
Abstract
Investigations into people’s ability to use multiple working memory representations to concurrently search for targets have led to mixed findings. Although the discourse has predominantly centered around capacity limits in multitarget search, we here propose that people can switch between sequential and concurrent search. In Experiment 1 (n = 16 adults), manual responses and oculomotor behavior revealed that participants could search sequentially, and concurrently for at least two targets, when instructed. In Experiments 2a (n = 16 adults) and 2b (n = 16 adults), participants were free to choose how they searched. Trial-level modeling showed that participants primarily used sequential and concurrent search as specific modes and flexibly adjusted between either mode depending on template set size, template availability, stimulus properties, and individual preference. Our findings stress the dynamic and adaptive nature of visual search. Moreover, understanding that different search modes can be flexibly picked as “tools from the toolbox” may reconcile inconsistencies in prior findings.
When assembling a piece of furniture, you will often need several small objects, such as screws, wooden pegs, and plastic clips to finish one set of instructions. In order to achieve this, you may look at the assembly manual, memorize one screw, and search for it among the pile of hardware before moving on to the next screw.
When humans perform such a search task, attention first needs to be directed at the image of the to-be-found item (an external target template; Hoogerbrugge et al., 2023), which must then be encoded into visual working memory (VWM) as an internal target template (Awh et al., 2006; Fougnie, 2008). The item must subsequently be actively maintained in VWM so that its representation can be used to guide attention toward locations in the search array which are most likely to contain a matching target (Desimone & Duncan, 1995; Gunseli et al., 2014; Wolfe, 2021). Once a target candidate is selected and attention is shifted toward that candidate, the attended item must be compared with the internal template in VWM, and a target or no-target decision is made (Hout & Goldinger, 2015; Moore & Wolfe, 2001; Ort & Olivers, 2020; Palmer et al., 2000).
Alternatively, you may solve the furniture-assembly task by attempting to memorize multiple small parts and then search until you have found all of them before moving onto the next set of instructions. There are conflicting accounts regarding how attention is deployed during multitarget search and whether multiple distinct templates in working memory can be used to guide attention concurrently. By some accounts, humans are able to hold multiple representations simultaneously activated in VWM, which can then be used to guide search (Beck & Hollingworth, 2017; Beck et al., 2012; Godwin et al., 2015; Grubert et al., 2024; R. S. Williams et al., 2023). Other studies have opposed this account of simultaneous control, arguing that, although multiple representations can be stored in VWM, only one can be used to guide attention in search at any moment in time (Houtkamp & Roelfsema, 2009; Ort et al., 2017, 2019; Van Moorselaar et al., 2014). Consequently, concurrent search for multiple items seems to be possible in some form, but the mixed findings in literature suggest that it is perhaps not used under all circumstances.
Even if humans can search for multiple targets concurrently, they may not always choose to actually do so. It has been established that humans often prefer to rely on VWM as little as possible, and the degree of this reliance depends on various factors, such as the ease with which external information can be accessed (Ballard et al., 1995; Böing et al., 2023; Draschkow et al., 2021; Hoogerbrugge, Strauch, Böing, et al., 2024; Qing et al., 2024; Somai et al., 2020), the complexity of stimuli (Hoogerbrugge et al., 2023), metacognitive factors (Hoogerbrugge, Strauch, Nijboer, & Van der Stigchel, 2024; Sahakian et al., 2023, 2024), and individual differences in preferred working memory load (Hoogerbrugge et al., 2023; Meyerhoff et al., 2021). One may therefore ask how often humans would opt to search concurrently when also given the option to do it sequentially.
We posit that, even if humans are able to use multiple VWM representations to guide attention, they may not consistently utilize this capability, depending on both task-related and individual factors—which could partially explain discrepant findings in the literature (cf. Fraătescu et al., 2019). In the aforementioned furniture example, this could either lead one to memorize a single screw at a time and search fully sequentially, or to memorize all items in a single inspection and then search concurrently, or even to memorize all items but still search for them sequentially (i.e., keep other items in accessory states; Olivers et al., 2011). In the present study, we aimed specifically at uncovering whether participants can and do use multiple VWM representations to guide attention across a search array when given the choice. Furthermore, machine-learning methods allowed us trial-level insights into whether participants searched sequentially or concurrently as specific search modes or whether they employed a mixture of both modes on a trial level. Last, we asked to which degree the choice for specific search modes depends on the individual and on task specifics—namely VWM load, stimulus properties, and template availability.
Research Transparency Statement
General disclosures
Study 1 disclosures
Study 2 disclosures
Experiment 1: Instructed Concurrent and Sequential Search
Experiment 1 tested whether participants can search sequentially or concurrently when explicitly instructed to do so. This also provided a reference profile for subsequent experiments in which participants were free to choose how to search.
Method
Participants and procedure
Sixteen participants (15 female;
Prior to the experiment, participants read the information letter, signed an informed consent form, and indicated their age and gender. Participants received €7 per hour or course credits; Experiment 1 took 60 to 90 min. The study was approved by the Faculty Ethics Review Board of Utrecht University (Protocol No. 21-0297).
Apparatus
Monocular gaze location was recorded with an EyeLink 1000+ (SR Research, Mississauga, Ontario, Canada) at 1 kHz. Stimuli were presented on a 27-in. 2,560 × 1,440 LCD monitor at 100 Hz. Participants were seated, and their heads were stabilized with a chin rest and forehead rest 67.5 cm from the monitor. The experiment was implemented with PyGaze (Dalmaijer et al., 2014).
All gaze metrics are reported in degrees of visual angle (°). Before the start of the experiment, and between each block, the eye tracker was calibrated and validated with a 9-dot grid, allowing a mean error of 0.5° and a maximum per-dot error of 1.0°. Fixations were detected using I2MC in Python (Hessels et al., 2017). All fixation candidates shorter than 60 ms were removed, and fixation candidates were separated by less than 1° distance were merged (cf. Hooge et al., 2022).
Stimuli
Stimuli were L, T, and † shapes about 1.27° × 1.27° in size. The stimuli could be shown in any of four 90° rotations and in any of seven canonical colors (blue, orange, green, red, purple, pink, yellow) thus providing a set of 84 unique stimuli in total. All stimuli were equally tall and wide and contained an equal number of colored pixels. Stimuli in the search array were separated from each other by about 2.54°. Consequently, it was difficult to peripherally distinguish shapes, making stimulus color the primary feature to guide attention across the search array.
Task and design
Participants performed a visual-search task, in which the screen was divided by a vertical line into two sections: a smaller template area and a larger search area (Fig. 1). The template area occupied the leftmost third (16.8°) of the screen and contained either two or four equally spaced templates. Templates would only be shown when gaze was detected in the template area, so participants could not covertly attend templates while their gaze was in the search area. The search area occupied the rightmost two thirds (32.9°) of the screen and contained a grid of 42 equally spaced stimuli.
