
Abstract
Accurate prediction of direct normal irradiance (DNI) is critical for optimizing solar energy integration in hydrogen production systems. This study proposes a novel hybrid forecasting model that integrates variational mode decomposition (VMD), sample entropy (SE), biogeography-based optimization (BBO), and histogram gradient boosting regression (HGBR) to enhance the accuracy of DNI prediction. VMD is used to decompose the nonlinear solar radiation signals, while SE clusters the resulting modes based on complexity. BBO fine-tunes the hyperparameters of HGBR, which serves as the core prediction engine. Applied to a case study in Jiangsu Province, China, the model demonstrates superior forecasting performance compared to conventional models. The proposed hybrid model achieves a coefficient of determination of 0.98 and a root mean square error of 39.69 W/m2. The predicted DNI values are used to optimize the design and operation of a solar-powered hydrogen refueling station (HRS), comprising the 1148-kW photovoltaic arrays, a 1000-kW proton exchange membrane, a 204-kWh battery storage system, and a 2000-kg hydrogen storage tank. These forecasts enable dynamic alignment between solar generation and hydrogen production, ensuring energy-efficient scheduling and load management. The techno-economic analysis confirms the system's feasibility, yielding a levelized cost of hydrogen of 3.20$/kg and a net present cost of 2,143,512$. The proposed hybrid model advances forecasting accuracy and can provide a scalable and cost-effective pathway for deploying sustainable hydrogen infrastructure in support of clean transportation.
Keywords
Introduction
Growing concerns about climate change, the depletion of fossil fuels, and the negative environmental effects of greenhouse gas (GHG) emissions are causing a significant shift in the global energy landscape. 1 The exponential increase in global energy demand brought on by population growth and industrialization, which severely strains conventional energy sources, adds to this urgency. Unless significant changes are made, the consumption of fossil fuels, in particular, is predicted to increase by about 1.1 million barrels per day by 2025, indicating a continued reliance on carbon-intensive energy sources. 2 Because internal combustion engine (ICE) vehicles continue to dominate the market despite their substantial contribution to carbon emissions and air pollution, the transportation sector continues to play a significant role in this trend. Clean energy alternatives like battery electric vehicles (BEVs) and, more significantly, fuel cell electric vehicles (FCEVs), which run on hydrogen fuel and only emit water vapor, are becoming more and more popular in response.3,4
Hydrogen refueling stations (HRSs), which are essential infrastructures for storing and delivering hydrogen fuel to vehicles, are a major requirement for FCEVs.5,6 Despite their significance, there is still a lack of global HRS deployment, which prevents FCEVs from being widely adopted.7,8 Governments all around have taken strong action to hasten the development of hydrogen infrastructure in recognition of this. This global change is exemplified by the U.S. H2@Scale program, Japan's H2 Mobility initiative, and China's hydrogen development roadmap, which aims to produce over 50,000 hydrogen vehicles.9–11 The on-site production of green hydrogen using renewable energy, especially solar photovoltaics (PV), is one of the most promising innovations in this field. It improves sustainability and lessens dependency on grid electricity. 12 However, this integration adds new technical and financial challenges because solar energy is intermittent, and FCEV users’ refueling habits are unpredic table. 13
With the development of techno-economically optimized HRSs driven by hybrid renewable energy systems, recent studies have made notable progress in tackling these issues.14–21 Key performance metrics like CAPEX, levelized cost of hydrogen (LCOH), and hydrogen production efficiency are highlighted in these works, which use a variety of techniques, including mixed-integer linear programming models, multi-objective optimizations, and HOMER simulations. Although Table 1 summarizes a significant drawback that most of these studies have in common is the lack of a reliable, accurate method for predicting direct normal irradiance (DNI), a critical parameter for solar hydrogen production.
Overview of the reviewed related studies.
For solar-powered HRSs to be designed and operated dependably, accurate DNI forecasting is necessary.22,23 Without it, the demand for hydrogen is not met by energy production, which can result in supply shortages, energy waste, or operational inefficiencies.24,25 Machine learning (ML) and deep learning (DL) approaches like artificial neural networks (ANNs), 26 long short-term memory networks (LSTMs), 27 gated recurrent units (GRUs), 28 and hybrid combinations involving genetic algorithms or reinforcement learning29–33 are the main methods used in current research in solar irradiance forecasting. Even though these models are better than conventional statistical models, they frequently undervalue the significance of data preprocessing methods that can deal with the non-linearity and non-stationarity that are inherent in data on solar radiation. Furthermore, there is a significant research gap because few studies directly connect their forecasting models to real-world energy applications like HRS design.
The potential of hybrid models that combine optimization and decomposition with sophisticated regressors has been demonstrated by some recent attempts. For instance, Jacques Molu et al. 33 proposes a new method for short-term solar irradiance forecasting, combining Bayesian optimized attention-dilated LSTM with Savitzky–Golay filtering. Applied to data from Douala, Cameroon, the approach enhances data quality and forecasts accuracy. Among several models, the proposed method, integrating attention mechanisms and dilated convolutional layers, showed the best performance with a symmetric mean absolute percentage error of 0.6564. This work introduces novel data processing techniques and a hybrid deep learning model, improving solar irradiance forecasting for researchers and solar plant managers. Gao et al. 34 suggest a deep forecasting strategy that utilizes a convolutional neural network (CNN) and LSTM to accurately estimate solar irradiance in a variety of locations. It is underscored that the precision of forecasts can be improved by decomposing the data. Puah et al. 35 employ an artificial neural network and exponential smoothing to estimate solar irradiance, utilizing the long-term recording data and timestamp. It is believed that the problem can be considerably simplified by decomposing solar data based on its relevance to trends. Lee et al. 36 propose four joint models to mitigate the variability of the solar irradiance prediction error.
Although forecasting solar radiation using individual ML or DL models has advanced significantly in the literature, a major drawback is the fragmentation of approaches. The majority of earlier research on solar irradiance prediction used separate parts, like regressors, optimization algorithms, or decomposition techniques, without integrating them into a cohesive, cooperative pipeline that captures the intricacy and dynamic nature of actual energy systems. This disparity is particularly important for solar-to-hydrogen applications, where cost-effectiveness, operational efficiency, and optimal system design depend on accurate and flexible forecasting. The incorporation of sophisticated computational methods is still mainly unexplored in this field. A forecasting architecture that not only increases accuracy but also fits the financial and practical limitations of hydrogen refueling infrastructure is vitally required. In order to bridge this gap, this study suggests a brand-new hybrid forecasting model, which is a coherent fusion of four different but complementary approaches: ensemble regression learning, entropy-based clustering, signal decomposition, and metaheuristic optimization. Each of these methods addresses a distinct problem related to the prediction of solar irradiance by adding a specific function to the model.
The first preprocessing approach is variational mode decomposition (VMD), which addresses the inherent nonlinearity and non-stationarity of solar radiation data by decomposing the original time series into a finite number of intrinsic mode functions (IMFs). By removing high-frequency noise and isolating oscillatory components, VMD reveals meaningful patterns in both the temporal and frequency domains.37,38 In contrast to traditional decomposition methods, VMD offers better control over the number of components extracted, reduced mode mixing, and improved stability39–41—all of which are crucial when dealing with highly variable atmospheric conditions that affect DNI readings. As a result, VMD improves the interpretability and tractability of the raw input data. The model uses sample entropy (SE) after decomposition to measure each IMF's complexity. This stage is essential for separating signal components with significant patterns from those that are primarily random or redundant. SE facilitates dimensionality reduction while maintaining the most informative features by grouping components with comparable entropy value.42,43 This step sharpens the downstream predictive model's learning focus while simultaneously enhancing computational efficiency. Crucially, this complexity-aware feature selection prevents the forecasting model from overfitting to trivial fluctuations or noise.
Biogeography-based optimization (BBO), a metaheuristic algorithm influenced by the migration and distribution patterns of biological species across ecosystems, is incorporated into the model to further improve predictive performance. By balancing exploration and exploitation throughout the search space to prevent local minima, BBO is used to adjust the learning model's hyperparameters. BBO optimizes the histogram gradient boosting regressor (HGBR) parameters in this study, including learning rate, number of estimators, and tree depth. BBO offers a more flexible and biologically inspired exploration mechanism than grid search or random search techniques,44–46 making it ideal for intricate, multimodal optimization issues like solar forecasting. Through its integration, the regression model is ensured to function with optimal accuracy, customized to the unique features of the dataset.
The HGBR, a powerful ensemble learning algorithm known for its effectiveness with large data sets, noise tolerance, and potent generalization powers, is at the core of the model.47,48 In a sequential fashion, HGBR builds several decision trees, each of which fixes the mistakes of the one before it. 49 In contrast to conventional gradient boosting, HGBR uses histogram-based binning, which reduces computation time without sacrificing accuracy. Because speed and accuracy are essential in energy systems, it is perfect for real-time or near-real-time forecasting applications. The final model achieves a high degree of predictive power with low overfitting risk by optimizing it with BBO and applying HGBR to the entropy-filtered VMD components.
The methodologically cohesive integration of VMD, SE, BBO, and HGBR into a single, fully optimized forecasting pipeline, rather than their separate application—all of which have been used in previous works—is what sets this study apart. In the context of DNI forecasting for solar-powered hydrogen refueling stations, this study is the first to combine these four methods. The strength of the model is its modular design, in which every component strengthens a particular shortcoming of conventional models, compounding the improvement in overall performance. Furthermore, this model has been meticulously developed with practical application in mind, making it more than just theoretical in nature. In particular, it is incorporated into the planning and design of a hydrogen refueling station (HRS) in Jiangsu Province, China, an area with a variety of climates and a rising need for transportation options powered by renewable energy. The VMD-SE-BBO-HGBR model's predicted DNI values are crucial in this scenario because they inform the HRS's operational strategy, which consists of a battery energy storage system to balance load variability, a PV power generation system, and a proton exchange membrane (PEM) electrolyzer for hydrogen production. In order to optimize energy conversion efficiency and ensure a more stable and responsive hydrogen supply chain, the station can dynamically modify hydrogen production schedules to correspond with real-time solar availability by integrating precise solar irradiance forecasting into the core of system management. The integration of advanced hybrid models with renewable infrastructure to improve the responsiveness, flexibility, and sustainability of hydrogen energy systems is an example of a larger systems-level innovation that goes beyond predictive accuracy. In order to reduce the risks associated with intermittency and demand fluctuations, the forecasting model also aids in strategic decision-making regarding energy dispatching, component sizing, and storage utilization. The HRS case study provides a concrete illustration of how forecasting tools can enable new performance and resilience levels in clean energy applications when they are properly customized and integrated into system architecture. By doing this, the research can establish the foundation for wider replication in other technical and geographic contexts where hydrogen infrastructure is being investigated or developed. Thus, this work offers the following dual contributions to the field:
Through the methodical integration of decomposition, clustering, optimization, and ensemble regression, this study presents a unified and modular hybrid model that addresses significant shortcomings of current forecasting techniques. The model is implemented and validated within a fully designed, renewable-powered HRS, addressing the gap between algorithmic development and real-world energy systems from the standpoint of practical application.
Together, these contributions represent a significant advancement in both the theory and practice of solar energy integration, which can offer a replicable framework for optimizing renewable hydrogen infrastructure worldwide. The study's remaining portions are as follows: The dataset and case study description are given in Section “Case study.” The methodology is presented in Section “Methodology.” Results and discussions are provided in Section “Results and discussions.” The conclusion is offered in Section “Conclusions.”
Case study
Study area and data description
Jiangsu is a province located on the east coast of China which has illustrated in Figure 1. The location's latitude and longitude are
Illustration of the Jiangsu map.
Table 2 provides an overview of the key meteorological variables collected from Jiangsu City, which are critical for developing accurate solar irradiance forecasting models. These variables include temperature, relative humidity, dew point, precipitation, cloud cover, diffuse radiation, wind speed, wind direction, wind gusts, and DNI. The DNI is a vital metric for solar forecasting, is measured in
Overview of variable data obtained from Jiangsu City.

The solar irradiance dataset evaluated in this study gives a complete perspective of the region's DNI across a year, as depicted in Figure 2. The data provide hourly DNI measurements, an important metric for creating solar forecasting models. As demonstrated in Figure 2, the yearly fluctuation in DNI is displayed against the days of the year and hours of the day. The visualization of DNI demonstrates Jiangsu's distinctive climatic dynamics, including the fluctuation owing to seasonal variations in temperature, cloud cover, and precipitation.
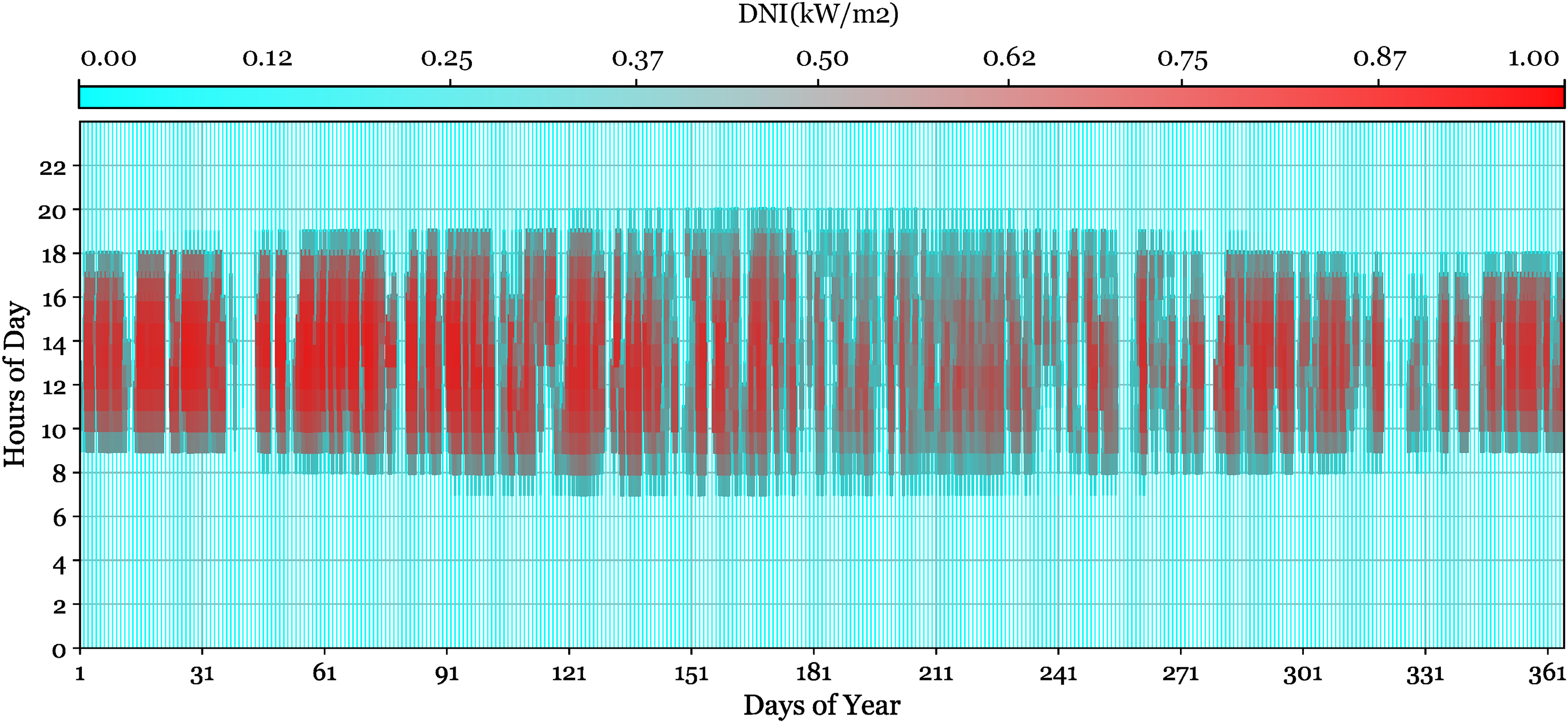
Hourly direct normal irradiance data for the site location over a year.
Feature selection
The correlation of DNI with the variables RH, Dew, RRC, CC, DHI, WS, WD, WSG, DNI, and Temp was investigated with the Pearson correlation test and illustrated by Figures 3 and 4. Variables that exhibited no significant correlation were excluded, while those demonstrating a significant correlation were retained for inclusion as input variables. Variables with correlation values ranging from −0.2 to 0.2 were considered to have a negligible relationship with DNI and were consequently removed. Specifically, Dew, WS, PRC, and WD were excluded due to their relatively weak correlation with DNI.
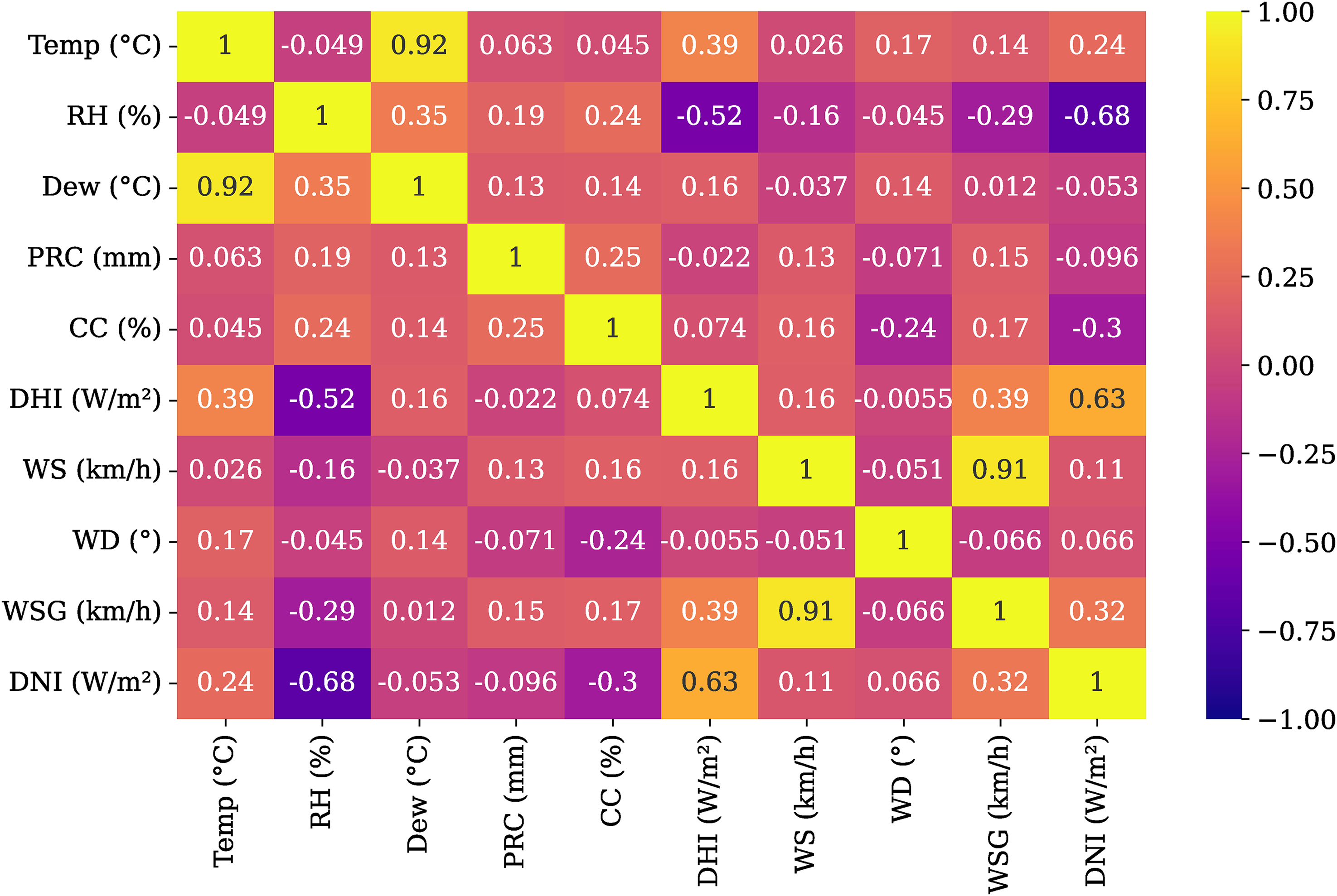
Heat map illustration showing variable correlation.
