/good. Scores were aggregated to create an index of self-evaluation (r = .52). Finally, as a feedback manipulation check, participants were asked to recall how well they performed relative to the 9 other students currently taking part in the experiment as well as how well they performed relative to the 4 other people in their small group (assuming they received this information).
Results
We removed the data of 4 participants because they failed one or more of the feedback manipulation checks. There were no gender effects in any of the analyses for this study; thus, gender is not discussed further.
A 2 × 2 analysis of variance was conducted on self-evaluation ratings, and only a Rank (fifth or sixth) × Group (grouped or ungrouped) two-way interaction was obtained, F(1, 92) = 7.33, p < .01, ηp 2 = .07 (see Fig. 1). Simple-effects tests showed that students who were told only that they ranked 5th in the room (M = 5.33) did not evaluate themselves significantly more favorably than students who were told only that they ranked 6th (M = 5.00, p > .15). 1 However, in keeping with the main prediction, students evaluated themselves significantly more favorably when they ranked 6th out of 10 but best in their 5-person group (M = 5.70) as opposed to 5th out of 10 but worst in their 5-person group (M = 4.78), t(92) = 2.81, p < .005, d = 0.90.
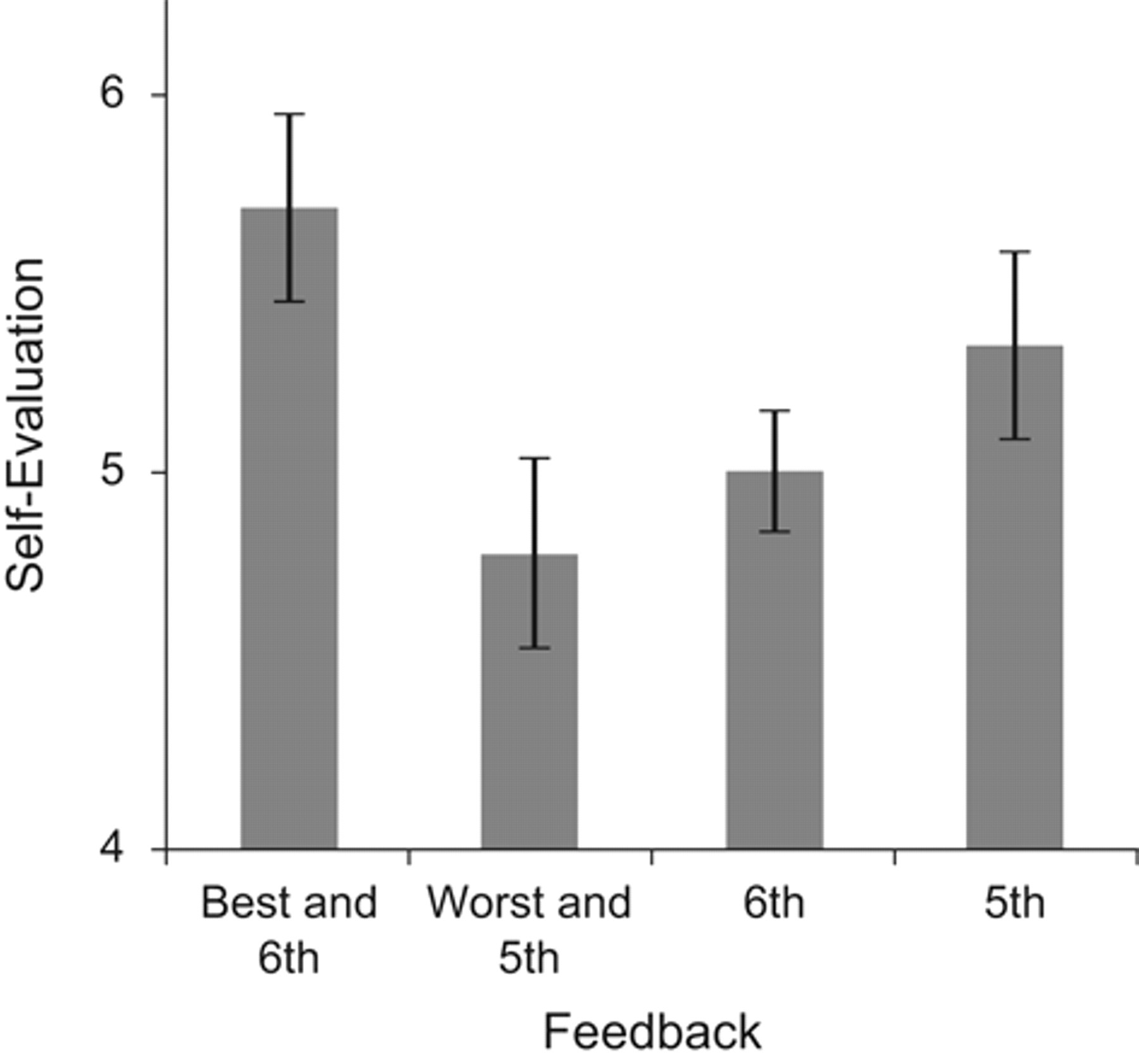
Participants’ mean self-evaluations (rated on a scale ranging from 1, very poorly/bad, to 7, very well/good) as a function of test feedback. Participants were told that their rank among 10 persons was 5th, 6th, 5th and worst in their 5-person group, or 6th and best in their 5-person group. Error bars represent ±1 SE.
Simple-effects tests were also conducted to examine whether ranking in the group of 5 altered self-evaluations relative to knowledge of overall ranking among the 10 participants. As expected, students evaluated themselves significantly more favorably when they learned that they ranked 6th out of 10 but best in their 5-person group as opposed to simply learning that they ranked 6th out of 10, t(92) = 2.17, p < .02, d = 0.67. Additionally, students evaluated themselves significantly less favorably when they ranked 5th out of 10 but worst in their 5-person group as opposed to just 5th out of 10, t(92) = 1.67, p < .05, d = 0.45.
Discussion
