
Abstract
Humans imitate each other during social interaction. This imitative behavior streamlines social interaction and aids in learning to replicate actions. However, the effect of imitation on action comprehension is unclear. This study investigated whether vocal imitation of an unfamiliar accent improved spoken-language comprehension. Following a pretraining accent comprehension test, participants were assigned to one of six groups. The baseline group received no training, but participants in the other five groups listened to accented sentences, listened to and repeated accented sentences in their own accent, listened to and transcribed accented sentences, listened to and imitated accented sentences, or listened to and imitated accented sentences without being able to hear their own vocalizations. Posttraining measures showed that accent comprehension was most improved for participants who imitated the speaker’s accent. These results show that imitation may aid in streamlining interaction by improving spoken-language comprehension under adverse listening conditions.
Humans often imitate each other in social interaction (Chen, Chartrand, Lee-Chai, & Bargh, 1998). These imitative actions cover a wide range of behaviors, including manual gestures, body postures, facial expressions, mannerisms, and speech patterns (Chartrand & Bargh, 1999). Imitative behavior in humans streamlines social interaction by increasing affiliation and empathy between interaction partners (La France, 1979). In addition, imitative behavior aids in vicarious learning (Bandura, 1977; Mattar & Gribble, 2005), which occurs as a function of observing, processing, and replicating the actions of other people. The present study was designed to investigate whether vocal imitation can improve comprehension of language spoken in an unfamiliar accent.
The motivation for this study comes from theoretical approaches that propose that action comprehension activates internal cognitive mechanisms also used in action execution (Bandura, 1986; Brass, Wohlsläger, Bekkering, & Prinz, 2000; Meltzoff & Moore, 1977; Meltzoff & Prinz, 2002; Wilson & Knoblich, 2005), and that action execution can, in turn, improve action understanding (Hecht, Vogt, & Prinz, 2001; Prinz, 1992, 1997). Moreover, it has been suggested that imitating other people’s actions may make it easier to predict their subsequent actions, especially when the meaning they are trying to convey is ambiguous or distorted (Kappes, Baumgaertner, Peschke, & Ziegler, 2009; Pickering & Garrod, 2007; Wilson & Knoblich, 2005).
The present study used a novel speech accent to test whether imitation of unfamiliar actions indeed improves understanding of these actions. Imitation of accented speech is especially suited for testing this hypothesis, for two reasons. First, accented speech contains phonetic and phonological variations (Adank, van Hout, & Van de Velde, 2007; Best, McRoberts, & Goodell, 2001) that may lead to ambiguities and other distortions that listeners must resolve during spoken-language understanding. For instance, Japanese learners of English have difficulty in producing a distinction between the vowels in slip and sleep, as these vowels are not contrastive in Japanese. This ambiguity in pronunciation may make it difficult for native English listeners to determine which word is being spoken. Consequently, comprehension of an unfamiliar accent is reflected in slower and less efficient processing compared with comprehension of a familiar accent (Adank, Evans, Stuart-Smith, & Scott, 2009; Floccia, Goslin, Girard, & Konopczynski, 2006).
The second reason that speech with an unfamiliar accent is suited for testing our hypothesis is that vocal imitation of phonetic and phonological variation is already commonplace in everyday life. For instance, people engaged in dialogue spontaneously imitate each others’ intonation patterns (Goldinger, 1998), clarity of speech (Lakin & Chartrand, 2003), speech rate (Giles, Coupland, & Coupland, 1992), regional accent (Delvaux & Soquet, 2007), and style of speech (Kappes et al., 2009). If imitation of an ambiguous action improves subsequent understanding of that action (Kappes et al., 2009; Pickering & Garrod, 2007; Wilson & Knoblich, 2005), then imitating an unfamiliar accent may subsequently improve comprehension of utterances spoken in that accent; that is, imitation may allow listeners to better anticipate the phonetic and phonological variation in accented speech.
