
Abstract
People often understand parts of languages that are closely related to their native tongue. But do they understand what the speaker intends to convey? We discovered that linguistic similarity induces an illusion of understanding, leading people to believe they understand more than they actually do. In Study 1, adult native Italian speakers overestimated their understanding of a speaker’s intent more when they listened to Spanish (close language) than to Northern Jiangsu Chinese (distant language). In Study 2, adult native Mandarin Chinese speakers overestimated their understanding more when they listened to Northern Jiangsu Chinese (close language) than to Spanish (distant language). When listening to the closer language, listeners were more confident, and this mediated their overestimation of understanding. An illusion of understanding, then, increases not despite language closeness but because of it. This has theoretical implications for the role of calibration in communication and practical implications for miscommunication in international settings.
Keywords
It is a truism that to understand a language you need to know it. But if you are listening to a language closely related to your native tongue, you may understand bits and pieces despite having never learned it. For example, when Luigi, an Italian, visits Madrid, he may not respond when asked “Quieres comer?” (Do you want to eat?) because the phrase is very different from his native Italian’s “Vuoi mangiare?” Yet he may happily embrace his friend on hearing “Te amo mi amigo” (I love you my friend) because it is so similar to “Ti amo mio amico” in his native Italian. But even if Luigi understood the components of the sentence, did he understand the speaker?
Here we report our discovery that language closeness, such as that between Italian and Spanish, induces an illusion of understanding. We found that native speakers grossly overestimated how well they understood the intention of a speaker of a highly related language. In fact, close-language listeners overestimated their understanding as if they were native speakers of the language. We show that this exacerbated illusion of understanding occurs not despite the linguistic overlap but because of it. Language closeness leads to overconfidence in understanding, which in turn leads us to believe that we understand more than we actually do.
Understanding the Sentence but Not the Intention
Cross-linguistic intelligibility is often rooted in languages sharing historical linguistic origins, rendering a high degree of overlap in word forms between the two languages. For instance, Italian and Spanish have a relatively high degree of mutual intelligibility because, through their shared roots, they have a 75% semantic word similarity (Camacho-Collados et al., 2017; Clackson, 2007). More broadly, languages within the same language family often have similar word forms and syntactic features that can render them mutually intelligible in part (i.e., Dinu & Dinu, 2005). Such overlap of word forms and syntactic structures can help listeners extract the semantics of a sentence and, with some guessing, allow an understanding of the propositions that the sentence presents. However, understanding the semantics is not the same as understanding what the speaker intends to convey.
A speaker can use a particular sentence to convey one of multiple meanings. This ambiguity is inherent in any utterance. Therefore, the ultimate goal of listeners is not just to understand the meaning of the words but to identify the particular intention of the speaker. When Luigi visits his friend Maria in Madrid, he might be delighted when she says “Te amo mi amigo.” He easily sees that it means “I love you my friend.” But what does she actually mean? Did Maria just confess that she is in love with him? Did she mean that she loves him, but only as a friend? Was she expressing how much she loves spending time with him? Was she expressing delight at his sense of humor? Or perhaps she was mad at him, but instead of yelling, decided to diffuse the tension by reaffirming their friendship. For the communication to be successful, Luigi must be able to determine not only the meaning of the sentence but also Maria’s intention to identify what is called the “utterer’s meaning” (or “speaker’s meaning”; see Grice, 1968, 1989; Margolis, 1973).
Calibrated Judgment and the Illusion of Understanding
It is intuitive that identifying the intention of a speaker would be aided by language overlap. If a listener can guess the meaning of more words, they might be likely to assume that they would be more calibrated in knowing how well they understood the intention. For example, it makes sense that Luigi will be better able to know how well he understood Maria’s intentions when she speaks in Spanish than in Mandarin Chinese because the latter language is unrelated to his native Italian. We suggest that the opposite is true, that the closeness of the languages may lead listeners to fail to appreciate the ambiguity of a message, creating a larger illusion of understanding. Put otherwise, it makes them believe that they understand the intention of the speaker much more than they actually do. If this is true, then this illusion should be larger for a language that is close to the native tongue of the listeners than for a language that is more remote.
The illusion of understanding that we focus on is not about how accurate listeners are in assessing the speaker’s intention. Instead, we are interested in how calibrated they are in their assessments. The idea of calibration is illustrated well in the literature on confidence (e.g., Hoffrage, 2004; Moore & Healy, 2008; Moore & Schatz, 2017). For example, in answering trivia questions, the percentage of correct answers represents accuracy, and the percentage of how many questions you think you solved represents estimated accuracy. If you estimate that you correctly solved 80% but actually solved only 60%, you are not calibrated. You are overestimating your performance. If you think you correctly solved 50% but only solved 30%, your lack of calibration is identical because you are still off by 20 percentage points. Hence, calibration is not accuracy, but rather it is knowing how accurate you were. Solving 40% and knowing you solved 40% is perfect calibration. Similarly, we are not looking at how accurate listeners are but rather how well they gauge their ability to understand the speaker.
