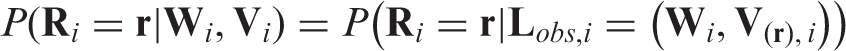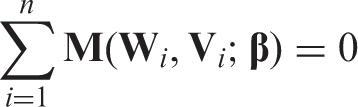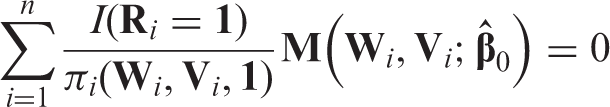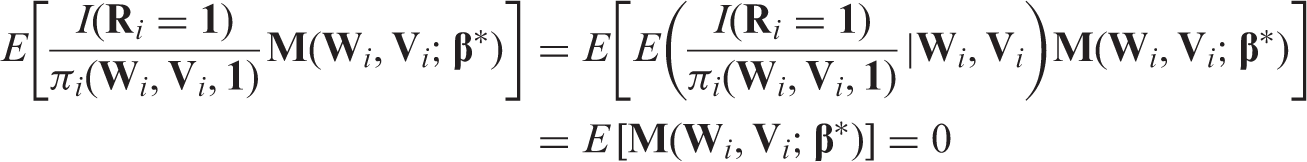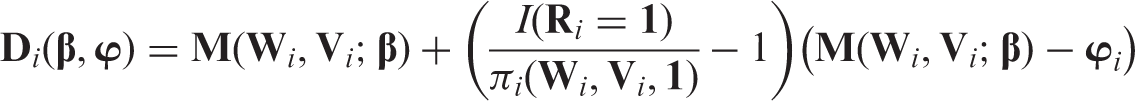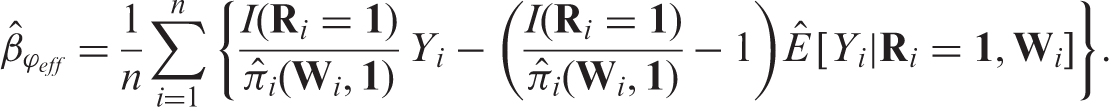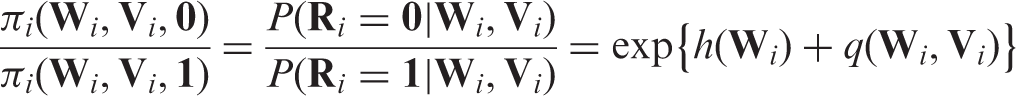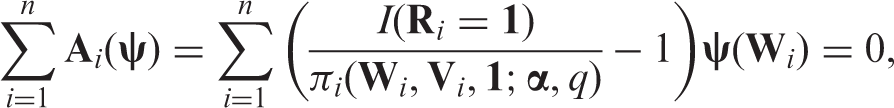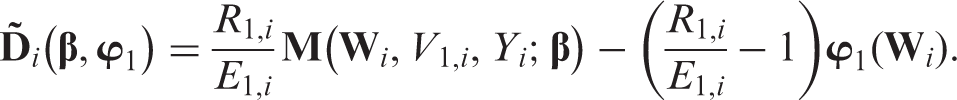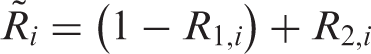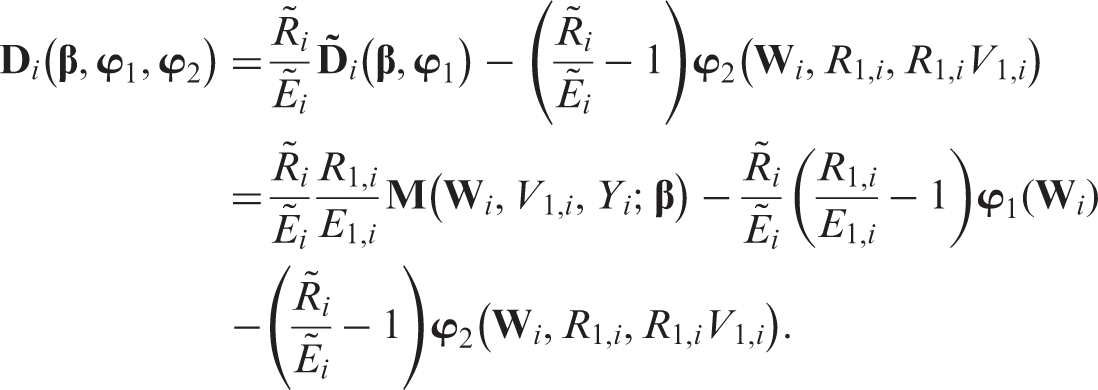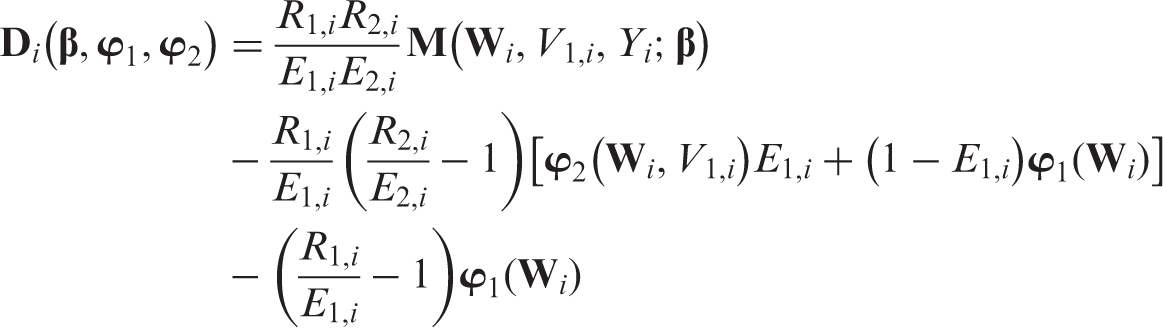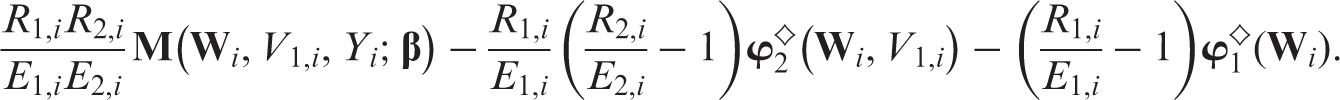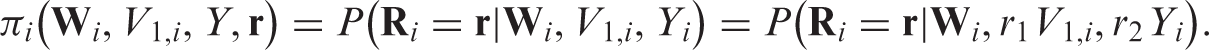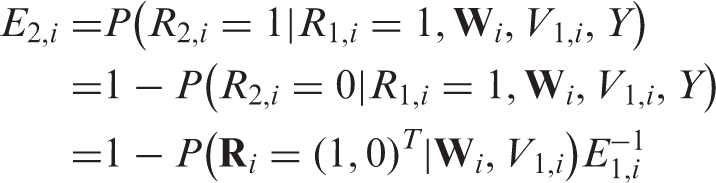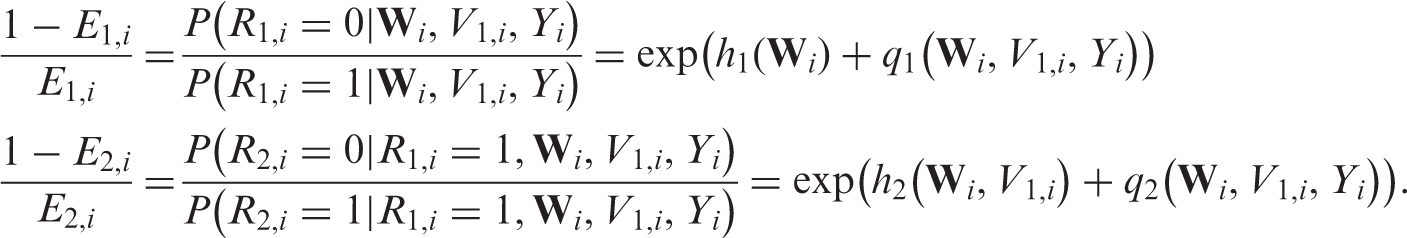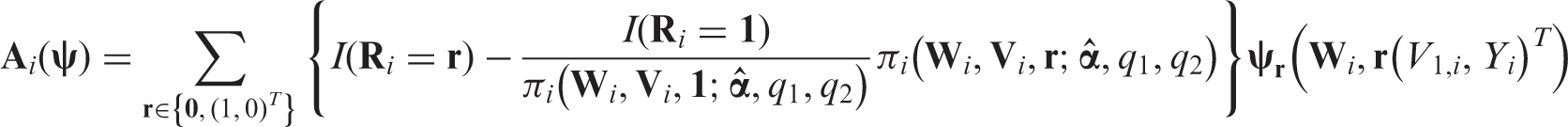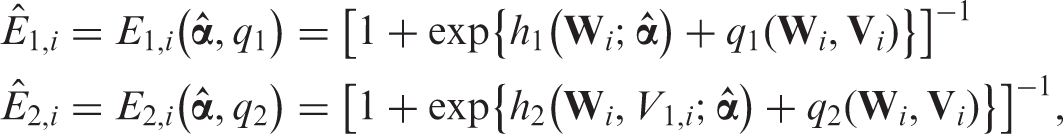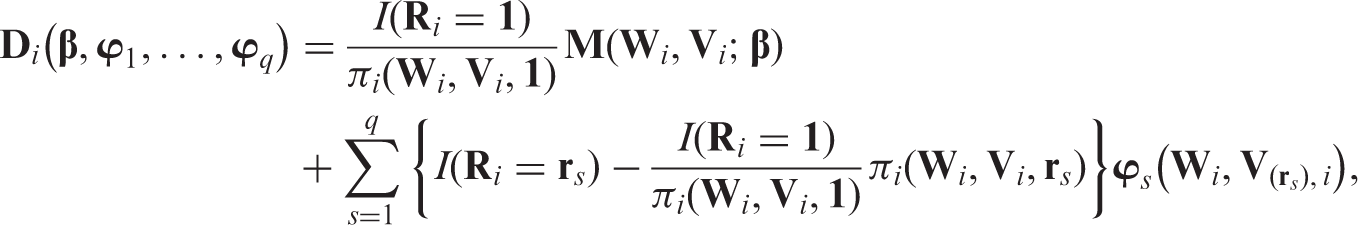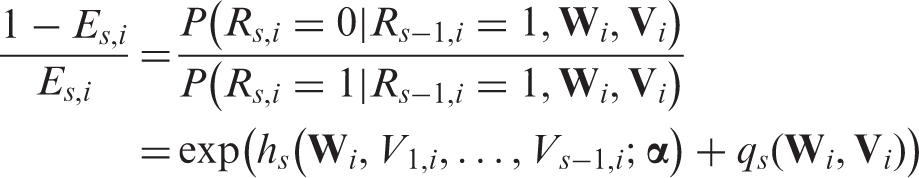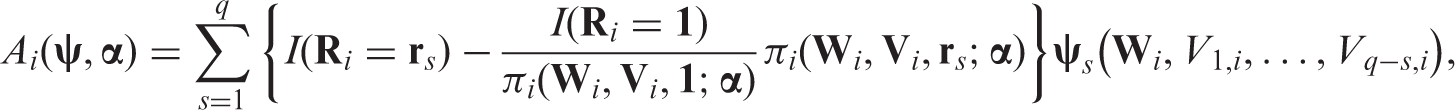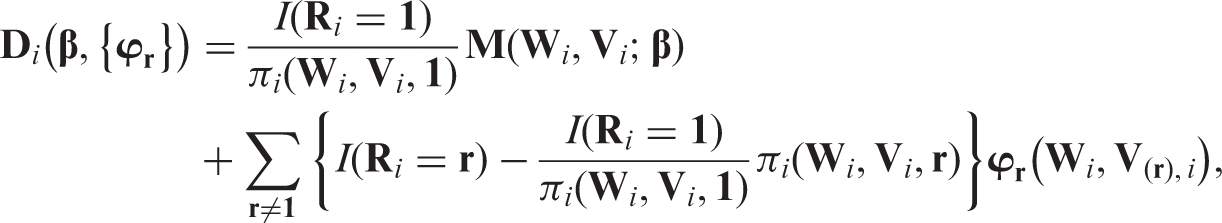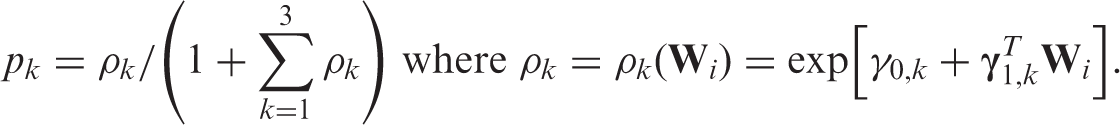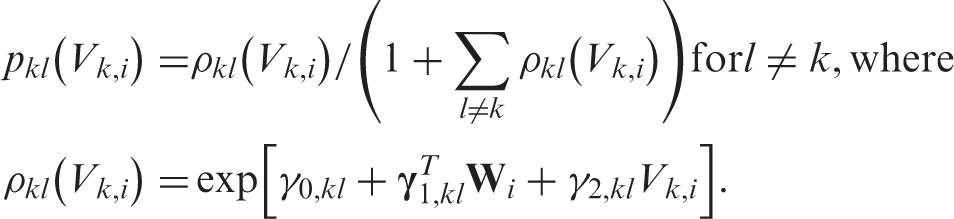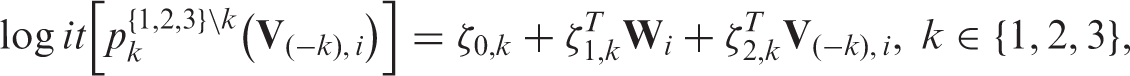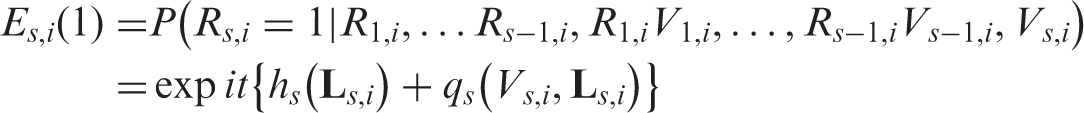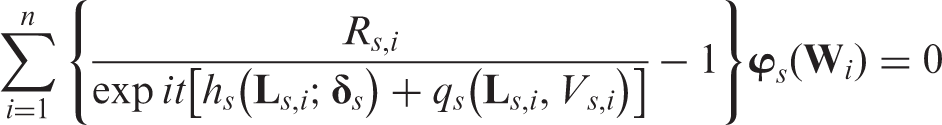We review the class of inverse probability weighting (IPW) approaches for the analysis of missing data under various missing data patterns and mechanisms. The IPW methods rely on the intuitive idea of creating a pseudo-population of weighted copies of the complete cases to remove selection bias introduced by the missing data. However, different weighting approaches are required depending on the missing data pattern and mechanism. We begin with a uniform missing data pattern (i.e. a scalar missing indicator indicating whether or not the full data is observed) to motivate the approach. We then generalise to more complex settings. Our goal is to provide a conceptual overview of existing IPW approaches and illustrate the connections and differences among these approaches.
Interest in the use of secondary healthcare databases (e.g. administrative claims, electronic health records (EHRs) and cancer registries) for medical research is increasing, partially because these data are readily available, relatively inexpensive to access and cover large representative populations. However, these databases are collected for non-research purposes. For example, administrative and medical claims databases are assembled for the purposes of administering, billing and reimbursing healthcare services. Moreover, patients in clinical practice settings are not monitored as closely as those in clinical trials. In consequence, a substantial fraction of the needed data is missing for some subjects. These data issues pose analytic challenges and raise validity concerns.