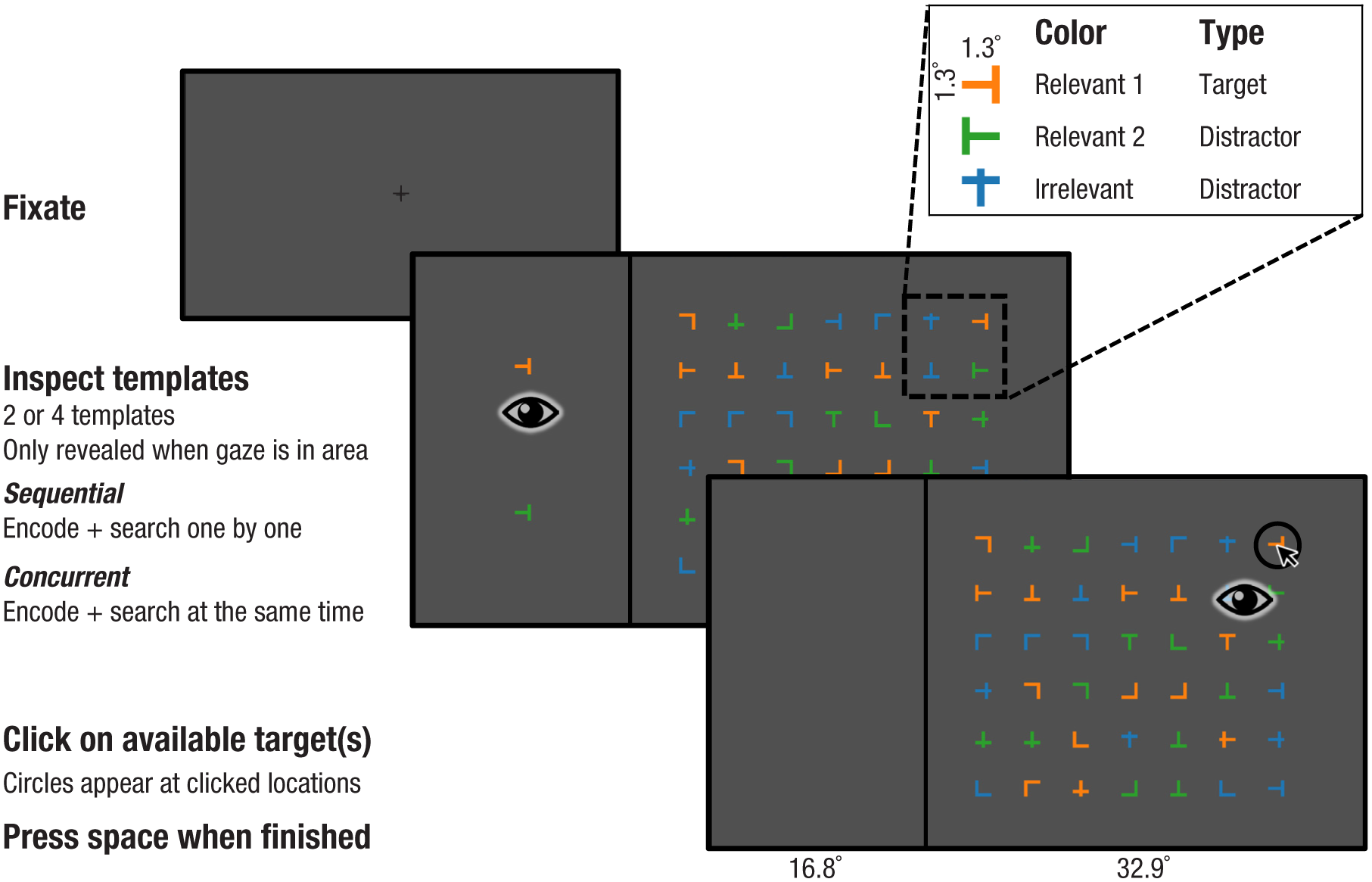
Experimental design. Participants searched whether one or more of the templates on the left-hand side of the vertical line were present in the search array. They clicked on each target that they could find (using shape, rotation, and color match) and pressed the space bar when they were satisfied that they had found all present targets. There were two or four templates, and likewise there could be 0–2 or 0–4 targets, respectively. Stimuli in the search area could be of a relevant color (matching one of the template colors) or an irrelevant color. In Experiment 1, participants were instructed to either search sequentially or concurrently. In Experiments 2a and 2b, participant were free to choose how to search. In Experiments 1 and 2a, all templates were of the same shape and rotation within trials (as shown in the figure). In Experiment 2b, templates were all of the same shape but could be of different rotations.
Templates always differed from each other in color, but their shapes and rotations were identical within trials. Thus, in each trial participants effectively only had to memorize one stimulus in two or four colors. The search area contained zero, one, or two target stimuli in conditions with two templates, or zero to four targets in conditions with four templates; the other stimuli were distractors. Stimuli were considered targets only if their shape, rotation, and color matched one of the templates. The same target never occurred multiple times in a trial layout. Depending on the template set size, the search area contained two or four relevant colors (matching the template colors) and one additional irrelevant color (Fig. 1 inset box). There were equal numbers of stimuli, approximately, for each color. Distractor stimuli could occur multiple times in the search array.
Participants were instructed to click on all targets that they could find, and a circle appeared around each clicked location. When participants were satisfied that they had found all targets, they pressed the space bar to end the trial.
Importantly, participants were instructed to search in a specific manner in each condition. In sequential conditions, participants were instructed to start by encoding and searching for only the topmost template, ignoring all other templates. Subsequently, they were told to encode and search the next template from the top while ignoring all others—and so on. As such, participants should have had only one target template in memory at any given time. In concurrent conditions, participants were instructed to encode all templates before searching. Once they believed that they had memorized all templates, they were instructed to search for all targets at the same time. To encourage participants to memorize all items in the concurrent conditions, we designed the search so that templates did not reappear after search onset (when gaze first crossed from the template area to the search area).
Conditions consisted of 40 trials, which were blocked, and block order was counterbalanced according to a Latin square (see Section 6 in the Supplemental Material available online). Each trial started after fixation at a central cross. The experiment was preceded by four practice trials. Trials in which participants did not fixate templates in the correct order were excluded from analysis. Although templates were at least 4° apart, this methodology does not fully exclude the possibility that participants peripherally attended the color of other templates.
Analysis
Target-detection order
As a metric of sequential versus concurrent search, we report the order in which targets were clicked. For each trial, templates were assigned a relevant color index, from the top-most template to the bottom-most template. We use color index particularly to compensate for the fact that the subset and order of colors was different on each trial. In the case of Figure 1, relevant color index 1 would therefore be orange, and relevant color index 2 would be green. This top-to-bottom ordering of relevant colors matched the instructions given to participants.
All target clicks were assigned a proportion on the basis of the total number of clicks in their respective trials (the first click out of two, the second out of three, etc.) and then scaled between 0 and 1 per trial. Consequently, the first click received a value of 0 and the last click received a value of 1. Trials with fewer than two targets and fewer than two clicks were discarded because no slopes could be calculated.
