
Abstract
This work aims to study the construction of migrant categories and immigration discourse on Swedish-speaking Facebook pages in the last decade. It combines the insights from computational linguistics and distributional semantics approach with those from discursive psychology to explore a corpus of more than 1 M Facebook posts. This allows one to compare the meanings of labels denoting various categories of migrants and identify the key interpretative repertoires used to discuss the immigration topic. The study finds that the ‘immigrant’ category has stronger association with potential costs, benefits and threat to the host society, while the ‘refugee’ category is presented as in need of support and solidarity. Nevertheless, objectification and exclusionary rhetoric are used in relation to both categories, although in different ways, while the immigration issue is often interpreted as a matter of Sweden’s national concern rather than as a part of people’s actual experiences and life paths.
Keywords
Introduction
Language is an essential part of our everyday interactions in society that helps us to make sense of the things we see, hear and feel, and can be named as a necessary component in constructing social reality. Human migration, for instance, has been named as one of such social constructs that are collectively created through language and discourse. Media have been argued to be one of the most potent agents with respect to their opportunities to influence the representation of migrants in the public space and reproduce discrimination (Van Dijk, 1989). At the same time, language and communication have been named as essential means for discursive reproduction of racism (Van Dijk, 1993: 28). Social media seem to have a particularly peculiar role in these processes, fuelling these tendencies and giving voice to those usually enjoying less recognition from the mainstream publics, for example, extreme right-wing parties and nationalist movements (Wahlström and Törnberg, 2021).
In this article thus, I study Facebook as a medium where social reality takes form primarily through written text and where the idea of migration and images of migrants are constructed and made sense of by those using this medium. In particular, I combine the insights from computational linguistics and distributional semantics approach with discourse theory in order to study the use of language for the construction of discourse on immigration and corresponding immigrant and refugee categories on the Swedish-speaking Facebook pages and groups. My ambition is to understand to what extent this discourse is complicit with the representation of immigrants and refugees as belonging to the category of the Other. To answer these questions, I use a mixed-methods approach. The computational part of the study is represented by word embeddings (word2vec and doc2vec models) to map the location of words and documents from the corpus in a multidimensional semantic space, which is further supplemented by qualitative reading of specific documents. Thus, I ask two questions:
(1) Which interpretative repertoires are used in the corpus to construct the immigration discourse?
(2) What are the differences in the construction of the ‘refugee’ and ‘immigrant’ categories in the Facebook discourse?
This study’s ambition is to contribute to the existing research in several ways. One of them is to demonstrate the possibility for combination of computational and interpretative approaches in discourse studies and social media studies in general. In particular, the paper demonstrates that vector-space models can help researchers combine high-level quantitative analysis of the whole corpus with a more qualitative and close reading of individual documents. Moreover, this study seeks to contribute to the existing research on migrant categorisations by using a quantitative approach that makes it possible to validate the results of the previous studies that were often conducted with the help of qualitative methods. Further, while a large part of discourse analytic studies have focussed on the construction of differences between ‘native’ and ‘non-native’ populations, this work aims to provide new insights into the differences in the construction of specific migrant categories. Finally, it is especially interesting to focus on Facebook, a less studied social medium in comparison with, for instance, Twitter, because of the previously existing restrictions on using its data for research purposes.
The study uses a corpus of messages posted in 2012–2020 on the public Swedish-speaking Facebook pages and groups (N = 1.07 M). Although Sweden can be described as a relatively small European country in comparison with some of its’ European counterparts, it represents an interesting case of a seemingly colour-blind society (Hübinette and Lundström, 2014) that has been striving to ensure social inclusion of its inhabitants irrespective of their ethnic backgrounds (Borevi, 2013). It is especially interesting to study if, and to what extent, migration and migrants are constructed with reference to the categories of whiteness and otherness in such a colour-blind society. Since Facebook is one of the most popular social networks in Europe, I use this platform as an example of participatory media that plays an increasingly important role in the definition of public agenda worldwide.
Related work
Mainstream and social media, quite evidently, can be named as one of the leading entities participating in the social construction and reproduction of migrant identities (Van Dijk, 1989). In the European context, for instance, it has been pointed out that deserving refugees and undeserving migrants were presented as two contradictory positions during the European refugee crisis (Holmes and Castañeda, 2016). While the latter ones were constructed as a threat to the receiving societies that needed to be expelled, the former group was presented as requiring protection (Goodman et al., 2017). It has been argued that ‘Persons seeking refuge in Europe must sustain an identity of “non-threatening victim” if they are to gain recognition in a securitised culture of (mis)trust’ (Kyriakides, 2017). On the contrary, immigrant identities, it has been suggested, are constructed in such a way that a boundary between the Europeans and ‘criminal outsiders’ is created (Kreis, 2017). At the same time, the presence of immigrants was directly attributed to the terrorist threat to the host societies (Galantino, 2022). Some of the previous studies, however, have provided somewhat contradictory evidence that the refugee category was evaluated more negatively than the immigrant one (Findor et al., 2021).