By design, each of these secondary databases may contain only a subset of the variables of interest. For example, administrative claims data contain information on healthcare insurance membership, drug coverage, healthcare utilisations (i.e. diagnosis and procedure codes) and medication dispensing records. But more detailed clinical information (e.g. BMI, vital signs and laboratory tests results) are recorded in EHR. For cancer patients, the cancer stage and histology information are recorded in cancer registries. As a consequence, systematic missing data occurs for some study participants for whom the data in certain databases are unavailable. Even for those with linked databases, missing data may still occur for reasons such as missed office visits, loss to follow-up, switch of healthcare systems and coding errors. Thus, failure to appropriately handle missing data may lead to inefficient or even invalid use of available data sources.
The simplest and most commonly used method to deal with missing data is the complete case approach in which standard analyses are applied to subjects with complete data on relevant variables. However, this analysis is biased unless the complete cases are representative of the study population (i.e. the data is missing complete at random, MCAR). This MCAR assumption rarely holds in medical applications.1
More advanced statistical methods have been developed in the past decades to deal with missing data under less restrictive missing data mechanisms,2 i.e. missing at random (MAR) and missing not at random (MNAR). MAR means the probability of missingness does not depend on unobserved elements conditional on observed data.3 MNAR indicates settings in which neither MCAR nor MAR holds. In this article, we review a class of approaches for missing data – the inverse probability weighting (IPW) approaches. The intuitive idea is to create weighted copies of the complete cases to remove selection bias introduced by missing data processes. The weighting idea originates in the survey sampling literature.4 It has been further generalised by Robins, Rotnitzky, and others to address a variety of important issues such as confounding bias in observational studies and bias due to missing data.5–8 Alternatives to IPW include parametric likelihood inference,9–11 parametric Bayesian inference12–14 and parametric multiple imputation15–17 inference.
