
Abstract
In testing for non-inferiority or superiority in a single arm study, the confidence interval of a single binomial proportion is frequently used. A number of such intervals are proposed in the literature and implemented in standard software packages. Unfortunately, use of different intervals leads to conflicting conclusions. Practitioners thus face a serious dilemma in deciding which one to depend on. Is there a way to resolve this dilemma? We address this question by investigating the performances of ten commonly used intervals of a single binomial proportion, in the light of two criteria, viz., coverage and expected length of the interval.
1 Introduction
In biomedical research, the confidence interval (CI) of a single binomial proportion is frequently used in testing for non-inferiority or superiority. The typical one-sided hypothesis-testing formulation for non-inferiority is

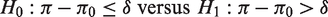
To carry out a test for non-inferiority (superiority), practitioners often use available statistical packages to compute an appropriate CI of a binomial proportion. Incidentally, almost all statistical packages provide more than one option to compute a CI for a single binomial proportion. For example, the current version of SAS 9.3 (The SAS Institute, Cary, NC) offers six different intervals, Stata (Stata Corp LP, College Station, TX, USA) offers five different intervals, and SPSS (SPSS Inc, IL) offers three different intervals. The consequences of too many available choices are that, inferences drawn from different intervals often lead to conflicting conclusions. Thus, the practitioners are pushed to a situation requiring them to make an informed choice.
To illustrate a similar situation we consider a recent post-market urology study; 31 patients were treated with a medical device for their stress urinary incontinence syndrome, where older women are unable to hold their urine, and it leaks due to minor physical activities like coughing, walking, etc. After 12 months, 28 patients reported the efficacy of the treatment, and three of them reported a worsened status. Based on the historical success rate of 85% for other devices already available in the market, the study was intended to check the non-inferiority of the device, with a 10% margin. Therefore, the null hypothesis
Two-sided 95% confidence intervals of the results of device study.
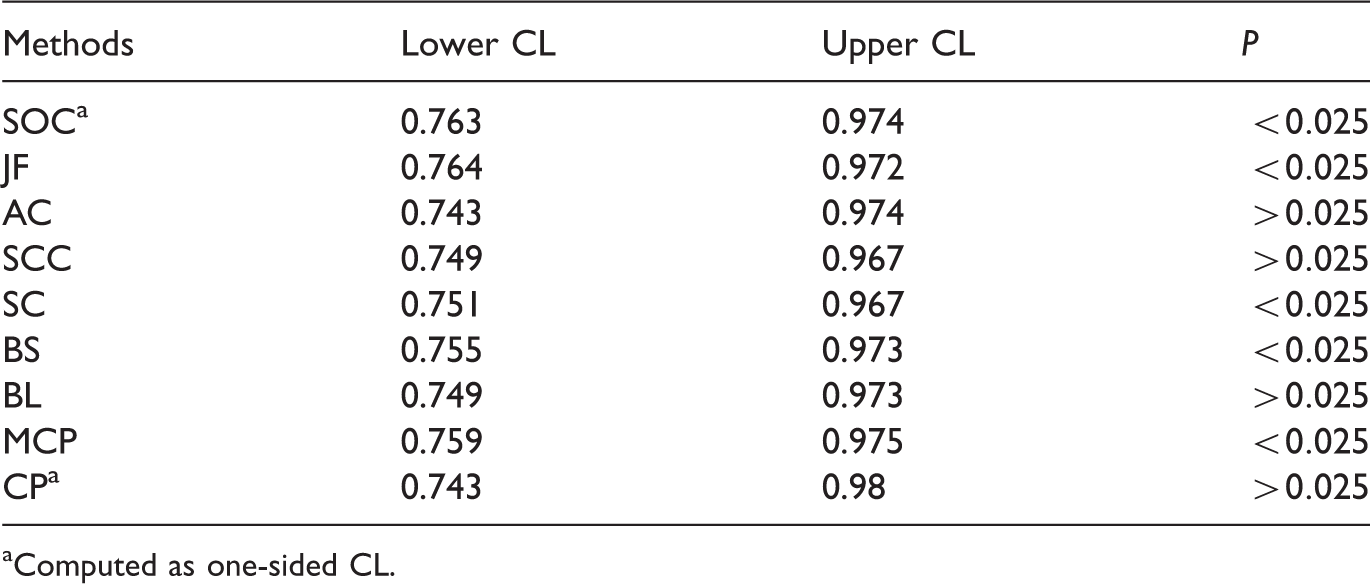
Computed as one-sided CL.