Such a ‘categorical fetishism’ has been argued to be a distinctive trait of the modern European securitised immigration regime (Coninck, 2020; Crawley and Skleparis, 2018). Moreover, the use of the two categories has been found to be temporal and dependent on the social and political climate in the host societies (Goodman et al., 2017). Obviously, such an obsession with migrant labelling plays its role in the reproduction of inequalities and exclusion and cannot reflect the whole complexity of migratory experiences that not always easily fall within one of the two categories (Crawley and Skleparis, 2018). Nevertheless, the notion of whiteness seems to play the key role in the construction of the European identity and comes into being with the help of a juxtaposition against the non-white population, irrespective of particular labels used (Ammaturo, 2019). Such a practice of migrant othering has been described as a form of cultural racism and a form of symbolic violence since it primarily includes overt forms of discrimination based on social or cultural difference (Delanty et al., 2008: 1–3).
Swedish social research, however, has primarily addressed the issue of migrant categorisations focussing on the construction of differences between the Swedish and ‘non-Swedish’ population with the help of the references to the concepts of otherness and whiteness (Hübinette and Lundström, 2014; Lundström, 2017). Another relevant insight about this general distinction between Swedes and migrants is that migrantness has an entirely different meaning in the public discourse. This position is not based on the experience of migration but rather on a degree of non-conformity with the existing norms (Myrberg, 2010: 50). Further, an analysis of discourse on Facebook has shown that there exist three ‘cybertypes’: immigrants, Swedes and politically correct elites (Merrill and Åkerlund, 2018). Nevertheless, the existing studies have generally paid less attention to the systematic exploration of this distinction between various labels and categories of migrants. The existing research on this topic is limited by the evidence on the diverging attitudes of the Swedish population towards immigrants and refugees that rely on ethnic origin, economic situation in the home country and home region as the main determinants of these attitudes (Coninck, 2020).
It seems that social media play an increasingly important role in the construction of biassed perceptions of migrants and the reproduction of inequalities. An extensive body of work has demonstrated, for instance, that exclusionary rhetoric has been quite common on the Twitter platform during the refugee crisis and afterwards (Erdogan-Ozturk and Isik-Guler, 2020; Kreis, 2017). Even more so, the research has documented the widespread use of social media, including Facebook, by populist movements (Ekman, 2019; Törnberg and Wahlström, 2018). In the Nordic context, the specifics of populist and right-wing rhetoric in social media is that it essentially represents migration as a threat to the traditionally strong welfare system (Sakki and Pettersson, 2016). One more work of the Swedish researchers has shown that the Facebook audience employed a range of specific perspectivising and persuasive strategies in order to contribute to the racist discourse (Merrill and Åkerlund, 2018).
As for the previous use of computational methods in discourse studies, the last decade has demonstrated a growing interest in their application, which is especially evident for topic modelling (Jacobs and Tschötschel, 2019) and concordance and collocation analysis (Baker et al., 2008). Although word embeddings have also been an increasingly popular research tool across the disciplines, those opportunities have not been sufficiently covered by discourse studies (see Brigadir et al., 2015; Sakamoto, 2020; Viola and Verheul, 2020 as exceptions). This could partly be explained by a previous debate on the applicability of corpus-based and automated analytic methods in discourse studies that most often rely on qualitative and in-depth research methodologies (Flowerdew, 2012: 174) that, indeed, can be difficult to reconcile. One of the existing exceptions is the use of diachronic word embeddings to study linguistic (Viola and Verheul, 2020) or ideology (Azarbonyad et al., 2017) change, as well as their applications for identifying gender or ethnic bias in corpora (Garg et al., 2018; Wevers, 2019). However, there seem to be further opportunities for the application of word vectors in discourse studies.
Discursive psychology
This paper is inspired by and builds its theoretical framework upon the discourse theory, first and foremost the writings of Jonathan Potter and Margaret Wetherell (Edley and Wetherell, 2001; Potter and Wetherell, 1987; Wetherell, 1992), who refer to discourse as a term ‘. . .to cover all forms of spoken interaction, formal and informal, and written texts of all kinds’ (Potter and Wetherell, 1987: 7). Just as most discourse theorists, they question the role of language as a tool for mere representation of the social world and acknowledge the role of language and discourse in the construction of social reality. What makes their approach stand out in comparison with some of the discourse theories is that they also emphasise that there exists duality in relation to the discourse – on the one hand, agents are ‘. . .strategically using discourse’ (Wetherell, 1992: 93), and, on the other hand, discursive forms are ‘. . .playing themselves out through the actions of individuals’(Wetherell, 1992).
Thus, the researchers recognise the power of individuals to interpret events and social phenomena and choose from a variety of interpretative repertoires, or ‘broadly discernible clusters of terms, descriptions and figures of speech assembled around metaphors and vivid images’ (Wetherell, 1992: 90). The concept of interpretative repertoires comes in extremely handy in corpus-based studies of discourse since the former help to uncover the content of discourse and a variety of existing and often competitive interpretations of the same phenomenon (Wetherell, 1992: 93) that can be subject to high variability and contextuality. The first discourse analytic task in this paper, therefore, is to uncover these interpretative repertoires that social media users choose from when discussing immigration since the idea of clusters of terms that denote a particular repertoire is fully coherent with the modern document clustering techniques used in computational text analysis.