Such calibration in communication is important because it drives effective communication. An essential dynamic of conversation involves a back-and-forth in which people do not only communicate but also signal comprehension, request clarification, and perform repairs to ensure the right intention is understood (Clark & Wilkes-Gibbs, 1986; Healey et al., 2018; Schegloff et al., 1977; Schober & Clark, 1989). Given that ambiguity is prevalent in language, the potential for miscommunication is large (Galantucci & Roberts, 2014; Galantucci et al., 2018; Keysar, 2007; Morgan, 2013). For example, Chang et al. (2010) documented extensive miscommunication between physicians in a hospital, in which about 60% of the information about patients was lost during shift handoff. Yet the physicians were completely unaware of the communication failure. If we overestimate our ability to understand what our interlocutor said, we might convey the impression that we understood, not giving the speaker an opportunity to clarify their intention. When Luigi is sure that Maria is confessing her romantic love to him, the consequences might be serious if he has misunderstood what she meant.
Despite its importance to effective communication, people are often not calibrated about their ability to communicate and understand the intentions of others. Listeners believe that they detect a sarcastic intention irrespective of the medium, when in reality they are less able to detect such an intention when they read the message (Kruger et al., 2005, 2006). Such insensitivity to communication constraints adds to insensitivity to the inherent ambiguity of language more broadly (Keysar, 1994, 1997, 2000). This leads to an illusion of understanding, as first documented by Keysar and Henly (2002), in which 80% of speakers overestimated how often listeners understood them. Savitsky et al. (2011) discovered that this illusion of understanding is exacerbated by familiarity. Speakers overestimated how much their spouses understood them more than how much strangers understood them. Last, this illusion of understanding occurs even when the speaker and listener do not share a language (Lau et al., 2022).
Theoretical Accounts and Current Study
It is possible that language proximity might reduce overestimation. Lau et al. (2022) demonstrated that when native English speakers listen to Mandarin Chinese, they overestimate their understanding. Perhaps people who understand part of a language because of its proximity would be able to be relatively calibrated. They would understand more, and that would allow them to know when they understand and when they do not. This theory would predict increased calibration with proximity.
We propose a different account. Our theory assumes that precisely the opposite happens. We argue that the partial understanding that comes with a language close to your native tongue might exacerbate the illusion of understanding. When listeners are able to understand words of a proximal language, this will make them overconfident and will lead them to believe that they actually understand the speaker’s intention. In this case, reduced calibration is not despite the ability to understand some words but because of that understanding. Hence, our theory predicts more overestimation with closer than with remote languages and that the underlying mechanism is increased confidence.
To test this hypothesis, we recruited native Italian speakers (Study 1) and native Mandarin Chinese speakers (Study 2) and randomly assigned them to listen to 12 utterances from a speaker of either a close or distant language and guess what they intended to convey. To control for the effects of certain languages and speakers, listeners heard the same speakers in both studies. Listeners were randomly assigned to listen either to recordings in Spanish (an Indo-European language) or in the Northern Jiangsu Chinese dialect (Sino-Tibetan language) and guessed the speaker’s intentions. In Study 1, in which participants were native speakers of Italian, Spanish served as the linguistically close language, and the Northern Jiangsu Chinese dialect served as the linguistically distant language. In Study 2, in which participants were native Mandarin Chinese speakers, the Northern Jiangsu Chinese dialect served as the linguistically close language, and Spanish served as the linguistically distant language. We proposed that overestimation would be greater when people were listening to a speaker of a close language than to a speaker of a distant language. Furthermore, we predicted that confidence, induced by listening to a familiar language close to your own, would mediate this language-closeness effect.
Research Transparency Statement
General disclosures
Study 1 disclosures
Study 2 disclosures
Baseline study disclosures
Method
Participants
For Study 1, we aimed to recruit 120 participants to reliably detect, with a probability greater than 0.90, a medium effect size (Cohen’s d) of 0.60, assuming a two-sided criterion for detection that allows for a maximum Type 1 error rate (α) of .05. Expecting some attrition, 125 native Italian speakers who did not speak Spanish or Chinese were recruited from Prolific. Participants were prescreened for speaking Italian as a native language, having no family background of speaking Spanish or Chinese, and having no experience learning Spanish or Chinese. Of the participants who completed the study, nine were excluded for (a) reporting knowing either Spanish or Chinese as a foreign language on completing the study or (b) failing the audio test. This left a sample of 116 participants (29.31% female, 70.69% male; age range = 25–34 years).
For Study 2, an a priori power analysis based on the results of Study 1 was conducted to estimate the number of subjects needed. This analysis revealed that we needed a sample size of 126 per cell to reliably detect, with a probability greater than 0.90, an effect size (d) of 0.41 (based on Study 1), assuming a two-sided criterion for detection that allows for a maximum Type 1 error rate (α) of .05. To account for possible exclusions, we aimed to recruit a total sample of 260 (130 per cell).
A total of 298 native Mandarin Chinese speakers who did not speak Spanish or the Northern Jiangsu Chinese dialect were recruited online to participate through an online advertisement. Because of an error in the quota system, the sample included 38 subjects more than we targeted. Participants were prescreened for speaking Mandarin Chinese as a native language, having no family background of speaking Spanish or the Northern Jiangsu Chinese dialect, no history of living in a region in which the Northern Jiangsu Chinese dialect is spoken, and having no experience learning Spanish or the Northern Jiangsu Chinese dialect as a foreign language. Of the participants who completed the study, one was excluded for knowing Spanish as a foreign language and one for knowing Shanghainese, which is mutually intelligible with the Northern Jiangsu dialect. This left a sample of 296 participants (62.84% female, 36.82% male, 0.34% nonbinary; age range = 18–24 years).
