
Abstract
Do reminders of God encourage people to take more risks? Kupor, Laurin, and Levav (2015) reported nine studies that all yielded statistically significant results consistent with the hypothesis that they do. We conducted two large-sample Preregistered Direct Replications (N = 1,104) of studies in Kupor et al.’s article (Studies 1a and 1b) and evaluated replicability via (a) statistical significance, (b) a “small-telescopes” approach, (c) Bayes factors (BFs), and (d) meta-analyses pooled across original and replication studies. None of these approaches replicated the original studies’ effects. Combining both original studies and both replications yielded strong evidence in support of the null over a default alternative hypothesis, BF01 = 11.04, meaning that the totality of evidence speaks against the possibility that religious primes increased nonmoral risk taking in these designs. This suggests that support for the “anticipating-divine-protection” hypothesis may be overstated.
Keep me safe, my God, for in you I take refuge.
Does thinking of God make believers feel more comfortable taking risks? To the extent that folks believe in a benevolent God who will shelter them from harm, reflecting on God might encourage believers to take more risks, provided the risks are not morally prohibited. That is, people might “anticipate divine protection” and take risks that they otherwise might have avoided. A previous Psychological Science article reported nine studies with statistically significant effects consistent with this possibility (Kupor, Laurin, & Levav, 2015). We sought to examine the replicability of these findings in two large Preregistered Direct Replications.
Independent replicability is one aspect among many (Devezer, Nardin, Baumgaertner, & Buzbas, 2019) of a progressive and cumulative science. Psychology has been leading the way in recent years by emphasizing increasing methodological rigor, including the use of large-sample direct replications of prominent findings (e.g., Hagger et al., 2016; Sanchez, Sundermeier, Gray, & Calin-Jageman, 2017). Of note, meta-science researchers have proposed various criteria for choosing replication candidates. In one such effort to combine these criteria in an a priori principled way—on the basis of ambiguous initial evidence via Bayesian reanalysis, novelty, influence, and feasibility—Kupor and colleagues’ anticipating-divine-protection studies emerged as ideal candidates for replication, one of only two top replication-candidate articles from a survey of Psychological Science articles (Field, Hoekstra, Bringmann, & van Ravenzwaaij, 2019). Specifically, Field and colleagues wrote, Our reanalysis of [Kupor et al.’s] results, in conjunction with other methodological and theoretical criteria considerations heavily underlines this replication candidate as a promising target, reporting results that are in need of independent corroboration. We recommend a direct, or pure replication, such that the findings exactly as they are presented can be verified. (Qualitative Target Selection section, para. 15)
We elected to replicate the first two studies of the Kupor et al. article, which addresses two related topics that have been at the center of recent methodological controversy: religious priming (Shariff, Willard, Andersen, & Norenzayan, 2016; van Elk et al., 2015) and so-called social priming more generally (e.g., Harris, Coburn, Rohrer, & Pashler, 2013; Payne, Brown-Iannuzzi, & Loersch, 2016). Although there are no known direct replications of the first two studies (those we chose to replicate), some related work does exist (Chan, Tong, & Tan, 2014), including one direct replication of a different study in Kupor et al.’s article that found results contradictory to the original (Gruneau Brulin, Hill, Laurin, Mikulincer, & Granqvist, 2018). Finally, we chose to replicate studies in domains in which we have considerable expertise, 1 hopefully minimizing concerns that any discrepancies between the original and replication results stem from lack of expertise or prior knowledge on our end. We were in contact with two of the original article’s authors during study design and implementation, and we thank Kupor and Laurin for their candor and helpfulness throughout the replication process.
We report how we determined our sample sizes, all data exclusions (if any), all manipulations, and all measures used in the studies. Experimental scripts, data, and code are available on the Open Science Framework (https://osf.io/64ct2/).