The correlations and distribution of the data.
A statistical metric that assesses the linear relationship among two variables that are continuous is the Pearson correlation, frequently referred to as Pearson's correlation coefficient or Pearson's r. This measure is represented by a numeric value between −1 and 1, where the magnitude and direction of the correlation between the variables are indicated. The proportional connection among the two variables is measured by the Pearson correlation coefficient. When the coefficient is close to 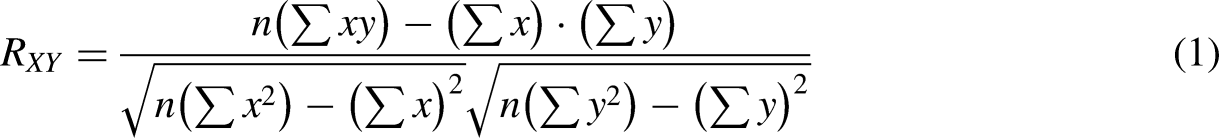
Figure 3 presents a heat map that visually illustrates the Pearson correlation coefficients among the variables under investigation, including Temp, RH, Dew, PRC, CC, DHI, WS, WD, WSG, and DNI. The heat map represents the strength and direction of the correlations, with yellow shades denoting strong positive correlations and purple shades indicating strong negative correlations. Several key relationships, such as the strong positive correlation between DNI and Temp (R = 0.63) and the notable negative correlation between DNI and RH (R = −0.68) are highlighted. Conversely, variables such as Dew, PRC, WS, and WD exhibit negligible correlations with DNI (R values ranging from −0.2 to 0.2), indicating a lack of significant linear relationships. These weaker correlations informed the feature selection process, leading to the exclusion of these variables from further modeling efforts.
Figure 4 displays a matrix of scatterplots and histograms, providing a comprehensive view of the pairwise relationships and distributions of the selected variables. Each scatterplot visually demonstrates the linear relationship between two variables, complemented by a regression line to indicate the trend. Diagonal elements of the matrix represent the univariate distributions of each variable through kernel density plots, offering insights into the spread and central tendency of the data. Figures 3 and 4 provide a robust framework for analyzing variable correlations and distributions, facilitating informed decisions during the feature selection process for the DNI forecasting model.
Electric and hydrogen demand load
Jiangsu Province served as the research location. Consequently, a crucial component of this study has been estimating the demand for electricity and hydrogen in order to evaluate the operational needs of the suggested HRS. Reports from the regional government and anticipated FCV deployment scenarios in Jiangsu were used to calculate the hydrogen demand numbers. With a fleet of roughly 40–50 light-duty FCVs, each requiring 2–2.5 kg of hydrogen per day, the assumed average daily hydrogen consumption of 100 kg is equivalent. A high-throughput refueling scenario is reflected in the peak hydrogen load of 18.04 kg/hr, ensuring that the station design can handle surge demand during periods of peak operation. In keeping with Jiangsu's roadmap for the development of hydrogen energy, this estimate creates a realistic and scalable demand profile. The electrical consumption of different components, such as compressors and auxiliary equipment necessary for the station's operation, is also included in the hydrogen load profile. The load factor, which is the ratio of average to peak load, is 0.23, indicating moderate variability in hydrogen use, and the average hydrogen demand of 100 kg/day is equivalent to 4.17 kg/hr. The majority of the electrical load comes from auxiliary systems used in the compression and distribution of hydrogen. A variety of subsystems rely on the conversion of AC power into DC. With an hourly average of 3.16 kW, the average daily electric demand is 75.9 kWh. With an electric load factor of 0.25 and a maximum electric load of 12.46 kW during peak refueling activity, the energy consumption appears to be comparatively stable with sporadic spikes. The station's overall design incorporates these demand profiles to support scalability for projected increases in hydrogen consumption and ensure dependable operation in both average and peak operations. The larger objective of facilitating the development of sustainable hydrogen infrastructure in Jiangsu Province is supported by this thorough energy assessment.
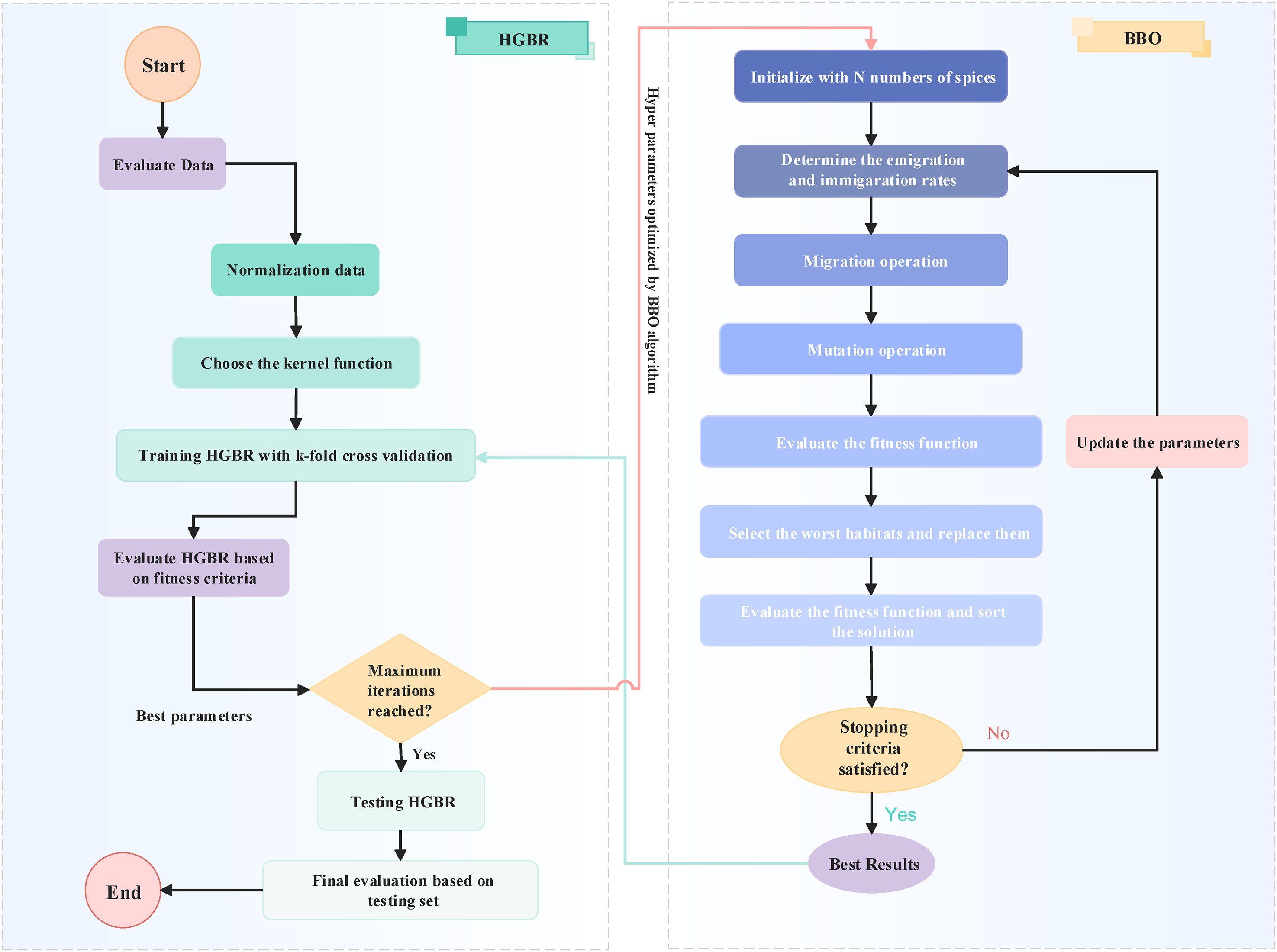
Methodology
SARIMAX
SARIMAX is an extended version of the ARIMA model, considering that the seasonality in the time series data may be influenced by other external factors. It is now extensively used and integrates all the major properties of autoregression with moving averages, with the possibility of incorporating exogenous variables for greater precision. 52 Fundamentally, the SARIMAX accounts for both internal patterns of the time series data and external causes of variation. The autoregressive part models the relation of the current observation and past data points, while the moving average component focuses on the dependency from the previous errors or shocks that the current value depends upon. The time series data needs to be stationary; hence, the integration part of the model applies differencing. 53 It includes the basic SARIMA model and adds to it the possibility of inclusion of external factors. This model, by including such additional variables, allows taking care of the problems of autocorrelation, thus making the model even better with respect to forecasts and forecast errors. By allowing the addition of these exogenous variables, greater sophistication is allowed; this permits a more accurate reflection of the real underlying pattern of the data. These exogenous variables can represent a variety of factors that influence the data but are not part of the primary time series itself. For example, they may include external time series data that are related to the primary series, such as weather conditions. It is crucial to accurately predict these external factors in advance, as they play a significant role in the model's performance. The SARIMAX model effectively integrates those additional exogenous inputs into the refinement of its predictions. Considering exogenous variables, it enhances the model to capture complex patterns or improves forecasting accuracy. Therefore, the SARIMAX can very well turn out to be an important tool for the prediction of seasonal temporal data resulting from external influences. 53
Gated recurrent unit
The GRU is a type of RNN architecture used primarily for sequence modeling and prediction tasks. The main objective behind developing the GRU was to address some of the limitations posed by the vanishing gradient problem, which can hinder the performance of traditional RNNs.54,55 However, the GRU model, despite its merits, did not always turn in performances as expected in some applications, while in contrast, the HGBR model has proved to give more positive and acceptable results in certain scenarios. GRU was hence introduced by Kyunghyun Cho as a solution to computational load issues that could lead to delays when using LSTM networks. Unlike LSTMs, which have three gates (input, forget, and output), a standard GRU combines the forget and input gates into two simplified gates: the reset gate and the update gate. 56 This simplification reduces the model's complexity; hence, GRUs are faster and less computationally intensive compared to LSTMs. However, this means GRUs might not be that powerful and effective in solving certain complex problems because of their simpler structure. The GRU is represented by two key gates: the reset gate, which helps in deciding how much of the previous hidden state to forget, and the update gate, which will determine how much of the new information should be passed forward. 56 These gates work together to update the network's state in a more efficient manner than traditional RNNs, though they are not always the best fit for every task. Despite its computational efficiency, the GRU-based systems are not suitable for all types of problems. The simplicity of the architecture, while beneficial in terms of speed, may limit the model's ability to capture the complexity of certain data patterns, leading to suboptimal performance in some use cases.
Histogram gradient boosting regressor
HGBR refers to a machine learning technology that combines the ideas of gradient boosting with a histogram-based approach for feature division and orients it to perform regression tasks. It is an adaptation of the well-known method known as the gradient boosting machine. Gradient boosting is a particular class of the most powerful machine learning algorithms; these have been used to solve tasks such as regression and classification. 57 Unlike some other methods, HGBR is designed to address more complex and large-scale problems, making it suitable for tasks that require high levels of computational efficiency. 58 The HGBR approach is mainly effective for handling regression challenges, particularly those problems characterized by high-dimensional datasets. Included among the strengths of this approach are strengths to handle high-dimensional features while maintaining efficiency. This histogram-based approach greatly improves performance for decision trees by reducing computational resources required and is, therefore, much more efficient compared to traditional methods of decision trees. 59 By discretizing the input features, HGBR creates a set of bins that represent the feature values. This division improves the speed of the learning process, particularly when handling large datasets with numerous variables. The HGBR method has found applications in various fields, including solar radiation forecasting, due to its ability to process large, complex datasets with minimal computational overhead. Its advantage lies in its efficient handling of high-dimensional data, which is particularly useful when dealing with vast amounts of information. 60 As illustrated in Figure 5, the histogram-based approach involves dividing the feature ranges into smaller bins. This process allows for a more efficient training process, as it reduces the need to evaluate the entire range of feature values during decision tree learning. These bins are used to create histograms that capture the variation in feature values, allowing for basic statistics like data counts and gradient totals within each bin. The decision tree would analyze these statistics to identify optimum break points for base learners. This histogram-based technique has massive computational advantages because the amount of data being processed at each step decreases, which also means that memory and computational needs are smaller. Another big plus is lesser sensitivity to noise, hence improving generalization capability for the model. 61
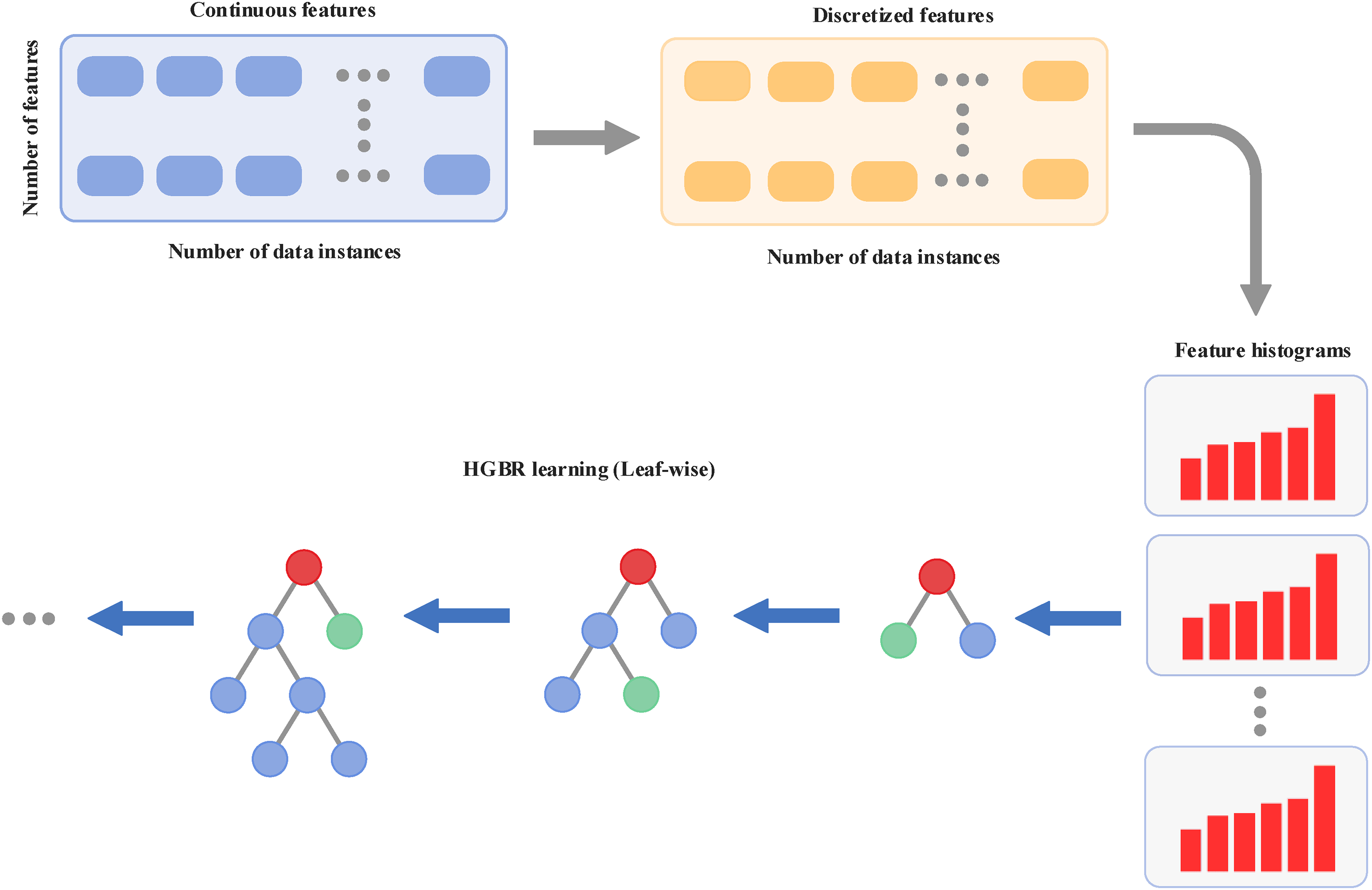
The histogram-based approach structure.
Decomposition method
The VMD model or variable mode decomposition is basically a technique of data decomposing. VMD in signal processing utilizes signals of time series with intrinsic IMF, inherent functions set. Each of these IMFs is expected to characterize only one underlying the original signal detailed oscillatory mode or portion. 62 The VMD method plays a key role in breaking down complex signals into small interpretable signals. The use of VMD was found to simplify the understanding and interpretation of difficult and complex signals, and, ultimately, more accurate predictions could be provided through this analysis method. 63
The advantages that VMD has over other methods are that VMD is a data-driven method and requires no prior knowledge and assumptions. VMD can help in predicting solar radiation by analyzing and then identifying and characterizing the patterns of solar radiation. This decomposition technique will be a very useful signal analyzing tool and thereafter for solar radiation prediction. An important point to note is that VMD can be influenced by various factors, some of which are environmental characteristics and solar radiation data.