Informed consent was given prior to the experiment, and participants were debriefed after the study was done. Both studies were approved by the University of Chicago Institutional Review Board.
Materials
Experimental materials were adapted from Savitsky et al. (2011). In total, 12 pragmatically ambiguous sentences were recorded, each with four potential meanings. For example, the sentence “What time is it?” was used to convey the following intentions: suggesting someone is impatient and wants to leave, curious about what time it is now, flirting and calling attention to oneself, and cannot believe that time passed by so quickly. Eight speakers recorded the utterances: four native Spanish speakers (two males and two females) and four native Northern Jiangsu Chinese dialect speakers (two males and two females). They each recorded in their native language all 12 sentences in each of their four corresponding meanings for a total of 48 utterances. Each speaker was trying their best to convey the specific intended meaning. For the exact wording of the sentences or to access the recordings, see the materials on OSF (https://osf.io/8fbqr).
Procedure
At the start of the study, participants were given informed consent and told they were going to participate in a communication study. Participants then identified their gender (male, female, or other) and completed a computer audio test to ensure their audio equipment was functioning. Participants who passed this audio test were randomly assigned to one of two listening conditions, with half of the participants listening to a linguistically close language and the other half listening to a linguistically distant language. To control for any gender effects, listeners were randomly assigned to listen to one of the two speakers who matched their gender. So if the listener identified themselves as a male at the start of the study, he was randomly assigned to one of the two male speakers of the assigned language, and if the listener identified themselves as a female, she was randomly assigned to one of the two female speakers of the assigned language. Listeners who identified themselves as nonbinary were randomly assigned to either a male or female speaker.
Participants then listened to each of the 12 sentences in a randomized order. For each sentence, they were randomly assigned to listen to a recording that conveyed one of the four possible intended meanings of this sentence. Therefore, of the 48 recordings of the speaker, they listened to a subset of 12 recordings (one recording for each sentence). Participants saw the translations for each sentence in their native language followed by an audio box where they could click the play button to play the recording once. After listening to the utterance, listeners received the four possible intended meanings in their native language and were asked to select the one the speaker intended. Last, they were asked to report whether they thought they had chosen the correct answer (yes/no) as well as report how confident they were in their selection on a scale from 1 to 7 (1 = not confident at all, 7 = very confident).
After listening to all 12 recordings, participants answered a few demographic and language-background questions. For the language questions, participants were asked how familiar they were with Spanish and the Northern Jiangsu Chinese dialect as well as how close they thought the language they just listened to was to their native language. After the language questions, participants were asked to report their native language, languages they knew as a foreign language, age, and educational background.
Results
Perceived language closeness: manipulation check
First, we assessed how close to their native tongue participants rated the language they listened to. Although each language pairing for both studies was selected so that one of the two languages was from the same language family and therefore linguistically closer, we wanted to ensure that listeners did in fact perceive the linguistically closer language as closer to their native tongue than the distant language.
Participants rated the linguistically close language as being closer to their native tongue than the linguistically distant language. In Study 1, Italian listeners rated Spanish as significantly closer to Italian than the Northern Jiangsu Chinese dialect (mean Spanish = 4.92, SD = 1.18; mean Northern Jiangsu Chinese dialect = 1.15, SD = 0.49), t(83.99) = 23.02, p = .001, d = 4.08, 95% confidence interval (CI) = [3.45, 4.10]. In Study 2, native Mandarin Chinese participants rated the Northern Jiangsu Chinese dialect as closer to Mandarin than Spanish (mean Northern Jiangsu Chinese dialect = 4.39, SD = 1.40; mean Spanish = 2.05, SD = 1.22), t(285.67) = 15.31, p = .001, d = 1.79, 95% CI = [2.04, 2.64]. This demonstrates that the language-distance manipulation was successful.
Accuracy and overestimation
In both studies, listeners overestimated their understanding of the close language more than they overestimated their understanding of the distant language. In Study 1, Italian listeners’ averaged accuracy in choosing the correct intended meaning of sentences was above chance (0.25) for Spanish (mean = 0.40, SD = 0.16), t(61) = 7.18, p = .001, 95% CI = [0.36, 0.44], but not significantly different from chance for the Northern Jiangsu Chinese dialect (mean = 0.26, SD = 0.14), t(53) = 0.64, p = .53, 95% CI = [0.22, 0.30]. However, although Italian listeners were more accurate in guessing the intended meaning in the close Spanish compared with the Northern Jiangsu Chinese dialect (39.78% in Spanish vs. 26.23% in the Northern Jiangsu Chinese dialect), t(113.99) = 4.79, p = .001, d = 0.88, 95% CI = [0.08, 0.19], they believed they correctly guessed the meaning when listening to Spanish for 9.61 of the 12 sentences (80.11%, SD = 17.62) compared with only 6.54 of 12 sentences (54.48%, SD = 30.92) when listening to the Northern Jiangsu Chinese dialect. Most importantly, this resulted in a significant difference in overestimation: Italian listeners overestimated their understanding of Spanish more than they overestimated their understanding of the Northern Jiangsu dialect (40.32% overestimation in Spanish vs. 28.24% in the Northern Jiangsu Chinese dialect), t(91.14) = −2.13, p = .04, d = −0.41, 95% CI = [−0.23, −0.01] (see Fig. 1).