Our study evaluated the effect of several forms of training on the comprehension of accented speech. Listeners heard sentences spoken in an unfamiliar accent of Dutch. This unfamiliar accent was obtained by systematically altering the pronunciation of vowels in stressed lexical positions, with the aim of creating a nonexistent accent of Dutch. Using such a novel accent ensured that all listeners were equally unfamiliar with the speech we used in the study. This approach was necessary because relative familiarity with an accent affects the processing of accented speech (Adank et al., 2009; Floccia et al., 2006). Comprehension of this novel accent, which the first author has used in a previous study, has been found to resemble comprehension of existing regional and foreign accents (Adank & Janse, 2010).
Following a pretest that measured their accent comprehension, listeners were split into six groups. The baseline group received no training. Participants in the other groups heard 100 sentences spoken in the unfamiliar accent. In the listening group, participants were instructed to merely think about the sentences they heard. In the repeating group, participants repeated the sentences in their own accent (i.e., without imitating the unfamiliar accent). The transcription group wrote a semiphonetic transcription of the pronunciation aspects of the sentences. The imitation group verbally imitated the exact pronunciation of the sentences, and the imitation-plus-noise group listened to the sentences without background noise and then imitated the sentences while their own vocalizations were masked with noise. Finally, all listeners were tested again on their comprehension of the unfamiliar accent, using the same procedure as in the pretest. The duration of the whole experiment was approximately 25 min for the baseline group and 35 min for the other groups.
The baseline group was included in the study to ascertain whether training in itself would lead to posttest improvement. The listening group was included to ensure that mere additional auditory exposure to the unfamiliar accent could not explain posttest improvement. The repeating group was included to test whether the motor act of speaking influenced posttest performance. The transcription group was included to ensure that paying attention to phonetic and phonological aspects of the accented sentence could not explain posttest improvement. The imitation group was included to test whether imitation of the unfamiliar accent resulted in a posttest improvement in comprehension of the unfamiliar accent. The imitation-plus-noise group was included to investigate whether improvement in the imitation group was due to imitation per se or to auditory feedback from the participants’ own voices while imitating the recordings. We reasoned that if comprehension improved more in the imitation and imitation-plus-noise groups than in the other groups, this would support the hypothesis that imitation improves understanding of ambiguous or distorted actions.
Method
Participants
One hundred twenty participants took part in the experiment. Participants were native monolingual speakers of Dutch from The Netherlands, had no history of oral or written language impairment, had no neurological or psychiatric diseases, and had no known hearing problems. None of the participants had special expertise related to the tasks to be executed. All gave written informed consent and received course credit for participation.
Twenty participants were randomly assigned to each of six groups. Each group contained 2 males and 18 females, except for the imitation-plus-noise group, which contained 4 males and 16 females. Participants’ age varied across groups—baseline group: mean = 23.6 years, median = 20.0 years, range = 18 to 41 years; listening group: mean = 21.9 years, median = 20.5 years, range = 18 to 30 years; repeating group: mean = 20.6 years, median = 20.0 years, range 18 to 29 years; transcription group: mean = 21.8 years, median = 21 years, range = 18 to 33 years; imitation group: mean = 21.8 years, median = 21.0 years, range = 18 to 29 years; and imitation-plus-noise group: mean = 21.4 years, median = 20.0 years, range = 18 to 31 years. Participants were tested individually in a soundproof booth.
Stimuli
All stimuli were identical across groups. The testing stimulus set consisted of 120 sentences (evenly divided between the pretest and posttest), and the training stimuli consisted of a different set of 100 sentences. All sentences were short declarative statements pronounced in an accent that was unfamiliar to participants. The testing sentences were taken from the literature on speech reception threshold (SRT; Plomp & Mimpen, 1979) and had also been used in Adank and Janse (2010). The testing and training sentences are listed in Tables S1 and S2 in the Supplemental Material available online. Stimuli were presented over headphones (HD477; Sennheiser, Old Lyme, CT) at a comfortable sound level.
