
Abstract
The objective was to compare classical test theory and Rasch-family models derived from item response theory for the analysis of longitudinal patient-reported outcomes data with possibly informative intermittent missing items. A simulation study was performed in order to assess and compare the performance of classical test theory and Rasch model in terms of bias, control of the type I error and power of the test of time effect. The type I error was controlled for classical test theory and Rasch model whether data were complete or some items were missing. Both methods were unbiased and displayed similar power with complete data. When items were missing, Rasch model remained unbiased and displayed higher power than classical test theory. Rasch model performed better than the classical test theory approach regarding the analysis of longitudinal patient-reported outcomes with possibly informative intermittent missing items mainly for power. This study highlights the interest of Rasch-based models in clinical research and epidemiology for the analysis of incomplete patient-reported outcomes data.
Keywords
1 Introduction
Patient-reported outcomes (PROs) are more and more used in health studies in order to evaluate the perception of patients regarding concepts that are not directly observable such as health-related quality of life, well-being, pain for example. 1 For this reason, such unobservable variables assessed by PROs are often called latent variables. They are usually measured using the answers of patients to items belonging to a scale that can be unidimensional or multidimensional with different items grouped into each dimension. 2 The patient’s collected answers to a scale can be referred to as a form.
Longitudinal data are frequently collected to allow analysing PROs evolution over time such as, for instance quality of life. Missing data, which are frequent in longitudinal studies particularly in chronic disease contexts, are an issue that may engender two main problems: a potential loss of power and bias of estimates.3,4 Different patterns of missing data can be encountered: complete dropout, intermittent missing forms, intermittent missing items. In the first pattern, whole forms are missing from a certain point in time.5,6 Indeed, it is possible that a patient drops out from the study because this person has moved or has deceased for example. In the second pattern, one or more whole forms are not available at different times of the study. 7 For instance, a patient could be missing once, twice or more times during the study. In the last pattern, incomplete forms are collected. 8 For example, a patient might not answer to some items of the scale at each time. In the present paper, we will study the last pattern (intermittent missing items).
Moreover, several types of missing data (informative or non-informative) exist and some of them can seriously impact the conclusions of the analysis. 9 Their origins can be miscellaneous. Little and Rubin10,11 described the mechanisms that engender missing data and defined three types of missing data: MCAR (missing completely at random), MAR (missing at random) and MNAR (missing not at random). MCAR and MAR data are considered when the probability to have a missing value is independent of the measured latent variable. MCAR and MAR data are non-informative missing data because they are not related to the missing data. MCAR data are also independent of previous observed data. For instance, the patient could forget to answer to an item: the missing item is then MCAR and considered as non-informative. MAR data are not linked to the unobserved data but they are completely explained by the previous observed data. Such a case can be design-based when, for instance, a patient only responds to a given part of the questionnaire if an answer to a given item is ‘yes’. Otherwise the patient does not have to respond to this part of the questionnaire at all. Hence, the missing data will then be considered as MAR and non-informative. 12 MNAR data correspond to the informative missing case. In the latter, the probability to observe a missing data depends on the unobserved data. The informative missing data (the MNAR data) correspond to data where a link exists between the measured latent variable and the probability of non-response. For example, a patient with a poor quality of life could have a higher propensity of non-response than a patient with a good quality of life: the corresponding missing item is in this case MNAR and considered as informative. 13
Two main approaches exist for PROs analysis: the classical test theory (CTT) and the item response theory (IRT). Rasch-family models derive from IRT and have particular psychometric properties. CTT relies on the observed scores that are assumed to provide a good representation of a ‘true’ score, while Rasch model relies on an underlying response model relating the items responses to a latent parameter, often called latent trait, interpreted as the true individual quality of life, for instance. It has been shown that both approaches are very similar and perform as well when longitudinal data are complete (no missing data). 14 They remain quite similar in case of complete dropout longitudinal data, both displaying poor power (especially CTT) and biased estimates in case of MNAR data. 15 However, the relative performance of CTT and Rasch-family models derived from IRT in case of possibly informative intermittent missing items in longitudinal PROs data is unknown and remains to be identified. Longitudinal PROs data are usually gathered to assess whether quality of life, for instance, is evolving with time, that is whether a time effect exists (significant increase or decrease in quality of life) or not (non-significant evolution of quality of life with time).
The aim of the present study was to compare CTT-based and Rasch-based approaches regarding the identification and quantification of a time effect in the framework of longitudinal PROs data with possibly informative intermittent missing items. A simulation study was performed in order to assess and compare the performance of CTT-based and Rasch-based methods in terms of bias, control of the type I error and power.
2 Methods
PROs data may be analysed with CTT using a method based on score mixed (SM) models and with Rasch model using a method based on a longitudinal Rasch mixed (LRM) model. 14 The different methods are detailed in the following.
2.1 Longitudinal PROs analysis
2.1.1 SM method (Figure 1, parts C and D)
CTT approach is based on a score. It is assumed that a true score exists and that the observed score allows estimating this true score.
16
These two scores are linearly associated.