We address this issue by comparing the performances of the often used CIs based on two criteria, viz. coverage and expected length. Newcombe3–5 compared the performances of seven two-sided confidence intervals of a single binomial proportion. Unlike Newcombe, in this paper we address the problem of testing non-inferiority (superiority) using a confidence interval approach. Thus our focus is on studying the performance of
There are statisticians who question the legitimacy of taking up an inflexible stance on attaining nominal coverage as stated above. Brown et al. 10 (BCD) in an important paper suggested that one should instead consider a trade-off between the coverage and the precision (expected length) for comparing different intervals. Following BCD recently, Newcombe and Nurminen 11 have come up with an interesting idea that “in the evaluation of various methods it is more appropriate to consider the moving average of the coverage probabilities” over an interval of parameter values, instead of sticking to the requirement of nominal coverage probabilities. But, in this paper, we refrain from entering into the philosophical debate of coverage versus precision, and the trade-off thereof that one could look for. We would rather keep the option open for the practitioners to decide what suits them best in a given situation.
Another good reason for considering exact CIs is that, with the availability of high-speed computers, exact intervals are now easily computable for any reasonable sample size and thus have become quite popular among the practitioners. In fact, these intervals are now available in standard statistical packages; for example, the Clopper–Pearson interval (CP) is available in SAS, StatXact, R, and S-Plus; the Blyth-Still-Casella interval (BS) is available in StatXact; and the interval due to Blaker (BL) and the mid-p adjusted Clopper–Pearson interval (MCP) are available in R.
In this article, we compare five asymptotic intervals – Wald with continuity correction (AS) (Fleiss et al.
12
), Wilson (SC),
13
Wilson with continuity correction (SCC) (Fleiss et al.
12
), Agresti-Coull (AC),
14
and second-order corrected (SOC)
In Section 2, we briefly describe the methods of finding the above confidence intervals. Section 3 presents an extensive simulation study comparing the intervals in terms of coverage and expected length. In Section 4, we present our case with a real-life dataset, and finally, in Section 5 we give the concluding discussion.
2 Confidence intervals
We consider intervals of three types viz., Asymptotic, Bayesian and Exact, depending on the methodology being used for finding them. Suppose X denotes the number of successes in n independent Bernoulli trials with constant probability of success π. Given x, the observed value of X, we denote the observed success rate
2.1 Asymptotic intervals
2.1.1 AS: asymptotic Wald interval with continuity correction
This is a continuity-corrected Wald interval given in Fleiss et al.
12
The Wald interval is obtained by inverting the Wald test for π and is given by

The continuity-corrected interval uses the following formula:

2.1.2 SC: Score interval (Wilson 13 )
The CI based on the score statistic was first proposed by Edwin B. Wilson.
13
Setting the score statistic equal to the critical z values,

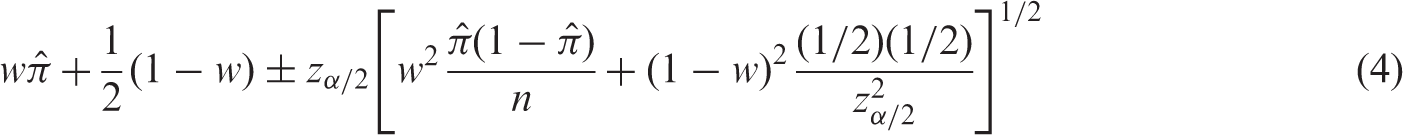
It is a frequently used CI in many applications, especially in biomedical research, since it is known to have good coverage properties with shorter length. Both Newcombe 3 and BCD 10 recommend this interval.
2.1.3 SCC: score interval with continuity correction
The continuity-corrected version of the score interval is obtained by replacing 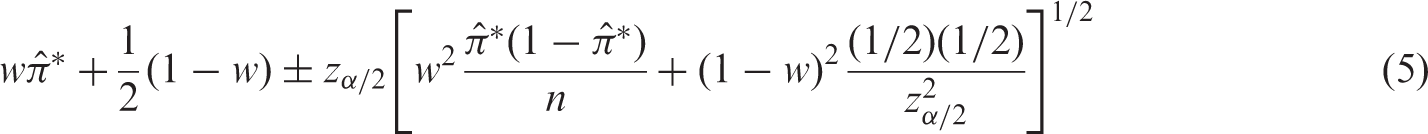
2.1.4 AC: Agresti–Coull interval
An asymptotic interval proposed by Agresti and Coull
14
is based on a simple adjustment of the Wald interval obtained by adding “two successes and two failures” to the sample when the nominal coverage probability is 0.95. Therefore, the point estimate is 
BCD 10 recommended this interval based on their study.