Method
Replication Study 1a
Participants
We aimed to collect samples at least 2.5 times as large as in the original studies and maximized the sample sizes that we could acquire given our financial constraints. These constraints led us to fall a little short of our preregistered target of 600 participants per replication: We recruited 566 American participants from Mechanical Turk (MTurk). We excluded 9 participants for failing an attention check and 1 participant for failure to complete the dependent variable, leaving a total sample of 556 (304 women, 250 men, 2 unreported). 2 The average age was 36.27 years (SD = 11.40). Additionally, 59.9% of participants reported believing in God. This sample size afforded us power greater than .999 to detect the originally reported effect size (d = 0.57) and greater than .91 for detecting an effect half as large. Table 1 summarizes demographic statistics.
Demographic Statistics for the Sample in Both Replication Studies

Procedure
We consulted with the original authors as we designed our studies. We also sent them a copy of our survey, and they concurred that it was a high-fidelity replication of their studies. Participants were recruited to an MTurk task on word games. After consenting to participate in the study, each participant was randomly assigned to either a God (n = 275) or a control (n = 281) condition, following previous religious-priming research (Gruneau Brulin et al., 2018). Participants completed a scrambled-sentence priming task in which they were asked to create 10 sets of four-word sentences out of five provided words. Importantly, in the God condition, 5 of the 10 provided word strings contained words related to religion (e.g., divine, spirit, God), whereas the control condition did not contain such words. After completing the scrambled-sentence task, all participants then completed the Domain Specific Risk-Taking Scale (DOSPERT; Blais & Weber, 2006). The DOSPERT is a 40-item scale used to assess risk-taking behaviors that asks participants to indicate how likely they are to engage in various behaviors (e.g., going whitewater rafting at high water in the spring, taking a skydiving class) on a scale from extremely unlikely (1) to extremely likely (5). The DOSPERT is composed of five subscales assessing different types of risks: ethical, 3 financial, health/safety, recreational, and social. The DOSPERT is originally scored with an algorithm including both risk perception and risk taking, but—following Kupor and colleagues (2015)—we simply averaged DOSPERT responses across all subscales, with higher numbers indicating more risk taking. Both manipulation and measure were as used in the original research.
As an active control, participants then completed a conjunction-fallacy task (Tversky & Kahneman, 1983), unrelated to the previous measures. Participants completed the focal tasks with no knowledge that the conjunction-fallacy task would follow. In the task, participants learned about “Mary.” All participants read, “Mary went to the store and bought tofu, eggplant, broccoli, and frozen meatless lasagna. Is it more likely that Mary is . . . ?” All participants were given the option of choosing “a woman”; however, half of the participants were given a stereotype-consistent second option (“a woman who is a vegetarian”), and the other half of participants were given a stereotype-inconsistent second option (“a woman who is a big game hunter”). Typically, participants are more likely to select the second option for stereotype-consistent targets (vegetarian) than for stereotype-inconsistent targets (big game hunter). This task was included merely to assess whether we could replicate any effects with our participants, and performance on the conjunction task was not treated as diagnostic of anything else. However, if we could not replicate even a phenomenon that is known to be replicable, such as the representative heuristic in these samples, we would have concluded that we had a faulty sample, for whatever unknown reason.
Finally, participants answered demographic questions regarding age, gender, belief in God, race/ethnicity, and education level. The full survey is available at https://osf.io/79kqa/, and a preview survey can be completed at https://virginia.az1.qualtrics.com/jfe/preview/SV_81vV0F11PYzq61v?Q_CHL=preview&Q_JFE=qdg.
Replication Study 1b
Participants
We aimed to collect samples at least 2.5 times as large as the original studies and maximized the sample sizes that we could acquire given our financial constraints. Falling slightly short of our preregistered target of 600 participants, we were able to recruit 548 American participants (329 women, 217 men, 2 indicating “other”) from MTurk. The average age was 36.45 years (SD = 11.73). Additionally, 63.5% of participants reported believing in God. All participants completed the dependent measure. Our sample size gave us power greater than .96 to detect the originally reported effect size (d = 0.32) but only .46 to detect an effect half that size. Table 1 summarizes demographic statistics.