2
With the SM method, the patient’s score is computed at each time. The observed score ( Schematic outline of methods used to simulate and to analyse datasets.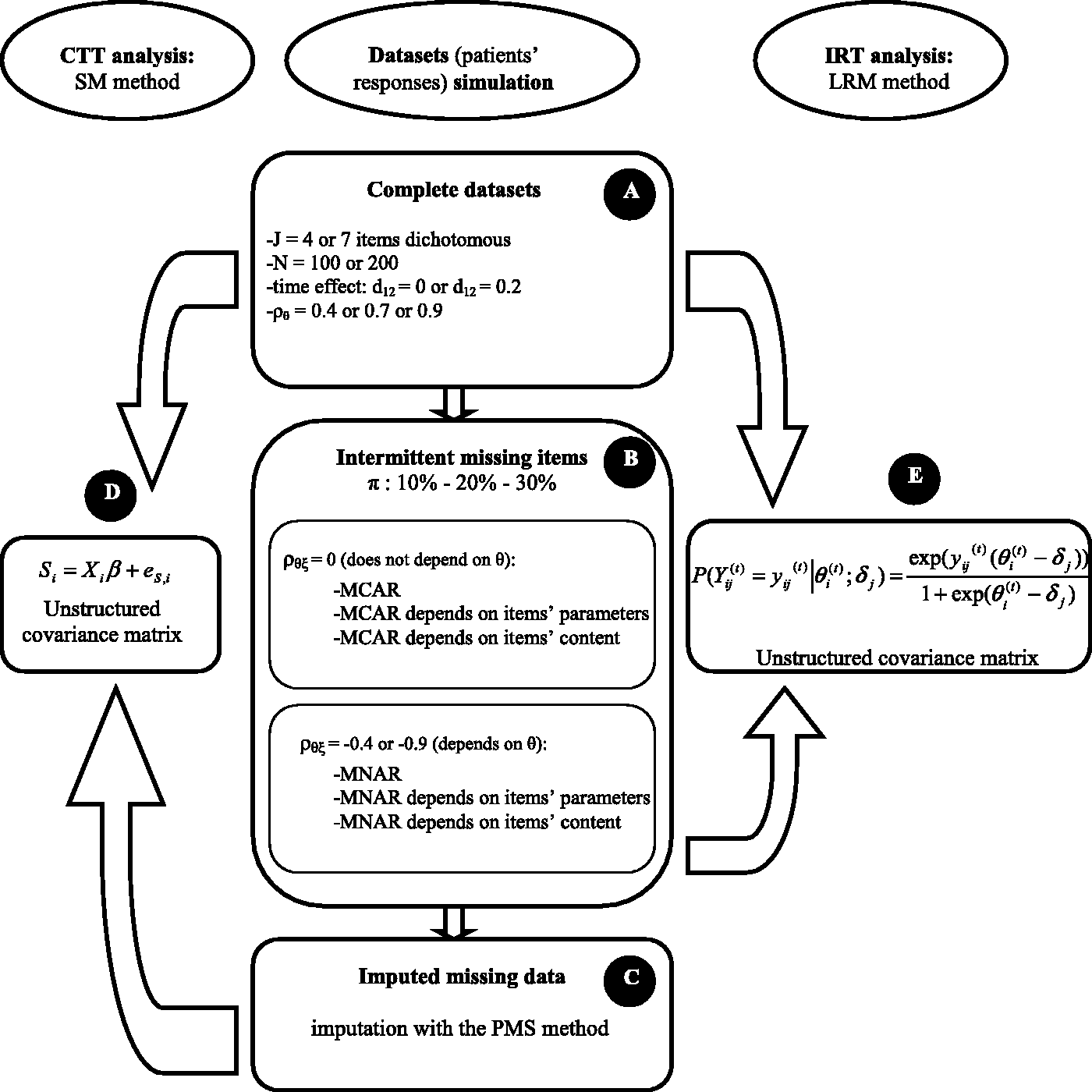
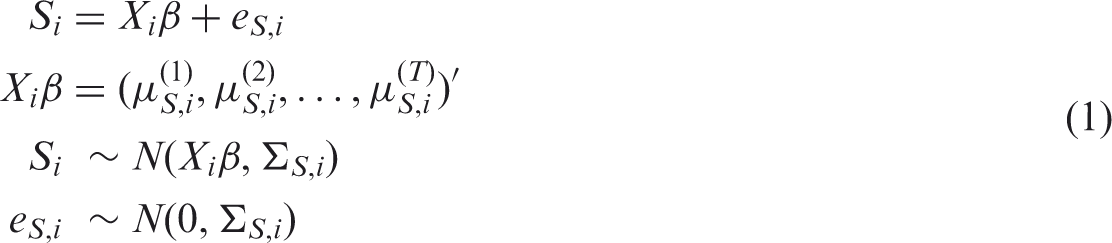
In presence of intermittent missing items, the computation of the score cannot be performed if at least one item is missing. Some scoring manuals of scales (SF-36, QLQ-C30) recommend imputing a missing value by the mean response of the patient to the other items in order to decrease the rate of missing values. This method is named personal mean score (PMS) 17 and is generally used when the amount of missing items at a given time t does not exceed 50% for a given patient (SF-36 manual). 18 Otherwise the score is not computed. The PMS imputation was used before applying SM method.
The restricted maximum likelihood (REML) estimation in SAS Proc MIXED was used to estimate parameters of the model. 19
2.1.2 LRM method (Figure 1, part E)
For the Rasch-family models, the probability of a response to an item is modelled as a function of the latent trait and of parameters characterizing the items. The LRM belongs to the Rasch-family models which rely on fundamental assumptions. First, all responses to items must be influenced by the same concept (unidimensionality). Secondly, the probability to obtain a positive answer (the most favourable response regarding the latent trait) to an item increases with the latent trait (monotonicity). Last, the answer to an item for a patient is independent of answers of this patient to other items (local independence). The LRM method is a longitudinal counterpart of the Rasch model.20–22 The relationship between the items’ answers and the latent variable is modelled by a logistic link function.