We introduce and illustrate the class of IPW approaches for three missing data patterns, uniform missingness, monotone missingness and non-monotone missingness. For each pattern, we consider both MAR and MNAR mechanisms. We begin with relatively simple scenarios, and then generalise to more complex settings. Due to space limitations, we do not dwell on mathematical details but refer the interested readers to the original journal articles or to the books by Tsiatis or van der Laan and Robins.18,19
This article is organised as follows. In Section 2, we introduce the notation and models needed to formalise the missing data patterns and mechanisms we consider. We also introduce four motivating examples. In Section 3, we motivate the weighting approaches by demonstrating the bias in the complete case approach when MCAR does not hold. In Sections 4–6, we introduce weighting approaches for our three missing data patterns. We conclude with a discussion.
2 Models and notations
We let denote the full data on the n study subjects, where the p-dimensional vector denotes the variables that are always observed for each subject i and the q-dimensional vector denotes the variables that are subject to missingness. We let denote the vector of missing indicators for subject i where the sth element () equals 1 if is observed, and 0 otherwise. Let denote the observed components of . Let denote the observed data for subject i and let denote the unobserved components of . Here denotes a vector of 1’s. This notation can be used to represent a wide class of missing data patterns. For example, in a missing outcome model, W represents a vector of covariates and V is the outcome of interest Y. The parameter of interest might be the marginal outcome mean or the coefficients β in an outcome regression model . In missing data models with missing outcome and covariates, W would represent the covariates that are always observed and V would include both the outcome of interest and the covariates that are subject to missingness.
Throughout we assume that , are independent and identically distributed random vectors. We assume the parameter of interest is the unique solution to the equation , where is a known m-dimensional function of the full data and a parameter β, is the true value of β, and the expectation is under the distribution of . Thus, is an unbiased estimating function for . Here is a functional of the distribution of the full data .
We consider the following three missing data patterns: uniform missingness, monotone missingness and non-monotone missingness. The weighting approach applies equally to all. However, its implementation is much more complicated for non-monotone missing data patterns. We will start with a simple uniform missing pattern to illustrate and motivate the basic idea.
