
Abstract
The rapid integration of artificial intelligence (AI) into information services has raised critical questions about ethics, privacy, and user trust. This study explores the ethical and privacy concerns surrounding AI-based information services. It investigates their implications for perceived ethical legitimacy, which is conceptualized as a precursor to user trust in AI-based information services. A quantitative research design was employed, utilizing a structured survey distributed to 278 library users in Thai universities. The instrument, validated through expert review and reliability analysis (Cronbach’s alpha = 0.870), measured perceptions of 10 ethical constructs, including data responsibility and privacy, fairness, security, transparency, and accountability. Data were analyzed using correlation and multiple regression techniques. The results revealed that while users overwhelmingly perceived AI in libraries as beneficial (mean score = 4.34/5), perceptions of ethical legitimacy were strongly associated with ethical safeguards, which may influence trust formation. Specifically, data responsibility & privacy, fairness, and ethics & regulations emerged as significant predictors of overall perceptions of AI ethics, collectively explaining 26.6% of the variance. Other constructs, such as security, accountability, and trust, while valued, did not demonstrate unique predictive power within the model. The findings underscore that ethics are not peripheral but central to technology acceptance in information services. This study contributes to theory by extending technology adoption frameworks to include ethical dimensions and to practice by offering evidence-based guidance for policymakers and library administrators to prioritize privacy, fairness, and regulatory clarity in AI deployment. Although limited to a single national context and cross-sectional design, these findings provide a foundation for future comparative and longitudinal research. Ultimately, the study highlights that sustainable adoption of AI in academic libraries depends not only on technical innovation but also on embedding robust ethical practices that foster user trust and confidence.
Introduction
Recent reports indicate that over 60% of global organizations have already integrated AI into their information services, yet nearly half of users express concerns about privacy and ethical risks when engaging with these systems (Yu et al., 2023). This paradox raises an urgent question: Can users truly trust AI-driven information services if ethical safeguards and privacy protections remain uncertain? As artificial intelligence continues to transform domains ranging from healthcare to libraries and digital platforms (Kabir, 2025; Suleiman, 2024), addressing this tension becomes central to sustaining user confidence.
Previous studies have demonstrated the efficiency and engagement benefits of AI adoption in information services. For example, AI-powered recommendation systems and chatbots can improve accessibility, streamline workflows, and personalize information delivery (Frick et al., 2019). Similarly, healthcare and educational contexts illustrate how generative AI can augment professional performance (Kabir, 2025; Yu et al., 2023). However, while these works highlight the promise of AI, they often underestimate the risks associated with data misuse, surveillance, and opaque decision-making processes. For instance, Alekseeva (2025) emphasizes that regulatory frameworks are lagging behind technological deployment, creating a gap between innovation and governance. This indicates that much of the existing literature tends to prioritize functional outcomes over ethical safeguards.
Moreover, studies exploring adoption of AI-based library services (Suleiman, 2024) stress the necessity of trust-building mechanisms but stop short of examining how privacy violations or lack of transparency erode long-term trust. In contrast, works on design requirements for AI-based services (Frick et al., 2019) propose user-centered solutions but neglect to situate these within broader ethical and legal debates. Consequently, there is a fragmented understanding: one strand of research focuses on adoption and benefits, while another deals with regulatory or technical design, yet few synthesize these perspectives to examine how ethical and privacy challenges directly influence user trust.
While existing scholarship provides a robust foundation for understanding AI ethics, privacy, and user trust, significant gaps remain in the context of AI-based information services. Foundational studies outline global ethical principles (Jobin et al., 2019; Kim, 2022), privacy-risk trade-offs (Dinev and Hart, 2006; Smith et al., 1996), and theoretical frameworks for trust in automation (Campagna and Rehm, 2025; Lee and See, 2004). Research on transparency and fairness has also matured, offering insights into how explainability and bias mitigation influence trust (Guidotti et al., 2019; Wang, 2023; Zerilli et al., 2022). However, most of this work remains conceptual or domain-general, with limited application to library and information service environments, where the stakes of ethical compliance and privacy protection are increasingly high. Recent domain-specific studies highlight ethical concerns and adoption challenges in libraries (Gasparini and Kautonen, 2022; Narendra et al., 2025; Tsekea and Mandoga, 2025), yet they stop short of empirically examining how ethical practices, privacy safeguards, and transparency measures jointly shape user trust. This study contributes by bridging these gaps: it integrates established theoretical models of privacy and trust with the emerging discourse on AI ethics and fairness, and situates them within the real-world operational context of information services, offering both conceptual advancement and practical guidance for institutions seeking to foster trustworthy AI adoption.
Recent empirical studies have further emphasized the role of trust and explanation in shaping user acceptance of AI-based services. For instance, Jang (2024) highlights the relationship between trust in AI and privacy-related behaviors, while Nizette et al. (2025) demonstrate how explanation design influences user trust and decision-making in AI-driven environments. These studies provide an important foundation for understanding how ethical considerations, transparency, and user perceptions interact in shaping trust in AI-based information services.
Although the study is situated in a Thai context, the literature review focused on English-language publications to ensure the inclusion of internationally indexed and peer-reviewed research. This approach enables the study to engage with globally recognized theoretical and empirical developments, while acknowledging that relevant local-language studies may not be fully captured.
While this study is situated within the broader discourse on user trust in AI-based systems, the present analysis focuses specifically on perceived ethical legitimacy as an antecedent to trust. Drawing on trust in automation theory (Lee and See, 2004) and privacy calculus perspectives, ethical perceptions—such as fairness, transparency, and data responsibility—are conceptualized as foundational conditions that shape users’ willingness to trust AI systems. Accordingly, this study does not directly model trust as a dependent variable but instead examines the ethical determinants that underpin trust formation.
This study explores the ethical and privacy concerns surrounding AI-based information services and investigates their implications for user trust. By critically synthesizing legal, organizational, and user-centered perspectives, this work aims to provide a more holistic account of trust in AI-mediated environments. Unlike prior studies that emphasize either technological potential (Kabir, 2025; Yu et al., 2023) or regulatory framing (Alekseeva, 2025), this research bridges these approaches by analyzing how ethical lapses and privacy breaches concretely shape user perceptions and willingness to adopt AI-based services.
Hypotheses are designed to test the relationships between specific ethical constructs and the overall perception of ethics in this context. The following presents the null (H0) and alternative (Ha) hypotheses for the study. This hypothesis addresses the overall predictive power of the model.
The significance of this study lies in its contribution to both theory and practice. Theoretically, it advances discussions on technology acceptance by foregrounding ethical and privacy dimensions often overlooked in mainstream adoption models. Practically, it informs policymakers, designers, and service providers about strategies to embed ethical safeguards, thereby strengthening user trust and ensuring sustainable AI deployment in information services. In doing so, this work extends current debates and provides a timely response to one of the most pressing challenges of the AI era.
Methodology
This study aimed to examine ethical and privacy concerns in AI-based information services and their impact on user trust, with a particular focus on university libraries in Thailand. The scope included both student users and service providers, ensuring a comprehensive understanding of how AI adoption in academic libraries is perceived across different institutional and demographic contexts.
Prior to designing the empirical survey, a literature review was conducted to contextualize the study and identify existing gaps. The search was carried out across academic databases including Scopus, Web of Science, IEEE Xplore, and Google Scholar. Keywords such as artificial intelligence in libraries, AI ethics, privacy in information services, and user trust in digital systems were employed. Searches were limited to publications between 2019 and 2025 to capture recent developments in AI ethics. Reference lists of relevant articles were also screened to identify additional studies.
The final set of articles included in the review comprised 58 studies, selected after an initial retrieval of 214 records across the selected databases. Following the removal of duplicates and the application of inclusion and exclusion criteria, 96 articles were retained for full-text screening, resulting in a final corpus of 58 studies for in-depth analysis. This process ensured that the theoretical model was grounded in a comprehensive and systematically selected body of literature.
Studies were included if they addressed (a) AI adoption in library or information services, (b) ethical or privacy challenges, or (c) user trust in AI-based systems. Articles focusing solely on technical performance without ethical considerations were excluded. Only peer-reviewed journal articles, conference proceedings, and book chapters in English were selected, which may have introduced language bias and excluded potentially relevant non-English contributions.
Primary data were collected using a structured survey distributed via Google Forms between June and August 2025. The final sample consisted of 278 respondents drawn from Thai universities, including undergraduate students, graduate students, and academic staff who regularly engage with university library services. This sampling approach ensures that participants represent active users of academic library environments where AI-based information services are increasingly being introduced.