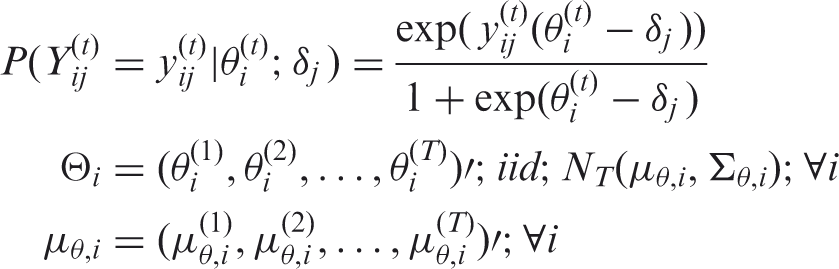
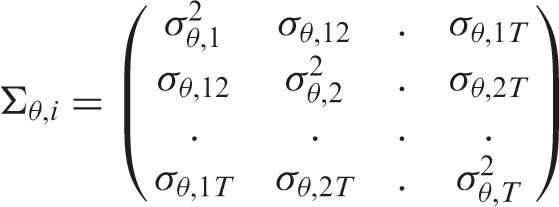
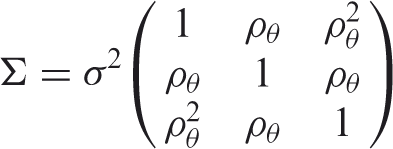
Gllamm in Stata has been used to estimate parameters of the model. 23
2.2 Longitudinal PROs simulation
As our purpose was to evaluate the performance of both methods, a simulation study was used. Datasets that follow a given statistical model and several defined assumptions can be created using simulation. In that case, the parameters’ values used to simulate datasets can be considered as their true values. Thus, by analysing these datasets, estimated parameters can be compared to the true values and possible bias are deduced. 24 The bias of the time effect estimations, the type I error and the power of the tests were examined. A t-test was used in order to compare the means of the time effect estimation (means obtained with SM and LRM methods) to the true value (simulated value) and, therefore to conclude about the potential bias of this estimation. The number of time effect estimations that were above, below or equal to the time effect true value was computed and a sign test was used for comparing SM and LRM methods. The type I error was determined as the proportion of rejection of the null hypothesis H0 (H0: there is no time effect) for all of the simulated datasets corresponding to each case where no time effect had been simulated. The power was computed as the rate of rejection of H0 for all of the simulated datasets corresponding to each case where a time effect had been simulated. The expected rate for the type I error was 5%.
2.2.1 Complete datasets (Figure 1, part A)
In a first step, complete datasets which represented PROs data were simulated. We assumed that the corresponding PROs had been previously validated with both score and Rasch-based approaches as it is currently performed nowadays.25–27 This corresponds to the situation where PROs are intended to be analysed using either a Rasch-based model or a CTT approach. Indeed, the assumptions required for the analysis of data with a CTT approach are necessarily fulfilled when data satisfy the assumptions of a Rasch model. 28 The design of the simulated study involved dichotomous items with three times of assessment for scales containing four or seven items. The patients’ responses were simulated using Monte Carlo simulations with a longitudinal Rasch model. 14
The time effect between two consecutive measures was
The items’ parameters were regularly distributed and defined by the vectors Δ4 and Δ7 for respectively the four-items scale and the seven-items scale.
The latent trait vector
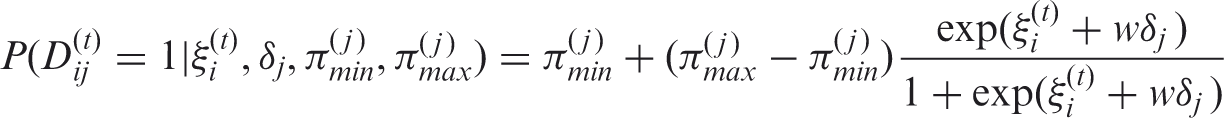
This structure assumed that correlations between two consecutive measures decrease exponentially with the distance between two consecutive times. Three different values for the correlation coefficient of the latent trait between two consecutive times (
Five-hundred datasets were simulated for each case.
2.2.2 Intermittent missing items (Figure 1, part B)
In a second step, different types of intermittent missing items (informative or non-informative) were generated from the complete simulated datasets.
The intermittent missing items were simulated using a variable (ξ), which represented the non-response propensity. (
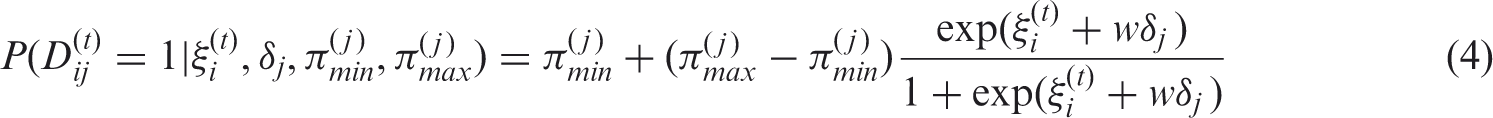
The PMS imputation has only been used when the amount of missing items did not exceed 50% for a given patient. Thus, one and three items maximum were imputed for the four-item scale and the seven-item scale, respectively.
3 Results
Parameters used for complete datasets simulation and missing items mechanisms with N the sample size, T the number of assessments, J the number of items, Δ
J
the vector of items’ parameters,

MCAR: missing completely at random; MNAR: missing not at random
Time effect estimation between time 2 and time 1 (
Tables 2 to 5 show the results for complete datasets and for intermittent missing items (the items’ parameters and the content of items do not play a role in missing data mechanisms for these datasets).