2.1 Missing pattern 1: uniform missing data, i.e.
Under uniform missingness, either the entire vector is observed for subject i or it is completely missing. This pattern often occurs when information is extracted from multiple data sources. For example, administrative claims data contain information on basic demographics (age, gender), healthcare utilisations and medication dispensing records. However, more detailed clinical information such as vital signs and lab test results would be available only for a subset of the study participants with linked EHR data.
2.2 Motivating example 1
Consider a hypothetical study evaluating the 1-year incidence rate of heart disease among new users of non-steroidal anti-inflammatory drugs. Data are extracted from a health insurance administrative claims database which contains information on medication dispensing records and disease diagnosis history. The indicator variable indicates whether heart disease occurred during the 1-year follow-up period after drug initiation. Let . Then is . The outcome will be missing in participants who dis-enroll from the insurance plan during the follow-up period. The vector of covariates W includes demographics (age, gender), geographic region, geographically derived socioeconomic status and comorbidity conditions.
2.3 Missing pattern 2: monotone missing data
Under monotone missingness, if the sth element () of is missing then all subsequent elements are missing ( for any ). This pattern occurs frequently in longitudinal studies with repeated measurements in which subjects who drop out of the study never re-enter. Then Vs might denote the data that were to be collected at the sth planned clinic visit. Even if some subjects return after missing one or more visits, one can choose to make the data ‘monotone’ for purposes of data analysis by choosing to ignore in the analysis any data recorded subsequent to a missing visit. Note uniform missing data is actually a special case of monotone missing data.
2.4 Motivating example 2
Consider an observational study to compare the effects of two anti-hypertensive agents (e.g. angiotensin-converting enzyme inhibitors and beta-blockers) on reducing blood pressure (BP) level among incident users. The study participants were identified using claims and EHR data. Then W contains the treatment indicator and some baseline covariates (e.g. age, sex and comorbidity conditions). The vector V contains two elements; V1 records the baseline BP and records the BP at the end of a 12-month follow-up period. The baseline BP V1 is incomplete as some patients do not have EHR data available or did not have their BP measured during the baseline period. Similarly, some subjects have missing. We decide to make the data ‘monotone’ by ignoring the data on V2 for subjects missing V1. Suppose we are interested in the coefficient β in the regression model . We would take .
2.5 Missing pattern 3: non-monotone missing data
Non-monotone missingness refers to any missing data pattern that is not monotone. Thus, we may have but for some subjects and but for others. This is the most complicated missing data pattern. We consider two motivating examples for this pattern.
2.6 Motivating example 3
Consider a regression analysis with missing covariates. Suppose we are interested in identifying predictors of episodes of exacerbation for children with persistent asthma. The study cohort of children with persistent asthma was identified using healthcare claims data. The vector W, ascertained from claims data, includes data on demographic characteristics and a binary outcome encoding 2 or more ER visits for asthma during a 12-month study period. Surveys were mailed to parents to obtain data on a baseline asthma severity score (V1), household income (V2) and a measure of the parents’ expectation on child functioning with asthma (V3). Parents may answer none, one, two or three of the three questions. This missing pattern is non-monotone. We are interested in the regression parameter in a logistic regression model regressing the outcome on potential predictors. The estimating equation is the score function for β.
2.7 Motivating example 4
Consider a longitudinal follow-up study with repeated measurements of BP at three time points, . As before, W contains the treatment indicator and baseline covariates (e.g. age and sex). Let indicate the BP measured at the sth time point and . Unlike in example 2, we do not ignore subsequent data on subjects missing V1 or V2. Thus, this missing pattern is non-monotone. We are interested in the mean of , . Thus, .
For each missing pattern, we consider both MAR and MNAR data generating processes.3 Data are said to be MAR if the conditional missing probabilities given the full data do not depend on the unobserved components of V, i.e.
In the special case of MCAR, is constant. Let γ denote the parameters governing the missing data process and θ denote the parameters governing the distribution of the full data , and assume they are variation independent. Then under MAR, the likelihood of the observed data factors into a component depending on γ alone and a component depending on θ alone. Thus, MAR is referred to as ignorable missingness because the missing data process can be ‘ignored’ in likelihood-based inference on a parameter that are functions of the parameters θ governing the marginal distribution of the full data L. The IPW approach takes a different perspective than likelihood-based approaches by using estimates of the missing data process to derive valid inferences on the parameter of interest .
When MAR fails to hold, the missing data mechanism is said to be MNAR or non-ignorable, i.e. the missing probabilities depend on unobserved components of V conditional on observed data. In this setting, the parameter of interest is typically unidentifiable unless additional assumptions on the missing data process are imposed. These assumptions usually are investigator specified and cannot be empirically tested when the full data model is non-parametric. Therefore, it is a common practice to conduct a sensitivity analysis in which we vary these additional assumptions over a plausible range and examine how inferences on change. As we will show next, weighting approaches in MAR settings can be naturally extended to MNAR settings by specifying a selection bias function to quantify the residual association of the missing probabilities and unobserved components of V after adjusting for observed data. Sensitivity analysis can then be conducted by varying the parameters in the selection bias function and/or the functional form.
We let denote the conditional missing probability . Throughout we assume that with probability 1.
3 Why the complete case approach may be biased?
We first illustrate why the complete case approach may be biased when MCAR does not hold.10 If the full data were observed, could be estimated by solving
the empirical version of . Unfortunately, when missing data exist, the solution to Equation (2) depends on unobserved components of V. Suppose , but , then if we use complete cases only and estimate by solving the estimating equation , it is obvious that the solution to the equation above, , may be biased unless , e.g. is constant.
Heuristically, when MCAR fails to hold, the complete cases are a selected, non-random subsample of the study population. Thus, inference obtained by applying standard approaches to the complete cases may be biased for . The IPW approach restores unbiasedness by creating a pseudo-population in which selection bias due to the missing data is removed. We next introduce the IPW methods for the three missing data patterns respectively.
4 Uniform missing pattern
A uniform missing data pattern is a pattern in which the missing indicator vector R takes only two possible values or . Noted above, unless MCAR holds, the complete case approach is likely biased. To remove selection bias due to missing data, the IPW approach weights each subject i with complete data () by the inverse of the conditional probability of observing the full data . For illustration, we temporarily assume is a known function of as is the case in studies with missingness by design (e.g. studies with two-stage sampling). Then, the simple IPW estimator solves the following estimating equation20
Under regularity conditions, is a consistent estimator of since
Note that the above equalities hold regardless of whether or not the missingness is ignorable (i.e. MAR or MNAR). In addition, a fully parametric model for the full data is not required. Under mild conditions, the solution to Equation (3) is a consistent and asymptotically normal (CAN) estimator of .20
This IPW estimator demonstrates the fundamental principle of the weighting approach; weighted copies of complete cases remove the selection bias introduced by the missing data process. However, note Equation (3) depends only on data from complete cases. Then, is not fully efficient. To increase efficiency, we can add to the estimating equation augmentation terms. These terms depend on data from both complete and incomplete cases.