The questionnaire comprised three sections. The first gathered demographic information, the second measured factors influencing AI-based information services, and the third assessed ethical constructs using a five-point Likert scale (1 = strongly disagree to 5 = strongly agree). Ethical dimensions included data responsibility and privacy, fairness, security, transparency, accountability, trust, technology misuse, and value alignment. To ensure content validity, the instrument was reviewed by three domain experts. The Index of Item-Objective Congruence (IOC) exceeded 0.5 for all items, with an average score of 0.91, confirming acceptable content validity (Rovinelli and Hambleton, 1976). Reliability testing produced a Cronbach’s alpha coefficient of 0.870, exceeding the 0.70 threshold (Hair et al., 2006), indicating strong internal consistency. The dependent variable (AT) represents users’ overall perception of the ethical legitimacy of AI-based information services, treated as a precursor construct influencing trust.
Survey responses were cleaned, translated where necessary, and standardized for analysis. Correlation analysis, multiple regression, and predictive equation modeling were conducted using SPSS and Python to test the study hypotheses. The analysis examined the predictive power of ethical constructs on overall perceptions of AI ethics in libraries while also checking for multicollinearity and other statistical assumptions.
Findings were synthesized by integrating survey results with insights from the literature review. The empirical evidence was evaluated against established research on AI ethics, privacy concerns, and technology acceptance frameworks to ensure theoretical robustness.
The study acknowledges several limitations. First, the reliance on English-language sources in the literature review may have excluded relevant studies published in other languages. In addition, the restriction to English-language sources may have excluded relevant Thai-language studies that could provide further contextual insights into local AI adoption practices. Second, the cross-sectional survey design captured perceptions at a single point in time, limiting generalizability to evolving contexts. Third, the sample was restricted to Thai university populations, which may not reflect broader cultural or institutional differences. These limitations, however, provide opportunities for future research through cross-cultural comparisons, longitudinal studies, and qualitative investigations that could capture deeper insights into user experiences with AI-based information services.
Results
The results of this study provide a comprehensive picture of how university library users in Thailand perceive and engage with AI-based information services, highlighting both their patterns of technology use and their ethical expectations. Analysis of the survey data from 278 respondents revealed 3 overarching trends. First, users demonstrated high levels of digital literacy, with strong reliance on social media platforms and widespread adoption of AI applications such as ChatGPT and Canva for academic and creative tasks. Second, respondents expressed overwhelmingly positive perceptions of the benefits of AI in libraries, with more than 84% agreeing or strongly agreeing that AI integration enhances information services. Third, ethical concerns emerged as a central determinant of trust, with data responsibility and privacy, security, and transparency ranking as the most important principles. Correlation and regression analyses further underscored that perceptions of AI ethics were significantly influenced by data privacy, fairness, and regulatory clarity, offering insight into the conditions under which users are willing to embrace AI-driven information services.
As the respondents are affiliated with university environments and regularly interact with academic library systems, their perceptions reflect expectations and experiences relevant to AI-driven information services in academic libraries. Therefore, the findings should be interpreted within the context of evolving digital library ecosystems in Thai higher education institutions.
Social media usage analysis
Figure 1 illustrates the distribution of social media platforms most frequently used by survey respondents. The reported platforms were cleaned and consolidated to account for variations such as “IG” and “Instagram,” resulting in 36 unique platforms. The distribution was heavily concentrated on a few dominant services, with Instagram (142 mentions), Facebook (107 mentions), and TikTok (70 mentions) emerging as the most widely used platforms. Less frequently mentioned platforms were grouped under the category “Others” to improve the figure’s clarity and interpretability.
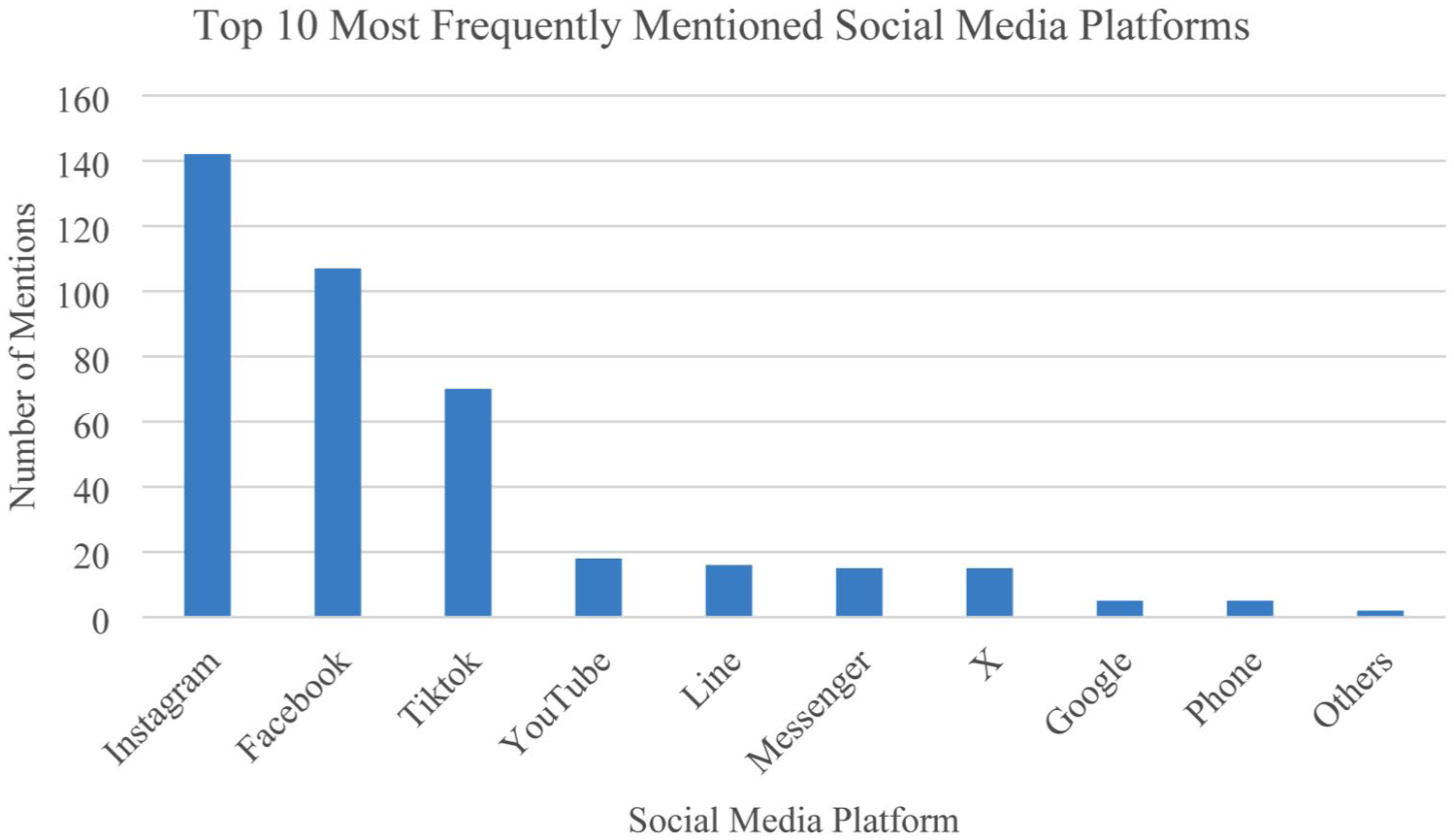
Top 10 most frequently mentioned social media platforms.
While social media usage is not the primary focus of this study, it provides an important contextual indicator of users’ digital literacy and engagement with algorithm-driven platforms. Frequent interaction with such platforms exposes users to AI-based recommendation systems, content filtering, and personalization mechanisms, which may shape their expectations, awareness, and concerns regarding AI technologies more broadly.
In this context, highly engaged social media users are more likely to be familiar with issues related to data privacy, algorithmic bias, and transparency. This familiarity can influence how they perceive and evaluate AI-based information services in libraries, particularly regarding ethical safeguards and trustworthiness. Therefore, the analysis of social media usage serves as a proxy for understanding users’ digital readiness and prior exposure to AI-mediated environments, which is relevant to interpreting their ethical expectations and perceptions of trust in AI-driven library services.
In addition, this level of engagement with algorithm-driven platforms may influence users’ expectations regarding transparency, data use, and fairness, which are central to ethical AI systems. As a result, social media usage not only reflects digital literacy but also provides insight into users’ readiness to evaluate and respond to ethical issues in AI-based information services, thereby indirectly shaping the conditions under which trust may develop.
Importance of ethical principles for AI in information services
Figure 2 presents the analysis of survey responses regarding ethical principles for AI in information services, revealing a clear hierarchy of user priorities. After translating and consolidating responses in both Thai and English, 9 distinct ethical principles emerged, with data and privacy responsibility (237 mentions), security (218 mentions), and transparency (152 mentions) identified as the foremost concerns. Beyond these top priorities, accountability (109 mentions), trust (104 mentions), and fairness (98 mentions) formed part of a core ethical framework that respondents expect to underpin AI applications in libraries. These findings indicate that users assign high importance to ethical considerations—particularly data privacy, security, and transparency—when evaluating AI-based information services. Rather than demonstrating causal relationships, the results reflect users’ prioritization of these ethical principles relative to others. The prominence of accountability and fairness suggests that users value responsible and equitable AI practices; however, the present data do not directly measure users’ awareness of algorithmic bias. Therefore, these findings should be interpreted as indicative of perceived importance rather than evidence of specific cognitive awareness or behavioral conditions.