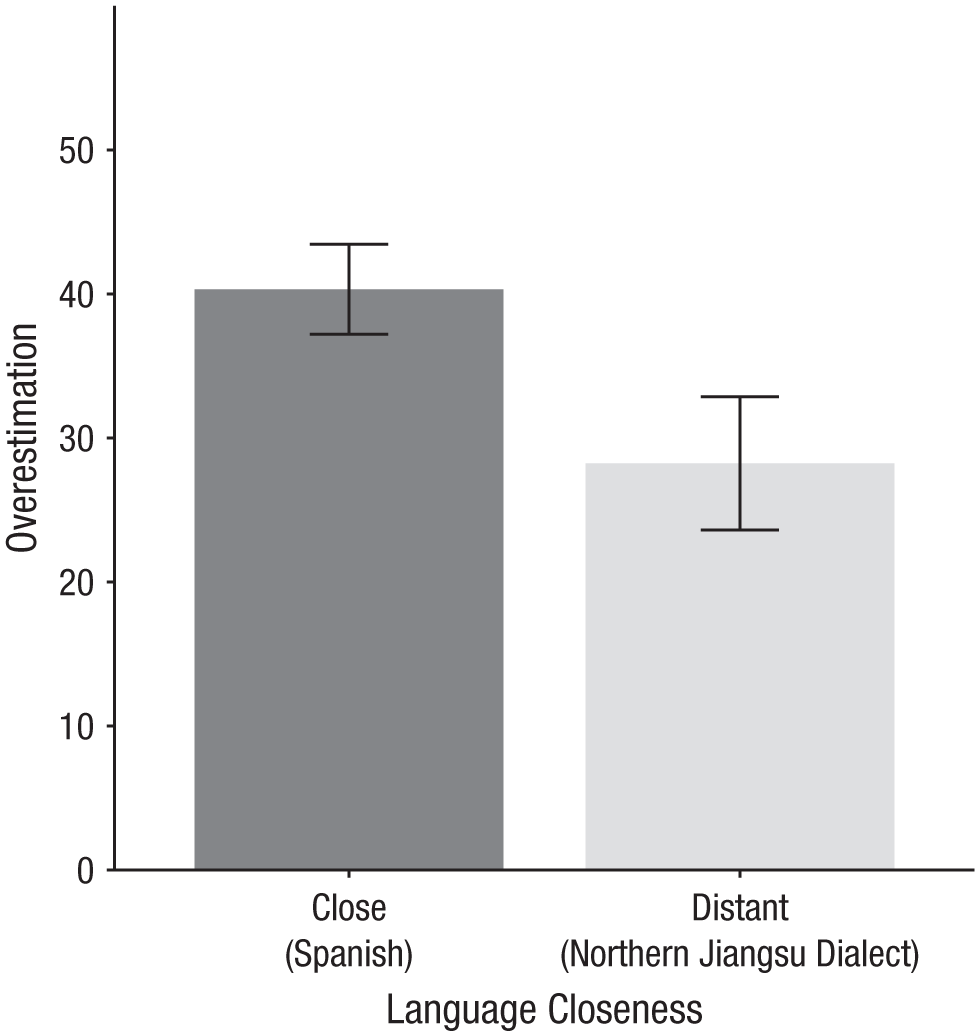
Italian listeners’ overestimation of their understanding in a close (Spanish) or distant (Northern Jiangsu Chinese dialect) language in Study 1. The y-axis represents overestimation, which was calculated as a percentage point difference of perceived accuracy minus actual accuracy.
Study 2 replicated these findings. Mandarin Chinese listeners’ averaged true accuracy in choosing the correct intended meaning of sentences was above chance (0.25) for both the Northern Jiangsu Chinese dialect (mean = 29.77%, SD = 12.72), t(144) = 4.52, p = .001, 95% CI = [0.28, 0.32], and Spanish (mean = 32.23%, SD = 14.74), t(150) = 6.03, p = .001, 95% CI = [0.30, 0.35]. Although Mandarin Chinese listeners were not significantly more accurate when listening to the close Northern Jiangsu Chinese dialect than to the distant Spanish (32.23% in Spanish vs. 29.77% in the Northern Jiangsu Chinese dialect), t(290.73) = −1.54, p = .13, d = −0.18, 95% CI = [−0.06, 0.01], they still overestimated how accurate they were more when listening to the close than to the distant language. Specifically, the mean estimated accuracy was 9.93 of 12 sentences (82.76%, SD = 18.81) for the Northern Jiangsu Chinese dialect and 9.27 of 12 sentences (77.21%, SD = 24.53) for Spanish. Again, overestimation was larger for the close than for the distant language: Mandarin Chinese participants overestimated their understanding of the close Northern Jiangsu Chinese dialect significantly more than they overestimated their understanding of the distant Spanish (52.99% overestimation in the Northern Jiangsu Chinese dialect vs. 44.98% in Spanish), t(285.98) = −2.71, p = .007, d = −0.31, 95% CI = [−0.14, −0.02] (see Fig. 2).
