
Abstract
Objective
To assess the accuracy, completeness, and reproducibility of Large Language Models (LLMs) (Copilot, GPT-3.5, and GPT-4) on antimalarial use in systemic lupus erythematosus (SLE).
Materials and Methods
We utilized 13 questions derived from patient surveys and common inquiries from the National Health Service. Two independent rheumatologists assessed responses from the LLMs using predefined Likert scales for accuracy, completeness, and reproducibility.
Results
The GPT models and Copilot achieved high scores in accuracy. However, the completeness of outputs was rated at 38.5%, 55.9%, and 92.3% for Copilot, GPT-3.5, and GPT-4. When questions related to “mechanism of action” and “lifestyle”, were analyzed for completeness (n = 8), ChatGPT-4 scored significantly higher (100%) compared to Copilot (37.5%). In contrast, questions related to “side-effects” (n = 5) scored higher for ChatGPT models than Copilot, and the differences were not statistically significant. All three LLMs demonstrated high reproducibility, with rates ranging from 84.6% to 92.3%.
Conclusions
Advanced LLMs like GPT -4 offer significant promise in enhancing patients’ understanding of antimalarial therapy in SLE. Although chatbots’ capability can potentially bridge the information gap patients face, the performance and limitations of such tools need further exploration to optimize their use in clinical settings.
Introduction
Antimalarial (AM) drugs, chloroquine, and hydroxychloroquine (HCQ) are keystones in treating systemic lupus erythematosus (SLE).1,2 AMs are helpful in the management of mucocutaneous and musculoskeletal involvement in SLE. 3 They effectively prevent flares, reduce disease activity and damage, and reduce mortality.4,5 AMs have also been shown to be relevant in the management of lupus nephritis (LN), a frequently life-threatening involvement of SLE. 6 In addition, those drugs provide better clinical outcomes in pregnant women with lupus. 7 AMs might reduce the risk of thromboembolism when antiphospholipid antibodies are present 8 and improve insulin sensitivity, diminishing the risk of developing diabetes. 9 According to a population-based study, individuals with SLE who adhere to AMs obtained a 70% and 80% lower mortality risk than patients with non-adherence or discontinuation, respectively. 10
Although AMs are widely employed in the management of various inflammatory rheumatic diseases, the dose-response relationship for these medications remains poorly defined, and there is no established minimum dose that is clinically effective. Notably, AM use is associated with significant risks; for instance, maculopathy occurs in approximately 2% of patients treated with chloroquine and 0.1% of those receiving HCQ within a decade of therapy initiation. 11 Additionally, cardiomyopathy has emerged as another serious adverse event potentially linked to prolonged antimalarial treatment. 12
Research on patient comprehension of AMs is especially insufficient. According to a qualitative study, patients reported receiving incomplete or conflicting information significantly influenced their decision to initiate or discontinue HCQ therapy. 13 Additionally, patients described that receiving incomplete information about HCQ compelled them to seek additional details from unreliable sources, such as the Internet, which subsequently increased their anxiety regarding HCQ. Regrettably, the reliability of digital platforms often suffers due to uncontrolled data input practices on platforms commonly used by patients. 14
Innovations in interesting information communication options, such as Large Language Models (LLMs) operated using artificial intelligence (AI), have started changing the approaches to online data access. The training of LLMs, based on massive databases, shows a substantial proficiency in organizing and deciphering human language, bridging a wide range of life’s outlook, and incorporating health information. Although these models hold considerable promise, they are not without errors. Their usefulness in health has been evaluated in diverse roles, from problem-solving to patient education, generating varied findings. 15 Within this group of models, ChatGPT (GPT) (Open AI) has been a favorite in the sector.
Nevertheless, the performance of other Large Language Models, such as Microsoft’s Copilot, has yet to be determined. Although all three are LLM models, their training data, algorithms, and output generation methods differ. GPT is known for producing pertinent text from a comprehensive database current through September 2021. 16 In February 2023, Microsoft launched its chatbot called Copilot. 17 Our study was aimed to assess the accuracy, completeness, and reproducibility of Copilot, GPT-3.5, and GPT-4 in the context of patient information on antimalarial use in lupus care.