2.1.5 SOC: Second order corrected interval
Cai
6
proposes a 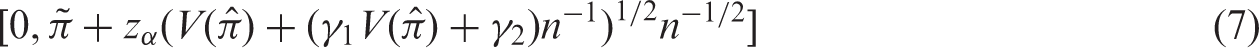
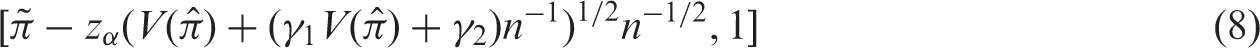
For further details we refer to Cai. 6
2.2 Bayesian interval
2.2.1 JF: Jeffreys’ prior interval
This is an equal-tailed posterior probability interval using Jeffreys noninformative prior which is Beta(1/2,1/2) having density 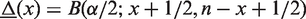
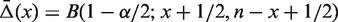
2.3 Exact intervals
2.3.1 CP: Clopper–Pearson interval
The lower 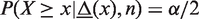
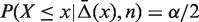
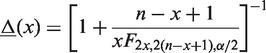
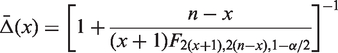
2.3.2 MCP: Mid-P adjusted Clopper–Pearson interval
Exact intervals are known to be conservative, and consequently they are wider in length than their asymptotic counterparts. Agresti and Gottard
21
revisited mid-p adjustment (Lancaster
22
), Berry and Armitage,
23
Vollset,
2
Newcombe
3
) of the Clopper–Pearson interval. In the computation of the mid-P value, only 1/2 of the point probability 
2.3.3 BL: Blaker’s interval
This is a less popular CI, which is available in R and S-Plus. Blaker uses Spjøtvoll’s (Spjøtvoll,
24
Blaker and Spjøtvoll
25
) notion of a preference function (PF) to improve upon the interval proposed by Birnbaum.
26
Birnbaum bases his interval on the P-value of the equal-tailed test of
Given
Note
2.3.4 BS: Blyth-Still-Casella interval
This interval is available only in StatXact software. A confidence set of π, say C, is a collection of 
The expression inside the parentheses represents the probability that the random interval 
3 Simulation study
In this section, we discuss the results of an extensive simulation study. We consider sample sizes 
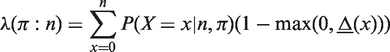
Note coverage and expected length are functions of success probability π and sample size n. For a fixed sample size, the distributions of these entities could be found assuming a uniform distribution of π. We produce BliP plots (Lee and Tu 28 ) for representing these distributions pictorially. The vertical bars in each plot show the deciles of the corresponding distribution. For the coverage plot, a long vertical line is drawn at the 97.5% coverage.
The BliP plots of coverage and expected length of all the intervals except AS and SOC are presented in Figure 1 for the sample sizes mentioned above. Blip plot for AS is not included since its performance as expected is way below the others. On the other hand for values of π near the boundaries the under-coverage of SOC interval is worse than Jeffreys’ (see Figure 2), though the overall coverage behaviour of SOC is slightly better than Jeffreys’. Thus inclusion of SOC interval in the Blip plot creates a scaling problem in the sense that the visual comparison of others becomes difficult. We draw the Blip plot of SOC interval (see Figure 2) while revisiting the example in Section 4. For moderately large sample sizes its performance is similar to Jeffreys’.