MCAR: missing completely at random; MNAR: missing not at random
Italicised numbers indicate that the t−test comparing the time effect estimation
§: according to Blanchin et al. 15
Type I error of the tests of time effect for score mixed model (SM) with personal mean score (PMS) imputation or without and longitudinal Rasch mixed model (LRM) methods for different values of sample size (N), number of items (J), latent variable correlation (

MCAR: missing completely at random; MNAR: missing not at random
The expected value of 5% is not included in the 95% confidence interval.
Italicised numbers indicate that the time effect estimation
Time effect estimation between time 2 and time 1 (

MCAR: missing completely at random; MNAR: missing not at random
Italicised numbers indicate that the t-test comparing the time effect estimation
§: according to Blanchin et al. 15
Power of the tests of time effect for score mixed model (SM) with personal mean score (PMS) imputation or without and longitudinal Rasch mixed model (LRM) methods for different values of sample size (N), number of items (J), latent variable correlation (

MCAR: missing completely at random; MNAR: missing not at random
Italicised numbers indicate that the time effect estimation
3.1 Complete datasets
For complete datasets, similar results were observed for SM and LRM methods regarding type I error and power. The type I errors were close to the expected value (5%). Both methods displayed unbiased results and similar power whatever the values of the parameters (results ‘complete data’ in all tables).
3.2 Intermittent missing items (item non-response)
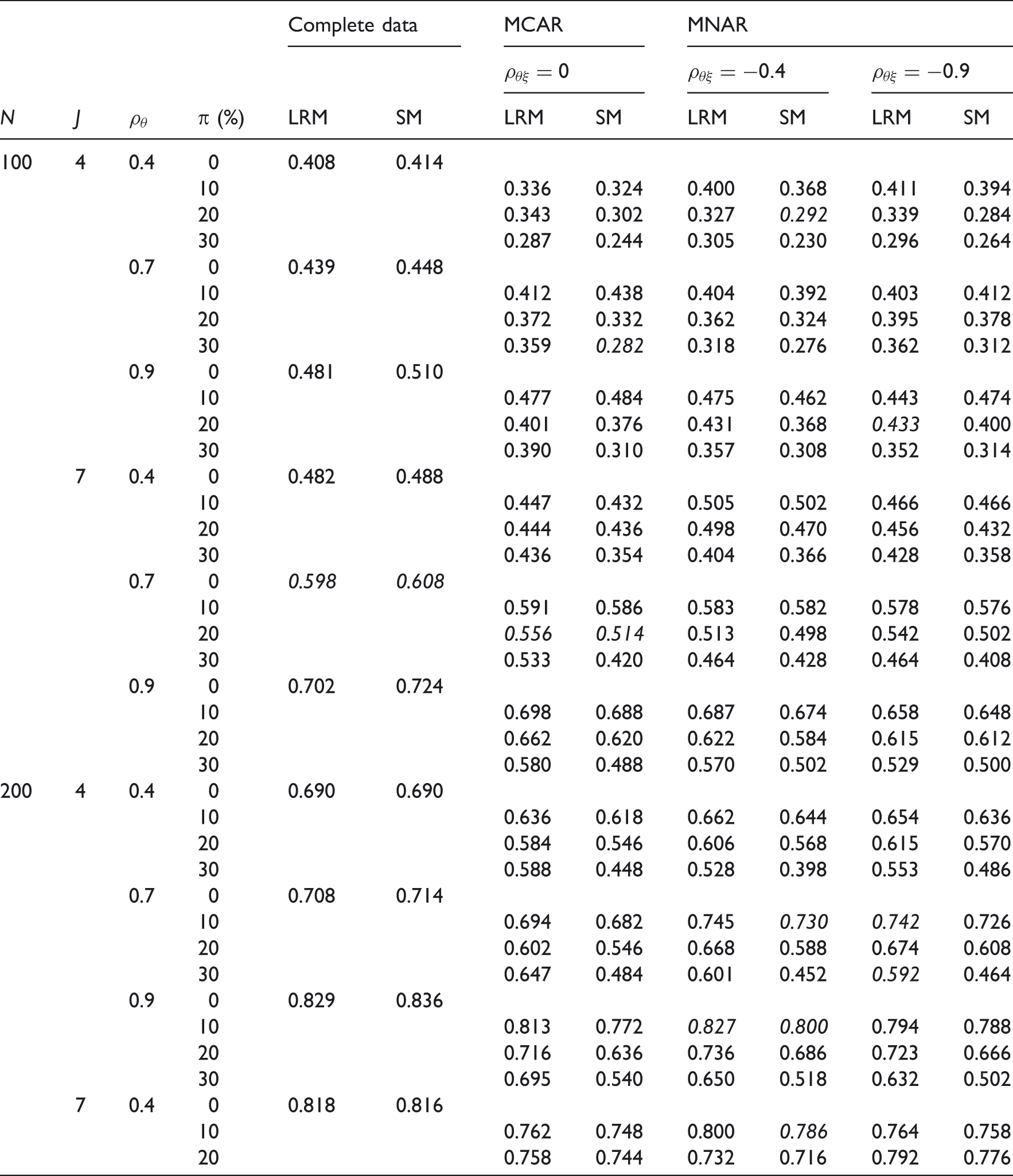
Table 2 shows the results of the time effect estimation between time 2 and time 1 when no time effect was simulated. Globally, there were more biased values for SM as compared to LRM method (eight for SM and four for LRM). Biased values concerned more often MNAR data than MCAR data (respectively eight- and four-biased values) with six MNAR-biased values for SM and only two for LRM. These results were comparable to those corresponding to the time effect estimation between time 3 and time 2 (results not shown). The number of times means of the time effect estimations between time 2 and time 1 were above, below or equal to the true value of the time effect seemed to be similar for both methods (two significant sign tests for SM and one for LRM).