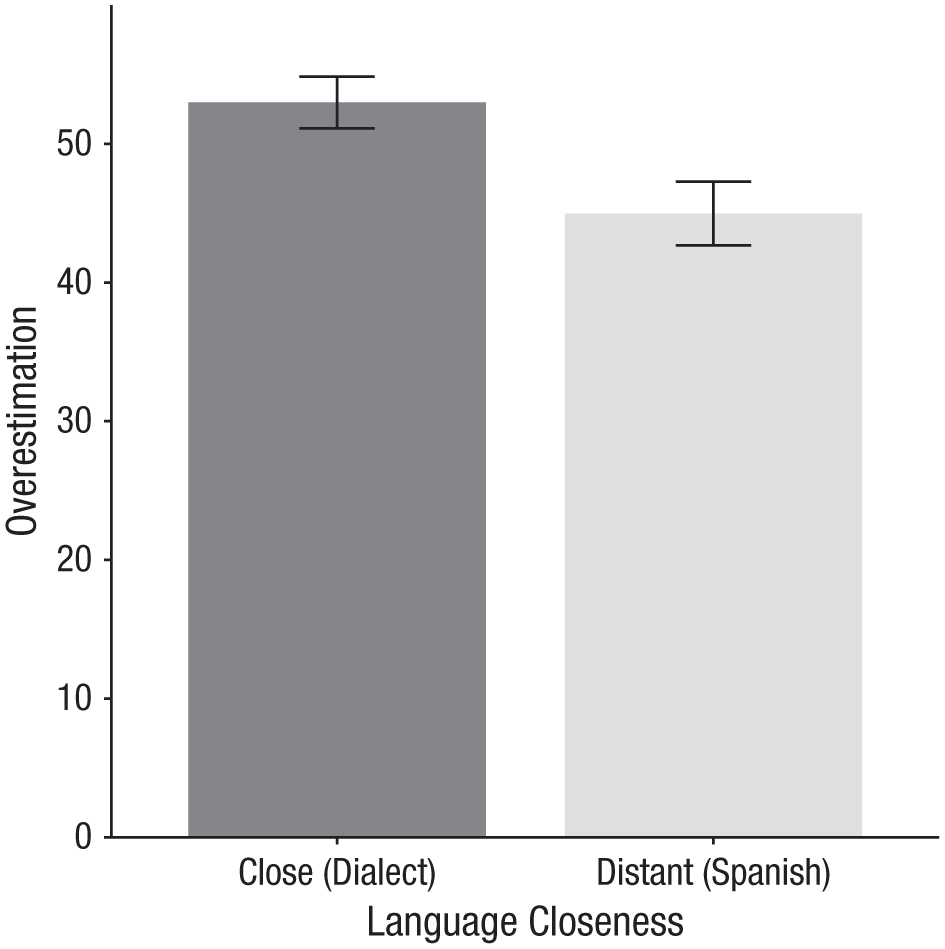
Mandarin Chinese listeners’ overestimation of their understanding in a close (Northern Jiangsu Chinese dialect) or distant (Spanish) language in Study 2. The y-axis represents overestimation, which was calculated as a percentage point difference of perceived accuracy minus actual accuracy.
To examine whether the extent of overestimation across languages depended on how accurately an individual understood the speaker, we examined whether actual accuracy moderated the effects of language on overestimation. For Studies 1 and 2, there was no significant interaction between actual accuracy and language condition—Study 1: b = 0.21, SE = 0.31, t(112) = 0.67, p = .51, η² = .01; Study 2: b = −0.08, SE = 0.19, t(292) = −0.42, p = .68, η² = .01. Thus, differences in overestimation across languages did not significantly depend on the actual accuracy of the listener.
Reported confidence
We theorized that when listening to a language that is closer linguistically to their native tongue, listeners may be more confident in their perceived understanding, which in turn may boost overestimation in their understanding. To test this theory, we first assessed whether participants were more confident in their understanding when listening to the close than the distant language. In Study 1, Italian listeners were more confident when listening to the close Spanish than to the distant Northern Jiangsu Chinese dialect (mean close = 4.65, SD = 0.65; mean distant = 3.51, SD = 1.10), t(83.33) = 6.68, p = .001, d = 1.29, 95% CI = [0.88, 1.68]. Study 2 showed the same pattern: Mandarin Chinese listeners were more confident when listening to the close Northern Jiangsu Chinese dialect than to the distant Spanish (mean close = 4.66, SD = 0.89; mean distant = 4.33, SD = 1.10), t(285.82) = 2.84, p = .005, d = 0.33, 95% CI = [0.10, 0.56].