We used linear regression models (Lm2 in Pymer4 0.8.1; Jolly, 2018) to estimate per-participant slopes for target-click order (rescaled to be between 0 and 1) and to report the average estimated slope (
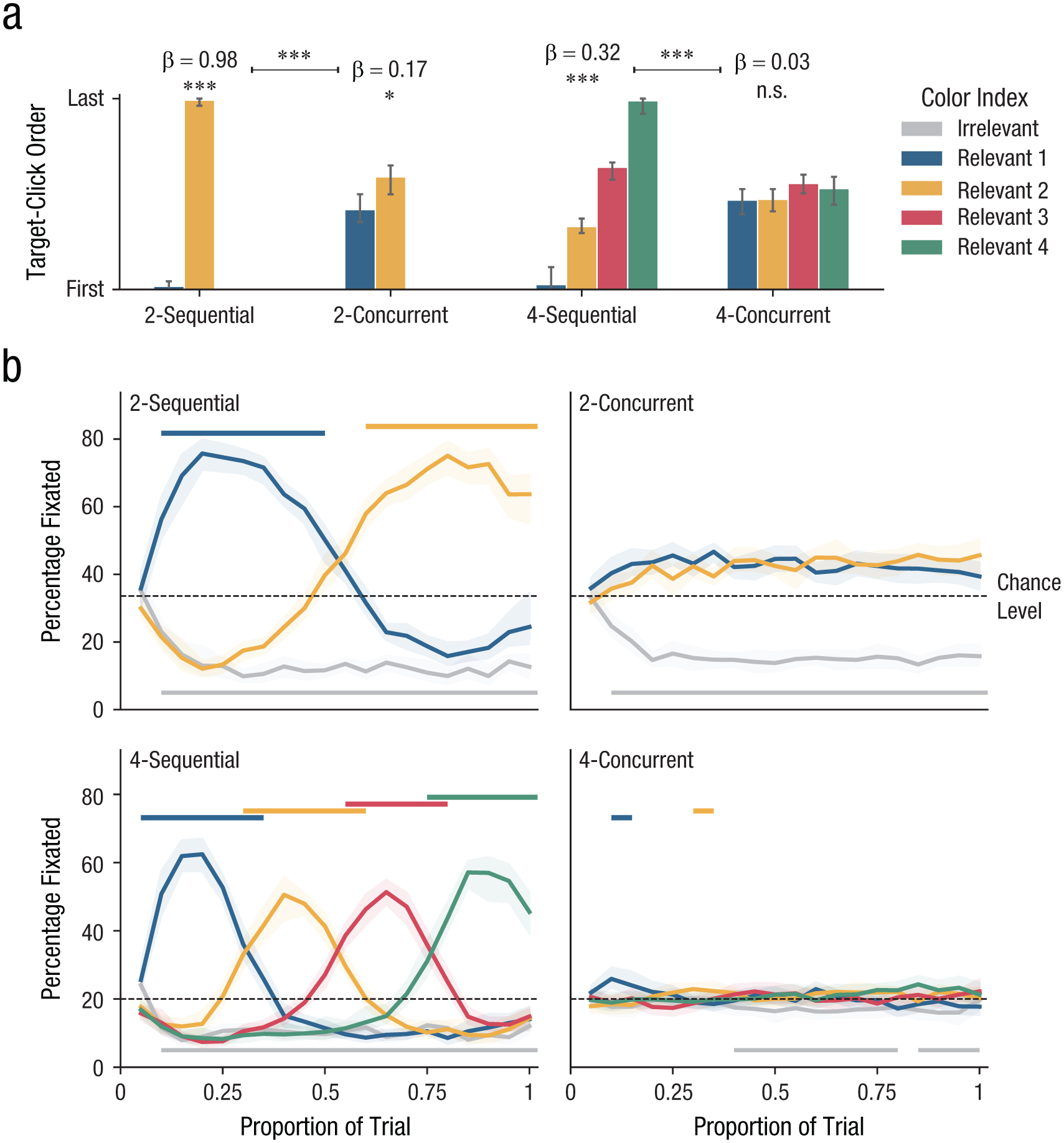
Outcomes of Experiment 1. Target click order is shown in (a). Bars denote the across-participant average of each color index’s scaled position (between 0 and 1). Error bars denote ±95% within-participant confidence intervals (Morey, 2008) and were clamped between 0 (first) and 1 (last).
Attentional guidance
Besides target-click patterns, we report how frequently colors were fixated over the course of trials. If search occurred fully sequentially, all stimuli of one template color should be fixated exhaustively (or until a target is found) before stimuli of the next color are fixated, and so on. By contrast, in fully concurrent search, all template colors should be fixated approximately equally often across a whole trial. In all conditions, if search could be guided effectively on the basis of color, the irrelevant color should be fixated at below-chance level.
We filtered all gaze data to retain only fixations within the search array, and each fixation was linked to the color of the stimulus that was nearest to fixation. Subsequently, each fixation in the search array was assigned to its relevant color index, as described in the previous section. The residual color in the search array (e.g., blue in Fig. 1) was labeled as irrelevant. Because trials contained varying numbers of fixations and had varying response times, we report the normalized time course of a trial, computed with the proportion of fixations made in that trial (e.g., the fifth fixation in a trial with 10 fixations occurs at proportion .5; the last fixation occurs at proportion 1.0). This measure was then split into 20 equally sized bins. Within each of those bins, we computed the percentage of fixations made on each color in the search array. Because participants gazed at a central fixation cross before the onset of each trial, the very first detected fixation was usually a residual from that central fixation—and therefore on a random color.
To evaluate whether relevant colors were searched sequentially or concurrently, we tested whether each relevant color was fixated more than the averaged prevalence of the remaining relevant colors, using paired-samples t tests at each binned time point. To evaluate whether attentional guidance could be used to suppress irrelevant colors, we tested whether the irrelevant color was fixated below chance level using one-sample t tests. All statistics were computed using SciPy 1.12 (Virtanen et al., 2020) and corrected for false discovery rate within colors at
Results
The number of template inspections, response times and accuracy, are reported in the Supplemental Material (Section 1).
Target-detection order shows sequential and concurrent search under instruction
Participants could search sequentially, when instructed. This is indicated by the order of targets clicked approximating the expected slopes of 1.0 and 0.33 (Fig. 2a). When searching for two targets, relevant color 1 was clicked before relevant color 2, as demonstrated by a significant regression slope,
Participants could also search more concurrently when instructed. However, for the two-target condition this was not perfect, as the first relevant color was sometimes clicked earlier than the second color (59.1% versus 40.9%),
Participants could apply both search modes when instructed to do so; per-participant slopes were significantly different between sequential and concurrent conditions—two templates, t(15) = 11.12, p < .001; four templates, t(15) = 13.46, p < .001.
Although target clicks are useful behavioral markers of sequential versus concurrent search, they capture only a few discrete points in time. Moreover, the reported target clicks do not inform us about guidance and may, for example, reflect a strategy in which participants nonselectively scanned the search array. As an extension of target clicks, we next analyzed gaze behavior as a more detailed marker of how participants searched.
Sequential and concurrent search are distinguishable from gaze behavior
Fixation patterns showed that participants were able to search sequentially for two targets as well as for four targets, with color as the main guiding feature. Participants encoded and searched each relevant color sequentially, while successfully ignoring the other colors for which they were not searching at that time (as evidenced by consecutive peaks in fixation frequency; Fig. 2b). Moreover, and notably, participants were able to ignore the irrelevant color throughout the whole trial: All but the first time bin were significantly below chance in both two- and four-target search. Together, these fixation patterns suggest that observers were only looking for the target colors and not just any color, and that attentional guidance was very effective when searching for only one target at a time.
When instructed to search concurrently, gaze behavior was noticeably different than in sequential search. When they were searching for two targets, participants fixated both relevant colors equally often throughout trials; at no point was either relevant color fixated significantly more than the other (Fig. 2b). Moreover, the irrelevant color was effectively ignored in all but the first time bin. Given that the first relevant target color was sometimes clicked before the second relevant color, we speculate that this color may have been more strongly represented in VWM, causing the target to be found first on average, without affecting attentional guidance (see the General Discussion).