From the definition of , it is clear that an augmentation term that takes the form has mean zero, where is an m-dimensional vector of arbitrary functions of the always observed variables . Let be . Then, is mean zero at and the solution to is a consistent estimator of under regularity conditions.21 Moreover, the asymptotic variance of equals Γwhere Γ. This implies that the choice of ϕ affects the efficiency of only through the term . By simple algebra, one can easily show that
and
as the two terms in the above representation of are uncorrelated. We want to select ϕ so that for any . Since the first term in does not depend on ϕ, we need to select ϕ such that . The inequality above is satisfied when = is the projection of onto a subspace of , as the norm of the residual from a projection is smaller than or equal to the norm of the original vector. For a given , the most efficient augmentation term, , is obtained by projecting onto the entire space . With uniform missing patterns, when MAR holds, equals . For example, in our motivating example 1, and thus . See references for technical details.6,19–30
So far we have assumed that is known, i.e. missingness by design, which occurs infrequently in medical applications. Therefore, we need to estimate using the observed data. We next discuss strategies to obtain estimated missing probabilities under MAR and MNAR mechanisms respectively.
4.1 Missing at random
Under MAR, by Equation (1), depends on only since is an empty set. Thus also depends only on since . In other words, for , . Since is observed for each subject i, then the estimated conditional missing probability can be obtained by regressing the missing indicator on the always observed covariates via either a parametric regression model (e.g. logistic regression) or non-parametric, data-adaptive algorithms (e.g. tree-based methods).31–35
In many studies that obtain data from electronic medical databases, the number of covariates that need to be adjusted for to make the MAR assumption plausible is quite large.36 Then it will be difficult to impose a correct parametric model for due to the curse of dimensionality. A mis-specified parametric model may result in significantly biased results. Data-adaptive, tree-based methods provide promising alternatives.32,33,35 They are designed to minimise the mean squared prediction error, no matter how many covariates need to be adjusted for. The methods are easy to implement with minimum analyst input. Trees have many advantages including being robust to outliers, insensitive to covariate transformation, and the ability to capture complex interactions and highly correlated variables. See Hastie et al.35 and Therneau and Atkinsoon37 for a comprehensive review of the method and software programs.
After are obtained, the IPW estimator is obtained by solving equation (3), with substituted for . To obtain the efficient augmented IPW estimators , additional modelling and estimation are needed since depends on the unknown outcome regression function . In example 1, . We use the complete cases to estimate . As before, we can use either a parametric working model or data-adaptive, tree-based regression techniques. After all the unknown functions and parameters are estimated, the augmented estimator is obtained by solving the augmented estimating equation . In this example 1,
It is worth noting that is doubly robust (DR) in the sense that it is consistent for if either the working model for the missing data process or the working model for the outcome regression function is correctly specified, but not necessarily both.38 This nice property offers analysts two chances of making correct inference. Furthermore, the specified working models are practically certain to be incorrect especially in the presence of high-dimensional covariates. But as long as at least one model is nearly correct, the bias of will be small by theory and simulation results.38 The variance estimates of can be obtained using either the asymptotic theory and delta methods or bootstrap re-sampling approaches.
4.2 Missing not at random
The MAR assumption cannot be empirically tested using observed data except under limited scenarios.39 Subject matter expertise is usually required to judge its plausibility. When MAR does not appear to be reasonable, then additional assumptions on the missing data process need to be imposed to make the parameters of interest identifiable. Since these additional assumptions are not verifiable under a non-parametric full data model for , a sensitivity analysis is recommended. There are different ways of conducting a sensitivity analysis for MNAR (i.e. non-ignorable) data. We focus on the selection bias function approach for IPW estimators.27,30 This approach decomposes the non-ignorable missing data process in a natural and straightforward manner, and thus makes it relatively easy to impose sensitivity assumptions using background information and substance knowledge.
Under MNAR, depends on both and . The selection bias function approach uses a user-specified function to quantify the residual association between the missingness probability and the possibly unobserved components of V conditioning on observed data. Specifically, we assume that
where is an unrestricted function of and is the selection bias function. In other words, the ‘odds’ of having missing data depends on the possibly unobserved components through the selection bias function . Note that needs to be specified by investigators, e.g. where c is a given constant vector. When the model for the full data is non-parametric, the functional form chosen for and the value of the parameter c are not empirically testable. In this article, we do not dwell on the choice of the selection bias function as it depends heavily on the study setting and existing substance knowledge about the missing mechanism.27,30
Assuming equation (4) holds and has been specified, we still need to estimate to obtain an estimated missing probability . To do so, we usually impose a parametric working model indexed by a unknown parameter α, e.g. . If W is categorical and the sample size is large, then we can use a saturated model to avoid model mis-specification. The parameter estimate is obtained by solving the unbiased estimating equation
where and ψ is a vector of selected functions of (e.g. ). Note that the dimension of ψ needs to be equal to the dimension of α. Under regularity conditions, the corresponding is consistent for the true value as long as the parametric working model is correct and equation (4) holds. However, the variance of depends on ψ.
As with MAR settings, the IPW estimator can be obtained as the solution to equation (3) using the estimated missing probability . See references27,28,40 for details on doubly-robust estimators and other, more efficient augmented estimators.
5 Monotone missing pattern
We now introduce the weighting approach for monotone missing patterns. Without loss of generality, we assume for any . Equivalently, for each subject i, if the sth element is missing, then all subsequent elements are missing.
We first focus on example 2 and then present general results. Specially, we consider the setting in which contains the treatment indicator and a vector of baseline covariates that are recorded for each subject (e.g. age, sex and comorbidity conditions); while denotes the BP measured at baseline and at 12 months. We make the data ‘monotone’ by ignoring on subjects missing V1 ( if ). We will estimate the coefficients β in the outcome regression model with .
Monotone missing data can be analysed by applying the weighting approach for a uniform missing pattern in a nested fashion; that is, a monotone missing pattern can be decomposed into multiple uniform missing data models. For example, in example 2, since we have two missing components, we derive our estimators in two steps. In the first step, we derive estimators under an artificial missing data model in which the full data is but the observed data is . That is, both and Yi are observed whenever the missing indicator is 1. In the second step, we consider a second artificial missing data model with now the full data and the observed data. Our final estimator will only depend on the actual data .
Specifically, let and . Then, under monotone missingness, , and . As above, suppose and are known functions. Later we relax this assumption.