64
On begin, the Hilbert transform is applied to each IMF to produce the one-sided spectra. In the second step, the IMF spectrum is transferred to the baseline area by combining it with a measure adjusted to the predicted center frequencies. Furthermore, the range of each IMF is determined utilizing the demodulated signal's Normal smoothness, that is, the square of the gradients L2 parameter. After the main signal was decomposed into several smaller signals using the VMD method, several IMFs were provided. Subsequently, after each IMF was predicted, its estimated bandwidth was summed. In addition, the accumulation of each of the IMFs must be with the input signal 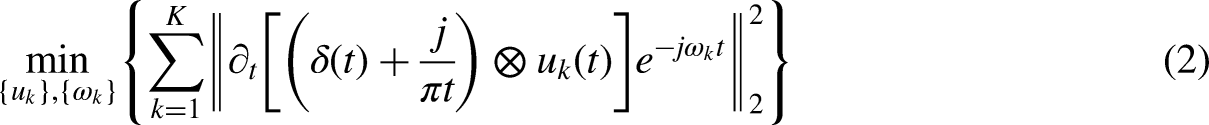
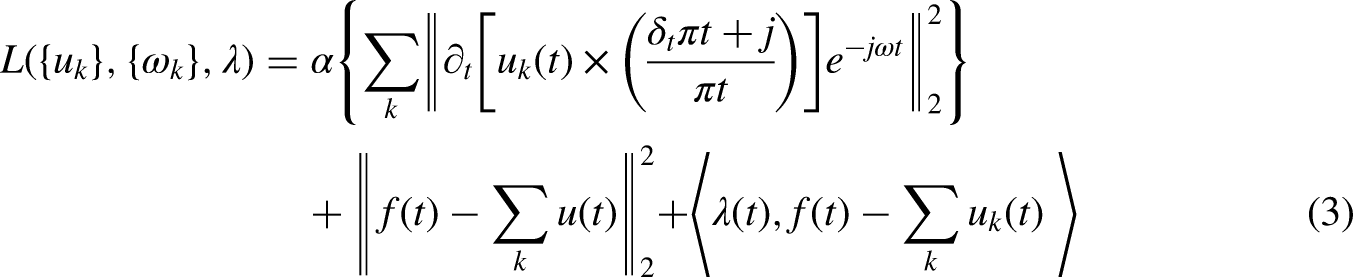
The combination of the quantitative penalization and Lagrangian multipliers gives the benefits of the quadratic penalty's superior convergence skills and the rapid implementation of the constraint by the Lagrangian multiplier. The alternate directions technique of multiplies can be used to solve the equation (3). The two main stages of equation (3) are as follows:
uk minimization
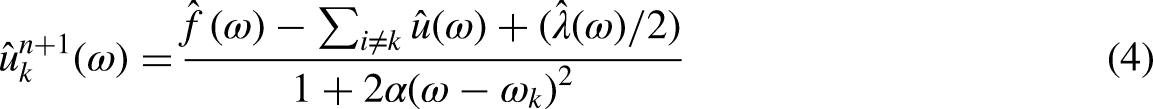

In which n is the total amount of iterations, and the Fourier transform of
Sample entropy
By applying decomposition techniques, a specific time series can be separated into multiple modes. When the algorithm is applied directly, the computational complexity of the forecasting method increases. Taking into account the disaggregated and fragmented components, the SE technique selects and reconstructs patterns to reduce the required computational effort, enabling the analysis of the detail level of the separated elements. Higher SE values indicate stronger autocorrelation, while lower SE values suggest weaker autocorrelation. The following terms can be used to explain the operation of the SE technique.65,66
Step 1: The following is the definition of the reported time period F with N sample items
66
:
Step 2: The aforementioned formula can be expressed in m-dimensions as follows: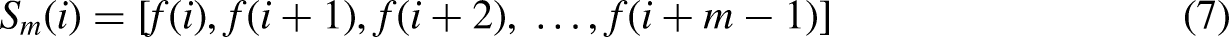
Step 3: Determine and calculate the distances that existed between 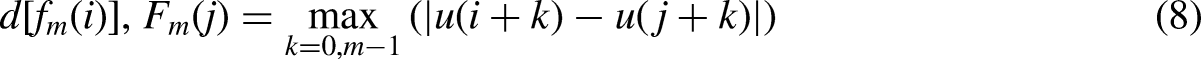
Step 4: Compute the following 
Step 5: After repeating steps (2) through (4), get 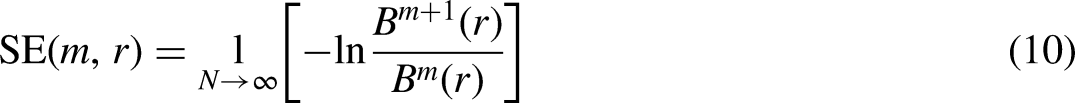
Step 6: The formula above becomes the following when N is assumed to be finite
65
: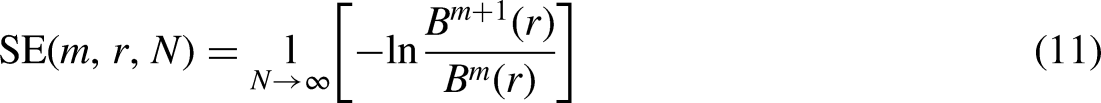
Biogeography-based optimization
Biogeography is the study of the spatial distribution of biological organisms. The development and formulation of mathematical equations governing the dispersal of organisms began in the 1960s. 67 The concept of nature serving as a source of inspiration for human knowledge has led to the creation of an adaptive algorithm and metaheuristic known as BBO. This method draws upon biogeographic principles such as speciation (the formation of new species), species movement between islands, and species extinction. Initially proposed by Dan Simon in 2008, 68 BBO utilizes a mathematical framework to model species movement across habitats, characterized by emigration from less favorable habitats and immigration into more suitable ones.
The suitability of habitats is quantified and stored as the habitat suitability index, which is determined by the objective function of the optimization problem being addressed. As one of the most well-known evolutionary algorithms (EAs), BBO optimizes a function by repeatedly and randomly improving the best solutions based on a defined quality or fitness function. 68 Figure 6 provides a visual representation of the structure of BBO. Figure 7 illustrates the general flowchart of the BBO method, outlining the necessary steps to achieve the optimal solution.
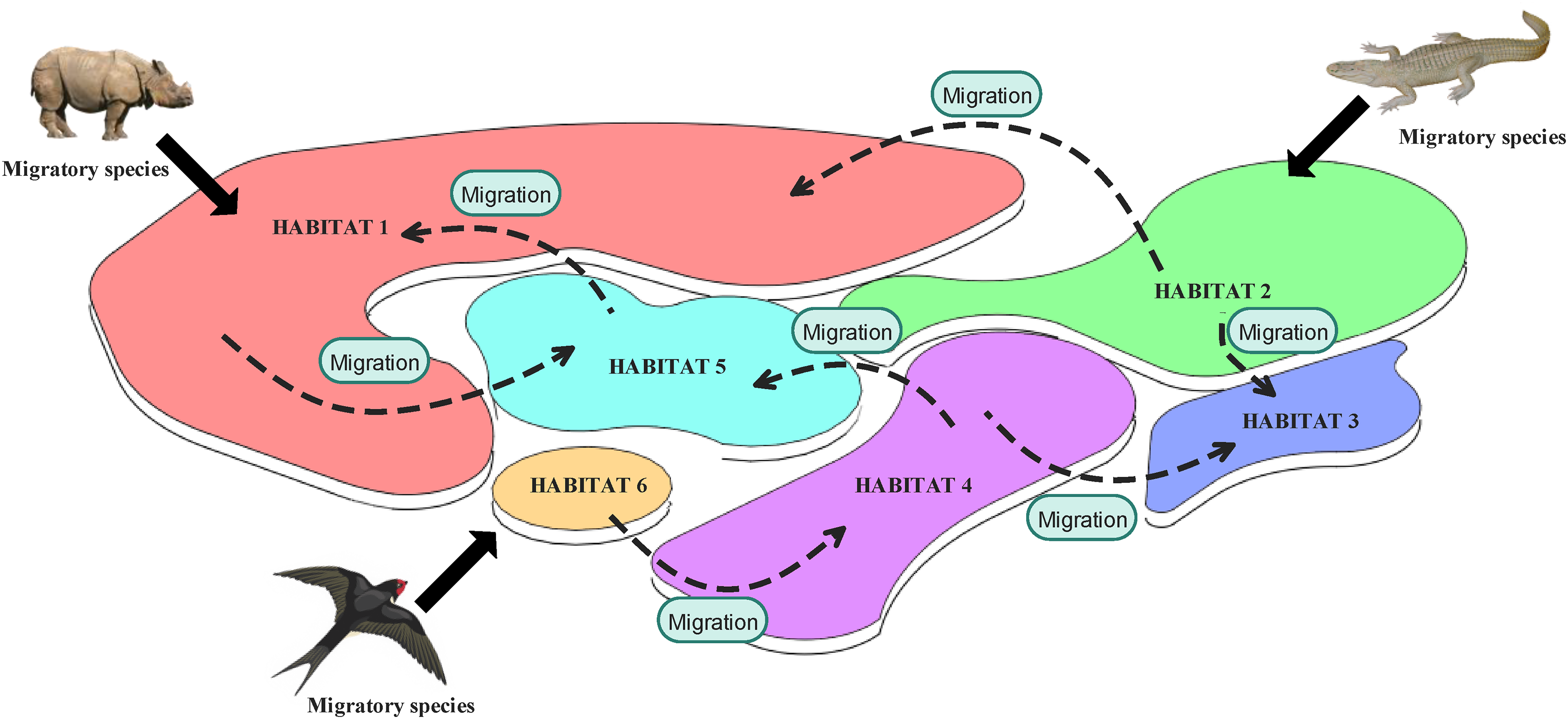
An illustration of biogeography-based optimization.
Flowchart of DNI prediction based on BBO-HGBR.
Evaluation metrics
To evaluate the forecasting performance of the two established models, this study employed several key metrics, including root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and the coefficient of determination (R2).
60
Among these, R2 is a commonly used metric for assessing the effectiveness of regression models.
69
It provides valuable insight into how well the model's independent variables (predictors) explain the variation in the dependent variable. The following mathematical formulas describe applied metrics70,71:



Applied configuration
The suggested HRS, as shown in Figure 8, offers a scalable and modular design for combining solar power with technologies for hydrogen production and storage. The basic goal of this system's design is to optimize the use of renewable energy sources while preserving operational responsiveness and dependability in the face of fluctuating demand and generation circumstances. PV output scheduling and downstream component operation more precise control. PV arrays produce electricity; irradiance, panel temperature, and environmental losses like dust and aging all affect how well they work. Direct current (DC) electricity produced by the PV modules is sent to both DC and AC loads via a high-efficiency bidirectional inverter. This inverter is essential to the power balance and flexibility of the system because it ensures smooth energy transfer between AC and DC busbars with little loss.
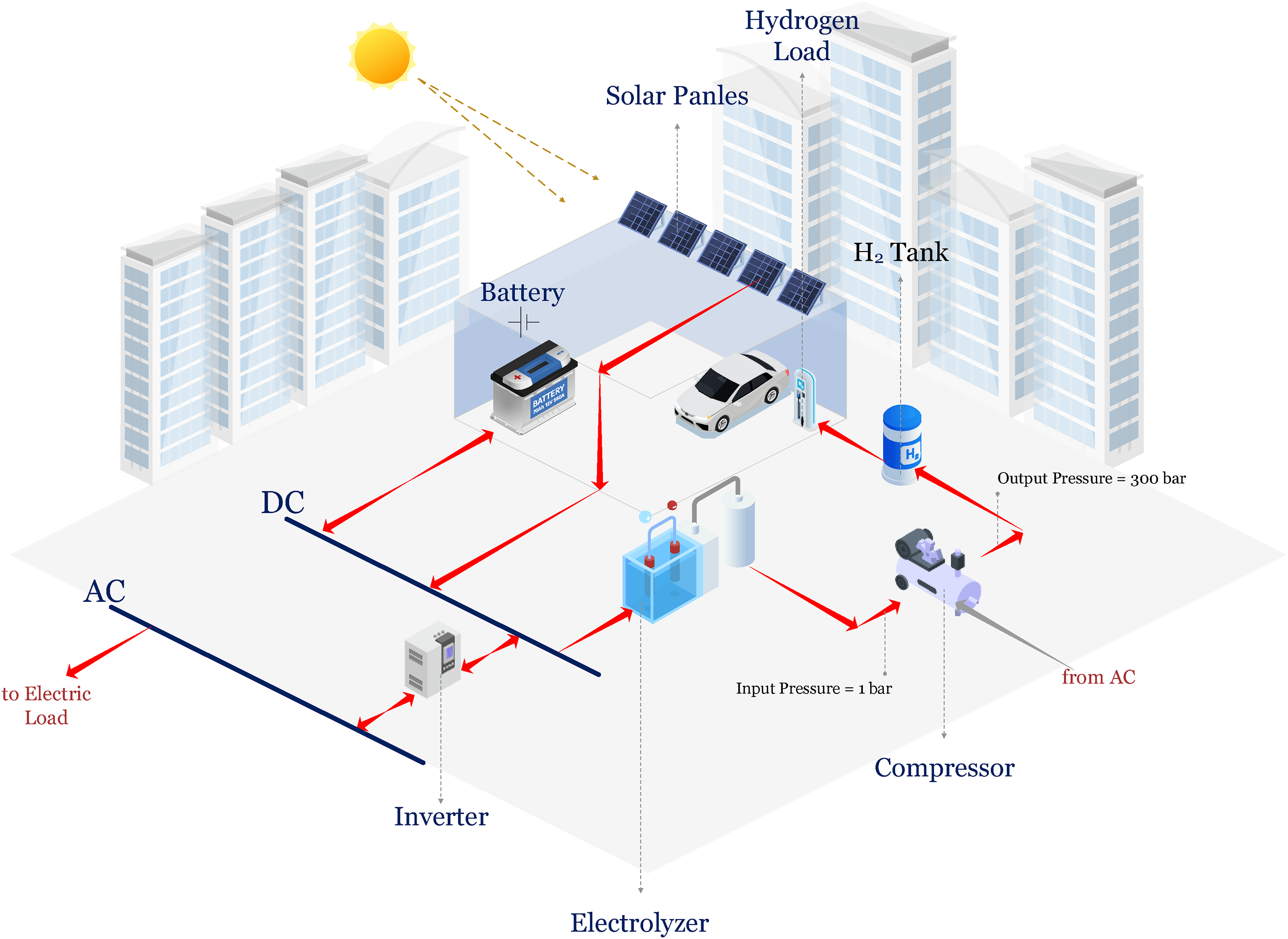
Schematic of the hydrogen refueling station system.
A PEM electrolyzer, which separates water into hydrogen and oxygen, receives the majority of the DC electricity from the PV system. Because of its high hydrogen purity output, quick dynamic response, and compatibility with intermittent renewable inputs, the PEM electrolyzer was selected. Hydrogen is then directed to a compressor, which increases its pressure from atmospheric (∼1 bar) up to standard refueling levels (typically 300 bar depending on vehicle class), making it suitable for storage in a low-pressure hydrogen tank (is approximately 68.75 m3, which corresponds to a spherical vessel with a radius of approximately 2.5 m). The average refueling time per vehicle is designed to fall within 3–5 minutes, subject to tank size, refueling protocol, and temperature compensation strategies. The buffer capacity of the central hydrogen tank ensures that demand surges can be met without immediate reliance on electrolyzer operation.
A battery storage subsystem is another component of the system that serves as a temporary buffer to support system startup, smooth power fluctuations, and handle brief discrepancies between component demand and electricity supply. It is essential for preserving voltage stability, safeguarding delicate parts like the electrolyzer, and increasing operational adaptability. A control and energy management unit coordinates the entire system, dynamically regulating energy flows according to current system status and anticipated solar availability. Reducing curtailment, increasing energy efficiency, and optimizing the flow of hydrogen and electricity are all made possible by accurate DNI forecasting, which allows for proactive modifications to component operation. This arrangement allows for the time-shifting of hydrogen use for energy backup or vehicle refueling because the hydrogen tank functions as the main energy storage medium for longer periods of time. Considering the tank capacities, efficiency, and average range of different commercial FCEVs, the system has been sized to satisfy their refueling needs. From solar generation and forecasting to conversion, buffering, and refueling, this integrated workflow creates a comprehensive and repeatable model for green hydrogen production suited to transportation requirements.
Mathematical modeling
Photovoltaic
Solar panels are devices that transform solar radiation into electrical energy. The output power of a solar panel is influenced by many elements, namely irradiance levels, air temperature, and different losses that diminish panel efficiency.
72
Panel losses include losses in wiring, panel deterioration, and losses attributable to dust, snow, and debris on the panel surface.
73
The output power of a solar array is determined by equation (16).
74
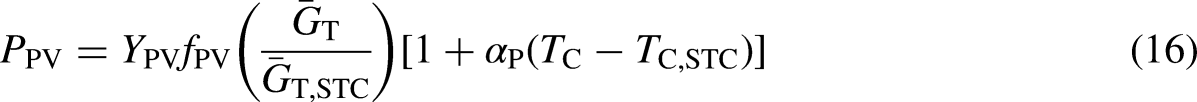
In this context,
The output power of solar arrays is in DC, hence the efficiency of the DC–AC inverter 
This study discusses the use of SunPower E20-327 PV panels, which have a rated capacity of 0.327 kW.
Electrolyzer
The electrolyzer produces hydrogen by electrolysis with electrical energy. Electrolysis is the method of using electricity to decompose water into hydrogen and oxygen.
76
PEM water electrolyzers are preferred over alkaline water electrolyzers due to their superior efficiency, extended lifetime, enhanced adaptability, and simpler design.77,78 The chemical processes taking place at the anode and cathode are shown in equations (18) and (19), respectively.

A comparison of the main electrolyzer and fuel cell technologies is given in Table 3 to help further explain the reasoning behind the choice of the PEM in this investigation. High hydrogen purity, quick reaction to varying solar input, small size, and compatibility with renewable energy sources are some of the main benefits of the PEM. For solar-powered hydrogen production systems, like the one created in this study for the Jiangsu hydrogen refueling station, these features make it particularly efficient.

To verify the accuracy of the developed PEM electrolyzer model, simulation results were compared with experimental data reported by Ioroi et al. 81 Figure 9 presents a side-by-side comparison of cell voltage versus cell density for both the present study and the reference work. The results show consistent alignment across most voltage ranges, with a maximum deviation of 1.64% observed at peak current density. This validation confirms the model's suitability for accurately representing the electrochemical behavior of PEM electrolyzers under various operational conditions.