Concurrent four-target search showed similar, but less pronounced, patterns. Relevant colors received an equal number of fixations over the course of trials, except for two time bins. Crucially, participants were less able to confine search to the relevant colors and included the irrelevant color in their search more often than in concurrent search for two targets. The irrelevant color was fixated significantly below chance in only 11 out of 20 time bins (compared with 19 out of 20 in 2-concurrent), marking a decrease in the effectiveness of top-down attentional guidance.
In sum, we identified markers (click order and fixation patterns) of both sequential and concurrent search, and we have shown that both modes of search are indeed possible when instructed, although top-down guidance was weaker when participants searched for four targets. Perhaps participants used a search mode that was not selective for color in the latter condition; we speculate about this in the General Discussion.
Experiments 2a and 2b: Free-Choice Search
We investigated in Experiments 2a and 2b which mode of search participants actually opted to use when given free choice on how to search. Given consistent findings that humans tend to minimize simultaneous VWM load, one may expect that participants generally prefer sequential search (thereby keeping VWM load low), if those target templates could be reinspected during trials (in line with, e.g., Hoogerbrugge, Strauch, Nijboer, & Van der Stigchel, 2024; Hoogerbrugge et al., 2023; Qing et al., 2024). Furthermore, what if participants were forced to memorize all target templates? When all templates are encoded in VWM, participants may opt to search for those items concurrently, or they may choose to sequentially prioritize representations in VWM while leaving other representations in accessory states (Lewis-Peacock et al., 2012; Olivers et al., 2011).
In Experiment 2, participants were able to reinspect templates in half of conditions (unlimited conditions), but restricted in the other half of conditions (view-once conditions). These two conditions allowed us to study whether participants searched differently when templates remained available compared with when VWM must be fully loaded.
Experiment 2a: low search difficulty
Sixteen participants (12 female;
Experiment 2a was identical to Experiment 1, except for the following: Participants were not instructed on which search strategy to use, but could either reinspect templates as often as they wished throughout the trial (unlimited conditions), or only gaze in the template area once per trial (view-once conditions). In the latter conditions they could inspect templates as long as they wanted, but the templates would not reappear after search onset. Blocked conditions consisted of 50 trials. Blocks were again counterbalanced according to a Latin square, and no effects of block order were found (see Section 6 in the Supplemental Material).
Experiment 2b: increased search difficulty
Sixteen participants (12 female;
Experiment 2b was identical to Experiment 2a, except for one change: Templates could be shown in varying 90° rotations. Again, stimuli in the search array were considered targets only if their shape, rotation, and color matched one of the templates. Consequently, participants had to remember more features than in Experiment 2a, making the task more difficult. Rotations of templates were randomly applied.
Results
Target-detection order reveals a mix of strategies
Target-detection patterns in Experiment 2a provided evidence for a mix of sequential and concurrent search (Fig. 3a). Participants searched at least somewhat sequentially both when templates could be reinspected (unlimited conditions) as well as when all templates had to be memorized before search onset (view-once conditions), but these patterns were less pronounced than the sequential patterns in Experiment 1. Notably, participants frequently searched in a sequential manner even when all templates were in memory, suggesting sequential prioritization in memory.
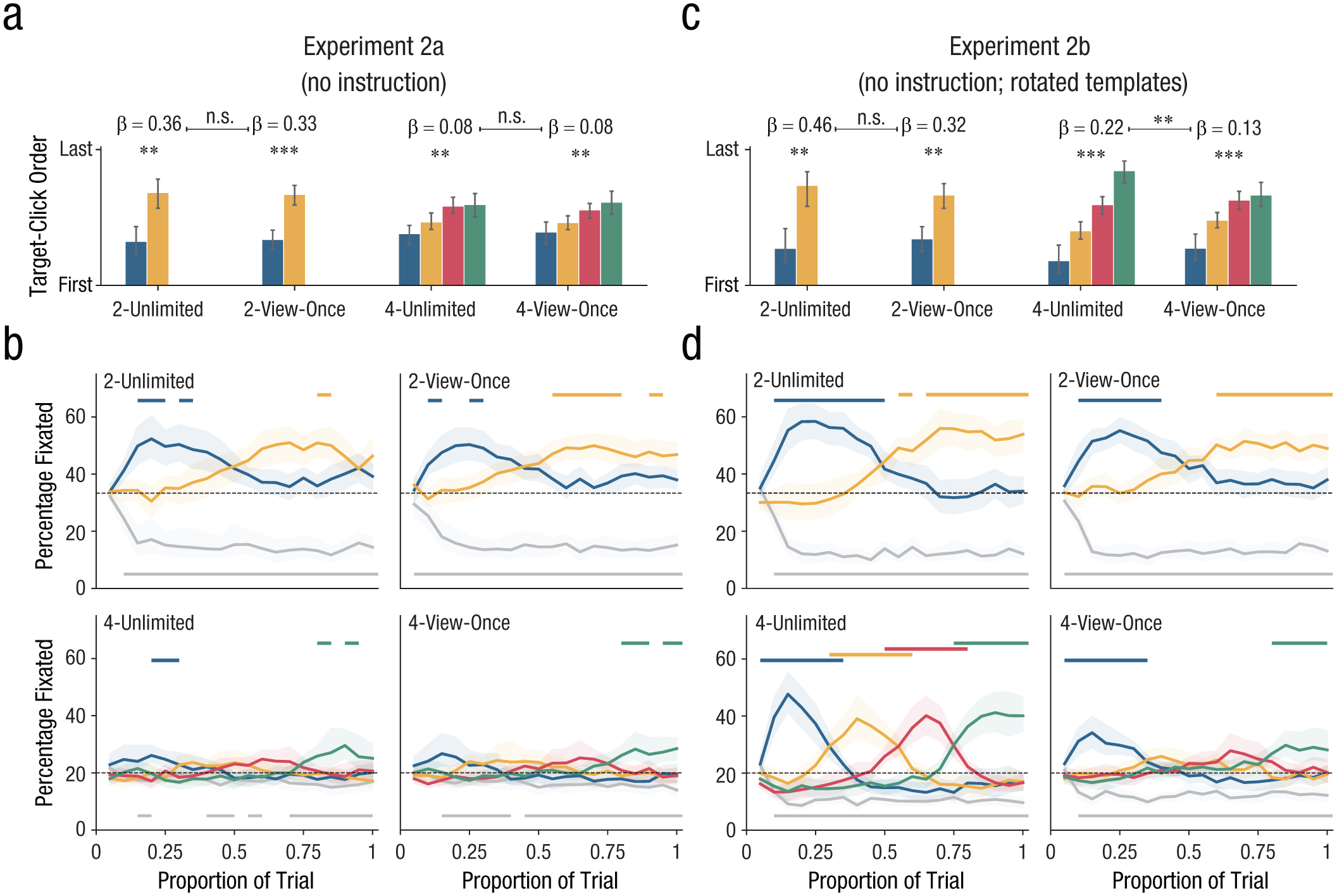
Outcomes of Experiments 2a and 2b. Target-click order is shown in (a) and (c). Bars denote across-participant averages, and error bars denote ±95% within-participant confidence intervals (Morey, 2008). Fixation patterns are shown in (b) and (d). The percentages at each time point sum to 100. Given random eye movements, each color’s percentage fixated would be around 33% and 20% for two- and four-template conditions, respectively. Lines denote across-participant averages, and shaded areas denote ±95% within-participant confidence intervals. Dashes at the top of figures indicate a significantly greater percentage of fixations on that color than on the other relevant colors; dashes at the bottom of figures indicate that the irrelevant color was fixated significantly below chance (corrected p < .05). 2-unlimited = two-template unlimited condition; 2-view-once = two-template view-once condition; 4-unlimited = four-template unlimited condition; 4-view-once = four-template view-once condition. ***p < .001, **p < .01, n.s. = not significant.