Because confidence and overestimation significantly differed across language conditions, we ran a bootstrapped mediation with 10,000 simulations to test whether increased confidence mediated the language-closeness effect. In both studies, the effect of language closeness was rendered nonsignificant when controlling for reported confidence. For Study 1, confidence had an estimated indirect effect of 0.20, 95% CI = [0.11, 0.28], with the effect of language closeness dropping from 0.12, 95% CI = [0.01, 0.23], to −0.07, 95% CI = [−0.18, 0.04], consistent with a full mediation. Likewise, in Study 2, confidence had an estimated indirect effect of 0.04, 95% CI = [0.01, 0.08], with the effect of the language-closeness condition dropping from 0.08, 95% CI = [0.02, 0.14], to 0.04, 95% CI = [−0.01, 0.09], also consistent with a full mediation. Hence, listeners were more confident that they understood the speaker of a close language than a distant one, and that led them to overestimate their understanding even more (see Figs. 3 and 4).
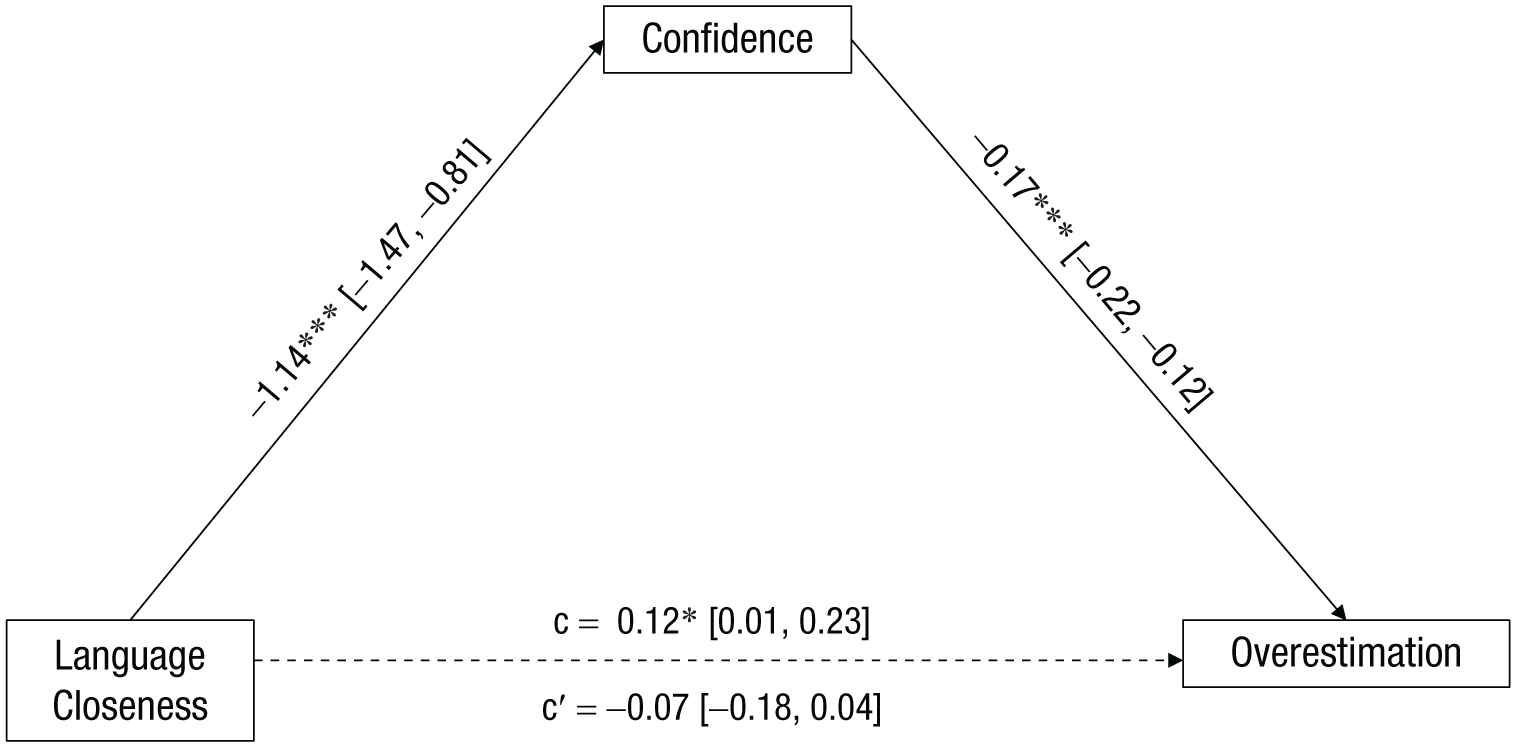
Mediation analysis of the indirect effect of confidence on the direct effect of language closeness on overestimation for Italian listeners in Study 1. Mediation coefficients refer to unstandardized coefficients. Asterisks indicate significant coefficients (*p = .05, **p = .01, ***p = .001).