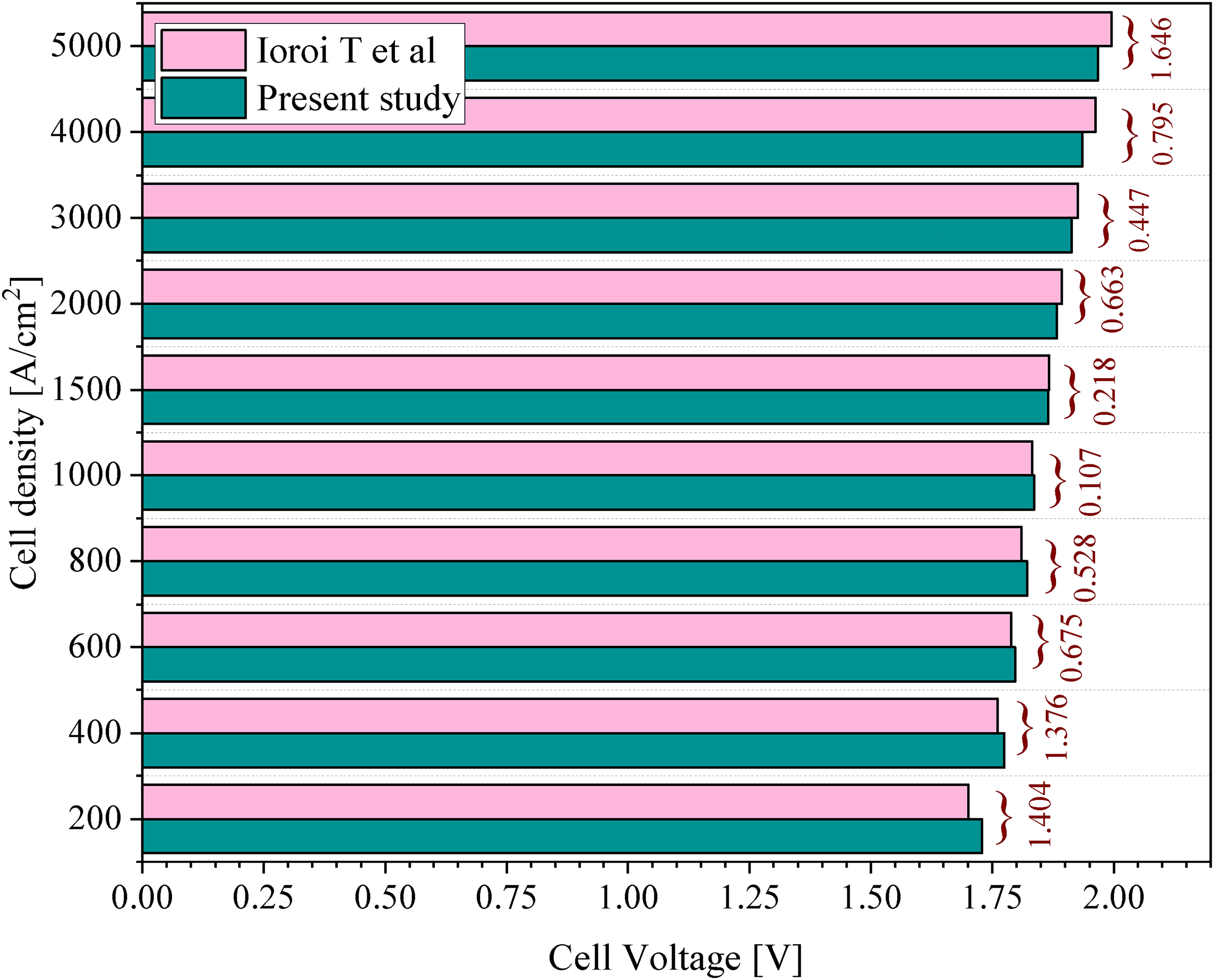
Validation of the PEM electrolyzer model.
Converter
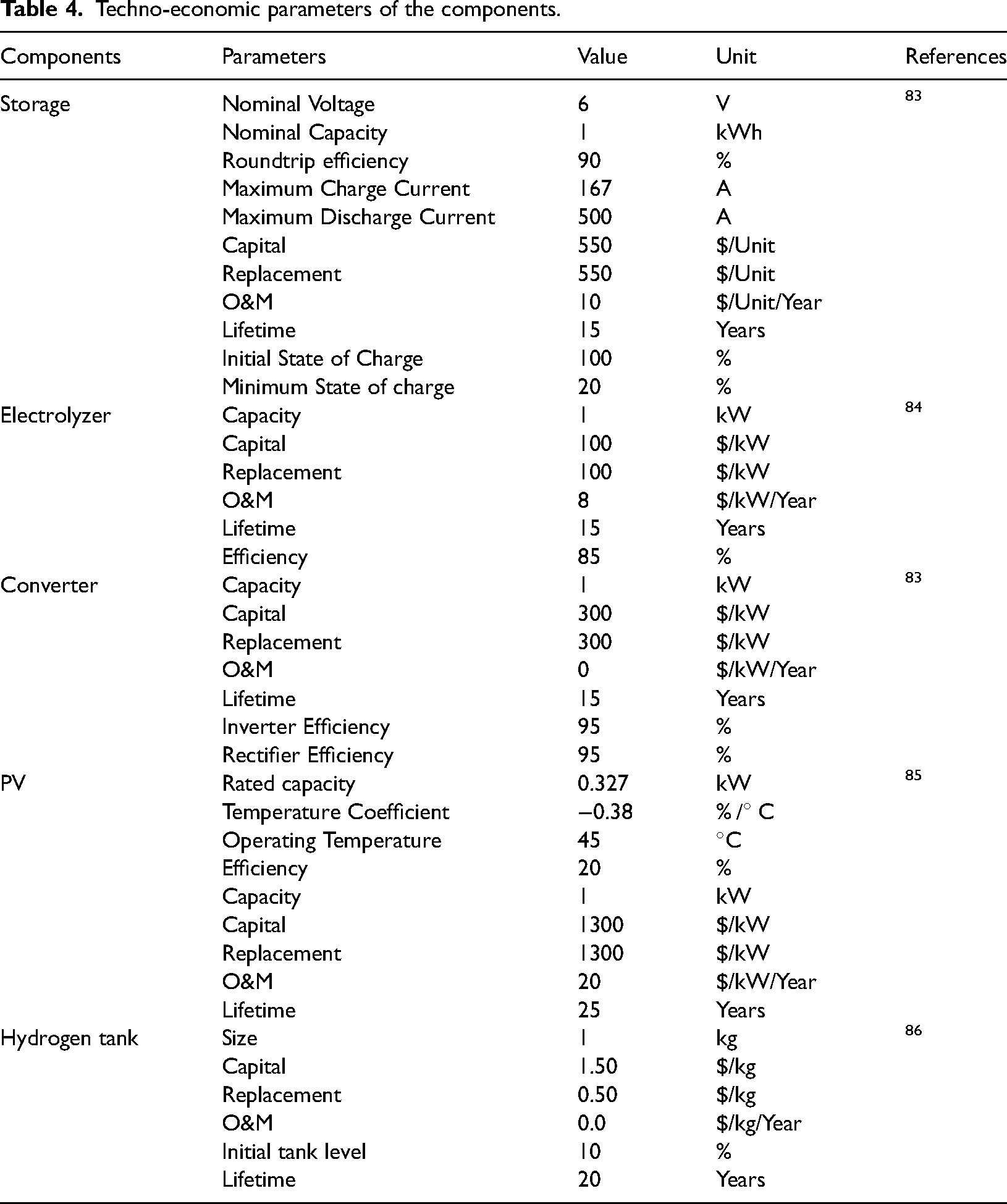
The converter's principal role is to regulate energy transfer between the AC and DC busbars, operating as both an inverter and a rectifier. The converter module's characteristics and specifications are detailed in Table 4. The converter's power rating is dictated by the system's maximum energy demand or supply.
82
The required rating for the converter in the system is as follows:
Techno-economic parameters of the components.
Storage
The battery stores electricity chemically, allowing the stored energy to be recharged and utilized for continued functioning as needed. To ensure the lifespan of the battery bank, it is essential to maintain the battery charge within 20%.
87
This study assumes four battery technologies, with their specifications detailed in Table 4. The below equation illustrates the estimation of battery energy levels.
88


Hydrogen tank
The volume of hydrogen produced has practical uses and may be used across several industries, mostly for recharging hydrogen cars. Excess electricity or lack of hydrogen demand results in the storage of hydrogen generated by the electrolyzer in a hydrogen tank. The beginning tank level in this investigation is set at 10% of the tank's capacity, using a standard hydrogen tank. The capacity of the hydrogen tank was assessed within a defined range of 0 to 2000 kg. Table 4 presents the efficiency of the hydrogen tank together with the comprehensive cost estimates. 86
Hydrogen fuel cell electric vehicles
A comparison of performance and requirements was conducted for the various hydrogen cars are illustrated in Table 5. The range, fuel efficiency, and hydrogen tank capacity for chosen FCEVs including Toyota MIRAI II, Hyundai Nexo, Mercedes-Benz GLC F-CELL, and Hyundai ix35 are presented. These specs illustrate the concept of energy demand and storage capacity for the efficient refueling of automobiles. The Hyundai Nexo offers the longest range at 756 km, predicated on an economical fuel consumption of 0.84 kg/100 km and a hydrogen tank capacity of 6.3 kg. In contrast, the Mercedes-Benz GLC F-CELL achieves a shorter distance of merely 478 km, attributed to a higher fuel consumption of 0.97 kg/100 km and a smaller hydrogen tank capacity of 4.4 kg. Consequently, both the Toyota MIRAI II and Hyundai ix35 exhibit commendable performance in this regard, with ranges of 650 km and 594 km, respectively, while their hydrogen consumption rates are correlated with tank capacity. This data supports the need to enhance hydrogen storage and refueling infrastructure, taking into account the diverse energy requirements of these vehicles. Thus, this substantiates the need of developing a scalable hydrogen filling station capable of accommodating various applications for FCEVs.
Specifics regarding hybrid vehicles. 89

Carbon footprints of hydrogen production methods
Figure 10 provides a summary of the carbon dioxide emissions associated with different hydrogen generating processes. Biomass gasification emits 5000 units of
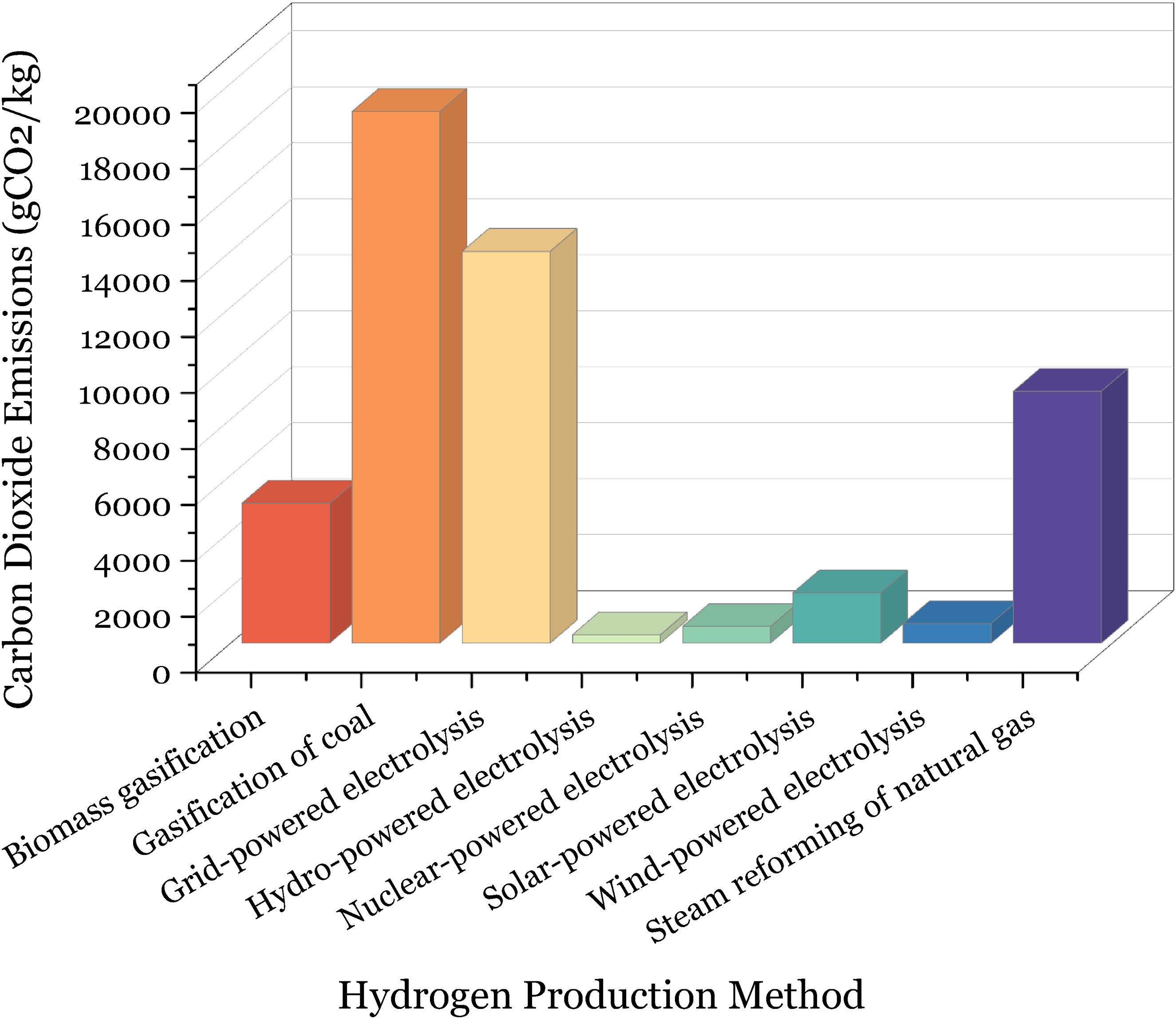
CO2 emissions associated with various hydrogen production techniques. 90
Economic criteria
NPC is derived from the assessment of the comprehensive expenditures related to a project, including capital, operational, and maintenance costs. The NPC during the project's duration is computed as91,92:
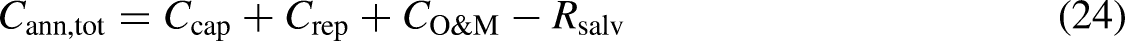


The LCOH is used to evaluate the feasibility of an energy system. It denotes the mean expense of generating and distributing a unit of hydrogen during the system's operational duration, including for capital expenditures, operational and maintenance costs, and the system's lifespan. The calculation involves dividing the entire yearly cost by the annual hydrogen output as shown in
93
:
Study framework
The proposed model integrates advanced data processing techniques and renewable energy optimization to create a comprehensive framework for efficient hydrogen production and storage. This study combines machine learning methodologies with sustainable energy solutions to address the challenges of clean energy management. The workflow of the model is detailed step-by-step in Figure 11. The process begins with data preprocessing and correlation analysis, where raw data is collected, refined, and analyzed to identify significant correlations with DNI. Irrelevant data points are removed to finalize a robust dataset suitable for further analysis. The prepared dataset is further divided into four seasonal subsets, namely Spring, Summer, Autumn, and Winter. Further, each subset has been split into training and testing datasets comprising 80% for training and 20% for testing to effectively gauge the predictive performance of the model. First of all, benchmark models are compared by using the prepared dataset in order to find the best model among the three machine learning approaches taken for comparison. Once the optimal model is identified, it undergoes hyperparameter optimization to enhance its performance. Following optimization, the prediction accuracy of the model is further improved by utilizing the decomposed dataset and clustering processes. In the case of VMD, seasonal data is decomposed into small and manageable signal components for further analysis of signals in detail. Further, the process goes ahead to the clustering and consolidation of the signals after decomposition. The SE method will be applied in the grouping of such signals into classes like High, Medium, Low, and Residual classes for a focused analysis of certain behaviors of these signals. The optimized BBO-HGBR network predicts the clustered signals, and the resulting outputs are aggregated to produce the final prediction outcomes. These predictions are then seamlessly integrated into the hydrogen refueling station framework, ensuring efficient and reliable energy management. The station is powered by a PV array, which converts solar energy into DC electricity. This energy is processed through an inverter to supply AC to system components. Hydrogen is produced in the PEM electrolysis water. The excess energies from the photovoltaic are either stored at short-term fluctuations or converted into hydrogen for long-period storage in the battery unit. Hydrogen generated from each and every producing unit is passed through high-pressure tanks for high-capacity purposes, which eventually work as a suitable energy source that can be either employed for vehicle fueling or is used as backup during periods with a lack of sufficient renewable energy conversion. The integration of advanced data processing, renewable energy optimization, and scalable hydrogen refueling infrastructure demonstrates a sustainable and efficient approach to meeting clean energy demands. The system ensures flexibility, and maximum utilization of renewable resources, contributing to the growing adoption of hydrogen as a clean energy solution.
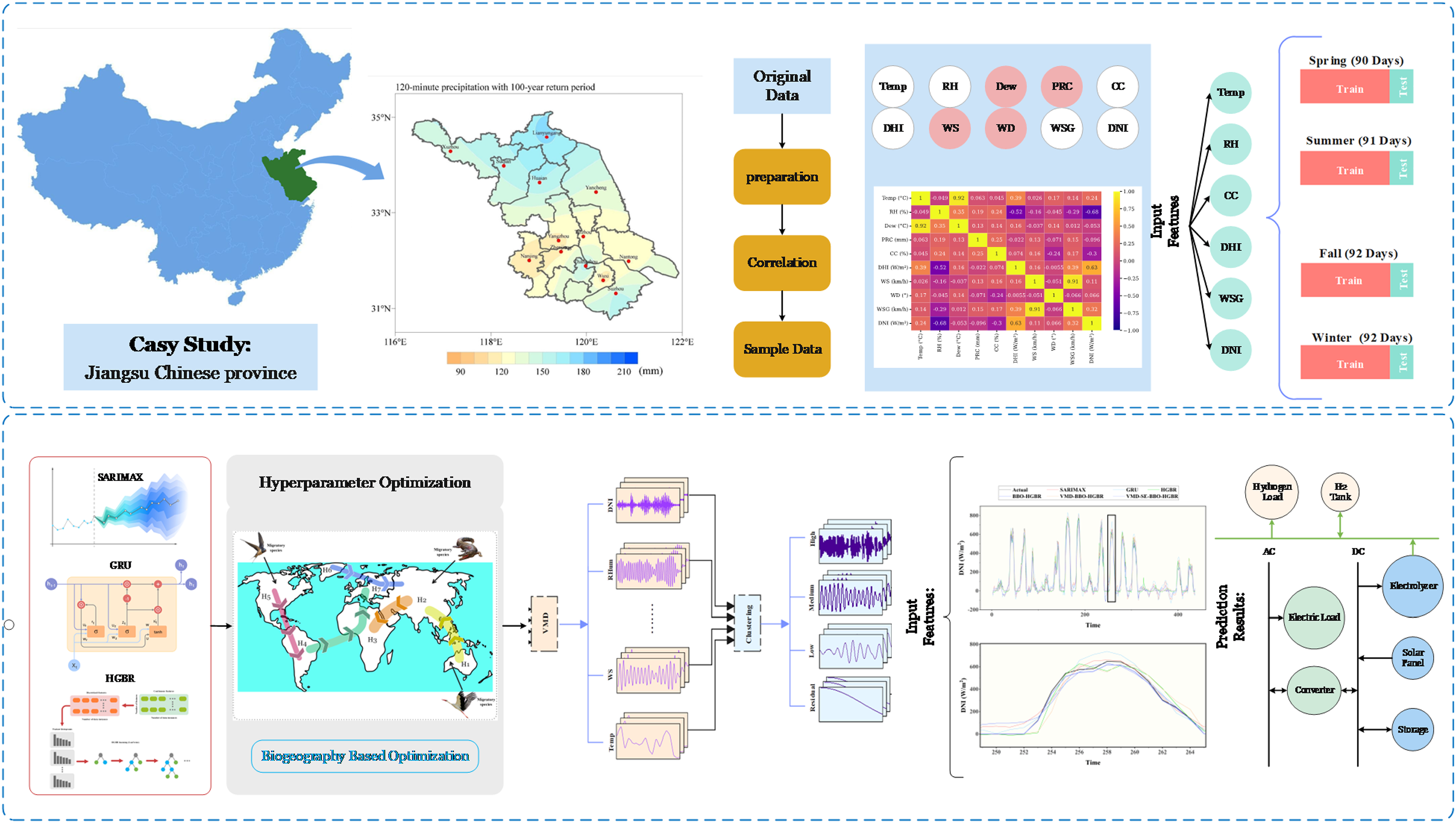
A step-by-step flowchart outlining the overall process of the proposed model.