The first step of our estimation procedure is to apply the IPW approach to the first artificial missing data model. In Section 4, we obtain a first-stage class of estimators by solving the estimating equation where
Here is a vector of selected functions of the observed components . However, the first term in depends on the outcome Yi which might still be missing in the actual data even if . To obtain unbiased estimating equations that depend only on the observed data , in the second stage of our estimation procedure, we apply the IPW approach to the second artificial missingness model, where is now the full data and is the observed data. Note that in this artificial missingness model, the missing indicator does not equal . Rather, the missing indicator equals one when the ‘full’ data and the observed data are the same. Since if or , we define a new missing indicator
with . Thus, our second-stage IPW estimators are solutions to the estimating equation where
By definition, and . Thus, . For simplicity, we denote as . After some algebra, one has
Under regularity conditions, it can be proved that is a CAN estimator of .21 Let and . We can rewrite as
To maximise efficiency under MAR, we select to be and to be . See Robins, Rotnitzky, and others for further discussions of efficiency.5,6,20–22,24,25,40
Next we consider how to estimate and under MAR and MNAR mechanisms, respectively.
5.1 Missing at random
If MAR holds, then for ,
Thus, is a function of only, whereas
depends on . That is, . Therefore, can be estimated using the observed data by regressing on using either a parametric working model or data-adaptive non-parametric techniques. Similarly, can be estimated using the observed data by regressing on among those with .
5.2 Missing not at random
When the missing data process depends on possibly unobserved data and the full data model is non-parametric, we must impose additional assumptions to make the parameters of interest identifiable. We extend the sensitivity analysis approach for the uniform missing pattern and assume that
Here, and are investigator-specified selection bias functions. To estimate and , we impose parametric working models and , and obtain the estimated parameter by solving the unbiased estimating equation where
Here
, , and . Moreover, is a vector of functions of the variables that are observed when .
5.3 General monotone results
The results we introduced above for example 2 can be extended to multiple-occasion monotone missing data models. In such models, consists elements and indicates the corresponding vector of missing indicators. If the sth component () is missing (), all subsequent components of are missing ( for any ). Let indicate a q-dimensional vector with the first elements being 1 and the remaining s elements being 0 (i.e. the first elements of are observed while the remaining s elements are missing). The class of IPW estimators is constructed based on the estimating equations where
where is a vector of selected functions of the variables and , which are observed when . For any , let denote subject i’s conditional probability of observing the sth element given the full data and the event that all previous elements are observed. Due to monotone missingness, .
Under MAR, depends on only, i.e. . Then can be estimated from the observed data by regressing on among those with .
The estimation of the missing data process under MNAR is much more complicated. As before, selection bias functions need to be specified for the ‘odds’ of having missing data. Specifically, for any ,
Then and . The estimated solves the estimating equation where
and is a vector of functions of .
6 Non-monotone missing pattern
In non-monotone missing data models, the q-dimensional vector of missing indicators can take possible values as each element can be either 0 or 1. For example, when , . In such models, the estimation of the missing data process is substantially more challenging.
The estimation of the parameter of interest β when the missing probabilities are known is similar to the estimation in monotone missing data models. Specifically, the IPW estimator is obtained by solving the estimating equation where
and is a selected vector of functions of the observed components when . Unlike in Section 5.3, r is no longer restricted to .
In most applications, is unknown and must be estimated from the observed data. Robins and colleagues proposed the randomised monotone missingness (RMM) processes41 to analyse non-monotone ignorable missing data, and the selection bias permutation missingness (PM) models42,43 to analyse non-monotone non-ignorable missing data. These approaches are sometimes plausible. However, they are quite complex and computationally intensive. There currently exists no user-friendly software program to facilitate their implementation. These limitations likely contribute to lack of wide adoption. Through introducing the heuristic ideas behind these approaches, we hope to encourage researchers to develop user-friendly software tools for these methods.
We use two motivating examples for MAR and MNAR mechanisms respectively; PM models are best explained in the context of a longitudinal study. In contrast, RMM models do not apply to longitudinal data. Both examples share common notation. The full data is denoted by , and the observed data is denoted by where is the vector of missing indicators. The parameter of interest is the unique solution to .
6.1 Missing at random
We consider example 3. Under MAR, for any , .
If is discrete with few levels, the estimated missing probabilities can be obtained as the empirical proportions within each covariate level. In practice, we need to impose parametric working models for to reduce dimension and borrow information across different covariate levels. To simultaneously satisfy the restrictions imposed by MAR, the inequalities , and the equality , it will be difficult, if not impossible, to directly model .
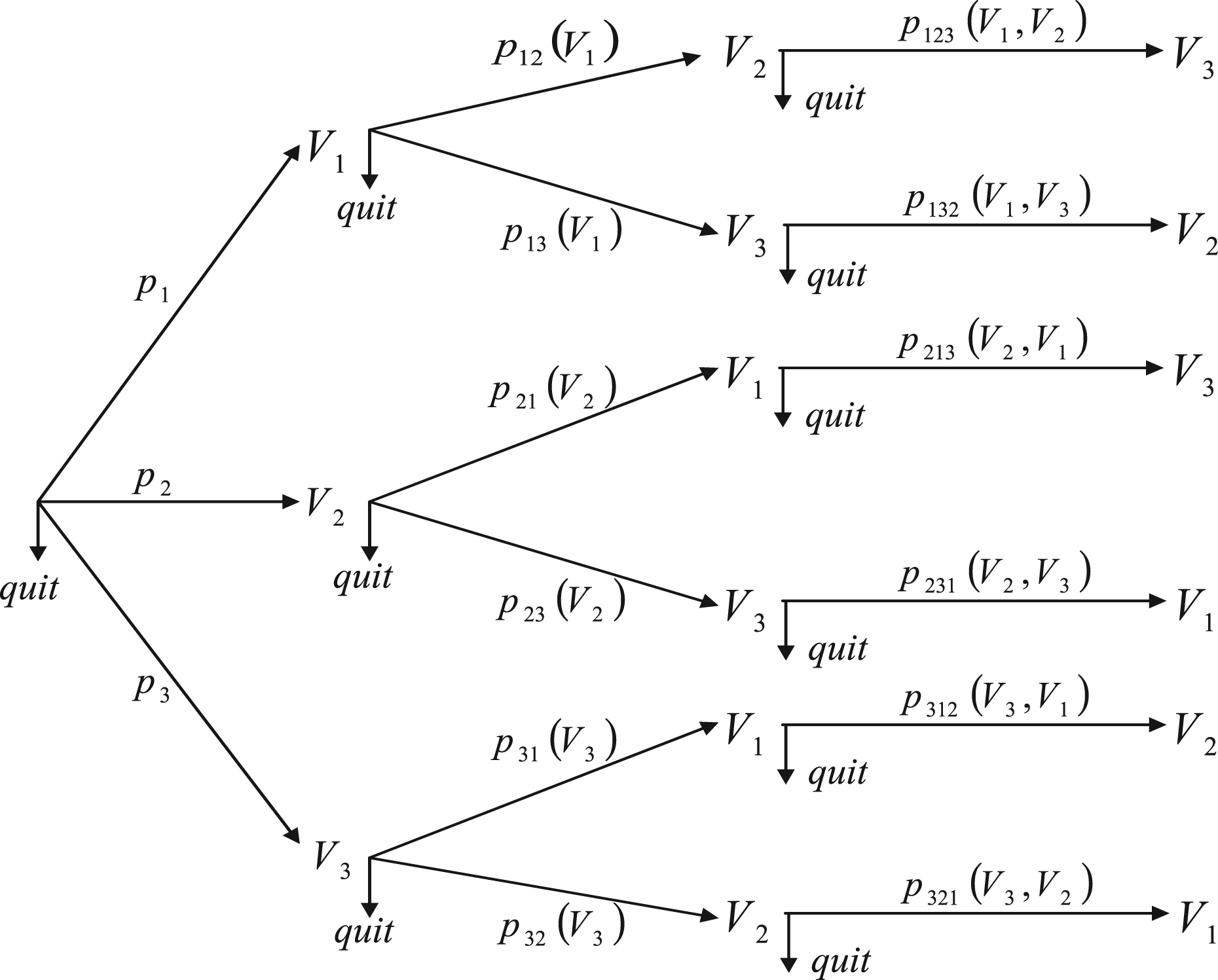