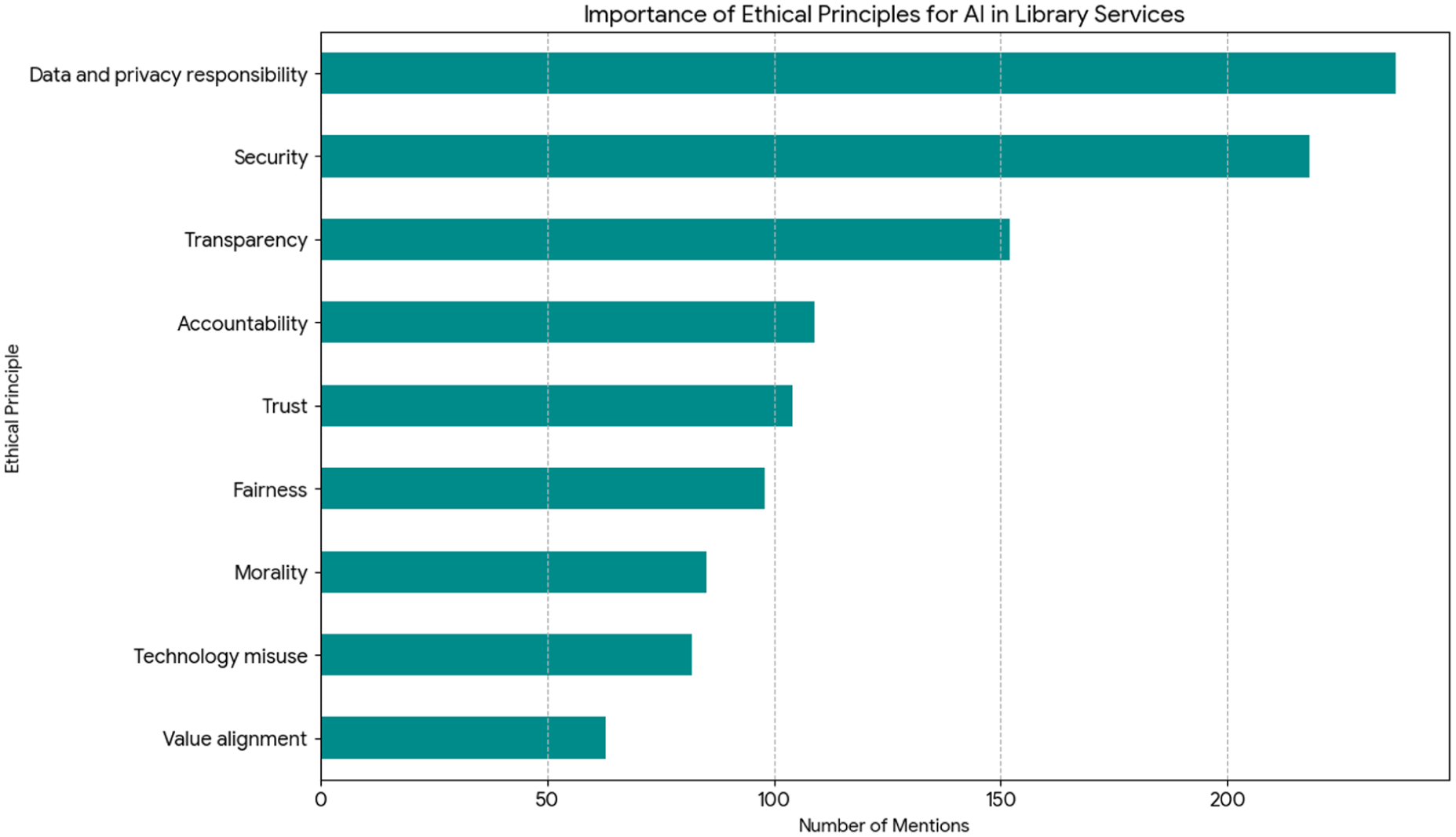
Importance of ethical principles for AI in information services.
It is important to distinguish this analysis from the mean-based evaluation presented later in Figure 5. While Figure 2 reflects the relative importance that users assign to different ethical principles, it does not measure their satisfaction or evaluation of how these principles are currently implemented. This distinction allows for a more nuanced understanding of user expectations versus perceived performance.
AI-based technology use
Figure 3 illustrates the patterns of AI-based technology usage among respondents, showing a strong concentration on tools that support content creation, writing, and academic research. After cleaning and standardizing the data, ChatGPT emerged as the most widely used application with 276 mentions, followed closely by Canva with 239 mentions, reflecting their roles as versatile platforms for general-purpose assistance and creative design. Academic writing tools also featured prominently, with Grammarly cited 63 times, Quillbot 45 times, and Turnitin 38 times, while specialized research applications such as ScopusAI and Scite.ai were also reported as useful for literature discovery and analysis. These findings suggest a pragmatic approach to AI adoption, where users favor applications that deliver direct benefits to academic and creative workflows. The widespread reliance on ChatGPT and Canva, along with consistent use of writing and research tools, demonstrates that AI is not perceived as a novelty but as an integral part of respondents’ professional and academic toolkit, underscoring their high level of digital literacy and practical engagement with AI technologies.
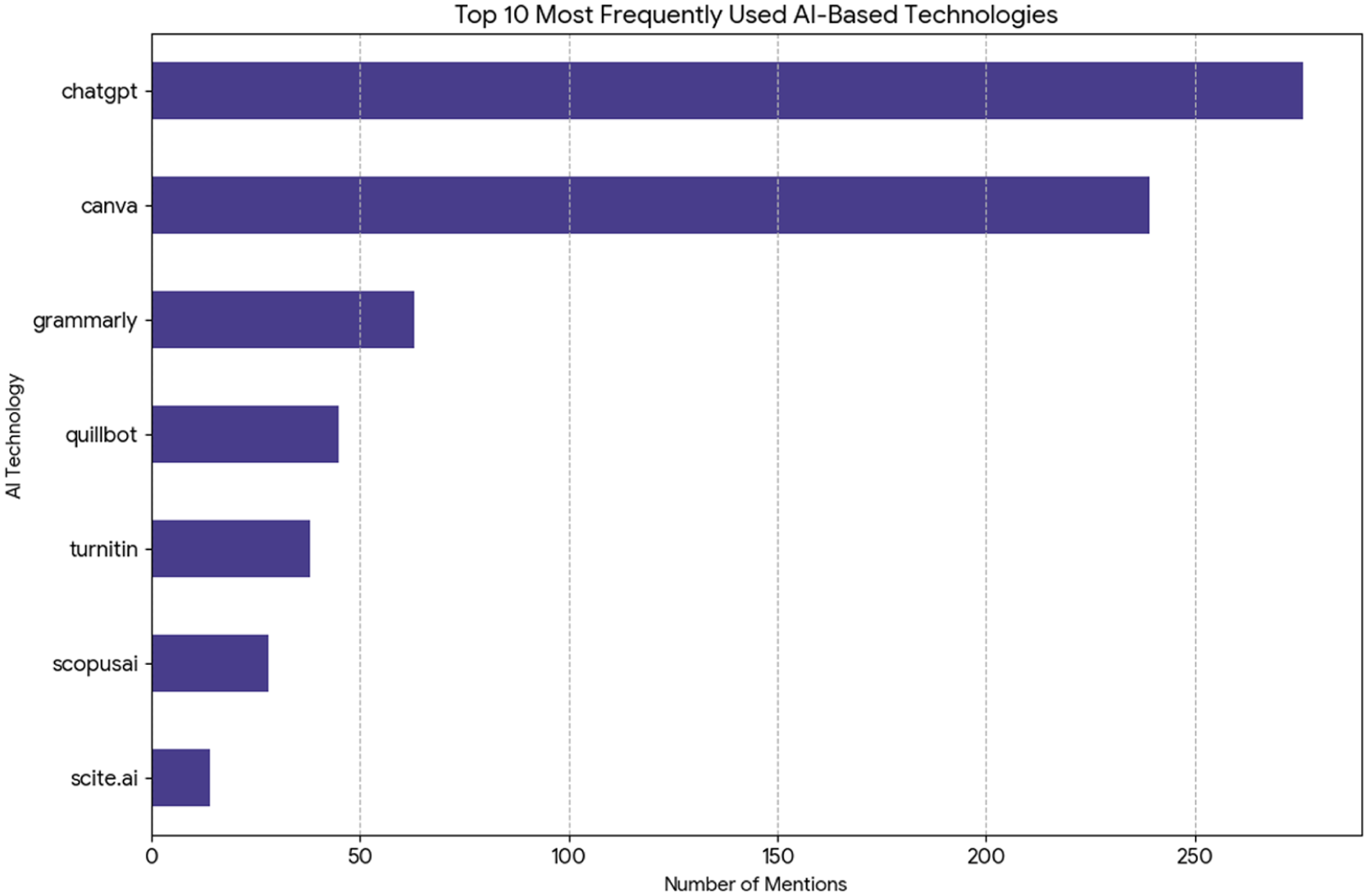
Top 10 most frequently used AI-based technologies.