Table 3 shows results of the type I error. The type I errors were close to the expected value (minimum: 3%, mean: 5% and maximum: 9%). The number of patients and items, the correlation of the latent trait between two consecutive times, the correlation between the latent trait θ and the variable ξ seemed to have no influence on the type I error. Results were similar whatever the type (MCAR or MNAR) or rate (10%, 20% and 30%) of missing items. Therefore, it seemed that the type I error was controlled for SM and LRM.
Table 4 shows results of the time effect estimation between time 2 and time 1 when a time effect was simulated. Quite similarly as the case where no time effect was simulated, SM engendered slightly more biased values than LRM: seven for SM and five for LRM. Moreover, MNAR data were more often impacted than MCAR data by these biases. These results were comparable to those corresponding to the time effect estimation between time 3 and time 2 (results not shown). The number of times means of the time effect estimations between time 2 and time 1 were above, below or equal to the true value of the time effect seemed to be similar for both methods (only one significant sign test for SM).
Table 5 presents results on the power of time effect tests. Some power must be interpreted with caution because the associated time effect estimations were biased. Several parameters impacted power for both methods and for all types of intermittent missing items (MCAR or MNAR): the number of patients and of items and the correlation between two consecutive times. As expected, when the sample size was lower, the power decreased, and it increased with the number of items. Similarly, when the correlation of the latent trait between two consecutive times was higher, the observed power increased.
By contrast with the type I error which was not impacted, power decreased when the rate of intermittent missing items increased. However, it could be noticed that the loss of power induced by an increase of the rate of intermittent missing items was lower for LRM than for SM. No variation could really be explained by the type of intermittent missing items for SM and for LRM and conclusions were indeed the same for MCAR and MNAR items.
For the LRM method, power was overall higher than the one obtained with SM method, whatever the values of the parameters and the type of intermittent missing items (Figure 2). The difference in power between LRM and SM ranged from 0.01 to 0.20.
Comparison of power of the tests of time effect for score mixed model (SM) with PMS imputation and longitudinal Rasch mixed model (LRM) methods for one case: sample size (N = 200), number of items (J = 7), latent variable correlation (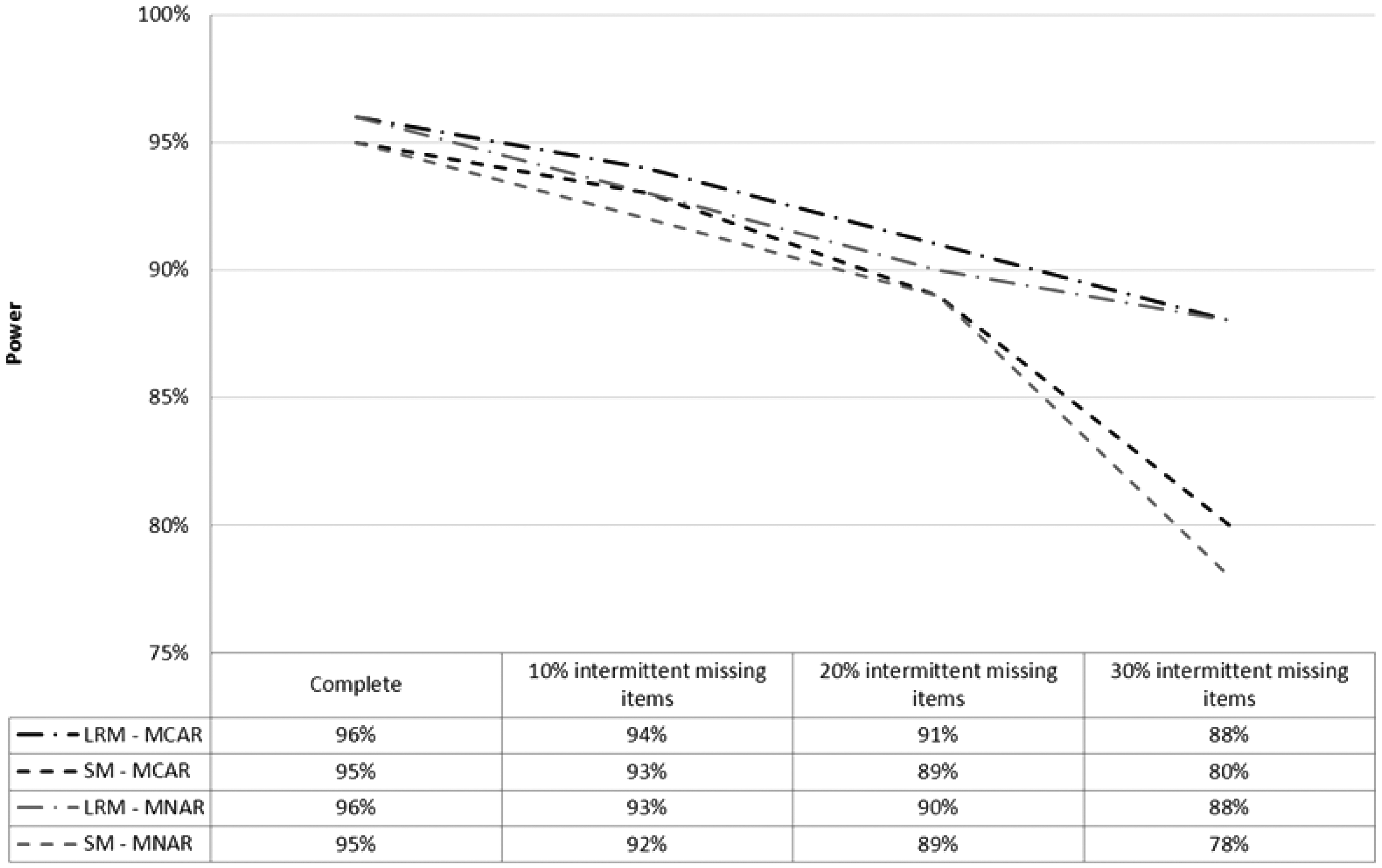
3.3 Supplementary results
Results for datasets obtained with the mechanisms numbered 2, 5 and 8 (Table 1) which depend on items’ parameters (w = 1) and results of datasets obtained with the mechanisms numbered 3, 6 and 9 (Table 1) which take into account the impact of a possible very personal content for one item are not shown. Indeed, the conclusions were very similar regarding type I error, power and time effect estimations when missing items depended on items’ parameters or on the content of items.