Robins and Gill41 proposed an algorithm to estimate under a sub-model of MAR models, which they referred to as a RMM model. This model is assumed to be generated as follows. For each subject i, is observed. Then one of the three elements of , , is observed with probability , or one quits without observing any element of with probability . If, for example, is observed, then in a second step, we observe with a conditional probability , or observe with a conditional probability , or quit with probability . Note that the conditional probabilities and depend both on and the value of observed at the first step. For simplicity, we suppress the dependence on when no ambiguity arises. Suppose is observed at the second step, then in the third step, we observe the third component with a conditional probability or quit with probability . The following figure is similar to Figure 1 in Robins and Gill41 to help understanding.
Missing data process in a RMM process.
An RMM process satisfies MAR. For example, the overall probability of observing , , equals , since we either observe at the first step and then at the second step and then quit without observing , or observe at the first step and then at the second step and then quit without observing . This overall probability depends on which are observed when . It can be shown that the probabilities sum to 1.
Gill and Robins44 showed that there do exist ignorable (i.e. MAR) missing data processes that are not RMM. However, such processes are often unrealistic ‘due to the subtle and precise manner in which the data must be “hidden” to insure that the process is MAR’.
The estimation of is non-trivial for RMM processes. To reduce the dimension, the authors considered Markov RMM processes in which the conditional probabilities do not depend on the order in which the variables were observed. For example, and will be denoted as . Parametric working models are imposed for these conditional probabilities. For example, for any , we model the first-step probabilities with a multinomial logistic regression model
The second-step probabilities are modelled by
Finally, the third-step probabilities are modelled by,
where indicates the two elements other than (e.g., ). When appropriate, we can further decrease the dimension of the parameter space by assuming, for example, does not depend on k.
The maximum likelihood estimates (MLEs) of the unknown parameters cannot be directly obtained as the order in which variables were observed is missing. For example, there are two paths in the figure above by which and could be observed: , or . The authors suggest treating the path information as missing and to obtain the MLE with the Expectation-Maximisation (EM) algorithm. See Ref.41 for details.
6.2 Missing not at random
For non-monotone non-ignorable missing data processes, Robins et al.43 propose selection bias PM models. Consider our motivating example 4, a longitudinal study with three BP measurements. In longitudinal studies, the PM order is the reverse of the temporal order. Under a PM model, we assume that the conditional probability of observing at the sth visit depends (i) on the observed components from previous visits (i.e. ) but not on the unobserved components of ; (ii) on the value of through a specified selection bias function; and (iii) on both observed and unobserved components in future visits (). In our motivating example 4, we consider a simplified PM model in which the conditional probability of observing does not depend on any future data. Thus, is , where satisfies
Here is an investigator specified selection bias function and is an unrestricted function to be estimated. By Equation (6), the conditional probability depends on the possibly unobserved value of through .
In most applications, we impose parametric working models for to overcome the curse of dimensionality. The parameter can be estimated by solving
where is a vector of selected known functions of and has the same dimension as . See Vansteelandt et al.30 for an extension of this approach to estimate the mean vector of repeated outcomes in a non-ignorable, non-monotone missing data model.
Although a subject’s decision to miss the sth visit cannot directly depend on future data. But Rs, the indicator variable indicating whether Vs was observed, might be statistically associated with future data, when some factors that affect the decision are not recorded in but are associated with . See Robins et al.43 for further discussions.
7 Discussion
We have introduced the IPW approaches in a wide range of settings with different missing data patterns and mechanisms. These weighting approaches share the same basic idea. However, different strategies are needed to estimate the missing probabilities depending on the missing data pattern and mechanism. Our goal in this review article was to provide a conceptual overview of existing weighting approaches.
Our review began with a simple uniform missing data model; for each subject i, either the entire vector is observed or it is completely missing. We then discussed monotone missing data patterns. We show these models can be decomposed into multiple ‘artificial’ uniform missing data models and estimators are obtained by applying weighting approaches for uniform missing data models in a nested fashion. In Section 6, we discussed non-monotone missing patterns and notice that the estimation of the missingness probabilities is substantially more challenging and complex. We then introduced the RMM processes for non-monotone MAR data and the selection bias PM approach for non-monotone MNAR data. User-friendly software programs need to be developed to make these methods useful for practice.
We considered both MAR and MNAR mechanisms. IPW estimators for MNAR are natural extensions of IPW estimators for MAR in which selection bias functions quantify the residual association of the missing probabilities and unobserved data conditional on observed data. The MAR assumption cannot be empirically tested when the model of the full data is non-parametric. Subject matter expertise and prior information are typically required to judge its plausibility. In uniform and monotone missing patterns, MAR sometimes is reasonable if data on a large set of variables are collected. The MAR assumption is less likely to hold with non-monotone missingness.30 Unless strong prior information is available, we recommend analysts consider the possibility that the missingness mechanism is non-ignorable and conduct a sensitivity analysis.
References
1.
LittleRRubinD. Statistical analysis with missing data , New York: John Wiley & Sons, 1987.
2.
RaghunathanTE. What do we do with missing data? Some options for analysis of incomplete data. Ann Rev Public Health2004; 25: 99–117.