Stimuli were created by instructing a female speaker of Standard Dutch to read sentences with an adapted orthography (Table 1). The orthography was altered systematically to achieve the following changes in all Dutch vowels: All tense-lax vowel pairs were switched (e.g., /ε/ was pronounced as /e:/, and vice versa), /u/ was pronounced as /Y/, and all diphthongal vowels were realized as monophthongal vowels (e.g., /œy/ was pronounced as /y/). Only vowels bearing primary or secondary stress were included in the orthography conversion. The following is an example of a sentence in Standard Dutch and a converted version of the sentence, including a broad phonetic transcription of each sentence using the International Phonetic Alphabet (International Phonetic Association, 1999):
Standard Dutch: “De bal vloog over de schutting” (“The ball flew over the fence”) /dǝ bɑl flo: After conversion: “De baal flog offer de schuuttieng” /dǝ ba:l flɔx ɔfǝr dǝ sxy:ti:ŋ/
Vowel Conversions for Obtaining the Novel Accent
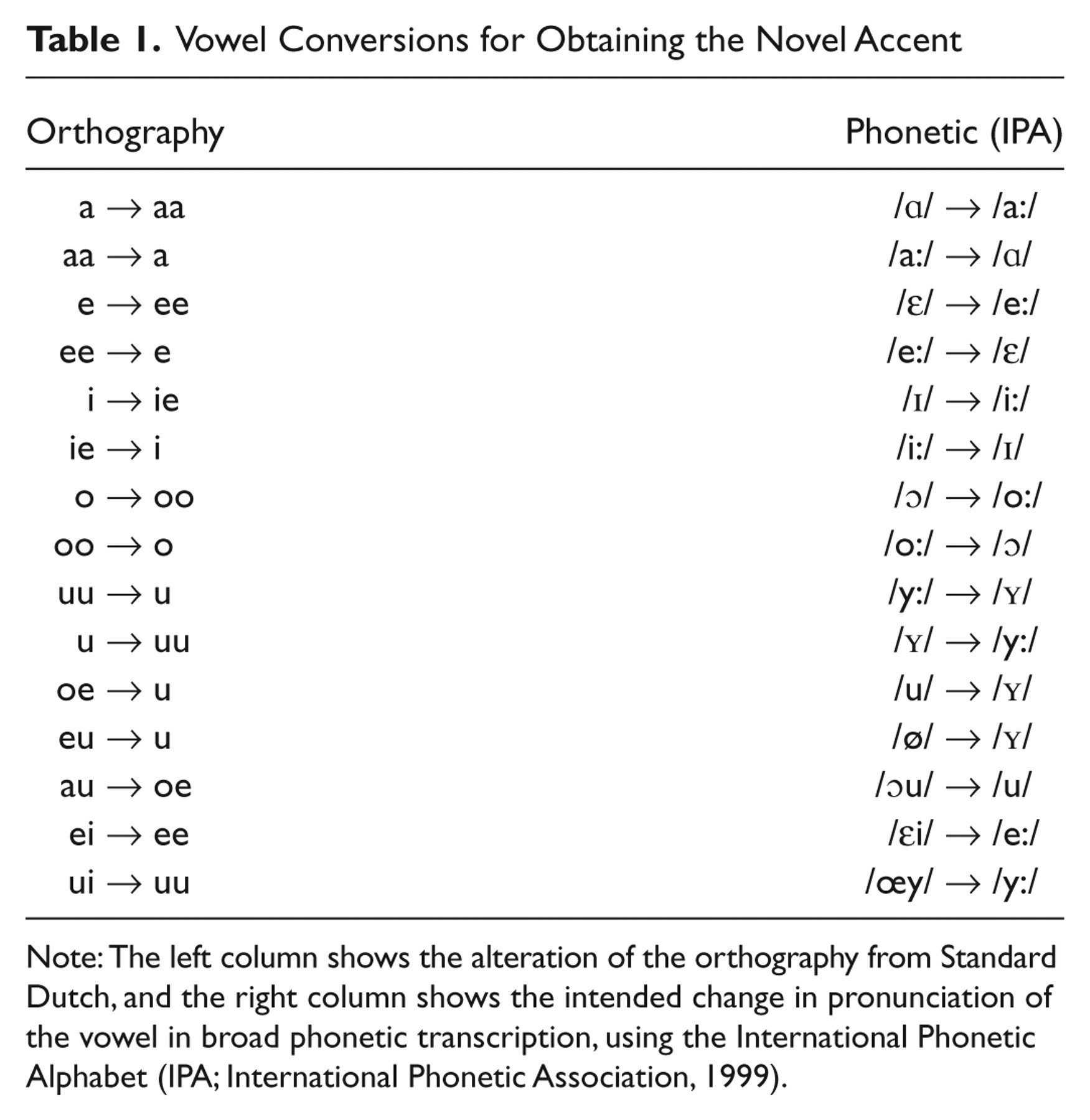
Note: The left column shows the alteration of the orthography from Standard Dutch, and the right column shows the intended change in pronunciation of the vowel in broad phonetic transcription, using the International Phonetic Alphabet (IPA; International Phonetic Association, 1999).
The recordings were made in a soundproof booth. The speaker was monitored from sentence to sentence during recording by the first author (a trained phonetician). All sentences were saved into separate sound files. The beginnings and endings of the sentences were trimmed at zero crossings and resampled at 22,050 Hz at 70 dB sound pressure level (SPL).
Procedure
Pretest and posttest
The procedure for pretesting and posttesting was identical across groups. Using an auditory staircase procedure (Baker & Rosen, 2001), we determined each listener’s SRT (Plomp & Mimpen, 1979) in decibels. The SRT is expressed using the signal-to-noise ratio (SNR) at which listeners can repeat 50% of the key words in a sentence (key words were taken from a previous study—Adank & Janse, 2010—and are indicated in Table S1 in the Supplemental Material). The SRT has been used as a measure of speech intelligibility (Dubno, Dirks, & Morgan, 1984; van Wijngaarden, Steeneken, & Houtgast, 2002) and is a naturalistic method of establishing comprehension skills. The SRT was estimated after each block: four times in the pretest and four times in the posttest. Participants listened to each sentence with speech-shaped background noise. After hearing each sentence, they were instructed to repeat in Standard Dutch as many words as they had heard. They were told not to imitate the speaker’s accent.