Perceived benefits of AI in academic libraries
Figure 4 presents the analysis of responses to the statement, “The use of AI in libraries is beneficial,” which reveals a strongly positive perception among survey participants. Out of 278 respondents, more than 84% either agreed or strongly agreed with the statement, with 151 individuals (54.3%) selecting “Strongly Agree” and 85 (30.6%) selecting “Agree.” Neutral responses accounted for 11.9% (33 participants), while disagreement was minimal, with only 9 participants expressing negative views. The overall mean score of 4.34 out of 5 quantitatively confirms this favorable sentiment. These findings demonstrate that the user community is highly receptive to AI integration in libraries and anticipates significant benefits, including enhanced search capabilities, personalized recommendations, and improved efficiency. Importantly, while the perception is overwhelmingly positive, it also reflects implicit expectations that such benefits will be delivered ethically, with particular attention to data privacy and transparency, aligning with broader concerns identified elsewhere in the survey.
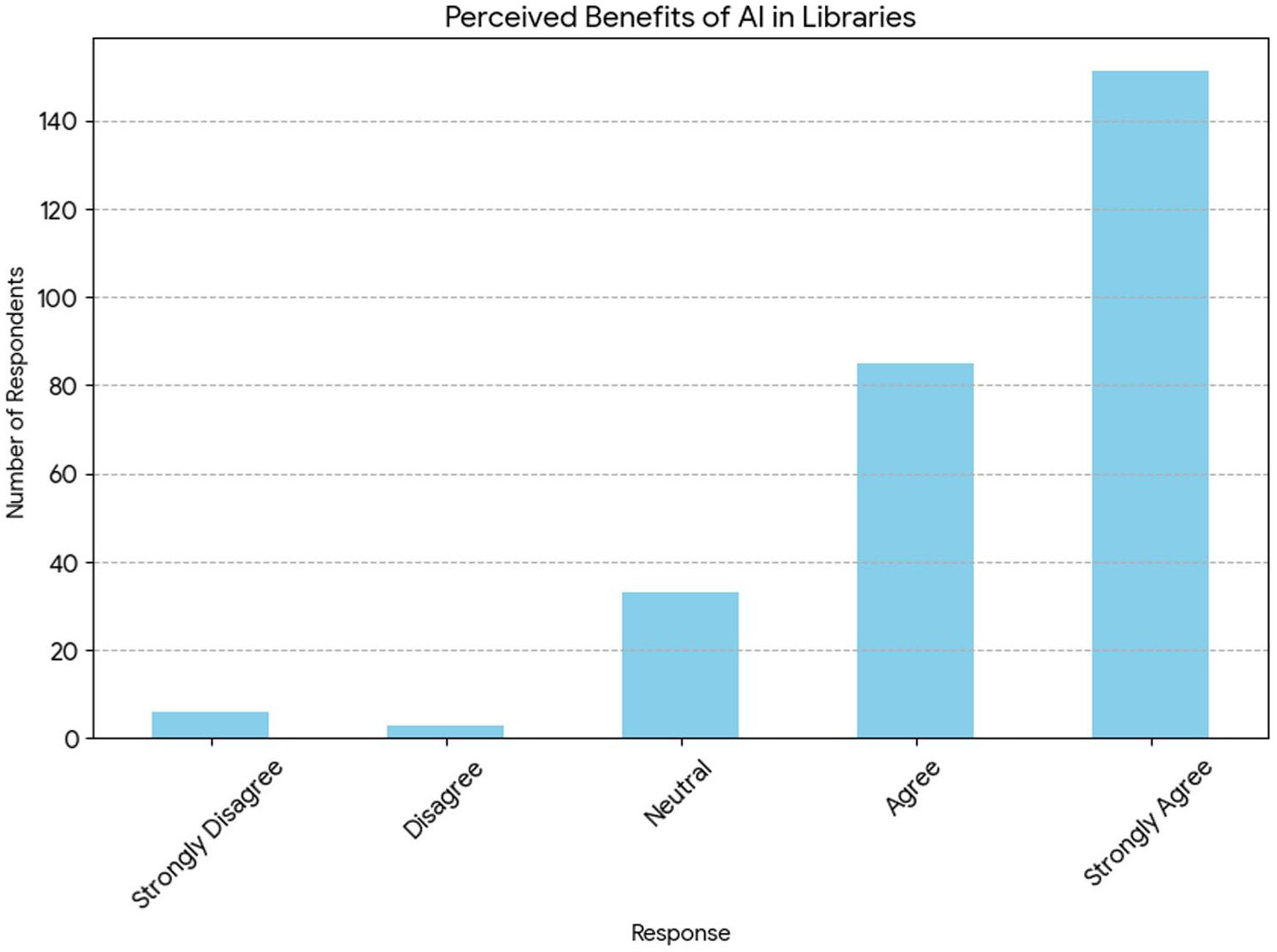
Perceived benefits of AI in academic libraries.
Ethical constructs in AI-based information services
Figure 5 presents the mean scores of ethical constructs, reflecting users’ evaluative perceptions of how these principles are manifested in AI-based information services. Unlike Figure 2, which captures the relative importance assigned to ethical dimensions, this analysis provides insight into how users assess the current state or perceived presence of these ethical attributes.
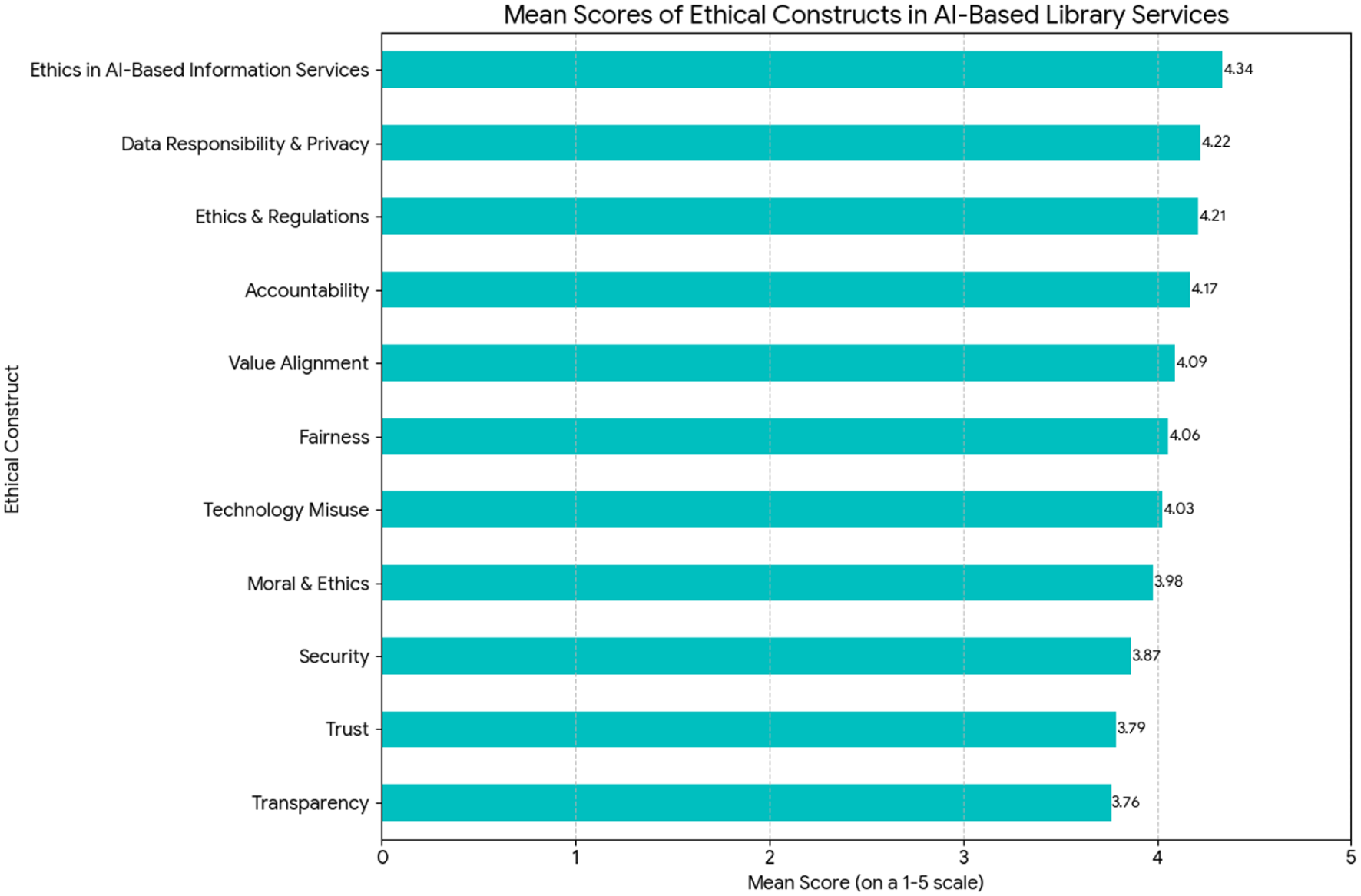
Mean scores of ethical constructs in AI-based information services.
