
Abstract

Social scientists have described noise as “sound out of place” (Bailey, 1996, p. 50). This implies that the human experience of a stimulus is not simply a reflection of its intrinsic properties, but depends on the social-contextual meanings attributed to it. Following Bruner’s lead (Bruner, 1957; Bruner & Goodman, 1947), psychologists have confirmed the importance of social meaning for perception, especially visual information processing (Balcetis & Lassiter, 2010). In the research reported here, we extended this perspective to time perception and asked if an ambiguous auditory stimulus is processed differently as a function of its social meaning.
When research participants are asked to reproduce a sound’s duration, they typically underestimate it. The extent of such underestimation is affected by the complexity, familiarity, and valence of the stimulus and by the participants’ characteristics (Block & Zakay, 1997; Brown, 2010; Kowal, 1987; Ornstein, 1969; Phillips & Cross, 2011; Tobin, Bisson, & Grondin, 2010). These effects have been explained as the results of attentional and memory-related processes, with the latter being particularly relevant in retrospective paradigms (i.e., those in which participants are not aware that they will be asked to make duration estimates; see Block, Hancock, & Zakay, 2010).
Our research was conducted with pilgrims attending a Hindu festival (Mela) in India. Every year, thousands of such pilgrims (kalpwasis) live by the Ganges River for a month in a tented encampment and renounce the everyday concerns that inhibit a focus on spiritual matters. However, the simple life pursued at the Mela is far from tranquil: Pilgrims are surrounded by multiple loudspeaker broadcasts of different songs, religious speeches, and announcements. This auditory multiplicity often makes it difficult to discern the contents of these broadcasts. The result is a loud cacophony (85–90 dB) that often resembles the sound of a busy city street. Despite this, because these sounds have religious connotations, pilgrims describe them as nonintrusive and meaningful (Prayag Magh Mela Research Group, 2007).
We prepared a sound clip that contained very little recognizable material, so that it could be labeled as coming either from the religious festival itself or from the everyday secular setting of busy city streets. Using a design in which participants knew in advance that they would be asked about the sound, but not that they would be asked to estimate its duration (i.e., a retrospective paradigm), we predicted that participants would make longer duration estimates when the sound clip was attributed to the Mela than when it was attributed to a city setting. We expected that when the sound clip was attributed to the Mela, the various snippets of sound within the sound clip would capture participants’ attention (because imagined religious associations were primed) and that the encoding of the stimulus would therefore be richer. In turn, this richer encoding would facilitate remembering the material, which would result in participants making longer duration estimates (for evidence of the role of memory-related processes in retrospective paradigms, see Block et al., 2010). In contrast, when the sound clip was attributed to everyday city streets, we expected that the same sounds would have less symbolic significance and would attract less encoding, and that participants would therefore make shorter duration estimates.
Given that longer duration estimates do not necessarily indicate an effect of encoding, we also manipulated when participants were given an attribution for the sound’s source (either prestimulus or poststimulus). This allowed us to test whether social meaning affects encoding rather than simply retrieval. We hypothesized that when the attribution occurred prestimulus, the sound’s meaning would influence encoding and therefore lengthen duration estimates. When the attribution was made poststimulus, there would be no effect on encoding, and therefore we expected no effect of source attribution on duration estimates.
Method
Sixty-nine male pilgrims (mean age = 65 years, SD = 5) participated in a retrospective time-duration experiment conducted in a tent in the Mela. Participants listened to a 20-s, noisy sound clip (90 dB) through headphones that were capable of blocking out any extraneous noises. The sound clip was identical across conditions and included elements recorded at the Mela, on city streets, and also white noise that was added in order to make it impossible to identify specific sounds. Pilot testing confirmed that its contents were unclear and ambiguous.
Participants were told that the clip comprised several sounds. Half were told (city condition), We have jumbled together various sounds from the city—for example, from markets, from railway stations, from bus stations, from various places in the city. OK? So now you are going to listen to the sounds of the city.
The other half were told (Mela condition), We have jumbled together various sounds from the Mela—for example, from religious broadcasts over the loudspeaker system, from the Ghats on the Ganges, from the Sangam, from various places in the Mela. OK? So, now you are going to listen to the sounds of the Mela.
Among participants in each condition, half received this source attribution before exposure to the stimulus (prestimulus), and half received this source attribution (with minor grammatical rewording) after exposure to the stimulus (poststimulus).
After listening to the sound clip, participants reproduced its duration. An experimenter said “start,” and participants said “stop” when they thought the sound would have stopped. This interval (during which participants wore headphones, yet did not have the sound clip played to them) was timed. At the end of the study, we asked participants about the attributed source of the sound clip.