4 Illustrative example
This example is based on data of a longitudinal study which has been set up in order to evaluate the evolution of health-related quality of life and coping of breast cancer patients and their caregivers. The aims of this study were to identify if the quality of life and coping strategies of the patients and their caregivers vary over time and if the coping strategies and quality of life of caregivers have an impact on the quality of life of the patients. 30 This study took place in Institut de Cancérologie de l’Ouest René Gauducheau (René Gauducheau Cancer Center) in Nantes, France. It is often observed that diagnosis of breast cancer and its treatment instigate stress for patients and their caregivers and that they can use different strategies to cope with this stress. Coping indicates all processes that patients and caregivers use to overcome a negative event that impacts their physical and psychological well-being. Several coping strategies can be employed such as problem-focused coping or emotion-focused coping 31 to reduce or manage the problem source or the emotional distress, or support-seeking strategies when patients or caregivers look for a social support. Coping was assessed using the ways of coping checklist (WCC) adapted in French by Cousson et al. in 1996. 32 The WCC contains twenty seven items with ten items assessing problem-focused coping, nine items for emotion-focused coping and eight items for social support-seeking strategies. A hundred patients were followed at three time points: about two or three weeks after diagnosis (T1), at the end of treatments (T2) and six month after treatments (T3).
Distribution of missing data by item for problem-focused coping.