Results and discussion
Data decomposition
The VMD method is an important approach in this work, decomposing the complex time-series data into simpler, more interpretable components. This technique is especially suitable for capturing seasonal variability in DNI, which is one of the most important variables in renewable energy forecasting. The VMD technique helps in the detailed analysis of the signal by decomposing the DNI signal into IMFs and a residual component, which will increase the accuracy of the predictive models.94,95 Figure 12 depicts the implementation of the VMD method on the DNI time-series data, categorized by season comprising Spring, Summer, Autumn, and Winter. This decomposition is essential for converting complicated, nonlinear, and non-stationary data into separate components that facilitate analysis. The VMD allows for the decomposition of the DNI signal into seven IMFs and a residual component, in descending frequency and ascending wavelength order for Spring season. The decomposition done here forms the basis for subsequent signal clustering and predictive modeling within the framework of the study. This is supported by the seasonal decomposition, which supports the two major phases of the study. First, it allows the detailed analysis of the signal and its clustering by splitting the signals into high, medium, low, and residual groups, which can enable the focused study of different seasonal behaviors of these signals. Second, the decomposed signals improve predictive accuracy for the optimized BBO-HGBR network, leading to better predictions of both DNI and renewable energy output. This enables the research to discern seasonal fluctuations, indicating that conditions may alter with each season, while also augmenting the robustness of the forecast model. The higher-order IMFs indicate rapid and transient variations resulting from sporadic meteorological phenomena, such as cloud cover, in the spring season. The mid-range IMFs signify medium-term fluctuations, exhibiting semi-daily oscillations in meteorological circumstances. The residual component establishes a consistent baseline trend that aligns with the overall solar radiation pattern for Spring as demonstrated in Figure 12(a). This breakdown pertains to frequent fluctuations in solar energy throughout this season, necessitating good clustering and prediction techniques. During summer, the higher-order IMFs are characterized by less short-term swings due to steady meteorological conditions prevalent in this season demonstrated in Figure 12(b). Mid-range IMFs, namely IMF3 to IMF6, predominate with periodic fluctuations in diurnal cycles. This residual component exhibits elevated and steady baseline solar radiation in summer, making the season particularly dependable for solar energy generation owing to its stability and reduced short-term variability. The accurate prediction of mid-range IMFs is crucial for generating a precise projection of output energy.
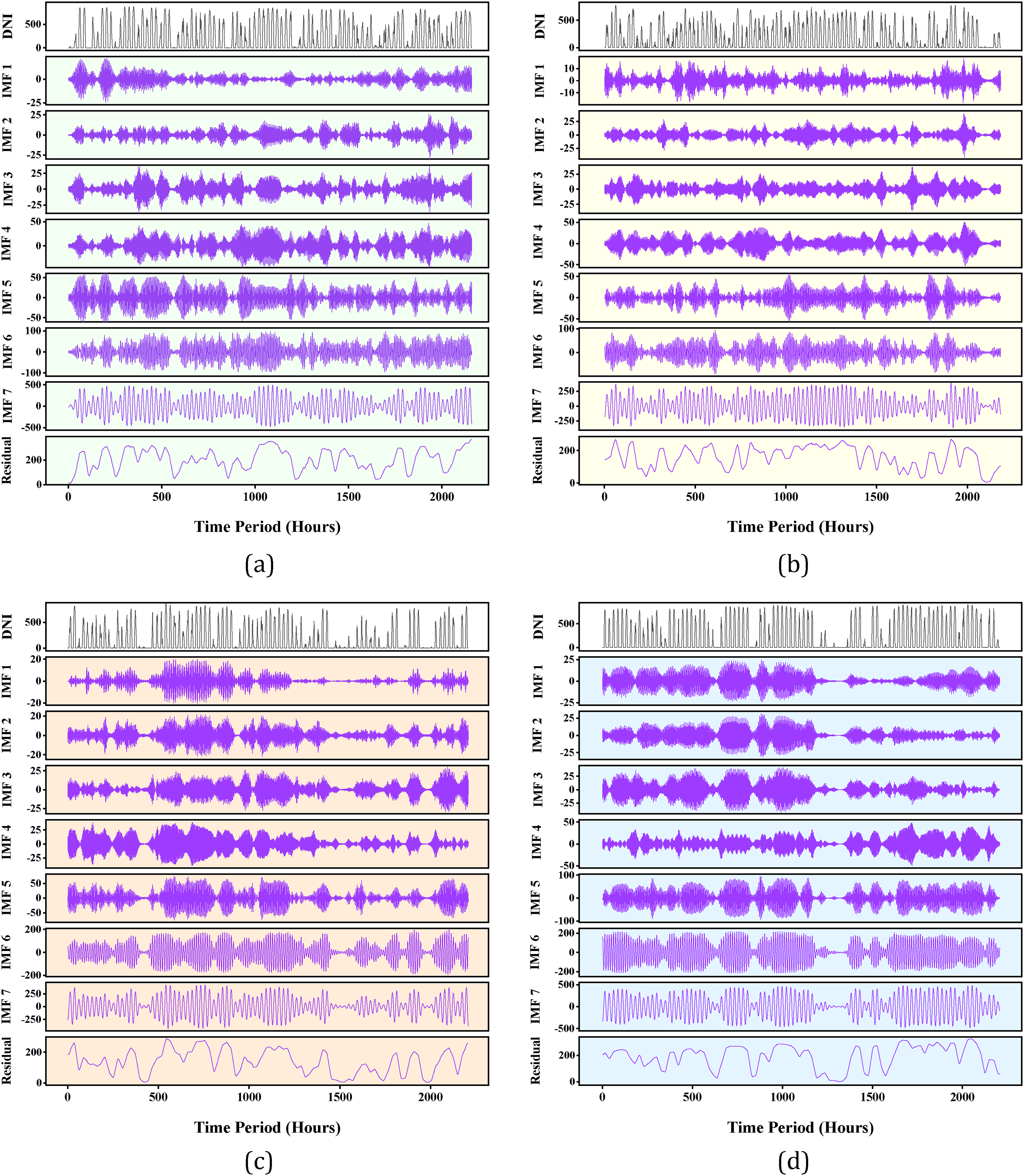
The results of the data decomposition across different seasons: (a) spring, (b) summer, (c) autumn, and (d) winter.
The higher-order IMFs for Autumn are IMF1–IMF3, indicating active short-term variations and therefore unpredictable weather as the season transitions into winter as presented in Figure 12(c). The mid-range IMFs of IMF4–IMF6 correspond to modest periodic fluctuations, indicative of semi-stable situations. The residual component reveals a diminishing baseline trend corresponding with decreased sun radiation in autumn. This kind of seasonal decomposition makes it an appropriate transitional variation of solar radiation, combining stability with variability in order to give effective energy forecasts. The higher-order IMFs (IMF1–IMF3) indicate a pronounced activity during Winter as outlined in Figure 12(d), signifying frequent short-term fluctuations attributed to gloomy weather, snowfall, or reduced daylight duration. Mid-range IMFs are hardly discernible due to the modest periodic fluctuations throughout this timeframe. The residual component provides a low and constant baseline, indicating less solar radiation. Winter data decomposition illustrates the challenges in predicting caused by significant amplitude, high-frequency noise and a little steady-state baseline trend. High-order IMFs encapsulated short-term changes, mid-range IMFs illustrated medium-term patterns, whilst the residual component represented the baseline trend. These investigations are crucial in enhancing the performance of the BBO-HGBR network, notably in clustering and predictive modeling. It addresses the distinct characteristics of each season, so facilitating accurate energy forecasting, optimizing hydrogen production, and enhancing the sustainable and effective operation of clean energy systems.
Computation of sample entropy
The computing requirements of the model might markedly escalate if all modal components derived from VMD processing are used. The generation of numerous modes via VMD necessitates the processing of extensive data, hence augmenting both the processing duration and computing complexity. The SE method is used to mitigate the total computing cost associated with this difficulty. 65 The SE approach categorizes various states based on their corresponding SE values, reducing the need for individual mode analysis and significantly streamlining the computing process. 96 In this approach, SE values are computed for all created states to measure the complexity of the signal. The SE quantifies the degree of unpredictability or disorder within a signal; elevated SE values indicate a more intricate and less predictable signal, whilst lower SE values denote simpler or more regular signal patterns. Figure 13 shows that the value of SE is directly proportional to signal complexity: the higher the value of SE, the more complex and detailed the signal, while the lower the value of SE, the simpler and more ordered the signal is. The last step is to divide the complexity of the signals into four groups, each of them according to its value of SE, so that the clarity of the features displayed by the analyzed signal is enhanced. The first category, known Residual, encompasses signals with SE values between 0 and 0.25, indicating little complexity. These indications are often consistent and foreseeable. The second group, with low complexity, includes signals with SE values ranging from 0.25 to 1, indicating signals that exhibit considerable fluctuation while remaining relatively simple. The third group, with medium complexity, encompasses signals with SE values between 1 and 1.5, indicating patterns that are more intricate and less predictable. The high complexity category encompasses signals with SE values over 1.5, indicative of very complex signals marked by significant unpredictability and disorder. The complexity of the signals is included into this categorization, facilitating the assessment of different degrees of signal intricacy and optimizing the computer resources needed for further analysis, hence alleviating the processing burden.
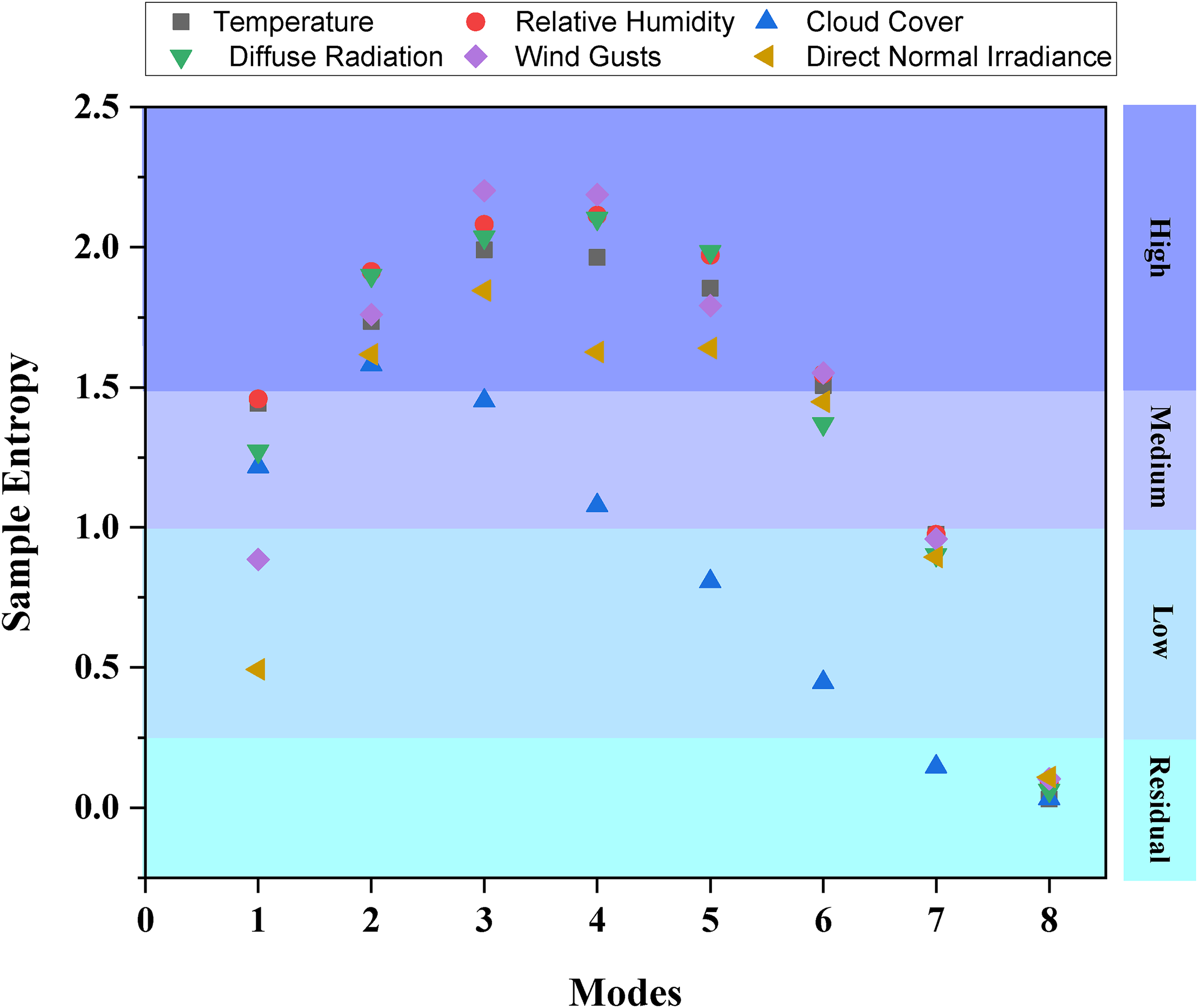
Calculation of sample entropy for VMD-derived decomposed.
Hyperparameter optimization
Perfect operation of models depends on exact specification of hyperparameters. Setting the ideal hyperparameter settings will help to raise processing model correctness. One may discover the ideal hyperparameters by means of manual or automated optimization. 97 The manual optimization approach selects hyperparameter values through try and error. During this time-consuming procedure, it is possible that the poorest hyperparameter values can be applied. It necessitates extensive knowledge of the parameters as well as competence in the relevant sector. Furthermore, the procedure might be time-consuming and not always dependable. The automated optimization method, on the other hand, is more successful since it employs optimizers to automatically determine the best hyperparameters. 98 This approach benefits from using algorithms that can simultaneously maximize many aspects, hence accelerating and improving the process. Moreover, it can manage complex models more skillfully than the hand-based optimization approach. When the parameters are difficult to understand or too numerous to handle by hand, the automated procedure comes in handy. While human optimization can be ideal in some certain situations, auto-optimization is more effective, reliable, and accurate for finding the best hyperparameters. In the current study, the BBO optimizer was used for the optimization of the hyperparameters of the HGBR model. Optimization of the models required defining the lower and upper bounds of the hyperparameters. The lower and upper boundaries of the hyperparameters are reported in Table 6. These hyper-parameters were then fine-tuned for optimum results using the BBO optimizer and henceforth improving the precision of the HGBR model.
Adjustment of HGBR hyperparameters.

Prediction results
The test data of all four seasons were used to test these models to evaluate their performance in the prediction of DNI. The different performance measures of models, MAE, RMSE, MAPE, and the R2, are illustrated in Table 7 and Figure 14. Because of geographical and climatic reasons, solar irradiance shows a seasonal pattern; therefore, the data set is split into separate subsets for Spring, Summer, Autumn, and Winter. The idea is that such a division into seasons can ensure that these models will be tested for their performance across different settings-indeed similar in real-life application scenarios. Among the six proposed models, the performance of VMD-SE-BBO-HGBR was promising in all evaluated metrics. It had an average R2 of 0.98, markedly surpassing the other three models assessed comprising the SARIMAX model at 0.80, GRU at 0.86, and HGBR at 0.91. Furthermore, the integration of BBO with VMD enhanced the efficacy of the HGBR model, as shown by the elevated R2 values from 0.93 with BBO alone to 0.95 when both VMD and BBO are used in conjunction, resulting in the VMD-BBO-HGBR model. These findings suggest the use of embedding decomposition, clustering, and optimization methods to enhance the prediction efficacy of conventional machine learning models. The lowest RMSE for the optimal model, VMD-SE-BBO-HGBR, fluctuated between 37.89 W/m2 and 41.70 W/m2 across seasons, yielding an annual average of 39.69 W/m2. The findings indicate that the MAPE ranged from 0.68% to 2.65%, with an annual mean of 1.95%. In terms of the yearly average, the MAE was 21.21 W/m2, ranging between 20.61 W/m2 and 22.84 W/m2. These results demonstrate the model's exceptional accuracy in producing projections closely aligned with the values obtained throughout the solar radiation testing phase. Accuracy is key in this respect for renewable energy management systems; even small deviations have the potential to cause huge losses in the efficiency of energy generation and storage. The real-time forecast variations over the seasons corresponding to the different models, such as the SARIMAX, GRU, HGBR, BBO-HGBR, and VMD-BBO-HGBR, are presented in Figures 15–18. The forecasted curves obtained using the VMD-SE-BBO-HGBR model fitted very well with the real solar irradiance data and therefore establish the superiority of the model beyond its competitors. Sophisticated signal decomposition integrated with clustering and optimization approaches captures the key strengths in seasonal fluctuation, thereby allowing VMD-SE-BBO-HGBR to handle the core complexity and nonlinearities inherent in solar irradiance.
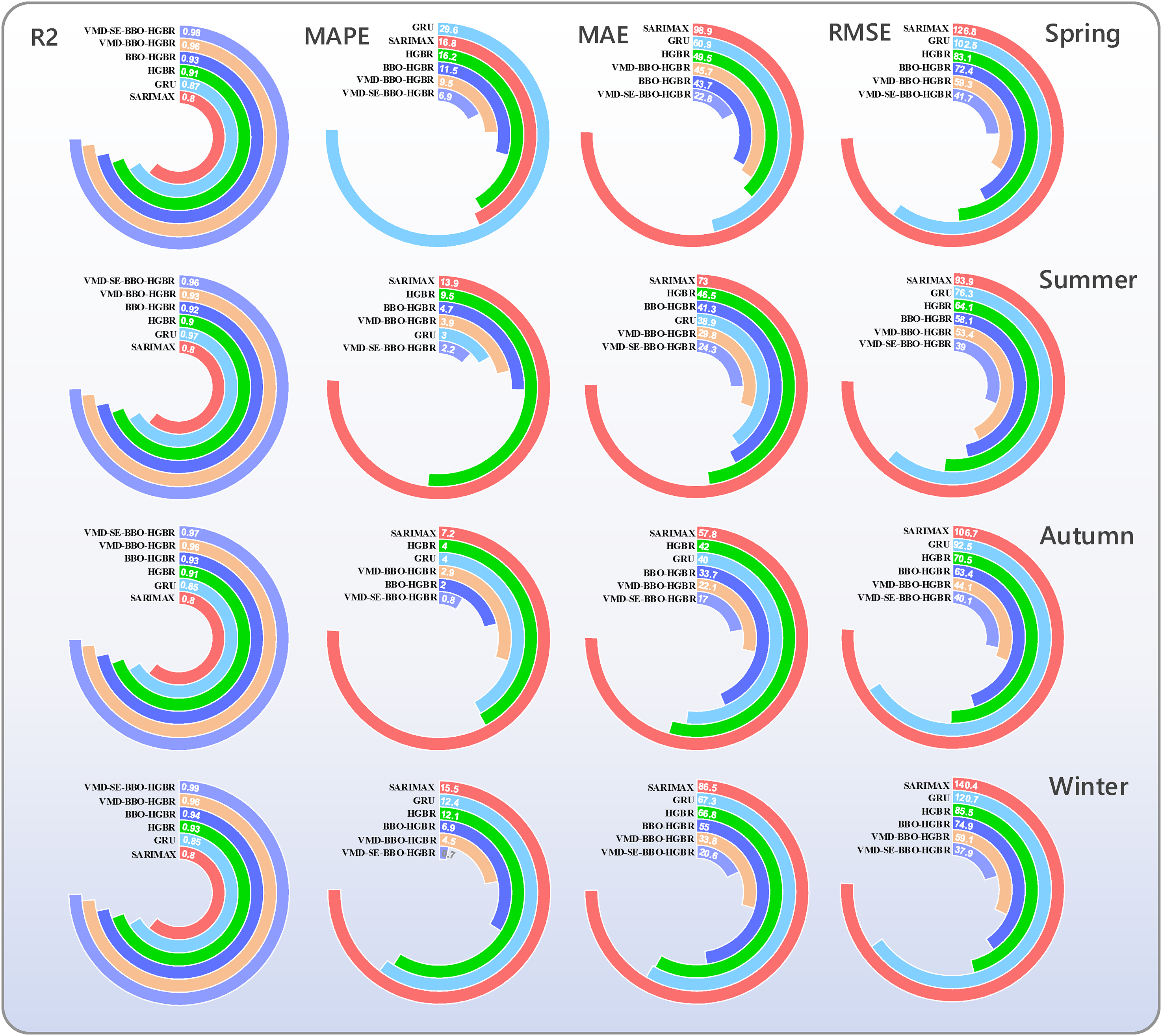
The evaluation values of each model for each season.