Results
Two participants were excluded because they misremembered the sound’s ostensible origins. Four participants were excluded because their duration estimates were more than 3 standard deviations from the mean. The final sample included 17 people in the Mela, prestimulus condition, 18 people in the city, prestimulus condition, and 14 people each in the Mela, poststimulus and city, poststimulus conditions. Participants’ time- duration estimates were inspected in a 2 (timing of attribution: prestimulus, poststimulus) × 2 (source attribution: Mela, city) analysis of variance. The main effects were marginal—timing of attribution: F(1, 59) = 3.78, p = .057, η p 2 = .06; source attribution: F(1, 59) = 2.73, p = .10, η p 2 = .04—and qualified by the predicted interaction, F(1, 59) = 5.63, p = .021, η p 2 = .09 (see Fig. 1). When the sound clip’s source was labeled prestimulus, duration estimates were longer in the Mela condition (M = 14.85 s, SE = 0.85) than in the city condition (M = 11.26 s, SE = 0.83), t(33) = 2.69, p = .011, d = 0.91. When the sound clip’s source was labeled poststimulus, the means in the Mela and city conditions did not differ (Mela: M = 11.00 s, SE = 0.94; city: M = 11.64 s, SE = 0.94), t(26) = −0.59, p = .56, d = 0.22. As expected, when the sound was attributed to the Mela, duration judgments were longer when attribution occurred prestimulus than when it occurred poststimulus, t(29) = 3.19, p = .003, d = 1.16.
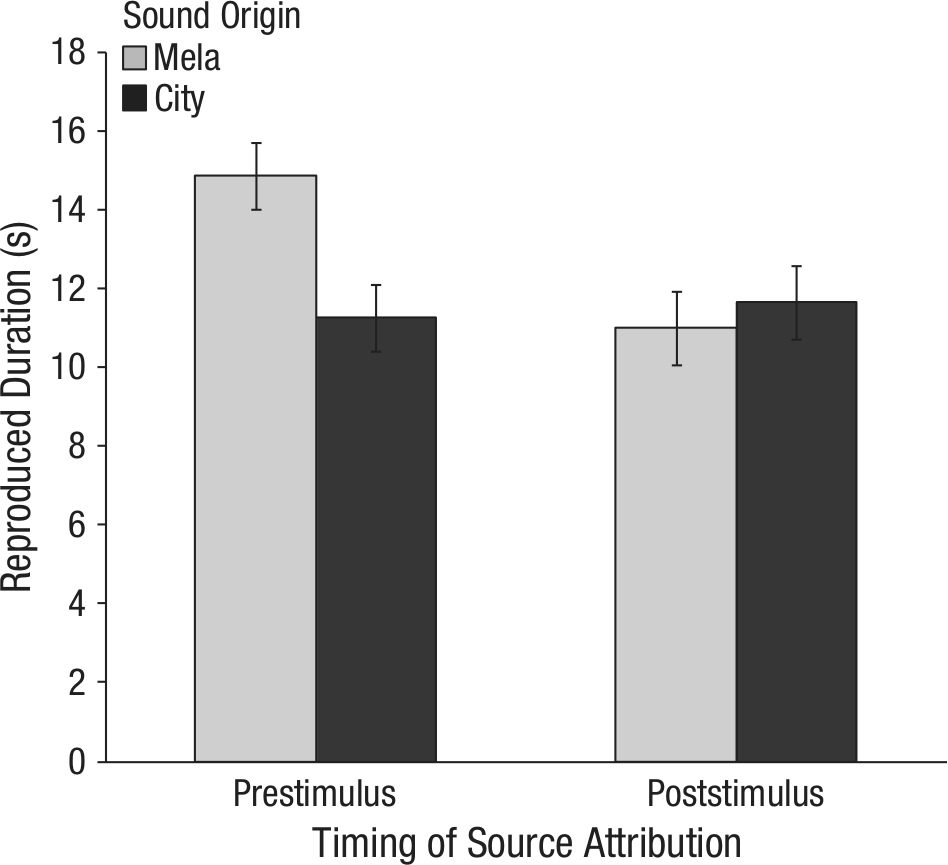
Estimates of the sound clip’s duration as a function of the sound’s attributed origin and the timing of this source attribution. The error bars denote ±1 SEM.
Discussion
Consistent with other studies, our study found that participants underestimated sound duration (Eisler, 1995). More important, the labeling of the sound’s origins affected duration estimates, but only when this attribution was given prestimulus, a result indicating that the effect occurs during encoding rather than during retrieval. Specifically, a prestimulus attribution of the sound clip to the religious Mela produced longer estimates than a prestimulus attribution of the sound clip to city streets. Given that the stimulus was constant across all conditions, this effect of the sound clip’s labeling is evidence for the effect of social meaning on stimulus processing. It is likely that pilgrims who were told to expect a Mela-related sound clip interpreted the sounds (despite their ambiguity) as having religious associations. These associations could have caused some snippets to capture the pilgrims’ attention and consequently allowed for a richer encoding of the stimulus material. This explanation is congruent with the results of other studies using retrospective paradigms (Block et al., 2010; Block & Zakay, 1997), in which longer duration estimates reflect memory-related processes associated with better encoding.
Although additional studies are needed to identify the exact mechanisms involved, these data show that the social meaning of sound matters. Moreover, our data suggest that psychologists can help other social scientists explore how the same auditory stimulus can be experienced differently depending on its contextual associations and symbolic significance (Bailey, 1996).
Footnotes
Acknowledgements
We thank the editor, an anonymous reviewer, and Richard A. Block for their helpful comments.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This research was funded by the Economic and Social Research Council (Grant RES-062-23-1449).