Blip plot of 97.5% one-sided coverage and expected length for n = 25, 50, 100, 1000. Blip plot of one-sided 97.5% coverage and expected length for n = 31.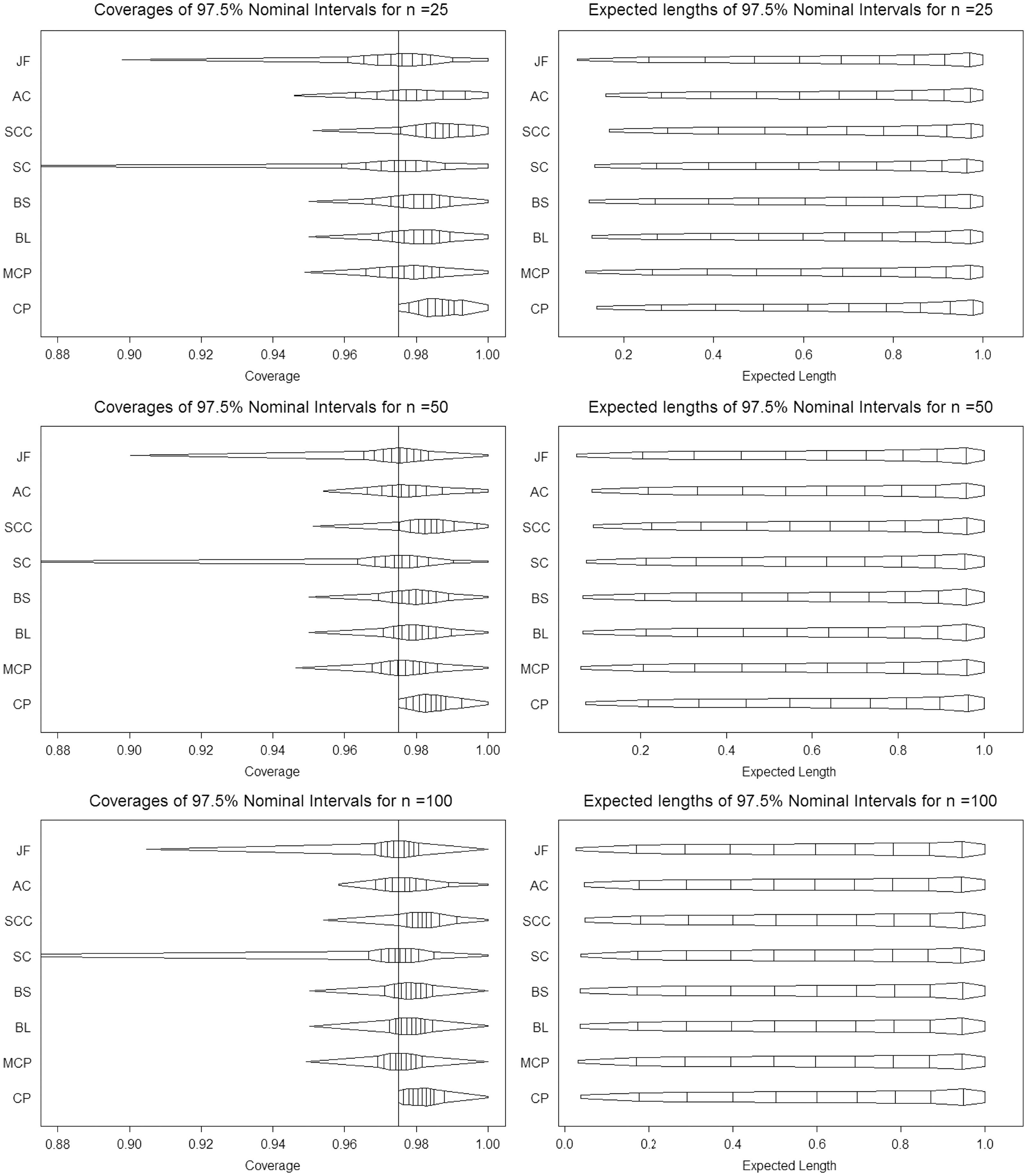
It is evident that from the standpoint of aligning minimum coverage with
4 Revisiting the example: stress urinary incontinence study
We revisit the example that we have considered in the beginning. We find this example useful for two reasons. First, it is about a study that was conducted. Secondly, it leads to conflicting inference. The intervals BL, AC, SCC, and CP do not reject the null hypothesis of non-inferiority, while the intervals JF, SOC, SC, AS, MCP, BS reject. In order to understand the phenomenon, we draw the blip plots of the CI’s for
5 Concluding remarks
This article is written primarily for two reasons. First, as practitioners, we often encounter a situation similar to the one presented in this paper. By conducting an extensive simulation study and drawing upon theoretical insights, we could explain why such a situation arises. Second, we reason that, if we understand why such a situation could arise, we are in a position to take an informed decision. We take an eclectic view on this matter and would not like to offer a solution. We leave it to the practitioner to decide depending on his or her own perspective. However, “there is a caveat”. Our study clearly shows that with increase in sample size the gain in expected length is clearly outweighed by loss in coverage.
We have noted at the outset that for testing inferiority practitioners prefer to use CI. One may wonder why a hypothesis test is not carried out directly instead of using CI for finding the P-value in an indirect way. The reason is, for some of the CIs (like SOC, BS and BL) finding the acceptance regions of the corresponding tests by inverting it is difficult although theoretically possible. Thus for these intervals a direct test of hypothesis is difficult to implement. On the other hand for intervals like AS, SC, AC and CP the hypothesis of inferiority could be easily tested directly.
Finally, we want to make a few remarks about the computation methods used. We have used StatXact to compute all confidence intervals for BS; to our knowledge StatXact is the only commercially available software to compute a confidence interval using BS method. For implementing Blaker’s interval, MCP, and a number of the asymptotic intervals, we used the R codes from Alan Agresti (http://www.stat.ufl.edu/ aa/cda/R/one-sample/R1/).
Footnotes
Acknowledgements
We thank Professor Newcombe and an anonymous referee for many useful comments that led to substantial improvement of the presentation of this article. We also thank Brian Johnson for his constructive comments on an early version of this manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.