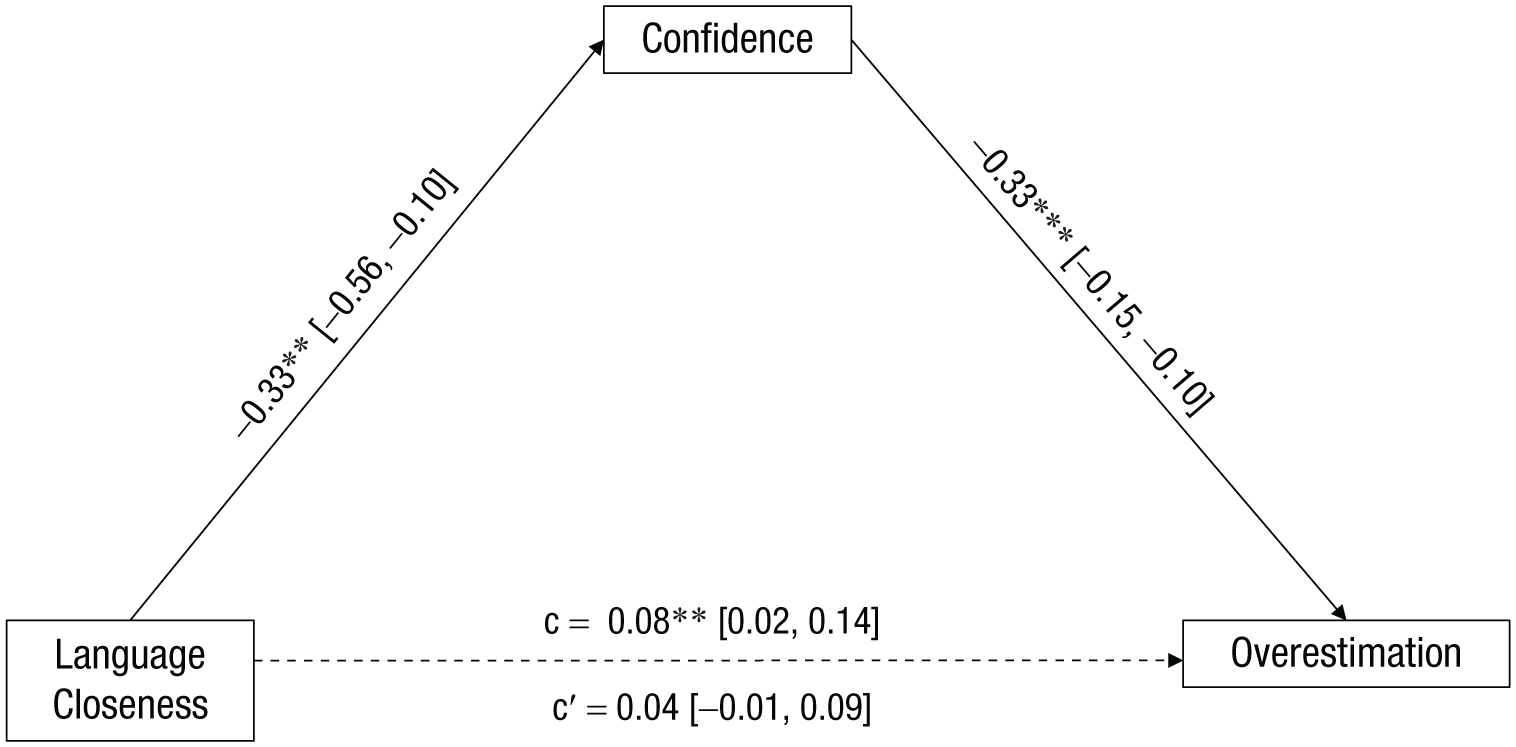
Mediation analysis of the indirect effect of confidence on the direct effect of language closeness on overestimation for Mandarin Chinese listeners in Study 2. Mediation coefficients refer to unstandardized coefficients. Asterisks indicate significant coefficients (*p = .05, **p = .01, ***p = .001).
Overconfidence by Native Speakers: Establishing a Baseline
Studies 1 and 2 showed that people overestimated their understanding more when they listened to a language that was close to their native tongue than to a language that was distant from it. Previous studies have also found that people overestimate their understanding of native speakers of their own language (e.g., Keysar & Henly, 2002; Lau et al., 2022; Savitsky et al., 2011). However, prior studies have primarily been conducted with native English listeners, so to assess the extent to which native speakers may have overestimated their understanding with the materials we used, we replicated Study 1 with native Spanish listeners instead of Italian listeners.
We recruited 259 native Spanish listeners (41.70% female, 57.92% male, 0.39% nonbinary; age range = 25–34 years) living in Spain from Prolific. Thirty-three participants were excluded from the analysis for noncompletion and for not speaking Spanish as a native language. We randomly assigned them to listen to one of the four native Spanish speakers using the same recordings and procedure as Study 1.
Speaker-by-speaker analysis
To examine the extent to which speakers varied in their effectiveness in communicating each intended meaning, we examined differences in listener accuracy by speaker. Results showed that there were no significant differences in listeners’ actual accuracy by speaker, F(3, 255) = 1.46, p = .23, η² = .02. This shows that the speakers’ effectiveness in communicating their intended meaning to native listeners was comparable.
Overestimation
Native Spanish listeners overestimated their understanding of the native Spanish speakers, consistent with Studies 1 and 2. Spanish listeners’ average accuracy in choosing the correct intended meaning of the Spanish utterances was above chance (41.63% accurate; five of 12 sentences), t(258) = 15.32, p = .001, 95% CI = [39.50%, 43.77%]. Yet their perceived accuracy was much higher than their actual accuracy: They believed they correctly guessed the meaning of 89.45% (SD = 12.88) of the sentences (10.73 of the 12). This shows that the listeners significantly overestimated their accuracy by an average of 47.81%, t(258) = −35.00, p = .001, 95% CI = [−0.51, −0.45]. Last, confidence in one’s accuracy was significantly positively correlated with the extent to which listeners overestimated their accuracy (R2 = .25), t(257) = 4.19, p = .001, 95% CI = [0.14, 0.36].