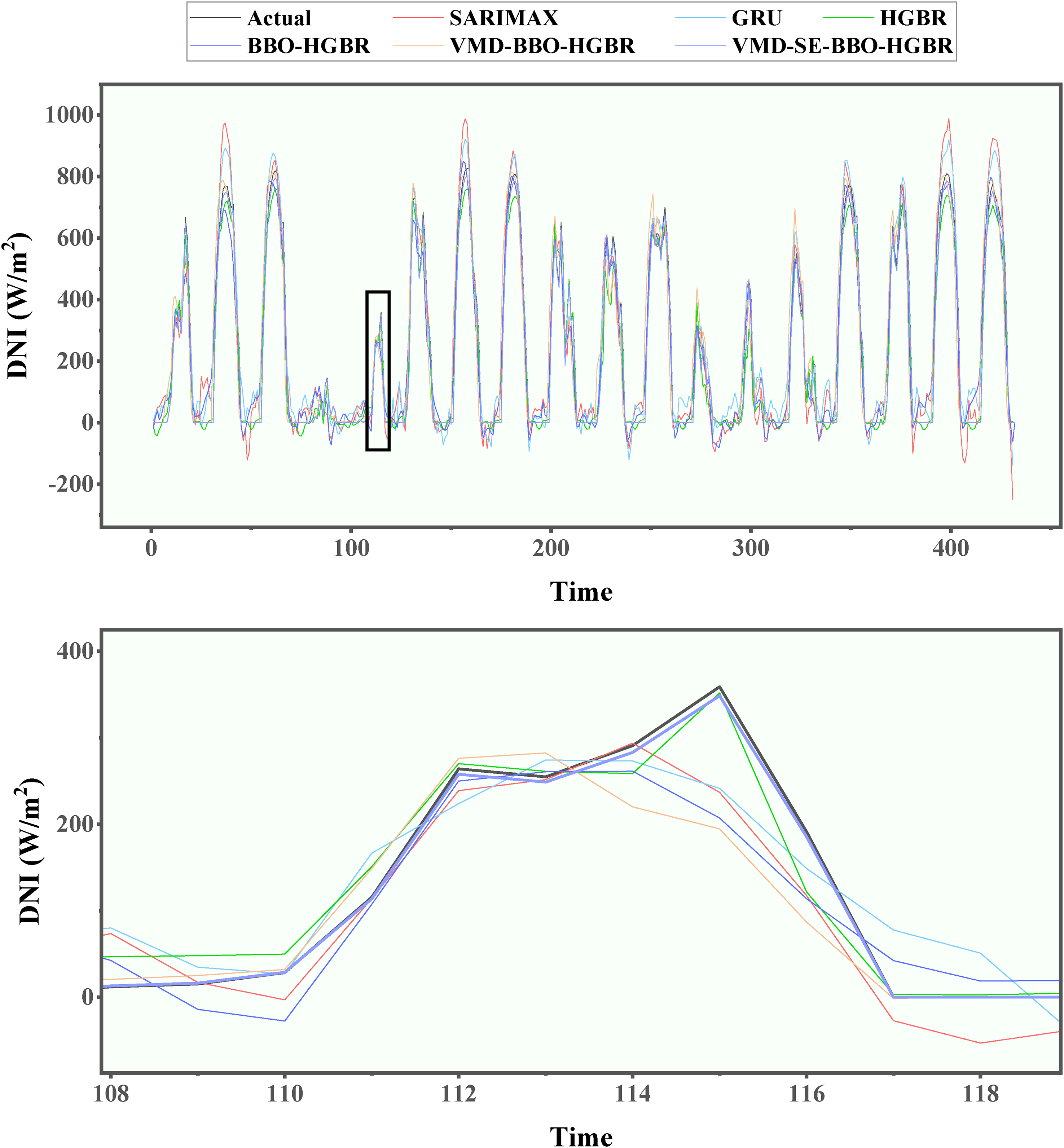
Prediction curves of the generated models during testing for the spring.
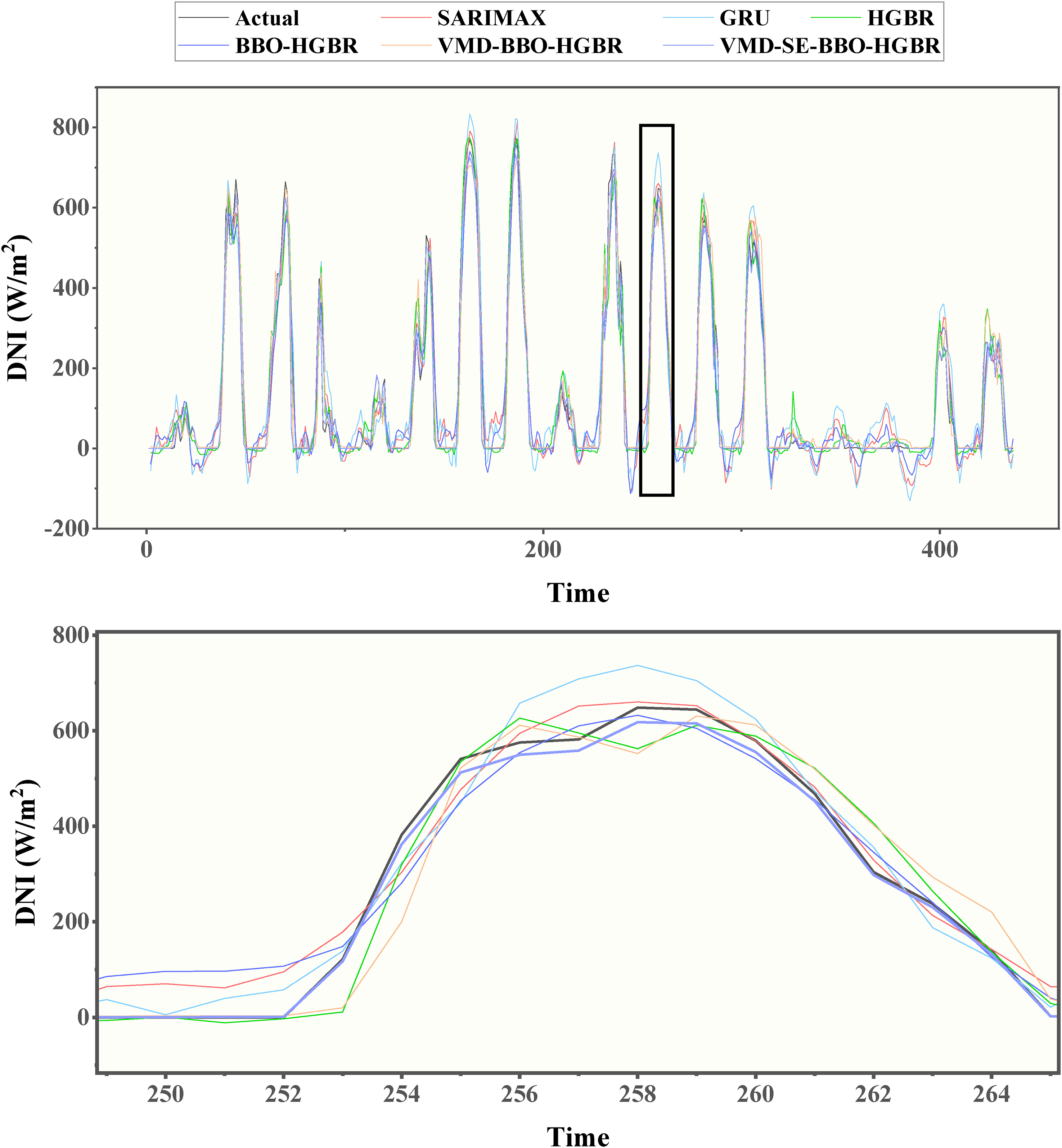
Prediction curves of the generated models during testing for the summer.
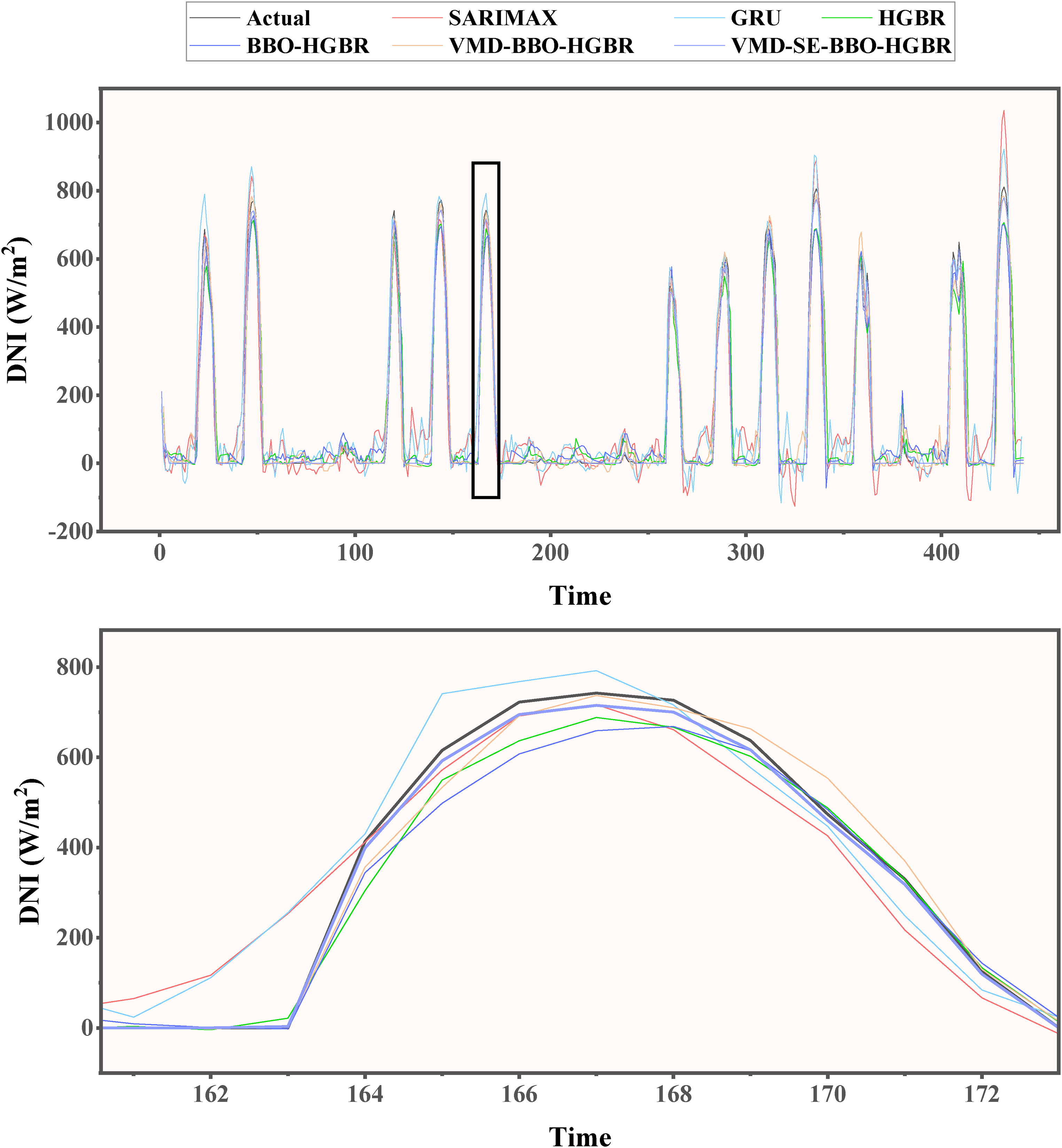
Prediction curves of the generated models during testing for the autumn season.
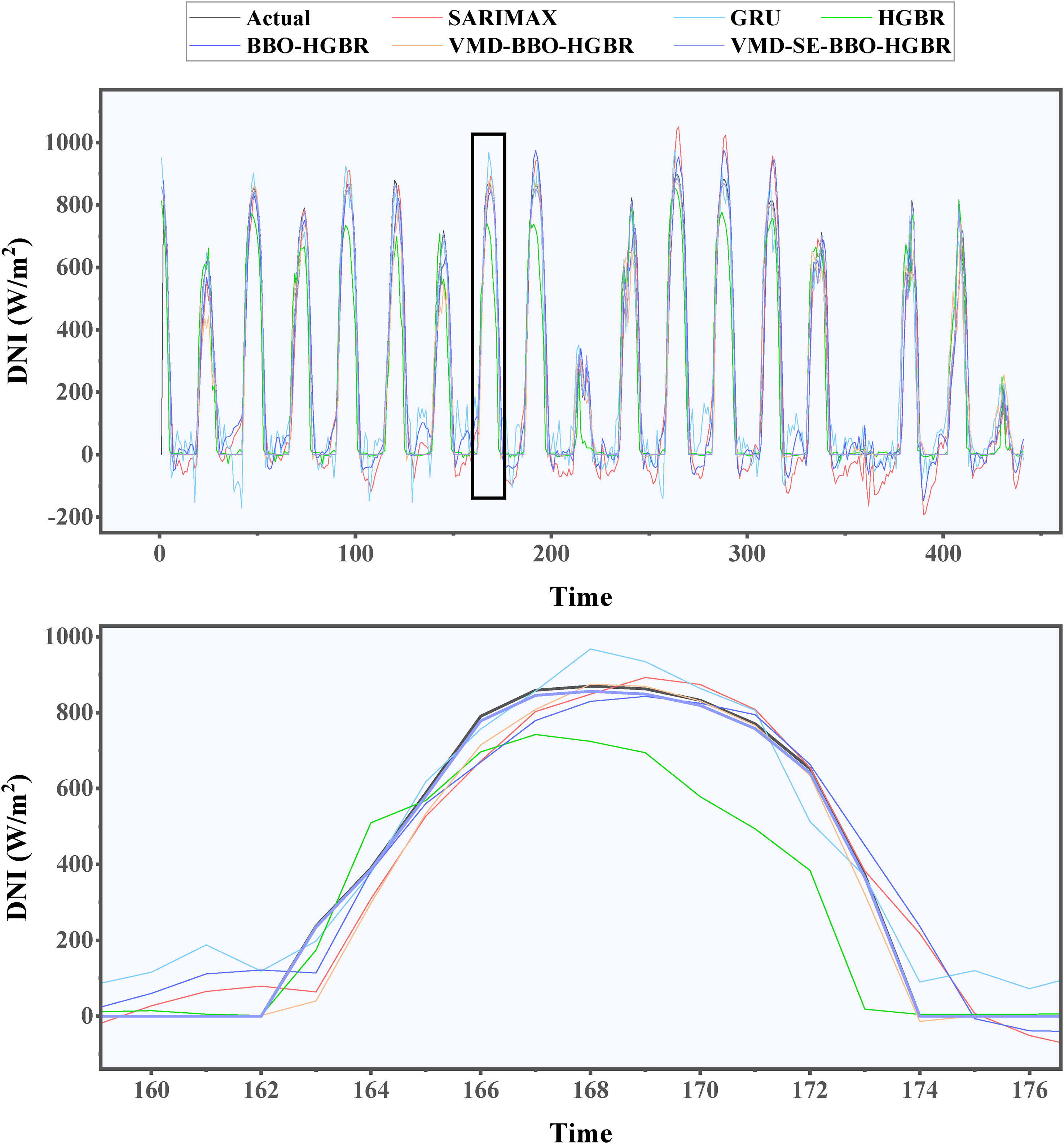
Prediction curves of the generated models during testing for the spring season.
Statistical prediction results for the six benchmarking methods.