When templates could be reinspected, relevant color 1 was often clicked before relevant color 2, as reflected by a significant regression slope,
Neither the ability to reinspect nor increased stimulus complexity strongly affected in which order participants clicked on targets; only when searching for four complex targets did participants detect targets relatively more sequentially. In Experiment 2b (increased template complexity), regression slopes were descriptively larger than in Experiment 2a (Fig. 3c). However, one-tailed paired-samples t tests between the 12 participants who performed both experiments showed that only the slopes in the 4-unlimited condition were significantly larger in Experiment 2b than in Experiment 2a, t(11) = −3.59, p = .002, d = −1.04 (all other p > .05; the same results hold when performing independent-samples t tests on all participants of both experiments). Moreover, slopes in Experiment 2b were similar between two-template conditions, t(15) = 1.07, p = .30, but significantly greater in the 4-unlimited condition than in the 4-view-once condition, t(15) = 3.13, p = .007.
Eye movements reveal consistent attentional guidance
Fixation patterns also provided evidence for a mix of both sequential and concurrent search when participants were not instructed whether to search sequentially or concurrently. When templates could be reinspected, gaze patterns were not as pronounced as in fully sequential search in Experiment 1, suggesting some degree of concurrent search. Vice versa, in conditions in which all templates were encoded before search onset, participants still exhibited some degree of sequential search.
In Experiment 2a, sequential patterns emerged when searching for two targets, whilst the irrelevant color was effectively ignored (Fig. 3b). When searching for four targets, moderate peaks could be discerned in sequential order in both the 4-unlimited condition and the 4-view-once condition, but statistically the signal-to-noise ratio was very limited. The irrelevant color was effectively ignored in all but the 4-unlimited condition, indicating that participants were predominantly able to guide top-down attention even when all items were in VWM. These findings suggest that participants searched with some degree of sequential prioritization but often used another search mode. It is unclear why suppression of the irrelevant color was worse in the 4-unlimited condition than in other conditions, especially because it was not fully absent; participants still ignored the irrelevant color in some stages of trials. We speculate on this in the General Discussion.
In Experiment 2b, stronger sequential patterns emerged in all conditions relative to Experiment 2a, further evidenced by more statistically significant differences (Fig. 3d). Results from eye movements thus resemble those from the target-click order; participants searched more sequentially when templates were complex, and there were limited differences in how participants searched between the unlimited and view-once conditions. Only in the four-template conditions in Experiment 2b was there a marked difference between the unlimited and the view-once conditions: there, participants searched more sequentially when templates could be reinspected.
What Drives Concurrent Versus Sequential Search?
Search behavior in free-choice search showed a mix of search modes, with evidence for a balance between sequential and concurrent search. However, interpretation of our findings may be complicated by averaging artifacts; if half of trials were fully sequential and the other half were either fully concurrent or nonselective, target-detection order would show moderate slopes and guidance patterns would show at least some bumps, obstructing clear interpretation of how participants searched. Consequently, we could not clearly state whether participants switched between strictly sequential and concurrent search between trials or whether they used a mixed or nonselective search mode within trials. Moreover, even though participants were not instructed to do so, they often encoded and searched templates in our specified order of relevance (top to bottom). Nonetheless, there could be trials in which participants searched sequentially but did not follow this order. Those trials would then reduce the averaged slopes and gaze patterns, giving the impression that search was concurrent. In view of this, an analysis method was required that was order-agnostic and could indicate for individual trials, rather than on a group level, whether search was sequential or concurrent.
We here introduce a novel analysis method that can distinguish on a trial-by-trial basis whether search was sequential or concurrent. This method allowed us to investigate in more detail how often either mode of search was used within participants and conditions, as well as across participants and experimental manipulations.
We trained Random Forest classifiers on gaze data from Experiment 1, in which participants were instructed on which search strategy to use (Step 1 in Fig. 4). These instructions (sequential or concurrent) served as reference labels for our classifier. Notably, the color index labels were shuffled on each iteration and independently for each trial, thereby ensuring that the classifier learned to detect patterns instead of specific orders of color labels. Models validated within Experiment 1 were highly accurate and robust; they classified trials at
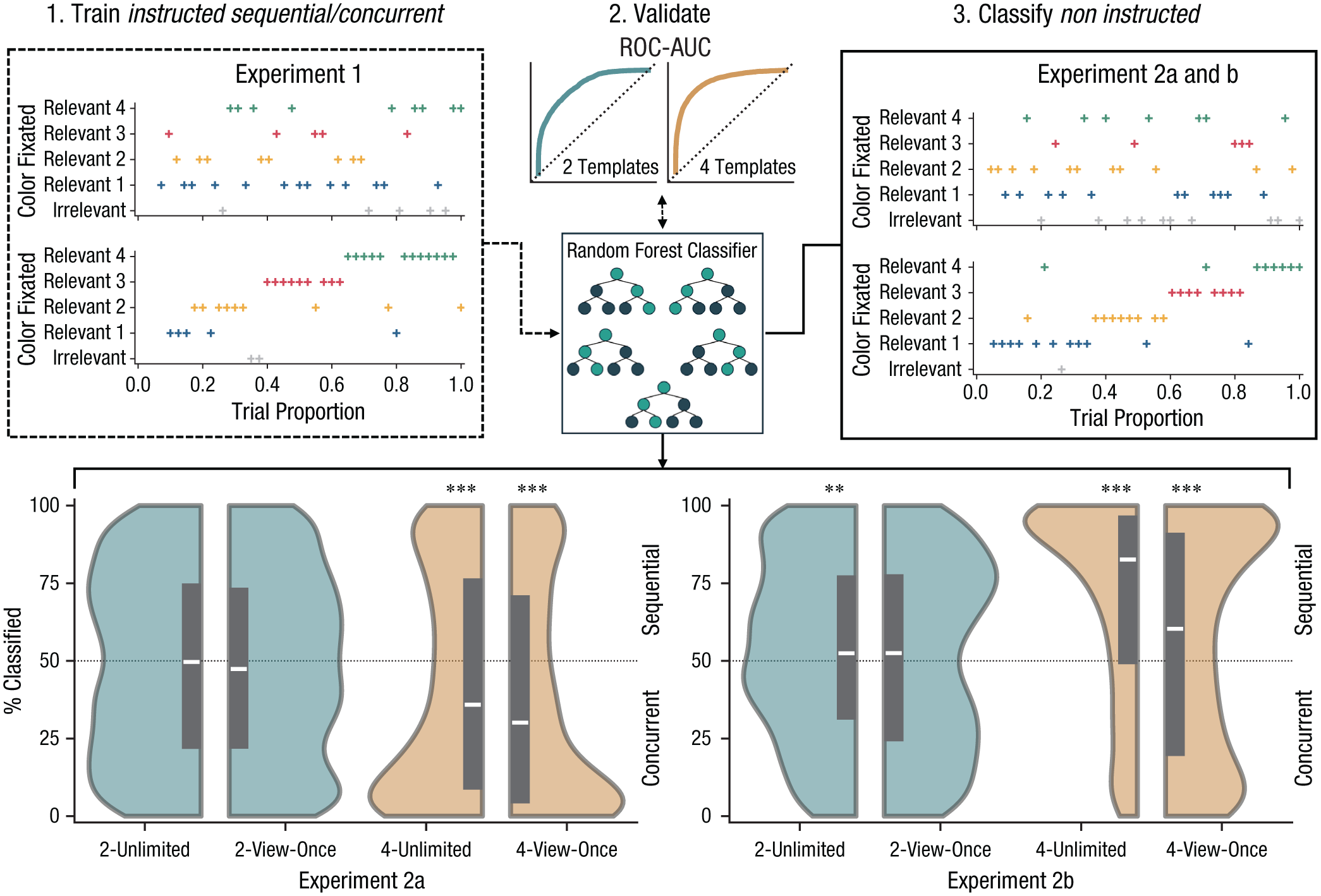
Methods and results for dissociating search strategy on the basis of gaze. In step 1, Random Forest classifiers were trained on 85% of instructed sequential or concurrent trials from Experiment 1, separately for two- and four-template conditions. This process was bootstrapped for 100 iterations. The two subfigures show fixation sequences in example trials from four-template concurrent trials and four-template sequential trials, respectively. In step 2, trained classifiers were validated using the remaining 15% of trials in each iteration. The two subfigures show averaged receiver operating characteristic (ROC) curves from the 100 bootstrap iterations ±95% range. In Step 3, new Random Forest classifiers were trained on all data from Experiment 1 and then used to classify data from Experiments 2a and 2b (the two subfigures show example trials). This process was bootstrapped for 1,001 iterations, after which classifications were averaged for each trial. The bottom violin plots show the distribution of data (kernel-density estimation), as well as the median and interquartile range over all trials. 2-unlimited = two-template unlimited condition; 2-view-once = two-template view-once condition; 4-unlimited = four-template unlimited condition; 4-view-once = four-template view-once condition. ***p < .001,**p < .01 (one-sample t test against 50% chance level).