3.
RubinD. Inference and missing data (with discussion). Biometrika1976; 63: 581–592.
4.
HorvitzDGThompsonDJ. A generalization of sampling without replacement from a finite universe. J Am Stat Assoc1952; 47: 663–685.
5.
RobinsJRotnitzkyAZhaoL. Estimation of regression coefficients when some regressors are not always observed. J Am Stat Assoc1994; 89: 846–866.
6.
RobinsJRotnitzkyAZhaoL. Analysis of semiparametric regression models for repeated outcomes in the presence of missing data. J Am Stat Assoc1995; 90: 106–121.
7.
RobinsJHernanMBrumbackB. Marginal structural models and causal inference in epidemiology. Epidemiology2000; 11: 550–560.
8.
HernanMBrumbackBRobinsJ. Marginal structural models to estimate the causal effect of Zidovudine on the survival of HIV-positive men. Epidemiology2000; 11: 561–570.
9.
HortonNJLairdNM. Maximum likelihood analysis of generalized linear models with missing covariates. Stat Methods Med Res1999; 8: 37–50.
10.
IbrahimJGChenMHLipsitzSRHerringAH. Missing-data methods for generalized linear models: a comparative review. J Am Stat Assoc2005; 100: 332–346.
11.
IbrahimJGMolenberghsG. Missing data methods in longitudinal studies: a review. Test2009; 18: 1–43.
12.
IbrahimJGChenMH. Power prior distributions for regression models. Stat Sci2000; 15: 46–60.
13.
ChenMHIbrahimJGLipsitzSR. Bayesian methods for missing covariates in cure rate models. Lifetime Data Anal2002; 8: 117–146.
14.
IbrahimJGChenMHLipsitzSR. Bayesian methods for generalized linear models with covariates missing at random. Can J Stat2002; 30: 55–78.
15.
HarelOZhouXH. Multiple imputation: review of theory, implementation and software. Stat Med2007; 26: 3057–3077.
16.
RubinDB. Multiple imputation for nonresponse in surveys , New York: Wiley, 1987.
17.
SchaferJL. Multiple imputation: a primer. Stat Methods Med Res1999; 8: 3–15.
18.
TsiatisA. Semiparametric theory and missing data , New York: Springer, 2006.
19.
van der LaanMRobinsJ. Unified methods for censored longitudinal data and causality , New York: Springer, 2003.
20.
RobinsJMRotnitzkyA. Semiparametric efficiency in multivariate regression-models with missing data. J Am Stat Assoc1995; 90: 122–129.
21.
RotnitzkyARobinsJMScharfsteinDO. Semiparametric regression for repeated outcomes with nonignorable nonresponse. J Am Stat Assoc1998; 93: 1321–1339.
22.
RobinsJMRotnitzkyAZhaoLP. Analysis of semiparametric regression-models for repeated outcomes in the presence of missing data. J Am Stat Assoc1995; 90: 106–121.
23.
RotnitzkyARobinsJM. Semiparametric regression estimation in the presence of dependent censoring. Biometrika1995; 82: 805–820.
24.
RotnitzkyARobinsJM. Semiparametric estimation of models for means and covariances in the presence of missing data. Scand J Stat1995; 22: 323–333.
25.
RotnitzkyAHolcroftCARobinsJM. Efficiency comparisons in multivariate multiple regression with missing outcomes. J Multivariate Anal1997; 61: 102–128.
26.
BickelPJKlaassenCARitovYWellnerJA. Efficient and adaptive estimation for semiparametric models , New York: Springer Verlag, 1998.
27.
ScharfsteinDORotnitzkyARobinsJM. Adjusting for nonignorable drop-out using semiparametric nonresponse models. J Am Stat Assoc1999; 94: 1096–1120.
28.
ScharfsteinDORotnitzkyARobinsJM. Adjusting for nonignorable drop-out using semiparametric nonresponse models – Rejoinder. J Am Stat Assoc1999; 94: 1135–1146.
29.
RobinsJMRotnitzkyA. Inference for semiparametric models: some questions and an answer – Comments. Stat Sin2001; 11: 920–936.
30.
VansteelandtSRotnitzkyARobinsJ. Estimation of regression models for the mean of repeated outcomes under nonignorable nonmonotone nonresponse. Biometrika2007; 94: 841–860.
31.
BreimanLFriedmanJHOlshenRAStoneCJ. Classification and regression trees , Belmont, CA: Wadsworth International Group, 1984.
32.
FriedmanJHastieTTibshiraniR. Additive logistic regression: a statistical view of boosting. Ann Stat2000; 28: 337–374.
33.
FriedmanJHastieTTibshiraniR. Additive logistic regression: a statistical view of boosting – Rejoinder. Ann Stat2000; 28: 400–407.
34.
BreimanL. Random forests. Mach Learn2001; 45: 5–32.
35.
HastieTTibshiraniRFriedmanJ. The elements of statistical learning: data mining, inference, and prediction , 2nd ed. New York: Springer, 2009.
36.
SchneeweissSRassenJAGlynnRJAvornJMogunHBrookhartMA. High-dimensional propensity score adjustment in studies of treatment effects using health care claims data. Epidemiology2009; 20: 512–522.
37.
Therneau TM and Atkinsoon EJ. An introduction to recursive partitioning using the RPART routines. Technical Report 61, Rochester, MN, Mayo Clinic, Section of Statistics, 1997.
38.
BangHRobinsJ. Doubly robust estimation in missing data and causal inference models. Biometrics2005; 61: 962–972.
39.
PotthoffRFTudorGEPieperKSHasselbladV. Can one assess whether missing data are missing at random in medical studies? Stat. Methods Med Res2006; 15: 213–234.
40.
RotnitzkyARobinsJ. Analysis of semi-parametric regression models with non-ignorable non-response. Stat Med1997; 16: 81–102.
41.
RobinsJMGillRD. Non-response models for the analysis of non-monotone ignorable missing data. Stat Med1997; 16: 39–56.
42.
RobinsJM. Non-response models for the analysis of non-monotone non-ignorable missing data. Stat Med1997; 16: 21–37.
43.
RobinsJMRotnitzkyAScharfsteinDSensitivity analysis for selection bias and unmeasured confounding in missing data and causal inference models. In: HalloranMBerryD (eds). Statistical models in epidemiology: the environment and clinical trials , New York: Springer-Verlag, 1999, pp. 1–92.
44.
GillRDvan der LaanMRobinsJMCoarsening at random: characterizations, conjectures and counterexamples. In: LinDY (ed.) Proceedings of the first Seattle symposium on biostatistics: survival analysis , New York: Springer Verlag, 1997, pp. 255–294.