Procedure
We consulted with the original authors as we designed our studies. We also sent them a copy of our survey, and they concurred that it was a high-fidelity replication of their studies. Participants were first asked to describe a recreational risk that they had considered taking in the past (e.g., hiking a potentially unsafe trail, going down a potentially dangerous ski slope). All participants then completed the same scrambled-sentence priming task (Shariff & Norenzayan, 2007) as in Study 1a and likewise were each randomly assigned to either the God (n = 267) or control (n = 281) condition. After completing this task, participants were reminded of their recreational risk and asked, “What is the likelihood that you will take this risk in the next month?” (1 = extremely unlikely, 7 = extremely likely).
Subsequently, participants were given a conjunction-fallacy task (Tversky & Kahneman, 1983) as an active control. In this task, they read that “Eric has a career related to finance and he intensely dislikes new technology. He longs for the old days when things were done with paper and relationships were more important. Which of the following statements is more likely?” All participants were given the option of “Eric is a senior citizen,” but the other option was randomly assigned to each participant to be either stereotype consistent (“Eric is a senior citizen who owns a smart phone but rarely uses it”) or stereotype inconsistent (“Eric is a senior citizen who is an avid video game player”).
Finally, participants answered demographic questions regarding age, gender, belief in God, race/ethnicity, and education level. The full survey is available at https://osf.io/h5n36/, and a preview survey can be completed at https://uky.az1.qualtrics.com/jfe/preview/SV_4MCyK8KuHjdnMqh?Q_SurveyVersionID=current&Q_CHL=preview.
Results
Replication results
In our preregistration (https://osf.io/m28xv/), we defined replication success according to three criteria: (a) producing statistically significant results in the same direction as the original article, (b) the use of a “small-telescopes” approach for assessing the detectability of effects (Simonsohn, 2015), and (c) a Bayes factor (BF) analysis comparing a point null hypothesis with an alternative hypothesis based on the original studies’ reported effect sizes (Gronau, Ly, & Wagenmakers, 2020). Figure 1 displays raw results.