Methods
Healthcare setting and LLM role
This study pertains to adult patients diagnosed with SLE and prescribed antimalarial therapy, specifically HCQ or chloroquine. In typical healthcare settings, patient education on antimalarials is provided primarily through interactions with healthcare professionals (HCPs), such as rheumatologists. It is often supplemented by information leaflets or online resources recommended by the care team. However, many patients report lingering questions following brief consultations and may seek additional information online. The role of LLMs, such as GPT-4 and Copilot, as explored in this study, is to serve as a supplemental resource accessible outside clinical settings. The study hypothesizes that LLMs could provide timely, detailed responses to patient questions, potentially reducing reliance on less validated online sources. While this study does not directly compare LLMs to HCP-provided information or recommended websites, it offers an initial assessment of LLM performance in answering common patient questions on antimalarial therapy. Future studies should expand upon this foundation by comparing LLM outputs directly with information provided by HCPs and vetted online health resources to determine if LLMs can reliably meet the standards set by these established sources.
We utilized 13 questions based on two sources: (1) a survey described by Garg et al., 13 which took into account medication information gaps (n = 4) and conflicting information and misbeliefs and assumptions (n = 3), and (2) common questions suggested by the National Health Service (NHS) (n = 6), 18 to assess the performance of the models. Every question posed to ChatGPT was formulated in English. ChatGPT was not provided with any feedback. The proposed questions were input into Copilot, GPT-3.5, and GPT-4 on February 26, 2024 (Supplemental material). After data collection, responses generated by each model were evaluated by two independent reviewers, each with over 10 years of experience in rheumatology. This study did not require ethics committee approval because neither human nor animal data were used.
Johnson et al. detailed how the investigators evaluated the accuracy and completeness of the responses using two predetermined scales. For accuracy, a six‐point Likert scale was utilized, with one being a completely incorrect answer, two being more incorrect than correct, three being approximately an even mix of accurate and inaccurate components, four being more correct than incorrect, five being almost entirely correct, and six being entirely correct.
Regarding completeness, a three‐point Likert scale was employed: one incomplete (partially addressed the question, leaving significant portions either missing or incomplete), two adequate (fully covered all elements of the question and provided the necessary information needed for completeness), and three comprehensive (encompassed every facets of the question and offered extra information or perspectives that exceeded prospects).
Each question was entered on two separate occasions using the “new chat” function to produce two responses per question, aiming to assess the reproducibility of responses to identical inquiries. Reproducibility was graded based on the similarity in accuracy of the two responses generated by the chatbots. The responses were considered reproducible if the two reviewers had the identical scores. If the answers varied and scores differed between reviewers, these questions were assessed as non-reproducible.
If two reviewers assign differing scores to a specific question after evaluating them, a third reviewer contributes to achieving consensus.
Given that no patient records were utilized, approval from an ethics committee was not necessary.
Statistical analysis
The acquired results were analyzed descriptively. Categorical variables are shown in frequencies and percentages. Means with standard deviations (SD) of scores were estimated. To compare overall accuracy and comprehensiveness scores across answers from all LLM-Chatbots, we conducted the Kruskal-Wallis rank-sum test and Dunn’s multiple comparison post-hoc tests, as the data failed to satisfy parametric conditions. The reproducibility of responses was expressed as %. The threshold for statistical significance was established at p < .05.
The analyses were carried out utilizing the SPSS (IBM SPSS Statistics for Mac, Version 26.0. Armonk, NY: IBM Corp.) software.
Results
The mean accuracy of Copilot, GPT-3.5, and GPT-4 were 5.85 (SD = 0.38), 5.92 (SD = 0.28), and 5.92 (SD = 0.28), respectively. The Copilot, GPT-3.5, and GPT-4 models had correct or almost correct response rates of 100%, 100%, and 100%, respectively. When assessing the accuracy of the responses for entirely correct results, Copilot obtained 84.6%, GPT-3.5 rated 100%, and GPT-4 rated 100% with no statistical difference. The rates of completely incorrect scores were 0% in all models.