The results indicate that constructs such as data responsibility, ethics, and regulations received the highest mean scores, suggesting that users generally perceive these aspects positively. However, when interpreted alongside the importance rankings in Figure 2, a more nuanced picture emerges: certain dimensions that are considered highly important (e.g. security and transparency) do not necessarily correspond to the highest evaluative scores. This divergence highlights potential gaps between user expectations and perceived implementation, offering a more analytically meaningful interpretation than considering each figure independently.
The user community generally supports the adoption of AI in libraries. However, this positive perception coexists with strong expectations regarding ethical safeguards, particularly regarding data privacy, security, and transparency. While the study does not directly test conditional relationships, the coexistence of high perceived benefits and strong ethical concerns suggests that ethical considerations may play an important role in shaping user acceptance. The findings provide a clear mandate for library administrators: the development of AI-driven services must be led by a robust ethical framework centered on user privacy, data security, and operational transparency. Users are not just passive consumers; they are critical stakeholders with well-defined expectations for how their data is used and how technology serves them. Building and maintaining user trust through a demonstrated commitment to these ethical principles will be the cornerstone of a successful transition to an AI-enhanced library ecosystem.
Correlation analysis
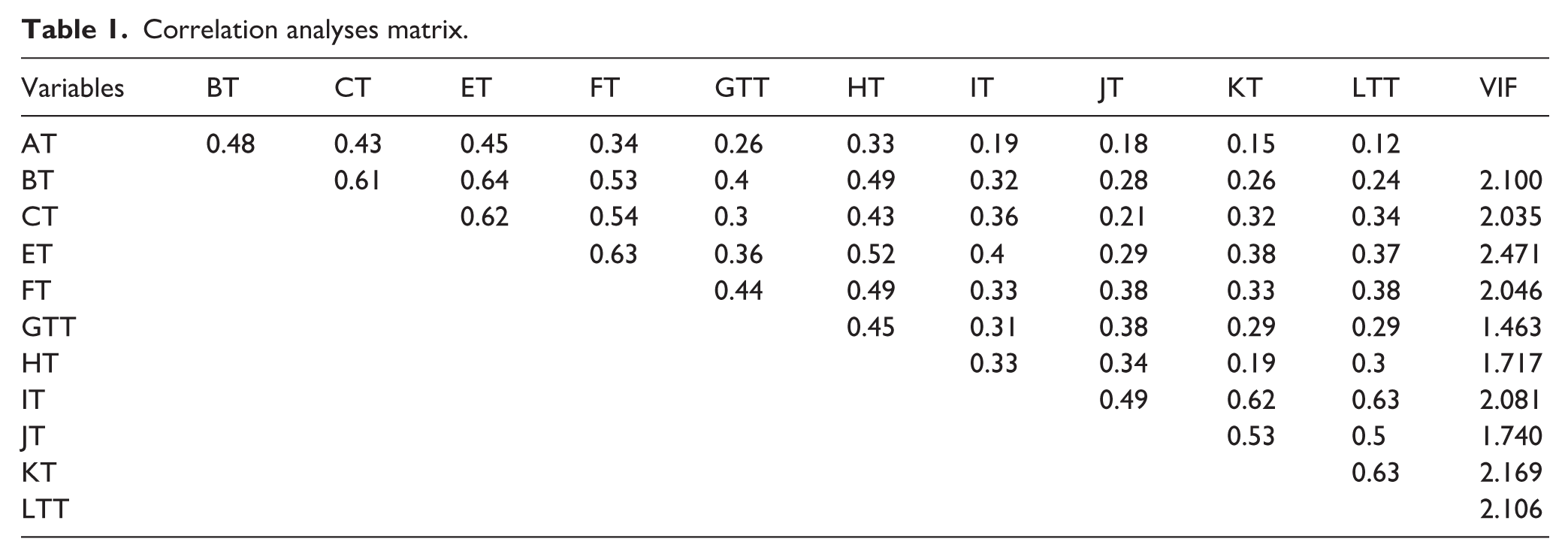
A correlation analysis was conducted to assess potential multicollinearity among the independent variables in the model by examining Pearson correlation coefficients, correlation matrices, and variance inflation factor (VIF) values. The results, summarized in Table 1 and illustrated in Figure 6, revealed that the highest correlation coefficient was 0.64, observed between ET and BT. As this value falls below the commonly accepted threshold of 0.80 for identifying multicollinearity (Gujarati and Porter, 2009), the findings suggest that multicollinearity was not a concern in this study, and the variables could be reliably included in the regression model. The variables AT (Ethics in AI-Based Information Services in Libraries), BT (Data Responsibility & Privacy), CT (Ethics & Regulations), ET (Fairness), FT (Moral & Ethics), GTT (Security), HT (Transparency), IT (Accountability), JT (Trust), KT (Technology Misuse), and LTT (Value Alignment).
Correlation analyses matrix.
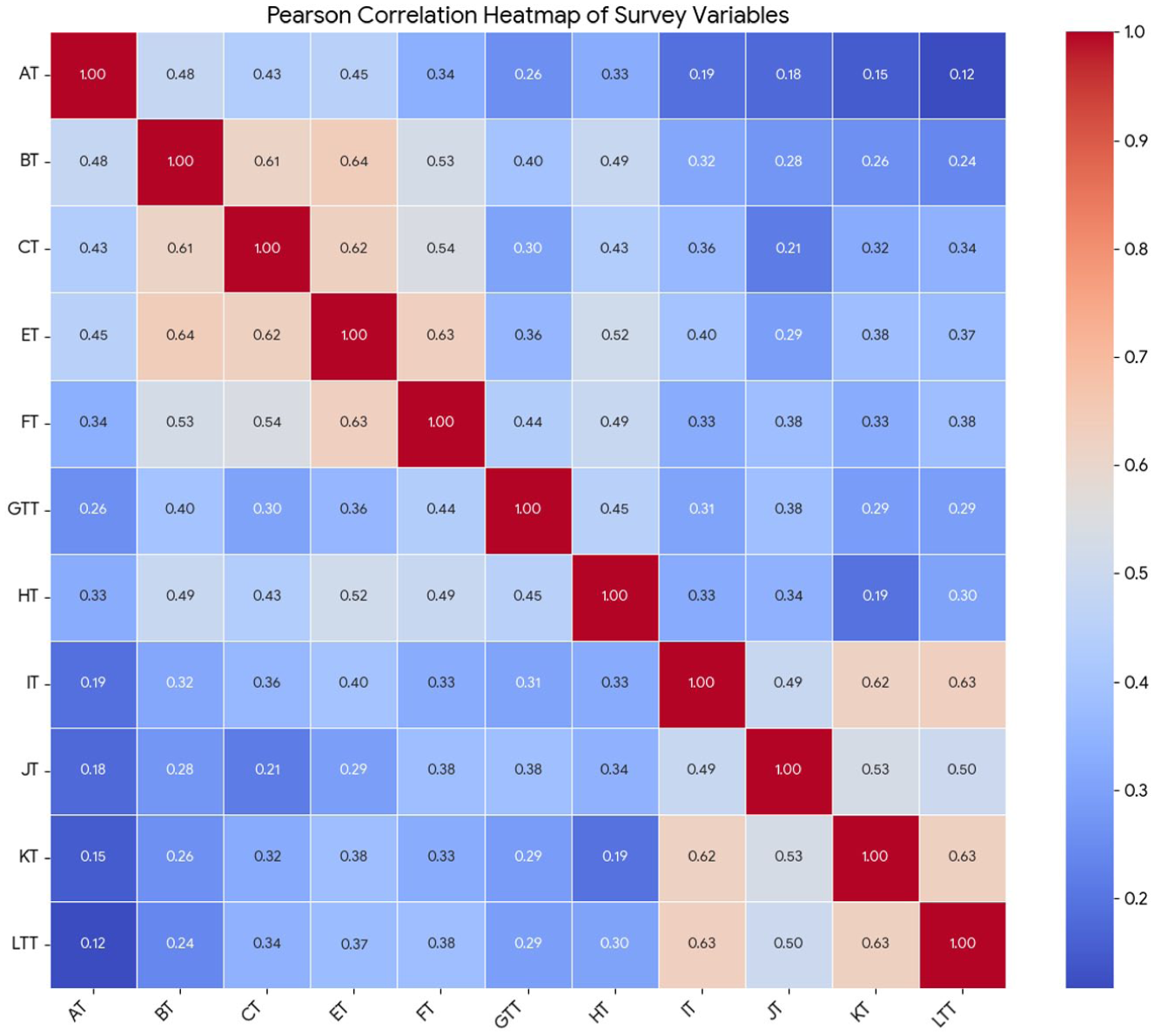
Correlation analyses matrix graph.