Sequential and concurrent are distinct and dissociable modes of search
Predictions from order-agnostic models showed that sequential and concurrent search are clearly dissociable strategies based on gaze alone.
Within conditions, we found that participants used three overarching search strategies (Fig. 4 shows aggregates across participants; Fig. 5a shows an example participant; and all individual participants and conditions are reported in Section 3 of the Supplemental Material). Most commonly, participants were consistent in opting for one mode of search during the whole condition, as evidenced by skewed classification distributions toward either consistently sequential or concurrent behavior. Alternatively, participants sometimes switched between trials (but within conditions) from sequential to concurrent search modes or vice versa, as evidenced by bimodal distributions. Most trials were classified confidently as either sequential or concurrent behavior. Least commonly, participants sometimes appeared to employ a hybrid mode of search within trials, neither fully resembling sequential nor concurrent search behavior. These modes of search were typified by Gaussian distributions of model predictions. Some participants even switched between these three strategy types across the experiment (Fig. 5a).
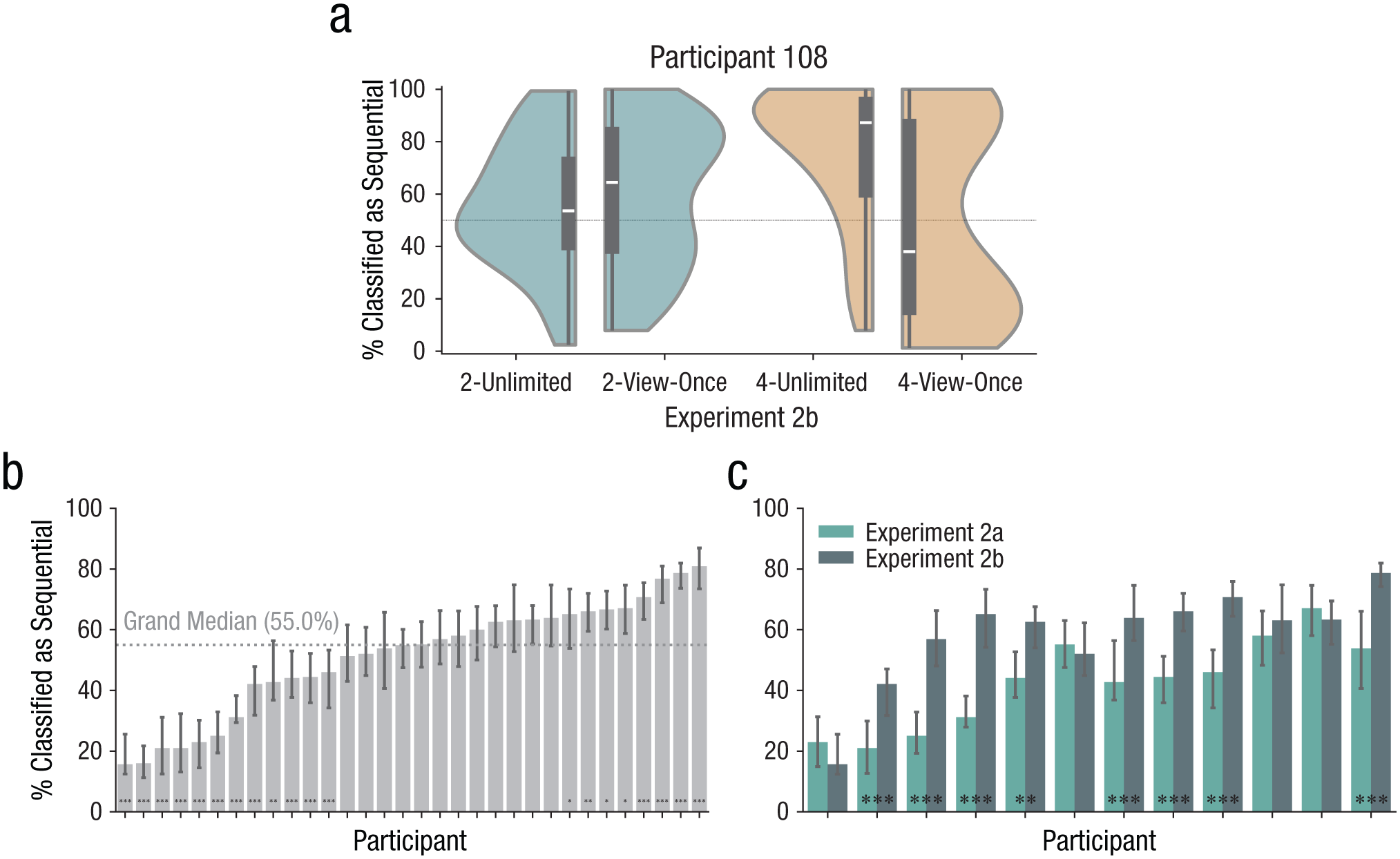
Individual differences in search behavior. In (a) we show violin plots of an example participant who showed a less definable mode of search (2-unlimited), clearly defined sequential search (4-unlimited), and bimodal distributions of either search mode (2-view-once, 4-view-once). Distributions show kernel-density estimation, and inner boxes show the median and interquartile range. In (b) we show model predictions per participant, compared with the grand median of all predictions. Bar heights denote within-participant medians ±95% confidence intervals. Asterisks denote significance of one-sample t tests against the grand median. In (c) we illustrate model predictions for the 12 participants who participated in both Experiments 2a and 2b, split between experiments. Bar heights denote medians, error bars denote ±95% confidence intervals, and asterisks denote the significance of t tests. 2-unlimited = two-template unlimited condition; 2-view-once = two-template view-once condition; 4-unlimited = four-template unlimited condition; 4-view-once = four-template view-once condition. ***p < .001, **p < .01, *p < .05.