The idea of meaning also has a very special role not only in discourse studies but also in relation to the vector-space representation of words. The distinction between the form and meaning is best reflected with the help of a famous notion of a sign that consists of a signified and a signifier (Potter and Wetherell, 1987: 25), which also points at the fact that ‘There is nothing that determines the nature of the signifier or the nature of signified; there is no intrinsic relationship between them’ (Potter and Wetherell, 1987). In relation to the immigration agenda, it is interesting to compare how the meanings (signified) of various linguistic forms (signifiers), such as immigrant, refugee or undocumented migrant, are being constructed through the discourse. While, possibly, one can assume that there are some ‘dictionary’ meanings of the words immigrant and refugee, the idea of signs and the statement about the contextual and constructive role of discourse allow suggesting that the meanings of the labels immigrant and refugee are not exhausted by their dictionary definitions.
With this regard, Potter and Wetherell (1987) discuss the notion of social categories whose members are presumed to possess certain qualities just because of the corresponding category membership (p. 117). However, in contrast to the tradition of categorisation research in psychology, Wetherell and Potter point out that people’s decisions to assign others to particular categories are highly variating and context-dependent – in other words, the same person can assign another person to different categories depending on the circumstances (Potter and Wetherell, 1987: 136). On top of this, the categories themselves are actively reconstructed through the discourse (Potter and Wetherell, 1987). Therefore, the second analytic task is to study the construction of various categories of migrants through the discourse and to identify the actual meanings behind the labels of immigrants and refugees.
While classical discourse analysis is usually performed qualitatively by, for instance, reading a collection of texts, the age of big data allows performing the same task in an automated way with the help of natural language processing methods. Word2vec represents one of more sophisticated tools for computer-mediated discourse analysis in comparison with some classical methods such as the study of collocations or word keyness (Boréus, 2017: 164). The idea that word embeddings can be used in the study of discourse can be easily demonstrated with the following passage: ‘The choice, frequency and distribution of words can indicate what a segment of discourse is about (topicality), as well as communicators’ attitudes and affective states’ (Herring and Androutsopoulos, 2015: 134). The choice, frequency and distribution of words are precisely what the distributional semantics approach is concerned with.
Methods
As mentioned above, discourse is associated with language use, and, therefore, the ambition of this study is to identify how language is used in the Facebook corpus to construct various migrant categories, such as immigrant versus refugee, by studying the context in which these labels appear. The hypothesis is that words located near each other in a text also have similar meanings (Harris, 1954). Therefore, by studying how context words relate to the target labels, one can single out the meanings of these labels. We can then quantify the meanings of different words constituting the documents or documents constituting the corpus by assigning them with numeric vectors of 100/300 dimensions where each dimension would represent some aspect or a sense of the word or document. The closer the two documents or words are in this semantic space, the more similar their meanings are to each other.
It can be suggested that word embeddings can be used as an alternative to collocation analysis or topic modelling that have been traditionally used in corpus-assisted discourse studies (Baker et al., 2008). Nevertheless, in comparison with other techniques used in corpus-assisted discourse studies, word or paragraph vectors can be named as a technique that allows not only combining the two previous tasks, but also calculating the distances between words or documents and projecting them into a multidimensional space. The above-mentioned allows studying word choices and particular words’ meanings, as well as capturing and quantifying similarities and differences between words and documents. The strength of the doc2vec approach is also that it allows combining distant and close reading of a corpus, or an abstract overview of the corpus and a more specific focus on the qualitative aspects of the discourse (KhosraviNik and Esposito, 2018; for a discussion on close and distant reading, see, for instance, Jänicke et al., 2015). In this way, this study uses a mixed-methods approach that employs both distant and close reading of the corpus.
The data for this paper were collected in October 2020–March 2021 via Facebook’s platform CrowdTangle (Fan, 2021) that enables access to the Facebook posts published on the public pages and groups with more than 50,000 members (followers) each. A total of 1.07 M unique messages in Swedish dated from the 1st of January, 2012 to the 31st of December, 2020, were collected for the analysis. This timeframe was chosen based on data availability (posts before 2012 were few) and my interest in the European refugee crisis 2015 as a central event that boosted users interest in the topic. The search on CrowdTangle was performed with the help of keywords (e.g. ‘immigrants’, ‘refugees’, ‘immigration’, ‘integration’, ‘refugee policy’, etc.). After the pre-processing steps that are described in detail in Supporting Information, the resulting corpus included 983,000 documents and 41.5 M terms.