As languages become closer to one another, one could think about one’s own native tongue as the limit of closeness. It is in a way the “closest” one can get. What we found was that native listeners showed, if anything, a larger degree of overestimation when listening to their native language (47.8%) compared with the Italian listeners listening to a close (40.3%) or distant (28.3%) language. Hence, the closer the language, the larger the illusion.
Discussion
We found that people overestimated their understanding more when listening to a linguistically close language than to a remote one. This resulted from increased confidence: The closer the language, the more confident people became in their ability to understand, which boosted their overestimation.
Our baseline study also found that in their native tongue of Spanish, listeners overestimated their understanding. These results in the context of communication could be relevant to the study of overconfidence more broadly. Moore and colleagues (Moore & Healy, 2008; Moore & Schatz, 2017) distinguished between three types of overconfidence: overestimation (in which people think they are better than they are), overplacement (in which people exaggerate the degree to which they are better than others), and overprecision (in which people are too sure they are right). Our findings might reflect either overestimation or overprecision. It might be overestimation in the sense that listeners overestimated their ability to detect the intention of the speaker. It might be overprecision in the sense that they felt like they knew more than they did. Once they identified one of the four intentions as the intended one, they did not adequately consider the possibility that any of the other three could have been intended. Such overprecision benefits from a “construal effect” (Griffin & Ross, 1991; Moore, 2023), which is likely to have played a role in our experiments.
Given noise and error, performance estimates tend to be regressive; people overestimate performance on hard tasks and underestimate performance on easy tasks (Erev et al., 1994; Moore & Healy, 2008). The accuracy level in the baseline study, which was around 42%, is consistent with a regressive effect because one has more room to overestimate (up to 100%) than to underestimate (down to the 25% chance level). So the overestimation that we found in the baseline study is consistent with the literature on overconfidence.
Interestingly, the language-distance effect we found showed the opposite pattern. In Study 1, Italian listeners’ accuracy for the Spanish was much higher than for the Chinese language, for which they were at chance. This shows that understanding Spanish was easier for them than understanding Northern Jiangsu Chinese. A regression-based account for the language-distance effect would predict that the harder task would lead to greater overestimation, but we found the opposite: Italians’ level of overconfidence was larger with Spanish, which was easier for them, than with Northern Jiangsu Chinese, which was harder. In Study 2, the native Mandarin Chinese listeners were similarly accurate in deciphering the correct meaning in both Spanish and Northern Jiangsu Chinese, which would predict similar levels of overconfidence, yet nonetheless the native Mandarin Chinese speakers were more overconfident when listening to the closer Chinese dialect than the distant Spanish. Hence, the familiar, closer language instilled more confidence in listeners than the unfamiliar, distant language, which in turn increased their overconfidence.
Theoretically, these findings reveal a counterintuitive relationship between language closeness and feeling of understanding. It makes sense for theories of communication to assume that having a partial grasp of words and sentences would allow people to be more calibrated when they gauge their understanding. Instead, we found the opposite. Precisely because of language closeness, listeners became more confident, which increased their overestimation of their understanding. Theories of communication rarely consider the idea of calibration, namely the extent to which listeners know when they understand and when they do not. Our results demonstrate the importance of studying the role of calibration and incorporating it into theories of communication.
Our findings could therefore give rise to new and interesting avenues for research. For example, one could examine overestimations of understanding in other forms of linguistic similarity, such as the closeness of the speaker’s accent to a listener within a language. The familiarity of speech style that arises from someone using a similar accent may lead to overconfidence, which may boost overestimation of communicative effectiveness. Further, because there is evidence suggesting that people make perspective-taking errors in written language (e.g., Kruger et al., 2005), it would also be interesting to test overconfidence when reading languages that vary in linguistic closeness to one’s native tongue. Last, one limitation concerns the generalizability of the findings because participants were recruited from online samples that may not fully represent the broader populations of these language communities.
Practically, our discovery could have implications for domains such as diplomacy and cross-national communication, in which overconfidence in understanding another language can lead to misunderstandings and even conflict. Given extensive global linguistic diversity, understanding the differences between perceived and actual understanding could anticipate miscommunication, thereby facilitating collaborative efforts. These findings could also inform educational practices, ensuring teachers and students are attuned to this illusion of mutual intelligibility in close languages, which in turn could help foster more effective multilingual education.
So, can Italians understand Spanish? They probably understand many words, but they have the illusion that they understand what the speaker intended much more than they actually do, not despite the closeness of the languages but because of it.
Footnotes
Acknowledgements
We thank Don Moore for providing important advice on this article’s connections to the overconfidence literature. We are grateful for Veronica Vazquez-Olivieri, Zeynep Aslan Sisman, and Janet Geipel for inspiring the study idea and providing critical feedback. We thank Kexin Peng and Songyang Zhang for assisting and checking the study materials.
Transparency
Action Editor: Ulrike Hahn
Editor: Simine Vazire
Author Contributions