Tables 6 and 7 show the results for illustrative example.
These data were analysed using SM (Proc MIXED in SAS) and LRM (Proc NLMIXED in SAS) methods in order to test whether a time effect exists. The implementation of the two models using SAS is available (Figure 3). Before applying SM, a PMS imputation was used only when the amount of missing items did not exceed 50% for a given patient. Thus, four items maximum were imputed. The computation of the score was made according to the scoring manual: sum of patients’ answers to the 10 items multiplied by 2.5 in order to obtain a score between 0 and 100. For both methods, analyses were performed with a compound symmetry covariance matrix. Indeed, it provided the best fit for these data. Table 7 shows results of these analyses.
Example of LRM and SM implementations for two times of assessment, ten items with two possible levels of response for eight items (responses 0 or 1 or 2 for items 1; 2; 3; 4; 5; 6; 7 and 8) and only one level for the two other items (responses zero or one for items 9 and 10). Time effect estimations between time 1 and time 2 (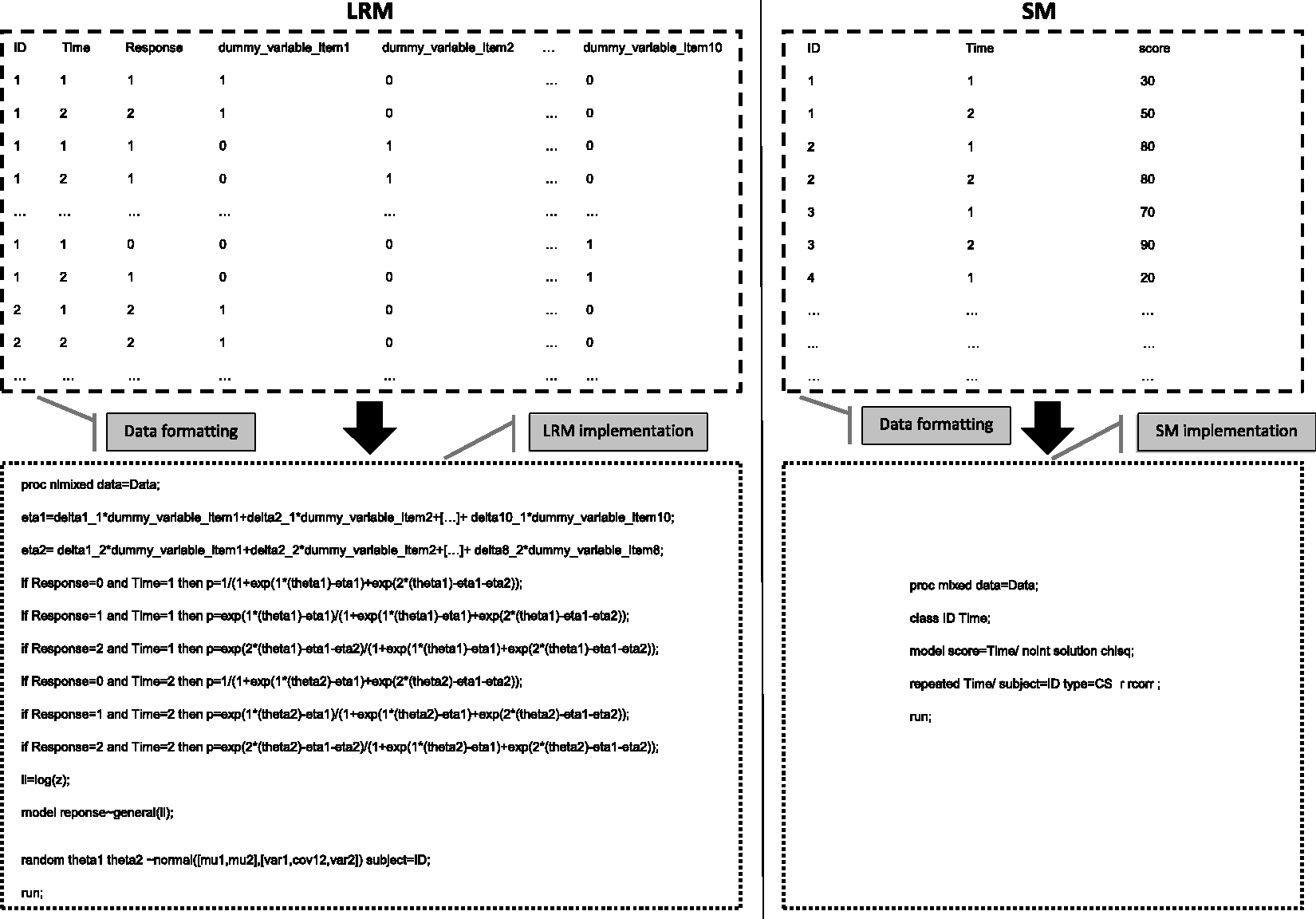
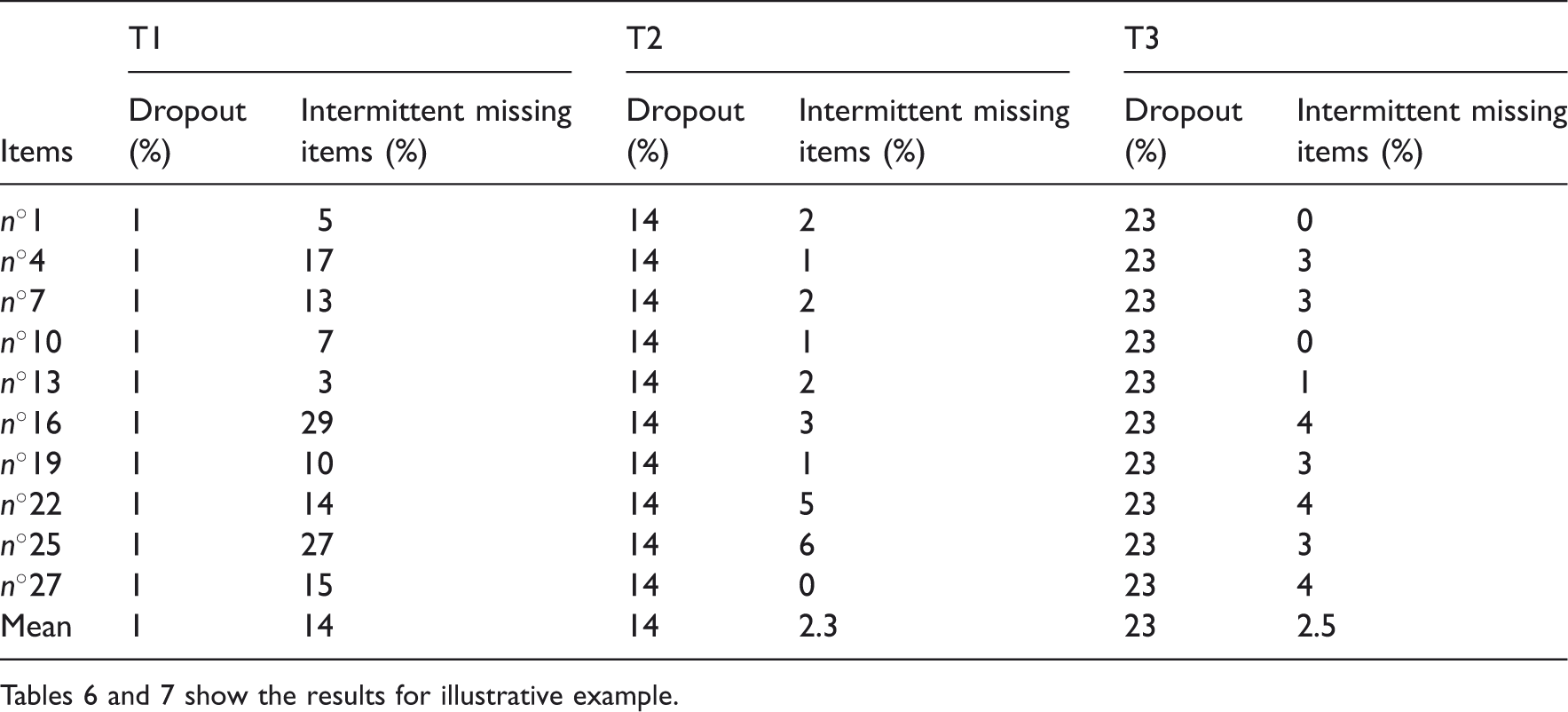
Time effects estimations described similar trends for both methods: signs of coefficients were negative between T1 and T2 and positive between T2 and T3. Time effect appeared to be non-significant whatever the method used. Considering the number of patients and the rate of intermittent missing data, these results are in accordance with results obtained in the following case of the simulation study: number of patients N equal to 100, number of items J higher than seven and rate of intermittent missing data ranging from 0% (2.3% and 2.5% for respectively T2 and T3) to 20% (14% for T1).