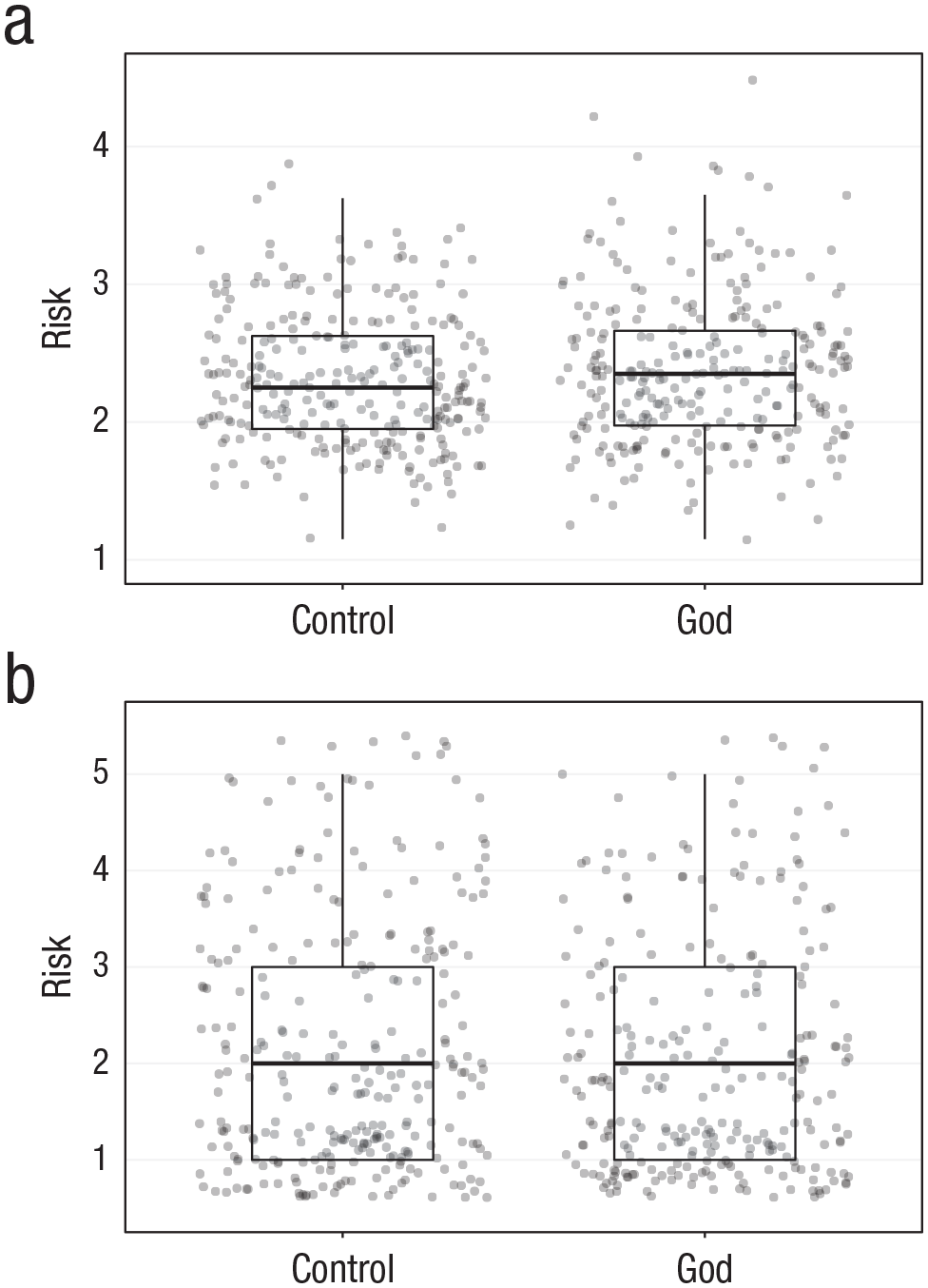
Raw results for (a) Replication Study 1a and (b) Replication Study 1b: risk taking in each condition. In each box, the central horizontal line represents the median, and the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively. Whiskers span 1.5 times the interquartile range. Dots indicate individual data points.
Statistical significance
Both original studies used two-tailed t tests. We followed suit in both replications, using Welch’s t tests. Neither replication study yielded directionally consistent statistically significant results, and results in the second replication were in the opposite direction—Study 1a: t(544.6) = 1.618, p = .106, d = 0.14, 95% confidence interval (CI) = [−0.03, 0.30]; Study 1b: t(546.0) = −1.320, p = .187, d = −0.11, 95% CI = [−0.28, 0.06], respectively. Neither of our studies replicated the original findings by this criterion.
Small telescopes
The small-telescopes approach (Simonsohn, 2015) assesses the detectability of effects by evaluating the power that original studies would have to detect the replication’s effect size. It considers a result to be a failed replication if the original studies lacked sufficient power to detect the replication result’s detected effect size. The sample size of the original Study 1a was 61, which would give it 8% power to detect the replication’s effect size (upper bound = 19% power). The sample size of the original Study 1b was 202, yielding power of 12% (upper bound = 42%), although it is important to note that the replication produced directionally opposite results from the original, giving the original study effectively zero power to detect the replication’s effect size in a way that would support the original study’s described effect. Simonsohn recommends a cutoff of 33% power to assess detectability. Neither of our studies replicated the original findings by this criterion.