For each participant, per condition, we tested whether model classifications across trials deviated from normal distributions using Shapiro-Wilk tests. In all conditions except two, the assumption of normality was violated for 75% to 100% of participants. Only in the 2-view-once condition in Experiment 2a and the 2-unlimited condition in Experiment 2b, model predictions followed a normal distribution for 63% and 50% of participants, respectively, suggesting that some participants may have used a hybrid of sequential and concurrent search. In sum, search behavior was strongly skewed toward either clearly sequential or clearly concurrent search as specific modes of search, although on some trials participants may have employed a mix of the two modes (e.g., concurrent search for both templates, but with one template more strongly represented than the other).
It should be noted that this analysis approach is contingent on how participants were instructed; outcomes are more reflective of how participants behaved as a result of our instructions in Experiment 1 rather than factually sequential or concurrent search. However, we found compelling evidence for participants’ ability to follow our instructions and to search both sequentially and concurrently in all but the 4-concurrent condition, in which concurrent search only appeared somewhat weakened. Moreover, our classification accuracy of .885 in four-template search shows that there is a clear observable distinction between instructed-sequential and instructed-concurrent search, which further affirms that instructed-sequential and instructed-concurrent search are distinguishable search modes. Future research may attempt to identify analyses that are grounded in more exact definitions of sequential and concurrent search.
Search modes are used dynamically
Outcomes from our models revealed that participants applied sequential and concurrent search modes dynamically, not only within conditions but also between conditions and across experiments. Across all conditions in both experiments, 51.1% (SD = 33.5) of trials were classified as sequential search, and 48.9% as concurrent search.
Being able to reinspect templates was linked to more sequential search, F(1, 30) = 13.78, p < .001, η p 2 = .32, and this effect was stronger in the more difficult Experiment 2b than in the easier Experiment 2a, F(1, 30) = 5.18, p = .030, η p 2 = .15. Being able to reinspect templates also interacted with the number of templates in its effect on search mode; the higher prevalence of sequential search in unlimited conditions compared with view-once conditions was greater when searching for four templates than for two templates, F(1, 30) = 9.00, p = .005, η p 2 = .23.
In Experiment 2a (Fig. 4, bottom left), when participants searched for two templates, trials were equally likely to be classified as sequential and concurrent; 48.7% (SD = 30.5) of trials were classified as sequential when templates remained available, and 48.2% (SD = 30.6) of trials were classified as sequential when templates could only be viewed once. When participants searched for four templates, 42.7% (SD = 35.2, p < .001) of trials were classified as sequential when templates remained available, and 38.9% (SD = 35.4, p < .001) of trials were classified as sequential when templates could only be viewed once.
In Experiment 2b (Fig. 4, bottom right), participants searched more often in a sequential manner than in Experiment 2a, F(1, 30) = 10.19, p = .003, η p 2 = .25. Moreover, participants adjusted their behavior more when they were able to reinspect templates in Experiment 2b than in Experiment 2a, F(1, 30) = 5.18, p = .030, η p 2 = .15. When participants searched for two templates, there was a higher prevalence of sequential search when templates could be reinspected (53.4%, SD = 28.9, p = .001). When templates could only be viewed once, around half of trials were classified as sequential, meaning that both search modes were used approximately equally often (51.0%, SD = 30.6, p = .38). When participants searched for four templates, trials were significantly more often classified as sequential (four-template unlimited: 70.2%, SD = 31.1, p < .001; four-template view once: 55.4%, SD = 35.7, p < .001).
In sum, participants used both sequential and concurrent search modes depending on template availability, the number of templates, and template complexity.
Individuals use sequential versus concurrent search idiosyncratically
Using predictions from the models, we were further able to distinguish that participants employed sequential versus concurrent search to differing degrees. Overall, 12 out of 32 participants were classified as sequential significantly less often compared with the grand median over all predictions (as indicated by one-sample t tests, corrected for false discovery rate). Their averages ranged from 15.7% to 46.0%. Conversely, 8 participants were classified as sequential significantly more often compared with the grand median (their averages ranged from 65.1% to 80.9%; Fig. 5b).
Not only was search behavior a result of general individual preference, but individuals differed in the degree to which they changed search modes as a result of stimulus complexity. Eight out of 12 participants who participated in both Experiments 2a and 2b searched significantly more sequentially in Experiment 2b than in Experiment 2a (independent-samples t tests), whereas 4 participants did not significantly change how they searched (Fig. 5c).
General Discussion
Investigations into people’s ability to use multiple working memory representations to concurrently search for targets have led to mixed findings. The results presented here provide evidence that people can search concurrently for at least two targets when instructed to do so and that people use a mix of sequential and concurrent search when given free choice. We further revealed that sequential and concurrent can be considered specific and dissociable modes of search. Finally, we showed that the choice of search mode is flexibly adjusted as a result of task specifics and individual differences.
In Experiment 1, manual responses and oculomotor behavior showed that participants were able to search concurrently for two targets when instructed to do so, but that attentional guidance suffered when searching concurrently for four items. In Experiments 2a and 2b, participants freely chose how they searched. Here, they exhibited a mix of sequential and concurrent search. A parsimonious model, using only fixation locations over time, was able to predict with high accuracy and robustness whether individual trials in Experiment 1 contained sequential or concurrent search. This model was then applied to make predictions of search strategies in Experiments 2a and 2b. Participants most often used sequential and concurrent search as specific search modes, although some trials were less dissociable, which argues for a hybrid mode of search within a limited number of trials. Our model further revealed that participants were flexible in which search mode they used, depending on VWM load, stimulus properties, and template availability.
These findings highlight an interesting point: The fact that we can do something does not mean that we will do it—and conversely, the fact that we do not do something does not mean that we cannot. It has been established that humans are conservative in their willingness to expend more cognitive effort than is minimally necessary, as evidenced by, for example, the tendency to avoid simultaneous VWM load when possible (Ballard et al., 1995; O’Regan, 1992; Van der Stigchel, 2020; Wilson, 2002). However, this willingness can be modulated by task demands, and it differs on an individual level (Draschkow et al., 2021; Hoogerbrugge et al., 2023; Meyerhoff et al., 2021; Qing et al., 2024; Sahakian et al., 2023; Somai et al., 2020). It follows that, if maintaining multiple attentional templates is cognitively challenging, humans might avoid doing so if the task does not explicitly require them to. In line with this idea, even when participants were forced to memorize all templates, they exhibited some degree of sequential search. On those trials, participants must therefore have sequentially prioritized templates in VWM, possibly leaving the others in accessory states (Olivers et al., 2011). The increased prevalence of sequential-search usage in Experiment 2b compared with 2a is also consistent with findings from foraging tasks, where participants made fewer switches in conjunction foraging than in feature foraging (e.g., Kristjánsson et al., 2014). The popular explanation for discrepant findings in the multitarget search literature is that concurrent search is capacity limited (e.g., Houtkamp & Roelfsema, 2009; Ort & Olivers, 2020; Ort et al., 2017, 2019; Van Moorselaar et al., 2014), and we likewise found that concurrent search for four targets was limited. However, when searching for two targets, these limits were less obvious. As a result, our findings may provide an alternative account of why Kristjánsson et al. (2014) found some participants to be “immune” to the task changing from feature foraging to conjunction foraging (given that all experiments in our paradigm are arguably conjunction-search tasks); those immune participants were not super-foragers, but simply opted to keep using a concurrent foraging mode, whereas the other participants did not. It would be interesting to find out whether these same individuals hold these foraging patterns when searching for more than two targets.