The mean completeness scores of Copilot, GPT-3.5, and GPT-4 were 2.23 (SD = 0.73), 2.46 (SD = 0.66), and 2.92 (SD = 0.28), respectively. The completeness of answers from Copilot, GPT-3.5, and GPT-4 was scored at 38.5%, 53.9%, and 92.3%, respectively (p = .02). In a post-hoc analysis, there was an evident discrepancy between Copilot and GPT-4 (p = .01), but not among Copilot and GPT-3.5 (p = .95) and GPT-3.5 and GPT-4 (p = .15). Figure 1 displays the distribution of completeness across each model. The variation in completeness scores among different models.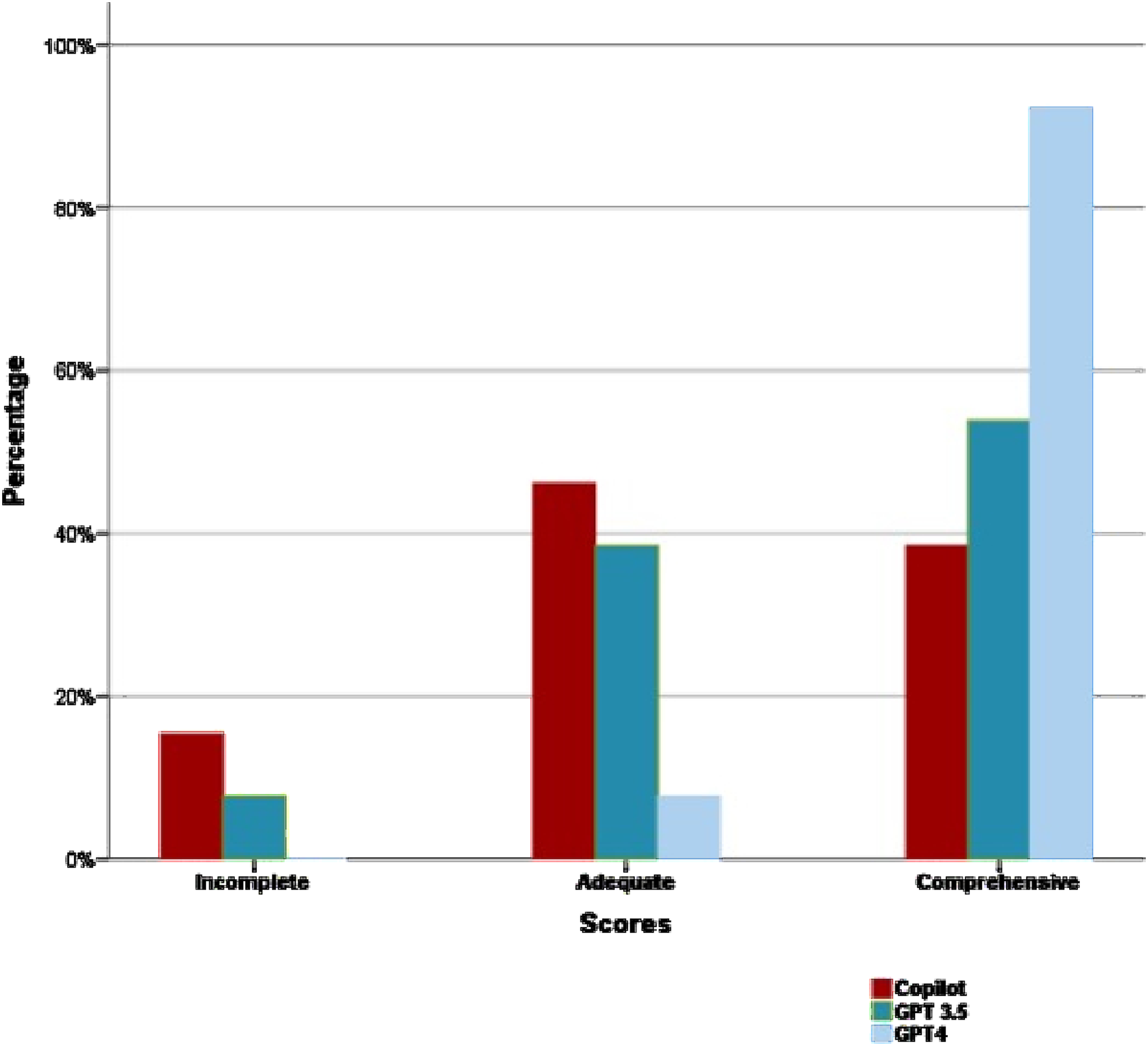
In the category of “side effects” (n = 5), GPT models (3.5 and 4) produced more correct answers (100% and 100%, respectively) when compared to Copilot (80%), but without statistical significance. Although the ChatGPT models produced more comprehensive results (80% and 60%, respectively) than Copilot (40%) in the category of “side effects,” those differences are without statistical significance. However, in other questions related to the “mechanism of action” (n = 7) and “lifestyle” (n = 1), ChatGPT-4 outperformed significantly at the highest rate (100%) and Copilot at the lower rate (37.5%), (p = .03). Furthermore, all three LLMs demonstrated high reproducibility, with rates ranging from 84.6% to 92.3%.