It is worth emphasising that this study is by no means representative of the Swedish Facebook discourse in general since data collection with CrowdTangle has several constraints. Namely, one constraint related to document sampling is that only documents in Swedish were used to build the model. Moreover, data collection is restricted only to posts from public pages and groups, which leaves out posts published by users on their personal pages, and to initial messages, but not subsequent comments to them, which does not allow fully grasping the interactional aspect in the discourse production, which, on the other hand, can also be seen as a way to preserve users’ integrity. With regard to the ethical aspects of data collection and processing, it is worth adding that collected data is presented in the study in such a way that no individual users could be identified.
In this study, I used a doc2vec model, an extension of a famous word2vec model that was first described in a seminal paper by Mikolov et al. (2013). In a nutshell, word2vec learns a multidimensional vector-space representation of each word in a corpus by studying its closest neighbours in each document. In this multidimensional space, each dimension represents some sense of a word (for illustrative purposes, these can be colour, shape, size, etc.). Word2vec calculates each word’s ‘score’ on each of these dimensions and represents it in the form of a numeric vector. Semantically similar words (e.g. ‘car’ and ‘vehicle’), thus, tend to be located close to each other. Paragraph2vec model (or doc2vec, as it is also called), then, not only calculates such vectors for individual words but also for the whole paragraphs or documents in a corpus (Le and Mikolov, 2014). More technical details on the methods used in this study can be found in the Supporting Information file.
After the model training, the documents were divided into clusters representing various interpretative repertoires and described with the help of key words. This was supplemented by the qualitative reading and analysis of the 50 documents located closest to each of the cluster centres. To explore the discursive construction of the migrant categories, I performed several steps, such as building semantic network that demonstrated the labels’ proximity to and relationship with the most contextually similar words. Secondly, I compiled several lists of descriptive terms related to finances (costs and benefits), threat and solidarity issues that, as argued by the previous research, have been used especially frequently to construct the immigrant and refugee categories (among others, Galantino, 2022; Goodman et al., 2017; Sajjad, 2018) to evaluate the relationship between these discursive categories and neutral word lists. Thirdly, I identified top-50 documents located closest to each of the target categories in the learned multidimensional space, which provided an additional qualitative perspective of which utterances represented typical ways of talking about the two labels.
Results
Interpretative repertoires in the Facebook discourse
The documents were divided into eight clusters using K-means clustering, and top-20 keywords for each of the document clusters were obtained with the help of TF-IDF weighting (Table 1). Generally speaking, the main repertoires can be divided into several groups: those discussing international relations and conflicts (cluster 7), those in one way or another discussing the reception and integration of newcomers in Sweden (clusters 2, 4, 5, 8), and a group of documents that are specifically focussed on the assistance and help to the refugees (clusters 3 and 6). On top of this, one can also distinguish a smaller group of documents that discuss migration in the context of potential threat to the Swedish society (cluster 1, and, partly, cluster 8).
Interpretative repertoires used on Facebook (a solution with eight clusters). Document clusters were identified with the help of K-means clustering, and keywords with the help of TF-IDF weighting.

The issue of integration and reception of migrants in Sweden seems to have one of the central roles in the discourse, and it also has the biggest size with respect to the number of documents since around two-thirds of all documents discuss it in one way or the other. The following pieces exemplify typical utterances:
(5) Will we get a proposal to create an integration school from the politicians in this election round? (Cluster 4 - Migrant reception and immigration policy)
(6) How do you work with the intercultural approach and how does it look in your environment? (Cluster 5 - Integration of newcomers)
In contrast to the major part of the documents that represent immigration as a matter of primarily Sweden’s national concern, another group of messages is also focussed on the conflicts and crises elsewhere in the world. Yet, as exemplified by the utterance below, this topic is mainly contextualised as a matter of international politics and neglects the experiences of people directly affected by the instability and warfare:
(7) EU and Nato support the attacks. Syria and Russia condemn them. That's what has happened (Cluster 7 - Global politics)
A sufficiently large part of the posts centres around the assistance to the refugees both in Sweden and abroad, which is not surprising given the media resonance that the refugee crisis caused in the European countries in 2014–2016 and the wave of public support for the refugees that was more typical for the first part of the crisis (i.e. until the end of 2015). Social media in general and Facebook in particular could be quite naturally seen as the most popular and effective platforms to coordinate the effort of individual activists and the non-profit sector:
(8) Hi, I have some clothes and shoes that I would like to donate to refugees. But I don't really know where I can bring them. So I wonder if there's anybody who knows? (Cluster 6 - Help refugees)
(9) Welcome to a multicultural party on Saturday in Västerås! (Cluster 2 - Civil activity and non-profit sector)
Finally, a minor part of the messages in the corpus discusses migration in the context of potential threat to the Swedish society, primarily concerning illegal entry into the country, deportations and commitment of crimes: (10) THE PROSECUTOR REQUESTED DEPORTATION THE MAN FULLY FREED (Cluster 1 - Crime and illegality)
This, however, does not mean that the rest of the messages in the corpus take a positive stance on the topic – in fact, the assignment of documents to clusters happens irrespective of the messages’ general stances or sentiments, as demonstrated by the utterance below:
(11) DON'T WANT TO HAVE MORE ASYLUM SEEKERS AND IMMIGRANTS IN SWEDEN IT IS ENOUGH (Cluster 4 - Migrant reception and immigration policy)
In this way, the immigration discourse cannot be described as fully coherent. Rather, it consists of several possible interpretations of the topic that can clash or contradict each other.