It should be noted that this paradigm may not be sensitive enough to distinguish between fully parallel search (i.e., when templates are activated in memory at the same time, as described by e.g., Ort & Olivers, 2020) or search that appears parallel to an observer but contains serial cognitive processes in the form of rapid alternation of template activation. However, such alternation has been found to be relatively slow (e.g., Dombrowe et al., 2011; Pomper & Ansorge, 2021; Wilschut et al., 2013) and is accompanied by switch costs (e.g., Ort & Olivers, 2020; Ort et al., 2017; Wolfe et al., 2019), for which we found no evidence here (see Section 5 in the Supplemental Material). Nonetheless, we suggest that the theory should be extended beyond capacity limitations to include the role of willingness to search concurrently, which in turn is related to environmental demands and individual factors.
When participants were instructed to search concurrently for four items, they exhibited behavior in which they selectively fixated items of the relevant colors less distinctly and ignored the irrelevant color less strongly. In that condition, participants may have sometimes used other ways of searching that circumvented our instructions to search concurrently. In some cases, participants may have switched to a shape-search mode, of which only one needed to be remembered. Dropping the color dimension from memory would still allow participants to find all targets while lowering memory load, but this would also increase the chance of false alarms if correct shapes—but incorrect colors—were clicked. Indeed, false-alarm rates were highest in the four-template concurrent condition in Experiment 1 and the four-template view-once condition in Experiment 2a, compared with other conditions (see Fig. S1 in the Supplemental Material). In the four-template view-once condition in Experiment 2b, participants could still drop the color dimension, but even then they had to memorize four shapes. Hit rates in this condition were also markedly lower, which suggests that participants approached a general VWM capacity limit, not only a concurrent-search limit. Moreover, participants may have used a memory-search mode, in which they nonselectively shifted attention across the search array (rather than selecting where to fixate next on the basis of guiding templates in memory) and searched through all memory items at each fixation. Shape search and memory search may have been used individually but could also be combined (i.e., drop the color dimension and perform memory search). Gaze behavior can provide support for both nonselective search and shape search (which would arguably decrease the size of the functional viewing field and thereby decrease saccade amplitudes and selectivity; Hulleman & Olivers, 2017; Wolfe, 2021; Wu & Wolfe, 2022). Namely, supplemental analyses showed that saccade amplitudes were indeed smallest and that gaze behavior was most systematic (i.e., scanning the array as if reading a book instead of selecting the next best option) in the four-template concurrent condition compared with other conditions (although systematicity was not significantly different from the other conditions; see Fig. S4 in the Supplemental Material Section 4). However, whether participants used shape search or nonselective memory search or both—and if so, to what degree—is difficult to estimate exactly from the current data. Interestingly, saccade amplitudes and systematicity showed much less pronounced effects when participants had free choice on how to search (Experiment 2) than in instructed search (Experiment 1), which may be another explanation for the observed mix of sequential and concurrent search modes; participants chose whichever mode allowed them to retain as much top-down guidance as possible. To avoid the possibility of participants’ using search modes that are nonselective for the intended guidance dimension (color, in our case), it may be desirable to design multitarget search tasks in such a way that participants cannot reduce their template representation to a single dimension, and to keep track of how they move their gaze across the search array.
Interestingly, because targets occurred at most once per trial, template representations of found targets may be dropped from memory (Lewis-Peacock et al., 2018; Oberauer, 2001). This could in turn leave more cognitive overhead to actively guide search for the remaining items (Olivers et al., 2011). Participants were better able to ignore irrelevant colors in the second half of trials, which provided initial evidence for this idea (Fig. 2, 4-concurrent condition). Thus, there may be environmental circumstances in which people use nonselective search or simplify their search in such a way that only a single VWM representation is required (if possible). However, they may then also be able to switch back to concurrently guided search, as targets are found and cognitive load decreases. It would be interesting to study multitarget search with paradigms in which each target can occur multiple times (e.g., foraging tasks; cf. Kristjánsson et al., 2014, and Wolfe, 2013, although these may be difficult to reconcile with the aforementioned dimensionality issue).
We additionally suggest that concurrent search does not need to be equally balanced across templates. Our results from instructed search likely showed one such instance: In sequential search for two items, guidance seemed perfectly concurrent, although one item was often found before the other. Relatedly, participants were generally able to ignore the irrelevant color in free-choice search, even with four template representations in memory. We therefore speculate that templates were not always equally strongly represented in VWM. Possibly, participants were able to have a stronger “blue” than “yellow” template (causing more likely detection of the blue target when attending it; Bays & Husain, 2008), while still allowing a similar amount of guidance and suppression from each of those templates (Yu et al., 2023; but see J. R. Williams et al., 2022). These findings highlight the added value of using multiple modalities (i.e., manual responses and gaze behavior) in order to dissociate distinctive stages of search (Ort & Olivers, 2020) when investigating multitarget search.
Given the paradigm, one might question whether the templates guiding performance rely on working memory or on longer-term memory representations. It is conceivable that objects maintained for several seconds, or repeatedly encountered across trials, could engage long-term memory processes. However, previous research using highly similar paradigms suggests that such visual templates are not consolidated into long-term memory (Hoogerbrugge, Strauch, Nijboer, & Van der Stigchel, 2024) after only a few repetitions. Moreover, if items were consolidated into longer-term memory, working memory was likely needed within trials in order to prevent proactive interference from those longer-term representations (Makovski & Jiang, 2008). Importantly, our focus lies not on the precise memory system involved, but on how individuals use internal representations to guide flexible behavior—whether they rely on stored information simultaneously or sequentially, and how this usage varies across individuals. Our conclusions therefore hold regardless of whether these representations are best characterized as short- or longer-term memory traces.
In sum, we here report that sequential and concurrent multitarget visual search are both possible (although concurrent search has capacity limits), and that they can be considered two specific modes of search which are applied flexibly. Each of these modes of search may be considered as ‘tools in the toolbox’ of search strategies—tools that can be used depending on task demands. In the analogy of furniture assembly, in some cases one requires a steel hammer, and in other cases one requires a wooden mallet; both can do similar jobs, but both are best suited for slightly different tasks. We argue that incorporating knowledge about this dynamic application of search modes may contribute toward a better understanding of multitarget search and be the key to reconciling inconsistencies in prior findings.
Supplemental Material
sj-pdf-1-pss-10.1177_09567976261442169 – Supplemental material for Multitarget Visual Search Flexibly Switches Between Concurrent and Sequential Search Modes
Supplemental material, sj-pdf-1-pss-10.1177_09567976261442169 for Multitarget Visual Search Flexibly Switches Between Concurrent and Sequential Search Modes by Alex J. Hoogerbrugge, Christoph Strauch, Noa Hoevers, Christian N. L. Olivers, Tanja C. W. Nijboer and Stefan Van der Stigchel in Psychological Science
Footnotes
Transparency
Action Editor: Vishnu Sreekumar
Editor: Simine Vazire
Author Contributions
ORCID iDs
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.