Bayes factors
BFs provide a direct measure of evidence by evaluating the degree to which data support one hypothesis vis-à-vis another hypothesis. In psychological research, this typically means pitting a point null hypothesis (d = 0) against an alternative hypothesis describing a distribution of plausible effect sizes. All BF calculations used JASP (Version 0.8.3.1; Jasp Team, 2017) and the BayesFactor (Morey & Rouder, 2018) package in the R programming environment (Version 3.6.1; R Core Team, 2019). For replications, we pitted the null hypothesis against an alternative hypothesis consistent with the effect sizes reported in the original studies. Original Study 1a revealed an effect size (d) of 0.574 (95% CI = [0.04, 1.09]), so our alternative prior was set to “Normal ~ (M = .574, SD = .267).” This produced a BF in which the data supported the null, relative to the original study’s effect size, by a factor of 3.00; this is generally considered moderate support for the null hypothesis. In an alternative analysis, we used JASP’s suggested default priors for the alternative hypothesis (Cauchy, with rscale value of .707, one sided in the predicted direction) and found weak support for the null, BF01 = 1.56. Original Study 1b yielded an effect size (d) of 0.323 (95% CI = [0.04, 0.60]), so our alternative prior was set to “Normal ~ (M = .323, SD = .142).” This produced a BF in which the data supported the null, relative to the original study’s effect size, by a factor of 26.13; this is generally considered strong support for the null hypothesis. In an alternative analysis, we again used JASP’s suggested default priors for the alternative hypothesis and found strong support for the null, BF01 = 23.31. Neither of our studies replicated the original findings by this criterion.
Meta-analyses
Finally, we performed mini meta-analyses of the replicated effects as an exploratory addition to our preregistered analyses. These were meant to synthesize results from the two original studies and our replications, not to summarize all conceptually related work or to generalize to as-yet-unconducted studies on the topic. We merely wished to summarize the best estimate available from only the original studies and our direct replications. To obtain pooled effect-size estimates for each set of studies, we performed two separate random-effects meta-analyses (one on the original study and Replication Study 1a, one on the original study and Replication Study 1b). Neither yielded pooled effects that significantly differed from zero, d = 0.29, 95% CI = [−0.11, 0.68], p = .16; and d = 0.09, 95% CI = [−0.33, 0.51], p = .66, respectively. To obtain a pooled effect-size estimate including all available data, we performed a random-effects meta-analysis including all four studies (two original and two replication). Again, this meta-analysis revealed a pooled effect size not significantly differing from zero, d = 0.17, 95% CI = [−0.08, 0.42], p = .18. Figure 2 summarizes this final model. Neither of our studies replicated the original findings by this criterion.
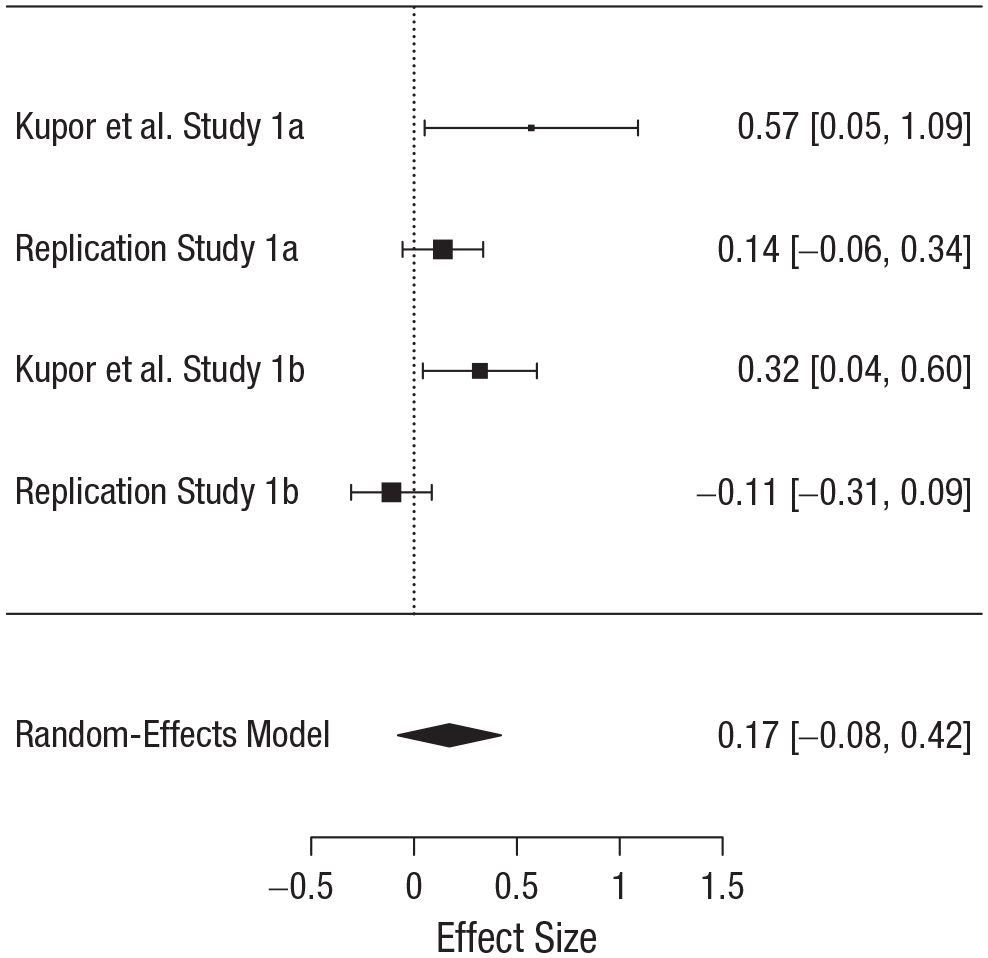