The findings of this study suggest strongly that social categorization contributes to the well-known frog-pond effect, as well as to local dominance more generally. Simply dividing participants into groups arbitrarily produced a tendency to favor local information for self-evaluation over a larger data source. These findings suggest that the frog-pond and local dominance effects are pervasive phenomena that occur whenever local comparison data are available with which to categorize one’s standing in a group, even when group membership is minimal.
The present findings also provide further validation for frog-pond findings that have been obtained in real educational settings. Although research on the frog-pond effect statistically equates good members of bad groups and bad members of good groups (Marsh & Parker, 1984; Marsh et al., 2008), there is always the possibility in nonexperimental designs that the findings may reflect accurate self-evaluations, that is, that the good students in mediocre schools are in some way superior to the poorer students in superior schools. Excellent students attend mediocre schools for various reasons, whereas superior schools almost inevitably contain some unmotivated students. Our experimental design demonstrated frog-pond type effects in a context in which their accuracy or inaccuracy could be objectively assessed. In other words, although ranking 5th among 10 people is objectively better than ranking 6th, categorization into groups produced a situation in which being ranked 6th led to more favorable self-evaluations than being ranked 5th. Those who ranked 5th contrasted their ability from the group standard, a finding consistent with those of Huguet et al. (2009); that is, contrast typically occurs when comparisons are forced or encountered (as they were in our study) as opposed to selected by the participant.
A logical outgrowth of the present research is to see how far these findings can be extended. Would seventh-ranked members evaluate themselves more favorably than fourth-ranked members based on group categorization? Eighth better than third? At some point, reality constraints will operate to negate the local dominance effect, but further research is needed to establish the extent to which local group categorization overrides more diagnostic data from a larger information source.
Footnotes
The authors declared that they had no conflicts of interests with respect to their authorship and/or the publication of this article.
1.
Because we had clear directional predictions, and strong theoretical justification for these predictions, all reported t tests are one-tailed.