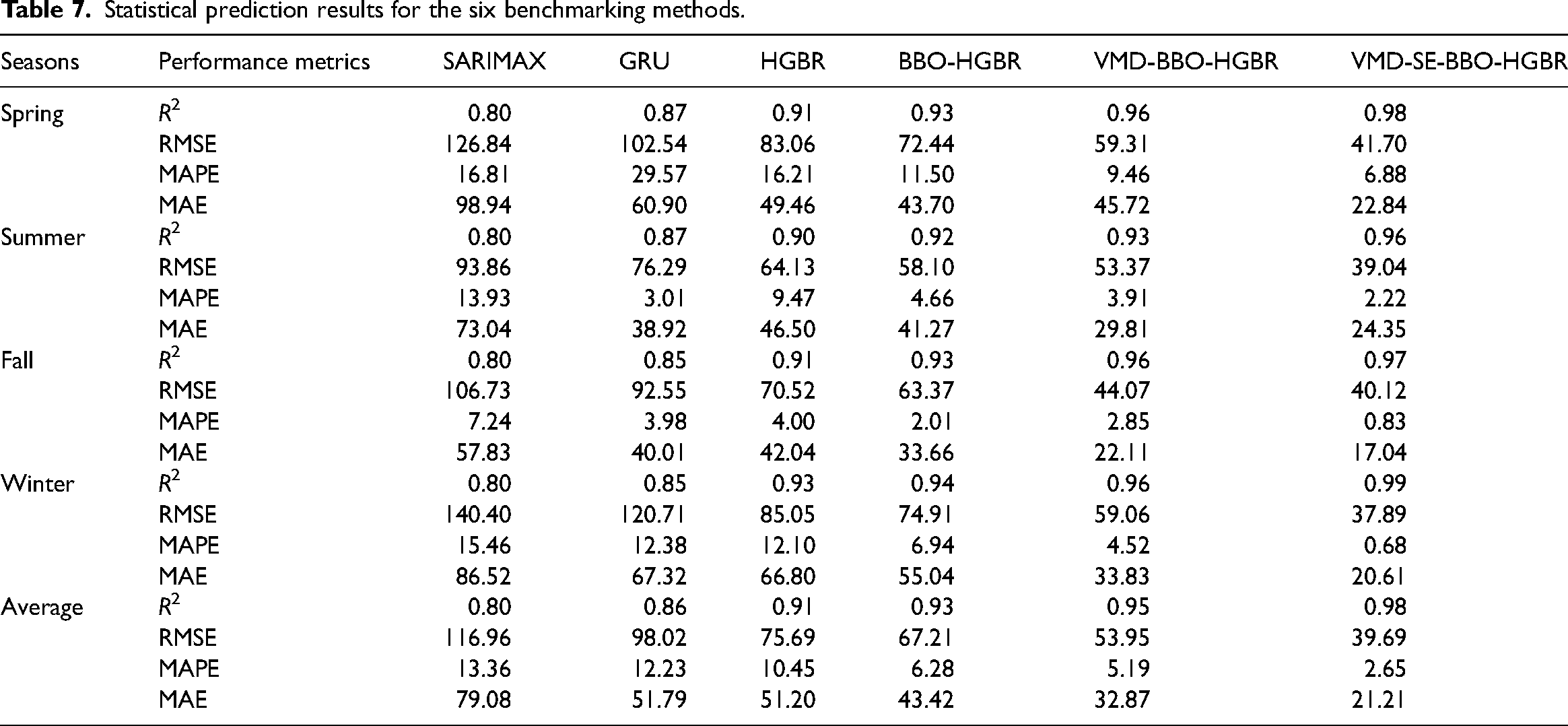
The extraordinary performance of VMD-SE-BBO-HGBR proves that the application of sophisticated preprocessing and optimization methods plays a vital role in enhancing the accuracy of the prediction. VMD decomposes a dataset into smaller, manageable signal components and then arranges the signals into significant clusters using the SE approach. This provides noise attenuation and improves the quality of the input data stream sent to the model. Furthermore, the application of the BBO optimization approach ensures that hyperparameters are set precisely to elicit optimum performance in the HGBR model. Furthermore, the VMD-SE-BBO-HGBR model demonstrates a significant improvement across all evaluated measures in comparison to leading machine learning models like SARIMAX and GRU. For many traditional methods that perform well on basic datasets, accurately capturing the intricate nonlinear patterns associated with sun irradiance may be challenging. Despite its considerable power, the HGBR significantly profited from its integration with VMD and BBO. This highlights the additional advantages of hybrid methods compared to traditional methods in predicting efforts in recent times. One notable discovery from the data is that this model has exceptional performance throughout all seasons. The MAPE values were very low, even in challenging conditions like Winter, when solar irradiance data typically exhibits more fluctuation. This demonstrates the model's accuracy and adaptability to various environmental circumstances, making it valuable for year-round forecasting.
These findings are quite significant for renewable energy systems, especially in the domain of optimizing the production and storage of solar energy. The higher the accuracy in DNI prediction, the more adequate will be the planning of energy production, storage, and distribution for establishing efficient hydrogen refueling stations and other solar energy systems. It should also be noted that further reduction of the prediction error, as achieved in VMD-SE-BBO-HGBR, will also help to realize significant cost benefits by avoiding overproduction or underutilization of energy resources. The incorporation of sophisticated signal processing methods such as VMD with machine learning models represents a significant advancement compared to the current research. This study emphasizes preprocessing and optimization, in contrast to other techniques that primarily concentrate on enhancements to model design. The VMD-SE-BBO-HGBR model addresses the limitations of conventional models and enhances their efficacy using hybrid techniques, establishing a new standard for solar irradiance prediction. The VMD-SE-BBO-HGBR model regularly demonstrates outstanding performance across all criteria, highlighting its potential as a reliable and efficient forecaster. The deployment of real-world renewable energy systems is crucial for advancing sustainable energy solutions, promoting effective resource use, and tackling clean energy management difficulties.
Simulation results
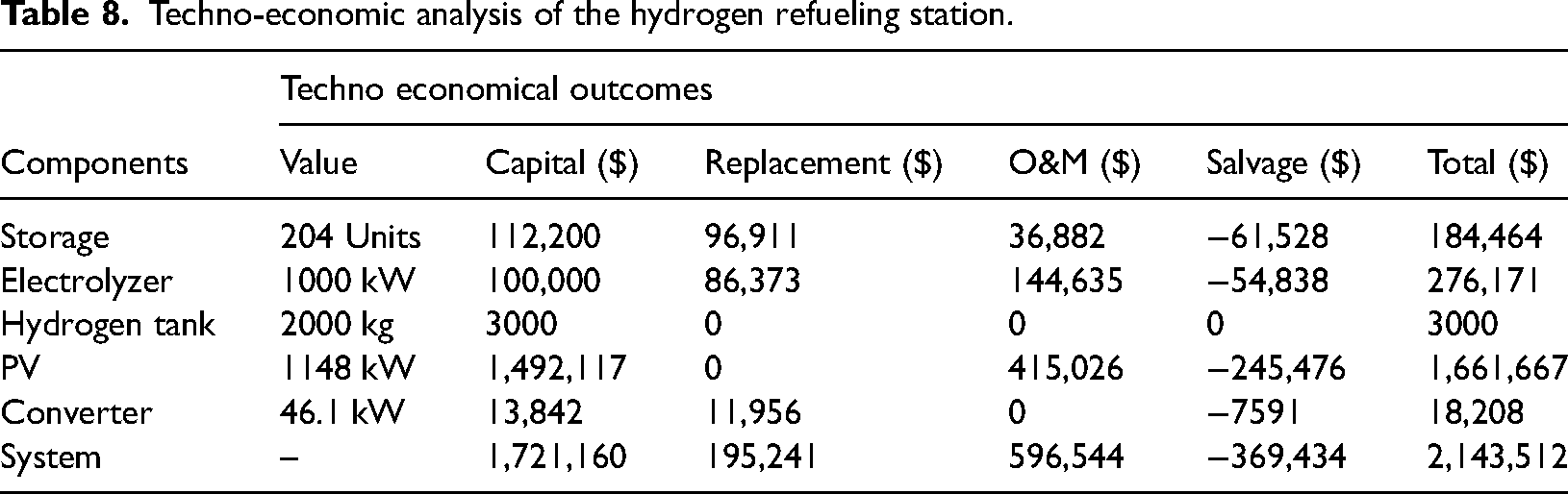
The simulation results demonstrate the basic techno-economic and operational feasibility of the suggested HRS, which is tailored for solar PV energy integration. The system's estimated total NPC over its anticipated lifecycle is 2,143,512 $, as shown in Table 8. This sum includes salvage values, operation and maintenance (O&M) expenses, capital investment, and component replacement. The PV system accounts for the largest portion of the investment among the components, at about 1,661,667 $, highlighting the importance of clean electricity in promoting the viability of renewable hydrogen. The energy storage components, which include 204 battery units and a 2000 kg hydrogen tank, add 187,464 $ to the total cost, while the 1000 kW PEM electrolyzer accounts for 276,171 $. With an LCOH of 3.20 $/kg, the system is highly economically competitive when compared to other renewable-integrated systems and traditional hydrogen pathways. Importantly, this price is consistent with long-term decarbonization plans since it represents a completely renewable architecture free from reliance on fossil fuel-based grid electricity. Economic sustainability depends on an efficient, demand-responsive design that reduces energy losses and overproduction, as evidenced by the close match between annual hydrogen production (36,998 kWh) and consumption (36,476 kWh). Comparing the suggested system's values with those published in the literature highlights its competitiveness even more. In a wind-based hydrogen production system limited by less-than-ideal wind resources, Ayodele et al. 99 reported an LCOH of 8.02 $/kg. While Rasool et al. 100 reported an LCOH of 9.52 $/kg for a similar PV–wind turbine (WT) system in Pakistan, Hussam et al. 101 found an LCOH of 6.85 $/kg for a PV–WT hybrid configuration. On the other hand, the much lower LCOH of the current system demonstrates the combined benefit of Jiangsu Province's advantageous solar conditions as well as the hybrid VMD-SE-BBO-HGBR model. Through precise, real-time alignment between generation and electrolyzer operation made possible by DNI's improved forecasting accuracy, excess energy use and operational inefficiencies are decreased, enhancing system reliability and economic viability.
Techno-economic analysis of the hydrogen refueling station.
To further clarify the techno-economic findings, Table 9 presents the estimated LCOH corresponding to different solar irradiance forecasting models utilized in system operation. The LCOH was estimated by scaling relative to the model performance metrics, including R2, RMSE, and MAPE, with the VMD-SE-BBO-HGBR model serving as the best model at 3.20 $/kg.
Techno-economic analysis of the hydrogen refueling station.

The results indicate that higher forecasting accuracy significantly improves the economic viability of the hydrogen refueling system. Accurate predictions enable better alignment between solar energy generation and electrolyzer operation, reducing excess energy storage requirements and operational inefficiencies. Consequently, improved forecasting directly translates into lower capital and operational expenditures, reflected in the reduced LCOH values. This techno-economic advantage highlights the importance of deploying advanced forecasting models such as the hybrid VMD-SE-BBO-HGBR to achieve cost-effective and sustainable renewable hydrogen production.
Table 10 indicates that the system exhibits high efficiency in hydrogen generation, with its consumption rate. The electrolyzer generates 36,998 kWh/year of hydrogen energy, which is used at full capacity. This output aligns precisely with hydrogen consumption, totaling 36,476 kWh/year. This implies that no resources are squandered, demonstrating the system's efficiency in fulfilling hydrogen demand for car refueling and energy storage without excess production.
Annual hydrogen and electrical energy production and consumption of the hybrid microgrid system.

The electrical performance of the photovoltaic system is encapsulated in Table 10. A total of 1,906,153 kWh/year of power is produced, fulfilling all electrical requirements while supporting hydrogen synthesis. A mere 27,696 kWh/year (1.59%) is allocated to the main AC load, which is not intended consumption but rather for the operation of various components in the hydrogen production process. The majority of the energy is dedicated to hydrogen generation processes. The system, while very efficient, generates an excess of 159,592 kWh annually. The surplus may be further enhanced by demand-side management tactics or supplementary energy storage options integrated into the system. The system has a capacity shortfall of just 11.7 kWh/year, signifying that the design is very dependable and the level of unmet energy demand is negligible. The simulation results demonstrate the system's capacity to optimize renewable energy use while maintaining operational dependability. The model used sophisticated technology to achieve equilibrium among energy generation, storage, and utilization. The system mitigates energy fluctuations by converting surplus energy into hydrogen and using high-capacity storage to provide a reliable supply for car refueling and other energy applications. The competitive LCOH and economical NPC of the system indicate its operational viability and financial feasibility. Moreover, the system's design flexibility enables scalability to accommodate varying energy needs and potential future expansions.
The temporal dynamics and operational features of the hydrogen refueling station are visualized the system's performance across different timeframes and operational parameters. Figure 19 depicts the annual distribution of PV power production, ranging from 0 to around 1350 kW. The heat map illustrates diurnal and seasonal trends in power production, with greater intensities (shown by lighter hues) during peak sun hours and summer months. Figure 19 reflects the system's PV capacity of 1148 kW as shown in Table 10, illustrating the actual operating performance of the installed capacity. The cyclical variations in power input and storage capacities illustrate the system's capability to equilibrate output and demand, sustaining operating efficiency despite the inconsistency of renewable energy sources. The storage configurations conform to the system's design specifications, using 204 storage units with an aggregate hydrogen tank capacity of 2000 kg, therefore guaranteeing a dependable supply for vehicle refueling purposes.
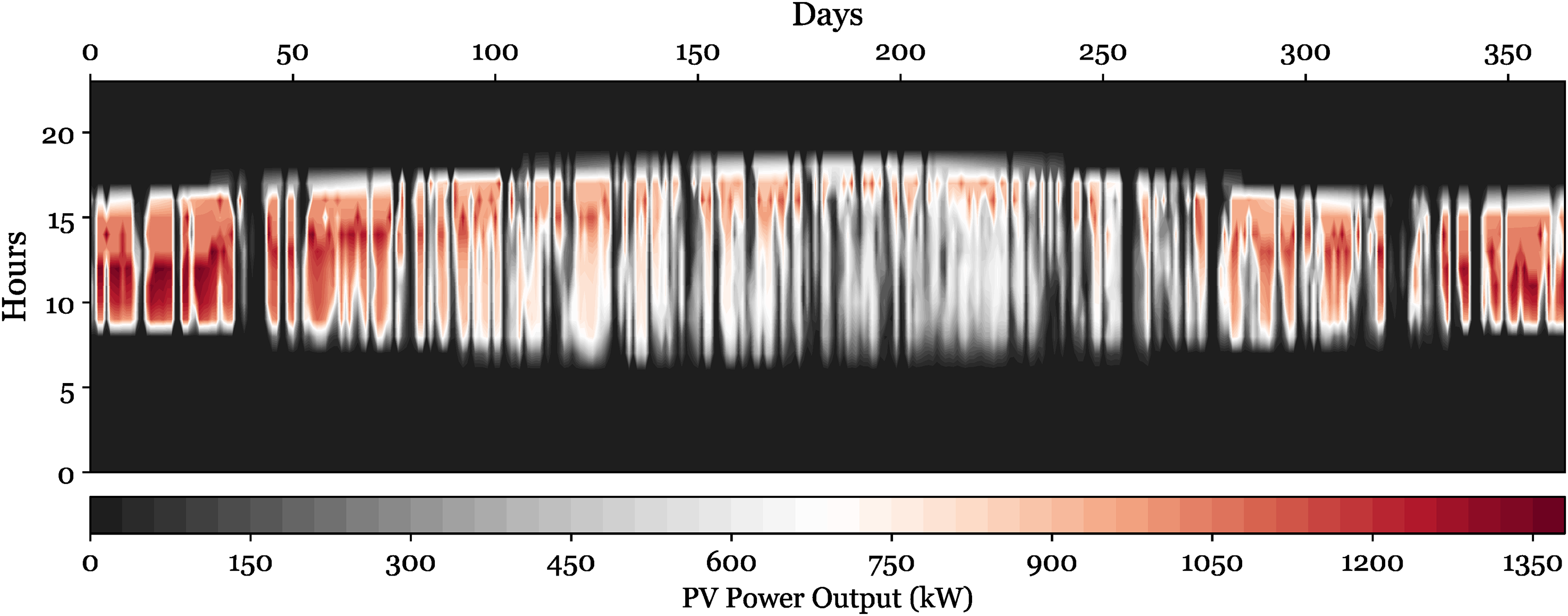
Annual photovoltaic power output distribution across hours and days.
Figure 20 illustrates the monthly variations in input power for the electrolyzer, highlighting the system's operating dynamics. The twelve-monthly subplots, each illustrating power intake patterns from 0 to 800 kW. The periodic fluctuations in power input correspond with daily solar availability patterns, while the differing amplitudes across the months indicate seasonal differences in solar resource availability. This corresponds with the total yearly electricity output of 1,906,153 kWh/year shown in Table 10, illustrating the system's ability to efficiently harness solar energy for hydrogen synthesis. Figure 21 illustrates a heat map representation of hydrogen storage levels throughout the course of the year, with values spanning from 0 to 1920 kg. The color gradient, illustrates clear seasonal variations in hydrogen storage. Significant buildup transpires throughout the summer months (May-August), as seen by the dominating yellow areas, indicating favorable circumstances for solar energy conversion. In contrast, the deeper blue areas during the winter months (November-January) indicate diminished storage levels, associated with less solar availability and perhaps increased demand. Figure 22 displays a histogram with a superimposed probability density curve illustrating the frequency distribution of stored hydrogen levels. The distribution has bimodal traits, with a modest peak at around 1000 kg and a prominent peak close to 2000 kg storage capacity. This distribution pattern indicates that the system often functions at elevated storage levels, signifying efficient hydrogen generation and storage management.
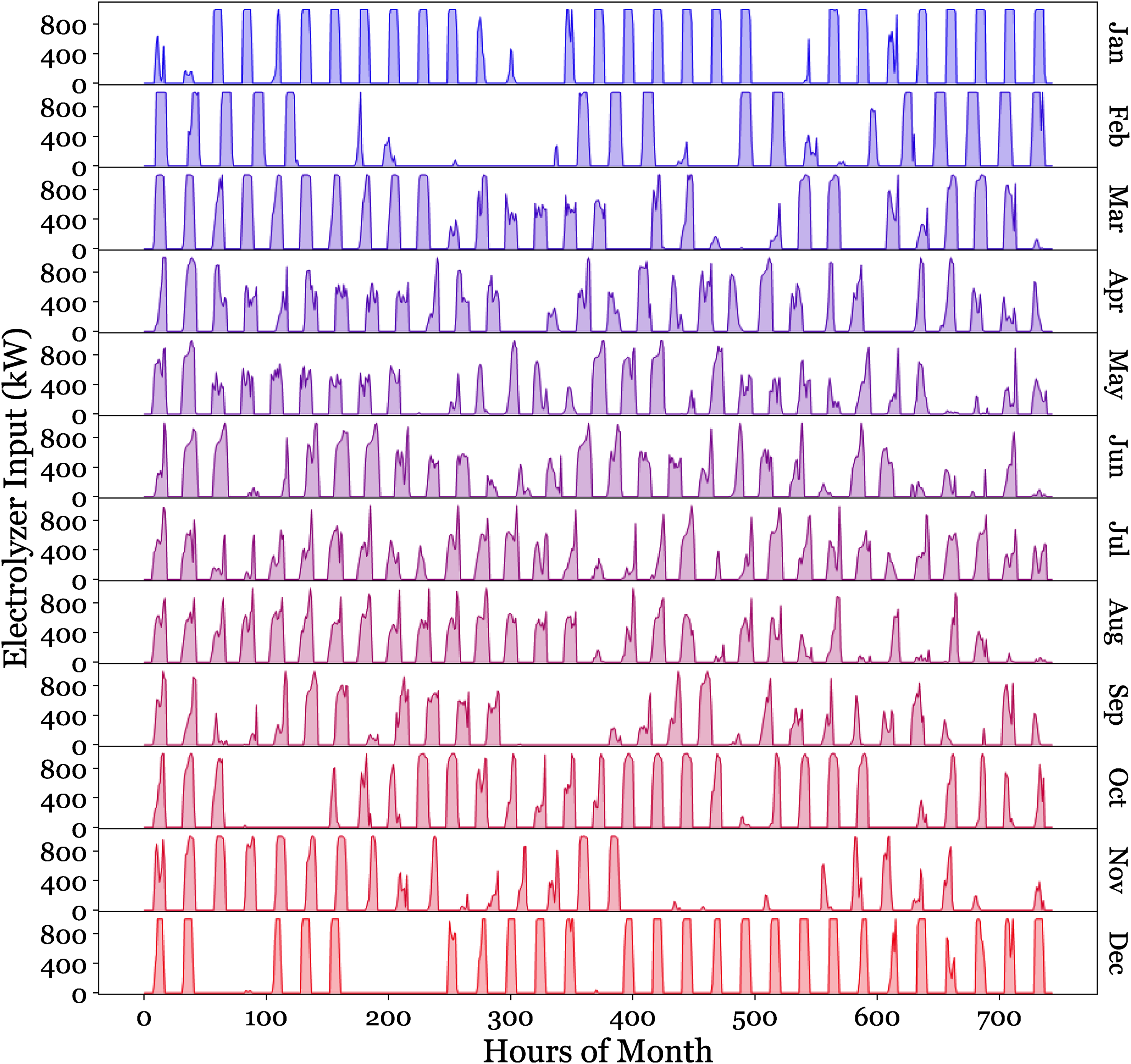
Monthly electrolyzer power input profiles throughout the year.