Discursive construction of migrant categorisations
As mentioned in the introductory section, the second goal of this work has been to compare how the two categories (immigrant vs refugee) are constructed. This goal was achieved by studying the location and closest neighbours of the target categories in this semantic space. A particularly interesting task has been to understand whether this contextualisation of the categories was performed in diverging ways and whether migrant categories were constructed with the help of the context words so that it sustained their representation as the Other.
The results suggest that the two categories are, in fact, constructed in somewhat different ways, as depicted in Figure 1. For instance, the labels denoting forced character of migration (‘asylum seeker(-s)’ or ‘refugee(-s)’) are located close to the words that are associated with the reasons behind emigration from the country of origin (e.g. ‘persecution’, ‘resettlement’, ‘residence permits’, ‘war’, ‘flight’ etc.). The categories that roughly denote voluntary migration (i.e. ‘immigrants’ and ‘immigration’) are contextualised differently and are associated with the words that refer to the immigration policy and reception in the destination country (e.g. ‘immigration policy’, ‘restrictive’, ‘uncontrolled’, ‘criminality’ and so on).
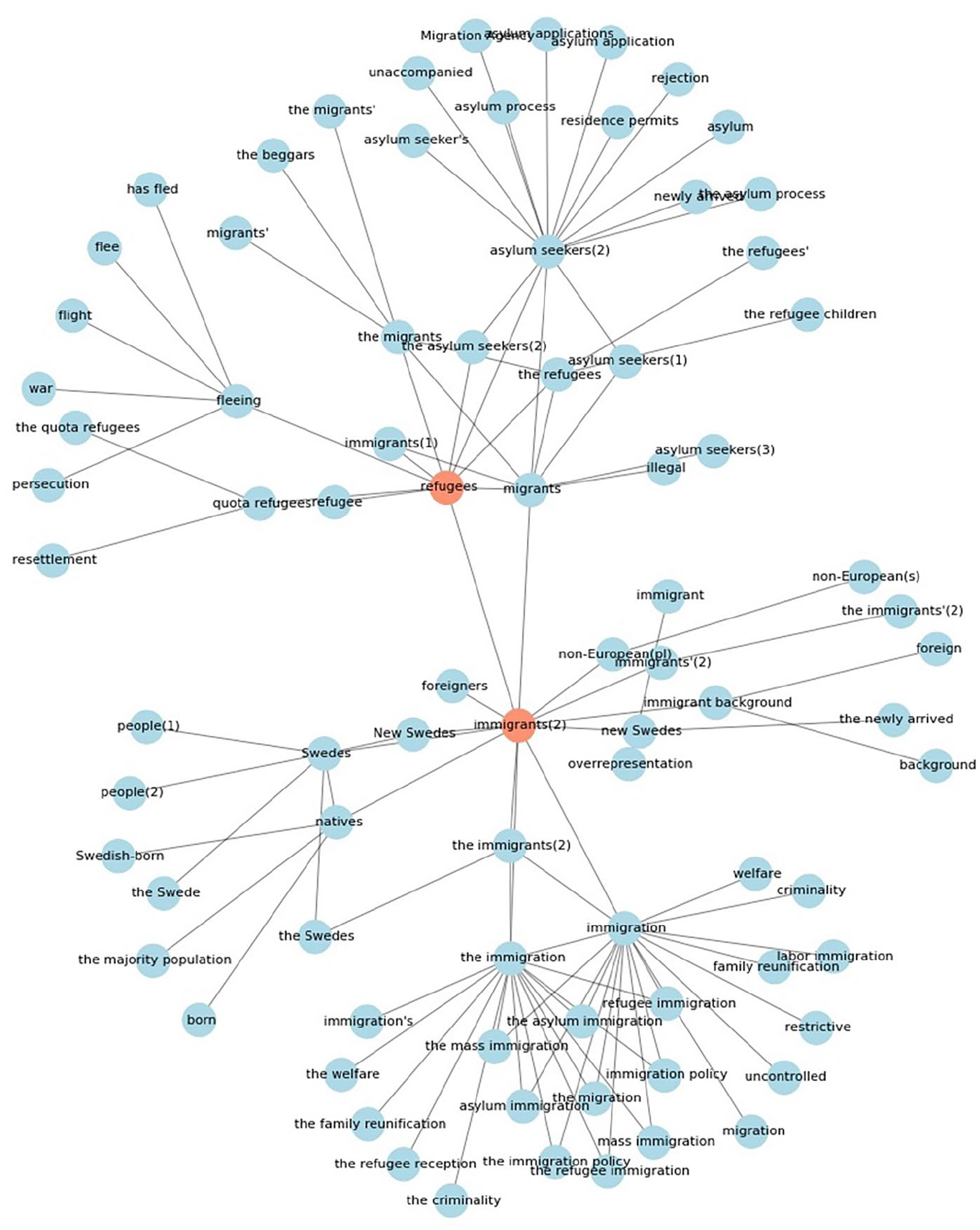
Semantic network of target and context words. Translation from Swedish. The closest neighbouring terms were chosen based on cosine similarity measure (see Supporting Information for more details).