Each sentence contained four key words. If listeners correctly reported three or four of the key words, the SNR for the next sentence to be presented deteriorated (i.e., more noise was added). If listeners correctly reported one of the key words, then the SNR was increased (i.e., less noise was added). If listeners correctly reported two of the key words, then the SNR stayed the same. Listeners received no explicit feedback. Every individual sentence was presented only once per participant, and presentation of all sentences was semirandomized and counterbalanced across the pretest and the posttest.
Training phase
Following the pretest, participants in all but the baseline group received training. Participants listened to 100 sentences that were different from the testing sentences. In the listening group, participants listened (without speaking) to the sentences without background noise. They were instructed to imagine what sentence the speaker was intending to say in Standard Dutch; this was done to discourage them from focusing too much on the phonetic and phonological aspects of the accented sentence. There was a 2-s pause between sentence presentations.
In the repeating group, the procedure was the same as for the listening group, except that participants repeated each sentence aloud in Standard Dutch after the recording stopped. Participants were explicitly instructed not to imitate the speaker’s accent. If participants did imitate the accent, then we instructed them to repeat the sentence in Standard Dutch (once per participant).
In the transcription group, participants first heard a sentence spoken in the unfamiliar accent without added background noise. They were then instructed to transcribe the sentence as they heard it. For instance, if they heard the accented sentence “De dur ies oppen” (Standard Dutch: “De deur is open”; English translation: “The door is open”), then they should type it as “De dur ies oppen,” or as closely as possible to its phonological manifestation.