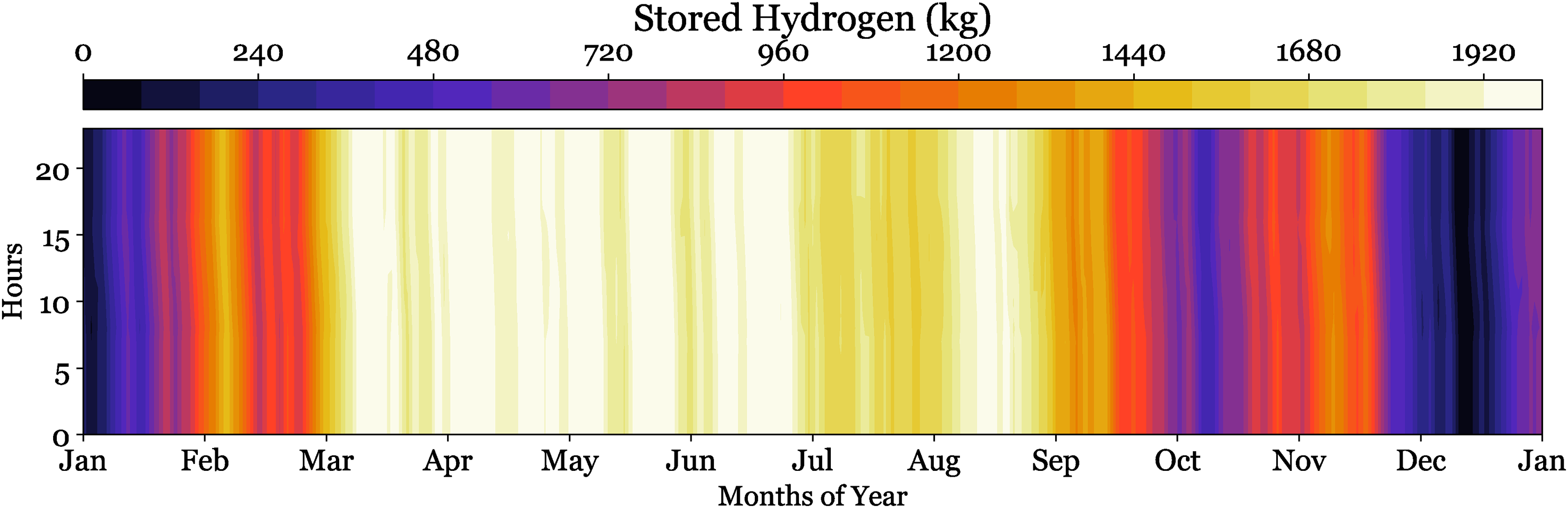
Temporal distribution of stored hydrogen levels across a year.
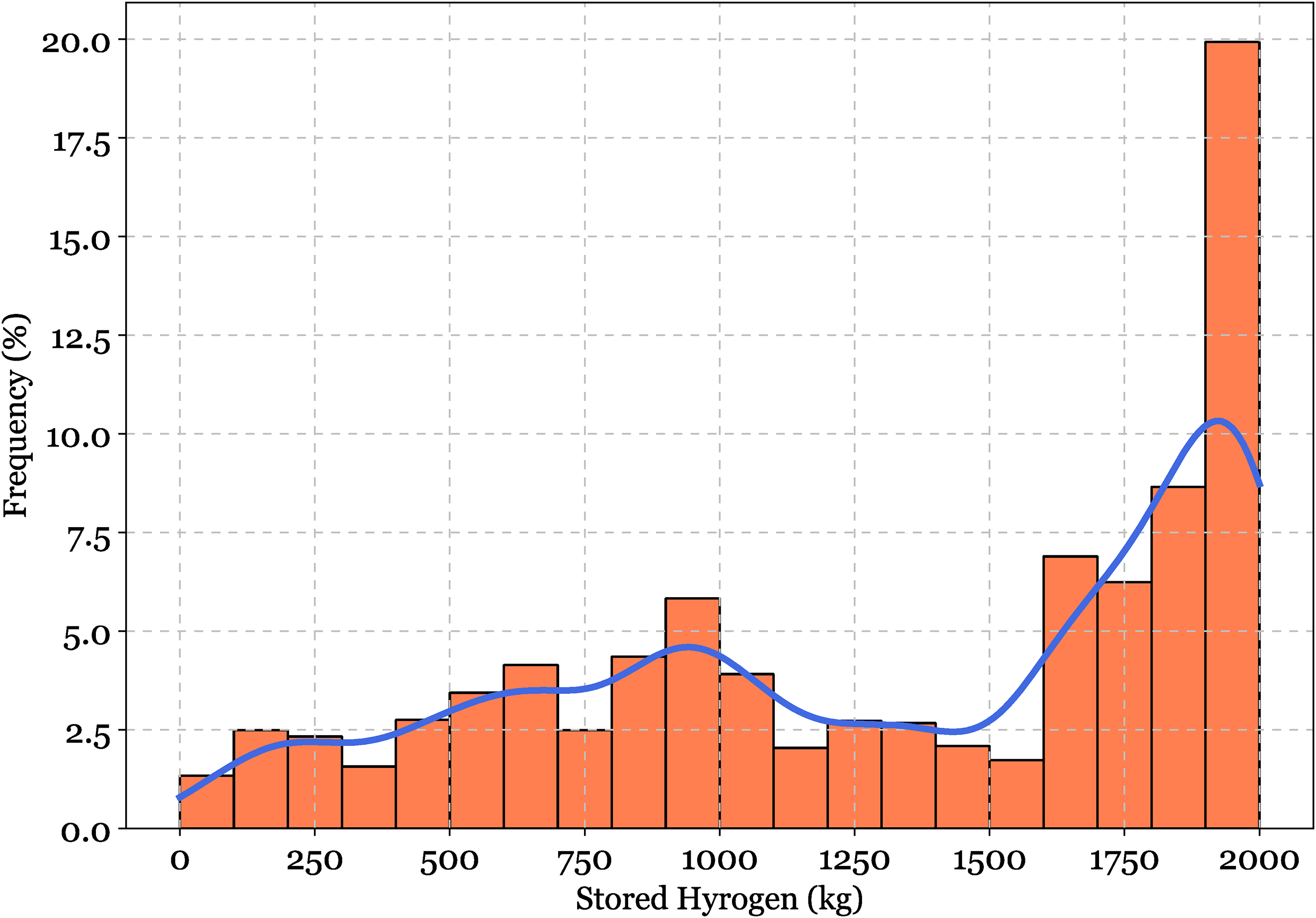
Frequency distribution of stored hydrogen levels with probability density overlay.
Figure 23 illustrates the inverter power output throughout the year, exhibiting stable functioning patterns between 2 and 12 kW. The dispersed point distribution illustrates the fluctuating nature of power conversion demands, with a concentrated cluster at 4–8 kW signifying standard functioning ranges. This pattern corresponds with the system's electrical consumption profile shown in simulation findings, whereby 27,696 kWh/year is designated for the AC main load, constituting 1.59% of overall electrical consumption. Figure 24 displays a dual-panel representation of the battery system's performance over the course of one year (8760 h). The battery state of charge (%), generally remaining elevated between 80–100%, with occasional deep discharges shown by abrupt downward spikes illustrated. The charging (green) and discharging (red) power profiles, reaching maxima of around 150 kW are depicted. This cycle pattern illustrates the battery's function in mitigating short-term variations in renewable energy production and system demand, facilitating the electrolyzer's operation during times of inconsistent solar availability.
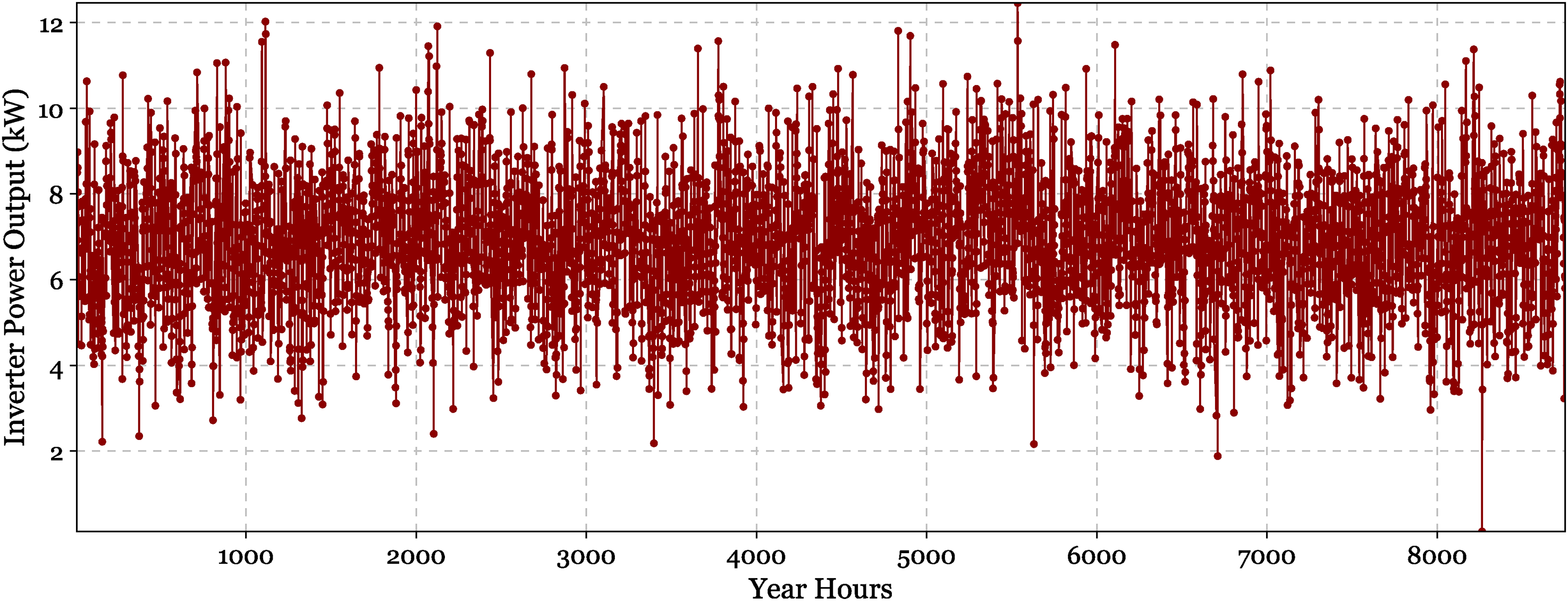
Temporal distribution of inverter power output throughout the year, illustrating the dynamic power conversion requirements for system operation.
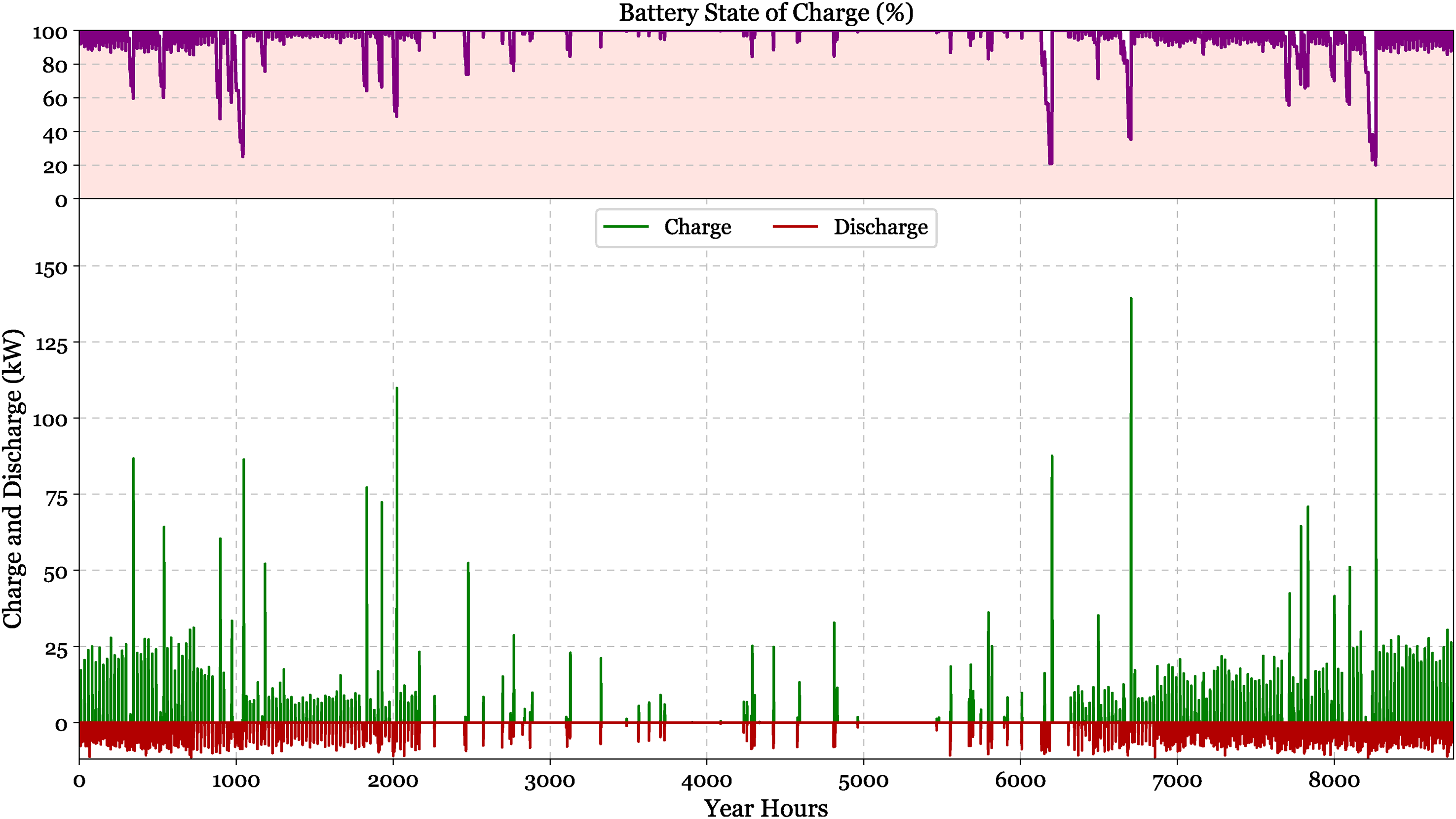
Annual battery performance profile showing state of charge variations and charging/discharging power dynamics.
The 3.20 $/kg LCOH that was attained is indicative of a promising level of economic performance for a fully renewable, solar-integrated HRS. This cost positions the system below numerous renewable hydrogen projects that have been reported in the literature and brings it closer to international cost targets. Hydrogen fuel becomes increasingly viable for medium- to large-scale applications, such as fleet-based transportation, at this level, particularly in regions with high solar resource availability, such as Jiangsu Province. A substantial but potentially manageable investment is indicated by the NPC of 2,143,512 $ when amortized over the station's operational duration and scaled across multiple deployment sites. The system's low operational costs are a result of its minimal external electricity requirements and reliance on free solar energy, which is in contrast to conventional fossil-based hydrogen production methods. These results underscore the economic viability of decentralized hydrogen infrastructure, particularly when accompanied by policies that reduce capital costs or increase the value of avoided emissions. Additionally, the system's cost-effectiveness is further reinforced by the integration of precise DNI forecasting, which leads to improved system reliability, operational efficiency, and tighter load matching.
From a systems-level and policy perspective, the results of this study add to the expanding knowledge of how integrated renewable-hydrogen systems can be both economically and technically feasible in practical operating environments. In the solar-rich environment of Jiangsu Province, the suggested HRS model, which is based on a decentralized, solar-powered architecture, shows how such systems can reach a competitive LCOH of 3.20 $/kg. The findings, though context-specific, imply that optimized renewable-hydrogen configurations might provide an economically feasible path to low-carbon and more resilient transportation infrastructure. Targeted policy interventions can be crucial to promoting wider deployment, especially in developing hydrogen economies. Improving cost structures and investment appeal would be achieved by lowering capital expenditure through subsidies for PV modules, PEM electrolyzers, and energy storage systems. Furthermore, considering their function in improving techno-economic performance, decreasing inefficiencies, and boosting system responsiveness, digital infrastructure initiatives could facilitate the integration of advanced forecasting models, like the VMD-SE-BBO-HGBR framework presented in this study. While replication feasibility will differ by region, the system architecture's scalability and modularity offer a solid basis for adaptation in various economic and geographic contexts. Planning for hydrogen supply chains, distributed energy systems, and mobility hubs could benefit from the methodology described in this study, especially as countries work to operationalize long-term decarbonization goals and national hydrogen roadmaps. In conclusion, this research highlights how crucial it is to incorporate component-level optimization, localized resource modeling, and data-driven forecasting into the design of upcoming green hydrogen systems. Realizing the full potential of hydrogen as an essential component of the global clean energy transition may require the convergence of these technical components under a logical policy and planning framework.
Conclusions
This study proposed a novel hybrid forecasting model—VMD-SE-BBO-HGBR—for accurate prediction of DNI, aimed at improving the efficiency and reliability of solar energy integration into HRSs in Jiangsu Province, China. The model combines VMD and SE for signal decomposition and feature clustering, while BBO is used to optimize HGBR parameters. This integrated structure significantly enhances the accuracy of short-term solar irradiance forecasting. The improved DNI forecasting directly supports the operational optimization of the HRS. The proposed model achieved an R2 of 0.98, with RMSE and MAE of 39.69 W/m2 and 21.21 W/m2, respectively. This high forecasting accuracy enables more effective scheduling of energy flows and electrolyzer operation, minimizing curtailment and improving system efficiency. Informed by these forecasts, the HRS system includes a 1148 kW PV array, a 1000 kW PEM electrolyzer, a 204-kWh battery storage unit, and a 2000 kg hydrogen tank. Simulation results indicate that the system can meet a hydrogen demand of up to 100 kg/day with minimal energy shortfall. Economically, the system achieves an NPC of 2,143,512 $ and an LCOH of 3.20 $/kg, positioning it as a competitive renewable hydrogen solution when compared to similar systems reported in the literature. Beyond its numerical performance, the proposed model demonstrates adaptability across varying meteorological conditions, while the system's modular design offers flexibility for scale-up and regional replication. The integration of accurate forecasting with optimized component sizing enhances energy utilization, cost control, and operational stability. This work delivers both a high-performance solar forecasting approach and a techno-economically feasible HRS design. It offers a replicable framework for deploying solar-powered hydrogen infrastructure in favorable irradiance zones. Future research may focus on real-time implementation, cross-regional validation, and integration with demand-side and policy-driven strategies to further reduce hydrogen costs and support clean energy transitions.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.