Discussion
In this study, we investigated the accuracy and completeness of GPT and Copilot chat applications in responding to patients’ frequent questions related to AM use. The LLMs applications responses to inquiries from a previously validated survey with patients’ concerns about HCQ and from common questions suggested by the NHS since no other questionnaires specifically consider the knowledge of pharmaceutical treatments such as AMs in patients with SLE were assessed for accuracy, completeness, and reproducibility by rheumatologists. Our study is the first to compare the performance of three AI chatbots regarding the main concerns in AM use in patients with SLE. According to the results gathered, the responses from ChatGPT were highly accurate across a comprehensive rating scale and highly reproducible. Overall, Copilot’s responses were accurate enough but exhibited less complete answers and, in certain instances, presented varied responses. In summary, ChatGPT models showed outstanding accuracy, with 100% of answers receiving the highest rating of 6. ChatGPT-4 demonstrated remarkable completeness, with 92.3% of complete responses. It also shows robust reproducibility by consistently responding to repeated inquiries. These findings support ChatGPT’s progressive capabilities in delivering detailed, thorough, and precise responses in this field.
Although Copilot exhibited fairly accurate responses, it showed poor performance in completeness. Most of the responses contained pertinent information but lacked all the anticipated details. Additionally, the tool displayed inconsistent reproducibility, producing varied outputs to the same queries.
The outcomes of our research may prove advantageous for doctors, researchers, and Internet users. The former group can leverage the insights gained to provide recommendations and guidance to patients who depend on various information sources. Researchers can derive valuable lessons from our analysis of LLMs, which delineate their strengths and weaknesses, aiding in advancing future studies. Furthermore, this research aims to enhance the discernment of Internet users by demonstrating the reliability of AI applications in obtaining health-related information, thus facilitating more informed decision-making. 19
Nune et al. outlined the potential utilization of GPT in rheumatology across five domains, including educating patients about disease-modifying anti-rheumatic drugs. 20 Likewise, another study revealed that GPT is a reproducible and practical application for accurately diagnosing a range of rheumatic diseases, such as osteoarthritis, rheumatoid arthritis (RA), ankylosing spondylitis, SLE, and psoriatic arthritis, among others. 21 In 2023, Coskun et al. 22 evaluated the accuracy and completeness of answers from ChatGPT models and Bard to 23 inquiries regarding the use of methotrexate in RA. The findings appeared encouraging, with ChatGPT-4 achieving 100% for complete and correct outputs. In addition, the authors emphasized a significant limitation of LLMs: the tendency to produce ‘hallucinated’ outputs. LLM hallucinations refer to information that lacks support from available evidence and generally is imprecise or spurious.
Enhancing Copilot’s knowledge base and robust reasoning skills can improve the precision and thoroughness of responses in this field. Continuous training to improve system functionalities is essential to closing these gaps successfully.
Given the popularity of the Internet as a primary source of health information 23 and the widespread use of social media, which draws large audiences, there is a significant issue with the reliability of the information provided. 24 Although numerous websites offer health-related content, the quality of information on most sites is often less than optimal. This situation is deeply concerning because some SLE patients receive information from other sources, including online platforms. 25 Reynolds et al. identified that online sources of SLE information that rank highly in search engine results are not always high quality. 26
Due to the critical need for reliable health information, patients often remain unaware of how to discern this. ChatGPT offers an innovative tool to access dependable and accurate health information by filtering through content and producing clear patient responses. ChatGPT can address the issue of laborious and misleading search engine queries by delivering conversational, trustworthy answers. 27
Based on our findings, Copilot has the potential to contribute to fulfilling user needs significantly and can enhance the user-system interface by addressing and overcoming existing limitations. Patients who take AM drugs for SLE may have several concerns in the administration of those drugs, particularly in the potential adverse events. In addition, patients have reported a misunderstanding of HCQ’s role in lupus as the primary reason for prematurely discontinuing HCQ. 28 They can impact adherence to AMs and, thereby, to SLE outcomes. Patients reported that due to rushed consultations during SLE visits,13,29 they received incomplete information about HCQ’s role in managing SLE, leading them to seek medication information on the Internet.13,28,30,31 Consulting these non-validated resources often exacerbated their existing concerns about side effects and rare toxicities, ultimately leading to premature self-discontinuation of AMs.28,32,33
Furthermore, in our stakeholder study, over 80% of patients reported being unaware that HCQ could improve survival and protect organs in lupus cases. They indicated that they might have continued with HCQ treatment if they had been informed about its benefits. 13 Therefore, delivering thorough and easily understandable information is essential in alleviating patients’ additional distress. Conventional clinic visits often do not afford adequate time to inform patients about their condition and treatment possibilities thoroughly. Moreover, the intermittent unavailability of healthcare professionals can also hinder patient education. LLM models, particularly ChatGPT, have significantly enhanced this digital learning system by integrating AI skills with an available platform.