In the imitation group, the procedure was the same as for the repeating group, but participants were instructed to imitate vocally the precise pronunciation of the sentence. If participants repeated the sentence in Standard Dutch, they were instructed to imitate the accent as they heard it spoken (once per sentence).
In the imitation-plus-noise group, the procedure was the same as for the imitation group, except that sentence presentation was followed by speech-shaped noise, which was played over the participant’s headphones. Participants listened to the training sentence and then waited for the noise to begin, after which they imitated the sentence.
Participants in both imitation groups were instructed not to raise their voices. Participants in the imitation-plus-noise group stated that they could not hear their voice through the air (although it cannot be excluded that they could hear themselves through bone conduction). When participants failed to replicate the pronunciation of the accented sentence, but instead lapsed into Standard Dutch, they were again reminded (once per participant) to imitate the speaker’s accent.
Results
We first established whether each groups’ performance differed before and after training. Performance was expressed through the mean SRT in decibel level across the eight repetitions of the auditory staircase procedure (four in the pretest and four in the posttest). Outliers—values with an SRT larger than 10 dB (8 out of 960 cases)—were removed. There was no significant difference in performance between groups after the pretest, F(5, 110) = 1.343, p = .252. This indicated that all groups showed the same average SRT across the first four blocks (i.e., prior to receiving training; Table 2). The results for the posttest showed a main effect of group, F(5, 110) = 13.939, p < .01, indicating that there were