To further validate the absence of multicollinearity, variance inflation factor (VIF) values were calculated and found to range between 1.463 and 2.471, as presented in Table 1, confirming that the independent variables related to ethics in AI-based information services were within acceptable thresholds and did not compromise the reliability of the regression model. Subsequent analysis of the correlation coefficients between the independent and dependent variables demonstrated significant positive associations, with values ranging from 0.18 to 0.64, all statistically significant at the 0.05 level. These results provide strong evidence that the independent variables function as meaningful predictors of the dependent variable (Al-Jamili et al., 2022). Building on these findings, the study proceeded with multiple regression analysis to further examine the predictive power of the identified constructs.
Figure 6 is a heatmap visually represents the linear relationships between the variables AT (Ethics in AI-Based Information Services in Libraries), BT (Data Responsibility & Privacy), CT (Ethics & Regulations), ET (Fairness), FT (Moral & Ethics), GTT (Security), HT (Transparency), IT (Accountability), JT (Trust), KT (Technology Misuse), and LTT (Value Alignment). Each cell in the grid shows the correlation coefficient between two variables. The analysis reveals several moderate to strong positive relationships between the variables, suggesting a consistent pattern in the responses. The most significant positive correlations are observed between ET and BT (r = 0.64) and between ET and FT (r = 0.63). This indicates a relatively strong linear relationship between these sets of variables. In addition, several other pairs exhibit moderate positive correlations, including IT, KT, and LTT, which are all correlated with each other in the range of 0.62–0.63. This suggests these three variables may be measuring a similar underlying construct. Notably, there are no strong or moderate negative correlations in this dataset, indicating that no two variables exhibit a strong inverse relationship.
Multiple regression analysis
We conducted a multiple regression analysis to evaluate how well 10 ethical constructs predicted the overall perception of “Ethics in AI-Based Information Services in Libraries” (AT). This analysis clearly demonstrates the model’s effectiveness and identifies the most influential factors, as shown in Table 2.
Multiple linear regression analysis.
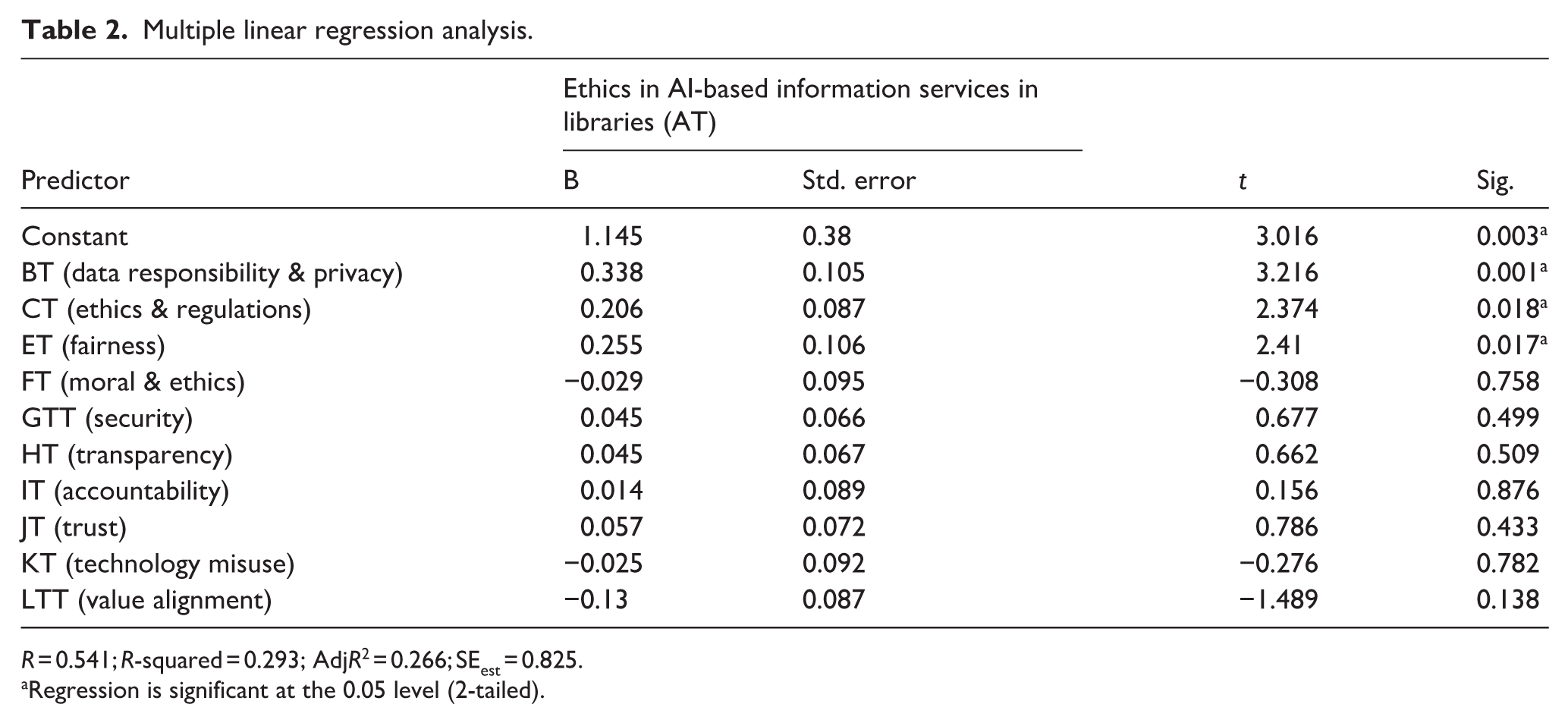
R = 0.541; R-squared = 0.293; AdjR2 = 0.266; SEest = 0.825.
Regression is significant at the 0.05 level (2-tailed).
Model fit and predictive power
The overall regression model was found to be statistically significant (p < 0.001), which confirms that the combination of the 10 independent variables is a valid predictor of the dependent variable - AT. The Adjusted R-squared value for the model is 0.266. This key metric indicates that 26.6% of the variability in the perception of overall AI ethics in libraries can be explained by the 10 variables included in this study. This represents a substantial and meaningful level of explanatory power.
While the model as a whole is significant, not all individual variables were found to be significant predictors when considered together. The analysis identified three constructs that have a statistically significant positive influence on the perception of AI ethics:
BT (Data Responsibility & Privacy): This was the strongest significant predictor (Coefficient = 0.338, p = 0.001). A stronger belief in the importance of data responsibility and privacy is associated with a more positive view of the overall ethics of AI services.
ET (Fairness): This factor also had a significant positive relationship (Coefficient = 0.255, p = 0.017). Higher importance placed on fairness in AI corresponds to a higher rating of overall AI ethics.
CT (Ethics & Regulations): This variable showed a significant positive relationship (Coefficient = 0.206, p = 0.018), indicating that a greater emphasis on the need for clear ethics and regulations is linked to a more positive overall ethical perception.
The other variables in the model, including Moral & Ethics (FT), Security (GTT), Transparency (HT), and Trust (JT) were not statistically significant. This suggests that while these factors are important, their predictive power is overshadowed by the stronger influence of Data Responsibility, Fairness, and Regulations in this particular model. Based on the multiple regression analysis, here is the regression equation and a summary of the findings.
Regression equation
The relationship between the predictor variables and the dependent variable, “Ethics in AI-Based Information Services in Libraries” (AT), can be expressed by the following equation:

A multiple regression analysis was performed to evaluate the extent to which 10 ethical constructs could predict the overall perception of ethics in AI-based information services. The results indicated that the overall model was statistically significant, successfully explaining 26.6% of the variance in the dependent variable, as indicated by the adjusted R-squared value. Among the 10 predictors, 3 were identified as having a statistically significant positive influence: Data Responsibility & Privacy (BT), Fairness (ET), and Ethics & Regulations (CT). The remaining seven variables did not demonstrate a significant unique predictive relationship in the presence of the other predictors. These findings suggest that while a broad range of ethical factors are considered important, perceptions of overall AI ethics in libraries are most strongly and significantly driven by concerns for data privacy, the fairness of AI systems, and the existence of clear ethical regulations.
Checking for regression assumptions
To validate the multiple regression analysis, a series of diagnostic plots were generated to check the underlying statistical assumptions. These plots help ensure the reliability and accuracy of the model’s results.
Diagnostic plots
Figure 7 shows that the diagnostic plots collectively confirm the assumptions for the linear regression model, thereby validating the reliability of the analysis.
Linearity (Residuals vs Fitted): This plot shows the residuals (the prediction errors) against the fitted (predicted) values. The points are randomly scattered around the horizontal line at zero, with no obvious curve or pattern. This confirms that the relationship between the predictors and the outcome variable is linear.