Forest plot of random-effects meta-analysis including all data from Kupor, Laurin, and Levav’s (2015) Studies 1a and 1b and the current Replication Studies 1a and 1b. The size of each square indicates the strength of the effect. Values shown on the right are Cohen’s ds, and 95% confidence intervals are given in brackets.
Moderation
In our preregistration, we specified that we would also probe to see whether any priming effects were moderated by participant belief in God, because there is some evidence that religious primes work only among religious believers (Shariff et al., 2016). There was no significant interaction of condition and participant belief in God in either replication study, F(1, 552) = 0.076, p = .783, and F(1, 544) = 0.075, p = .784, respectively.
Data quality and prime performance
Of late, there has been considerable concern over data quality and bot activity on MTurk. Although Kupor et al. did not report any screening for data quality or task performance, we performed additional exploratory analyses to assess the robustness of any effects among only the most adept participants. Thus, we coded performance on the scrambled-sentence task and ran ancillary analyses on only the participants who had zero errors in filling out all 10 scrambled sentences (most participants had errors on 1 or 2 sentences). This considerably reduced our effective sample size (Ns = 164 and 162, respectively) but ensured that we analyzed only nonbot participants who exhibited attentiveness, verbal fluency, and maximum engagement with the prime task. In both replication studies, even data from finely filtered participants failed to support the original studies’ inferences: Among highly attentive participants, religious priming did not significantly increase nonmoral risk taking—Replication Study 1a: t(104.9) = 0.55, p = .59, d = 0.09, 95% CI = [−0.24, 0.42], default BF01 = 8.14; Replication Study 1b: t(102.6) = −0.10, p = .92, d = −0.02, 95% CI = [−0.35, 0.31], default BF01 = 5.18. Even with the most stringent performance filter, we could not replicate the original effects, and results moderately to strongly supported the null hypothesis relative to a default alternative prior.
Active controls
Both replications included conjunction-fallacy tasks (Tversky & Kahneman, 1983) as active controls. They were included merely to see whether we could replicate well-known effects in our sample. In both replication studies, participants were significantly more likely to commit conjunction errors for stereotype-consistent targets (Study 1a: > 99%; Study 1b: 40%) than for stereotype-inconsistent targets (Study 1a: 17%; Study 1b: 1%), Study 1a: odds ratio = 522, 95% CI = [161, 3207], p < 2 × 10−16; Study 1b: odds ratio = 45.4, 95% CI = [18.6, 150.2], p = 1.9 × 10−13. We easily replicated a classic paradigm in each replication study, speaking imperfectly to the adequacy of these samples for evaluating basic psychological tasks. The active control was included merely to see whether we could replicate a classic effect, and we make no further inferences about it. It is less of a participant attention check and more of an MTurk nihilism check, to see whether we could make a classic paradigm work on an overgrazed common of cheap research-participant recruitment.