differences in SRT after participants received training. Post hoc tests (Tukey’s honestly significant difference, HSD; p < .05) showed that posttest scores of the imitation group and the imitation-plus-noise group were significantly lower than posttest scores of the baseline group. There was no significant difference in posttest scores of the baseline, listening, repeating, and transcription groups.
Mean Speech Reception Threshold (SRT) Values in Decibels
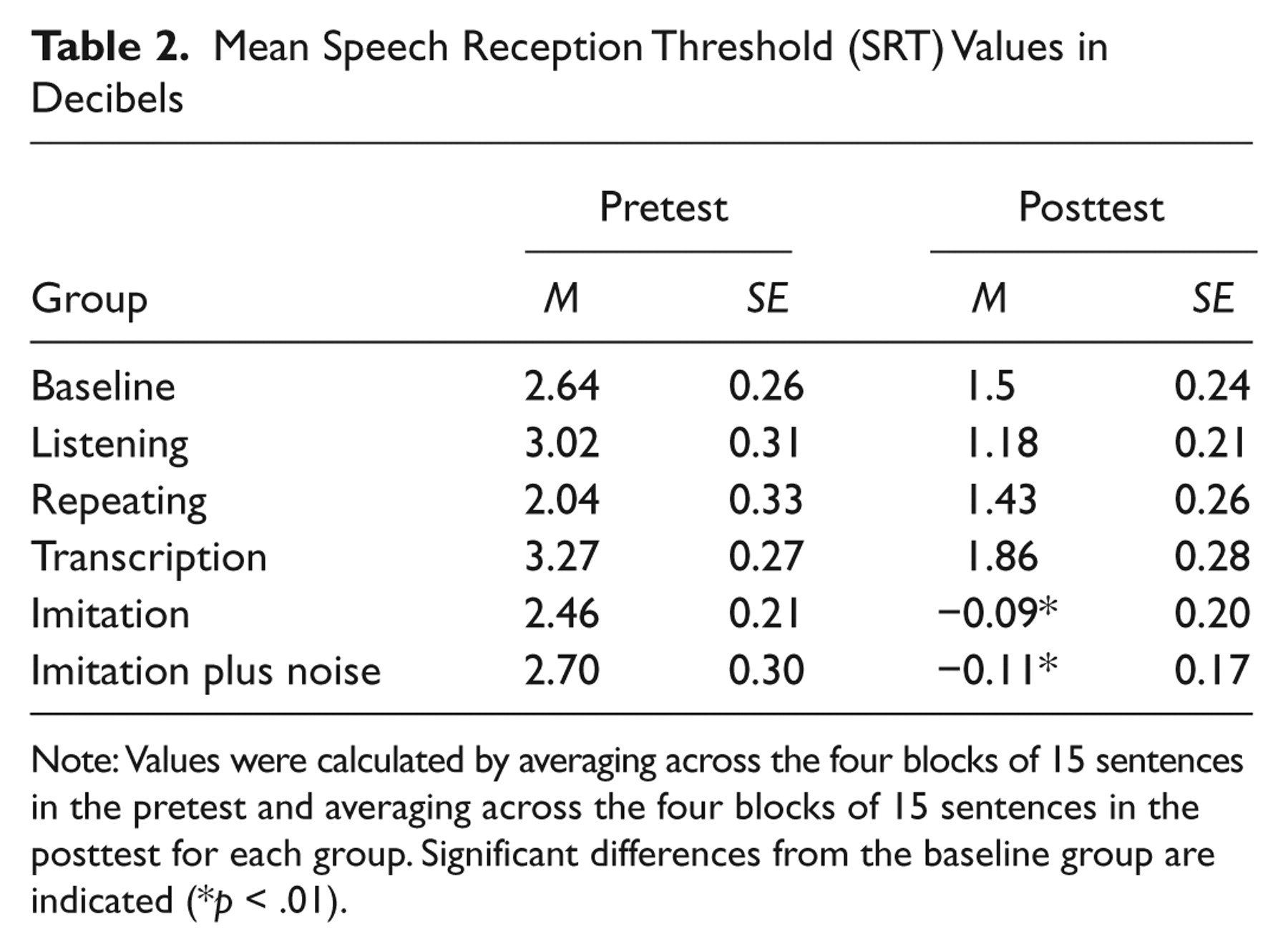
Note: Values were calculated by averaging across the four blocks of 15 sentences in the pretest and averaging across the four blocks of 15 sentences in the posttest for each group. Significant differences from the baseline group are indicated (*p < .01).
Next, we determined which group improved most after training. Improvement was calculated as the mean of all four SRTs estimated in the pretest minus the mean across the four SRTs estimated in the posttest. The difference scores showed an effect of group, F(5, 114) = 4.977, p < .01. Subsequent post hoc tests (Tukey’s HSD, p < .05) showed that difference scores for the baseline group were significantly lower (Fig. 1) than difference scores for the imitation group and the imitation-plus-noise group. There was no significant difference between scores for the baseline, listening, repeating, and transcription groups. In the baseline group, listeners showed a difference score of 1.11 dB in SRT (i.e., they repeated 50% of the key words at an SNR that was 1.11 dB lower in the posttest than in the pretest). This difference score was 2.68 dB averaged across both imitation conditions (2.54 dB for the imitation group and 2.81 dB for the imitation-plus-noise group). This indicates that listeners in both imitation groups could tolerate an additional decrease in SNR of 1.56 dB compared with the baseline group.