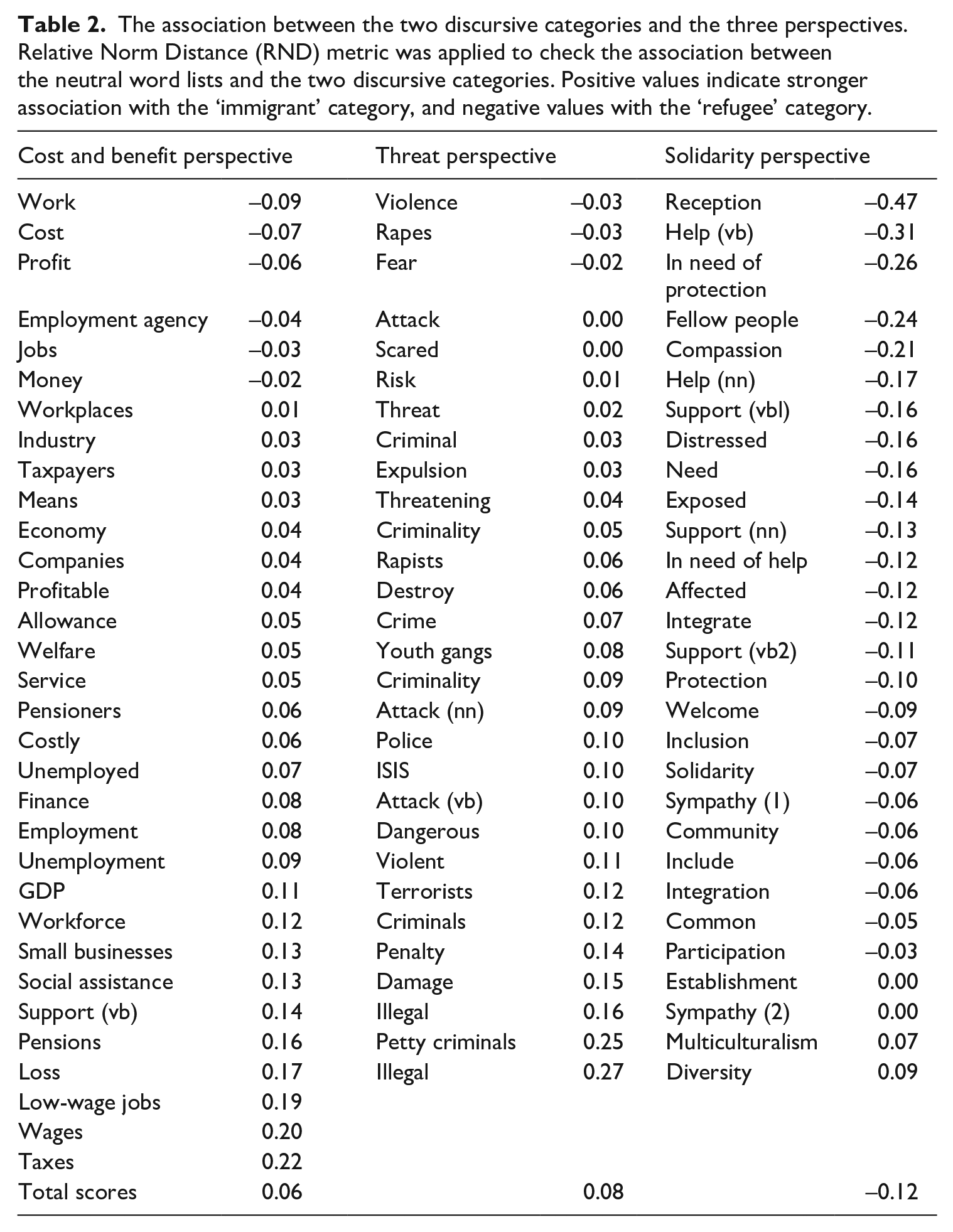
Table 2 presents the results of applying the Relative Norm Distance (RND) metric to the three perspectives described above as the most typical ones based on the previous findings: these are the costs and benefits, threat and solidarity perspectives. The initial assumption was that the immigrant category would be more strongly associated with the perspectives that contextualise it as a threat to the receiving society (for instance, violating laws, entering the country illegally and so on) or that would represent it as a group that can generate either economic profit or loss to the receiving society. It was also expected that the refugee category would be constructed as in need of help, protection and solidarity. These assumptions were, in fact, supported: the positive values of the RND metric for the ‘threat’ and ‘cost and benefit’ (0.08 and 0.06) perspectives denote stronger bias towards or association with the voluntary type of migration. In contrast, negative values for the ‘solidarity’ (−0.12) perspective denote stronger association with the forced type of migration.