While our findings indicate that LLMs like GPT-4 and Copilot can produce accurate and reproducible responses regarding antimalarial use in SLE, it is essential to recognize that not all patients have equal access to or can effectively use AI-driven tools. Digital literacy, health literacy, socioeconomic status, and geographic location significantly affect patients’ ability to engage with online health resources. Patients with limited access to reliable Internet, unfamiliarity with AI, or lower educational attainment may encounter difficulties interpreting AI-generated medical information. Furthermore, the cultural and linguistic diversity within the SLE population necessitates consideration, as AI-generated responses may not always be tailored to differing levels of health literacy or specific patient needs. These disparities highlight the need for future research to investigate the role of AI in patient education across diverse demographic and socioeconomic groups.
Limitations
This study has multiple limitations. First, it depends on the subjective judgment of reviewers. Given that responses from LLMs are narrative and not directly quantifiable, assessments could differ among evaluators. Secondly, this single-center, cross-sectional study was limited to evaluating LLM proficiency simultaneously among two rheumatologists. A longitudinal, multicenter study with a more extensive dataset would yield more profound insights into the consistency and adaptability of future LLMs. Thirdly, a significant limitation exists with the accuracy and completeness scores, which have not been validated for assessing AI-generated content. This might influence our evaluations’ strength and bring in assessment subjectiveness. In addition, the advancement and assessment of LLM models are constrained by the available versions during our research period. While our findings are encouraging, they should not be seen as supporting the direct clinical use of chatbots due to the uncertain limitations of these systems in complex decision-making. Furthermore, necessary ethical, regulatory, and validation considerations, which are not addressed in this report, must be considered.
Although this study provides insights into the accuracy, completeness, and reproducibility of LLM responses on antimalarial use, future research is needed to position LLMs within well-defined healthcare settings. Specifically, subsequent studies should compare LLM responses with information provided by HCPs, such as rheumatologists, or by validated online health resources recommended by medical providers. This approach would establish a more stringent benchmark to assess the non-inferiority of LLMs in delivering accurate and comprehensive health information. Moreover, studying LLM use in different healthcare contexts—such as after clinical visits where patients may seek additional information—will help clarify the practical role of LLMs as supplemental patient education tools. These enhancements in experimental design will allow researchers to determine whether LLMs can effectively bridge information gaps without undermining the importance of HCP-guided education. Finally, a critical limitation of this study is the potential influence of question phrasing on LLM-generated responses. While we incorporated patient concerns from a validated survey 13 and common questions from the NHS, professionals still formulated the questions, which may not fully reflect how patients naturally phrase their inquiries. LLMs are highly sensitive to input wording, and different phrasings—particularly those written by laypersons—might yield varying responses regarding accuracy and completeness. Future studies should aim to incorporate patient-generated questions in real-time to better assess LLM performance in responding to authentic, naturally expressed patient concerns. Additionally, further research should explore how variations in health literacy and digital proficiency among patients impact their ability to interpret AI-generated responses effectively.
Conclusions
This study provides an initial assessment of the performance of advanced LLMs, such as GPT-4 and Copilot, in generating responses to patient questions regarding antimalarial therapy for SLE. While the LLMs demonstrated high accuracy and reproducibility, the study’s design does not permit conclusions about their impact on actual patient understanding or knowledge retention. Additionally, the limited experimental design, which relied on rheumatologists’ assessments rather than direct patient comprehension measures, restricts these findings’ generalizability to real-world clinical settings. Further research with robust methodologies, including comparative studies in well-defined healthcare contexts and direct assessments of patient comprehension, is necessary to evaluate the potential of LLMs as reliable educational tools in patient care.
Supplemental Material
Supplemental Material - Evaluating large language models as a supplementary patient information resource on antimalarial use in systemic lupus erythematosus
Supplemental Material for Evaluating large language models as a supplementary patient information resource on antimalarial use in systemic lupus erythematosus by Pamela Munguía-Realpozo, Claudia Mendoza-Pinto, Ivet Etchegaray-Morales, Edith Ramírez-Lara, Juan Carlos Solis-Poblano, Socorro Méndez-Martínez, Laura Serrano Vertiz and Jorge Ayón-Aguilar in Lupus
Footnotes
Author contributions
PMR and CMP: Conceptualization, Project administration, Resources, Supervision, Validation, Visualization, Writing – review & editing. IEM and ERL: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Writing – original draft, Writing – review & editing. JCSP and SMM: Project administration, Supervision, Validation, Visualization, Writing – review & editing. LSV and JAA: Investigation, Supervision, Validation, Visualization, Writing – review & editing.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Juan Carlos Solis Poblano reports a relationship with Bristol-Myers Squibb Company that includes speaking and lecture fees. However, it was not related to the development of this research. The remaining authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical statement
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.