This example confirms that dropout generates a complete loss of information for both methods, especially between T2 and T3 where the rate of dropout is respectively 14% and 23%. Indeed, no difference between the two methods was noticed between T2 and T3. Moreover, it could be highlighted that the rate of intermittent missing items didn’t exceed 14% (14% for T1, 2.3% for T2 and 2.5% for T3) and that no difference between the two methods could be observed.
5 Discussion
PROs are widely used to measure patients’ perceptions. For this purpose, the evolution of quality of life for instance might be assessed over time and intermittent missing items are an issue that may be problematic if missing items are linked to the patient’s health status. The aim of the present study was to compare CTT and Rasch-based approaches for the detection and quantification of a time effect in the framework of longitudinal PROs with possibly informative intermittent missing items. Two models, each based on CTT and Rasch-based methods, were compared on simulated datasets: SM and LRM models. For the complete datasets, our results were very similar to those obtained by Blanchin et al.: 14 type I errors were maintained to their expected values (5%) and power was almost the same for SM and LRM. Moreover, for the incomplete datasets, the type I error rates were always controlled (close to 5%). In contrast with the conclusions that appeared for dropout missing data in the literature 15 where LRM and SM gave similar and poor results (low power and biased estimations), LRM appeared to perform somewhat better than SM for datasets with intermittent missing items, especially regarding power. Indeed, estimations obtained with LRM were unbiased and power was greater than the one obtained with SM. This study also highlighted a known impact of the type of missing items on the results: values of time effect estimation were more often biased for informative missing items (MNAR data) than for non-informative missing items (MCAR data).
It can be noted that we used a single imputation which is the most often encountered in many manuals (SF-36, QLQ-C30, etc.) for practical reasons. 33 However, it would be interesting to test other methods like multiple imputations in order to have an idea of the impact of other imputation methods in this framework. For LRM, no imputation was necessary and its corresponding power was overall higher than the one obtained with SM. Moreover, in this study, LRM appeared to be an unbiased method whatever the amount of missing items and their informativeness. The difference between the underlying theories for CTT and Rasch-family models might explain these results regarding the impact of intermittent missing items. Indeed, these results might be related to the specific objectivity property of the Rasch model that allows obtaining consistent estimations of the parameters associated with the latent trait independently from the observed items that are used for these estimations. 20
The fact that the simulated time effect was assumed to be linear could be considered as a limitation of our study. Indeed, several clinical examples with a non-linear time effect can be quoted. For instance, patients who start chemotherapy often experience a sharp decline of their quality of life which hopefully increases again towards its initial level after some time. As no assumption was made for the estimation of the time effect using SM or LRM, data with a non-linear time effect can be analysed using both methods and the results should be comparable to those obtained in this study. Another limitation could be related to the simulation of dichotomous items which may be remote from reality since polytomous items seem more common in clinical research. However, we could expect similar results for polytomous as for dichotomous items. Indeed, the mechanisms that engender missing items do not depend on the number of items response categories. As a matter of fact, if Rasch-family models are used for analysis, the results obtained might be extrapolated to polytomous items. Indeed, these models also possess the specific objectivity property.
Regarding the intermittent missing items, the MAR process was not simulated. The probability to observe a MAR item depends on observed values but not on unobserved values. It could be possible to simulate intermittent MAR items. As intermittent MAR items are considered as non-informative like MCAR items, the correlation between the latent variable of interest θ and the patient’s propensity of non-response ξ should be simulated at
We considered that the rate of missing items increased with the item parameter’s value but the opposite case could also be imagined. Indeed, it is possible that a patient prefers answering only when items are more appropriate. Moreover, we envisaged the case where a patient with a worse quality of life tends to respond less often to questions because she/he is too tired to answer compared to a patient with a better quality of life. The reverse case could be considered as well and would engender a positive correlation between the latent variable of interest θ and the patient’s propensity of non-response ξ for MNAR items. For instance, a patient with a better quality of life might not see the need to respond to an item because it does not seem appropriate to his/her case. In these scenarios, the rate of missing data would be reduced with item parameter and with the decrease of the quality of life level respectively and we could assume that the methods SM and LRM would perform similarly as in this study. Indeed, the global rate of missing data would not be impacted by these choices of hypotheses and should be quite similar as in our present study.
Our study showed that the LRM model performed better than the SM model regarding power for the analysis of longitudinal PROs with possibly informative intermittent missing items. Indeed, the specific objectivity allowed estimating the latent variable consistently even if the patients did not answer all items. Moreover, these results pointed out the limits of a single imputation like PMS imputation. This study highlighted the interest of the Rasch-based models in clinical research and epidemiology in order to analyse incomplete data from longitudinal PROs studies. Future works with a wider range of IRT models would be interesting.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by la Ligue Nationale Contre le Cancer.