Normality of Residuals (Normal Q-Q): This plot compares the distribution of the model’s residuals to a normal distribution. The points fall closely along the straight diagonal line, indicating that the residuals are normally distributed, which is a key assumption for the validity of the statistical tests.
Homoscedasticity (Scale-Location): This plot is used to check if the variance of the residuals is constant across all levels of the predicted values. The points are spread randomly, and the red trend line is roughly horizontal. This supports the assumption of homoscedasticity (equal variance).
Influential Outliers (Residuals vs Leverage): This plot helps identify data points that might have an undue influence on the regression results. While a few points show slightly higher leverage than others, none have a large Cook’s distance (a measure of overall influence). This suggests that there are no significant outliers that would distort the findings of the model.
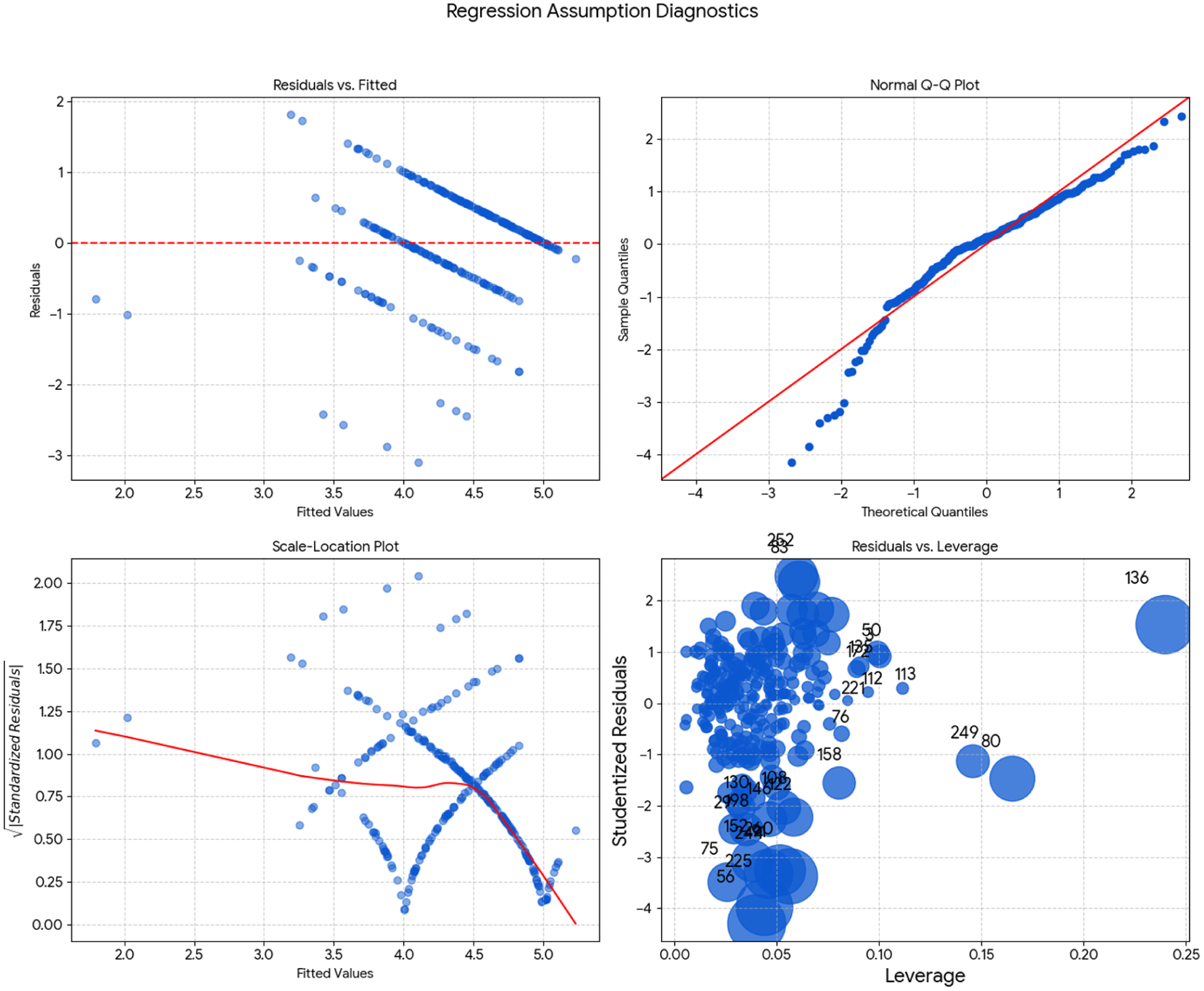
Regression assumption diagnostics.
Analysis of residuals distribution
The histogram of the residuals from the regression analysis, along with an interpretation of the plot, as shown in Figure 8.
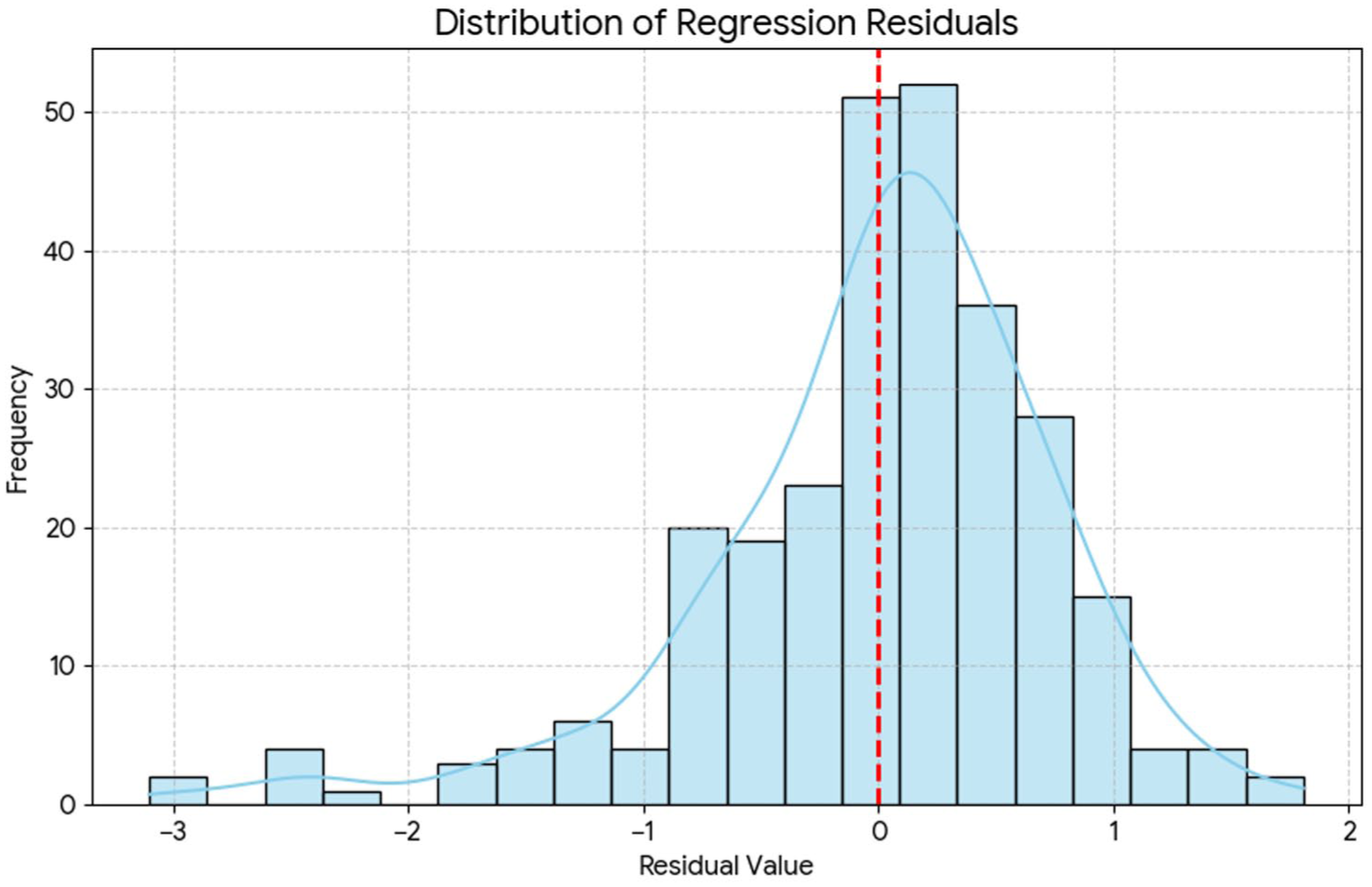
Distribution of regression residuals.
To further assess the assumptions of the regression model, a histogram of the residuals was generated. This plot provides a visual representation of the distribution of the prediction errors (the differences between observed and predicted values). The histogram displays a symmetrical, bell-shaped curve that is centered around zero, which is characteristic of a normal distribution. The overlayed Kernel Density Estimate (KDE) line smooths the distribution, further clarifying its near-normal shape. This visual evidence strongly supports the assumption that the errors are normally distributed, which corroborates the findings from the Normal Q-Q plot and strengthens the validity of the regression model’s statistical inferences.