The association between the two discursive categories and the three perspectives. Relative Norm Distance (RND) metric was applied to check the association between the neutral word lists and the two discursive categories. Positive values indicate stronger association with the ‘immigrant’ category, and negative values with the ‘refugee’ category.
The results of qualitative reading of the messages allow providing a more nuanced picture of the differences between the ways in which immigrants and refugees are constructed. For instance, they indicate that Facebook authors tend to distinguish between the ‘right’ and deserving type of immigrants (paying taxes, having employment and learning the Swedish language) that can be tolerated and let stay contrasted against the wrong and undeserving one (undocumented, receiving social assistance, struggling with the language or committing crimes). The strategy of distinction between deserving and undeserving immigrants seems, in this case, to act as justifying possible immigrant-hostile or prejudiced attitudes (author’s translation below and elsewhere in the text):
(1) Why not introduce a well-behaviour requirement for those who come to Sweden. . . when criminality means deportation. . . I think this would benefit all those immigrants who behave well and want to participate in society. Not to mention that we Swedes would treat well those immigrants who behave themselves..
Qualitative reading of the messages supports the finding that the immigrant category is more often associated with the cost and benefit and threat perspectives, and these two perspectives seem to form the ground for the above-mentioned decision on immigrant deservingness. In other words, the reception of immigrants is constructed as an issue that needs to be decided upon based on the expected net profit or loss (including possible threats) that this category can bring to the receiving society.
It seems that, generally, immigrants and the Swedish are represented as two contradictory positions that come into being precisely as a result of a reference to and the contradiction with the opposite category: Swedishness is presented as ‘inborn’, ‘ordinary’ and ‘normal’, whereas migrantness is something that is not. Nevertheless, some of the messages do construct migrant identities in a seemingly positive light, as it can be exemplified by the following piece, although the distinction between immigrants and the Swedish is in most cases preserved:
(2) We should not forget that we have many good immigrants better than many Swedes.
When it comes to the refugee category, this group’s right to reside in Sweden is not questioned in the same ways as the immigrants’, although, in this case, a certain boundary is created between the ‘real’ refugees who qualify for protection and help versus immigrants who claim to be refugees and are thus not entailed to the same rights as the first group:
(3) Migrants pretended to be Syrian refugees, stole asylum places from the real refugees.
Another observation concerning the discursive construction of the refugee category in the corpus is that Facebook users tend to represent refugee reception and management of refugee flows either as a matter of international or national concern that needs to be addressed or as an object of administrative interventions. Since the dataset spans the messages that were published during the 2014/2016 refugee crisis, references to statistics and forecasts on the number of arrivals, as well as news on other countries’ refugee reception policies, seem to represent quite typical ways for the contextualisation of the refugeehood, as follows from the following piece:
(4) Eksjö municipality will increase the number of asylum places for unaccompanied children next year.
Discussion
Summing up the results of the analysis outlined in the previous section, it seems that the interpretative repertoire used to contextualise the immigration topic on Facebook has many commonalities with the repertoires of other social media platforms and resources, such as Twitter and Flashback forum (Yantseva, 2020). Indeed, some of the themes, such as financial aspects, racism or migrant illegality, are echoed by the social media users across these media resources and seem to act as general ways to frame and contextualise the immigration agenda in Sweden. Yet, what makes the Facebook discourse stand out compared to other participatory media is its orientation towards the expression of solidarity and assistance to the newcomers, with two particular interpretations of the topic belonging to this category.
Nevertheless, the study finds that the reproduction of migrant otherness is a distinctive trait of the Swedish Facebook discourse, yet, there seems to be a large gap between the ways in which the images of immigrants and refugees are created in the corpus. This conclusion supports the results of previous work that finds that migrantness and refugeehood represent two distinct social categories that imply different consequences and status positions for their holders (Goodman et al., 2017; Kyriakides, 2017). At the same time, the presence of these competitive narratives of solidarity with migrants versus the narratives of migrant otherness provides some evidence for a possible polarisation of the Facebook audience. This suggestion can be supported by the results of previous studies finding that social media audiences are considerably polarised based on their ideological stances (Kaiser and Puschmann, 2017).
Although some of the existing studies highlight the difference between the deserving refugees and undeserving migrants (Holmes and Castañeda, 2016), I find that the idea of deservingness is more typical for the immigrant label. The concepts of criminality or threat, as well as costs and benefits, seem to be typically activated in the construction of deserving versus undeserving immigrants. Criminal record, type of entry, level of education and ability to pay taxes are the factors that seem to play the key role in this bordering process that, according to the Facebook users, defines whether particular groups of immigrants are to be tolerated. Open racism, in this case, is covered and rationalised by the argumentative character of the messages and extensive appeals to numbers and statistics, as well as references to external resources, which is argued to be one of the most basic discursive strategies (Van Dijk, 1993: 35).