Discussion
In a 2015 Psychological Science article, Kupor and colleagues presented nine studies suggesting that religious primes increase nonmoral risk taking. We attempted large Preregistered Direct Replications of the first two studies from that article. We could not replicate either study by any of four replication metrics. Indeed, Bayesian analyses indicated stronger evidence favoring the null hypothesis over the initially observed effects in our replications (BF01s = 3.00 and 26.13 for Studies 1a and 1b, respectively), compared with the evidence in the original studies favoring a default alternative hypothesis (BF10s = 1.96 and 1.68 for Studies 1a and 1b, respectively). Combining both original studies and both replication studies yielded strong evidence in support of the null over a default alternative hypothesis, BF01 = 11.04, meaning that the totality of evidence speaks against the possibility that religious primes increase nonmoral risk taking, at least in these designs. Further, a meta-analysis including both original studies and both replications yielded a pooled effect-size estimate not significantly different from zero. Combined, this suggests that the original report that God primes increase nonmoral risk taking may be less solid than initially presented.
Why might our pattern of results have diverged somewhat from Kupor and colleagues’ findings? We attempted to control many potential pitfalls by including active controls, choosing a topic with which we have considerable expertise, and collecting much larger samples from the same population as the original studies (MTurk). That said, it is possible that subtle changes in the makeup of the MTurk population, undetectable to us, may have “killed” these effects (e.g., perhaps through overexposure to similar experiments). Future research on this and related phenomena should provide more stringent tests for participant naivety and attentiveness. That said, our results were unchanged, and in some cases bolstered, when we filtered data on the basis of performance on the manipulation task. Although we worked with the original article’s authors to increase the fidelity of our replication, it is possible that some subtle task or recruiting difference—undetected by us or them—compromised our ability to replicate the findings. This possibility, however, speaks against the strength and generality of the phenomenon as initially reported.
Another possibility is that the strength of the original finding was simply overstated. The BFs in our replications supported the null more strongly than the initial studies supported the alternative in the first place. The original article contains nine statistically significant experiments. But given modest statistical power inherent to most work in this domain, generating long strings of only significant results is quite improbable (Schimmack, 2012). Further, most of the original p values were more suggestive than strong (Benjamin et al., 2018): Key p values generally ranged between .01 and .05. This pattern does not appear often in the wild, given genuine effects (Lakens & Etz, 2017), but is consistent with results reported in other similar work that has also faced challenges in replication (Gervais & Norenzayan, 2012; Sanchez et al., 2017). Perhaps there was never much reason to buy the initially reported effects. At the same time, we note that neither the original studies nor replication attempts conclusively rule out very small effects. Kupor and colleagues’ article included results that were consistent with a wide range of effects, including very nearly zero. We merely extended the range of plausibility so that it now also includes zero. It may be worth treating the anticipating-divine-protection hypothesis with skepticism.
Supplemental Material
Gervais_OpenPracticesDisclosure_rev – Supplemental material for Do Religious Primes Increase Risk Taking? Evidence Against “Anticipating Divine Protection” in Two Preregistered Direct Replications of Kupor, Laurin, and Levav (2015)
Supplemental material, Gervais_OpenPracticesDisclosure_rev for Do Religious Primes Increase Risk Taking? Evidence Against “Anticipating Divine Protection” in Two Preregistered Direct Replications of Kupor, Laurin, and Levav (2015) by Will M. Gervais, Stephanie E. McKee and Sarah Malik in Psychological Science
Footnotes
Acknowledgements
We thank students from the PSY 440 course at the University of Kentucky, who also worked with these designs and data as an enlightening pedagogical exercise. We also thank Bob Lorch who, as department chair, authorized funding for the data collection in this research and class exercise.
Transparency
Action Editor: D. Stephen Lindsay
Editor: D. Stephen Lindsay
Author Contributions
All the authors designed the studies. S. Malik and S. E. McKee assembled the experimental scripts. W. M. Gervais analyzed the data and wrote the initial draft. All the authors revised the manuscript and approved the final manuscript for submission.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.