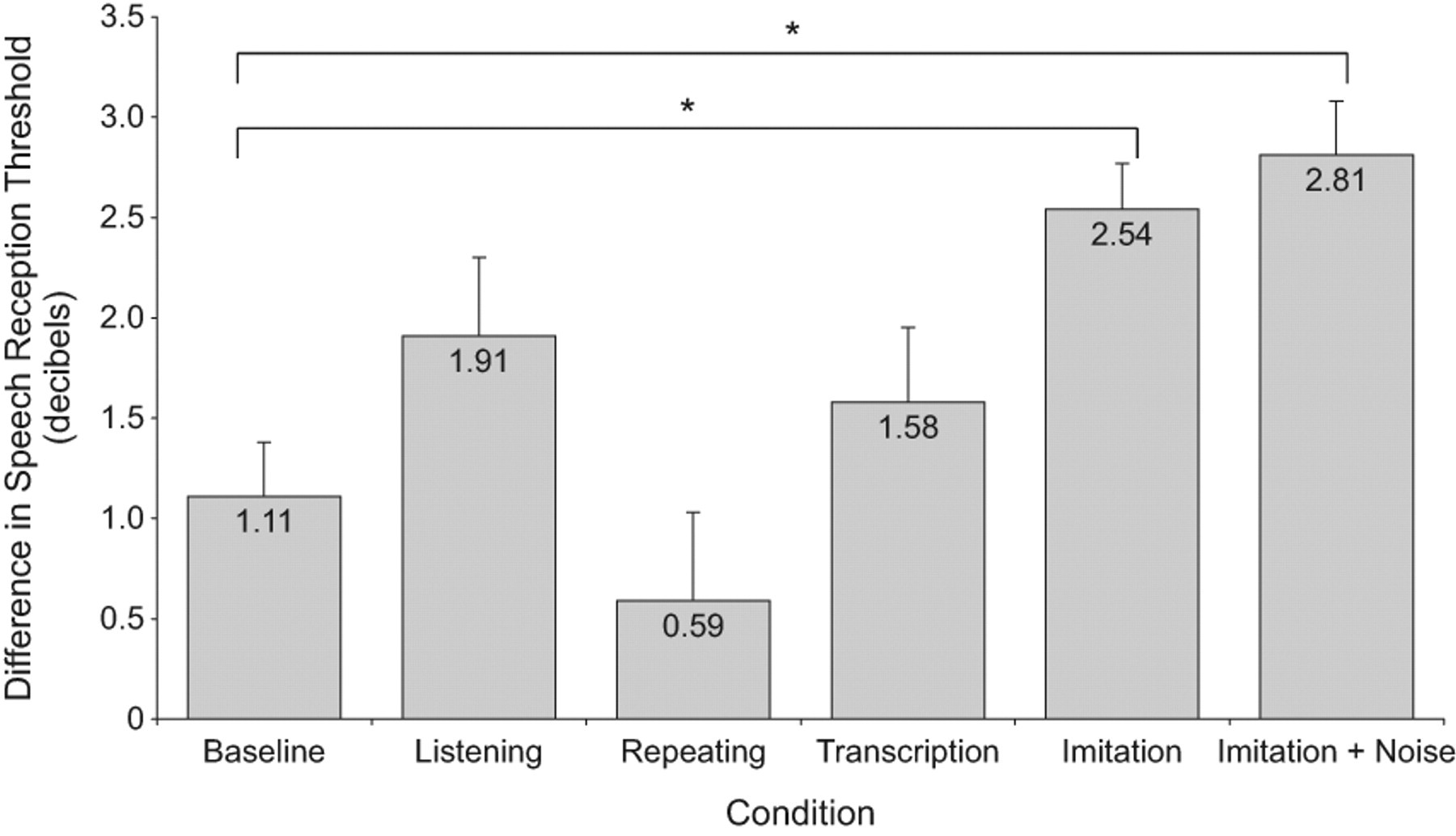
Difference between pretest and posttest speech reception thresholds (SRTs) for the six groups in the study. Scores were calculated by subtracting the average of the four SRTs in the posttest from the average of the four SRTs in the pretest. Error bars denote 1 SEM. Significant differences between the scores of the baseline group and the other groups are indicated (*p < .01).
Finally, we compared success at transcribing with improvement in SRT using the transcriptions made by the transcription group. Transcription performance was expressed using the number of correctly transcribed words for all participants in this group. A word was judged to be correctly transcribed when it matched the word in the orthographically altered sentences used to elicit the recordings (see Table S2 in the Supplemental Material). For instance, if the original accented sentence was “De dur ies oppen” and the participant wrote “De dur is oppen,” then the participant correctly transcribed two words out of a possible three. The scores were added and correlated with the improvement in decibels per participant. This correlation was not significant, r(18) = −.378, p = .891. This result shows that participants who performed well at the transcription task did not improve more in SRT than did participants who performed poorly at the transcription task.