Hopes for AI-based library services in the future
An analysis of the qualitative data from the survey reveals a consistent and forward-looking perspective on the future of AI-based library services. After translating and thematically analyzing the open-ended responses, several key aspirations emerged. Respondents expressed a strong desire for AI to evolve beyond a simple information retrieval tool into a more dynamic and intelligent partner in their academic and research pursuits. The core expectation is for future AI services to provide highly accurate, personalized, and efficient support, capable of understanding complex queries and delivering relevant, synthesized knowledge. A significant theme was the hope for AI to become an intelligent assistant that can help streamline the research process, from literature discovery to data analysis and even writing support. Furthermore, there is an underlying expectation for these advanced services to be accessible, user-friendly, and seamlessly integrated into the library’s digital ecosystem. Overall, the sentiment is optimistic, viewing AI as a transformative force that can elevate the library from a repository of information to an intelligent, interactive, and indispensable hub for knowledge creation and innovation.
Discussion
This study investigated ethical and privacy concerns in AI-based information services and their implications for user trust. The survey of 278 respondents revealed 3 major findings. First, users strongly value
The findings suggest that ethical perceptions—particularly data responsibility, fairness, and regulatory clarity—play a foundational role in shaping users’ evaluations of AI systems. While this study does not directly model trust, these ethical dimensions can be understood as critical antecedents that contribute to the development of trust in AI-based information services.
From a theoretical perspective, these findings can be interpreted through the lens of established frameworks on technology adoption and trust. First, in relation to the Technology Acceptance Model (TAM), traditional constructs such as perceived usefulness and ease of use are typically emphasized as primary drivers of adoption. However, the present findings suggest that ethical considerations—particularly data responsibility, fairness, and regulatory clarity—function as additional determinants shaping users’ evaluations of AI-based information services. This extends TAM by incorporating ethical legitimacy as a complementary dimension influencing technology acceptance in information-rich environments.
Second, the results align with privacy calculus theory, which posits that users weigh perceived benefits against potential privacy risks when engaging with digital systems. While respondents in this study expressed strong agreement regarding the benefits of AI in libraries, their simultaneous emphasis on data privacy and security indicates that risk considerations remain central to their evaluations. This suggests that perceived ethical safeguards may mitigate privacy concerns and support positive user perceptions.
Third, drawing on trust in automation theory (Lee and See, 2004), trust is understood as a function of perceived system reliability, transparency, and alignment with user expectations. Although trust was not directly modeled as a dependent variable in this study, the findings indicate that ethical perceptions—such as fairness and transparency—serve as foundational conditions that enable trust formation. In this sense, the study refines trust theory by empirically demonstrating how ethical legitimacy operates as an antecedent to trust in AI-based information services. Collectively, these findings contribute to a more integrated understanding of AI adoption by bridging ethical, cognitive, and trust-based perspectives within information service contexts.
The findings extend earlier research that highlighted the promise of AI in enhancing engagement and efficiency in library and educational services (Frick et al., 2019; Suleiman, 2024). While prior studies often emphasized the functional benefits of AI adoption (Kabir, 2025; Yu et al., 2023), the present results underscore that users evaluate these benefits through an
In contrast to works focusing narrowly on technical design or legal frameworks (Alekseeva, 2025; Sawhney et al., 2022), this study provides empirical evidence that users prioritize
An important and theoretically meaningful finding is that “Trust” (JT) and “Security” (GTT) did not emerge as statistically significant predictors in the regression model, despite being highly rated in descriptive analyses. Rather than indicating that these factors are unimportant, this result suggests that their influence may be indirect, mediated by more foundational constructs such as data responsibility, fairness, and regulatory clarity.
From the perspective of privacy calculus theory, users may evaluate trust and security not as independent determinants, but as outcomes of broader perceptions of how well their data are protected and governed. Similarly, trust in automation theory (Lee and See, 2004) suggests that trust develops based on perceived system characteristics such as transparency, reliability, and alignment with user expectations. In this context, constructs such as data responsibility and fairness may serve as more immediate evaluative criteria, whereas trust represents a higher-order perception that emerges only after these conditions are satisfied.
This finding refines existing models by suggesting that, within AI-based information services, trust may function less as a direct predictor and more as a consequential or emergent construct shaped by underlying ethical perceptions. Therefore, the absence of statistical significance for trust and security in the regression model should not be interpreted as a lack of importance, but rather as evidence of a more complex, layered relationship among ethical constructs in shaping user evaluations of AI systems.
The multiple regression analysis revealed that while a broad spectrum of ethical principles is valued, the overall perception of AI ethics in libraries is most significantly predicted by Data Responsibility & Privacy, Fairness, and Ethics & Regulations. This finding underscores the primacy of institutional governance and user-centric safeguards in the adoption of new technologies. It is particularly noteworthy that constructs such as “Trust” and “Security” did not emerge as significant predictors in the model, which suggests that their importance may be subsumed by the more foundational principles of privacy and regulatory oversight, rather than being independent drivers of ethical perception. These findings, when juxtaposed with the qualitative aspirations for AI to become a sophisticated research partner, imply that as AI’s role in the library evolves from a simple tool to an intelligent assistant, the imperative for transparent, fair, and secure operational frameworks will only become more critical to maintaining user confidence and upholding the library’s mission.
Importantly, the findings of this study are situated within the context of Thai academic libraries, as the respondents represent active users within university environments. Their interactions with digital library systems, academic databases, and AI-supported tools inform their perceptions of ethical practices and trust. Although some aspects of digital behavior—such as social media use—reflect broader technological engagement, these behaviors provide contextual insight into users’ familiarity with AI-driven systems increasingly integrated into academic library services. This contextual grounding reinforces the relevance of the findings for academic library policy and service design.
Theoretically, the findings contribute to the literature on technology acceptance by foregrounding
In the introduction, this study identified a gap between the
Practically, the study offers a roadmap for policymakers and library administrators. Embedding
Despite its contributions, this study has several limitations. The dataset was limited to
This study demonstrates that while users are open to AI-enhanced information services, their acceptance is conditional upon clear commitments to
Conclusion
This study revealed that while users strongly endorse the integration of AI in library services, their trust in this approach hinges on the presence of robust ethical safeguards. The multiple regression analysis revealed that while a broad spectrum of ethical principles are valued, the overall perception of AI ethics in libraries is most significantly predicted by Data Responsibility & Privacy, Fairness, and Ethics & Regulations, a finding that underscores the primacy of institutional governance and user-centric safeguards in the adoption of new technologies. It is particularly noteworthy that constructs such as “Trust” and “Security” did not emerge as significant predictors in the model, which suggests that their importance may be subsumed by the more foundational principles of privacy and regulatory oversight, rather than being independent drivers of ethical perception. By bridging fragmented strands of prior research that often emphasized either functional benefits or regulatory concerns, this work contributes a holistic understanding of how ethics directly shape user trust in AI-based information services, thereby filling a critical gap in the literature.
Although the findings are limited to university populations in Thailand and based on cross-sectional data, these constraints open opportunities for future research through cross-cultural, longitudinal, and mixed-method approaches to capture evolving perceptions and behaviors. These findings, when juxtaposed with the qualitative aspirations for AI to become a sophisticated research partner, imply that as AI’s role in the library evolves from a simple tool to an intelligent assistant, the imperative for transparent, fair, and secure operational frameworks will only become more critical to maintaining user confidence and upholding the library’s mission. Ultimately, the results highlight that the sustainable adoption of AI in libraries, and by extension in other domains such as healthcare, education, and governance, depends not only on technological advancement but also on embedding robust ethical practices that safeguard user rights and foster trust, ensuring that AI serves as a trusted partner in knowledge and service delivery.
Footnotes
Acknowledgements
The authors would like to express their sincere gratitude to all the participants who generously completed the questionnaire. Your valuable insights and thoughtful responses were essential to the success of this study. We deeply appreciate your contribution and commitment to advancing knowledge in this area of research.
Ethical considerations
This study was reviewed and approved by the Research Ethics Committee of the Faculty of Vocational Studies, Universitas Airlangga, Indonesia on May 27, 2025 (Approval No. 034.KKEP.05.2025).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Universitas Airlangga through the Airlangga Research Fund (ARF) Batch 1 under the scheme of International Research Collaboration Top over #300, 2025, Contract Number: 1733/UN3.LPPM/PT.01.03/2025.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data can be obtained from the authors upon reasonable request.
AI use statement
AI-assisted tools (including ChatGPT and Grammarly) were used in this study exclusively for language refinement and improving clarity of presentation. The authors retained full responsibility for the research design, data collection, coding, analysis, interpretation, and all substantive intellectual contributions. No AI tools were used to generate data, perform analysis, or make research decisions.