On the other hand, the concept of refugeehood is closely related to the idea that this is a matter that needs to be managed and administered, as demonstrated in the previous section. At the same time, solidaristic framing of the refugee reception is still quite common in the corpus. Yet, as argued by the previous research, the discourses on refugeehood mostly ignore the voices and lived experiences of those categorised as refugees (Chouliaraki and Zaborowski, 2017). The topic of refugee reception, then, is turned into a matter of Sweden’s national concern that needs to be addressed or as a subject of policy implementation, rather as an issue for those assigned with these categories. This argument can be supported by the results of previous studies that find ‘institutional framing’ of the refugee agenda in Sweden (Abdelhady, 2020).
Accordingly, what unites the representation of both discursive categories is their objectification. As pointed out by the earlier research, objectification can be called a typical strategy for the construction of images of the Other (Boréus, 2013), although, in this case, it seems to work in different ways for those identified as immigrants or refugees. While immigrants are seen as those who should contribute to the society and be capitalised upon, refugees, as mentioned above, are constructed as objects of administrative management and policy-making. In this way, those classified as belonging to either of the two categories are in some sense deprived of their agency.
These observations seem to resonate with the approach that distinguishes exploitative and exclusionary modes of racism (Mulinari and Neergaard, 2017). While the former presumes that only those who can immediately provide net profit to the Swedish society are to be tolerated, the latter suggests that the rest is to be excluded from the society if the immediate creation of net value is not viable or if the costs out-weight potential profit to the society. Researchers refer to this phenomenon as a form of discursive discrimination (Boréus, 2013).
While such a form of discursive discrimination is justified with the help of argumentation and reasoning, it can be related to the general socio-political context surrounding migrant reception and integration policies in Sweden. As noted in the introductory section, the competition between the narratives of old Sweden and good Sweden (Hübinette and Lundström, 2011) seems to play out in this particular case of the immigration discourse and, to some extent, can be described as users’ diverging stances on the topic. Further, as argued by the social researchers, the discourses on immigration in the Nordic countries are centred around its potential challenges to the welfare state (Sakki and Pettersson, 2016) that has lately undergone sufficient changes in favour of more neo-liberal social policy (Schierup and Ålund, 2011). This observation can be coupled with a statement about a prevailing sense of failure of multiculturalism and shrinking public support for the multiculturalist project (Dahlstedt and Neergaard, 2019). Thus, the Facebook discourse seems to reflect such processes that take place in Swedish society.
Nevertheless, as argued above, social media represent contradictory public arenas, and the results of the analysis quite evidently demonstrate these contradictions. As pointed out before, social networking sites can be used to de-monopolise and acquire discursive power in order to challenge common preconceptions about the Other (KhosraviNik and Esposito, 2018), which, however, does not seem to be the case for the Swedish Facebook discourse. On the contrary, one can argue that discursive power on Facebook is exercised to sustain the existing assumptions about the discursive categories in question, as demonstrated in the previous section. On the other hand, the researchers propose that new media facilitate the development of participatory culture (Benkler, 2006), and, in Sweden, the use of social media during the refugee crisis to support grass-roots activism has been demonstrated before (Kaun and Uldam, 2018). This work admittedly finds that the Facebook platform has enabled the expression of solidarity with refugees.
On the other hand, a particular trait of the technological design of new media is their tendency to the fragmentation of audiences (and, possibly, discourses) and the emergence of echo-chambers that provide favourable conditions for users’ radicalisation (Batorski and Grzywińska, 2018; Garimella et al., 2017), or, as a separate case, polarisation of the audiences (Kaiser and Puschmann, 2017). Indeed, I conclude that the Facebook discourse represents a set of competing contextualisations of the topic and find a distinct set of explicitly or implicitly biassed messages in the corpus, which, on the other hand, goes in line with the assumption about the presence of competing narratives as part of any set of interpretative repertoires (Boréus, 2017: 219). Nevertheless, this evidence allows hypothesising fragmentation of the Facebook audience. Digital racism and the prevention of potential spill-over of this form of racism into the mainstream discourse thus represent the challenges that need yet to be addressed in social media studies.
Conclusion
Summing up the findings of this paper, it seems that Facebook plays a contradictory role in the construction and reproduction of migrant categories. On the one hand, Facebook seems to enable the formation of affective publics and participatory culture (Papacharissi, 2016). On the other hand, it still plays some role in the re-enactment of migrant otherness as well as biassed and racialised forms of migrants’ representations that can be characterised as forms of discursive violence.
From the methodological point of view, this paper’s ambition has been to demonstrate the possibilities for the use of vector space models in social media and discourse studies. Word embeddings worked as a powerful tool that helped to get a glance at the existing repertoires, as well as to conceive of meanings of individual labels. On top of this, it provided an opportunity to combine distant reading of the whole corpus with close reading of individual documents, at the same time eliminating researcher bias with regard to the choice of particular documents.
Since the application of word embeddings in media and discourse studies is still much a work in progress, this opens up possibilities for developing new frameworks for the analysis of social media discourses with the help of this method. This can be seen as an exciting possibility for future research and suggests a path for a successful combination of corpus linguistics with discourse studies.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.