Discussion and Conclusion
Training with sentences spoken in an unfamiliar accent improved comprehension of that accent, but only when participants imitated the specific pronunciation of these sentences. It seems likely that this improvement was due to imitation, namely, vocal reproduction of similar sounds, as several alternative explanations can be ruled out by comparison with the various control conditions. First, it is likely that the improvement was not the result of training per se, or of the fact that people were actively speaking, as there was no significant difference in comprehension among the baseline, listening, and repeating groups. Second, the availability of auditory feedback during imitation also cannot explain our results, as the imitation and the imitation-plus-noise conditions did not differ from each other in improvement in their SRTs. Third, there was no difference in accent comprehension between the baseline group and the transcription group. This shows that paying explicit attention to the phonetic and phonological variation in the pronunciation of the stimuli by itself did not lead to improved posttraining comprehension. In other words, it is not so much the perceptual attention to the phonetic and phonological variation that caused improvement in comprehension compared with the baseline group, but it seems that vocal imitation itself was essential for improving language comprehension.
The present results are in line with the notion that imitative motor involvement helps perceivers anticipate other people’s actions better by generating forward models (Oztop, Wolpert, & Kawato, 2005). These forward models use information about the movement properties of muscles to simulate the course of a movement in parallel with the perceived movement. Any discrepancy between the simulated movement from the forward model and the real-world movement results in corrective commands. In such a case, the efferent copy of the articulatory commands is compared with the sensory feedback from the reafferent signals of muscles involved in articulation. A mismatch between these two signals results in correction (Wolpert, Ghahramani, & Jordan, 1995). This mechanism explains why the availability of auditory feedback in the imitation condition did not result in better performance compared with the imitation-plus-noise group. Such a correction indicates how a more stable motor representation of the unknown accent may be realized. Our results imply that this type of adjustment can be guided by imitation of another person’s actions, and that this adjustment occurs after a relatively short time (i.e., after imitating 100 sentences).
In sum, the results illustrate that imitation processes may aid social interaction by streamlining action understanding between partners. These results have implications for models of action understanding, especially for models suggesting a strong coupling between sensory and motor mechanisms in action comprehension. Specifically, the results support the revised version of the motor theory of speech perception (Galantucci, Fowler, & Turvey, 2006; Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967; Liberman & Mattingly, 1985), according to which comprehension of speech relies on sensorimotor integration between perception and production mechanisms. The results show that imitation aids comprehension when the incoming speech signal is distorted or ambiguous, such as is the case when background noise is present or when listeners hear an unfamiliar accent.
More generally, the results show that imitating an action results in improved understanding of that action. Replicating the specific aspects of the execution of an action may lead to updating representations associated with that action and thus allow for better anticipation of the imitated action. Furthermore, the results may have wider applications in such areas as second-language learning, adaptation to hearing devices and cochlear implants, and sports science (see also Vogt & Thomaschke, 2007).
In conclusion, by demonstrating that imitation improves action comprehension, the present study illustrates that imitative behavior in humans during social interaction (Chartrand & Bargh, 1999; Chen et al., 1998) may also serve to streamline interaction at an abstract communicative level by improving interaction partners’ comprehension of each other’s language in noisy or ambiguous conditions.
Footnotes
Acknowledgements
The authors thank Stuart Rosen for supplying the adaptive noise program and the speech-shaped noise; Joseph Devlin, James McQueen, and Cheryl Capek for useful comments on earlier versions of this article; Erik van den Boogert for technical assistance; and Esther Aarts for lending her voice.
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
This research was supported by the Netherlands Organization for Research (NWO) with a Veni subsidy to the first author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.